A Data Cleaning Method for Big Trace Data Using Movement Consistency




Abstract
:1. Introduction
2. Related Work
3. Preliminaries
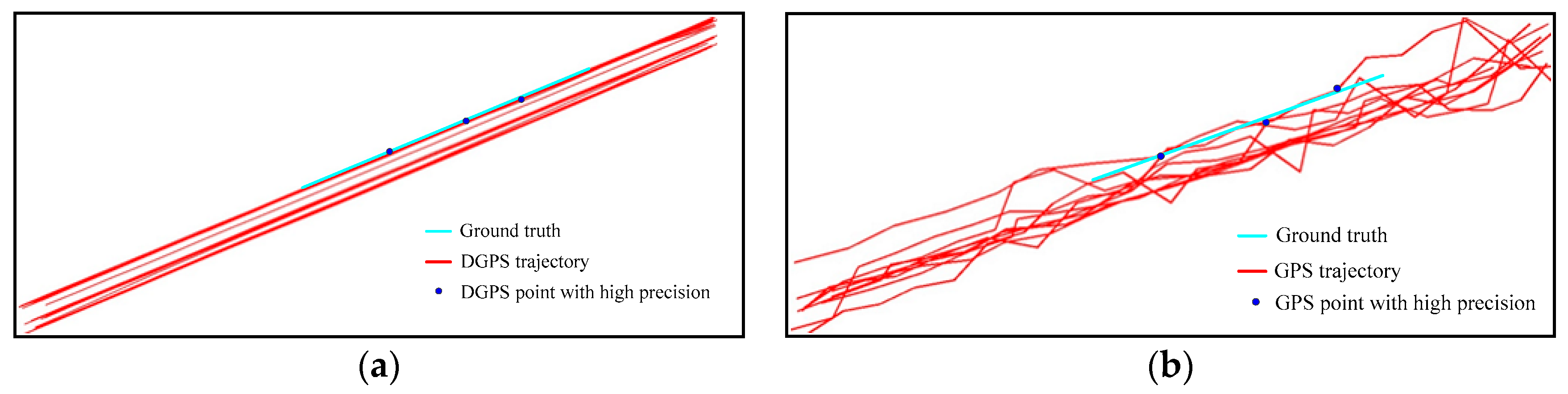
3.1. Spatial Big Data: Vehicle GPS Data
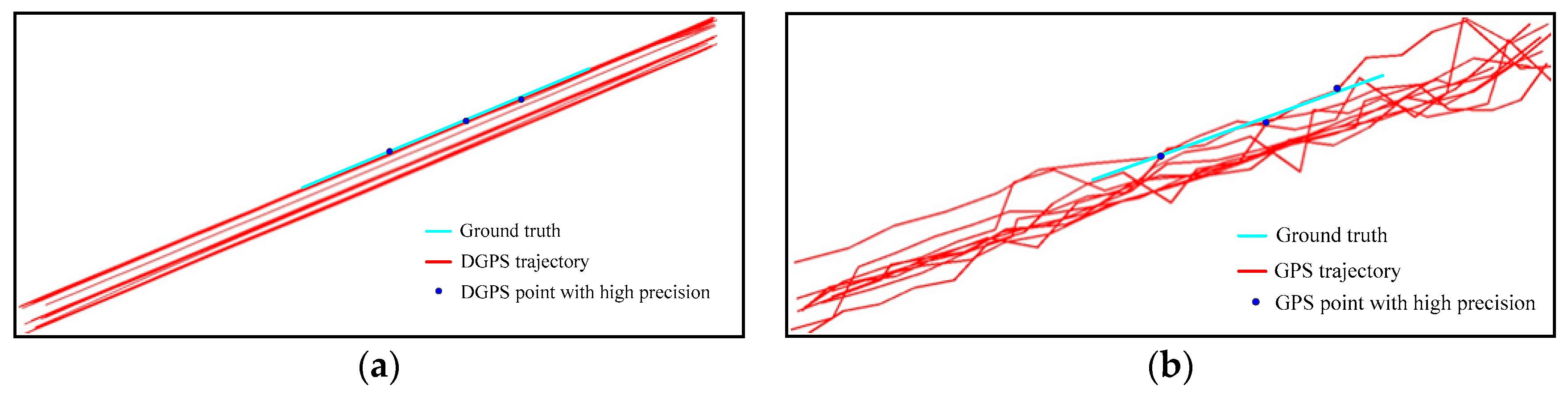
3.2. Discussion: Movement Consistency of Vehicle GPS Data
4. GPS Data Cleaning Method Based on Movement Consistency
4.1. Overview
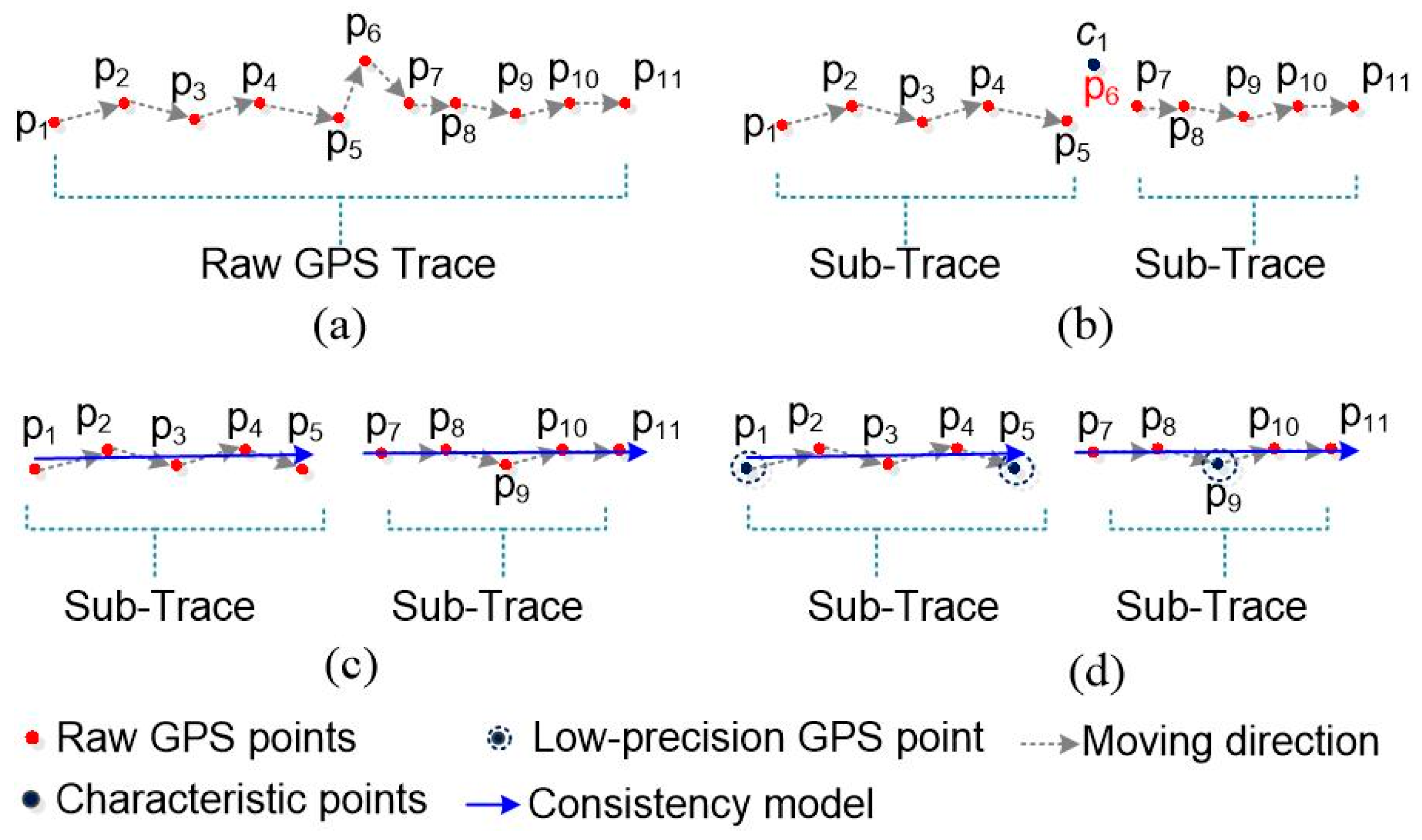
- Step 1.
