Learning-Directed Dynamic Voltage and Frequency Scaling Scheme with Adjustable Performance for Single-Core and Multi-Core Embedded and Mobile Systems †


Abstract
:1. Introduction
2. Related Works
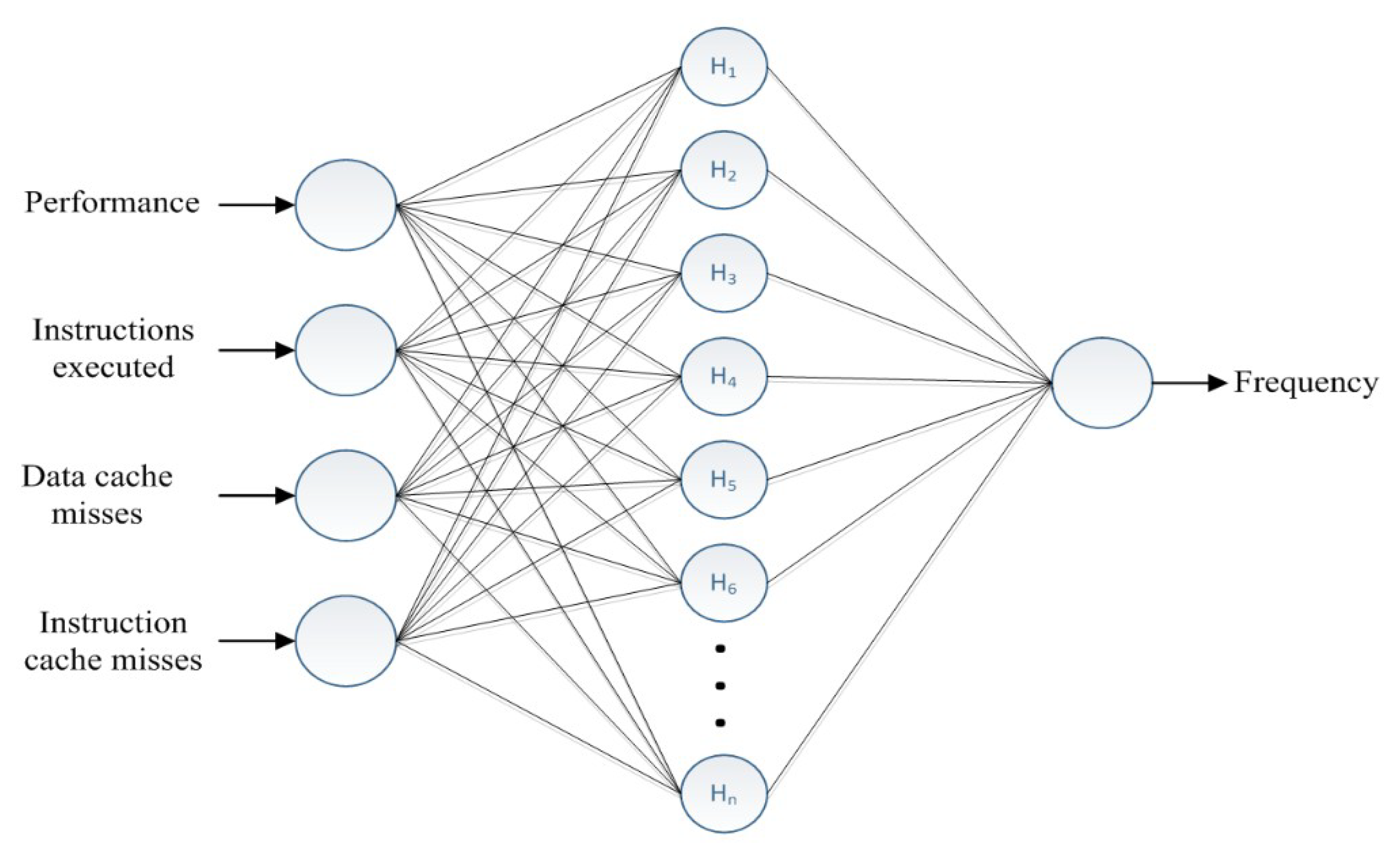
3. Counter Propagation Networks
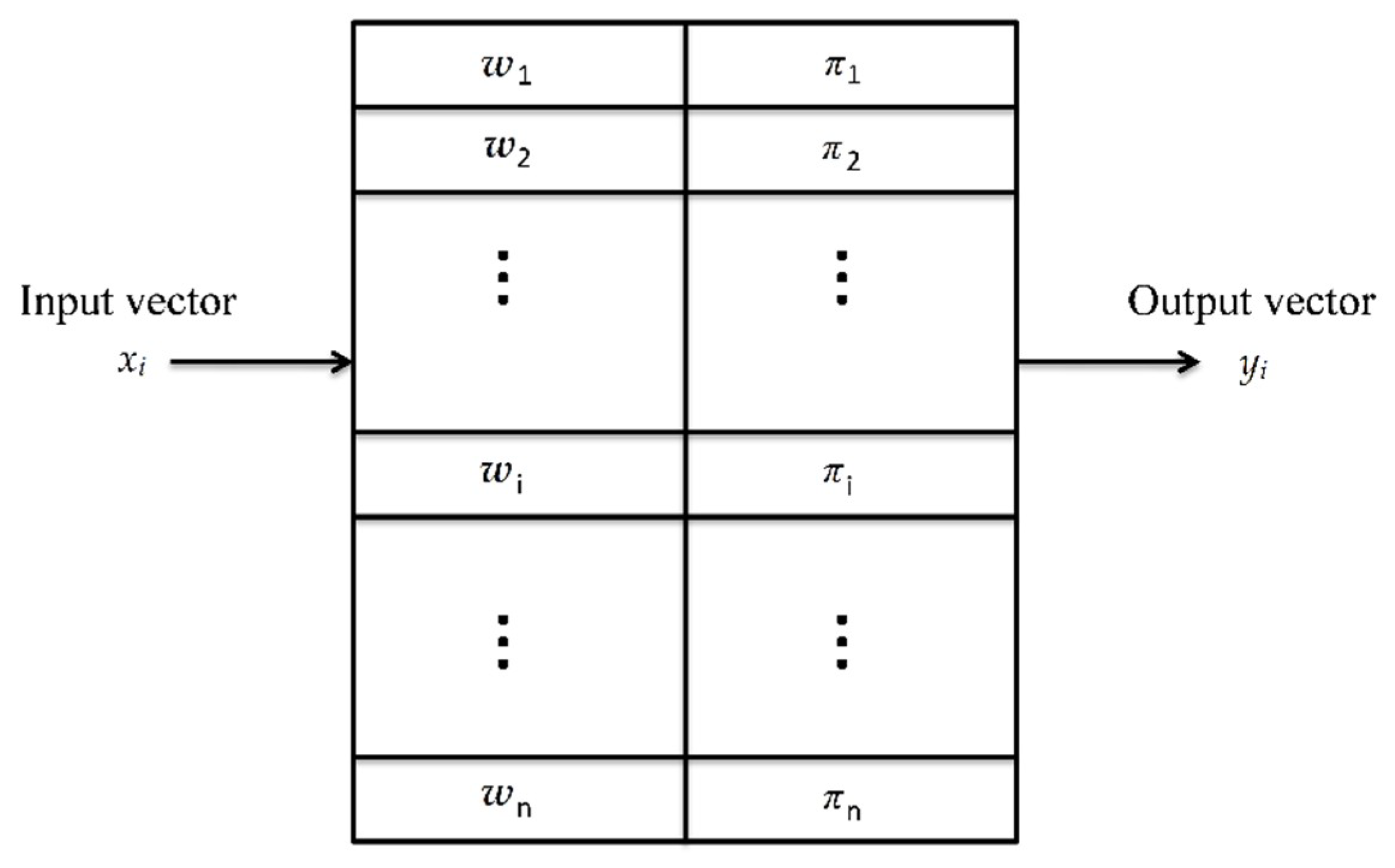
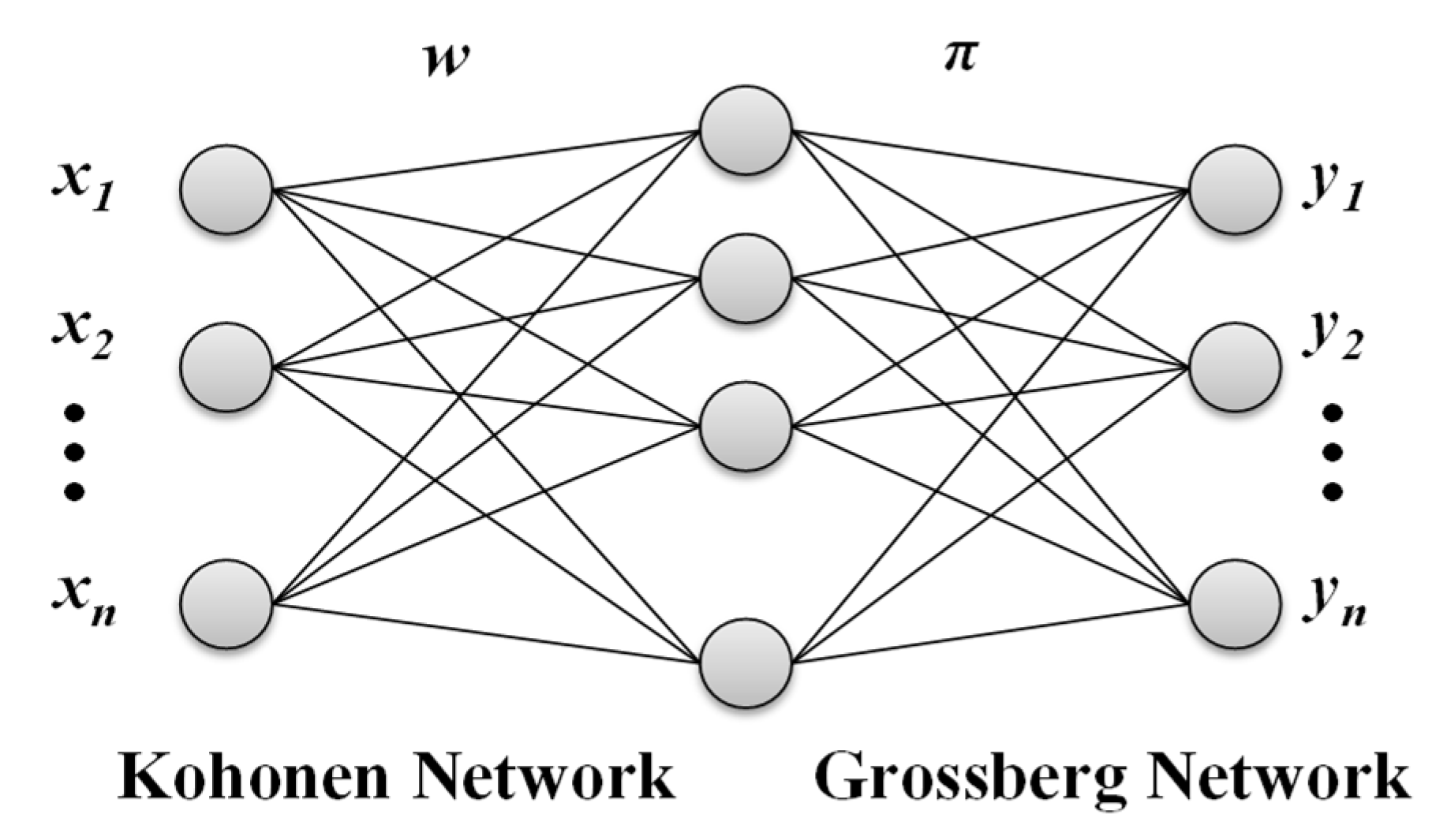
3.1. Counter Propagation Networks
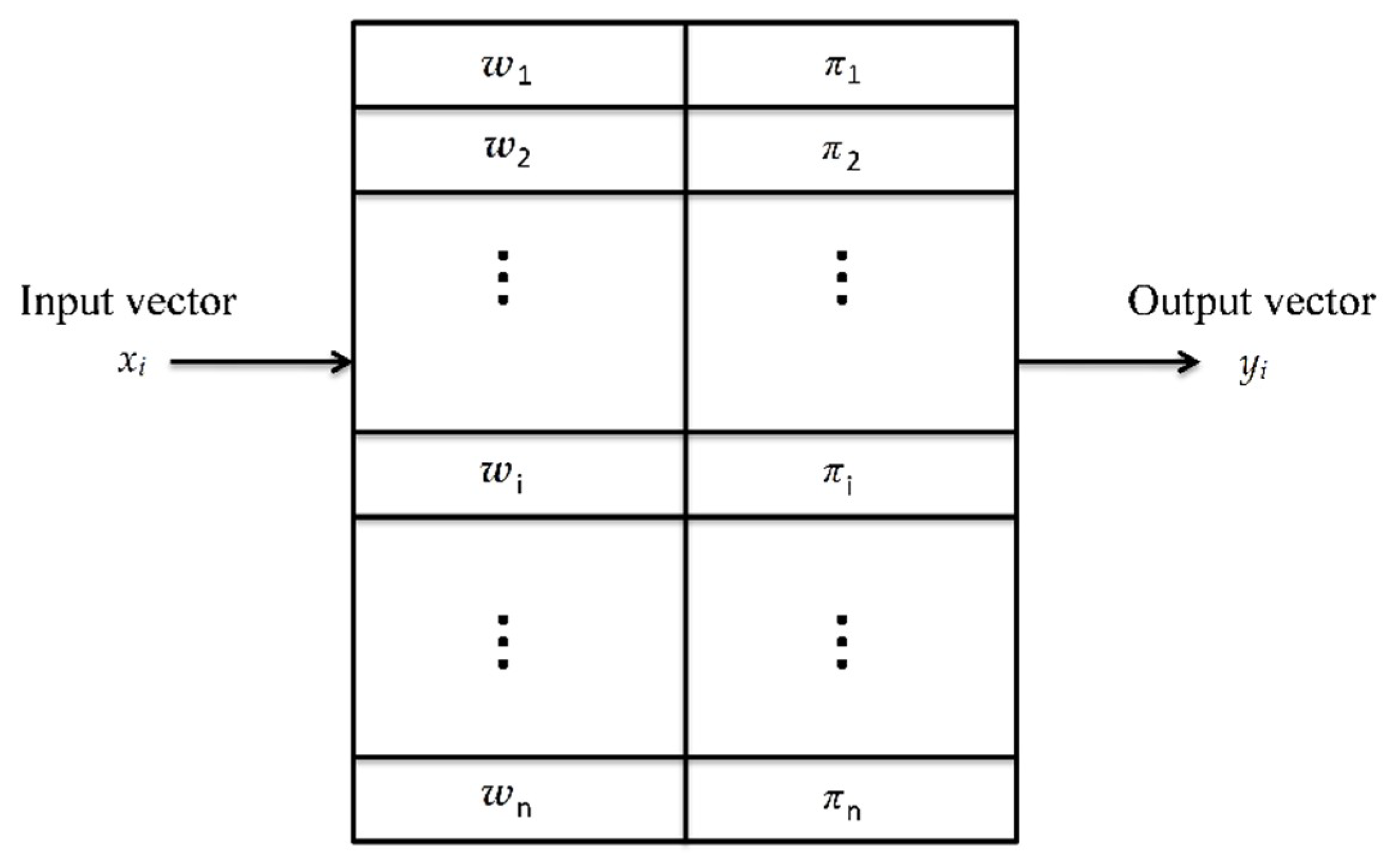
3.2. CPN Learning
3.3. CPN Algorithm
- (1)
- At the initial phase, the weight W and π are all set at zero. Δ is the acceptable distance. N is the number of hidden nodes and is initialized as zero. t is the learning counter.
- (2)
- First, the initial node is generated in the hidden layer. For all training data, the CPN learning algorithm compares the Euclidean distances between x(t) and W.
- (3)
- Second, the minimum distance between x(t) and W is found. After computing all the distances, the minimum distance D can be identified. If D is higher than Δ, then the CPN learning algorithm builds the new node in the hidden layer. If D is lower than Δ, then the minimum distance node j is chosen.
- (4)
- The final step is to adjust the weight and according to the input x(t) and output y(t). If the training process is not finished, then it reverts to reading input training data.
