1. Introduction
Visual tracking plays an important role in computer vision and has received fast-growing attention in recent years due to its wide practical application. In generic tracking, the task is to track an unknown target (only a bounding box defining the object of interest in a single frame is given) in an unknown video stream. This problem is especially challenging due to the limited set of training samples and the numerous appearance changes, e.g., rotations, scale changes, occlusions, and deformations.
To solve the problem, many effective trackers have been proposed [
1,
2,
3,
4] in recent years. Most methods are developed from the discriminative or generative perspectives. Discriminative approaches use an online updated classifier or regression model to distinguish the object from the background. Avidan [
5] uses AdaBoost to combine a set of weak classifiers into a strong classifier to label each pixel and develops an ensemble tracking method. Grabner et al. [
6] propose a semi-supervised online boosting algorithm to handle the drift problem in tracking by the usage of a given prior. Babenko et al. [
7,
8] introduce multiple instance learning (MIL) into online object tracking where bag labels are adopted to select effective features. Hare et al. [
9] propose the Struck tracker which directly estimates the object transformation between frames, thus avoiding the heuristic labels of samples. Kalal et al. [
10] propose a P-N learning algorithm which uses two experts to estimate and correct the errors made by the classifier and tracker. More recently, Li et al. [
11] proposed a novel tracking framework with adaptive features and constrained labels to handle illumination variation, occlusion and appearance changes caused by the variation of positions. Among all of the discriminative approaches, recently, correlation filter-based tracking algorithms [
12] have drawn increasing attention because of their dense sampling property and fast computation in the Fourier domain. Bolme et al. [
13] propose the MOSSE tracker which finds a filter by minimizing the sum of the squared error between the actual convolution outputs and the desired convolution outputs. The MOSSE tracker can handle several hundreds of frames per second because of the fast element-wise multiplication and division in the Fourier domain. Henriques et al. [
14] extend correlation filters to a kernel space, leading to the CSK tracker which achieves competitive performance and efficiency. To further improve the performance, the KCF method [
15] integrates multiple features into the CSK tracking algorithm. More recently, Xu et al. [
16] proposed a new real-time robust scheme based on KFC to significantly improve tracking performance on motion blur and fast motion.
In contrast, generative methods typically learn a model to represent target object appearances. The object model is often updated online to adapt to appearance changes. Comaniciu et al. [
17] use a spatial mask with an isotropic kernel to regularize the histogram-based target representations. The FragTrack [
18] represents template objects by multiple image fragments, which addresses the partial occlusion problem effectively. Ross et al. [
19] propose the IVT tracker, which incrementally learns a low-dimensional subspace representation of target appearances to account for numerous appearance changes. Sanna et al. [
20] propose a novel ego-motion compensation technique for UAVs (unmanned aerial vehicles) which uses the data received from the autopilot to predict the motion of the platform, thus allowing to identify a smaller region of the image (subframe) where the candidate target has to be searched for in the next frame of the sequence. Kwon et al. [
21] decompose the observation model into multiple basic observation models to cover a wide range of appearance changes for visual tracking. Lamberti et al. [
22] exploit a motion prediction metric to identify the occurrence of false alarms and to control the activation of a template matching (TM)-based phase, thus, improving the robustness of the tracker.