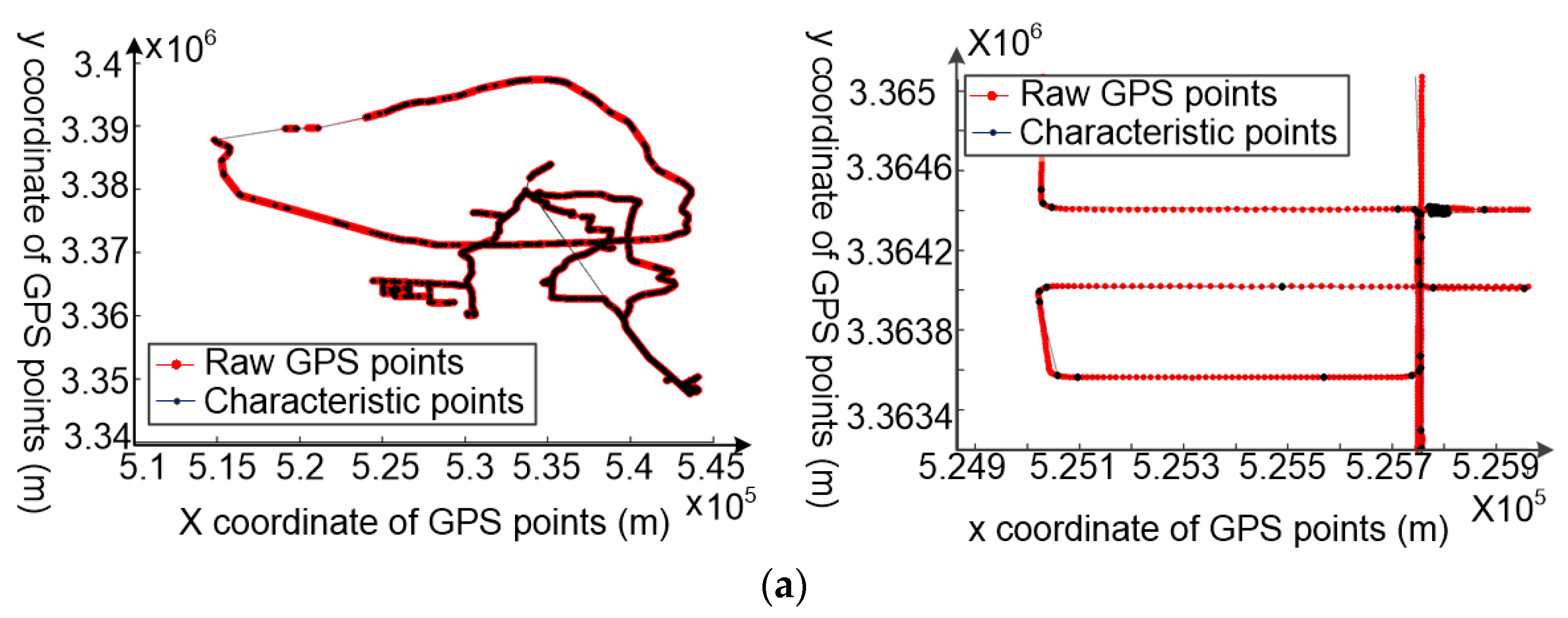
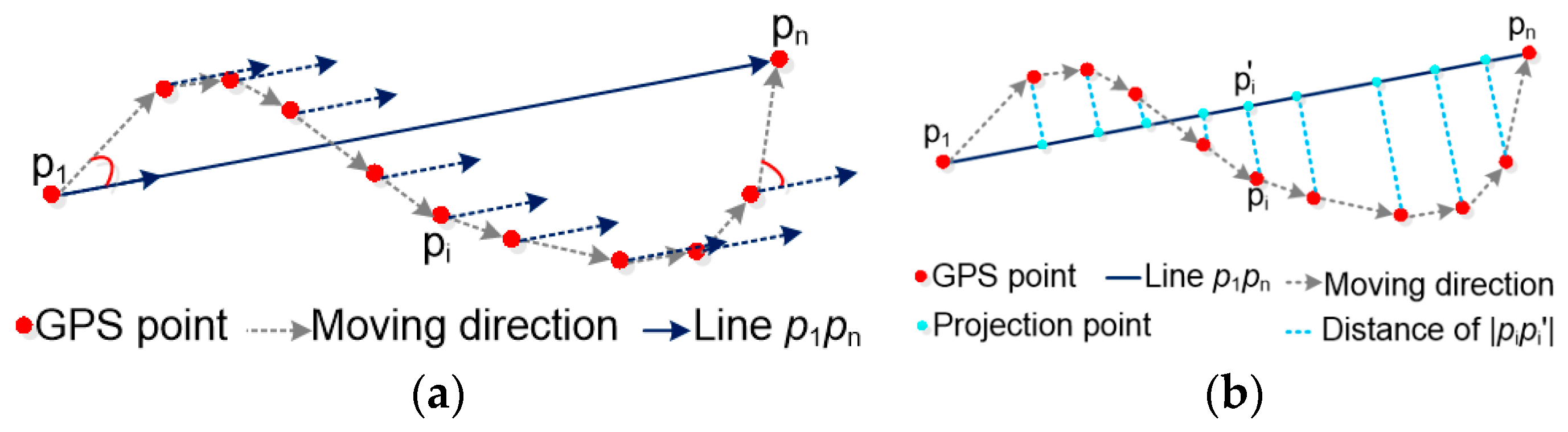
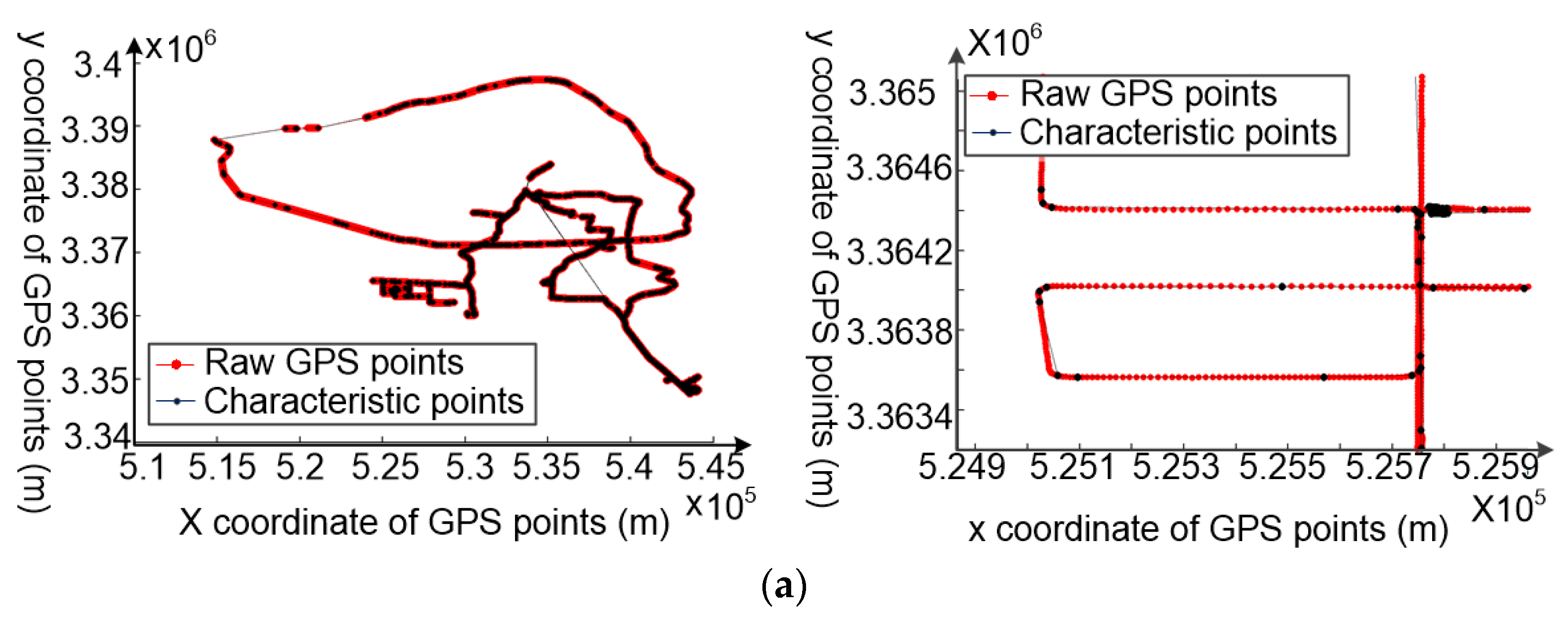
- The whole trajectory is partitioned into a set of sub-trajectories based on the movement characteristic constraints, as shown in Figure 2a,b. These split points, also called characteristic points, are the starting and ending points of each sub-trajectory.
- Step 2.
