A Personalized QoS Prediction Method for Web Services via Blockchain-Based Matrix Factorization


Abstract
1. Introduction
- We apply blockchain technology to web service QoS predictions, promoting blockchain in a broader field of applicability.
- We propose a blockchain-based matrix factorization prediction method that largely eliminates the interference of unreliable users in QoS predictions, thus improving the accuracy of QoS predictions.
- We compared the proposed method to other methods and analyzed the influence of the prediction model proposed in this paper under different parameters. The results demonstrate the superiority of our method.
2. Related Work
2.1. Personalized QoS Prediction
2.2. Blockchain Technology
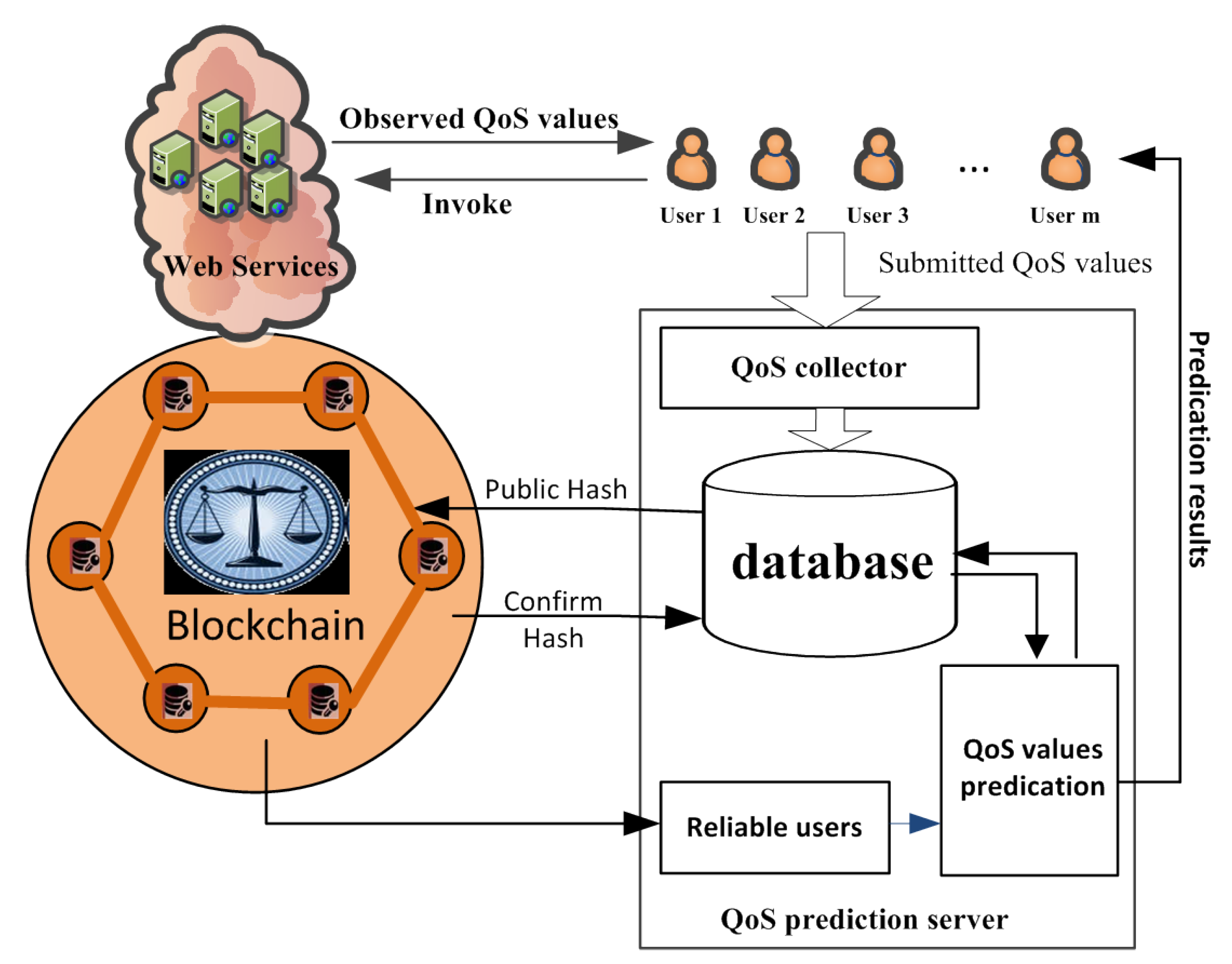
3. Prediction Framework
- Step 1: Collecting observed QoS data.When users invoke working services, we can collect their QoS values by providing them from users, and keep this data in reserve in our prediction server. It is worth noting that some users (e.g., service providers) can submit better QoS values for their own services and worse ones for rival services. Other users, such as those who like to play pranks, can also submit random or constant QoS values.
- Step 2: User requests.To receive services normally, user must request adding their own QoS values. This invokes service to the prediction system as a basis for obtaining unknown results.
