1. Introduction
A wireless sensor network (WSN) consists of spatially-distributed autonomous sensors to measure/monitor various conditions and transmit the collected data using wireless communications. WSNs are considered as a promising approach, enabling a wide spectrum of applications, such as area surveillance, traffic flow measurement, object tracking, and environment monitoring.
Due to the emerging demands for advanced applications, such as video sensor networks with image sensors and smart cameras, single-core embedded wireless sensor nodes face high-performance computation challenges. Recent technological improvements rendered multi-core processors as a viable and cost-effective option for coping with the computation challenges for sensor nodes [
1]. Hence, studies on multi-core sensor nodes have been actively conducted recently [
2,
3,
4].
Such multi-core sensor nodes require energy-efficient real-time scheduling algorithms to meet their timing requirements, accomplished by exploiting the multi-core processors, and to keep the battery life long enough to achieve such a goal. Among the real-time scheduling algorithms, the T-L plane-based scheme is known to be an optimal global scheduling technique for periodic real-time tasks on multi-cores. Unfortunately, there has been a scarcity of studies on extending T-L plane-based scheduling algorithms to exploit energy-saving techniques.
Voltage frequency scaling (VFS) [
5] and dynamic power management (DPM) [
6] are the most frequently adopted techniques for saving dynamic power dissipation. VFS scales the voltage and frequency of a processor in order to reduce the energy consumption. DPM exploits the idle time of a processor and switches the processor to lower energy consumption modes, such as sleep or deep sleep modes.
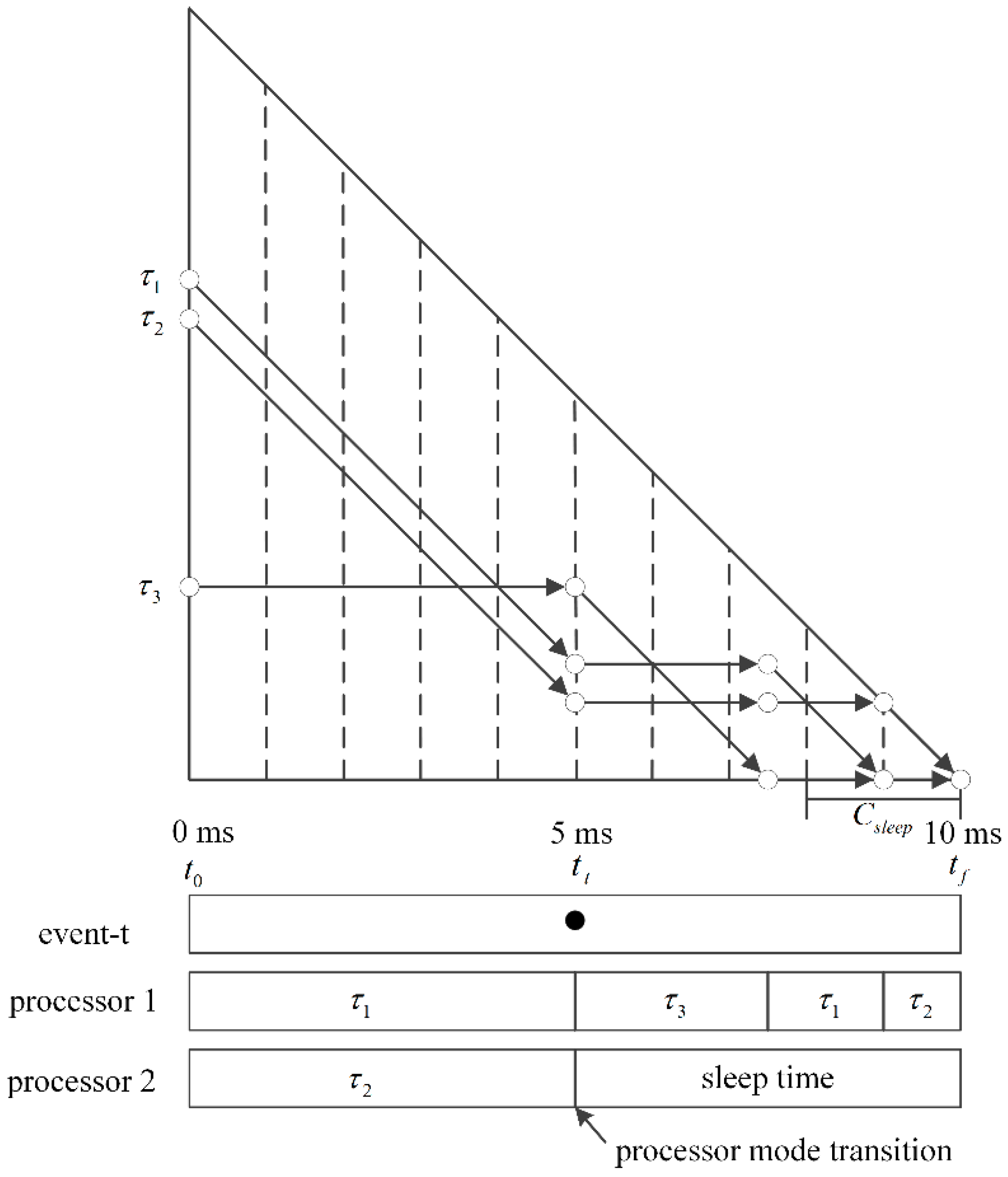
In this paper, we propose new events and associated algorithms to enable better energy management for multi-core sensor nodes operating with a T-L plane-based scheduling algorithm. More specifically, we extend the approach made previously [
7] by considering the characteristics of multi-core sensor nodes as follows.
The first extension is especially important for the T-L plane algorithm, which can frequently generate a series of short idle blocks, as shown in
Section 2. The previous technique [
7] was generalized to prefetch the tokens originally scheduled to the future planes, as well as the very next one, and then execute them during an idle interval whose length is too short to switch the processor into sleep mode. These efforts reduce the fragmented idle time durations and increase the chance of longer idle blocks where the sensor processors can be placed into sleep mode.
The second extension is pursued due to the observation of work load distributions in some sensor network applications. Note that the load of the task sets may significantly change in different time frames, such as during the daytime and nighttime. An imbalance of load indicates that there is an opportunity of turning some processors off during lighter load times. For example, a recent study [
8] on load monitoring stated that their system runs monitoring tasks heavily around midnight when the frogs are active. However, the system experiences silence during the daytime. Another example is energy-harvesting sensor networks, where day and night tasks must be different due to the availability of sunlight. There is an abundance of similar situations in various sensor networks. The idea is similar to the one used by chilled water plant engineers to solve chiller dispatching problems where optimization algorithms decide when to turn the chillers on and off [
9].
This paper is organized as follows:
Section 2 introduces major previous work involving real-time scheduling and energy management. In
Section 3, a short review of T-L plane abstraction is presented. In
Section 4, we present new events and associated algorithms extending the T-L plane scheduling to support the dynamic power management (DPM) technique. In addition, some theoretical findings are discussed. In
Section 5, we evaluate our algorithm by comparing it with other T-L plane-based energy-efficient algorithms. In
Section 6, we summarize the results of this study and suggest future work.
2. Related Work
This section briefly introduces the topic of multi-processor scheduling. It also summarizes previous major works on T-L plane-based real-time scheduling algorithms and associated extension efforts toward energy-efficiency. Interested readers are referred to extensive surveys of energy-efficient scheduling mechanisms on sensor networks [
10] and energy-aware real-time scheduling algorithms [
11].
