1. Introduction
Current computer vision algorithms start with a high-quality image as input. While such images may be acquired almost instantly in a well-lit scene, dark environments demand a significantly longer acquisition time. This long acquisition time is undesirable in many applications that operate in low-light environments: in biological imaging, prolonged exposure could cause health risks [
1] or sample bleaching [
2]; in autonomous driving, the delay that is imposed by image capture could affect a vehicle’s ability to stay on-course and avoid obstacles; in surveillance, long periods of imaging could delay response, as well as produce smeared images. When light is low, the number of photons per pixel is small and images become noisy. Computer vision algorithms are typically not designed to be robust
vis-a-vis image noise, thus practitioners face an uneasy tradeoff between poor performance and long response times.
Novel sensor technology offers a new perspective on image formation: as soon as a photon is sensed it should be transmitted to the host Central Processing Unit (CPU), rather than wait until a sufficient number of photons has been collected to form good quality image. Thus an image, in the conventional sense, is never formed. Designs and prototypes of photon-counting image sensors, such as the quantum sensors [
3], single-photon avalanche detectors [
4], quanta image sensors [
5,
6], and the giga-vision camera [
7], have been proposed recently. These sensors are capable of reliably detecting single photons, or a small number of photons. Instead of returning a high-quality image after a long exposure, photon-counting sensors report a stream of photon counts densely sampled in time.
Currently, the dominant use for photon-counting image sensors is image reconstruction [
8]: the stream of photon counts is used to synthesize a high-quality image to be used in consumer applications or computer vision. However, the goal of vision is to compute information about the world (class, position, velocity) from the light that reaches the sensor. Thus, reconstructing the image is not a necessary first step. Rather, one should consider computing information directly from the stream of photons [
9,
10]. This line of thinking requires revisiting the classical image-based paradigm of computer vision, and impacts both the design of novel image sensors and the design of vision algorithms.
Computing directly from the stream of photons presents the advantage that some information may be computed immediately, without waiting for high-quality image to be formed. In other words, information is computed incrementally, enabling the downstream algorithms to trade off reaction times with accuracy. This is particularly appealing in low-light situations were photon arrival times are widely spaced. As the hardware for computation becomes faster, this style of computation will become practical in brighter scenes, especially when response times are crucial (e.g., in vehicle control).
