3.4. Ontology-Driven Event Recognition
The proposed framework extends the declarative constraint-based ontology proposed by [
7] with knowledge about activities of daily living, scene information and domain physical objects. The video event ontology language (
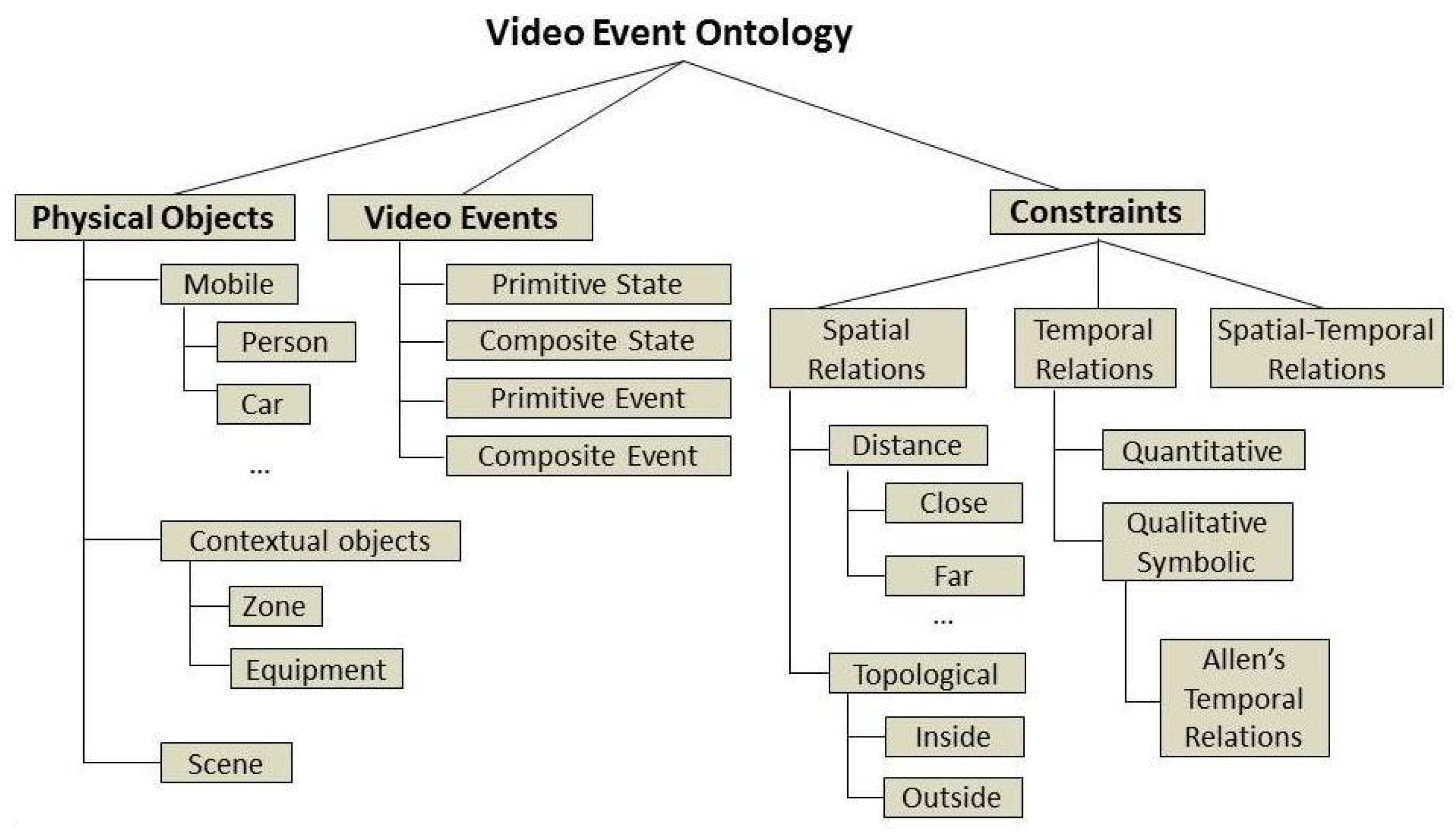
Figure 2) employs three main conceptual branches: physical objects, events and constraints. The first branch, physical objects, consists in the formalization—at conceptual level—of the observations of the vision pipeline, i.e., the people and objects in the scene. The remaining two branches—video events and constraints—provide the basis for event modeling, i.e., the types of event models and the possible relations between physical objects and sub-events (namely components) that characterize a composite activity (or event).
