1. Introduction
Nowadays, with the development of street-view panoramas, which provide
panoramic views along streets in the real world, the demand for high-quality panoramic images gradually becomes greater. Image stitching is the key technology to produce high-quality panoramic images, which is also an important and classical problem in the fields of photogrammetry [
1,
2,
3,
4,
5], remote sensing [
6,
7,
8,
9] and computer vision [
10,
11,
12,
13,
14,
15], which is widely used to merge multiple aligned images into a single wide-angle composite image as seamlessly as possible.
In an ideally static scene in which both the geometric misalignments and the photometric inconsistencies do not exist or are not obviously visible in overlap regions, the stitched or mosaicked image looks perfect only when the geometric distance criterion is used. However, as we know, most of the street-view panoramic images are captured by a panoramic camera mounted on a mobile platform. Generally, the panoramic camera is comprised of multiple wide-angle or fish-eye cameras whose projection centers are slightly different. Therefore, those images cannot be precisely aligned in geometry; namely, there exist the geometric deviations for corresponding pixels from different images to different extents. In addition, there also exist photometric inconsistencies to different extents in overlap regions between adjacent images due to illumination variations and/or different exposure settings. This paper focuses on creating a visually pleasant street-view panorama by stitching or mosaicking multiple street-view panoramic images among which there may exist the severe geometric misalignments and the strong photometric inconsistencies.
One traditional and efficient way to eliminate the stitching artifacts caused by the large geometric misalignments existing in the input aligned panoramic images is to detect the optimal seam lines that avoid crossing the majority of visually obvious objects and most of the overlap regions with low image similarity and large object dislocation. The optimal seam line detection methods search for the seam lines in overlap regions between images where their intensity or gradient differences are not significant. Based on the optimally-detected seam lines, multiple aligned images can be mosaicked into a single composite image in which the obvious image parallax caused by image misalignments can be magnificently concealed. Many methods [
2,
3,
4,
5,
6,
16,
17,
18,
19] regarded the optimal seam line detection as an energy optimization problem and solved it by minimizing a specially-designed energy function defined to represent the difference between the original images along the seam lines. For these methods, the key ideas concentrate on how to define the effective energy functions and how to guarantee the optimality of the solution. The energy functions are often defined by considering color, gradient and texture and are optimized via different optimization algorithms, e.g., the snake model [
20], Dijkstra’s algorithm [
21], dynamic programming [
22] and graph cuts [
23]. Nowadays, the optimal seam line detected by many algorithms can avoid crossing the regions with low image similarity and high object dislocation. In our previous work presented in [
19], we proposed an efficient optimal seam line detection algorithm for mosaicking aerial and panoramic images based on the graph cut energy minimization framework. In this paper, we will apply this algorithm to detect the optimal seam lines.
However, when the geometric misalignments are very large, the stitching artifacts perhaps cannot be completely avoided even though the optimal seam lines are detected, especially for street-view panoramic images among which there always exist geometric misalignments to different extents due to those images being captured from scenes with large depth differences by a panoramic camera comprised of multiple wide-angle or fish-eye cameras without a precisely common projection center, which means that the geometric misalignments are different at different positions. Therefore, the large geometric misalignments existing in the input aligned panoramic images should be eliminated as much as possible before finding the optimal seam lines. In this paper, we creatively propose an image warping algorithm based on the optical flow field to reduce the geometric misalignments between input panoramic images. Image warping is a transformation that maps all positions in one image plane to the corresponding ones in another plane [
24], which has been popularly applied in many fields of computer vision, such as image morphing [
25,
26], image retargeting [
27,
28] and image mosaicking [
29,
30]. The key technique of image warping is to find the appropriate transformation functions based on the control conditions and then eliminate the distortions between input images. One famous image warping algorithm worked based on thin-plate splines [
31] that attempted to minimize the amount of bending in the deformation. They used the radial basis functions with thin-plate splines to find a space deformation defined by control points. However, local non-uniform scaling and shearing possibly occurred in the deformed images. The work in [
32] firstly introduced the concept of as-rigid-as-possible transformations, which have the property that both local scaling and shearing are very slight. To produce as-rigid-as-possible deformations, [
33] proposed a point-based image deformation technique, which firstly triangulated the input image and then geometrically minimized the distortion associated with each triangle. However, this algorithm needs to triangulate the input image at first, and the results may not be smooth across triangle boundaries. The work in [
34] provided an image deformation method based on moving least squares [
35] using various classes of linear functions including affine, similarity and rigid transformations. It first found the deformation functions based on the control points or the line segments and then applied the deformation functions on each grid instead of each pixel to reduce the transformation time. At last, it filled the resulting quads using the bilinear interpolation. The work in [
36] proposed an image warping algorithm based on radial basis functions, which formulated the image warping problem as the scattered data interpolation problem and used the radial basis functions to construct the interpolation. It aimed at identifying the best radial basis functions for image warping. Our image warping method is similar to this algorithm, but we used the Multilevel B-splines Approximation (MBA) [
37] to solve the scattered data interpolation problem. Recently, the b-spline approximation technique has been widely used for image registration [
38,
39], image morphing, image warping, curve/surface fitting and geometric modeling.
In addition, due to the differences of both the image capturing viewpoints and the camera exposure settings, there are large differences of color and brightness between the warped panoramic images. The large color differences between those images also can cause the stitching artifacts in the last stitched or mosaicked panorama. Furthermore, the large color differences may affect the quality of the seam lines. Therefore, we also need to suppress the color differences between warped images before we apply the optimal seam line detection. Generally, the color correction approaches can be divided into two broad categories according to [
40]: parametric and non-parametric. Panoramic approaches assume that the color relationship between images can be described by a certain model. A few noteworthy parametric approaches are described here. The work in [
41] proposed a simple linear model to transform the color of the source image to the target image. The transformation matrix was estimated by using the histogram mapping over the overlap regions. The work in [
12] applied the gain compensation (i.e., the diagonal model) to reduce color differences between input images. They computed all gains by minimizing an error function, which is the sum of gain normalized intensity errors for all overlapping pixels. The work in [
42] also employed the diagonal model for the color and luminance compensation where the correction coefficients were computed as the ratio of the sum of pixel values in the overlap regions. As stated in [
43], the linear transformation models can provide a simple yet effective way to transform colors, but they have clear limitations in explaining the complicated nonlinear transformations in the imaging process. Non-parametric approaches can handle this problem well. Non-parametric approaches do not follow any particular model for the color mapping, and most of them use some form of a look-up table to record the mapping of the full range of color levels. As stated in [
40], parametric approaches are more effective in extending the color in non-overlap regions without generating gain artifacts, while non-parametric approaches can provide better color matching results. The work in [
44] proposed to use the joint histogram of correspondences matched using the SIFT features [
45] to correct the color differences. The color mapping function was estimated by using an energy minimization scheme. The work in [
46] proposed a color correction approach by using the cumulative color histogram. This method used the cumulative histogram-based mapping to automatically adapt the color of all source images to the reference image. The work in [
43] presented a nonlinear and nonparametric color transfer framework that operates in a 3D color space. Based on some control corresponding colors in a given image pair, this method used the probabilistic moving least squares to interpolate the transformation functions for each color. We correct the color differences between two images based on the matched extreme points, which are extracted from the histograms over the overlap regions. Both the Probability Density Functions (PDFs) and Cumulative Distribution Functions (CDFs) are used to find the reliably-matched extreme points. To reduce the gain artifacts in non-overlap regions, we propose to apply the alpha correction method to smooth the transition from non-overlapping regions to overlapping ones.
