1. Introduction
The ability to construct a map while the robot moves is essential for performing autonomous tasks and has been extensively studied in the literature. Map building allows the robot to develop autonomous skills such as navigation, interaction with environment and self-localization, among others. The scientific community has been studying new ways of representing the map of the environment in the last few decades (one of the most interesting surveys about mapping is found in [
1]). Most of the solutions proposed in the literature for this problem are addressed using representations of the spatial structure of the environment (e.g., occupancy cells or geometric features like segment lines). However, it is difficult to perform other tasks successfully using only a spatial representation of the environment. This tendency is now changing, and the scientific community is experiencing an increasing interest in so-called semantic solutions, which integrate semantic knowledge and geometrical information [
2].
Recently, several advances in mapping have been achieved. In fact, ground robots that incorporate capabilities for task planning and storing some semantic knowledge in their maps are commonly used (e.g., classification of spaces, such as rooms, corridors or garden, and labels of places and/or objects) [
2]. However, very few work has been achieved in underwater robotics where the semantic knowledge of the environment could be applied, for instance, to predict changes and to make high-level decisions. In fact, the mapping problem in underwater robots has been addressed typically by only using geometric information with sonar or Red-Green-Blue (RGB) sensors [
3,
4,
5].
In order to autonomously acquire semantic information from an underwater environment, robots have to be equipped with sensors and a system to extract high-level knowledge from the scene. Typically, RGB sensors have been used in the literature for extracting and characterizing robot’s environment. However, in underwater scenarios, these RGB images provide little information due to water turbidity.
The use of sonar offers the advantage to be invariant to the water turbidity; however, data suffer distortion and noise and thus processing the acoustic signal is still a challenge. The sonar data can be summarized to untextured range data and thus only information about the shape of the detected objects is able to be acquired.
Several works proposed methods to identify objects on acoustic data as [
6,
7,
8,
9,
10]. However, none of them recognize objects and their semantics in these scenarios. Galceran et al. [
6] proposed an underwater object classification on multi-beam sonar data by considering the specific domain knowledge with a limited number of shapes.
In this paper, a study of classification approaches applied to acoustic images is presented with the aim of being used in a localization and mapping system for underwater robots. The proposed study shows how objects can be detected and recognized in the scene allowing a robot to build a map. In addition, it can be integrated with the topological graphs proposed in [