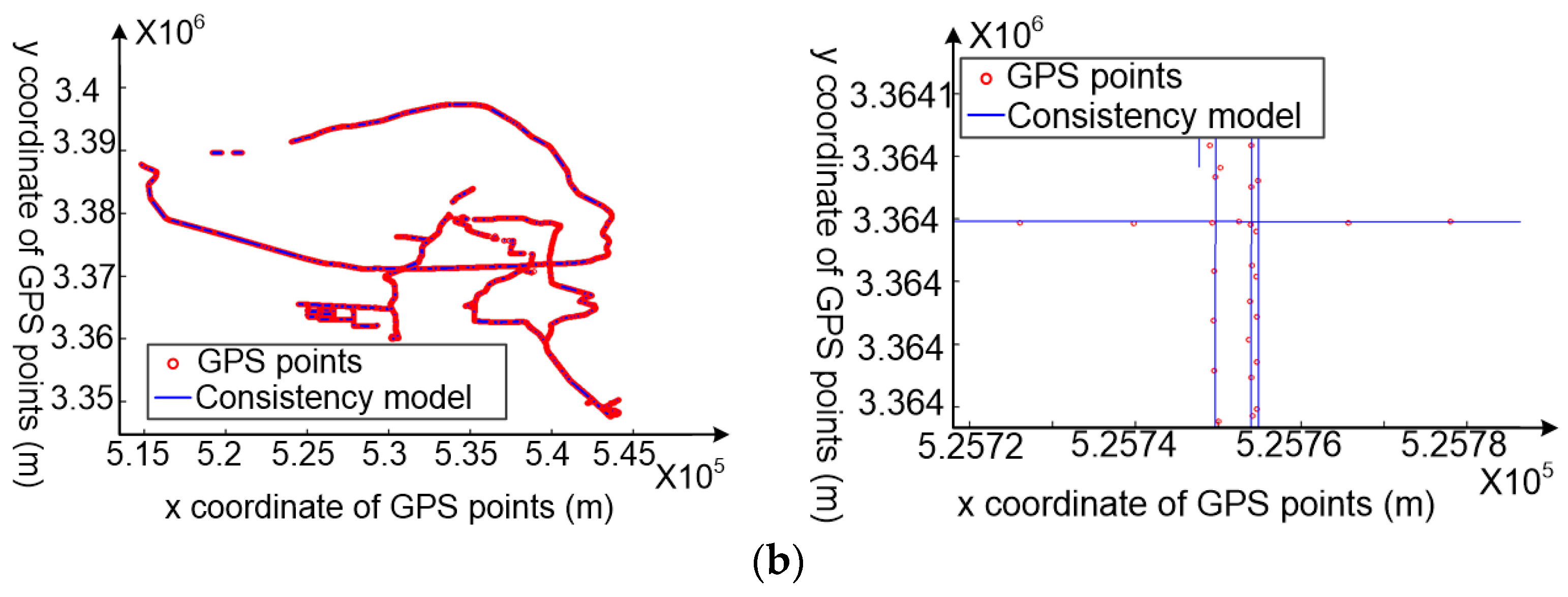
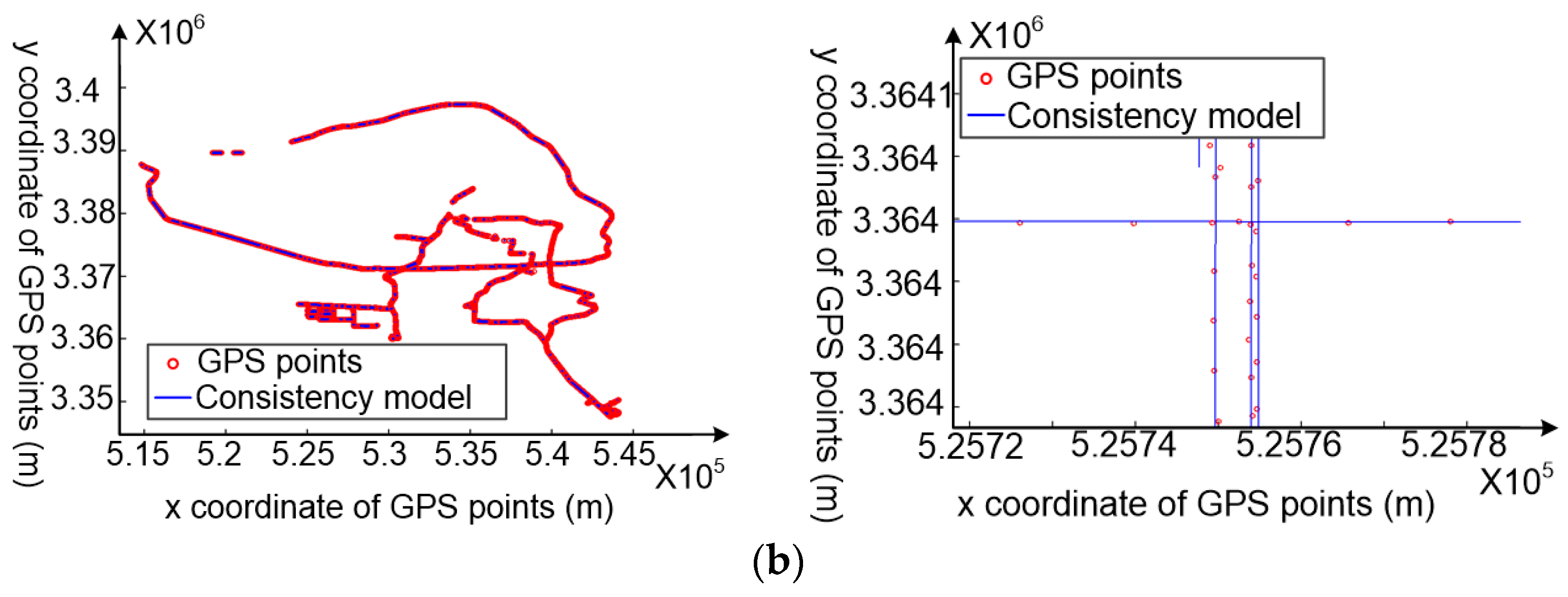
- The movement consistency model of each sub-trajectory is constructed using the random sample consensus algorithm based on the high spatial consistency of high-quality GPS data, as shown in Figure 2c,d. The movement consistency model is regarded as the linear position reference for cleaning points; the more similar the GPS points are to the movement consistency model, the more precise are the GPS points.
4.2. Trajectory Segmentation Based on the Changes in Motion Status of Vehicles
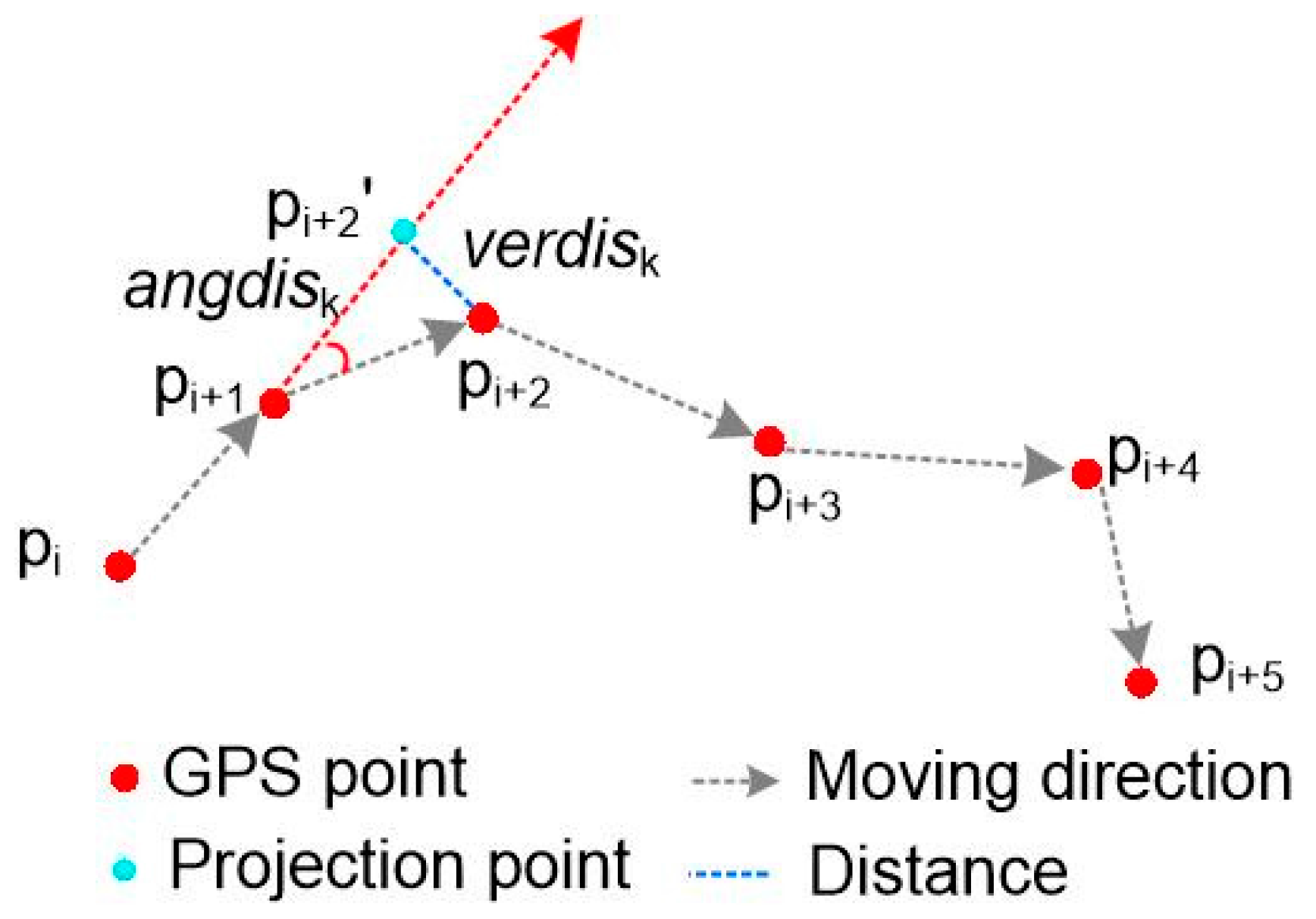
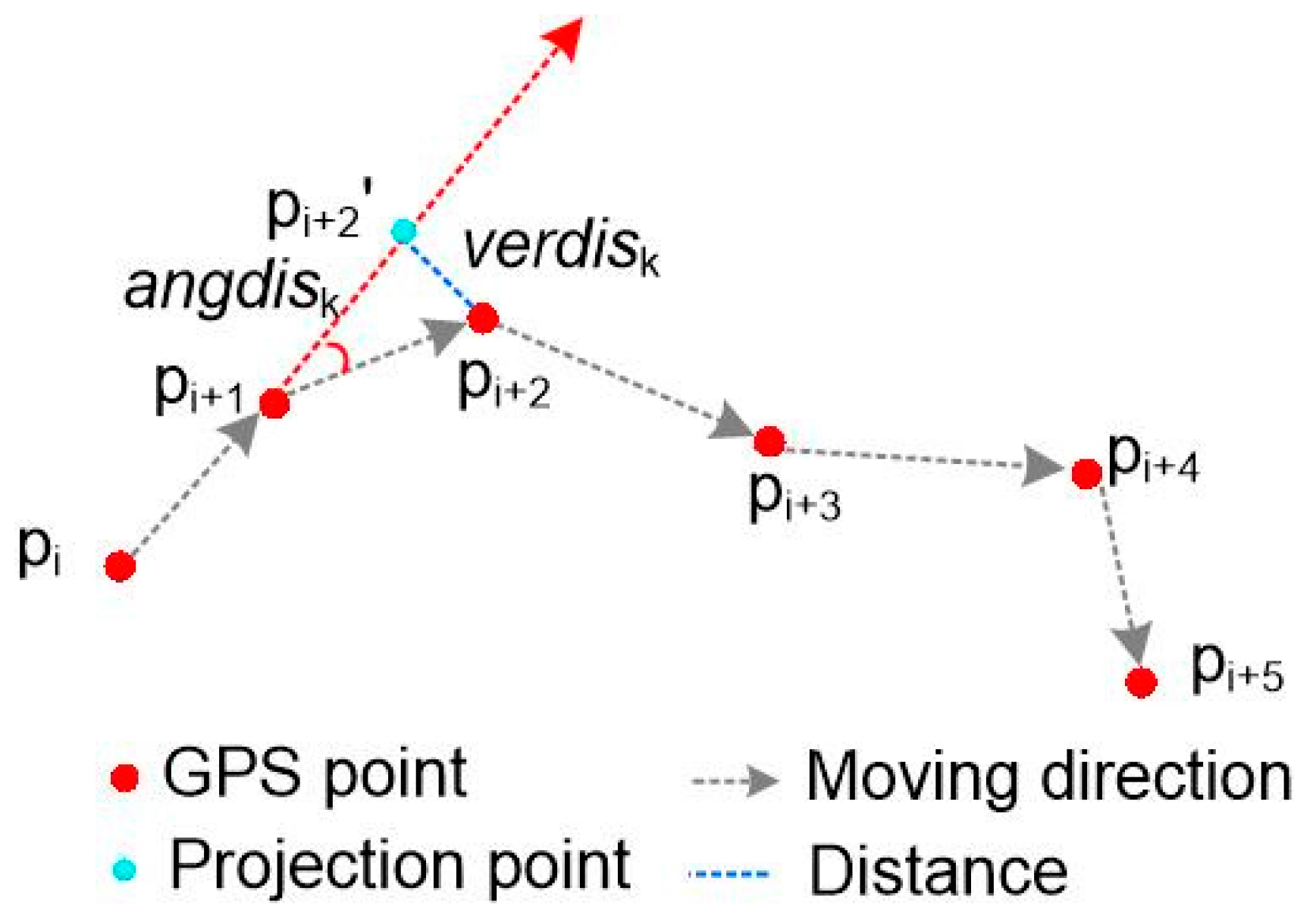
4.2.1. The Principle of Trajectory Segmentation
- Step 1.
