
Multi-Target State Extraction for the SMC-PHD Filter

College of Information and Communication Engineering, Harbin Engineering University, Harbin 150001, China
*
Author to whom correspondence should be addressed.
Sensors 2016, 16(6), 901; https://doi.org/10.3390/s16060901
Submission received: 27 March 2016
/
Revised: 3 June 2016
/
Accepted: 8 June 2016
/
Published: 17 June 2016
(This article belongs to the Section Physical Sensors)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The sequential Monte Carlo probability hypothesis density (SMC-PHD) filter has been demonstrated to be a favorable method for multi-target tracking. However, the time-varying target states need to be extracted from the particle approximation of the posterior PHD, which is difficult to implement due to the unknown relations between the large amount of particles and the PHD peaks representing potential target locations. To address this problem, a novel multi-target state extraction algorithm is proposed in this paper. By exploiting the information of measurements and particle likelihoods in the filtering stage, we propose a validation mechanism which aims at selecting effective measurements and particles corresponding to detected targets. Subsequently, the state estimates of the detected and undetected targets are performed separately: the former are obtained from the particle clusters directed by effective measurements, while the latter are obtained from the particles corresponding to undetected targets via clustering method. Simulation results demonstrate that the proposed method yields better estimation accuracy and reliability compared to existing methods.
1. Introduction
Multi-target tracking (MTT) has to deal with the detection and estimation problems of multiple targets in a cluttered environment [1]. Traditional solutions such as multiple hypothesis tracking (MHT) filter and joint probabilistic data association (JPDA) filter handle this problem through a divide-and-conquer approach that involves data association and filtering processes [2,3]. As an alternative to the association-based methods, the random finite sets (RFS) approach is an emerging technique to multi-target tracking (MTT), and the resulting optimal multi-target Bayes filter provides a rigorous theoretical basis for many novel multi-target filters [4,5,6]. In this context, the probability hypothesis density (PHD) filter [4] which is derived via first-order moment approximation of the multi-target posterior density, and its implementations such as sequential Monte Carlo PHD (SMC-PHD) filter [7,8] and Gaussian mixture PHD (GM-PHD) filter [9], have been widely studied in the area of MTT over the last decade [10,11,12,13,14].
From an engineering point of view, the SMC-PHD filter is more suitable for practical applications due to its ability to accommodate both nonlinear and non-Gaussian dynamics [8,13]. However, the SMC method leads to a troublesome problem in extracting the estimates of target states from the given particle approximation of the PHD (also known as intensity function), and the accuracy of the estimated multi-target state directly determines the tracking performance of a multi-target filtering algorithm. Thus it is a critical issue for the SMC-PHD filter to develop a reliable multi-target state extraction algorithm, which has attracted significant attention [15,16,17,18,19,20,21]. Typically, the clustering techniques such as k-means clustering [7,15] and c-means fuzzy clustering [16], and finite mixture models (FMM) algorithm via expectation-maximization (EM) [15] or Markov chain Monte Carlo (MCMC) sampling [17], have been investigated in this aspect. The results in [15] demonstrated that the k-means clustering outperforms the FMM algorithm with potential computational efficiency and fewer spurious estimates. In addition, the CLEAN method [18] was proposed to extract target states from the SMC-PHD filter. However, since this method only exploits the weight information of particles, the average performance of the CLEAN method is no better than the k-means clustering in general. Subsequently, the method in [19] introduced clustering algorithms to overcome the drawbacks of the CLEAN technique. Despite this, the effect is limited because the clustering algorithms [15,16] are particularly problematic and unreliable due to the hard limiting on the number of clusters (specified by the estimated number of targets), especially in the scenarios where there exist closely spaced targets or incorrect estimates of target number [19,20,21]. Moreover, such methods have high computational cost because of the requirement of iterative computing process.
To address these problems, some measurement-oriented methods that consider the relationships between weighted particles and measurements have been proposed to perform state extraction [20,21], where the ad-hoc particle clustering methods mentioned above are eliminated. Typically, the grouping method [20], implemented by replicating the current particle set and re-weighting them corresponding to individual measurements, has been a popular state extraction method in different versions of the SMC-PHD filter [10,12]. In contrast, the method in [21] introduced a maximum likelihood criterion for particle clustering. More recently, a systematic and theoretical analysis about the possibility of extracting point estimates from PHD with respect to the optimal sub-pattern assignment (OSPA) [22] metric was investigated in [23], however, how to design a reasonable loss function and extend the method to general cases need to be further researched. To facilitate the parallel implementation of the SMC-PHD filter, a new multi-expected a posterior (MEAP) method was outlined in [24], where the estimation procedure can still be seen as a kind of measurement-oriented technique by introducing particle-to-measurement association based on the near and nearest neighbor principle. Moreover, the concept of association measure was introduced to the PHD recursion [25], which theoretically makes it possible to extract track estimates from the PHD filter. Unfortunately, due to the complexity of measurement association and the fast augmentation of the number of observation paths, the feasible implementation method and its potential performance are not clear. Generally speaking, the measurement-oriented methods are more acceptable and practical than the clustering-based methods in terms of both reliability and computational efficiency [20,24]. On the other hand, the existing solutions of this category are all limited by the fact that only the targets that have been detected may have chances to be reported, which will result in inaccurate estimation when missed detections occur. Since the PHD recursion is sensitive to missed detections, to date, how to extract state estimates from the SMC-PHD filter accurately in the presence of detection uncertainty still remains a challenge.
The key contribution of this paper is a novel solution to achieving multi-target state extraction in the SMC-PHD filter. More specifically, the normalized likelihoods of the predicted particles with respect to individual measurements are introduced to develop a validation mechanism which aims at selecting effective measurements and particles, i.e., the target-originated measurements and the particles corresponding to detected targets. Subsequently, by constructing the association probability distributions between particles and measurements, the particles of detected targets are divided into different clusters corresponding to the effective measurements in a probabilistic manner. Then, according to the estimated target number, the point estimates of the target locations can be extracted from the resulting clusters. Moreover, benefiting from the proposed validation mechanism, we introduce a gating technique to further identify the particles of undetected targets, and then extract the corresponding target states, thereby implying an improved estimation performance in the circumstances with detection uncertainty. Simulation results demonstrate the effectiveness of our methods in comparison with the existing methods.
The remainder of this paper is organized as follows: Section 2 provides a brief review of the PHD filter and the SMC-PHD filter. The proposed multi-target state extraction method is presented in Section 3. Simulation results and analysis are presented in Section 4 and conclusions are drawn in Section 5.
2. Problem Formulation
2.1. The PHD Filter
The RFS method provides an elegant representation of multi-target systems. For example, let nk and mk represent the time-varying number of targets and measurements at time k, respectively, then the corresponding target states xk,1,xk,2,…xk,nk and measurements zk,1,zk,2,…zk,mk can naturally be modeled as the finite sets Xk = {xk,1,xk,2,…xk,nk} and Zk = {zk,1,zk,2,…zk,mk}, respectively [7,8]. Based on the RFS theory, the optimal multi-target Bayes filter was developed by Mahler. However, the calculations of high-dimensional integration of multi-target densities make it intractable to implement the full multi-target Bayes filter directly. To obtain a practical solution, the sub-optimal PHD filter was derived via moment approximation [4], which only recursively propagates the posterior intensity of the multi-target RFS in time. Under the assumptions of Poisson multi-target distributions [4], the PHD filter (without considering target spawning) is given by:
here is the posterior intensity associated with the multi-target state at time , is the intensity of newborn targets, is the probability that a target will survive at time given the state at the previous time step. is the transition probability density of a single target, is the probability of detection for a target with state , is the measurement likelihood of individual targets, and is the intensity of clutter. The integral of the PHD over the state space is the expected number of targets and the peaks of the PHD can be used to generate target state estimates [7].
2.2. Review of the SMC-PHD Filter
Although the PHD filter alleviates the computational complexity of the multi-target Bayes filter to a great extent, it can be seen from Equations (1) and (2) that the PHD recursion still involves multiple integrals. The implementation of the PHD filter generally resorts to some approximate methods, and we focus on the SMC implementation proposed in [7], henceforth referred to as the SMC-PHD filter. Suppose that at time , particles are drawn for the prior PHD and their weights are assigned as , where is the ith state particle and is the associated weight. The main steps of the SMC-PHD filter at time are briefly summarized as follows:
- Step 1 Prediction:
- For , sample from a proposal density for persistent targets and compute the predicted weights:where .
- For , sample from a proposal density for newborn targets and compute the corresponding weights:where is the number of particles for newborn targets.
- Step 2 Update:
- For each , compute:where and is the likelihood of a measurement resulting from a particle .
- For , update weights:
- Step 3 Resampling:
- Compute the total mass and then resample to get .
- Rescale the weights by to obtain .
- Step 4 Multi-Target Parameter Estimation:
- Estimate the number of targets (by rounding ).
- Extract the target state set from the particles that represent the posterior intensity, where denote the estimated multi-target state.
More details on the mathematical derivation and analysis can be found in [7]. Note that in standard SMC-PHD filter, the process of state estimation is not a necessary step and has no influence on the filter recursion itself, but for the purpose of MTT where the number and instantaneous positions of all targets need to be estimated, we consider this process as Step 4 in the original algorithm. The main contribution of our study is the techniques for Step 4 of the SMC-PHD filter and more specifically on the extraction of individual target states.
