1. Introduction
With the advancement of wireless sensor network (WSNs) and RFID technologies, the demands for indoor location information have promoted the extensive study of indoor localization methods over the past few years [
1]. There are increasing requirements of location-based services (LBS) in practical applications, such as indoor navigation systems, location-based social networks, indoor robot and healthcare [
2]. The reliability of the location accuracy is a major concern when providing the location information. Additionally, the target position can be obtained via range-based measurement, such as time-of-arrival (TOA), time-difference-of-arrival (TDOA) and received signal strength (RSS), by using WSNs or RFID. In a dynamic high noise environment, the multi-path and non-line-of-sight (NLOS) effects cause high interference during the signal transmission, and the range measurement contains high error. In this case, the PF is a promising estimation method in the nonlinear non-Gaussian environment due to its high accuracy and is widely applied in the indoor localization systems.
A particle filter (PF), which is a typical Bayesian estimation method, has drawn much attention in the fields of state estimation and signal processing for many years [
3]. Many applications employ the PF to process the collected data, such as target tracking [
4,
5] and localization systems [
6]. Based on Bayes’ theorem, PFs generate random samples, which are called particles with associated weights to represent the posterior PDF of the state. The associate weights are proportional to the prior PDF and the likelihoods and updated recursively.
However, the estimation accuracy of the PF can also be degraded due to the range measurement uncertainty. A traditional way is to generate high quality particles, since the PF is introduced to the localization problem [
7]. The bootstrap particle filter (BPF) is applied to generate and re-sample the particles during the recursive position estimation [
6]. Farahmand
et al. proposed a set-membership constraint particle filter (CPF) to select particles within the constrains [
8,
9]. Kwok
et al. introduce an adaptable sampling method based on the Kullback–Leibler divergence (KLD) [
10]. The Gaussian particle filter (GPF) generates the particles according to the Gaussian distributions and also approximates the estimated distribution as the Gaussian distributions [
11]. The accuracy of the GPF is widely evaluated in RFID and WSN-based indoor tracking [
12,
13]. Ristic
et al. proposed probability hypothesis density (PHD) and cardinalised PHD (CPHD) filters for target tracking [
14]. The other solution is to use an efficient wireless model to overcome the NLOS and multipath effects. The NLOS channel is believed to introduce additional bias error rather than the LOS ranging error. Thus, NLOS path identification and bias reduction methods are widely applied in the PF designs. Jung
et al. identify the NLOS path for the TOA ranging and use PFs to estimate the target according to the biased error model [
15]. Youssef
et al. provide the biased model of the RSS NLOS ranging error [
16]. In addition, the map information can also help to indicate the NLOS path [
17]. The problem is that the NLOS error cannot be simply modeled as an LOS error model plus a bias. A typical error model is required for the NLOS channel. The Markov state-space model for NLOS error is usually introduced into the PF-based indoor localization. Nicoli
et al. developed a recursive Bayesian estimator that combines the Markov transition model and the NLOS propagation in the indoor environment [
18]. Wang
et al. introduce the NLOS error model to the Markov model of the PF based on 802.15.4a [
19]. Papa
et al. proposed adaptive Bayesian methods to track the target using a sensor network [
20]. In addition, more information is employed to reduce the measurement error. The hybrid information of TOA and RSS is exploited for likelihood calculation in [
21]. Further, the combination of TOA/RSS with NLOS and the multipath mitigation method is introduced in [
22]. Bargshady
et al. also use the PF to process the hybrid WiFi and ultra wideband (UWB) measurements to reduce the NLOS effect [
23].
The PF achieves high estimation accuracy by using the prior probability and likelihood based on the Bayesian method. The likelihood relies on the measurement error distribution. However, there is no exact distribution to represent the measurement noise in the complicated indoor environment. Even if the distribution fitting or wireless propagation modeling methods can derive the model parameters, these parameters should be reset when the environment is changed, such as an infrastructure change or the target moves to another area. Thus, the indoor measurement noise shows nonparametric features [
24], which requires that the PF is robust to the unknown error models. In this paper, we propose a novel method to design the PF in order to achieve more accurate estimation in a complicated environment. We firstly analyze the measurement uncertainty for the likelihood function (LF) in the PF. The LF, which relies on the measurement and noise distribution, has a large proportion in determining the particle weights. Since the error model is unknown to the LF calculation, the posterior PDF of the state estimation is unreliable. We divide the measurement error model into two parts: the pre-assumed distribution and the unknown model, and use a dynamic Gaussian model (DGM) to comprehensively describe both parts [
25]. The DGM assumes that the real-time measurement error follows the pre-assumed distribution, which is dynamically deviated by the instantaneous unknown error. Then, the likelihood function (LF) in the PF, which relies on the measurement function and noise distribution, is calculated based on the DGM.
Our goal is to reduce the instantaneous unknown noise in LF according to our analysis, and the major contributions of our work are four-fold: (1) We propose a likelihood adaptation method, which is based on the DGM. The method combines the prior information and a tuning parameter to reduce the instantaneous unknown error: the prior information is the predicted measurement based on the predicted state; and the belief factor is the tuning parameter, which adapts the likelihood function to a more accurate one. By tuning , the impact of unknown error for likelihood calculation is reduced; (2) In order to obtain the optimal performance, we use the Kullback–Leibler divergence (KLD), which is an efficient metric to compare two distributions, to derive the optimal . The optimal can achieve the minimum KLD and attain the lowest estimation error of the PF; (3) We formulate the optimal performance of the adaptive method by using the Cramér–Rao lower bound (CRLB) analysis. The analytical results indicate that our method outperforms the conventional PF for the nonparametric measurement error models; (4) Three versions of PFs are improved based on our adaptation method, which are the BPF, the GPF and the CPF. The improved PFs are evaluated in the simulations and the real-world WSN indoor localization experiments. The results demonstrate that the proposed algorithms effectively reduce the estimation error and have robust performance in a high noisy wireless environment.