Here we explore three vision applications: classification, search and tracking. In each application, we will propose an algorithm that makes direct use of the stream of photons, rather than an image. We find that each one of these algorithms achieves high accuracy with only a tiny fraction of the photons required for capturing high-quality images. We conclude with a discussion of what was learned.
2. Results
2.1. Simplified Imaging Model
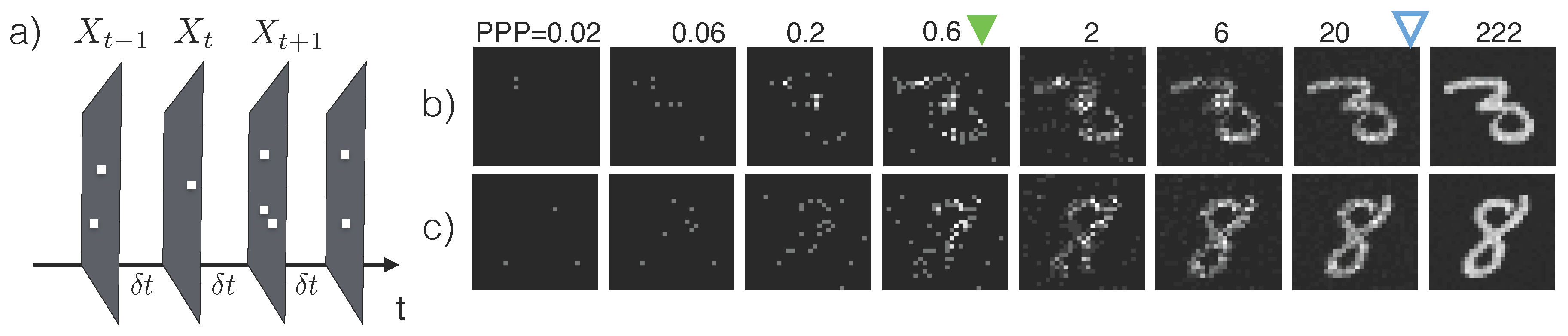
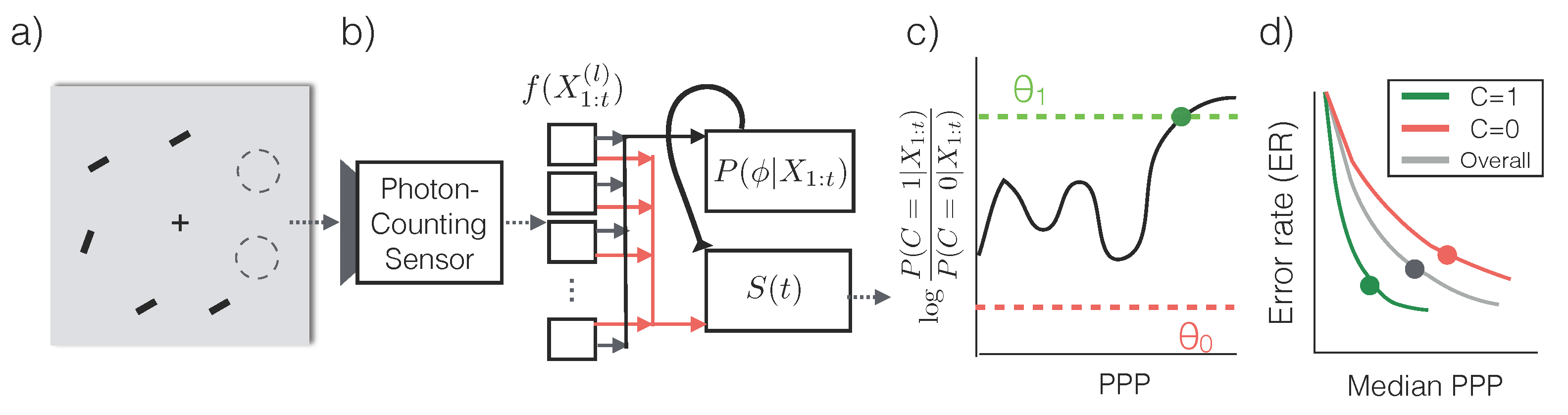
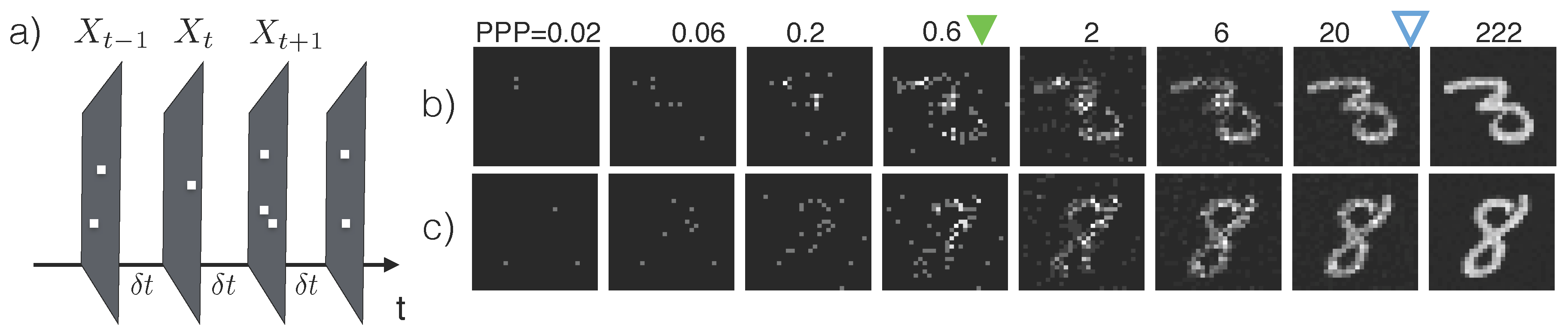
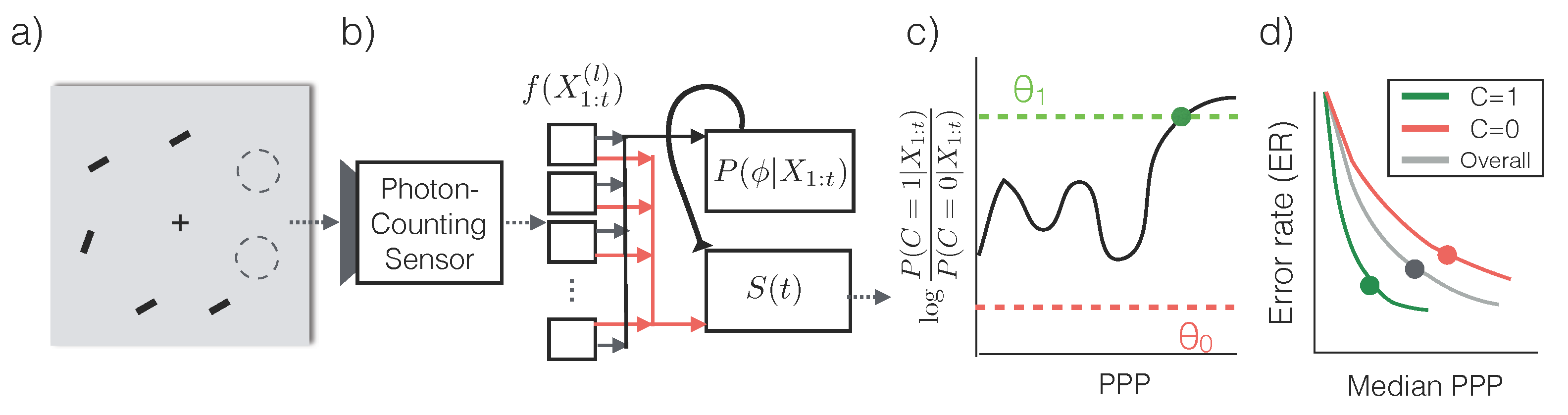
Assume that the scene is stationary and photon arrival times follow a homogeneous Poisson process. Within an interval of length
, the observed photon count
at pixel location
i is subject to Poisson noise whose mean rate depends on maximum rate
, the true intensity at that pixel
and a dark current rate
per pixel [
8]:
(a model including sensor read noise is described in
Section 3.1).
The sensor produces a stream of images
, where
contains the photon counts from
d pixel locations from the time interval
(
Figure 1a). We use
to represent the stream of inputs
.
When the illuminance of the environment is constant, the expected number of photons collected by the sensor grows linearly with the exposure time. Hence we use the number of photons per bright pixel (PPP) as a proxy for the exposure time
t. PPP
means that the a pixel with maximum intensity has collected 1 photon. Additionally, since PPP is linked to the total amount of information content in the image regardless of the illuminance level, we will use PPP when describing the performance of vision algorithms.
Figure 1b, c shows two series of inputs
with increasing PPP.
2.2. Classification
Distinguishing objects of different categories hinges upon the extraction of “features”, which are structural regularities in pixel values such as edges, corners, contours,
etc. For example, the key feature that set apart a handwritten digit “3” from a digit “8” (
Figure 1b,c, last column) is the fact that a “3” has open loops and “8” has closed loops—This corresponds to different strokes on the left side of the digit. In normal lighting conditions, these features are fully visible, may be computed by, e.g., convolution with an appropriate kernel, and fed into a classifier to predict the category of the image.
In low light, classification is hard because the features are corrupted by noise. A closed contour may appear broken due to stochastically missing photons. The noise in the features in turn translates to uncertainties on the classification decision. This uncertainty diminishes as the exposure time increases. It is intuitive that a vision algorithm that is designed to compute from a minimal number of photons should keep track of said uncertainties, and dynamically determine the exposure time based on the desired accuracy.
