1. Introduction
In recent years, with the rapid development of social networking, internet of things, digital city and other new generation of large-scale network applications, smart data convergence technologies for faster processing big data generated by sensor networks or other devices are urgently required. To solve the above problem, in 2006 Google, Amazon and other companies proposed a “cloud computing” concept [
1], presenting the use of network services anywhere and anytime on demand. It provides easy access to a shared resource pool (such as computing facilities, storage devices, applications, etc.). Through cloud computing, users can quickly apply or release resources according to their traffic load. Meanwhile, pay-as-you-consume cloud computing paradigm can improve the quality of services while reducing operation and maintenance costs [
2].
Based on MapReduce (MR), Big Table and Google File System (GFS) proposed by Google, Hadoop has become a typical open-source cloud platform. Recently, it has been accepted and well used in both industry and academia due to its features of scalability, easy to deploy and high efficiency. Apart from Hadoop, some novel distributed platforms, e.g., Apache Storm [
3] and Spark [
4], have also been proposed and widely applied to process big data [
5,
6]. Apache Storm [
3] is known as an efficient stream data preprocessing platform and has been steadily serving Twitter. Apache Spark [
4] is another platform for big data processing. It is more applicable and has more capabilities, which consists of Spark Streaming [
7], Spark SQL [
8], MLlib [
9] and GraphX [
10]. All of the above modules make Spark a powerful platform. However, Hadoop is still a good choice for off-line computation, especially for a cluster lack of memory [
