
Feature-Based Laser Scan Matching and Its Application for Indoor Mapping


Abstract
:
1. Introduction
- (1)
- We propose a new initial-free 2D laser scan matching method by combining point and line features, which is a very effective technique for indoor mapping and modeling.
- (2)
- We carefully design a framework for the detection of point and line feature correspondences from laser scan pairs. We also give an effective strategy to discard unreliable features. Thus, our detected feature correspondences are distinct, reliable, and invariant to rotation changes.
- (3)
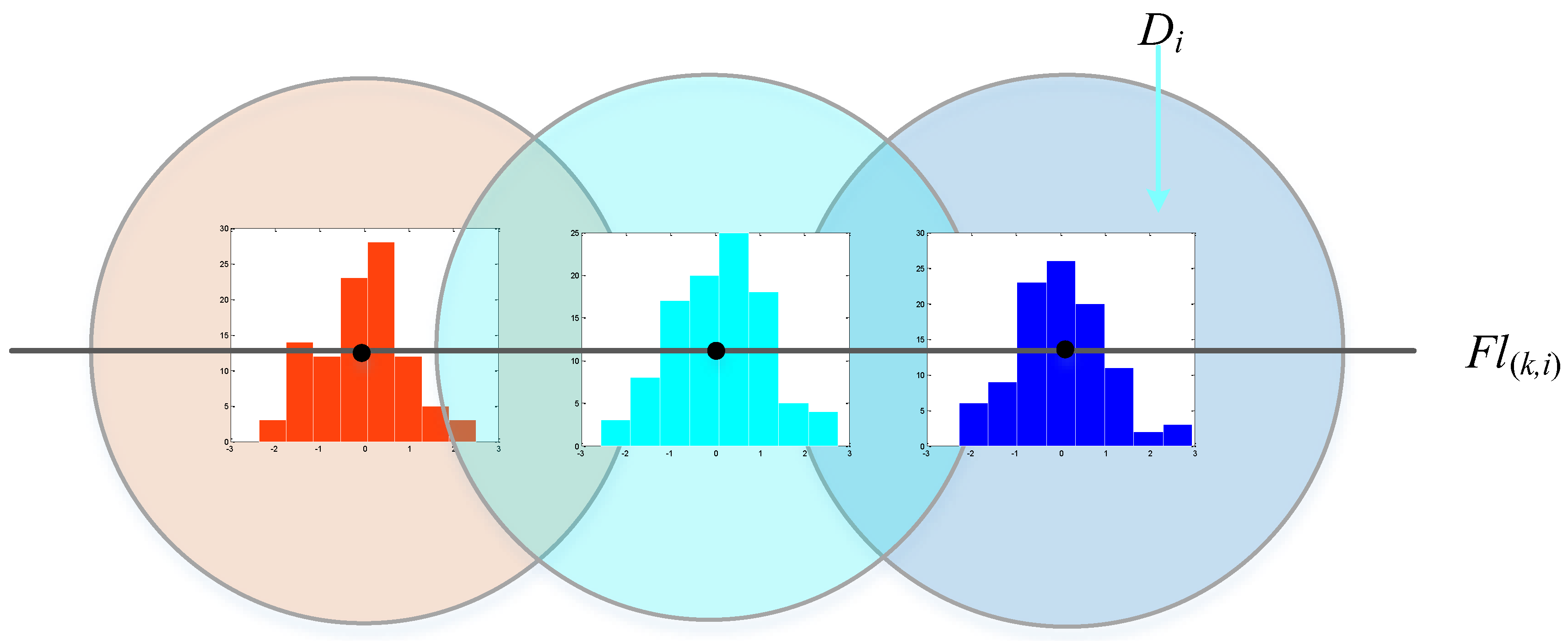
- We propose a new relative pose estimation method that is robust to outliers. We use the lq-norm (0 < q < 1) metric in this approach, in contrast to classic optimization methods whose cost function is based on the l2-norm of residuals. Unlike the conventional RANSAC-based [9] strategy, strategy, there is no gross error detection stage in our pose estimation algorithm. In addition, our pose estimation algorithm is more robust to noise than the RANSAC-based one.
- (4)
- We make an honest attempt to present our work to a level of detail allowing readers to re-implement the method.
2. Related Work
3. Scan Matching
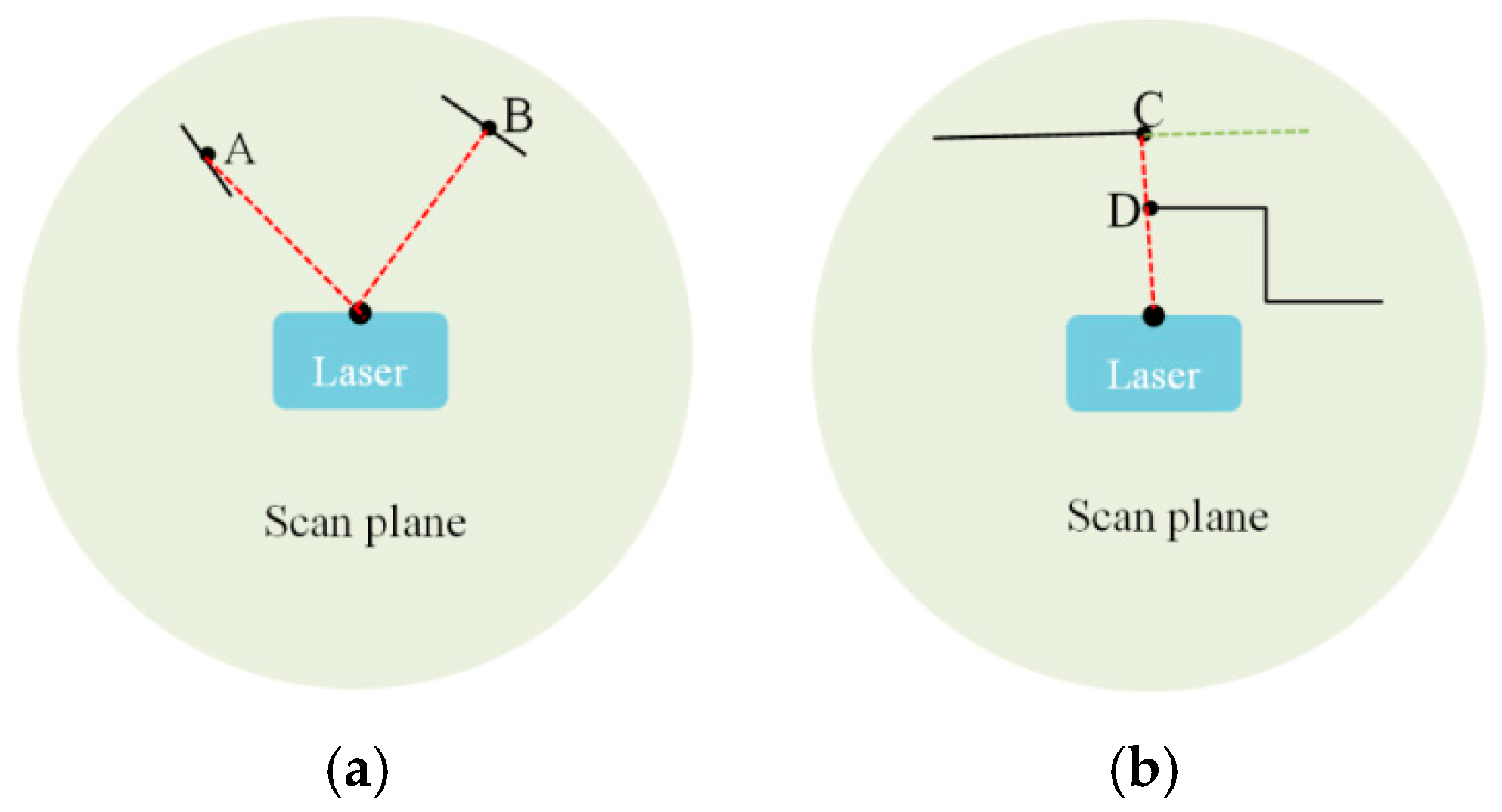
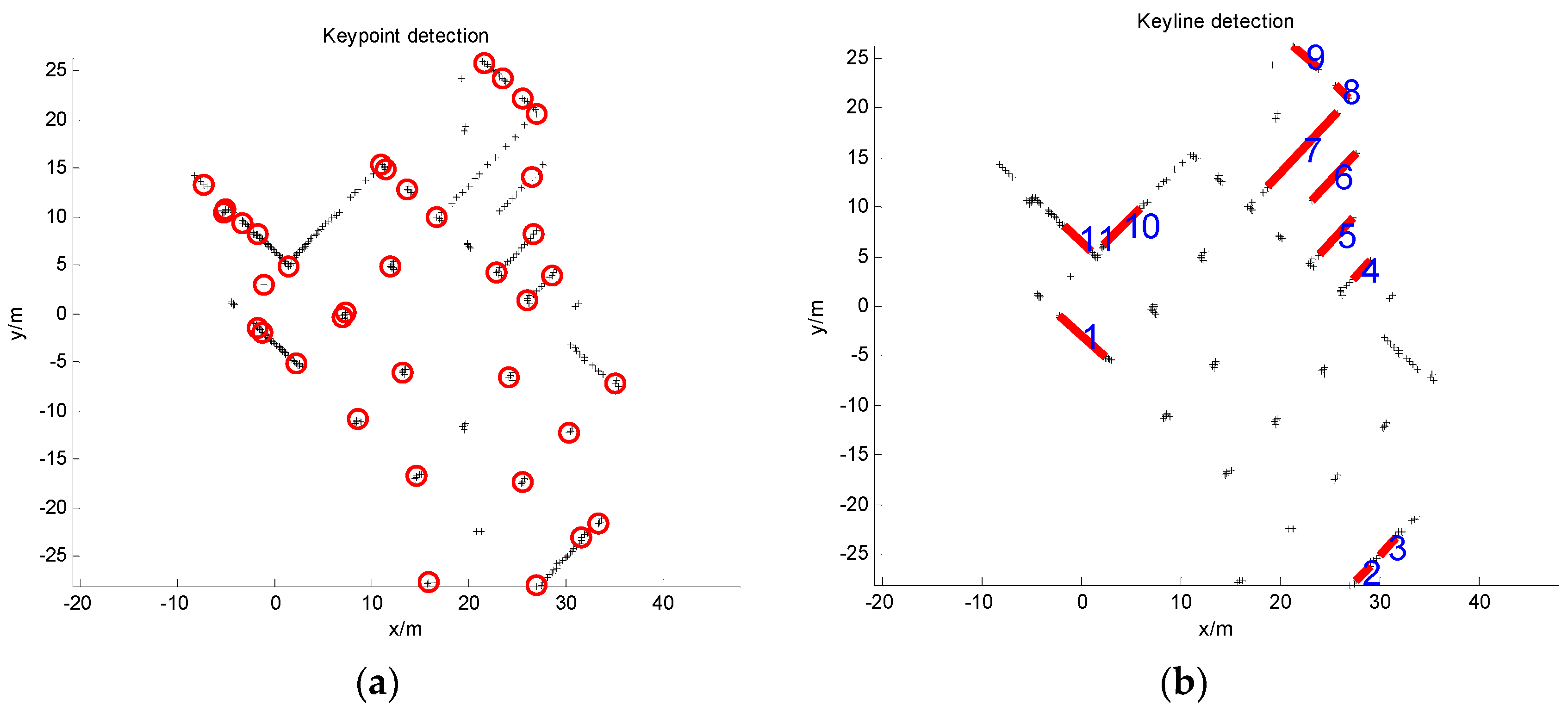
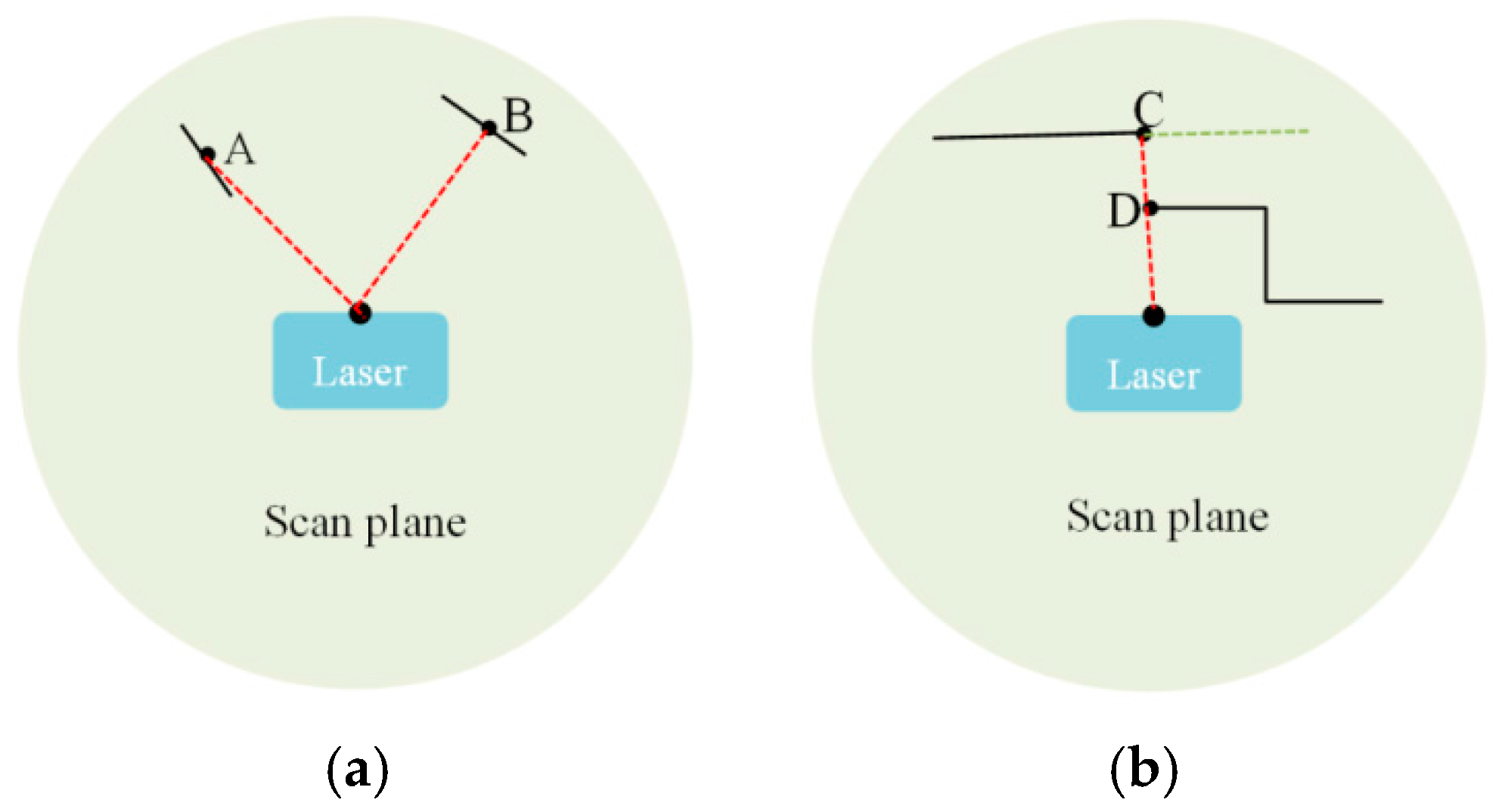
3.1. Feature Detection
| Algorithm 1. Line Segment Extraction |