Research on real-time scheduling for multi-processors has largely been focused on the problem of scheduling periodic tasks. The real-time scheduling algorithms on multi-processors for periodic tasks are categorized into global or partitioning-based scheduling [
12,
13,
14]. In global scheduling [
15,
16], task migrations between the processors are allowed since all of the tasks waiting for execution are in a single queue, where a task scheduler picks some tasks. In contrast, task migration is not permitted in partition-based scheduling. Each processor has its own waiting queue and an independent task scheduler.
The T-L plane-based scheme is an optimal global scheduling for independent real-time tasks on a homogeneous multi-processor system [
17]; there has been active research on the extension of this scheme since its seminal paper was published. A study involving synchronization mechanisms for lock-based, lock-free, and wait-free schemes in largest nodal remaining execution-time first (LNREF) scheduling was previously presented [
18]. The extension of T-L plane scheduling to support sporadic tasks was also performed [
19]. An optimal work-conserving scheduling was proposed to reduce the idle time in LNREF scheduling [
20,
21]. In addition, an approach to reduce task migrations in a T-L plane was presented [
22,
23].
Recent advances in T-L plane-based scheduling have started to consider energy efficiency. Most approaches propose to determine the frequencies and voltages of the processors rendering minimal energy consumption [
24,
25,
26,
27]. According to supply voltages and operation frequencies in a CMOS processor, the dynamic power consumption for charging and discharging switching capacity
can be computed as shown in the following:
where
is switching activity factor,
is switching capacitance,
is supply voltage, and
is frequency. The VFS technique reduces dynamic power consumption by scaling supply voltage and operation frequency of processors. It also reduces the power consumed by short circuit current appearing at rise and fall time of input signal. In contrast, DPM turns out more effective than VFS when there is enough idle time because DPM enables the shutdown of processors and decrease of supply voltage. DPM can reduce the static power consumed by leakage current, too.
Unfortunately, there has been little effort to extend T-L plane-based scheduling algorithms to support the DPM technique, despite the popularity of multi-processors and the issue of increasing dynamic power. Zhang et al. [
27] briefly mentioned the possibility of switching the processor’s mode to utilize idle time. However, it focuses exclusively on DVFS. We argue that such a basic attempt to apply the idea may not work, as shown in the following example.
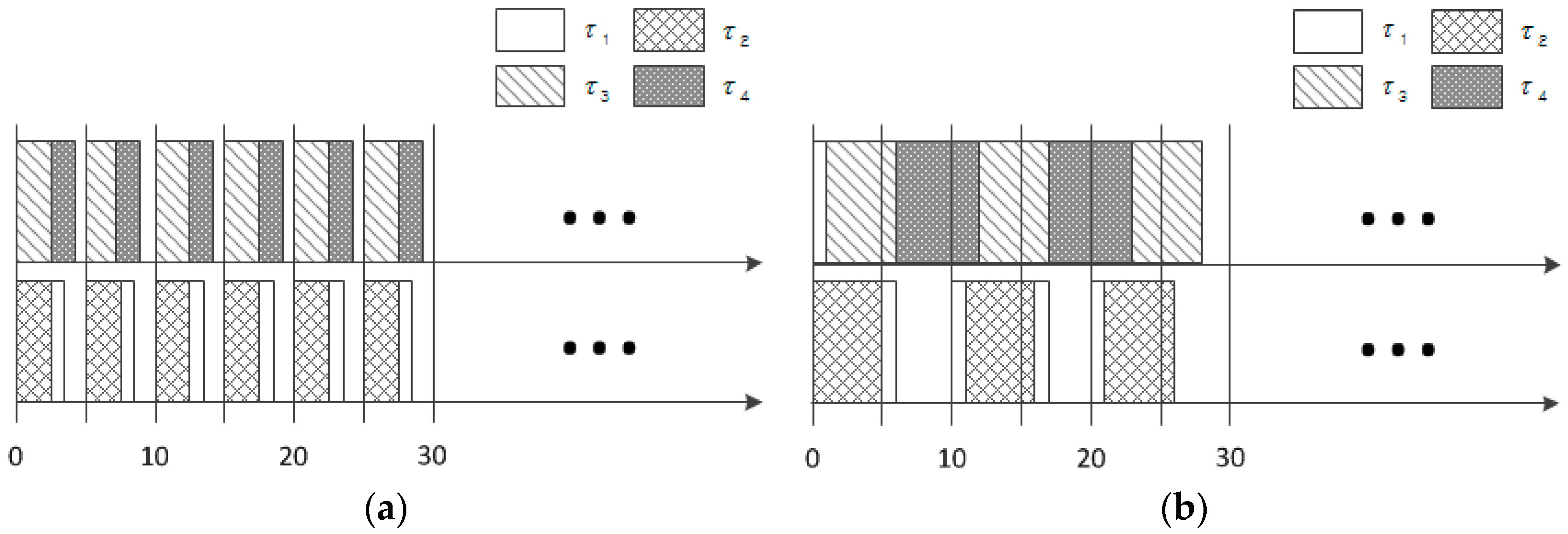
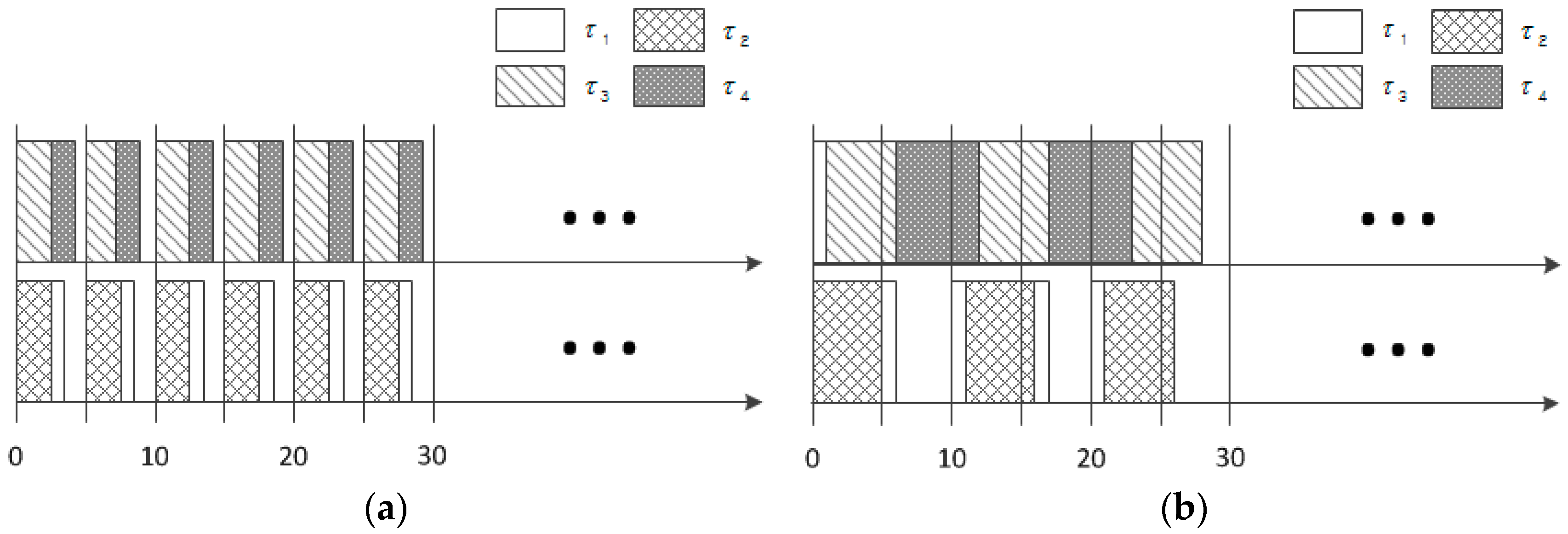
Figure 1 shows the schedules produced by LNREF and global-EDF [
14,
28] on two processors. It is noticeable that a series of idle times appear frequently in the schedule by LNREF compared to the schedule generated by global earliest deadline first (global-EDF). More specifically, there are two idle blocks with durations of 1 ms and 2 ms on every plane of the two processors, as shown in
Figure 1a. This is primarily due to the characteristics of T-L plane-based scheduling, where a task is broken down into a token of each plane whose deadline is the end time of the plane. The reason why we care about this issue is that such short durations of the idle time may not be long enough to exploit more energy-efficient modes, such as sleep mode.