In particular, one wishes to predict the category
of an image based on photon counts
. The predictions must minimize exposure time while being reasonably accurate,
i.e.,
where
T is a random variable denoting the exposure time required to classify an image,
∈
is the prediction of the class label,
γ is the maximum tolerable misclassification error, and the expectation is taken over all images in a dataset.
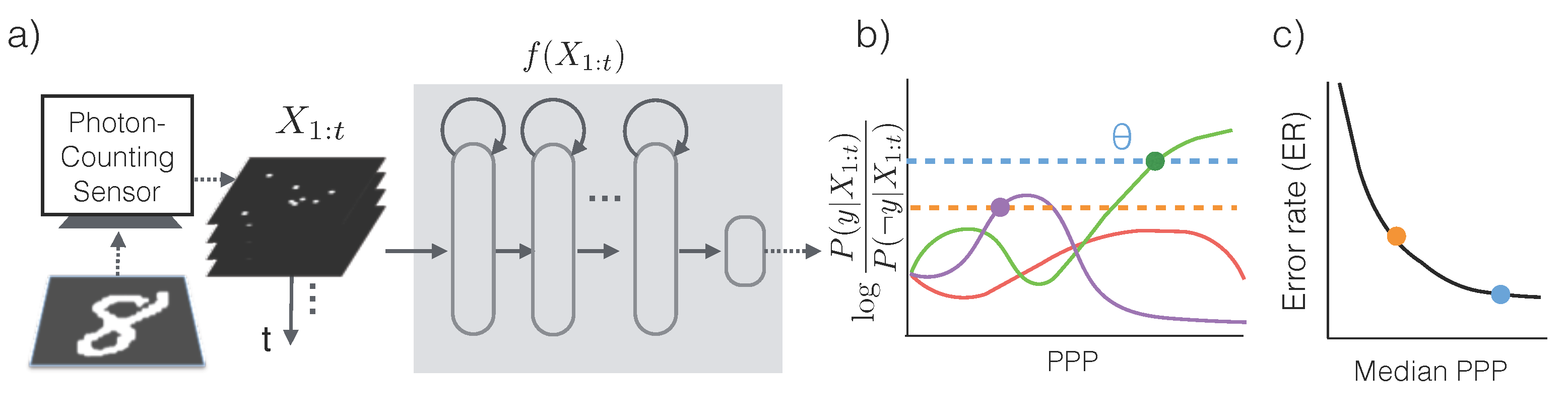
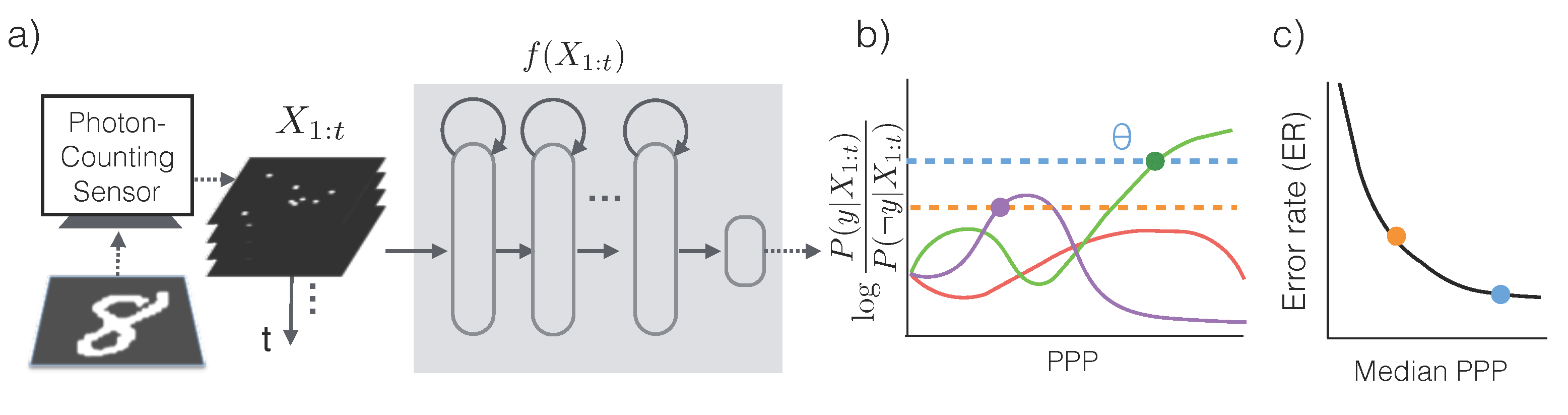
2.2.1. Classification Algorithm
In order to make the most efficient use of photons, we first assume that a conditional probabilistic model
is available for any
(we will relax this assumption later) and for all possible categories of the input image. An asymptotically optimal algorithm that solves the problem described in Equation (
2) is Sequential Probability Ratio Testing (SPRT) [
12] (
Figure 2a,b):
Essentially, SPRT keeps accumulating photons by increasing exposure time until there is predominant evidence in favor of a particular category. Due to the stochasticity of the photon arrival events and the variability in an object’s appearance, the algorithm observes a different stream of photon counts each time. As a result, the exposure time
T, and equivalently, the required PPP, are also different each time (see
Figure 3).
The accuracy of the algorithm is controlled by the threshold
θ. When a decision is made, the declared class
satisfies that
, which means that class
has at least posterior probability
according to the generative model, and the error rate of SPRT is at most
. For instance, if the maximum tolerable error rate is
,
θ should be set so that
, or
, while an error rate of
would drive
θ to
. Since higher thresholds lead to longer exposure times, the threshold serves as a knob to trade off speed
versus accuracy, and should be set appropriately based on
γ (Equation (
2)).
The assumption that the conditional distribution
is known is rather restrictive. Fortunately, the conditional distribution may be directly learned from data. In particular we train a recurrent neural network [
13]
to approximate the conditional distribution. This network has a compact representation, and takes advantage of the sparseness of the photon-counts for efficient evaluation. Details of the network may be found in
Section 3.2 and [
9].
