Sensor Selection for Decentralized Large-Scale Multi-Target Tracking Network

Ministry of Education Key Laboratory for Intelligent Networks and Network Security (MOE KLINNS), School of Electronics and Information Engineering, Xi’an Jiaotong University, Xi’an 710049, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(12), 4115; https://doi.org/10.3390/s18124115
Submission received: 11 October 2018
/
Revised: 20 November 2018
/
Accepted: 20 November 2018
/
Published: 23 November 2018
(This article belongs to the Special Issue Multiple Object Tracking: Making Sense of the Sensors)
Abstract
:A new optimization algorithm of sensor selection is proposed in this paper for decentralized large-scale multi-target tracking (MTT) network within a labeled random finite set (RFS) framework. The method is performed based on a marginalized δ-generalized labeled multi-Bernoulli RFS. The rule of weighted Kullback-Leibler average (KLA) is used to fuse local multi-target densities. A new metric, named as the label assignment (LA) metric, is proposed to measure the distance for two labeled sets. The lower bound of LA metric based mean square error between the labeled multi-target state set and its estimate is taken as the optimized objective function of sensor selection. The proposed bound is obtained by the information inequality to RFS measurement. Then, we present the sequential Monte Carlo and Gaussian mixture implementations for the bound. Another advantage of the bound is that it provides a basis for setting the weights of KLA. The coordinate descent method is proposed to compromise the computational cost of sensor selection and the accuracy of MTT. Simulations verify the effectiveness of our method under different signal-to- noise ratio scenarios.
1. Introduction
With the development of communication and information fusion technologies, multi-target tracking (MTT) [1] based on sensor network becomes a new research hotspot. In general, the sensor networks are divided into two main categories according to their structure: one is centralized network and the other is decentralized network. Compared with the centralized network, the decentralized network is more widely concerned because of its parallelism, flexibility, robustness, scalability, anti-interference and fault tolerance, et al. In most practical applications, due to the limitations of communication bandwidth, energy consumption, computational cost, storage space et al, not all sensors in a network can be activated to observe targets at the same instant. As a result, the problem of sensor selection arises from this, which actually belongs to a branch of sensor management [2]. Although some research results [3,4,5,6,7,8] have been proposed for it, none of them jointly consider the uncertainty of target number and data association.
In the past two decades, random finite set (RFS) [9] based MTT has attracted extensive attention. By the use of RFS, MTT is described as a Bayesian estimation of state and observation sets. RFS filtering has been developed from the primal probability hypothesis density (PHD) [10,11,12], cardinalized PHD [13,14] and multi-Bernoulli [15,16] filters to the latest δ-generalized labeled multi-Bernoulli (δ-GLMB) filter [17,18,19]. The advantage of the latter is its conjugacy and track formation. Nevertheless, the number of components involved in the GLMB density increases exponentially with the recursion. Therefore, two approximation methods, the LMB and Marginalized δ-GLMB (Mδ-GLMB) [20,21,22], are subsequently proposed to reduce the computational cost of GLMB. They are also more suitable for multi-sensor scenarios. [23] has shown that the filtering accuracy of Mδ-GLMB is close to δ-GLMB and the two are significantly superior to LMB in the scenarios of low signal-to-noise ratio (SNR).
Besides the δ-GLMB conjugate prior, the Poisson multi-Bernoulli mixture (PMBM) filter [24,25] and multi-Bernoulli mixture (MBM) filter [25] are also conjugate priors. Track formation in the (P)MBM formulation can also be attained using RFS of trajectories [26].
In recent years, although the RFS-based methods have been used to control the position of one or several mobile sensors for MTT [27,28,29,30,31,32,33,34], none of them refer to the sensor network. Actually, in many cases, the sensors in a network are immobile. Instead, the problems of structure, constraints, node selection and so forth become rather important especially for a large-scale sensor network.
As a result, this paper focuses on the emerging problem of sensor selection for decentralized large-scale MTT networks. A new optimization algorithm for sensor selection is proposed based on the Mδ-GLMB filter. In the proposed method, the fusion of local multi-target posterior densities is carried out by using the rule of weighted Kullback-Leibler average (KLA) [23].
The main contributions of our method includes four aspects. First, the sensor selection is described as a constrained optimization problem with a Bayesian recursion of labeled multi-target RFS. A new metric, named as the label assignment (LA) metric, is proposed to measure the distance for two labeled sets. The lower bound of LA metric based mean square error (MSE) between the labeled multi-target state set and its estimate is treated as the optimized objective function of sensor selection. The bound is derived by the information inequality to RFS measurement [35]. The detailed proofs for the LA metric and its lower bound are presented in the appendices. Second, the normalized weights of the KLA rule are set according to the proposed bound. Third, both the sequential Monte Carlo (SMC) [10,36] and Gaussian mixture (GM) [11,12,13,14,15,16] implementations for the bound are presented. Fourth, because the computational cost of selection optimization increases with sensor number in the form of combination explosion, a sub-optimization method called coordinate descent [37] is proposed to compromise the computational cost and tracking accuracy.
The simulation results show that when the sensors in a decentralized large-scale network have different observation performance, 1) the MTT accuracy of our method is much better than that of the Cauchy-Schwarz (CS) divergence based methods [31,32]; 2) compared with the genetic algorithm [38], the coordinate descent method significantly shortens the calculation time of sensor selection; 3) the GM implementation of the bound is obviously faster than its SMC implementation.
2. Mathematical Background
2.1. Labeled RFS and Mδ-GLMB
In this paper, the unlabeled and labeled variables are, respectively, represented by the italics and bold. For example, the unlabeled state, measurement and their sets are noted as , , and ; the labeled state and its set are noted as and , where is the discrete label of . Let , and denote the label set, cardinality and space of , where and are the spaces of the unlabeled state and label.
The state estimates of single-target and multi-targets derived from a measurement set are both the functions of . To make this clearer, they are, respectively, noted as and . and are their labeled versions.
Let , and denote the functions of generalized Kronecker, inclusion indicator and multi-object exponential,
where is abbreviated as . Furthermore, if , then let denote the complementary set of in . is abbreviated as .
For any real-valued function of , its set integral is defined as
where and , is a -element labeled set, and are the spaces of and .
If is a Mδ-GLMB RFS, then its density is described as [22]
where is a distinct indicator for the labels of , is a label set in the collection of finite subsets of , the weight is the existing probability of the label set , is the density of involved in . The Mδ-GLMB density is abbreviated as and its cardinality distribution is
where is the collection of -element subsets of .
2.2. Information Inequality to RFS Measurement
Let be an unbiased estimate of derived from an -element measurement set and be a joint density over the space . Assuming that regularity conditions hold and exists, the information inequality to RFS measurement is [35]
where , is the dimension of , and are the th components of the vectors and , is the Fisher information matrix (FIM) given ,
(7) holds with equality if and only if satisfies the distribution of exponential family.
2.3. A New Metric for Labeled RFS
It is well known that the optimal sub-pattern assignment (OSPA) metric [39,40,41] has been extensively used to measure the distance for two unlabeled sets. Although the OSPA metric could also measure differences in the set labels, it may not be very appropriate for the labeled RFS in some application scenarios. As a result, a new metric between two labeled sets and of order with cut-off is proposed as follows.
where and are the label sets of and , and are the unlabeled elements corresponding to the label , and respectively indicates the number of elements in and which have the same and different labels,
denotes the 2-norm of and cut off at .
See Appendix A for the proof that the is a metric.
The proposed metric, which is named as the LA metric by us, is a different metric than the OSPA. A physical meaning about the LA metric between two labeled sets and is explained as follows. For all and , if has the same label as , then is paired with and a ‘location’ error between them is involved in the metric; otherwise, is unpaired with and a ‘penalty’ error for them is involved in the metric.
The most significant difference between the OSPA metric and the LA metric is: In the OSPA metric, the elements of are paired with the elements of depending on the optimal assignment distance of their unlabeled versions. In contrast, in the LA metric, the elements of are paired with the elements of completely depending on their labels.