TL-DPM [
7] recently addressed this issue and proposed the idea of executing ahead of time the tasks originally scheduled for the plane that immediately follows when the idle time duration is too short to switch to sleep mode. This approach is based on the rationale that such actions can contribute to reduce the fragmented idle time durations and render them into larger blocks.
3. Review of T-L Plane Abstraction
In this section, we briefly review the concept of the T-L plane abstraction. Some scheduling algorithms on multi-processors adopt the concept of fluid schedule to achieve optimality. The core idea behind fluid schedule is to execute each task at a constant rate. Such scheduling algorithms frequently switch the context to satisfy the fluid schedule. Cho et al. [
17] proposed T-L plane abstraction to address this problem. In the T-L plane abstraction, a task is represented as a moving token. The x-axis and y-axis represent time and tasks’ remaining execution time, respectively.
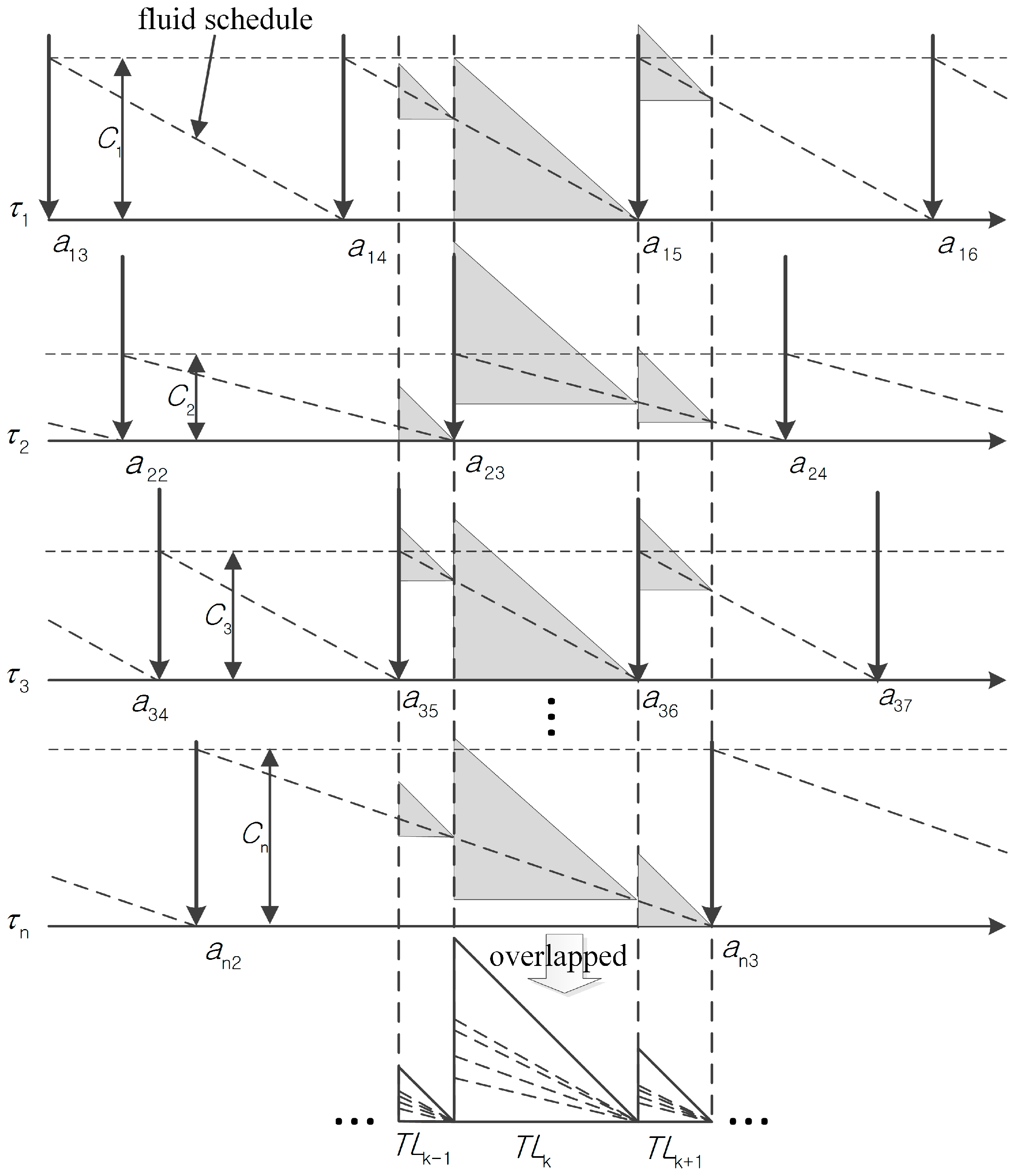
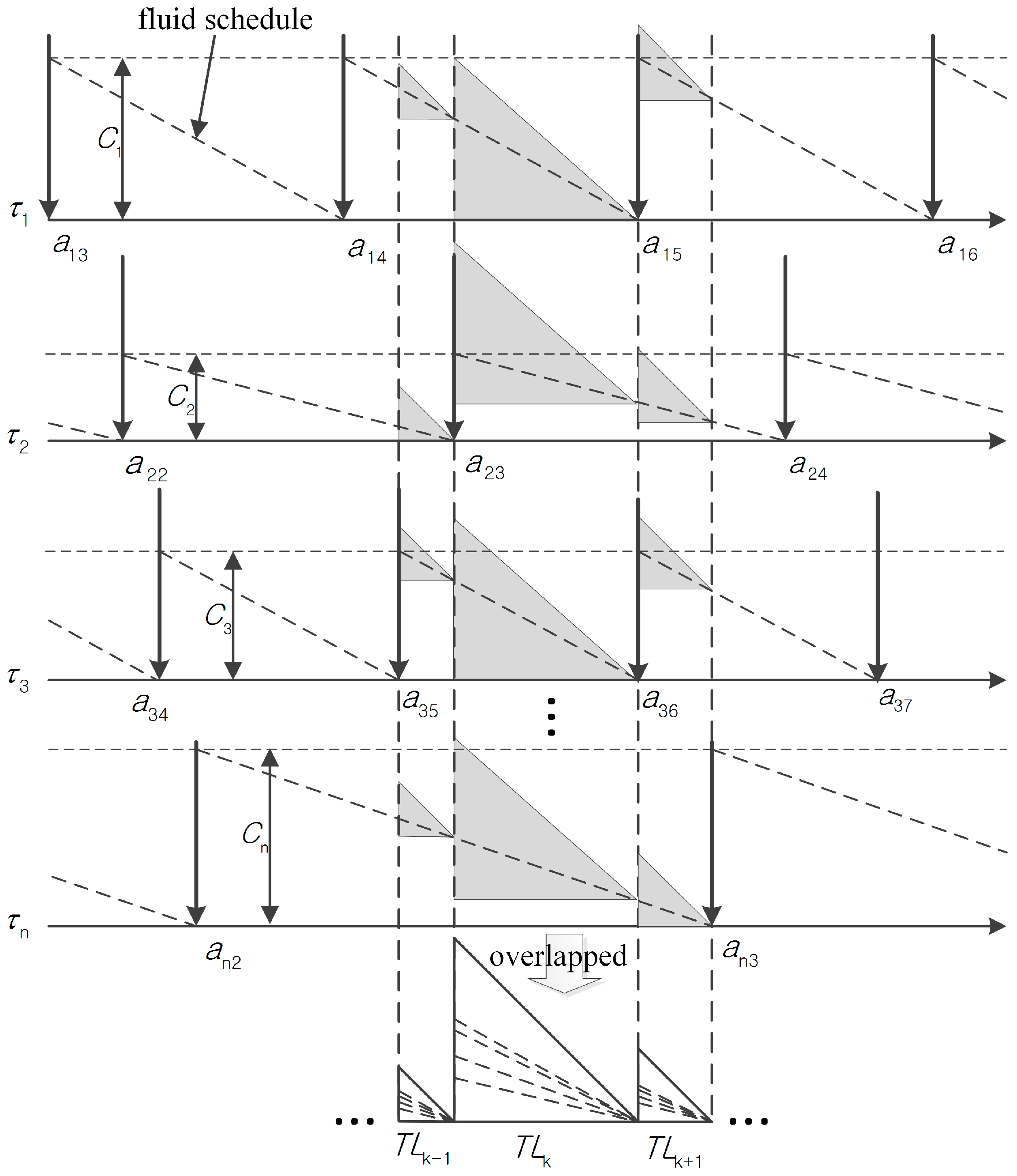
Figure 2 shows an example of T-L plane construction. For the
jth job of a task
with arrival at
and cost
, it should be executed and meet its implicit deadline before the arrival of the next job. Each arrival of a job is indicated by a down-directed arrow, which is extended by a dotted vertical line in the figure. The dotted slopes from
to
represent the fluid schedule of tasks. Note that there are the same
n isosceles triangles for
n tasks given a pair of consecutive dotted vertical lines, e.g., the ones extended from
and
. The height of each isosceles triangle is same to the interval length of the pair. Hence, the rightmost vertex of each isosceles triangle is an intersection point of its fluid schedule and a dotted vertical line. Then, we overlap these triangles in the same time intervals to construct a T-L plane.