The rest of the paper is organized as follows:
Section 2 analyzes the measurement uncertainty effect of the likelihood function in the PF algorithms.
Section 3 describes a dynamic Gaussian modeling method for the uncertainty and outlier measurement errors.
Section 4 proposes the likelihood adaptation method, and the adaptive PFs are designed in
Section 5. The theoretical analysis based on CRLB is described in
Section 6.
Section 7 presents the simulation and real experiment results of adaptive PFs in the indoor localization systems. Finally,
Section 8 concludes this paper.
3. Dynamic Gaussian Model
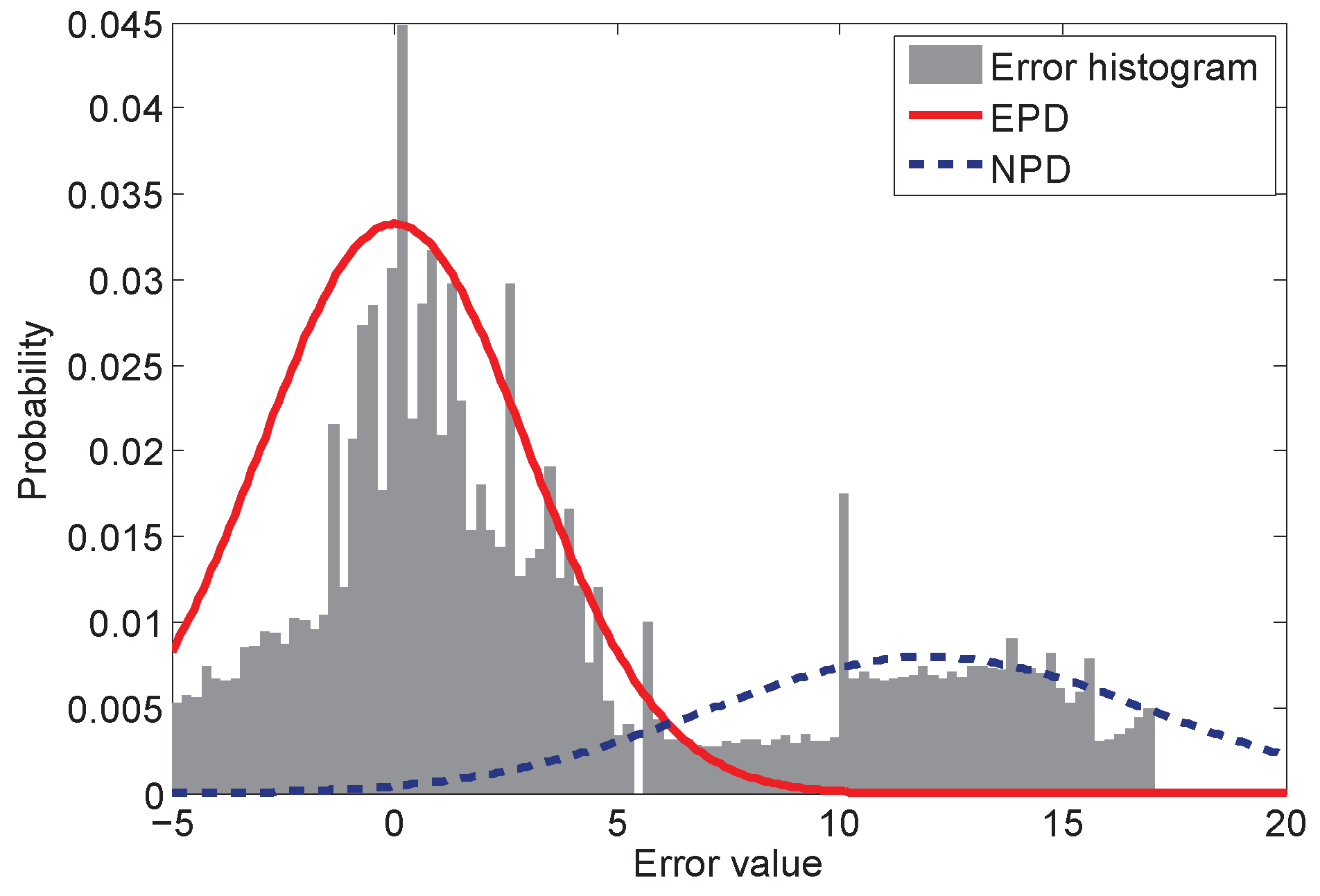
To address the measurement uncertainty problem and to make the PF robust to environmental change, we firstly introduce a dynamic Gaussian model (DGM) to the likelihood calculation. The main idea of the DGM is to classify the measurement error distribution into two parts: the first part is the expected parametric distribution (EPD), which is a pre-assumed distribution and known to the system. The EPD is obtained based on the knowledge or experiences of the system design, and the parameters can be attained via the system model or some pre-assumptions. The most popular EPD is the normal distribution. The second part is the non-parametric distribution (NPD), which is unknown to the system and for which it is hard to get the parameters. The conventional PFs only use EPD as the pre-assumed distribution model for estimation. The NPD is the compensation for the EPD when the PFs are in the dynamic environment without the knowledge of the noise model. The histogram of the EPD and the NPD is depicted in
Figure 1. In
Figure 1, the error value between −5 and 5 can mainly be modeled as the normal distribution, which is the EPD and denoted by the solid curve. For the outlier values, another Gaussian distribution NPD attempts to cover such values, which is depicted by the dashed curve.
