A Student’s t Mixture Probability Hypothesis Density Filter for Multi-Target Tracking with Outliers


1
Information and Navigation College Air Force Engineering University, Xi’an 710077, China
2
Unit 93786, Chinese People’s Liberation Army (PLA), Zhangjiakou 075000, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(4), 1095; https://doi.org/10.3390/s18041095
Submission received: 28 February 2018
/
Revised: 29 March 2018
/
Accepted: 29 March 2018
/
Published: 4 April 2018
(This article belongs to the Section Physical Sensors)
Abstract
:In multi-target tracking, the outliers-corrupted process and measurement noises can reduce the performance of the probability hypothesis density (PHD) filter severely. To solve the problem, this paper proposed a novel PHD filter, called Student’s t mixture PHD (STM-PHD) filter. The proposed filter models the heavy-tailed process noise and measurement noise as a Student’s t distribution as well as approximates the multi-target intensity as a mixture of Student’s t components to be propagated in time. Then, a closed PHD recursion is obtained based on Student’s t approximation. Our approach can make full use of the heavy-tailed characteristic of a Student’s t distribution to handle the situations with heavy-tailed process and the measurement noises. The simulation results verify that the proposed filter can overcome the negative effect generated by outliers and maintain a good tracking accuracy in the simultaneous presence of process and measurement outliers.
1. Introduction
Multi-target tracking (MTT) plays an important role in many sensing systems, such as infrared, radar, sonar, etc., which uses the sensor data to jointly estimate the target state and the number of targets. Nowadays it is widely used in civilian and military applications such as air traffic control, remote sensing, ballistic missile guidance, and computer vision [1,2]. In MTT, the time-varying number of targets causes a problem in that the associations between state and measurement sets of targets are hard to know, which makes the traditional data association-based multi-target tracking methods problematic. In recent years, the random finite set (RFS) theory-based multi-target tracking filters, such as probability hypothesis density (PHD) filter [3], cardinalized PHD (CPHD) filter [4], multi-target multi-Bernoulli (MeMber) filter [1] and cardinality-balanced MeMBer (CBMeMBer) filter [5], have attracted much more attention since they can avoid the combinatorial problem that arises from data association. Moreover, some labeled RFS-based multi-Bernoulli filters [6,7] which can accommodate target tracks were proposed.
The focus of this paper is the PHD filter, which has relatively simple recursion, making it suitable for the applications demanding real time results. The PHD filter provides a tractable sub-optimal strategy for jointly estimating the number and the state of a variable number of targets by propagating the first-order statistical moment of multi-target posterior probability density in time. It has two basic implementations: the sequential Monte Carlo (SMC) method [8] and the Gaussian mixture (GM) method [9] which can solve the problem of computationally intractable multiple integrals involved in the PHD recursions. Compared to SMC implementation, GM implementation of the PHD filter has the advantages of simple state extraction and low computational cost, which is suitable for the requirement of real-time scenes. Moreover, some nonlinear extensions [9,10,11] and improvements [12,13,14] extend the scope of applications for the GM-PHD filter.
In MTT, noise, as the important part of measurement uncertainty, is an inevitable problem that reduces estimation accuracy of the PHD filter. Vo [15] thought that the setting of a reasonably large noise variance can accommodate noise interference in most situations. However, this method is only suitable for Gaussian noise. In real applications, it is hard for the measurement noise from sensor data to follow the Gaussian distribution because of electromagnetic interference or sensors’ own unreliability. Such measurements with outliers, which often express heavy-tailed character, degrade the performance of the PHD filter strikingly. What’s worse, in some real applications, such as tracking some agile targets with unreliable sensors, outliers may appear in not only the measurement model, but also the process model. This situation with simultaneous heavy-tailed process and measurement noises reduces the performance of the PHD filter severely, and can even make it break down. Although the SMC-PHD filter can deal with the problem to a certain degree, it has to pay a high computational cost, especially in high dimensions. For the GM-PHD filter, its foundational Gaussian approximation limits the capability to handle heavy-tailed non-Gaussian noises. Although Huber’s M-estimation theory [16] or variational Bayesian (VB) method [17] can be utilized to improve the performance of the GM-PHD filter against outliers in the measurement model, they both cannot handle the outliers in the process model. More importantly, the two methods above do not change the foundation of the Gaussian approximation-based GM-PHD filter. This means that the noise model still cannot match the outliers-corrupted process and measurement noises well, leading to biased estimates of the target state and the number of targets. Obviously, the Gaussian noise model cannot handle the heavy-tailed non-Gaussian noise, so how to model the heavy-tailed noise becomes the key point. As [18] said, Student’s t distribution, which has a heavy tail characteristic, is a good choice to match the heavy-tailed non-Gaussian noise. Under the Bayesian filtering framework, the Student’s t approximation-based closed form recursions are obtained for the linear system [18]. Further, the Student’s t approximation-based approach also can be used in the nonlinear system [19,20,21,22]. However, up to the present, Student’s t approximation-based approaches to approximate a PHD filter with heavy-tailed process and measurement noises do not exist.
In this paper, a novel implementation of the PHD filter is proposed based on Student’s t mixture approximation, intending to improve the estimation accuracy in terms of the target states and the target number in the presence of heavy-tailed process and measurement noises. The proposed approach models the process noise and the measurement noise as a Student’s t distribution, meanwhile, the multi-target prior intensity is approximated as a mixture of the Student’s t distributions. Then, the Student’s t mixture-approximated predicted intensity and posterior intensity are obtained through utilizing Student’s t approximation, forming a closed form recursion of the PHD filter. The Student’s t mixture implementation is proposed in RFS-based MTT algorithms for the first time. Compared to the GM case, it is a Student’s t-based implementation, which propagates a mixture of Student’s t components. Because it utilizes the heavy-tailed characteristic of Student’s t distribution, the proposed filter has better accuracy and robustness in MTT scenes with heavy-tailed process and measurement noises. Moreover, the proposed filter also has relatively low computing cost just like the GM-PHD filter. The above advantages of the proposed approach are verified by simulations designed in linear scenario and nonlinear scenario, respectively.
The remainder of this paper is organized as follows: Section 2 presents an overview of the PHD filter and some properties of the Student’s t distribution. Section 3 presents the proposed filter for linear system and extends the proposed filter to the nonlinear system. Simulation results are given in Section 4, and conclusions are drawn in Section 5.
2. Background
2.1. The PHD Filter
The random finite set (RFS) approach [1] provides a mathematically elegant treatment for the difficult problem that is how to estimate the time-varying number of targets and their states jointly in MTT scenarios. According to RFS theory, the collections of target states and measurements at time k can be represented as finite sets () and () where and are the number of targets and the number of measurements, respectively, and are the collections of all finite subsets of target states and measurements, respectively, and are the dimensions of the state space and the measurement space , respectively. Let:
where is the RFS of survival targets at time k from target states and is the RFS of spawned targets at time k from target states , and is the RFS of birth targets at time k.
The RFS of measurements is defined as:
where and are the RFS of measurements coming from target and clutter at time k, respectively.
Based on the RFS approach, the MTT problem was recast into a Bayesian filtering framework, but optimal Bayesian recursions are computationally intractable due to their sets integral. Then the PHD filter, which recursively propagates the first-order moment of multi-target posterior probability density, was proposed as an approximate solution in [3]. Let denote the posterior intensity function at time k − 1, then the prediction step of the PHD filter is given by
where is transition density function in a Markov process from time k − 1 to time k, is the survival probability of each target at time k, is the intensity function of the RFS of targets spawning from previous state u, is the intensity function of birth targets at time k.
Given the predicted intensity , the update intensity can be given by:
where is the probability of detection at time k, denotes the measurement likelihood function at time k, is the intensity function of clutter. The integration domain of the integral functions in (3) and (4) is the state space .
2.2. Review of the GM-PHD Filter
The GM-PHD filter approximates the intensity function of multi-target as Gaussian mixture components under the assumption of the linear Gaussian dynamical model and measurement model. In addition, it still needs to satisfy the following assumptions: (1) the survival and detection probabilities are state-independent; (2) the intensities of the birth and spawn RFSs are Gaussian mixtures of the form. Then a closed-form solution of the PHD filter can be obtained as follows.
Prediction: The Gaussian mixture formulation of the PHD recursion at time k − 1 is given as:
where denotes that random vector x follows Gaussian distribution, and are the mean and the covariance matrix of the jth item in all Gaussian mixture components, respectively, is the corresponding weight, is the number of Gaussian components.
Assume that the intensities of survival targets, spawned targets and birth targets are Gaussian mixtures of the form, the predicted intensity is given by:
where:
Update: Given the PHD predictor as Equation (6), the PHD updater is formulated as:
where:
in the above, and are the state transition matrix and observation matrix, respectively, and are the process and measurement noise covariance, respectively.
2.3. Student’s t Distribution
Let a random vector admit the Student’s t distribution; its probability density function (PDF) can then be expressed as [23]:
where denotes Gamma function and . The above PDF abbreviated by with mean m, scale matrix P and degrees of freedom parameter . The corresponding covariance matrix can be calculated as () [23].
The tail behavior of the Student’s t distribution is very much influenced by the degrees of freedom parameter . The smaller is, the heavier the tail is, and vice versa. In addition, the Student’s t distribution reduces to the Gaussian as tends to infinity, thus includes it as a special case. A number of convenient properties are shared by both and can be easily derived. As for the PDF of affine mappings of Student’s t variables [23] we have that , with appropriate A and b, admits:
The degrees of freedom parameter remains unaltered. Turning to random vectors and that are jointly Student’s t distributed with:
The marginal PDF of can be computed by applying a linear transformation with to (18):
From (18) and (19), the conditional PDF is also a Student’s t as follows:
with:
It can be seen that the conditional mean (21) corresponds to the Gaussian conditional mean. The matrix parameter (22) is a scaled version of the conditional covariance in the Gaussian case, which is recovered as tends to infinity. In contrast to the Gaussian, depends on . Also, the degrees of freedom parameter in (23) increases. Above properties of Student’s t distribution like (17) and (20) are the foundations of Lemmas 1 and 2 (in Section 3.3) that are the key of our proposed approach.
3. Student’s t Mixture PHD Recursion
Differing from the GM-PHD recursion, the proposed approach approximates the intensity of multi-target RFS as the Student’s t mixture of the form, which is propagated in the closed-form recursions. The following gives the novel algorithm for linear system at first and then extends it to nonlinear system.
3.1. Basic Assumptions for Linear Model
As for the linear system, some foundational assumptions are given as follows.
Assumption 1.
Given that the process and measurement noises admit the zero-mean t distribution with scale matrix and , respectively, and the initial state vector also follows a t distribution, each target follows a linear Student’s t dynamical model and the sensor has a linear Student’s t measurement model, i.e.:
where and denote the transition matrix and measurement matrix, respectively. And assume the matrices , , and are known.
Assumption 2.
The survival and detection probabilities are state independent, i.e.:
Assumption 3.