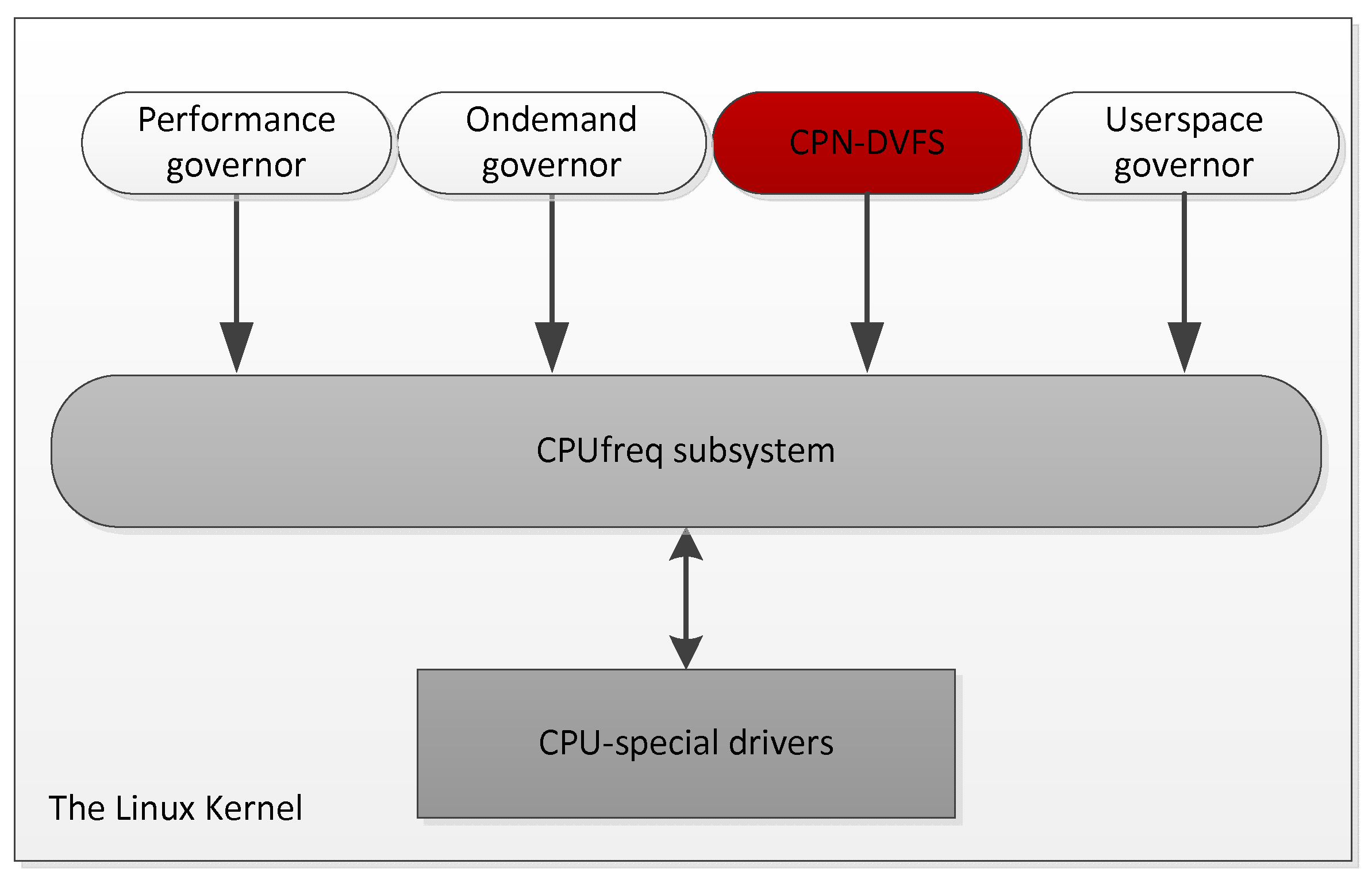
4. Learning-Based DVFS Schemes
4.1. Single-Core CPN-DVFS Scheme
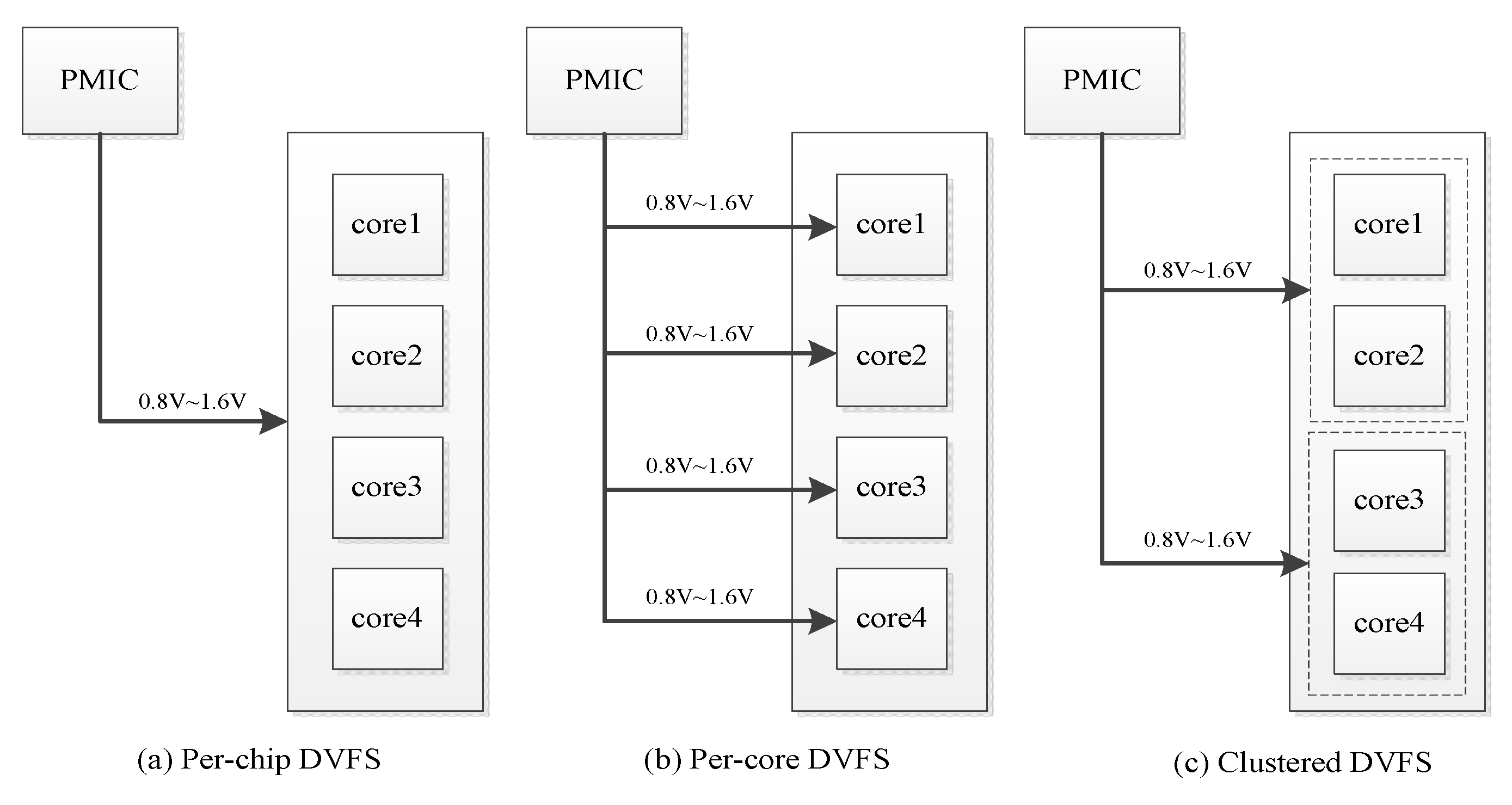
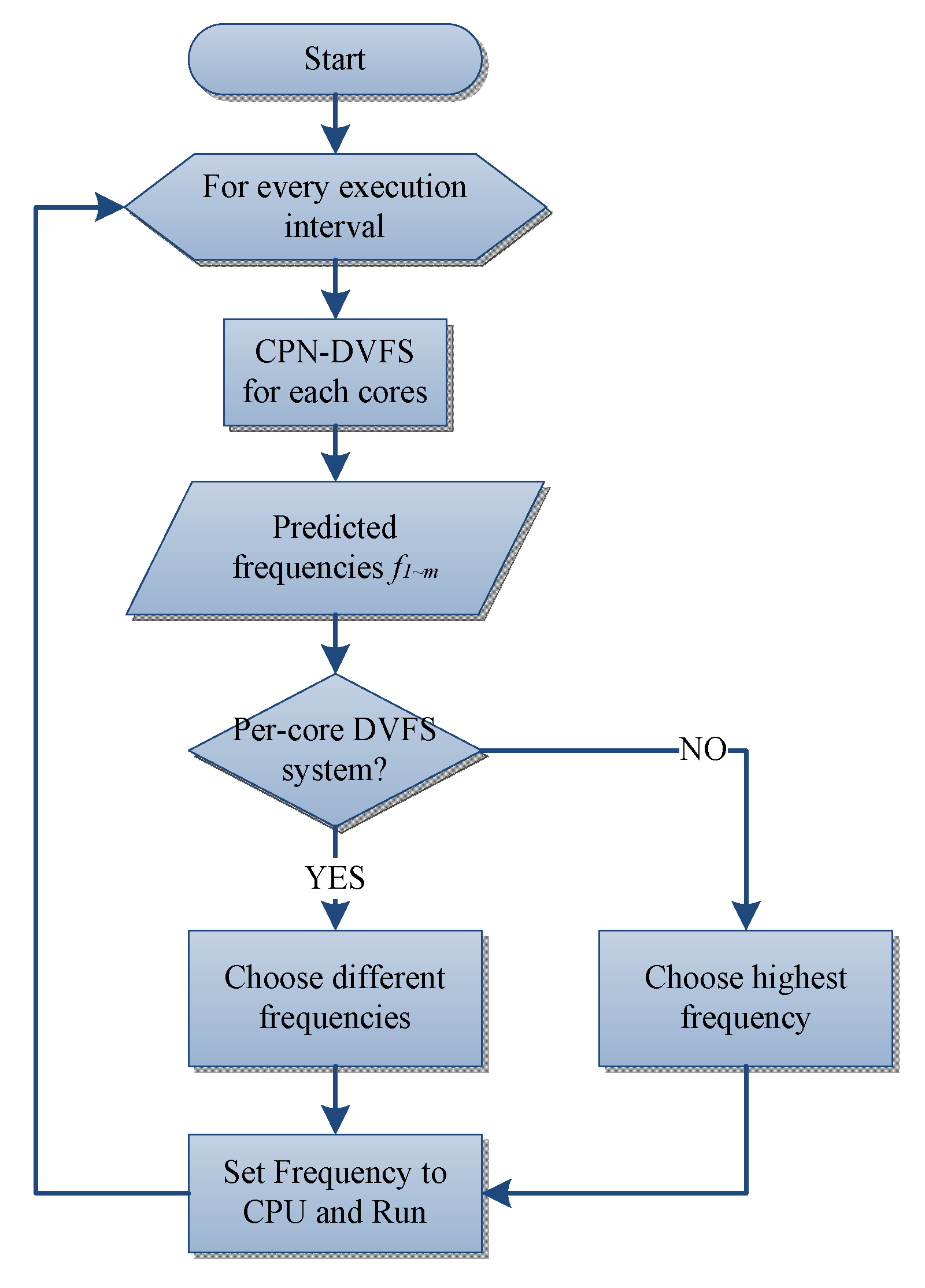
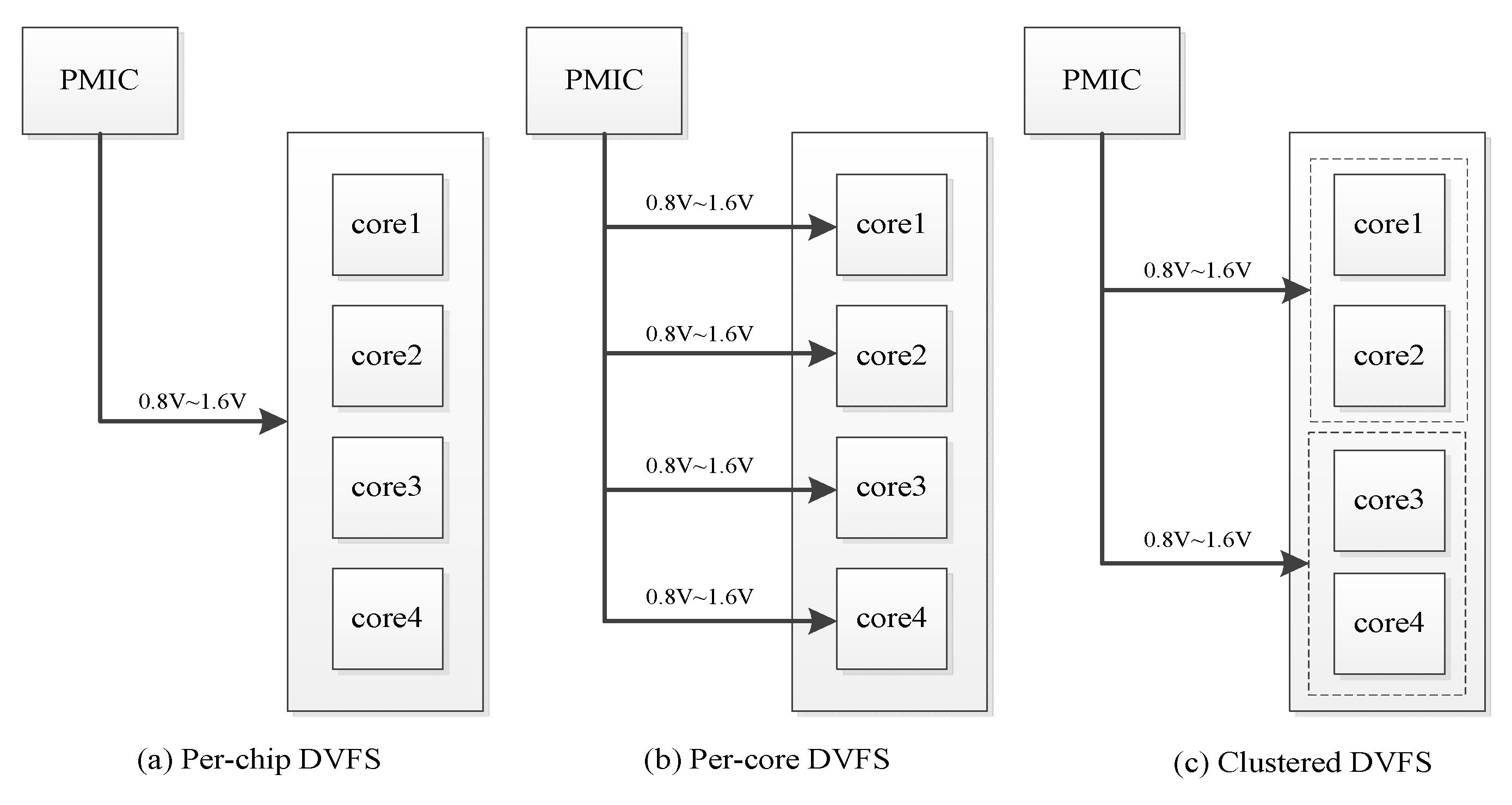
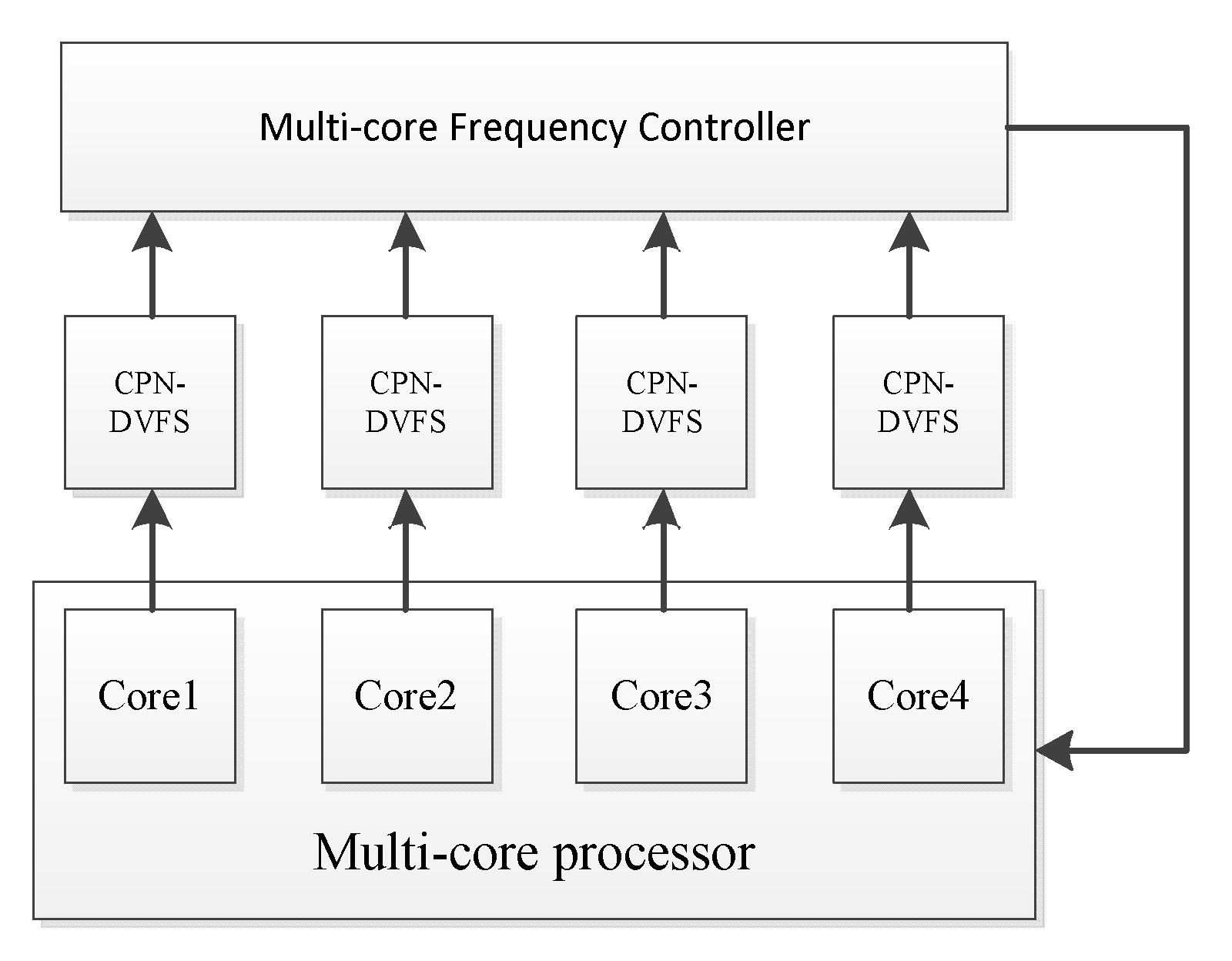
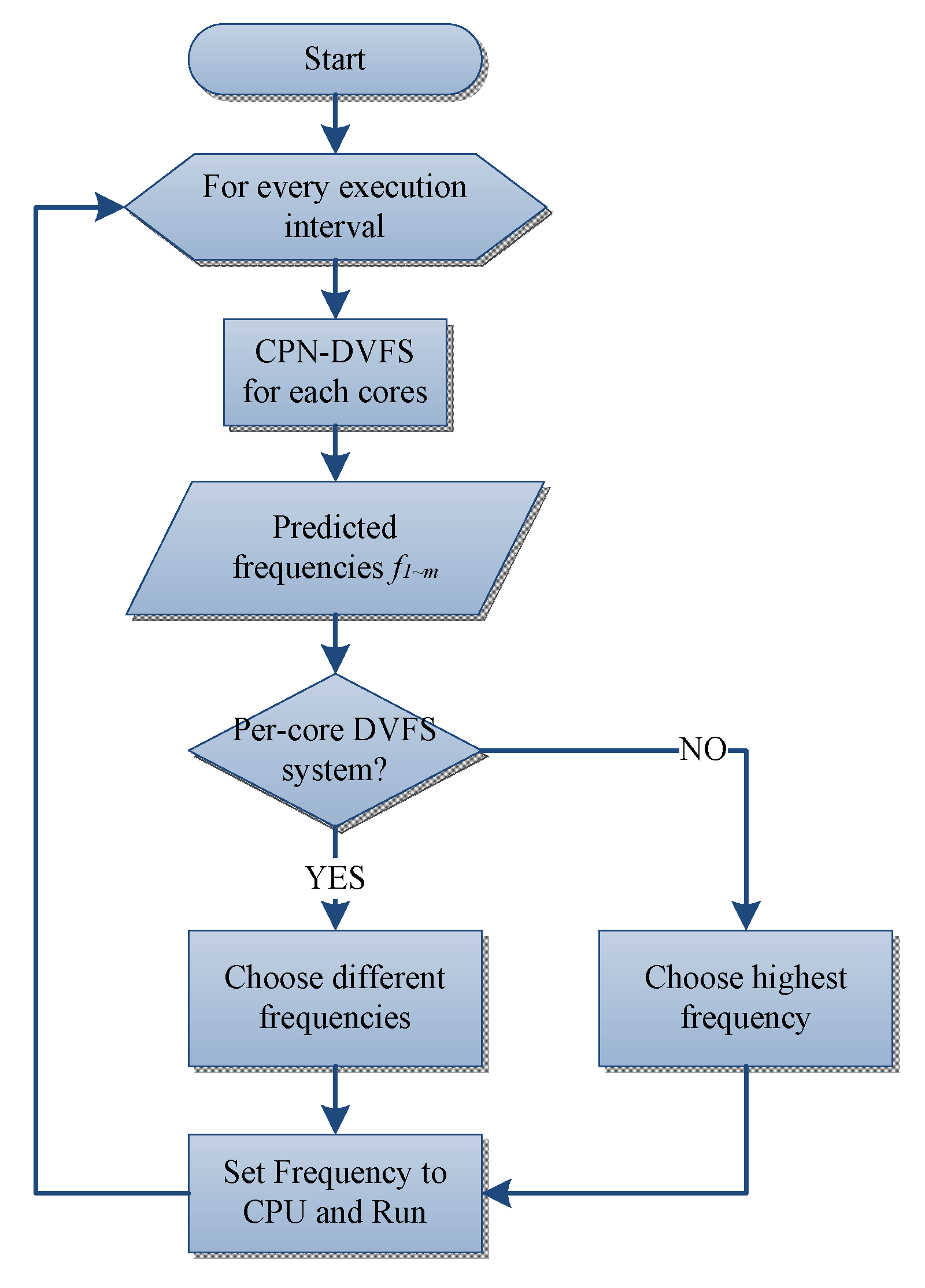
4.2. Multi-Core CPN-DVFS Scheme
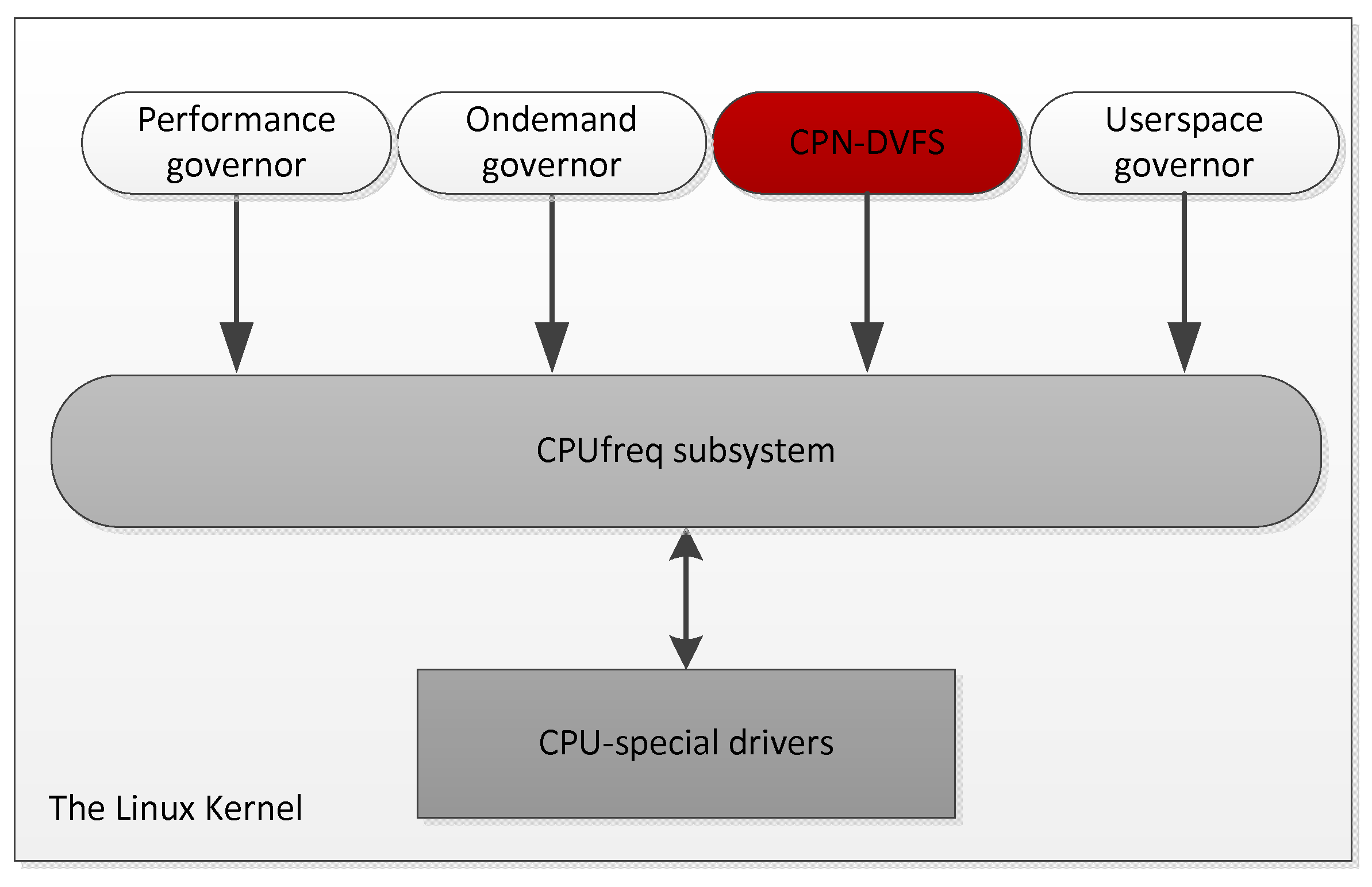
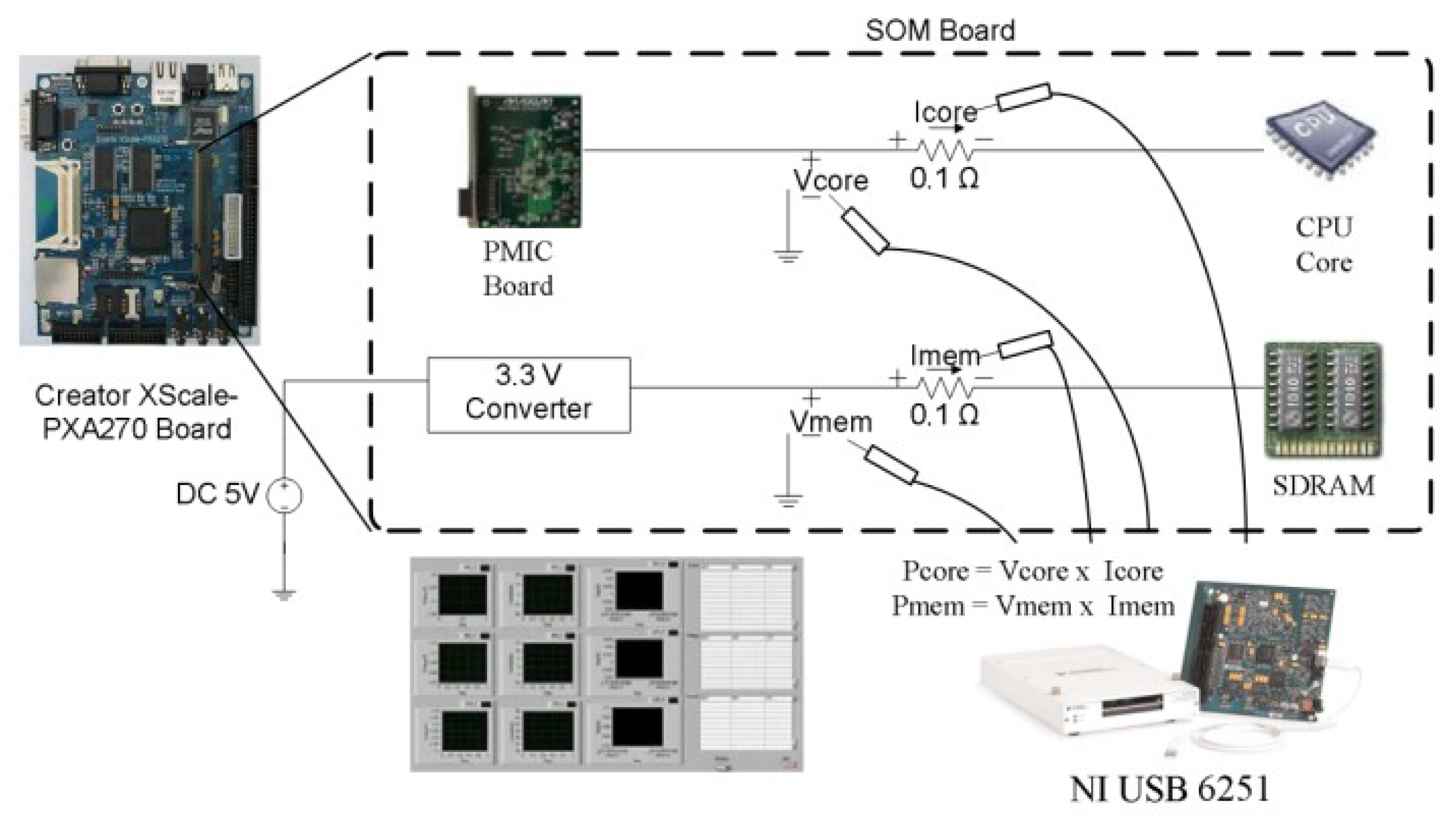
5. Implementation and Measurement
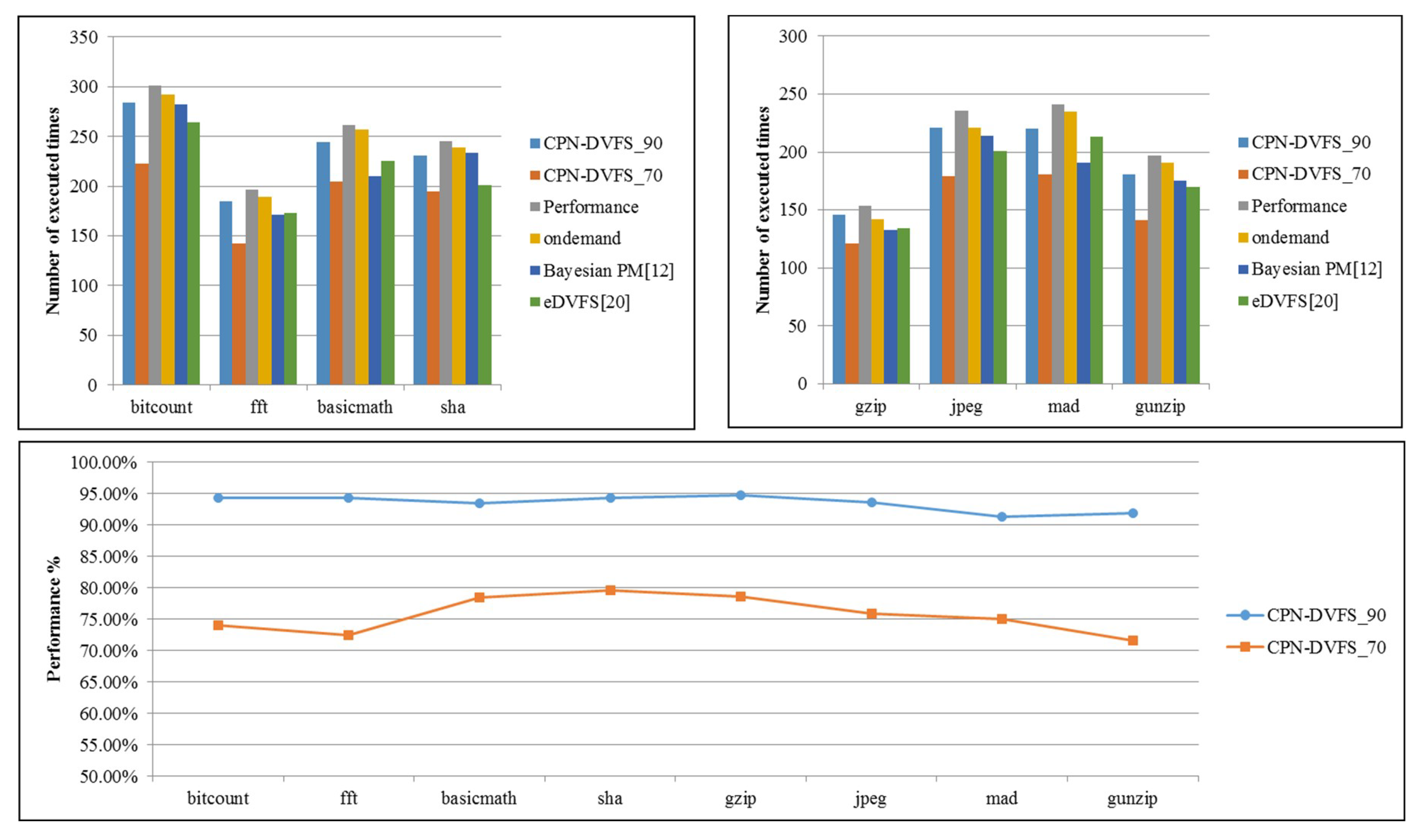
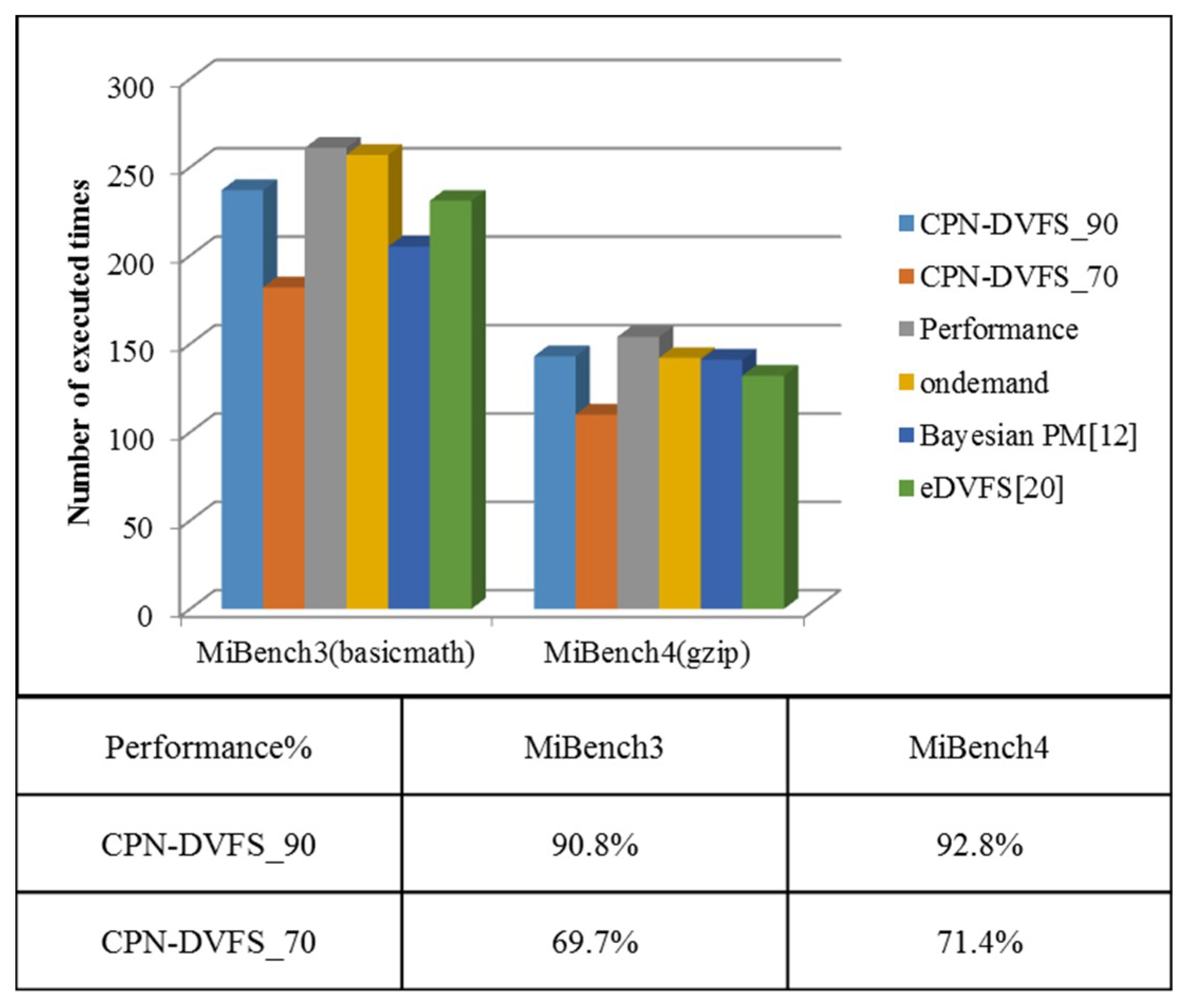
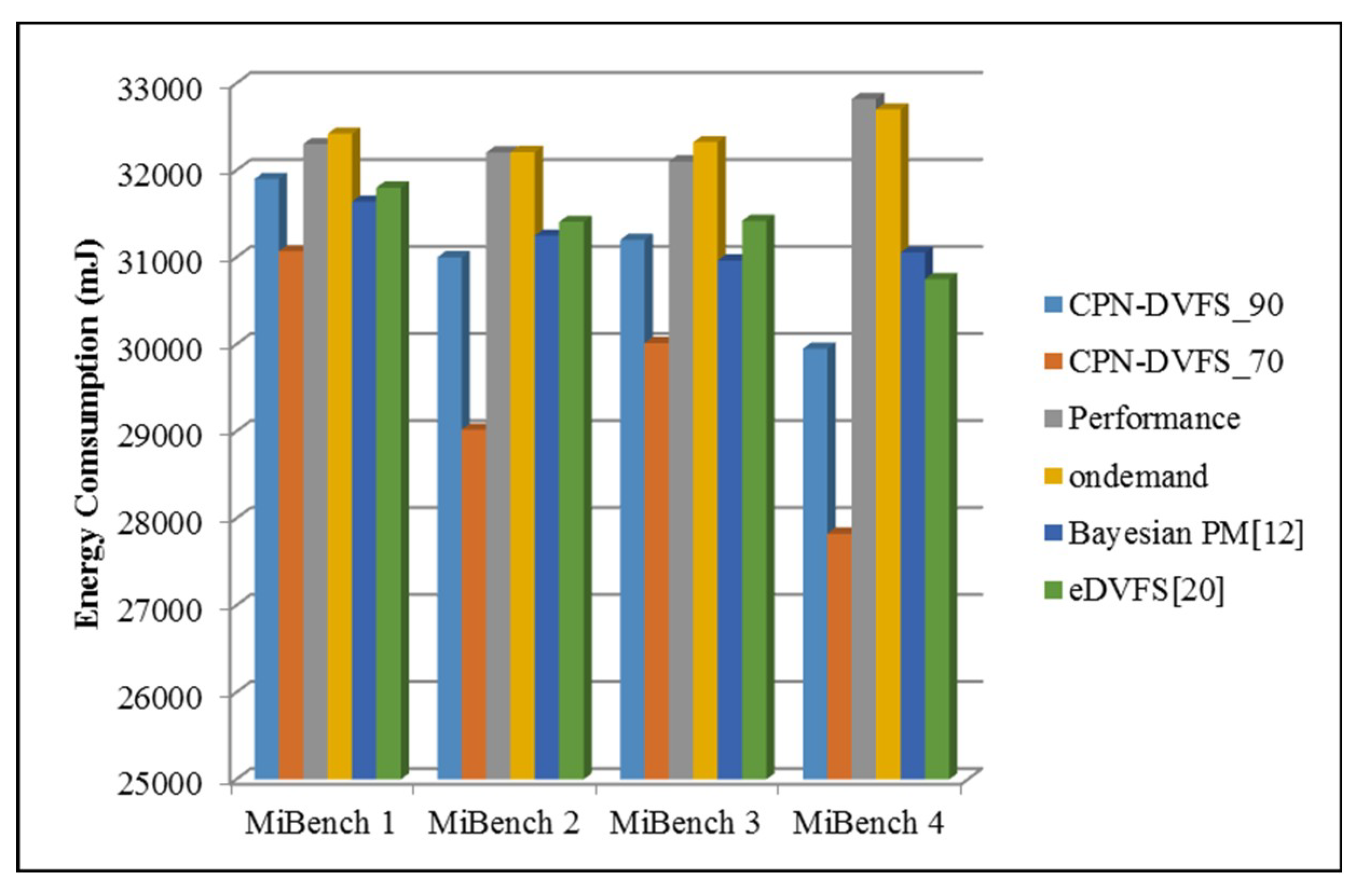
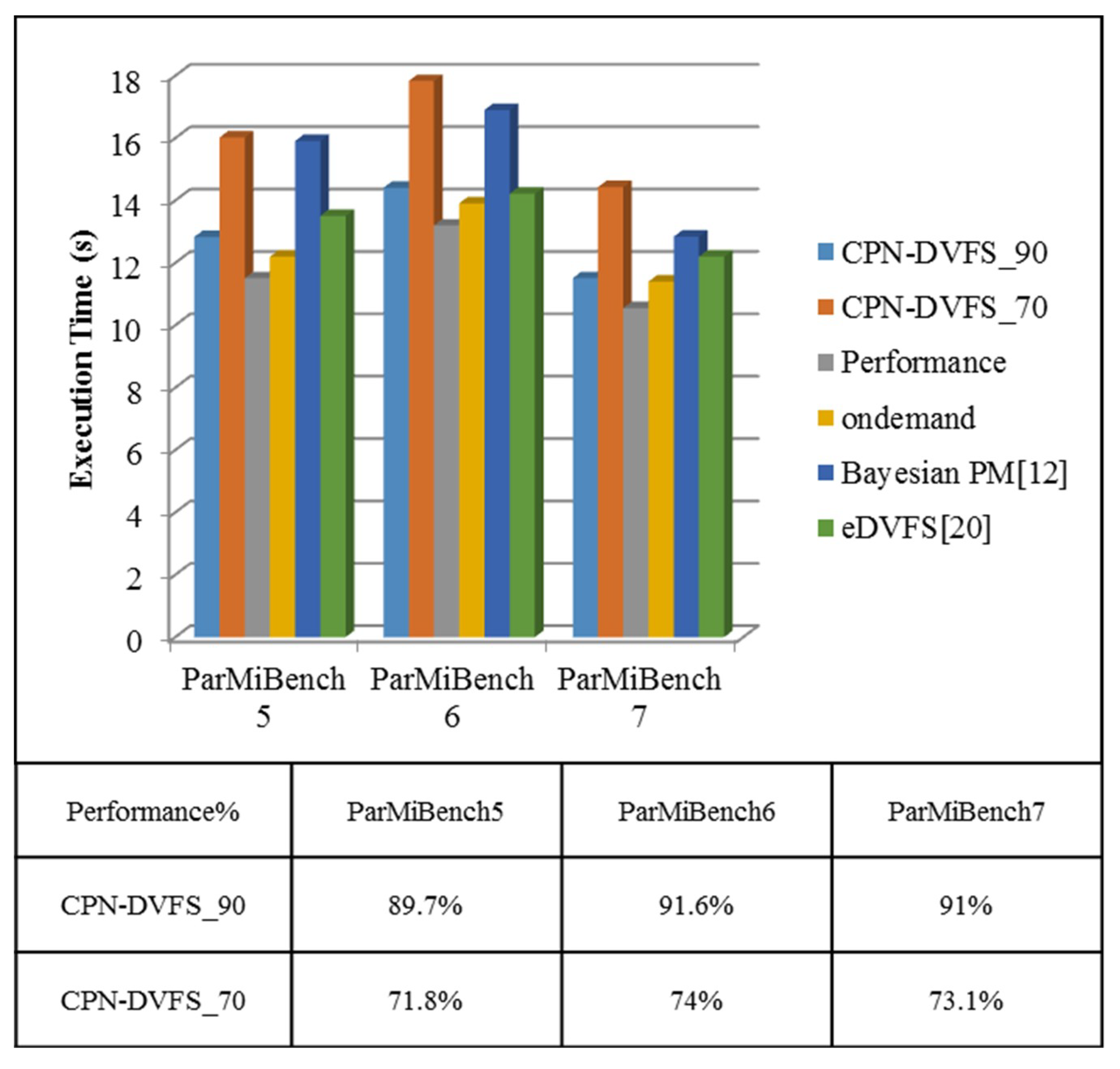
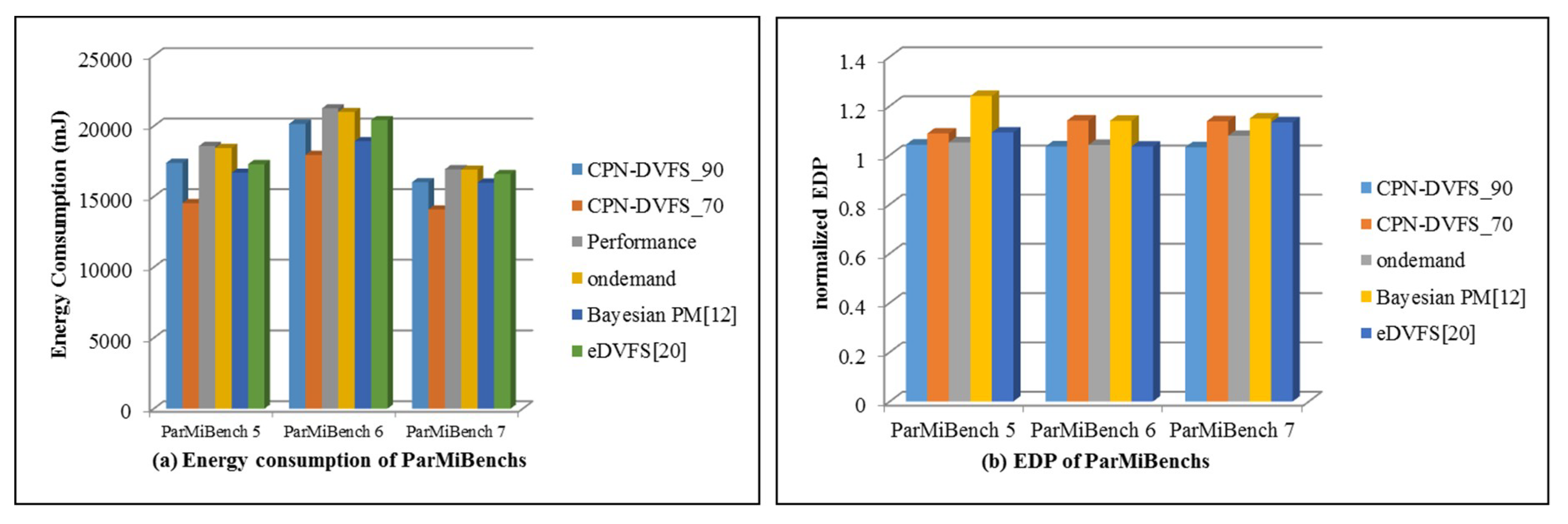
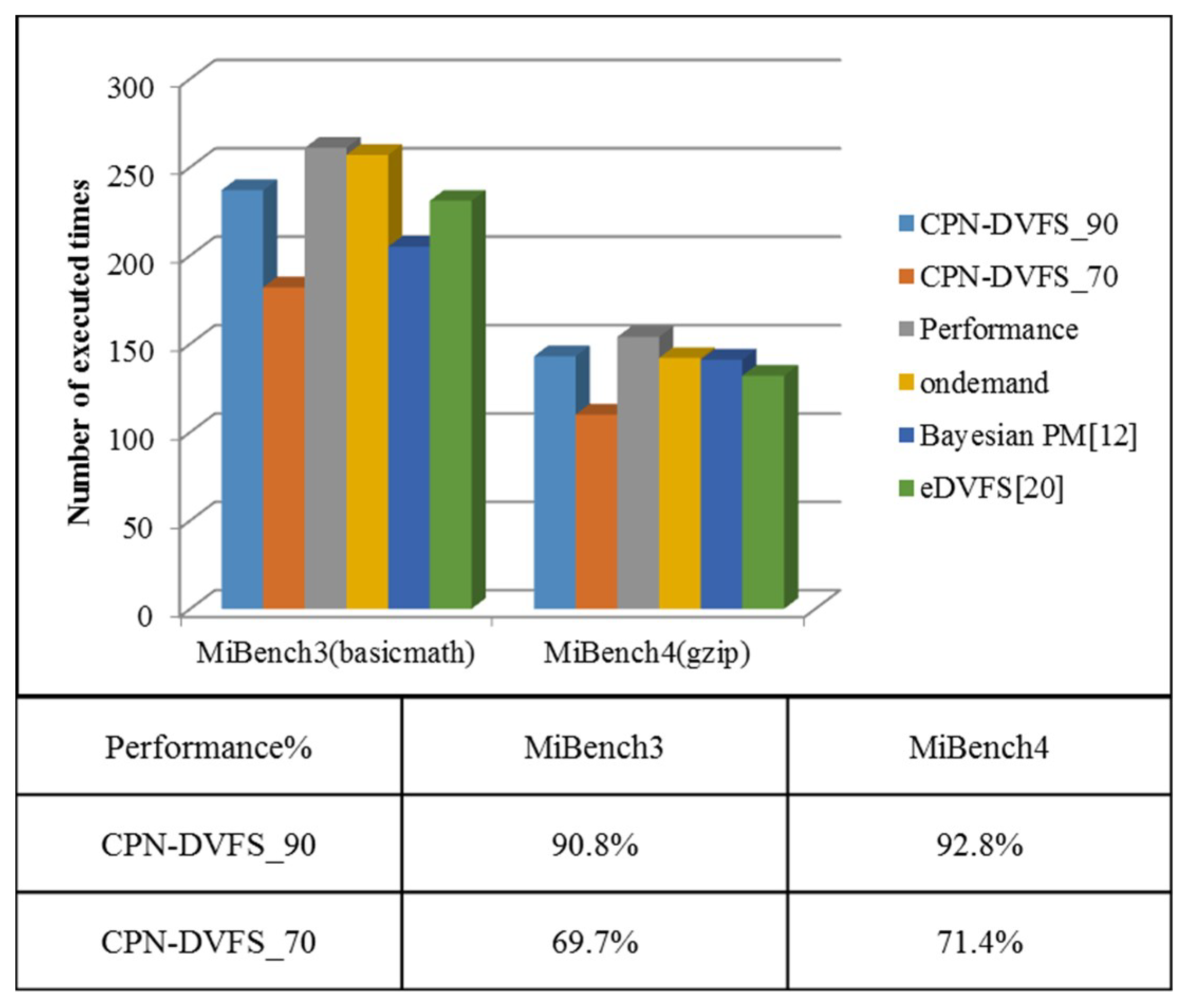
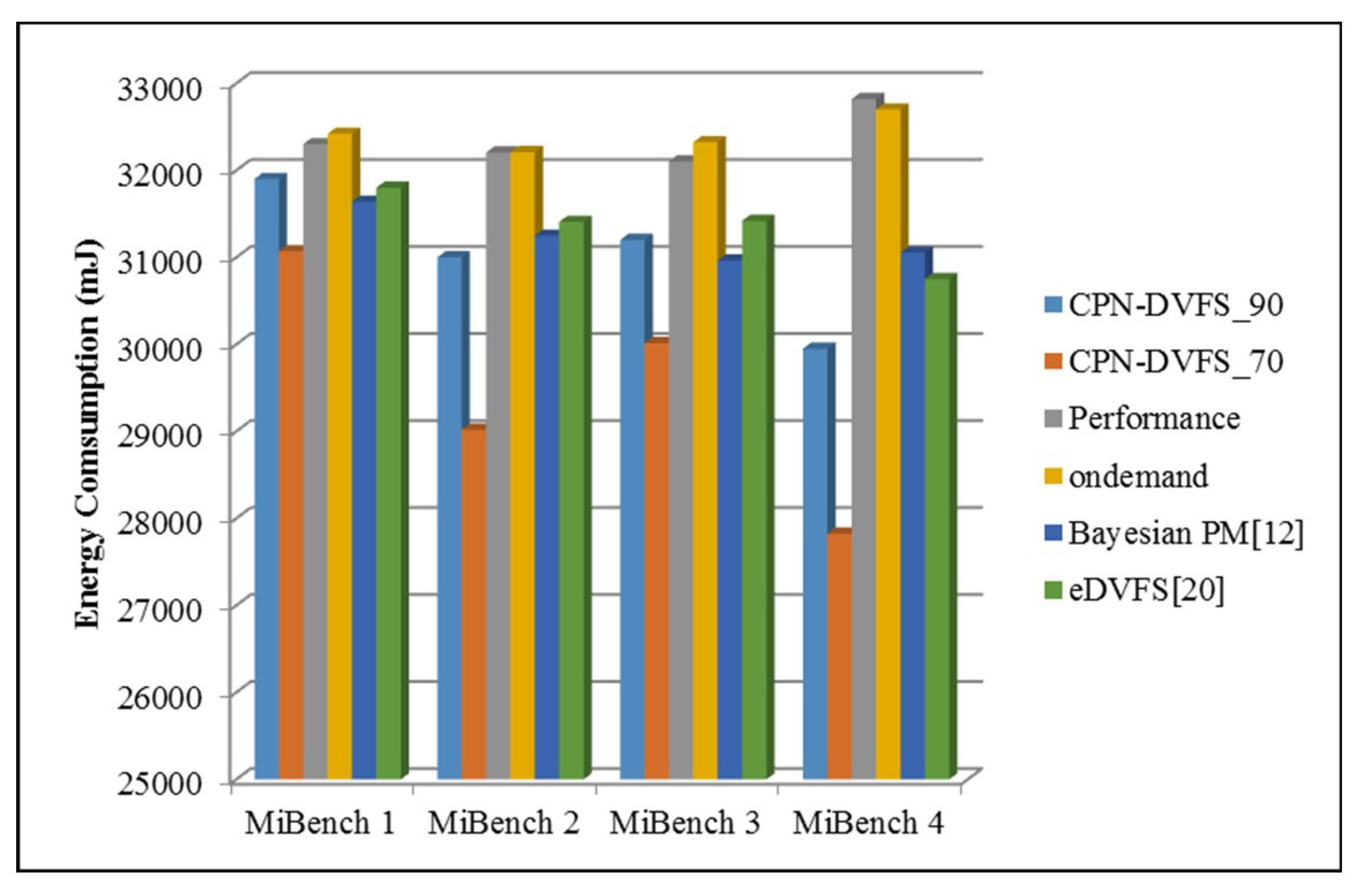
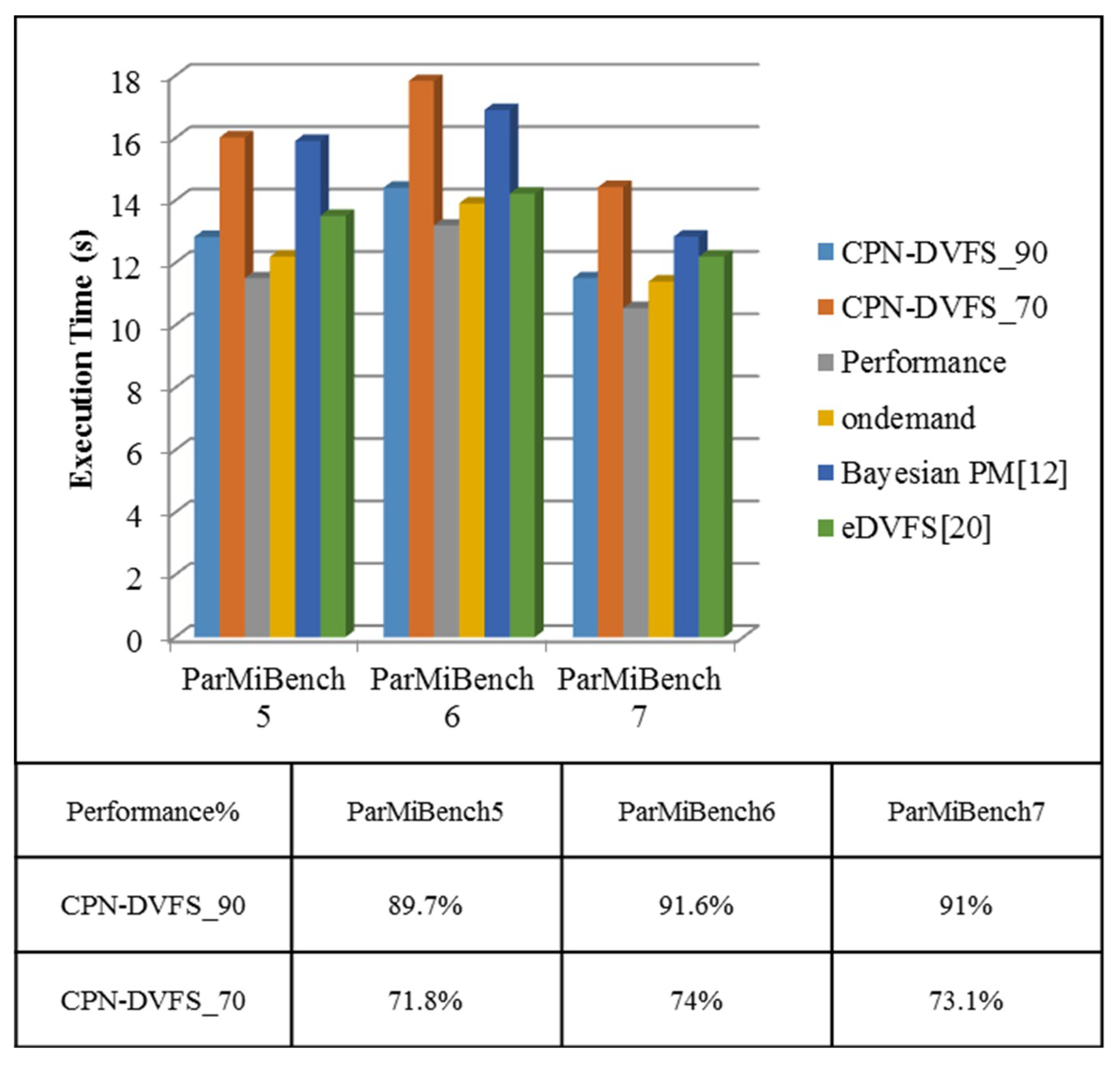
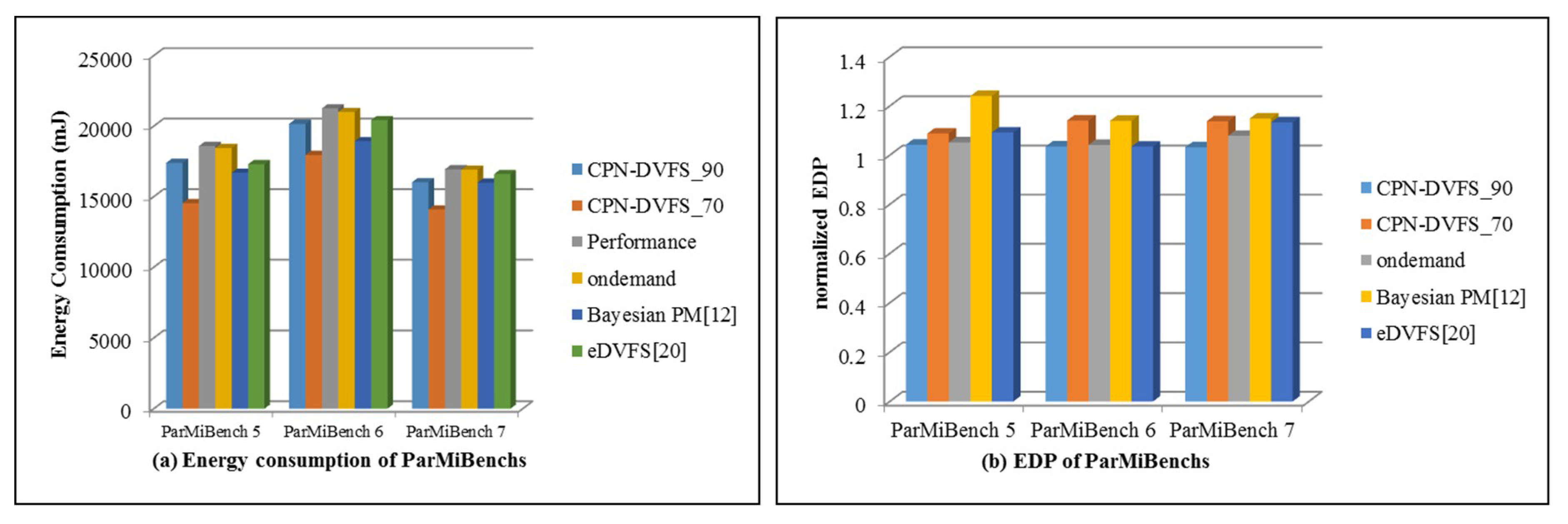
6. Experiments
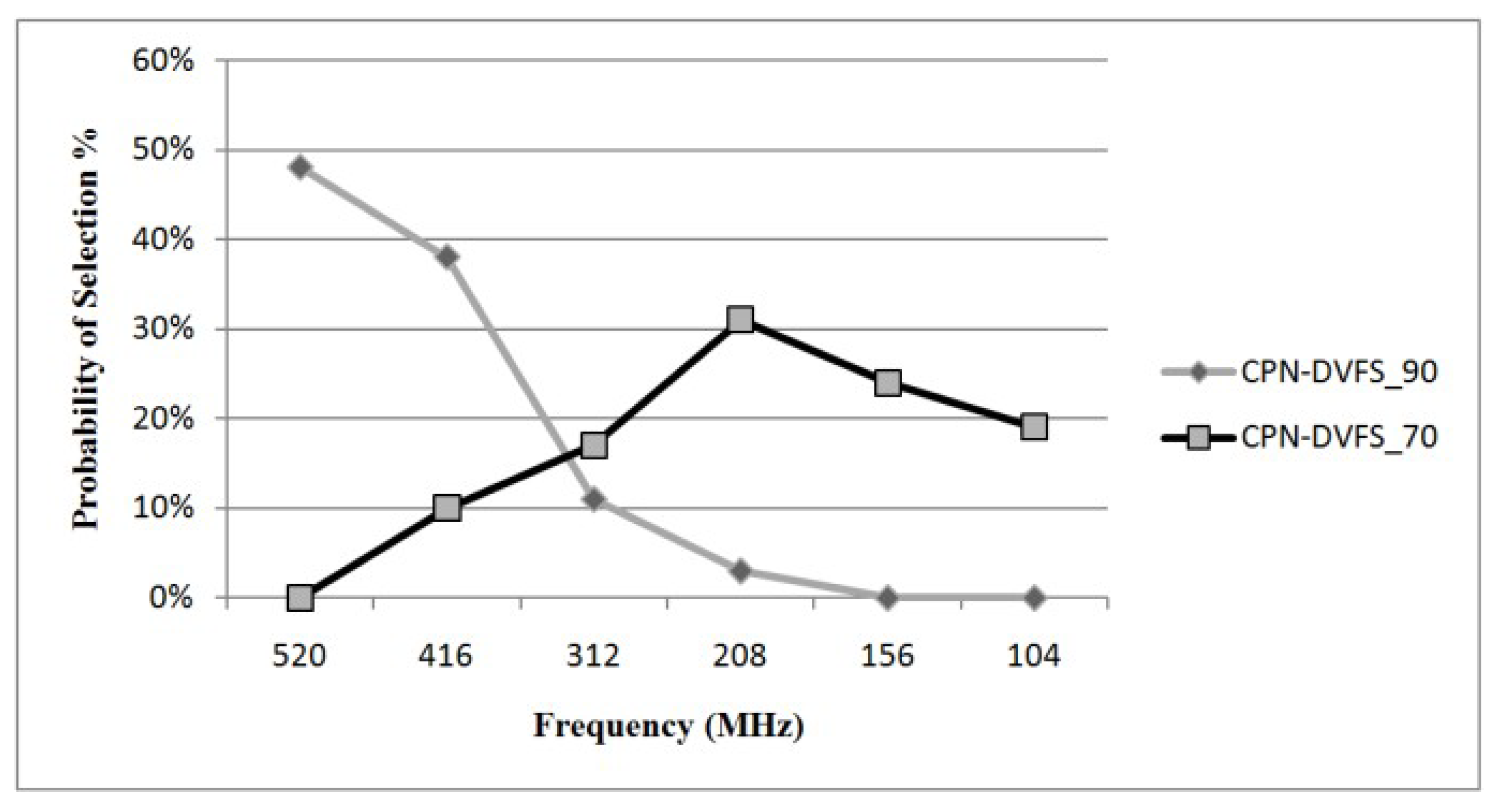
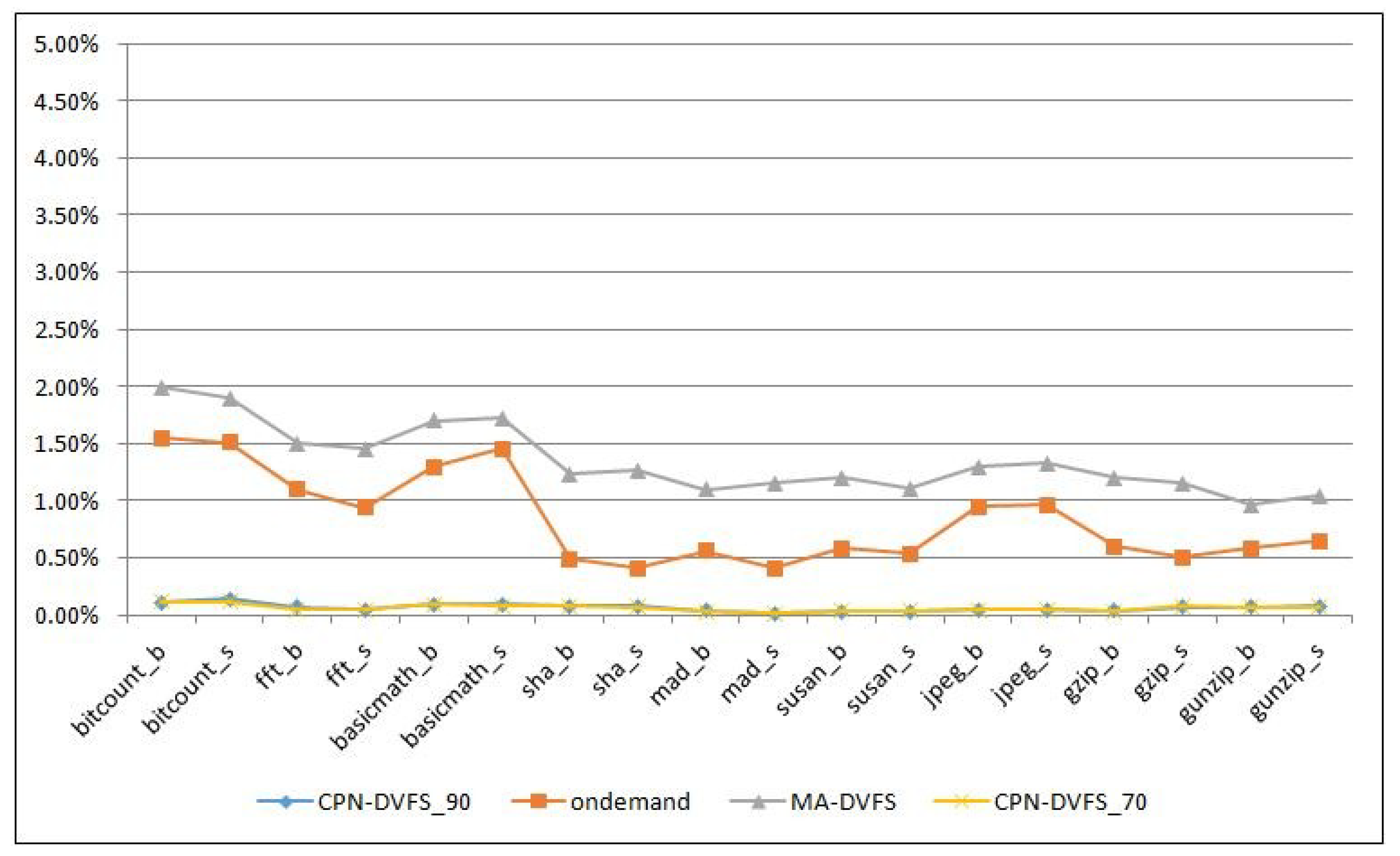
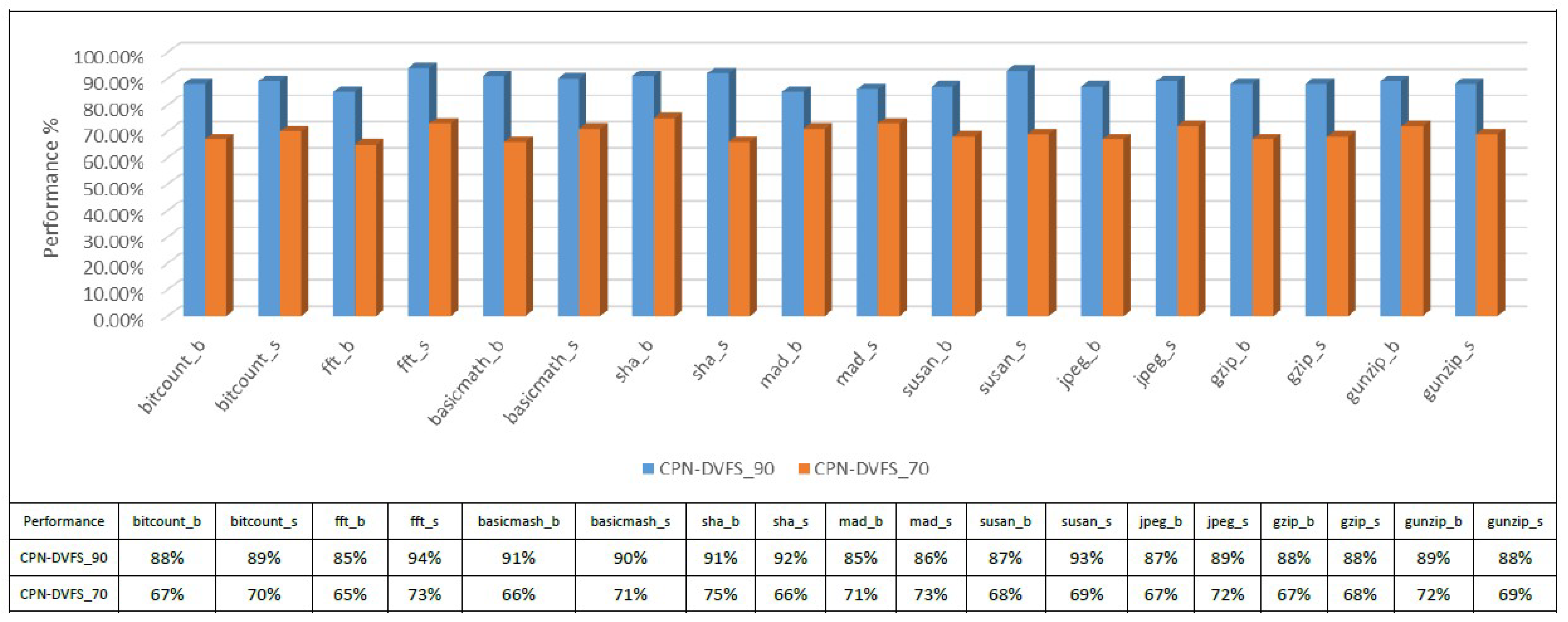
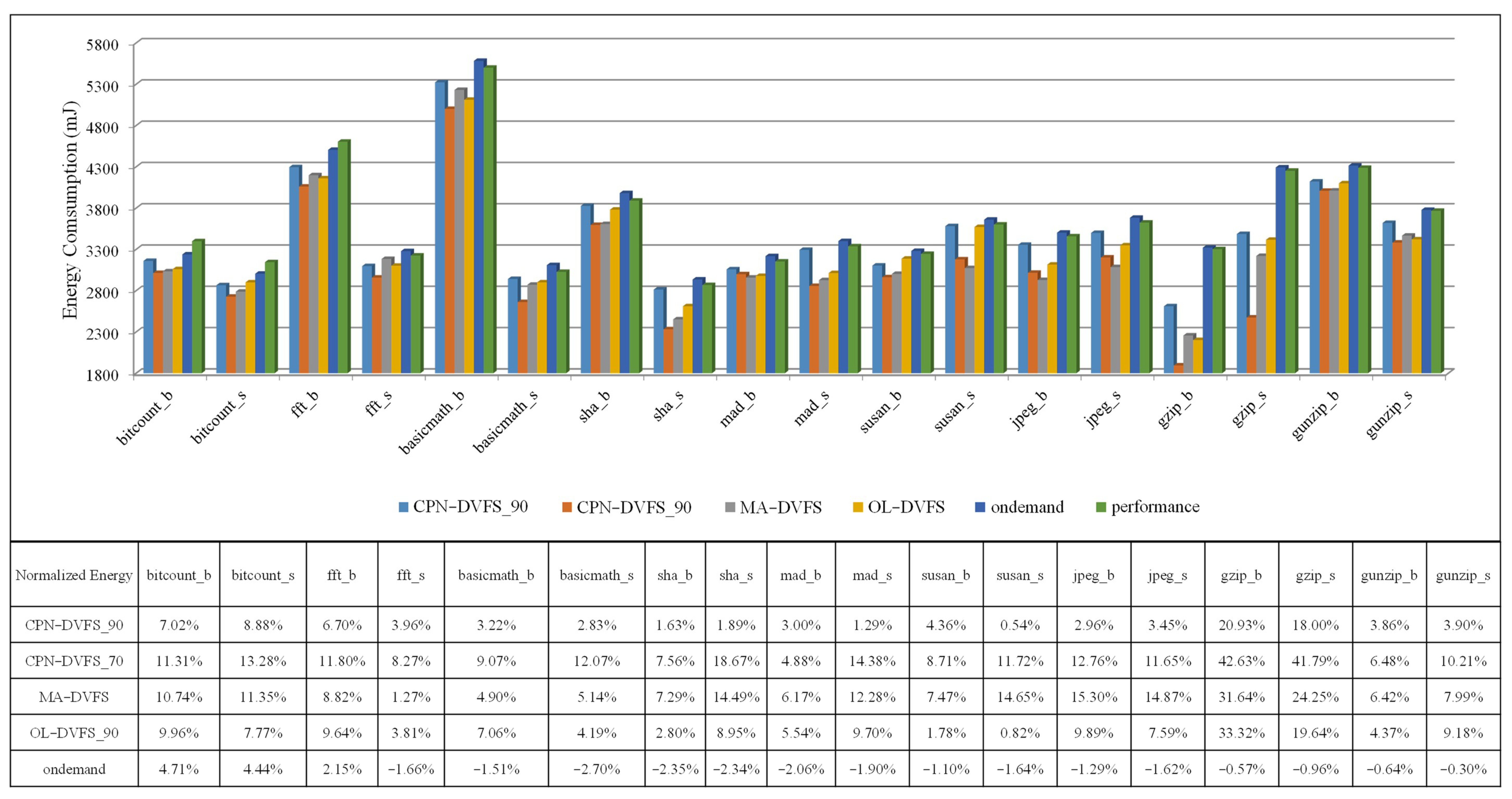
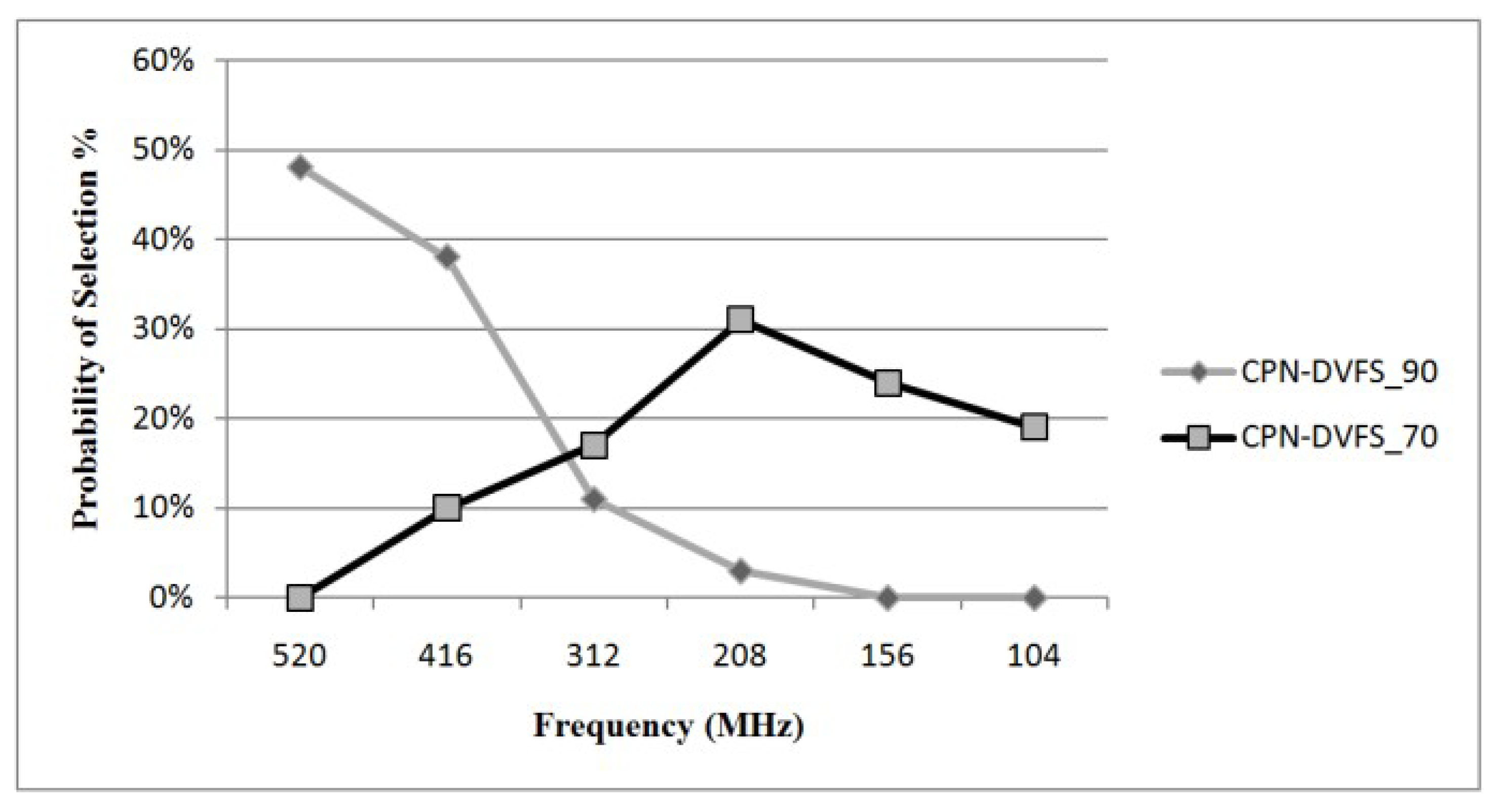
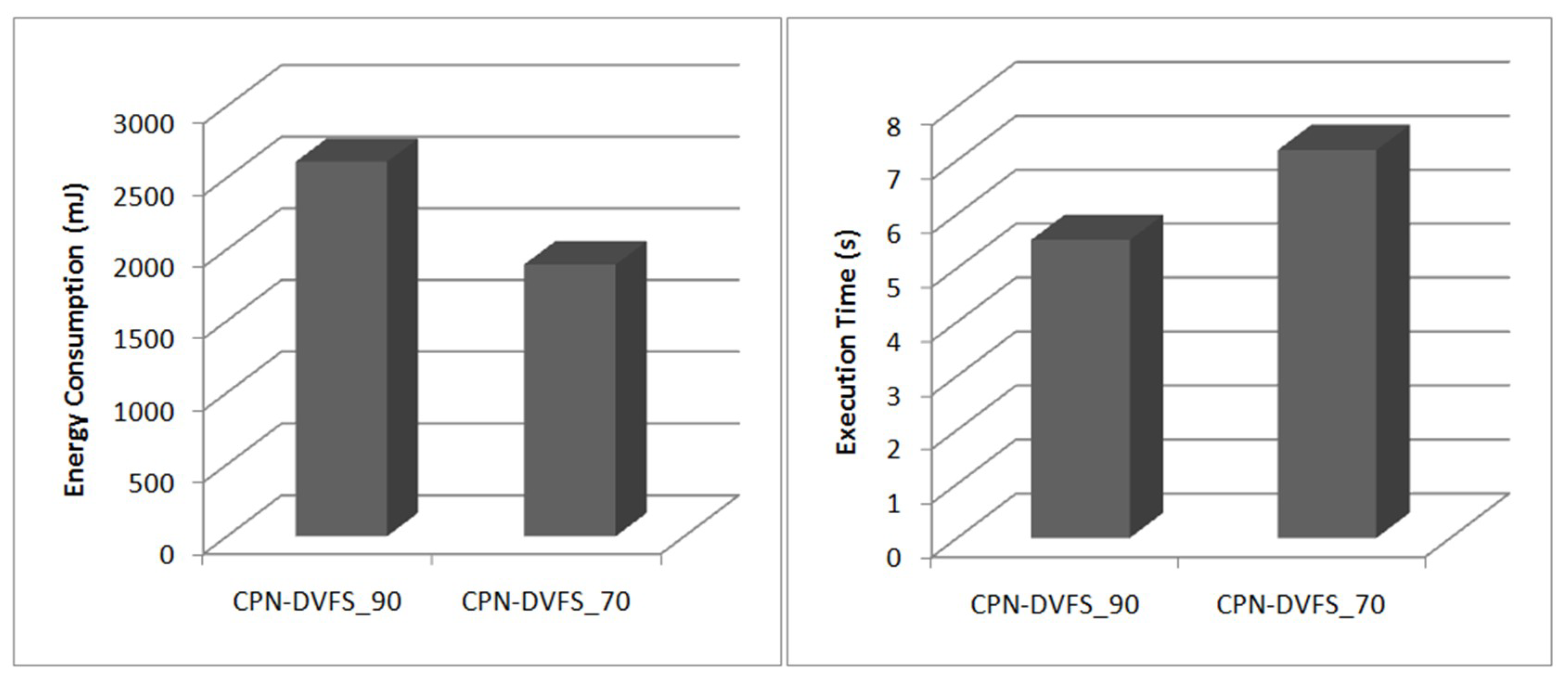
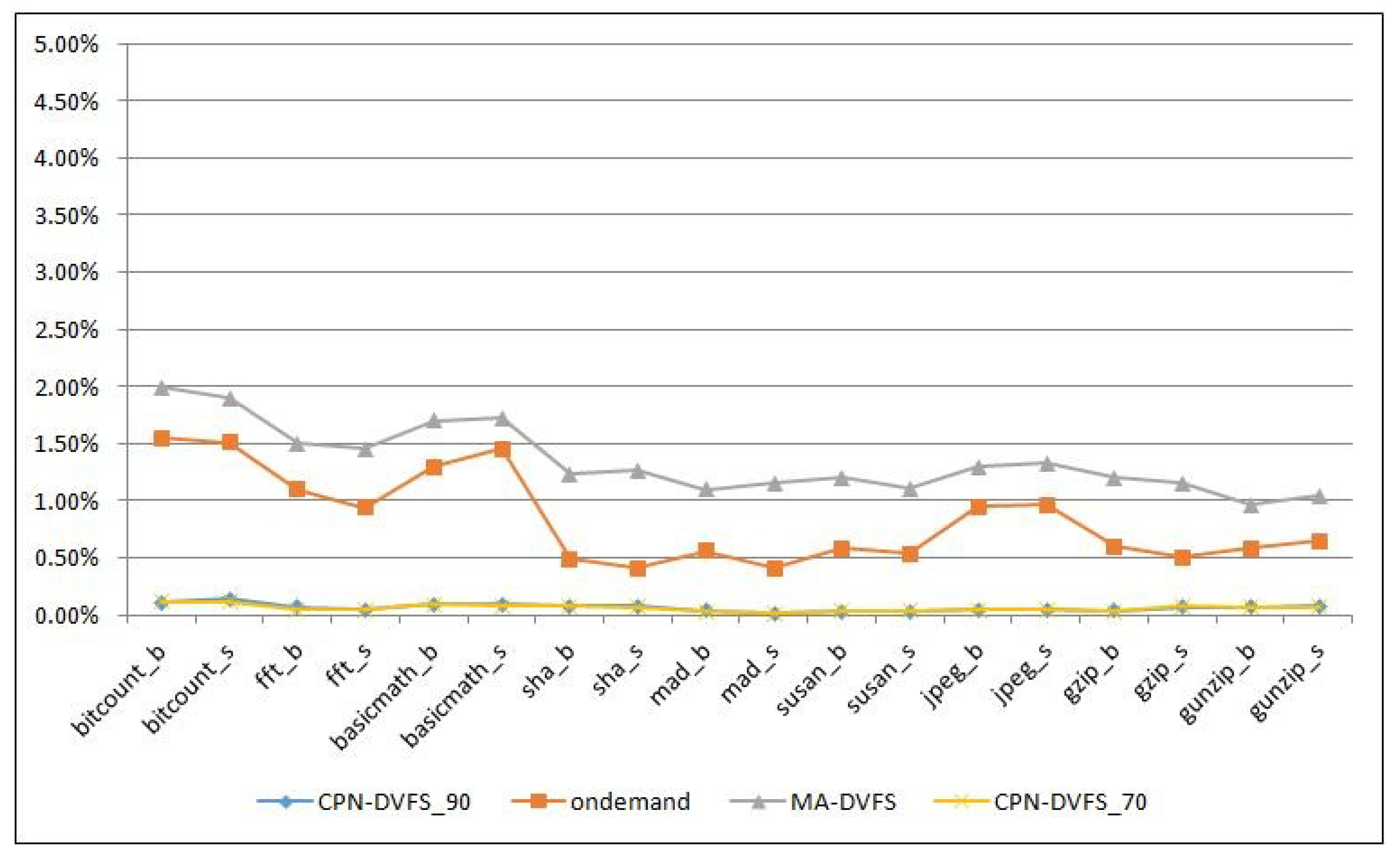
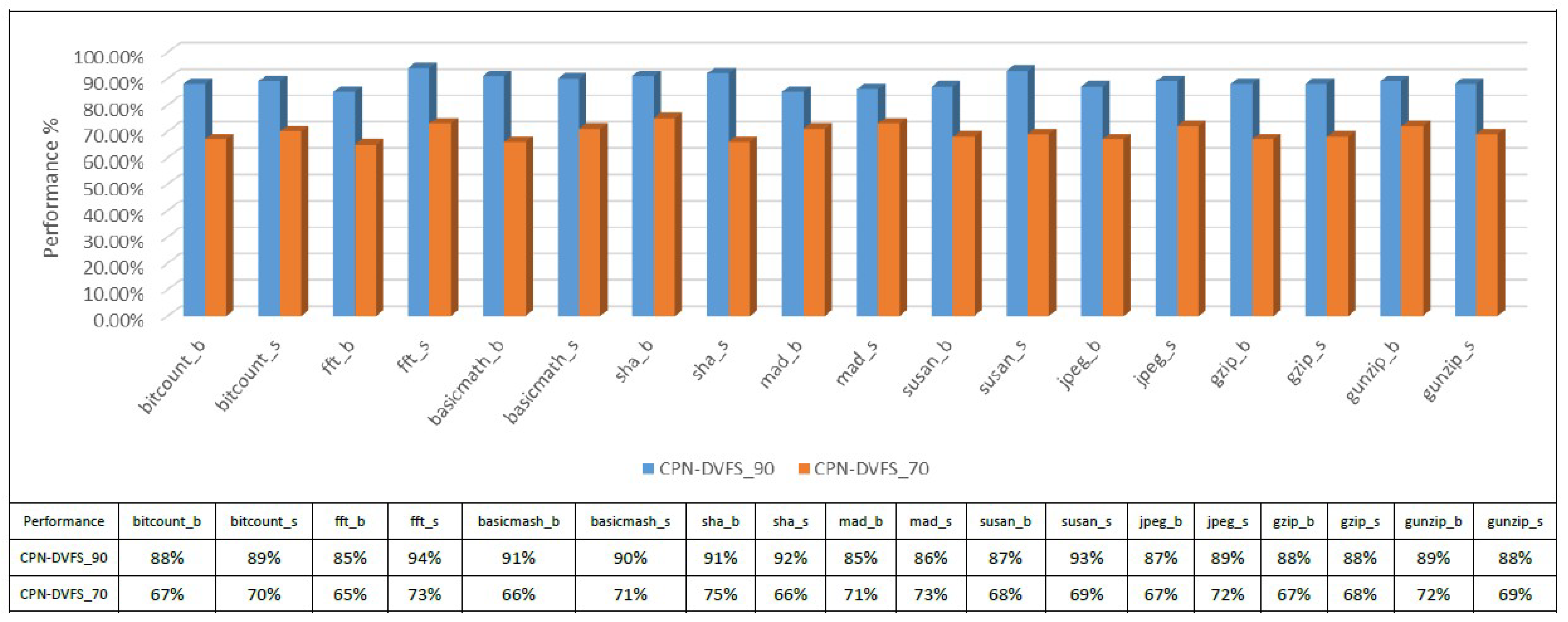
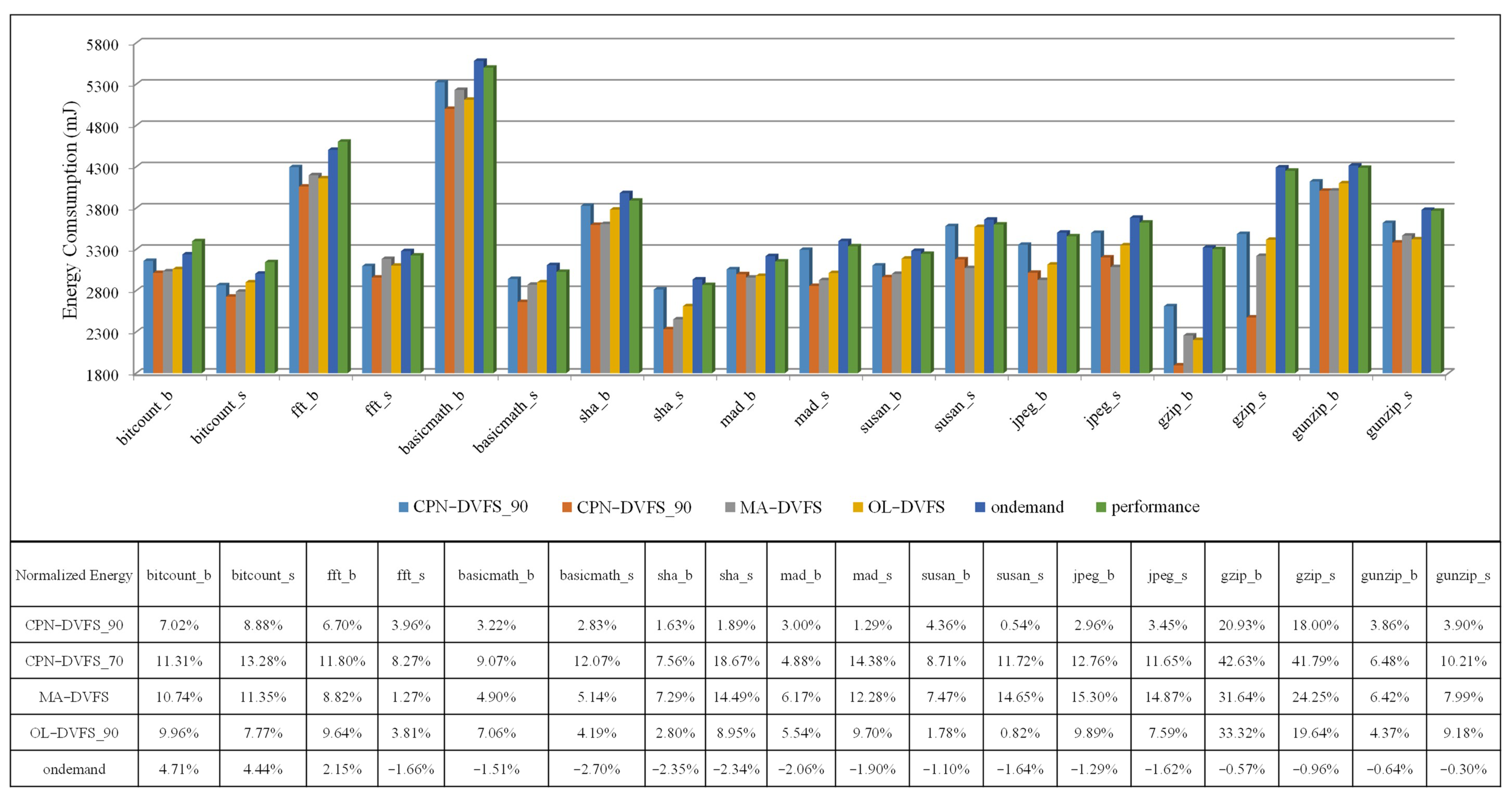
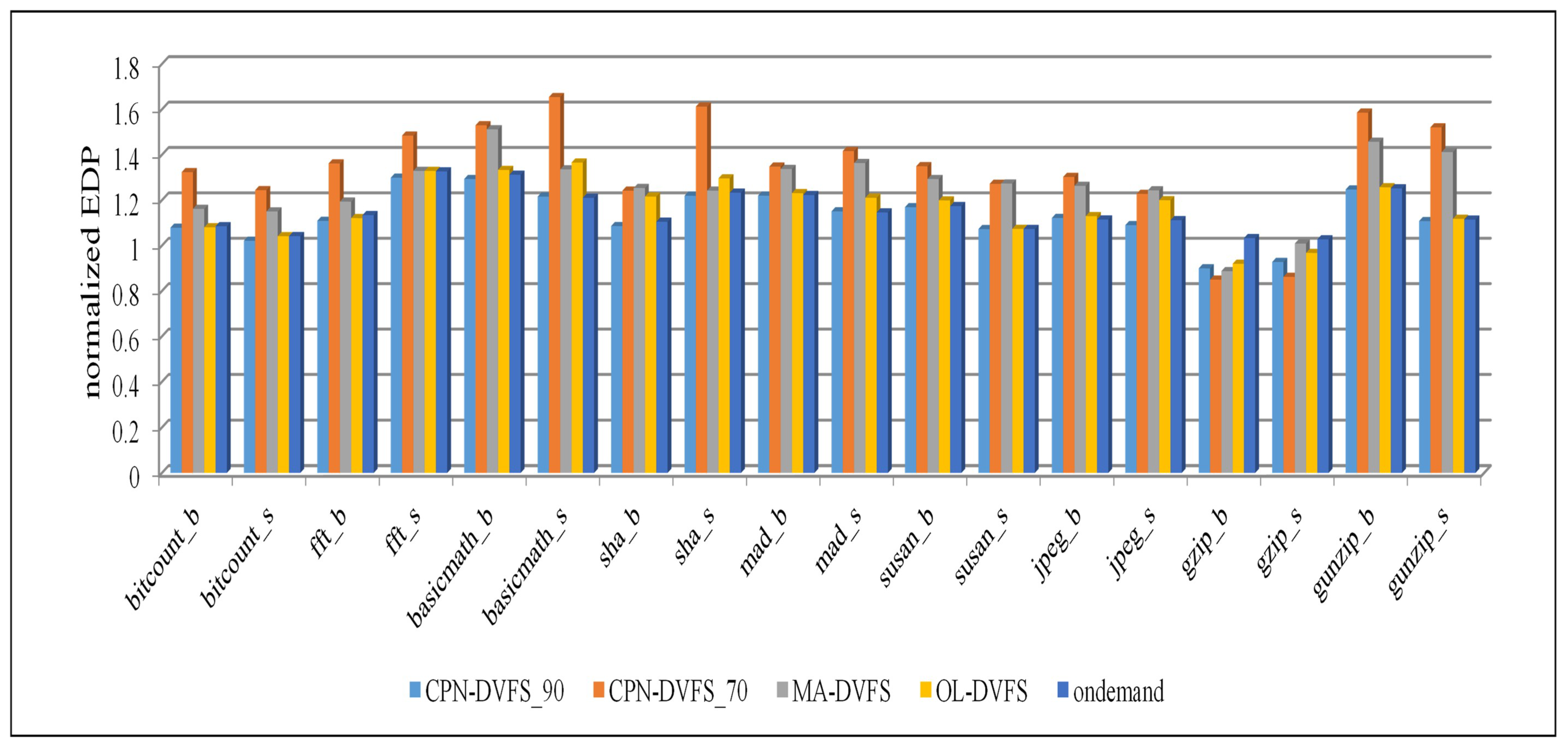
6.1. Single-Core Platforms
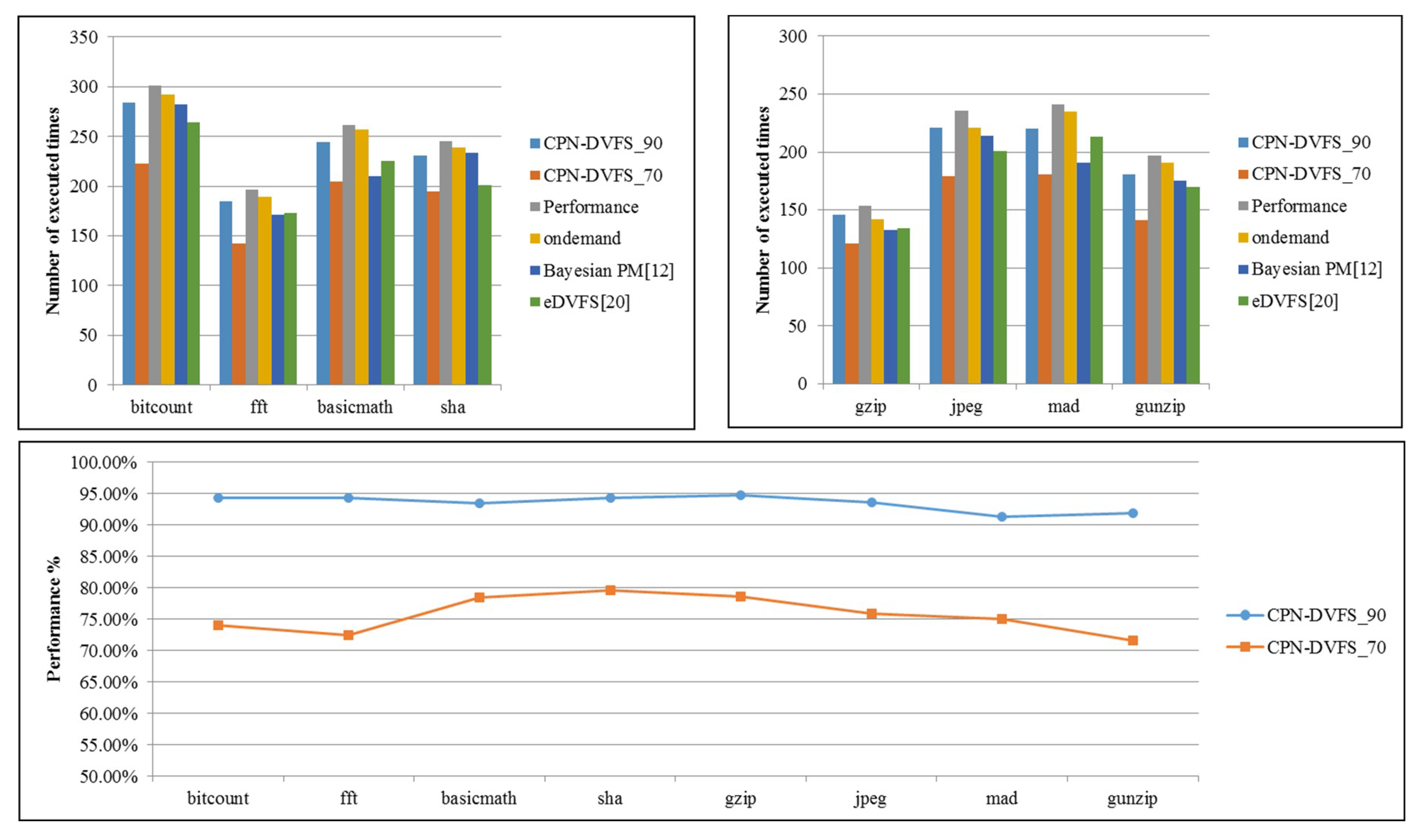
6.2. Multi-Core Platforms
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, W.; Gupta, M.S.; Wei, G.-Y.; Brooks, D. System level analysis of fast, per-core DVFS using on-chip switching regulators. In Proceedings of the IEEE 14th International Symposium on High Performance Computer Architecture (HPCA), Salt Lake City, UT, USA, 16–20 February 2008; pp. 123–134. [Google Scholar]
