1. Introduction
Direction of arrival (DOA) estimation of multiple far-field narrowband sources is a vital and interesting topic in a signal processing field, which has wide application in many areas such as radar, sonar, radio astronomy and wireless communications, etc. [
1,
2,
3,
4]. As we all know, the DOA estimation problem can be solved efficiently by classical subspace-based methods such as multiple signal classification (MUSIC) [
5] and estimation of signal parameters via rotational invariance technique (ESPRIT) [
6] in conditions where the receiving arrays are mostly uniform arrays, such as uniform linear array (ULA) [
7], uniform rectangular array (URA) [
8] and uniform circular array (UCA) [
9]. The inter-element spacing of these receiving arrays is required to be less than or equal to the half-wavelength of received signal. Therefore, the detection performance of these DOA estimation methods is greatly confined by the number of physical sensors. For example, a maximum of
sources can be detected when these algorithms are applied to a ULA with
M sensors. Accordingly, more sensors are needed in order to detect more sources and acquire the desirable estimation accuracy. However, a large number of sensors will increase the hardware cost and the difficulty of array calibration in practical applications. To overcome this challenge, some non-uniform array geometries, called sparse arrays, have been proposed, such as minimum redundancy arrays (MRAs) [
10], nested arrays (NAs) [
11,
12] and coprime arrays (CPAs) [
13,
14,
15]. Though MRAs can obtain more degrees of freedom (DOFs) through constructing an augmented covariance matrix, they have no closed form expressions for the optimal array configurations as well as the achievable DOFs for an arbitrary number of sensor elements. Unlike MRAs, the NAs with
physical sensors can achieve
DOFs and they have closed form expressions for the optimal sensors positions. However, mutual coupling arising from the dense subarray of NAs may exist, which will cause the DOA estimation performance degradation. To circumvent this problem, coprime arrays which can detect
sources with only
physical sensors were proposed in [
13], where
M and
N are coprime integers.
When the incident signals are received by the CPAs, a virtual array with extended aperture can be achieved by vectorizing the receiving data covariance matrix. Thus, more DOFs than sensors can be obtained. In order to exploit the extended DOFs for DOA estimation, many algorithms have been proposed. The spatial smoothing MUSIC (SS-MUSIC) algorithm for comprime arrays was first proposed in [
16], which has robust estimation performance and can detect more sources than sensors in coarray domain. Unfortunately, it needs to know the number of sources in advance. To this end, a MUSIC-like subspace method was proposed in [
17], in which the number of sources is a by-product of low rank denoising stage. In [
18], a novel coarray ESPRIT-based DOA estimation algorithm was proposed to balance the contradiction between estimation performance and computation complexity. However, all of the aforementioned subspace methods can only utilize the consecutive difference coarray. Additionally, due to the application of spatial smoothing technique [
19], half of the continuous DOFs are lost, which will result in a significant degradation of detection performance. Accordingly, in order to maximize the utilization of extended DOFs, some sparse representation methods for coprime arrays [
20,
21,
22] were proposed, which can be directly applied to derive the signal power vector without requiring decorrelation and covariance matrix rank recovery operation. Generally speaking, the extended virtual array aperture can be fully used for DOA estimation in these sparse-based methods. Consequently, they can detect more sources than those subspace methods and own better detection performance. On the basis of [
16], a least absolute shrinkage and selection operator (LASSO) algorithm with extended coprime array geometry [
23] was proposed, which can provide more DOFs than [
16]. Now, this extended coprime array geometry is used very widely due to its excellent performance. Though there are so many advantages for these sparse-based methods, there is still a disadvantage that they need to discretize the angle space and preset enough grid points. The precondition for estimating the DOAs successfully is that the locations of the sources must fall on the predefined grid points. However, in practical situations, no matter how fine the grids are, it is impossible that the sources always lie on the predefined grid points. Thus, the off-grid sources may cause dictionary mismatch problems. As a result, the recovery performance of these methods will be deteriorated.