11], allowing the construction of more reliable maps for the localization problem, since it would be possible to establish a reliability relation between the objects and their behavior in the environment. For example, static objects such as stones and poles have more confidence than dynamic objects, which change their position over time, such as fish, boats, and swimmers, for the localization problem.
This approach is limited to at least partially structured environments because it is necessary that our approach detects some man-made structures at least in a sparse frequency. Our approach should not be effective in open sea regions where sensory readings are predominantly monotonous.
This paper extends the contributions proposed in [
12], with modifications on the segmentation methodology. Now, the local parameter adjustment averages a window of bins in order to find peaks of intensities. These peaks define each local threshold parameter in the segmentation process. In addition, an extended study of the classification algorithms applied to acoustic images is presented, where the Support Vector Machine, Random Trees, and K-Nearest Neighbor classifiers were evaluated.
More specifically, this paper describes in detail the experiments and show new results evaluating the solutions on real data acquired by FLS in a harbor.
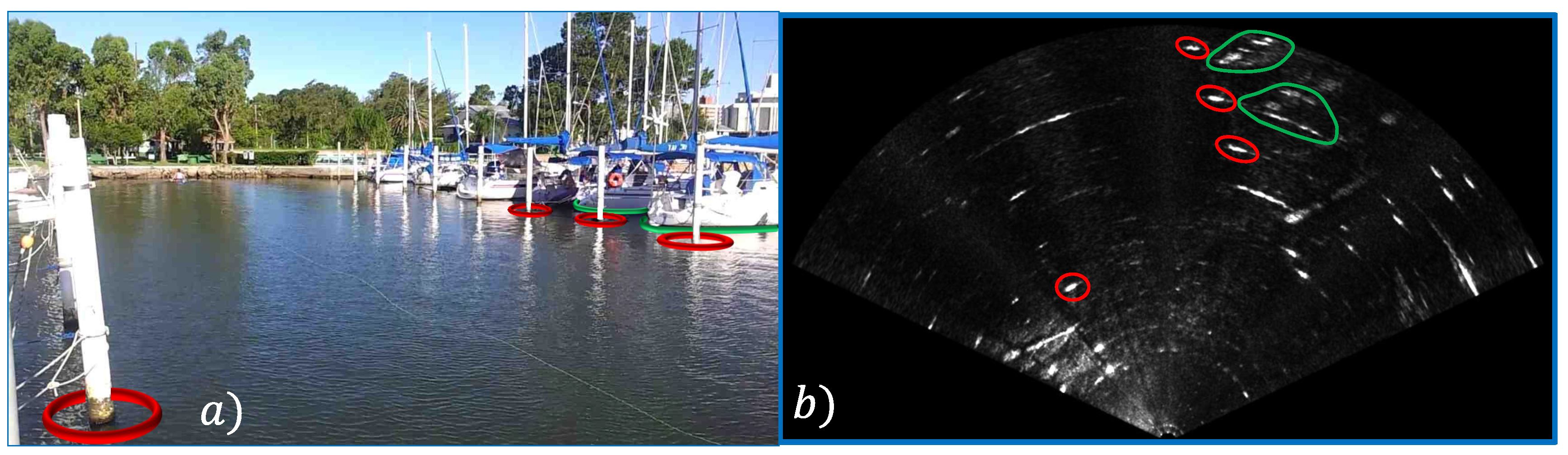
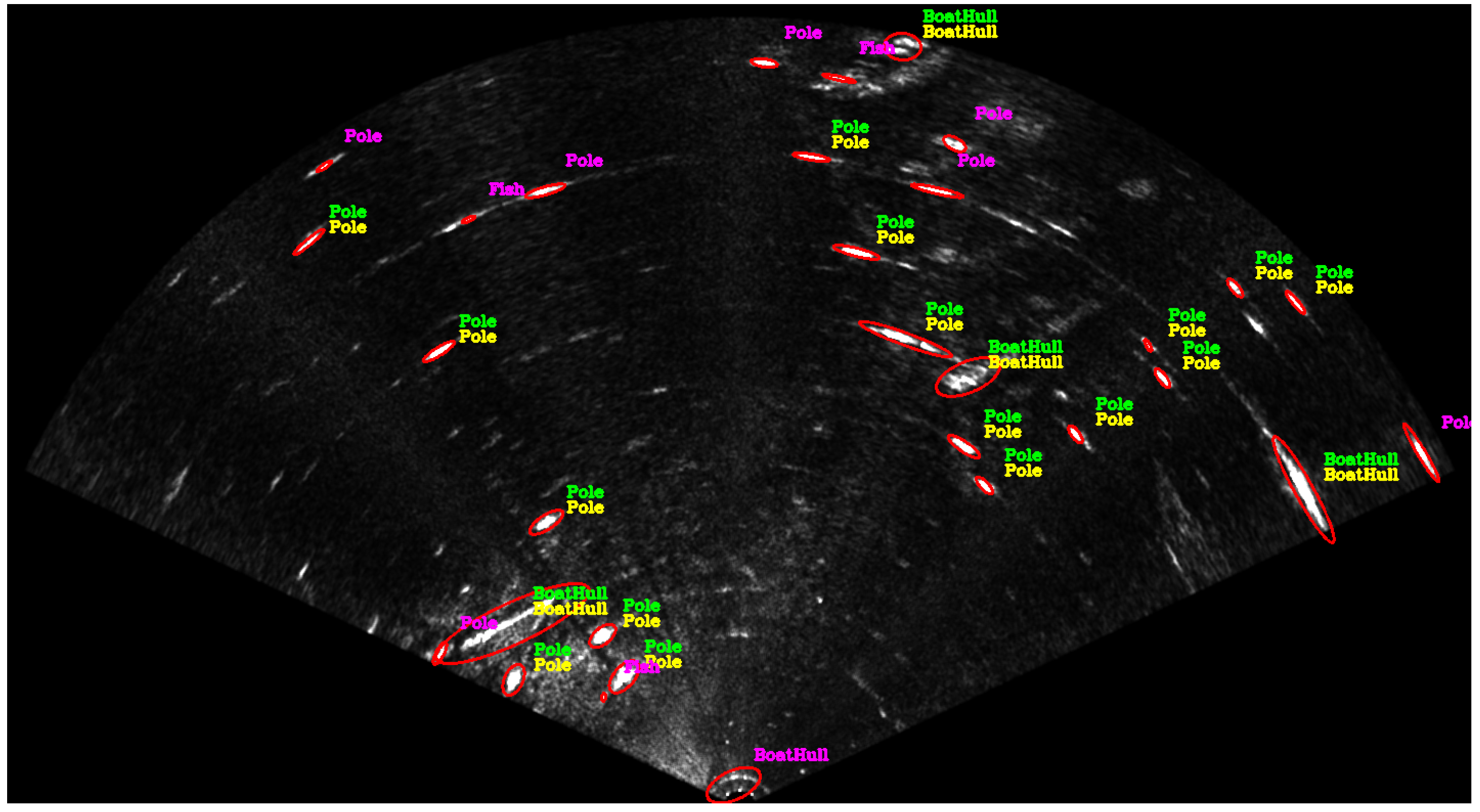
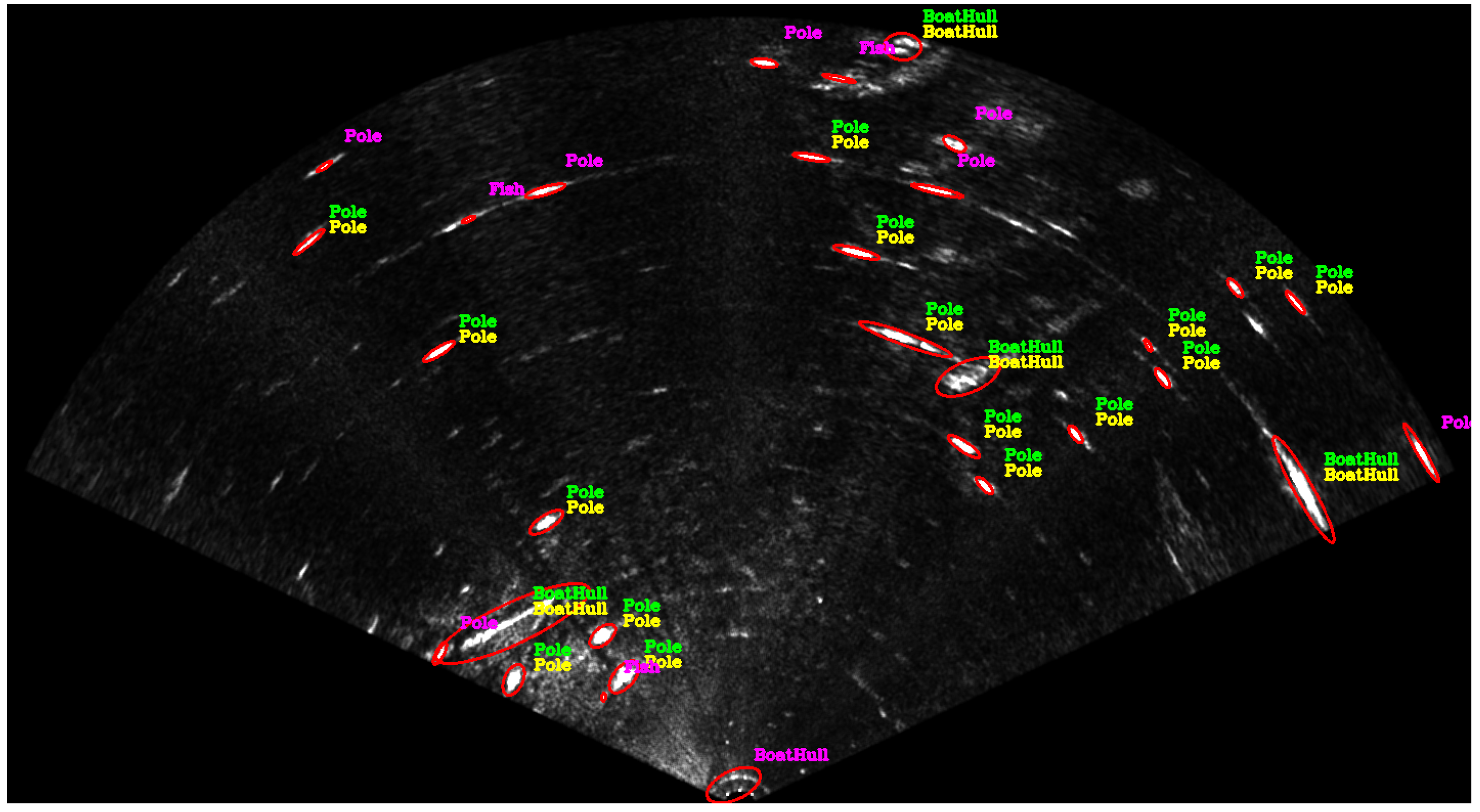
Figure 1 shows an example of the semantic information that can be obtained by the approach. The acoustic images are segmented and their shapes are described geometrically. Then, they are classified into five different classes (Pole, Boat Hull, Stone, Fish and Swimmer) using a tool developed to annotate the sonar data. The annotated data allow the training of supervised classifiers and all created datasets and developed code are made available. The code is available at [
13] and the dataset at [
14].
2. Acoustic Image from a Forward Looking Sonar
The Forward-Looking sonars (FLS) are active devices that produce acoustic waves that propagate through the medium until they collide with an obstacle or are completely absorbed. When a wave collides with an obstacle, a part of its energy is absorbed and a part is reflected. The reflected portion that returns to the sensor is recorded using an array of hydrophones. The round trip of the wave is called ping.
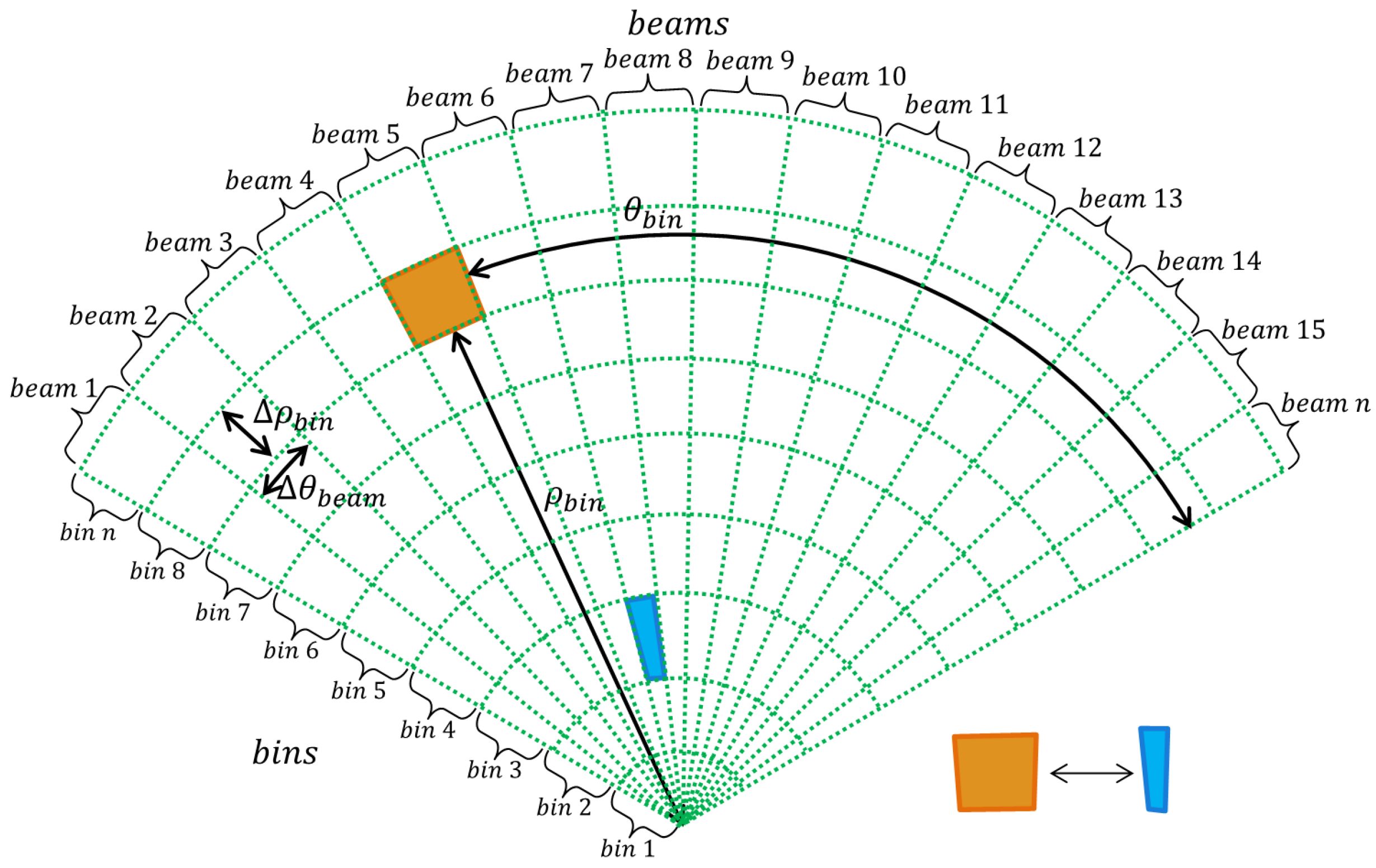
The waves captured by the hydrophones are organized according to their return direction and their distance to the reflecting object. Acoustic returns from the same direction belong to the same beam and are called bins. A fan-shaped acoustic image
is one of the ways to represent the beams and bins information recorded between a
ping interval.