11]. Actually, many research works based sensor networks have been continuously propelled. Several systems have been built based on Hadoop to speed up the procedure of sensor data analysis and data management [
12,
13,
14,
15,
16].
As the core module of Hadoop, MR has been well investigated in order to improve the performance of job allocation and distribution. Scheduler is one of the critical parts in MR, which decides whether data can be processed efficiently. Previous work has been tremendously conducted on optimizing the Scheduler [
17,
18,
19,
20,
21,
22,
23,
24]. Apart from the scheduler, speculative execution strategies have also gained wide attention [
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37], since incorrect estimating the running duration of a run-time task may cause its inappropriate allocation. For periodically executed jobs, an optimized speculative execution strategy can effectively improve the performance of entire MR processing.
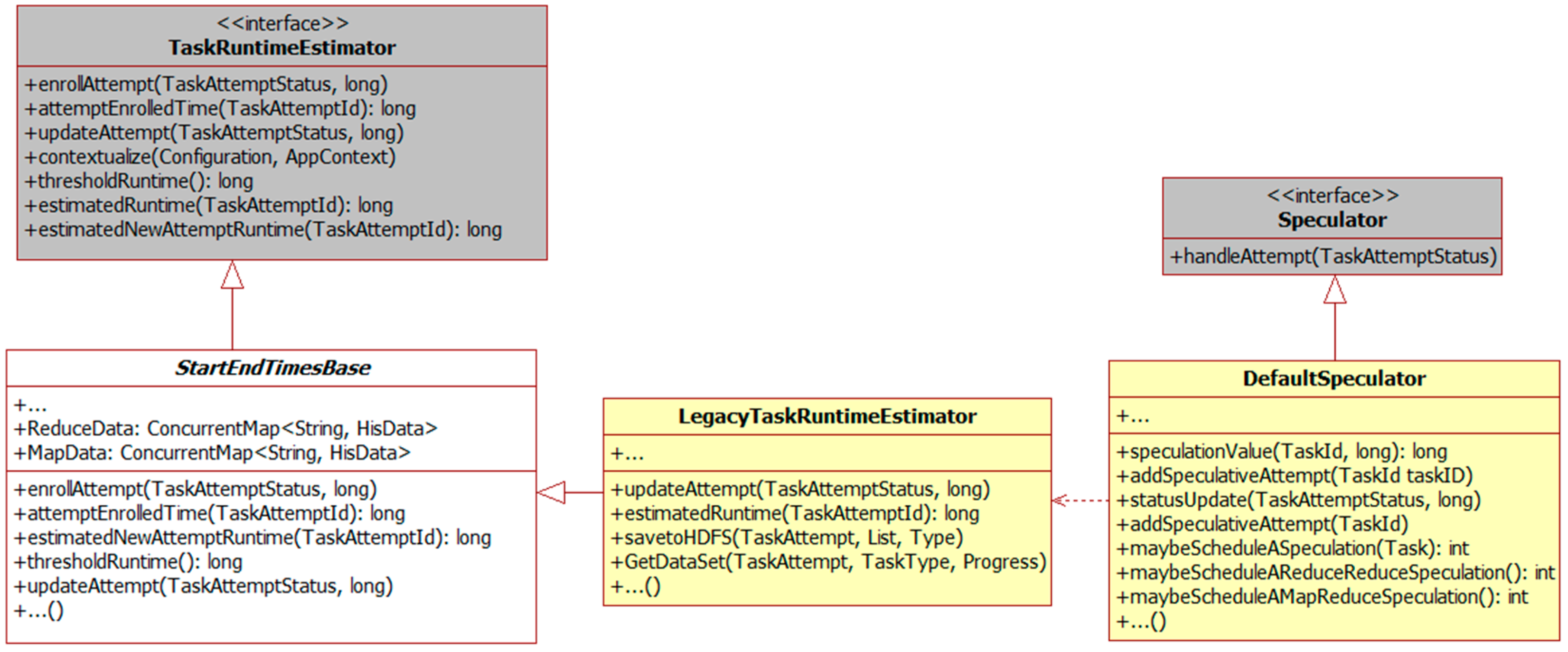
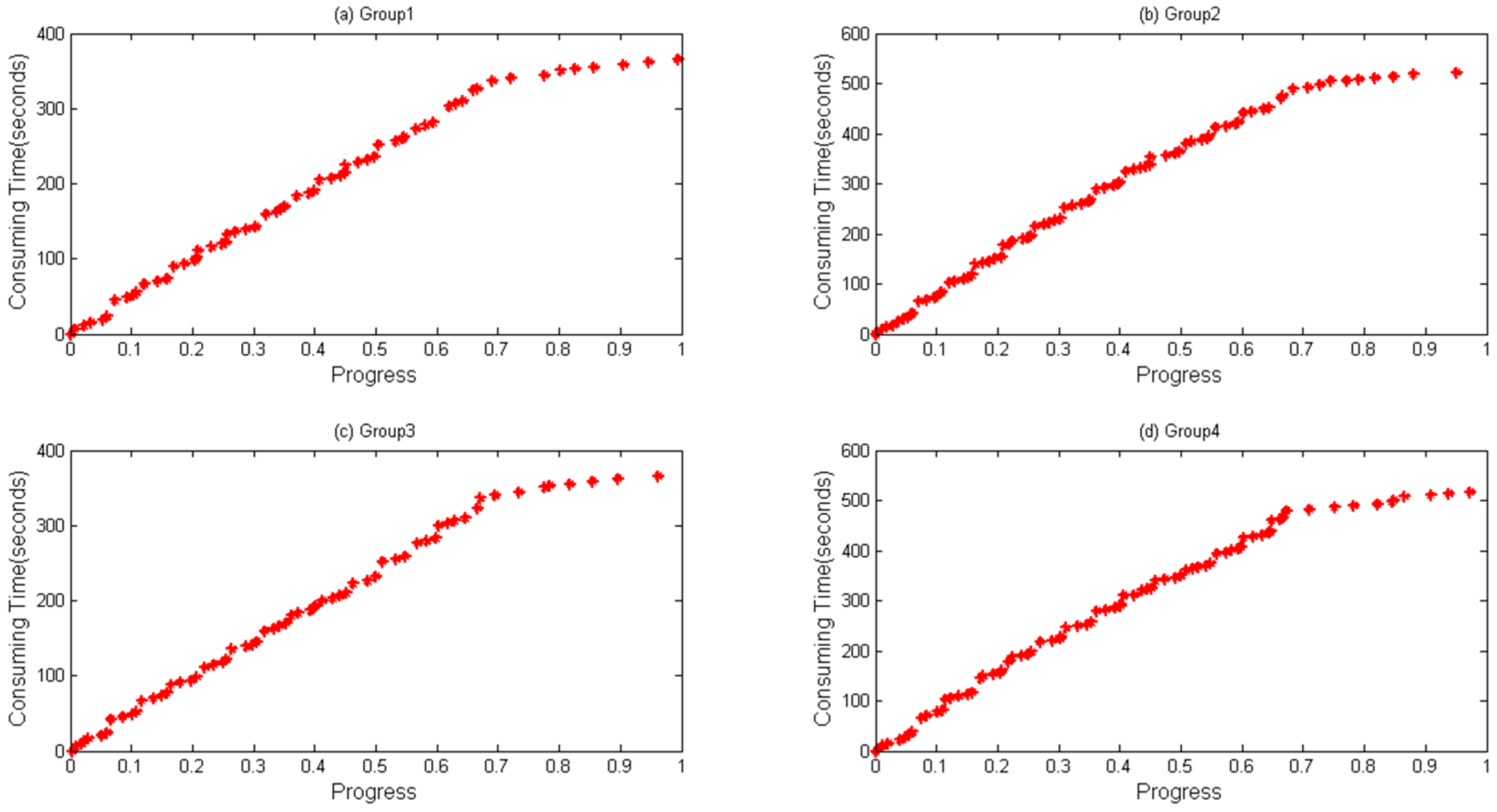
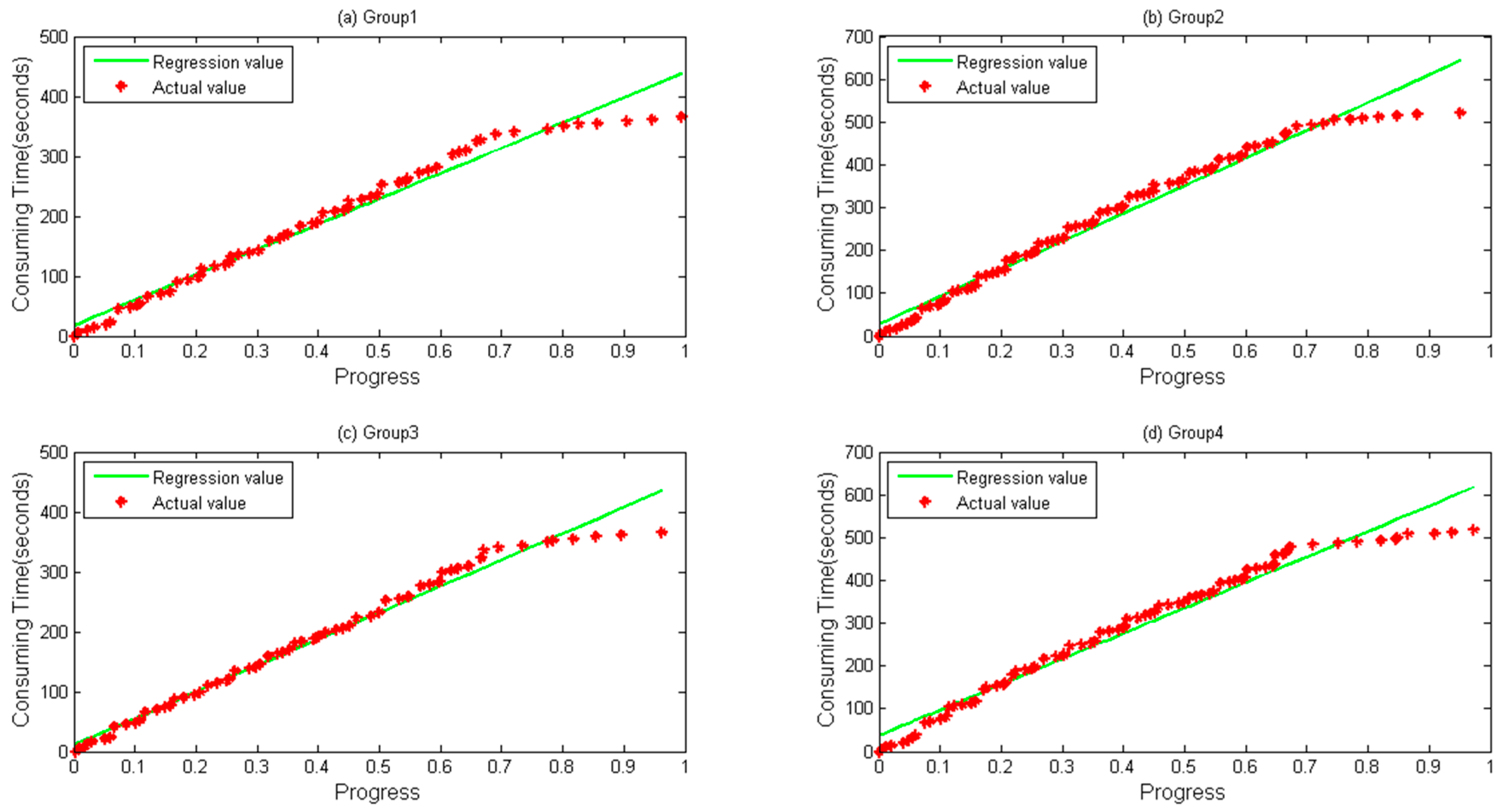
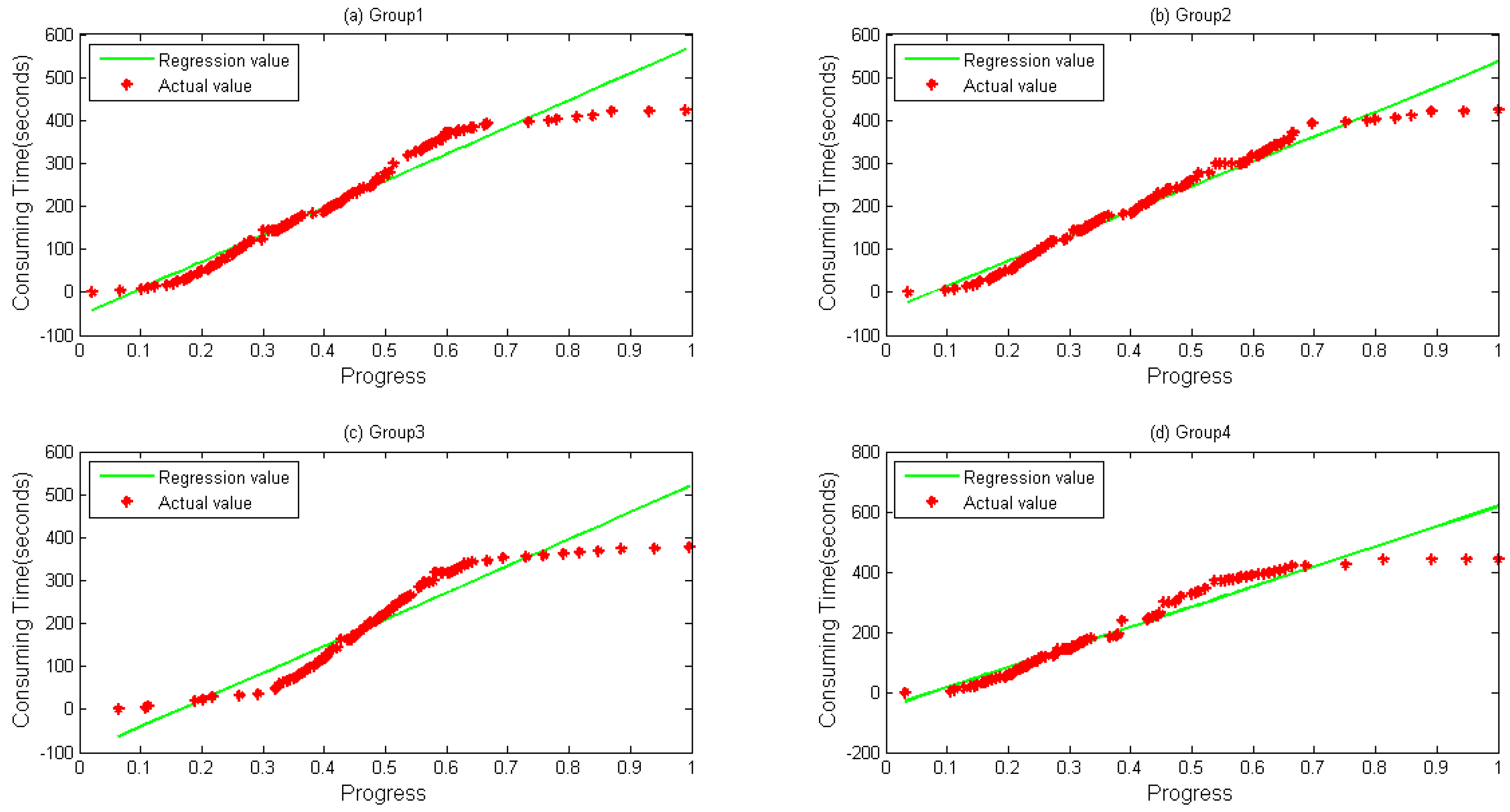
In this paper, a novel method is presented to improve the estimation accuracy of jobs’ execution time. Native Hadoop MapReduce is modified to collect data of run-time tasks. A linear model has been built based on the features of the data to predict the task finishing time more accurately.
The rest sections are organized as followed. Related work is introduced in
Section 2, followed by
Section 3, where our scheme for collecting historical data is presented. In
Section 4, the relationship between progress and timestamp is analyzed and verified for predicting running time of run-time tasks, moreover, reasons for some phenomenon are discussed. Finally, conclusion and future work are presented in
Section 5.