The intensities of the birth and spawn RFSs are Student’s t mixtures of the form:
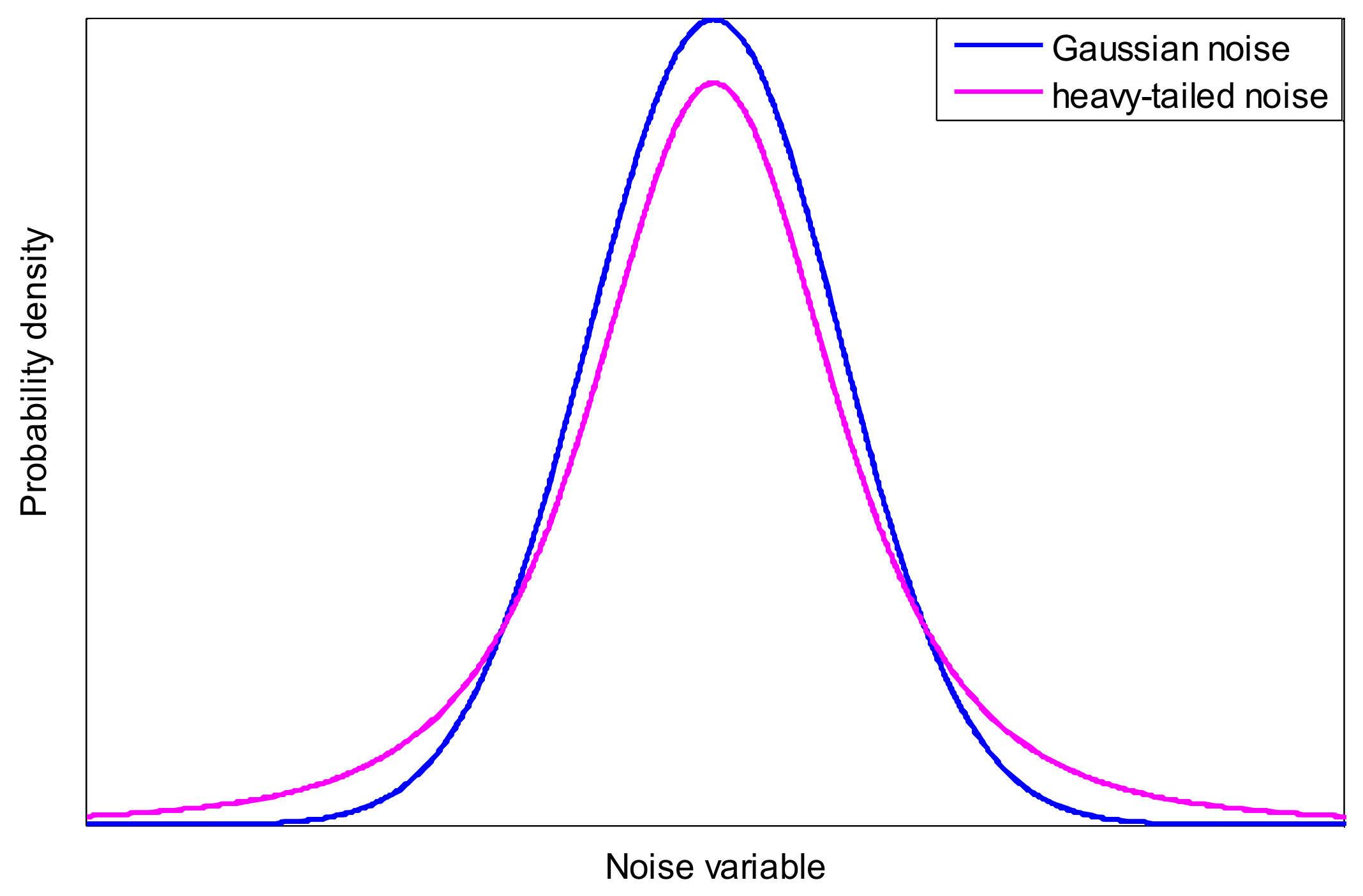
Assumption 1 is given according the affine transition nature of Student’s t variables [19]. Assumption 2 is commonly used in GM-PHD filters. Assumption 3 is given in the presence of process and measurement noises with heavy tails, so it is reasonable in actual applications, i.e., when using unreliable sensors or sensors suffer from electromagnetic interference while tracking some agile targets, where both process noise and measurement noise are prone to show a heavy-tailed character. For illustrating this, a one-dimensional heavy-tailed noise distribution and Gaussian noise distribution are given as Figure 1.
3.2. Student’s t Mixture PHD Recursion
Based on the Assumptions 1–3, the closed solution to the PHD recursion (3) and (4) is presented as two Propositions. The proposed Propositions show how the Student’s t components of the posterior intensity are analytically propagated to the next time, analogous to the GM-PHD recursion.
Proposition 1.
Suppose that Assumptions 1–3 hold and that the posterior intensity at time k − 1 is a Student’s t mixture of the form:
Then, the predicted intensity at time k is also a Student’s t mixture and is given by:
where:
Proposition 2.
Suppose that Assumptions 1–3 hold and that the predicted intensity for time k is a Student’s t mixture of the form:
Then, the posterior intensity at time k is also a Student’s t mixture and is given by:
where:
Aforementioned Propositions 1 and 2 can be established by applying the following approximated results for Student’s t functions.
Lemma 1.
Given that the jointly PDF of the current state and one-step ahead state vectors is Student’s t and F, Q, m and P of appropriate dimensions and that Q and P are positive definite:
Lemma 2.
Given that the jointly PDF of the state and measurement vectors is Student’s t and H, R, m, P of appropriate dimensions and that R and P are positive definite:
where:
Lemmas 1 and 2 are derived based on the properties of Student’s t distribution listed in Section 2.3. The detailed derivations of Lemmas 1 and 2 can be seen [19].
Proposition 1 is established by substituting (25), (27) and (29)–(31) into the PHD prediction (3), and replacing integrals of the form (51) by appropriate Student’s t as given by Lemma 1. Similarly, Proposition 2 is established by substituting (26), (28) and (39) into the PHD update (4), and then replacing integrals of the form (51) and product of Student’s t of the form (52) by appropriate Student’s t as given by Lemmas 1 and 2 respectively. The concrete proofs of Propositions 1 and 2 are given in Appendix B.
From (45), we know that the degree of freedom will increase infinitely with recursion performing, which results in that the Student’s t mixture degrades the Gaussian mixture according to [18]. It means that the robustness against outliers for the Student’s t mixture PHD filter will be lost with time going by. To solve the problem, we adapts the moment matching approach [18] to obtain the correction of posterior intensity at time k given as (59)–(61). A pseudocode of main process of the proposed algorithm is given by Table A1 in Appendix A:
Remark 1.
The degree of freedom parameters for the process noise model, measurement noise model and the initial multi-target state intensity are different in general. As in the recursion performed from (31) to (39), there is a problem that how to select the degree of freedom parameter between and as the degree of freedom parameter of predicted multi-target intensity to be propagated in the next recursive step. A valid method [18] is that choose the minimized value between and to be propagated. The same problem, existing in the recursion from (39) to (40), also can be handled by selecting the minimized value between and . For simplicity, this paper assumes that the degree of freedom parameters are equal.
Remark 2.
Analogous to the derivation of GM implementation of the CPHD filter in [24], the proposed Student’s t mixture implementation shown as in Propositions 1 and 2 can also be used in the CPHD filter, forming the corresponding Student’s t mixture CPHD recursion.
3.3. Implementation Issues
Like the GM-PHD filter, the Student’s t mixture PHD (STM-PHD) filter also suffers from the computation problem that the number of Student’s t components increases endlessly with recursive time, so a pruning procedure and a merging procedure are necessary for the STM-PHD filter. The concrete procedures are similar to the procedures in the GM-PHD filter (readers can refer to [9]). The different point is that the Student’s t components give the scale matrix not the covariance matrix, so the covariance matrix, calculated by , should be used in the merging procedure of the STM-PHD recursion. The estimated number of targets is obtained by summing up the weights of all the Student’s t components. This procedure for the STM-PHD filter is no different from the GM-PHD filter. Again, the state extraction is also analogous to the GM-PHD filter as to select the means of the Student’s t components that have weights greater than some threshold (generally set as 0.5 [9]).
In addition, for the scene with high clutter density, gating strategy is always used to reduce the computing cost for the GM-PHD filter. It is easy to know that the gating strategy is also suitable for the STM-PHD filter. The core principle to select the measurement can be expressed as:
where denotes the reduced set of the measurement at time k, is the innovation covariance matrix corresponding to the jth predicted measurement, and is the gate threshold. In contrast to the Gaussian mixture case, the judging variable for the Student’s t mixture case follows an F-distribution not a chi-squared distribution. It means that the gate threshold for the STM-PHD filter, which can be chosen from F-distribution table, is different from the GM-PHD filter at the same probability regions.
3.4. Extension to Nonlinear Model
This section considers the situation that process and measurement models are nonlinear. The models in Assumption 1 change to become:
where fk and hk are known nonlinear functions, wk−1 and vk are additional noises, which follow zero-mean Student’s t distribution with scale matrix Qk−1 and Rk, respectively.
Different from the GM-PHD filter to cope with nonlinear problems via giving the numerical solution to Gaussian integrals, the core problem of the STM-PHD filter for nonlinear systems is how to compute the Student’s t integrals. Some researchers have given numerical solutions to Student’s t integrals based on Taylor linearization, unscented transform or cubature rule [19,21,22]. Compared with Taylor linearization and unscented transform, the cubature rule-based filter is a derivative-free and vigorous method [25], so this paper utilizes the cubature rule to extend the STM-PHD filter to nonlinear system according to [22]. The proposed algorithm for handle nonlinearity is given as Table A2 in Appendix A.
4. Simulations and Results
To illustrate the performance of the proposed filter, simulation examples are designed to compare with standard GM-PHD filter in linear and nonlinear scenarios, respectively. To compare the performance of two filters, we choose the Optimal Sub-pattern Assignment (OSPA) distance as the metric, which can comprehensively measure the cardinality and localization errors [26]. The OSPA distance is defined as follows. Let for , and denotes the set of permutations on for any . For , and arbitrary finite subsets and belong to , where :
If , and if ; and if . is the order parameter that determines the sensitivity to outliers and is the cut-off parameter that determines the relative weighting of the penalties assigned to cardinality and localization errors. The details to choose the parameters and can be seen in [26]. In our simulation examples, we set and .
4.1. Linear Scenario
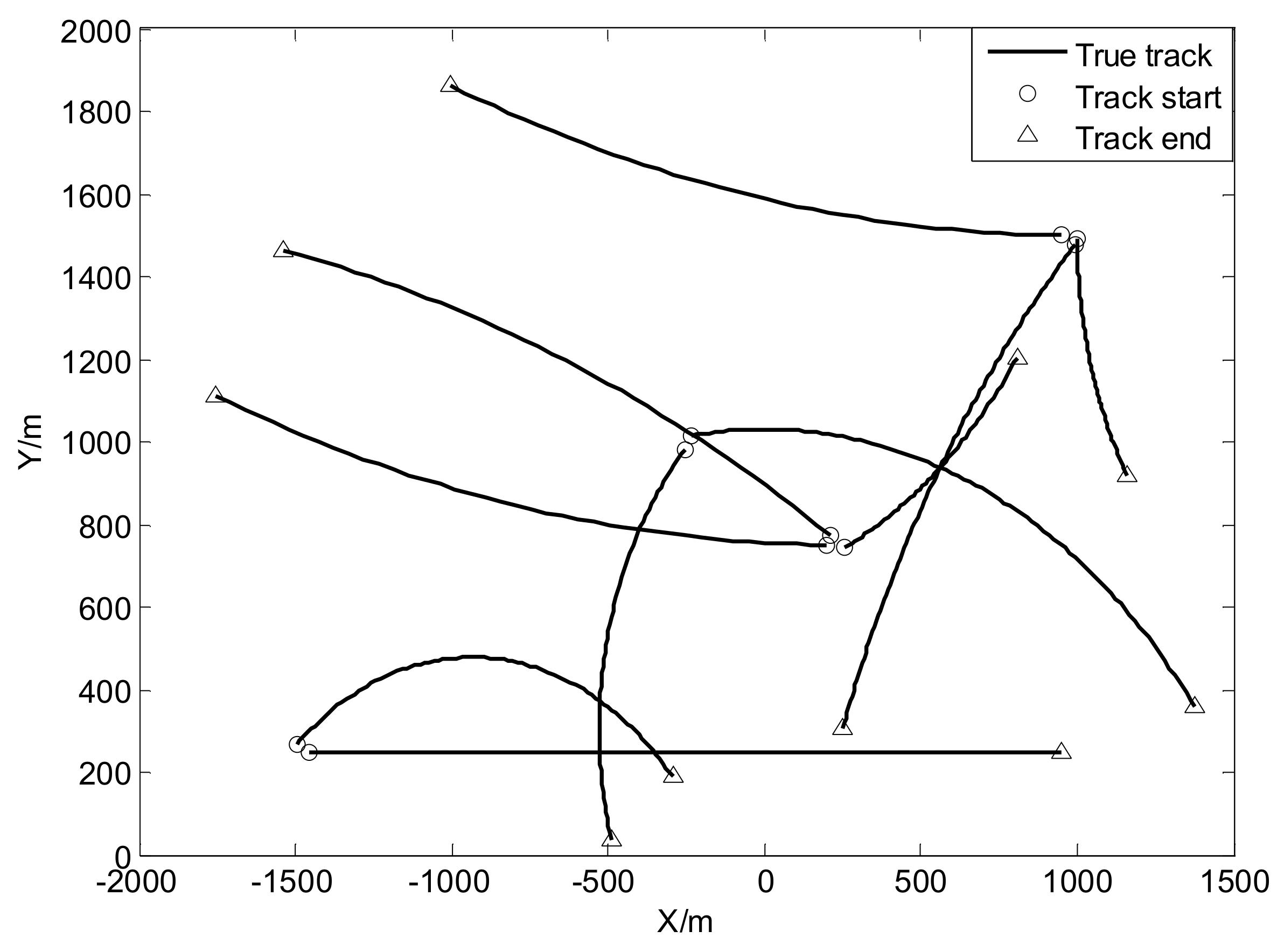
Consider a two-dimensional scenario where there are twelve targets over region × during the interval of 100 s. Assuming no target spawning and each target moves as a constant velocity model similar to [9] with:
where and . The state of each target consist of position and velocity at time k. Their corresponding initial state and life time of each target are given as Table 1.