3. The Proposed Multi-Target State Extraction Method
According to the definition of PHD [4], its peaks in the state space indicate the points with the largest expected target density. The SMC-PHD filter propagates a set of weighted particles to approximate the posterior intensity associated with the multi-target density, and the weights of different particles characterize the intensities at exactly the locations of the corresponding state particles [7]. During the filtering iteration, all measurements in including both target-originated measurements and clutter are used to update the weights of particles. Besides, some targets may not be detected due to detection uncertainty. Therefore, it is preferable to identify the measurements and particles that are closely related and decide whether they are related to the existing targets in a principled manner, which in turn can be exploited to provide accurate and reliable state estimation.
3.1. Particles and Measurements Classification
Since no explicit associations between measurements and targets are required in the SMC-PHD filter, all measurements are used to update the weight of each particle. A close inspection of Equation (6) reveals that the updated weight can be decomposed into a series of individual weight components corresponding to , which can be written as:
where represents the term caused by missed detection, and:
According to the representation in Equation (7), for a detected target represented by particle , the weight component measures the contribution degree that makes to the updated weight of , which is essentially established by the likelihood of the particle with respect to the underlying measurement. Based on this fact, the particles’ normalized likelihood distribution corresponding to measurement can be defined as:
where is introduced to suppress the influence of clutter. Otherwise, when is a clutter measurement that results in non-zero likelihoods for some particles, no matter how small these values are, there will be some large after the likelihood normalization processes. It is clear that . To identify the particles of detected targets, the following criterion is defined under the premise that there must be true measurements among .
Criterion 1:
The particles matching with a certain measurement in terms of significant likelihoods are more likely to represent detected targets.
Thus, given the measurement set , the particle that satisfies:
is selected as a candidate particle for detected targets, where is defined as a logic operation with and , is a preset threshold. An intuitive interpretation of Equation (10) is that the particle associated with at least one measurement with significant normalized likelihood is regarded as a candidate particle for detected targets. Note that when two or more measurements are closely spaced, the one-to-many relationship may occur. Repeating the process of Equation (10) for all , and then all the resulting candidate particles are collected to construct a new weighted particle set:
where is the total number of the candidate particles and is the new index of the particle in . As a result, the potential particles for undetected targets are given by:
On the other hand, Equation (8) further reveals that although all measurements are considered to update the particle weight, only the true measurement for the particle will generate a large weight component that represents a potential target in the state space. Thus, another validation technique is proposed to determine whether a measurement is effective by:
where denotes a threshold of the acceptable number of particles associated with a potential true measurement. The implication is that Equation (13) confirms the effectiveness of different measurements based on the candidate particles in , which is mutually complementary with Equation (10). Therefore, it is straightforward to obtain the effective measurement set:
where is the number of effective measurements. According to the principle of the SMC-PHD filter, the particles in can effectively capture the regions where the PHD peaks may appear after filtering update. Furthermore, limits the size of the measurement set which originates from true targets with high probability and also, to a certain extent, obviates unnecessary computation caused by partitioning particles corresponding to clutter measurements.
3.2. Multi-Target State Extraction
For detected targets, following the basic idea behind the measurement-oriented methods, the measurements in can be used to divide particles into different clusters; each one represents a possible peak in the particle approximation of the posterior intensity. It is worth emphasizing that although the idea has been adopted previously [20,21,24], the implementation presented here has significant differences. Firstly, we introduce a validation mechanism before this process, only the resulting measurement set and particle set are considered. Secondly, the particle-to-measurement associations are established in a principled probabilistic manner, where the association probability distribution over the elements of for each particle is formulated by:
Then, a maximum a posterior (MAP) rule is exploited to determine the label of a particle:
Obviously, is specified by one of the index of a measurement in . In addition, the weight of each particle is given by:
where the abbreviation is used for notational convenience.
Based on the results of Equations (16) and (17), the main steps of the proposed method are described in Algorithm 1. First, the process of partitioning particles (in lines 1 to 3 of Algorithm 1) into different clusters determines which particle belongs to which measurement, and each cluster corresponds to a potential target. Sequentially, we extract individual target states from the clusters with the largest total weights. It can be expected that the clusters restricted by the candidate particles together with effective measurements will be more effective and accurate to capture the peaks in the PHD. Finally, the weighted mean of state particles in each cluster is taken as the estimated location. Besides, given a state estimate for a cluster , its covariance estimate can be approximated by:
where denotes the number of elements in , and denotes the particle and its associated weight with index in .
| Algorithm 1. Multi-target state extraction for detected targets. |
Given: The estimated target number , and .
|
Theoretically, the SMC-PHD filter handles missed detection with a special term , and thus preserves the information of undetected targets. However, in reality, when missed detection occurs, the SMC-PHD filter tends to give an incorrect estimation of the target numbers [26]. In this case, it is impossible to extract the estimates of the undetected targets based on measurements.
Benefiting from the particles classification method in Section 3.1, this problem can be solved by the proposed Algorithm 2. The core idea behind this method is to identify the particles corresponding to undetected targets and then extract corresponding target states. Recall that the set contains all the particles that have no closely related measurements, which in turn can be interpreted as the particles corresponding to potentially undetected targets. In view of the fact that the particle distribution in the state space consists of different particle clusters which indicate the positions of persistent targets, once the set of estimated target states is obtained, all particles near the regions of the estimated target locations are more likely to have the identical sources. Therefore, the Mahalanobis distance is introduced to form validation gates to eliminate such particles in (lines 2 to 5 of Algorithm 2), and is a gating threshold which is used to determine the size of the validation region for each estimated target state. Based on the dimension of the state vector and an expected gate probability , can be obtained from the formulas in [27] (p. 337). In general, to compensate the possible statistical error in , a large gate probability which is very close to 1 is suggested to ensure overall effectiveness. Besides, the particles corresponding to newborn targets at current time should be removed (line 6 of Algorithm 2). Finally, is taken as the particle set of undetected targets.
Let represent the weighted particles in , in order to extract the estimates of the undetected targets, we first guess the number of undetected targets by:
The nonzero value of indicates that the particles in are sufficient to represent potential targets. Since no measurements are available to generate reliable weights for these particles at this stage, we suggest using the particles’ spatial distribution characteristic to extract potential target states. Thus the commonly used k-means clustering method [15] can be used to obtain the state estimate set . As a result, the modified estimation results are given by:
| Algorithm 2. Methods for state estimation of undetected targets. |
| Given: and |
| 1. Set , |
| 2. for do |
| 3. |
| 4. |
| 5. end for |
| 6. . |
| 7. Compute according to (19) |
| 8. if |
| 9. State extraction using clustering method |
| 10. end |
Remark: The proposed Algorithm 1 itself is sufficient to serve as a multi-target state extraction method for the SMC-PHD filter. However, just as the existing measurement-oriented methods, it is limited by the fact that no estimates for undetected targets will be reported. Then Algorithm 2 is proposed to compensate this disadvantage, which is an alternative technique particularly regarding the estimation of undetected targets. It can be combined with Algorithm 1 to further improve the estimation performance in the presence of detection uncertainty. This beneficial result comes with a slight increase in the amount of calculations arising from getting Uk and the clustering method. Fortunately, the clustering method operates only when the missed detections are confirmed by Equation (19). Moreover, the number of particles in Uk is much less than that in the original particle set, which will simplify the clustering process. In terms of computational complexity, the proposed Algorithm 1 has the same complexity of O(TN) as the methods in [20,21], where T is the number of targets and N is the number of particles, while the most popular k-means clustering method has a computational complexity of O(τTN), where τ is the number of iterations in the clustering procedure.
3.3. Notes on Implementation
From an implementation perspective, the proposed Algorithm 1 is potentially engineer-friendly as compared with the popular clustering or clustering-based techniques [15,16,19], where no iterative calculation is involved. Besides, taking advantages of the inherent information in the filtering stage, the variables originally computed in Step 1 and Step 2 are exploited to design our method, which makes the method more suitable for the SMC-PHD filter framework.
There are two empirical parameters, i.e., γg in Equation (10) and τn in Equation (13), which require to be determined when applying the proposed methods. The parameter γg is important for eliminating the particles that have negligible normalized likelihood with respect to the collected measurements. At each iteration of the SMC-PHD filter, a specified number of particles per target (denoted by β) will be allocated to guarantee a reasonable number of weighted particles for approximating the PHD of individual targets [7], and the updated weight of each particle contributes a certain proportion to the PHD of the underlying target. The normalized likelihood distribution in our method has a similar characteristic with respect to individual particles. It can be interpreted that γg is used to select the particles that make certain contributions to the whole distribution in Equation (9) as well as result in non-zero likelihoods corresponding to a given measurement. In general, the particle classification process is sensitive to γg. The smaller the γg, the more valid particles will be selected for detected targets. Accordingly, some of these particles tend to have negligible updated weights. However, this result will not have an obvious effect on the estimation accuracy for the reason that the weighted mean of the state particles in Algorithm 1 highlights the contributions of the particles with significant weights in each cluster. On the other hand, given an observation model, the value of γg highly depends on the β value used in the filter because all the particles of a target may generate non-zero likelihoods, which hence influence the results of Equation (9). Considering the spatial distribution characteristics of the particles and possible observation uncertainties in practical applications, we choose to use γg = 1/β as the threshold, which is consistent with the average contribution value of each particle. Equivalently, the contribution degree 1/β is acceptable for the valid particles.