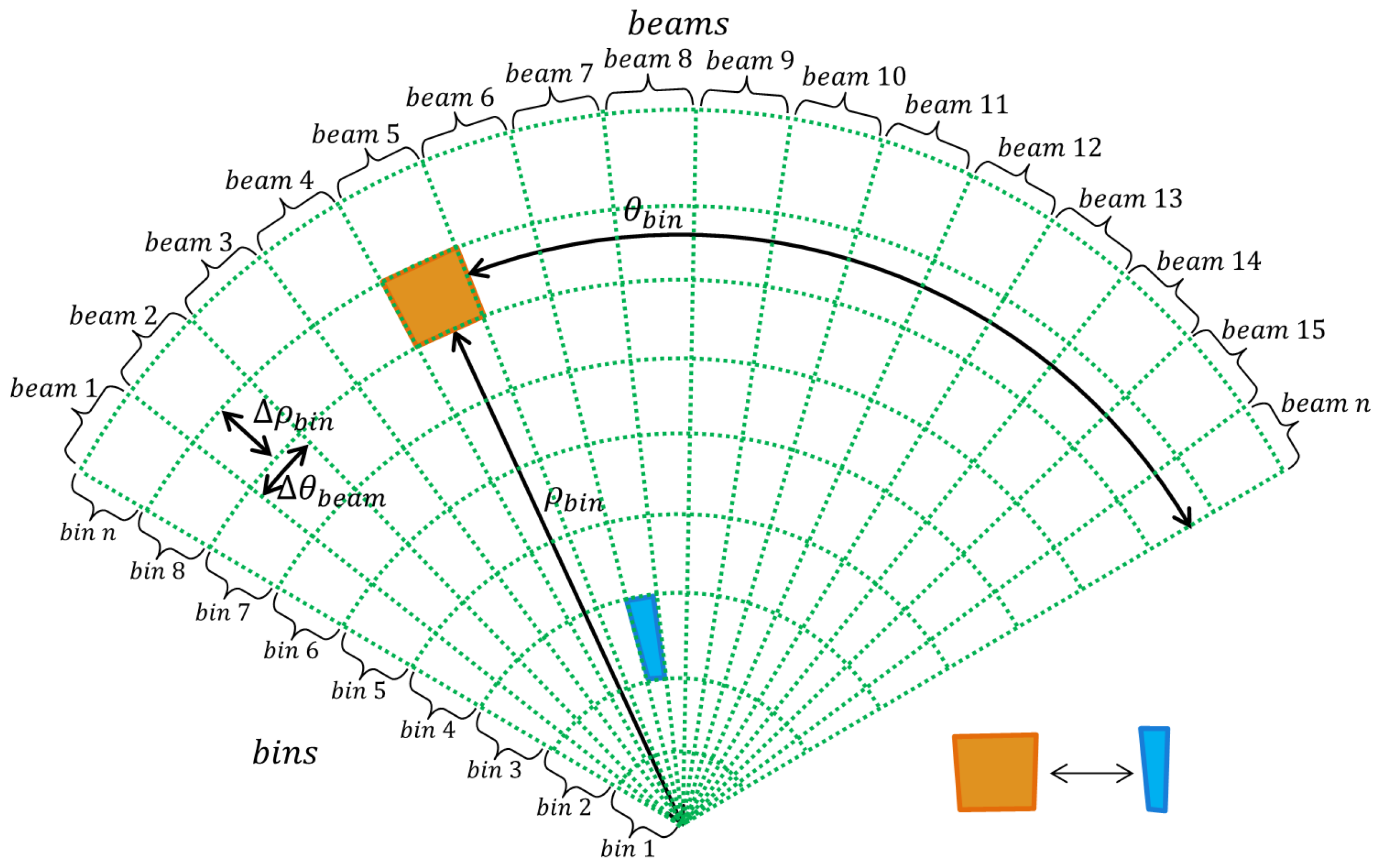
Figure 2 shows how an acoustic image is organized with respect to its beams and bins.
Figure 1b shows an example of an acoustic image captured in the harbor of the Yacht Clube of Rio Grande, Brazil. In this image, the pixels are associated with bins, and they are indexed according to their distance
and their azimuth direction
from the sonar, as shown in
Figure 2. Due to the FLS conception, the height information of a bin can not be distinguishable and, therefore, the acoustic image is a 2D projection on the horizontal plane of the observed environment.
Although the sonars are almost independent of the water turbidity conditions, they have some characteristics that make it difficult to handle and to extract information, such as:
The inhomogeneous resolution. The number of pixels to represent a bin varies according to its distance
to the sonar.
Figure 2 shows two bins overlapped by a box. The orange box covers the farther one and the blue box covers the closer one. The area covered by the orange box is bigger than the blue box. This fact causes image distortion and objects’ flatness.
The intensity variations of each bin. They are caused by water attenuation, changes in sonar tilt or sensitivity differences between the hydrophone.
Acoustic reverberation caused when two or more acoustic returns from the same object are captured producing duplicated objects in the image.
The acoustic shadow effect produced by objects that block the path of the acoustic waves, producing a region without acoustic feedback after the blocking objects. These regions are characterized by a black spot in the image and hide a part of the scene causing occlusion of objects.
The speckle noise due to the low signal-to-noise ratio caused by mutual interference of the sampled acoustic returns.
Because of these problems, techniques for enhancing, segmenting and describing of acoustic images, specifically developed for FLS, are required.