Figure 2 shows examples of constructing the
k-1th,
kth, and
k+1th T-L planes.
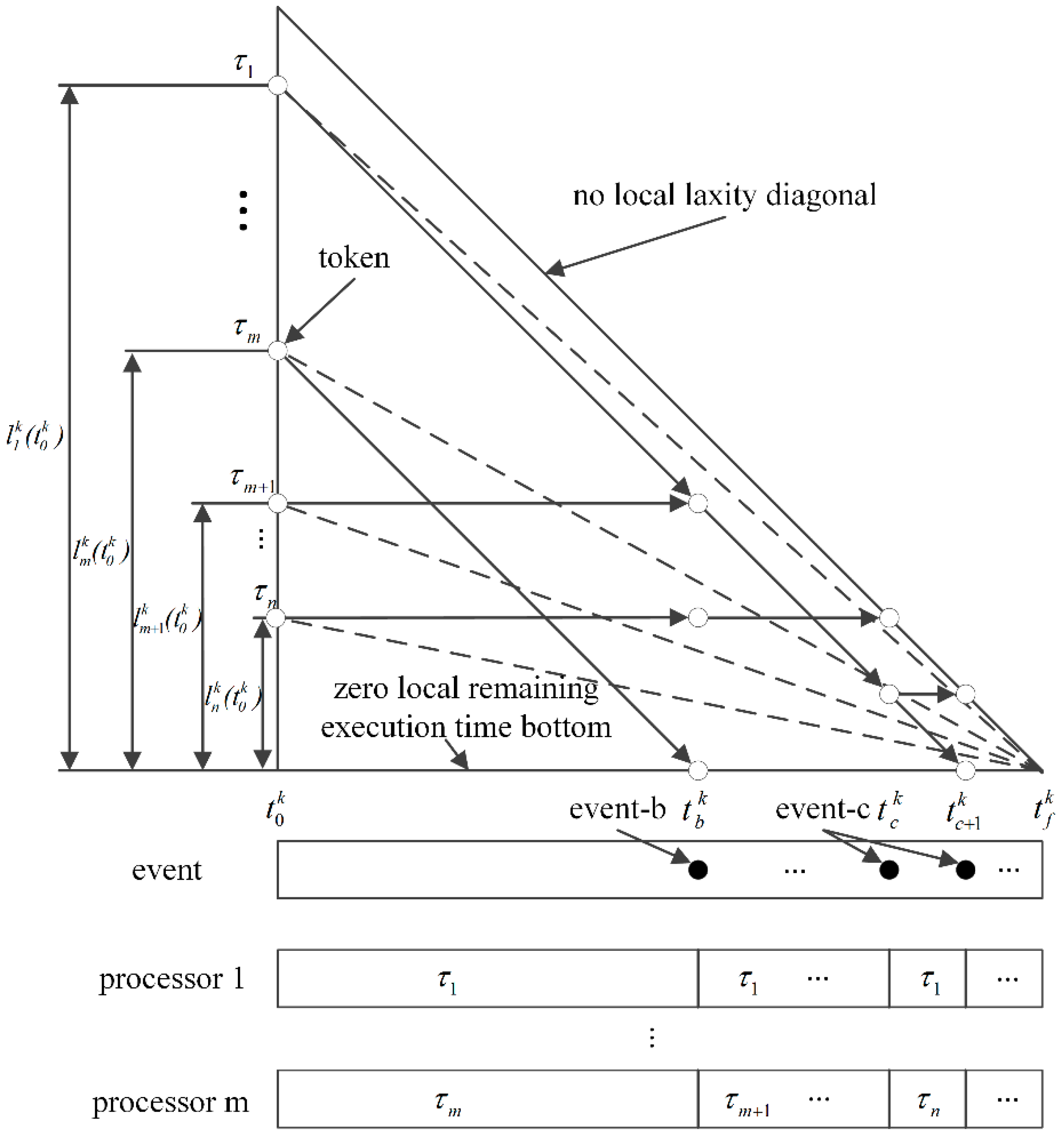
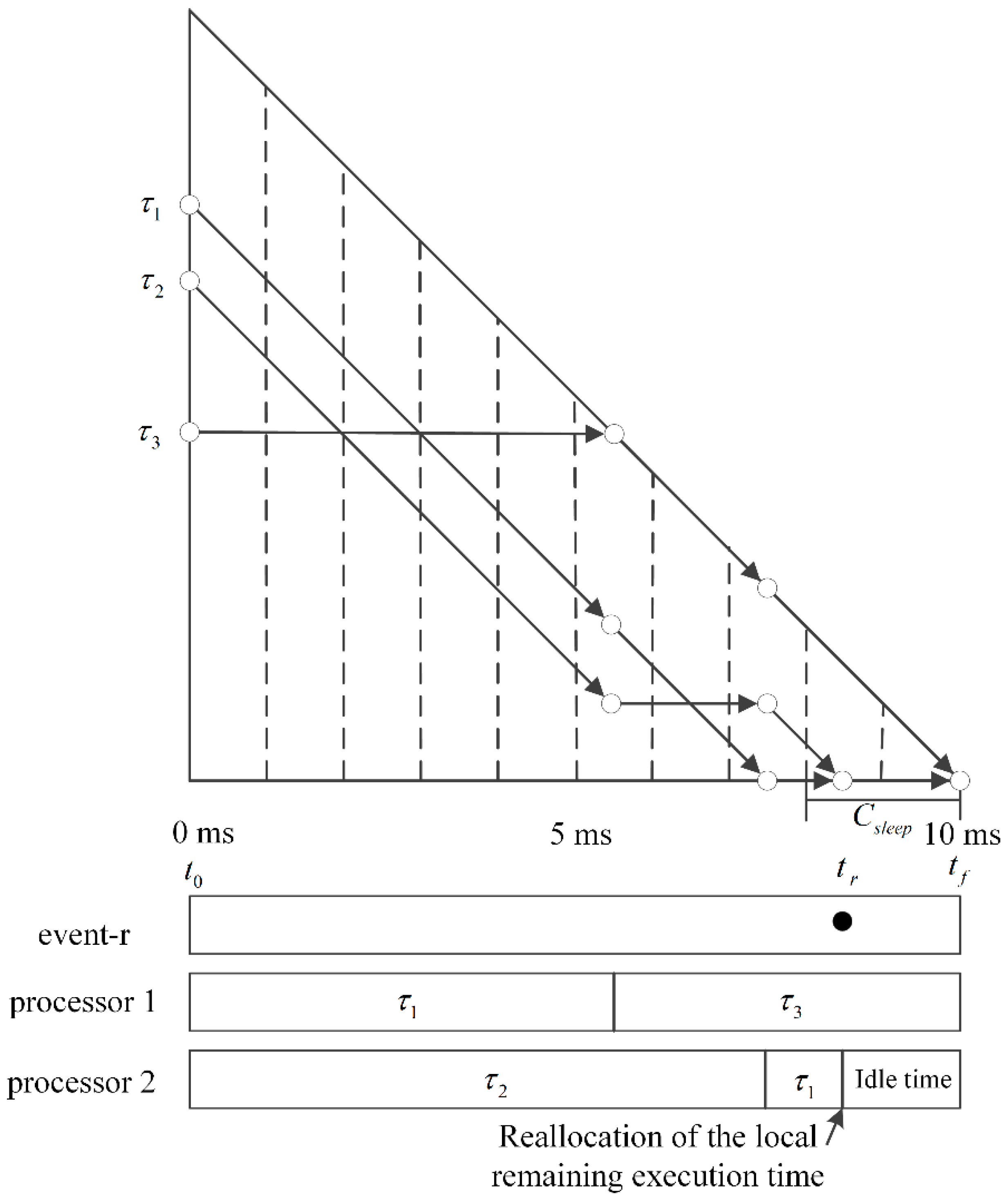
Figure 3 illustrates scheduling in the
kth T-L plane. A token represents the status of the corresponding task in the plane. Throughout this paper, the start time and finish time of the
kth plane are represented as
and
, respectively. The occurrence time of each event on the
kth plane is denoted as
, where
. We shall use a simpler notation
to indicate the occurrence time of an event in the current plane. At time
, a token corresponding to the task
is located on the left-most side of the
kth T-L plane, and its height represents the local remaining execution time
. Assume that we have
m processors. The tokens of tasks assigned to the processors move diagonally down as
,…,
, or else horizontally as
,…,
at
, as shown in
Figure 3.
In general, there are two time instants where the system has to reschedule tasks. One instant is when a token hits the “zero local remaining execution time bottom”, which means that the local remaining execution time of the task is completely consumed. The processor that has executed the task now becomes available to run another ready task with the highest local utilization. We refer to this as event-b. An example is shown at time in the figure. In the kth T-L plane, the local utilization for a task at time can be calculated by the expression , which amounts to the processor capacity needed by the task. The other instant is when a token hits the “no local laxity diagonal”, which means that the local laxity of the task becomes zero and the corresponding task must be executed immediately. Such an event is referred to as event-c. Two examples are shown in the figure at times and . Note that successful arrival of all of the tokens at the right apex means that the corresponding task set is locally feasible.
5. Experimental Results and Analysis
In this section, we compare the performance of the proposed algorithm with major real-time scheduling algorithms developed for efficient power management. For the experiments, we implemented a simulator using the Ruby language in Windows. The simulator can calculate energy consumption overheads associated with the state transitions for each scheduling algorithm, as well as the consumption for task executions. The experimental parameters of the simulator are set to reflect the characteristics of Marvell’s XScale-based processor PXA270 [