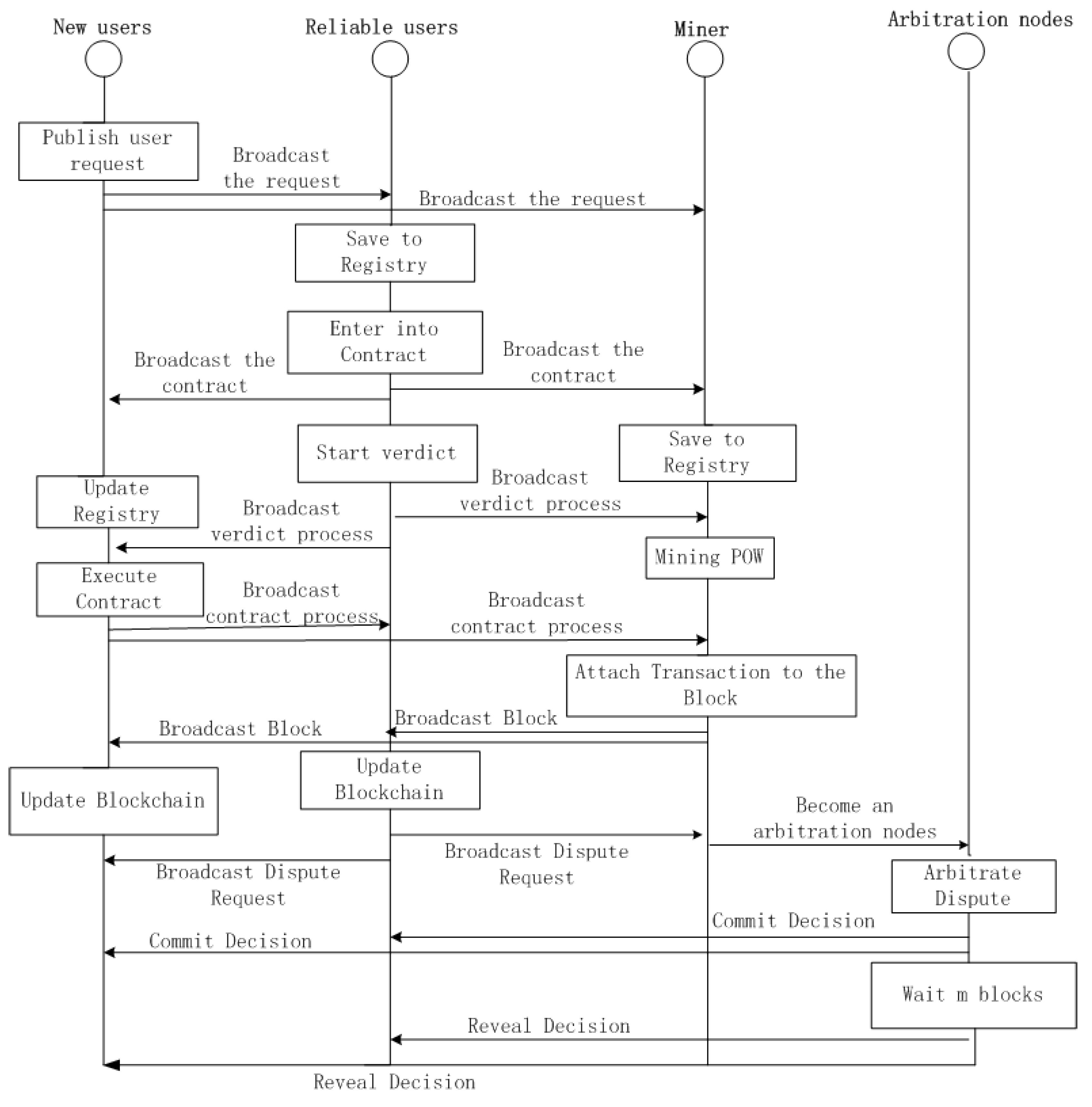
- Step 3: Confirming and verifying the user.User obtains the homomorphic hash value received from the blockchain account and compares its record on the blockchain stored in the service. If the hash values match, sends the corresponding confirmation transaction to the blockchain account of . Otherwise, it applies to rejoin its own information and match the Qos data values, which is already stored in the server and belongs to it.After receiving ’s confirmation, the account of is added in the model’s arbitration node, which is combined with the other’s trusted user beforehand. The smart contract for arbitration decides whether user can be included in the QoS forecast. In other words, the blockchain is a public ledger for all interactions involved in the execution of a service contract. Our approach can solve the arbitration process problem, which is described in Algorithm 1. In addition, to describe the blockchain architecture in more detail, we use a timing diagram to explain it. Figure 2 shows the interaction sequence if a dispute is raised by either the new user or the proven reliable user, and we would describe it in the next section. In short, if the blockchain account of an arbitration node agrees to trade with other trusted users, it is considered a reliable user. Otherwise, will invoke the smart contract to terminate user and add their own QoS values in the prediction system.
