An Efficient Implementation of Fixed Failure-Rate Ratio Test for GNSS Ambiguity Resolution


Abstract
:
1. Introduction
2. Methodology
2.1. General Ambiguity Resolution Model
2.2. Probability Parameters of the Ratio Test
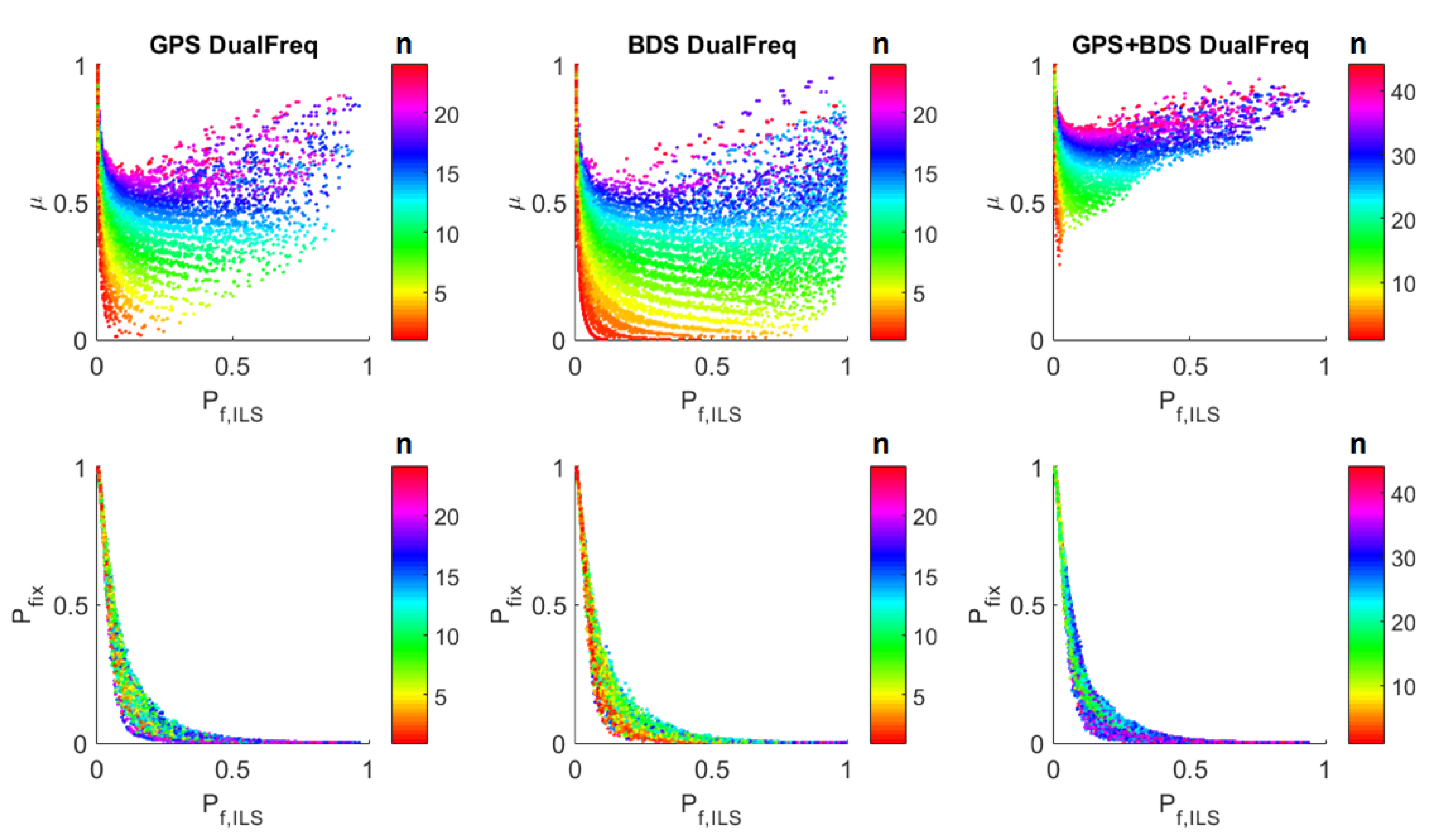
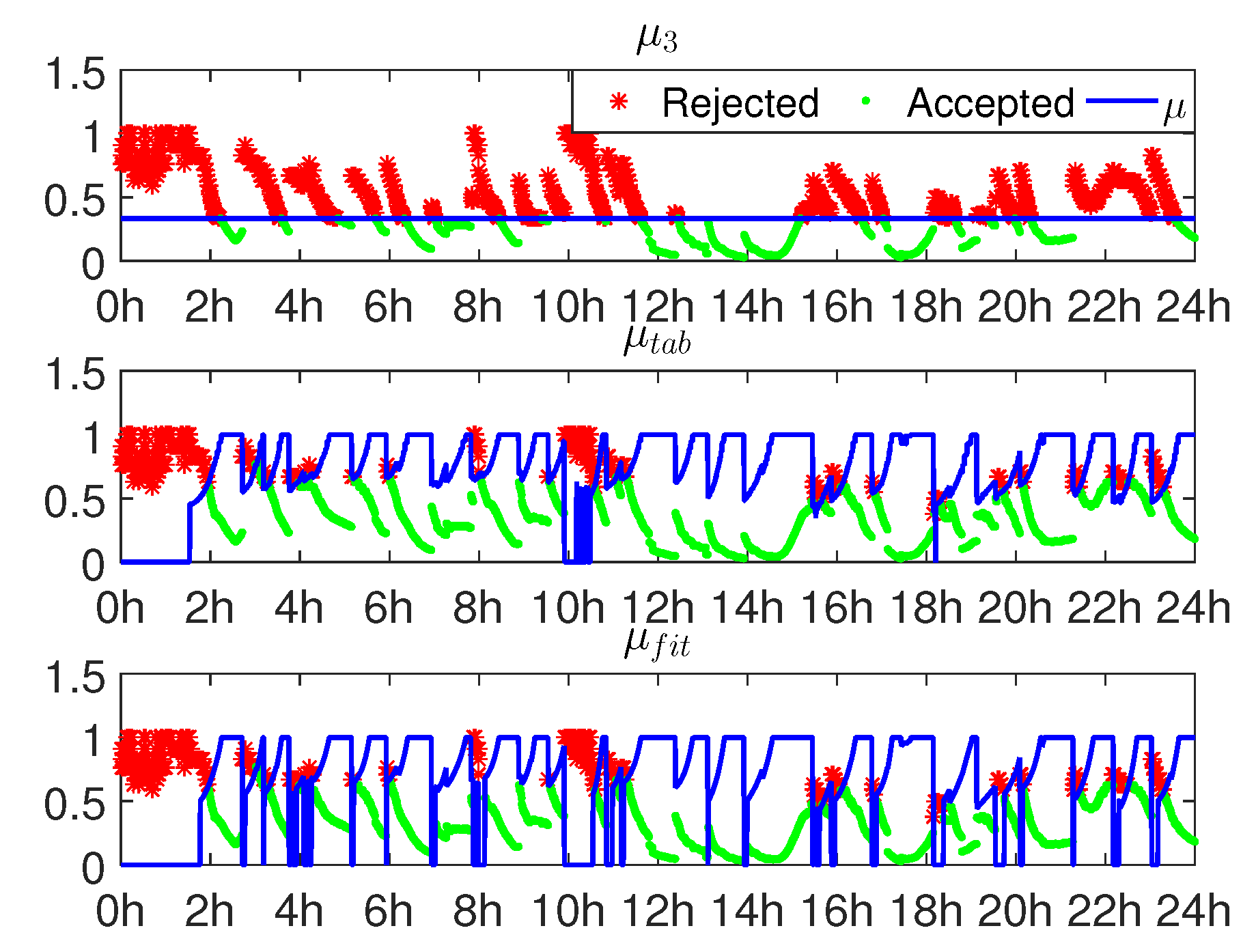
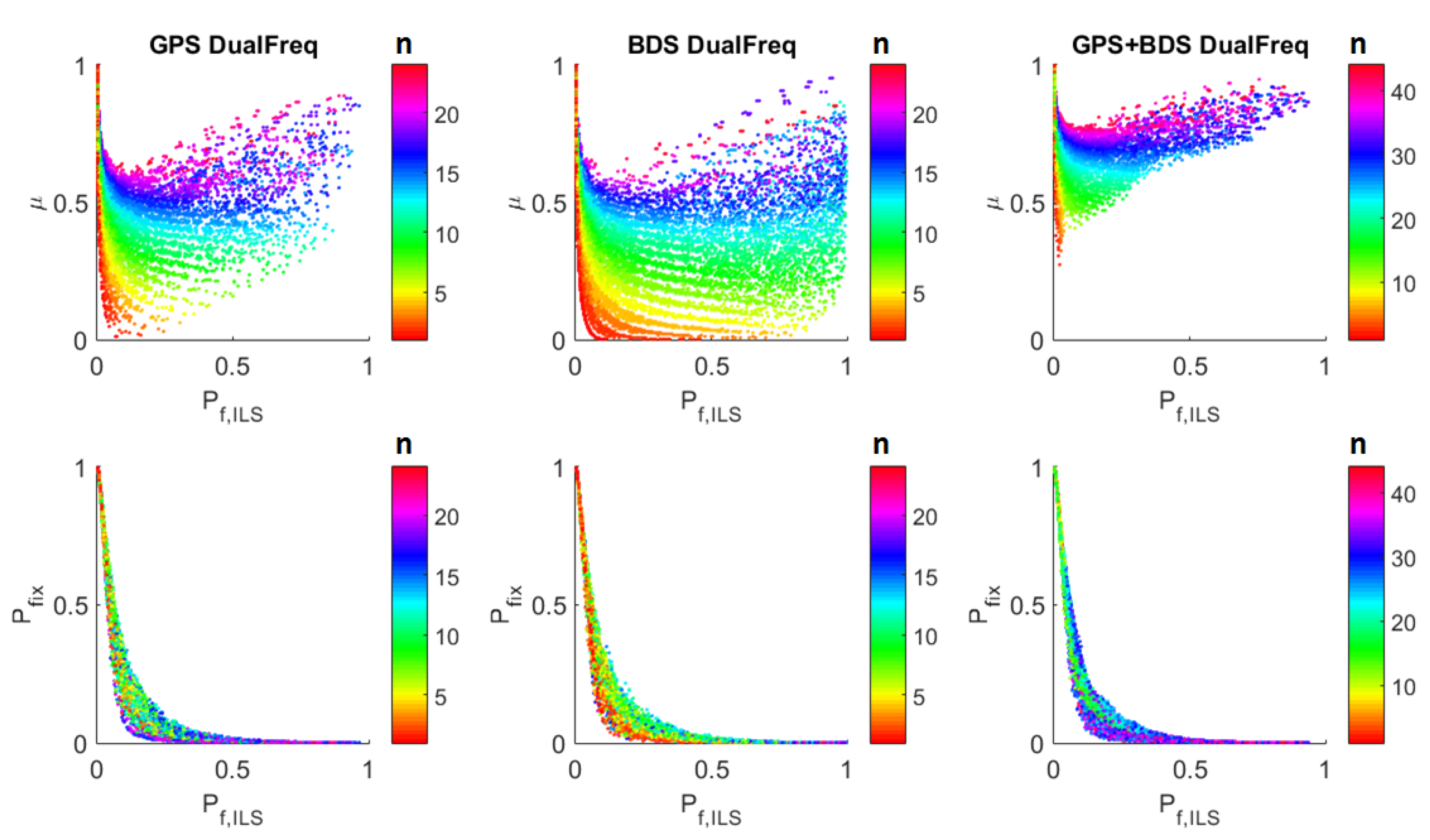
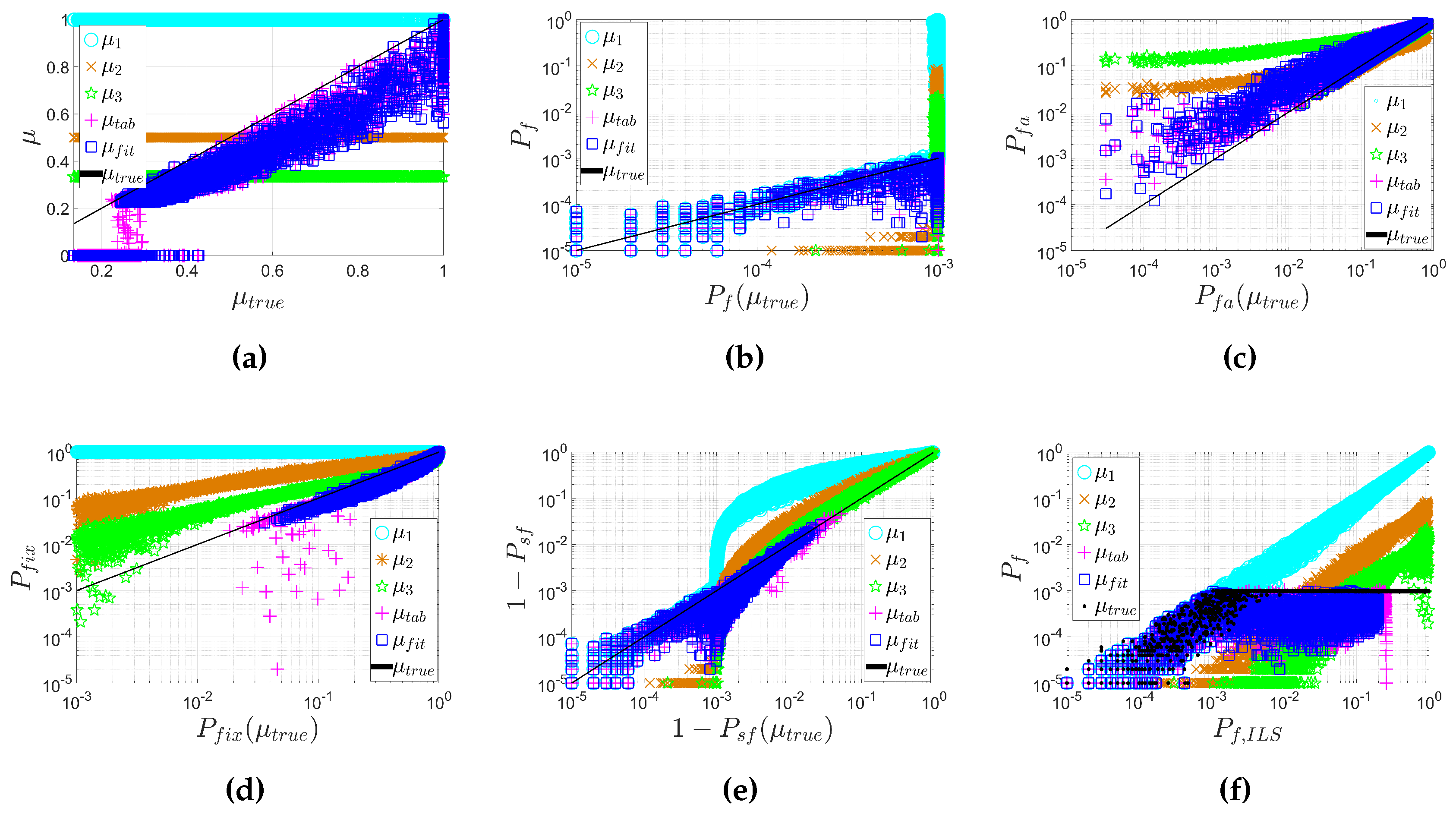
- The values of μ are grouped by n. The more the ambiguities, the larger the value of μ.
