RFID Data-Driven Vehicle Speed Prediction via Adaptive Extended Kalman Filter



Abstract
:1. Introduction
- We propose an RFID-based vehicle speed predication system, in which the current vehicle can obtain the speed information of the previous vehicle via communication between the RFID tag and RFID reader.
- We design an improved EKF algorithm (e.g., AEKF) to improve the accuracy of vehicle speed prediction by combining the adaptive forgetting factor and the EKF algorithm.
- We design three vehicle speed models to simulate the driving environment. Meanwhile, we introduce two evaluation indicators (i.e., MSE and MAE) to better evaluate the vehicle speed prediction error.
- Extensive simulations are conducted to evaluate the advantages of the AEKF algorithm. The results show that the AEKF algorithm has less error than the conventional EKF algorithm in vehicle speed prediction.
2. System Model
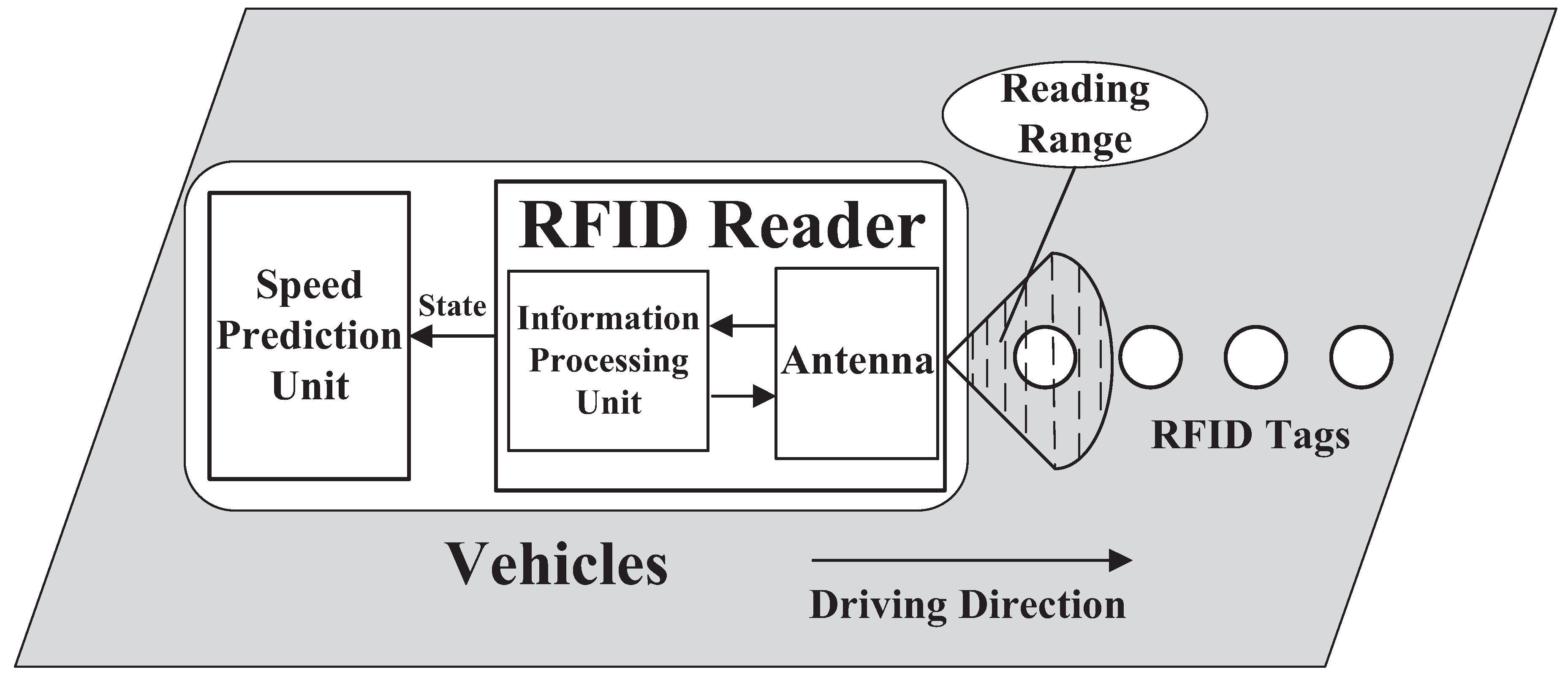
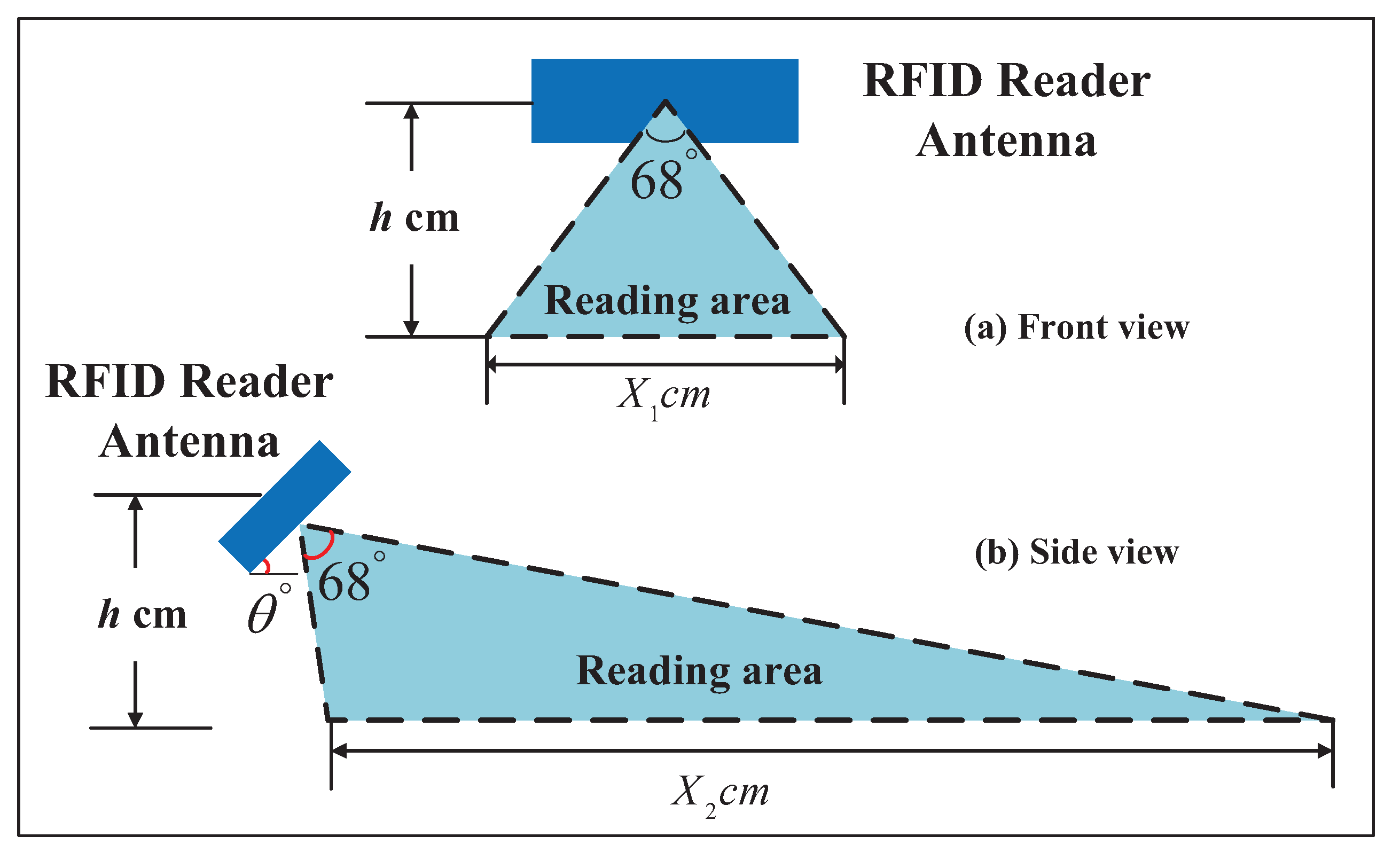
2.1. RFID Tag Deployment Subsystem
- The read area of each RFID reader should cover no more than one tag at any moment.
- Each RFID tag should be covered by no more than one RFID reader’s read area at any moment.
- The premise that the vehicle can read the tags deployed in the lane is that the vehicle is in the lane.
- If a vehicle can read a tag, at least half of its body should be in the lane where the tag is deployed.
- If less than half of a vehicle is in a lane, the vehicle cannot read any tags’ information in the lane.
- We set and h = 37.5 cm, and thus, the distance between tags should be at least 185.63 cm.