In recent years, lots of methods [
24,
25,
26,
27,
28,
29,
30,
31,
32] have been proposed for solving the off-grid problems. Zhang et al. [
24] presented a block-sparse Bayesian algorithm to solve the grid mismatch problem, in which the noise variance can be normalized to 1 and thus its effect on the estimation performance can be reduced. In references [
25,
26], the joint sparsity between the original signals and the grid biases was used to solve the off-grid problem. In a previous study [
27], a gridless sparse method was developed for off-grid/continuous DOA estimation by minimizing the reweighted atomic norm. In reference [
28], by first-order Lagrange approximation, an off-grid signal model with approximate dictionary matrix is established. Then, the grid biases are derived in sparse Bayesian learning approach by using the joint sparsity between different snapshots of the received signal. In reference [
29], a root sparse Bayesian learning method was proposed, in which there is no need to construct off-grid model. The grid points are iteratively updated by finding the roots of a polynomial. Based on Dai et al. [
29], a grid evolution direction of arrival (GEDOA) estimation method [
30], which includes two sub-processes, i.e., learning process and fission process, was proposed to solve the problem of more than one DOA in one initial grid interval and speed up the method proposed in reference [
29]. Wu et al. [
31] proposed two iterative methods, both of which update the signal power vector and off-grid biases alternately. Wang et al. [
32] proposed a real-valued formulation of covariance vector-based relevance vector machine (CVRVM) technique, which is implemented in a real domain and has low computation complexity. However, these methods are all applied on the traditional uniform linear array and they do not utilize the increased DOFs provided by the difference coarray of coprime arrays. Thus, they cannot detect more sources than sensors. As mentioned before, virtual array aperture extension can be described effectively by the vectorized covariance matrix model. However, it is not rational to directly apply most sparse-based methods to this model as those methods are usually designed to work in the raw data domain. Due to the superiority of coprime arrays, some off-grid DOA estimation methods have been proposed for coprime arrays. In reference [
33], an off-grid DOA estimation method based on the framework of sparse Bayesian learning was proposed for coprime arrays. The predefined grid points are directly updated by iteratively decreasing a surrogate function majorizing the given objective function. Sun et al. [
34] proposed an iterative method to obtain the final DOA estimation by gradually amending the offset vector with introducing a convex function majorizing the objective function. Both of the methods in references [
33,
34] need to use the gradient descent method, in which the gradient descent coefficient is difficult to choose. If the gradient descent coefficient is too large, the DOA estimation accuracy will be reduced. On the contrary, if the gradient descent coefficient is too small, the convergence speed of the algorithms will be limited.
To deal with the above difficulties, a sparse-based off-grid DOA estimation method for coprime arrays is proposed in this paper. The proposed method includes two processes, i.e., coarse estimation process and fine estimation process. In the coarse estimation process, we consider the estimation error caused by finite snapshots effect and remove the redundant elements in the covariance vector (i.e., vectorized covariance matrix). In addition, we circumvent estimating the noise variance by using a linear transformation to remove the noise-related part in the covariance vector. This is due to the fact that the noise variance is not so easy to evaluate especially under the underdetermined scenarios. Through a series of linear transformations, the covariance matrix estimation error can be normalized to an identity matrix. Then, according to the statistical property of the vectorized covariance matrix estimation error, DOA estimation can be cast as a problem of recovering a nonnegative sparse vector with an extended steering vector. The grid points corresponding to the non-zero elements in the recovered sparse vector are coarse DOA estimation results for the true signals, which are taken as the predefined grid points required for the fine estimation process. In practical applications, the number of snapshots is finite, which will cause the sample covariance matrix deviating from the actual covariance matrix largely [
35]. Therefore, in the fine estimation process, the sample covariance matrix is modified firstly and then the grid biases are derived by applying a two-step iterative technique to the vectorized modified covariance matrix. The final estimated DOAs can be obtained by integrating the coarse DOA estimation results and the grid biases.
The rest of the paper is organized as follows. The far-field narrowband signal model for coprime arrays is briefly introduced in
Section 2.