Take the MTT with the labeled RFS state for example. The calculation of the OSPA error may pair an estimate with a state due to the rule of optimal assignment even if they have different labels. Instead, the calculation of LA error prohibits this kind of pairing even if their unlabeled states are sufficiently close to each other. As a result, the LA metric involves not only the estimation error arising from the target number and individual states as the OSPA metric but also the additional estimation error arising from the labels. In this sense, the LA metric is more demanding than the OSPA metric for measuring the error between the labeled state set and its estimate.
3. Problem Formulation
To simplify the formulas, the time index is omitted and the subscript ‘’ is used to indicate the predicted density.
Multiple targets independently move in region with random birth and death. The multi-target states are modeled as a labeled RFS . The dynamic of a single state is described by the survival probability and transition density . The dynamic of multi-target states is described by the transition density . Here and are, respectively, the state and state set at the last time.
Targets are observed by the decentralized sensor network shown in Figure 1. The network is composed of sensor nodes (SNs) and local fusion centers (LFCs). Each SN receives measurements and communicates with its superior LFC. Each LFC receives the measurements, conducts data processing and storage, communicates with the other LFCs connected to it and manages its subordinate SNs.
The network structure is completely described by a topological graph with parameter , where and are the label sets of SN and LFC, is the set of directed connections between LFCs. If the LFC can receive data of the LFC , then . Let be the label set of the LFCs connected to the LFC (including itself) and be the label set of the SNs belonging to the LFC . Each SN only belongs to one LFC, which indicates and .
The most significant difference between the decentralized network and the centralized or hierarchical network is that the former has no global fusion center connected to all SNs or all LFCs. The network structure remains unchanged and all measurements are synchronized during the monitoring period.
For the SN , it may receive clutter and target measurement or miss the detection. The measurements are modeled as a RFS over the space . is a single measurement. Clutter is modeled as a Poisson RFS with intensity , and
is the clutter rate.
The multi-target likelihood of the SN is obtained from [9] as
where
where and are the single-target detection probability and likelihood, is a collection of association mapping . or indicates that the track generates a measurement or be missed. Each track at most generates one measurement and each measurement is at most generated by one track, which indicates that if . The number of association hypotheses is [42]
Due to some restrictions, only part of SNs involved in the sub-network of each LFC can be activated to observe targets at each scan. Assume that the multi-target likelihoods of all the SNs in the network are independent of each other given the labeled state set . Algorithm 1 presents the steps of sensor selection and MTT for the LFC under a Bayesian framework. Note that the sequence of measurement sets up to the last time is omitted here for simplifying the formulas of Bayesian recursion.
| Algorithm 1. Sensor selection and MTT for the LFC . |
| 1. Prediction: Calculate the current predicted density by , where is the fused density at the last time; |
| 2. SN selection: Select the SN subset and receive a collection of their measurement sets ; |
| 3. Update: Calculate the current posterior density by and then transmit the density to the LFCs connected to the LFC ; |
| 4. Fusion: Receive the posterior densities from the LFC set and then calculate the fused density by the weighted KLA rule , where () is the preset normalized weight; |
| 5. State extraction: Extract the current state estimate from as the output. Go to Step 1. |
Remark 1.
It can be seen from Steps 3 and 4 of Algorithm 1 that in this network, each LFC only communicates once with the LFCs connected to it per recursion. Because of this, the consensus iteration [43,44] of each LFC cannot be carried out since each LFC has to communicate with other LFCs more than once in the iterative process. Finally, the consensus fusion [23] over the entire decentralized sensor network cannot be achieved. As a result, the multi-target estimates outputted by different LFCs may be different. In fact, this character is consistent with most practical application systems.
The SN selection in Step 2 of Algorithm 1 is described as the following constrained optimization problems:
where , and are the objective function, inequality and equality constraints of given the predicted density .
The ultimate goal for a MTT network is to optimize the tracking precision. As is known to all, the MSE between target state and its estimate is currently the most widely-used evaluation indicator for tracking accuracy. Given the selected SN subset for the LFC , the MSE between and its Bayesian estimate is
where is the joint measurement space of the SN set , is the joint density of , denotes the error distance between and . In this paper, is measured by the 2nd-order LA metric in (9).
Nevertheless, cannot be used as the objective function of sensor selection optimization in (15) because is unknown before sensor selection. To solve this, we replace with its lower bound , which provides an online indication on the limit of MTT accuracy within the labeled RFS framework.
Treating as a default condition, (15) is finally rewritten as
4. Lower Bound For LA Metric Based MSE and Sub-Optimization For Sensor Selection
4.1. Derivation of LA Bound
In Section 4.1, Section 4.2, Section 4.3 and Appendix B, the superscript ‘’ for the index of LFC is omitted. For example, is abbreviated as .
In order to derive , it is assumed that
A1: Multi-target Bayesian recursion is a Mδ-GLMB RFS [22]. As a result, the predicted density and posterior density can be described as and .
A2: Although the optimal estimate of can be extracted from the fused density by using the joint or marginal multi-target estimator [9], both the methods are very difficult to be implemented. Alternatively, the target number is firstly estimated according to the maximum a posterior (MAP) criterion and then the individual states are estimated according to the unbiased criterion under the obtained target number. In fact, the suboptimal method is applied in almost all multi-target Bayesian filters.
Let be the collection of measurement sets from the SN set and be the space of , where is the number of measurements received by the SN . Let be the joint density over the space . According to Bayesian formula, is written as
where is a normalization factor,
where . (19) shows that is actually the probability , where and denotes . Substituting A1 and (12) into (19) as well as using Lemma 12 in [17], is obtained as
where denotes ,
Assume that if and if . Then, (21) can be rewritten as
where denotes the inner product corresponding to ,
denotes the probability that only the SN subset receives the measurement from state while the others miss the measurement.
(22) shows that is independent of the association mapping . From (14), (20) and (22), is finally obtained as
Since is permutation invariant over , its marginal density over any of is the same and is obtained by
Substituting (18) into (25) as well as using A1 and the identical equation , is written as
Substituting (12) into (26) and then simplifying the result, we get
where is the marginal density of over any of given the label set and association mapping ,
where denotes the remaining association mapping in except for .
MAP detection criterion determines () if and only if ,
where is the joint measurement subspace of the SN set where the target number is estimated as ; is a partition of ; is the posterior probability of given . From (6), is written as
where is the existing probability of the label set given . According to the update step of Mδ-GLMB [22], is obtained as
where we have from (29) and (33).
Let be the integral of over the space . From (18), can be written as
(34) shows that is actually the probability . Substituting A1 and (12) into (34) as well as using Lemma 12 in [17], is obtained as
where
Similar with , can be rewritten as
(38) shows that is independent of the association mapping . From (14), (35) and (38), is finally obtained as
Theorem 1: Given A1, A2 and the SN set , the lower bound for the 2nd-order LA metric based MSE of (16) is
where is the cut-off of the LA metric, is the dimension of , and are given in (24) and (39),
is actually the possible ratio of the number of common labels to the number of all distinct labels for the multi-target states and their estimates given (that is, ), is the FIM for a single-target state with the label given ,
where the integral region for measurement is given by (30), if , the integrand is
where is given in (27).
See Appendix B for proof of Theorem 1.
Remark 2.
The number of estimated targets is assumed to be unknown in the derivation of the proposed bound. Only the MAP rule, rather than the specific (or exact) number of estimated targets, is required to obtain the bound. The symbol used for calculating the bound in Theorem 1 is just an index for all possible (or unknown) number of estimated targets. This is similar with the symbols , , and in Theorem 1, which are just the indices for the labels, the number of common labels in true targets and their estimates, the number of true targets and the number of sensor measurements, respectively.
Furthermore, the reason for imposing the MAP rule has been explained in A2. (30) has also shown that the measurement space can be divided into according to the MAP rule. It is very helpful for the proof of Theorem 1.
Remark 3.