3. Methodology
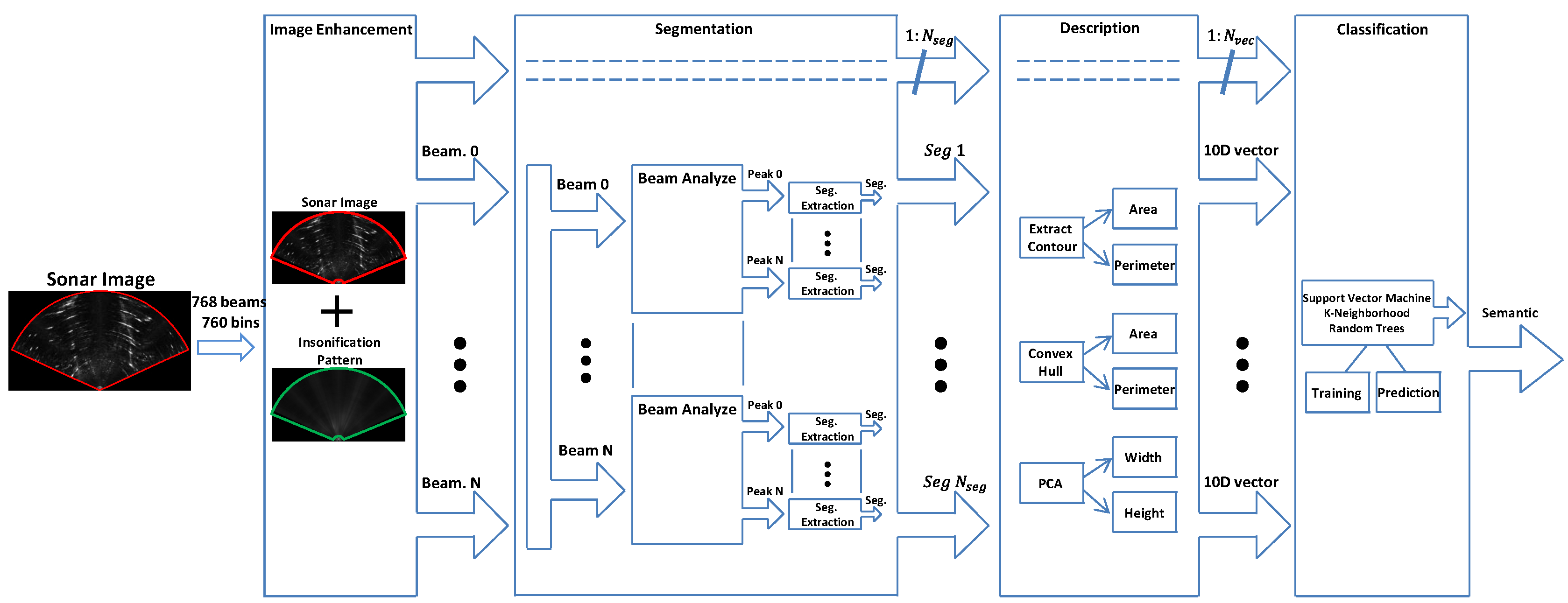
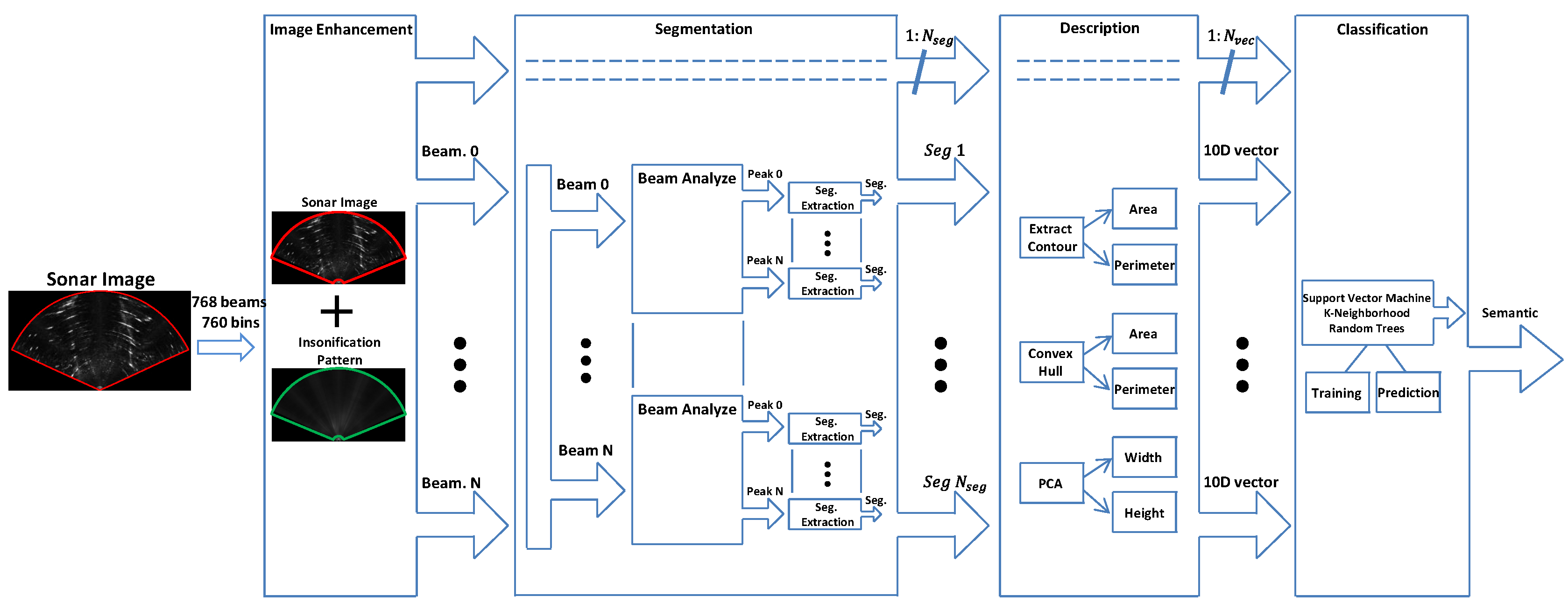
The proposed approach for object classification has four steps that include image enhancement, segmentation, description, and classification. A tool has been developed to perform all the steps and to create training data to the supervised classifier. An overview of the proposal is illustrated in
Figure 3.
3.1. Image Enhancement
We applied in this step an image correction method based on [
15]. First, we found the sonar insonification pattern by averaging a large group of acoustic images. After that, the sonar insonification pattern is applied to each image mitigating the effects of the nonuniform insonification and the overlapping problem of acoustic beams.
3.2. Image Segmentation
Because of low signal-to-noise ratio and the phenomena described in
Section 2, the acoustic images are very noisy and represent a significant challenge faced by our methodology and its quality directly influences the final results.
The main idea of this segmentation approach is to separate the objects of interest from the background. As objects are more efficient than the seabed to reflect acoustic waves, they are characterized by high intensity spots on the images. For this reason, we adopted an approach based on the principles of the sonar operation to detect peaks of intensity.
Each acoustic beam B is analyzed individually, bin by bin.
The average intensity
is calculated for each bin
b of a given beam
B through Equation (
1):
where
is the window size, in the number of bins, included in the averaging;
b and
i are bin identifiers;
B is a beam identifier; and
is the intensity of
-bin of
-beam. The intensity
is an offset of
as shown in Equation (
2).
where
is a constant that determines the minimum height of a peak of intensity. A sequence of bins with an intensity
greater than
is considered part of a peak and is not considered in the
computation. In this sequence, the bin
is the bin with the highest intensity. Its intensity
and position
are adopted to adjust the segmentation parameters.
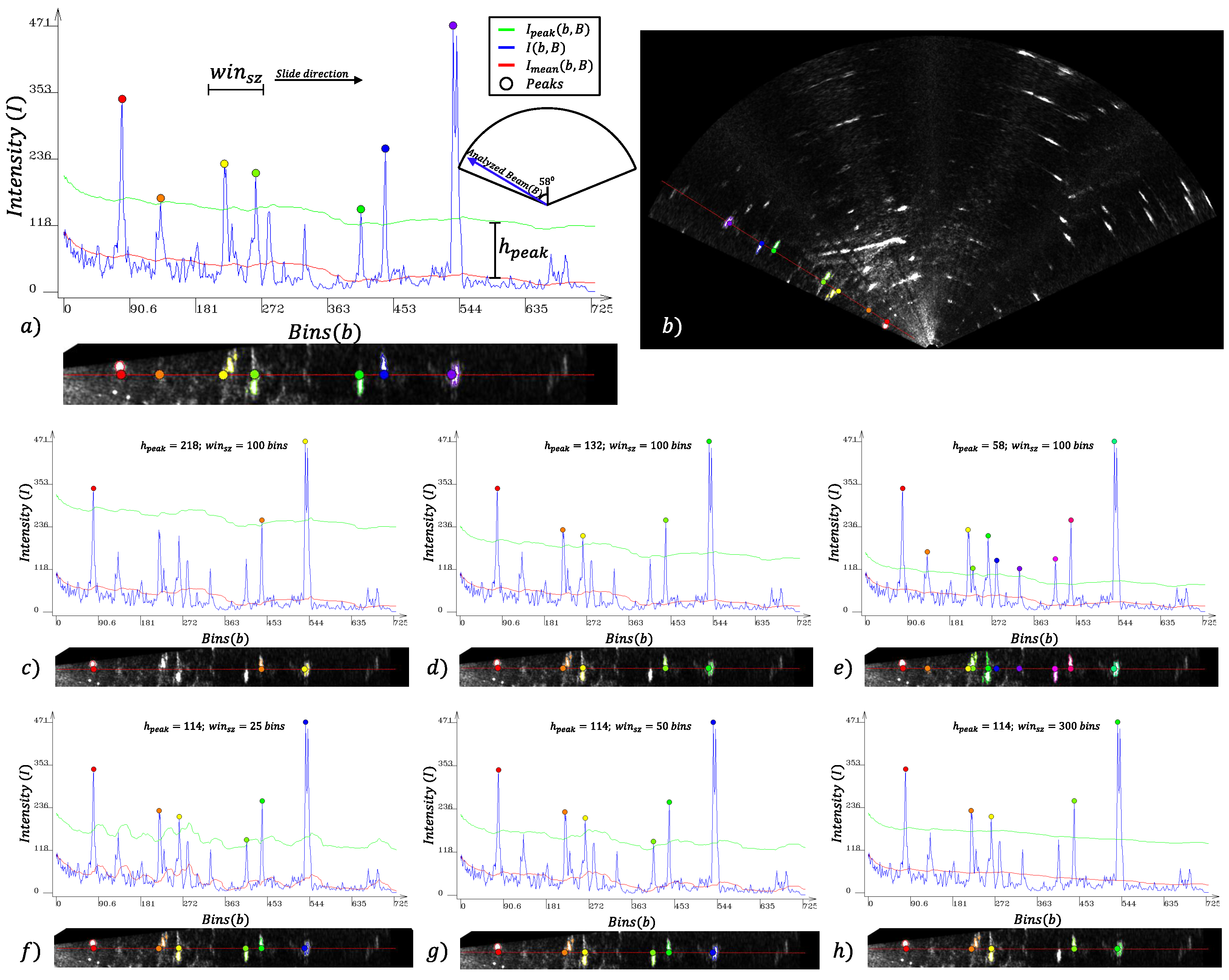
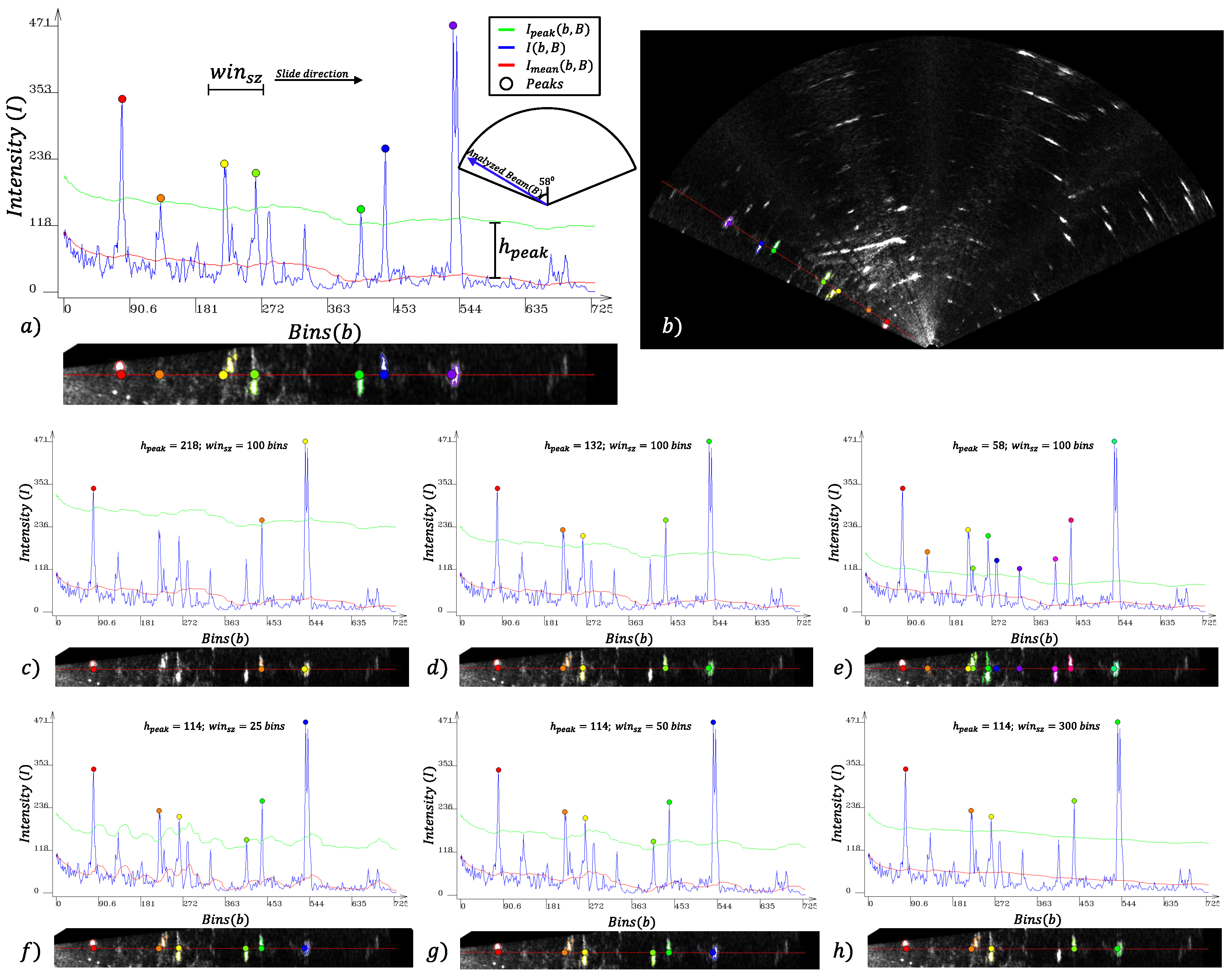
Figure 4 shows in red the
intensities, in blue the
intensities and in green the
intensities of all bins of a single beam
B. The peaks detected
are represented by colored circles.
From each peak bin , a quadruple is defined as , where x, y is the position in the image. After the detection of all peaks in the image, a search for connected pixels is performed for each peak, initiating on the peak of lower intensity to the highest one. The 8-way connection is adopted as the neighborhood criterion by the breadth-first search algorithm. In this search, all the connected pixels are visited according to the following criterion: A bin is visited if its intensity is greater than the peak intensity or its relative distance to a segment border is lower than the parameter in pixels.
The distance criterion is adopted to reduce the multi-segmentation issue of a single object caused when a group of high-intensity pixels is divided by low-intensity pixels. This effect is caused by noise or by acoustic shadows.
Figure 5 shows the behavior of the segmentation algorithm by changing the
parameter.
3.3. Describing Segments