- Step 4: Predicting the QoS value in the system.Currently, matrix factorizing is the most commonly used method for predicting QoS values. However, researchers have not been completely able to eliminate the interference of unreliable users before predictions. In our approach, a user invoking a service’s QoS value can only be added to the dataset used for prediction if it is verified by the blockchain arbitration mechanism. Finally, we make a personalized QoS prediction via the trusted users’ values in the database and return prediction results to the target user.
- Step 5: Application of results.Users use the corresponding results predicted by the system to select the best web service to invoke.
| Algorithm 1 Dispute arbitration algorithm. |
|
4. Blockchain-Based Matrix Factorization
4.1. QoS Prediction with the MF Model
4.2. Arbitration Process
- After confirming that the arbitration process has begun, every user in the blockchain acts as a node. Those who believe that a user violates an obligation (i.e, the standard for a trusted user) can opt to broadcast a dispute message. Meanwhile, the message will produce a fee attached for arbitration in this prediction system.
- The node, which requests as arbitration node, obtains the homomorphic hash value received from the existed blockchain account and compares its record on the blockchain stored in the service.
- The arbitration node, which is mined to the POW block, began examining the service transactions recorded in the blockchain against the service contract in the service registry, and determines the party at fault.
- The result of the arbitration will be encrypted (hidden) by the miner’s public key, so that no one can see the decision, which will be included in the block as a transaction and is broadcast to the system. After adding a certain number of blocks (m), the arbitrator will publish the signed explicit text decision on the blockchain. Each node can verify that the hidden decision is the same as the plaintext decision.
- According to public ledger —namely, the protocol proposed by Garay et al. [33] called Public Transaction Ledger and BA for Honest Majority—to ensure so-called persistence and liveness, we hold an honest majority that participates during the arbitration process. That is, the hashing power of the unreliable users in the blockchain is strictly less than 50%. Essentially, the unanimity of arbitrators composed of an honest majority determines that the arbitral award is impartial and accurate in most cases.
- To identify unreliable users more accurately, we use blockchain and bottom BAs as tools to build consensus among honest parties, while combining most functions to achieve reasonably accurate final judgments.
4.3. Blockchain-Based Matrix Factorization Algorithm
| Algorithm 2 BMF-based QoS prediction construction. |
|
5. Experiments and Results
5.1. Dataset Description
5.2. Evaluation Metrics
5.3. Performance Comparison
- UMean (user-mean): In this method, the average value of all known QoS values of users is calculated to predict the value of QoS.
- UPCC: This method is a collaborative filtering method [36] based on the user’s use of the similarity between users to predict the QoS value, and the use of similar users’ PCC and call history records.