30], which supports six voltage-frequency levels and five processor modes, as shown in
Table 1 and
Table 2. This particular processor is adopted in a wireless multimedia sensor network platform called CITRIC [
31] and was used in recent studies [
32,
33]. It is anticipated that more processors for high-end embedded systems will be equipped with VFS and DPM [
6,
11].
To measure the scalability of the algorithms, we varied the number of available processors from 4–32. For each trial, we generated 100 task sets of which the utilization is fixed to four, and the rate of each task was varied in the range of [0.01, 0.99] by following the Emberson procedure [
34]. Each task period is uniformly distributed over a range of [15, 150] and simulations were run for 1000 system time units.
The experiment includes the algorithms proposed by Funaoka et al. [
24], which are referred to as uniform RT-SVFS and independent RT-SVFS. They are known to be state-of-the-art SVFS-based scheduling algorithms for both uniform and independent multiprocessors. The experiment also includes earlier approaches to DPM enabled T-L plane-based scheduling algorithms, such as TL-DPM [
7] and LNREF with DPM [
7]. As a baseline, the original LNREF was considered as well. We implemented the models for these algorithms on the simulator, as well as the proposed algorithm.
Table 3 summarizes the characteristics of the algorithms. In case all the multiprocessors of a platform are assumed to have the same characteristics, the platform is referred to as “identical” type. A “uniform” type platform allows the processors at different speeds, but they are identical otherwise. Every job receives the same speed-up when assigned to faster processors. An “independent” type platform has independent computing characteristics on every processor. A job may experience different speed-up when assigned to different processors. Such a platform is also referred to as “unrelated”.
All of the T-L plane abstraction based scheduling algorithms discussed here are global optimal ones. Hence, there is no deadline miss as long as the total utilization is under the system capacity. The computational complexity of every algorithm under discussion is due to the burden of sorting tasks in the order of local remaining execution time.