Event models are defined by the triplet: physical objects, components (sub-events) and constraints; as described by Equation (
1).
where,
: event model j,
: set of physical object abstractions involved in model j, with ,
: set of components in model j, with ,
: set of constraints in model j, with .
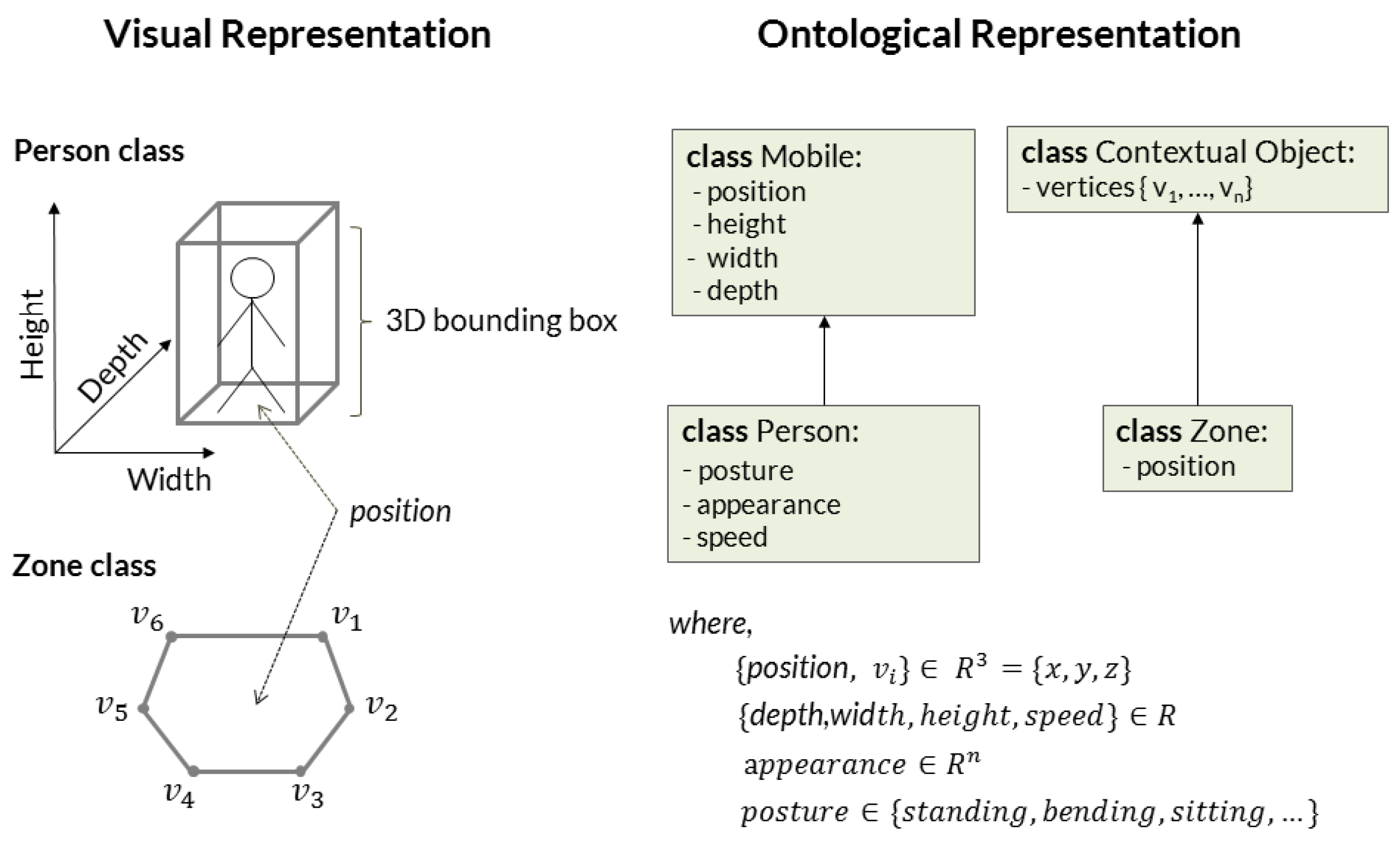
Physical object classes refer to abstractions of real-world objects that take part in the realization of target events (
Figure 3). The possible types of physical objects depend on the domain for which the event modeling task is applied for. For assisted living settings, this paper defines five types of objects (
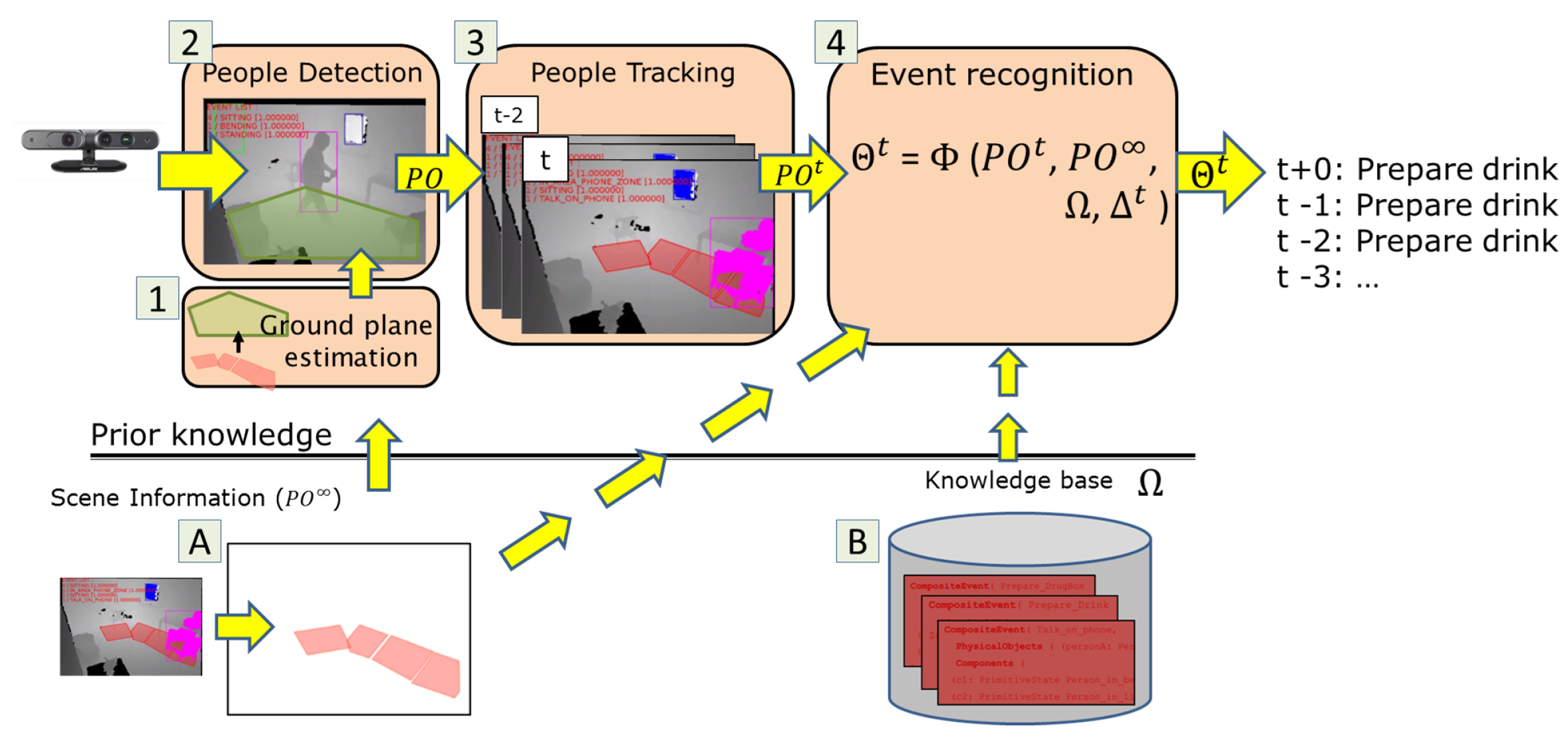
Figure 1): mobile, person, contextual zone, contextual equipment and scene. Mobile is a generic class that contains the basic set of attributes for any moving object detected in the scene (e.g., 3D position, width, height, length). It is represented as a 3D bounding box. Person is an extension of Mobile class whose attributes are “body posture”, “speed” and “appearance signature”. Scene class describes attributes of the monitored scene, like the number of people in the scene. Instances of mobile and person classes are provided to event recognition step by the underlying vision modules (
Figure 1, steps 2 and 3). Physical object’s instances are indexed by their time of detection
t and an instance identifier
i, i.e.,
.