- IPCC: This method is similar to UPCC, but it does not use similar users. Rather, it focuses on similar services and estimates missing QoS values using similar services’ QoS values.
- UIPCC: This method integrates UPCC and IPCC into a unified model and aggregates their prediction results, thus utilizing both similar users and similar services.
- PMF: This is an implementation of a widely used matrix factorization model, which uses two low-rank matrices to predict missing values in user service matrices.
- RMF: This is a method that calculates the credibility of each user according to the contribution of the QoS value. It quantifies the credibility of the user, and then considers the credibility of the user, to achieve more accurate QoS predictions.
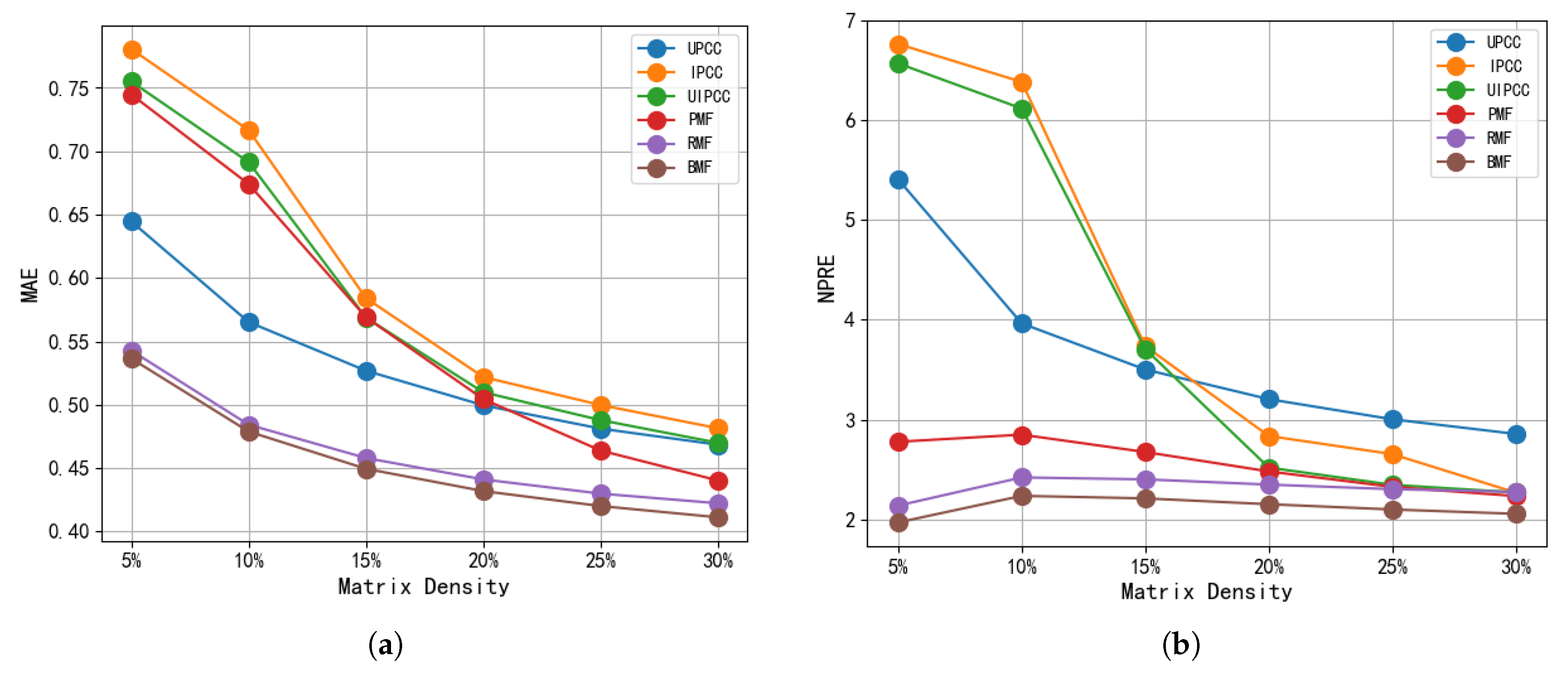
- For the response time of different matrix densities, our BMF method obtained lower MAE and NPRE values than other methods. This shows that our method is more accurate than existing methods, and further verifies the effectiveness of our method.Specifically, to more intuitively demonstrate the superiority of our algorithm in terms of accuracy, we calculated the percentage improvement of our method over the best optimal results of other methods. At different matrix densities, our method improved by 1.12–2.63% in terms of the MAE and by 7.62–9.66% in terms of the NPRE. In addition, because our method improves as a result of a PMF uniting blockchain, we also compared our model to the PMF model. At different densities, the BMF achieved a 6.61–28.97% and 7.97–29.08% improvement in terms of the MAE and NPRE, respectively.Ultimately, the effective improvement in the accuracy of our method in comparison to the RMF and PMF is on account of our perfect solution, which uses distributed ledger technology and distributed consensus, greatly reducing the influence of potential unreliable users for QoS predictions.
- Compared to UMEAN, UPCC, IPCC, and UIPCC, BMF makes more accurate predictions. The reason for this result is that BMF uses all available information in the user-service matrix for the predictions, while the neighbor-based method exclusively uses information similar to that of the neighbor (user or service).
- Relative to other methods, as the matrix became more dense (e.g., from 5% to 30%), the accuracy of the BMF predictions is more obvious. BMF was 1.16% more accurate than RMF in terms of the MAE when the matrix density was MD = 5%, and 2.63% more accurate when the matrix density was MD = 30%. Similarly, it was 7.89% more accurate than RMF in terms of the NPRE when the matrix density was MD = 5%, and 9.66% more accurate when the matrix density was MD = 30%.
- We also found that although UIPCC was more accurate than UPCC and IPCC in [38], PMF and RMF were better than the first three methods reported in [5,39]. All of these methods had considerable errors in terms of both the MAE and NPRE. Judging from the difference in accuracy between these methods and BMF, unreliable users seriously affect the prediction of QoS values, and the use of blockchain can indeed screen out trustworthy users.