- input the trajectory Ti (p1, p2, p3, …, pn);
- Step 2.
- initialize the partitioning parameters’ characteristic points C, c1, startIndex, currIndex, length, a1, and a2, and set c1 = p1, startIndex = 1, length = 1;
- Step 3.
- set currIndex = startIndex + length. If currIndex < n, go to Step 4; otherwise, go to Step 8;
- Step 4.
- set j = startIndex + 2;
- Step 5.
- calculate verdisj and angdisj. If verdisj > a2 || angdisj > a1, go to Step 6; otherwise, go to Step 3;
- Step 6.
- push pj into C and set startIndex = j − 1, j = j + 1;
- Step 7.
- if j < n, go to Step 5; otherwise, go to Step 3;
- Step 8.
- push pn into C, and return C.
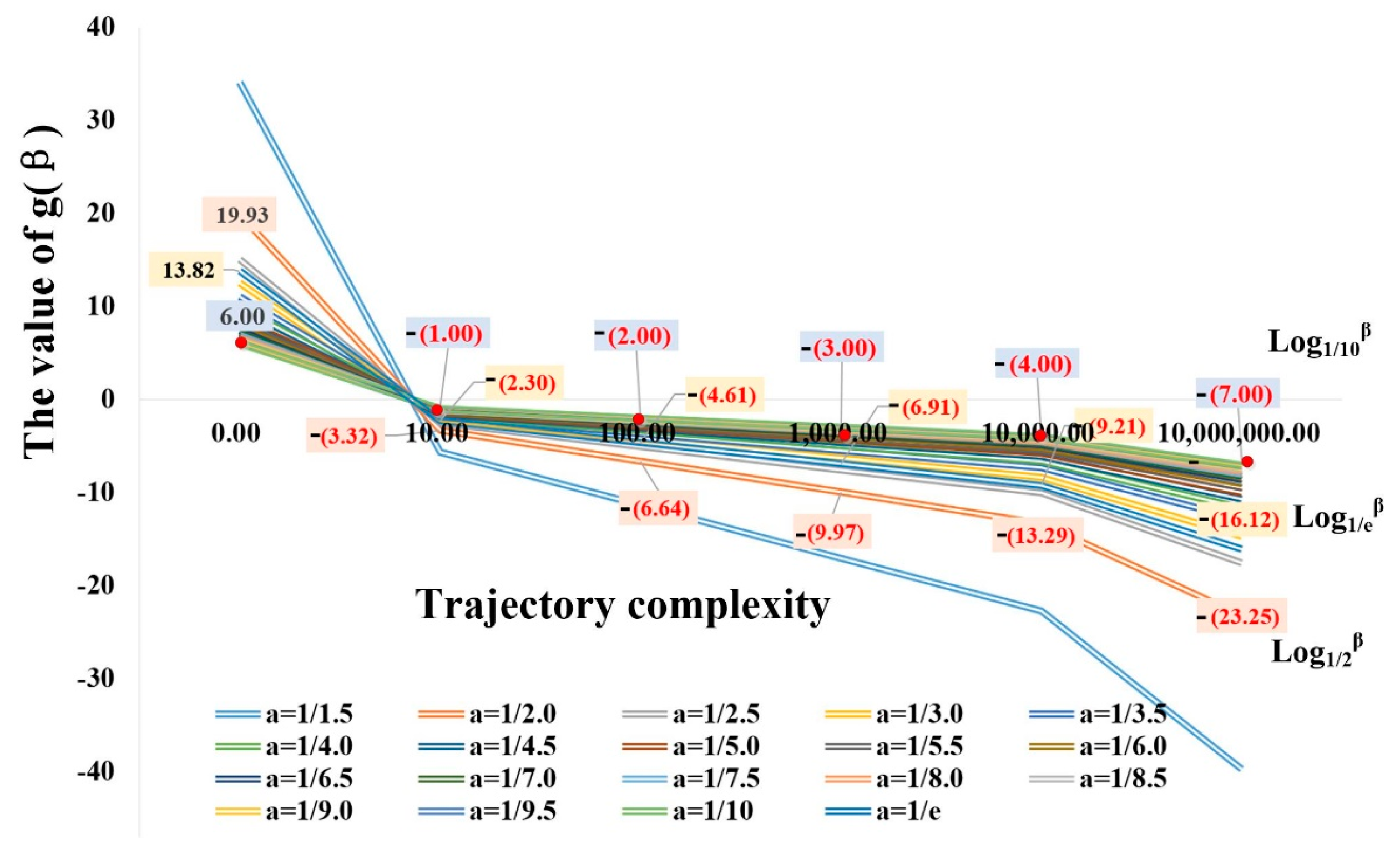
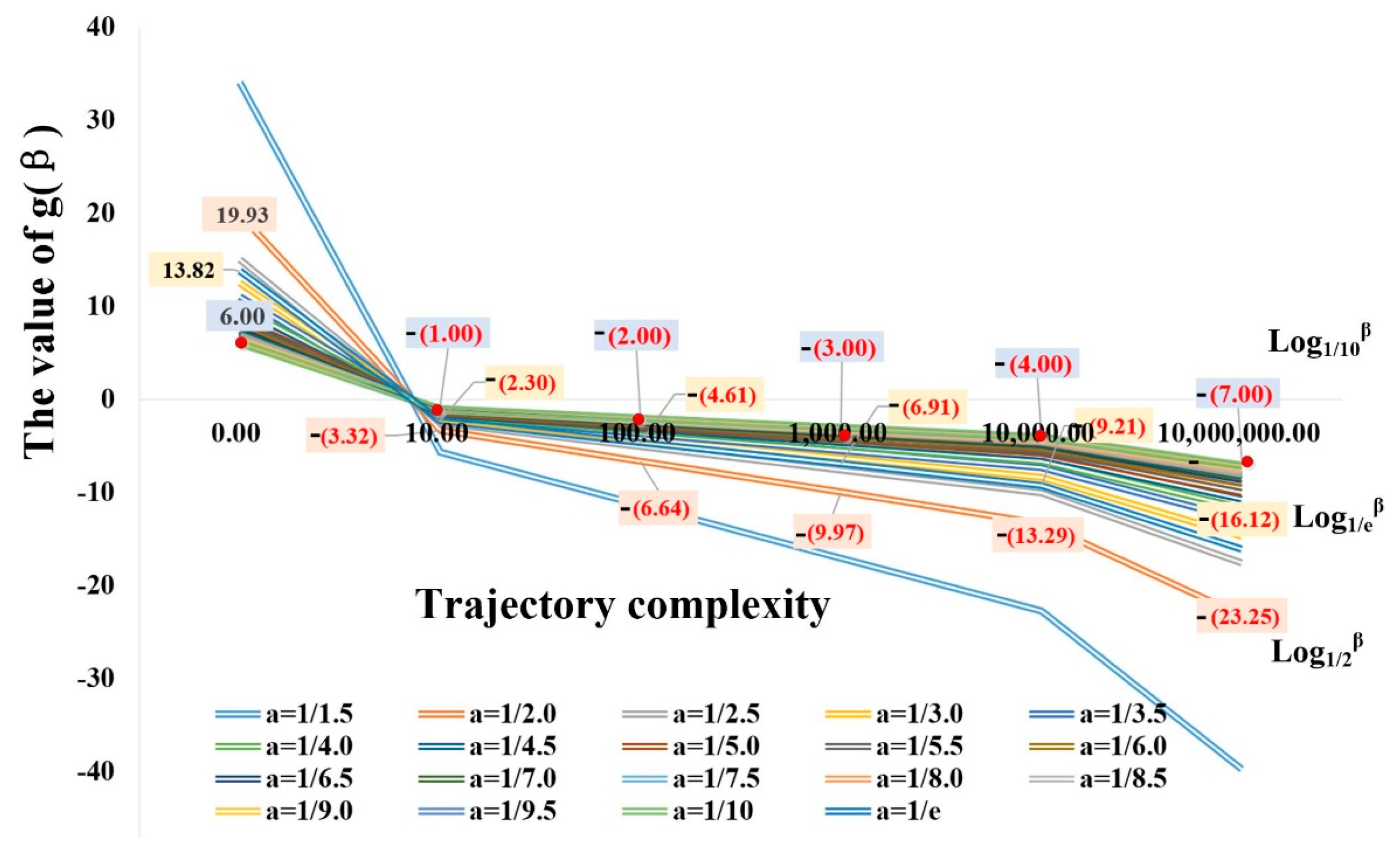
4.2.2. Segmentation Threshold Determination
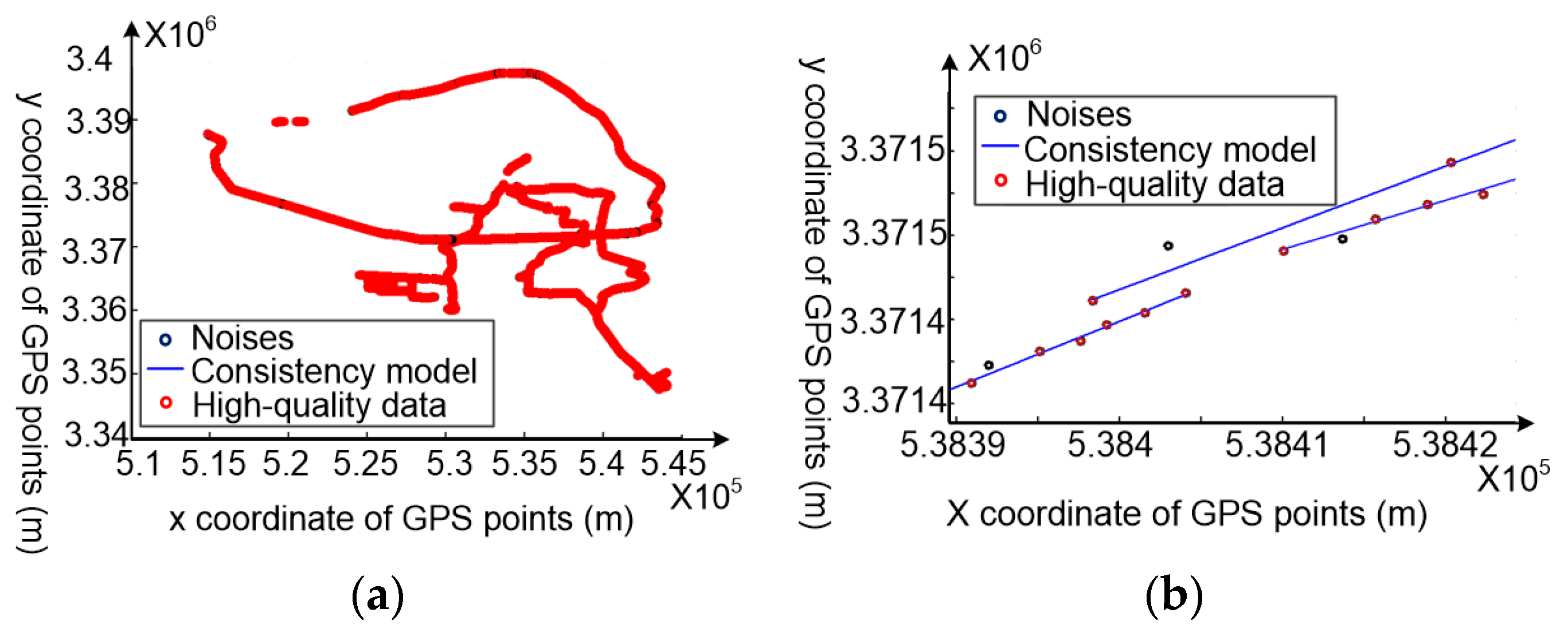
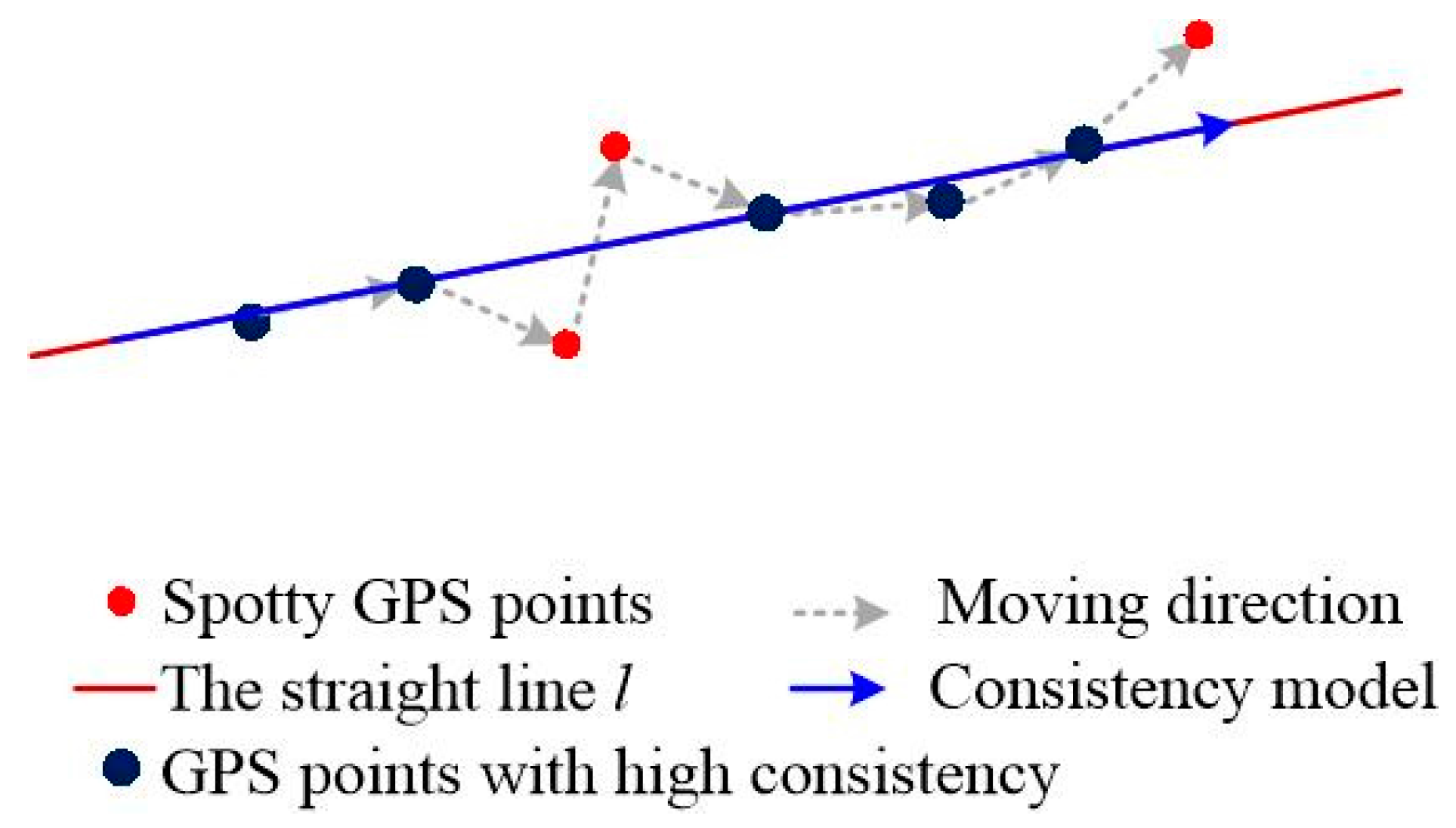
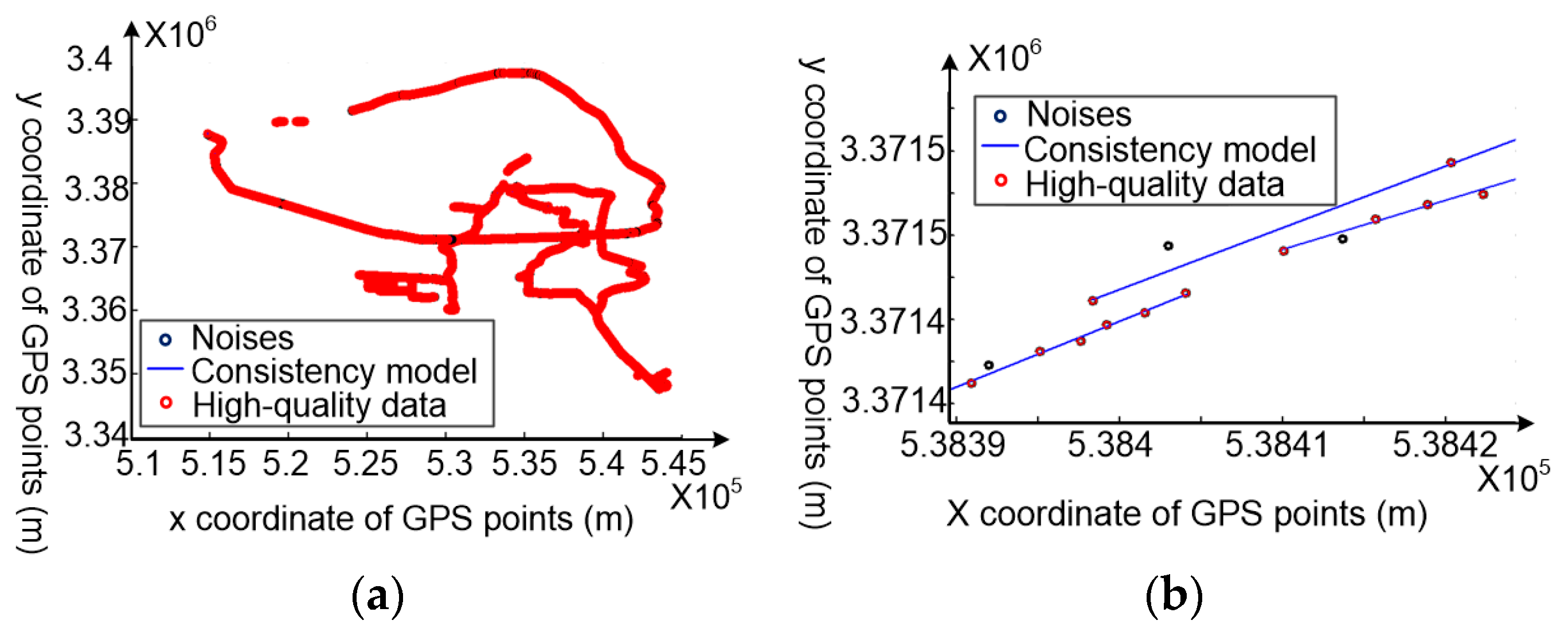
4.3. GPS Data Cleaning Based on Movement Consistency
4.3.1. The Consistency Model Construction for Each Sub-Trajectory
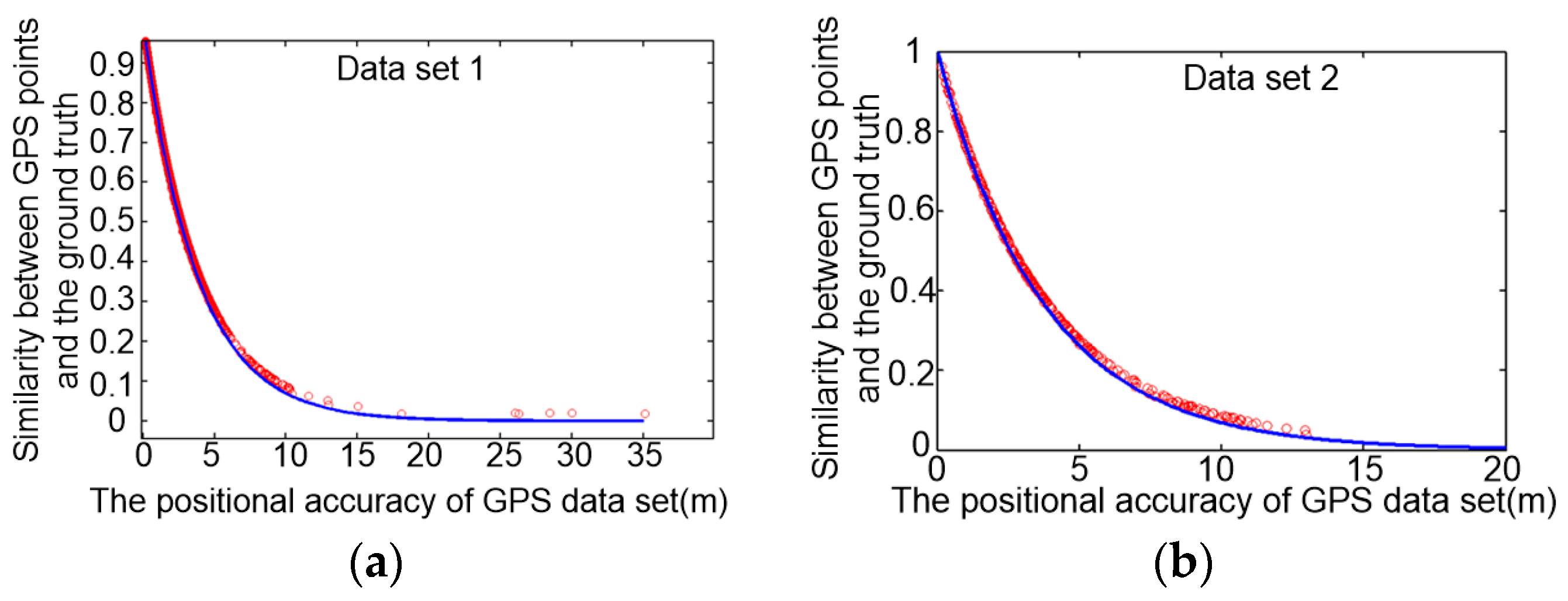
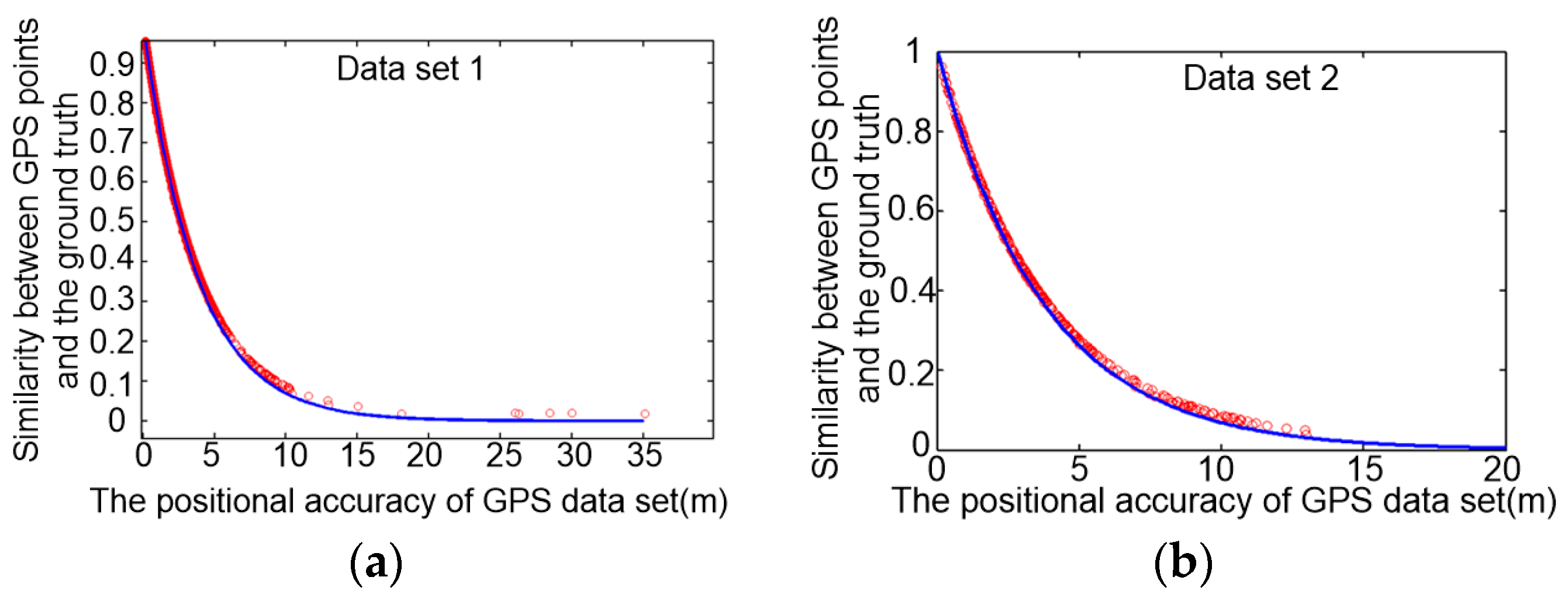
4.3.2. Discussion of Similarity and Consistency Model for GPS Data Cleaning
5. Experimental Study
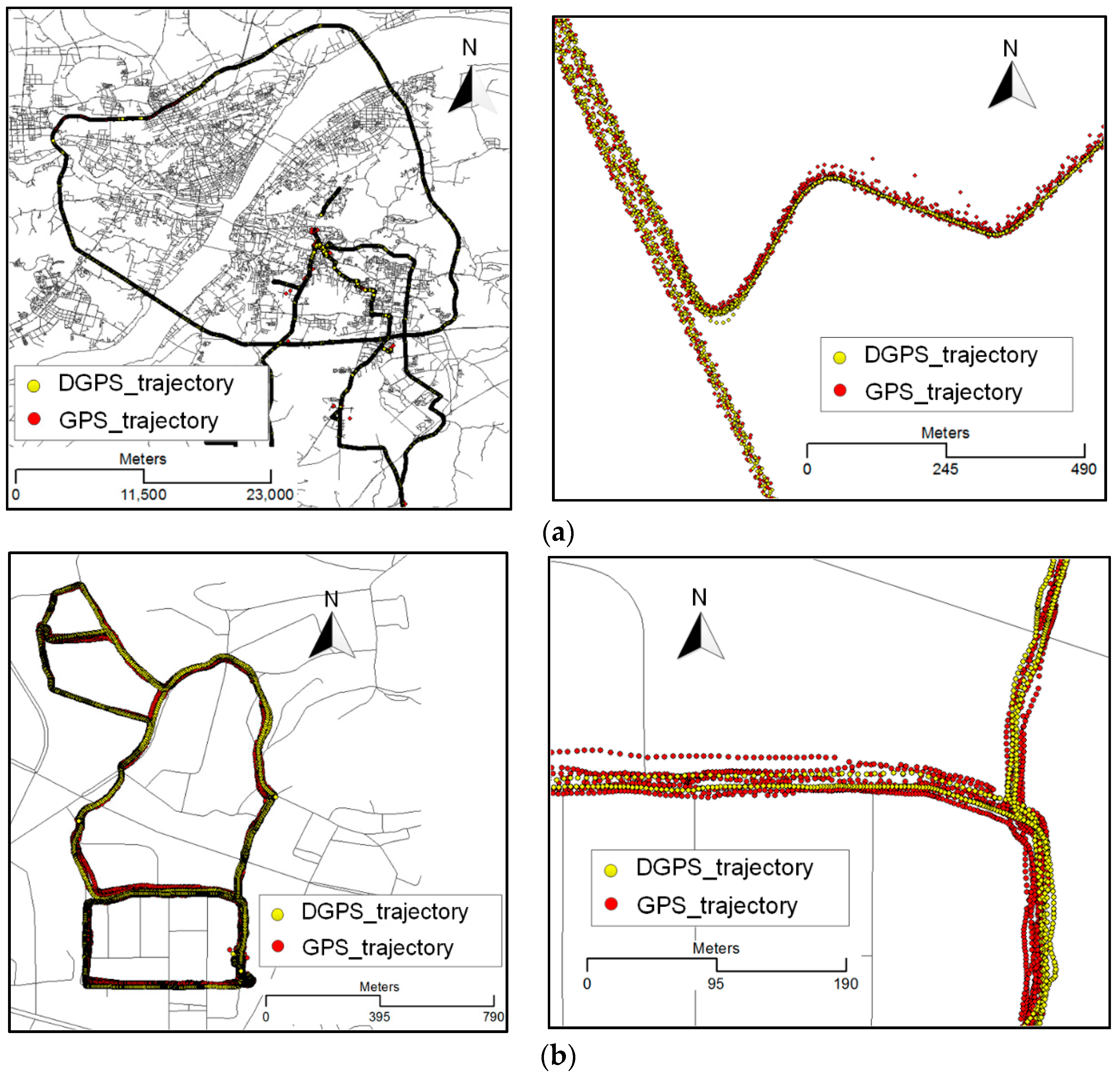
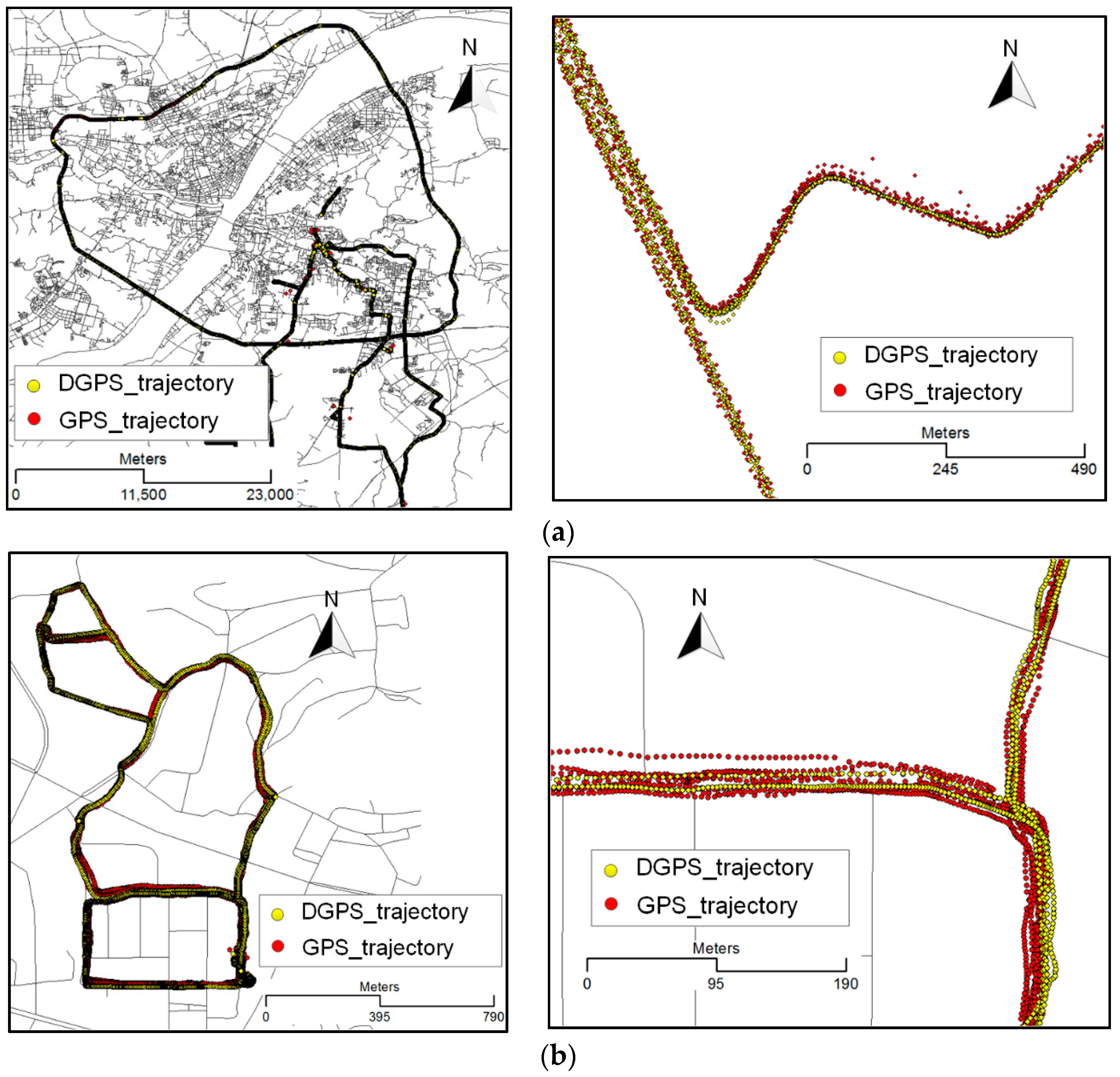
5.1. Experimental Dataset
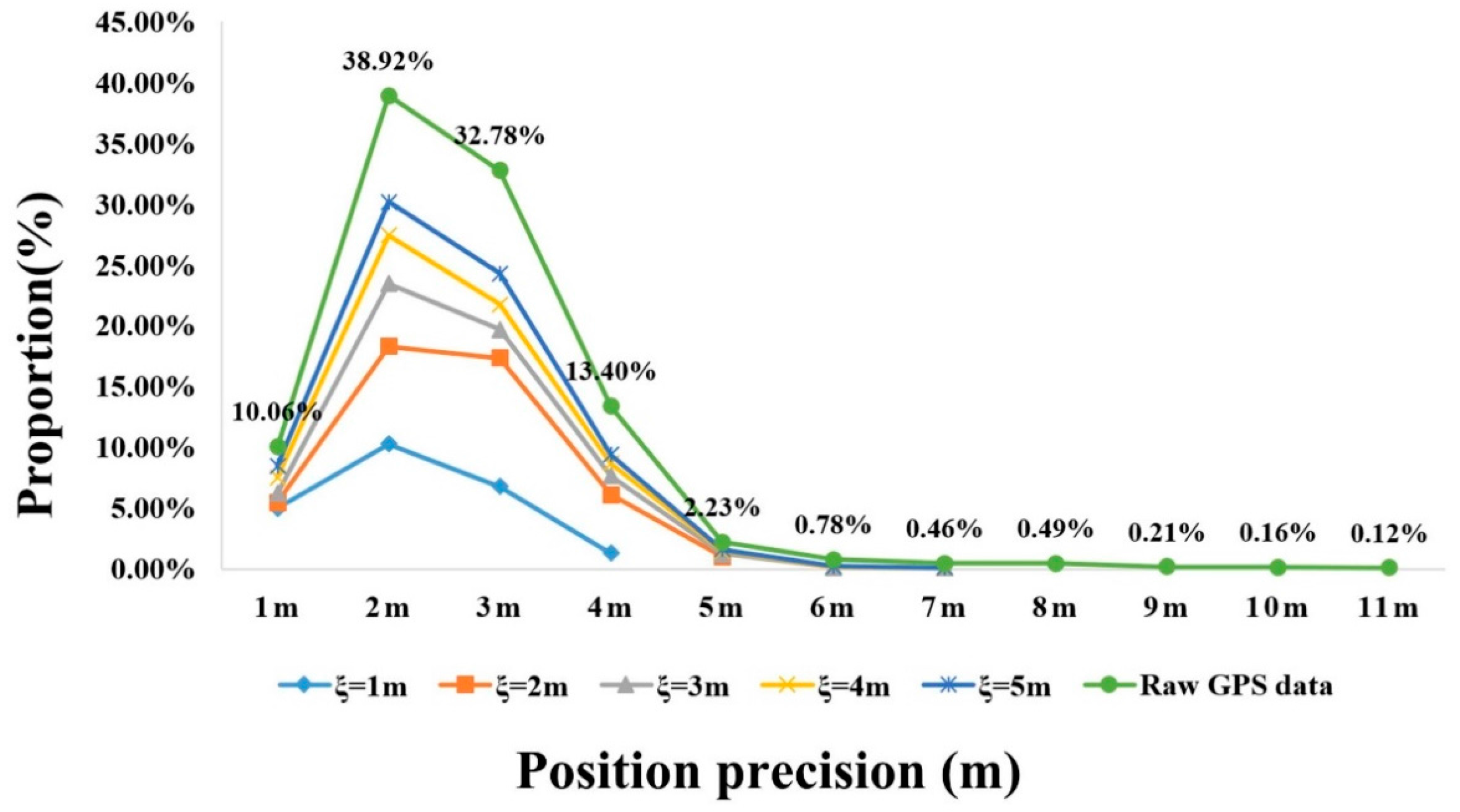
5.2. Parameters Discussion
5.3. Quantitative Evaluation and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- McAfee, A. Big data. The Management Revolution. Harv. Bus. Rev. 2012, 90, 61–67. [Google Scholar]
- Saha, B.; Srivastava, D. Data quality: The other face of big data. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering (ICDE), Chicago, IL, USA, 31 March–4 April 2014; pp. 1294–1297. [Google Scholar]