Contextual object class corresponds to a 3D polygon of
n-vertexes that describe a piece of semantic information about the scene. Zones and equipment extend contextual object class and refer to knowledge about the scene (e.g., kitchen and couch zones or TV and table furniture, etc.). They may be obtained automatically by algorithms for scene discovery or be provided based on human knowledge. For instance, with the help of a software, one can easily define a 3D decomposition of the scene floor plane into a set of semantic regions, i.e., spatial zones (e.g., “TV”, “armchair”, “desk”, “coffee machine”). In the context of this work, semantic zones are provided as prior knowledge about the scene (
) and their attributes are constant over time (non-temporal observations), since most semantic information about the target scenes refer to non-moving objects (e.g., furniture).
Figure 2 demonstrates how the proposed framework integrates 3D information about the scene (prior and dynamic) as instances of physical objects.
Components are sub-events which describe pieces of semantic information relevant for the modeled event. They are used to describe knowledge that is shared by hierarchically higher event models. Constraints are used to define conditions about attributes of physical objects or between sub-events (components) of an event model. They are categorized into temporal and non-temporal constraints. Non-temporal constraints refer to conditions that do not directly depend on time, like spatial relations (e.g., in, close, out) and posture values (e.g., sitting, standing and bending). Temporal constraints refer to relations between the time intervals of an event model’s components. (e.g., BEFORE, MEET and EQUAL) [
23] or about their duration.
Event models describe the relevant relations between the elements of the event triplet (physical objects, components and constraints). The ontology language provides model templates to support domain experts at modeling the hierarchical and temporal relations among events. Templates are categorized as follows (in ascending order of complexity):
Primitive State models the value of a attribute of a physical object (e.g., person posture, or person inside a semantic zone) constant over a time interval.
Composite State refers to a composition of two or more primitive states.
Primitive Event models a change in the value of a physical object’s attribute (e.g., person changes from sitting to standing posture).
Composite Event refers to a composition of two events of any type and it generally defines a temporal constraint about the time ordering between event components (sub-events).
Model 1 presents an example of composite event describing a temporal relation. The event model, “bed exit”, is composed of three physical objects (a person and two semantics zones) and two components. The components of the event, and , are, model respectively, “the person position lying on the bed” and “the person being outside of the bed” (). The abstraction corresponds to a person’s instance dynamically detected by the underlying vision module. Contextual zones and are abstraction for the semantic zones “bed” and “side of the bed”, which were a priori defined in the 3D coordinate system of the scene. The first constraint () defines that the time interval of component must start before the time interval of the component and both time intervals must briefly overlap. relation, for instance, also expects the first interval to start before the second one, but different from , it expects a time gap between them. The second constraint defines a lower bound to the duration of the sub-event , 3 s. Parameter values, such as minimum duration of an event model instance, are computed based on event annotations provided by domain experts.
Model 1. Composite Event bed exit.
CompositeEvent(BED_EXIT,
PhysicalObjects((p1:Person),(zB:Zone),(zSB:Zone))
Components(
(s1: PrimitiveState in_zone_bed (p1,zB))
(s2: PrimitiveState out_of_bed (p1,zSB)))
Constraints((s1 meet s2) // c1
(duration(s2) > 1)) //c2
Alarm ((Level : URGENT))
)
Event inference (or recognition) is performed per frame
t of a stored video sequence (or on the basis of a continuous video stream) using a sliding time window fashion. The inference step uses the temporal algorithm proposed by [
7] for event recognition. For each time step
t, the inference algorithm
takes as input the instances of physical objects present at
t (
), prior knowledge about the scene (
, event history (
) and the knowledge base to evaluate (
). The inference algorithm starts by evaluating the satisfaction of primitive states, since their constraints are only defined over instances of physical objects in the current frame (
). On
, it evaluates primitive and composite events that define constraints over instances of primitive states. On
, it evaluates the recognition of event models that define constraints over instances of events in lower levels of model hierarchy. Since the ontology language enables one to define a hierarchical structure among event models, inference step
is repeated until no model is satisfied by event instances from previous inference steps.
Given that event models are defined at conceptual level (using the event ontology language), the underlying vision pipeline can be fine tuned or replaced for a new scene without requiring changes to event models, as long as it keeps providing the same types of physical objects expected by the event models. Moreover, since the proposed framework stores event models as human-readable templates, it is very convenient to change models by adding new features or by adding models for new activities. For instance, when transferring the proposed system from location A to B, most changes refer to the update of contextual objects, i.e., the new location of semantic zones. Zone updates can be done in a couple of minutes using support software or be learned from labeled data. Supervised learning methods will require one to retrain all event classifiers once a new event class, input feature or dataset is considered. In the same situation, the proposed framework eases model addition and update, and by consequence, it facilitates knowledge transfer between different scenes (or datasets) with minimal changes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}