2. Related Work
Recently, with the development of cloud computing, many distributed big data progressing tools have been born. Hadoop, Storm [
3] and Spark [
4] that sponsored by Apache company have gained extensive attention due to their excellent performance. In stream processing field, Storm and Spark [
3,
4,
5,
6] have been the most important tools. Twitter used Storm to analyze and process data generated by social networks. Moreover, Alibaba, Baidu, Rocket Fuel, etc. also applied in their systems [
3]. Except for Storm, Spark [
4], as a new powerful framework, is being more and more attractive for some companies due to its convenience for machine learning and graph operator. Zaharia et al. proposed Spark Streaming [
7], in which a novel recovery mechanism grants itself higher efficiency over traditional backup methods, and tolerance strategies [
4]. Armbrust et al. presented a new module called Spark SQL [
8]. Spark SQL provided rich DataFrame APIs and automatic optimization, which makes it significantly simpler and more efficient over previous systems. Spark MLlib offerd a wide range of functions for learning parameter settings, and APIs for a number of popular machine learning algorithms, including some potential statistics, linear regression, naive Bayes and support vector machines [
9]. By taking advantage of distributed data flow architecture, GraphX brings low-cost fault tolerance and efficient graphic processing. On the basis of the data stream framework, GraphX achieved an exponential level performance optimization [
10]. These frameworks usually have better performance while processing stream data. However, they have to pay for more memory consumption, which means that when it is applied in industry, companies have to pay more money. Furthermore, they do not have an obvious improvement over Hadoop in off-line and batch computation fields. Therefore, Hadoop is still a good choice, especially for a cluster lack of memory [
11].
Many research works based sensor networks have been continuously propelled. Many systems have been built based to speed up the procedure of sensor data analysis [
12,
13,
14,
15,
16]. Almeer speeded up remote sensing image analysis through an MR parallel platform [
12]. Xu et al. introduced a Hadoop-based video transcoding system [
13]. Hundreds of HD video streams in the wireless sensor networks can be parallelly transmitted due to the features of MR. Finally, better performance was achieved by optimizing some important configuration parameters. Jung et al. presented a distributed sensor node management system based on Hadoop MR [
14]. With applying some specific MR and exploiting various crucial features of Hadoop, a dynamic sensor node management scheme was implemented. A solution for analyzing the sensory data was proposed in [
15] based on Hadoop MR. According to the method, user behavior can be detected, and lifestyle trends can be accurately predicted. Alghussein et al. proposed a method based on MR to detect anomalous events by analyzing sensor data [
16].
As the most critical part in MR, scheduler’s efficiency decides whether data can be processed efficiently and tremendous progress has been made now [
17,
18,
19,
20,
21,
22,
23,
24]. Apart from the scheduler, speculative execution strategies also gained wide attention with an increasing number of researchers concentrating on optimizing the performance of speculative execution [
25,
26,
27,
28,
29,
30,
31,
32,
33].
A map task scheduling algorithm was presented to improve the overall performance of MapReduce calculations [
17]. Their approach results in a more balanced distribution of the intermediate data. An approach to automating the construction of a job schedule was proposed that minimizes the completion time of such a set of MapReduce jobs [
18]. Dynamic MR [
19], which allows map and reduce slots to be allocated to each other, was proposed to facilitate the execution of the job. Yi proposed LsPS [
20], a scheduler based on job size for higher efficiency of task assignments by abolishing the same response time. The execution efficiency of Memory-Intensive MapReduce applications was introduced in [
21]. A resource-aware scheduler was proposed, in which a job is divided into phases. In each phase, a resource requirement is set constant, so phase-level scheduling can be achieved [
22]. Saving resources of the cluster were conducted in [
23], where a scheduler consisting of two algorithms called EMRSA-I and EMRSA-II was proposed. The disadvantages of current scheduler solutions for offline applications were analyzed in [
24], and two algorithms were therefore presented, by which span and total finishing time can be decreased.