The DGM is the drifted EPD, which is deviated by the instantaneous NPD value. Here, we use , where is the EPD error and is the NPD error. Then, follows the EPD, but deviated by . The DGM is different from the Gaussian mixture model. The Gaussian mixture model uses different Gaussian distributions to fit the non-Gaussian distributions. The results are still a static distribution model. However, DGM is dynamic and does not attempt to fit the error histogram, because the NPD part is not an exact model to fit the outlier values. It is rather a fuzzy function to cover such values. In addition, the Gaussian mixture model is a parametric model for the entirety of the error samples, and the DGM only contains a single instantaneous value of the NPD instead of the entirety of the data samples. In general, if , follows the EPD. However, for a typical measurement, consists of a drift value that deviates from the pre-assumed normal distribution to a certain distance. Then, the EPD should be adapted dynamically according to the instantaneous value of the NPD.
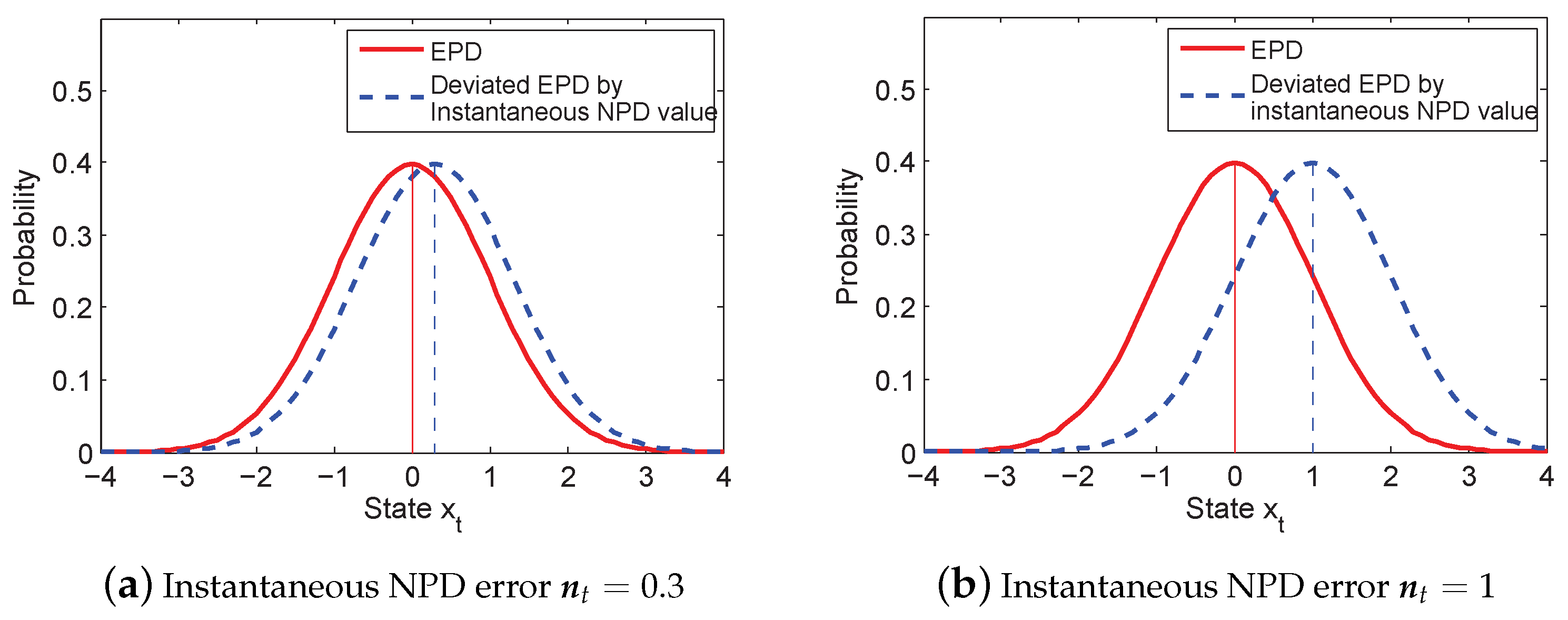
The DGM for a typical NPD error is depicted in
Figure 2. In
Figure 2, the solid curve represents the EPD, which is a zero mean normal distribution. When the instantaneous value of the NPD is introduced into the measurement noise, the EPD is deviated. Then, we obtain the likelihood calculation:
where an unpredictable instantaneous noise
is introduced into the likelihood function.
Equation (9) is illustrated as the dashed curve in
Figure 2, which is a biased non-zero mean Gaussian distribution. It is deviated from the original assumption due to considering the instantaneous value,
. If
is zero, the likelihood function
is the exact EPD of measurement noise:
where
represents the actual assumed probability; then, we would have optimal filtering with the increasing number of particles. However, in most real cases,
is not zero, and
is deviated by
in Equation (10), which leads to inaccurate estimation. When
becomes larger, the gap between the two curves is increasing, as shown in
Figure 2b, which degrades the estimation accuracy significantly. Therefore, our goal is to develop an adaptation method to mitigate
and approach the likelihood calculation of the exact assumed distribution.