In addition, the parameter τn in Equation (13) is introduced to give a high confidence level to the measurements which associate with a significant number of particles. Such measurements are referred to as effective measurements and will be useful for state extraction. Like γg, τn directly determines the number of effective measurements, a proper τn can help to eliminate clutter measurements, which in turn allows a high computational efficiency of the proposed method by obviating unnecessary computation due to partitioning particles corresponding to clutter measurements. There is a trade-off between including true measurements and eliminating clutter measurements. When the observation accuracy is high, a relatively large τn can be adopted, and vice versa. Empirically, is suggested.
4. Simulation
To evaluate the performance of the proposed methods, a two-dimensional tracking scenario with an unknown and time-varying number of targets is considered, where the target dynamic model is exactly the same as that in [7,24]. The position of the sensor platform is assumed to be known at coordinate origin, and the observation equations are given by:
where εk,1 and εk,1 are the zero-mean Gaussian white noise with respective standard deviations π/180° and 2 m. Assuming that the survival probability of each target is independent of its state and the value is set to be pS,k = 0.98 during the simulations. Clutter is uniformly distributed over the region [0, π/2](rad) × [0,700] (m), and the number of clutter measurements per scan is Poisson distributed with a specified mean value r. β = 500 is used in the SMC-PHD filter, and thus the number of particles varies according to the estimated number of targets. The parameters γg = 1/β , τn = 100 and λ= 25 (corresponding to pg = 0.9999) are used for the proposed Algorithms 1 and 2. Besides, the OSPA metric [22] is adopted to evaluate the estimation performance of different methods. The intensity of newborn targets is modelled as [7,15,24]:
where N(x;m,P) denotes a normal distribution with mean m and covariance P, and the values of and are configured as , , and . We compare the performance of the proposed methods with that of the k-means method [15], grouping method [20] and MEAP method [24] via Monte Carlo (MC) simulations.
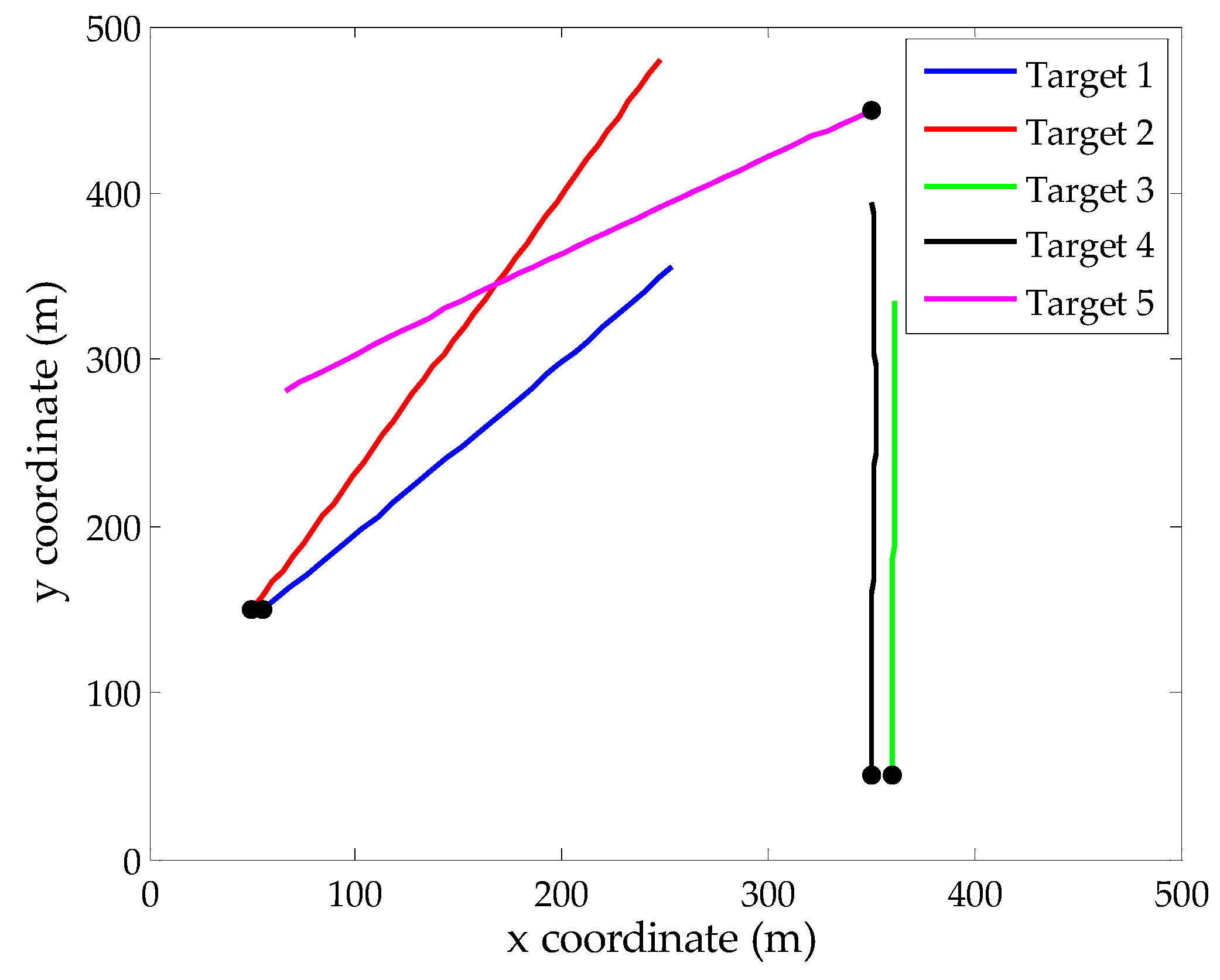
In the surveillance region, we design a relatively complex multi-target environment with crossing tracks and paralleling motion in close range. More specifically, target 1 exists in the surveillance region from time step 1 to 30. Target 2 and target 5 appear at time step 20 from different positions and their track crossing happens at time step 45. Target 3 and target 4 appear at time step 15 simultaneously and they keep parallel motion until time step 50. Figure 1 shows the true tracks of 5 targets in this scenario. To capture the localization errors of different state extraction methods, the parameters p = 2 and c = 20 are chosen to generate OSPA metric value.
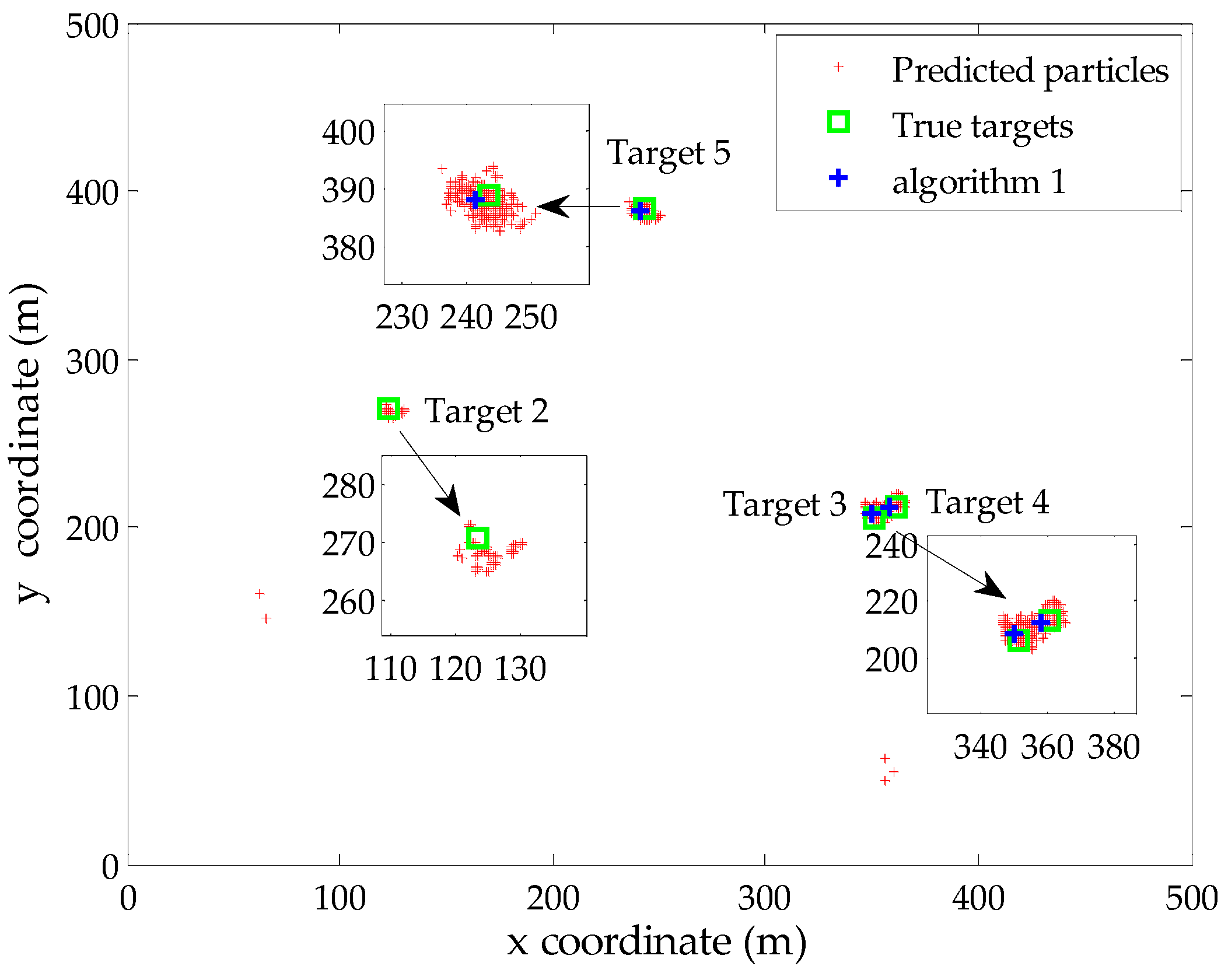
To verify the effectiveness of the proposed Algorithms 1 and 2 in an intuitive manner, we present a typical example of the filter output at time step 35 (missed detection occurs). The probability of detection and clutter rate are set to be pD = 0.90 and r = 10 in the simulation, respectively. There exist four true targets during this iteration, while the estimated number of targets is N35 = 3. Figure 2 gives the global distribution of the predicted particles corresponding to persistent targets at this time step. Besides, the true locations of targets and the extracted locations using Algorithm 1 are also displayed in the same figure. It is clear that the proposed Algorithm 1 provides accurate estimation of the existing three targets based on the estimated number of targets, although the particles of the target 3 and target 4 exhibit significant overlap due to the parallel motion in close space. Besides, target 2 is an undetected target and the existing measurement-oriented methods cannot extract its state in this case, including the proposed Algorithm 1.