- μ decreases with the increase of and when the number of ambiguities is large, it later increases again.
- decreases as increases.
- The values of are grouped by n. It does not show the monotonously increasing or decreasing relation with n.
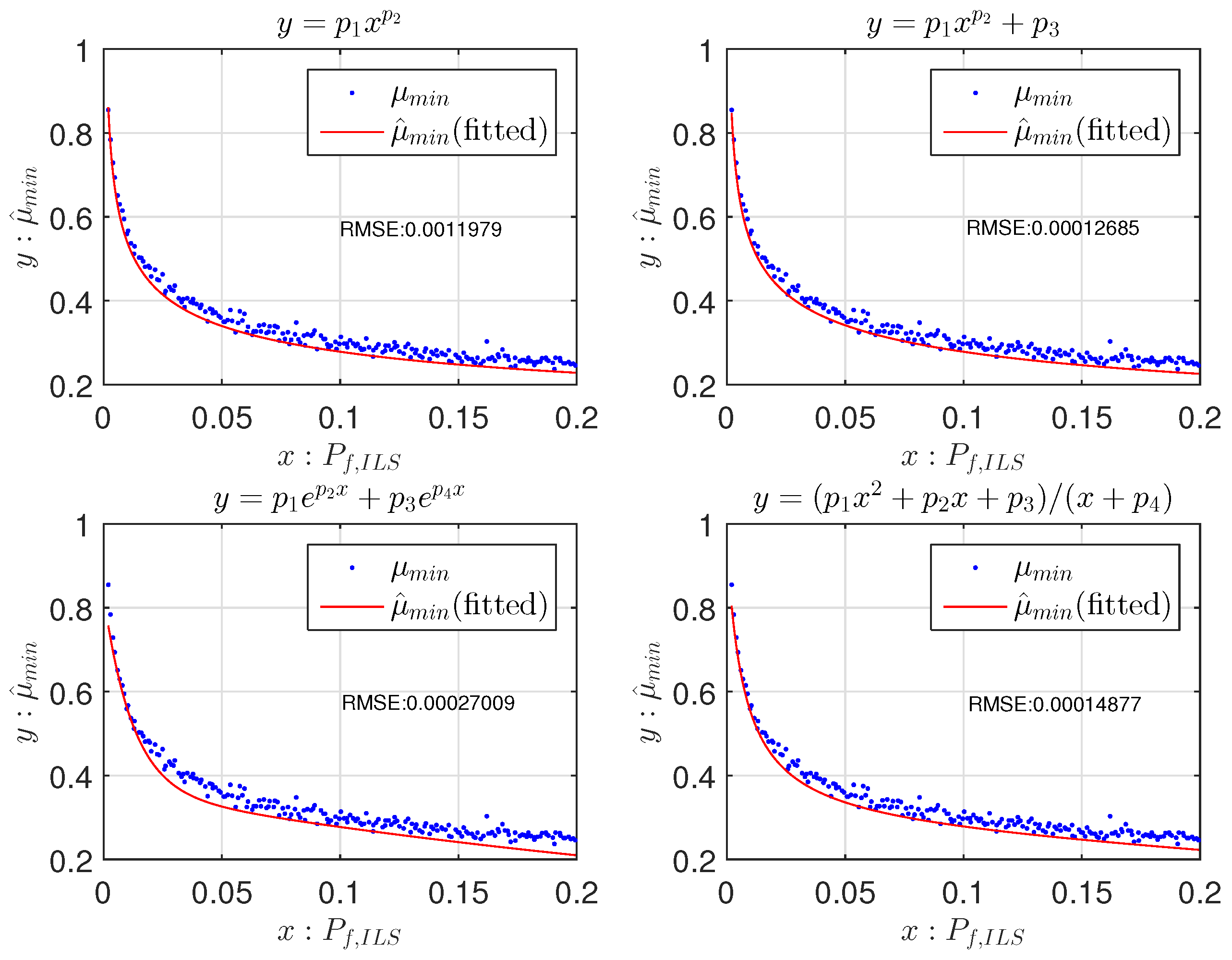
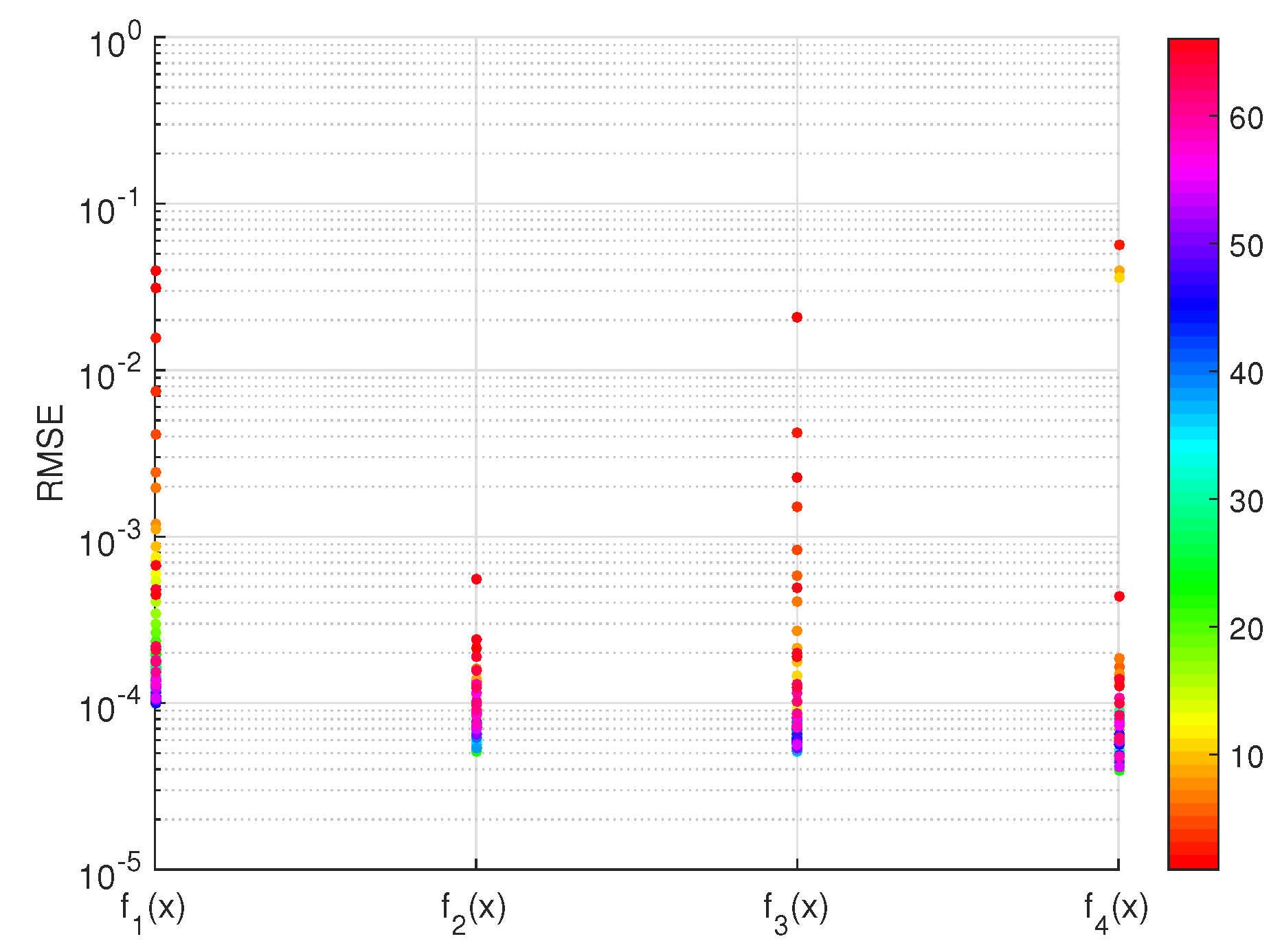
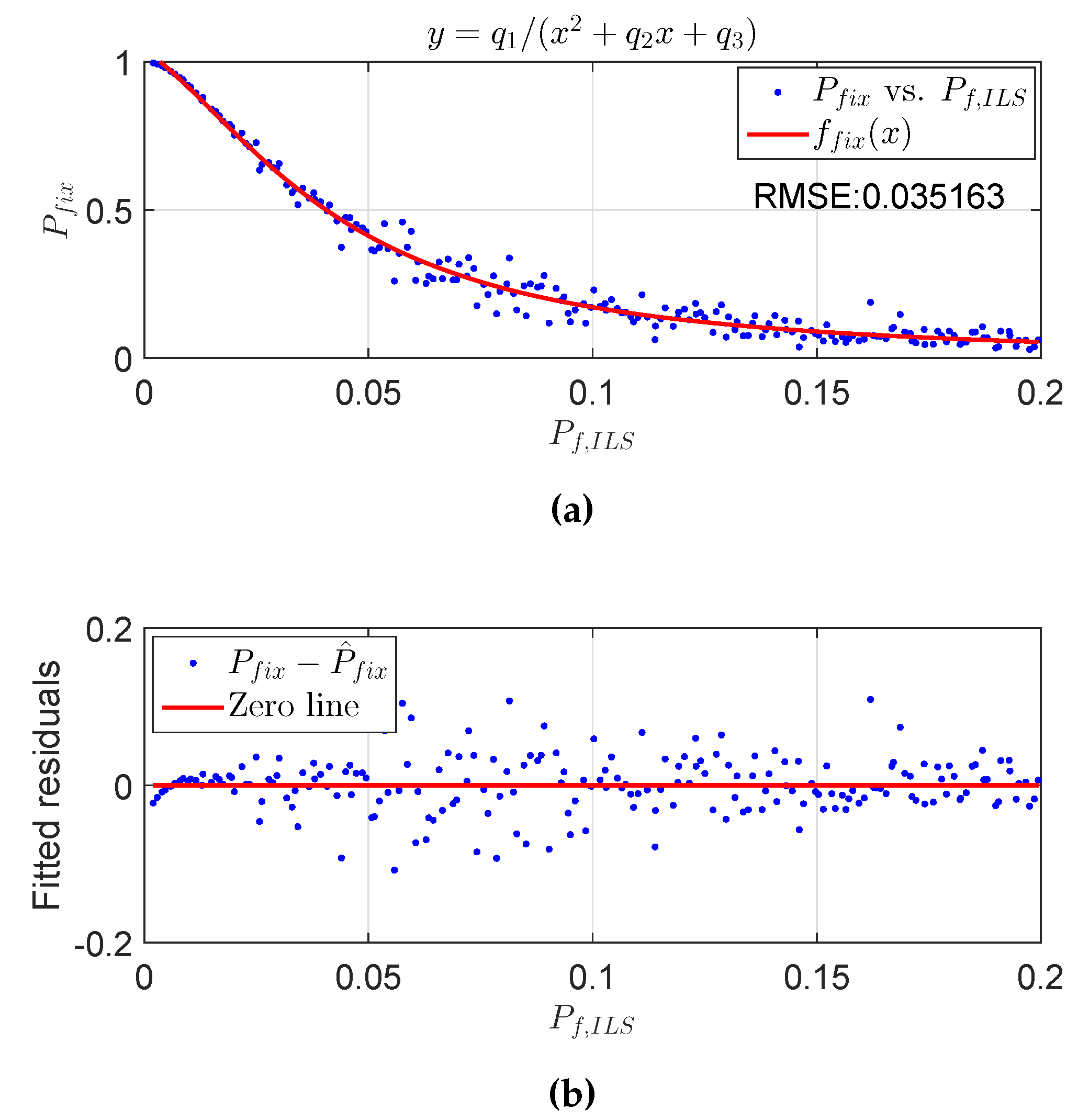
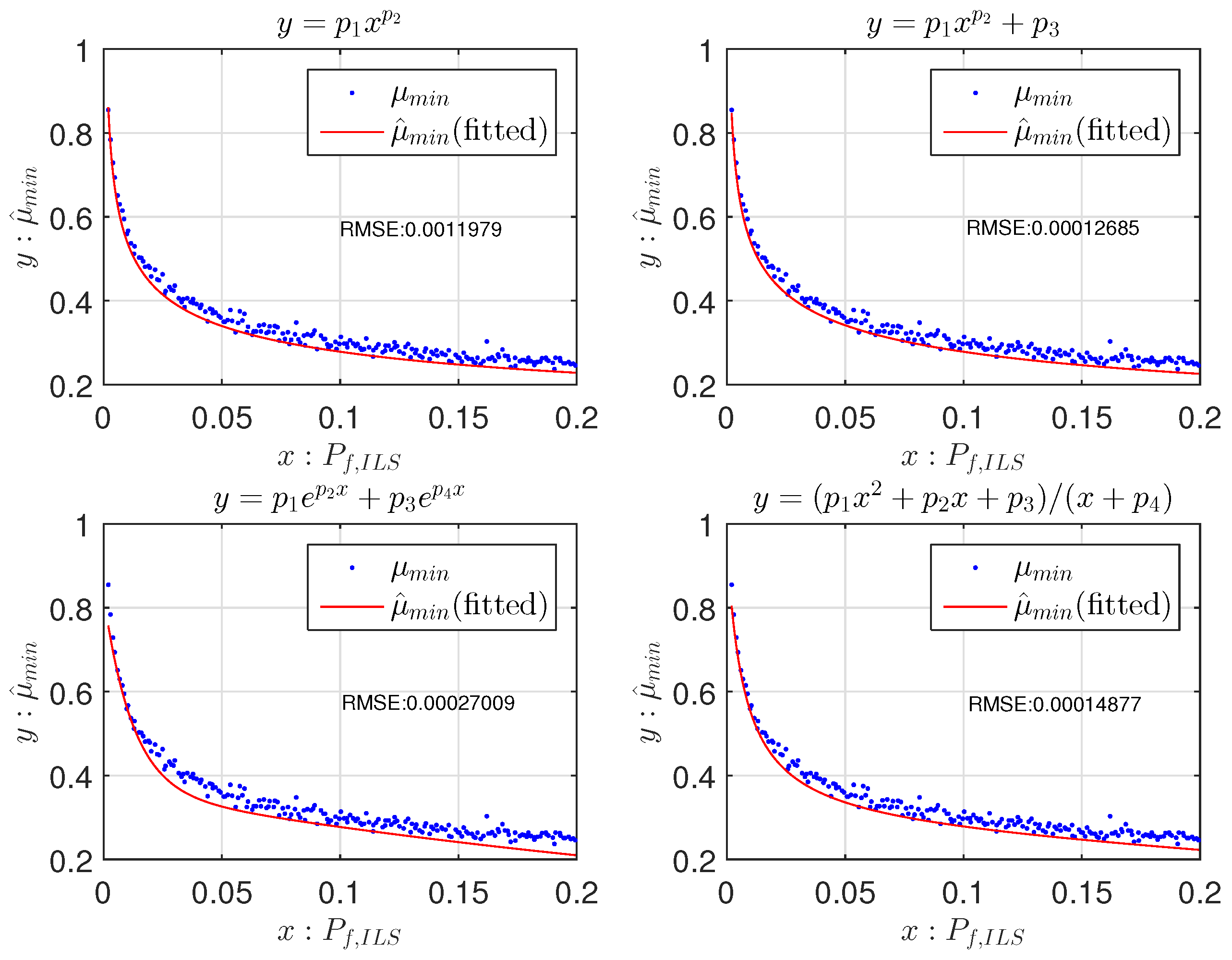
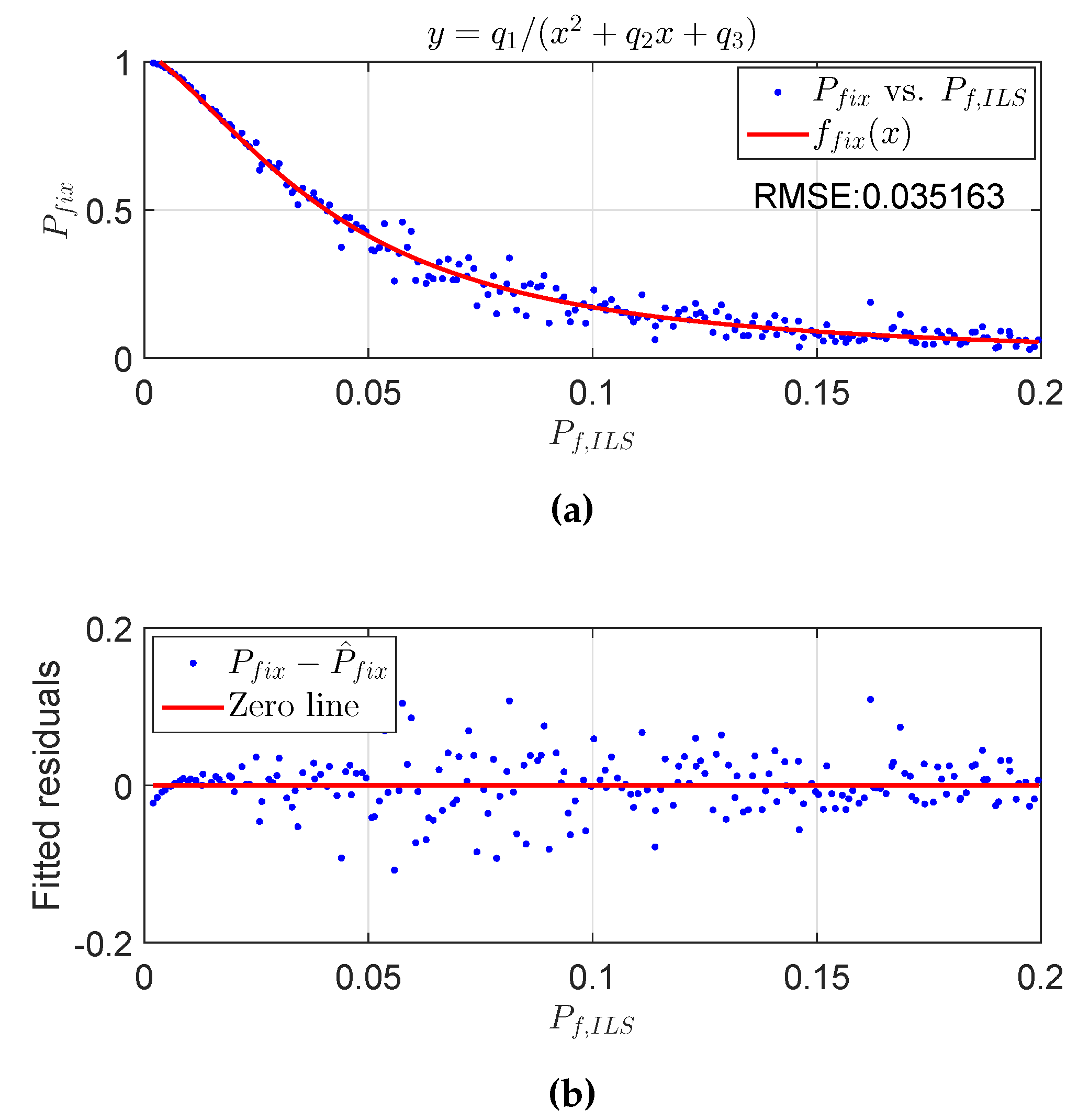
2.3. Fitting Functions for the Fixed Failure-Rate Ratio Test
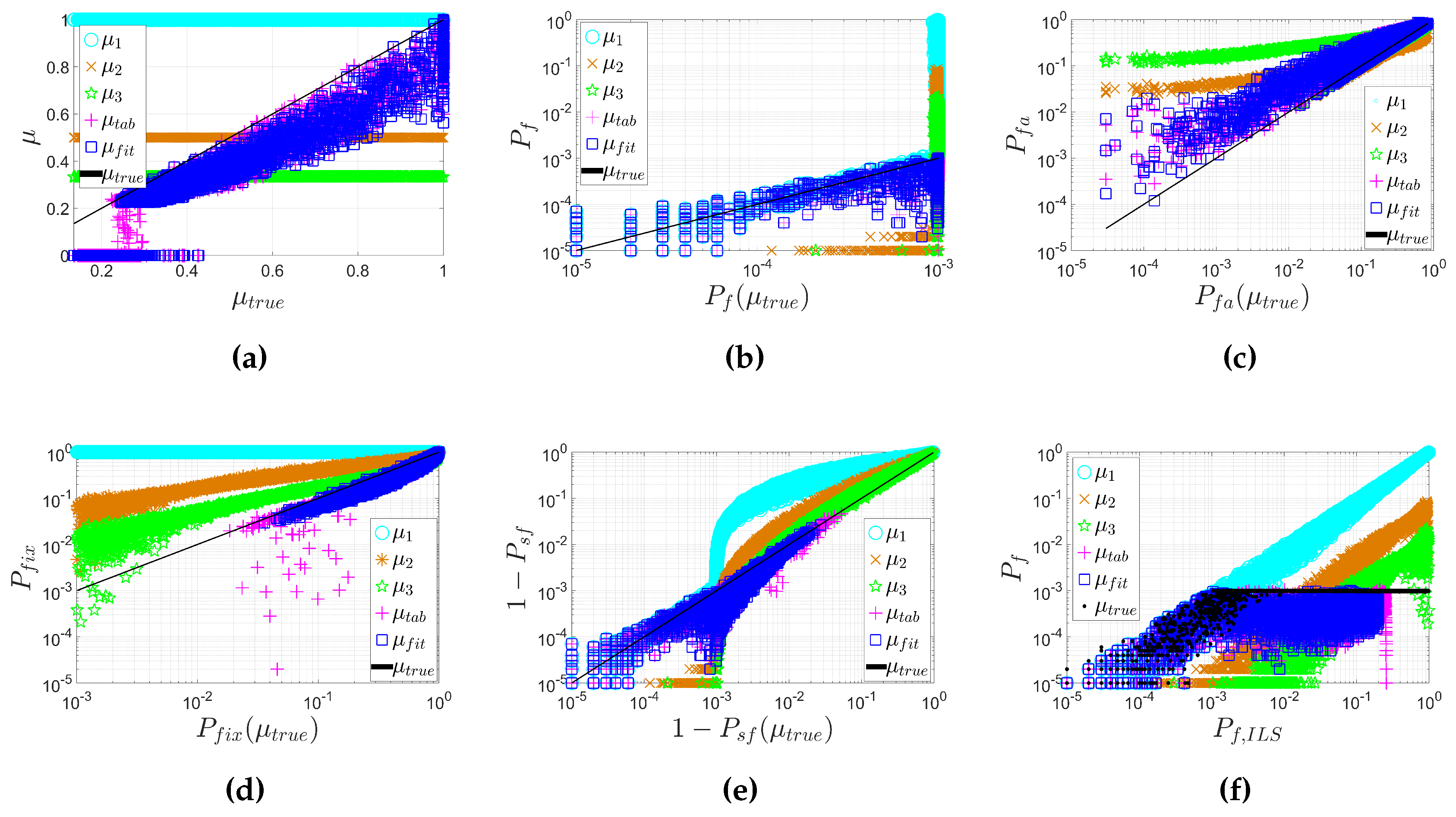