- Chatzimilioudis, G.; Konstantinidis, A.; Laoudias, C.; Zeinalipour-Yazti, D. Crowdsourcing with smartphones. IEEE Internet Comput. 2012, 16, 36–44. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Van der Spek, S.; van Schaick, J.; de Bois, P.; de Haan, R. Sensing Human Activity: GPS Tracking. Sensors 2009, 9, 3033–3055. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.A.; Yu, X.; Gu, Q.; Han, J.; Jiang, G.; Leung, A.; Porta, T.L. A framework of mining trajectories from untrustworthy data in cyber-physical system. ACM Trans. Knowl. Discov. Data 2015, 9, 16. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Addressing big data time series: Mining trillions of time series subsequences under dynamic time warping. ACM Trans. Knowl. Discov. Data 2013, 7, 10. [Google Scholar] [CrossRef]
- Castro, P.S.; Zhang, D.; Chen, C.; Li, S.; Pan, G. From taxi GPS traces to social and community dynamics: A survey. ACM Comput. Surv. (CSUR) 2013, 46, 17. [Google Scholar] [CrossRef]
- Tang, L.; Kan, Z.; Zhang, X.; Sun, F.; Yang, X.; Li, Q. A network Kernel Density Estimation for linear features in space—Time analysis of big trace data. Int. J. Geogr. Inf. Sci. 2016, 30, 1717–1737. [Google Scholar] [CrossRef]
- Song, J.H.; Jee, G.I. Performance Enhancement of Land Vehicle Positioning Using Multiple GPS Receivers in an Urban Area. Sensors 2016, 16, 1688. [Google Scholar] [CrossRef] [PubMed]
- Ertan, G.; Oğuz, G.; Yüksel, B. Evaluation of Different Outlier Detection Methods for GPS Networks. Sensors 2008, 8, 7344–7358. [Google Scholar]
- Yang, X.; Tang, L. Crowdsourcing big trace data filtering: A partition-and-filter model. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Prague, Czech Republic, 11–19 July 2016; pp. 257–262. [Google Scholar]
- Fan, H.; Zipf, A.; Fu, Q.; Neis, P. Quality assessment for building footprints data on OpenStreetMap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Berti-Equille, L.; Dasu, T.; Srivastava, D. Discovery of complex glitch patterns: A novel approach to quantitative data cleaning. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Washington, DC, USA, 11–16 April 2011; pp. 733–744. [Google Scholar]