Among all of the generative approaches, recently, sparse representation-based tracking methods [
23] have been developed for object tracking because of their demonstrated good performance in tracking. These methods can be categorized into methods based on a global sparse appearance model [
24,
25,
26,
27,
28], local sparse appearance model [
29,
30], and joint sparse appearance model [
31,
32,
33]. The global model represents each target candidate as a sparse linear combination of target templates. These methods can deal with slight occlusions but are less effective in handling heavy occlusions because of the global representation scheme, which loses partial information. Liu et al. [
29] proposed a local sparse model with mean-shift algorithm for tracking. However, it is based on a static local sparse dictionary and this is less effective in dealing with severe appearance changes. Jia et al. [
30] developed a tracking method based on a structural local sparse appearance model. The representation exploits both partial information and spatial information of the target based on a novel alignment-pooling method. However, it fails to consider the relationship among different candidates and their patches. The joint sparse appearance models [
31] aims to exploit the intrinsic relationship among different candidates. The assumption is that the corresponding features of the particles are likely to be similar because of the sample strategy in particle filter-based methods. Then all of the candidates can be jointly represented by the same few target templates. However, when abrupt motion occurs, most candidates will likely be background. In this situation, if the joint sparsity strategy is adopted, the handful of target candidates will be dominated by a big quantity of background candidates, thus failing to represent the target well and causing tracking failure. Zhang et al. [
33] proposed a structural sparse tracking algorithm which combines global and partial models together, then used the multi-task framework to exploit the intrinsic relationship among different candidates and their local patches. However, it also cannot well represent the target object when abrupt motion occurs. Zhuang et al. [
27] proposed a multi-task reverse sparse representation formulation. In the formulation, they use a Laplacian regularization term to preserve the similarity of sparse codes for the similar candidate features. However, the candidates which have similar features will have similar sparse codes even if the formulation does not contain the Laplacian regularization term. Additionally, all of these methods preserve the information of the target object’s appearances only with a couple of previous time instants, thus, they cannot cover numerous appearances of the target object.
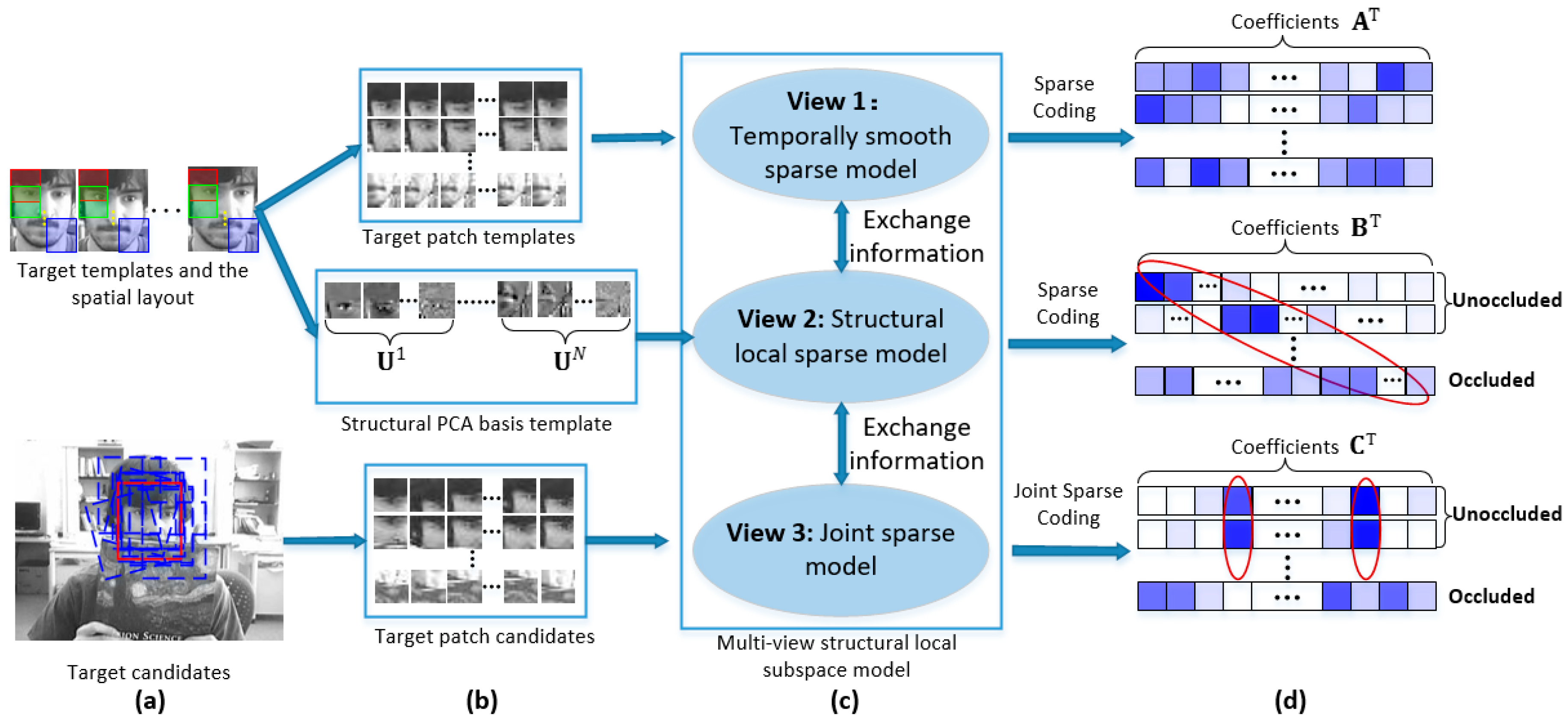
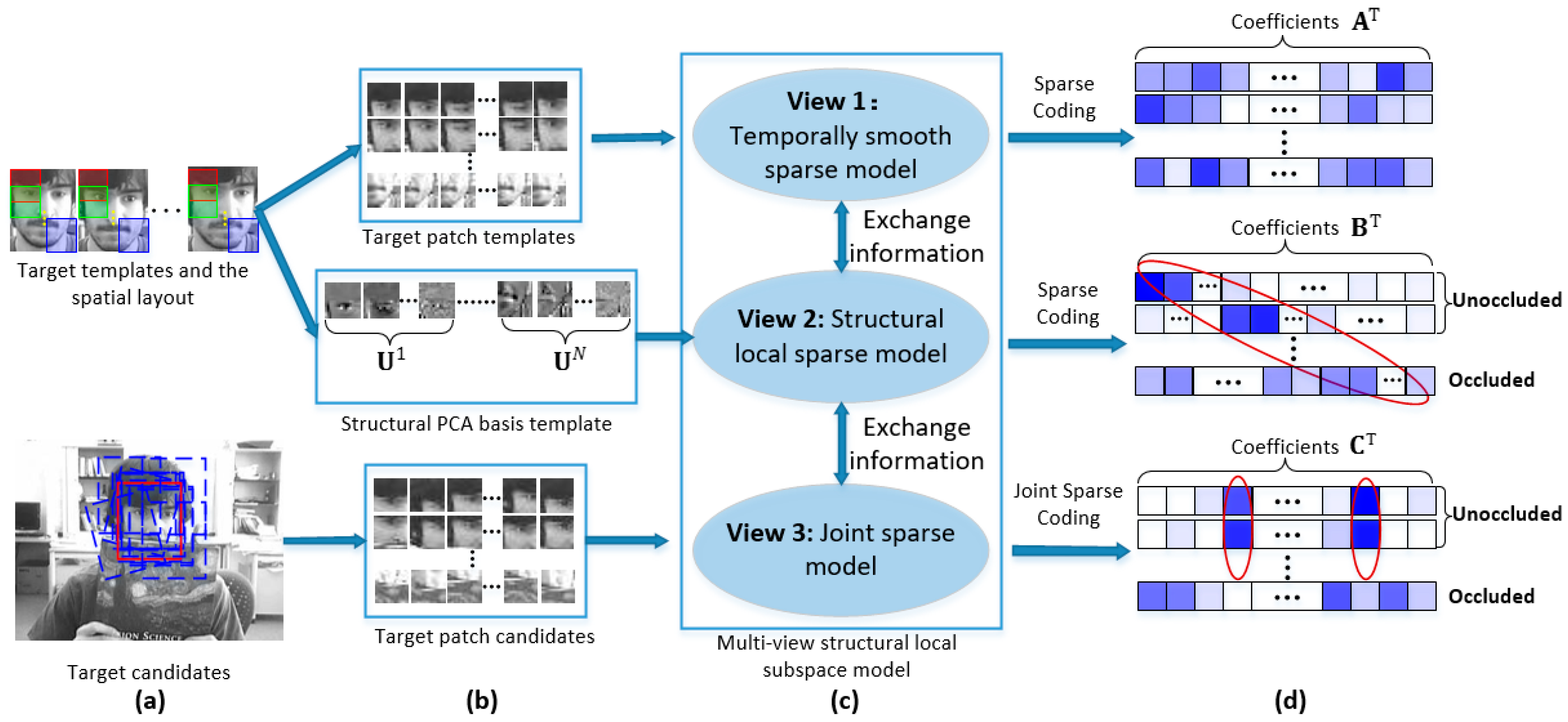
Motivated by the above discussions, we propose a novel multi-view structural local subspace model as shown in