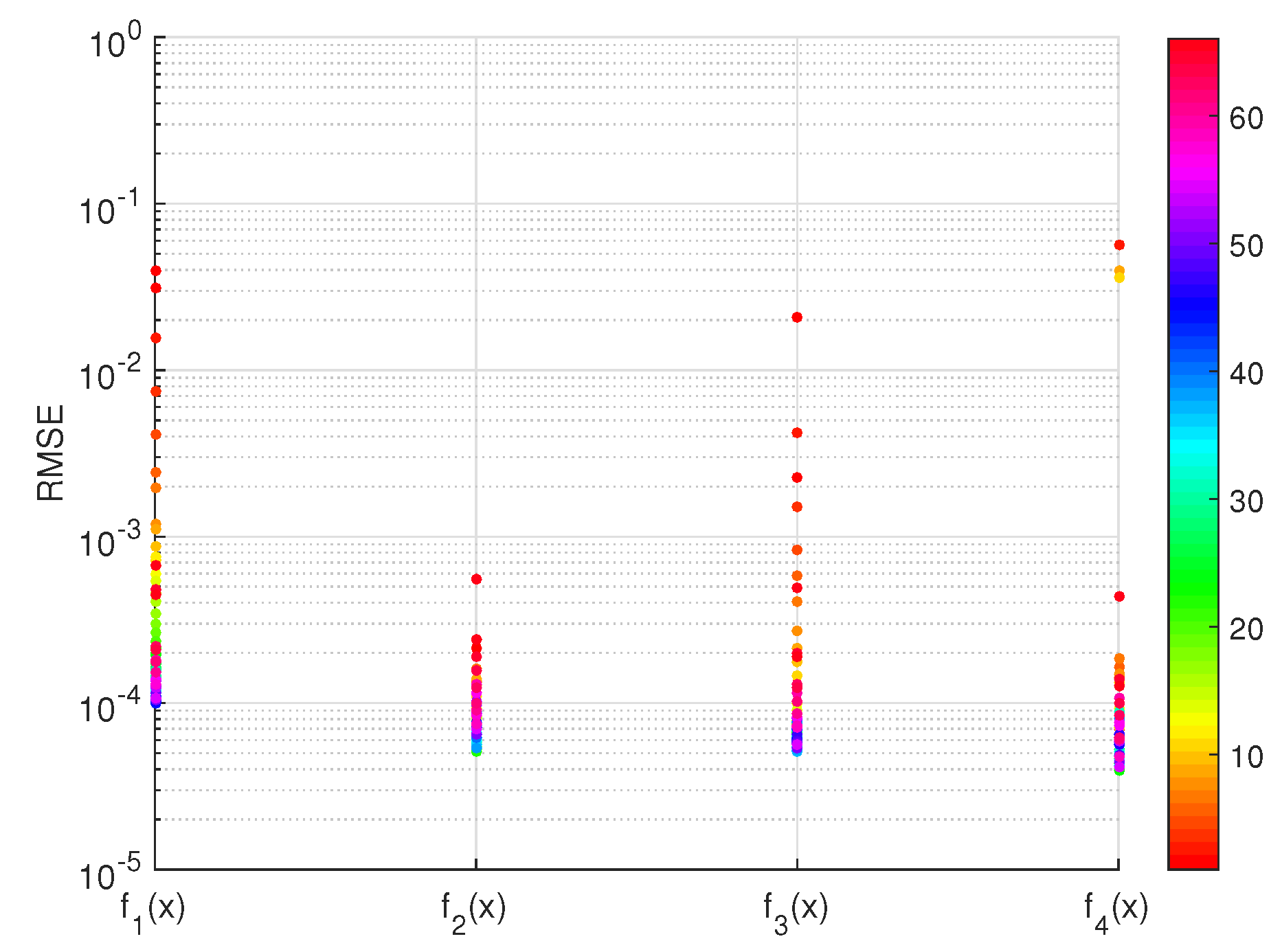
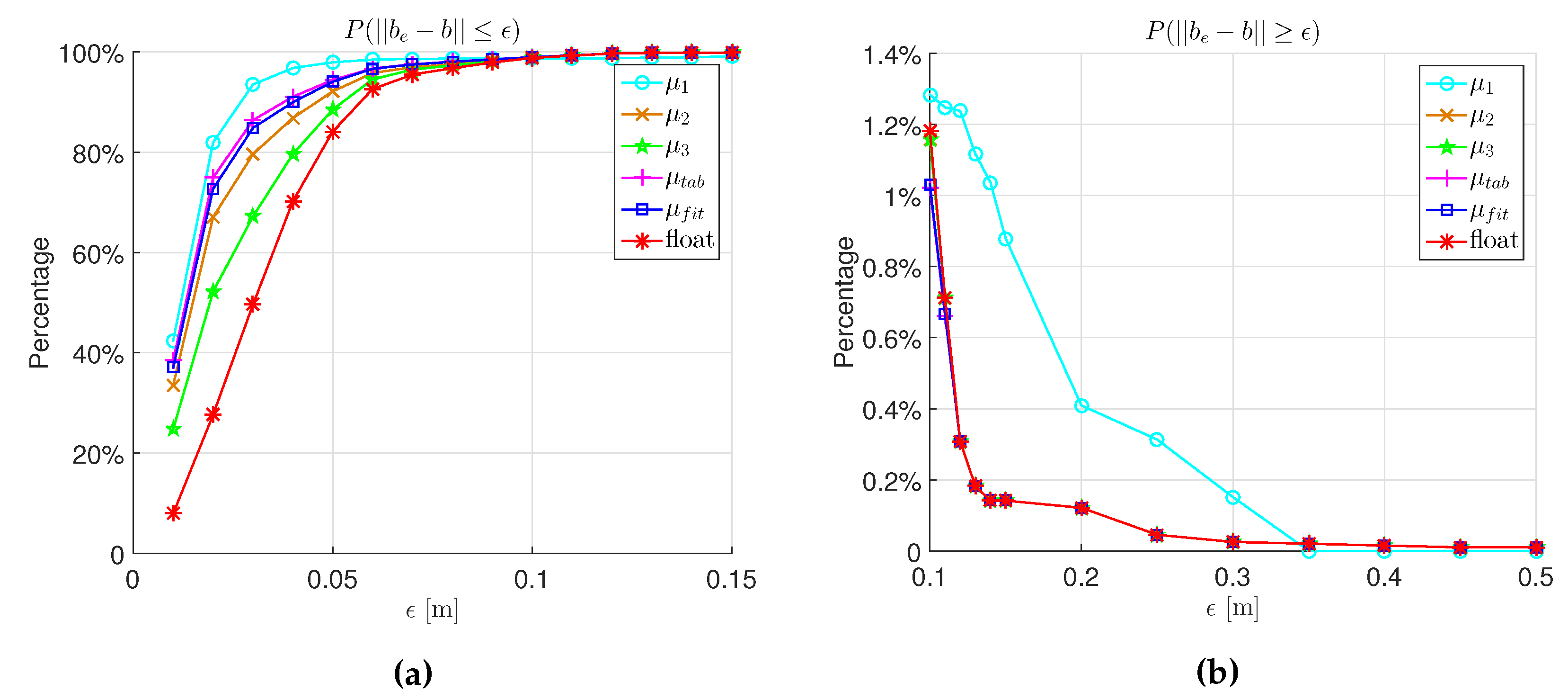
3. Numerical Validation
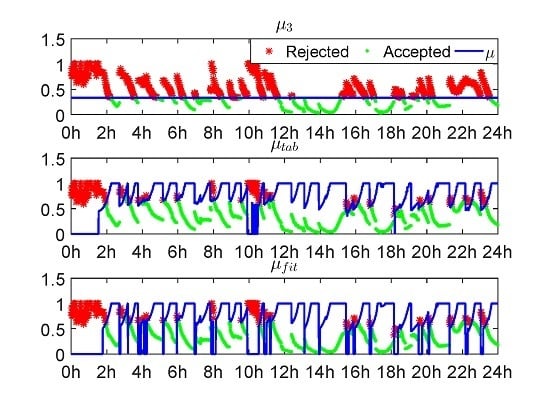
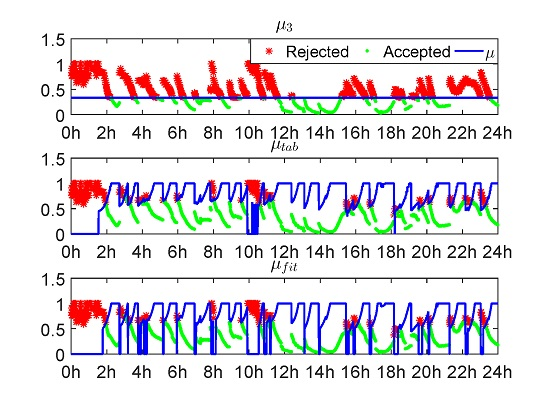
- In the look-up table algorithm, the lowest values are chosen to be μ [12], while in the fitting function algorithm, the 95% lower boundary of the original curve fitted from the lowest values is chosen as the final fitting function of μ;
- In the look-up table, μ is set to zero when [12], while in the fitting function, μ is set to zero when .