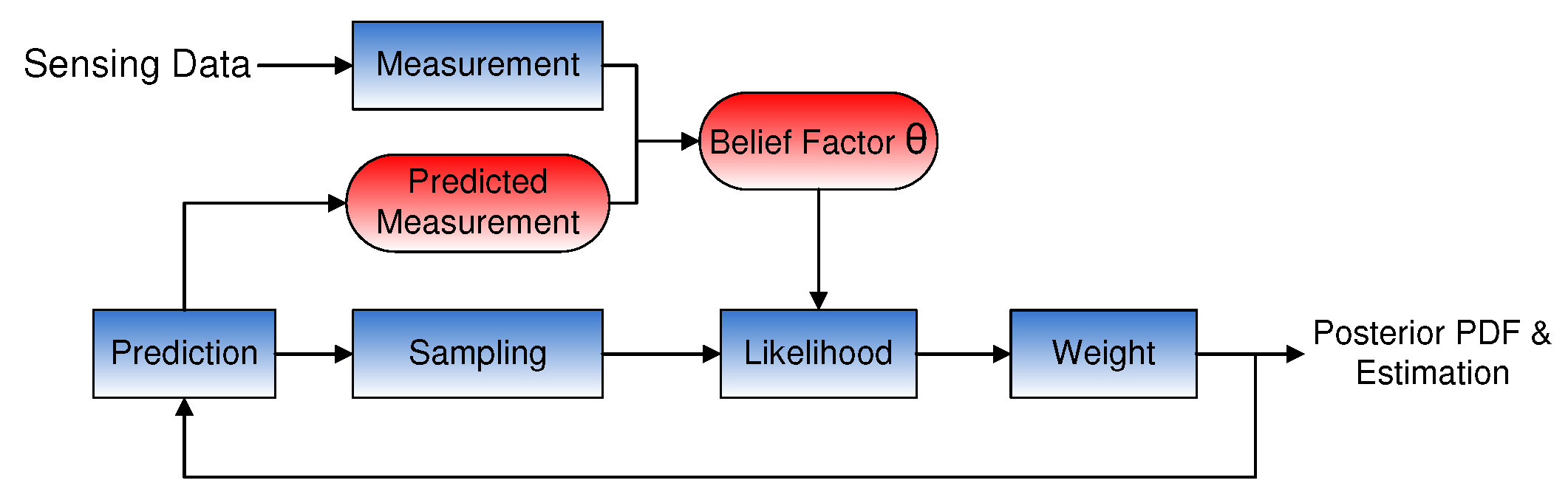
4. Likelihood Adaptation
We attempt to reduce the impact of the NPD and calculate the LF
based on the DGM in order to improve the estimation accuracy. Our adaptation method consists of two steps: the first step is to obtain a predicted measurement
according to the previous state; the second step is to adapt the LF based on
and a belief factor
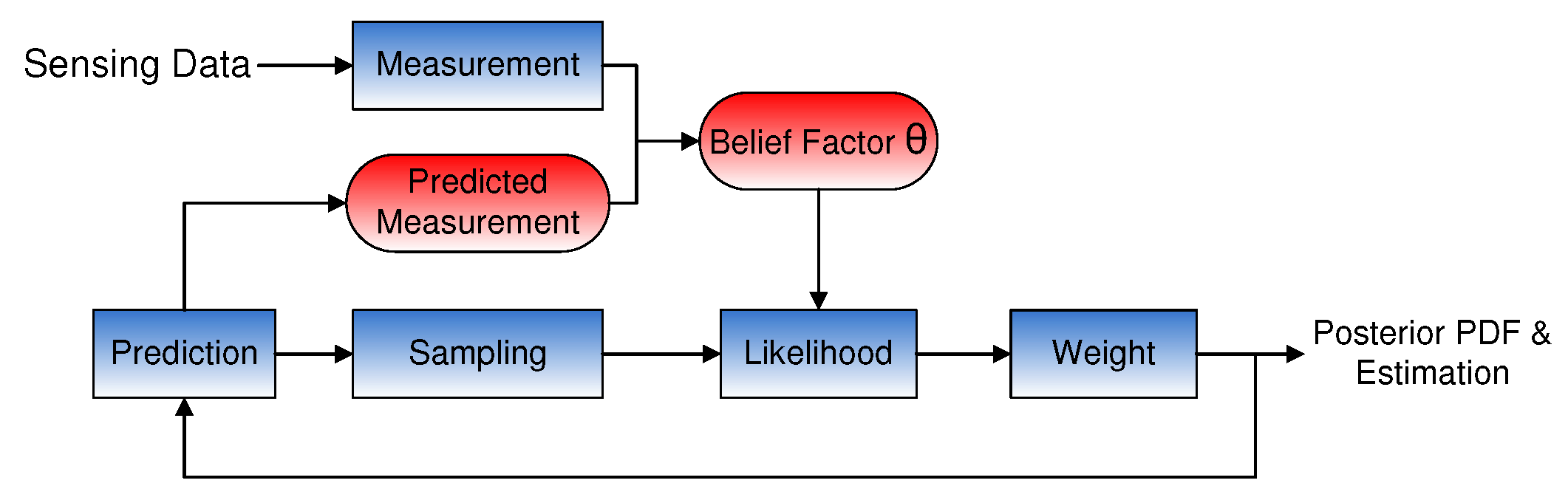
, which is a tuning parameter for adaptation. The structure of the adaptive PF, which integrates with the predicted measurement and
, is illustrated in
Figure 3. In the original PF, the LF is determined by the EPD, whereas in our algorithm, the likelihood calculation is based on the DGM. Belief factor
is used to adapt the value between
and
.
4.1. Predicted Measurement
The predicted measurement is derived based on the prediction state and is the reference for the real measurement. The calculation steps are as follows:
denotes the prediction value of
:
where
is the estimation at previous time
. When considering the processing noise
, we denote
as:
where
is assumed to be the additive noise and follows normal distribution
;
is the covariance at time
t. Then, we obtain a predicted measurement for: sensors:
in which
indicates the prediction of measurement derived from
. The predicted measurement
is not the actual measurement, but is used as prior information for measurement likelihood adaptation.