2.2.2. Experiments
We evaluate the low-light classification performance of the SPRT on the MNIST dataset [
11], a standard handwritten digits dataset with 10 categories. The images are
in resolution and in black and white. We simulate the outputs from a photon-counting sensor according to the full noise model (
Section 3.1). The images are stationary within the imaging duration. We do not assume a given conditional distribution
but train a recurrent network approximation
from data (
Section 3.2).
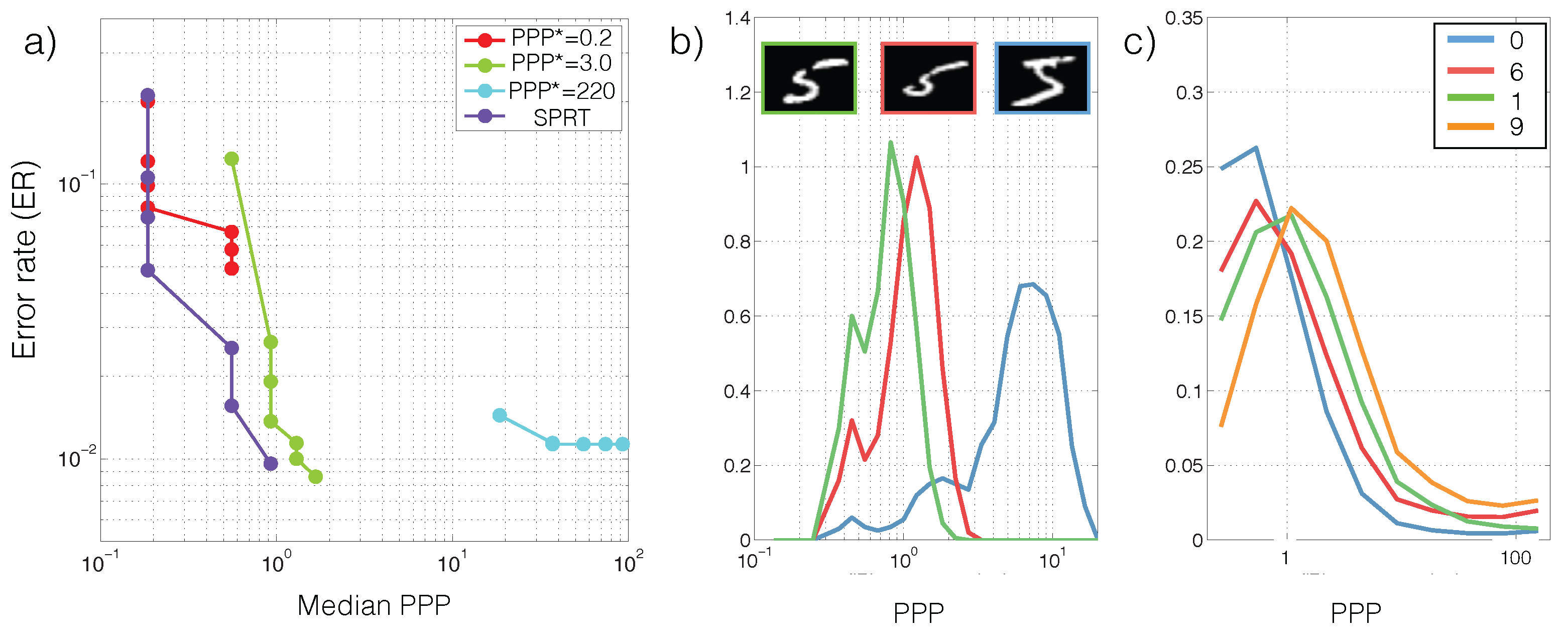
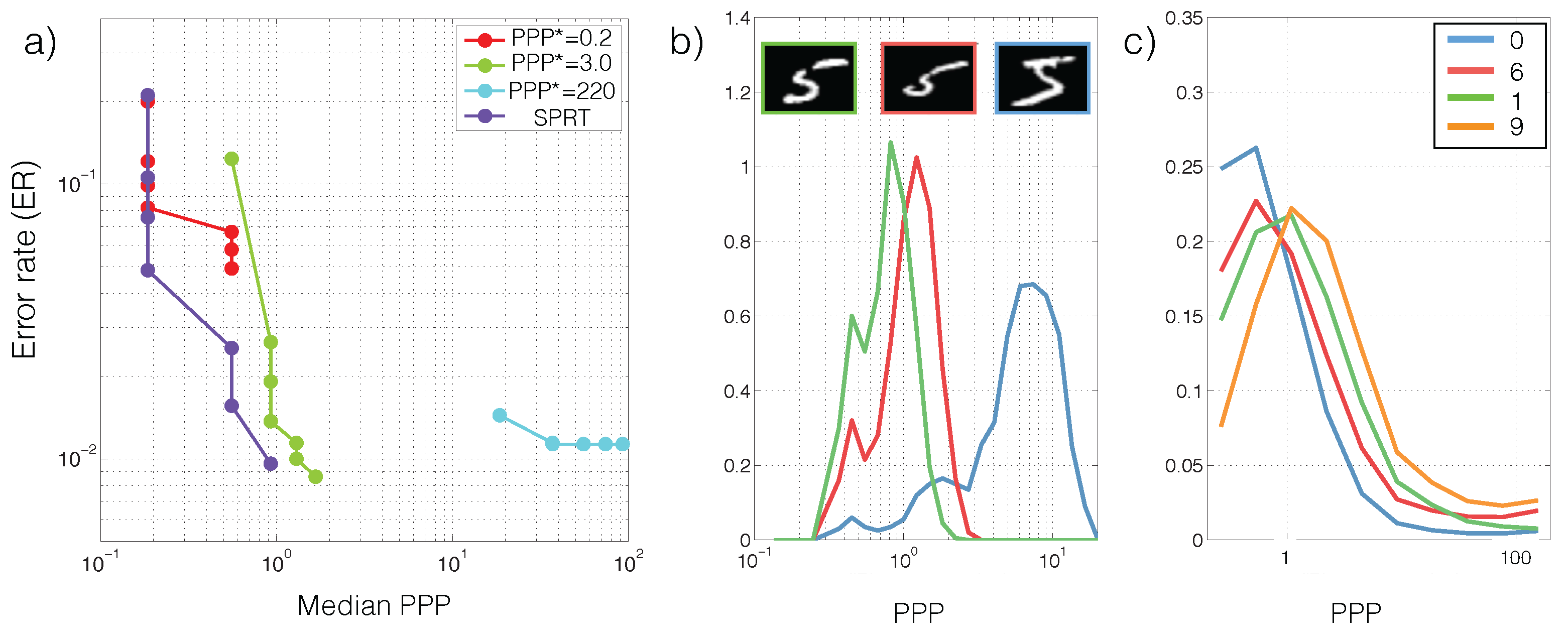
Recall that classification correctness in each trial and the required exposure time (or PPP) are random variables. We therefore characterize SPRT performance based on the tradeoff between error rates (ER,
) and the median PPP in