2.2. Information Acquisition Subsystem
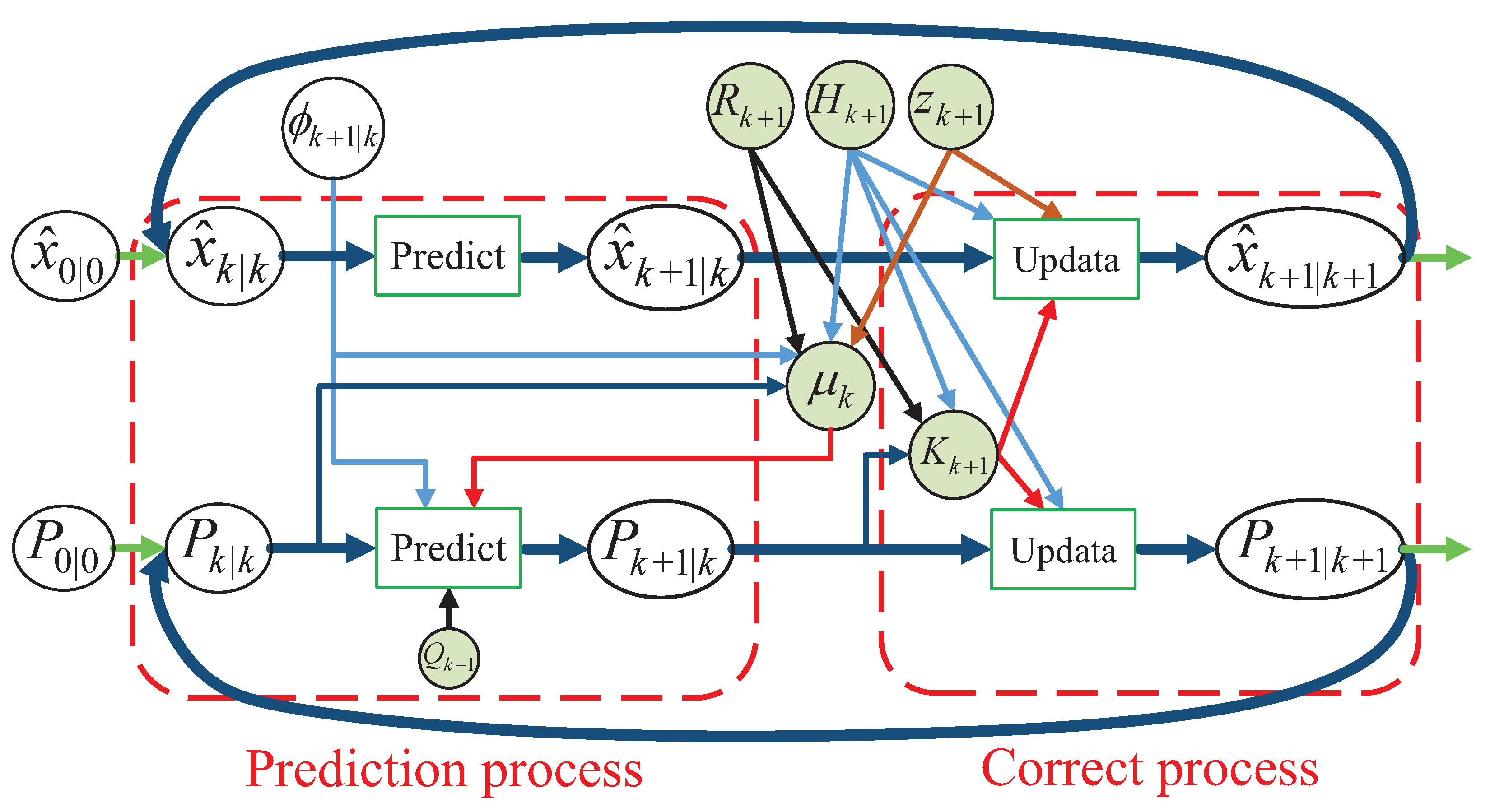
2.3. Speed Prediction Subsystem
- Linearization
- Time Update Process
- Measurement Update Process
- Adaptive Forgetting Factor
| Algorithm 1. RFID data-driven speed prediction based on the AEKF algorithm. |
|
3. Simulation Analysis