Section 3 formulates the proposed sparse DOA estimation method.
Section 4 provides several numerical simulation results to show the superior estimation performance for the proposed method and
Section 5 concludes this paper.
Notations: In this paper, italic lower-case (upper-case) bold characters are used to denote vectors (matrices). In particular, denotes the identity matrix. Sets are denoted by capital letters in blackboard boldface. Specifically, the symbols , and represent the sets of real numbers, complex numbers and integers, respectively. , , and imply conjugate, transpose, conjugate transpose and inverse, respectively. denotes the vectorization operator. The symbols ∘, ⊙ and ⊗ represent Hadamard product, Khatri–Rao product and Kronecker product, respectively. stands for a diagonal matrix whose diagonal elements are taken from the given vector , while represents a column vector whose elements are the diagonal elements of the given matrix . means taking the real part of a complex value. The -norm and -norm are respectively denoted by and . is the trace operator. denotes the statistical expectation operator. denotes a complex Gaussian distribution with mean vector and covariance matrix .
2. Signal Model
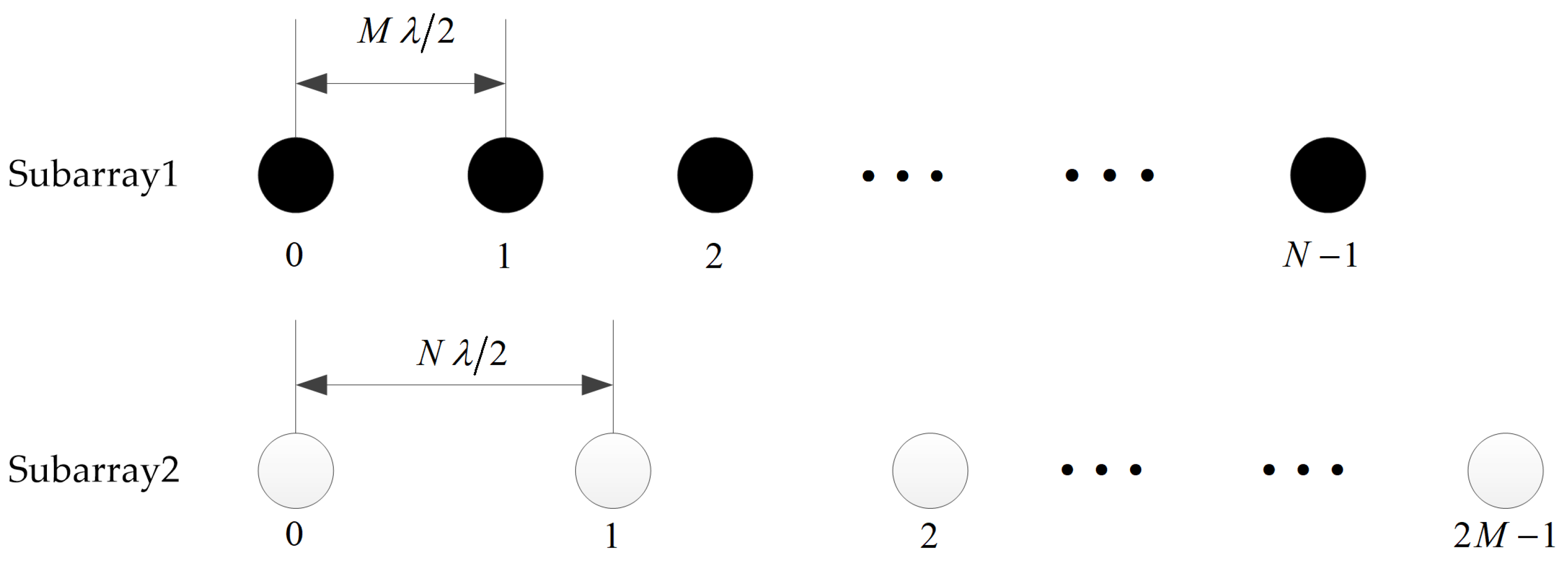
As illustrated in
Figure 1, consider the coprime arrays which are composed of two uniform linear subarrays. One includes
N sensors with inter-element spacing
, while the other owns
sensors with inter-element spacing
, where
is the wavelength of the received signal. As described in
Section 1,
M and
N are coprime integers. Without loss of generality, we assume that
M is less than
N. The two subarrays share the zeroth sensor, which is also the reference sensor. Thus, the total number of sensors in the coprime arrays is
, which are located at
where
is sorted in ascending order with
and
.