The noisy measurement model is the same as [9] with:
The process and measurement noises with heavy tails are given as (66) and (67):
For the process and measurement noises in (66) and (67), about one percent of process and measurement noise values are drawn from Gaussian with severely high covariance. This percentage is also called contaminated rate which can be denoted by [27].
Assuming no spawned target and birth targets appear spontaneously according to a Poisson point process with intensity function:
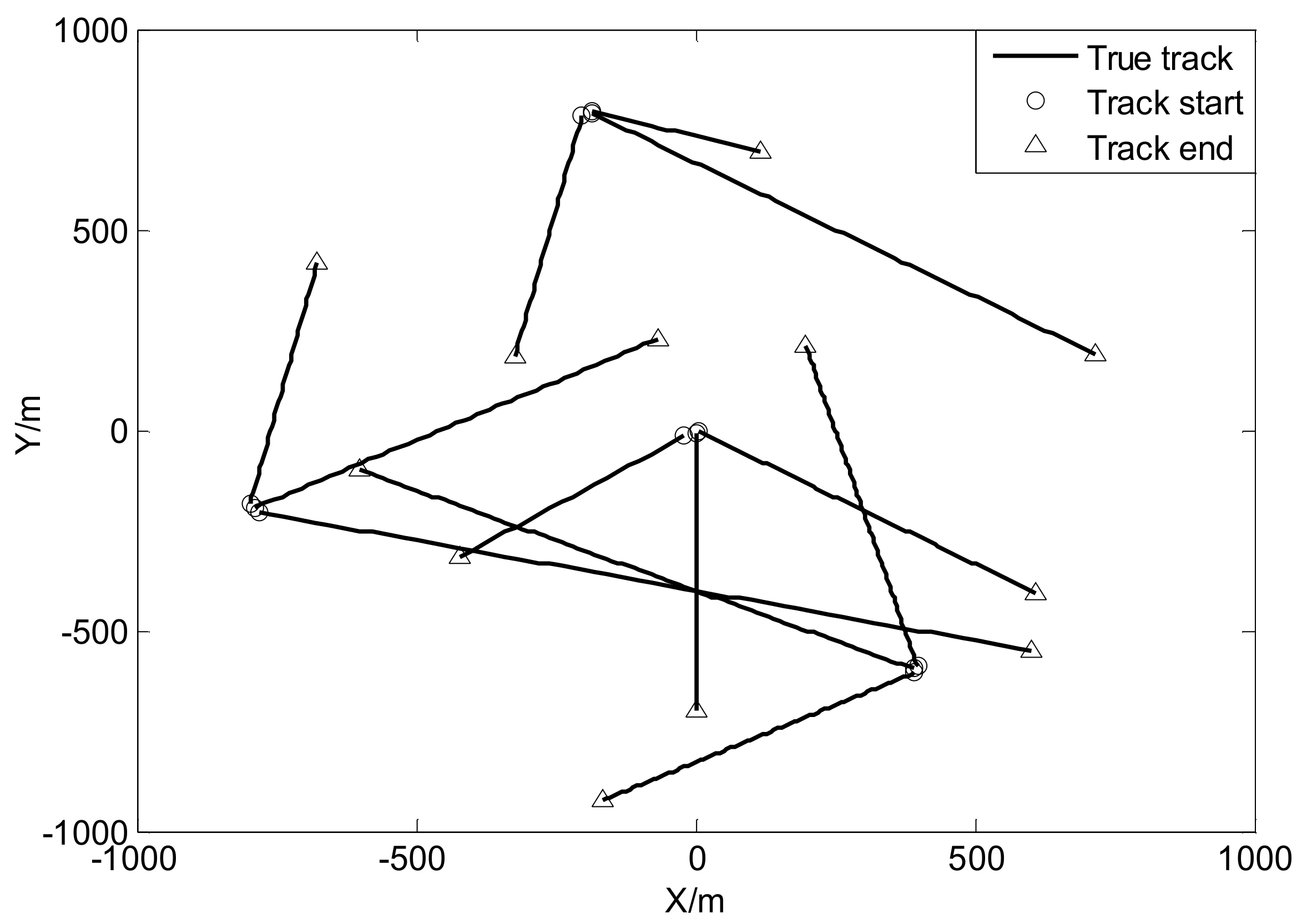
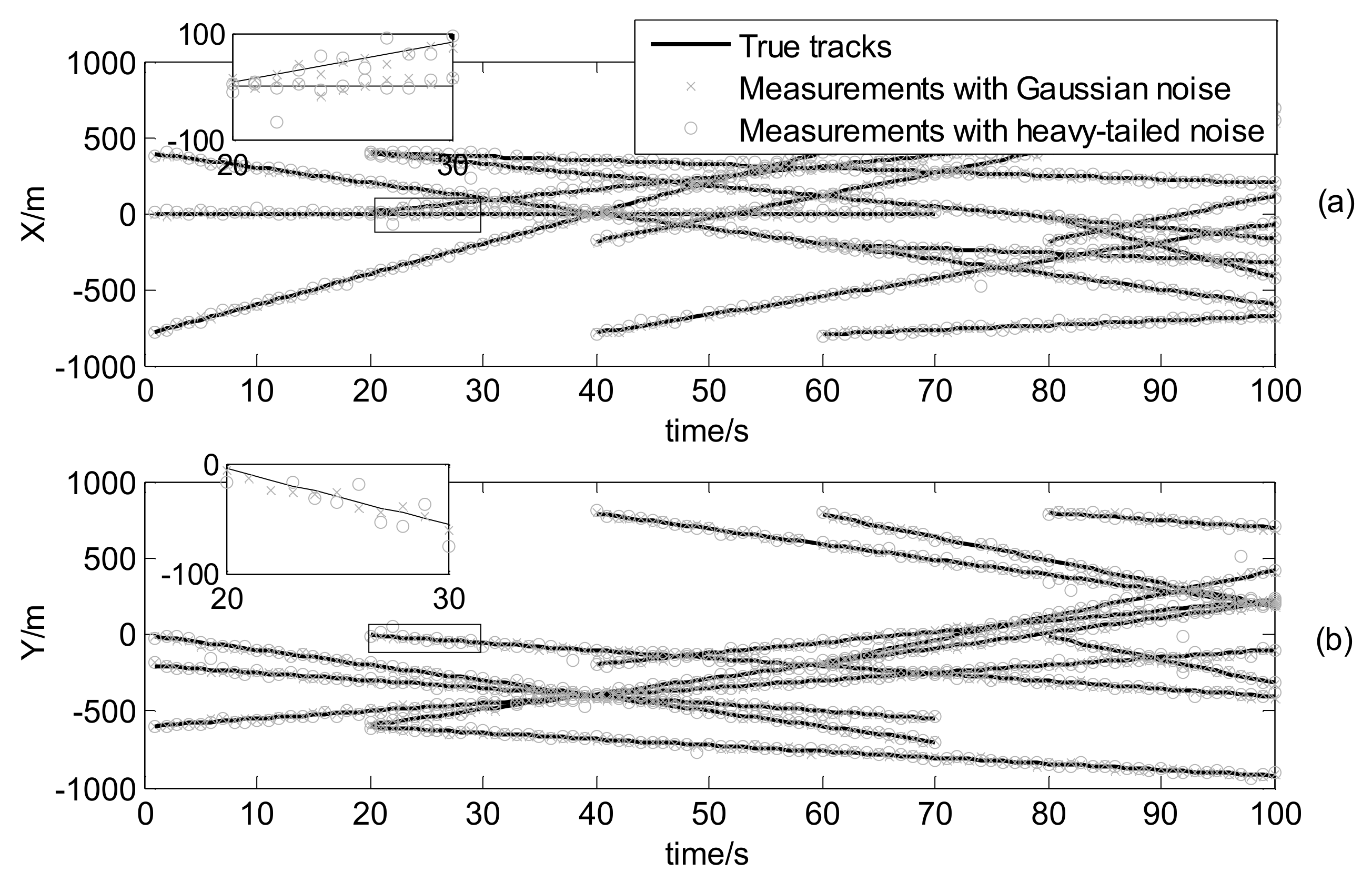
where , , and , and . The true trajectories of each target are shown in Figure 2, while Figure 3 plots these trajectories with Gaussian measurements and heavy-tailed measurements over time (not plot clutter in figure). From Figure 3, it is can be seen that the individual heavy-tailed measurements obviously bias the true position compared with the corresponding Gaussian measurements, which may degrade the estimation accuracy.
The detection probability and target survival probability are and , respectively. Truncated threshold, merged threshold and the maximum Student’s t components related to pruning and merging process are , and , respectively. For simplification, set .