Figure 3a. The tradeoff is generated by sweeping the thresholds
. For comparison we tested the performance of models that were trained to classify images from a single PPP. We call these models “specialists” for the corresponding PPP. The specialists are extended to classify images at different light levels by scaling the image to the specialized PPP. To get a sense of the intraclass and interclass PPP variability, we also visualize the PPP histograms for multiple runs of different images in the same class (
Figure 3b), and the overall PPP histograms for a few classes (
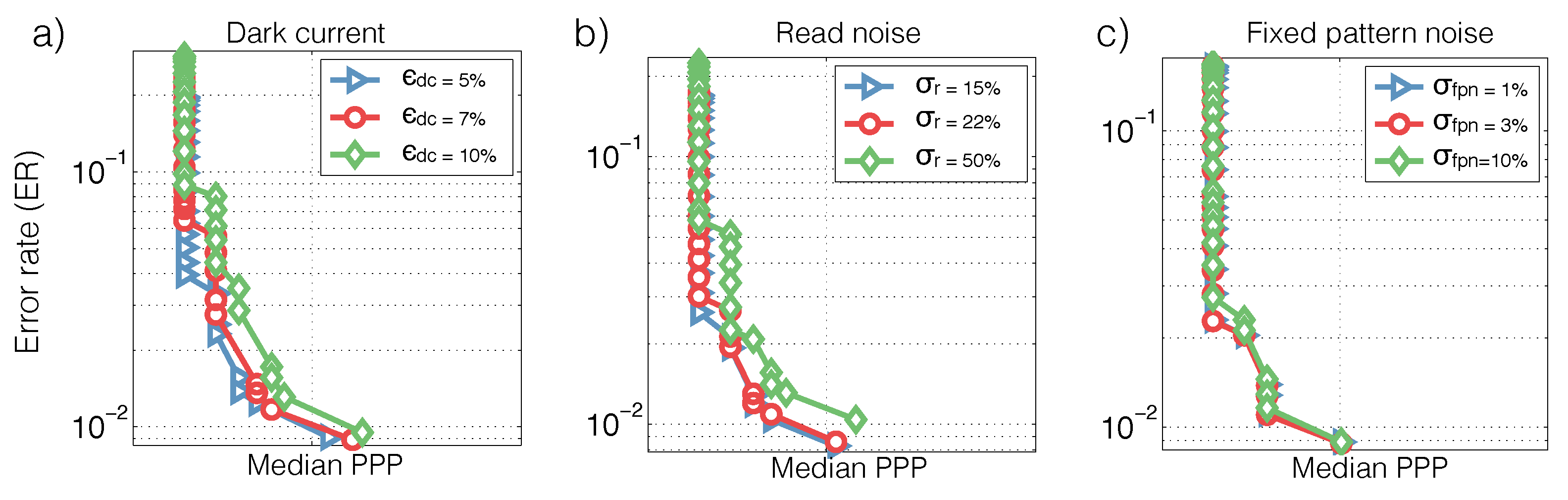
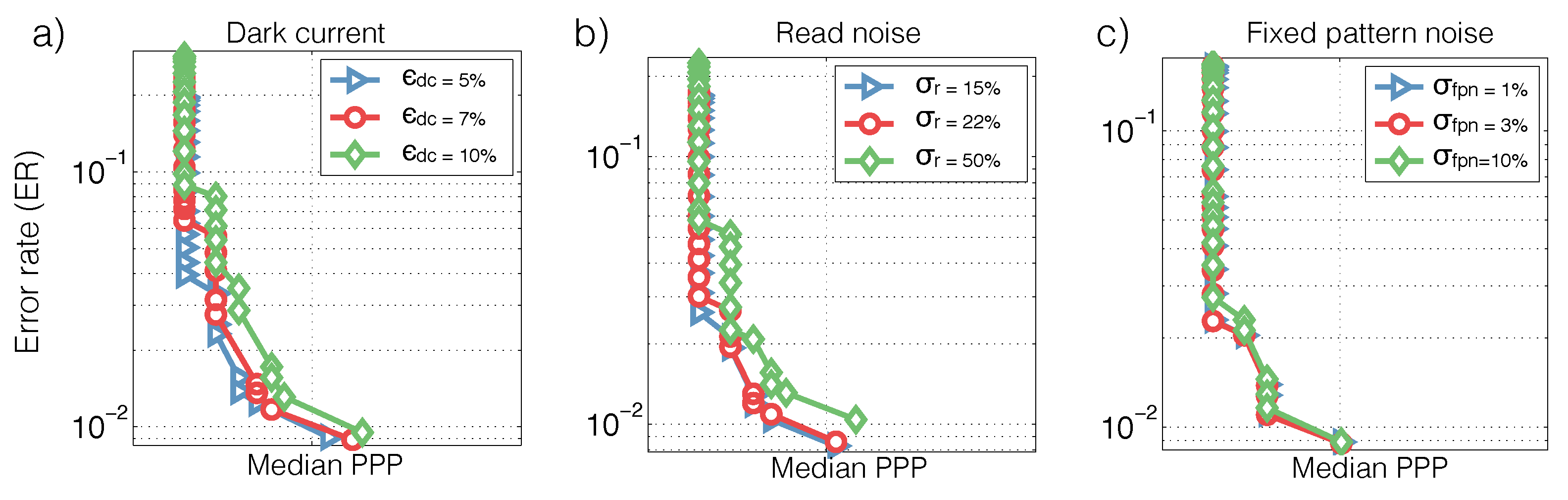
Figure 3c). Lastly, we analyze how SPRT’s performance is sensitive to sensor noises in
Figure 4. Details of the analysis procedure are found in
Section 3.1.