- Xin, J.; Goto, S. Hilbert Transform-Based Workload Prediction and Dynamic Frequency Scaling for Power-Efficient Video Encoding. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2012, 31, 649–661. [Google Scholar]
- Rangan, K.K.; Wei, G.-Y.; Brooks, D. Thread motion: Fine-grained power management for multi-core systems. ACM SIGARCH Comput. Arch. News 2009, 37, 302–313. [Google Scholar] [CrossRef]
- Guthaus, M.R.; Ringenberg, J.S.; Ernst, D.; Austin, T.M.; Mudge, T.; Brown, R.B. Mibench: A Free Commercially Representative Embedded Benchmark Suite. In Proceedings of the Fourth Annual IEEE International Workshop on Workload Characterization, Austin, TX, USA, 2 December 2001; pp. 3–14. [Google Scholar]
- Iqbal, S.M.Z.; Liang, Y.; Grahn, H. ParMiBench-An Open-Source Benchmark for Embedded Multiprocessor Systems. Comput. Arch. Lett. 2010, 9, 45–48. [Google Scholar] [CrossRef]
- Choi, K.; Soma, R.; Pedram, M. Fine-Grained Dynamic Voltage and Frequency Scaling for Precise Energy and Performance Trade-Off Based on the Ratio of Off-Chip Access to On-Chip Computation Times. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2005, 24, 18–28. [Google Scholar]
- Liang, W.-Y.; Chen, S.-C.; Chang, Y.-L.; Fang, J.-P. Memory-Aware Dynamic Voltage and Frequency Prediction for Portable Devices. In Proceedings of the 14th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Kaohsiung, Taiwan, 25–27 August 2008; pp. 229–236. [Google Scholar]
- Poellabauer, C.; Singleton, L.; Schwan, K. Feedback-Based Dynamic Voltage and Frequency Scaling for Memory-Bound Real-Time Applications. In Proceedings of the 2005 IEEE Real-Time and Embedded Technology and Applications Symposium, San Francisco, CA, USA, 7–10 March 2005; pp. 234–243. [Google Scholar]