| 1 input: a laser scan |
| 2 output: line segments |
| 3 begin |
| 4 segment the laser scan and remove small |
| segments to form clusters ; |
| 5 for each cluster do |
| 6 fit a line to , compute the length of ; |
| 7 remove line if its length is small; |
| 8 detect point with maximum distance to ; |
| 9 if then |
| 10 add the line segment to ; |
| 11 else |
| 12 split into two subclusters , at , |
| then, perform Algorithm 1 for each subcluster; |
| 13 end |
| 14 end |
| 15 computer the slope of each line segment in , |
| find adjacent line pairs in ; |
| 16 for each pair do |
| 17 if then |
| 18 calculate their middle point distance in normal direction ; |
| 19 if then |
| 20 merge into a single line, update ; |
| 21 end |
| 22 end |
| 23 end |
| 24 return line segment set ; |
| 25 end |
3.2. Feature Description
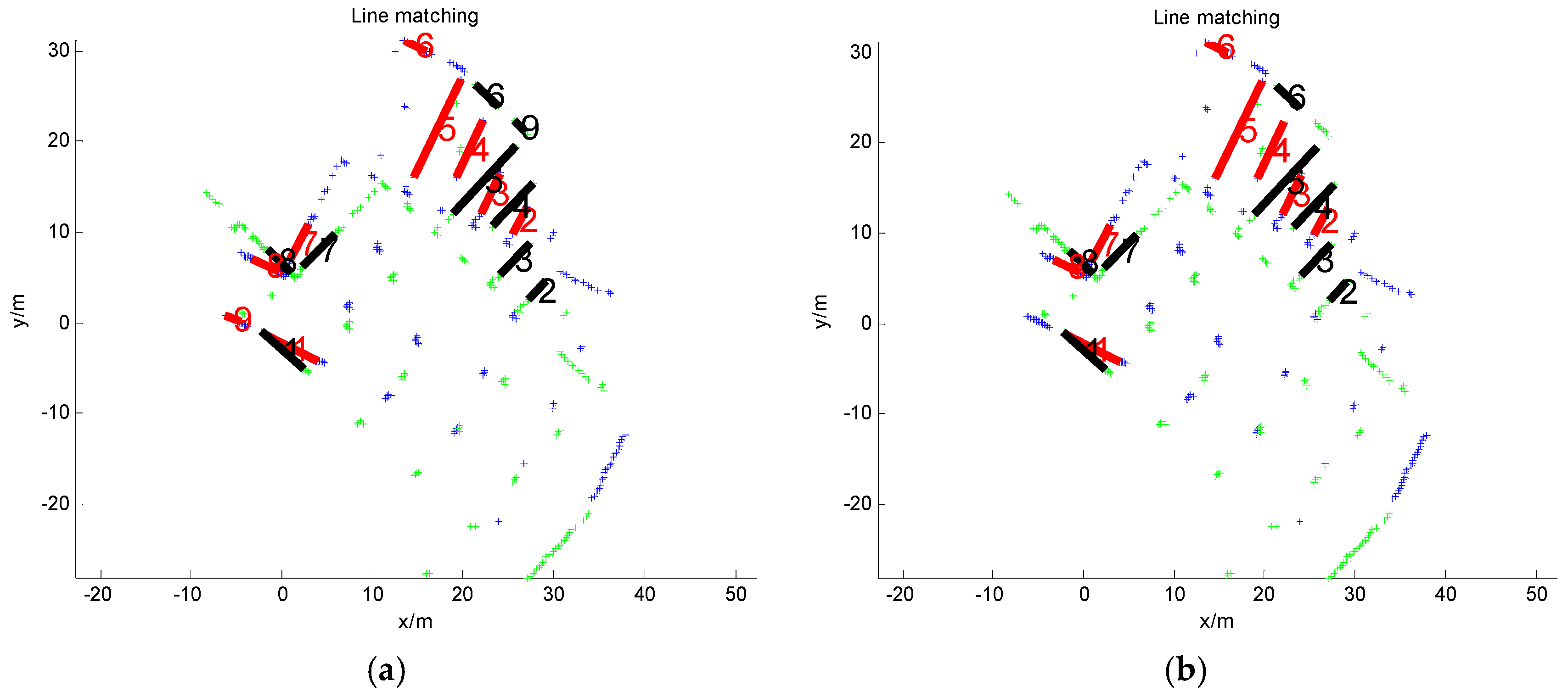
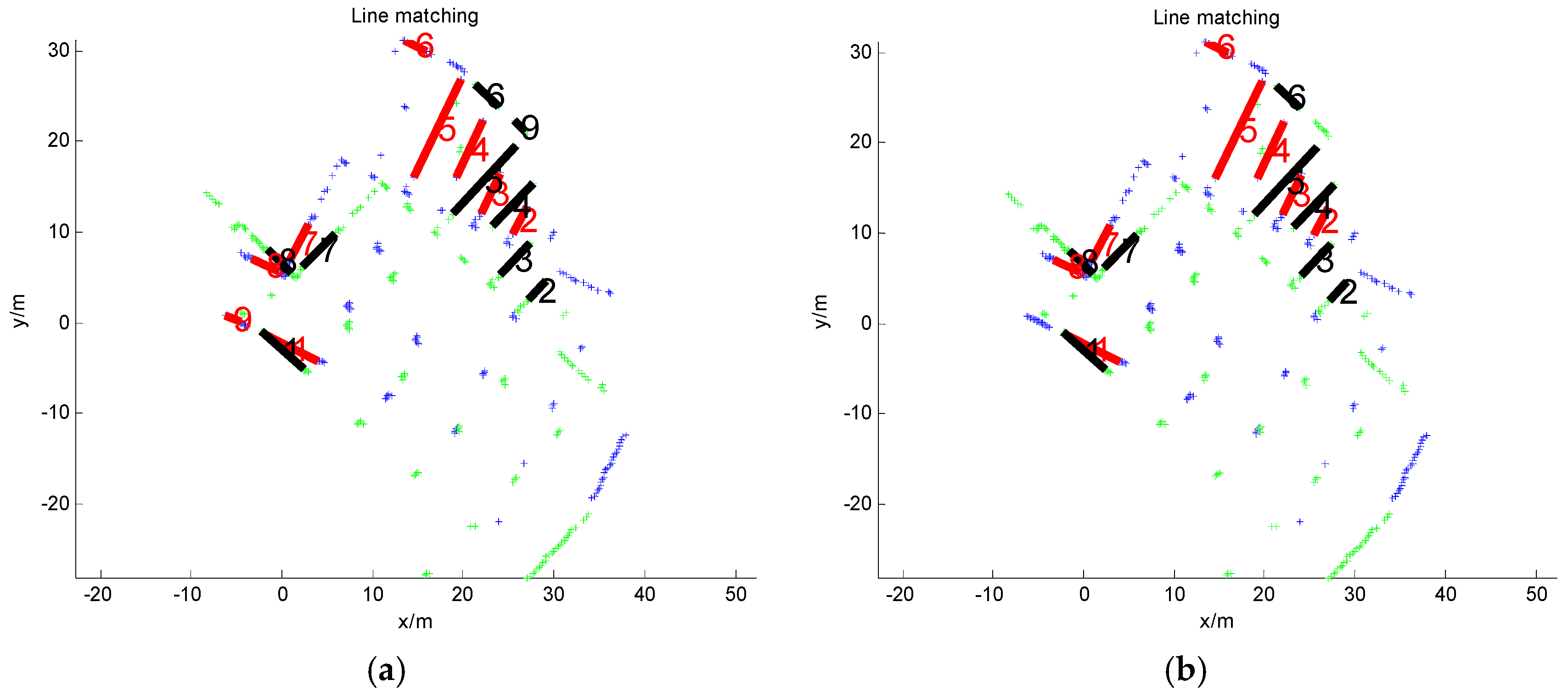
3.3. Feature Matching
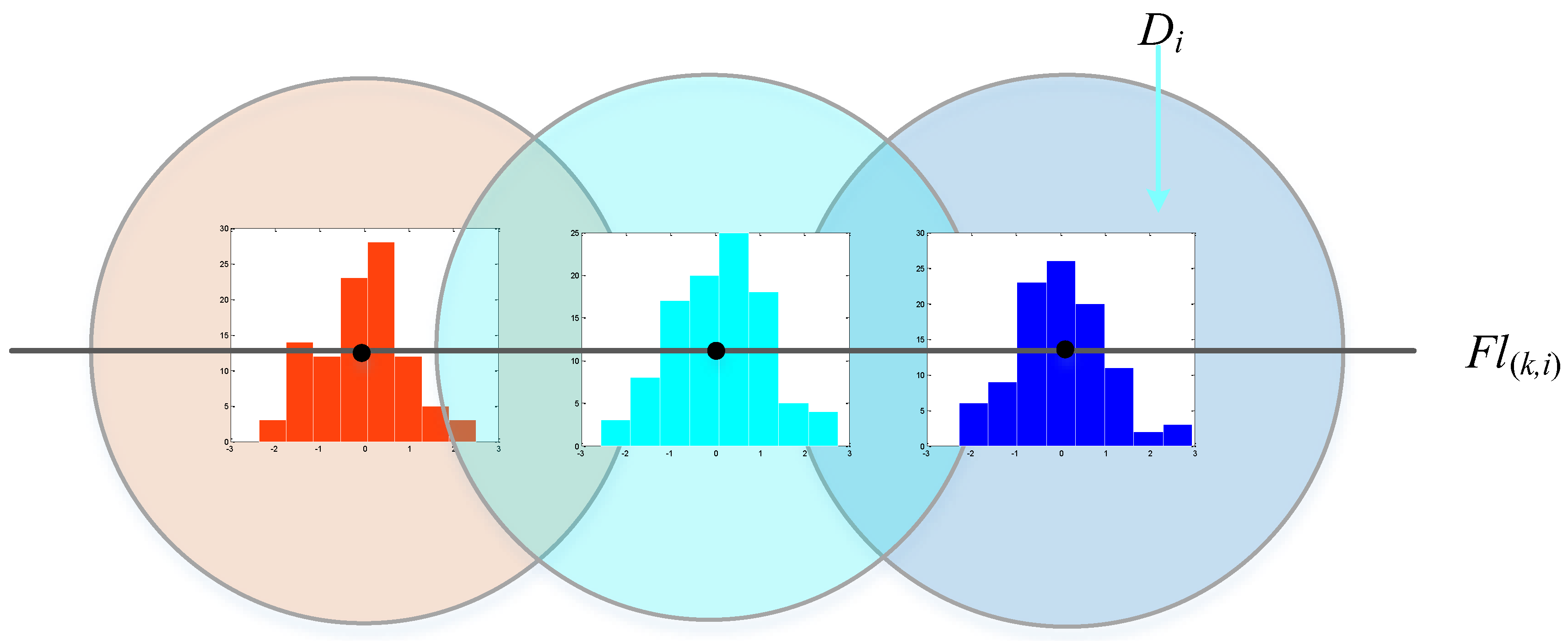
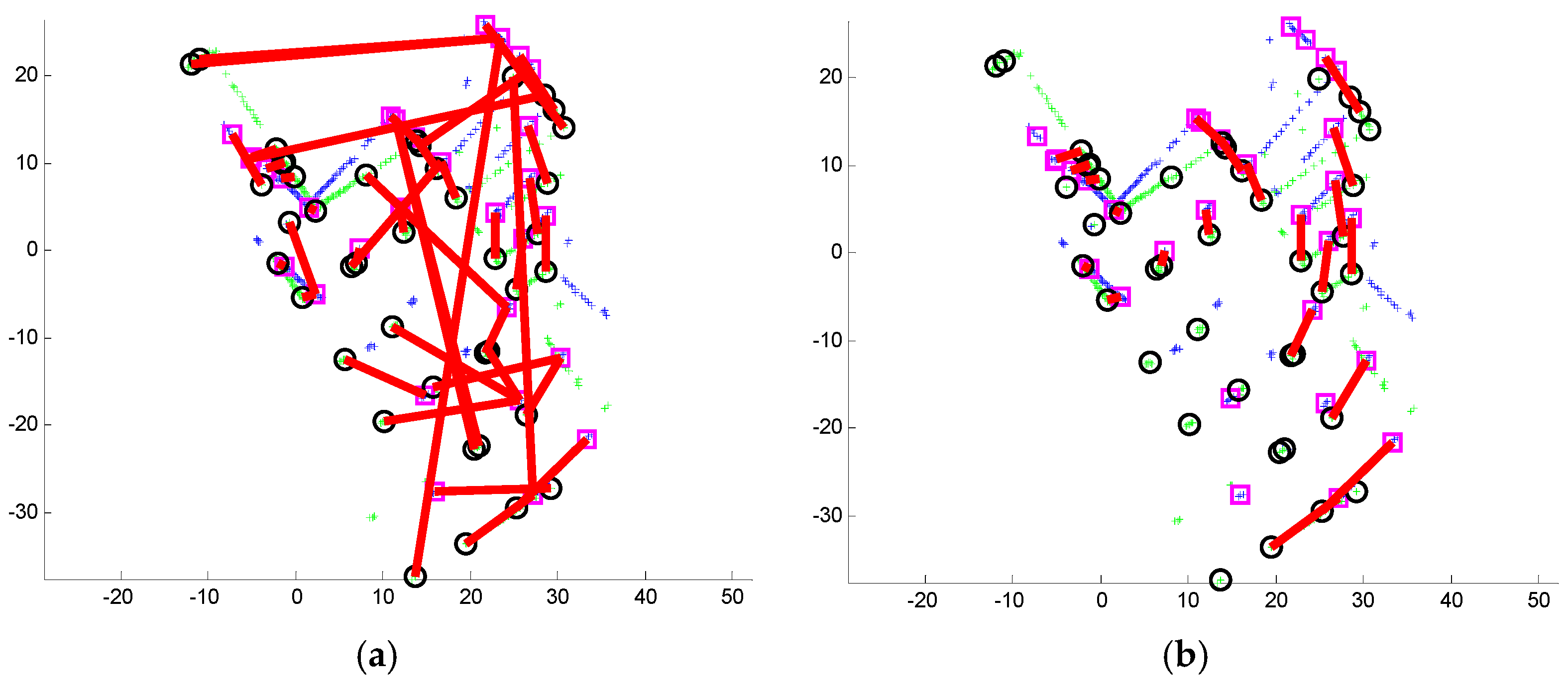
3.4. Transformation Estimation
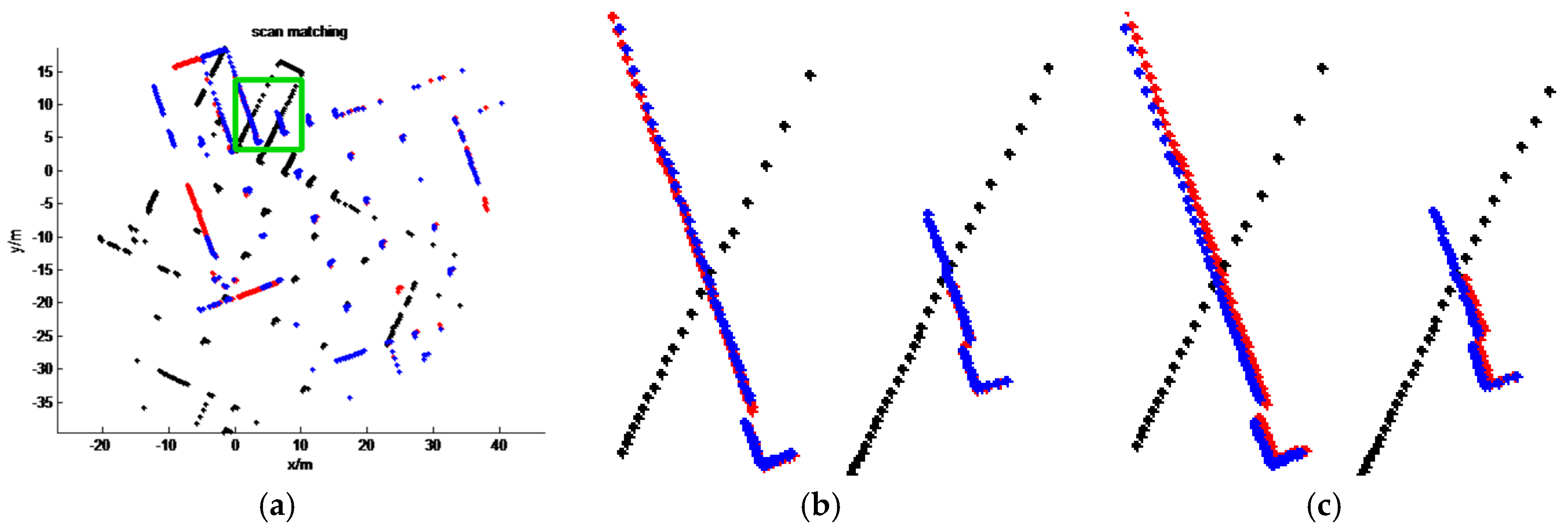
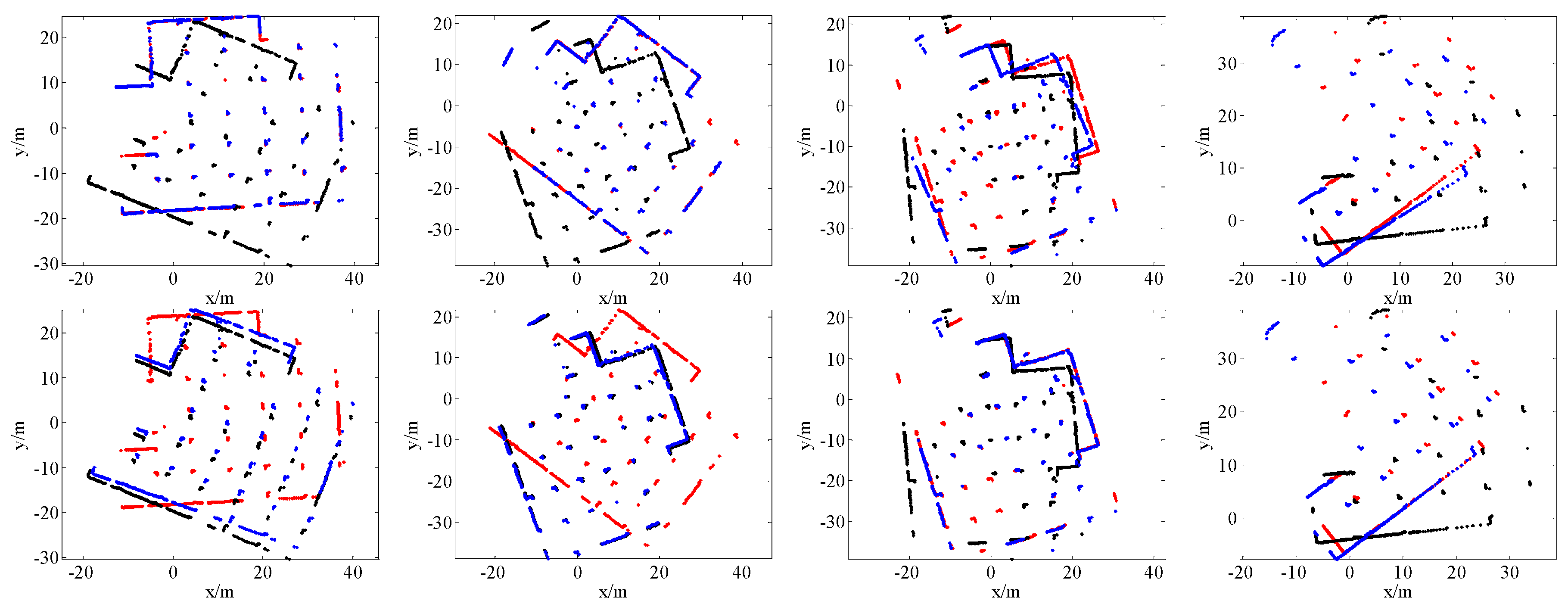
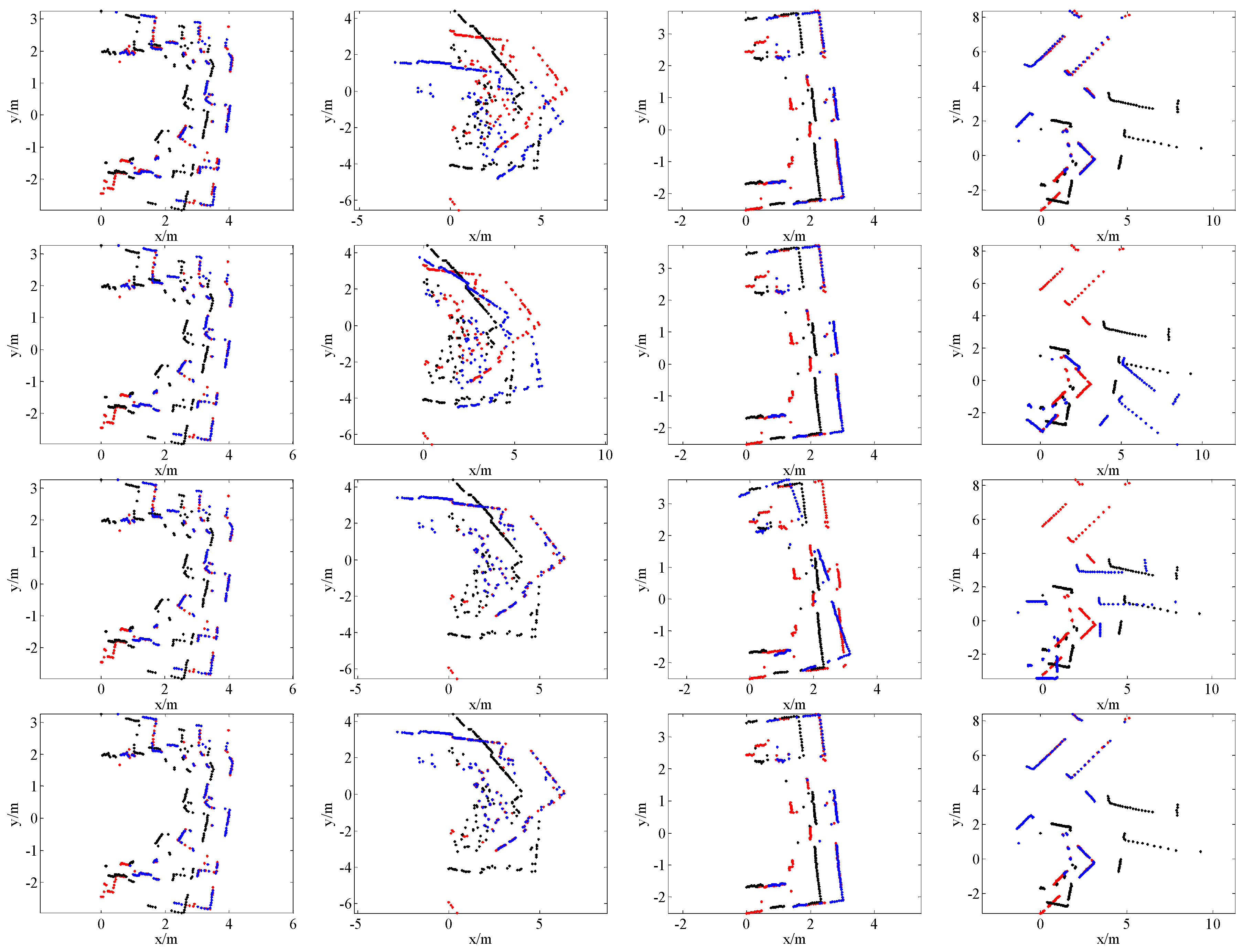
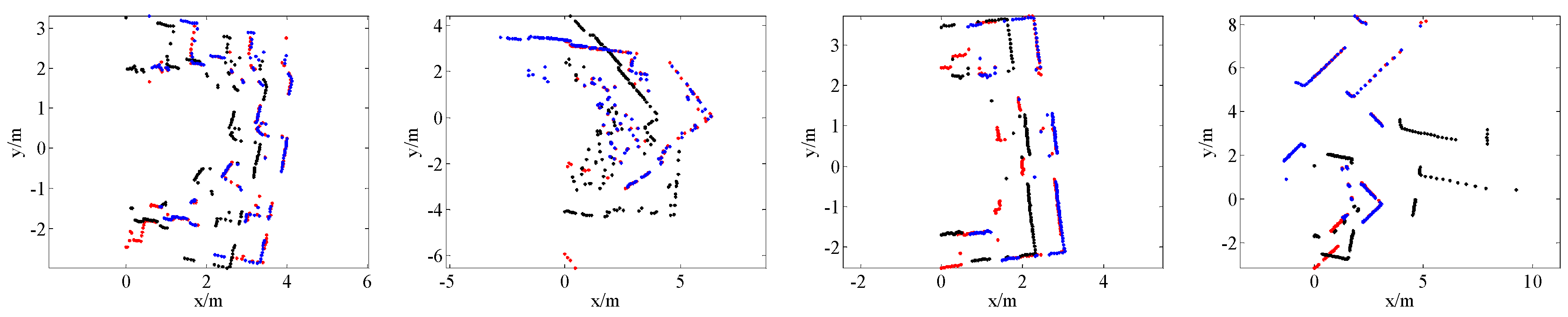
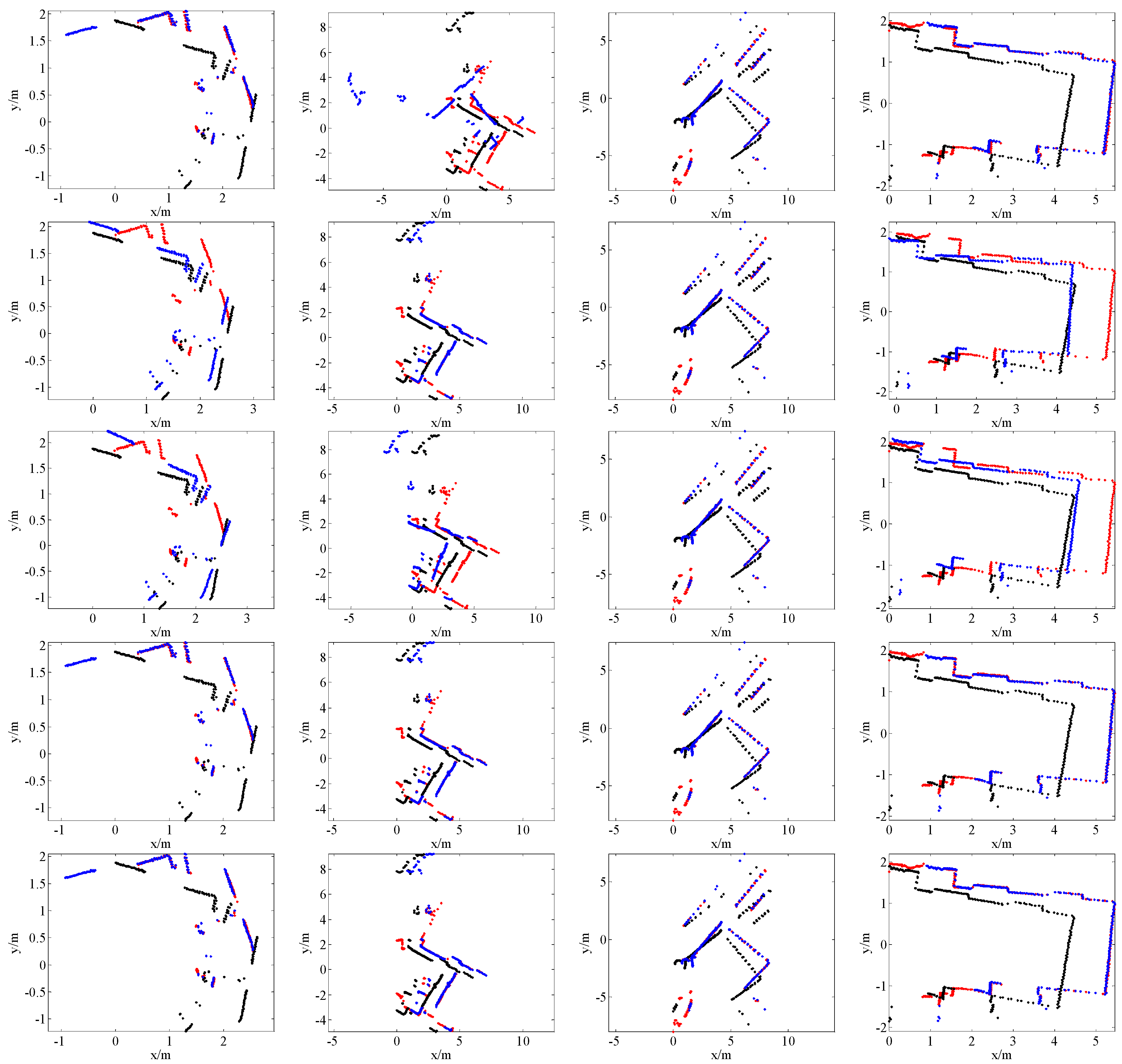
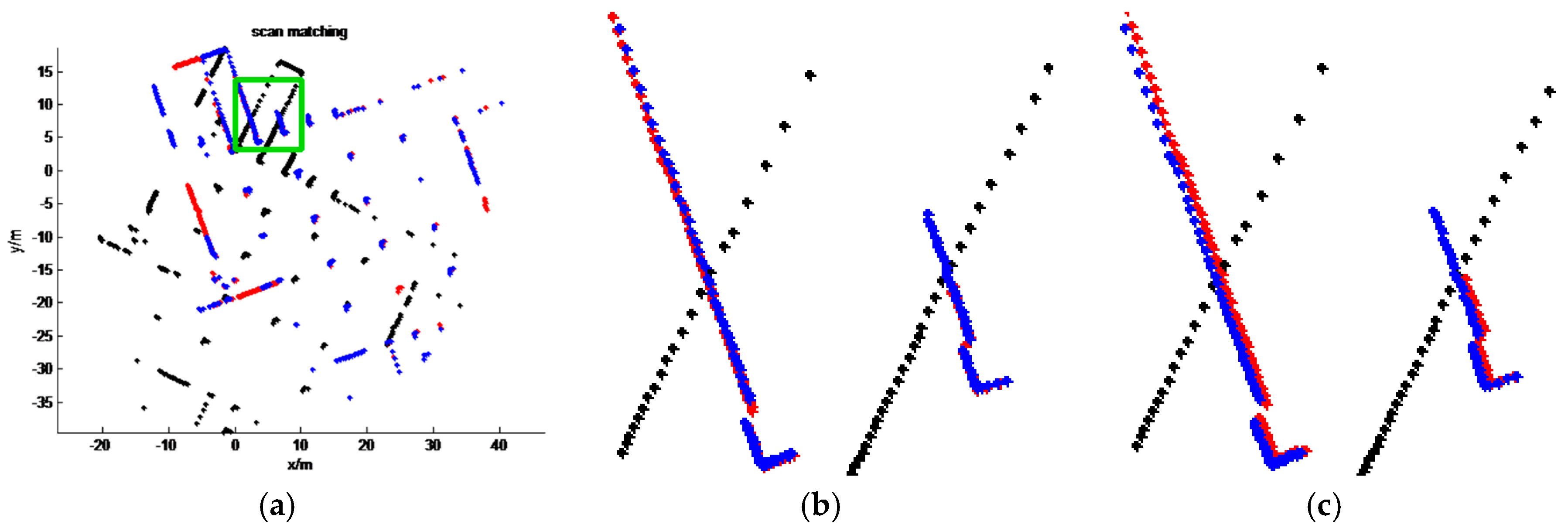
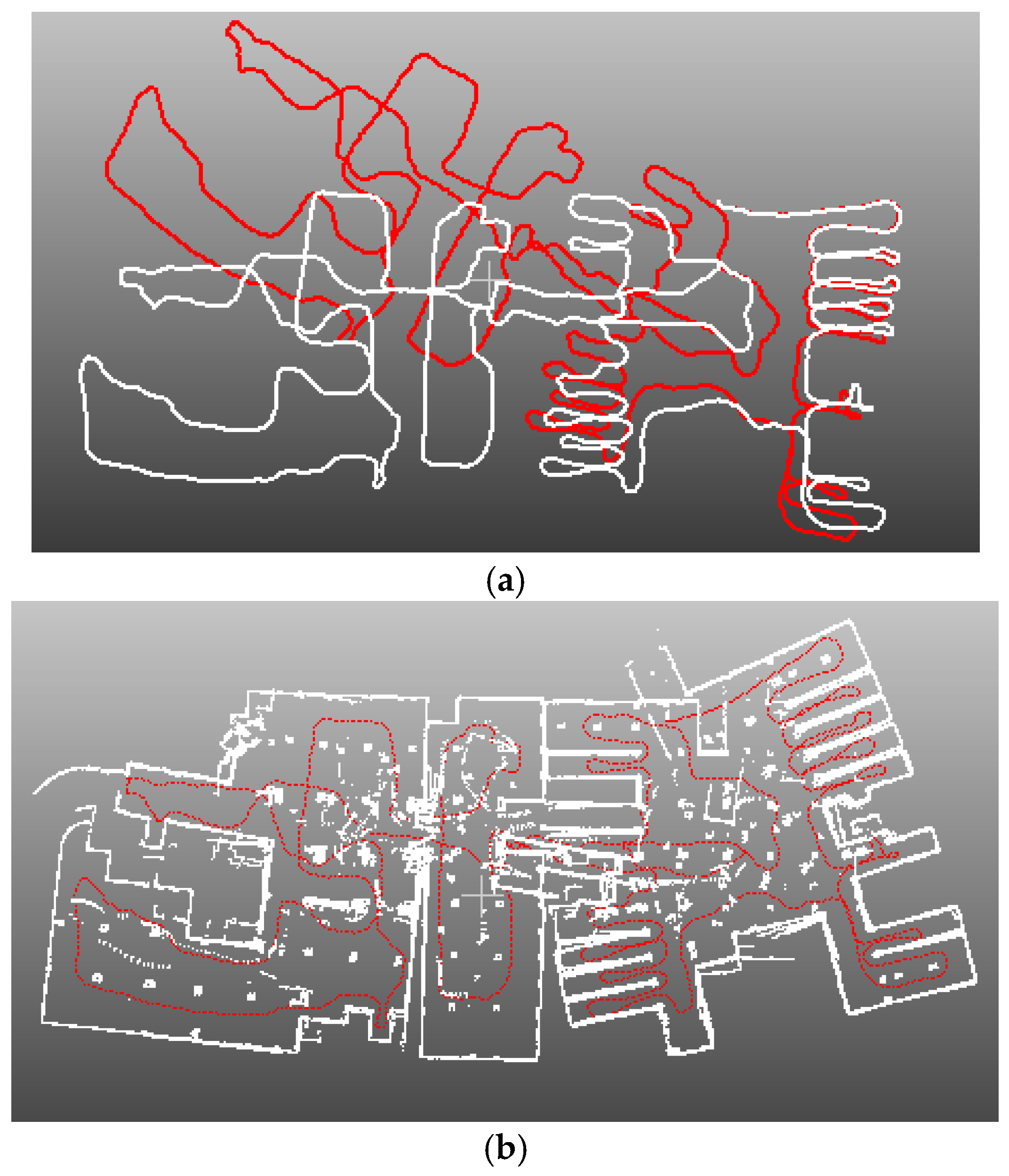
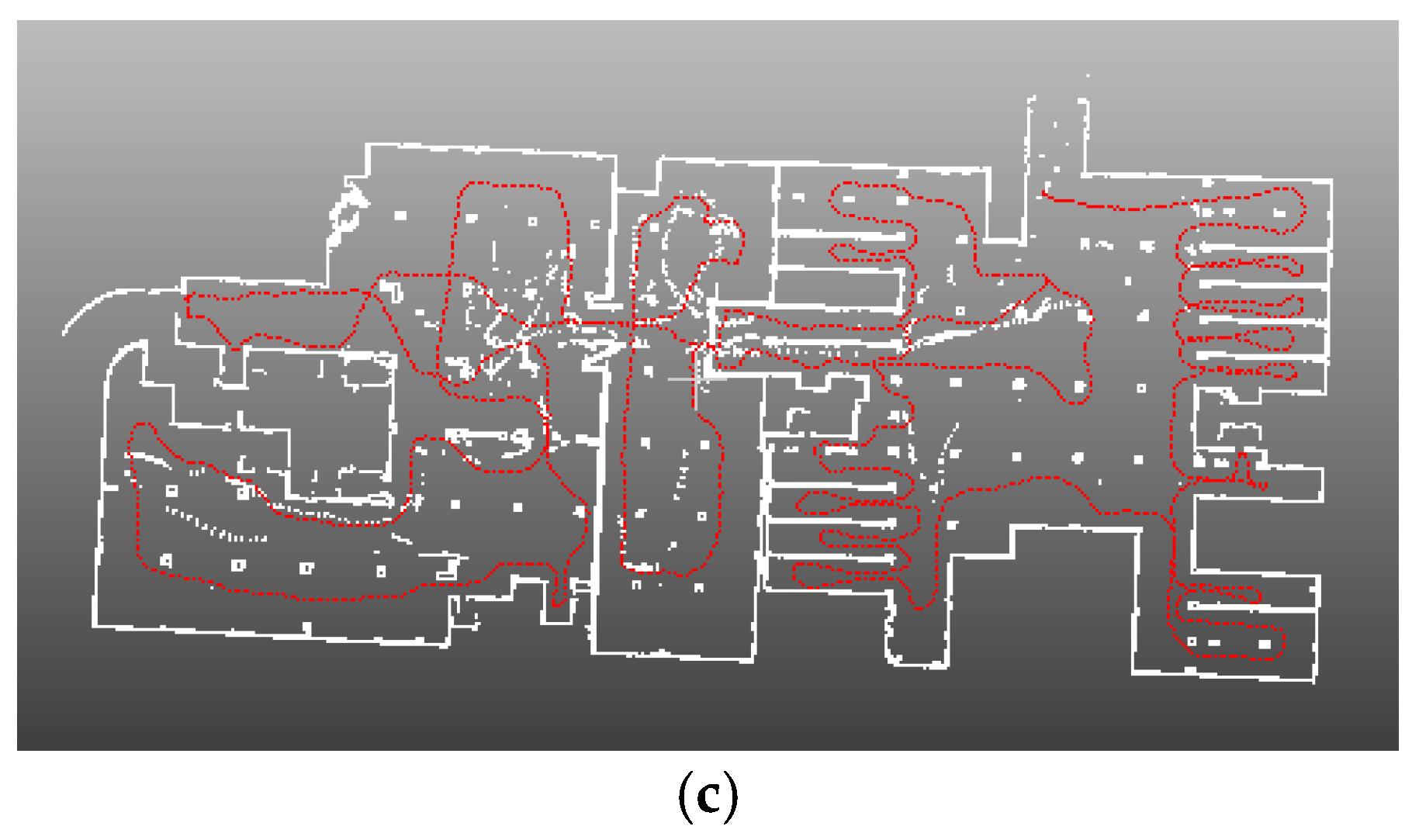
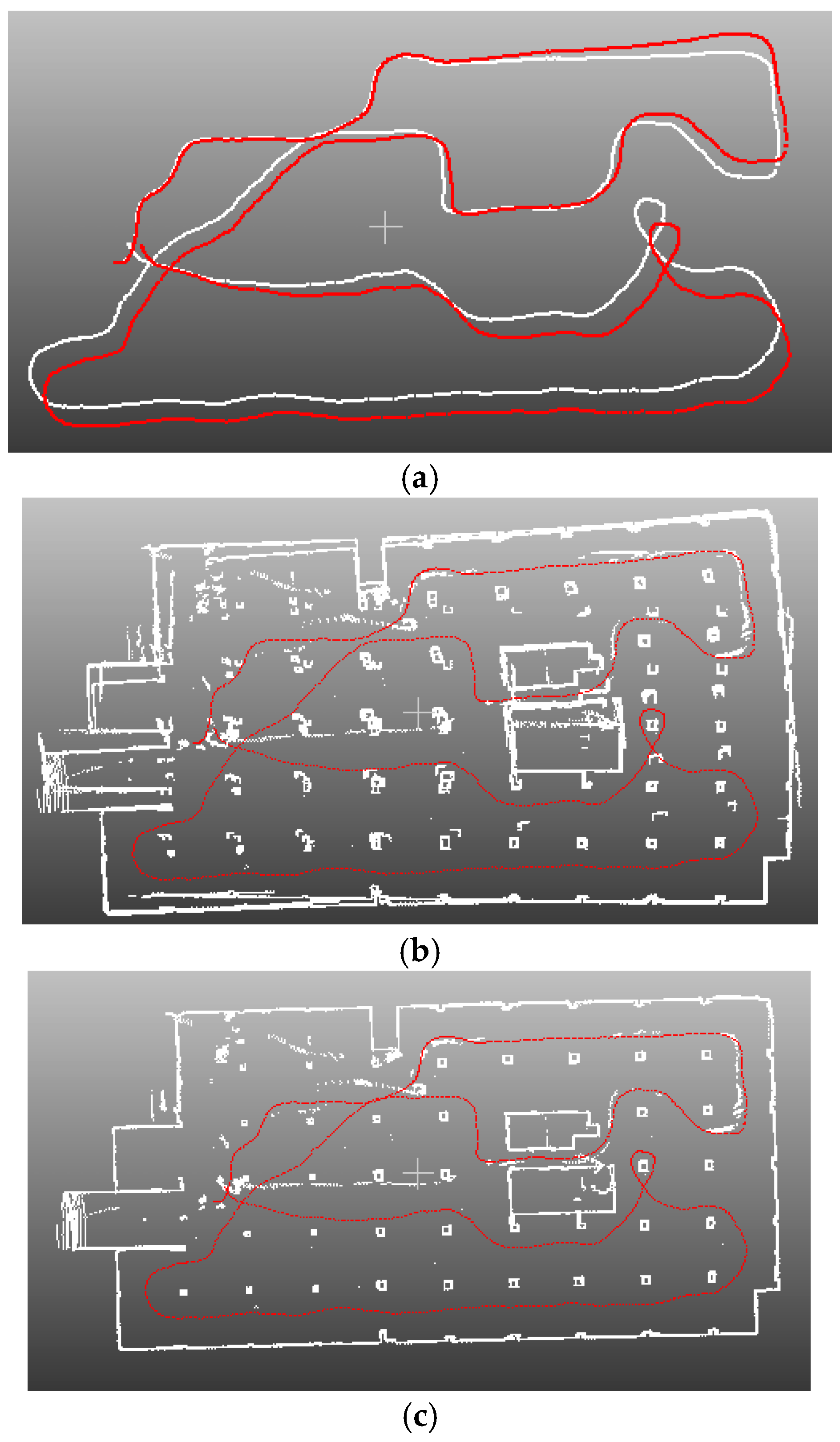