After the segmentation step, each segment is described using a Gaussian probabilistic function and the following information about each segment is computed.
Initially, width and height are computed using a covariance matrix that relates the x and y position of each pixel of the segment. The eigenvalues and eigenvectors of the covariance matrix are computed using Singular Value Decomposition (SVD). The width is defined as the largest eigenvalue and height is defined as the second largest eigenvalue.
Furthermore, the segment
area is computed using Green’s theorem that gives the relationship between a line integral around a simple closed curve. This area is computed using the implementation of the OpenCV library [
16]. Finally, we determine the
convex hull area, the
perimeter, the
mean intensities and the
intensities standard deviation of each segment. Almost all extracted information is geometrical, except the mean and the standard deviation of the intensities.
Based on this information, we defined a ten feature vector 10D features. This is composed of Inertia Ratio, i.e., width divided by the height, mean and standard deviation of the acoustic returns, segment area and convex hull area. Furthermore, we compute the convexity, i.e., the segmented area divided by the convex hull area, the perimeter and the number of pixels in the segment.
3.4. Segment Classification
After the description of the segments, they are classified by a supervised classifier. We evaluated some of the main classifiers: Support Vector Machine, Random Trees and K-Nearest Neighbors adopting the five classes of objects available in our dataset (Pole, Boat Hull, Stone, Fish and Swimmer).
The training data is generated by a developed tool that allows the manual annotation of each segment, training the classifiers and saving the manual annotations and the obtained results in text files.
Figure 6 shows how the tool displays the acoustic images with the annotated information and the results obtained by the classifier. It is an open source tool developed in C++ using the OpenCV library [
16]. The source code is avalible at [
13].
3.4.1. Support Vector Machine
The Support Vector Machine (SVM) technique is a classifier that models the data as a k-dimensional vector and defines an optimal hyperplane that best separates the vectors depending on your class. The hyperplane is defined by an optimization algorithm in the training step.
The classification using SVM is based on the libSM library [
18]. Its implementation presents several type of kernels that allow us to deal with nonlinear classification. The available kernels are: polynomial, radial basis function (RBF) and sigmoidal kernels. As described in [
18], the two kernel function parameters must be defined:
and
C. These parameters affect the nonlinearity properties of the kernel functions in the training stage.
These parameters are optimally defined by an auto training function that builds a grid with the classifier performance by varying the two parameters (, C). The classifier performance is calculated by cross validation, the training data are split into k groups, one of them is used for cross-validation and the others train the classifier. A range and discretization step to and C variation must be defined to build the grid. In this work, the grid is build starting in 0.1 and ending in 60 using a logarithmic step of 0.1 for both parameters and C.