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Improving Energy Efficiency in Wireless Network-on-Chip Architectures. J. Emerg. Technol. Comput. Syst. 2017, 14, 9. [Google Scholar] [CrossRef]
- Jejurikar, R.; Gupta, R.K. Dynamic Voltage Scaling for System wide Energy Minimization in Real-Time Embedded Systems. In Proceedings of the 2004 international symposium on Low Power Electronics and Design, Newport Beach, CA, USA, 9–11 August 2004; pp. 78–81. [Google Scholar]
- Eyerman, S.; Eeckhout, L. A Counter Architecture for Online DVFS Profitability Estimation. IEEE Trans. Comput. 2010, 59, 1576–1583. [Google Scholar] [CrossRef]
- Kim, S. Adaptive Online Voltage Scaling Scheme Based on the Nash Bargaining Solution. ETRI J. 2011, 33, 407–414. [Google Scholar] [CrossRef]
- Lahiri, A.; Bussa, N.; Saraswat, P. A Neural Network Approach to Dynamic Frequency Scaling. In Proceedings of the 2007 International Conference on Advanced Computing and Communications, Guwahati, India, 18–21 December 2007; pp. 738–743. [Google Scholar]
- Dhiman, G.; Rosing, T.S. System-Level Power Management Using Online Learning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2009, 28, 676–689. [Google Scholar] [CrossRef]
- Moeng, M.; Melhem, R. Applying statistical machine learning to multicore voltage & frequency scaling. In Proceedings of the 7th ACM international conference on Computing frontiers, Bertinoro, Italy, 17–19 May 2010; pp. 277–286. [Google Scholar]