Although we propose efficient approaches to correct the color differences and detect the optimal seam lines between warped panoramic images, there may also exist some color transitions along the seam lines due to the color differences not being able to be eliminated completely. In order to further conceal these artifacts, the image blending techniques can be further applied along the seam lines. In the last several decades, many image blending algorithms have been proposed to smooth the color differences along the seam lines, such as feathering [
47], alpha blending [
48], Laplacian pyramid blending [
49], Poisson blending [
50] and the gradient domain image blending approach [
51]. In this paper, we simply applied the Laplacian pyramid blending algorithm [
49] to eliminate the stitching artifacts and generate the last pleasant panorama.
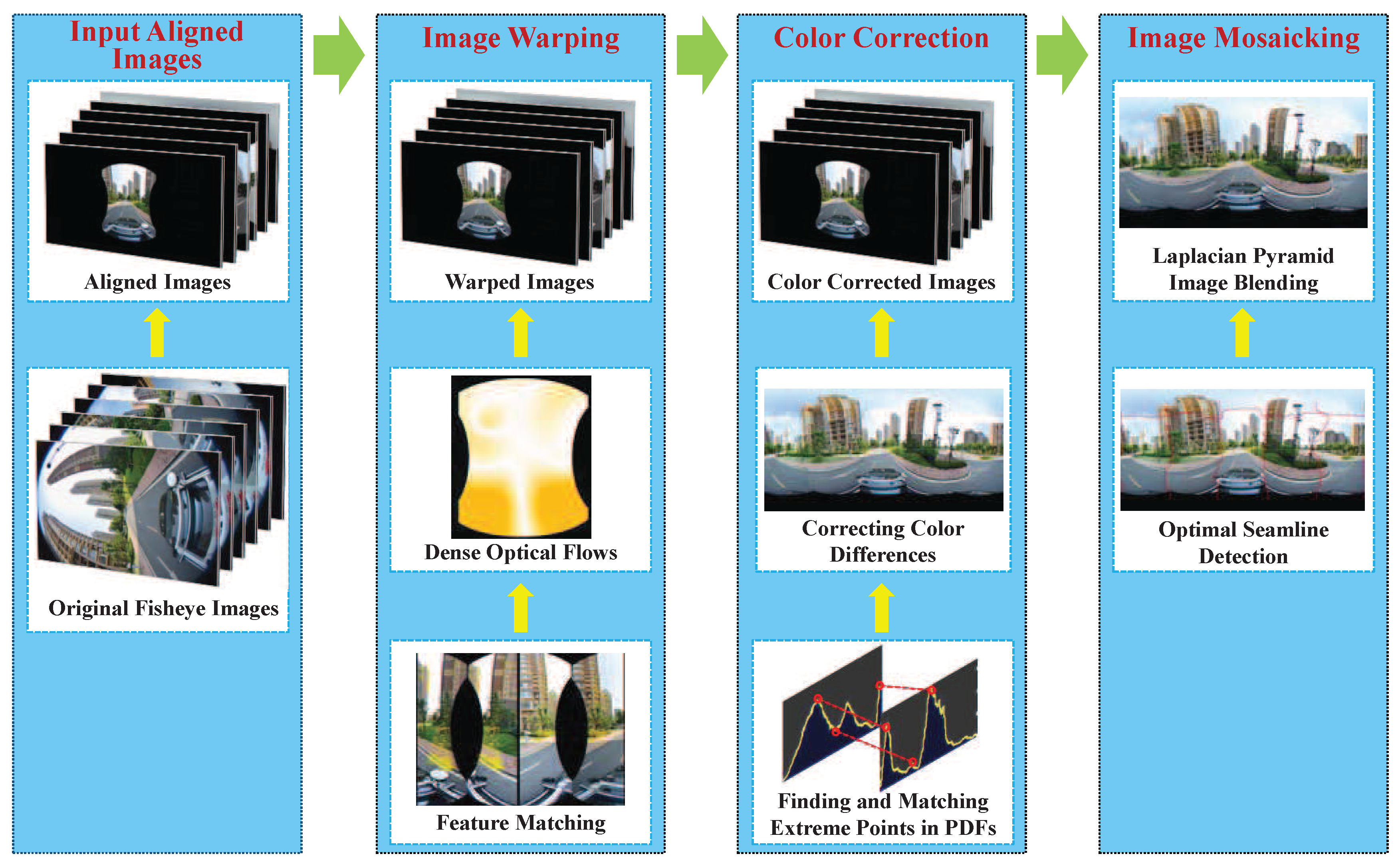
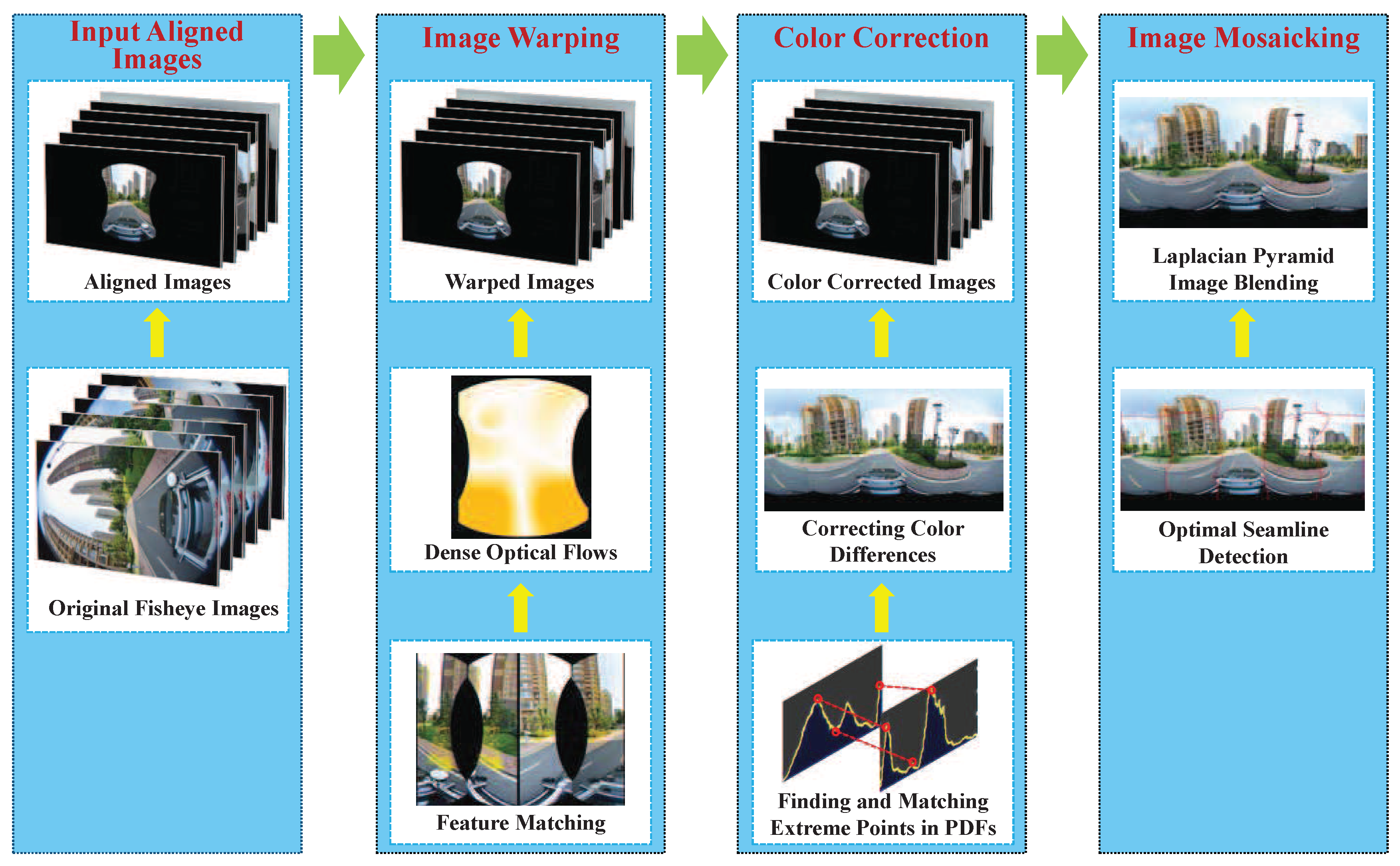
In this paper, we propose a unified framework for our developed street-view panorama stitching system, as described in
Figure 1. First, multiple original images, which were captured from a single panoramic camera comprised of multiple wide-angle or fish-eye cameras (usually digital SLR cameras) without a precisely common projection center, are fed into our stitching system as the input. Therefore, we will align these input images into a common spherical coordinate system based on the found feature correspondences using the existing open-source library. After that, our proposed image warping method based on the dense optical flow field approximately interpolated from the sparse feature matches, which is detailed described in
Section 2, is used to greatly reduce the geometric misalignments. Then, an automatic contrast adjustment and an efficient histogram matching-based color correction approach presented in
Section 3 are used to reduce the color differences. Finally, we adopt an efficient seam line detection approach based on the graph cut energy minimization framework to find the optimal seam lines between two overlapped images followed by applying the image blending to eliminate the color transitions along the seam lines. By our proposed unified panorama stitching framework, our system can generate a pleasant street-view panorama as seamlessly as possible by stitching multiple panoramic images from the cameras mounted on the mobile platform. Experimental results on challenging street-view panoramic images are reported in
Section 5 followed by the conclusions drawn in
Section 6.
2. Image Warping
In our developed street-view panorama stitching system, we first check whether all input images are geometrically aligned into a common spherical coordinate system. If not, we will align them by using the open-source library PanoTools (available at
http://www.panoramatools.com/), which also serves as the underlying core engine for many image stitching software, such as PTGui (available at
http://www.ptgui.com/) and Hugin (available at
http://hugin.sourceforge.net/). However, there always exist large geometric misalignments between these aligned images to different extents because those images were captured from scenes with large depth differences by a single panoramic camera comprised of multiple wide-angle or fish-eye cameras without a precisely common projection center. Those geometric misalignments are so large that the stitching artifacts cannot be avoided completely even though the optimal seam lines are detected for image stitching. To ensure the high quality of the last stitched panorama, we propose to apply the image warping technique to eliminate those large geometric misalignments as much as possible. To describe our proposed image warping algorithm more clearly, we first consider a simple case of two aligned images
and
with an overlap. The process of our proposed image warping algorithm is described as follows. Firstly, the corresponding points between two images are found as the control points of image warping, and the sparse optical flows are calculated for those control points. Secondly, the Multilevel B-splines Approximation (MBA) algorithm [