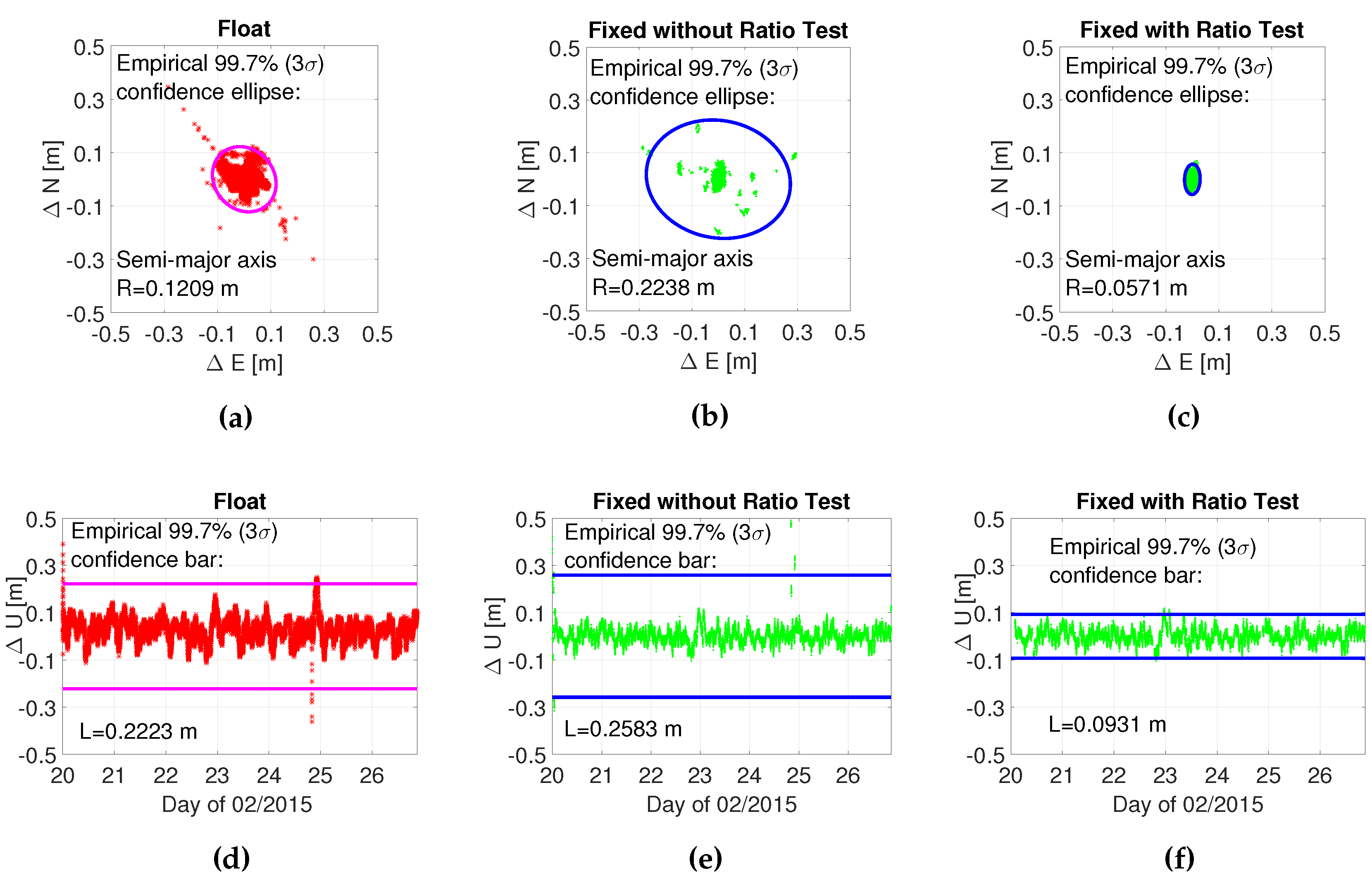
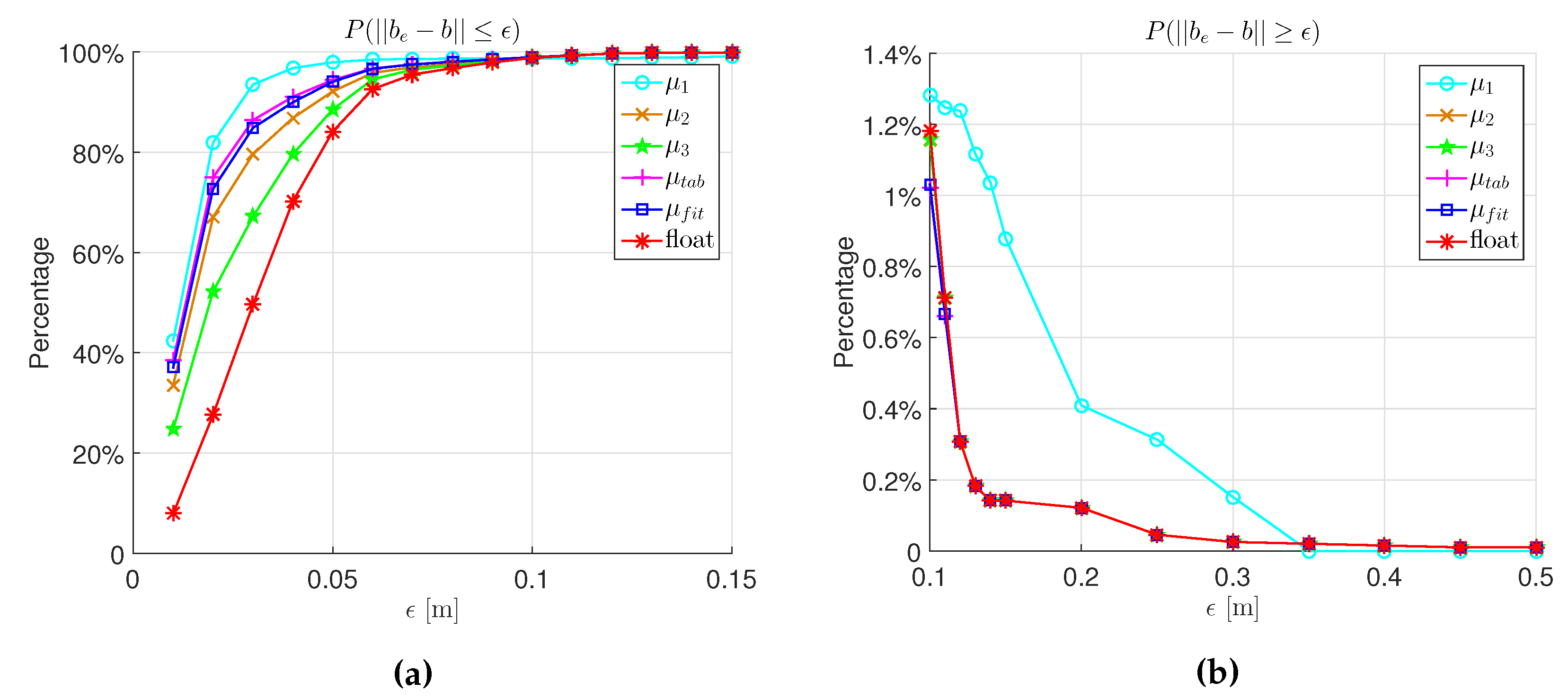
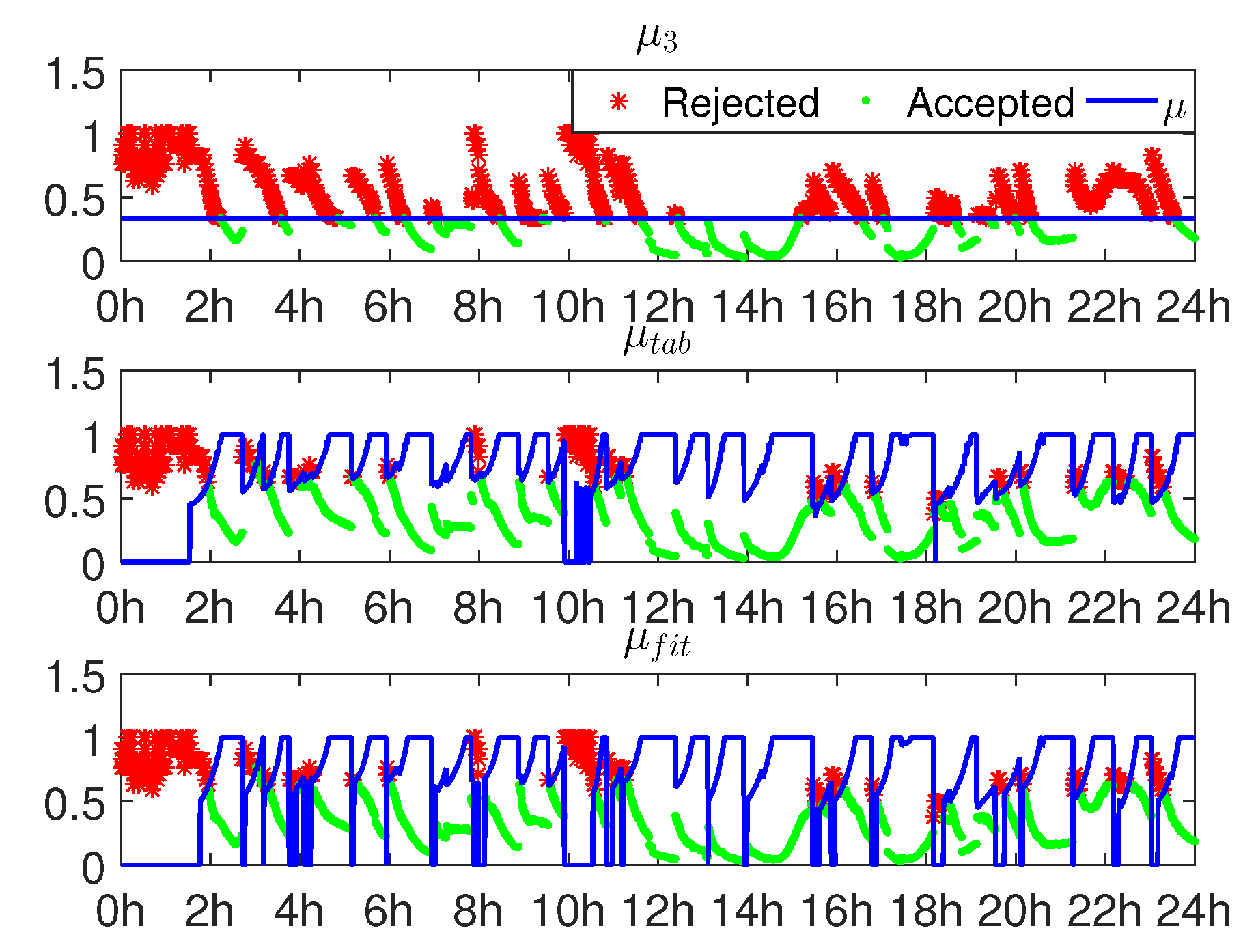
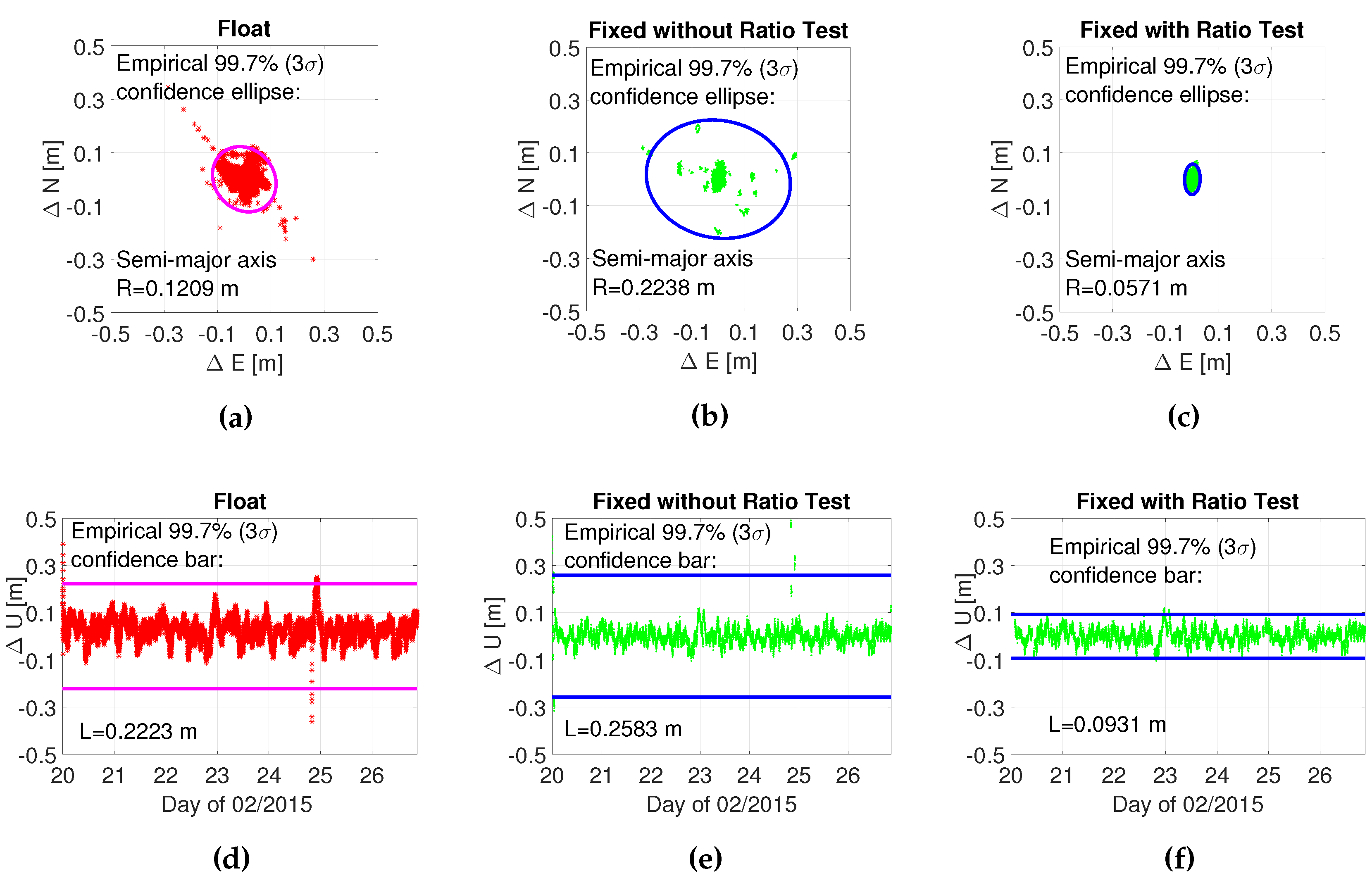
4. Experiment Validation
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Generate the Critical Value of the Ratio Test and the Fix Rate
- Generate many different models with various satellite geometries (system, time and location), number of frequencies, measurement noise, baseline length and the accuracy of atmospheric corrections.
- For each model, calculate following the error propagation law, and generate N samples with the zero mean and variance .
- For each sample , Z-transform to , and search the best and second best integer candidate of and with LAMBDA. Calculate the ratio .
- For each , calculate:and:
- After all N samples of a specific model are processed in the above three steps, the failure rate and fix rate for each are calculated as:with:Specifically, when , is the ILS failure rate .
- The maximum that meets is set as the for this model.
- Find for all generated models and different .