- Zhang, Q.; Lin, M.; Lin, L.T.; Yang, L.T.; Chen, Z.; Li, P. Energy-Efficient Scheduling for Real-Time Systems Based on Deep Q-Learning Model. IEEE Trans. Sustain. Comput. 2017. [Google Scholar] [CrossRef]
- Jung, H.; Pedram, M. Supervised Learning Based Power Management for Multicore Processors. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2010, 29, 1395–1408. [Google Scholar] [CrossRef] [Green Version]
- Tesauro, G.; Das, R.; Chan, H.; Kephart, J.; Levine, D.; Rawson, F.; Lefurgy, C. Managing power consumption and performance of computing systems using reinforcement learning. In Proceedings of the NIPS 2007, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Isci, C.; Contreras, G.; Martonosi, M. Live, Runtime Phase Monitoring and Prediction on Real Systems with Application to Dynamic Power Management. In Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, Orlando, FL, USA, 9–13 December 2006; pp. 359–370. [Google Scholar]
- Liang, W.-Y.; Chang, M.-F.; Chen, Y.-L.; Wang, J.-H. Performance Evaluation for Dynamic Voltage and Frequency Scaling Using Runtime Performance Counters. Appl. Mech. Mater. 2013, 284–287, 2575–2579. [Google Scholar] [CrossRef]
- Chang, M.-F.; Liang, W.-Y. Learning-Directed Dynamic Voltage and Frequency Scaling for Computation Time Prediction. In Proceedings of the IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16–18 November 2011; pp. 1023–1029. [Google Scholar]
- Liang, W.-Y.; Lai, P.-T. Design and Implementation of a Critical Speed-Based DVFS Mechanism for the Android Operating System. In Proceedings of the 2010 5th International Conference on Embedded and Multimedia Computing (EMC), Cebu, Philippines, 11–13 August 2010; pp. 1–6. [Google Scholar]