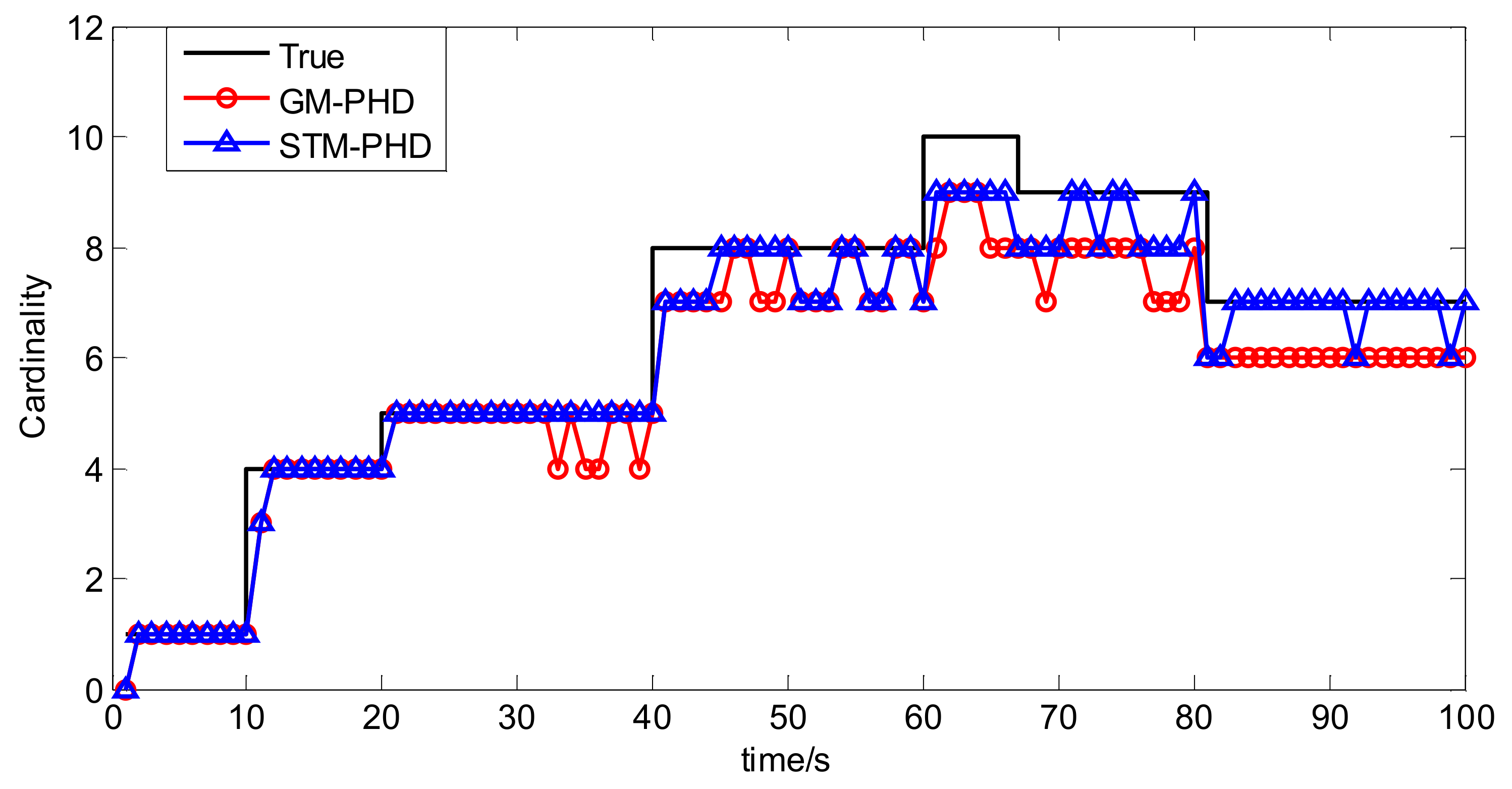
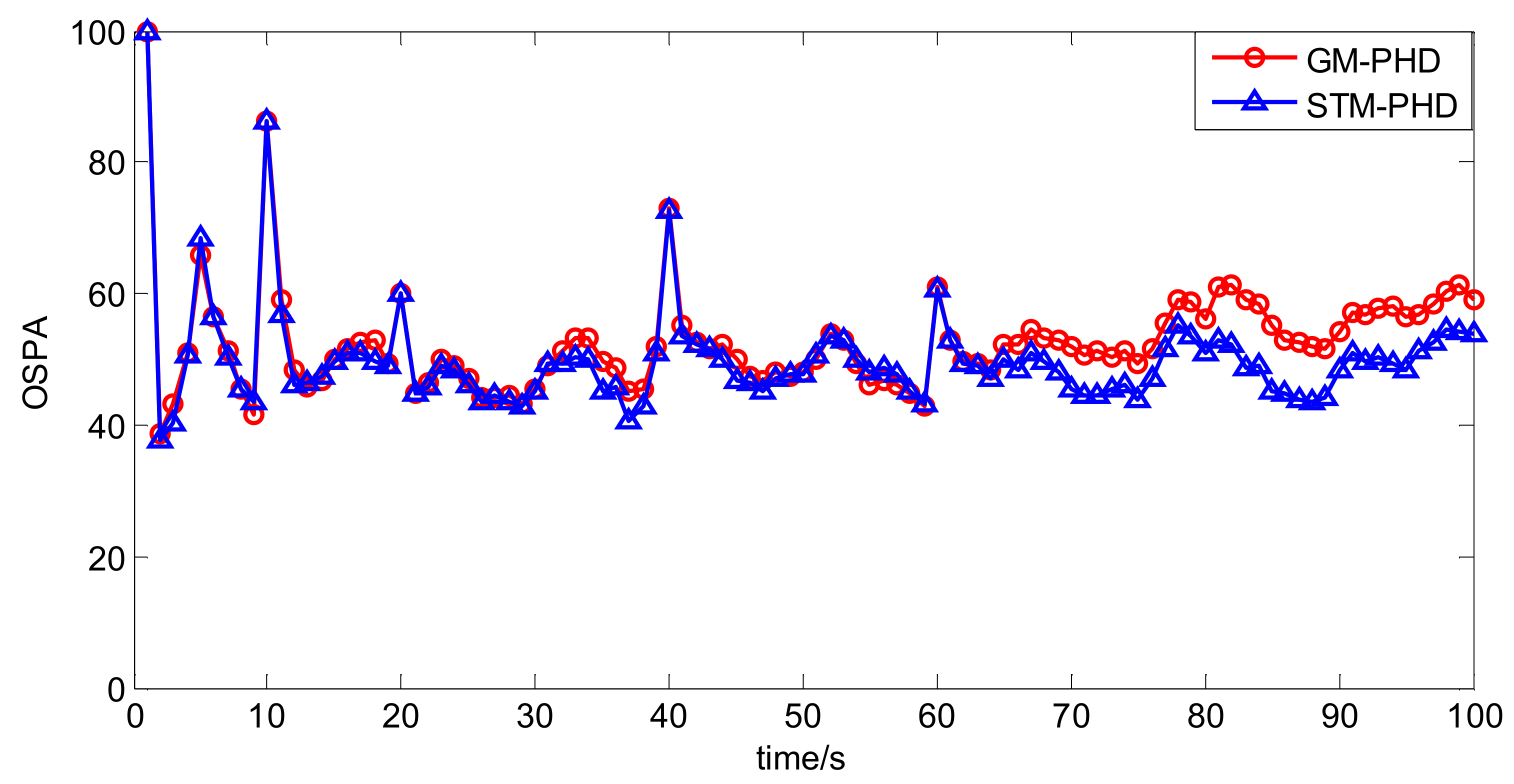
To evaluate the performance of the STM-PHD filter, we compare it with GM-PHD filter over 100 Monte Carlo (MC) trails with fixed clutter density. Under the uniform distribution assumption, the clutter density can be given by clutter rate λc with the relationship = λc/V. In this simulation, we set λc = 20 (giving an average of 20 clutter returns per scan). Figure 4 and Figure 5 respectively show the estimated cardinality and the OSPA distance for two filters. The result in Figure 4 shows that the STM-PHD filter provides a noticeable improvement in terms of cardinality estimation accuracy compared with the GM-PHD filter, although some biased cardinality estimates appear for the STM-PHD filter.
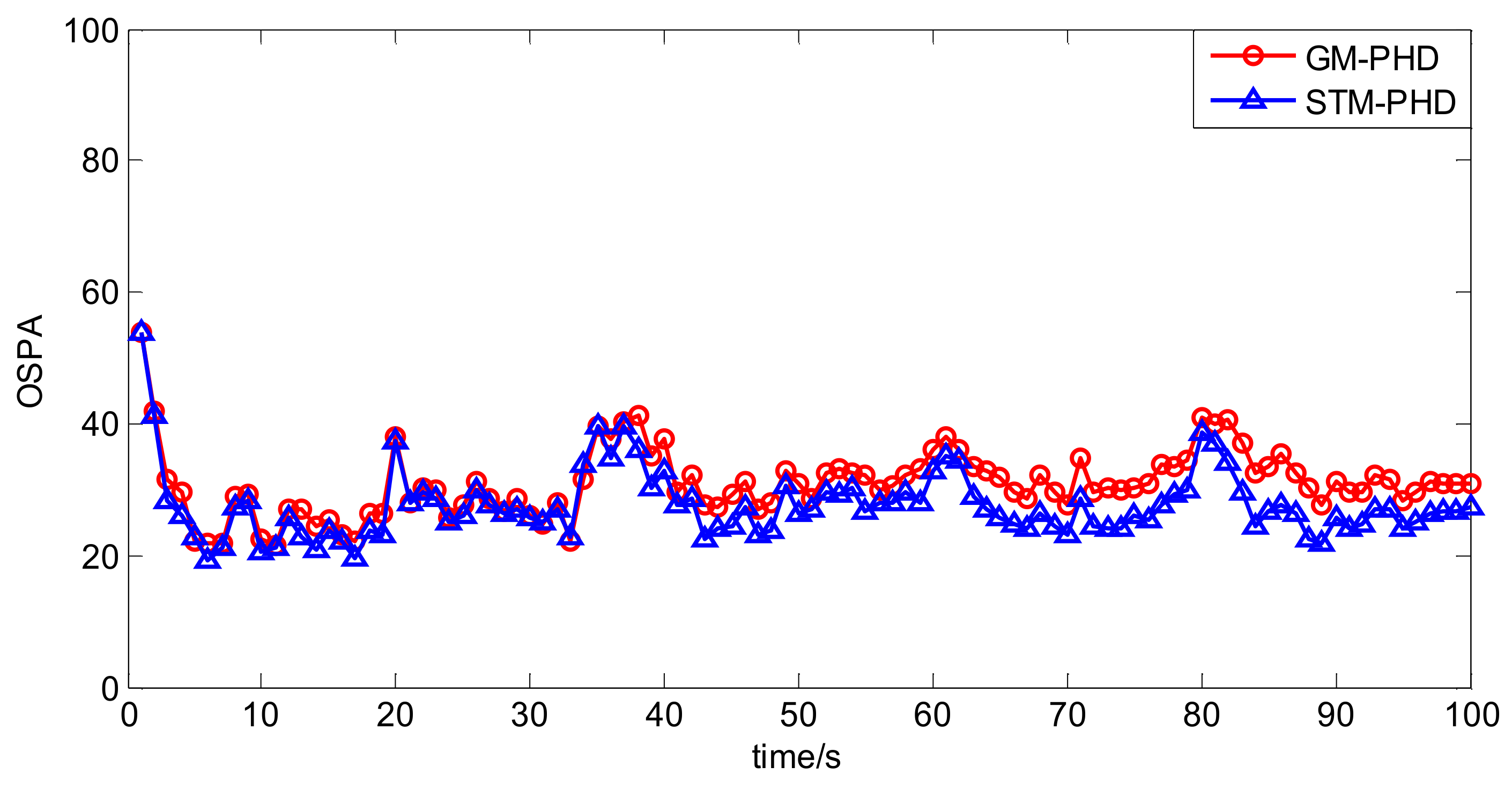
In Figure 5 the OSPA distance of the STM-PHD filter is lower than that of the GM-PHD filter. Especially after 40 s more targets appear, difference of the OSPA distance between two filters is more noticeable. The main reason is that the STM-PHD filter has more accurate cardinality estimation.