2.3. Search
Search is a generalization of classification into multiple locations. The task is to identify whether a target object (e.g., keys, a pedestrian, a cell of a particular type) is present in a scene cluttered with distractors (e.g., a messy desk, a busy street at night or a cell culture). Note that despite the multiple candidate positions for a target to appear, we consider search as a binary task, where the two hypotheses are denoted
(target-present) and
(target-absent). We assume for simplicity that at most one target may appear at a time (for multiple targets, see [
14]).
The difficulty of search in low-light conditions may be attributed to the following factors. (1) There are multiple objects in the display, and each object is subject to photon count fluctuations. (2) Long range constraints, such as the prior knowledge that at most one target is present in the visual field, must be enforced. (3) Properties of the scene, such as the amount of clutter in the scene and the target and distractor appearance, may be uncertain. For example, we may know that there may be either three or twelve objects in the scene, and intuitively the search strategy for these two scenarios should be drastically different. Therefore, scene properties must be inferred for optimal performance.
We assume that a visual field consists of L non-overlapping locations, out of which M locations may contain an object. M represents the amount of clutter in the scene. The objects are simplified to be oriented bars and the only feature that separates a target from a distractor is the orientation. The orientation at location l is denoted . The target orientation and the distractor orientation are denoted and , respectively. The scene properties are collected denoted . The scene properties may be unknown for many search tasks, thus φ is a vector of random variables. The variable of interest is : iff , (i.e., iff there exists a location that contains a target).
We also assume that a low-light classifier discussed in
Section 2.2 has been developed for classifying bar stimulus: the classifier computes
, the probability that the bar orientation at location
l is
y conditioned only on the local photon counts
.
2.3.1. Search Algorithm
Similar to the low-light classification problem, an asymptotically optimal search algorithm is based on SPRT. The detailed algorithm is [
12,
14]:
where
is the log likelihood ratio between the two competing hypotheses, target-present (
) and target-absent (
). This algorithm is a binary version of the classification algorithm in Equation (
3). Similar to Equation (
3), the two thresholds
and
controls the amount of false reject errors (
i.e., declare target-absent when target-present) and false accept errors (
i.e., declaring target-present when target-absent).
The key for SPRT is to compute
from photon counts
. The inference procedure may be implemented by two circuits, one infers the scene properties
φ, and the other computes
(see [
14]):
where
Therefore, may be computed by composing the low-light classifiers according to Equations (5)–(7). The probabilities used in Equations (6) and (7), such as = and = , may be estimated from past data.
2.3.2. Experiments
We choose a simple setup (
Figure 5a) to illustrate how the performance of the search algorithm is affected by scene properties: the amount of clutter
M, the target/distractor appearances
and
, as well the degree of uncertainty associated with them. The setup contains
locations, each occupying a
area from which the sensor collects photons. The area contains a
-pixel bar with intensity 1 and background pixels with intensity 0. The max emission rate is
photons/s, and the dark current is
(causing the background to emit 1 photon/s). Examples of the lowlight search setup are shown in
Figure 6d.
We conduct two experiments, one manipulates the scene complexity
M and the other target/distractor appearances. In the first experiment
M is either chosen uniformly from
, or fixed at one of the three values (
Figure 6a,b): (1) Despite the high dark current noise, a decision may be made quickly with less than 2 photons per pixel. (2) The amount of light required to achieve a given classification error increases as
M. (3) Not knowing the complexity further increases the required photon count. (4) Target-absent conditions requires more photons than target-present conditions. In the second experiment the target-distractor appearance difference
is either chosen uniformly from
or fixed at one of the three.
Figure 6c suggests that target dissimilarity heavily influences the ER-PPP tradeoff, while uncertainty in the target and distractor appearances does not.