4.2. Belief Factor and Measurement Adaptation
Belief factor
is the tuning parameter for
, and it is used to adapt the measurement
to reduce
. Note that our goal is to achieve Equation (10). Since Equation (10) can not be achieved directly, we use
and
to approach Equation (10) with
. Then, the adaptive likelihood function
is constructed as:
where
indicates the adaptive likelihood,
is the measurement vector,
is the predicted measurement and
. The notation ⊙ in Equation (14) is the Hadamard operator, which is used to expressed as
, and
is the vector of ones whose size corresponds to that of
. Note that
, which should be interpreted as the elements in
, are non-negative. The belief factor
indicates how much trust
assigns to the
. If
,
, which equals the measurement likelihood; whereas when
,
, which only trusts the predicted measurement.
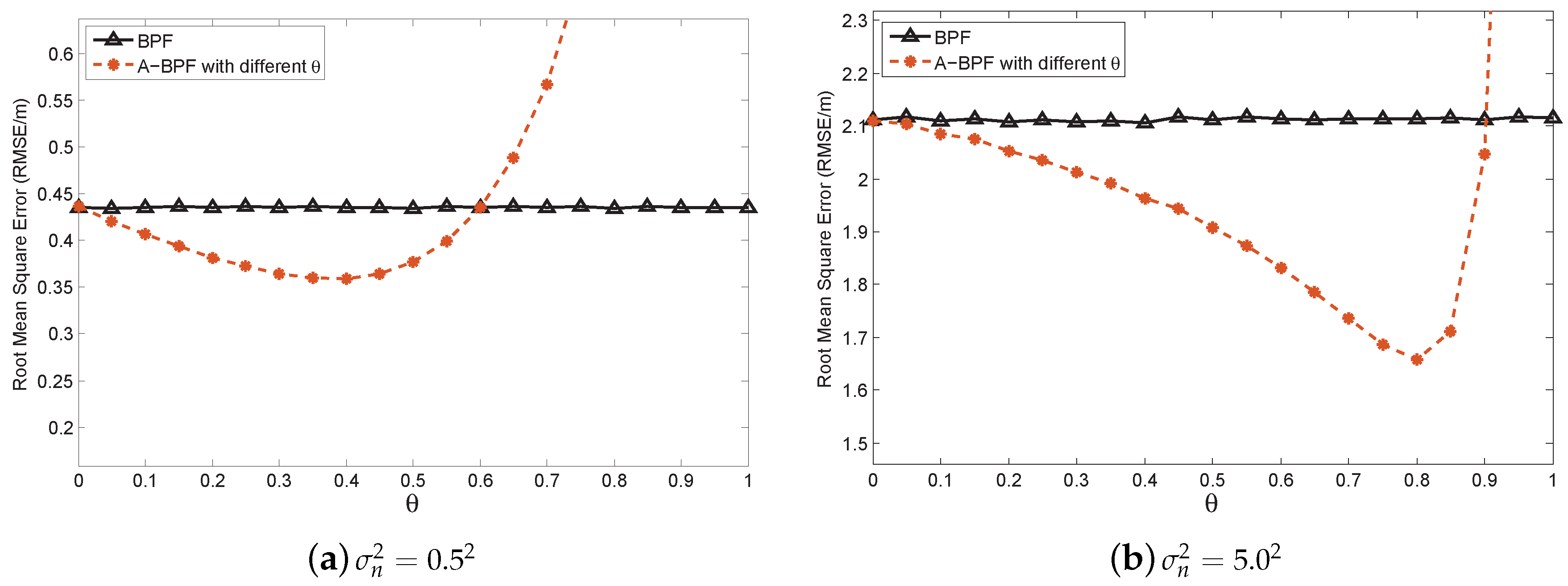
Here, two problems remains: (1) with introducing , the measurement error in is suppressed, but the error of is involved, which raises a question: in what condition can our method reduce ? (2) If our method can reduce this effect, a proper is required. Therefore, is there an optimal that can achieve the best performance?
4.3. Optimal Belief Factor and Likelihood Estimation
Since we intend to compare our adapted DGM to the EPD, the effective evaluation method is KLD [
31]. KLD, which also is denoted as relative entropy, quantifies the difference between two distributions. If
and
indicate two different distributions, KLD is formulated as:
where
denotes the KLD. The KLD is a non-negative distance between two different distributions, which is
. It can be shown that
. Additionally, small
indicates that
is similar to
. In addition, KLD is a convex function [
32].
We employ the KLD as a metric to find optimal
, which minimizes the distance between
and
. Here, we use
as the objective distribution and employ
as the tuning distribution with parameter
. Then, the KLD function is constructed as:
Then, optimal
is attained with minimum
:
If
and
are based on the same Gaussian distribution function, then Equation (16) is expressed as [
33]:
where
is the covariance of
. Since
is independent of
, the objective function is simplified as:
which turns out to be a least-squares approximation problem [
34]. Since
is the nonlinear functions of the prediction noise
according to Equation (13), it is difficult to obtain an analytical optimal result. Besides, the computational complexity is increased accordingly to obtain an optimal solution. Thus, linearizing the object function is preferred. We use first order Taylor series expansion at
to linearize Equation (13):
where
is the partial differential of
with respect to
. Additionally, substitute Equation (20) and Equations (2) into (19); we obtain:
Therefore, the problem is converted into a linear optimization problem, which is solvable analytically by expressing the objective as the convex quadratic function [
34]:
where
is the covariance of
and
is the covariance of
based on the assumed NPD model.