37] is used to approximately interpolate the dense optical flows for all integral pixels in the warped image with respect to the original one from the sparse optical flows. Lastly, we warp the two input images based on the dense optical flows, and thus, the geometric misalignments can be greatly lessened. For the case of multiple images, a simple strategy is proposed to first handle the horizontal images and then to deal with the vertical ones.
2.1. Feature Point Matching
To warp two images with large geometric misalignments, we need to find the control points at first. The quality of the warped image mainly depends on the accuracy and densities of control points. In this paper, we apply the feature matching algorithm to robustly find the sparse matching points, namely the control points. The main ideal for feature matching is to first extract local invariant features independently from two images and then characterize them by invariant descriptors. The distance between two descriptor vectors is used to identify candidate matches. However, the nearest neighbors is not always the best match due to occlusion and deformation derived from large viewpoint changes and repeated structures in the scenes. Then, we applied the assumption presented in [
52] and the epipolar geometrical constraint to remove the outliers. The major steps of the feature matching include initial matching and outlier detection, which are summarized in Algorithm 1. An example of finding point correspondences between two panoramic images with an overlap is illustrated in
Figure 2.
| Algorithm 1 The proposed feature point matching algorithm. |
Initial Matching- (a)
Extract and describe two sets of local invariant features from two overlapped images and by using the SURF algorithm, respectively; - (b)
Find the initial point matches between and according to the conditions listed in Section 2.1.1.
Outlier Detection- (a)
Find the neighboring inlier matches for each match . - (b)
Calculate the mean motion and the standard deviation of all matches in ; - (c)
Identify the outliers according to the criterion defined in Equation ( 3); - (d)
Further identify the outliers according to the epipolar geometric constraint.
|
2.1.1. Initial Matching
Given two adjacent images
and
with an overlap, the local invariant features are extracted and described by the SURF algorithm [
53]. Let
be a feature point where
denotes the 2D coordinate of this feature point, and
representing its corresponding invariant descriptor vector, and
and
be the feature point sets extracted from
and
, respectively, where
M and
N denote the numbers of the feature points extracted from
and
, respectively. Generally, for one feature point
in
, the feature point
with the nearest Euclidean distance
, which is not larger than a predefined threshold
, can be regarded as the corresponding matching point of
. However, this simple strategy has some drawbacks in the context of feature matching. This mainly because that the distance values between different corresponding pairs may vary in a relatively large range, so any permissive distance threshold
cannot avoid the appearance of high rate outliers when covering most of the good correspondences. Thus, we propose to modify the matching strategy as follows. In this paper, we accept two feature points
and
as a potential match only when they satisfy the following conditions:
The feature points and are the nearest neighbors of each other. Namely, for the feature point , is its nearest neighbor in . At the same time, for the feature point , is its nearest neighbor in .
The Euclidean descriptor vector distance between two feature points and is not larger than , i.e., .
We represent the nearest distance between and as and the next distance as , respectively. The distance ratio should be smaller than the predefined threshold . Similarly, for the feature point , the distance ratio should be smaller than as well.