3.1. Evaluation Indicator Setting
3.2. Simulation Model Setting
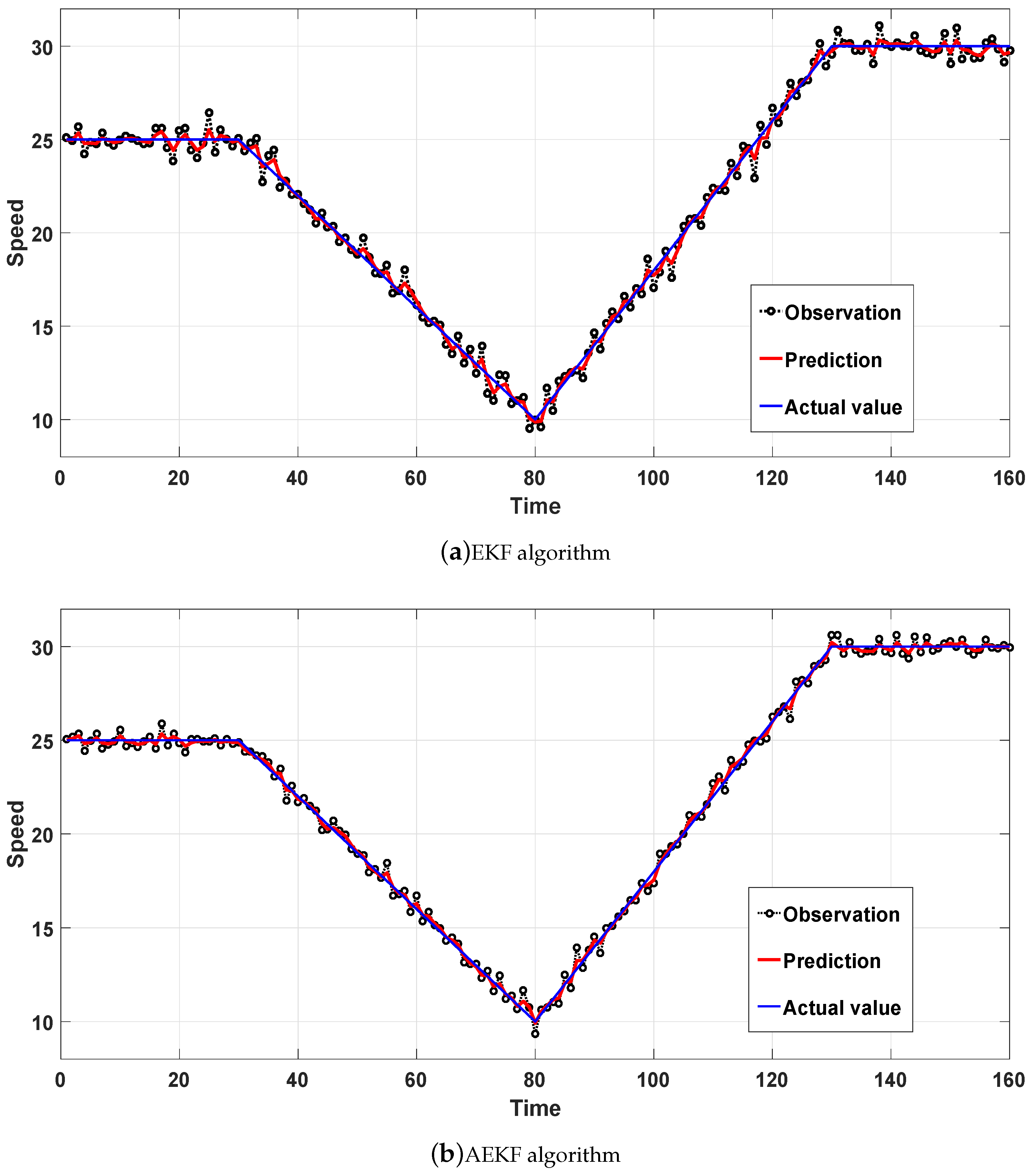
- Normal model: Vehicle moves with a constant speed at 25 m/s for 30 s, then it decelerates by −0.3 m/s2 for 50 s. After reaching 10 m/s, the vehicle accelerates at 0.4 m/s2 for 50 s. Finally, the vehicle moves with a constant speed of 25 m/s for 30 s.
