1. Introduction
Particle Swarm Optimization (PSO) is an evolutionary optimization algorithm based on swarm intelligence. It is originally proposed by Kennedy and Eberhart in 1995 [
1] and is known for its effectiveness and simplicity. It has been proved to be outstanding in solving many complex optimization problems such as power systems [
2], neural network training [
3], global path planning [
4], and feature selection [
5].
However, PSO also suffers from two limitations. One is that the original PSO tends to converge to the local optima when applied to complex problems. On the other hand, the convergence speed of the original PSO and most of its variants is slow, especially on high-dimensional problems [
6]. Therefore, accelerating the convergence speed and avoiding the local optima convergence have become the two most important and appealing goals in particle swarm optimization studies [
7,
8]. Specifically, the studies can be classified into three strategies: parameter selection strategy, topology strategy and learning strategy.
The parameter selection refers to the optimization of the inertial weight factor, convergence factor, and the acceleration constant. The inertial weight factor is introduced by Shi and Eberhart to improve the update of velocity [
9]. Further studies also show that applying linear decreasing [
10], nonlinear [
11], exponential [
12] and Gaussian [
13] strategy to optimize the inertia weight can enhance the overall performance. The convergence factor is proposed by Clerc and Kennedy to enhance the final convergence [
14]. In addition, detailed studies [
15,
16,
17] show that the acceleration constant takes an important role on convergence performance.
The topology strategy is generally employed to improve exploration and avoid premature convergence. In topology strategy, individuals learn from the neighborhood rather than the whole swarm. Therefore, more information would be shared during the search process, which is useful to improve optimization performance. A number of topologies including ring or circle topology, wheel topology, star topology, pyramid topology, Von Neumann topology and random topology are suggested by Kennedy in [
18]. Generally, a large neighborhood is good for simple problems, whereas a small neighborhood is helpful for avoiding premature convergence on complex problems [
19]. Reference [
20] studied the topology extensively, which provides a useful guide of topology selection. It points out that an optimal topology is both problem-specific and computational-budget-dependent and two formulas have been introduced to estimate optimal topology parameters based on numerical experiments.
In the original PSO, all individuals keep learning from the global best solution and their individual best experience in the whole search process. This may lead to premature convergence [
21]. To overcome the problem, some novel learning strategies have been developed in recent years. A comprehensive learning strategy is developed to improve the performance on complex multimodal functions in [
22]. Reference [
23] introduces a cooperative approach to solve high-dimensional optimization problems with multiple swarms. A cooperatively coevolving strategy is proposed in [
24] to further improve the performance. Sun et al. introduce a global guaranteed convergence optimizer called quantum behaved particle swarm optimization, which improves the performance by increasing the population diversity [
25]. A variant with double learning patterns is developed in [
26], which employs the master swarm and the slave swarm with different learning patterns to achieve a trade-off between the convergence speed and the swarm diversity.
However, the three strategies above still face the following shortcomings. In parameter selection, some strategies do improve the overall performance in many cases, but the effect is limited [
19], and it is hard to obtain an optimal parameter for all cases. In topology strategy and learning strategy, although the exploration is improved to avoid premature convergence, the convergence speed is reduced at the same time.
In this paper, we design a double-group particle swarm optimization (DG-PSO) to improve the performance. The whole population is divided into two groups: an advantaged group and a disadvantaged group. The modification is focused on the disadvantaged group. A novel learning strategy is developed based on the comprehensive learning strategy and the self-pollination strategy in another popular metaheuristic called Flower Pollination Algorithm (FPA). In addition, a diversity enhancing strategy is also designed to avoid premature convergence. Compared with those published works, the main contribution in this paper is that a novel variant called DG-PSO is proposed which shows remarkable performance compared with five other popular variants and two meta-heuristics. Two new ideas are developed in DG-PSO: a learning strategy, which combines the comprehensive learning strategy [
22] and the self-pollination strategy [
27], and a diversity enhancing strategy, which adds disturbance to the individuals in the disadvantaged group to avoid premature convergence in multimodal problem. In addition, we also apply the algorithm to multilevel thresholding for image segmentation, which verifies the effectiveness of DG-PSO and provides a good choice of the metaheuristic algorithm to implement multilevel thresholding. The rest of the paper is organized as follows:
Section 2 reviews the original PSO and some related works. The strategies and framework of the proposed algorithm are presented in detail in
Section 3, followed by the experiments in
Section 4. Then, the further application on multilevel thresholding for image segmentation is shown in
Section 5.
3. The Proposed Algorithm
In this section, we describe the proposed algorithm.
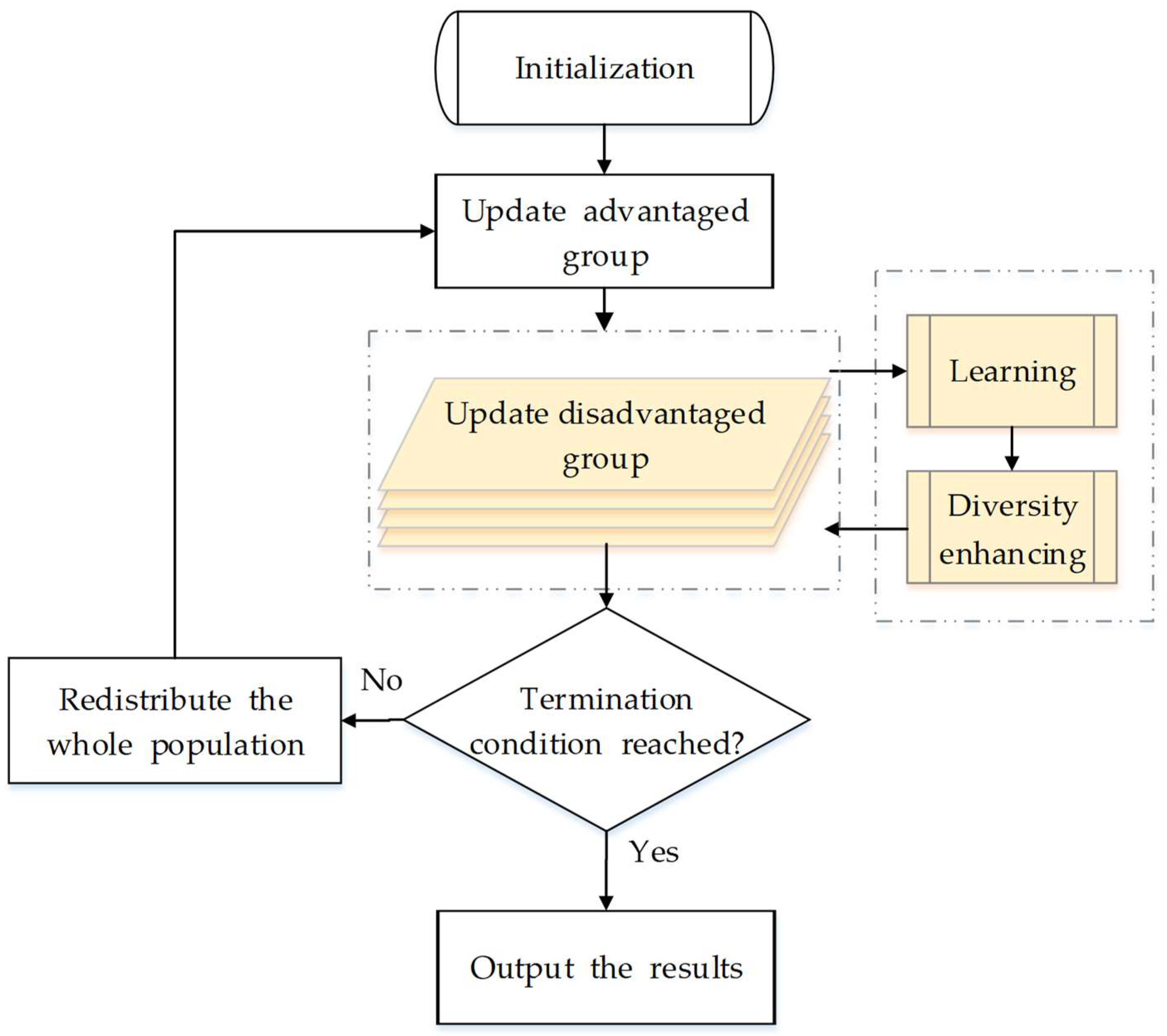
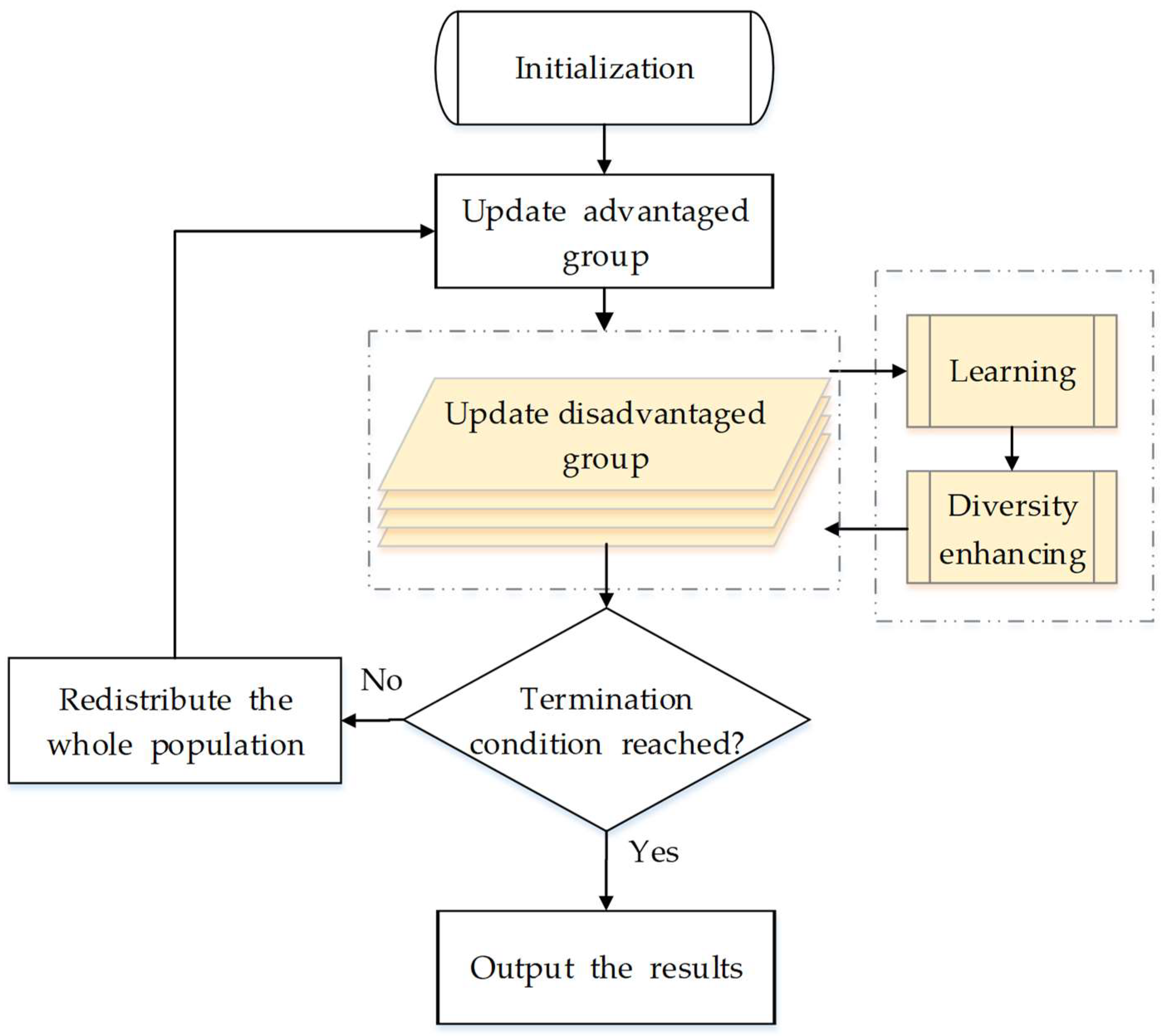
Figure 1 shows the overall flowchart, where the process colored by yellow is the core idea of our algorithm. Different from the original PSO, we separate all particles into two groups in DG-PSO: an advantaged group (with the population of
) and a disadvantaged group (with the population of
, where
). The advantaged group evolves according to the same theory as the original PSO (Equations (1) and (2)), while the disadvantaged group is updated with two novel strategies: a learning strategy and a diversity enhancing strategy. We focus on the explanation of how the disadvantaged group works. As shown in
Figure 2, the two new strategies work as two sequential processing stages in the update of the disadvantaged group, which will be discussed carefully in the following two subsections. In addition, the detailed steps and the whole framework of the proposed method are given in
Section 3.3. Finally, we discuss and compare the proposed algorithm with other related works in
Section 3.4.
3.1. The Learning Strategy
The learning strategy is based on the self-pollination strategy introduced in
Section 2. We firstly employ the previous best solution
to be the solution “
” in Equation (4) (rather than the position
, this is because
represent the best historical experience of each particle, which is more worthy to learn from compared with the position
). Then, it becomes Equation (5) for the particle
:
where
denotes the particles in the disadvantaged group;
and
are two solutions chosen randomly from the
of the whole population (Specifically,
and
are two random integers chosen from sequence
. These two parameters keep the same for all dimensions when updating a particle
. In addition, they are regenerated for different particles.).
represents the scaling factor to perform a random walk satisfying a uniform distributed within
. Similar to the original self-pollination strategy, Equation (5) can be considered as the local search around the solution (position)
.
On the other hand, as the comprehensive learning strategy generally defines a more suitable solution for the particles to learn from, we additionally replaced the
in Equation (5) with
given in Equation (6), where
is the strategy to identify a particle’s
for the
dimension of particle
to learn from:
works according to the comprehensive learning strategy. For the dimension of particle , the specific procedure to identify the is shown as follows:
Randomly choose two particles out of the advantaged group;
Compare the fitness of the two particles’ and choose the better one;
Use the dimension of the winner’s as the for the corresponding dimension of the particle to learn from.
Then, a new position is generated using Equation (6) for the particle in the disadvantaged group to update. Using (6), the particles in the disadvantaged group can learn from the information derived from different particles’ historical best position. The strategy is different from the original self-pollination because we perform local search around the new generated position rather than the particle itself. The reason is that always searching the area around the position itself may reduce the search efficiency because some particles may be located in the low-promising area. In contrast, making more use of the good information from the advantaged group (using the comprehensive learning strategy) is inductive to the search efficiency.
3.2. The Diversity Enhancing Strategy
PSO often suffers from premature convergence, especially when optimizing the multimodal problem. It is because the original PSO algorithm only employs an attraction phase Equation (1), in which all particles in the swarm move quickly to the same area and the diversity decreases quickly [
35]. This generally leads to converging to the local optima due to the loss of diversity [
22]. In such case, improving diversity becomes an important issue in PSO research [
22,
36]. As diversity is lost due to particles getting clustered together [
37], adding disturbance to the particles is helpful for them to escape from the local optimal and enhance diversity. Therefore, we developed a strategy to push the particle away from their current position by adding disturbance given in Equation (7):
where
is the scaling factor that controls the intensity of the disturbance. As shown in Equation (8), it is identified using the whole search range of the corresponding dimension (which denotes the strong disturbance) or the Euclidean distance of the two
chosen in the learning strategy (which denotes a relatively weak disturbance). The strong disturbance is designed for the case that the particle falls
into a large-area local optimum. Therefore, a big jump is needed to escape. The weak disturbance is designed for the case that the particle is close to the global optimum. In such case, a small random walk is more helpful to approaching the optimum.
where,
and
are two random number uniformly generated within
and
and
represents the upper and lower bounds of the search space.