4. Results
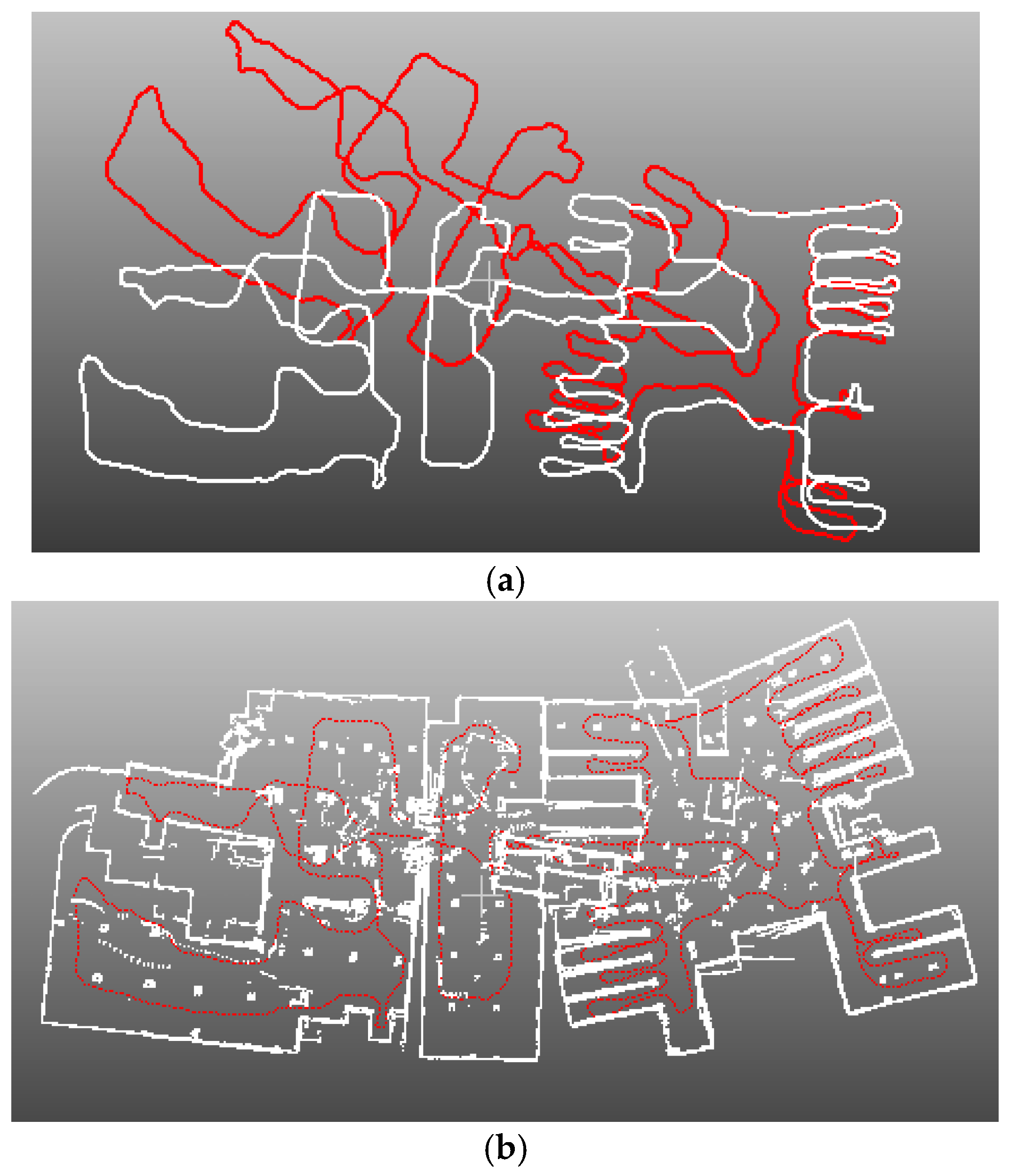
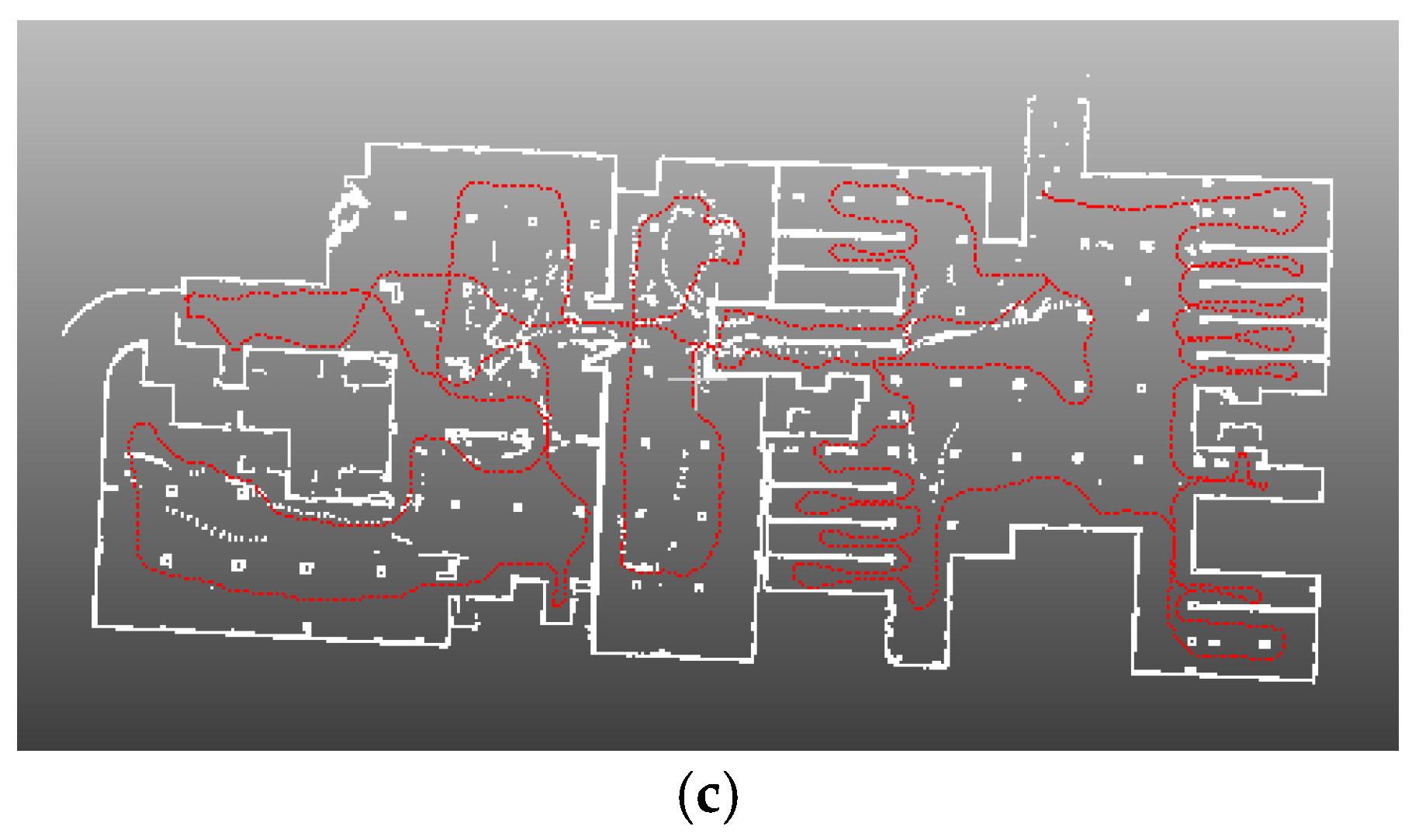
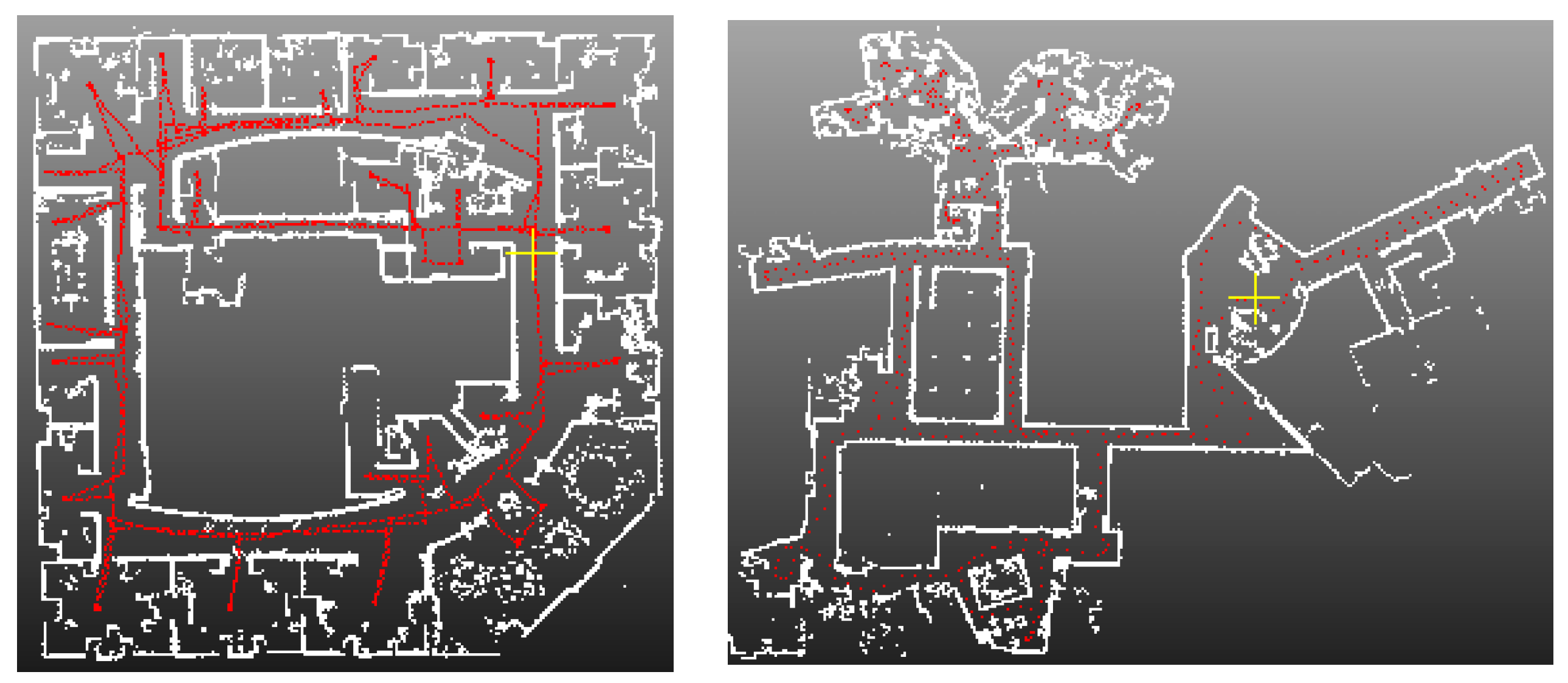
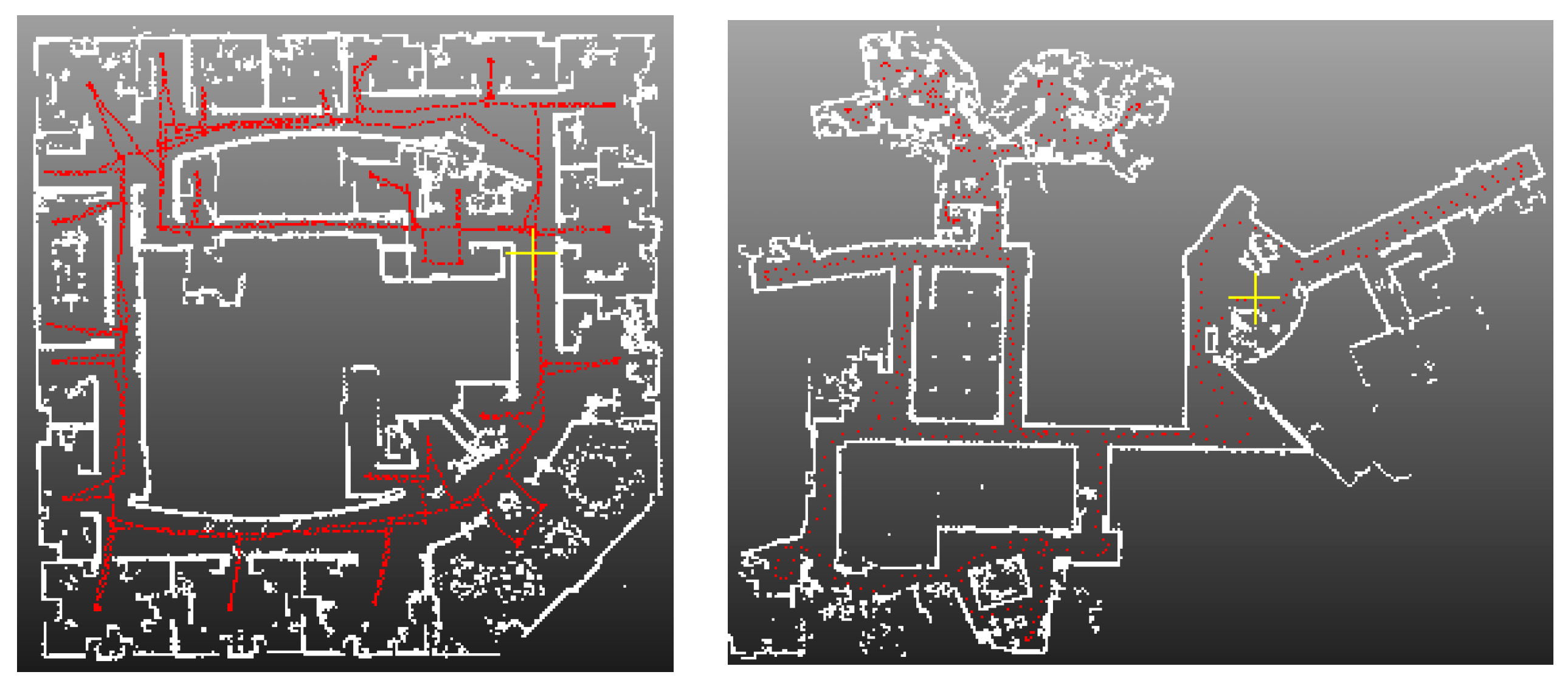
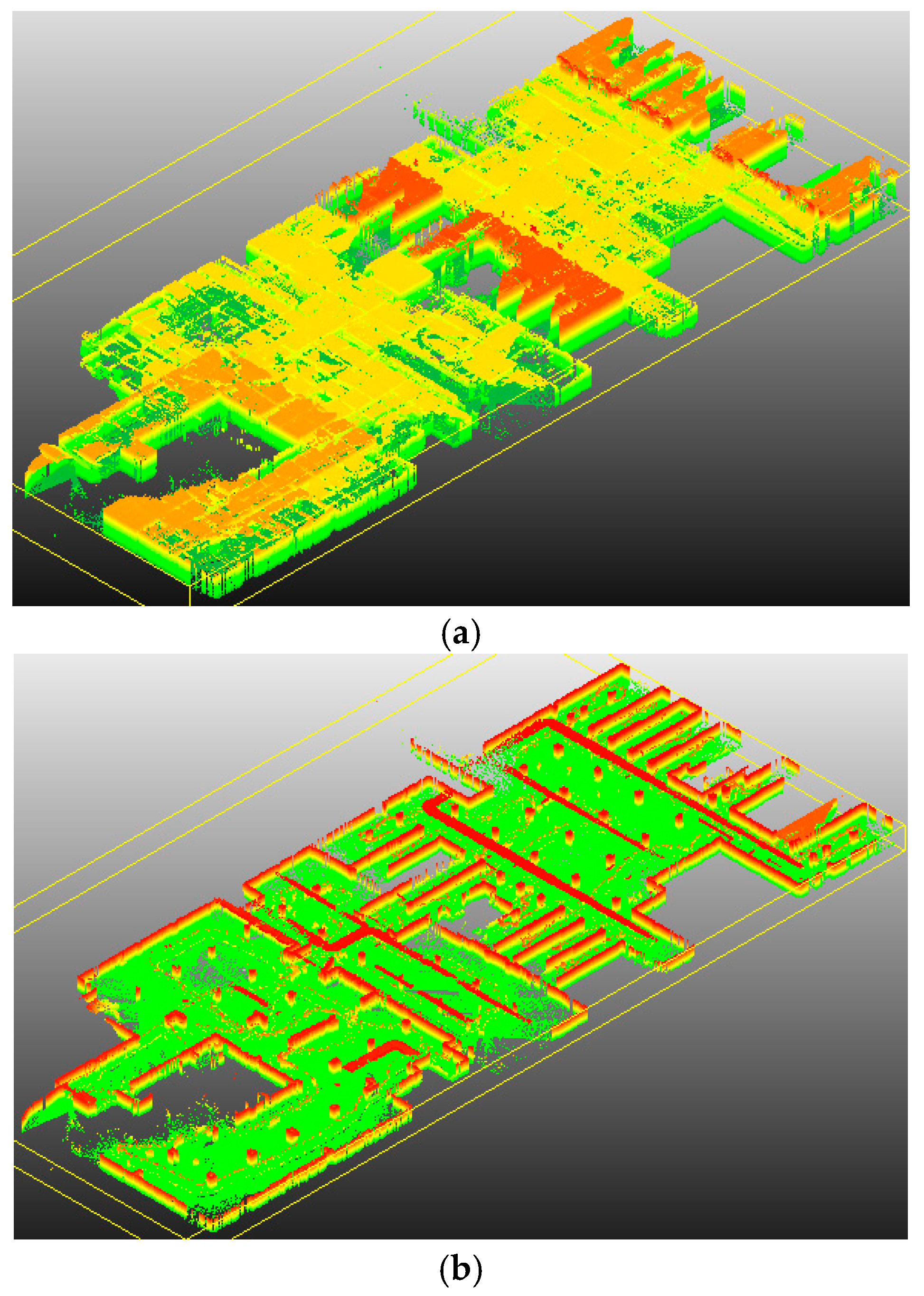
4.1. SLAM System and Datasets
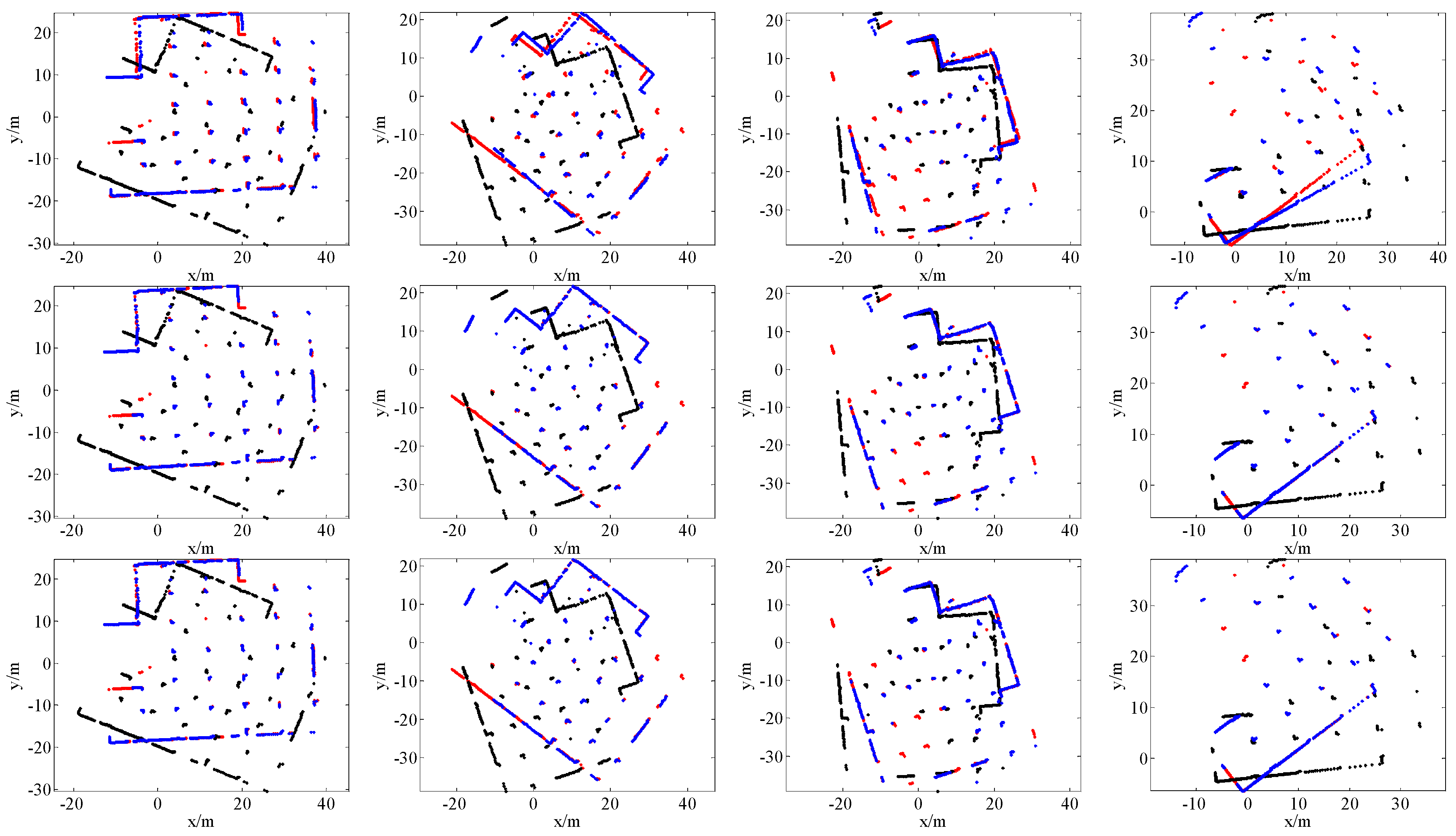
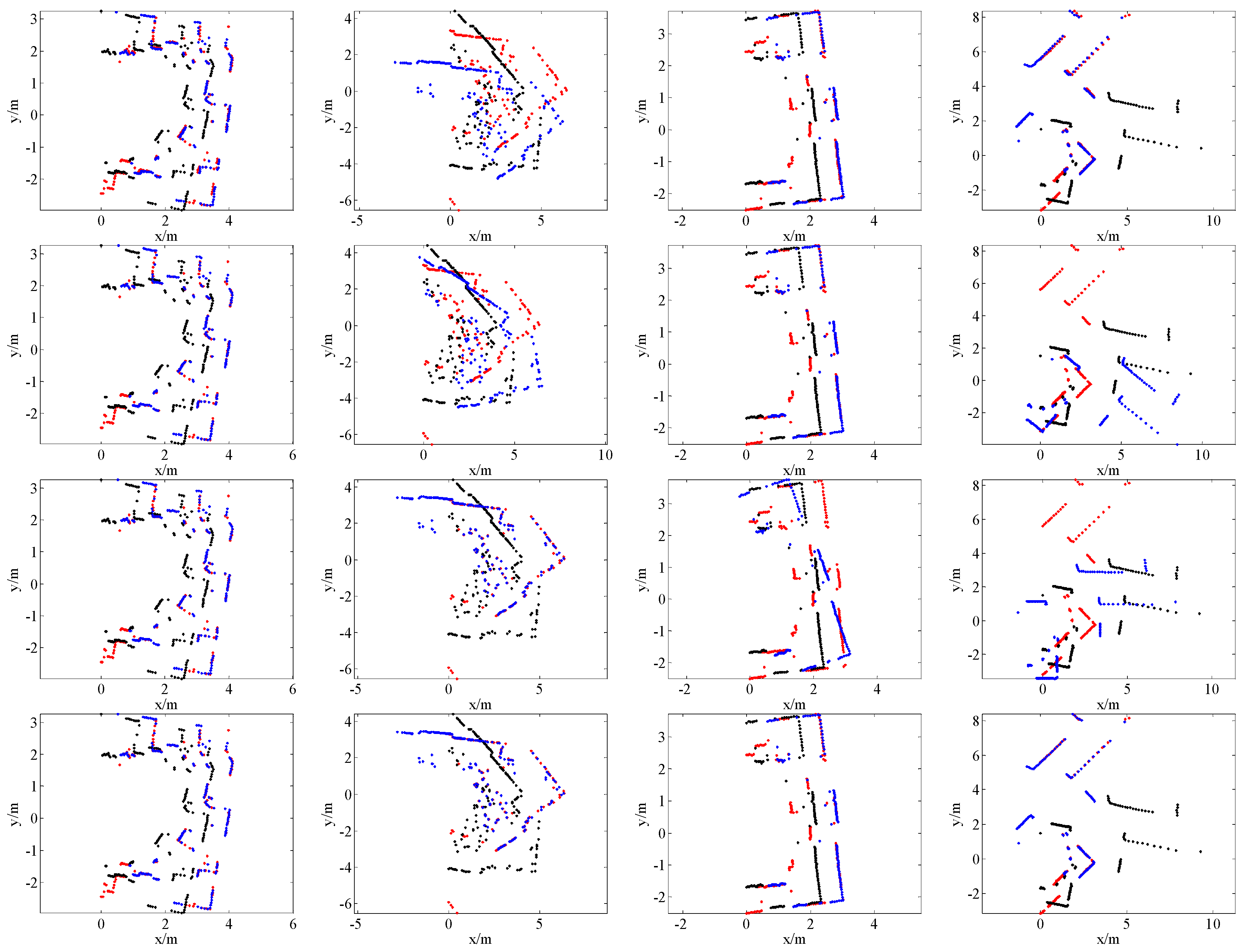
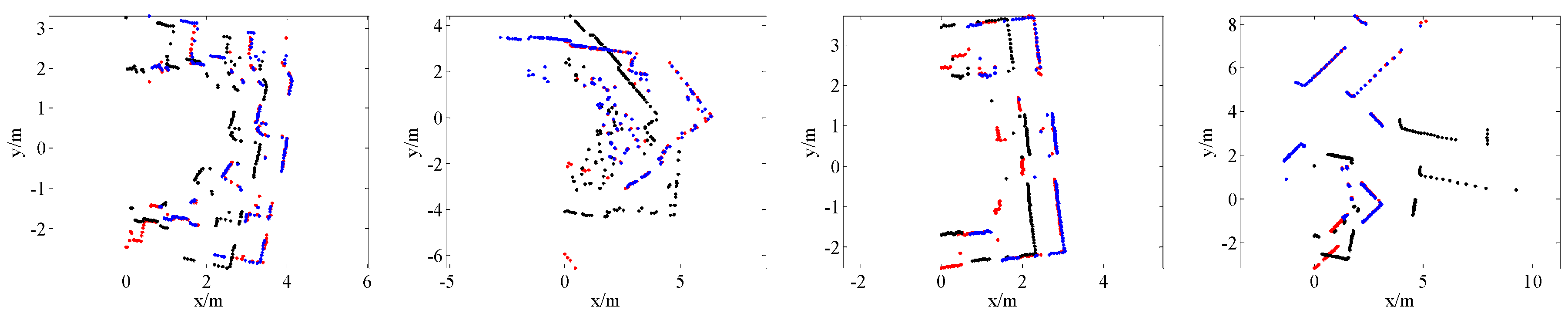
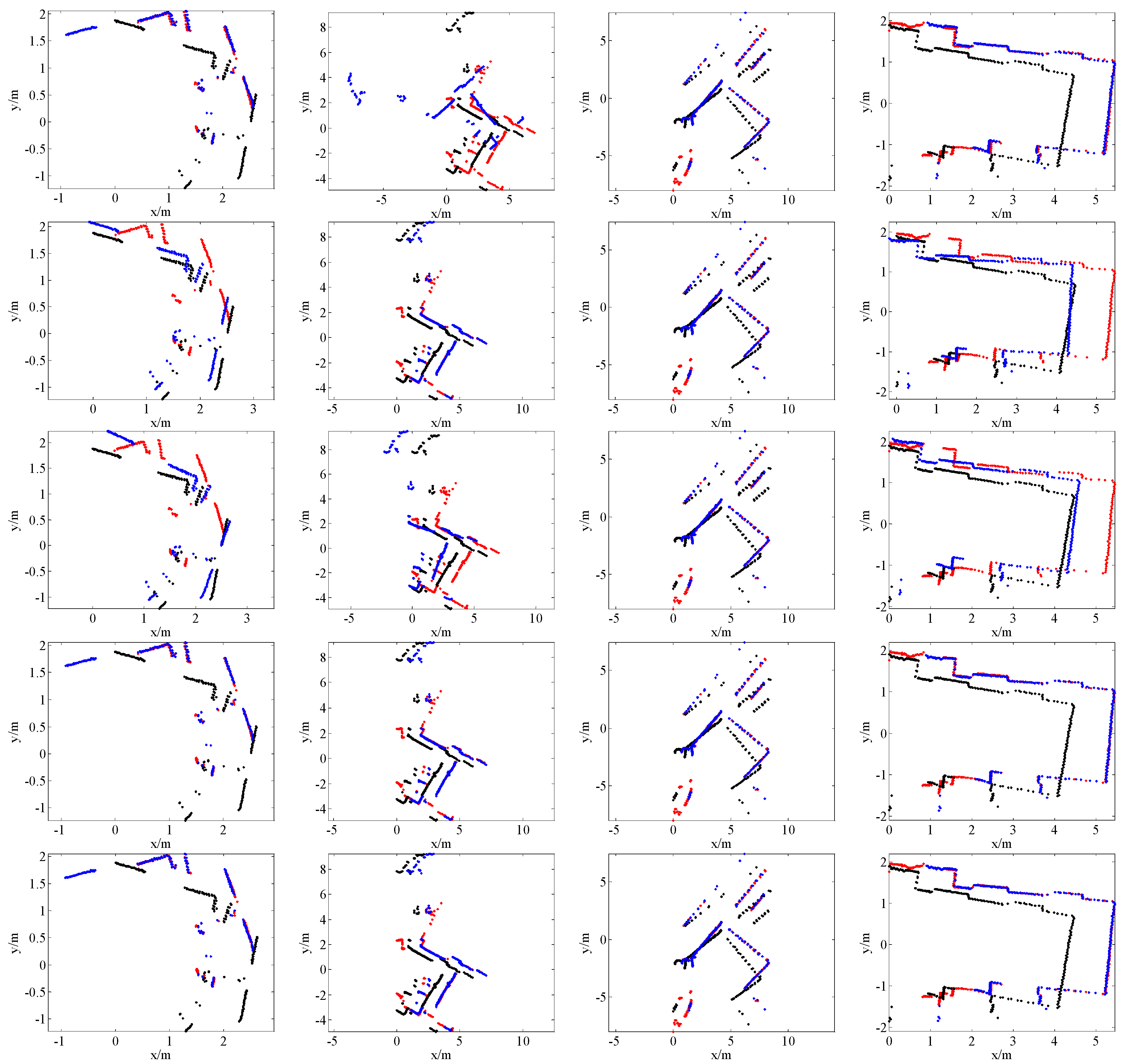
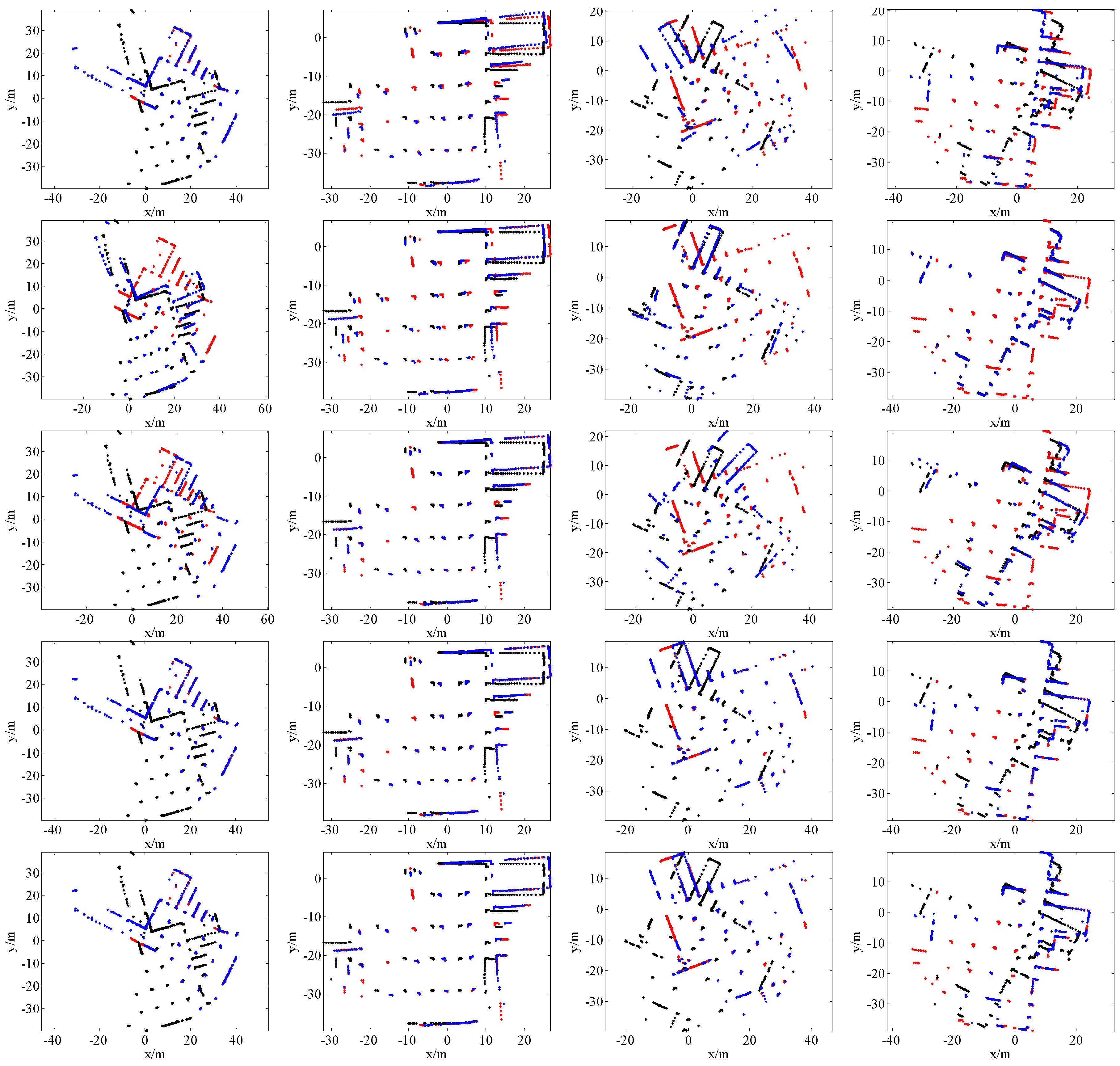
4.2. Comparison with State-of-the-Art Methods
4.3. Running Time
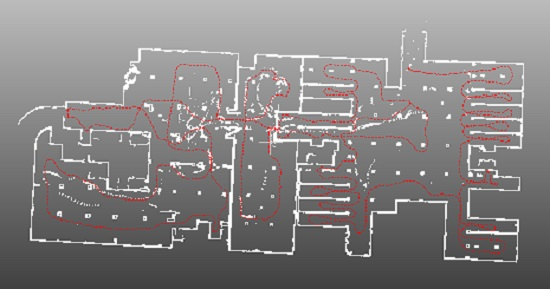
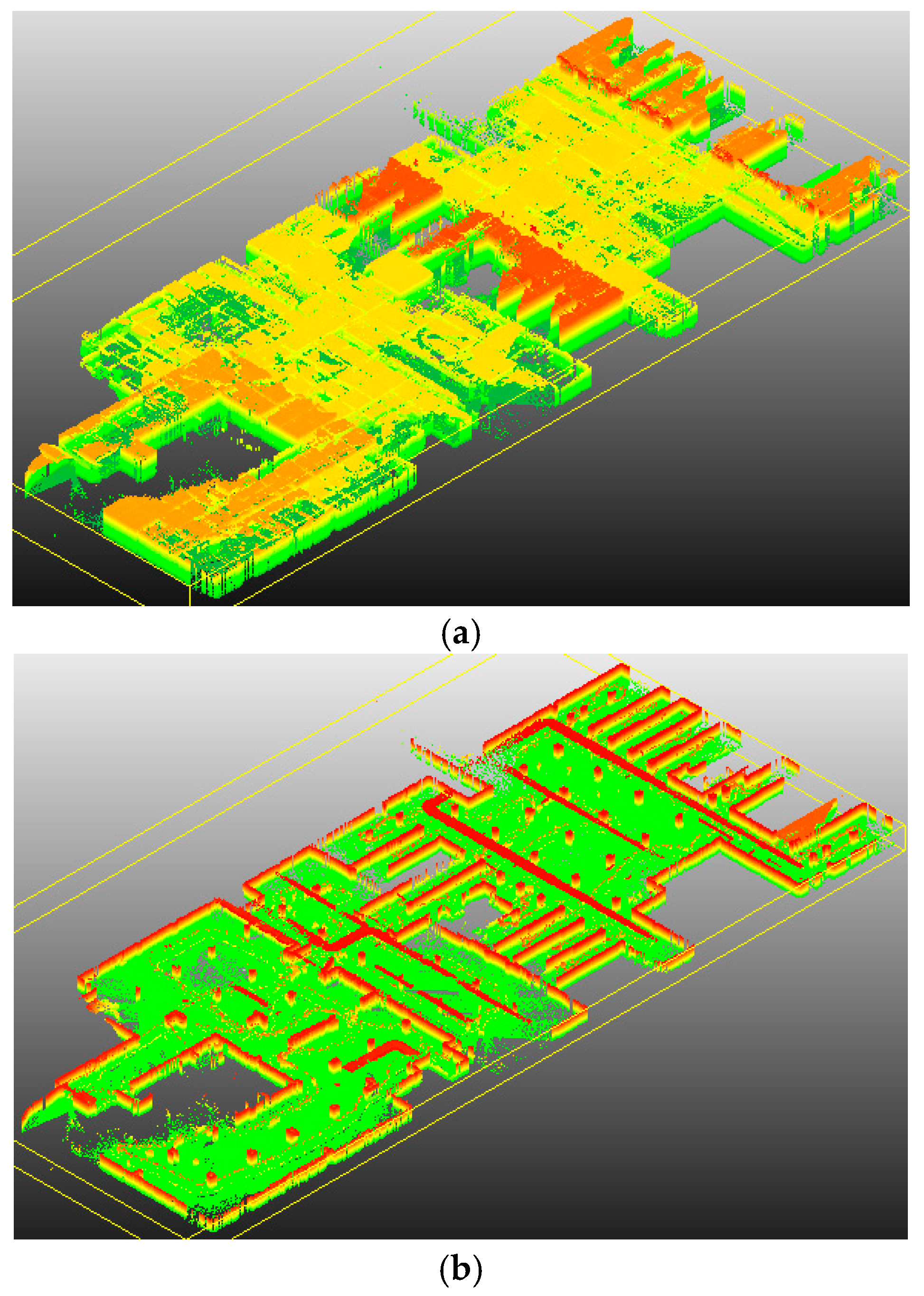
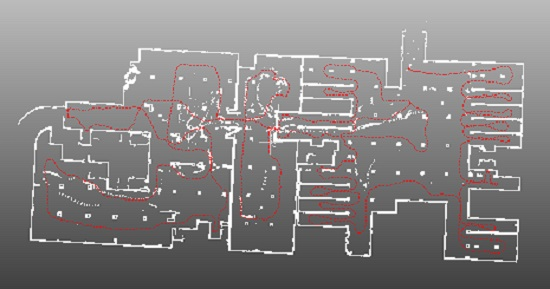
4.4. Application for SLAM
4.5. Limitations
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Best, P.J.; McKay, N.D. A method for registration of 3-d shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Magnusson, M.; Lilienthal, A.; Duckett, T. Scan registration for autonomous mining vehicles using 3D-NDT. J. Field Robot. 2007, 24, 803–827. [Google Scholar] [CrossRef] [Green Version]
- Censi, A. An ICP Variant Using a Point-to-Line Metric. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (surf). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. Orb: An Efficient Alternative to Sift or Surf. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. Brisk: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Einsele, T. Real-Time Self-Localization in Unknown Indoor Environment Using a Panorama Laser Range Finder. In Proceedings of the 1997 IEEE/RSJ International Conference on Intelligent Robots and Systems, Grenoble, France, 11 September 1997.