Suppose
K far-field narrowband signals are incident on the coprime arrays from directions
, where
is the direction of the
k-th signal. Then, the received signal at time
t can be expressed as
In Equation (
2),
is the signal vector at time
, which is independent from the signal vectors at other time instances.
T is the number of snapshots.
is the noise vector at time
t, the elements of which are assumed to be temporally and spatially independent and identically distributed (i.i.d.) random variables which satisfy the complex Gaussian distribution with zero mean and variance
. When the number of sampled snapshots is sufficiently large, the signal vectors can be assumed to be independent from the noise vectors.
is the array manifold matrix, where
is the steering vector for source
k and it can be written as
Since the number of sampled snapshots is finite in practical applications, the sample covariance matrix can be approximated as
4. Numerical Simulations
In this section, we perform several simulation experiments to demonstrate the excellent performance of the proposed method for DOA estimation, and also compare it with SS-MUSIC [
16], low rank matrix denoising (LRD) [
17], LASSO [
23] and off-grid sparse Bayesian inference (OGSBI) [
28]. In particular, for estimation accuracy comparision, the Cramer–Rao bound (CRB) for coprime arrays [
40] is included. The coprime arrays considered here are composed of ten sensors with two coprime integers
and
. The positions of sensors in the first subarray are
and the others in the second subarray are
. The zeroth sensor is assumed to be the reference element, which is shared by the two subarrays. The scale factor
in (
26) is determined by traversal simulation experiments [
41]. The regularization parameter
in (
29) is set as 0.3. The iterative convergence criterion is
and the maximum number of iterations is 60. The predefined grid points for LASSO, OGSBI and the coarse estimation process in the proposed method are sampled from
with sampling interval being
. For fair comparison, the peak search process in SS-MUSIC and LRD is performed with the same step size of
in
.
4.1. Detection Performance
In this subsection, the detection performance of the proposed method is compared with that of the methods OGSBI, LASSO and LRD. All of these methods can detect more sources than sensors with using coprime arrays. In theory, LRD can only identify at most 17 sources under the coprime arrays set above. Therefore, for convenience of comparison, we consider 17 randomly distributed narrowband uncorrelated sources here, which are located at
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
and
. The number of sampled snapshots is 800 and the Signal-to-Noise Ratio (SNR) is set as 0 dB. The scale factor
is 0.5. The spatial spectra of the four algorithms are shown in
Figure 2a–d, respectively. In these figures, the red dashed line indicates the true direction of the incident signal, and the solid blue line indicates the estimated spectral line.
From
Figure 2, we can see that OGSBI, LASSO and the proposed method can detect all 17 sources successfully. However, there are still some small spurious peaks in
Figure 2a for OGSBI and
Figure 2c for LASSO. Furthermore, from
Figure 2b, it is easy to find that LRD fail to detect all sources. In its spatial spectrum, several peaks are missed and some of the existing spectral peaks deviate from the true signals a lot. Therefore, it can be concluded that the detection performance of the proposed method is superior to the other three algorithms.