By this matching strategy, we obtain a set of initial matches denoted as .
2.1.2. Outlier Detection
After initial matching, there may still exist a few outliers in
. Of course, we need to filter out those outliers. According to the assumption proposed by [
52] that the matches in a small neighborhood tend to have the consistent location changes (i.e., motions), in this paper, we firstly apply this assumption to identify the outliers. Then, we applied the widely-used constraint of the epipolar geometric to further identify the outliers.
Given a match
, the motions from
to
along the horizontal direction and the vertical one are calculated, respectively, as follows:
where
and
. Thus, the magnitude value of the motion vector
can be calculated as:
Here, we use to represent all the three motion components of the match .
At first, we assign the labels of all matches as
Inlier, namely, for each match
, the label
, and then we iteratively find the outliers. For each match
, we find
(
was used in this paper) neighboring match points of
from
denoted as the set
. Then, we collect all matches whose labels are
Inlier from
as a new set
. If the number of inliers in
, namely, the size of
, is less than
(
was used in this paper), we directly label this match as an
Outlier, namely,
, otherwise, we determine whether this match is an inlier by checking whether it has the consistent motion with its neighbors
. For each match
, the motion
from
to
can be calculated according to both Equations (
1) and (
2). Then, the mean motion
and the standard deviation of all the motions
of all match points in
can be determined easily. According to the following measurement proposed by [
52], the label of the match
can be determined as follows:
where
denotes the absolute distances in three components between the motion
of the match
and the mean motion
of its neighbor matches.
λ is a predefined parameter, and we set as
.
After that, we applied the epipolar geometric constraint based on the estimated fundamental matrix to further detect the outliers. The fundamental matrix is estimated by using the RANSAC algorithm. As we known, we cannot estimate the fundamental matrix between two panoramic images which have been projected into the spherical coordinate at first. Therefore, we first project the panoramic images into the perspective plane, and the fundamental matrix is estimated in this plane by using the RANSAC algorithm. The epipolar lines are calculated in the perspective plane at first, and then we re-project them into the spherical coordinate to identify the outliers. At last, we can find all the inliers from denoted as of the set .
2.2. Approximate Interpolation of Dense Optical Flows
Let
and
be the warped images of two adjacent images
and
, respectively. The aim of our proposed image warping algorithm is to ensure that the geometric alignments between the warped images
and
become smaller. To achieve this objective, we propose to approximately interpolate the optical flows of all of the integral pixels in
with respect to
and all of the integral pixels in
with respect to
based on the disparity vectors of the reliable point matches with respect to each other as the control points. Firstly, we calculate the disparity vectors
and
of each reliable point match
in
from the warped images to the original ones as follows:
where
and
. In this way, we expect to warp the images
and
based on the half offsets of real disparity vectors to reduce the warping distortion.
Secondly, we propose to approximately interpolate the optical flows of all integral pixels in the warped images
and
based on the disparity vectors
and
of the control points
and
, respectively. This problem can be formulated as the scattered data interpolation problem. Due to the sparsity of the control points, in this paper, we adapt to apply the Multilevel B-Splines Approximation (MBA) [
37] to solve this problem, which has been widely used for image registration, image morphing, image warping, curve/surface fitting and geometric modeling. By this MBA interpolation, we separately interpolate the horizontal and vertical components of optical flows (i.e., disparity vectors) of all the integral pixels in
and
, respectively. In this way, we finally obtain the dense optical flows
and
of all of the integral pixels
and
in the warped images
and
with respect to the original images
and
, respectively.
2.3. Two Image Warping
Here, we demonstrate how to generate the warped image from the original image based on the dense optical flows of with respect to , and the generation of the warped image is similar. For each pixel , we can easily calculate its corresponding 2D position in based on its approximately interpolated optical flow (i.e., disparity vector) as . Then, we use the bilinear interpolation algorithm to interpolate the intensity of the corresponding point in as the intensity of the integral pixel .
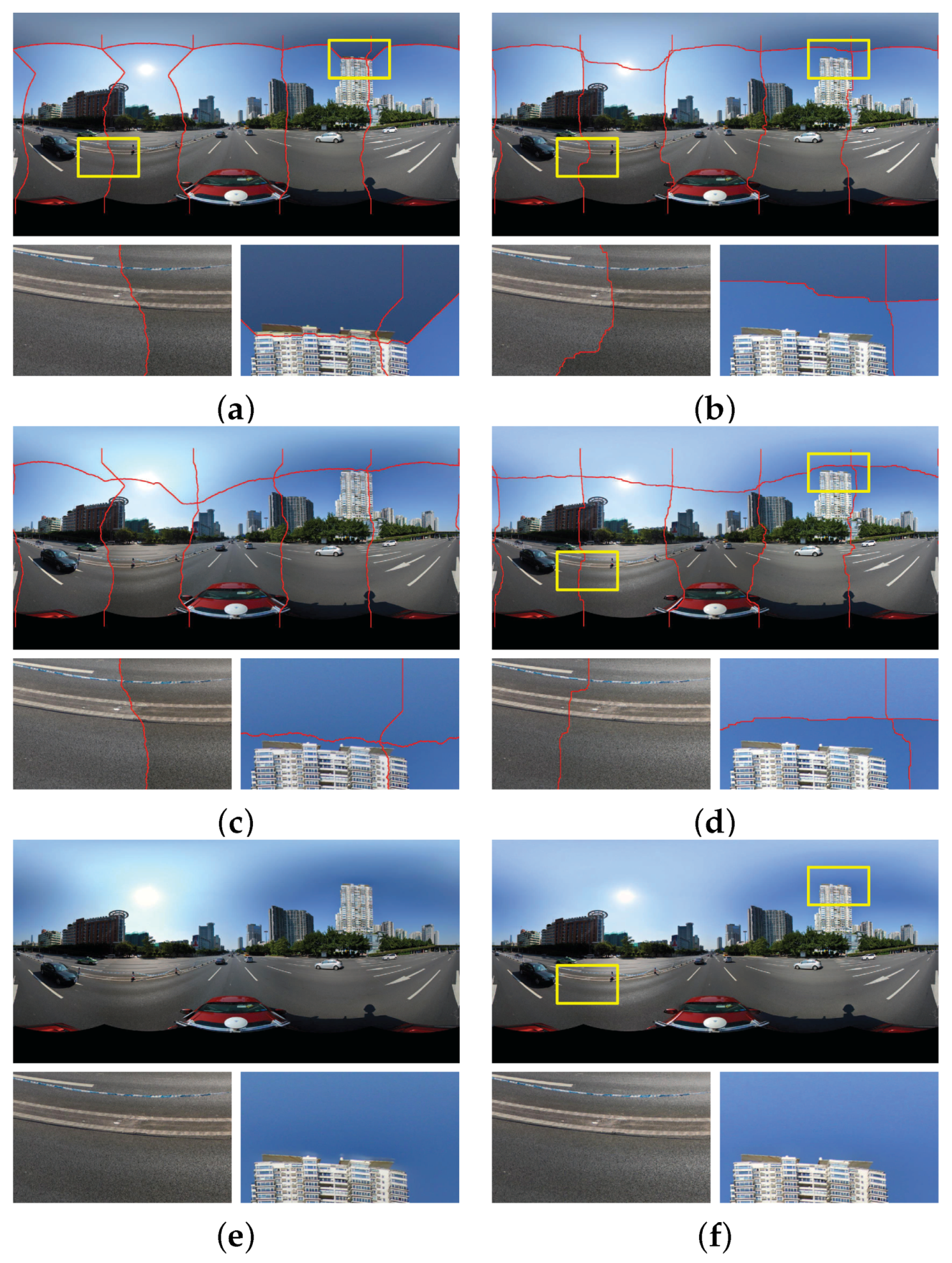
According to the above image warping procedure, we can obtain two warped images from two input panoramic images with the overlap. The geometric misalignments between warped images become smaller than those between the original images after warping correction.