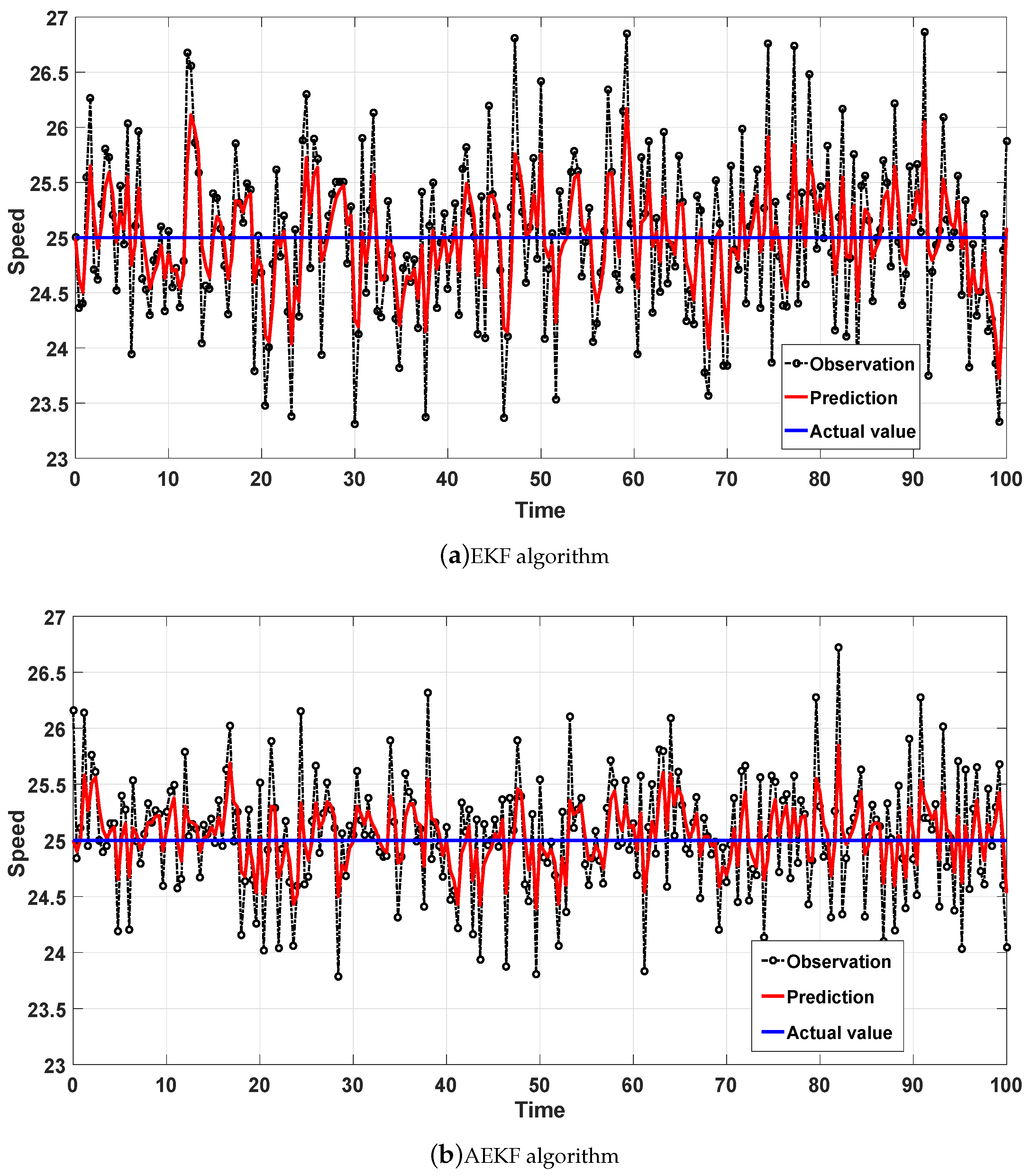
- Constant speed model: Vehicle moves with a constant speed at 25 m/s for 100 s.
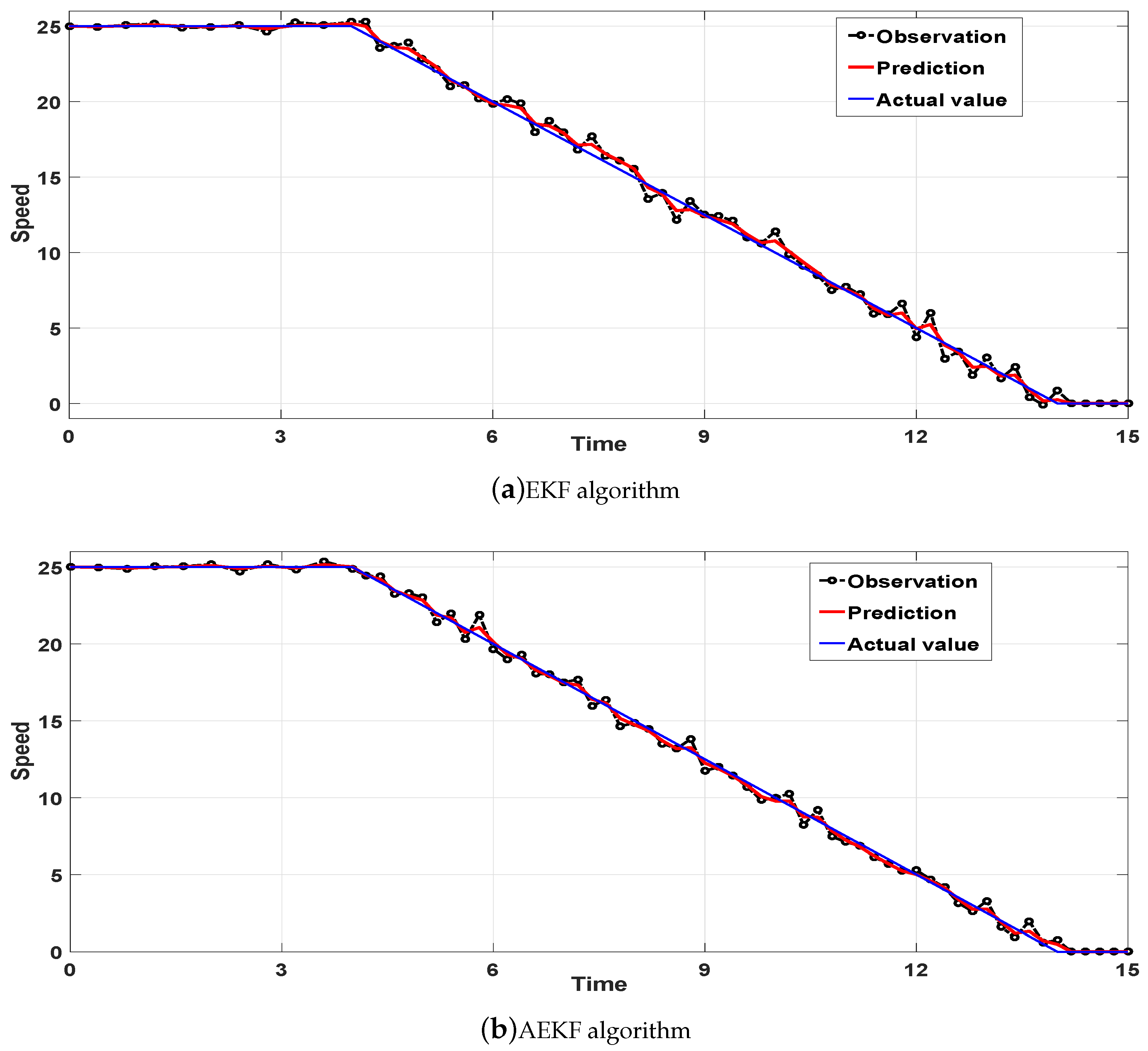
- Deceleration model: Vehicle moves with a constant speed at 25 m/s for 4 s, and then it decelerates at −2.5 m/s2.