4.2. Resolution Ability
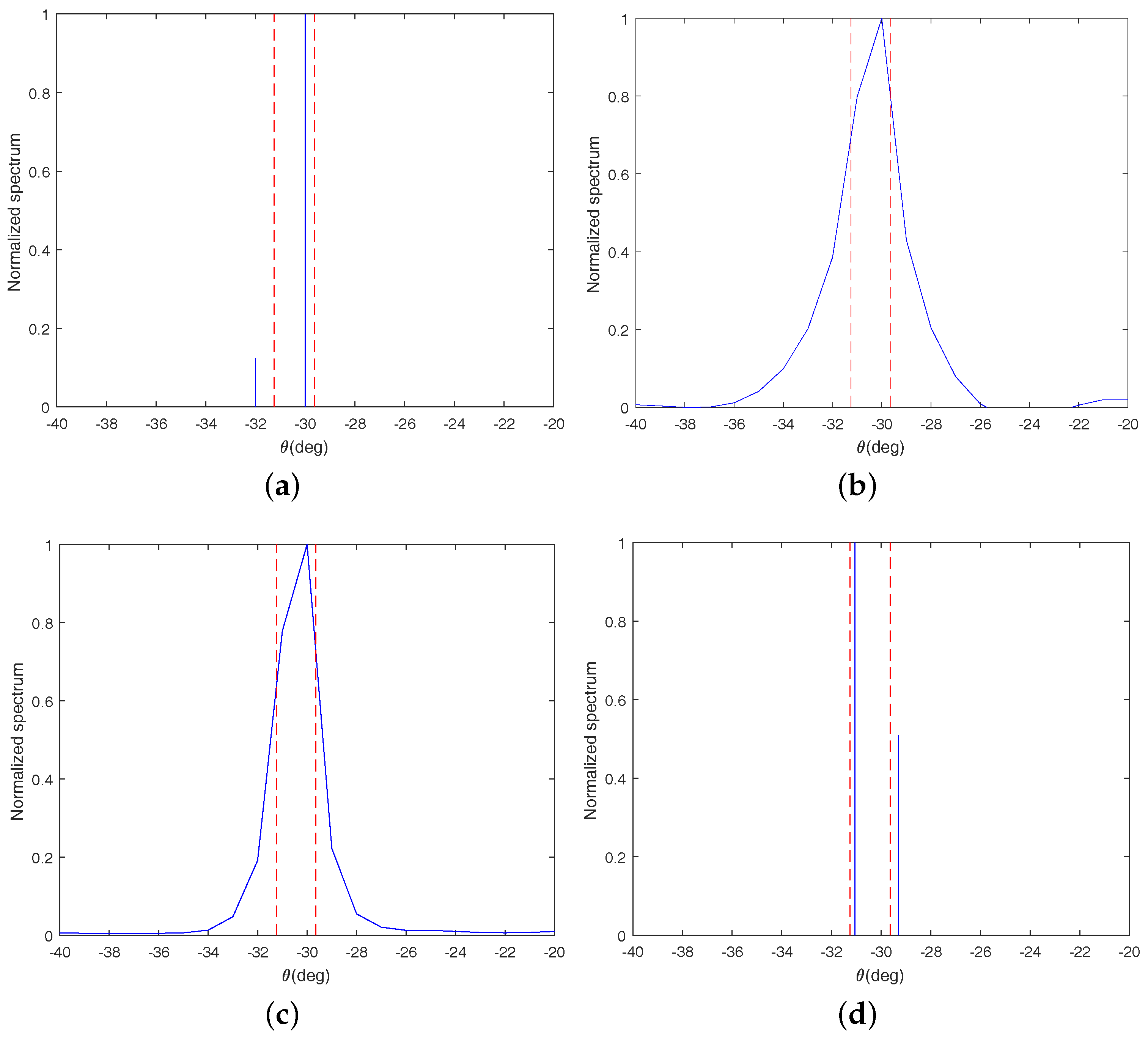
In this subsection, the resolution ability of the proposed method is still compared with that of the three algorithms mentioned in
Section 4.1. We test the resolution abilities of these algorithms by detecting two closely spaced sources which are located at
and
, respectively. Here, the SNR is set as 0 dB and the number of sampled snapshots is set as 800. Additionally, the scale factor
is identical with that in
Section 4.1.