2.4. Multiple Image Warping
Until now, we have introduced how to warp two images based on the optical flows. However, we need to warp multiple input images to generate the last panorama. In the experimental results presented in this paper, the input images are comprised of five horizontal ones and one vertical one, which are represented as
, whose correspondingly warped images are represented as
, and the overlap relationship of those images is shown in
Figure 3. For this particular case, here we will in detail introduce how to warp these six images for producing the last panorama before color correction. Other cases of multiple images can be handled in a similar way. For multiple input panoramic images, we first collect all image pairs according to their overlap relationship, as shown in
Figure 3. Obviously, there are five image pairs along the horizontal direction, and one image pair along the vertical direction. We first handle the horizontal image pairs and then deal with the vertical image pair. For each horizontal image pair, we match them one by one by the method presented in
Section 2.1, as an illustrative example shown in
Figure 4, from which we can find that one horizontal image is overlapped with two adjacent images in the horizontal direction. For example, for the image
, it overlaps with
and
, respectively, so we need to collect all matching points from these two overlap regions as the control points for warping
. The dense optical flow field of the warped image
with respect to the original image
can be approximately interpolated based on those control points via the MBA algorithm. Therefore, five horizontal warped images
,
,
,
and
can be generated by warping their corresponding original images according to the method presented in
Section 2.3, respectively.
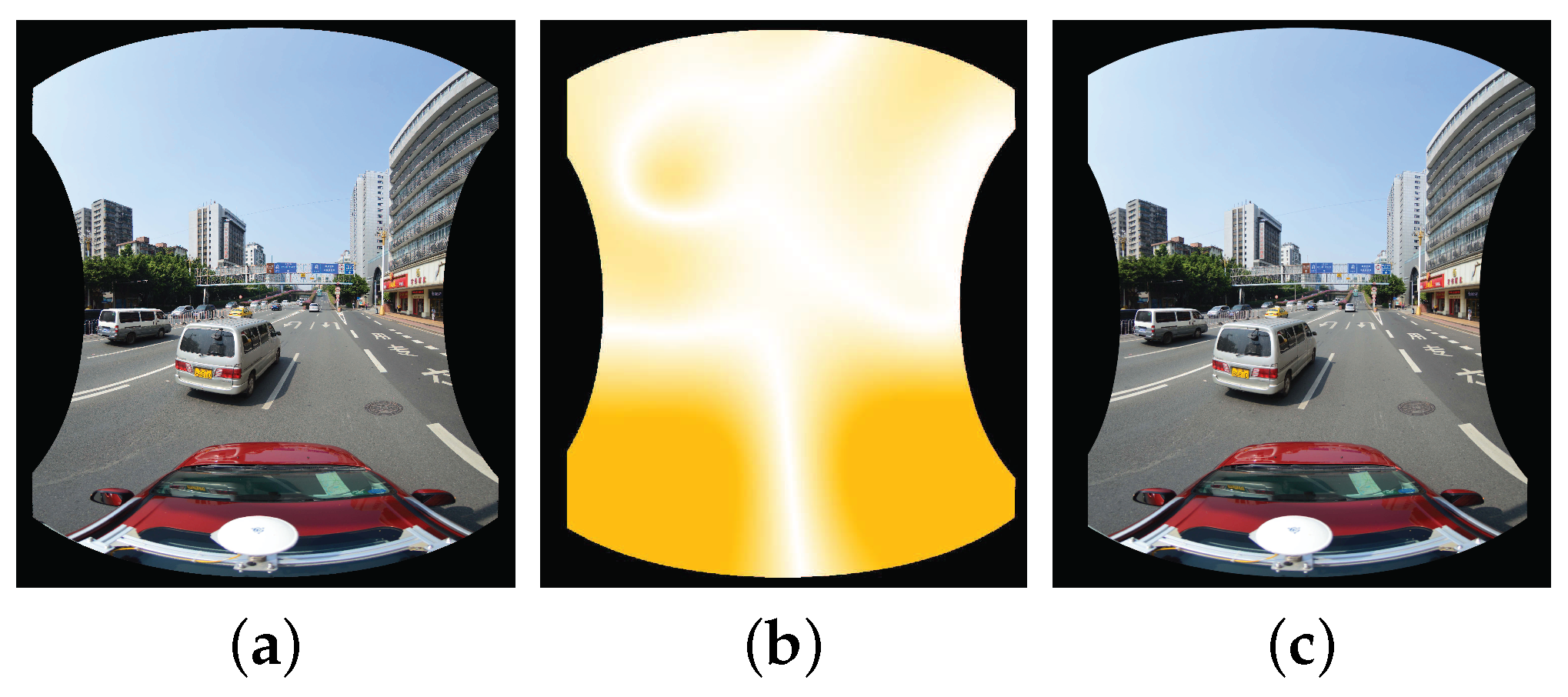
Figure 5 shows an example for warping one horizontal image. After that, we generate the bottom blended image
by blending all horizontal warped images according to the proposed color correction method presented in
Section 3 and the adopted image mosaicking strategy described in
Section 4. Finally, to produce the last panorama, the top image
and the horizontal blended image
will be warped according to those matching points as the control ones.
2.5. Summary
In this section, we proposed a new image warping method to eliminate the large geometrical misalignments between adjacent aligned images. This method includes three stages: feature point matching, approximate interpolation of dense optical flows and image warping. In the first stage, we first used the SURF algorithm [
53] to find the initial matching points between two images and then applied the assumption presented in [
52] and the epipolar constraint to eliminate outliers. The sparse optical flows can be calculated between two matched feature points. In the second stage, we proposed to apply the dense optical flows to simulate the non-rigid deformations between aligned images. The dense optical flows will be interpolated via the MBA algorithm [
37] from sparse ones. In the last stage, we proposed to warp the initially aligned images based on the dense optical fields, and we also proposed a strategy to handle multiple image warping. The key contribution of this section is that we proposed to use the optical flows to simulate and eliminate the large non-rigid geometrical misalignments between input aligned street-view images. This method is simple and completed by combining some conventional algorithms, such as SURF, MBA, and so on. However, to the best of the authors’ knowledge, no one has applied this efficient strategy to handle the large geometrical misalignments between street-view panoramic images before color correction and image mosaicking.