In general, the maximum number of targets and measurements can be presented by prior knowledge. Moreover, the label space , where and are the label spaces for the last time and new-born targets. In general, can also be preseted by prior knowledge. According to these presets, the sum of infinite terms in (40) becomes the sum of finite terms.
Remark 4.
Once the specific forms of , and are given, and in can be obtained from (27) and (28).
Remark 5.
| Algorithm 2. Steps for calculating and . |
| 1. Prediction sampling: Generate samples of multi-target state sets from the predicted density ; |
| 2. PIMS generating: For , generate PIMS of the SN set based on [31]; |
| 3. PIMS partitioning: Divide PIMS into the measurement subspace () according to (30); |
| 4. MC integration: Given the PIMS assigned to , and are obtained by applying MC integral formula [45] to (39) and (42). |
4.2. SMC and GM Implementations for the Bound
In order to derive the SMC implementation of the bound in Theorem 1, it is assumed that
A3: Each involved in the predicted Mδ-GLMB density is described by a set of weighted particles ,
Substituting (44) into (22), (28), (29), (33) and (38), , , , and are rewritten as
Finally, the SMC forms of , , and are respectively obtained by substituting (45)–(49) into (24), (27), (39) and (43), where and involved in are
In order to derive the GM implementation of the bound in Theorem 1, it is assumed that
A4: Each involved in the predicted Mδ-GLMB density is described by the GM form of
where denotes the Gaussian density with mean and covariance matrix , and are the weights and number of GM terms.
A5: The detection probability is independent of and the likelihood function is linear Gaussian,
where and are the observation function and covariance matrix for measurement noise.
From A5 and (23), we have
where
Substituting (53) into (22), is rewritten as
Similarly, substituting (51), (53) and (54) into (29), (33) and (38), , and are rewritten as
Finally, the GM forms of , , and are respectively obtained by substituting (56)–(61) into (24), (27), (39) and (43). Obviously, they no longer contain integrals of state and have analytic forms except for . Here and in are both linear functions of and , which can be obtained by the following formulas:
4.3. Sub-Optimization Based on Coordinate Descent
The computational cost of this method is composed of three parts: sensor selection, Mδ-GLMB filtering and weighted KLA fusion. The latter two have been analyzed in Reference [22,23]. This paper only studies the computational cost of sensor selection and its approximate algorithm. When the number of SNs is large, it has a much more significant effect on the total amount of computation than the last two.
As shown in (15) and (17), sensor selection is actually a constrained combinatorial optimization problem. To find the optimal solution by the exhaustive search method, the objective function needs to be repeatedly calculated for times. Obviously, its computational cost increases with the SN number in the form of combination explosion. In order to reduce the computational cost, some heuristic optimization algorithms, such as genetic algorithm [39] and so forth, is used to tackle this problem. However, the convergence speed of the heuristic algorithms will become rather show when the objective function is relatively complex. As a result, to further improve the computational speed, coordinate descent method [37] is proposed to find a sub-optimal solution of (17). Its computational cost increases with the SN number in an approximate polynomial form.
Set a binary switch variable , , for each SN. indicates while indicates . The vector is composed of the switch variables of all SNs belonging to the same LFC. Clearly, the set is completely determined by . Then, (17) is relaxed to an unconstrained optimization problem by the augmented objective function
where is a barrier factor, and are inequality and equality penalty terms.
Algorithm 3 presents the iteration steps for handling the relaxed problem by using the coordinate descent method.
| Algorithm 3. Coordinate descent method. |
| Step 1: Set initial iteration number , initial SN switch vector , initial barrier factor and its reduction coefficient ; |
| Step 2: From to , calculate , where are treated as constants; |
| Step 3: If , then go to Step 4; Otherwise, set , go to Step 2; |
| Step 4: If , then output as the solution of (17); Otherwise, set , , and then go to Step 2. |
In order to improve the probability to converge to the global optimum and accelerate the convergence speed for the coordinate descent method, the initial barrier factor and its reduction coefficient can be appropriately selected by the methods in Reference [48], the initial SN switch vector is set as , where is the outputted switch vector at the last time.
4.4. Weighted KLA Fusion
A1 indicates that the posterior density of each LFC is a Mδ-GLMB form of , . Then, for the LFC , given the LFC subset connected to it and the normalized nonnegative fusion weights (), its fused density obtained by the weighted KLA rule is still a Mδ-GLMB form of [23],
where the weight reflects the effect of local posterior density on the fusion of the LFC . The larger the weight is, the greater the impact it has on the KLA fusion.
The bound in Theorem 1 reflects the optimal MTT accuracy that is potentially achieved by a LFC after sensor selection. The larger the proposed bound of a LFC is, the worse the precision limit that it can achieve is. Therefore, the normalized weight in the KLA fusion of the LFC should be set inversely proportional to the proposed bound ,
which indicates that the larger the proposed bound of the LFC is, the smaller the proportion of its posterior density in the KLA fusion should be; and vice versa.
5. Simulations
The main goal of the simulations is to verify the following two points under different SNR conditions. First, our method conducts the sensor selection more effectively than the CS divergence based methods for the decentralized large-scale MTT network. This case is much more obvious when the sensors have different observation performance. Second, the coordinate descent method significantly shortens the calculation time of genetic algorithm at the expense of slight loss in tracking accuracy. To highlight these, the specific scenarios, including the multi-target dynamic model, sensor network architecture, observation model for SNs and so forth, are designed as follows.
Multiple targets move in a constant velocity (CV) model [49] over a two-dimensional region and the number of targets is unknown and changes over time. The label of state is noted as , where is the birth time and is the index to distinguish the birth targets at the same time. The unlabeled state is noted as , where and are the positions and velocities in the X and Y directions. The single-target transition density is in the Gaussian form of
where and are the transition matrix and process noise covariance matrix for unlabeled state,
where is the sampling interval, is the process noise standard deviation. In this example, , and survival probability .
The target birth is modeled as an LMB RFS with density , where and are the existing probability and density of the new-birth target with label ,
where in this example, , and ~ are , , , , , , , , , , , in turn, where the units of position and speed are and .