- Hellerstein, J.M. Quantitative Data Cleaning for Large Databases. White Paper, United Nations Economic Commission for Europe (UNECE). 2008. Available online: http://db.cs.berkeley.edu/jmh/ (accessed on 4 March 2018).
- Bohannon, P.; Fan, W.; Geerts, F.; Jia, X.; Kementsietsidis, A. Conditional functional dependencies for data cleaning. In Proceedings of the 2007 IEEE 23th International Conference on Data Engineering, Istanbul, Turkey, 11–15 April 2007; pp. 746–755. [Google Scholar]
- Cong, G.; Fan, W.; Geerts, F.; Jia, X.; Ma, S. Improving data quality: Consistency and accuracy. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 315–326. [Google Scholar]
- Chen, Y.; Krumm, J. Probabilistic modeling of traffic lanes from GPS traces. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 81–88. [Google Scholar]
- Wang, J.; Rui, X.; Song, X.; Tan, X.; Wang, C.; Raghavan, V. A novel approach for generating routable road maps from vehicle GPS traces. Int. J. Geogr. Inf. Sci. 2015, 29, 69–91. [Google Scholar] [CrossRef]
- Tang, L.; Yang, X.; Kan, Z.; Li, Q. Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification. ISPRS Int. J. Geo-Inf. 2015, 4, 2660–2680. [Google Scholar] [CrossRef]
- Tang, L.; Yang, X.; Dong, Z.; Li, Q. CLRIC: Collecting Lane-Based Road Information Via Crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2552–2562. [Google Scholar] [CrossRef]
- Mohamed, A.H.; Schwarz, K.P. Adaptive Kalman filtering for INS/GPS. J. Geodesy 1999, 73, 193–203. [Google Scholar] [CrossRef]
- Jiang, Z.; Shekhar, S. Spatial Big Data Science; Springer International Publishing: New York, NY, USA, 2017. [Google Scholar]
- Lee, W.; Krumm, J. Trajectory preprocessing. In Computing with Spatial Trajectories; Zheng, Y., Ed.; Springer: New York, NY, USA, 2011; pp. 3–33. [Google Scholar]