Figure 1. For each view, we build a sub-model to exploit the useful information in the view. The whole model iteratively exchanges information among three sub-models. In the target template view, each patch of target object is sparsely represented by the target patch templates independently with a temporally smooth regularization term. The target templates have a strong representation of the current object’s appearance. We use them to account for the short-term memory of target object. In the PCA Eigen template view, we construct a structural local PCA Eigen dictionary to exploit both partial information and spatial information of the target object with sparse constraint. Additionally, the PCA Eigen template model has the ability to effectively learn the temporal correlation of target appearances from past observation data by an incremental SVD update procedure, thus, it can cover a long period of target appearances. We use it to account for the long-term memory of the target. In the target candidate view, we use a Laplacian regularization term to keep the similarity of sparse codes among those unoccluded patches and keep the independence of sparse codes which belong to the occluded patches by an occlusion indicator matrix. Note that the use of the Laplacian regularization term in our model is more meaningful than it is in [
27]. The whole model has many good properties. It takes advantages of both sparse representation and incremental subspace learning. This makes the model less sensitive to incorrect updating and makes the model have a proper memory of the target appearances. The model exploits the intrinsic relationship among different target candidates and their local patches, forming a strong identification power to locate the target from many candidates. It can also estimate the reliability of different local patches. This causes the model make full use of the reliable patches and ignore the occluded patches.
We built the model to deal with many tracking problems, e.g., occlusion, deformation, fast motion, illumination variation, scale variation, background clutters, etc. The sparse representation-based tracking method can handle partial occlusion and background clutter to some extent, and the incremental learning of the PCA subspace representation can effectively and efficiently deal with appearance changes caused by rotations, scale changes, illumination variations, and deformations. The proposed tracker takes advantages of both methods, and by considering time consistency, intrinsic relationships among target candidates and their local patches, different reliability of different patches, and the rational update strategy, the proposed method significantly improves the robustness of tracking performance.
The main contributions of this paper are as follows:
- (1)
A novel multi-view structural local subspace tracking method is proposed. The model jointly takes advantages of three sub-models by a unified objective function which is proposed to integrate the three sub-models together. The proposed model not only exploits the intrinsic relationship among target candidates and their local patches, but also takes advantages of both sparse representation and incremental subspace learning.