From
Figure 3, it is obvious to find that there is only one peak in the spatial spectrums for LRD and LASSO, which means that both of them can not identify the two signals successfully. In addition, from
Figure 3d, we can find that the proposed method identifies the two signals successfully and its estimated DOAs about the two signals are
and
, respectively. Though there are errors between the estimated DOAs and the true DOAs, the errors are very small and within an acceptable range. From
Figure 3a, it can be seen that OGSBI can also identify the two signals, but the estimation error for OGSBI is larger than the proposed method. Therefore, it can be concluded that the resolution ability of the proposed method is the best among all four of the algorithms.
4.3. Estimation Accuracy
In this subsection, the estimation accuracy of each algorithm is reflected by its root-mean-square error (RMSE), which is defined as
where
Q is the total number of Monte Carlo trials,
represents the estimate of the
k-th source in the
q-th trial. For each scenario, we conduct 1000 Monte Carlo trials to get the corresponding RMSE. The estimation accuracy of the proposed method is compared with that of SS-MUSIC, LRD, LASSO, OGSBI and CRB. Although SS-MUSIC and LRD can theoretically identify at most 17 sources, in reality, the peak leakage phenomenon often occurs when applying them to estimate 16 or 17 sources impinging on the coprime arrays. Therefore, we consider 15 narrowband uncorrelated sources that come from the directions of
,
,
,
,
,
,
,
,
,
,
,
,
,
and
, where
is chosen randomly from the interval
in each trial to remove the possible prior information contained in the predefined direction set in the coarse estimation process.