- Bogdan, P.; Marculescu, R.; Jain, S.; Gavila, R.T. An Optimal Control Approach to Power Management for Multi-Voltage and Frequency Islands Multiprocessor Platforms under Highly Variable Workloads. In Proceedings of the 2012 Sixth IEEE/ACM International Symposium on Networks on Chip (NoCS), Copenhagen, Denmark, 9–11 May 2012; pp. 35–42. [Google Scholar]
- Lee, J.; Nam, B.-G.; Yoo, H.-J. Dynamic Voltage and Frequency Scaling (DVFS) scheme for multi-domains power management. In Proceedings of the IEEE Asian Solid-State Circuits Conference (ASSCC), Jeju, Korea, 12–14 November 2007; pp. 360–363. [Google Scholar]
- Elewi, A.; Shalan, M.; Awadalla, M.; Saad, E.M. Energy-efficient task allocation techniques for asymmetric multiprocessor embedded systems. ACM Trans. Embed. Comput. Syst. (TECS) 2014, 13, 27. [Google Scholar] [CrossRef]
- ARM.com. Cortex-A15 Performance Monitor Unit. Available online: http://infocenter.arm.com/help/index (accessed on 15 June 2015).
- Pallipadi, V.; Starikovskiy, A. The on-demand governor-past, present, and future. In Proceedings of the Linux Symposium, Ottawa, ON, Canada, 23–26 July 2006; p. 223. [Google Scholar]
- Kim, S.G.; Eom, H.; Yeomand, H.Y.; Min, S.L. Energy-centric DVFS controlling method for multi-core platforms. Computing 2014, 96, 1163–1177. [Google Scholar] [CrossRef]
- Etinski, M.; Corbalan, J.; Valero, M. Understanding the future of energy-performance trade-off via DVFS in HPC environments. J. Parallel Distrib. Comput. 2012, 72, 579–590. [Google Scholar] [CrossRef]
- Calore, E.; Gabbana, A.; Schifano, S.F.; Tripiccione, R. Evaluation of DVFS techniques on modern HPC processors and accelerators for energy-aware applications. Concurr. Comput. Pract. Exp. 2017, 29, e4143. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm: CPN Algorithm | |