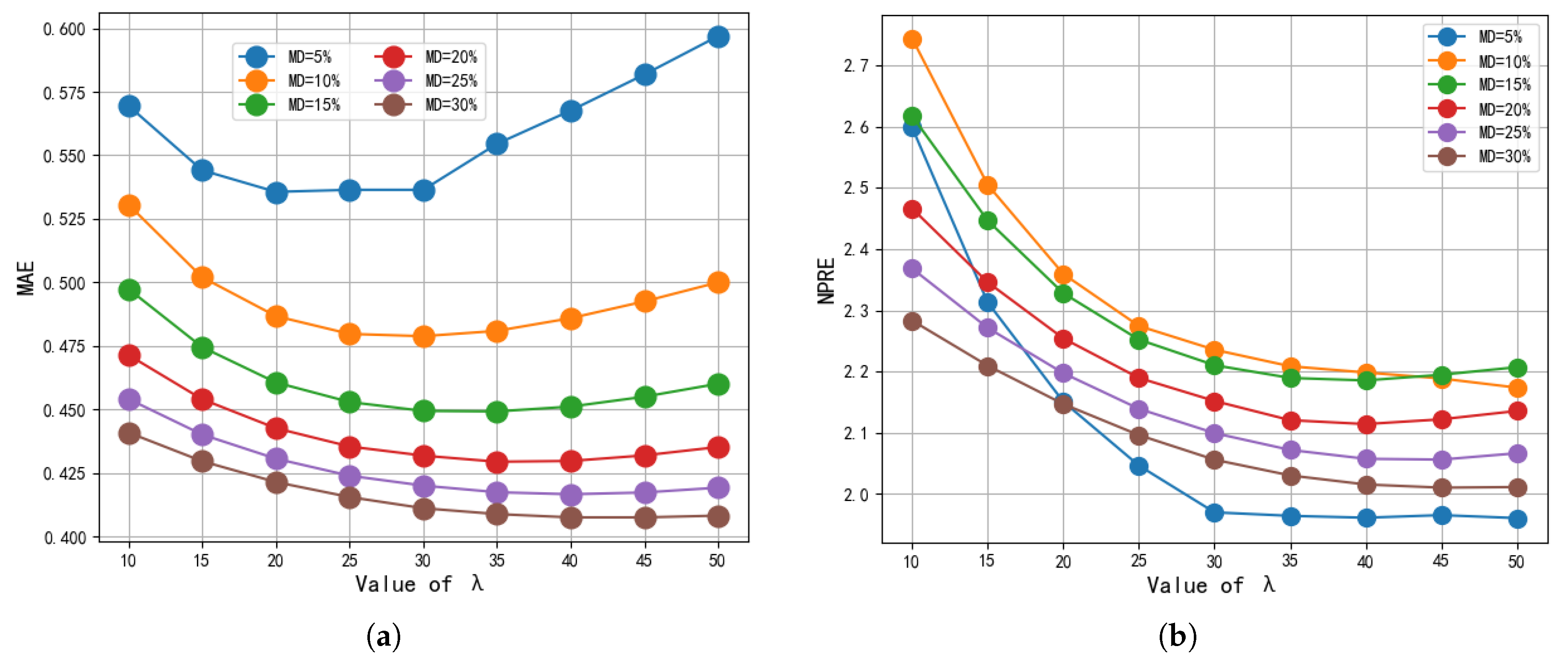
5.4. Impact of and
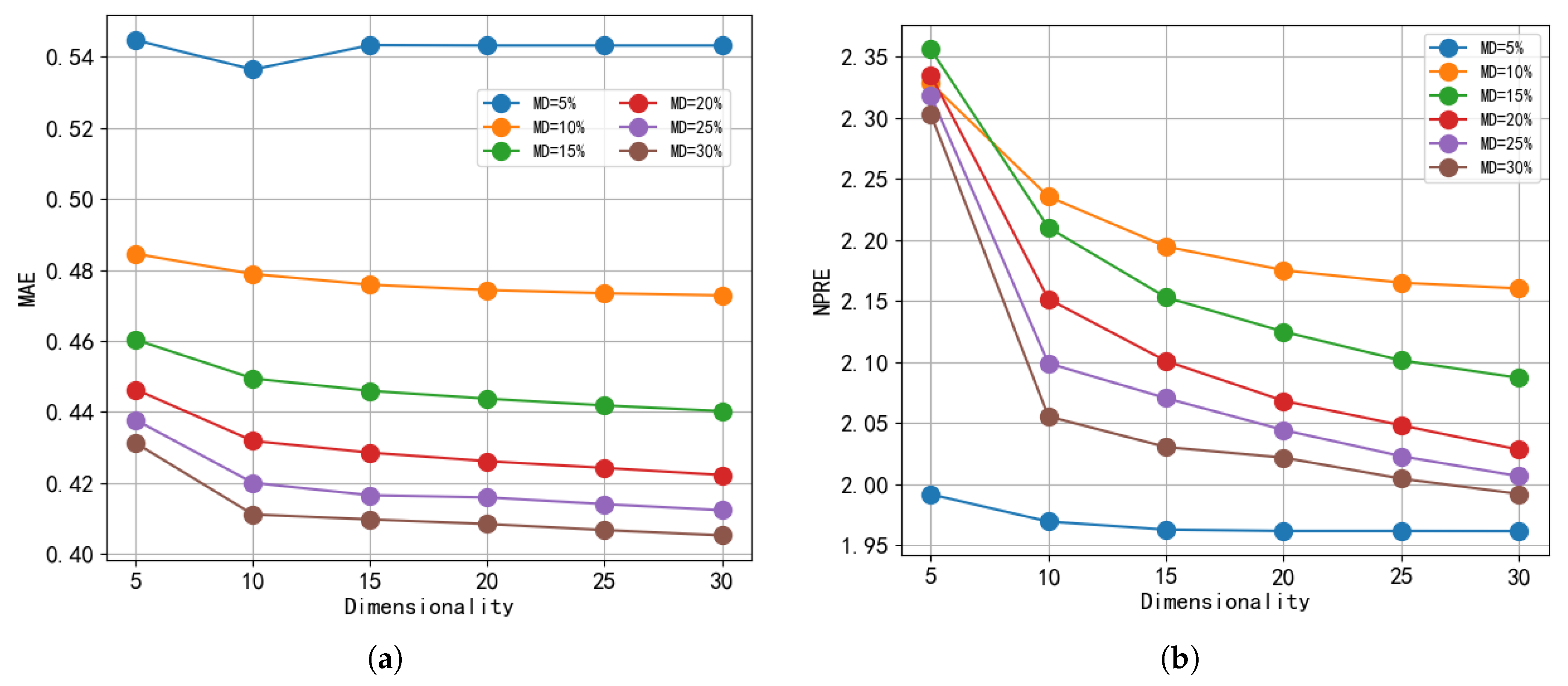
5.5. Impact of Dimensionality
5.6. Impact of Matrix Density
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, L.J.; Cai, H.; Zhang, J. Services Computing; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Zheng, Z.; Lyu, M.R. QoS Management of Web Services. Adv. Top. Sci. Technol. China 2011, 32, 94–96. [Google Scholar]
- Calinescu, R.; Grunske, L.; Kwiatkowska, M.; Mirandola, R.; Tamburrelli, G. Dynamic QoS management and optimization in service-based systems. IEEE Trans. Softw. Eng. 2011, 37, 387–409. [Google Scholar] [CrossRef]
- Wu, H.; Yue, K.; Hsu, C.H.; Zhao, Y.; Zhang, B.; Zhang, G. Deviation-based neighborhood model for context-aware QoS prediction of cloud and IoT services. Future Gener. Comput. Syst. 2017, 76, 550–560. [Google Scholar] [CrossRef]
- Xu, J.; Zheng, Z.; Lyu, M.R. Web service personalized quality of service prediction via reputation-based matrix factorization. IEEE Trans. Reliab. 2016, 65, 28–37. [Google Scholar] [CrossRef]
- Li, S.; Wen, J.; Luo, F.; Cheng, T.; Xiong, Q. A location and reputation aware matrix factorization approach for personalized quality of service prediction. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 652–659. [Google Scholar]
- Chen, X.; Zheng, Z.; Liu, X.; Huang, Z.; Sun, H. Personalized qos-aware web service recommendation and visualization. IEEE Trans. Serv. Comput. 2013, 6, 35–47. [Google Scholar] [CrossRef]
- Chen, Z.; Shen, L.; Li, F. Exploiting Web service geographical neighborhood for collaborative QoS prediction. Future Gener. Comput. Syst. 2017, 68, 248–259. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Luo, J.; Yue, K.; Hsu, C.H. Multiple Attributes QoS Prediction via Deep Neural Model with Contexts. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Sun, L.; Dong, H.; Hussain, F.K.; Hussain, O.K.; Chang, E. Cloud service selection: State-of-the-art and future research directions. J. Netw. Comput. Appl. 2014, 45, 134–150. [Google Scholar] [CrossRef]
- Pan, Y.; Ding, S.; Fan, W.; Li, J.; Yang, S. Trust-enhanced cloud service selection model based on QoS analysis. PLoS ONE 2015, 10, e0143448. [Google Scholar] [CrossRef]
- Shao, L.; Zhang, J.; Wei, Y.; Zhao, J.; Xie, B.; Mei, H. Personalized qos prediction for web services via collaborative filtering. In Proceedings of the IEEE International Conference on Web Services (ICWS 2007), Salt Lake City, UT, USA, 9–13 July 2007; pp. 439–446. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, H.; Lyu, M.R.; King, I. Wsrec: A collaborative filtering based web service recommender system. In Proceedings of the 2009 IEEE International Conference on Web Services, Los Angeles, CA, USA, 6–10 July 2009; pp. 437–444. [Google Scholar]
- Zhu, J.; Kang, Y.; Zheng, Z.; Lyu, M.R. A clustering-based QoS prediction approach for Web service recommendation. In Proceedings of the 2012 IEEE 15th International Symposium on Object/Component/ Service-Oriented Real-Time Distributed Computing Workshops, Shenzhen, China, 11 April 2012; pp. 93–98. [Google Scholar]