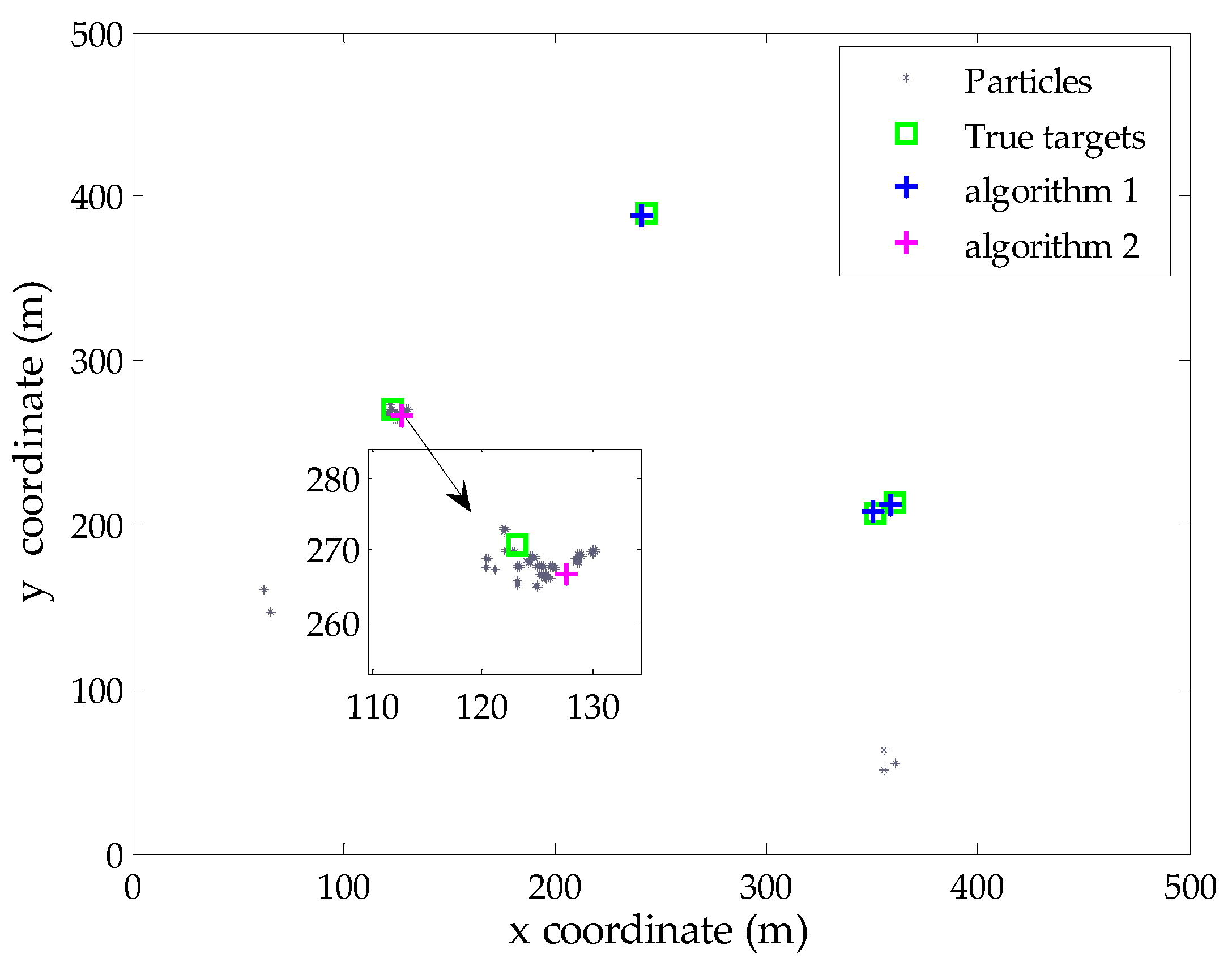
Subsequently, the proposed Algorithm 2 is performed. Figure 3 shows the particles (in Uk) corresponding to undetected targets at this time step, as well as the extracted target state from these particles. The results demonstrate that the proposed Algorithm 2 can effectively identify the potential particles of undetected target and then extract the state estimate. As shown in Figure 3, there are a few spurious particles around the birth regions. This phenomenon is caused by the resampling process in the previous iteration, where the filter needs to draw particles from the birth intensity to exploit potential new targets at each scan.
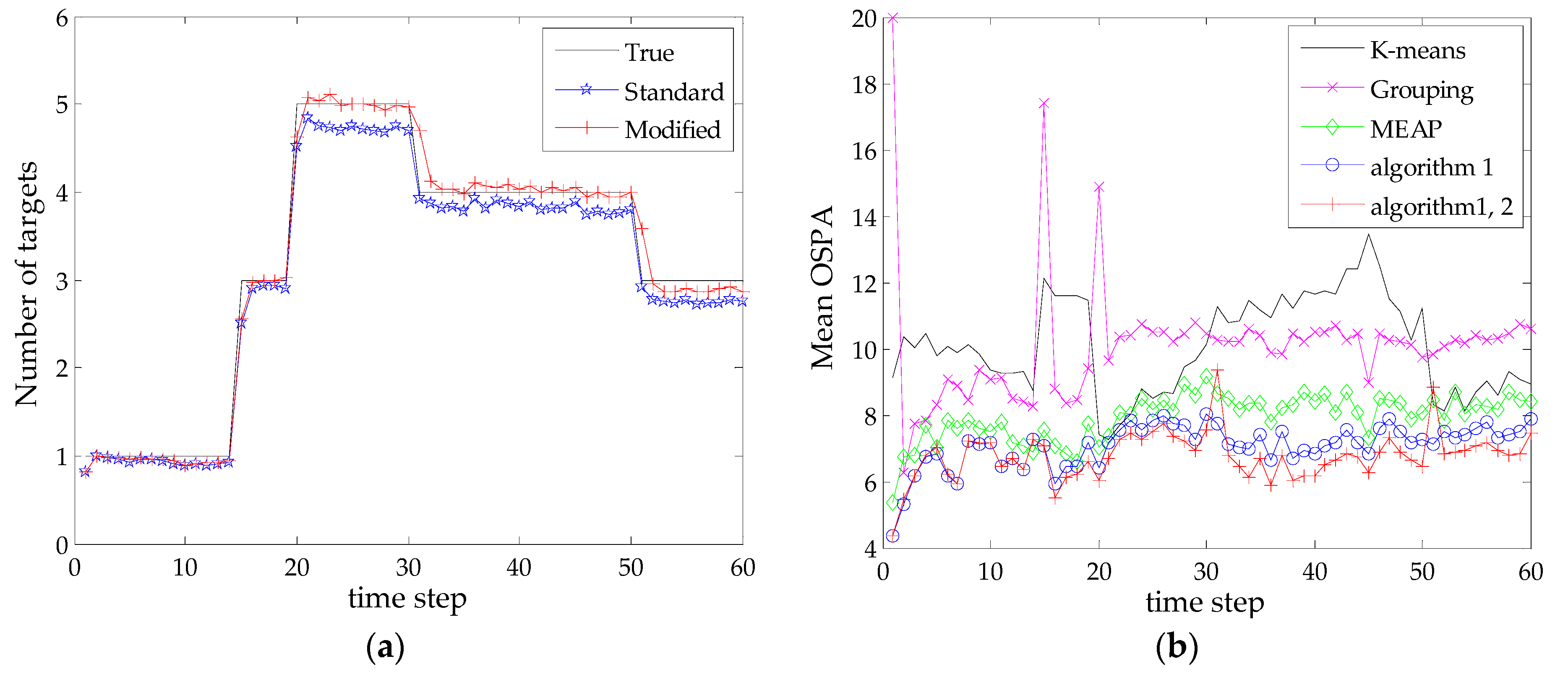
To compare the average performance, 200 MC runs are performed for the SMC-PHD filter with different state extraction methods. The target tracks are fixed but clutter and measurements are independently generated for each trial. Note that the effectiveness of the proposed Algorithm 2 is examined by combining its estimated results with that of the Algorithm 1, namely, the modified results in Equations (20) and (21), in subsequent simulations. Figure 4 shows the statistical results of the estimated number of targets and mean OSPA distances of five methods at each time step. The true number of targets and the estimated results from SMC-PHD filter are shown in Figure 4a. Based on the extracted multi-target state using different methods, the corresponding mean OSPA distances are shown in Figure 4b.