- (2)
We propose an algorithm which can solve the optimization problem well by three customized APG methods, together with an iteration manner.
- (3)
An alignment-weighting average method is proposed to exploit the complete structure information of the target for robust tracking.
- (4)
A novel update strategy is developed to account for both short-term memory and long-term memory of target appearances.
- (5)
Experimental results show that the proposed method outperforms twelve state-of-the-art methods in a wide range of tracking scenarios.
The rest of the paper is organized as follows: In
Section 2, we introduce the multi-view structural local subspace model in detail. The optimization of the unified objective function and the overall tracking algorithm are presented in
Section 3. Details of the quantitative and qualitative experiments of our method compared with the state-of-the-art methods are discussed in
Section 4. In
Section 5, we reach the conclusions of the paper.
2. Multi-View Structural Local Subspace Model (MSLM)
Most tracking methods use only one clue to model the target appearance. However, only one clue can hardly handle the complicated circumstances that visual tracking faces. Some methods try to fuse different models together to use all of their advantages, but they either simply combine these models or increase the computation burden by using some complicated models. Our method exchanges information among target templates, PCA bases, and candidates in one model to simultaneously use all of the advantages, while keeping computational complexity favorable.
To better illustrate our model, we assume that the optimal state
in the current frame is already known and the corresponding observation is
. The state
includes six affine parameters, where
denote
translations, rotation angle, scale, aspect ratio, and skew, respectively. The observation is extracted according to them. We sample a set of overlapped local image patches inside the target region with a spatial layout illustrated in
Figure 1. Then we obtain an optimal patch vector
, where
is the dimension of the image patch vector, and
is the number of local patches sampled within the target region. Each column in
is obtained by
normalization on the vectorized local image patches extracted from
. The goal is to mine the most useful information lying in the target patch templates, patch PCA basis, and candidates’ patches to approximate the optimal observation jointly. First, we approximate the optimal patches
by exploiting the sparsity in the target patch templates. Second, we construct a structured local PCA dictionary to exploit both partial information and spatial information of the target with a sparse constraint. Third, we adopt a Laplacian term to exploit the intrinsic relationship among target candidates and their local patches. Fourth, we propose a unified objective function to integrate these three models and find an iterative manner to effectively exchange information among all of these three models, thus, taking full advantage of all the three subspace sets simultaneously.