Recently, speculative execution strategies (SE) have been proposed [
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37]. Due to the unreasonable scheduling algorithms, SE strategy is used for solving the struggles and usually seen as a fault-tolerant mechanism. Proposed in Google, the speculative execution was implemented in Apache Hadoop and Microsoft Dryad. However, the current native SE strategy in Hadoop suffered from low accuracy [
25]. Facebook disabled their SE strategy to avoid extra resource waste [
26]. An optimized strategy, called LATE, was presented in [
25], and weights of three stages (shuffle, sort, and reduce) in reduce task are set 1/3. MCP was proposed in [
26], where data volume was considered when calculating the remaining time of run-time tasks. Maximizing Cost Performance was used as another limit for launching a backup task other than the difference between remaining time and backup time. EURL [
27] was proposed where system load was seen as a key factor during calculating the remaining time of a task. An extended MCP was proposed while a load curve was added [
28]. A smart strategy was proposed based on hardware performance and data volume of each phase [
29]. In [
30], the differences of work nodes were investigated to estimate backup tasks precisely. Optimal Time Algorithm (OTA) is another method that aims at improving the effectiveness of the strategy. However, the difference between the nodes’ processors are not well considered [
31]. A new Speculative Execution algorithm based on C4.5 Decision Tree (SECDT) was proposed to predict execution time more accurately. In SECDT, completion time of straggling tasks is speculated based on the C5.4 decision tree [
32]. Wang et al. proposed a strategy called Partial Speculative Execution (PSE) strategy. By leveraging the checkpoint of original tasks, the efficiency of the MR is therefore improved [
33]. Adaptive Task Allocation Scheduler (ATAS) was presented to improve the original strategy. The ATAS reduces the response time and backs up tasks more quickly. Therefore, the success ratio of backup tasks is enhanced [
34].