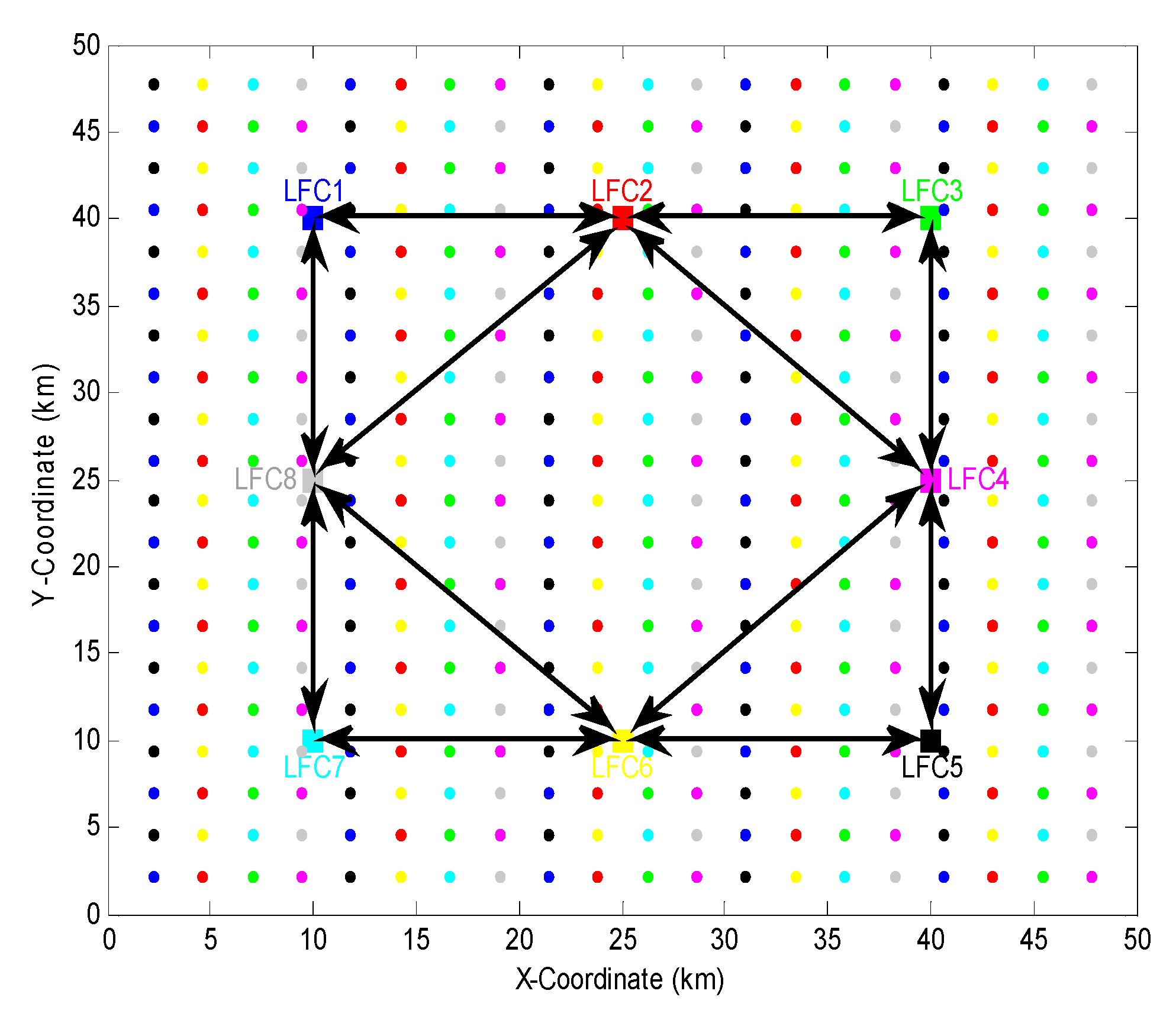
The decentralized sensor network is composed of LFCs, which are noted as LFC1~LFC8. The positions (unit: ) of the LFCs are , , , , , , , in turn. Each LFC has subordinate SNs (). So there are in total SNs in the entire network. Each LFC can communicate with other LFCs within 25 apart away from it. Finally, the directed connection set for the LFCs and the locations for all SNs are shown in Figure 2.
The clutter is a uniformly distributed Poisson RFS over the region . In this example, the clutter rate and detection probability of each SN are firstly set as and , .
To embody the performance variation of sensor observation, the network is assumed to consist of different types of SNs with distinctive observation function and noise covariance. The single-target likelihoods of the SNs are all Gaussian distributed as shown in (63). Each SN of LFC1 and LFC5 receives the distance and angle measurements of target, so its observation function is
where is the known position of the SN , is the distance between the SN and target. The measurement noise covariance matrix is also modeled as a nonlinear function of state ,
Each SN of LFC2 and LFC6 only receives the distance measurement of target. Its and are
Each SN of LFC3 and LFC7 only receives the angle measurement of target. Its and are
Each SN of LFC4 and LFC8 receives distance and Doppler measurements of target. Its and are
In this example, there are three constraints for the sensor selection optimization of (17), which are
C1: Due to the limitations of communication bandwidth, energy consumption, computation capacity and storage space, the LFC can only select SNs at each scan (),
In this example, if , then ; otherwise .
C2: The field of view (FoV) of the SN is modeled as a circular area with the center and radius , , . The FoVs of different SNs can be overlapped. To ensure that the FoVs of the SN set can totally cover the region , it is required that
In this example, if , then ; otherwise .
C3: To avoid mutual interference between the homogeneous SNs belonging to the same LFC, the distance between any two SNs in must be not smaller than the threshold ,
In this example, for .
According to the objective function and calculation method used for sensor selection, our algorithm is abbreviated as LA bound with coordinate descent. It is firstly implemented by the SMC technique and coded by MATLAB R2018a. Each involved in the Mδ-GLMB density is approximated by 500 particles on average. In this example, the maximum numbers of targets and measurements of each SN per scan are set as 25 and 200, the cut-off is set as . The algorithm is testing on a desktop with the CPU of AMD Ryzen 7 2700X and 64 GB RAM. We conduct 500 MC simulations, each of which includes scans (a total of 250 s). In these simulations, the target tracks (including the instants of birth and death), clutter and measurements originating from targets are generated independently according to the aforementioned models.
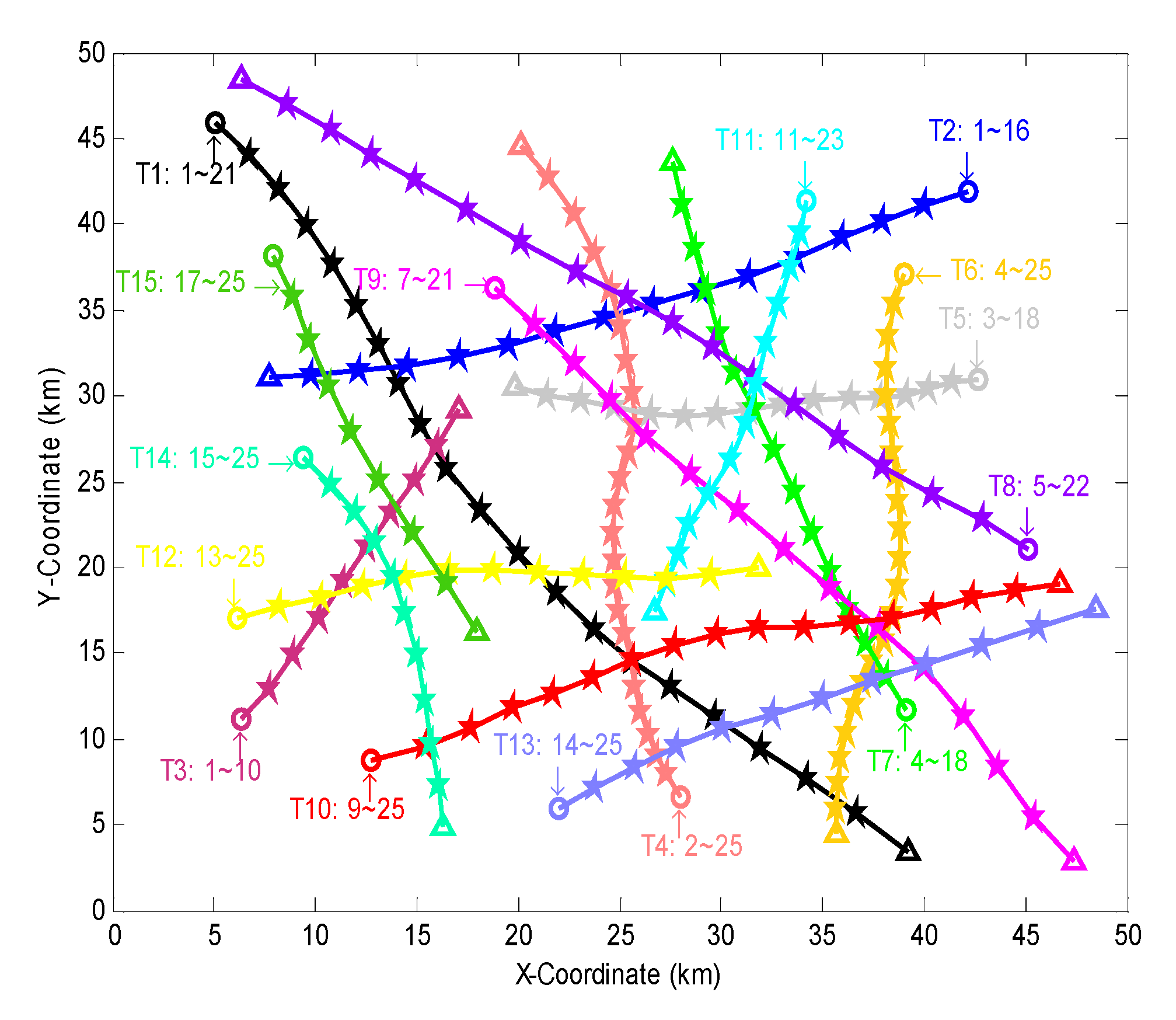
We firstly present the result of sensor selection obtained by the algorithm in one simulation. Figure 3 shows the target trajectories in the simulation, where a total of 15 targets are generated at different instants and locations. For easy description, the targets are named as T1~T15 in turn. The name and survival period of each target are marked at the start point of the target. During the surveillance period, the number of targets at the initial time is the least (3 targets). The number of targets at the 15th~18th scans is the most (13 targets). The target T1 intersects with the target T10 at the 15th scan.