- Nguyen, V.; Martinelli, A.; Tomatis, N.; Siegwart, R. A Comparison of Line Extraction Algorithms Using 2D Laser Rangefinder for Indoor Mobile Robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005.
- Lu, F.; Milios, E.E. Robot Pose Estimation in Unknown Environments by Matching 2D Range Scans. In Proceedings of the 1994 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994.
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C.; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Minguez, J.; Lamiraux, F.; Montesano, L. Metric-Based Scan Matching Algorithms for Mobile Robot Displacement Estimation. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005.
- Diosi, A.; Kleeman, L. Laser Scan Matching in Polar Coordinates with Application to Slam. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005.
- Diosi, A.; Kleeman, L. Fast laser scan matching using polar coordinates. Int. J. Robot. Res. 2007, 26, 1125–1153. [Google Scholar] [CrossRef]
- Hong, S.; Ko, H.; Kim, J. Vicp: Velocity Updating Iterative Closest Point Algorithm. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010.
- Montesano, L.; Minguez, J.; Montano, L. Probabilistic Scan Matching for Motion Estimation in Unstructured Environments. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005.
- Olson, E.B. Real-Time Correlative Scan Matching. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009.
- Ramos, F.T.; Fox, D.; Durrant-Whyte, H.F. Crf-Matching: Conditional Random Fields for Feature-Based Scan Matching. In Proceedings of the Robotics: Science and Systems, 2007, Atlanta, GA, USA, 27–30 June 2007.
- Tipaldi, G.D.; Arras, K.O. Flirt-Interest Regions for 2d Range Data. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010.
- Tipaldi, G.D.; Braun, M.; Arras, K.O. Flirt: Interest Regions for 2d Range Data with Applications to Robot Navigation. In Proceedings of the Experimental Robotics, 2014, Marrakech and Essaouira, Morocco, 15–18 June 2014.
- Lindeberg, T. Scale-space theory: A basic tool for analyzing structures at different scales. J. Appl. Stat. 1994, 21, 225–270. [Google Scholar] [CrossRef]
- Lowe, D.G. Fitting parameterized three-dimensional models to images. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 441–450. [Google Scholar] [CrossRef]
- Marjanovic, G.; Solo, V. On optimization and matrix completion. IEEE Trans. Signal Process. 2012, 60, 5714–5724. [Google Scholar] [CrossRef]
- Marjanovic, G.; Solo, V. Lq Matrix Completion. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012.
- Marjanovic, G.; Hero, A.O. On Lq Estimation of Sparse Inverse Covariance. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014.