3.4.2. Random Trees
The Random Trees algorithm introduced by Leo Breiman and Adele Cutler [
19] adopt the principle that the combination of learning models increases the classification accuracy. Then, a collection of decorrelated decision trees is adopted to predict the object classification using a vote based approach.
A feature vector is used as the input of each decision tree and its output is a vote. The class that receives the majority of the votes is adopted as the class of the feature vector.
Each decision tree is trained using the same parameters but with different datasets. The training set of each tree is a random selection of the original training set. In addition, one-third of the training set of each tree is left out to get a running unbiased estimate of the classification error and to get estimates of the variable importance of the feature vector.
The OpenCV implementation of Random Trees was used on this work. The main parameters are: Max. Depth, defining max depth of the trees, Min. Sample Count, defining the minimum samples required to split a leaf node of the tree and Terminatio Criteria, defining when to stop the training stage.
3.4.3. K-Nearest Neighbors
The K-Nearest Neighbors (KNN) is a non-parametric algorithm that stores all training feature vectors. To predict the class of a new and unknown feature vector, the algorithm finds the K nearest feature vectors (neighbors) using an appropriate distance metric to the feature space—in this case, the Euclidean distance. The classification of the unknown feature vector is determined by the majority of the vote of its neighbor’s classes.
When the algorithm directly assigns the class of the closest neighbor to the unknown feature vector. To avoid cases of a tie, the constant K must not be a multiple of the total number of classes.
4. Experimental Results
The experimental results are performed using the acoustic images of an FLS from dataset ARACATI 2014. The training dataset was created using the developed tool. Results are performed using the 10D features as described in
Section 3.3.
4.1. Dataset ARACATI 2014
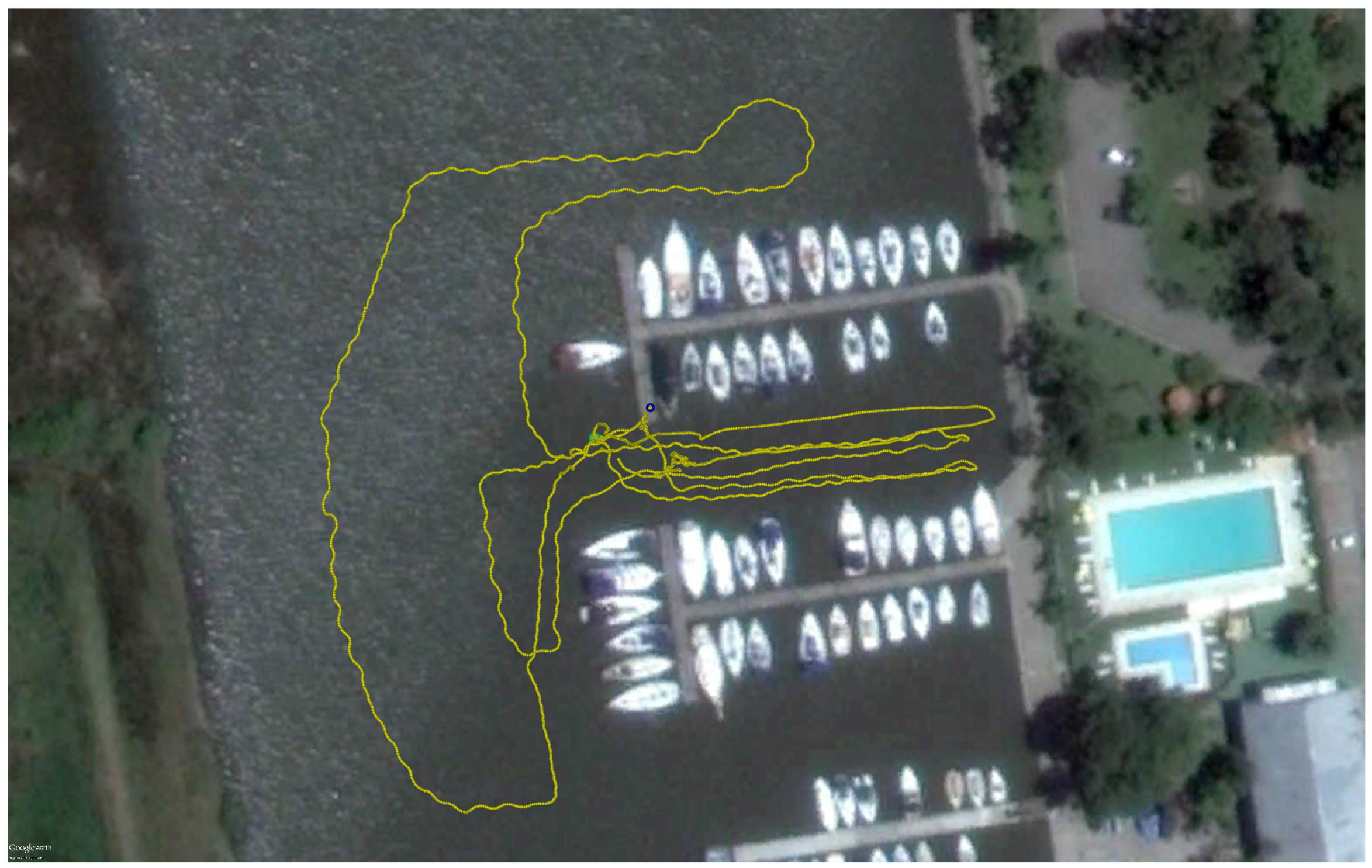
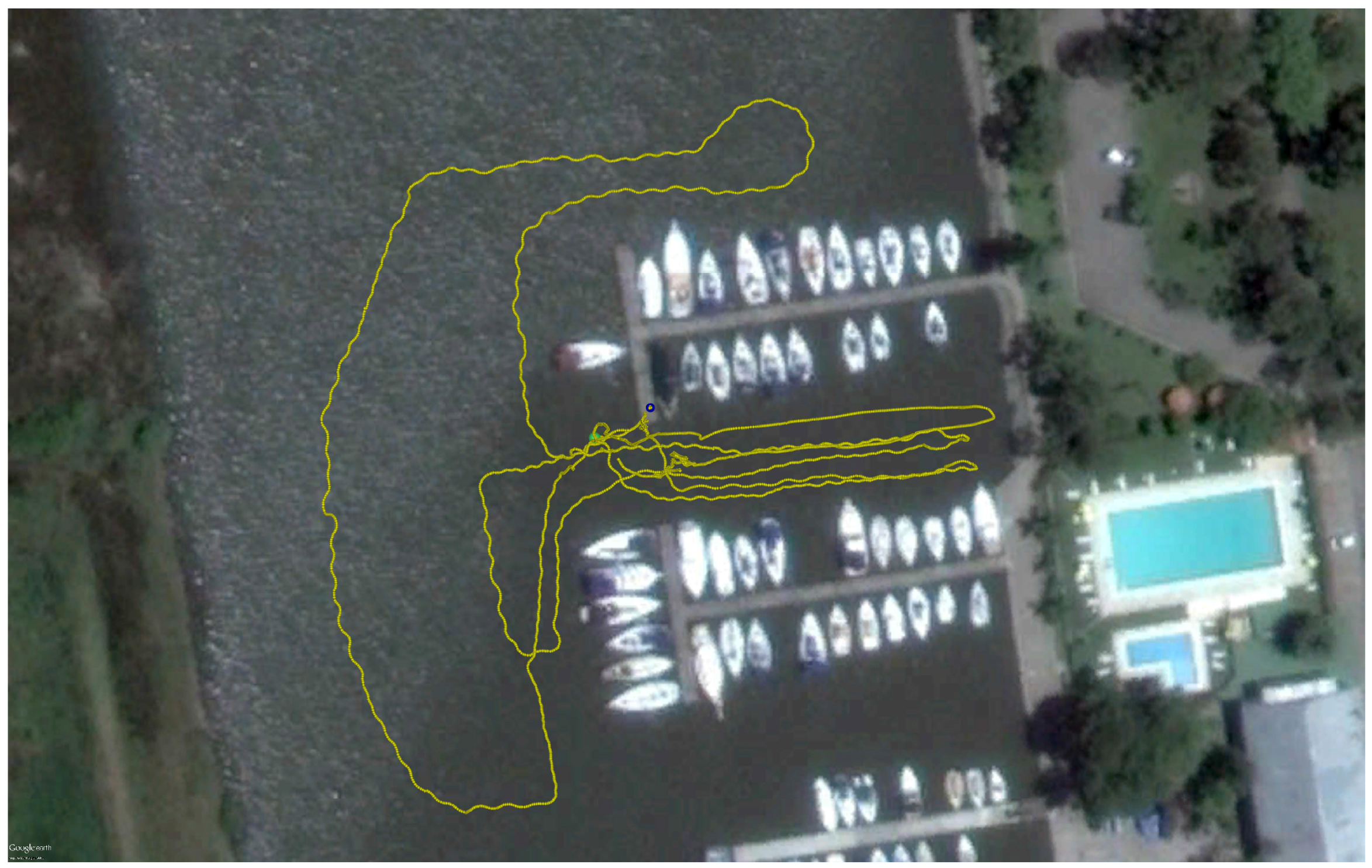
The dataset ARACATI 2014 provided by [
20] was created using a mini Remote Operated Vehicle (ROV) LBV300-5 manufatured by Seabotix (San Diego, CA, USA) equipped with a Forward Looking Sonar BlueView P900-130 (900kHz) and a Differential Global Positioning System (DGPS). The sonar was configured to cover a range of 30 meters and it was mounted under the robot facing forward with a tilt of 0
degrees.