2.1. View 1: Approximating the Optimal Observation with Target Templates
We collect a set of target templates
, where
is the number of target templates. Then a set of overlapped local patches are sampled inside each target template using the same spatial layout to construct the patch dictionaries
, where
. Dictionary
denotes the dictionary constructed by the
local image patches of all these
target templates. Each column in
is obtained by
normalization on the vectorized grayscale image observations extracted from. We assume that the optimal observation
and its patch vectors
has already been known. Then the goal is to find the most useful information in target patches templates which can represent the optimal observation as far as possible. Due to the good modelling ability of sparse representation witnessed in [
23], we decided to explore the information in target templates which can reflect the current target state with sparsity constraint:
where
denotes the
optimal patch and
is the corresponding sparse code of that patch;
is the sparse patch code of last frame;
and
controls the regularization amount. The last term in Equation (1) is a temporally smooth term which is derived from the observation that target object in neighboring frames are always very similar to each other.
2.2. View 2: Approximating the Optimal Observation with Structural Local PCA Basis
To adapt to the target appearance variations caused by illumination change and pose change, the target templates described in last section are updated dynamically. However, these templates are only obtained from the previous couple of time instants. It is a short-term memory of the target appearances. Thus, they cannot cover the numerous appearance variations well. This can be solved by the Eigen template model which has been successfully used in visual tracking scenarios [
34]. The Eigen template model has the ability to effectively learn the temporal correlation of target appearances from the past observation data by an incremental SVD update procedure. The incremental visual tracking (IVT) method [
19] presents an online update strategy which can efficiently learn and update a low-dimensional PCA subspace representation of the target object. It has been shown that the incremental learning of the PCA subspace representation can effectively and efficiently deal with appearance changes caused by rotations, scale changes, illumination variations, and deformations. However, the holistic PCA appearance model has been demonstrated sensitive to partial occlusion. Since the underlying assumption of PCA is that the error of each pixel is Gaussian distributed with small variances, but when partial occlusion occurs, this assumption no longer holds. Meanwhile, the holistic appearance model does not make full use of partial information and spatial information of the target and, hence, may fail to track when there is occlusion or similar object in the scene.
Motivated by the above observations, we construct a structural local PCA basis dictionary to linearly represent each patch with
-norm constraint. The PCA basis dictionary
is concatenated by the PCA basis component of each partial patch, where
is the number of PCA basis of each patch used to construct
and
is the eigenvectors corresponding to the
patch. The dictionary
is redundant for each patch. We can see that each patch will likely be linearly represented by the eigenvectors corresponding to itself and the coefficients of other eigenvectors will be zeros or close to zero. Thus, with the
-norm constraint, each local patch will be represented as the linear combination of a few main eigenvectors in
by solving:
where
is the regularization parameter and
is the corresponding sparse code.
2.3. View 3: Approximating the Optimal Observation with Target Candidates
The goal of tracking in the Bayesian framework is to find the combination of candidates or the candidate which can best approximate the optimal state. In every frame, we extract a set of target candidates
according to a candidate state set
, where
is the number of target candidates. The sampling strategy of the candidate state set
will be described in detail later. Like the above two model, we sample a set of overlapped local image patches inside each candidate region with the spatial layout forming a candidate patch dictionary
in the same way as how dictionary
is constructed, where
. Then we approximate the optimal observation with target candidates by:
where
and
are regularization parameters,
is the corresponding sparse code and
is an occlusion indicator matrix with
, where
is the occlusion rate of the
patch. Details of the occlusion rate are described in
Section 3.2.1. The last term in Equation (3) is a Laplacian regularization term inspired by [
27]. Different with [
27], our model uses this term to exploit the similarity of sparse codes among different spatial layout patches. Note that the number of different spatial layout patches is
. It is actually a small number which does not increase the computation. The occlusion indicator matrix
can indicate if any two different spatial layout patches are both occluded or not. If both are not occluded, the corresponding factor in
will be large to constrain the two sparse codes to have similar values. If any of the two patches is occluded, the corresponding factor in
will be small, thus letting the model avoid the influence of the occluded patches. Similar to [
27], we transform the Laplacian term and the optimization problem is reformulated as:
where
is the Laplacian matrix,
the degree of
is defined as
and
.