- Marjanovic, G.; Solo, V. Sparsity penalized linear regression with cyclic descent. IEEE Trans. Signal Process. 2014, 62, 1464–1475. [Google Scholar] [CrossRef]
- Mazumder, R.; Hastie, T.; Tibshirani, R. Spectral regularization algorithms for learning large incomplete matrices. J. Mach. Learn. Res. 2010, 11, 2287–2322. [Google Scholar] [PubMed]
- Mohimani, G.H.; Babaie-Zadeh, M.; Jutten, C. Fast sparse representation based on smoothed ℓ0 norm. In Independent Component Analysis and Signal Separation; Springer: Berlin, Germany, 2007; pp. 389–396. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Slam Benchmarking Dataset. Available online: http://kaspar.informatik.uni-freiburg.de/~slamEvaluation/datasets.php (accessed on 17 June 2016).
- Icp. Available online: http://www.mathworks.com/matlabcentral/fileexchange/27804-iterative-closest-point (accessed on 14 January 2016).
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A General Framework for Graph Optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011.
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Scan Pair 1 | Scan Pair 2 | Scan Pair 3 | Scan Pair 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad |
| PSM | 1.22 | 0.55 | 0.84 | 0.51 | 0.09 | 0.11 | −1 | −0.62 | 1 | −0.29 | 0.57 | 0.33 |
| PLICP | 1.03 | 0.61 | 0.13 | 0.16 | 0 | 0.07 | 0.56 | -0.08 | 0.08 | 0.01 | −0.25 | 0 |