Figure 4a~f show the results of sensor selection at the 1st, 5th, 10th, 15th, 20th and 25th scans. It can be seen that the SNs selected by each LFC will change adaptively with the multi-target movement versus time. Specifically, in order to minimize the bound in Theorem 1, most of the selected SNs locate in the regions closer to the survival targets at each scan. A few SNs which are far from the survival targets are selected to satisfy Constraint C2. Moreover, due to Constraint C3, the homogeneous SNs of each LFC cannot be excessively concentrated in a small region.
In order to further verify the performance of this method in tracking accuracy and computational time, it is compared with the methods of LA bound with genetic algorithm, CS divergence with genetic algorithm and Random selection under the same test platform. In the genetic algorithm, the population size is 50, crossing rate is 0.9, mutation rate is 0.001, elite rate is 0.04 and the maximum number of iterations is 500. In the CS divergence method, the objective function of the LFC is
where denotes the CS divergence between the densities and . [31] presents the specific form of the CS divergence when and are both GLMB densities. Since the posterior density is unknown before sensor selection, the expected value rather than real value of the CS divergence is applied in (82). In order to calculate the expected value, the MC integration based on PIMS also needs to be used here.
For comparison, both the OSPA and LA metrics are used to measure the error of multi-target position estimates.
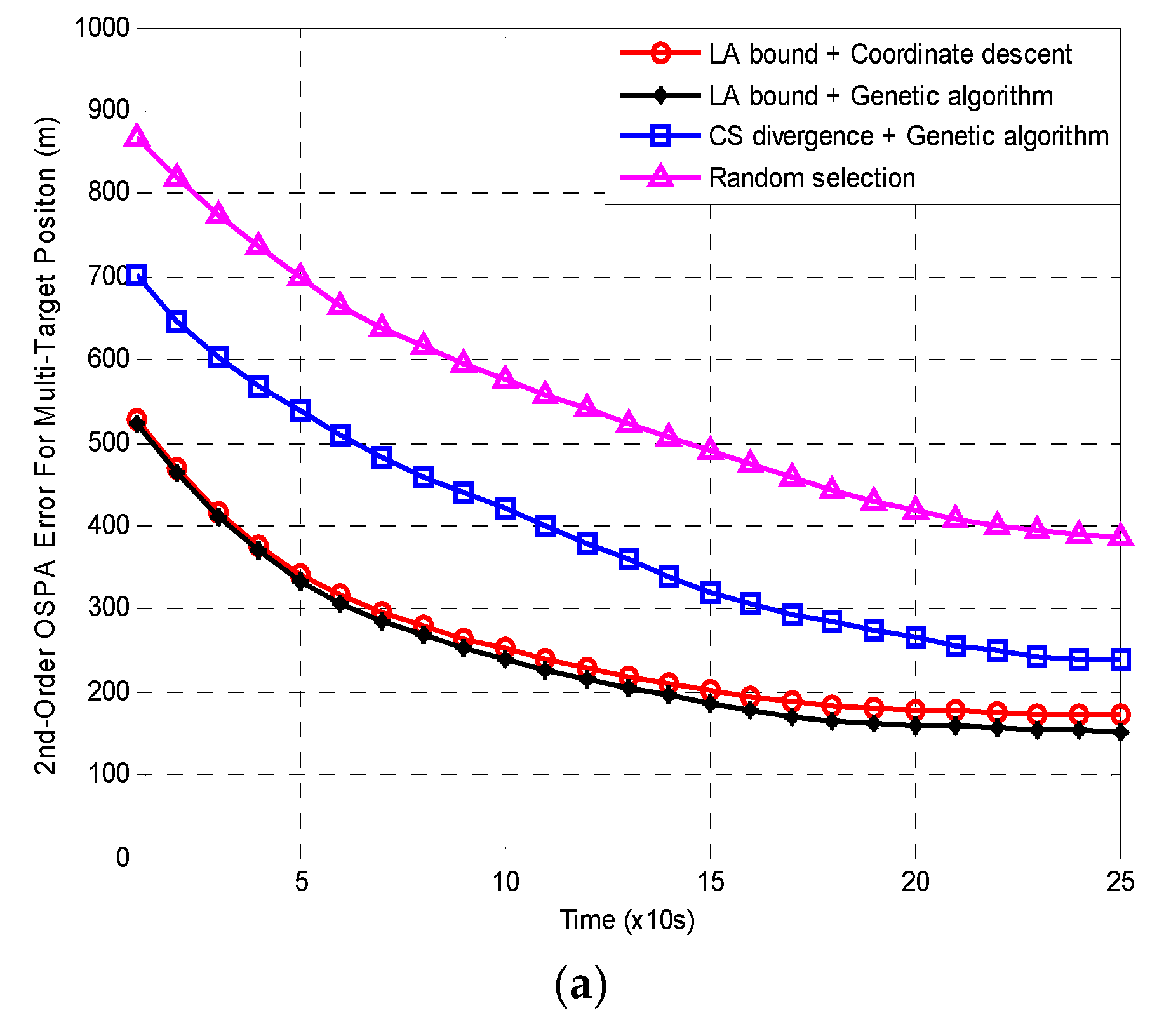
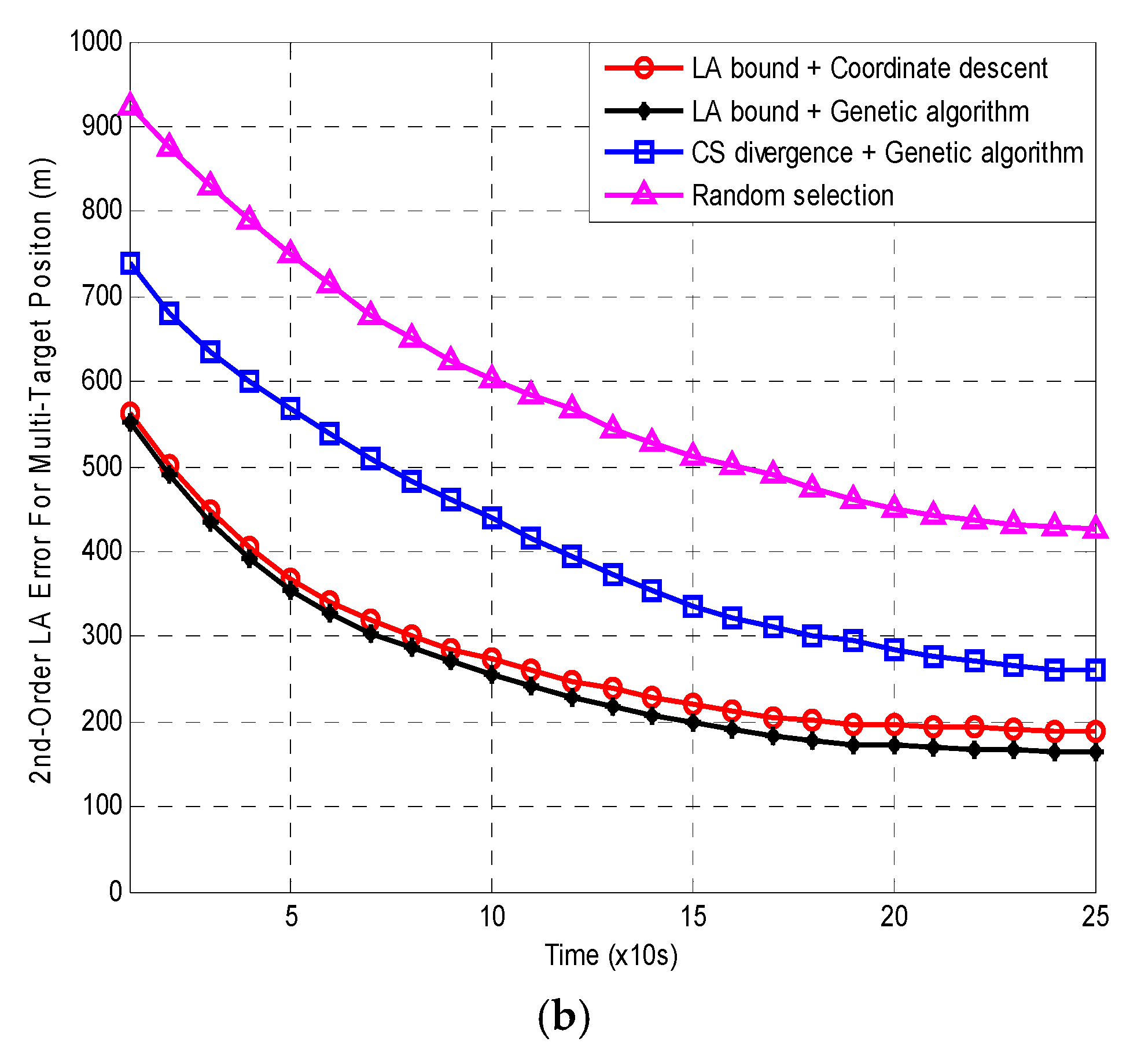
Figure 5a,b present the 500 MC averages of the OSPA and LA errors for the four methods. Note that the error here is selected as the average of all LFCs because of Remark 1.