As shown in Figure 4a, the standard SMC-PHD filter gives a satisfactory performance on the target number estimation in this scenario, while the modified estimate by Algorithm 2 follows the true value more closely. In terms of state estimation, it can be seen from Figure 4b that the grouping method shows a slight advantage over the k-means clustering method at most time steps but has a large error when new targets appear. The reason is that the method only reports the estimates whose total weights are above a certain threshold value (we adopt 0.8 as was done in [20]), which is not favorable for the estimation of newborn targets. By contrast, the superiorities of the MEAP method and the proposed methods are remarkable. It can be seen that the proposed Algorithm 1 exhibits a better performance than that of the MEAP method. This can be attributed to the proposed mechanism for selecting particles and measurements, where the contributions of particle likelihoods are evaluated and the scopes of particles are restricted corresponding to effective measurements. Such kind of particles can exactly capture the regions of PHD peaks for state extraction. Moreover, the combination of Algorithms 1 and 2 achieves the best estimation accuracy as compared with all other methods in the presence of detection uncertainty. Figure 4b also indicates that the estimation of undetected targets will cause a short delay response (exhibits large error at time steps 31 and 51) when targets really disappear. In reality, it is difficult to discriminate the two cases in a single iteration.
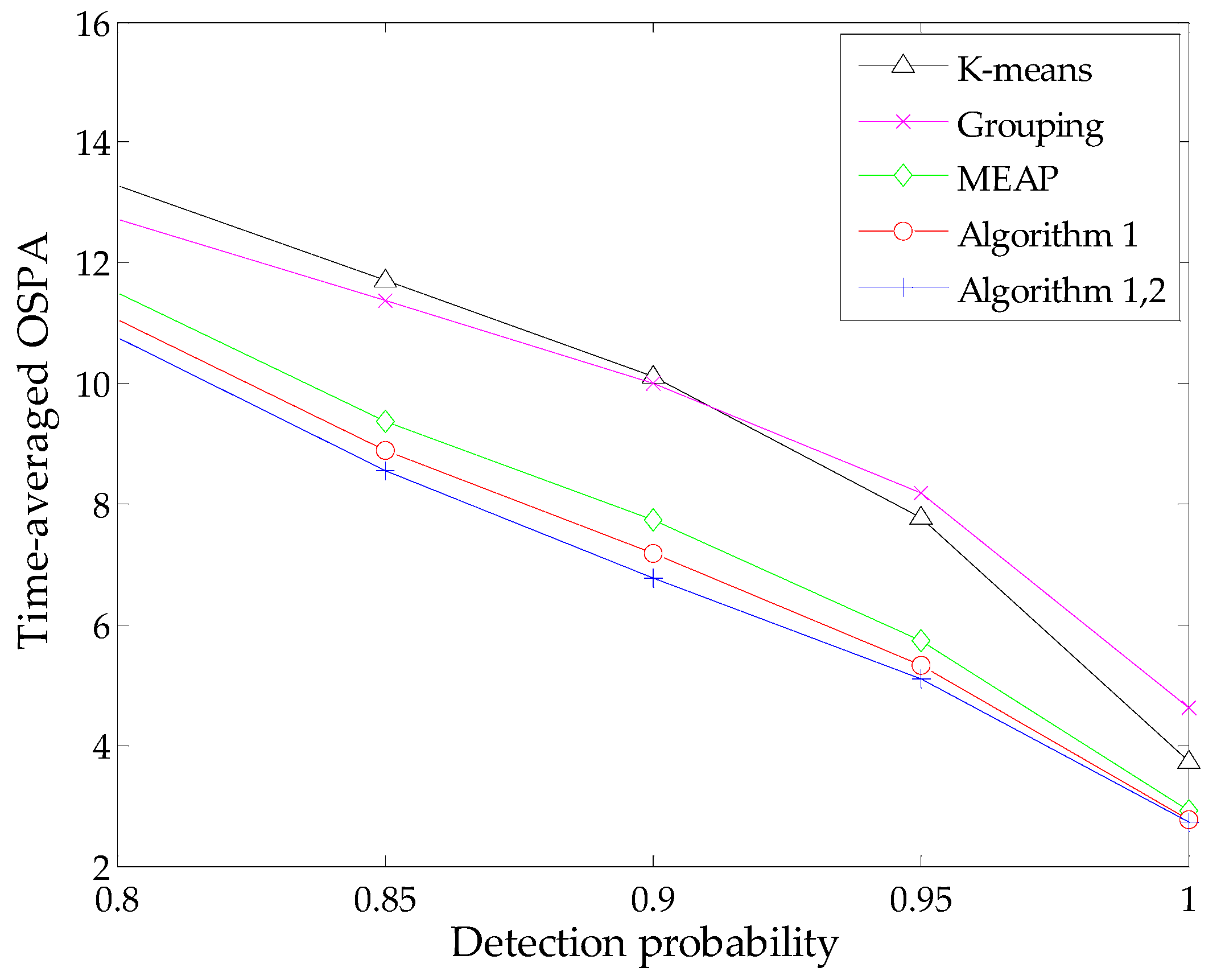
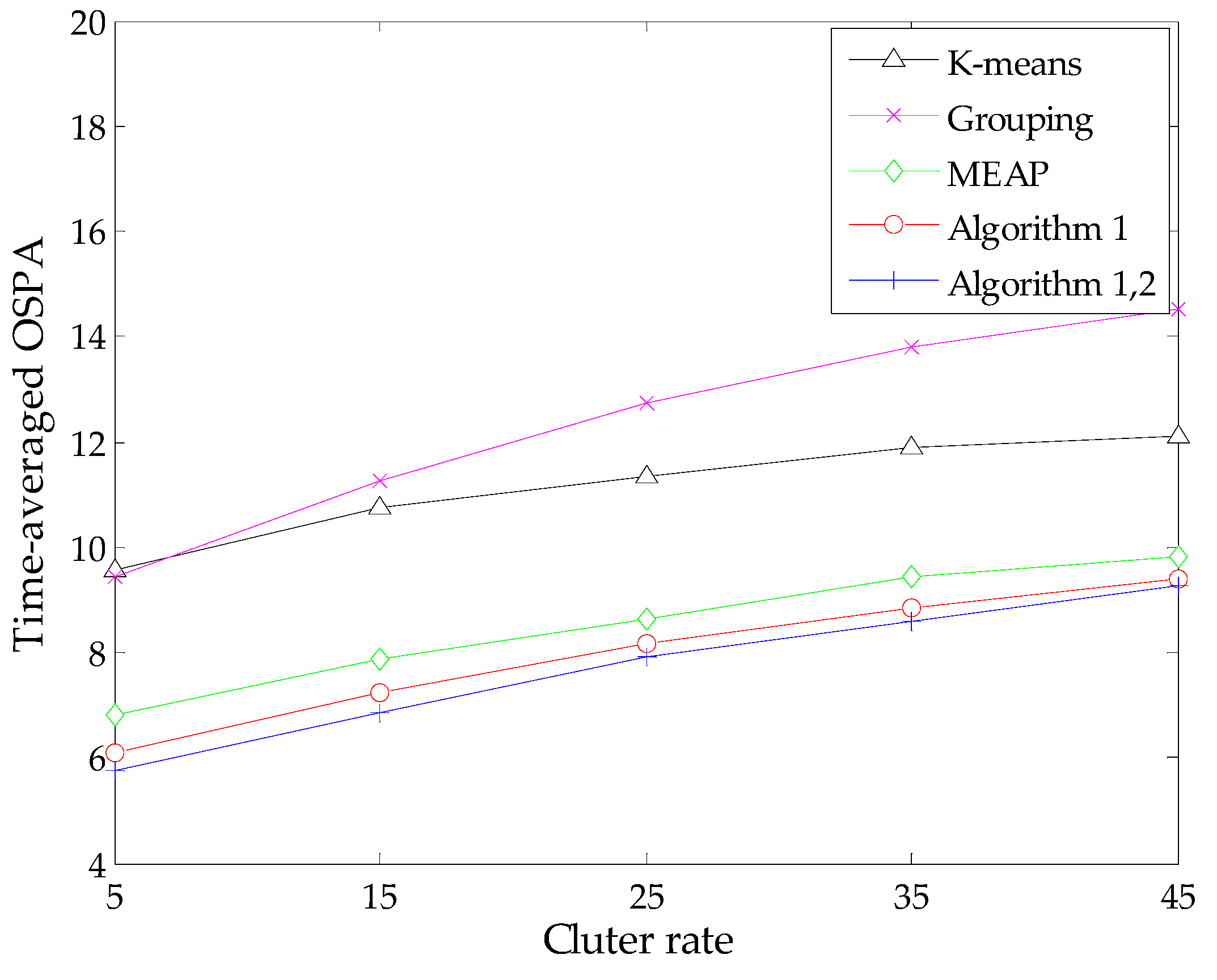
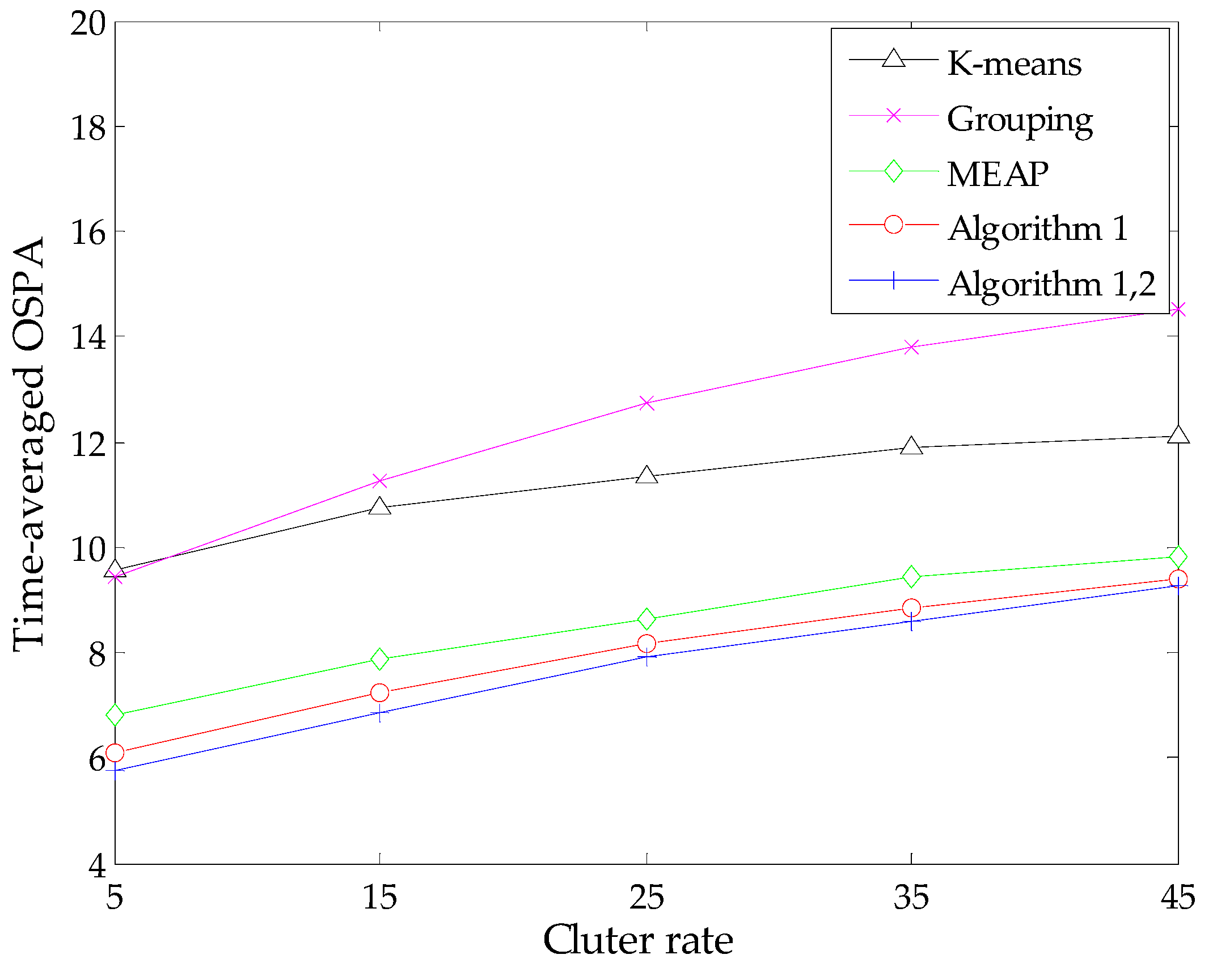
To present a more comprehensive evaluation, we also study algorithm performance against different detection probabilities via MC simulations with fixed clutter rate r = 10. In addition, similar simulations are performed against various clutter rates under the condition of a constant detection probability pD = 0.90. We compute the time-averaged OSPA distance of each method during these simulations. The results are presented in Figure 5 and Figure 6, respectively.
As expected, all methods exhibit some performance degradation under the condition of low signal-to-noise ratio. This is because the estimated number of targets given by the SMC-PHD filter becomes increasingly unreliable with an increase of detection uncertainty or the amount of clutters, which in turn has an influence on the state estimation. In addition, when the clutter rate increases, the probability that some clutter measurements appear at the regions of true targets or the birth intensities will increase correspondingly. It is possible that the contributions of these measurements are significant as those of true measurements. Therefore, the measurement-oriented methods (grouping method, MEAP method and Algorithm 1) are prone to be influenced by such clutter measurements. Obviously, the performance degradation of the grouping method is more apparent. Both the results in Figure 5 and Figure 6 demonstrate that the proposed methods yield the best performance in terms of estimation accuracy and robustness. Meanwhile, the improvement of Algorithm 2 seems limited in the case of lower detection uncertainty due to the following reasons: the SMC-PHD filter will lose tracking of targets frequently in such cases, while the estimation of undetected targets is performed under the premise that the corresponding particles exist in the state space. Thus, the improvement tends to be weakened when considering the global effect via evaluating the time-average of the OSPA metric.
5. Conclusions