Then, the optimal
can be obtained if and only if:
Then, the unique
is derived:
Since is the belief factor for the predicted measurement, Equation (24) indicates that when NPD error is high with a large , offers more contribution than the noisy measurement. In other words, when the prediction covariance is larger than , our method should assign more belief to . In this case, is useless and can introduce more estimation error. Thus, when the measurement error is quite small and the prediction error exceeds the measurement error, using our method will introduce extra estimation error. Then, the conventional methods can outperform our algorithms. This means that our method is useful when the measurement uncertainty is higher than the predicted state uncertainty, and the optimal exists. Fortunately, in the indoor wireless tracking system, the measurement uncertainty and outlier values are always high. In addition, if the measurement noise is low, the prediction error is also small, due to the performance of the Bayesian filtering estimation. Therefore, our method can effectively improve the estimation accuracy in the noisy environment.
5. Adaptive Particle Filter
According to the architecture in
Figure 3, we integrate our adaptation method with three main PFs, which are BPF, GPF and CPF, and design new PF versions: adaptive BPF (A-BPF), adaptive GPF (A-GPF) and adaptive CPF (A-CPF).
5.1. Adaptive Bootstrap Particle Filter
In A-BPF, the prediction state
is obtained through:
where the previous state
is calculated based on:
. Then, we obtain the predicted measurement
according to Equation (13).
When the measurement is available, the adapted measurement likelihood for each particle is calculated as Equation (14). Additionally, then, the particle weight is calculated and normalized as , which determines the posterior PDF of the estimated state . Finally, is attained: . The importance sampling and resampling parts are still the same, and the predicted measurement and optimal is easy to obtain based on the analytical formulation. Therefore, our likelihood adaptation does not introduce much computational complexity to the original PFs. The algorithm of A-BPF is presented in Algorithm 1. Our adaptation method is implemented in the importance sampling part and the weight adaptation part of PF.
5.2. Adaptive Gaussian Particle Filter
The GPF approximates the estimated PDF by Gaussian distributions using the PF method. The GPF assumes that PDF of the state follows a Gaussian distribution, and it samples particles according to the estimated PDF [
11]. Therefore, only the mean and covariance of the estimated PDF are calculated and propagated. Due to the simplicity, the GPF is widely used in distributed PF applications [
12].
Particles are drawn from the Gaussian distribution functions,
, where
is the mean value of estimated state and
is the covariance of PDF. The Gaussian PDF evolves according to the transition model:
. Thus, the covariance is assumed to propagate to the next time step, which is
. Then, the initial weight for each particle is calculated as:
When the measurements are available, the weight for each particle updates:
where
is the likelihood.
| Algorithm 1 Adaptive bootstrap particle filter (A-BPF). |
Prediction: ; Prior Measurement: ; //Importance Sampling Draw: ; //Measurement Adaptation for particle do Likelihood: ; Weight: ; end for Normalizing: ; Resampling: ; State Estimation ;
|
In the A-GPF, the LF fuses both the prior information and current data based on the DGM. The optimal is derived based on the previous estimated and current NPD covariance . Thus, calculating the optimal is a recursive procedure in A-GPF. The procedure of A-GPF is illustrated in Algorithm 2.
| Algorithm 2 Adaptive Gaussian particle filter (A-GPF). |
Prediction: Calculate based on Equation (13) Randomly Draw: for particle do Likelihood: ; Weight: ; Gaussian Distribution Estimation: Mean: Covariance: end for
|
The difference between A-BPF and A-GPF is: the prediction error in A-BPF follows an arbitrary assumed distribution, whereas A-GPF uses the Gaussian distribution to indicate such a distribution. The assumed distribution in A-BPF is obtained based on the statistical analysis, and the estimation of A-BPF can be accurate if the assumed distribution is correct.
5.3. Adaptive Constraint Particle Filter
The CPF randomly samples particles not only based on both the assumed distribution and some constraint conditions, e.g.,
, where
is the constraint functions [
9]. The constraint conditions guarantee the particle generated in the target region with a very high probability by allocating a higher previous weight. In this case, both the previous weight and adaptive parameters are maintained during the estimation, where the complexity is still high. Thus, we use the constraint conditions only to sample the particles, and the weights are calculated according to the adaptive likelihoods. Then, the complexity of A-CPF is reduced.
The constraint conditions can be set up according to different applications. We will detail the conditions for the range-based target tracking in the next section. After sampling the particles, the prediction is obtained based on the prediction function. Then, our adaptation method is used, and the weight calculation follows the same procedure as A-BPF, which is illustrated in Algorithm 3. The major difference between A-BPF and A-CPF is the additional constrains for particles, which can improve the performance of BPF with additional information.