Figure 5 shows that both the averaged OSPA and LA errors from all the four methods decrease with time. Furthermore, the LA errors are always larger than the relevant OSPA errors. The reason for this has been explained in Section 2.3. In both of Figure 5a,b, the errors from Random selection are always the largest. The next is the errors from CS divergence with genetic algorithm. The errors from LA bound with genetic algorithm are always the smallest. The errors from LA bound with coordinate descent are slightly larger than those of LA bound with genetic algorithm. Compared with Random selection, the errors of the other three algorithms are approximately reduced by 40%, 60% and 55%, respectively. Obviously, the two LA bound based methods outperform the CS divergence based method in MTT accuracy. There are three reasons for this:
1) The LA bound has a clearer physical meaning than the CS divergence. This is because that the former indicates the achievable optimal MTT accuracy with labeled RFS state. In contrast, the latter is not directly related to the MTT accuracy since maximizing the CS divergence in (82) cannot guarantee to minimize the OSPA or LA error.
2) The CS divergence cannot provide a basis for setting the weights of KLA rule as the LA bound. Therefore, in the CS divergence based method, the KLA weights can only be set to the same by convention [32]. However, in this example the MTT accuracy of different LFCs is probably not the same because of the distinguishing observation performance of the diverse SNs. If the KLA weights are set to the same without discrimination, the fusion efficiency will decline dramatically in this case.
3) In the step of sensor selection optimization, the coordinate descent method may trap in one of local optimums. In contrast, the genetic algorithm may jump out of local optimums with certain probability by its randomness. This leads that the MTT accuracy of the former is a litter worse than the latter.
On the other hand, the computational cost of a method is in general measured by its CPU run time. Then, the averaged CPU run time per scan for LA bound with coordinate descent, LA bound with genetic algorithm and CS divergence with genetic algorithm are 0.62s, 6.18s and 5.69s, respectively. Note that the run time here is also selected as the average of all LFCs because of Remark 1. Random selection obviously does not need the optimization for sensor selection, so it has no time consumption of this step. It can be seen from this that although the coordinate descent method is slightly worse than the genetic algorithm in tracking accuracy, it significantly shortens the calculation time of sensor selection optimization. In addition, the time consumption of CS divergence with genetic algorithm is slightly less than that of LA bound with genetic algorithm. This case indicates that the computational cost of the proposed bound is a little larger than that of the CS divergence expectation in (82).
In order to show the influence of different SNR on our method, the clutter rate and detection probability of each SN are changed into , , and . Table 1 and Table 2 present the final values of the OSPA and LA errors for the four methods in each scenario after 500 MC run average.
Moreover, the CPU times consumed by the sensor selection optimization for the first three methods are nearly the same for all the SNR scenarios. This is because that the sensor selection is irrelevant to the specific measurement realizations since it must be completed before the measurements are received.
It can be seen from Algorithm 1 and 2 that as clutter density increases and detection probability decreases,
1) The OSPA and LA errors of all the four methods increase in different degrees but the size order of them is always the same as that of Scenario 1;
2) Taking the error of Random selection as the benchmark, the improvement ratio of CS divergence with genetic algorithm is gradually reduced from about 40% to about 20%. Meanwhile, the improvement ratios of the two LA bound based methods are, respectively, maintained at about 60% and 55%.
The two points reflect that the lower the SNR is, the worse the sensor selection efficiency and tracking accuracy of the CS divergence based methods become. By contrast, the tracking accuracy of the LA bound based methods always maintains a good improvement ratio for all the SNR scenarios.
Assuming that the simulation scenarios remain unchanged, the above four methods are re-implemented by the GM technique where the non-linear likelihood of each SN is approximated by the EK filter,
The pruning and merging technology [11] are used to manage the GM terms. Let the number of the GM terms approximating to each be no more than 30. The thresholds for merging, pruning and state extraction are set to 4, and 0.5, respectively. The simulation results of the GM implementation are basically consistent with those of the SMC implementation, except that the OSPA or LA error increases by about 8%. But the calculation time for sensor selection decreases by about 70%.
6. Conclusions and Future Work
A sensor selection optimization algorithm is proposed for the decentralized large-scale MTT network under the labeled RFS framework. The LA metric defined in this paper is used to measure the error between the labeled multi-target states and their estimates. The lower bound of the LA metric based MSE is taken as the cost function of sensor selection. The bound is derived by the information inequality and then, implemented by the SMC or GM technique. Then, the coordinate descent method is used to reduce the computational cost of sensor selection. Simulation results show that when the sensors of the decentralized network have different observation performance, our method outperforms the CS divergence based sensor selection algorithm in MTT accuracy.
Our future work will focus on the following two aspects:
1) Extend the proposed method to the cases of asynchronous measurement or correlated measurement noise;
2) Reference [50] has presented a very efficient implementation of the GLMB filter with linear complexity in the number of measurements and this filter has been demonstrated to handle over 1 million tracks simultaneously [51]. Therefore, it would be very helpful to improve our current study by the use of the methods proposed in Reference [50,51].
Author Contributions
Conceptualization, F.L.; Methodology, F.L.; Software, L.H.; Validation, F.L., L.H., B.W. and C.H.; Formal Analysis, B.W.; Investigation, C.H.; Resources, B.W.; Data Curation, F.L.; Writing-Original Draft Preparation, F.L.; Writing-Review & Editing, L.H.; Visualization, B.W.; Supervision, C.H.; Project Administration, F.L.; Funding Acquisition, F.L.
Funding
This research was supported by the National Natural Science Foundation of China (61473217) and the National Key Fundamental Research & Development Programs (973) of China (2013CB329405).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A.
Proof thatis a metric
A mapping is called a metric if it obeys the following three properties
1) Identity:if and only if;
2) Symmetry:for all;
3) Triangle inequality:for all.
It can be obtained easily from the definition of in (9) that and obeys the properties of identity and symmetry. Next, we will prove the triangle inequality
Let and denote the individual elements and label sets of , respectively. We firstly set
where and satisfy
for all and all .
Based on the setting of (A2)–(A5), the definition of in (9) is rewritten as
We will prove that the triangle inequality of (A1) holds for all six possible ranks of , and .