Specifically, the strategy works as follows. For each dimension of particle , we generate a random number within . If the number is smaller than the given threshold , the diversity of the corresponding dimension will be enhanced by adding a random disturbance using (7) and (8). With the disturbance, the particles are more capable to escape from the local optimal and avoid premature convergence.
3.3. The Framework
Algorithm 1 shows the detailed steps of updating the disadvantaged group, which is the core of our modification. Apart from Algorithm 1, another minor modification in the proposed algorithm is that all particles in the two groups should be redistributed according to their fitness at the end of each generation.
particles with better fitness (for minimization problem, “better” means “smaller”) are distributed to the advantaged group, whereas others are distributed to the disadvantaged group. The overall framework and the detailed steps are shown in
Figure 1 and Algorithm 2, respectively, where
MaxFEs is the maximum number of function evaluations that represent the maximum computation cost.
| Algorithm 1. The Steps for Updating the Disadvantaged Group |
| 1 | For |
| 2 | Randomly choose two : and out of the whole population; |
| 3 | /* Learning stage */ |
| 4 | For |
| 5 1 | Generate two different integers and within [1,2…m]; |
| 6 2 | If |
| 7 | ; |
| 8 | Else |
| 9 | ; |
| 10 | End |
| 11 | ; |
| 12 | End |
| 13 | /* Diversity Enhancing stage */ |
| 14 | For |
| 15 | If |
| 16 | Draw a scaling factor using Equation (8); |
| 17 | Add disturbance for the current dimension using Equation (7); |
| 18 | End |
| 19 | End |
| 20 | End |
| Algorithm 2. The Steps of the Proposed Algorithm |
| 1 | Randomly initialize n particles; |
| 2 | m particles with better fitness value for the advantaged group; others for the disadvantaged; |
| 3 | While |
| 4 | For |
| 5 | Update the particle in the advantaged group using Equations (1) and (2); |
| 6 | End |
| 7 | Evaluate the fitness of the advantaged group; |
| 8 | Update pbest and record the corresponding fitness as fpbest. |
| 9 | Update the disadvantaged group using Algorithm I; |
| 10 | Evaluate the fitness of the disadvantaged group; |
| 11 | Update pbest and record the corresponding fitness as fpbest. |
| 12 | ; |
| 13 | Redistribute the whole population; |
| 14 | End |
3.4. Discussion and Comparison of the Proposed Algorithm with Other Related Works
As mentioned above, we combined the current existing comprehensive learning strategy with the self-pollination strategy in FPA. Specifically, we firstly applied the self-pollination strategy to PSO. Then, the comprehensive learning strategy is used to identify an exemplar for the particles in the disadvantaged group to learn from. Note that we choose the exemplar in the advantaged group rather than in the whole swarm. This strategy aims to improve the learning efficiency of the disadvantaged group. Obviously, such strategy is different from CLPSO (because CLPSO uses the comprehensive learning to modify the learning strategy of the original PSO as introduced in
Section 2, whereas we proposed a new learning strategy).
Based on the analysis above, CLPSO, FPA would be used to compare with the proposed one. In addition, since we also developed a diversity enhancing strategy to further improve the performance, it is also necessary to evaluate its effectiveness. We firstly define:
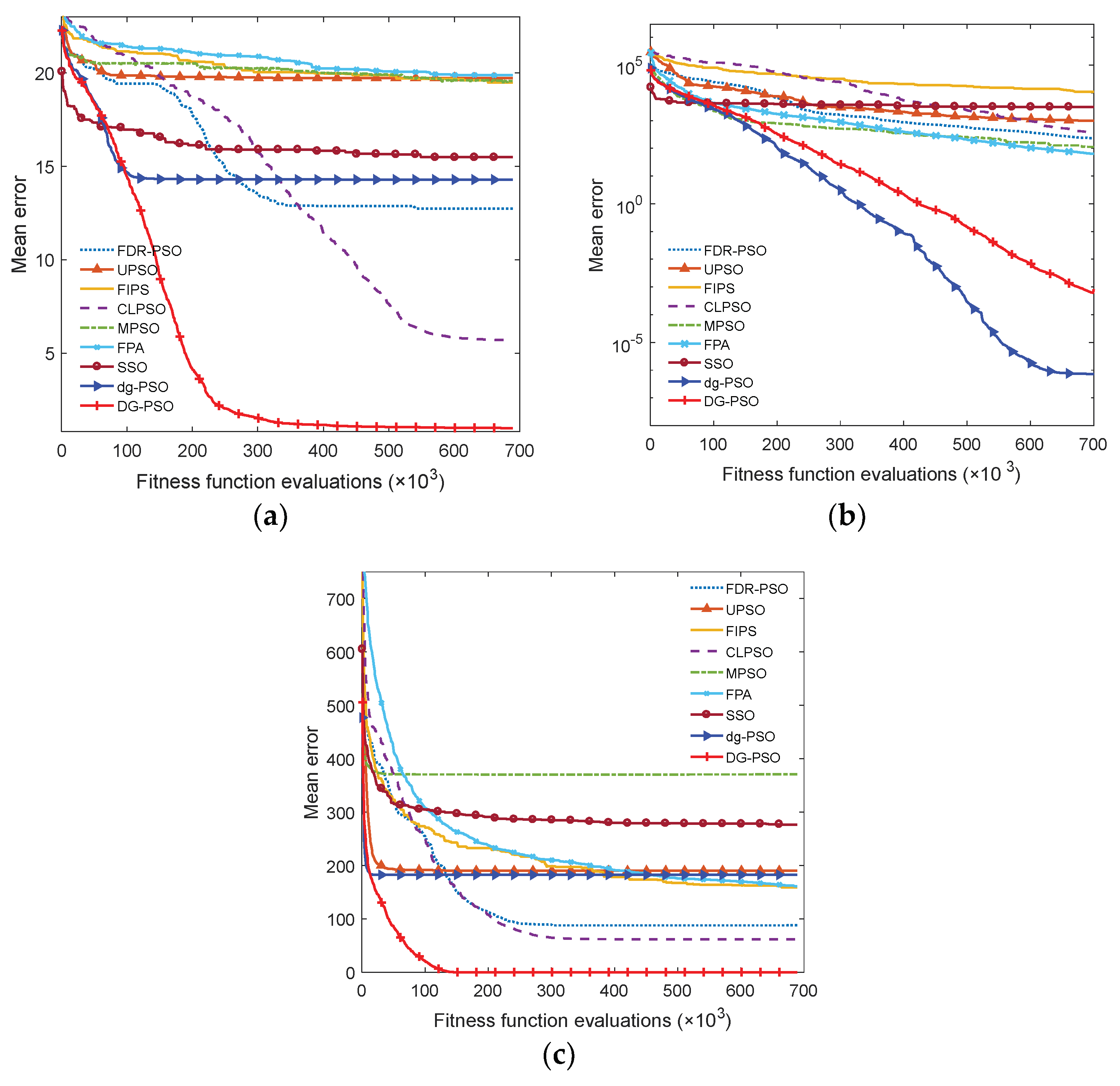
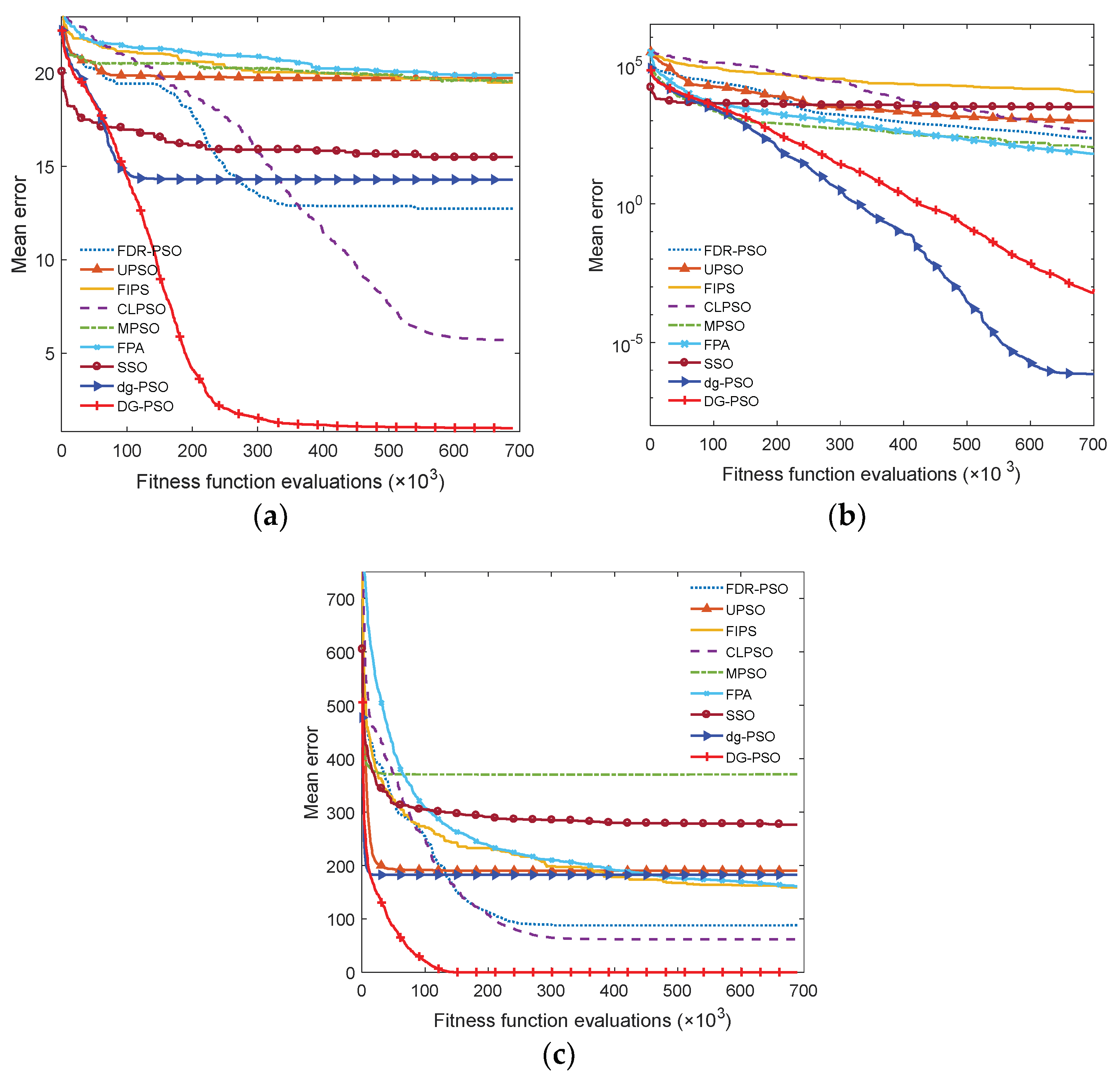
Then, the effectiveness of the diversity enhancing strategy can be evaluated by comparing the performance of dg-PSO with DG-PSO.
5. DG-PSO Based Remote Sensing Image Segmentation
Image segmentation is a fundamental task in remote sensing applications [
49], such as change detection and object-based classification. It is used with the expectation that it will divide the image into semantically significant regions, or objects, to be recognized by further processing steps [
50]. This work attracts a lot of researchers in the past decade but is still an intractable problem [
51]. In terms of all the existing segmentation methods, one of the most popular segmentation techniques is thresholding due to its simplicity, robustness and accuracy [
52].
The thresholding methods can be divided into two categories: the bi-level thresholding and multilevel thresholding. If the object in an image is separated from the background using a single threshold value, it is called the bi-level thresholding. In contrast, the multilevel thresholding means that the given image are classified into several different regions according to multiple thresholds. In remote sensing image segmentation, bi-level thresholding does not give appropriate performance, and there are strong requirements of multilevel thresholding [
53]. Therefore, numerous studies have been reported [
47,
53,
54,
55,
56,
57,
58] in multilevel thresholding.
The most popular way [
53,
54,
55,
56,
57,