- Gupta, M.; Ga1, J.; Aggarwal, C.; Han, J. Outlier detection for temporal data. Synth. Lect. Data Min. Knowl. Discov. 2014, 5, 129. [Google Scholar] [CrossRef]
- Parkinson, B.W.; Enge, P.; Axelrad, P.; Spilker, J.J. Global Positioning System: Theory and Applications I. 1996. Available online: https://ci.nii.ac.jp/naid/10012561387/ (accessed on 4 March 2018).
- Rasetic, S.; Sander, J.; Elding, J.; Nascimento, M.A. A trajectory splitting model for efficient spatio-temporal indexing. In Proceedings of the International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 934–945. [Google Scholar]
- Gonzalez, P.A.; Weinstein, J.S.; Barbeau, S.J.; Labrador, M.A.; Winters, P.L.; Georggi, N.L.; Perez, R. Automating mode detection for travel behaviour analysis by using global positioning systems-enabled mobile phones and neural networks. IET Intell. Transp. Syst. 2010, 4, 37–49. [Google Scholar] [CrossRef]
- Lee, J.; Han, J.; Li, X. Trajectory outlier detection: A partition-and-detect framework. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering Workshop, Cancun, Mexico, 7–12 April 2008; pp. 140–149. [Google Scholar]
- Zhang, L.; Wang, Z. Trajectory Partition Method with Time-Reference and Velocity. J. Converg. Inf. Technol. 2011, 6, 134–142. [Google Scholar]
- Fisher, N.I. Statistical Analysis of Circular Data; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Nams, V.O. Using animal movement paths to measure response to spatial scale. Oecologia 2005, 143, 179–188. [Google Scholar] [CrossRef] [PubMed]
- Li, X. Using complexity measures of movement for automatically detecting movement types of unknown GPS trajectories. Am. J. Geogr. Inf. Syst. 2014, 3, 63–74. [Google Scholar]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester N. Y. 2010, 4, 2–3. [Google Scholar]