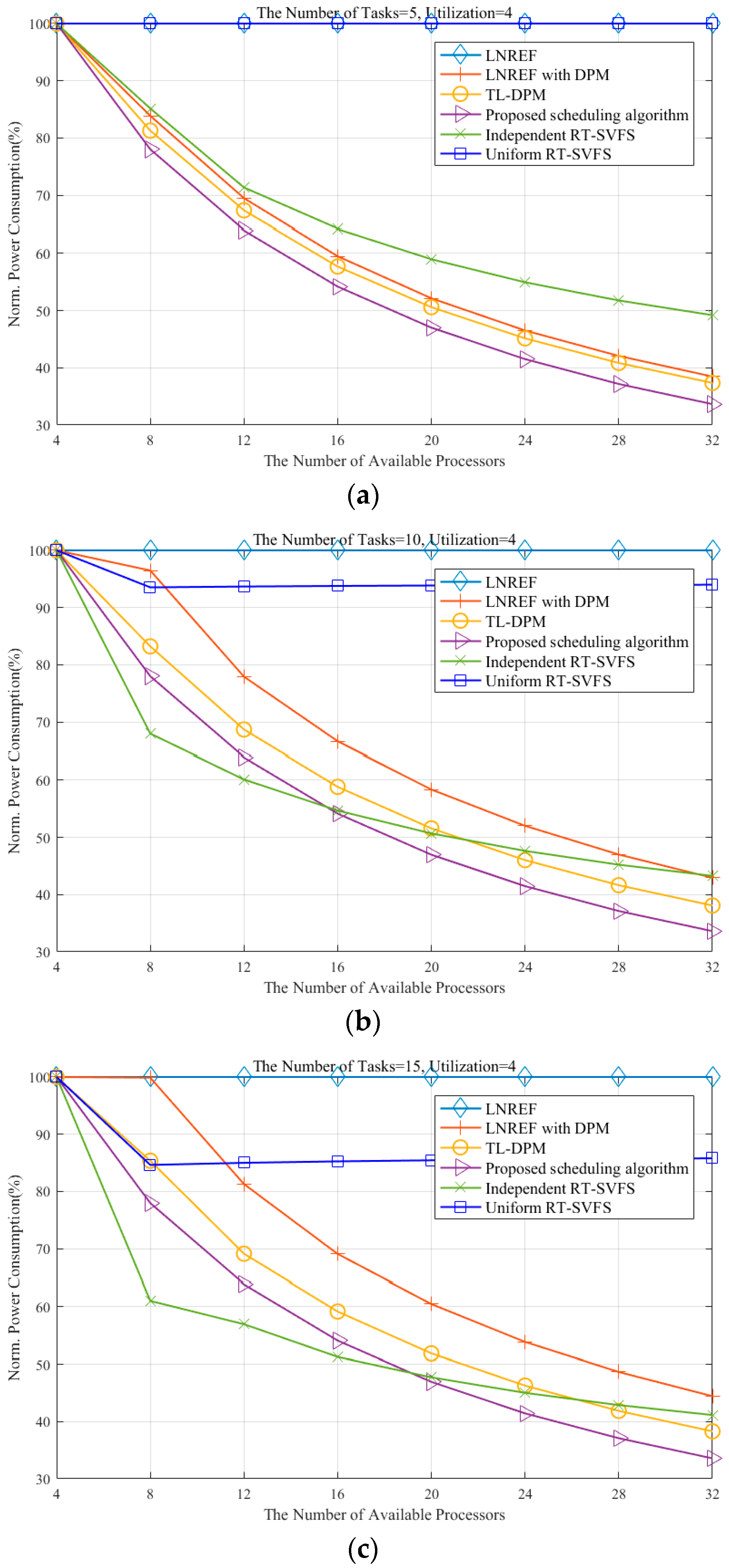
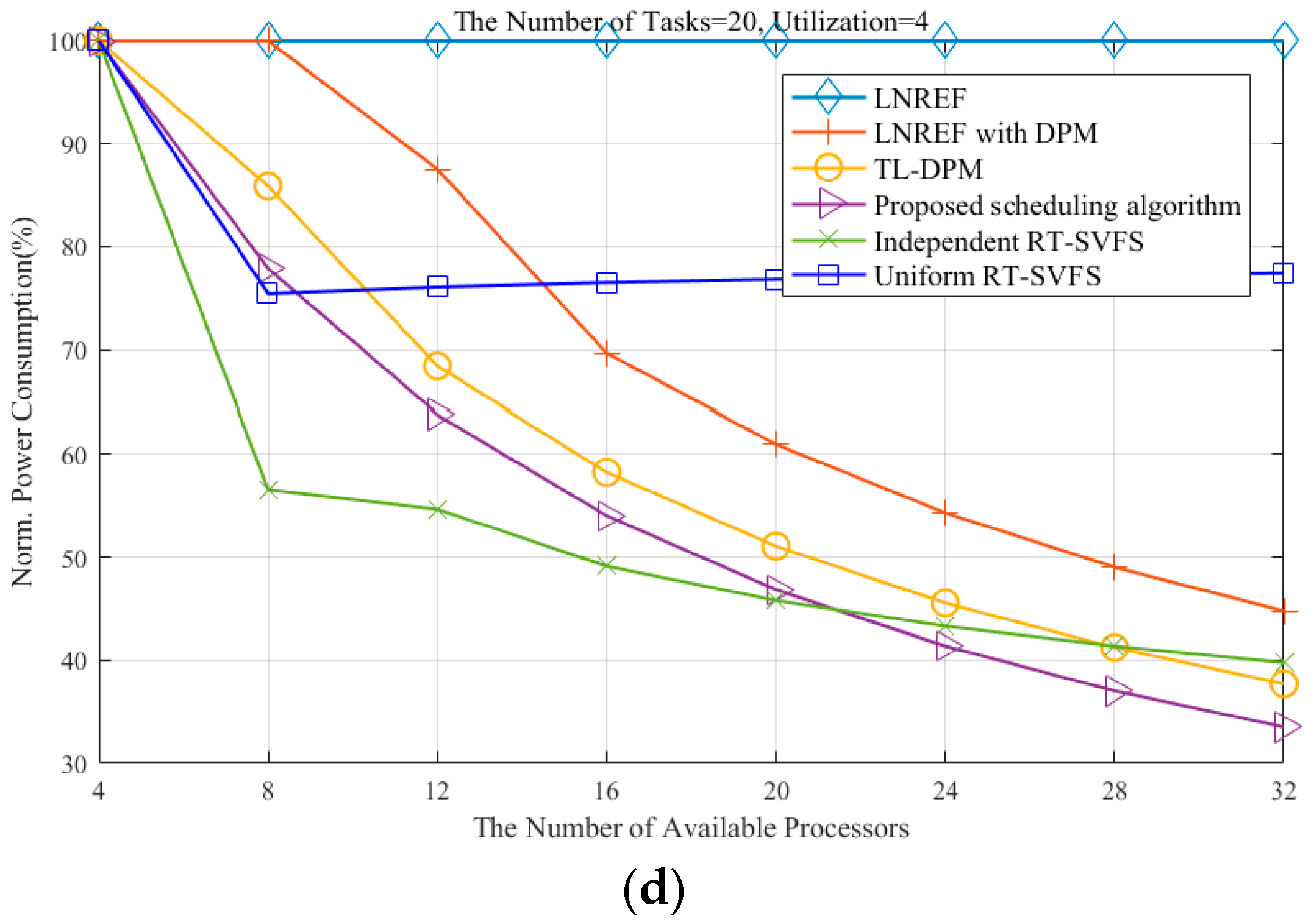
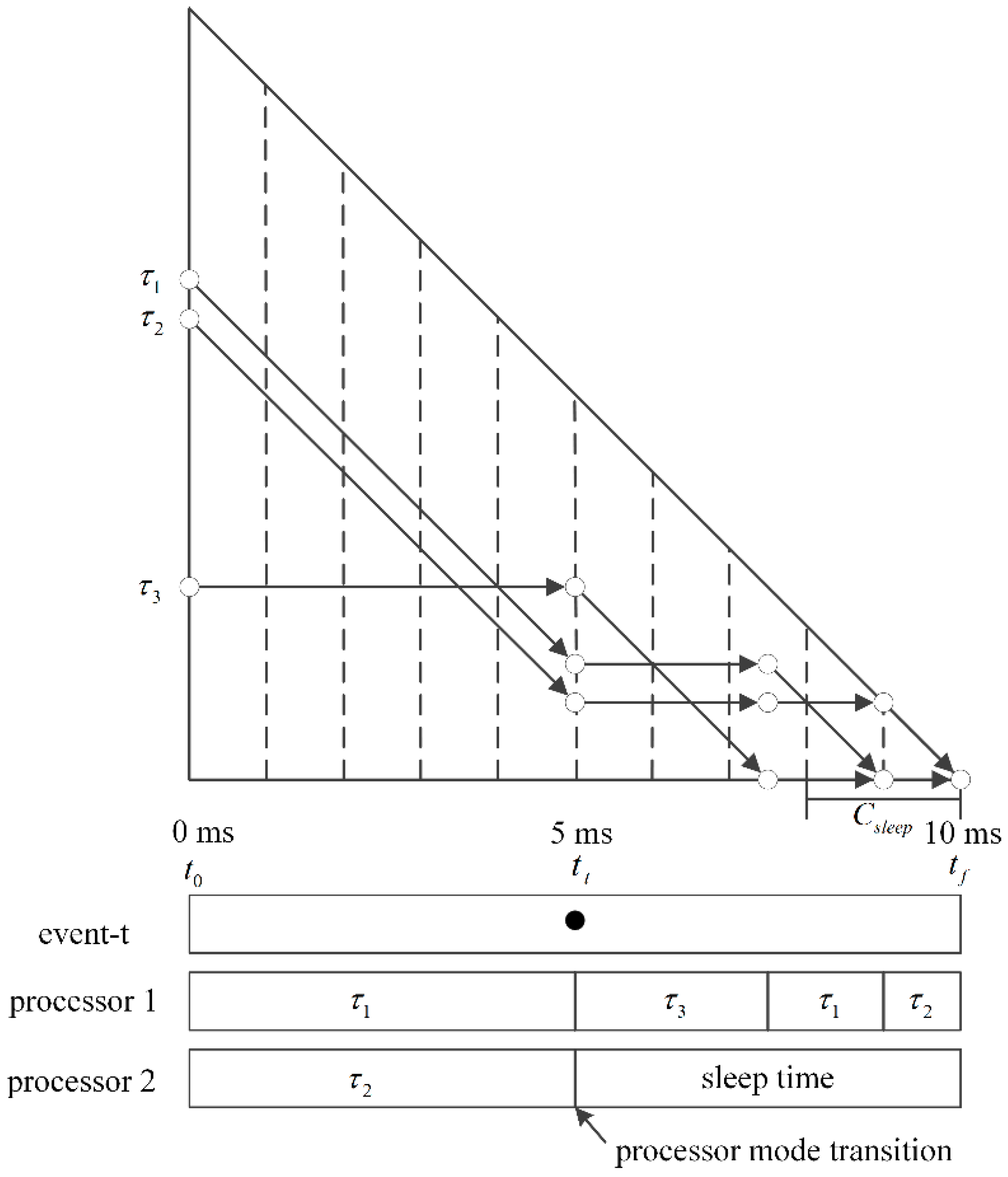
Figure 6 shows the power consumption measures for the six algorithms mentioned above: LNREF—the original LLREF algorithm without any power management; LNREF with DPM—a trivial extension to LNREF for DPM [
7]; TL-DPM—a recent extension to T-L plane-based scheduling [
7]; our proposed scheduling algorithm, independent RT-SVFS [
24]; and uniform RT-SVFS [
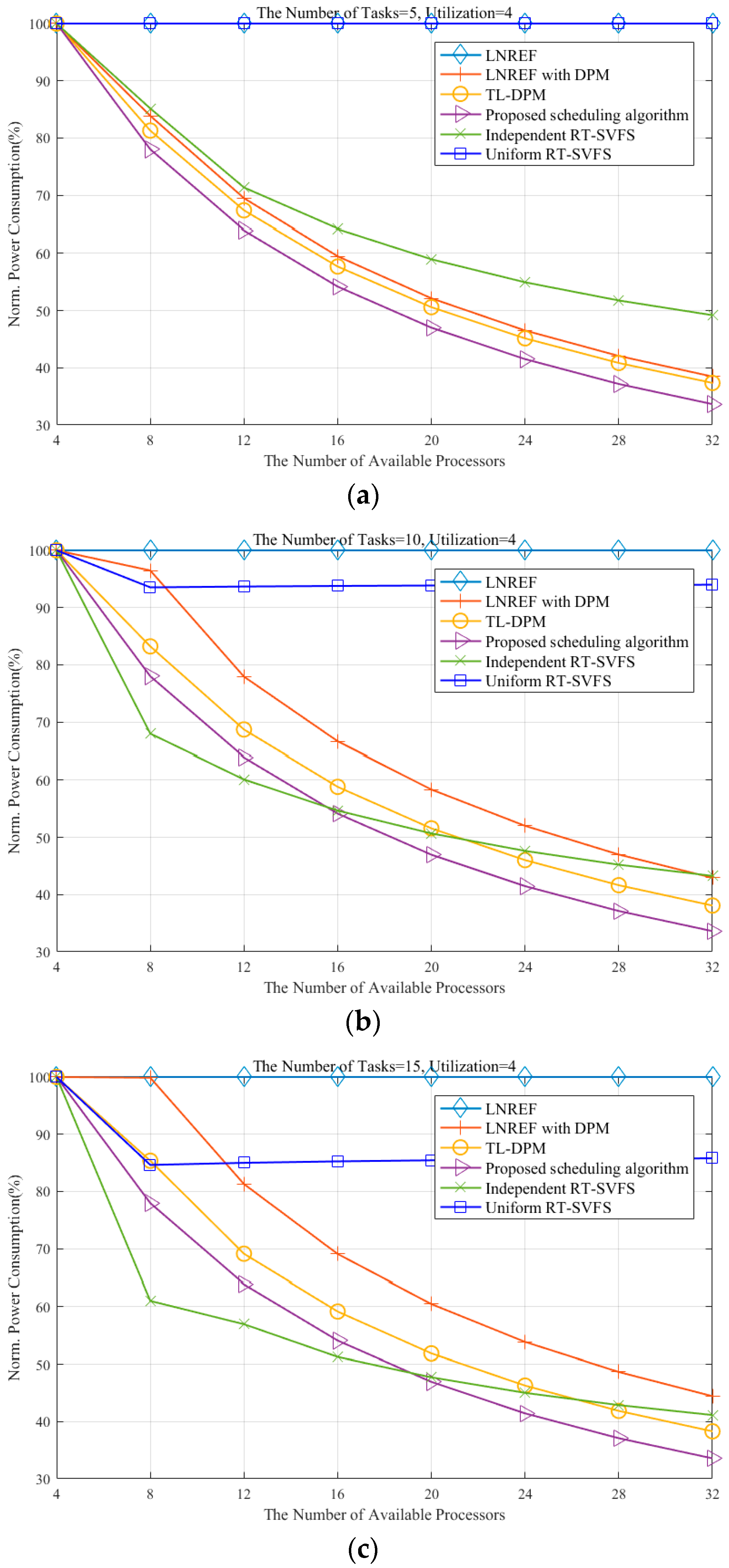
24]. The X-axis shows the number of available processors and the Y-axis represents the normalized power consumption (NPC), which is the ratio of the power consumption of an algorithm to that of LLREF. The task set sizes indicating the number of tasks in the task set are set to 5, 10, 15, and 20 in (a), (b), (c), and (d), respectively.
Notice that the NPC of every algorithm reaches 100% when the number of available processors is four because we intentionally adjusted the total utilization of each task set to four. It is observed that the algorithms utilizing the DPM technique exhibit better performance when the size of the task set (the number of tasks in the task set) is small and the task utilization is high, as shown in
Figure 6a. In contrast, the algorithms based on the RT-SVFS technique show better performance when the task set size is large and the task utilization is low, as shown in
Figure 6d.
Notice that the uniform RT-SVFS guarantees meeting the deadlines of a task set with the total utilization being less than or equal to
and the maximum utilization of tasks being less than or equal to
on
processors with a frequency of
. When the number of processors in the simulation is increased from 8 to 32, the uniform RT-SVFS allows the processors to run with a frequency equal to the maximum utilization of tasks. Therefore, the results from the uniform RT-SVFS are shown to be constant even when there are more than eight processors, as shown in
Figure 6b–d.