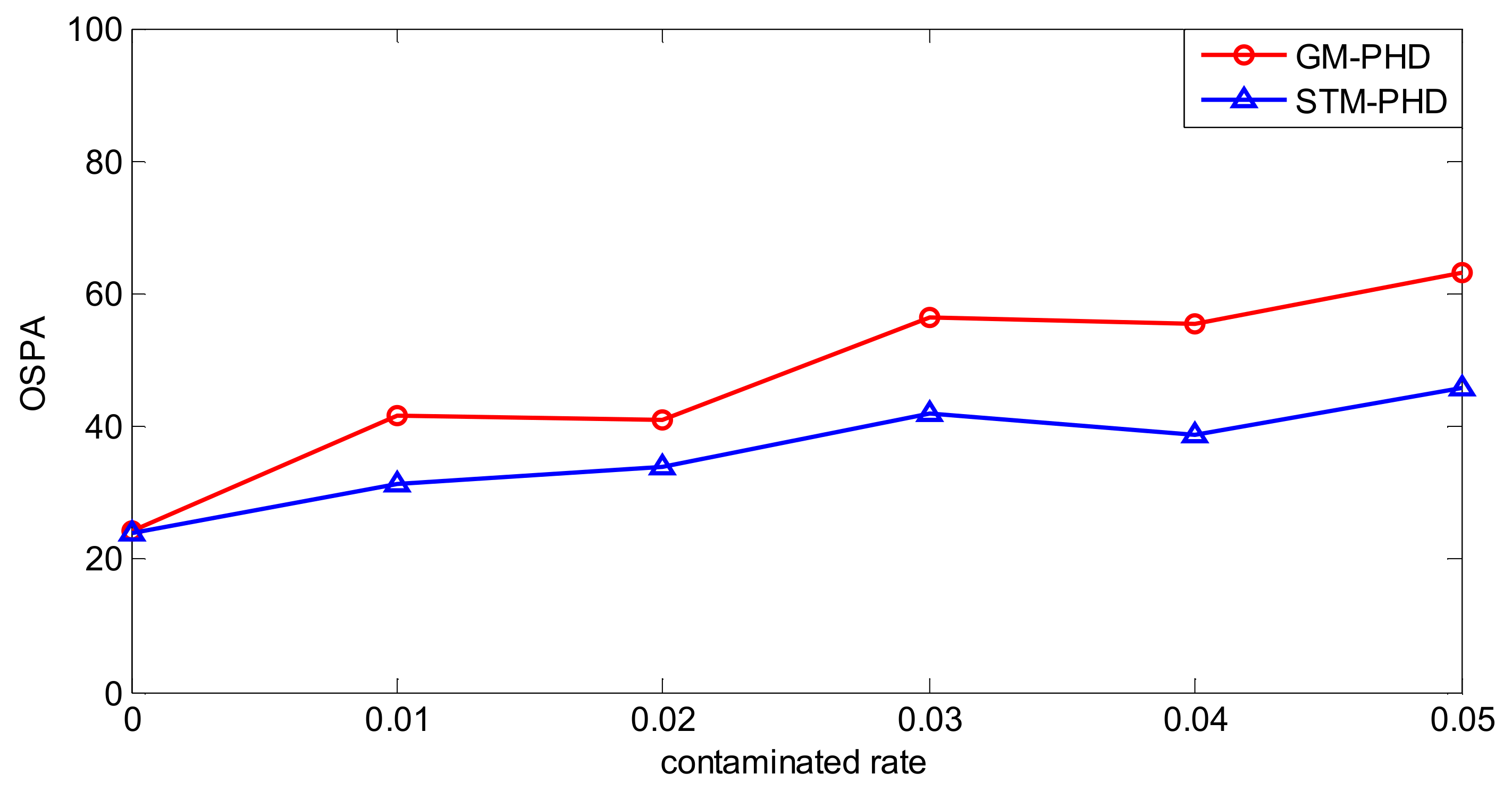
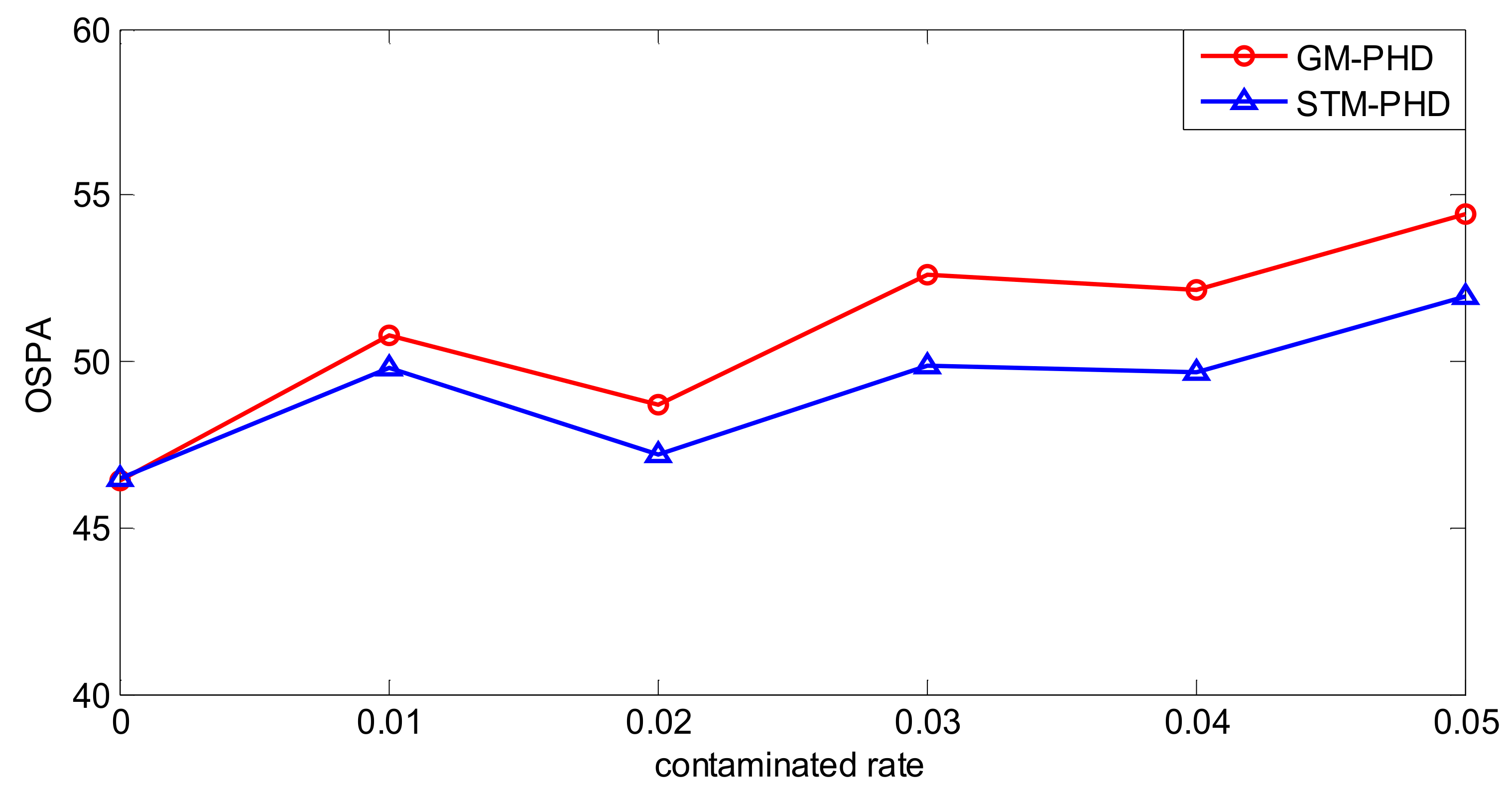
To evaluate the performance of the proposed filter sufficiently, a simulation is executed over 100 MC trials with different contamination rates from to . Then the time averaged OSPA distance of the STM-PHD filter and the GM-PHD filter, respectively, are shown in Figure 6.
From Figure 6, it can be seen that the time averaged OSPA distance of the STM-PHD filter is lower than that of the GM-PHD filter overall. The time averaged OSPA distances of two filters increases with the increasing contamination rate. Remarkably, the gap of OSPA distance between the STM-PHD filter and the GM-PHD filter changes wider from to . It means that the STM-PHD filter has strong robustness against the negative effect of outliers, especially for high contamination rates. This is due to the fact the Student’s t noise model in the proposed approach can match the heavy-tailed non-Gaussian noise well. On the contrary, the Gaussian-based GM approach matches such a non-Gaussian noise worse and worse with the increasing of contaminated rate. Additionally, at , the OSPA distance for the STM-PHD filter is the same as the GM-PHD filter. It indicates that the STM-PHD filter and the GM-PHD filter have the same tracking performance when outliers do not exist.
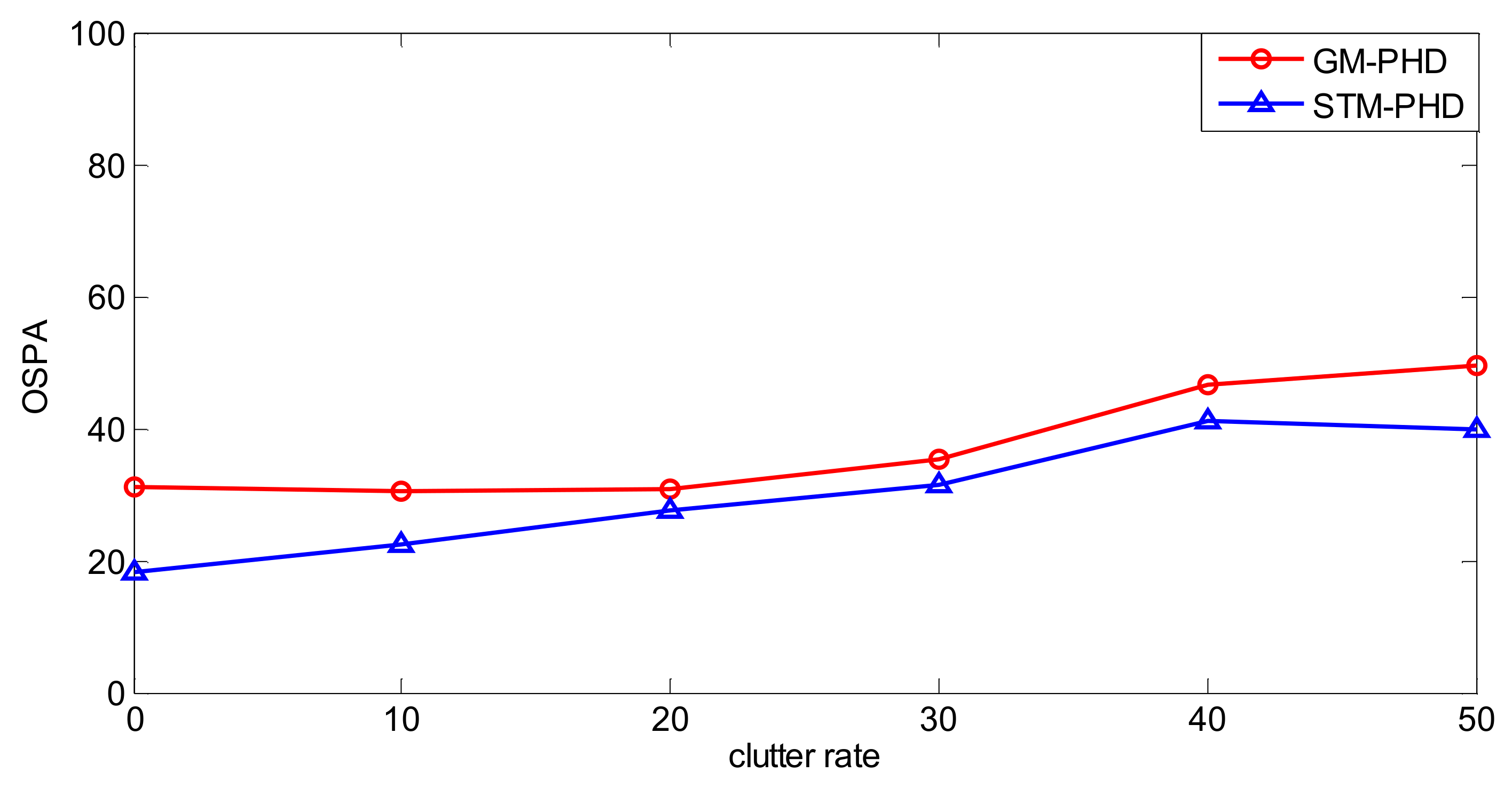
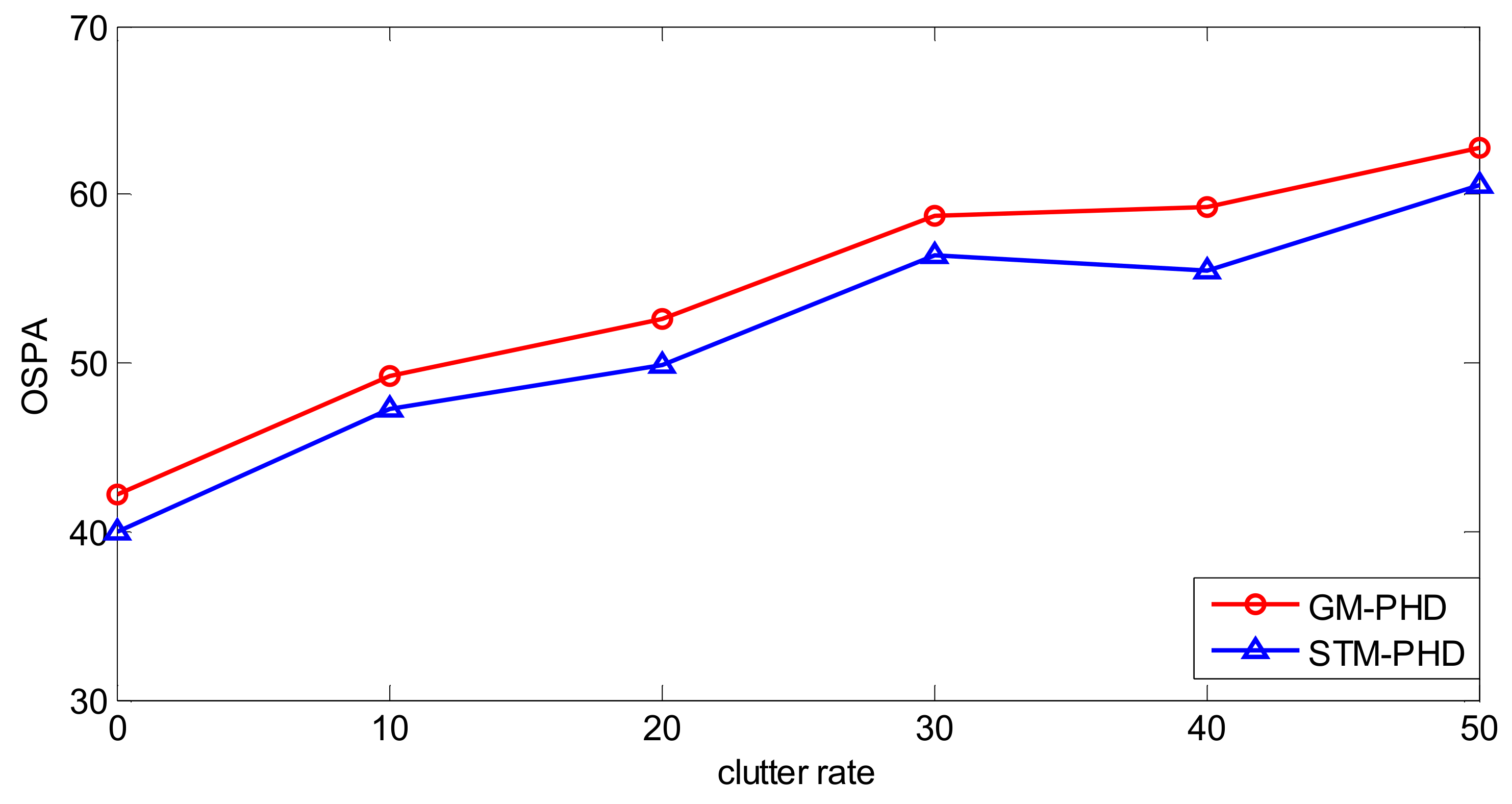
To further evaluate the performance of the proposed filter, a simulation is performed over 100 MC trails with different clutter rates from λc = 0 to λc = 50. The resulting time averaged OSPA distances of the proposed filter and the GM-PHD filter are shown in Figure 7. It can be seen that the time averaged OSPA distances of two filters increase with the increasing clutter rate and the time averaged OSPA distance of the STM-PHD filter is always lower than that of the GM-PHD filter under different clutter rates. This means that the STM-PHD filter generally outperforms the GM-PHD filter when outliers exist, no matter what the clutter rate is.