During the entire path, the ROV remained close to the water surface to not lose the DGPS signal. The sonar stays 40 centimeters from the water surface and four meters from the seabed. The harbor structures such as poles, piers, boat hulls and stones are visible in the acoustic images. Some of them are highlighted in
Figure 1.
Figure 7 shows a satellite image of the harbor with the trajectory traveled by the ROV.
4.2. The Classification Dataset
A new classification dataset was generated on this extended work using the developed tool. The training data consists of a total of 531 labeled segments over 257 acoustic images that were manually classified in one of the five different classes: Pole, Boat Hull, Stone, Fish and Swimmer.
The data were split into two sets: the validation data (20%) and the training data (80%). To avoid the overfitting problem, the validation set is never used in the training stage, and the training set is never used to evaluate the classifiers.
The total number of segments in each class is shown in
Table 1. In order to mitigate the effects caused by the unbalanced dataset, our results were generated twice: once with the original unbalanced dataset (the third column) and once compensating the classes in smaller numbers by replicating the segments of the training set (the fifth column).
The parameters adopted in the segmentation algorithm are shown in
Table 2, and these parameters were empirically determined by performing several qualitative tests.
The classifier space must be normalized before training to eliminate the range differences between each variable and thus achieve better results. This normalization reduces the scale problem and makes all the dimensions have the same importance to the classifier. The maximum and minimum values adopted in the normalization are shown in
Table 3. These values were obtained analyzing the training data.
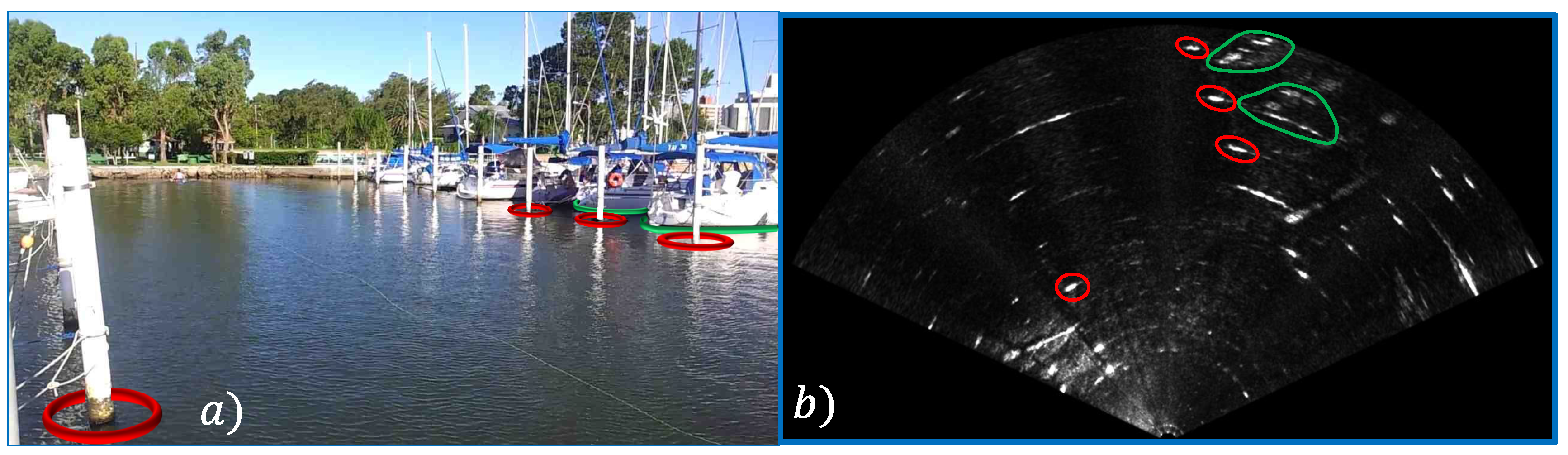
The object recognition in acoustic images is not a trivial task due to the low resolution of the sonar images, as shown in
Figure 8. We believe the segment shape and size are the most distinctive features for object recognition, but this information also suffers from image distortion and non-homogeneous resolution problems.
Quantitative information extracted from the segments of
Figure 8 is shown in
Table 4. The highest and lowest values of each segment are bolded. Some characteristics are easily perceptible, as, for example, the stones are the largest segments, the fish are the smallest segments and the poles are the most convex segments for this dataset.
4.3. Best 2D Feature Combination
In this section, we are interested in investigating the best combination of features for the segment classification problem. First, we computed the Pearson correlation coefficient for the 10D features variables unsing the Dataset ARACATI. The result is shown in
Table 5.
The Pearson coefficients are shown in percentage. The values close to 100% mean strong correlation, values close to negative 100% mean strong inverse correlation and values close to zero mean no correlation. Each row and column represent one feature variable. The main diagonal always has a value of 100% because it indicates the correlation of the variable with itself. In each line, the symbol (∧) indicates the highest correlation and (∨) indicates the lowest correlation.
It is possible to observe that the variables area (6) and pixel count (10) have a strong correlation and the size related variables such as width (1), height (2), and area (6) do not correlation with intensity related variables such as the standard intensity (4) and mean intensity (5). These correlations may be an indication of which values are better for the classification problem, as, for example, pixel count and area can be considered redundant information for the problem.
We also trained the Random Tree classifier for all combinations of two possible variables (2D Feature) using the replicated training set of
Table 1. The obtained hit rate using the validation set can be visualized in
Table 6.