| ICP1 | 6.94 | −2.76 | 0.82 | 1.46 | 0.13 | 0.07 | 7.63 | 3.76 | −0.3 | 1.84 | −0.27 | −0.05 |
| ours | 1.21 | 0.58 | 0.83 | 1.55 | 0.05 | 0.07 | 1.9 | 0.64 | 0.79 | 2.08 | 0.31 | 0.3 |
| ICP2 | 1.24 | 0.55 | 0.84 | 1.53 | 0.09 | 0.07 | 1.85 | 0.55 | 0.8 | 2.07 | 0.31 | 0.3 |
| d(PSM–ICP2) | 0 | 0 | 0 | −1.06 | 0 | 0.04 | −2.87 | −1.28 | 0.2 | −2.41 | 0.24 | 0.02 |
| d(PLICP–ICP2) | −0.21 | 0.06 | −0.71 | −1.37 | −0.09 | 0 | −1.29 | −0.63 | −0.72 | −2.06 | −0.56 | −0.3 |
| d(ICP1–ICP2) | 5.7 | −3.31 | −0.02 | −0.07 | 0.04 | 0 | 5.78 | 3.21 | −1.1 | −0.23 | −0.58 | −0.35 |
| d(ours–ICP2) | −0.03 | 0.03 | −0.01 | 0.02 | −0.04 | 0 | 0.05 | 0.09 | −0.01 | 0.01 | 0 | 0 |
| Data | Scan Pair 1 | Scan Pair 2 | Scan Pair 3 | Scan Pair 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad | tx/m | ty/m | rθ/rad |
| PSM | 0.68 | 0.1 | 0.45 | 1.34 | 0.55 | 0.59 | −0.56 | −0.78 | 0.31 | −1.36 | −1.91 | 0.46 |
| PLICP | 0.5 | 1.46 | 0.04 | −0.62 | −0.05 | 0.02 | 1.85 | 0.22 | 0.21 | 0.42 | −0.62 | 0.54 |
| ICP1 | 1.19 | 0.12 | 0.43 | 2.45 | 1.07 | 0.52 | 1.98 | 0.34 | 0.17 | 1.87 | 0.51 | 0.4 |
| ours | 0.65 | 0.07 | 0.45 | 1.34 | 0.54 | 0.58 | 1.85 | 0.25 | 0.22 | 1.94 | 0.55 | 0.54 |
| ICP2 | 0.64 | 0.08 | 0.44 | 1.37 | 0.55 | 0.58 | 1.85 | 0.21 | 0.22 | 1.96 | 0.55 | 0.54 |
| d(PSM–ICP2) | 0.04 | 0.02 | 0.01 | −0.03 | 0 | 0.01 | −2.41 | −0.99 | 0.09 | −3.32 | −2.46 | −0.08 |
| d(PLICP–ICP2) | −0.14 | 1.38 | −0.4 | −1.99 | −0.6 | −0.56 | 0 | 0.01 | −0.01 | −1.54 | −1.17 | 0 |