- Hofmann, T. Latent semantic models for collaborative filtering. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 89–115. [Google Scholar] [CrossRef]
- Rennie, J.D.; Srebro, N. Fast maximum margin matrix factorization for collaborative prediction. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; ACM: New York, NY, USA, 2005; pp. 713–719. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Bayesian probabilistic matrix factorization using Markov chain Monte Carlo. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 880–887. [Google Scholar]
- Zheng, Z.; Lyu, M.R. Personalized reliability prediction of web services. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2013, 22, 12. [Google Scholar] [CrossRef]
- Lo, W.; Yin, J.; Deng, S.; Li, Y.; Wu, Z. An extended matrix factorization approach for qos prediction in service selection. In Proceedings of the 2012 IEEE Ninth International Conference on Services Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 162–169. [Google Scholar]
- He, P.; Zhu, J.; Zheng, Z.; Xu, J.; Lyu, M.R. Location-based hierarchical matrix factorization for web service recommendation. In Proceedings of the 2014 IEEE International Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 297–304. [Google Scholar]
- Zhang, Y.; Zheng, Z.; Lyu, M.R. WSPred: A time-aware personalized QoS prediction framework for Web services. In Proceedings of the 2011 IEEE 22nd International Symposium on Software Reliability Engineering, Hiroshima, Japan, 29 November–2 December 2011; pp. 210–219. [Google Scholar]
- Fan, X.; Hu, Y.; Zheng, Z.; Wang, Y.; Brezillon, P.; Chen, W. CASR-TSE: Context-Aware Web Services Recommendation for Modeling Weighted Temporal-Spatial Effectiveness. IEEE Trans. Serv. Comput. 2017. [Google Scholar] [CrossRef]
- Qiu, W.; Zheng, Z.; Wang, X.; Yang, X.; Lyu, M.R. Reputation-aware QoS value prediction of web services. In Proceedings of the 2013 IEEE International Conference on Services Computing, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 41–48. [Google Scholar]
- Kuang, L.; Yu, L.; Huang, L.; Wang, Y.; Ma, P.; Li, C.; Zhu, Y. A personalized qos prediction approach for cps service recommendation based on reputation and location-aware collaborative filtering. Sensors 2018, 18, 1556. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Xie, S.; Dai, H.N.; Wang, H. Blockchain challenges and opportunities: A survey. Int. J. Web Grid Serv. 2018, 14, 352. [Google Scholar] [CrossRef]
- Brundo, R.; De Nicola, R. Blockchain-based decentralized cloud/fog solutions: Challenges, opportunities, and standards. IEEE Commun. Stand. Mag. 2018, 2, 22–28. [Google Scholar]
- Liang, W.; Tang, M.; Long, J.; Peng, X.; Xu, J.; Li, K. A Secure Fabric Blockchain-based Data Transmission Technique for Industrial Internet-of-Things. IEEE Trans. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Perazzo, P.; Dini, G. A uniformity-based approach to location privacy. Comput. Commun. 2015, 64, 21–32. [Google Scholar] [CrossRef]