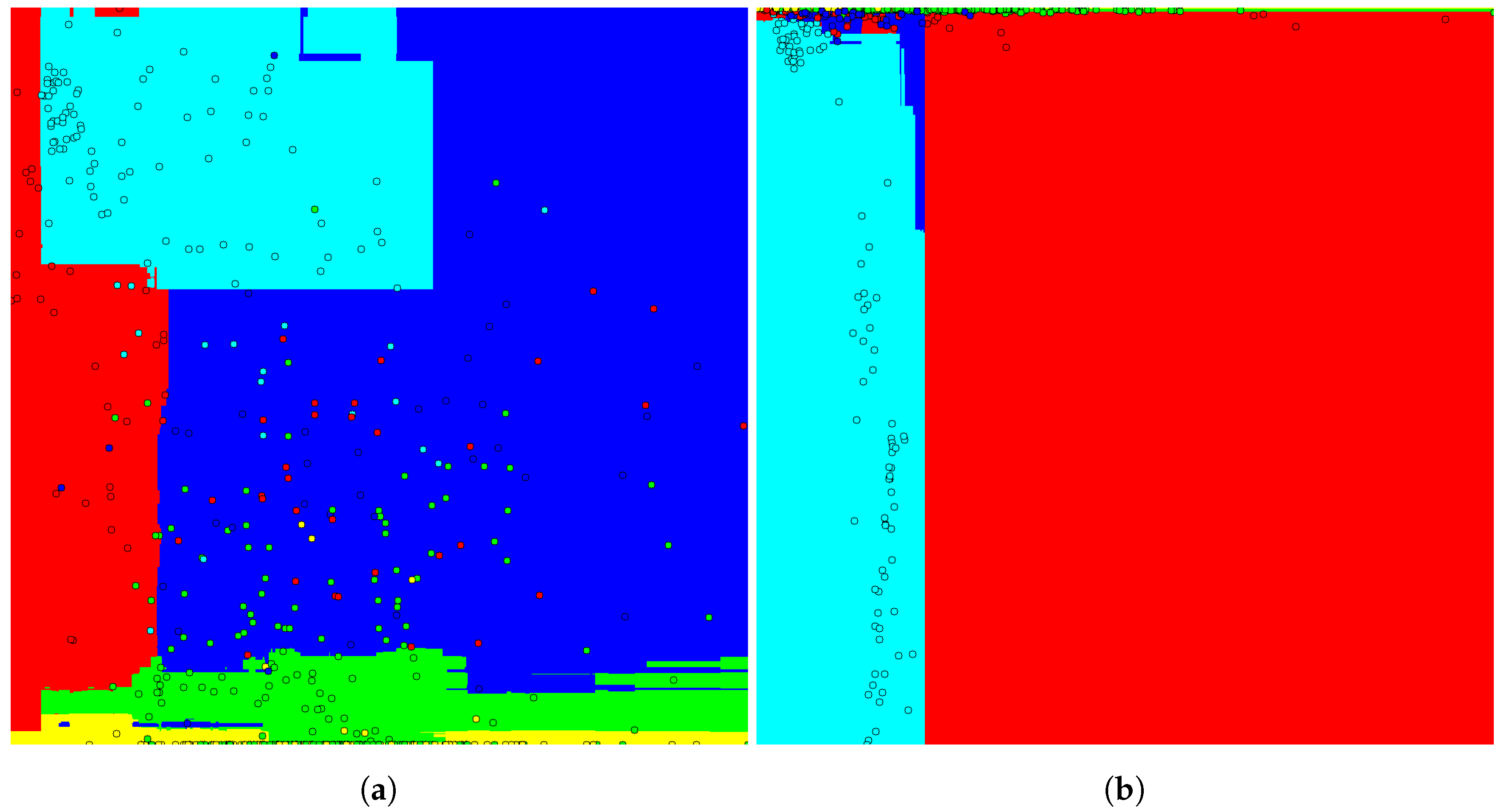
The results show that the worst combination is variable Inertia Ratio (3), with Convexity (8) reaching 51.6% percent of hit rate, and the best is Mean Intensity (5), with Convex Hull Area (7) reaching 89.83% percent of hit rate at least for the Random Tree classifier.
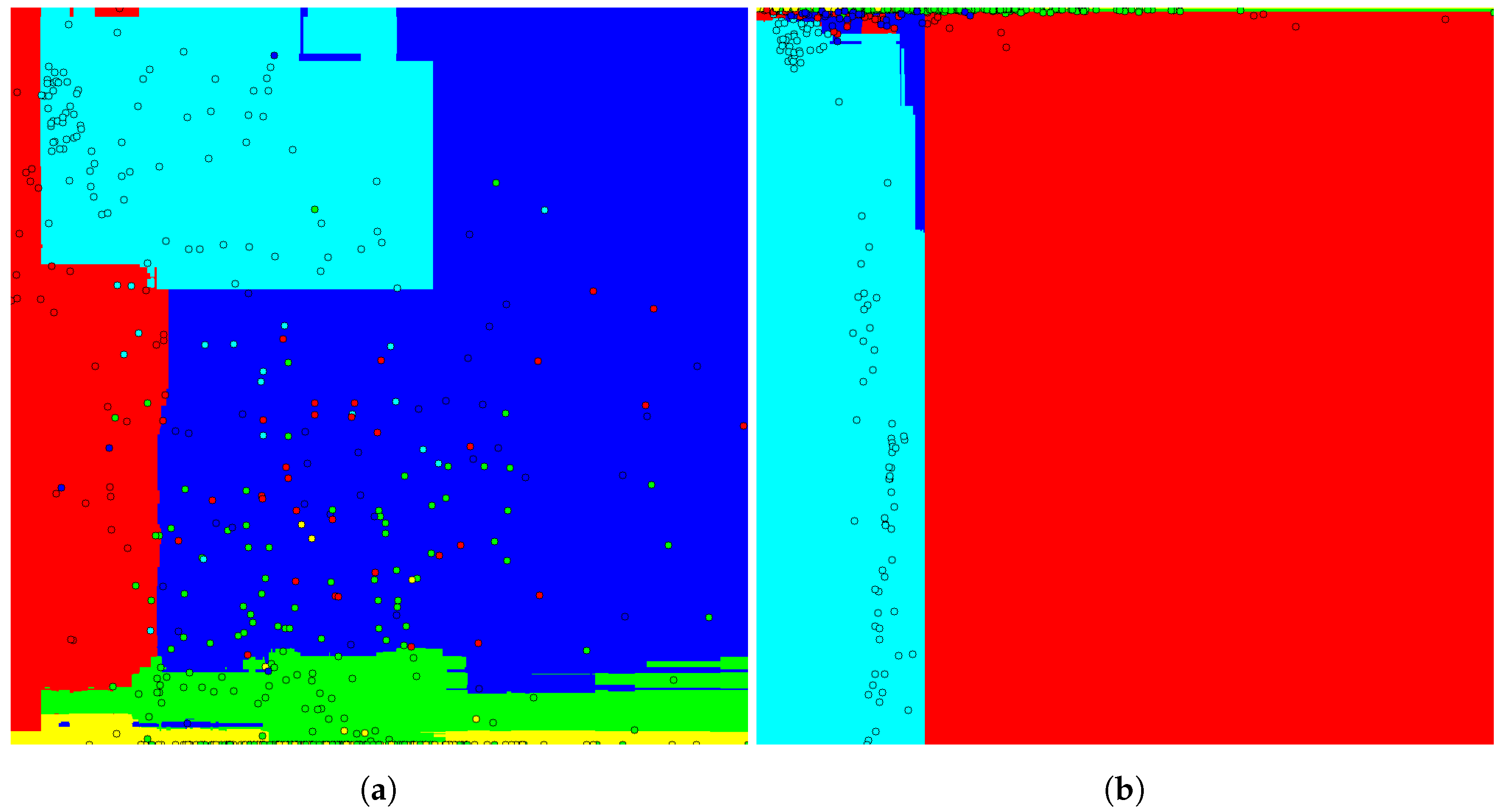
Because it is a 2D space, an image representing the classification space for the best and the worst feature combination can be generated. The images are shown in
Figure 9. The colors represent the objects classes, each circle represents a feature vector and the background represents the classification space.
The classification space is determined by the horizontal and vertical axis of the image that indicates the first and second dimension of the feature vector, respectively. The values increase from left to right and from the top to bottom of the image. In addition, the class colors are represented as, for example, the fish is yellow, the pole is green, the boat hull is red, the swimmer is blue and the stone is cyan.
The presence of feature vector clusters with the same class in the classification space of
Figure 9b is notable, making its classification easier, whereas, in
Figure 9b, the feature vectors are spread almost randomly, making classification more difficult.
Therefore, the results show that geometric information combined with acoustic intensity information can achieve better results than using purely geometric information.
4.4. Results Using 10D Features
In this section, it is investigated which is the classifier that obtains the best results using 10D features. We performed the tests twice: one using unbalanced training data and another using repetitive feature vectors to make the training set balanced as shown in
Table 1.
The results showed that the best performance was achieved by the KNN classifier, with K = 1 reaching a hit rate of 93.57 percent followed by the SVM with the RBF kernel and Random Trees. The balancing technique of the training dataset caused, in general, a decrease in the performance of the classifiers and an improvement in the hit rate of the classes with lower samples in the training set.
5. Conclusions
This work presented a complete approach to the object classification problem using the Forward Looking sonar that includes segmentation, description, and classification.
An open source tool for manual annotation and automatic classification of objects in acoustic images has been developed. In addition, some studies were presented based on a real dataset of a harbor area that indicates that the best combinations of features to describe acoustic objects combining geometric and acoustic intensity information. Finally, an evaluation of the Support Vector Machine (SVM), Random Trees (RT), and K-Nearest Neighbor (KNN) classifiers concluded that the KNN classifier with K = 1 is the most suitable object classifier for acoustic images.
Future work will be focused on expanding the study conducted using new and larger datasets with different classifiers, exploring the use of Convolutional Neural Networks (CNNs), integrating the proposed approach with the Simultaneous Localization and Mapping (SLAM) method, and developing an autonomous navigation system using semantic information.
Finally, regarding the presented segmentation method, we intend to evaluate some modifications like replacing the parameter by a standard deviation of intensity and the use of median filter instead of the average of intensity to detect the peak of intensity.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}