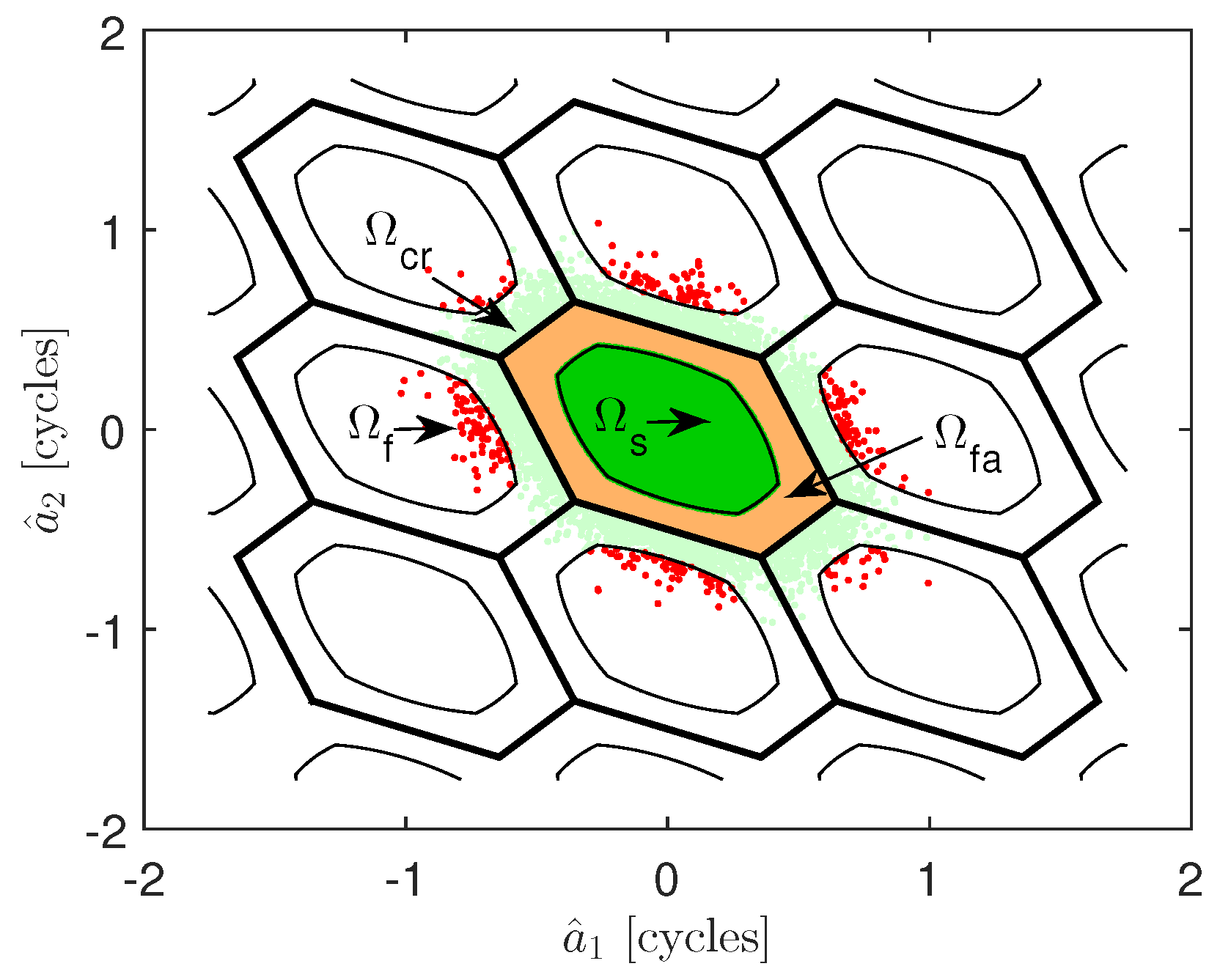
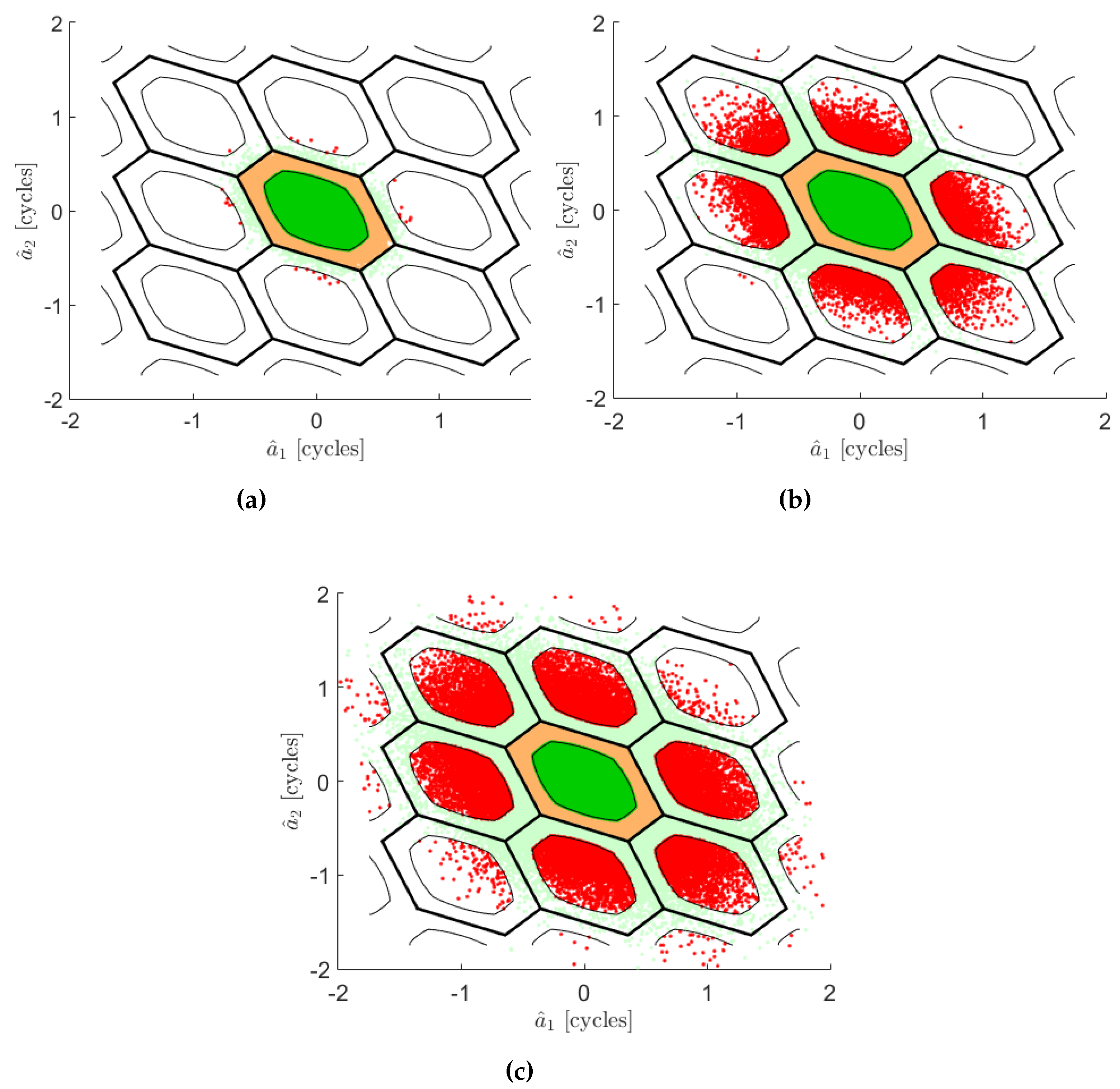
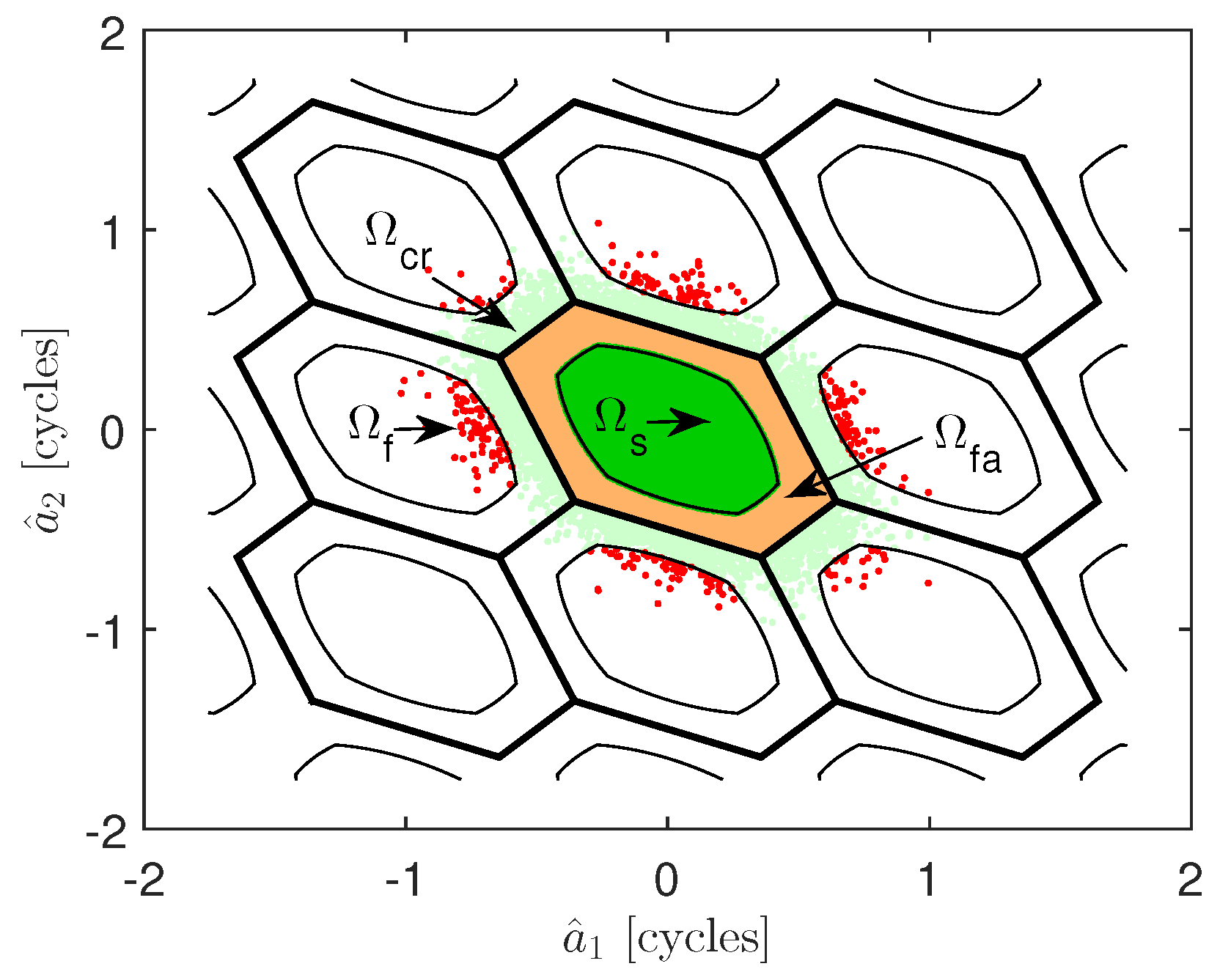
Appendix B. The Conceptual Explanation of the Trend of μ against the Curve
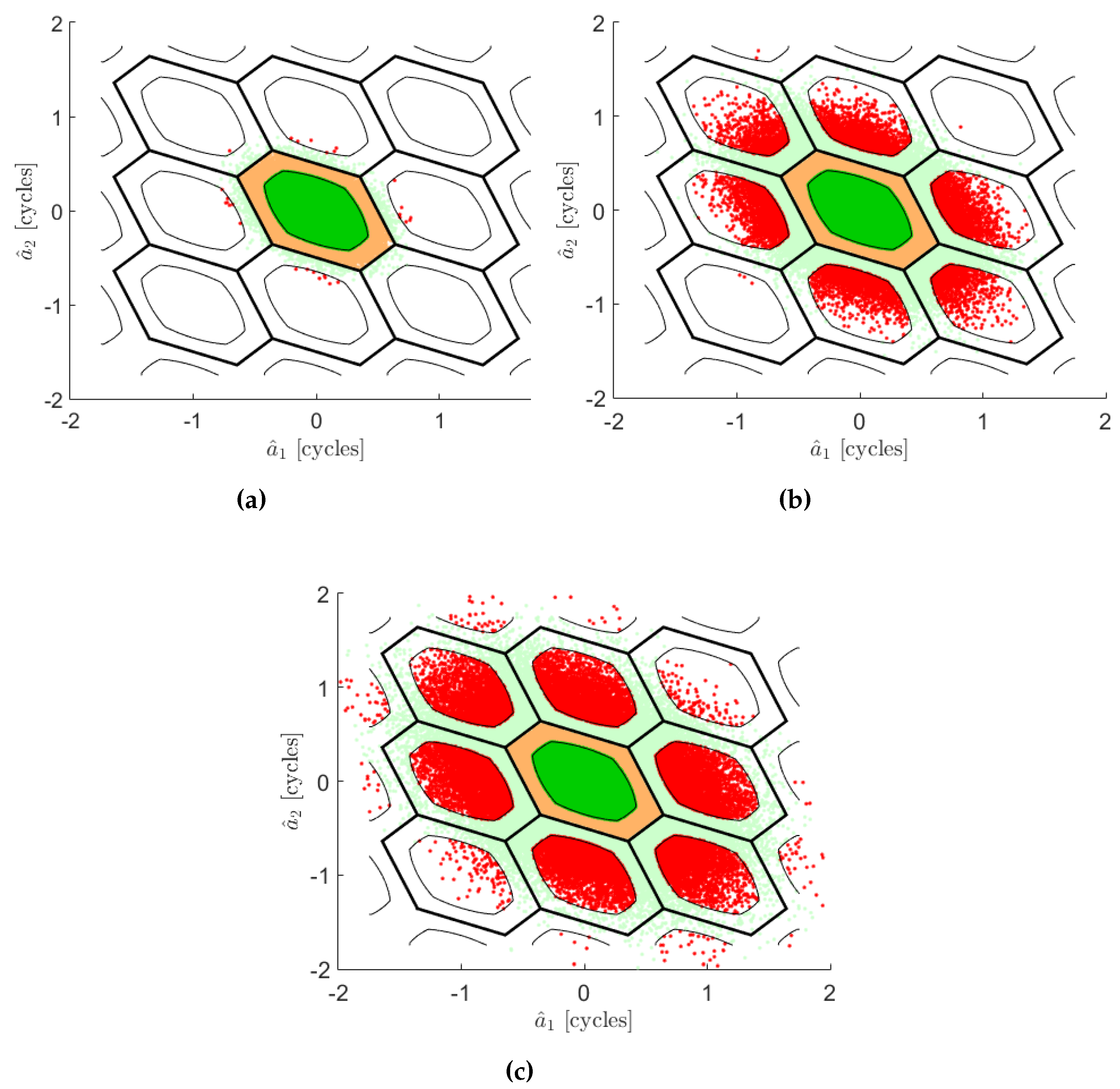
Appendix C. The Coefficient Table for Fitting Functions
Appendix C.1. Coefficient Table for Fitting Functions of μ against in the Ratio Test

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | n | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0916 | −0.5801 | −0.2850 | 23 | 0.0514 | −0.4286 | 0.6342 | 45 | 0.0249 | −0.4505 | 0.8036 |
| 2 | 0.1576 | −0.4633 | −0.3145 | 24 | 0.0519 | −0.4202 | 0.6435 | 46 | 0.0269 | −0.4332 | 0.8037 |
| 3 | 0.2164 | −0.3864 | −0.2878 | 25 | 0.0529 | −0.4098 | 0.6531 | 47 | 0.0237 | −0.4527 | 0.8119 |
| 4 | 0.3364 | −0.2968 | −0.3335 | 26 | 0.0425 | −0.4442 | 0.6762 | 48 | 0.0250 | −0.4390 | 0.8129 |
| 5 | 0.4401 | −0.2435 | −0.3686 | 27 | 0.0381 | −0.4575 | 0.6916 | 49 | 0.0255 | −0.4322 | 0.8148 |
| 6 | 0.3794 | −0.2521 | −0.2291 | 28 | 0.0458 | −0.4183 | 0.6885 | 50 | 0.0259 | −0.4265 | 0.8167 |
| 7 | 0.2904 | −0.2793 | −0.0730 | 29 | 0.0386 | −0.4443 | 0.7059 | 51 | 0.0231 | −0.4418 | 0.8240 |
| 8 | 0.2874 | −0.2702 | −0.0146 | 30 | 0.0387 | −0.4380 | 0.7124 | 52 | 0.0217 | −0.4504 | 0.8280 |
| 9 | 0.1797 | −0.3314 | 0.1593 | 31 | 0.0385 | −0.4329 | 0.7204 | 53 | 0.0220 | −0.4457 | 0.8305 |
| 10 | 0.1569 | −0.3439 | 0.2290 | 32 | 0.0384 | −0.4287 | 0.7267 | 54 | 0.0253 | −0.4180 | 0.8279 |
| 11 | 0.1310 | −0.3615 | 0.2998 | 33 | 0.0393 | −0.4191 | 0.7318 | 55 | 0.0211 | −0.4461 | 0.8367 |
| 12 | 0.0793 | −0.4428 | 0.3928 | 34 | 0.0360 | −0.4300 | 0.7419 | 56 | 0.0193 | −0.4585 | 0.8414 |
| 13 | 0.0839 | −0.4222 | 0.4166 | 35 | 0.0392 | −0.4103 | 0.7426 | 57 | 0.0166 | −0.4850 | 0.8472 |
| 14 | 0.0721 | −0.4411 | 0.4563 | 36 | 0.0345 | −0.4277 | 0.7549 | 58 | 0.0243 | −0.4120 | 0.8373 |
| 15 | 0.0700 | −0.4381 | 0.4825 | 37 | 0.0323 | −0.4356 | 0.7627 | 59 | 0.0179 | −0.4638 | 0.8492 |
| 16 | 0.0664 | −0.4378 | 0.5096 | 38 | 0.0300 | −0.4443 | 0.7704 | 60 | 0.0205 | −0.4360 | 0.8478 |
| 17 | 0.0645 | −0.4339 | 0.5321 | 39 | 0.0286 | −0.4493 | 0.7759 | 61 | 0.0195 | −0.4434 | 0.8505 |
| 18 | 0.0674 | −0.4175 | 0.5449 | 40 | 0.0264 | −0.4594 | 0.7842 | 62 | 0.0145 | −0.4951 | 0.8605 |
| 19 | 0.0683 | −0.4074 | 0.5598 | 41 | 0.0245 | −0.4695 | 0.7904 | 63 | 0.0166 | −0.4634 | 0.8581 |
| 20 | 0.0647 | −0.4090 | 0.5783 | 42 | 0.0267 | −0.4501 | 0.7905 | 64 | 0.0149 | −0.4873 | 0.8628 |
| 21 | 0.0659 | −0.3980 | 0.5912 | 43 | 0.0254 | −0.4545 | 0.7966 | 65 | 0.0071 | −0.6131 | 0.8773 |
| 22 | 0.0661 | −0.3910 | 0.6039 | 44 | 0.0249 | −0.4550 | 0.8004 | 66 | 0.0228 | −0.4002 | 0.8536 |
| n | n | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0549 | −0.4626 | −0.1968 | 23 | 0.0347 | −0.3933 | 0.5322 | 45 | 0.0095 | −0.4982 | 0.7474 |
| 2 | 0.0507 | −0.4739 | −0.1450 | 24 | 0.0321 | −0.3999 | 0.5500 | 46 | 0.0095 | −0.4969 | 0.7525 |
| 3 | 0.0838 | −0.3960 | −0.1556 | 25 | 0.0318 | −0.3958 | 0.5613 | 47 | 0.0085 | −0.5058 | 0.7578 |
| 4 | 0.1343 | −0.3225 | −0.1755 | 26 | 0.0273 | −0.4144 | 0.5805 | 48 | 0.0098 | −0.4837 | 0.7602 |
| 5 | 0.1946 | −0.2672 | −0.1980 | 27 | 0.0261 | −0.4147 | 0.5928 | 49 | 0.0105 | −0.4706 | 0.7633 |
| 6 | 0.1876 | −0.2651 | −0.1429 | 28 | 0.0242 | −0.4219 | 0.6072 | 50 | 0.0108 | −0.4651 | 0.7673 |
| 7 | 0.1645 | −0.2750 | −0.0755 | 29 | 0.0226 | −0.4288 | 0.6193 | 51 | 0.0072 | −0.5210 | 0.7757 |
| 8 | 0.1751 | −0.2605 | −0.0404 | 30 | 0.0208 | −0.4348 | 0.6309 | 52 | 0.0079 | −0.5051 | 0.7767 |
| 9 | 0.1229 | −0.3011 | 0.0634 | 31 | 0.0172 | −0.4602 | 0.6431 | 53 | 0.0082 | −0.4956 | 0.7819 |
| 10 | 0.1133 | −0.3065 | 0.1151 | 32 | 0.0189 | −0.4421 | 0.6524 | 54 | 0.0094 | −0.4744 | 0.7840 |
| 11 | 0.0938 | −0.3238 | 0.1795 | 33 | 0.0212 | −0.4206 | 0.6574 | 55 | 0.0077 | −0.5017 | 0.7885 |
| 12 | 0.0636 | −0.3737 | 0.2505 | 34 | 0.0197 | −0.4278 | 0.6673 | 56 | 0.0056 | −0.5433 | 0.7956 |
| 13 | 0.0630 | −0.3670 | 0.2833 | 35 | 0.0206 | −0.4178 | 0.6716 | 57 | 0.0057 | −0.5400 | 0.7998 |
| 14 | 0.0522 | −0.3879 | 0.3263 | 36 | 0.0174 | −0.4399 | 0.6852 | 58 | 0.0086 | −0.4742 | 0.7975 |
| 15 | 0.0512 | −0.3843 | 0.3543 | 37 | 0.0182 | −0.4294 | 0.6901 | 59 | 0.0070 | −0.4977 | 0.7998 |
| 16 | 0.0498 | −0.3824 | 0.3789 | 38 | 0.0161 | −0.4431 | 0.7004 | 60 | 0.0085 | −0.4741 | 0.8039 |
| 17 | 0.0483 | −0.3801 | 0.4054 | 39 | 0.0132 | −0.4681 | 0.7071 | 61 | 0.0107 | −0.4327 | 0.8016 |
| 18 | 0.0489 | −0.3726 | 0.4257 | 40 | 0.0137 | −0.4613 | 0.7155 | 62 | 0.0058 | −0.5173 | 0.8121 |
| 19 | 0.0492 | −0.3659 | 0.4450 | 41 | 0.0117 | −0.4808 | 0.7232 | 63 | 0.0050 | −0.5369 | 0.8181 |
| 20 | 0.0454 | −0.3699 | 0.4690 | 42 | 0.0118 | −0.4736 | 0.7286 | 64 | 0.0081 | −0.4521 | 0.8137 |
| 21 | 0.0443 | −0.3689 | 0.4880 | 43 | 0.0103 | −0.4912 | 0.7351 | 65 | 0.0015 | −0.7293 | 0.8205 |
| 22 | 0.0419 | −0.3721 | 0.5072 | 44 | 0.0111 | −0.4773 | 0.7402 | 66 | 0.0016 | −0.7571 | 0.8317 |
Appendix C.2. Coefficient Table for Fitting Functions of against in the Ratio Test
| n | n | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0225 | 0.0242 | −0.3189 | 23 | 0.0218 | 0.0906 | 0.0200 | 45 | 0.0203 | 0.0476 | 0.0195 |
| 2 | 0.0081 | −0.0139 | 0.0082 | 24 | 0.0180 | 0.0549 | 0.0168 | 46 | 0.0203 | 0.0423 | 0.0196 |
| 3 | 0.0132 | 0.0260 | 0.0127 | 25 | 0.0204 | 0.0574 | 0.0194 | 47 | 0.0194 | 0.0352 | 0.0188 |
| 4 | 0.0153 | 0.0252 | 0.0148 | 26 | 0.0228 | 0.0906 | 0.0211 | 48 | 0.0206 | 0.0412 | 0.0200 |
| 5 | 0.0176 | 0.0337 | 0.0170 | 27 | 0.0218 | 0.0833 | 0.0202 | 49 | 0.0229 | 0.0567 | 0.0220 |