In addition, the computational cost for the STM-PHD filter lies at the same level as that of the GM-PHD filter for the linear system. Running on a computer with an Intel(R) Core(TM) i5-4570 CPU at 3.2 GHz, the average computing times per execution of the GM-PHD filter and the STM-PHD filter with different clutter rate are given in Table 2.
4.2. Nonlinear Scenario
In this example, we assume a maximum of ten targets appears on the observation region × and a nearly constant turn state model and nonlinear bearings and range measurement model are considered according to [9]. The state consists of position and velocity as well as the turn rate . The state model is given by:
where:
The noisy measurement model with range and bearing measurement is given by:
Like the linear scenario, the outliers contaminated process and measurement noises can be given by:
with , .
In the simulation, we assume no spawned target and that the birth target is Poisson with intensity:
where , , and , and . (The unit of distance, angle and time in this paper are meter, radian and second, respectively.)
The initial target states are given by Table 3 and the true trajectories of each target are shown as Figure 8. In addition, Figure 9 plots corresponding measurements with Gaussian noise and heavy-tailed noise respectively over time (not plot clutter in figure). In Figure 9, it also shows the results analogous to the linear case as shown in Figure 3.
To evaluate the performance of the CKF based STM-PHD filter to cope with nonlinear problem, we compare it with CKF based GM-PHD filter [11] over 100 Monte Carlo (MC) trails with fixed clutter rate λc = 20. Figure 10 and Figure 11 respectively show the estimated cardinality and the OSPA distance of two filters. From Figure 10, it can be seen that the STM-PHD filter is superior to the GM-PHD filter in terms of cardinality estimation accuracy, although the STM-PHD filter has cardinality bias when the number of targets increases. The main reason for generating cardinality bias is that some necessary approximations for coping with nonlinear problems induce errors.
In Figure 11 the OSPA distances of the STM-PHD filter and the GM-PHD filter are at the same level before 65 s and later on the OSPA distance of the STM-PHD filter is obviously lower than that of the GM-PHD filter. This result matches the result in Figure 10 well. It indicates that the difference of OSPA distance between two filters is due to the difference of cardinality estimation accuracy.
To evaluate the performance of the STM-PHD filter sufficiently, simulation is performed over 100 MC trials with different contaminated rate from to . Then the time averaged OSPA distances of the STM-PHD filter and the GM-PHD filter are shown in Figure 12.
Analogous to the linear scenario, it can be seen that the time averaged OSPA distance of the STM-PHD filter is lower than that of the GM-PHD filter at almost all contaminated rates. The gap of the time averaged OSPA distance between the STM-PHD filter and the GM-PHD filter also changes widely as the contamination rates increase. Nevertheless, the gap is not noticeable like in the linear scenario. This is due to the relatively big approximation error induced in the nonlinear scenario. The result indicates that the STM-PHD filter still outperforms the GM-PHD filter to cope with outliers for nonlinear systems.
To further evaluate the performance of the proposed filter, 100 MC trails are performed from λc = 0 to λc = 50. The time averaged OSPA distances versus varying clutter rate for the STM-PHD filter and the GM-PHD filter are shown in Figure 13. It can be seen that the time averaged OSPA distance of the STM-PHD filter is lower than that of the GM-PHD filter at different clutter rates, and the trend for two filters goes up with the increase of clutter rate. Generally speaking, the STM-PHD filter is superior to the GM-PHD filter but the superiority is not noticeable like in the linear scenario. This is due to the fact the approximation error induced in a nonlinear scenario is bigger than that in a linear scenario. Nevertheless, the results still indicate that the STM-PHD filter is valid to handle the outliers.
Again, the computing time for each filter under the different clutter rate is given in Table 4. It shows that the STM-PHD filter has a higher computing cost compared to the GM-PHD filter and the higher the clutter rate is, much more time is consumed for the STM-PHD filter. The reason is that computing nonlinear Student’s t integrals is more complex than computing nonlinear Gaussian integrals.
5. Conclusions
To solve the problem that the process and measurement outliers degrade the performance of PHD filter, this paper proposes a Student’s t mixture-based PHD filter, where the prior multi-target intensities are approximated as a mixture of the Student’s t components to be propagated in time and the Student’s t mixture approximated posterior multi-target intensity are obtained through a Student’s t approximation-based recursion. The proposed approach can efficiently suppress the negative impact caused by the process and measurement outliers, while still maintaining good estimation accuracy. The advantages of the proposed filter are verified sufficiently by simulation. The simulation results also imply that the proposed approach outperforms the GM-based approach in scenarios where outliers appear due to electromagnetic interference or sensors’ own unreliability. In addition, the proposed approach is also suitable for the CPHD filter. However, the proposed approach has relatively high computational cost for nonlinear systems. In further study, we will try to improve this. Moreover, how to combine the proposed Student’s t mixture implementation with the multi-Bernoulli filters (including CBMeMBer filter and labeled RFS based multi-Bernoulli filter) is also our focus in the next work.
Acknowledgments
This work was partly supported by the National Natural Science Foundation of China (Grants No. 61673392 and Grants No. 61703420).
Author Contributions
Zhuowei Liu performed the simulations and wrote the paper; Shuxin Chen and Hao Wu revised this paper and offered some useful suggestions in methodologies and simulations; Renke He and Lin Hao offered revision during the whole process.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Pseudocode for the STM-PHD filter.
Table A2.
Pseudocode for the cubature rule based STM-PHD filter.
| (see [22]) |
Appendix B
Proof of Proposition 1:
Proof of Proposition 2:
Using Lamma 2:
with:
Using Lamma 1:
so:
References
- Mahler, R.P.S. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2014. [Google Scholar]
- Bar-Shalom, Y.; Kirubarajan, T.; Li, X.R. Estimation with Applications to Tracking and Navigation; Wiley: Hoboken, NJ, USA, 2001; pp. 993–999. [Google Scholar]
- Mahler, R.P.S. Multitarget Bayes Filtering via First-Order Multitarget Moments. IEEE Trans. Aerosp. Electron. Syst. 2004, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R.P.S. PHD Filters of Higher Order in Target Number. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1523–1543. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The Cardinality Balanced Multi-Target Multi-Bernoulli Filter and its Implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Vo, B.T.; Vo, B.N. Labeled Random Finite Sets and Multi-Object Conjugate Priors. IEEE Trans. Signal Process. 2013, 61, 3460–3475. [Google Scholar] [CrossRef]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The Labeled Multi-Bernoulli Filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Vo, B.N.; Singh, S.; Doucet, A. Sequential Monte Carlo Methods for Multitarget Filtering with Random Finite Sets. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1224–1245. [Google Scholar]
- Vo, B.N.; Ma, W.K. The Gaussian Mixture Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Macagnano, D.; De Abreu, G.T.F. Adaptive Gating for Multitarget Tracking with Gaussian Mixture Filters. IEEE Trans. Signal Process. 2012, 60, 1533–1538. [Google Scholar] [CrossRef]
- Macagnano, D.; De Abreu, G.T.F. Multitarget Tracking with the Cubature Kalman Probability Hypothesis Density Filter. In Proceedings of the International Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010; pp. 1455–1459. [Google Scholar]
- Zhang, L.; Wang, T.; Zhang, F.; Xu, D. Cooperative Localization for Multi-Auvs Based On GM-PHD Filters and Information Entropy Theory. Sensors 2017, 17, 2286. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Song, T.L. Improved Bearings-Only Multi-Target Tracking with GM-PHD Filtering. Sensors 2016, 16, 1469. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Wang, Y.; Chen, H.; Zhang, P.; Liang, Y. Adaptive Collaborative Gaussian Mixture Probability Hypothesis Density Filter for Multi-Target Tracking. Sensors 2016, 16, 1666. [Google Scholar] [CrossRef] [PubMed]
- Vo, B.T.; Vo, B.N.; Hoseinnezhad, R.; Mahler, R.P.S. Robust Multi-Bernoulli Filtering. IEEE J. Sel. Top. Signal Process. 2013, 7, 399–409. [Google Scholar] [CrossRef]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Šmídl, V.; Quinn, A. The Variational Bayes Method in Signal Processing; Springer: Heidelberg, Germany, 2006. [Google Scholar]
- Roth, M.; Özkan, E.; Gustafsson, F. A Student’s T Filter for Heavy Tailed Process and Measurement Noise. In Proceedings of the 38th International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 5770–5774. [Google Scholar]
- Huang, Y.; Zhang, Y.; Li, N.; Chambers, J. Robust Student’s T Based Nonlinear Filter and Smoother. IEEE Trans. Aerosp. Electron. Syst. 2017, 52, 2586–2596. [Google Scholar] [CrossRef]
- Straka, O.; Dunik, J. Stochastic Integration Student’s-T Filter. In Proceedings of the 20th International Conference on Information Fusion (FUSION), Xi’an, China, 10–13 July 2017; pp. 1–8. [Google Scholar]
- Tronarp, F.; Hostettler, R.; Särkkä, S. Sigma-Point Filtering for Nonlinear Systems with Non-Additive Heavy-Tailed Noise. In Proceedings of the 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 1859–1866. [Google Scholar]
- Huang, Y.; Zhang, Y.; Li, N.; Naqvi, S.M.; Chambers, J. A Robust Student’s T Based Cubature Filter. In Proceedings of the 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 9–16. [Google Scholar]
- Kotz, S.; Nadarajah, S. Multivariate T-Distributions and their Applications; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Vo, B.T.; Vo, B.N.; Cantoni, A. Analytic Implementations of the Cardinalized Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2007, 55, 3553–3567. [Google Scholar] [CrossRef]
- Arasaratnam, I.; Haykin, S. Cubature Kalman Filters. IEEE Trans. Autom. Control 2009, 54, 1254–1269. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A Consistent Metric for Performance Evaluation of Multi-Object Filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Chang, G. Robust Kalman Filtering Based on Mahalanobis Distance as Outlier Judging Criterion. J. Geod. 2014, 88, 391–401. [Google Scholar] [CrossRef]
Figure 1.