3. Color Correction
The large geometric misalignments can be efficiently eliminated by our proposed image warping algorithm, but there also exist the color differences between the warped images, so the stitching artifacts are still visible. Generally, the image blending technique can solve this easily by smoothing the color along the seam lines. However, it does not work well for input images with very large color differences. The simple image blending may not be able to efficiently conceal the artifacts if we don not magnificently correct color differences between images in advance, which results in low-quality panoramic images, as the illustrative example shown in
Figure 6. In addition, the large color differences maybe also affect the quality of the detected seam lines. Thus, in this paper, we propose to reduce the color differences between warped images before the optimal seam lines are detected. Generally, the color differences should be also corrected before the image warping step to ensure the quality of feature matching results. However, our adopted SURF feature matching algorithm is robust enough to the large photometric inconsistencies, so there is no obvious influence on our algorithm if we apply the color correction after image warping.
In this paper, we first apply the automatic contrast adjustment to reduce the brightness differences between images and then propose a novel and efficient color correction algorithm via matching extreme points of intensity histograms to further reduce the color differences. For the overlap image regions between two images, we construct their own Probability Density Functions (PDFs) and Cumulative Distribution Functions (CDFs) with respect to the intensity histograms in the three HSV channels, respectively. One way to eliminate color differences is to ensure that the three CDFs of the overlap regions in the first image in the three HSV channels are approximately the same as those CDFs of the overlap regions in the second image, respectively. Obviously, we can correct the CDFs based on several uniformly-spaced knots, as [
54] did. However, due to the existence of geometric misalignments, the scenes presented by two images in the overlap regions are not completely consistent. To solve this problem, we replace the knots by the matched extreme points extracted from the two PDFs. If the number of matched extreme points is not sufficient, we will suitably introduce those uniformly-space knots. At last, the intensities of all of the pixels in the two images are modified afterwards based on the matched extreme points extracted from the PDFs, not only for the pixels in the overlap regions, but also in the non-overlap regions.
3.1. Automatic Contrast Adjustment
At first, in order to make sure that multiple images have the similar contrast, which can produce satisfactory blending results, the three RGB channels of individual images are automatically adjusted in contrast. The histograms of a color image are calculated firstly in each of the three RGB channels, respectively. Let
be a single-channel image and
be a set of one-dimensional sorted intensities of all valid pixels in
in the ascending order, where
N denotes the total number of valid pixels in
and
represents the intensity of the
k-th sorted pixel in
. The minimal and maximal intensities
and
in
are defined, respectively, as follows:
where
denotes the upper integer of a real value Δ and
c is a small percentage value in the range of
(
was empirically used in this paper), which can be used to skip over a part of the real minimal and maximal intensities due to the fact that these pixels may be caused by noises and information lacking in most cases. The minimal and maximal intensity values of the
R,
G and
B channels of a color image are denoted as
,
,
,
,
, and
, respectively. The minimal and maximal intensity values of the whole color image are defined as
and
, respectively. Therefore, any intensity
I of the
R,
G and
B channels of a color image will be modified as:
In the same way, all of the images to be used for creating a panorama will be automatically adjusted in contrast, which will slightly reduce the brightness differences between images.
3.2. Finding Extreme Points
After applying the automatic contrast adjustment on the multiple panoramic images, we propose to further reduce the color differences between panoramic images by matching extreme points of histograms. For the statistic analysis, only valid pixels in the overlap regions between two images are considered. Let and be the overlap image regions in two images, respectively. To make a better description of the information hidden behind the image, we convert and from the original RGB color space to the HSV color space, respectively. For each channel of and , we calculate their PDFs and CDFs, which are denoted as , , and , respectively.
To robustly find extreme points in both and , these two PDFs are smoothed first by a Gaussian function to suppress possible noise. The initial local extreme points can be easily obtained from the smoothed and . In an ideal situation, the extreme points should be uniformly distributed in the color space. However, most of the extreme points are relatively centralized in some cases, which will lead to the information redundancy due to that multiple extreme points being selected out to represent the similar image statistical information. To avoid the situation mentioned above, we further checkout all initial extreme points by the local window suppression. Let be the intensities of K extreme points in , which are sorted in the ascending order. Given an extreme point , we generate a neighborhood range centered on the corresponding intensity with the size of . We set if not specifically stated in this paper. If there exists more than one extreme points located in this neighborhood range, the extreme point with the highest frequency in will be retained, and other extreme points will be removed. All initial extreme points are checked in this way, and the retained extreme points are used for the following matching. The final extreme points extracted from and are represented as and , where and are the numbers of extreme points in and , respectively. For each extreme point , it consists of 4 components according to , where F denotes the frequency of this point in PDF, L represents the corresponding intensity and and mean the cumulative values of the intensities and in CDF (we set if not specifically stated in this paper).
3.3. Matching Extreme Points
The extreme points can sufficiently reflect image statistical characteristics. To efficiently adjust the color differences, one way is to ensure that the intensities of corresponding extreme points are the same. Thus, we should match the extreme points firstly. To reliably match these extreme points
and
, we define a cost function to measure the matching similarity of two extreme points
and
as:
where
is the maximal frequency of all of the extreme points in both
and
. The above cost function judges the two extreme points from the view of both PDF and CDF. The first term
indicates that those possibly matched extreme points with the higher frequencies generate higher costs, which may be peak out first in the following matching selection strategy. The second term
indicates that there are the similar frequencies for two possibly matched extreme points
and
. The last term is applied to ensure that the accumulative values of two possibly matched extreme points
and
are approximate. From this term, we can find that if the small ranges of cumulative values of two extreme points are similar, the numerator
is close to the denominator
, which results in that this term being close to one. In contrast, if the numerator is smaller and the denominator is larger, this term will approach to zero. In summary, if the frequencies of two extreme points are larger and more similar and the accumulative values of those points are more approximate, their matching cost is bigger. In contrast, it is smaller. The higher the cost function value is, the more likely these two extreme points are matched. Based on this cost definition, a
matching cost matrix
is created. In order to efficiently eliminate the impossibly matched extreme points, we empirically designed three hard conditions from the view of both PDF and CDF to check whether two extreme points
and
are possibly matched as follows:
where
and
are two empirical thresholds (
and
were used in this paper)
is the maximal value of CDF, namely the valid pixel number of overlap regions. The matching cost
is set to zero, i.e.,
, if at least one of the above three conditions is not met, namely
and
are not possibly matched. From the view of PDF, the first condition indicates that the frequencies of the two possibly matched extreme points
and
should be a relatively small difference. From the view of CDF, the second and third conditions indicate that
and
are possibly matched if their corresponding CDF values are approximate. According to the above three hard conditions, the matching cost matrix
will be updated, in which all of the zero elements indicate that they are not possibly matched.
Based on the computed matching cost matrix
, we propose an efficient iterative strategy to find the matched extreme points as the following steps:
Step 1: Finding the highest non-zero cost element from the matrix and its corresponding extreme points and is selected out as a reliable extreme point match.
Step 2: Updating the matrix by removing the i-th row and the j-th column due to that and have been successfully matched.
Step 3: Performing the above two steps iteratively until the updated matrix is empty or there exists no non-zero element in .