| d(ICP1–ICP2) | 0.55 | 0.04 | −0.01 | 1.08 | 0.52 | −0.06 | 0.13 | 0.13 | −0.05 | −0.09 | −0.04 | −0.14 |
| d(ours–ICP2) | 0.01 | −0.01 | 0.01 | −0.03 | −0.01 | 0 | 0 | 0.04 | 0 | −0.02 | 0 | 0 |
| Datasets | Intel | MIT | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | ex/m | ey/m | eθ/rad | Success Rate | ex/m | ey/m | eθ/rad | Success Rate |
| PSM | 0.06 | 0.22 | 0.08 | 82% | 0.28 | 0.09 | 0.13 | 80% |
| PLICP | 0.17 | 0.22 | 0.39 | 66% | 0.53 | 0.29 | 0.26 | 50% |
| ICP1 | 0.44 | 0.36 | 0.41 | 58% | 0.58 | 0.27 | 0.25 | 44% |
| Ours | 0.02 | 0.01 | 0.01 | 100% | 0.01 | 0.02 | 0.01 | 100% |
| Methods | 180/ms | 360/ms | 720/ms | 1080/ms |
|---|---|---|---|---|
| PSM | 2 | 5 | 10 | 14 |
| PLICP | 32 | 96 | 252 | 364 |
| ICP1 | 37 | 117 | 286 | 372 |
| Ours | 15 | 34 | 57 | 92 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhong, R.; Hu, Q.; Ai, M. Feature-Based Laser Scan Matching and Its Application for Indoor Mapping. Sensors 2016, 16, 1265. https://doi.org/10.3390/s16081265
Li J, Zhong R, Hu Q, Ai M. Feature-Based Laser Scan Matching and Its Application for Indoor Mapping. Sensors. 2016; 16(8):1265. https://doi.org/10.3390/s16081265
Chicago/Turabian StyleLi, Jiayuan, Ruofei Zhong, Qingwu Hu, and Mingyao Ai. 2016. "Feature-Based Laser Scan Matching and Its Application for Indoor Mapping" Sensors 16, no. 8: 1265. https://doi.org/10.3390/s16081265