58,
59,
60,
61] to search the optimal thresholds is to maximize some discriminating criteria (fitness function). The traditional method searches the optimal thresholds using exhaustive search strategies, which lead to high computation costs. In recent years, meta-heuristics based methods gained the attention of researchers because of the high computation inefficiency. Quantities of algorithms have been introduced to this area such as PSO [
36], Differential Evolution (DE) [
62], Artificial Bee Colony (ABC) [
59,
63,
64], Wind Driven Optimization (WDO) [
56], Cuckoo Search (CS) [
65] and SSO [
47]. However, the remote sensing images are very difficult to segment accurately due to multimodality of the histograms [
53]. Therefore, improving the performance of the metaheuristic algorithms is necessary for the remote sensing image segmentation.
In this section, we applied the proposed algorithm to multilevel thresholding for optical remote sensing image segmentation. We first describe the problem. Then, the experimental setup is introduced carefully in
Section 5.2. Finally, the results and analysis are given in detail.
5.1. Problem Definition
This subsection deals with the problem definition of multilevel thresholding problem. As we mention above, multilevel thresholding methods generally search the optimal thresholds by maximizing some criteria. In the literature, Otsu’s criterion [
66] has been widely employed [
36,
67,
68]. It generally provides image segmentation with satisfactory results [
69] and is known for its simplicity and effectivity with respect to uniformity and shape measures and can usually obtain optimal global threshold value [
58].
Let
be the gray level of a given an image
, where
is the total gray levels, the problem is then defined as follows. Firstly, the image histogram is calculated and normalized, which is denoted by
,
. For the
thresholding problem, there are
thresholds
, (
) that segment the image into
classes. Assume that
and
denote the upper and lower bound. Then, the thresholds can be sorted with
, and the problem is defined using (9):
where
,
. Here,
is the probability of the occurrence of the
dth class.
is the total mean intensity of the original image.
5.2. Experimental Setup
To demonstrate the superiority of the proposed method, five popular meta-heuristic algorithms in multilevel thresholding including DE, ABC, CS, MPSO, SSO are chosen to compare with the proposed algorithm. All of these algorithms are demonstrated to have good performance in multilevel thresholding in the corresponding reference in
Table 6. Specifically, ABC performs better than PSO when the level of thresholds is higher than two in [
59]. Reference [
53] demonstrates that CS showed remarkable performances in multilevel thresholding problems and could outperform the other known algorithms, such as DE, PSO, WDO and ABC. MPSO shows better performance than Genetic Algorithm (GA) and the original PSO [
36]. SSO is applied to multilevel thresholding in [
47] and it clearly outperforms PSO, BAT algorithm and FPA in [
47]. The parameters of these algorithms are set according to the corresponding work shown in
Table 6. The parameters of our proposed algorithm are the same as that in
Section 4.
All populations are uniformly randomly initialized. Thirty independent runs are carried out for each algorithm on each image on 2, 3, 4, 5, 7, 9, 15 and 20 thresholds [
68,
69], respectively. All algorithms are conducted with the same maximum function evaluation:
in identical search space:
. All methods are adapted for integer optimization problems using the rounding method. Specifically, the search space is defined as
for 8-bit gray-scale images, and the integer is obtained by rounding down (e.g., 255.6 is rounded to 255).
Figure 6 shows the test images (These images are taken from a very-high-resolution remote sensing image dataset constructed by Gong Cheng et al. from Northwestern Polytechnical University [
70].
5.3. Results and Discussion
In detail, the mean fitness and the corresponding standard deviation are given in
Table 7, where the best one in each case of the mean fitness is shown in bold. It is easy to find that our algorithm obtains the best results in all cases in terms of the mean fitness, except the case of 7-level thresholding (
D = 7) of image C. To evaluate the effectiveness of our algorithm’s improvement over other ones, the involved algorithms are also ranked with the Friedman test. We conduct two tests that ranked the algorithms on the normal (
D = 2, 3, 4 and 5) level and high level (The high level thresholding is popularly employed in multilevel thresholding [
68,
69]) (
D = 7, 9, 15 and 20), respectively. Therefore, 40 variables
are used in each comparison in each test, where
is the number of images,
denoted the number of levels, and
denoted the number of used measures including the meant fitness and the corresponding standard deviation. The significance level is set to 0.05.