|---|---|
| Parameters: Initialization: Weight vector wj and πj are all zeroed. Weight vector x(t) and y(t) are training samples. t = 1, N = 0. | |
| 1: | Build the first hidden node. |
| 2: | N = 1, t = t + 1 |
| 3: | For every training data input do |
| 4: | Choose the nearest node: |
| 5: | if D ≦ Δ is true then |
| 6: | Update the weight vector: |
| 7: | |
| 8: | |
| 9: | t = t + 1 |
| 10: | else then |
| 11: | Build the new hidden node. |
| 12: | N = N + 1, t = t + 1 |
| 13: | end if |
| 14: | end for |
| Benchmark | Small Instruction Count | Large Instruction Count |
|---|---|---|
| basicmath | 65,459,080 | 1,000,000,000 |
| bitcount | 49,671,043 | 384,803,644 |
| susan.corners | 1,062,891 | 586,076,156 |
| susan.edges | 1,836,965 | 732,517,639 |
| susan.smoothing | 24,897,492 | 1,000,000,000 |
| jpeg.decode | 6,677,595 | 990,912,065 |
| jpeg.encode | 28,108,471 | 543,976,667 |
| mad | 25,501,771 | 272,657,564 |
| sha | 13,541,298 | 20,652,916 |
| FFT | 52,625,918 | 143,263,412 |
| FFT.inverse | 65,667,015 | 377,253,252 |
| CPU Frequency (MHz) | Performance Score (0~100) | Instructions Executed | Data Cache Miss | Instruction Cache Miss |
|---|---|---|---|---|
| 512 | 100 | 1514 | 67 | 266 |
| 512 | 100 | 969 | 1433 | 847 |
| 416 | 63 | 1207 | 116 | 168 |
| 416 | 82 | 1236 | 344 | 300 |
| 312 | 94 | 981 | 692 | 35 |
| 312 | 100 | 1035 | 1471 | 13 |
| 208 | 60 | 660 | 421 | 16 |
| 156 | 69 | 250 | 796 | 35 |
| 104 | 65 | 305 | 689 | 211 |
| Algorithm: CPN-DVFS Algorithm | |
|---|---|