| 6 | 0.0192 | 0.0482 | 0.0183 | 28 | 0.0198 | 0.0535 | 0.0189 | 50 | 0.0238 | 0.0605 | 0.0228 |
| 7 | 0.0176 | 0.0407 | 0.0169 | 29 | 0.0230 | 0.0902 | 0.0213 | 51 | 0.0175 | 0.0210 | 0.0172 |
| 8 | 0.0177 | 0.0384 | 0.0171 | 30 | 0.0207 | 0.0668 | 0.0195 | 52 | 0.0207 | 0.0432 | 0.0201 |
| 9 | 0.0186 | 0.0537 | 0.0176 | 31 | 0.0206 | 0.0521 | 0.0197 | 53 | 0.0193 | 0.0281 | 0.0189 |
| 10 | 0.0196 | 0.0630 | 0.0184 | 32 | 0.0191 | 0.0417 | 0.0184 | 54 | 0.0210 | 0.0358 | 0.0205 |
| 11 | 0.0205 | 0.0704 | 0.0192 | 33 | 0.0227 | 0.0634 | 0.0217 | 55 | 0.0213 | 0.0426 | 0.0206 |
| 12 | 0.0163 | 0.0644 | 0.0149 | 34 | 0.0235 | 0.0717 | 0.0223 | 56 | 0.0164 | 0.0137 | 0.0162 |
| 13 | 0.0139 | 0.0331 | 0.0132 | 35 | 0.0243 | 0.0709 | 0.0231 | 57 | 0.0160 | 0.0114 | 0.0159 |
| 14 | 0.0116 | 0.0203 | 0.0111 | 36 | 0.0252 | 0.0803 | 0.0239 | 58 | 0.0191 | 0.0316 | 0.0187 |
| 15 | 0.0121 | 0.0229 | 0.0115 | 37 | 0.0270 | 0.0964 | 0.0253 | 59 | 0.0165 | 0.0099 | 0.0164 |
| 16 | 0.0136 | 0.0342 | 0.0128 | 38 | 0.0273 | 0.1016 | 0.0255 | 60 | 0.0231 | 0.0528 | 0.0223 |
| 17 | 0.0164 | 0.0541 | 0.0153 | 39 | 0.0223 | 0.0605 | 0.0213 | 61 | 0.0224 | 0.0516 | 0.0216 |
| 18 | 0.0164 | 0.0443 | 0.0155 | 40 | 0.0252 | 0.0812 | 0.0239 | 62 | 0.0172 | 0.0197 | 0.0170 |
| 19 | 0.0163 | 0.0413 | 0.0154 | 41 | 0.0261 | 0.1038 | 0.0242 | 63 | 0.0151 | 0.0094 | 0.0150 |
| 20 | 0.0158 | 0.0395 | 0.0149 | 42 | 0.0216 | 0.0604 | 0.0205 | 64 | 0.0153 | 0.0065 | 0.0153 |
| 21 | 0.0193 | 0.0579 | 0.0183 | 43 | 0.0218 | 0.0560 | 0.0209 | 65 | 0.0106 | −0.0266 | 0.0110 |
| 22 | 0.0210 | 0.0686 | 0.0198 | 44 | 0.0210 | 0.0542 | 0.0201 | 66 | 0.0148 | −0.0067 | 0.0149 |
| n | n | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0229 | 0.0584 | −0.3400 | 23 | 0.0036 | 0.0557 | 0.0032 | 45 | 0.0040 | 0.0395 | 0.0038 |
| 2 | 0.0012 | −0.0065 | 0.0013 | 24 | 0.0037 | 0.0529 | 0.0035 | 46 | 0.0039 | 0.0312 | 0.0038 |
| 3 | 0.0016 | 0.0058 | 0.0016 | 25 | 0.0040 | 0.0588 | 0.0037 | 47 | 0.0039 | 0.0328 | 0.0038 |
| 4 | 0.0023 | 0.0216 | 0.0022 | 26 | 0.0039 | 0.0635 | 0.0036 | 48 | 0.0042 | 0.0413 | 0.0041 |
| 5 | 0.0029 | 0.0275 | 0.0028 | 27 | 0.0038 | 0.0590 | 0.0035 | 49 | 0.0038 | 0.0299 | 0.0037 |
| 6 | 0.0028 | 0.0280 | 0.0027 | 28 | 0.0037 | 0.0488 | 0.0035 | 50 | 0.0040 | 0.0293 | 0.0039 |
| 7 | 0.0025 | 0.0255 | 0.0024 | 29 | 0.0037 | 0.0528 | 0.0034 | 51 | 0.0041 | 0.0358 | 0.0039 |
| 8 | 0.0026 | 0.0252 | 0.0025 | 30 | 0.0039 | 0.0484 | 0.0036 | 52 | 0.0039 | 0.0306 | 0.0037 |
| 9 | 0.0024 | 0.0272 | 0.0022 | 31 | 0.0035 | 0.0363 | 0.0034 | 53 | 0.0037 | 0.0228 | 0.0036 |
| 10 | 0.0023 | 0.0263 | 0.0022 | 32 | 0.0040 | 0.0452 | 0.0037 | 54 | 0.0042 | 0.0296 | 0.0041 |
| 11 | 0.0025 | 0.0321 | 0.0023 | 33 | 0.0044 | 0.0509 | 0.0041 | 55 | 0.0043 | 0.0385 | 0.0041 |
| 12 | 0.0014 | 0.0076 | 0.0014 | 34 | 0.0049 | 0.0629 | 0.0046 | 56 | 0.0034 | 0.0227 | 0.0034 |
| 13 | 0.0016 | 0.0127 | 0.0015 | 35 | 0.0045 | 0.0459 | 0.0043 | 57 | 0.0030 | 0.0143 | 0.0030 |
| 14 | 0.0013 | 0.0061 | 0.0013 | 36 | 0.0053 | 0.0753 | 0.0049 | 58 | 0.0034 | 0.0176 | 0.0033 |
| 15 | 0.0014 | 0.0068 | 0.0014 | 37 | 0.0056 | 0.0787 | 0.0052 | 59 | 0.0037 | 0.0216 | 0.0037 |
| 16 | 0.0017 | 0.0169 | 0.0016 | 38 | 0.0062 | 0.0980 | 0.0057 | 60 | 0.0038 | 0.0271 | 0.0037 |
| 17 | 0.0019 | 0.0195 | 0.0018 | 39 | 0.0055 | 0.0763 | 0.0052 | 61 | 0.0035 | 0.0215 | 0.0034 |
| 18 | 0.0025 | 0.0328 | 0.0023 | 40 | 0.0056 | 0.0817 | 0.0052 | 62 | 0.0031 | 0.0155 | 0.0030 |
| 19 | 0.0026 | 0.0304 | 0.0024 | 41 | 0.0050 | 0.0710 | 0.0046 | 63 | 0.0024 | 0.0033 | 0.0024 |
| 20 | 0.0029 | 0.0401 | 0.0027 | 42 | 0.0045 | 0.0489 | 0.0043 | 64 | 0.0028 | 0.0080 | 0.0028 |
| 21 | 0.0032 | 0.0400 | 0.0030 | 43 | 0.0045 | 0.0493 | 0.0043 | 65 | 0.0029 | 0.0030 | 0.0029 |
| 22 | 0.0035 | 0.0504 | 0.0033 | 44 | 0.0042 | 0.0426 | 0.0040 | 66 | 0.0040 | 0.0266 | 0.0040 |
References
- Misra, P.; Enge, P. Global Positioning System, Signals, Measurements, and Performance; Ganga-Jamuna Press: Lincoln, MA, USA, 2006. [Google Scholar]
- Euler, H.J.; Schaffrin, B. On a Measure for the Discernibility between Different Ambiguity Solutions in the Static-Kinematic GPS-Mode. In Proceedings of the International Association of Geodesy Symposia, Vienna, Austria, 11–24 August 1991; pp. 285–295.
- Abidin, H. Computational and Geometrical Aspects of on-the-Fly Ambiguity Resolution; Technical Report 164; Department of Surveying Engineering, University of New Brunswick: Fredericton, NB, Canada, 1993. [Google Scholar]
- Tiberius, C.; de Jonge, P. Fast positioning using the LAMBDA method. In Proceedings of the DSNS-95, Bergen, Norway, 24–28 April 1995; Volume 30.
- Wang, L.; Verhagen, S. A new ambiguity acceptance test threshold determination method with controllable failure rate. J. Geod. 2014, 89, 361–375. [Google Scholar] [CrossRef]
- Han, S. Quality-control issues relating to instantaneous ambiguity resolution for real-time GPS kinematic positioning. J. Geod. 1997, 71, 351–361. [Google Scholar] [CrossRef]
- Wang, J.; Stewart, M.; Tsakiri, M. A discrimination test procedure for ambiguity resolution on-the-fly. J. Geod. 1998, 72, 644–653. [Google Scholar] [CrossRef]
- Landau, H.; Euler, H.J. On-the-fly ambiguity resolution for precise differential positioning. In Proceedings of the 5th International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GPS 1992), Albuquerque, NM, USA, 16–18 September 1992; pp. 607–613.
- Wei, M.; Schwarz, K.P. Fast ambiguity resolution using an integer nonlinear programming method. In Proceedings of the 8th International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GPS 1995), Palm Springs, CA, USA, 12–15 September 1995; pp. 1101–1100.