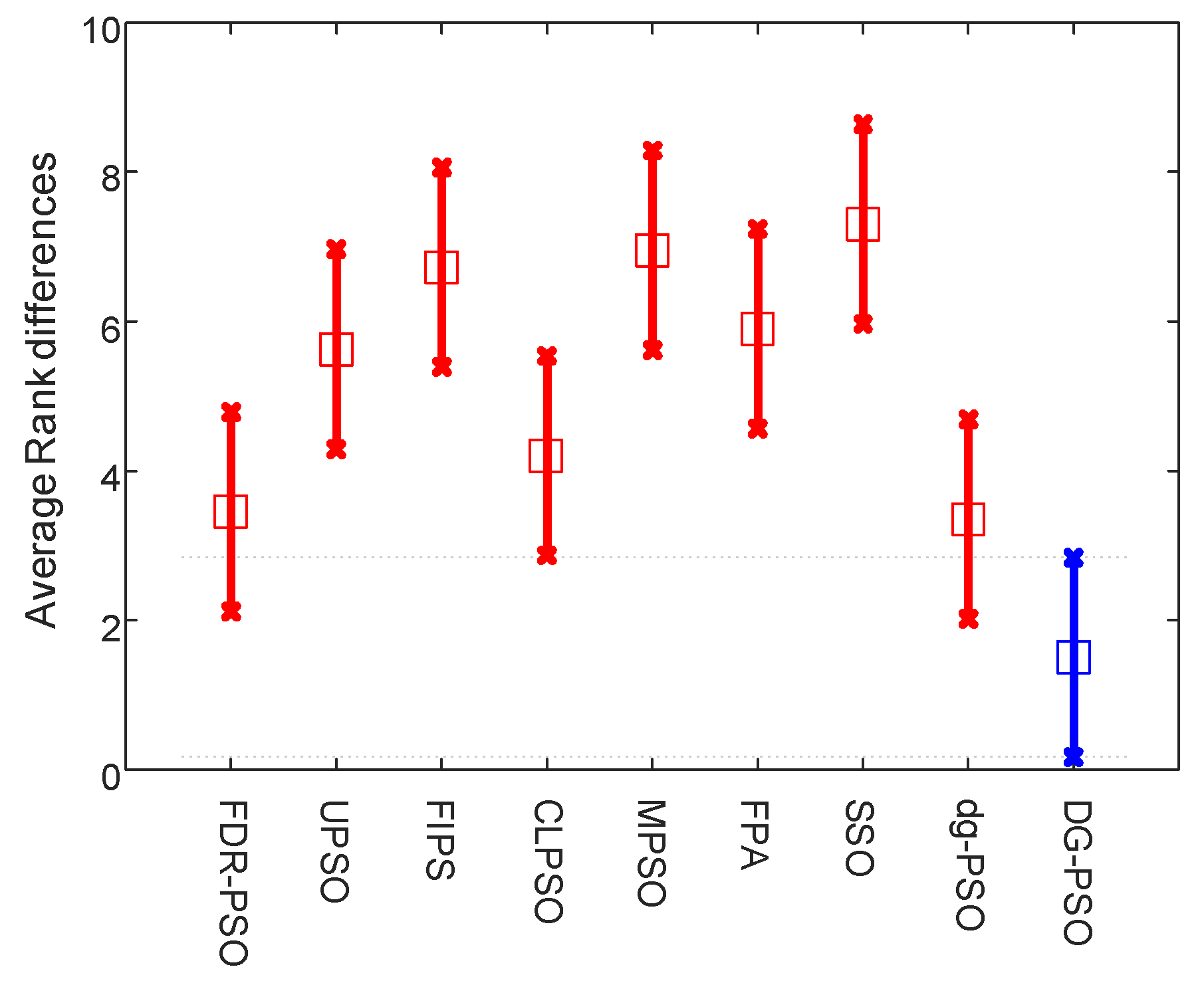
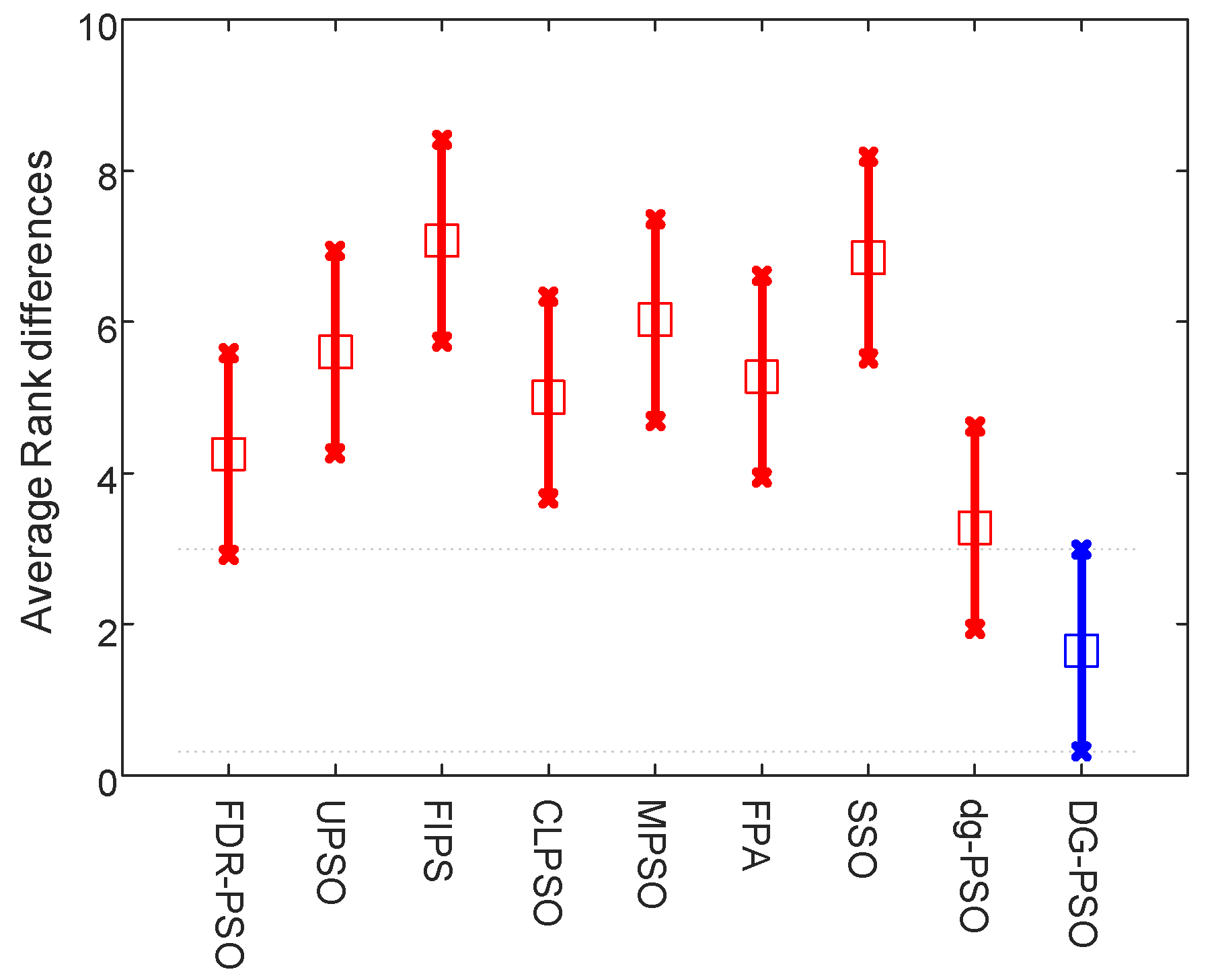
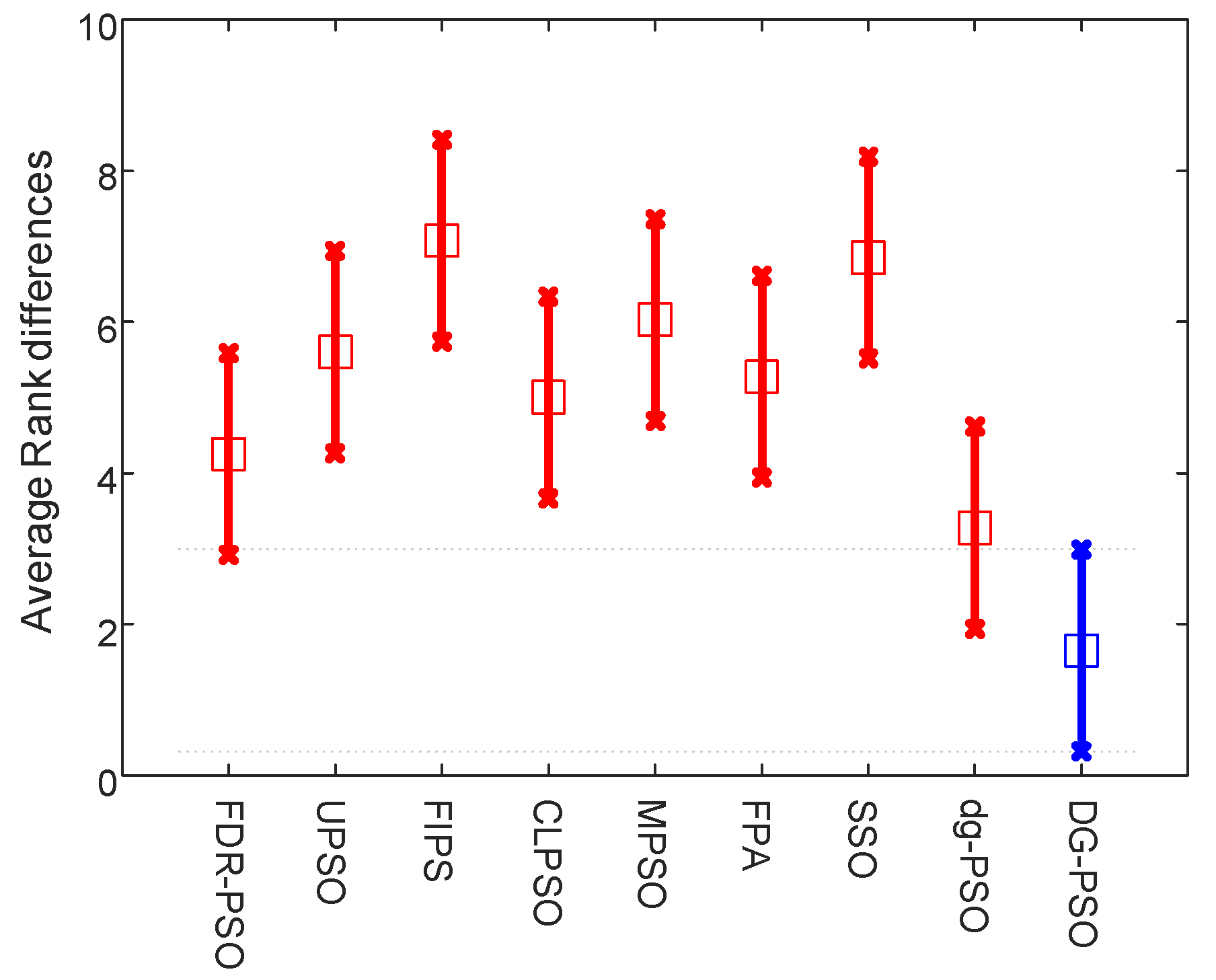
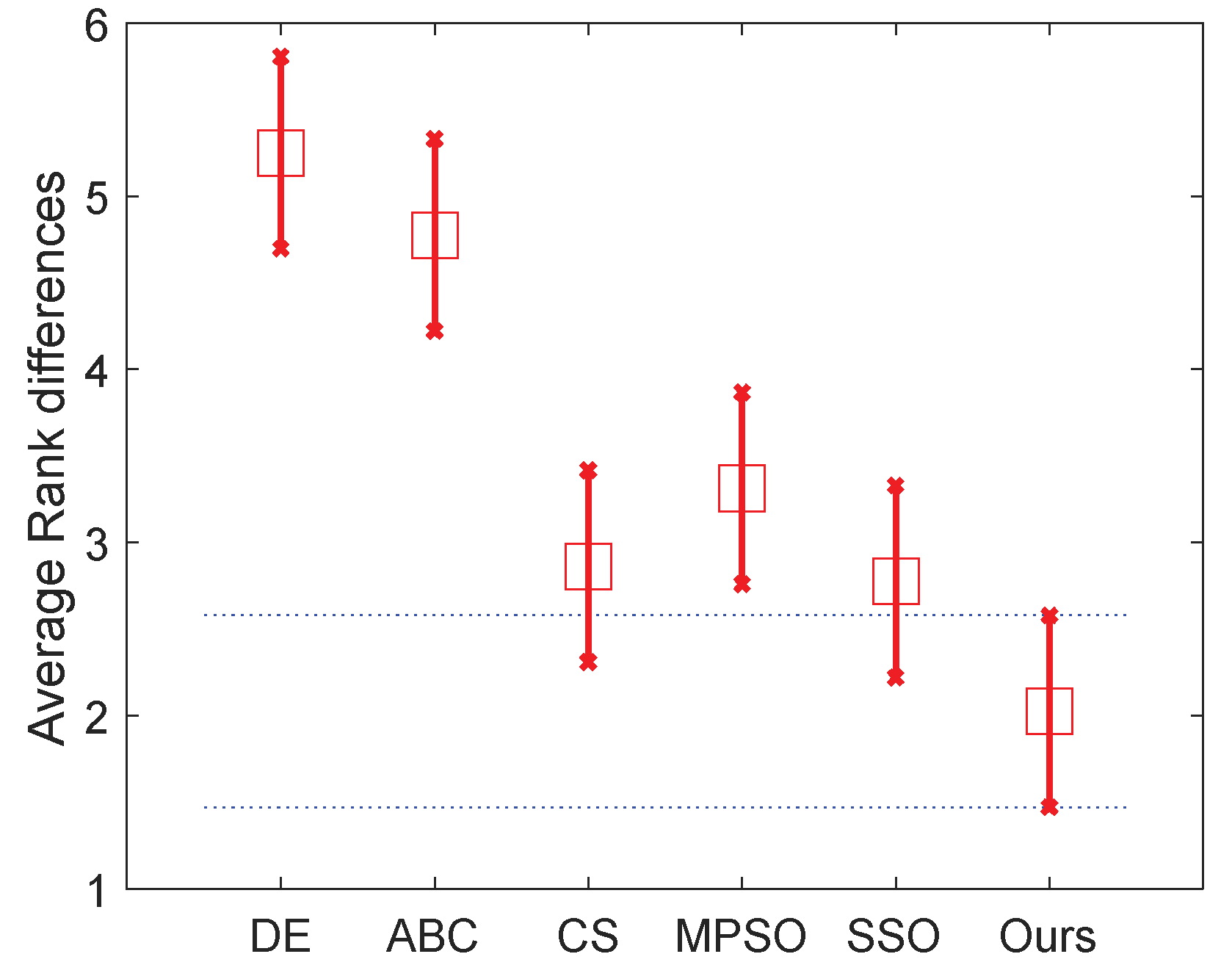
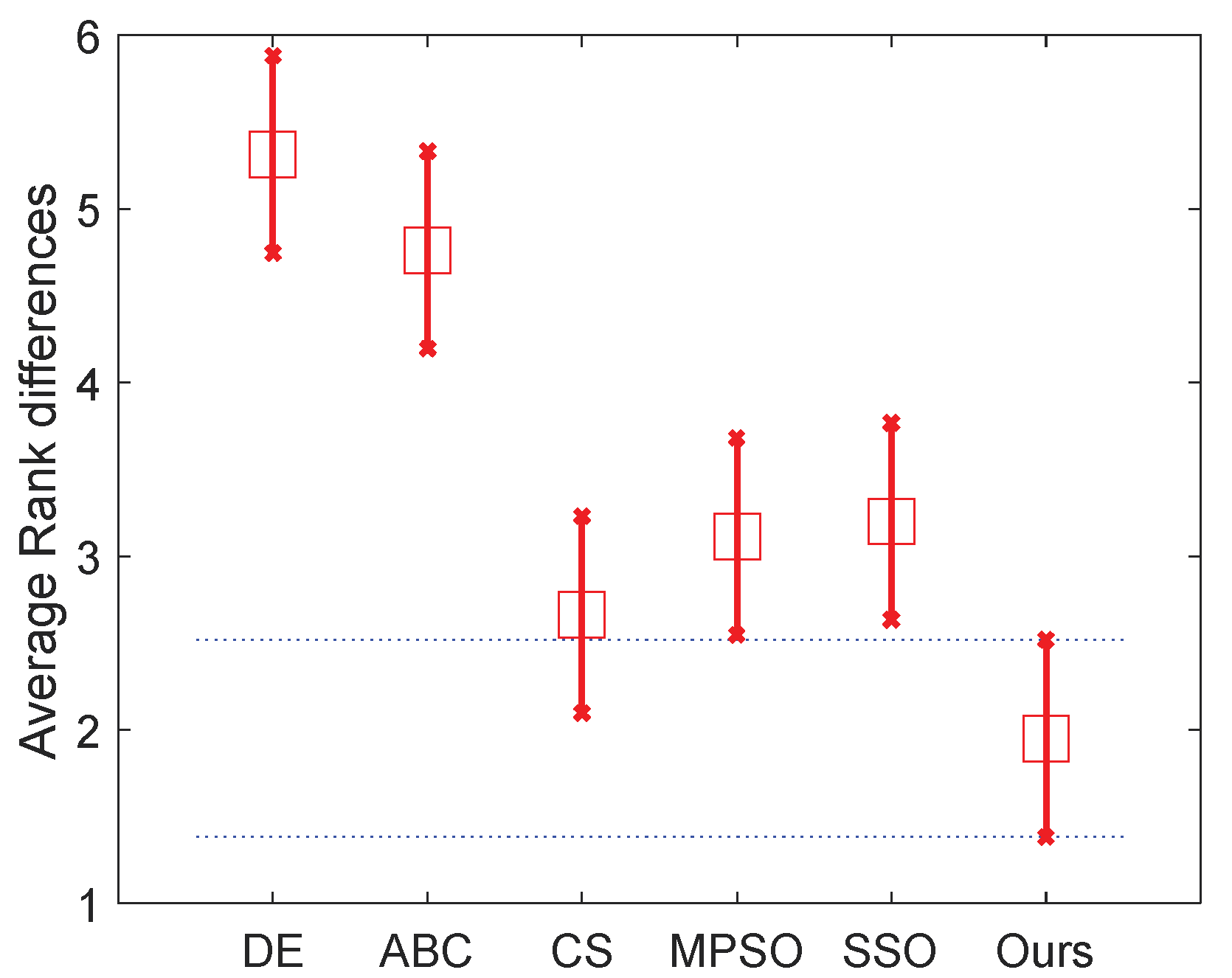
Table 8 and the two figures (
Figure 7 and
Figure 8) present the numerical rankings and graphical results obtained by the test, where better performance is denoted by smaller ranks.