Illustration of heavy-tailed noise distribution and Gaussian noise distribution.

Figure 2.
True trajectories of each target.
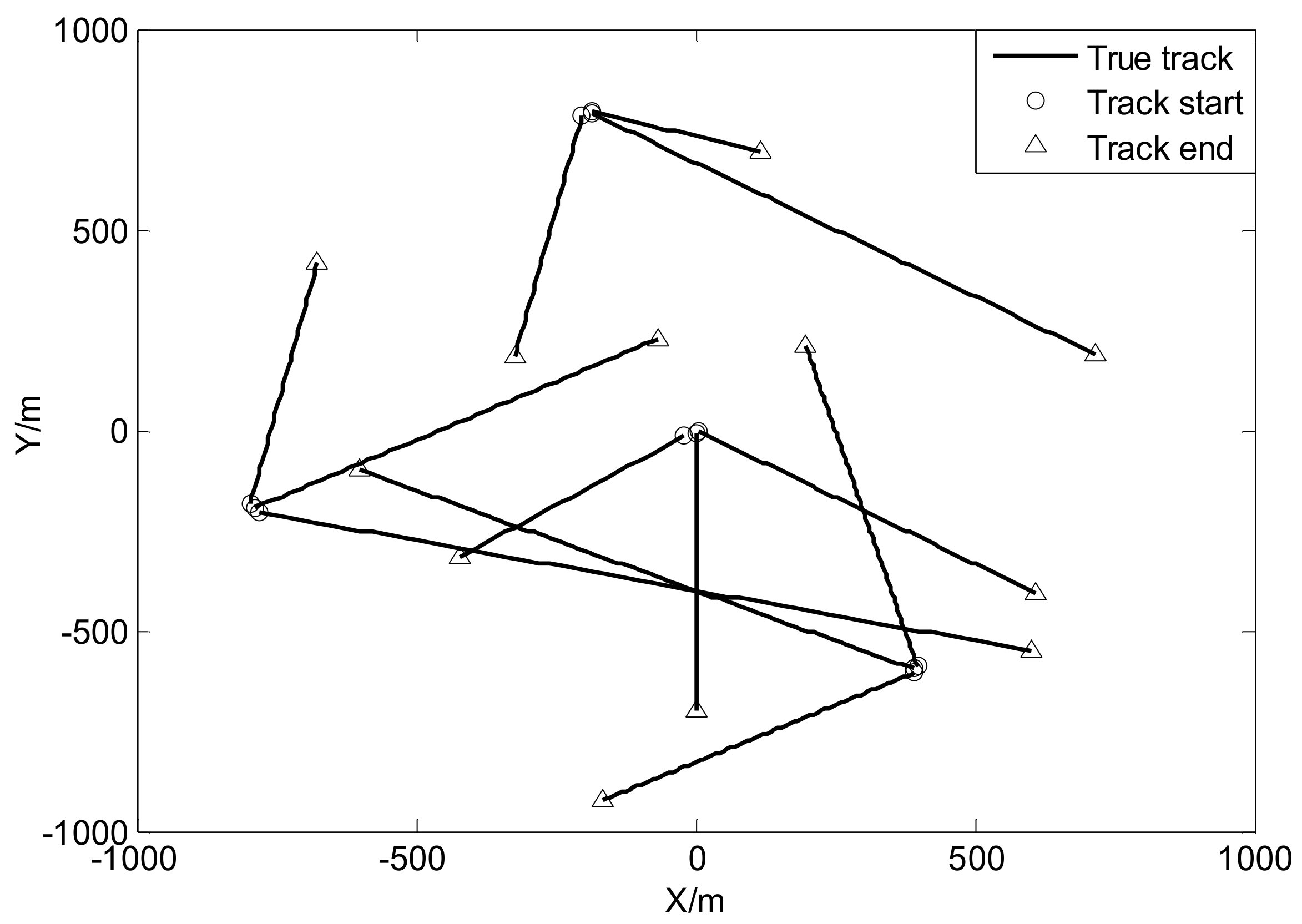
Figure 3.
Measurements and true target positions versus time: (a) in x coordinate; (b) in y coordinate.
Figure 3.
Measurements and true target positions versus time: (a) in x coordinate; (b) in y coordinate.

Figure 4.
Comparison of cardinality estimation of two filters with fixed clutter rate (λc = 20).

Figure 5.
Comparison of OSPA distance of two filters with fixed clutter rate (λc = 20).

Figure 6.
Comparison of OSPA distance of two filters with different contaminated rate.

Figure 7.
Comparison of OSPA distance for two filters with different clutter rate.

Figure 8.
True trajectories of each target.
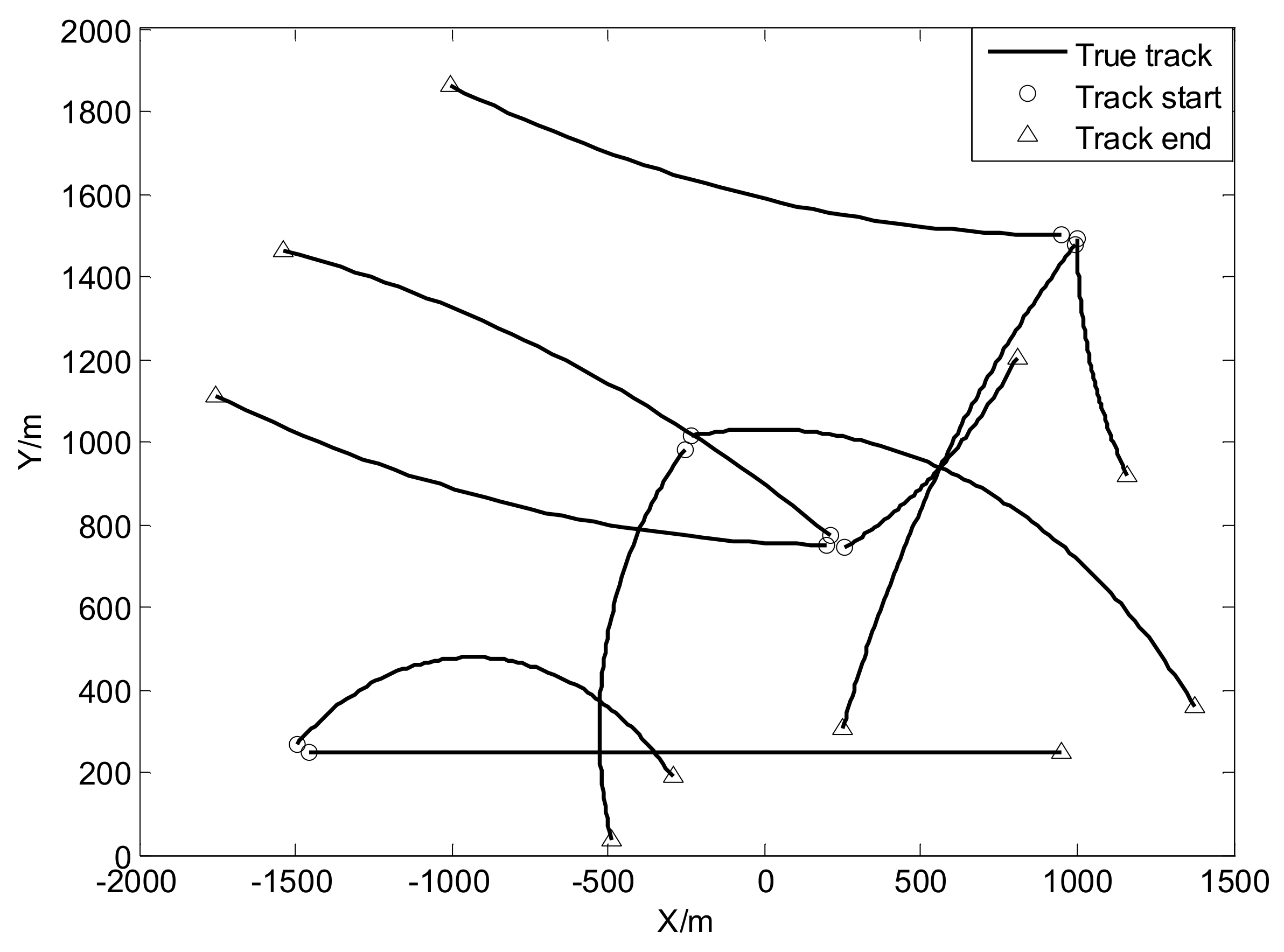
Figure 9.
Measurements and true target positions versus time: (a) in x coordinate; (b) in y coordinate.
Figure 9.
Measurements and true target positions versus time: (a) in x coordinate; (b) in y coordinate.
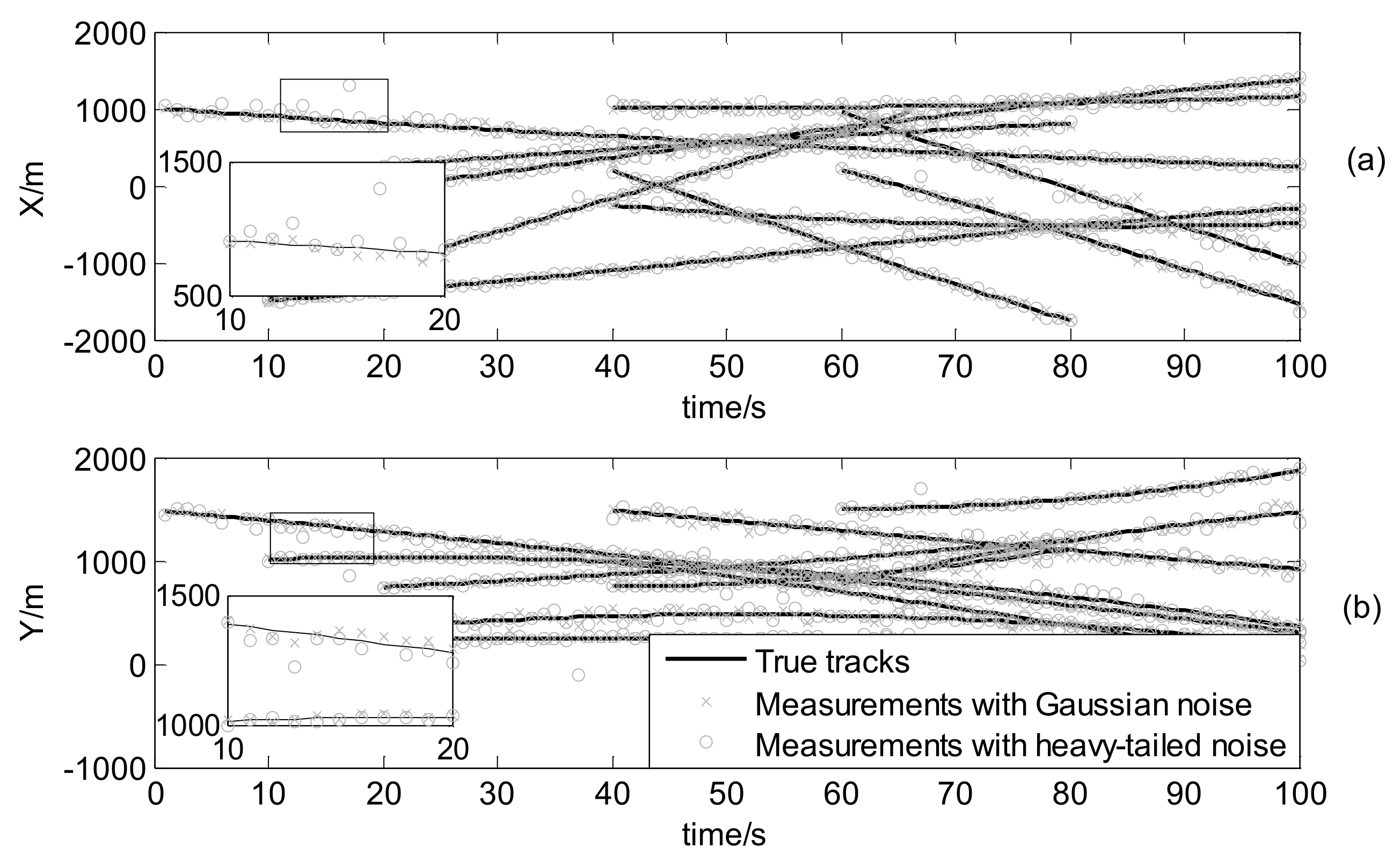
Figure 10.