This paper proposes a more practical and effective solution to the problem of extracting multi-target states from the SMC-PHD filter. Based on the proposed measurement and particle validation mechanism, the estimates of detected targets and undetected targets are extracted separately within the filter framework. For the detected targets, the estimation is achieved by partitioning particles with respect to effective measurements according to their association probabilities, which is more computationally efficient than the traditional clustering-based algorithms. For the undetected targets, we first identify the corresponding particles and then extract the estimates by exploiting clustering method. Simulation results demonstrate that the proposed method outperforms the state-of-the-art measurement-oriented methods and the popular k-means clustering method in terms of both estimation accuracy and reliability in the presence of clutter and detection uncertainty. Moreover, it is possible to extend the proposed methods to SMC implementation of the cardinalised PHD filter [12]. However, like most of the existing solutions, the proposed methods are also heuristic to some extent, and there exist empirical parameters during the implementation of our methods. In the further work, developing state extraction method with strong theoretical justification for the PHD-based filter is an important topic.
Acknowledgments
This work is supported by the Aeronautical Science Foundation of China (Grant No. 201401P6001) and Fundamental Research Funds for the Central Universities (Grant No. HEUCF160807).
Author Contributions
The main idea was proposed by Weijian Si and Liwei Wang. Zhiyu Qu performed the experiments and analyzed the simulation results. Liwei Wang wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| FMM | Finite mixture models |
| JPDA | Joint probabilistic data association |
| MEAP | Multi-expected a posterior |
| MHT | Multiple hypothesis tracking |
| MTT | Multi-target tracking |
| OSPA | Optimal Sub-pattern Assignment |
| PHD | Probability hypothesis density |
| RFS | Random finite sets |
| SMC | Sequential Monte Carlo |
References
- Shalom, Y.B.; Daum, F.; Huang, J. The probabilistic data association filter estimation in the presence of measurement uncertainty. IEEE Control Syst. Mag. 2009, 6, 82–100. [Google Scholar] [CrossRef]
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Habtemariam, B.; Tharmarasa, R.; Thayaparan, T.; Mallick, M.; Kirubarajan, T. A multiple-detection joint probabilistic data association filter. IEEE J. Sel. Top. Signal Process. 2013, 7, 461–471. [Google Scholar] [CrossRef]
- Mahler, R. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R. PHD filters of higher order in target number. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1523–1543. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled random finite sets and the Bayes multi-target tracking filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef]
- Vo, B.N.; Singh, S.; Doucet, A. Sequential Monte Carlo methods for multi-target filtering with random finite sets. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1224–1245. [Google Scholar]
- Whiteley, N.; Singh, S.; Godsill, S. Auxiliary particle implementation of probability hypothesis density filter. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 1437–1454. [Google Scholar] [CrossRef]
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Yoon, J.H.; Kim, D.Y.; Yoon, K.J. Efficient importance sampling function design for sequential Monte Carlo PHD filter. Signal Process. 2012, 92, 2315–2321. [Google Scholar] [CrossRef]
- Zhang, F.H.; Buckl, C.; Knoll, A. Multiple Vehicle Cooperative Localization with Spatial Registration Based on a Probability Hypothesis Density Filter. Sensors 2014, 14, 995–1009. [Google Scholar] [CrossRef] [PubMed]
- Ristic, B.; Clark, D.; Vo, B.N.; Vo, B.T. Adaptive target birth intensity in PHD and CPHD filters. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 1656–1668. [Google Scholar] [CrossRef]
- Battistelli, G.; Chisci, L.; Morrocchi, S.; Papi, F.; Farina, A.; Graziano, A. Robust multisensor multitarget tracker with application to passive multistatic radar tracking. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3450–3472. [Google Scholar] [CrossRef]
- Ristic, B. Efficient update of persistent particles in the SMC-PHD filter. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 4120–4124.