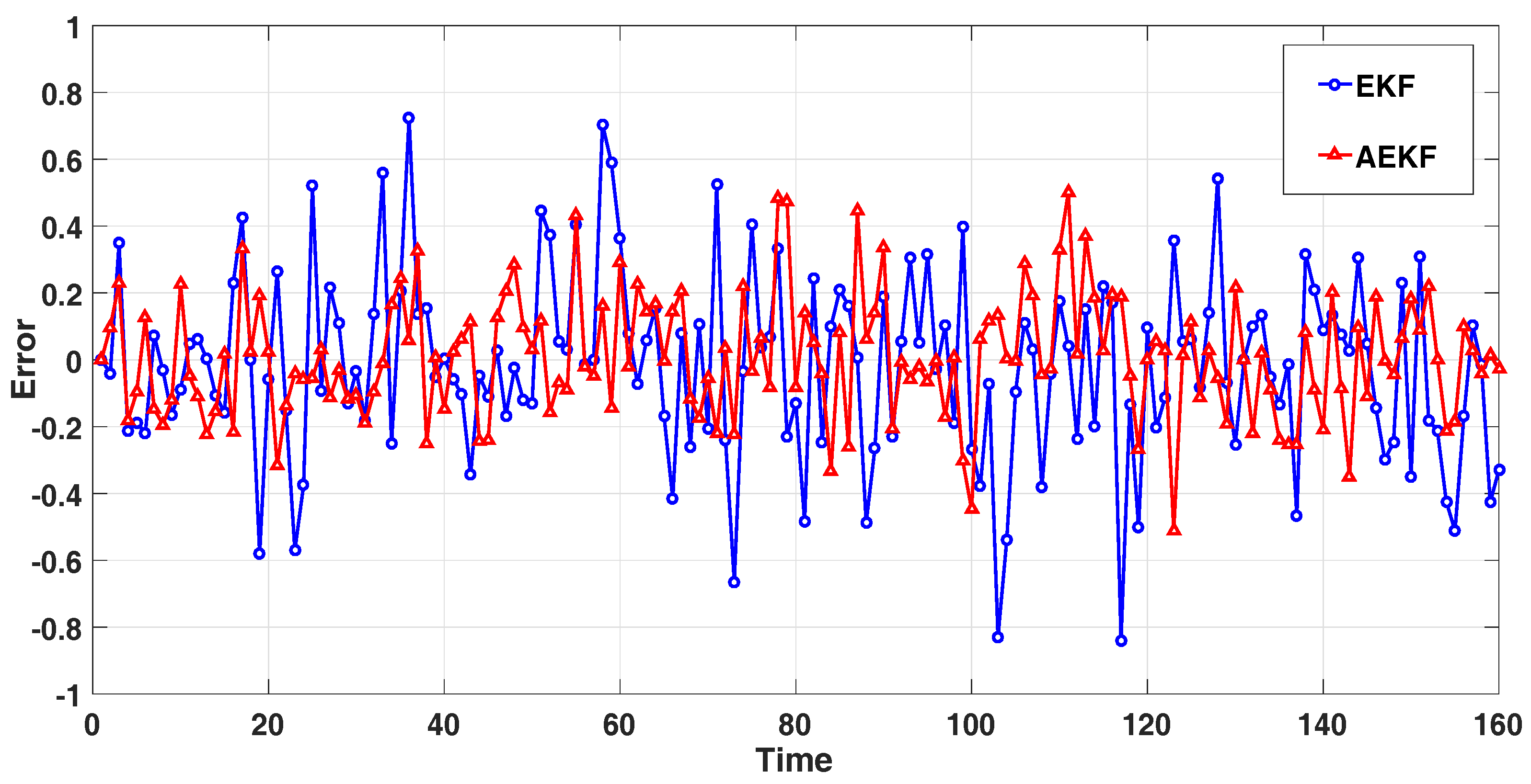
3.3. Analysis of Simulation Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Qian, L.P.; Wu, Y.; Zhou, H.; Shen, X.S. Non-orthogonal multiple access vehicular small cell networks: Architecture and solution. IEEE Netw. 2017, 31, 15–21. [Google Scholar] [CrossRef]
- Bi, Y.; Zhou, H.; Xu, W.; Shen, X.S.; Zhao, H. An efficient PMIPv6-based handoff scheme for urban vehicular networks. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3613–3628. [Google Scholar] [CrossRef]
- Zhou, Z.; Yu, H.; Xu, C.; Zhang, Y.; Mumtaz, S.; Rodriguez, J. Dependable content distribution in d2d-based cooperative vehicular networks: A big data-integrated coalition game approach. IEEE Trans. Intell. Transp. Syst. 2016, 19, 953–964. [Google Scholar] [CrossRef]
- Qian, L.P.; Wu, Y.; Zhou, H.; Shen, X.S. Dynamic cell association for non-orthogonal multiple-access V2S networks. IEEE J. Sel. Areas Commun. 2017, 35, 2342–2356. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Leung, V.C.M.; Wang, K.; Zhang, Y.; Zhang, L. Toward big data in green city. IEEE Commun. Mag. 2017, 55, 14–18. [Google Scholar] [CrossRef]
- Wu, Y.; Qian, L.P.; Mao, H.; Yang, X.; Zhou, H.; Tan, X.; Tsang, D.H.K. Non-orthogonal multiple access vehicular small cell networks: Architecture and solution. IEEE Netw. 2018, 32, 84–91. [Google Scholar] [CrossRef]
- Qian, L.P.; Wu, Y.; Zhou, H.; Shen, X.S. Joint uplink base station association and power control for small-cell networks with non-orthogonal multiple access. IEEE Trans. Wirel. Commun. 2017, 16, 5567–5582. [Google Scholar] [CrossRef]
- Jiang, B.; Fei, Y. Vehicle speed prediction by two-level data driven models in vehicular networks. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1793–1801. [Google Scholar] [CrossRef]
- Cebecauer, M.; Jenelius, E.; Burghout, W. Integrated framework for real-time urban network travel time prediction on sparse probe data. IET Intell. Transp. Syst. 2018, 12, 66–74. [Google Scholar] [CrossRef]
- Liu, L.; Li, J.; Chen, F.; Ye, J.; Huai, J. Road traffic speed prediction: a probabilistic model fusing multi-source data. IEEE Trans. Knowl. Data Eng. 2018, 30, 1310–1323. [Google Scholar]
- Richard, B. Floating car data projects worldwide: A selective review. In Proceeding of the ITS America Annual Meeting, San Antonio, TX, USA, 26–28 April 2004; pp. 192–197. [Google Scholar]
- Thiagarajan, A.; Ravindranath, L.; Lacurtsa, K.; Madden, S.; Balakrishnan, H. VTrack: Accurate, energy-aware road traffic delay estimation using mobile phones. In Proceeding of the 7th ACM Conference on Embedded Networked Sensor Systems, Berkeley, CA, USA, 4–6 November 2009; pp. 85–98. [Google Scholar]