Comparison of cardinality estimation of two filters with fixed clutter rate (λc = 20).
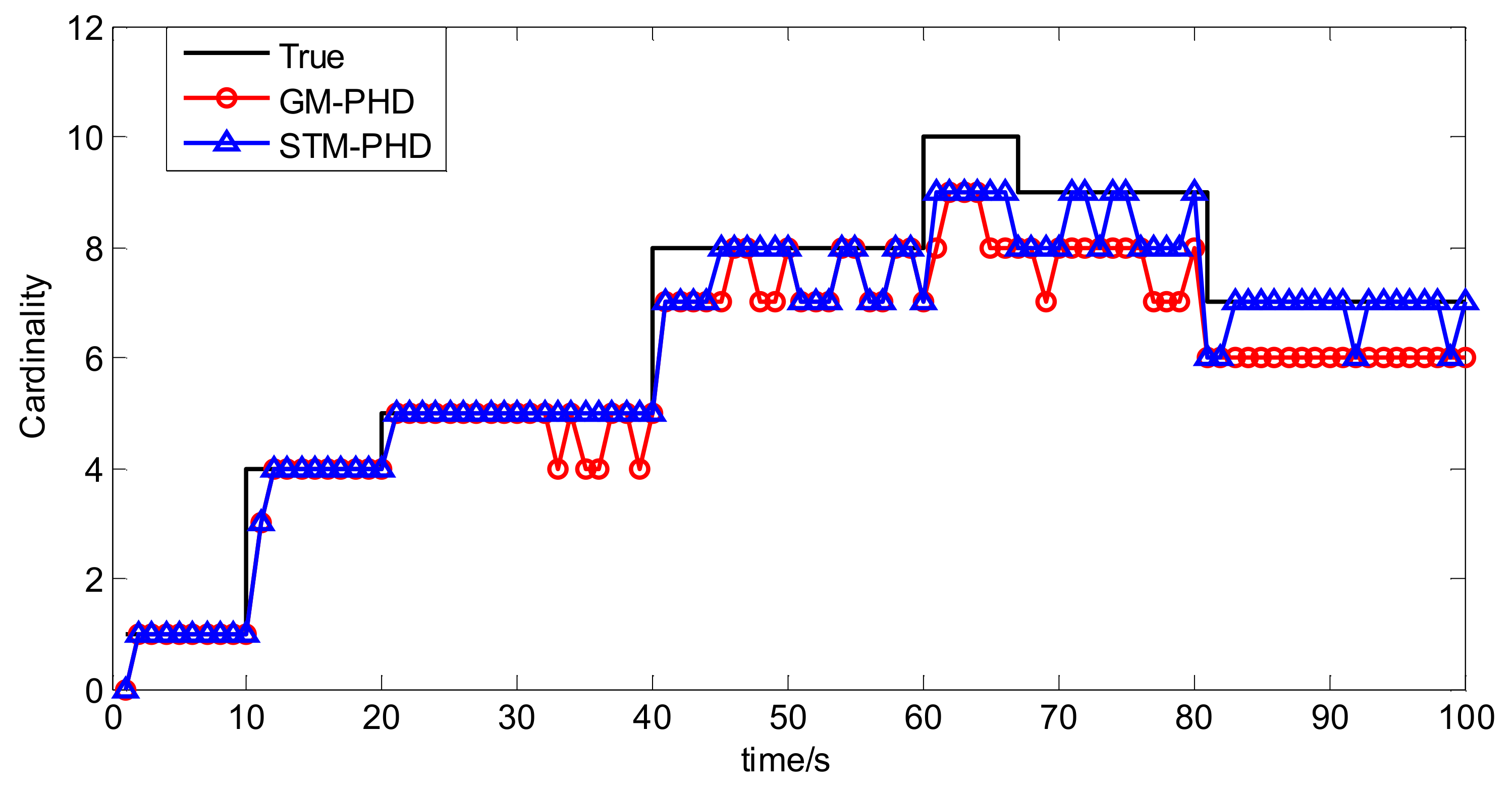
Figure 11.
Comparison of OSPA distance of two filters with fixed clutter rate (λc = 20).

Figure 12.
Comparison of OSPA distance of two filters with different contamination rates.
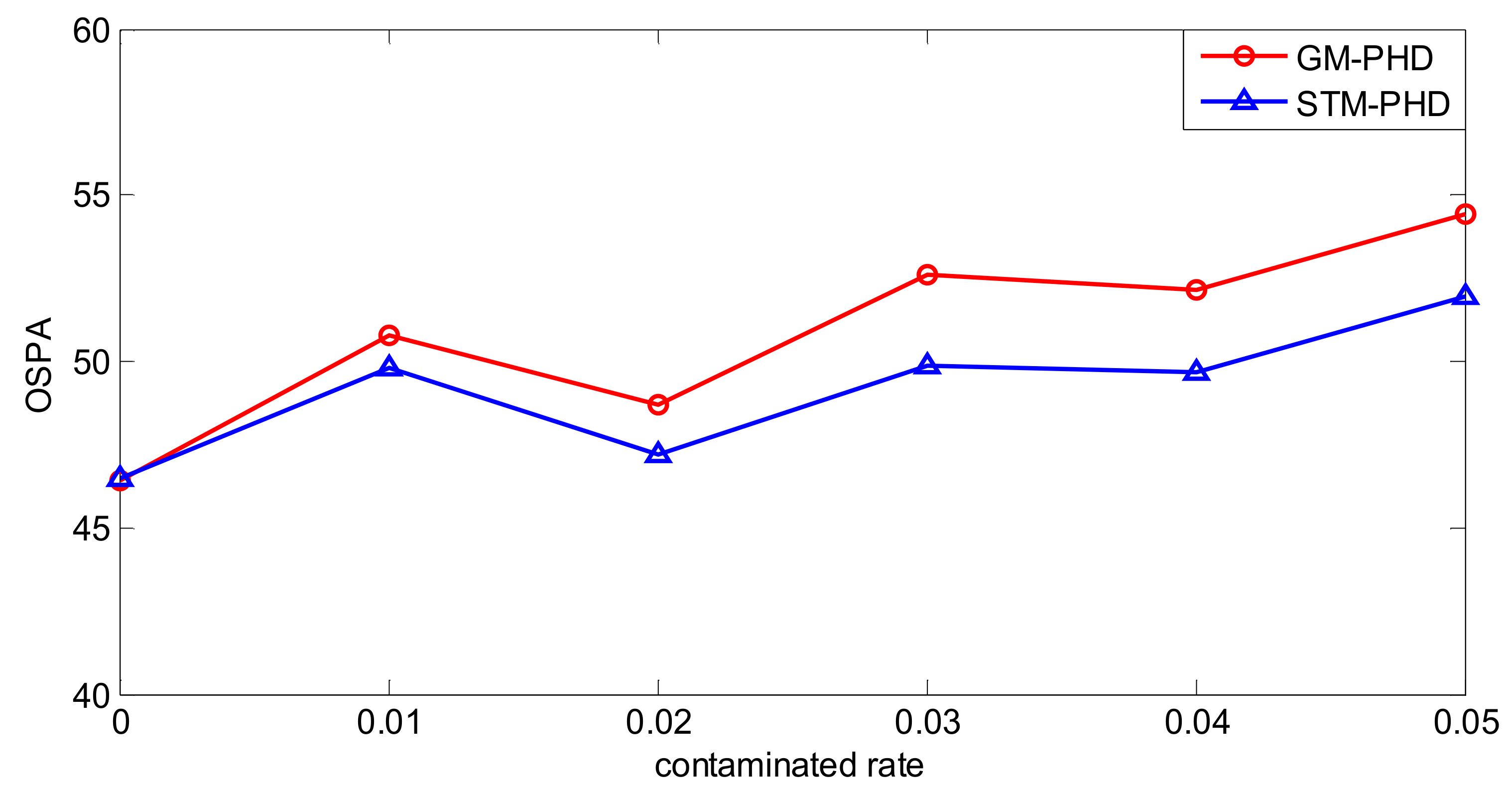
Figure 13.
Comparison of OSPA distance of two filters with different clutter rates.

Table 1.
A list of initial target states.
| Target Index | Life Time (s) | Initial States (m, m/s, m, m/s) |
|---|---|---|
| #1 | (1, 70) | [0, 0, 0, −10] |
| #2 | (1, 100) | [400, −10, −600, 5] |
| #3 | (1, 70) | [−800, 20, −200, −5] |
| #4 | (20, 100) | [400, −7, −600, −4] |
| #5 | (20, 100) | [400, −2.5, −600, 10] |
| #6 | (20, 100) | [0, 7.5, 0, −5] |
| #7 | (40, 100) | [−800, 12, −200, 7] |
| #8 | (40, 100) | [−200, −3, 800, −10] |
| #9 | (60, 100) | [−800, 3, −200, 15] |
| #10 | (60, 100) | [−200, −3, 800, −15] |
| #11 | (80, 100) | [0, −20, 0, −15] |
| #12 | (80, 100) | [−200, 15, 800, −5] |
Table 2.
Average computing time with different clutter rates.
| Clutter Rate | ||||||
|---|---|---|---|---|---|---|
| 0 | 10 | 20 | 30 | 40 | 50 | |
| GM-PHD | 0.9217 s | 0.9917 s | 1.0782 s | 1.1253 s | 1.1938 s | 1.2068 s |
| STM-PHD | 0.9146 s | 0.9961 s | 1.0780 s | 1.1417 s | 1.2576 s | 1.2486 s |
Table 3.
A list of initial target states.
| Target Index | Life Time (s) | Initial States (m, m/s, m, m/s, rad/s) |
|---|---|---|
| #1 | (1, 100) | [1000, −10, 1500, −10, 2π/(180 × 8)] |
| #2 | (10, 100) | [−250, 20, 1000, 3, −2π/(180 × 3)] |
| #3 | (10, 100) | [−1500, 11, 250, 10, −2π/(180 × 2)] |
| #4 | (10, 66) | [−1500, 43, 250, 0, 0] |
| #5 | (20, 80) | [250, 11, 750, 5, 2π/(180 × 4)] |
| #6 | (40, 100) | [−250, −12, 1000, −12, 2π/(180 × 2)] |
| #7 | (40, 100) | [1000, 0, 1500, −10, 2π/(180 × 4)] |
| #8 | (40, 80) | [250, −50, 750, 0, −2π/(180 × 4)] |
| #9 | (60, 100) | [1000, −50, 1500, 00, −2π/180 × 4] |
| #10 | (60, 100) | [250, −40, 750, 25, 2π/(180 × 4)] |
Table 4.
Average computing time with different clutter rate.
| Clutter Rate | ||||||
|---|---|---|---|---|---|---|
| 0 | 10 | 20 | 30 | 40 | 50 | |
| GM-PHD | 1.0142 s | 1.3780 s | 1.8481 s | 2.4988 s | 3.3321 s | 3.9051 s |
| STM-PHD | 1.8534 s | 3.3179 s | 5.4081 s | 8.5213 s | 12.9163 s | 16.6113 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, Z.; Chen, S.; Wu, H.; He, R.; Hao, L. A Student’s t Mixture Probability Hypothesis Density Filter for Multi-Target Tracking with Outliers. Sensors 2018, 18, 1095. https://doi.org/10.3390/s18041095
AMA Style
Liu Z, Chen S, Wu H, He R, Hao L. A Student’s t Mixture Probability Hypothesis Density Filter for Multi-Target Tracking with Outliers. Sensors. 2018; 18(4):1095. https://doi.org/10.3390/s18041095
Chicago/Turabian StyleLiu, Zhuowei, Shuxin Chen, Hao Wu, Renke He, and Lin Hao. 2018. "A Student’s t Mixture Probability Hypothesis Density Filter for Multi-Target Tracking with Outliers" Sensors 18, no. 4: 1095. https://doi.org/10.3390/s18041095
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.