- Clark, D.E.; Bell, J. Multi-target state estimation and track continuity for the particle PHD filter. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1441–1452. [Google Scholar] [CrossRef]
- Dunne, D.; Tharmarasa, R.; Lang, T.; Kirubarajan, T. SMC-PHD-based multi-target tracking with reduced peak extraction. In Proceedings of the SPIE 7445, Signal and Data Processing of Small Targets, San Diego, CA, USA, 4–6 August 2009.
- Liu, W.F.; Han, C.Z.; Lian, F.; Zhu, H.Y. Multitarget state extraction for the PHD filter using MCMC approach. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 864–883. [Google Scholar] [CrossRef]
- Tobias, M.; Lanterman, A.D. Techniques for birth-particle placement in the probability hypothesis density particle filter applied to passive radar. IET Radar Sonar Navig. 2008, 2, 351–365. [Google Scholar] [CrossRef]
- Tang, X.; Wei, P. Multi-target state extraction for the particle probability hypothesis density filter. IET Radar Sonar Navig. 2011, 5, 877–883. [Google Scholar] [CrossRef]
- Ristic, B.; Clark, D.; Vo, B.N. Improved SMC implementation of the PHD filter. In Proceedings of the 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 1–8.
- Lin, L.K.; Xu, H.; Sheng, W.D.; Wei, A. Multi-target state-estimation technique for the particle probability hypothesis density filter. Sci. China Inform. Sci. 2012, 55, 2318–2328. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Baum, M.; Willett, P.; Hanebeck, U.D. MMOSPA-based track extraction in the PHD filter-a justification for k-means clustering. In Proceedings of the 53th IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 1816–1821.
- Li, T.C.; Sun, S.D.; Bolić, M.; Corchado, J.M. Algorithm design for parallel implementation of the SMC-PHD filter. Signal Process. 2016, 119, 115–127. [Google Scholar] [CrossRef]
- Pierre, D.M.; Houssineau, J. Particle Association Measures and Multiple Target Tracking. In Theoretical Aspects of Spatial-Temporal Modeling; Peters, G.W., Matsui, T., Eds.; Springer: Tokyo, Japan, 2015; pp. 1–30. [Google Scholar]
- Erdinc, O.; Willett, P.; Bar-Shalom, Y. The bin-occupancy filter and its connection to the PHD filters. IEEE Trans. Signal Process. 2009, 57, 4232–4246. [Google Scholar] [CrossRef]
- Blackrnan, S.; House, A. Design and Analysis of Modern Tracking Systems; Artech House: Boston, MA, USA, 1999; pp. 336–337. [Google Scholar]
Figure 1.
True target tracks in xy-plane, the start points for each track are denoted by •.
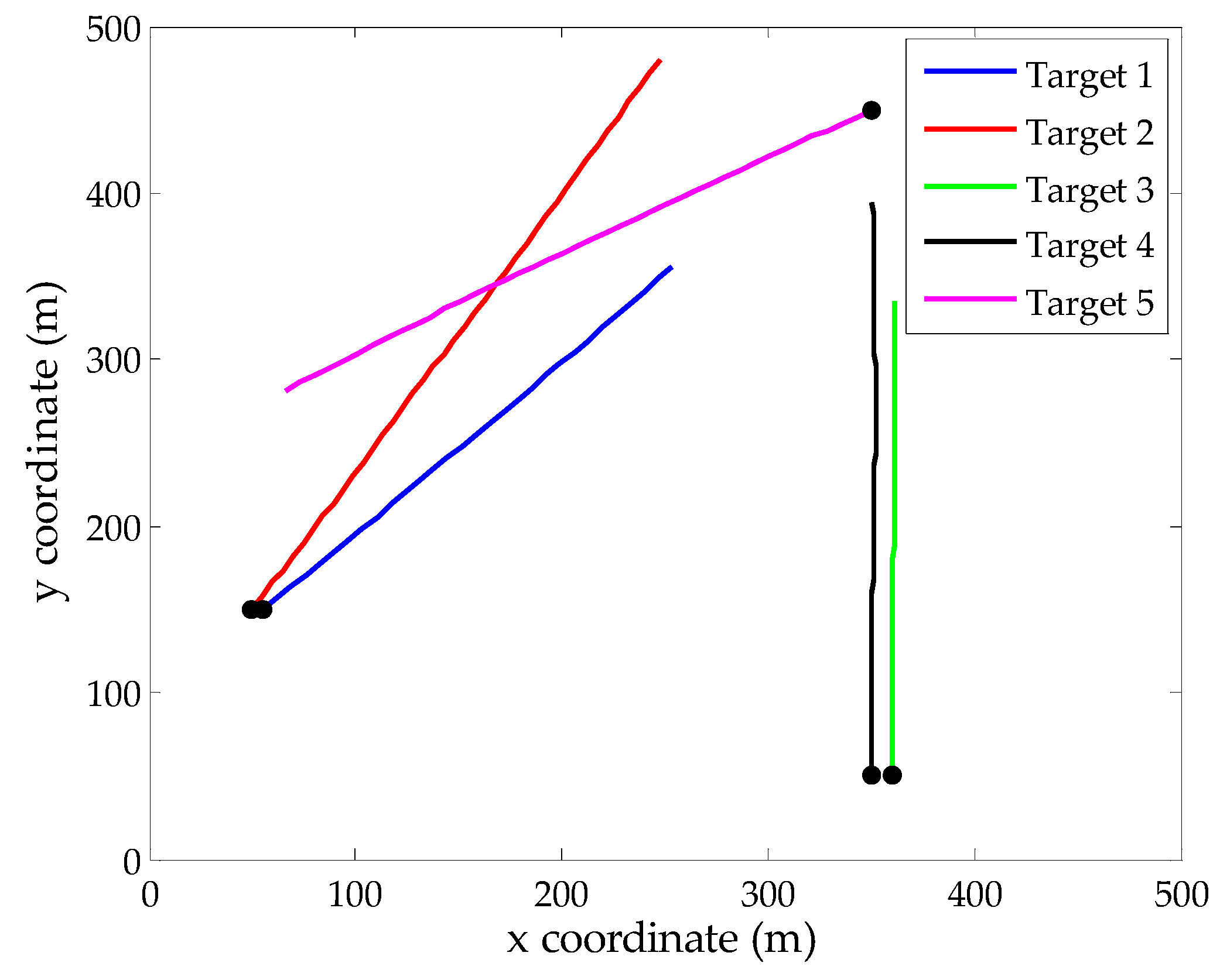
Figure 2.
The output of the SMC-PHD filter at time step 35.
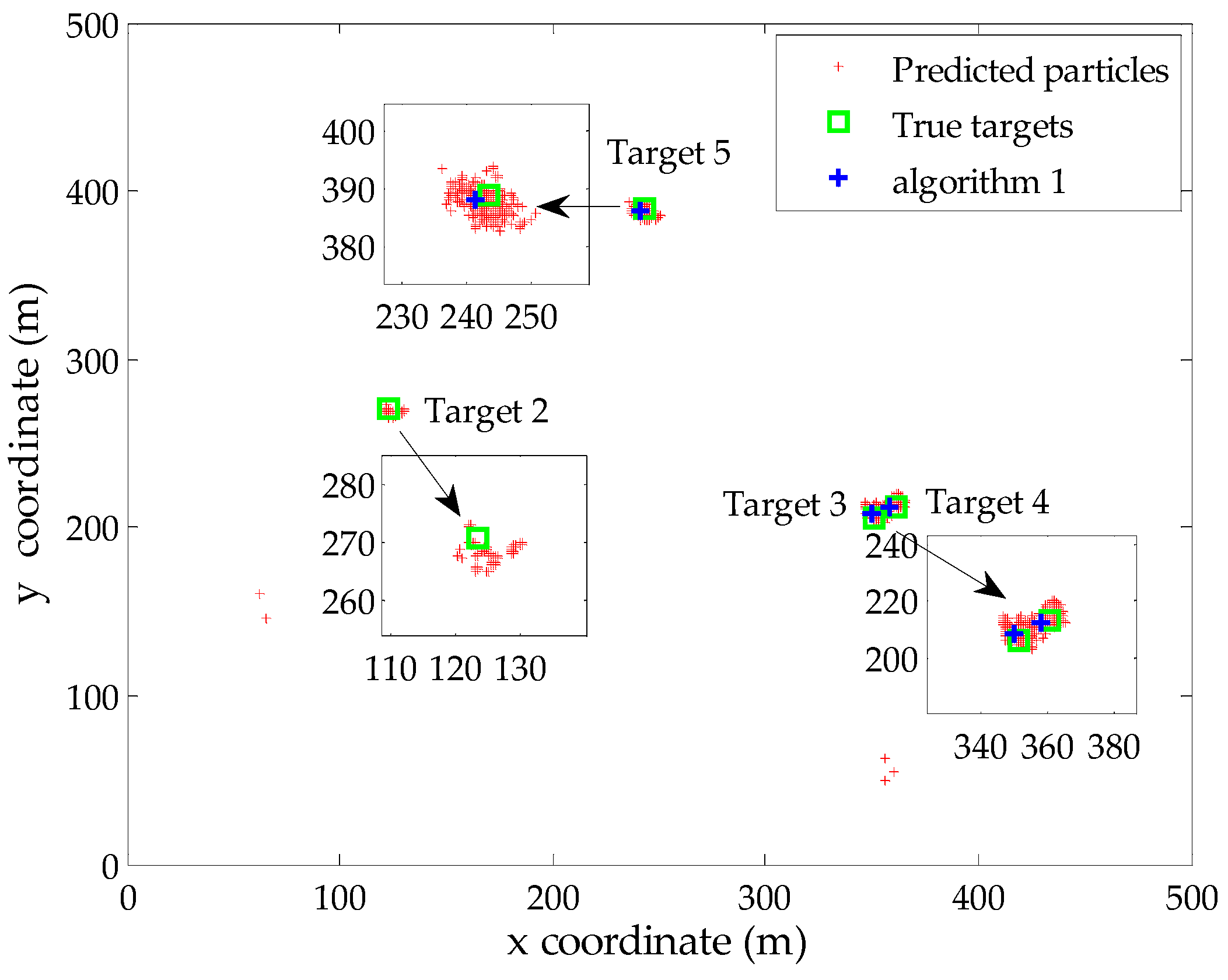
Figure 3.