2.4. Multi-View Structural Local Subspace Model
In the descriptions of above three view models, we assume that the optimal target state
and its corresponding observation vector
have already been known. However, in reality, the goal is to find the optimal state in current frame. From above three subsections, we know the optimal state can be approximated from three different views, and every view has its own advantages against others. Thus, we propose a unified objective function to exchange information among different views and jointly exploit all the advantages by:
where
and
;
is a constant that balances the importance between the two terms. The estimated coefficients
,
, and
can be achieved by minimizing the objective function (Equation (5)) with non-negativity constraints:
However, there exists no close-form solution for the optimization problem with Equation (6). Thus, we develop an iterative manner to solve it.
4. Experiments
The proposed method in this paper is implemented in MATLAB 2014a. We perform the experiments on a PC with Intel i7-4790 CPU (3.6 GHz) and 16 GB RAM memory and the tracker runs at 3.1 fps. We test the performance of the proposed tracker with the total 51 sequences using in the visual tracker benchmark [
2] and compare it with the top 12 state-of-the-art trackers, including SST [
33], JSRFFT [
36], DSSM [
27], Struck [
9], ASLA [
30], L1APG [
35], MTT [
31], LSK [
29], VTD [
21], TLD [
10], IVT [
19], and SCM [
37]. Among the 12 selected trackers, the Struck, SCM, TLD, and ASLA are the four best-performed ones demonstrated in the benchmark and our tracker outperforms all of them in terms of the overall performance. Some representative tracking results are shown in
Figure 3.
The parameters, which are fixed for each sequence, are summarized as follows. We resize the target image patch to
pixels and extract
overlapped local patches within the target region with eight pixels as step length, like in [
30]. The number of target templates is set to be 10. The regularization parameters
,
,
,
, and
are set to be 0.01, 0.01, 0.01, 0.04, 0.2, and 1, respectively. We let the number of PCA basis be 10. The candidate number in each frame is 600. The iteration numbers in Algorithm 1–3 are all set to be 5, and the Lipschitz constant
is equal to 20 for all the three algorithms. Among all the parameters,
balances the importance between the candidates and the templates. This is a very important factor to our model. We did many experiments to obtain the optimal value of
.
Table 1 summarizes the overall performance of our tracker in terms of
.
4.1. Qualitative Evaluation
The 51 sequences pose many challenging problems, including occlusion (OCC), deformation (DEF), fast motion (FM), illumination variation (IV), scale variation (SV), motion blur (MB), in-plane rotation (IPR), out-of-plane rotation (OPR), background clutter (BC), out-of-view (OV), and low resolution (LR). The distributions of the 51 sequences in terms of the 11 attributes are shown in
Table 2.
The most challenging and common problems in tracking are occlusion, deformation, background clutter, illumination change, scale variation, and rotation. We mainly describe how our tracker outperforms the other trackers in these challenging scenarios in details.
Occlusion: In 29 of the total 51 sequences, the targets undergo partial or short-term total occlusions. We can see from
Figure 3 that the remarkable sparse representation-based trackers (i.e., SCM, DSSM, JSRFFT, SST, ASLA, LSK, L1APG, and MTT) and the well-known incremental subspace-based IVT tracker all fail in some sequences somehow, while our tracker can effectively track almost all of the targets in the 29 sequences when occlusion occurs. This is mainly attributed to the part-based strategy used in our method. The occlusion vector
in
Figure 2, which is constructed from the PCA basis coefficients
, can effectively indicate the occlusion degree of each patch. If a patch is occluded, the corresponding element in
will be large, making the tuned confident vector
very small, thus alleviating the influence of the bad patches. In addition, we exploit the joint-sparsity in patches which are not occluded. This strategy allows the method to fully utilize the spatial information among these patches, making the model more robust.