Case 1 (): Since the cut-off distance for all and , (A6) can be amplified to
where the last line holds because obeys the triangle inequality.
Applying Minkowski’s inequality to (A7), we get
Similar with the derivation of the first line in (A7), the second term on the right-hand side of ‘=’ in (A8) can be amplified to
because of and .
Finally, the triangle inequality of (A1) for Case 1 is obtained by substituting (A9) into (A8).
Case 2 ():
The proof of Case 2 is similar with that of Case 1 except that its first amplification is completed by using and its last amplification is completed by using .
Case 3 ():
Using the triangle inequality of , (A6) can be amplified to
where the last line is derived from Minkowski’s inequality.
Because of , (A10) can be amplified to
Then, based on the setting of (A2)–(A5), we have
Substituting (A12) into (A11), (A11) can be amplified to
which is just the triangle inequality of (A1) for Case 3.
Case 4 ():
The proof of Case 4 is exactly the same as that of Case 3.
Case 5 ():
First, (A10) still holds for Case 5 depending on the triangle inequality of and Minkowski’s inequality.
Since for all and , we have
From , we have
where the second line is obtained due to (A12).
Substituting (A14) and (A15) into (A10), we finally obtain the triangle inequality of (A1) for Case 5.
Case 6 ():
The proof of Case 6 is similar with that of Case 5, except that (A14) is derived from and (A12) while (A15) is derived from and .
Above all, the proof that in (9) is a metric has been completed. □
Appendix B.
Proof of Theorem 1
From (4) and (18), in (16) is written as
where and are defined in (18) and (19), is finally obtained as (24).
Dividing the integral region of (A16) into according to (30), is rewritten as
where the error is measured by the 2nd-order LA metric defined in (9). Substituting into (A17) and then using the identical equation , we get
where are the labels of . It is obvious that .
Let . . Given and , there are possible choices from for the elements of . Then, (A18) can be rewritten as
where is defined in (34) and finally obtained as (39), denotes the residual label sequence of after the label is separately excluded from .
Note that the estimate involved in (A19) is independent of . So, the integral term in the last line of (A19) is obtained as
where the last line is obtained according to the marginal density of (25) and the definition of 2-norm, L is the dimension of , denotes the residual integral of after the term is separately excluded from .
Since A2 has shown that the estimator is unbiased, the information inequality of (7) can be applied to (A20),
where the FIM is shown in (42). (A21) holds with equality if and only if satisfies the distribution of exponential family.
Substituting (A21) into (A20) and then (A19), we get
where the second line is derived from the fact that the FIM is the same for all given .
Finally, (40) can be obtained by substituting the notation defined in (41) into (A22). □.
References
- Blackman, S.; Popoli, R. Design and Analysis of Modern Tracking Systems; Artech House: Norwood, MA, USA, 1999. [Google Scholar]
- Hero, A.O.; Castanón, D.A.; Cochran, D.; Kastella, K. Foundations and Applications of Sensor Management; Springler: New York, NY, USA, 2008. [Google Scholar]
- Tharmarasa, R.; Kirubarajan, T.; Hernandez, M.L.; Sinha, A. PCRLB-based multisensor array management for multitarget tracking. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 539–555. [Google Scholar] [CrossRef]
- Tharmarasa, R.; Kirubarajan, T.; Sinha, A.; Lang, T. Decentralized sensor selection for large-scale multisensor-multitarget tracking. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1307–1324. [Google Scholar] [CrossRef]
- Fu, Y.; Ling, Q.; Tian, Z. Distributed sensor allocation for multi-target tracking in wireless sensor networks. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3538–3553. [Google Scholar] [CrossRef]
- Mohammadi, A.; Asif, A. Decentralized computation of the conditional posterior Cramér-Rao lower bound: Application to adaptive sensor selection. In Proceedings of the 38th IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Herath, S.C.K.; Pathirana, P.N. Optimal sensor arrangements in angle of arrival (AoA) and range based localization with linear sensor arrays. Sensors 2013, 13, 12277–12294. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Shen, X.; Wang, P.; Zhu, Y. The Cramér-Rao bounds and sensor selection for nonlinear systems with uncertain observations. Sensors 2018, 18, 1103. [Google Scholar] [CrossRef] [PubMed]
- Mahler, R. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2014. [Google Scholar]
- Vo, B.N.; Singh, S.; Doucet, A. Sequential Monte Carlo methods for multi-target filtering with random finite sets. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1224–1245. [Google Scholar]
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Zhang, Q.; Song, T.L. Improved bearings-only multi-target tracking with GM-PHD filtering. Sensors 2016, 16, 1469. [Google Scholar] [CrossRef] [PubMed]
- Vo, B.T.; Vo, B.N.; Cantoni, A. Analytic implementations of the cardinalized probability hypothesis density filter. IEEE Trans. Signal Process. 2007, 55, 3553–3567. [Google Scholar] [CrossRef]
- Si, W.; Wang, L.; Qu, Z. Multi-target tracking using an improved Gaussian mixture CPHD filter. Sensors 2016, 16, 1964. [Google Scholar] [CrossRef] [PubMed]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- He, X.; Liu, G. Cardinality balanced multi-target multi-Bernoulli filter with error compensation. Sensors 2016, 16, 1399. [Google Scholar] [CrossRef] [PubMed]
- Vo, B.T.; Vo, B.N. Labeled random finite sets and multi-object conjugate priors. IEEE Trans. Signal Process. 2013, 61, 3460–3475. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled random finite sets and the Bayes multi-target tracking filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef]
- Liu, C.; Sun, J.; Lei, P.; Qi, Y. δ-generalized labeled multi-Bernoulli filter using amplitude information of neighboring cells. Sensors 2018, 18, 1153. [Google Scholar]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Papi, F.; Vo, B.N.; Vo, B.T.; Fantacci, C.; Beard, M. Generalized labeled multi-Bernoulli approximation of multi-object densities. IEEE Trans. Signal Process. 2015, 63, 5487–5497. [Google Scholar] [CrossRef]
- Fantacci, C.; Papi, F. Scalable multisensor multitarget tracking using the marginalized δ-GLMB density. IEEE Signal Process Lett. 2016, 23, 863–867. [Google Scholar] [CrossRef]
- Fantacci, C.; Vo, B.N.; Vo, B.T.; Battistelli, G.; Chisci, L. Robust fusion for multisensor multiobject tracking. IEEE Signal Process Lett. 2018, 25, 640–644. [Google Scholar] [CrossRef]
- Williams, J.L. Marginal multi-Bernoulli filters: RFS derivation of MHT, JIPDA and association-based MeMBer. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1664–1687. [Google Scholar] [CrossRef]
- García-Fernández Á, F.; Williams, J.L.; Granström, K.; Svensson, L. Poisson multi-Bernoulli mixture filter: Direct derivation and implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef]
- Granström, K.; Svensson, L.; Xia, Y.; Williams, J.; García-Femández Á, F. Poisson multi-Bernoulli mixture trackers: Continuity through random finite sets of trajectories. In Proceedings of the 21st International Conference on Information Fusion, Cambridge, UK, 10–13 July 2018. [Google Scholar]
- Ristic, B.; Vo, B.N. Sensor control for multi-object state-space estimation using random finite sets. Automatica 2010, 46, 1812–1818. [Google Scholar] [CrossRef]
- Ristic, B.; Vo, B.N.; Clark, D. A note on the reward function for PHD filters with sensor control. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1521–1529. [Google Scholar] [CrossRef]