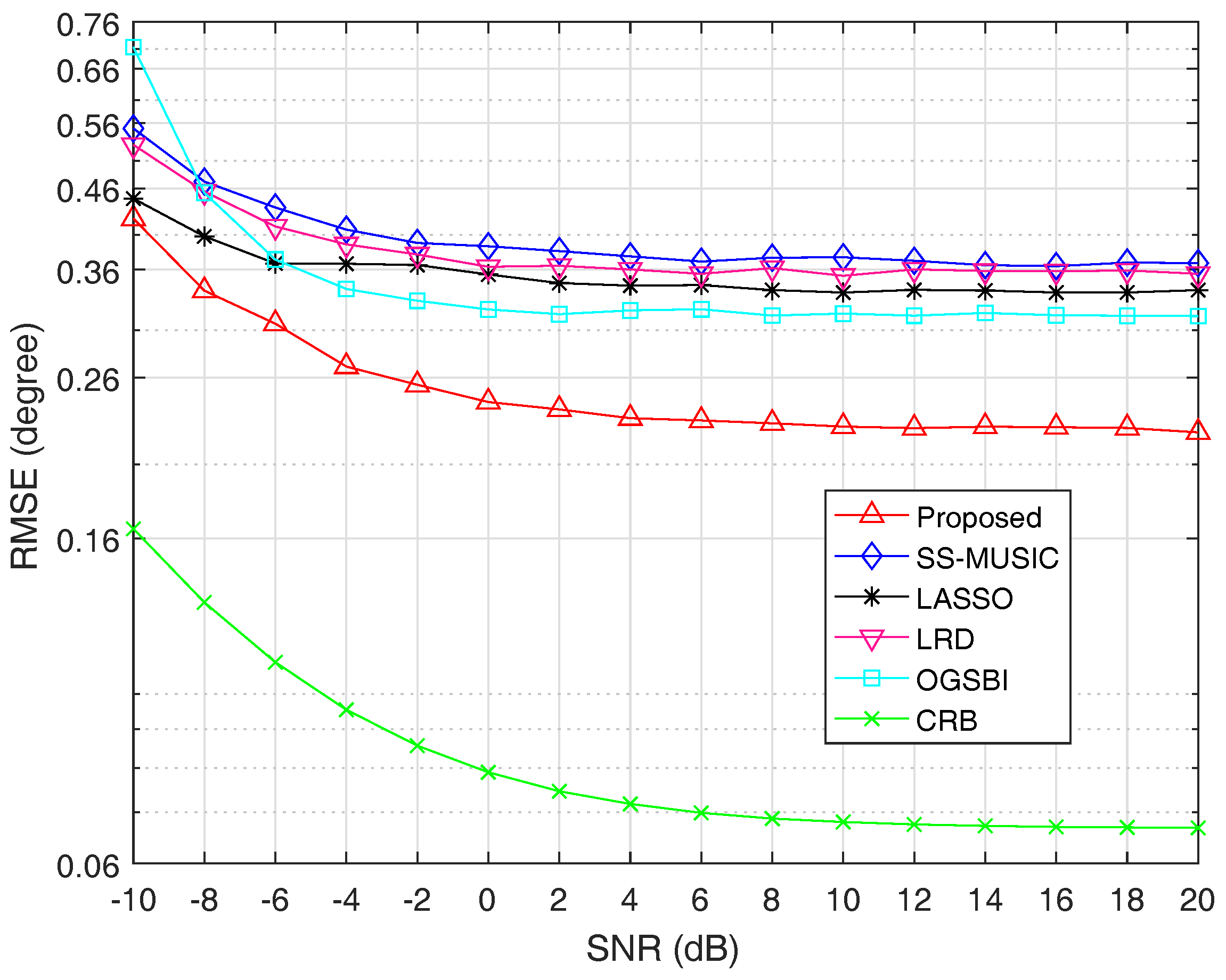
In the first experiment of this subsection, we fix the number of snapshots at 800 and vary SNR from
to
. When SNR is less than or equal to
,
is set as 0.5. Otherwise,
is set as 0.7.
Figure 4 shows the RMSE curves of the five algorithms and CRB as a function of SNR, respectively.
From
Figure 4, we can see that the estimation accuracy is improved with the increase of SNR for all algorithms. It is obvious that the estimation performance of the proposed method outperforms the other four methods. The reason is that spatial smoothing technique causes the extended DOF loss for SS-MUSIC and LRD. Though LASSO can utilize all of the extended DOFs, the assumption that incident signals must fall on the predefined grid points causes its estimation performance degradation. The algorithm OGSBI needs to update the noise variance in each iteration, which makes it sensitive to the noise. In addition, the covariance matrix estimation error and the correlation terms between signal and noise vectors are not considered in OGSBI, which is another reason that the proposed method has better estimation performance than OGSBI.
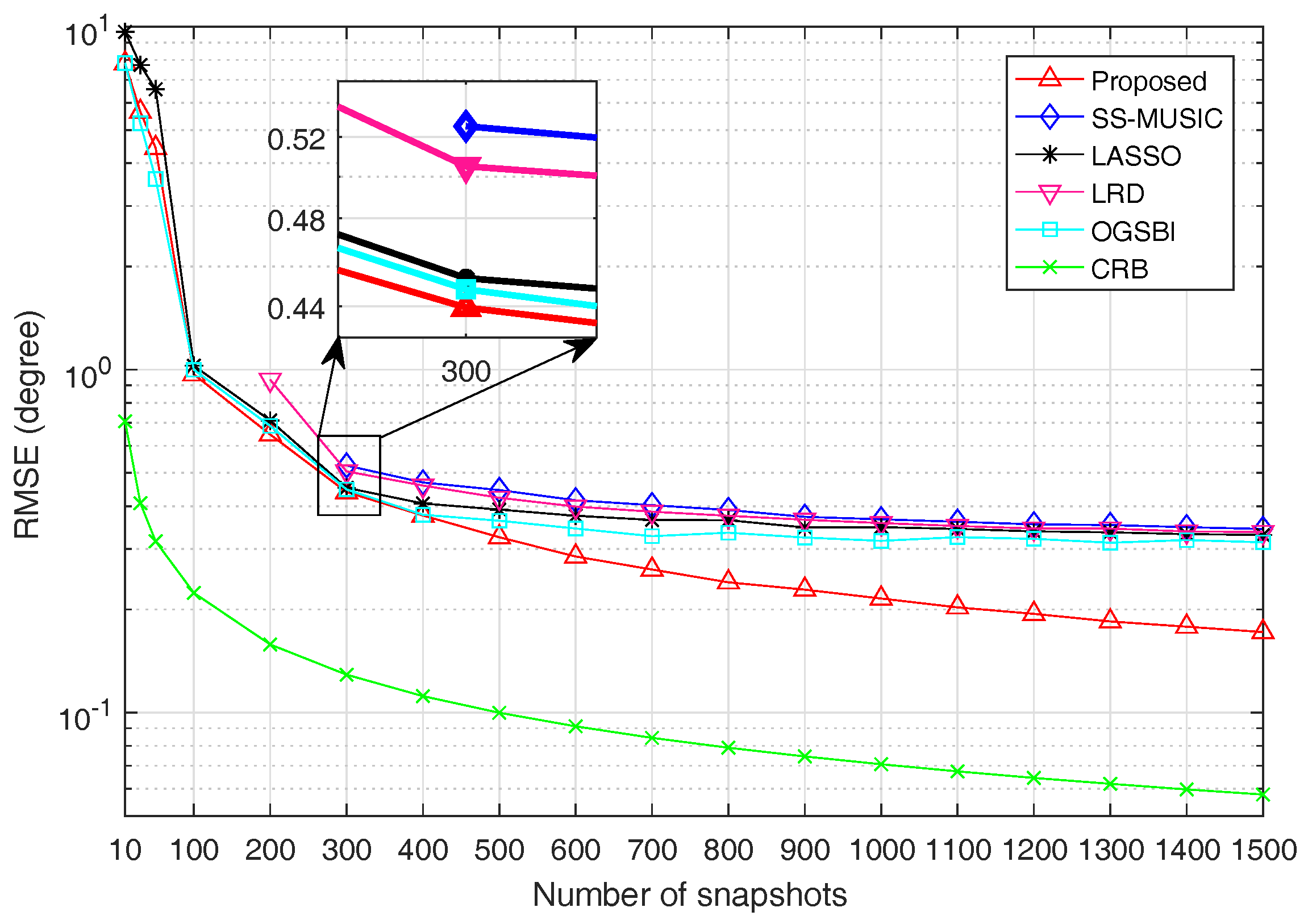
For the second experiment, the SNR is fixed at
and RMSE is a function of snapshots, the number of which varies from 10 to 1500. When the number of snapshots is less than or equal to 800,
is set as 0.5. Otherwise,
is set as 0.8. The RMSE values for all algorithms and CRB versus snapshots are shown in
Figure 5.
It is obvious from
Figure 5 that the estimation accuracy is improved with the increase of snapshots for all algorithms. For the same reason as described above, the estimation performance of SS-MUSIC, LRD, LASSO and OGSBI is inferior to the proposed method. It can be seen from
Figure 5 that when the number of snapshots changes from 10 to 1500, the estimation accuracy of the proposed method is getting better and better than the other four algorithms and finally outperforms the other four algorithms notably by a large margin.
In addition, to have an intuitive understanding on the computation complexity, we compute the average execution time of each algorithm on an Intel Core i7-7700@3.6GHz, 16G RAM PC. Under the same conditions, it takes 0.006 s for SS-MUSIC, 0.670 s for LRD, 0.285 s for LASSO, 1.343 s for OGSBI and 1.599 s for the proposed method. It can be found that SS-MUSIC has the shortest running time. The algorithm OGSBI and the proposed method are a little time-consuming. However, it is worth noting that the simulation results show that the estimation performance of the proposed method is the best among all five of the algorithms. According to the characteristics of each algorithm, they can be applied in different scenarios, respectively. When applied in scenarios where the real-time demand is not very high but the estimation accuracy demand is high, the proposed method is the preferred choice. Conversely, the other several comparison algorithms can be used in the scenarios with high real-time requirements but low estimation accuracy requirements. As we all know, the trade-off between the estimation accuracy and the computation complexity has always been an intractable problem for nearly all algorithms. Therefore, reducing the computation complexity on the basis of the proposed method will be a research direction for us in the future.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