The modified estimate result and selected particles corresponding to undetected target.
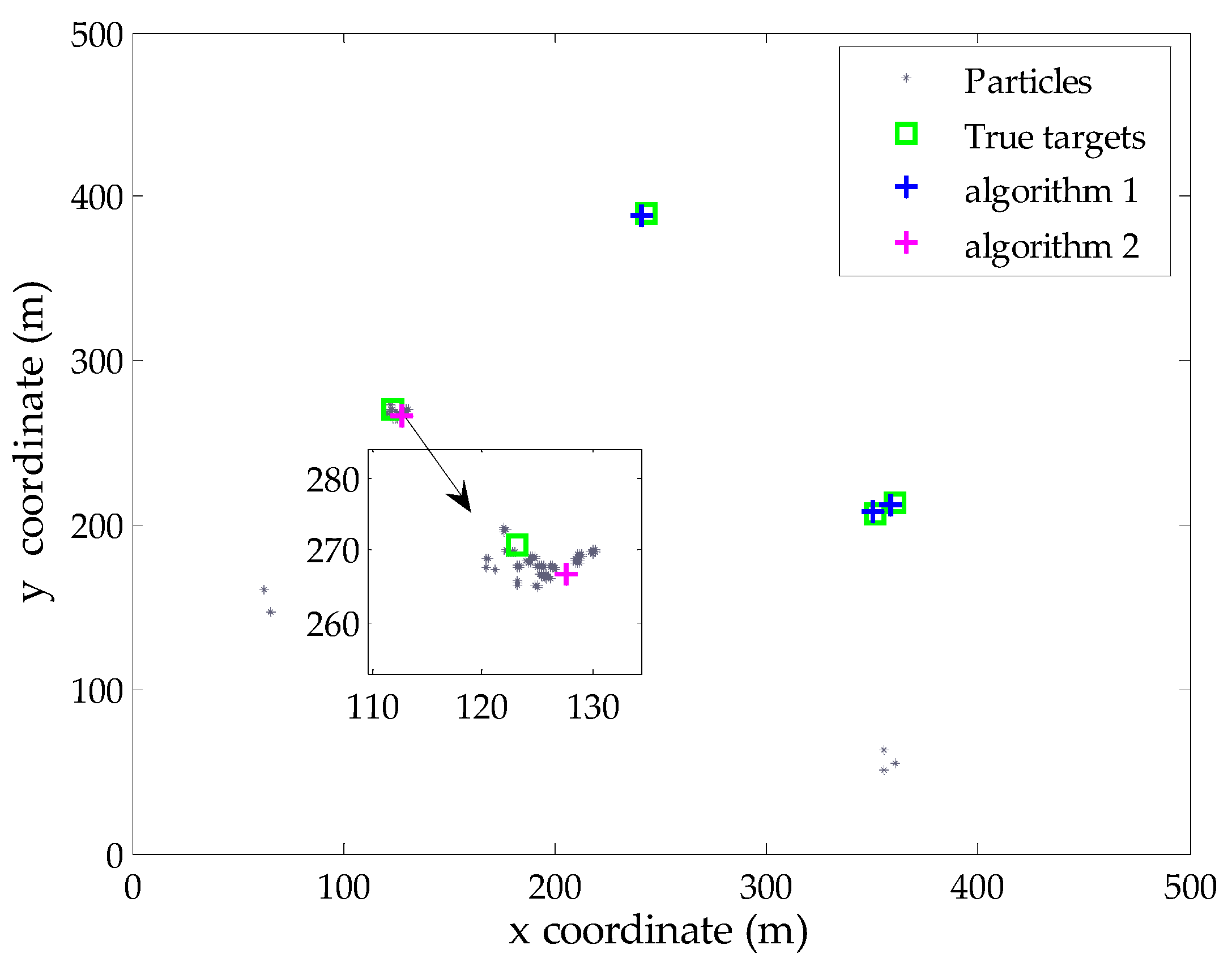
Figure 4.
Target number estimate and mean OSPA distance versus time (): (a) Target number estimate versus time; (b) Mean OSPA distance versus time.
Figure 4.
Target number estimate and mean OSPA distance versus time (): (a) Target number estimate versus time; (b) Mean OSPA distance versus time.
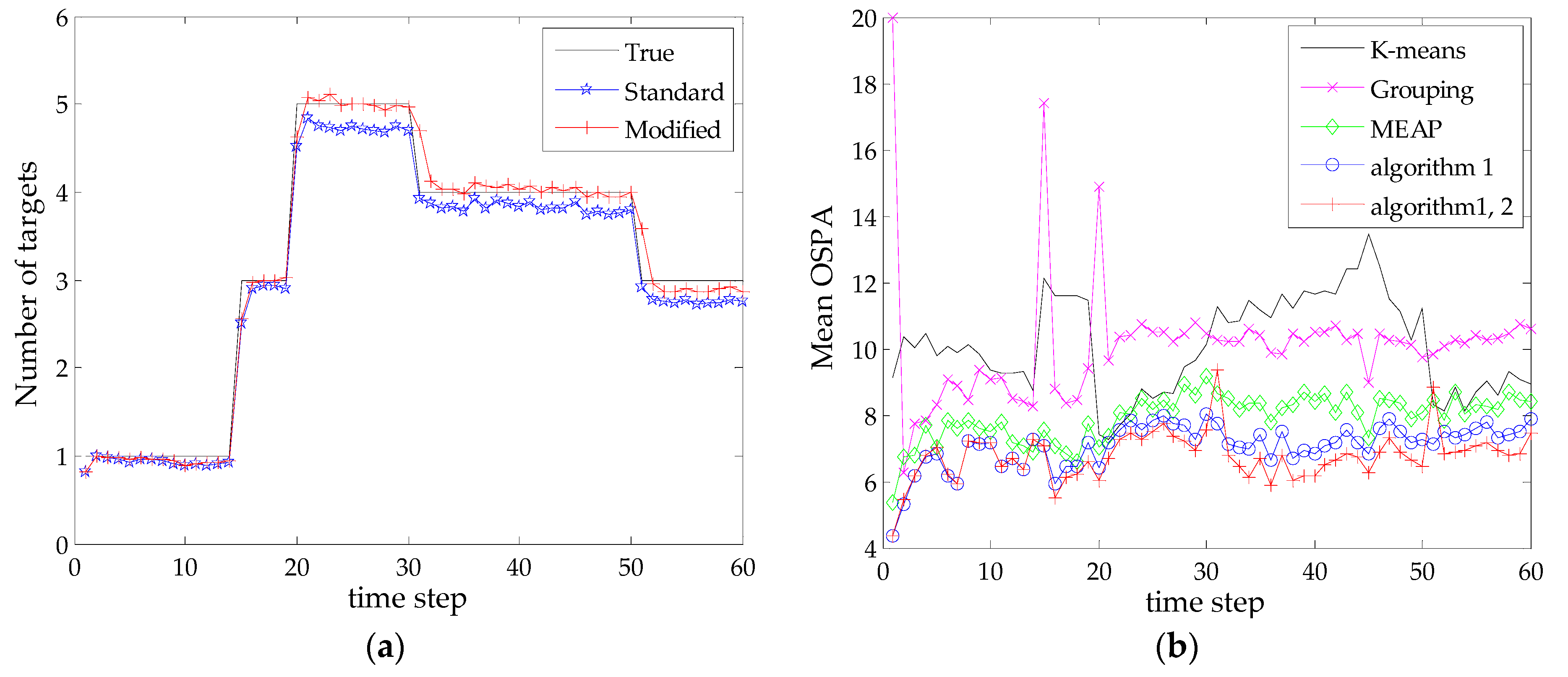
Figure 5.
Time-averaged OSPA distance versus detection probability ().

Figure 6.
Time-averaged OSPA distance versus clutter rate (pD = 0.90).
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Si, W.; Wang, L.; Qu, Z. Multi-Target State Extraction for the SMC-PHD Filter. Sensors 2016, 16, 901. https://doi.org/10.3390/s16060901
AMA Style
Si W, Wang L, Qu Z. Multi-Target State Extraction for the SMC-PHD Filter. Sensors. 2016; 16(6):901. https://doi.org/10.3390/s16060901
Chicago/Turabian StyleSi, Weijian, Liwei Wang, and Zhiyu Qu. 2016. "Multi-Target State Extraction for the SMC-PHD Filter" Sensors 16, no. 6: 901. https://doi.org/10.3390/s16060901
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.