| Parameters: Initialization: Reset PMU counter registers. Get weight vector wj and πj from training phase. pmu_start() for first times calculate. | |
| 1: | For every execution interval do |
| 2: | Pmu_stop() |
| 3: | Choose the nearest node: |
| 4: | target_freq = πj |
| 5: | set_freq(target_freq) |
| 6: | pmu_start() |
| 7: | end for |
| CPU Frequency | CPU Voltage |
|---|---|
| 104 MHz | 0.9 V |
| 156 MHz | 10 V |
| 208 MHz | 1.15 V |
| 312 MHz | 1.25 V |
| 416 MHz | 1.35 V |
| 520 MHz | 1.45 V |
| Core1 | Core2 | Core3 | Core4 | |
|---|---|---|---|---|
| MiBench 1 | bitcount | fft | basicmath | sha |
| MiBench 2 | gzip | jpeg | mad | gunzip |
| MiBench 3 | basicmath | basicmath | basicmath | basicmath |
| MiBench 4 | gzip | gzip | gzip | gzip |
| ParMiBench 5 | Bitcount | |||
| ParMiBench 6 | Basicmath | |||
| ParMiBench 7 | Dijkstra | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-L.; Chang, M.-F.; Yu, C.-W.; Chen, X.-Z.; Liang, W.-Y. Learning-Directed Dynamic Voltage and Frequency Scaling Scheme with Adjustable Performance for Single-Core and Multi-Core Embedded and Mobile Systems. Sensors 2018, 18, 3068. https://doi.org/10.3390/s18093068
Chen Y-L, Chang M-F, Yu C-W, Chen X-Z, Liang W-Y. Learning-Directed Dynamic Voltage and Frequency Scaling Scheme with Adjustable Performance for Single-Core and Multi-Core Embedded and Mobile Systems. Sensors. 2018; 18(9):3068. https://doi.org/10.3390/s18093068
Chicago/Turabian StyleChen, Yen-Lin, Ming-Feng Chang, Chao-Wei Yu, Xiu-Zhi Chen, and Wen-Yew Liang. 2018. "Learning-Directed Dynamic Voltage and Frequency Scaling Scheme with Adjustable Performance for Single-Core and Multi-Core Embedded and Mobile Systems" Sensors 18, no. 9: 3068. https://doi.org/10.3390/s18093068