- Zou, J.; Wang, Y.; Orgun, M.A. A dispute arbitration protocol based on a peer-to-peer service contract management scheme. In Proceedings of the 2016 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 27 June–2 July 2016; pp. 41–48. [Google Scholar]
- Xu, Y.; Ren, J.; Wang, G.; Zhang, C.; Yang, J.; Zhang, Y. A Blockchain-based Non-Repudiation Network Computing Service Scheme for Industrial IoT. IEEE Trans. Ind. Inform. 2019, 15, 3632–3641. [Google Scholar] [CrossRef]
- Perazzo, P.; Dini, G. Secure positioning with non-ideal distance bounding protocols. In Proceedings of the 2015 IEEE Symposium on Computers and Communication (ISCC), Larnaca, Cyprus, 6–9 July 2015; pp. 907–912. [Google Scholar]
- Garay, J.; Kiayias, A.; Leonardos, N. The bitcoin backbone protocol: Analysis and applications. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 26–30 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 281–310. [Google Scholar]
- Dennis, R.; Owen, G. Rep on the block: A next generation reputation system based on the blockchain. In Proceedings of the 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 14–16 December 2015; pp. 131–138. [Google Scholar]
- Zhou, H.; de Laat, C.; Zhao, Z. Trustworthy Cloud Service Level Agreement Enforcement with Blockchain Based Smart Contract. In Proceedings of the 2018 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Nicosia, Cyprus, 10–13 December 2018; pp. 255–260. [Google Scholar]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; ACM: New York, NY, USA, 1994; pp. 175–186. [Google Scholar]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the WWW ’01 Proceedings of the 10th international conference on World Wide Web, Hong Kong, China, 1–5 May 2001; Volume 1, pp. 285–295. [Google Scholar]
- Zheng, Z.; Ma, H.; Lyu, M.R.; King, I. Collaborative web service qos prediction via neighborhood integrated matrix factorization. IEEE Trans. Serv. Comput. 2013, 6, 289–299. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems 20; Curran Associates, Inc.: Red Hook, NY, USA, 2008; pp. 1257–1264. [Google Scholar]
- Zheng, Z.; Zhang, Y.; Lyu, M.R. Distributed qos evaluation for real-world web services. In Proceedings of the 2010 IEEE International Conference on Web Services, Miami, FL, USA, 5–10 July 2010; pp. 83–90. [Google Scholar]
- Zheng, Z.; Zhang, Y.; Lyu, M.R. Investigating QoS of real-world web services. IEEE Trans. Serv. Comput. 2014, 7, 32–39. [Google Scholar] [CrossRef]
- Zhu, J.; He, P.; Zheng, Z.; Lyu, M.R. Online QoS prediction for runtime service adaptation via adaptive matrix factorization. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2911–2924. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Easy to Build | Missing Data | Algorithms | Unreliable Users- Aware | Unreliable Users- Eliminate | |
|---|---|---|---|---|---|
| UPCC [36] | Yes | No | user-based collaborative filtering | No | No |
| IPCC [37] | Yes | No | item-based collaborative filtering | No | No |
| WSRec [14] | Yes | No | neighborhood-based collaborative filtering | No | No |
| UIPCC [38] | Yes | No | combing both UPCC and IPCC | No | No |