- Fabritiis, C.; Ragona, R.; Valenti, G. Traffic estimation and prediction based on real time floating car data. In Proceeding of the 2008 11th International IEEE Conference on Intelligent Transportation Systems, Beijing, China, 12–15 October 2008; pp. 197–203. [Google Scholar]
- Jenelius, E.; Koutsopoulos, H. Travel time estimation for urban road networks using low frequency probe vehicle data. Transp. Res. Part B Methodol. 2013, 53, 64–81. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Rao, Q.; Yang, W.; Zhang, M. An improved K-nearest neighbor model for short-term traffic flow prediction. Procedia-Soc. Behav. Sci. 2013, 96, 653–662. [Google Scholar] [CrossRef]
- Gong, J.; Qi, L.; Liu, M.; Chen, X. Forecasting urban traffic flow by SVR. In Proceeding of the 25th Chinese Control and Decision Conference, Guiyang, China, 25–27 May 2013; pp. 981–984. [Google Scholar]
- Qian, L.P.; Zhang, Y.J.; Huang, J.; Wu, Y. Demand response management via real-time electricity price control in smart grids. IEEE J. Sel. Areas Commun. 2013, 31, 1268–1280. [Google Scholar] [CrossRef]
- Al-Gindy, A.; Tawfik, A.; Sakhi, L.; Mohamad, H.; Mustafa, M. RFID speed monitoring system. In Proceeding of the International Conference on Developments in eSystems Engineering, Abu Dhabi, UAE, 16–18 December 2013; pp. 328–331. [Google Scholar]
- Huo, Y.; Lu, Y.; Cheng, W.; Jing, T. Vehicle road distance measurement and maintenance in RFID systems on roads. In Proceeding of the International Conference on Connected Vehicles and Expo, Vienna, Austria, 3–7 November 2014; pp. 30–36. [Google Scholar]
- Eom, K.; Lee, S.; Kyung, Y.; Lee, C.; Kim, M.; Jung, K. Improved kalman filter method for measurement noise reduction in multi sensor RFID systems. Sensors 2011, 11, 10266–10282. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Sui, Y.; Wang, G. Vision-based real-time aerial object localization and tracking for UAV sensing system. IEEE Access. 2017, 5, 23969–23978. [Google Scholar] [CrossRef]
- Chen, J.; Wang, N.; Ma, L.; Xu, B. Extended target probability hypothesis density filter based on cubature Kalman filter. IET Radar Sonar Navig. 2015, 9, 324–332. [Google Scholar] [CrossRef]
- Chen, Z.; Fu, Y.; Mi, C. State of charge estimation of lithium-ion batteries in electric drive vehicles using extended kalman eiltering. IEEE Trans. Veh. Tech. 2013, 62, 1020–1030. [Google Scholar] [CrossRef]
- Xia, Q.; Rao, M.; Ying, Y.; Shen, X. Adaptive fading kalman filter with an application. Automatica 1994, 30, 1333–1338. [Google Scholar] [CrossRef]
- Li, M.; Kang, R.; Branson, D.; Dai, J. Model-free control for continuum robots based on an adaptive kalman filter. IEEE/ASME Trans. Mechatron. 2018, 33, 286–297. [Google Scholar] [CrossRef]