| Algorithm 3 Adaptive constraint particle filter (A-CPF). |
Constraint Sampling: Prediction: Calculate based on Equation (13) for particle do Likelihood: ; Weight: ; Normalizing: ; Resampling: ; end for
|
5.4. Performance Comparison
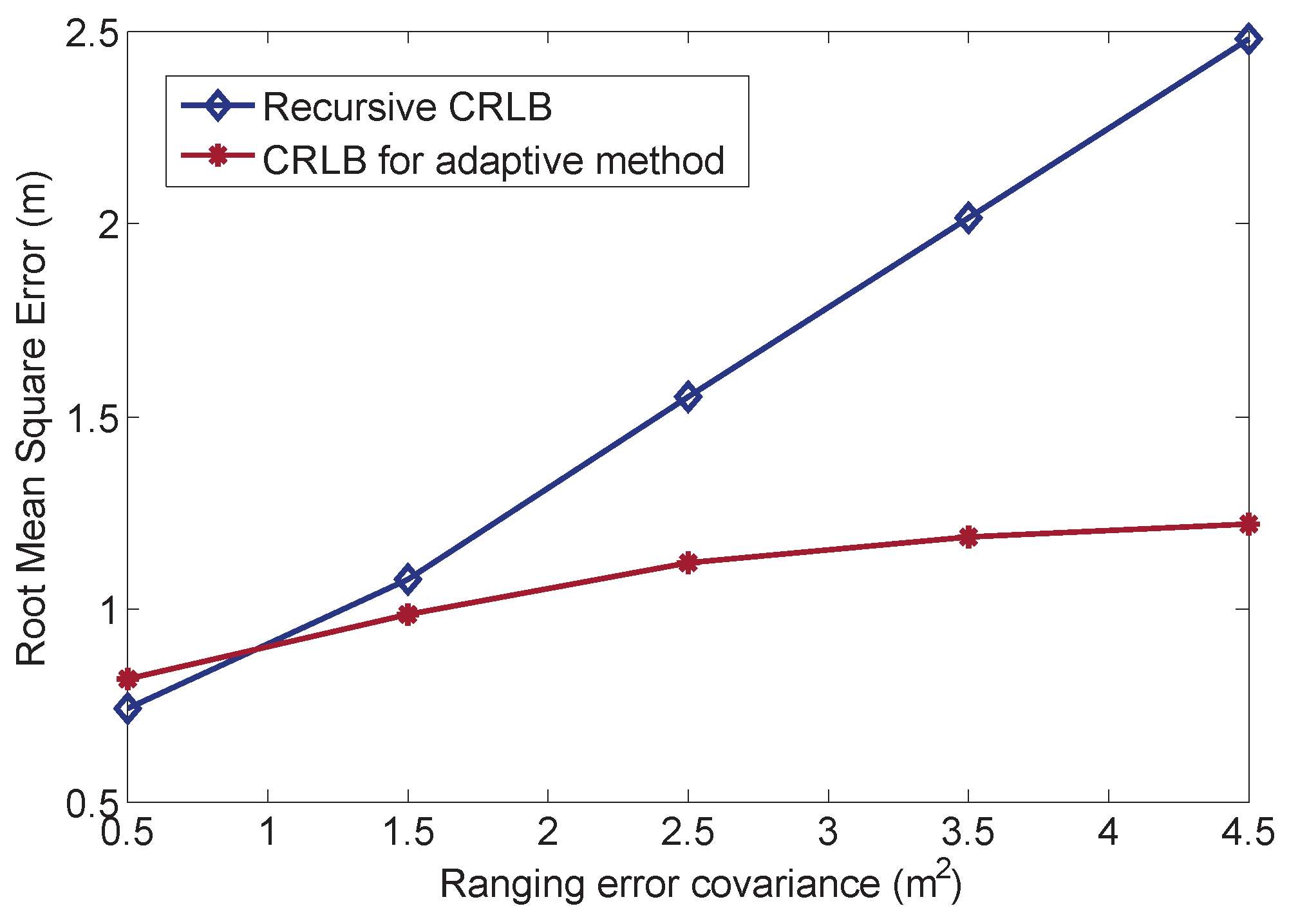
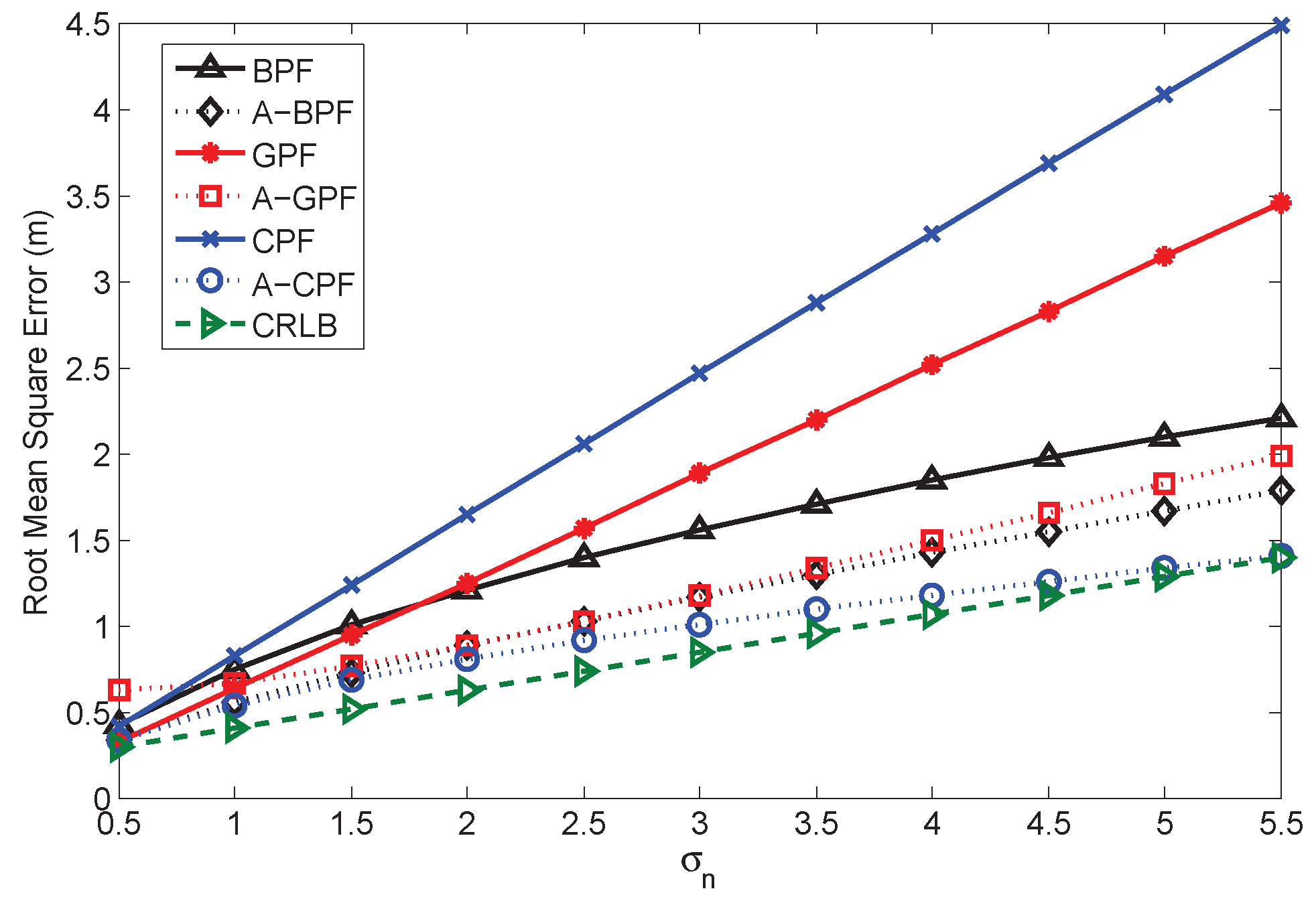
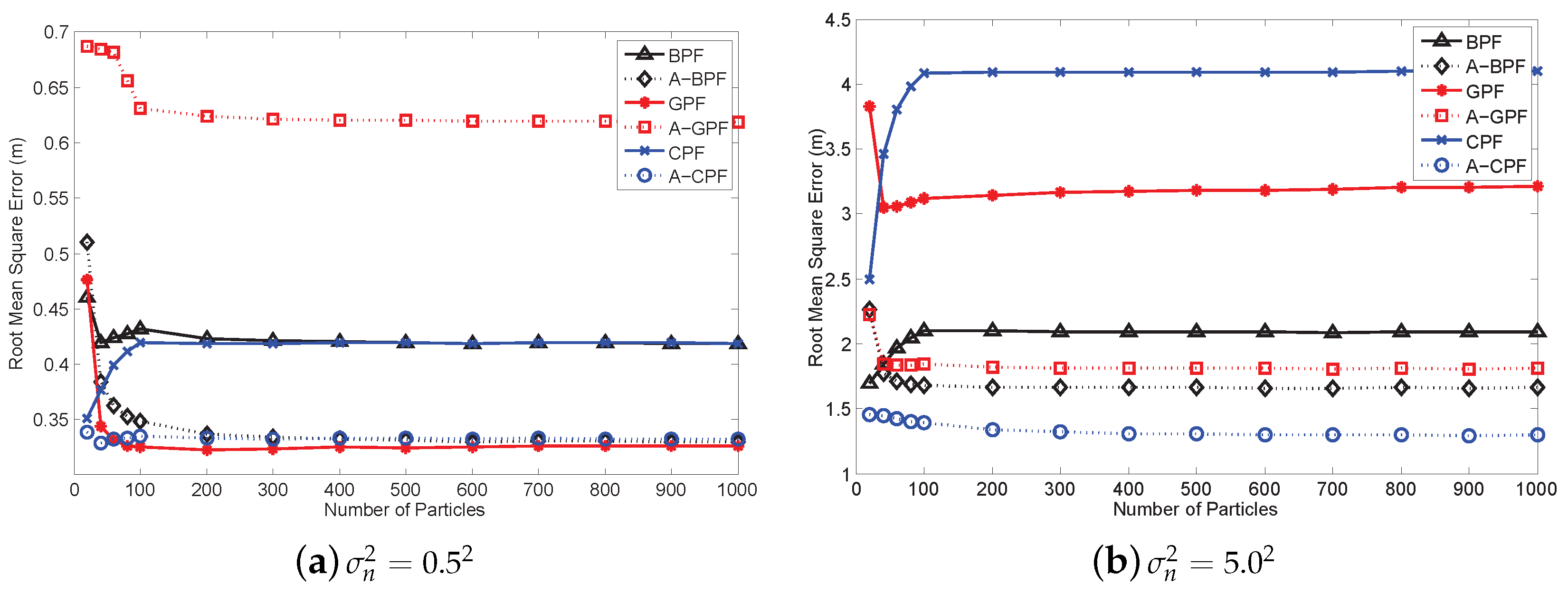
Note that the performances of the proposed APFs are different and suitable for different scenarios. In general, all of the APFs can effectively reduce the estimation error in the high noise environment, which will be proven in
Section 6. The A-BPF reduces the estimation error by using arbitrary prior information. Such information is set up since the initial sampling scheme. If the sampling scheme and prior information are accurate, the estimation results can be good. However, the system cannot adjust the prior information at every time step. Thus, the A-BPF cannot further reduce the error if the measurement error is small. The A-GPF is quite suitable for adjusting itself during the recursive estimation. At each time step, A-GPF calculates the estimation covariance using the current particles and propagates to the next time step as the prior information. This is quite flexible for a dynamic environment. However, the disadvantage of the A-GPF is that there is some error in the covariance calculation. Thus, if the measurement error is too high, the performance of the A-GPF is not as good as A-BPF. The most robust feature for the dynamic environment is A-CPF, which employs constraint conditions to restrict error. In a high noise environment, the estimation error of the A-CPF can be controlled. However, the A-CPF has an inherent error from the constraint condition. Thus, it is still not as good as the A-BPF if the measurement error is small.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}