2.4. Tracking
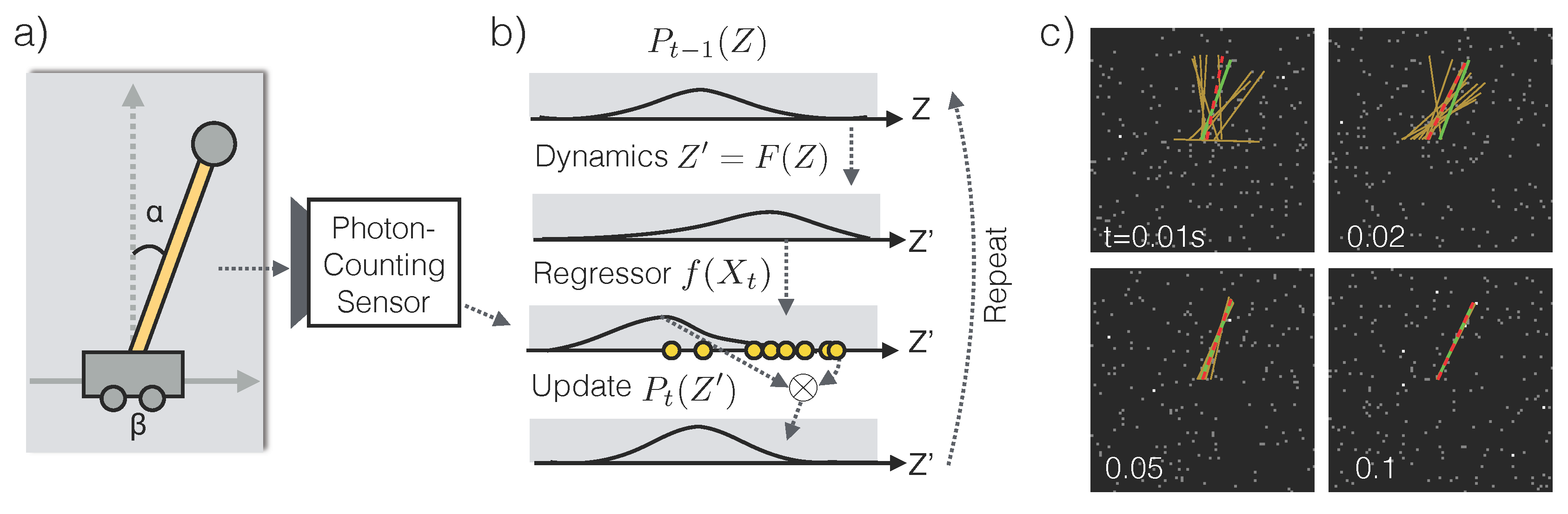
Finally, we demonstrate the potential of photon-counting sensors in tracking under low-light conditions. The goal of tracking is to recover time-varying attributes (i.e., position, velocity, pose, etc.) of one or multiple moving objects. It is challenging because, unlike classification and search, objects in tracking applications are non-stationary by definition. In low-light environments, as the object transitions from one state to another, it leaves only a transient footprint, in the form of stochastically-sprinkled photons, which is typically insufficient to fully identify the state. Instead, a tracker must postulate the object’s dynamics and integrate evidence over time accordingly. The evidence in turn refines the estimates of the dynamics. Due to the self-reinforcing nature of this procedure, the tracker must perform optimal inference to ensure convergence to the true dynamics.
Another challenge that sets low-light tracking apart from regular tracking problems is that the observation likelihood model is not only non-Gaussian, but also often unavailable, as it is commonly the case for realistic images. This renders most Kalman filter algorithms [
15] ineffective.
2.4.1. Tracking Algorithm
The tracking algorithm we have designed is a hybrid between the Extended Kalman Filter [
15] and the Auxiliary Particle Filter [
16]. Let
denote the state of the object,
F the forward dynamics that govern the state transition:
, which are known and differentiable, and
the posterior distribution over the states at time
t:
.
We make two assumptions: (1)
may be approximated by a multivariate Gaussian distribution; (2) A low-light regressor
is available to compute a likelihood score of
given only the snapshot
at time
t.
does not have to be normalized. We justify assumption (1) and describe algorithms for realizing assumption (2) in
Section 3.3. As we will see in Equation (
17), the Poisson noise model (Equation (
1)) ensures that
exists and takes a simple form.
Given a prior probability distribution
, our goal is to compute the posterior distribution
for all
t. The tracking algorithm starts with
and repeat the following procedure (
Figure 7b).
Under the Gaussian assumption for
, both steps 1 and 4 may be computed in close-form (
Section 3.3). This is in sharp contrast to regular particle filters, which do not assume any parametric form for
and accomplish steps 1 and 4 using samples. Empirically we found that the Gaussian assumption is reasonable and often leads to efficient solutions with less variability.
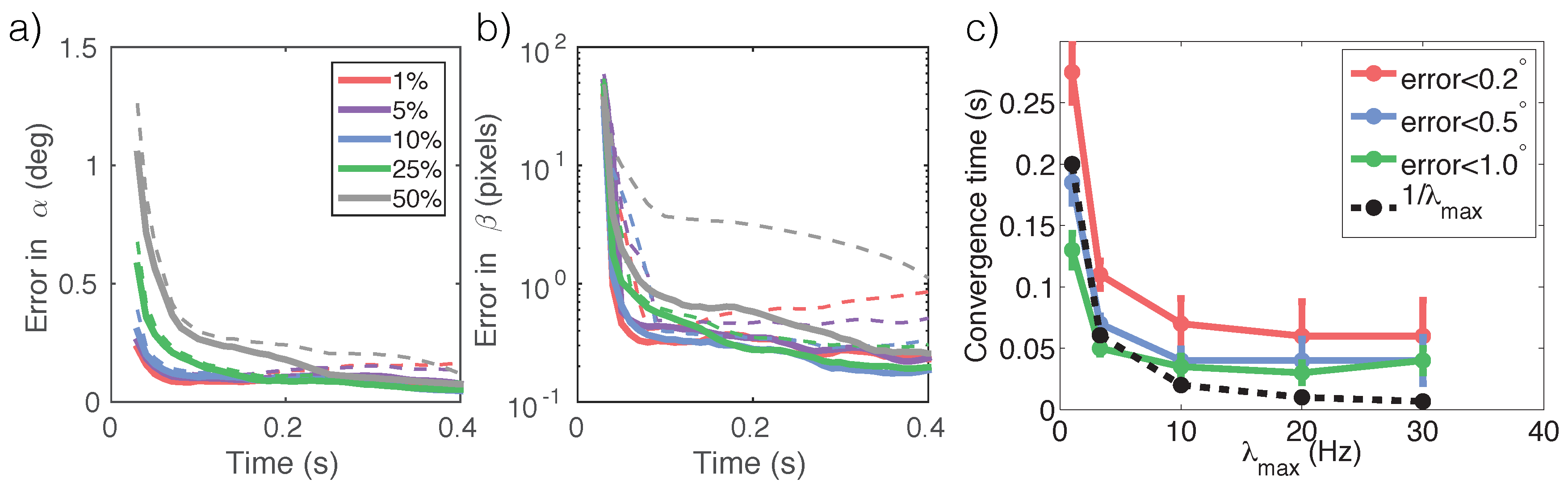
2.4.2. Experiments
We choose the 1D inverted pendulum problem (
Figure 7a) that is standard in control theory. A pendulum is mounted via a a massless pole on a cart. The cart can move horizontally in 1D on a frictionless floor. The pendulum can rotate full circle on a fixed 2D plane perpendicular to the floor. The pendulum is released at time
at an unknown angle
from the vertical line, while the cart is at an unknown horizontal offset
. The task is to identify how the angle
and the offset
change through time from the stream of photon counts
. The state of the pendulum system is
. The system’s forward dynamics is well-known [
17].