- Hoang, H.G.; Vo, B.T. Sensor management for multi-target tracking via multi-Bernoulli filtering. Automatica 2014, 50, 1135–1142. [Google Scholar] [CrossRef] [Green Version]
- Gostar, A.K.; Hoseinnezhad, R.; Bab-Hadiashar, A. Multi-Bernoulli sensor control via minimization of expected estimation errors. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1762–1773. [Google Scholar] [CrossRef]
- Beard, M.; Vo, B.T.; Vo, B.N.; Arulampalam, S. Sensor control for multi-target tracking using Cauchy-Schwarz divergence. In Proceedings of the 18th International Conference on Information Fusion, Washington, DC, USA, 6–9 July 2015. [Google Scholar]
- Jiang, M.; Yi, W.; Kong, L. Multi-sensor control for multi-target tracking using Cauchy-Schwarz divergence. In Proceedings of the 19th International Conference on Information Fusion, Heidelberg, Germany, 5–8 July 2016. [Google Scholar]
- Gostar, A.K.; Hoseinnezhad, R.; Rathnayake, T.; Wang, X.; Bab-Hadiashar, A. Constrained sensor control for labeled multi-Bernoulli filter using Cauchy-Schwarz divergence. IEEE Signal Process Lett. 2017, 24, 1313–1317. [Google Scholar] [CrossRef]
- Wang, X.; Hoseinnezhad, R.; Gostar, A.K.; Rathnayake, T.; Xu, B.; Bab-Hadiashar, A. Multi-sensor control for multi-object Bayes filters. Signal Process. 2018, 14, 260–270. [Google Scholar] [CrossRef]
- Rezaeian, M.; Vo, B.N. Error bounds for joint detection and estimation of a single object with random finite set observation. IEEE Trans. Signal Process. 2010, 58, 1493–1506. [Google Scholar] [CrossRef]
- Arulampalam, S.; Maskell, S.; Gordon, N.J.; Clapp, T. A tutorial on particle filters for on-line non-linear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Wright, S.J. Coordinate descent algorithms. Math. Program. 2015, 151, 3–34. [Google Scholar] [CrossRef] [Green Version]
- Hristakeva, M.; Shrestha, D. Solving the 0-1 knapsack problem with genetic algorithms. In Proceedings of the 37th Midwest Instruction and Computing Symposium, Morris, MN, USA, 16–17 April 2004. [Google Scholar]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Ristic, B.; Vo, B.N.; Clark, D.; Vo, B.T. A metric for performance evaluation of multi-target tracking algorithms. IEEE Trans. Signal Process. 2011, 59, 3452–3457. [Google Scholar] [CrossRef]
- Rahmathullah, A.S.; Garcia-Fernandez, A.F.; Svensson, L. Generalized optimal sub-pattern assignment metric. In Proceedings of the 20th International Conference on Information Fusion, Xi’an, China, 10–13 July 2017. [Google Scholar]
- Zhou, B.; Bose, N.K. Multitarget tracking in clutter: Fast algorithms for data association. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 352–363. [Google Scholar] [CrossRef]
- Battistelli, G.; Chisci, L.; Fantacci, C.; Farina, A.; Graziano, A. Consensus CPHD filter for distributed multitarget tracking. IEEE J. Sel. Top. Sign. Proces. 2013, 7, 508–520. [Google Scholar] [CrossRef]
- Battistelli, G.; Chisci, L. Kullback-Leibler average, consensus on probability densities and distributed state estimation with guaranteed stability. Automatica 2014, 50, 707–718. [Google Scholar] [CrossRef]
- Davis, P.J.; Rabinowitz, P.; Rheinbolt, W. Methods of Numerical Integration, 2nd Ed. ed; Mineola; Dover Publications: New York, NY, USA, 2007. [Google Scholar]
- Anderson, B.D.; Moore, J.B. Optimal Filtering; Prentice-Hall: Englewood Cliffs, NJ, USA, 1979. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming, 4th Ed. ed; Springer: New Yeak, NY, USA, 2015. [Google Scholar]
- Li, X.R.; Jilkov, V.P. Survey of maneuvering target tracking, part V: Multiple-model methods. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1255–1321. [Google Scholar]
- Vo, B.N.; Vo, B.T.; Hoang, H.G. An efficient implementation of the generalized labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2017, 65, 1975–1987. [Google Scholar] [CrossRef]
- Beard, M.; Vo, B.T.; Vo, B.N. A solution for large-scale multi-object tracking. arXiv. 2018. Available online: https://arxiv.org/abs/1804.06622 (accessed on 22 November 2018).
Figure 1.
Diagram for decentralized sensor network. ○ and ■ denote SN and LFC, solid lines with arrows denote directed connections between LFCs, the dotted lines denote connections between LFC and its subordinate SNs.
Figure 1.
Diagram for decentralized sensor network. ○ and ■ denote SN and LFC, solid lines with arrows denote directed connections between LFCs, the dotted lines denote connections between LFC and its subordinate SNs.

Figure 2.
Locations of LFCs and SNs in the decentralized sensor network. ■ denotes LFC, ● denotes SN, different colors correspond to different LFCs and their subordinate SNs. Solid line with directed arrow indicates a communication connection between two LFCs. Each SN is 2.4 km apart away from other one.
Figure 2.
Locations of LFCs and SNs in the decentralized sensor network. ■ denotes LFC, ● denotes SN, different colors correspond to different LFCs and their subordinate SNs. Solid line with directed arrow indicates a communication connection between two LFCs. Each SN is 2.4 km apart away from other one.

Figure 3.
Target trajectories in a simulation. ○, △ and ★ are the start point, end point and rest positions of a target, the solid line is the track of a target, different colors correspond to different targets.
Figure 3.
Target trajectories in a simulation. ○, △ and ★ are the start point, end point and rest positions of a target, the solid line is the track of a target, different colors correspond to different targets.

Figure 4.
Sensor selection using LA bound with coordinate descend at (a) the 1st scan; (b) the 5th scan; (c) the 10th scan; (d) the 15th scan; (e) the 20th scan; (f) the 25th scan. ★ and ☉ denote the targets and selected SNs, different colors correspond to different targets and SNs of different LFCs.
Figure 4.
Sensor selection using LA bound with coordinate descend at (a) the 1st scan; (b) the 5th scan; (c) the 10th scan; (d) the 15th scan; (e) the 20th scan; (f) the 25th scan. ★ and ☉ denote the targets and selected SNs, different colors correspond to different targets and SNs of different LFCs.



Figure 5.
500 MC averages of (a) OSPA and (b) LA errors versus time with .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Final value of OSPA error (Unit: m).
| Clutter rate and Detection Probability | ||||||
|---|---|---|---|---|---|---|
| Sensor Selection Method | ||||||
| LA bound with coordinate descent | 171.3 | 193.0 | 218.9 | 249.1 | 283.7 | |
| LA bound with genetic algorithm | 151.9 | 170.8 | 193.6 | 220.5 | 251.6 | |
| CS divergence with genetic algorithm | 238.6 | 278.5 | 333.7 | 405.3 | 494.4 | |
| Random selection | 386.7 | 436.0 | 490.5 | 550.1 | 615.2 | |
Table 2.
Final value of LA error (Unit: m).
| Clutter rate and Detection Probability | ||||||
|---|---|---|---|---|---|---|
| Sensor Selection Method | ||||||
| LA bound with coordinate descent | 188.8 | 223.9 | 255.0 | 288.6 | 323.9 | |
| LA bound with genetic algorithm | 165.7 | 199.6 | 229.5 | 262.9 | 292.3 | |
| CS divergence with genetic algorithm | 260.1 | 321.2 | 383.9 | 463.9 | 562.8 | |
| Random selection | 426.7 | 500.5 | 564.3 | 634.2 | 710.9 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lian, F.; Hou, L.; Wei, B.; Han, C. Sensor Selection for Decentralized Large-Scale Multi-Target Tracking Network. Sensors 2018, 18, 4115. https://doi.org/10.3390/s18124115
AMA Style
Lian F, Hou L, Wei B, Han C. Sensor Selection for Decentralized Large-Scale Multi-Target Tracking Network. Sensors. 2018; 18(12):4115. https://doi.org/10.3390/s18124115
Chicago/Turabian StyleLian, Feng, Liming Hou, Bo Wei, and Chongzhao Han. 2018. "Sensor Selection for Decentralized Large-Scale Multi-Target Tracking Network" Sensors 18, no. 12: 4115. https://doi.org/10.3390/s18124115
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.