- Leick, A. GPS Satellite Surveying, 3rd ed.; John Wiley and Sons: New York, NY, USA, 2004. [Google Scholar]
- Takasu, T.; Yasuda, A. Kalman-filter-based integer ambiguity resolution strategy for long-baseline RTK with ionosphere and troposphere estimation. In Proceedings of the ION GNSS 2010, Portland, OR, USA, 21–24 September 2010; pp. 161–171.
- Verhagen, S.; Teunissen, P. The ratio test for future GNSS ambiguity resolution. GPS Solut. 2012, 17, 535–548. [Google Scholar] [CrossRef]
- Teunissen, P. Least-squares estimation of the integer GPS ambiguities. Invited Lecture, Section IV “Theory and Methodology”. In Proceedings of the General Meeting of the International Association of Geodesy, Beijing, China, 8–13 August 1993; pp. 1–16.
- Teunissen, P. The least-squares ambiguity decorrelation adjustment: A method for fast GPS integer ambiguity estimation. J. Geod. 1995, 1/2, 65–82. [Google Scholar] [CrossRef]
- Teunissen, P. GNSS integer ambiguity validation: Overview of theory and methods. In Proceedings of the Institute of Navigation Pacific PNT, Honolulu, HI, USA, 23–25 April 2013; pp. 673–684.
- Jonge, P.D.; Tiberius, C.C.J.M. The LAMBDA Method for Integer Ambiguity Estimation: Implementation Aspects; Technical Report; LGR-Series; Delft University of Technology: Delft, The Netherlands, 1996. [Google Scholar]
- Brack, A.; Günther, C. Generalized integer aperture estimation for partial GNSS ambiguity fixing. J. Geod. 2014, 88, 479–490. [Google Scholar] [CrossRef]
- Dong, D.; Bock, Y. Global Positioning System network analysis with phase ambiguity resolution applied to crustal deformation studies in California. J. Geophys. Res. 1989, 94, 3949–3966. [Google Scholar] [CrossRef]
- Teunissen, P. Success probability of integer GPS ambiguity rounding and bootstrapping. J. Geod. 1998, 72, 606–612. [Google Scholar] [CrossRef]
- Teunissen, P. An optimality property of the integer least-squares estimator. J. Geod. 1999, 73, 587–593. [Google Scholar] [CrossRef]
- Verhagen, S.; Li, B.; Teunissen, P. Ps-LAMBDA: Ambiguity success rate evaluation software for interferometric applications. Comput. Geosci. 2013, 54, 361–376. [Google Scholar] [CrossRef]
- Teunissen, P. The success rate and precision of GPS ambiguities. J. Geod. 2000, 74, 321–326. [Google Scholar] [CrossRef]
- Brack, A. On reliable data-driven partial GNSS ambiguity resolution. GPS Solut. 2015, 19, 411–422. [Google Scholar] [CrossRef]
- Teunissen, P. The parameter distributions of the integer GPS model. J. Geod. 2002, 76, 41–48. [Google Scholar] [CrossRef]
- Odijk, D. Stochastic modelling of the ionosphere for fast GPS ambiguity resolution. In Geodesy Beyond 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 387–392. [Google Scholar]
- Eueler, H.J.; Goad, C.C. On optimal filtering of GPS dual frequency observations without using orbit information. Bull. Géod. 1991, 65, 130–143. [Google Scholar] [CrossRef]
- Donald, W.M. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar]
- Takasu, T. RTKLIB: Open Source Program Package for RTK-GPS. Available online: http://www.rtklib.com (accessed on 20 June 2016).
- Bruyninx, C. The EUREF Permanent Network: A multi-disciplinary network serving surveyors as well as scientists. GeoInformatics 2004, 7, 32–35. [Google Scholar]
- Wang, X. Volumes of Generalized Unit Balls. Math. Mag. 2005, 78, 390–395. [Google Scholar] [CrossRef]
| Date | 22 November 2013, 23 November 2013, 0:1:23 h (in total 48 epochs) |
| Location([Lat, Lon]) | [30N°, 115E°], [50N°, 115E°], [30N°, 140E°] |
| Measurements | L1, B1 , L1B1, L1L2, B1B2, L1L2 + B1B2, B1B2B3, L1L2L5, B1B2B3 + L1L2L5 |
| {2, 3} mm | |
| {100, 150} × | |
| {5, 10, 15, 20, 30} mm | |
| Troposphere model | Canceled when mm, and Estimate ZTD when mm |
| Ionosphere model | Ionospheric weighted model [25] |
| Elevation ( ) weight | , [26] |
| Cutoff angle | 10° |
| {5:1:9} , {1:1:10} |
| μ | Meaning |
|---|---|
| Accept all candidates. | |
| Commonly-used value [6,8,9]. | |
| Commonly-used value [10,11]. | |
| From the look-up table [12]. | |
| Calculated by the fitting function. | |
| Benchmark value from simulation. |
| 17.9 | 33.7 | 50.2 | 99.9 | 100 | 100 |
| Parameter | Value |
|---|---|
| Time | 20 February 2015–26 February 2015 (7 days, 20,160 epochs) |
| Baseline | WSRA-DLF1(182.7 km) |
| Measurements | L1L2 code and phase |
| Cutoff angle | 10° |
| Epoch interval | 30 s |
| 3 mm | |
| 30 cm | |
| 2 cm | |
| Troposphere model | Estimate ZTD |
| Ionosphere model | Ionosphere-weighted [25] |
| Elevation () weight | , [28] |
| Process mode | Kinematic |
| AR mode | Continuous AR |
| Float | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.7732 | 0.5462 | 0.8715 | 0.8241 | 0 | |
| m) | 0.9353 | 0.7961 | 0.6719 | 0.8641 | 0.8487 | 0.4962 |
| m) | 0.0125 | 0.0071 | 0.0071 | 0.0066 | 0.0067 | 0.0071 |
| m) | 0.0015 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Verhagen, S.; Wu, J. An Efficient Implementation of Fixed Failure-Rate Ratio Test for GNSS Ambiguity Resolution. Sensors 2016, 16, 945. https://doi.org/10.3390/s16070945
Hou Y, Verhagen S, Wu J. An Efficient Implementation of Fixed Failure-Rate Ratio Test for GNSS Ambiguity Resolution. Sensors. 2016; 16(7):945. https://doi.org/10.3390/s16070945
Chicago/Turabian StyleHou, Yanqing, Sandra Verhagen, and Jie Wu. 2016. "An Efficient Implementation of Fixed Failure-Rate Ratio Test for GNSS Ambiguity Resolution" Sensors 16, no. 7: 945. https://doi.org/10.3390/s16070945