| PMF [39] | No | No | probability-based matrix factorization | No | No |
| RMF [5] | No | Yes | L1AVG-based matrix factorization | Yes | No |
| LRMF [6] | No | Yes | location and L1AVG-based matrix factorization | Yes | No |
| BMF | No | Yes | blockchain-based matrix factorization | Yes | Yes |
| Parameter | Value | Means |
|---|---|---|
| dimensionality | 10 | the number of latent features used to factorize the user-service matrix |
| iterations | 20 | the number of iterations in the prediction process. |
| and | 30 | The parameters control the proportion of the two regularization terms that are used to avoid overfitting in the final predicted value. |
| densities | 5–30% | the percentage of unremoved entries in the user-service matrix |
| unreliable users | 40 | users may submit unreliable QoS values to impact the prediction system |
| reliable users | 339 | users submit reliable QoS values to the prediction |
| services | 5825 | the services that users’ invoke |
| Method | Density = 5% | Density = 10% | Density = 15% | Density = 20% | Density = 25% | Density = 30% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | NPRE | MAE | NPRE | MAE | NPRE | MAE | NPRE | MAE | NPRE | MAE | NPRE | |
| UMEAN | 0.8654 | 9.0086 | 0.8643 | 8.9920 | 0.8636 | 8.9859 | 0.8633 | 8.9865 | 0.8631 | 8.9853 | 0.8631 | 8.9900 |
| UPCC | 0.6446 | 5.4047 | 0.5652 | 3.9627 | 0.5268 | 3.5008 | 0.4995 | 3.2041 | 0.4811 | 3.0026 | 0.4684 | 2.8556 |
| IPCC | 0.7806 | 6.7609 | 0.7167 | 6.3810 | 0.5841 | 3.7355 | 0.5218 | 2.8352 | 0.4997 | 2.6536 | 0.4814 | 2.2682 |
| UIPCC | 0.7550 | 6.5664 | 0.6914 | 6.1147 | 0.5686 | 3.7061 | 0.5098 | 2.5189 | 0.4878 | 2.3456 | 0.4699 | 2.2700 |
| PMF | 0.7448 | 2.7772 | 0.6741 | 2.8484 | 0.5690 | 2.6746 | 0.5044 | 2.4803 | 0.4638 | 2.3255 | 0.4402 | 2.2337 |
| RMF | 0.5427 | 2.1382 | 0.4842 | 2.4199 | 0.4579 | 2.4008 | 0.4410 | 2.3483 | 0.4298 | 2.3025 | 0.4222 | 2.2754 |
| BMF | 0.5364 | 1.9695 | 0.4788 | 2.2355 | 0.4494 | 2.2102 | 0.4318 | 2.1517 | 0.4200 | 2.0991 | 0.4111 | 2.0556 |
| Impro.vs. RMF (%) | 1.16% | 7.89% | 1.12% | 7.62% | 1.86% | 7.94% | 2.09% | 7.92% | 2.28% | 8.83% | 2.63% | 9.66% |
| Impro.vs. PMF (%) | 27.98% | 29.08% | 28.97% | 21.52% | 21.02% | 17.36% | 14.39% | 13.25% | 9.44% | 9.74% | 6.61% | 7.97% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, W.; Du, X.; Xu, J. A Personalized QoS Prediction Method for Web Services via Blockchain-Based Matrix Factorization. Sensors 2019, 19, 2749. https://doi.org/10.3390/s19122749
Cai W, Du X, Xu J. A Personalized QoS Prediction Method for Web Services via Blockchain-Based Matrix Factorization. Sensors. 2019; 19(12):2749. https://doi.org/10.3390/s19122749
Chicago/Turabian StyleCai, Weihong, Xin Du, and Jianlong Xu. 2019. "A Personalized QoS Prediction Method for Web Services via Blockchain-Based Matrix Factorization" Sensors 19, no. 12: 2749. https://doi.org/10.3390/s19122749
APA StyleCai, W., Du, X., & Xu, J. (2019). A Personalized QoS Prediction Method for Web Services via Blockchain-Based Matrix Factorization. Sensors, 19(12), 2749. https://doi.org/10.3390/s19122749