Deformation: There are 19 sequences involve target deformations. We can see from
Figure 3 that our tracker can handle deformation better than the other methods. In the
Jogging-1 and
Jogging-2 examples, the proposed method effectively deals with short-term total occlusion when the target undergoes deformation, while most of the other methods fail in these sequences. This is because our method takes advantages of the incremental subspace learning model, which still performs well when deformation occurs.
Background clutter: There are total 21 sequences in which the targets suffer background clutter. As the background of the target object becomes complex, it is rather rough to accurately locate the right position of the target, since it is difficult to discriminate the target object from the background in a rather simple model. It is worth noticing that the proposed method performs better than the other algorithms. Thanks to the structural local model and the rich target information preserved in the PCA basis, our model learns a more robust and compact representation of target object, making it easier to capture the target appearance change information.
Illumination change: In 25 out of the 51 sequences, the target undergoes severe illumination change. In the Singer1 sequence our tracker and the IVT tracker performs well in tracking the woman, while many other methods drift to the cluttered background or cannot adapt to scale changes when illumination change occurs. This can be attributed to the use of incremental subspace learning which is able to capture appearance change due to lighting change. In the Fish sequence, the target undergoes illumination change together with fast motion. In the Crossing sequence, the target has a low resolution observation and goes through illumination change. In all these 25 sequence, our tracker generally outperforms the other trackers.
Scale variation and rotation: There are total 44 sequences which undergo scale variation or rotation. As we use the affine transformation parameters that include the scale and rotation sampling, we can capture the candidates with different scales and rotations for further selection. Together with the sampling strategy, the robust representation model proposed in this paper can effectively estimate the current scale and rotation angle of the target object. We also observe that some trackers, including the well-performed Struck tracker, do not adapt to scale or rotation.
4.2. Quantitative Evaluation
We use the score of the precision plot and the score of the success plot to estimate the 13 trackers on the 51 sequences. Note that a higher score of the precision plot or a higher score of the success plot means a more accurate result. The overlap rate is defined by
, where
is the estimated bounding box and
is the ground truth bounding box. We use the precision and success plots used in [
2] to demonstrate experiment results of the trackers.
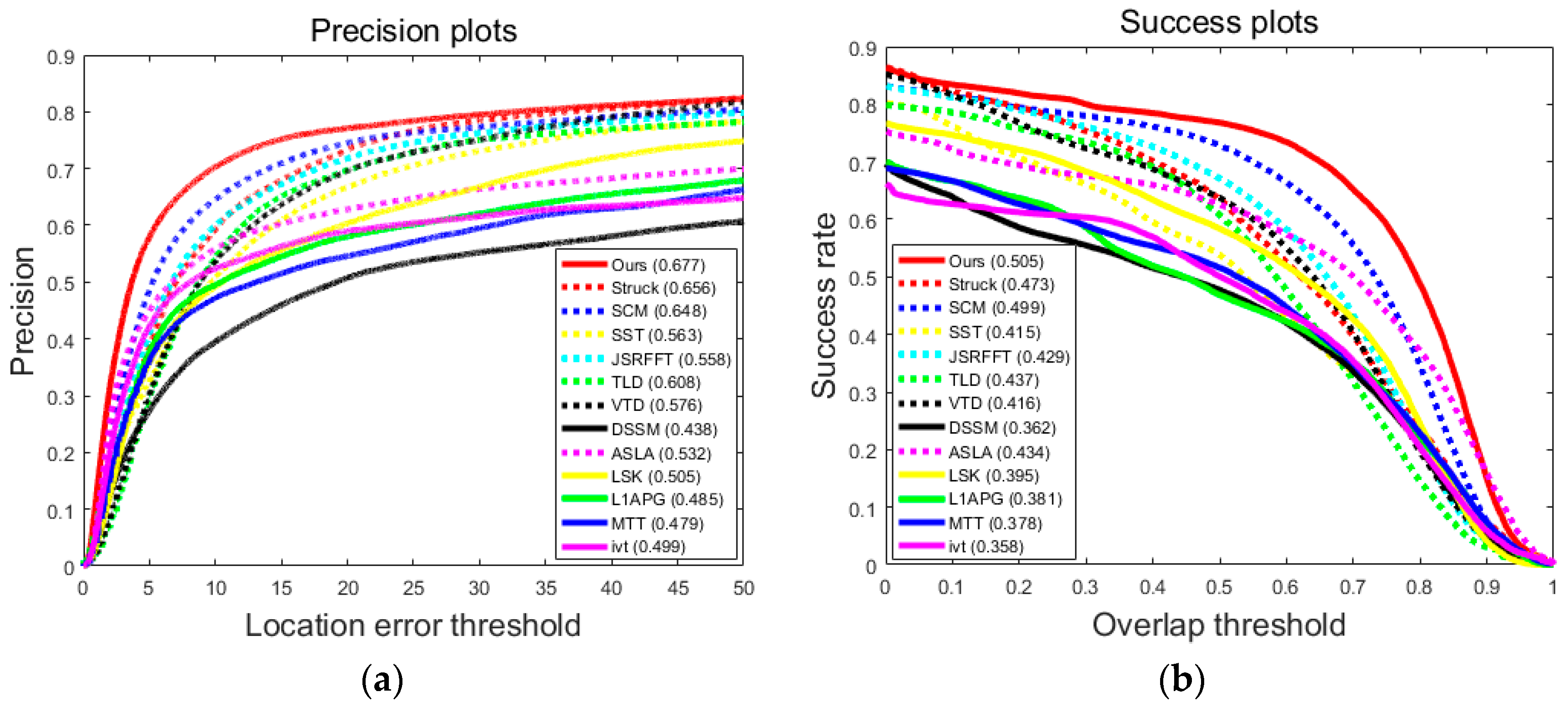