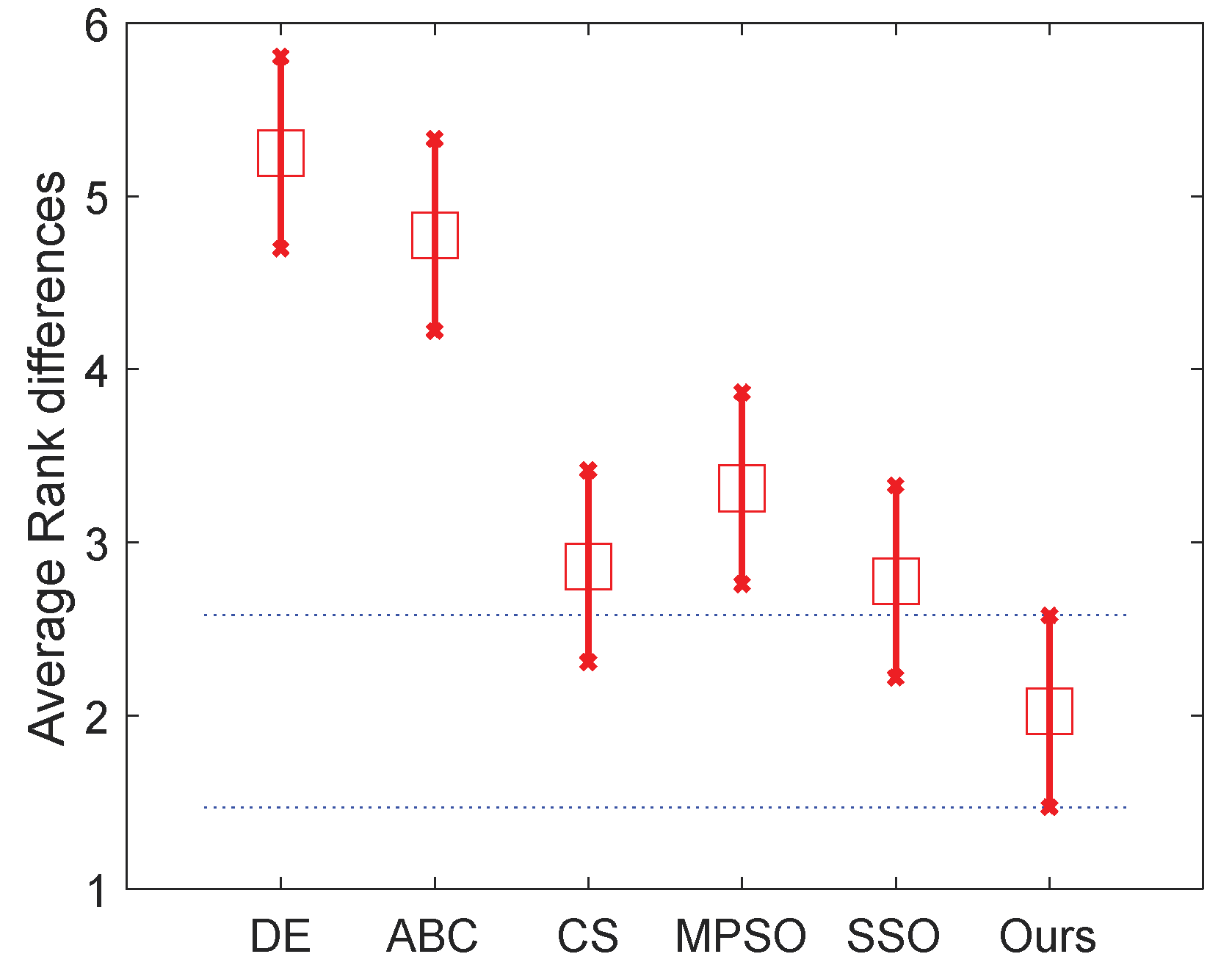
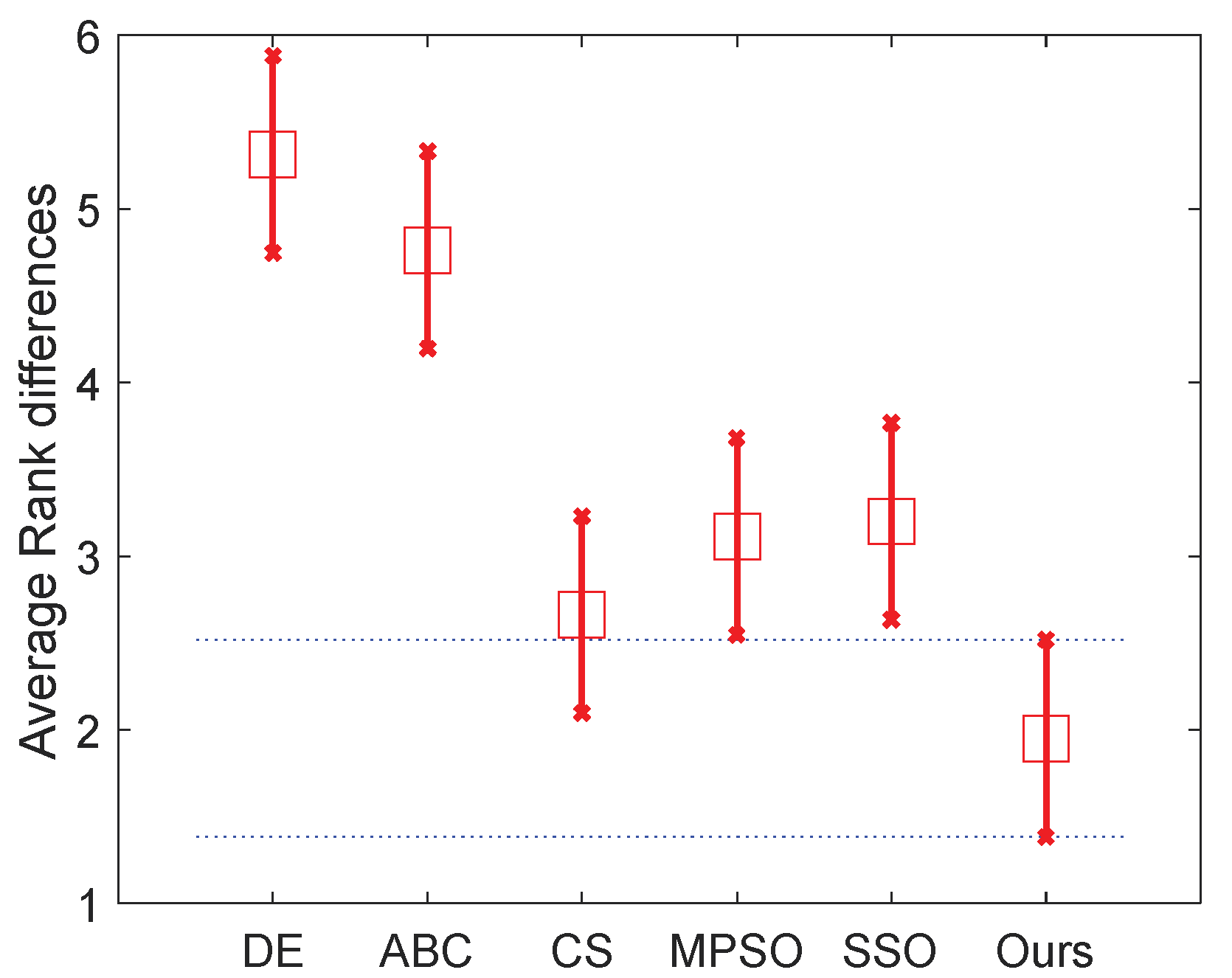
From the results of normal level thresholding shown in
Figure 7, the proposed algorithm significantly outperforms DE, ABC and MPSO, and also showed an advantage over the other two algorithms. It can be observed from
Figure 8 that the proposed algorithm ranks even better in high