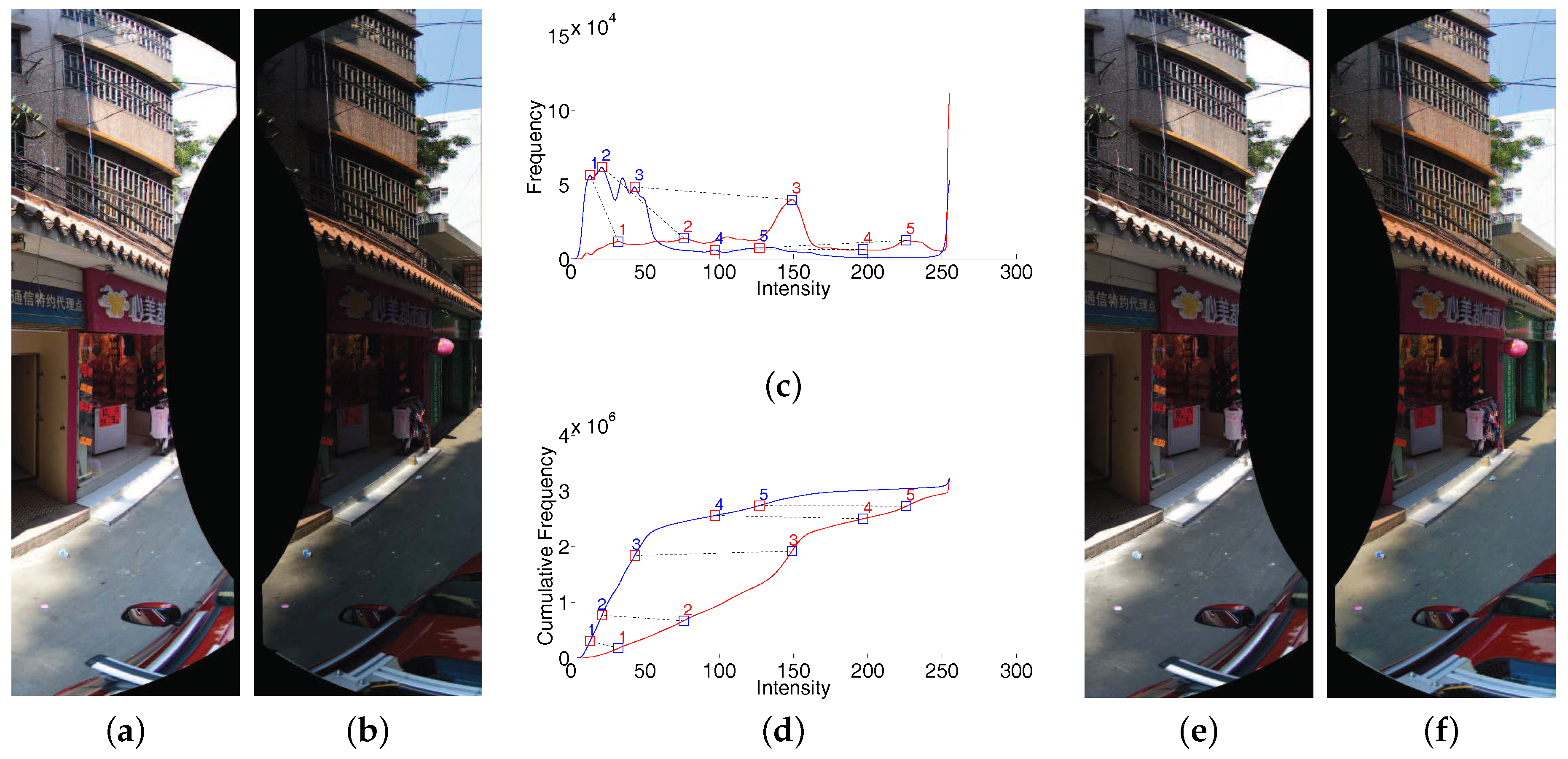
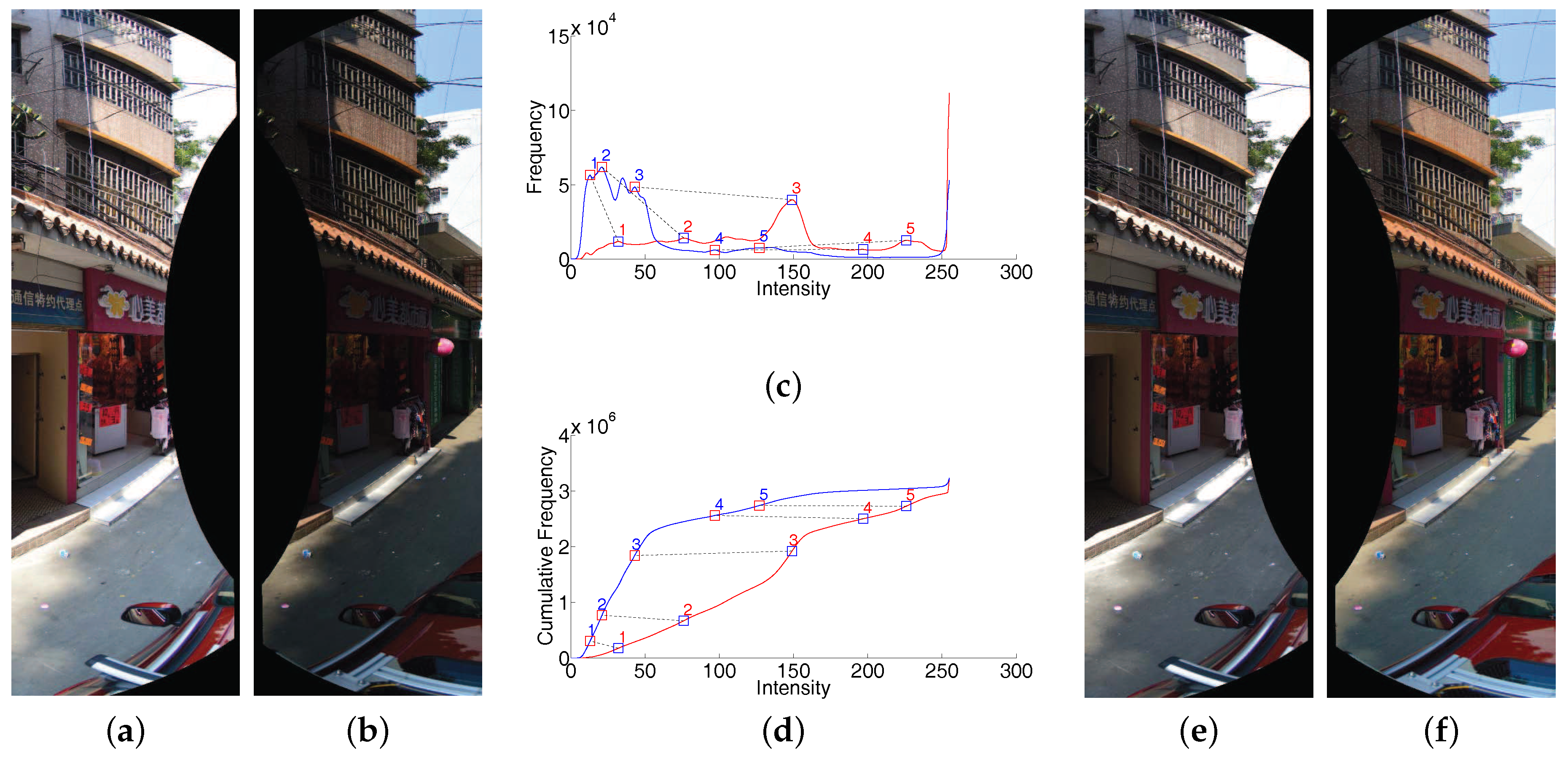
By the above iterative strategy, a set of reliable extreme point matches will be found. In
Figure 7, we have shown a visual example of our proposed color correction approach. The two input images have large color differences in overlap regions, as shown in
Figure 7a,b. We find 5 matched extreme points in the PDF of one channel. Based on those correspondences, the large color differences can be eliminated, as shown in
Figure 7e,f. From this example, we can find that our proposed approach can handle the images with large color differences very well.