Figure 4 contains the precision plots which show the percentage of frames whose estimated location is within the given threshold distance of the ground truth and success plots which show the ratios of successful frames at the thresholds varied from 0 to 1. Both precision plots and success plots show that our tracker is more effective and robust than the 12 state-of-the-art trackers in terms of the total 51 challenging sequences in the benchmark.
Table 3 and
Table 4 report the scores of precision plots and the scores of success plots of different tracking methods. In attributes BC, DEF, IV, IPR, and OV, our tracker achieves the highest scores of precision plots, which means that our method is more robust than the other state-of-the-art trackers. In the MB and LR attributes, the scores of the precision plots of the proposed method are not among the best three. This is because, when undergoing motion blur, different spatial patches of one target tend to have similar blur, making the model distinguish different spatial patches with difficulty. Additionally, along with motion blur, the targets may also go through fast motion or illumination variation. This makes the model even more difficult to accurately track the targets. However, 0.410 of the precision score is still a relatively good one among all of the trackers. In attributes OCC, DEF, IV, IPR, and OV, the proposed tracker achieves the highest scores of success plots which demonstrates that our approach computes the scale more accurately. In the LR attributes, the score of the success plot of the proposed method is also not among the best three. This is because of the low resolution of the target object. Since our tracker is a patch-based method, when the target undergoes low resolution, the patch features will be extracted from even lower resolution patches, resulting in relatively poor representation of each patch, thus causing drift. In the other attributes, our tracker gains the precision scores and success scores very close to the best ones. The last rows of
Table 3 and
Table 4 show the overall precision scores and success scores of the thirteen trackers over all of the 51 sequences. Our tracker achieves the best scores in both evaluation metrics, which shows that our tracker outperforms all of the other state-of-the-art trackers.
The last row in
Table 4 shows the comparison results about computational loads in terms of fps. Our candidate sampling strategy is based on the sampling strategy in [
19] and all the candidate patch are resized to
pixels which means that all of the candidate features are normalized to a fixed size. Thus, the fps of different sequences are the same as long as the candidate numbers are fixed. Actually, we set the candidate number fixed to be 600, so the fps are almost the same in different sequences (ignore the feature extracting time, because it is trivial compared with the time used for solving the whole model.). This shows that our tracker runs at 3.1 fps. Although it does not reach real-time processing, it outperforms most other sparse representation-based trackers (i.e., SCM, MTT, L1APG, DSSM, JSRFFT, and SST) in terms of both accuracy and speed.






{kind=link}
{kind=link}
{kind=link}
{kind=link}