- Li, H.; Shen, I.F. Similarity measure for vector field learning. In Proceedings of the Advances in Neural Networks—ISNN 2006, Chengdu, China, 28 May–1 June 2006; pp. 436–441. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trajectory Acquisition Device | Estimation Accuracy: ε (m) | Proportion of the Cleaned Data (%) | The Accuracy of GPS Data after Cleaning (Average Value/m) | The Accuracy of GPS Data after Cleaning (Standard Deviation/m) |
|---|---|---|---|---|
| Trimble R9 | 2 | 46.62 | 2.1 | 1.0 |
| 3 | 58.87 | 2.9 | 1.2 | |
| 4 | 66.30 | 3.5 | 1.8 | |
| 5 | 72.48 | 4.1 | 1.8 | |
| Hand-held GPS | 2 | 36.86 | 2.0 | 0.8 |
| 3 | 41.38 | 2.4 | 1.2 | |
| 4 | 46.32 | 2.9 | 1.3 | |
| 5 | 48.76 | 3.7 | 2.3 | |
| Smartphones | 2 | 27.43 | 3.8 | 2.4 |
| 3 | 32.69 | 4.8 | 2.9 | |
| 4 | 40.23 | 5.1 | 3.0 | |
| 5 | 48.11 | 5.6 | 3.3 |
| Methods for GPS Data Cleaning | Vehicle Trajectories Collected by Trimble R9 | |
|---|---|---|
| Mean Value of the Accuracy of the Cleaned Data (m) | Standard Deviation of the Accuracy of the Cleaned Data (m) | |
| Method proposed in this paper | 2.1 | 1.0 |
| RGCPK | 2.5 | 1.2 |
| ADOM | 4.5 | 3.2 |
| KDE | 4.6 | 3.3 |
| KF | 3.8 | 7.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Tang, L.; Zhang, X.; Li, Q. A Data Cleaning Method for Big Trace Data Using Movement Consistency. Sensors 2018, 18, 824. https://doi.org/10.3390/s18030824
Yang X, Tang L, Zhang X, Li Q. A Data Cleaning Method for Big Trace Data Using Movement Consistency. Sensors. 2018; 18(3):824. https://doi.org/10.3390/s18030824
Chicago/Turabian StyleYang, Xue, Luliang Tang, Xia Zhang, and Qingquan Li. 2018. "A Data Cleaning Method for Big Trace Data Using Movement Consistency" Sensors 18, no. 3: 824. https://doi.org/10.3390/s18030824
APA StyleYang, X., Tang, L., Zhang, X., & Li, Q. (2018). A Data Cleaning Method for Big Trace Data Using Movement Consistency. Sensors, 18(3), 824. https://doi.org/10.3390/s18030824