Sometimes, no match or too few matches can be reliably found via the above matching strategy in the whole CDF range or some relatively large CDF range. In this case, we will introduce more matches with the help of both and , which are selected from H uniformly distributed points and from and , respectively, but not from the previously found extreme points. The same number of sampling points in and are uniformly selected in accordance with the cumulative density values. In our experiments, the percentages of sampling intervals were used as [0.1, 0.3, 0.5, 0.7, 0.9]. If there exists no extreme point match found in the ranges and , the current sampling points and will be added into the matching set as a new point match, where κ is a given threshold in advance ( was used in this paper).
3.4. Correcting Color Difference
The extracted matching points in the overlap image regions are then applied to correct the intensities of two adjacent images, including the pixels in non-overlap regions. Let
and
be the final matching points in CDFs in the overlap regions
and
with
N point matches. Based on the matching results, the intensities of the matching points
and
are modified to
where
and
denote the intensities of
k-th match
in CDFs, respectively. In this way, the intensities of
are corrected to
, respectively, where
. Based on these corrections, the intensity of any pixel in both
and
will be adjusted linearly. For example, given a pixel
whose intensity
will be linearly corrected as:
where
,
and
denote the intensities of two matching points in
that are closest to
, and the
and
are the corresponding corrected intensities. In order to produce a smooth and gradual transition from non-overlaping regions to overlaping ones, the alpha correction method is conducted as:
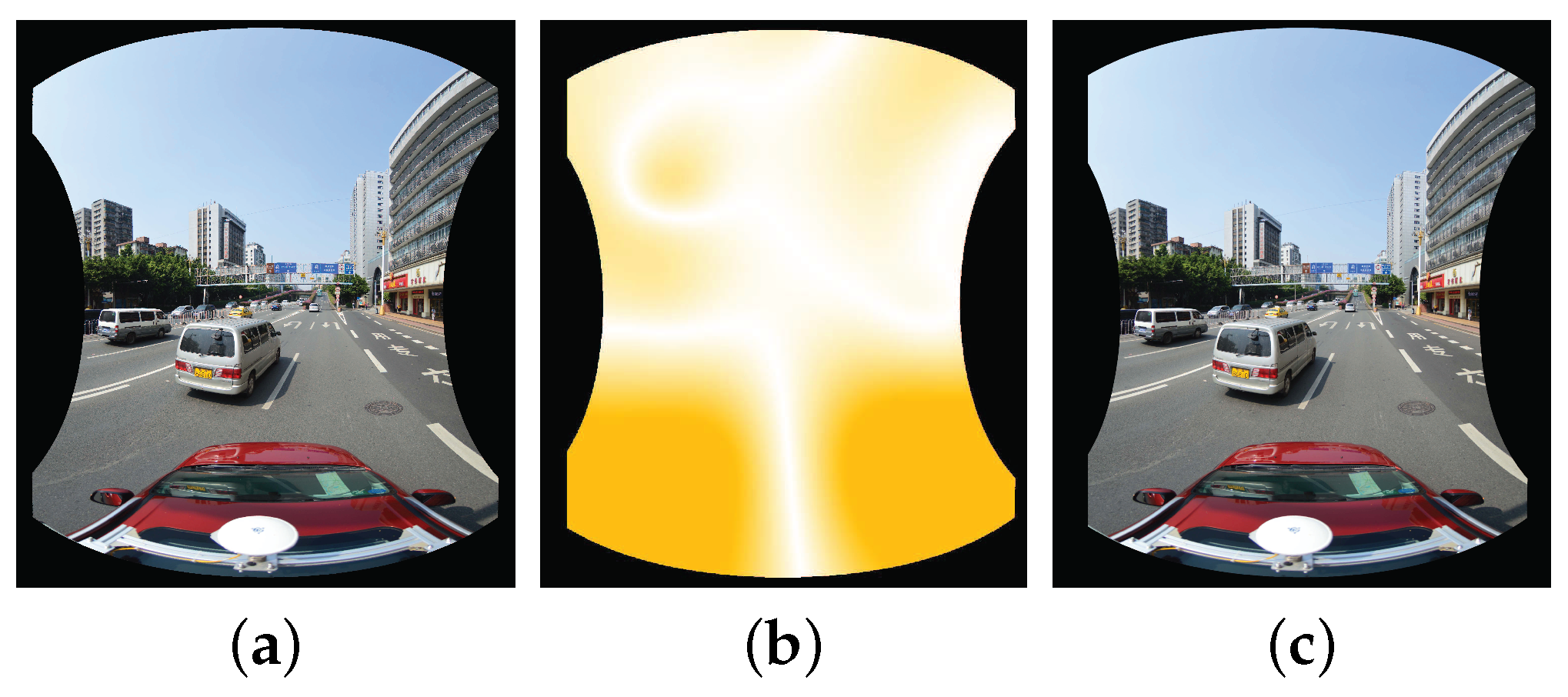
where
denotes the finally fused intensity of the pixel
,
is the original intensity of the pixel
while
is the corrected intensity of the corresponding pixel based on the above-mentioned correction method, and
is a function that related to the distance between the pixel
and the center line of the overlap image region, which ranges between zero and one as shown in
Figure 8, where the smaller the distance to the center line, the larger the
α is. All the pixels in other images will be processed in the same way.
3.5. Summary
In this section, we proposed a new color correction method to reduce the color differences between warped images. This method also includes three stages: automatic contrast adjustment, histogram extreme point detection and matching and color difference correction. In the first stage, we applied the traditional method to adjust the image contrast. This stage can be regarded as the pre-processing. The second stage is the key contribution of the proposed color correction method. In this stage, we proposed a new cost function to evaluate the similarity between two extreme points extracted from two PDFs and then find all matched extreme points iteratively. In the last stage, based on the matched histogram extreme points, the color differences can be corrected easily. The key contribution of this section is that we proposed a new color correction method via matching extreme points of histograms. This method is effective and efficient, which can handle large color differences between two images.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}