- Chopin, N.; Jacob, P.; Papaspiliopoulos, O. SMC2: An Efficient Algorithm for Sequential Analysis of State-Space Models. Royal Stat. Soc. 2013, 75, 397–426. [Google Scholar] [CrossRef]
- Martino, L.; Read, J.; Eivira, V.; Louzada, F. Cooperative Parallel Particle Filters for Online Model Selection and Urban Mobility. Digital Signal Process. 2017, 60, 172–185. [Google Scholar] [CrossRef]
- Jung, J.; Kim, H.; Lee, H.; Yeom, K.W. An UHF RFID tag with long read range. In Proceeding of the 2009 European Microwave Conference (EuMC), Rome, Rome, Italy, 29 September–1 October 2009; pp. 1113–1116. [Google Scholar]
- Chon, H.; Jun, S.; Jung, H.; An, W. Using RFID for accurate positioning. Positioning 2004, 3, 32–39. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 1.2 | 1.4 | 1.6 | 1.8 | 2 | 2.2 | 2.4 | 2.6 | 2.8 | 3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | 0.0396 | 0.0441 | 0.0485 | 0.0530 | 0.0572 | 0.0613 | 0.0653 | 0.0690 | 0.0724 | 0.0757 | 0.0788 |
| MAE | 0.1525 | 0.1614 | 0.1702 | 0.1784 | 0.1861 | 0.1931 | 0.1994 | 0.2052 | 0.2105 | 0.2152 | 0.2195 |
| Stage | EKF | AEKF | EKF vs AEKF | |||
|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | |
| 1 | 0.0608 | 0.1833 | 0.0232 | 0.1257 | 61.8% | 31.4% |
| 2 | 0.0828 | 0.2114 | 0.0356 | 0.1494 | 57.0% | 29.3% |
| 3 | 0.0862 | 0.2247 | 0.0418 | 0.1673 | 51.5% | 25.5% |
| 4 | 0.0609 | 0.2017 | 0.0240 | 0.1233 | 60.6% | 38.9% |
| Total | 0.0756 | 0.2084 | 0.0330 | 0.1457 | 56.3% | 30.1% |
| Stage | EKF | AEKF | EKF vs AEKF | |||
|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | |
| Normal model | 0.0756 | 0.2084 | 0.0330 | 0.1457 | 56.3% | 30.1% |
| Constant speed model | 0.1746 | 0.3269 | 0.0705 | 0.2115 | 59.6% | 35.3% |
| Deceleration model | 0.1085 | 0.2489 | 0.0493 | 0.1732 | 54.5% | 30.4% |
| Average | 0.1196 | 0.2614 | 0.0509 | 0.1768 | 57.4% | 32.4% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Qian, L.; Feng, A.; Wu, Y.; Zhu, W. RFID Data-Driven Vehicle Speed Prediction via Adaptive Extended Kalman Filter. Sensors 2018, 18, 2787. https://doi.org/10.3390/s18092787
Huang Y, Qian L, Feng A, Wu Y, Zhu W. RFID Data-Driven Vehicle Speed Prediction via Adaptive Extended Kalman Filter. Sensors. 2018; 18(9):2787. https://doi.org/10.3390/s18092787
Chicago/Turabian StyleHuang, Yupin, Liping Qian, Anqi Feng, Yuan Wu, and Wei Zhu. 2018. "RFID Data-Driven Vehicle Speed Prediction via Adaptive Extended Kalman Filter" Sensors 18, no. 9: 2787. https://doi.org/10.3390/s18092787
APA StyleHuang, Y., Qian, L., Feng, A., Wu, Y., & Zhu, W. (2018). RFID Data-Driven Vehicle Speed Prediction via Adaptive Extended Kalman Filter. Sensors, 18(9), 2787. https://doi.org/10.3390/s18092787