level thresholding, which showed a significant difference from all algorithms except CS (our algorithm also ranks better than CS).
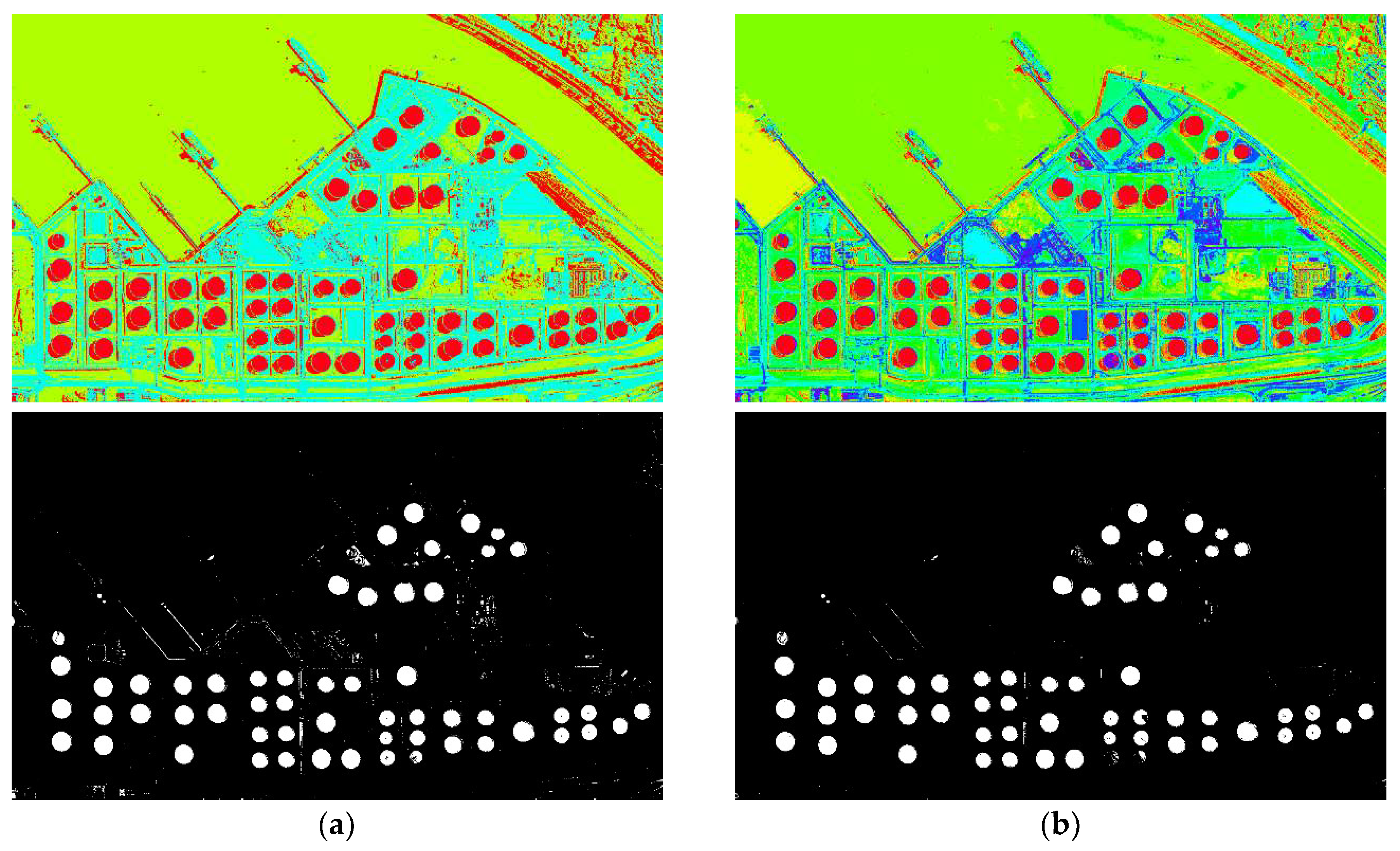
Figure 9 and
Figure 10 show the segmentation results. The pseudo color image shows the whole thresholding results, where each level of the image is represented by the regions with the same color. The binary images show some of the objects separated from the original image, which proved the effectiveness of the segmentation.
In conclusion, the results demonstrated that the proposed algorithm shows remarkable performance in multilevel thresholding when compared with other popular meta-heuristics in this research area.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}