When scheduling a task set of which the total utilization is less than or equal to
on
processors running at a frequency of
, the dependent RT-SVFS algorithm classifies the tasks triggering deadline misses into the heavy task set and allocates a dedicated processor to each heavy task exclusively. Therefore, the NPC of the dependent RT-SVFS algorithm plummets until there are eight available processors, as shown in
Figure 6b–d. The NPC of dependent RT-SVFS monotonically decreases as the number of available processors increases in all cases, unlike uniform RT-SVFS.
Since the LNREF with DPM approach produces schedules by utilizing all available processors, even when not all of them are needed, increasing the number of tasks renders more fragmentations of the idle time in general. This behavior was also confirmed in our experiments, where the NPC of the LNREF with DPM approach increases as the number of tasks was increased, as shown in
Figure 6. In order to reduce fragmentation of the idle time, the TL-DPM algorithm steals the local execution time of tokens originally scheduled to the next plane, which helps to prevent frequent occurrences of idle time whose duration is not long enough to switch to sleep mode. We observe that TL-DPM consumes less power compared to the LNREF with DPM approach, as shown in
Figure 6.
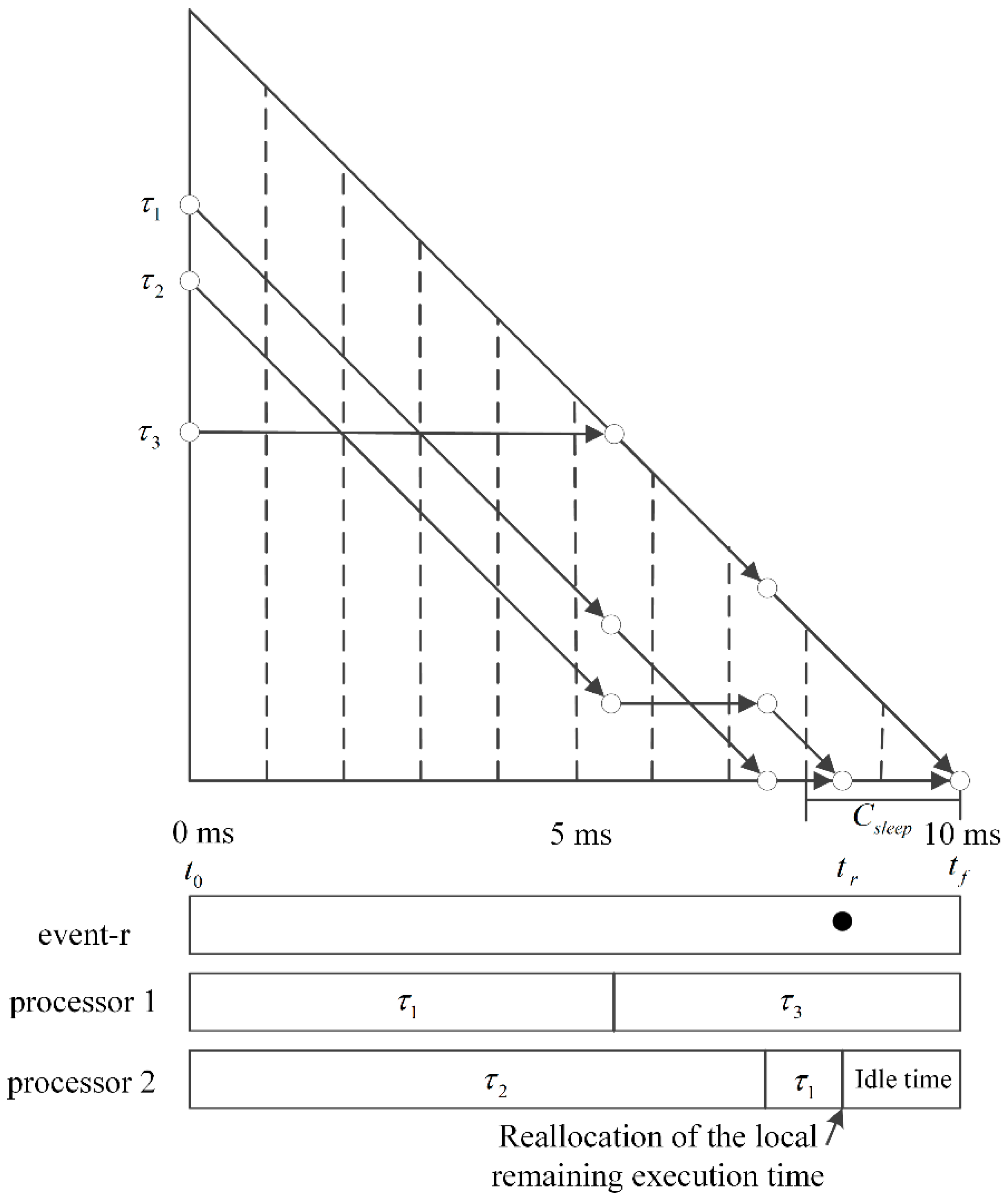
Our proposed algorithm consumes the minimum number of processors needed to schedule a task set and reallocates the local remaining execution time incurred by idle durations that are not long enough to switch the processor to sleep mode. The experimental results show that the proposed algorithm consistently provides better power management in every case compared to the LNREF with DPM and TL-DPM, as shown in
Figure 6. It should be noted that when the number of available processors is large enough for the task load, our proposed algorithm outperforms the independent RT-SVFS. We suspect that this is due to the limitations of the independent RT-SVFS, as it does not consider the tokens scheduled to the future planes and wastes energy by letting unassigned processors remain idle instead of switching them to sleep mode.
In addition, the proposed algorithm exhibits consistent performance with respect to the number of tasks, whereas the performance of the VFS-based approaches fluctuates with different task sets. More specifically, if each task set requires the same utilization, the proposed algorithm shows the same performance regardless of the other characteristics of the task sets, as shown in
Figure 6. This is because the behavior of our proposed algorithm is mainly controlled by the total utilization of the task set. For example, if the proposed algorithm is given two task sets requiring the same utilization, then the two schedules produced by the algorithm have exactly the same mode transitions (i.e., active, idle, sleep, and deep sleep) during the same durations.
Table 4 and
Table 5 summarize the main results of the experiments.
Table 4 shows that the percentage of power consumption saving from our proposed algorithm remained stable when the number of tasks are varied. This is due to the performance of the proposed algorithm is not affected by the number of tasks, but only by the total utilization. It is also notable that SVFS algorithms perform better when the number of tasks is high; however, our proposed algorithm outperforms them when the number of tasks are low.
Table 5 clearly shows the advantage of the proposed algorithm. It can cope with the increased computing power and exploits the maximum energy saving among the T-L plane based algorithms.
6. Conclusions and Future Work
There has been little work in the area of energy-efficient scheduling on T-L plane abstractions. In this paper, we present a new T-L plane-based scheduling algorithm for DPM-enabled multi-processors, which considers mode transition overhead and reduces fragmentations of the idle time. The issue of fragmentations of the idle time is inherent in T-L plane-based algorithms and we solve this problem by introducing three new events: the arrival event, event-t (transition event), and event-r (reallocation event). We implemented a simulator to measure the power consumption of various scheduling algorithms. The experimental results show that the proposed algorithm consistently outperforms other DPM-based approaches for T-L plane abstraction. In addition, the proposed algorithm provides better scalability to the number of available processors than VFS-based approaches.
Currently, our proposed algorithm can handle periodic tasks with implicit deadlines. In future work, we plan to extend our approach to handle sporadic tasks with constrained deadlines as well. It would also be very interesting to combine VFS and DPM approaches for T-L plane abstraction. We are planning to extend our experiments on actual platforms. In addition, the studies on trade-offs between power usage and the computational complexity, as well as performance evaluations on overloaded situations, are interesting, potential future studies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}