SE strategies based on the Microsoft’s distributed system have also been proposed. Using real-time progress reports, outliers of all tasks can be detected in an early stage of their lifetime [
35]. Consequent actions setting free resources were then conducted to accelerate the overall job execution. To maximize job execution performance, Smart Clone Algorithm (SCA) was proposed in [
36], which obtains workload thresholds used for speculative execution. The enhanced speculative execution (ESE) [
37] algorithm was proposed for heavy clusters, as an extension of Microsoft Mantri programs.
Though many strategies have been proposed as above, detailed data of each task have drawn no interests with no detailed analysis report being made. Current existing SE strategies still have low accuracy while estimating the finishing time of running tasks.








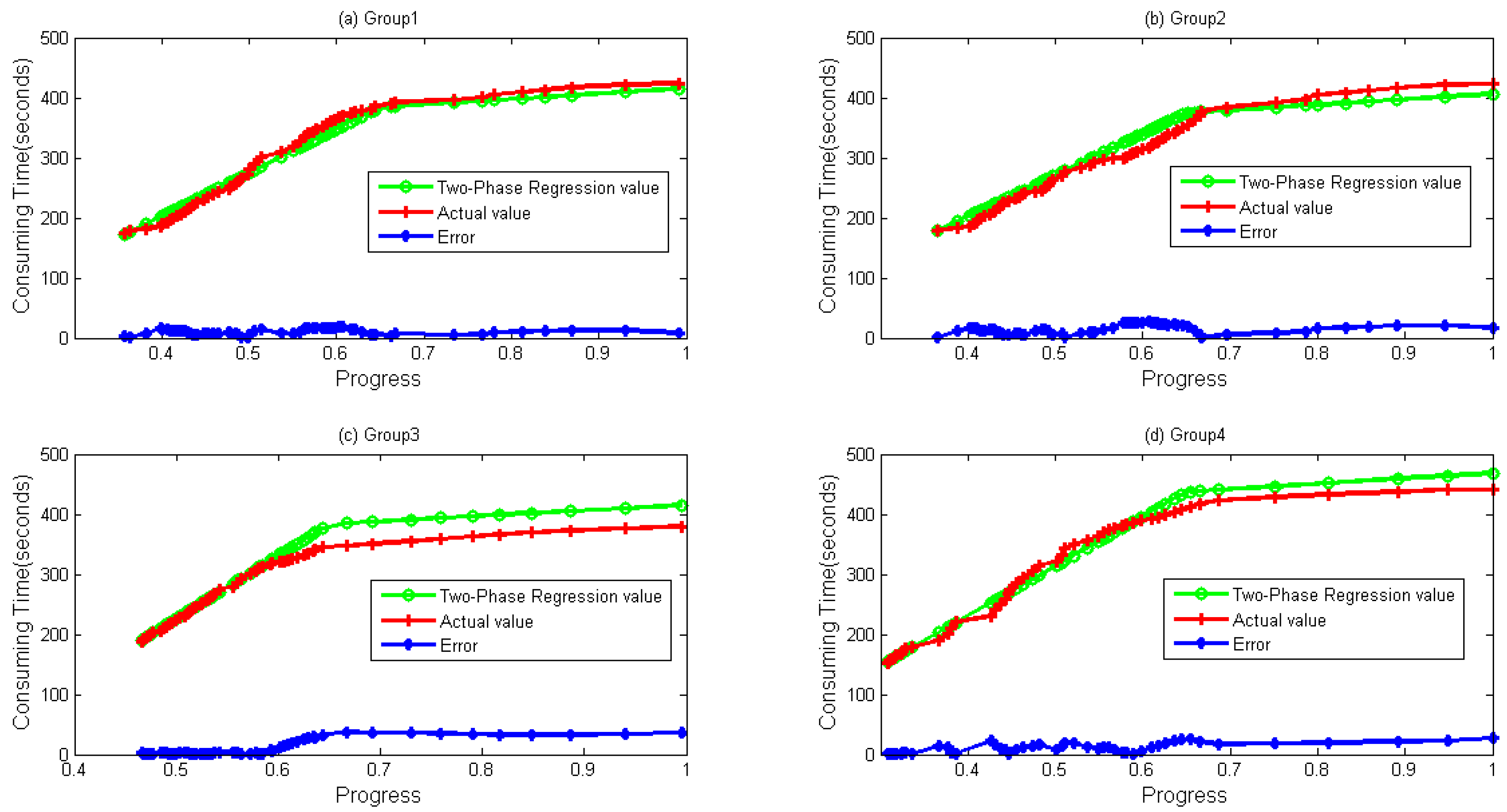

{kind=link}
{kind=link}
{kind=link}
{kind=link}
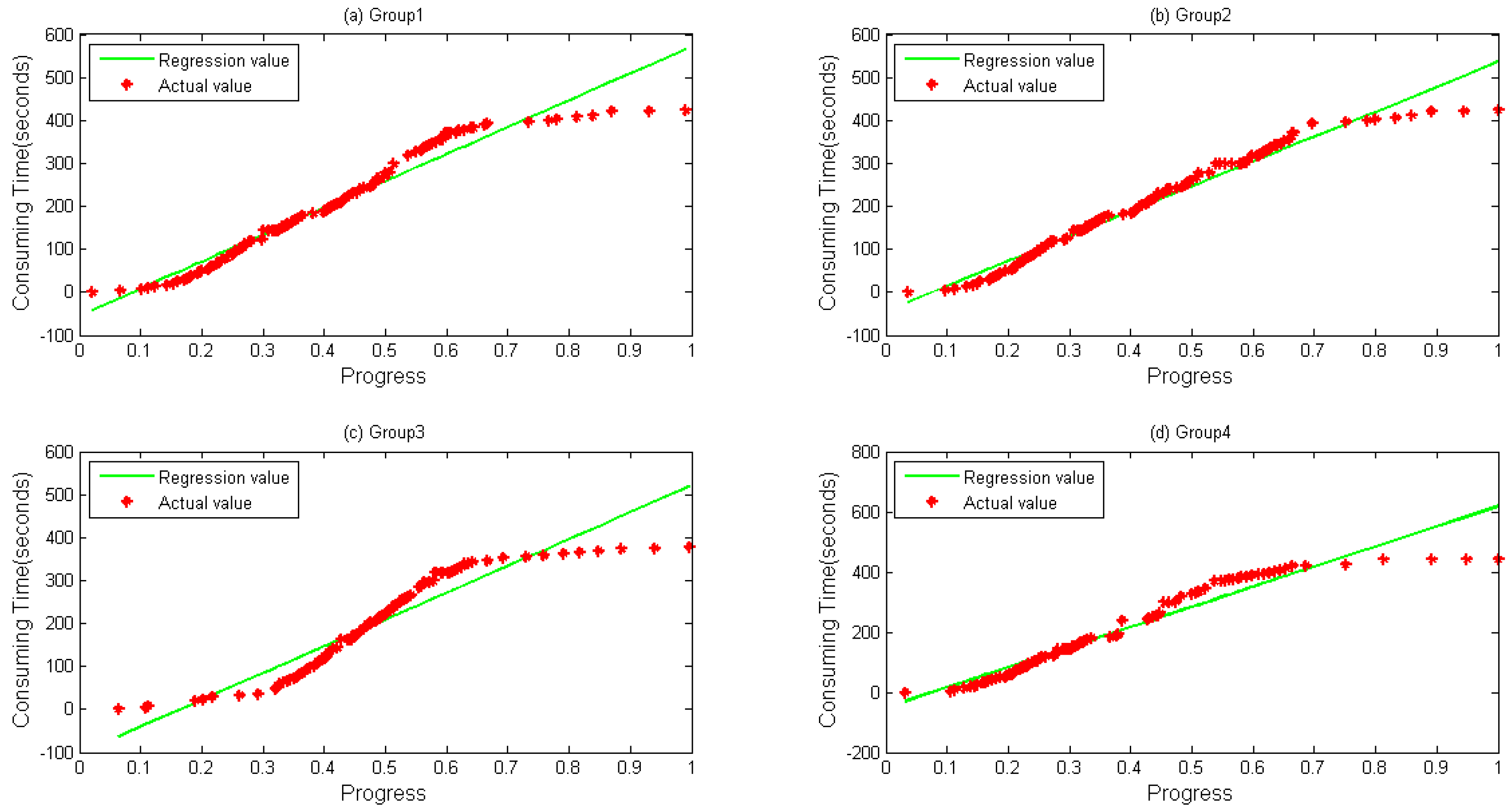{kind=link}
{kind=link}
{kind=link}
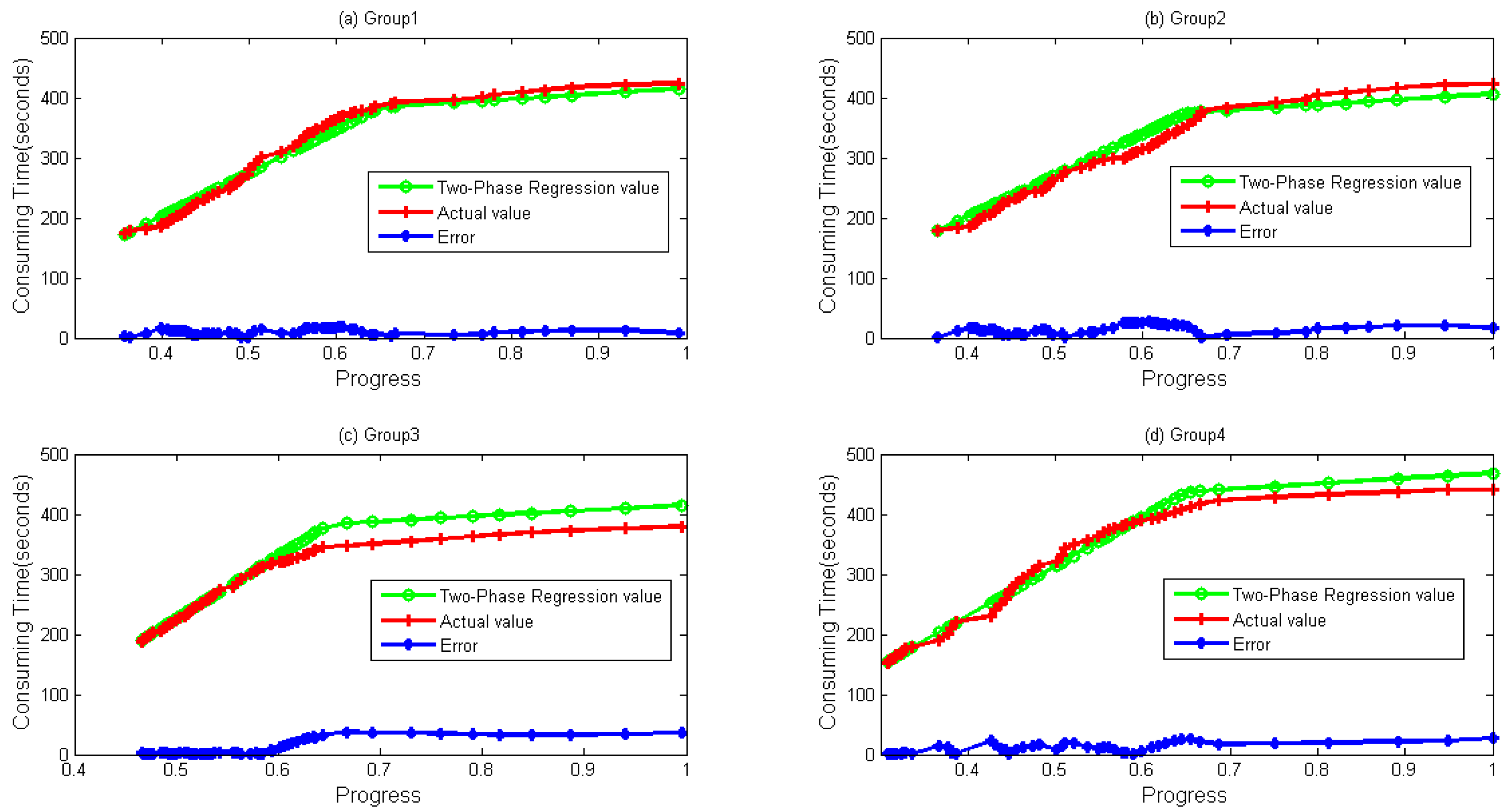{kind=link}