In our simulations, only the pole of the pendulum is white and everything else is dark. The highest photon emission rate of the scene is
and the dark current rate is
. We systematically vary
and
and observe the amount of estimation error in the angle
and cart position
. See
Section 3.4 for the simulation procedure.
We see that (1) estimation errors decrease over time (
Figure 8a,b), (2) smaller
leads to faster reduction in estimation error on average (
Figure 8a,b), and (3) the tracker’s
convergence time,
i.e., the time it takes to achieve a certain level of estimation accuracy, decreases with illuminance (
Figure 8c). The time required to satisfy high accuracy requirements (e.g., <1
for
α estimation) does NOT follow a simple inverse proportional relationship with illuminance. Instead, the convergence time plateaus, potentially due to the noise in the sampling procedure (Equation (
8), step 2).
4. Discussion and Conclusions
The advent of photon-counting sensors motivates us to reconsider the prevalent paradigm in computer vision: Rather than first capturing an image and then analyzing it, we should design algorithms that incrementally compute information from the stream of photons that hits the sensor, without any attempt to reconstruct the image. This style of thinking is particularly attractive in low light conditions, where the exposure time required for capturing a high-quality image is prohibitively lengthy.
Photon-counting sensors deliver small increments of the image at short delays and high frequencies. We show that this incremental input could in principle be applied to solve a variety of vision problems with a short exposure time. Algorithms that are inspired by the asymptotically optimal SPRT appear particularly well suited for minimizing photon counts while satisfying a desired accuracy bound.
Our first finding is that useful information may be computed in a short amount of time, well ahead of the integration time that is required for forming (or reconstructing) a high quality image. In
Figure 1b,c, we see that a low-light classification algorithm can achieve
classification error of handwritten digits before one photon per pixel has been collected. The low-light classifier may be viewed as reconstructing the features (instead of the image), and carrying the uncertainty of the features all the way to classification. This uncertainty is essential in a sequential decision making setting to determine when to stop collecting more photons. In comparison, conventional approaches simply reconstruct the image, and pass it to a classifier trained on high-quality images. The conventional approach suffers from two issues. (1) Since the conventional approach discards the uncertainty information, it is not clear how to determine the required exposure time; and (2) statistics of the reconstruction may be different from that of high-quality images, hence the classifier’s performance may not be guaranteed.
Second, algorithms for classification and search from streams of photons are photon-efficient: they stop as soon as a confident decision is made. This efficiency is critical for domains such as astrophysics where each photon is precious [
19], and cell imaging applications where the dies that are employed to visualize cell structures are phototoxic [
20,
21]. As an example of the photon efficiency,
Figure 3a shows that at PPP
the low-light classifier based on SPRT can already achieve a better performance than a classifier using PPP
. Additionally, contrary to the conventional paradigm that obtains images with a fixed duration, low-light classifiers and search algorithms uses different exposure times depending on the specific photon arrival sequence (
Figure 3b) and on the overall classification difficulty of the example (
Figure 3b,c).
Third, algorithms become faster when more light is present. For classification and search where the input image is stationary, time is synonymous with the amount of photons. Higher illuminance therefore translates to faster decisions. This simple relationship is useful in that a low-light system trained for classification or search at one illuminance level may be easily applied at another illuminance level. The transition only requires knowing the illuminance level of the new scene, which may be estimated either via an explicit illuminance sensor or from the total photon count across the image [
22]. In addition, the ER
vs. median PPP tradeoff (
Figure 3a and
Figure 6a–c) is an illuminance-independent characteristic of the algorithm and the task.
Last, the relationship between illuminance and speed is not always simple in tracking. The dynamics governing the object movement/state transition has its own time scale. A regressor
thus has only a finite duration for integrating information before the object moves too far. A tracker relies on accurate prediction of the regressor to postulate the object’s next position. An inaccurate prediction due to short exposure time may cause tracking failure. In addition, internal noise in the tracking algorithm (
Section 3.4) may cause the speed to plateau after a certain illuminance level. As a result, the relationship between illuminance and convergence time is not a simple inversely proportional relationship, as shown in
Figure 8c.
Although we have provided proof-of-concept illustrations of low-light vision applications with photon-counting sensors, many challenges still remain. (1) We are not aware of any hardware specialized at processing streams of photon counts at high speeds. Nonetheless, current Field-programmable Gate Array (FPGA) implementations have achieved over 2000 Hz throughput for classifying images of a similar resolution as those in
Section 2.2 [
23]. In addition, the low-light classifiers implemented as a recurrent neural network (
Section 2.2) can be updated incrementally,
i.e.,
can be computed from the internal states of
and
with sparse updates. The sparseness may be key to expedite computation. (2) We do not yet have datasets collected directly from photon-counting sensors to verify the robustness of the proposed methodology, as many such sensors are still in the making [
5,
6,
7]. (3) Our noise model (
Section 3.1) may be a crude approximation to handle moving objects. For example, we do not model motion induced blur or input disturbances due to camera self-motion. Nonetheless, motion induced blur may not be an issue if the sensor is collecting a single photon at a time, such as in low light and/or high-frequency imaging scenarios. In these scenarios even though the amount of photons is so low that full image reconstruction is difficult, our algorithm can still make correct and full use of the where and when of photon arrivals. This is precisely the advantage of image-free vision.
In conclusion, we propose to integrate computer vision with photon-counting sensors to address the challenges facing low-light vision applications. We should no longer wait for a high-quality image to be formed before executing the algorithm. Novel algorithms and hardware solutions should be developed to operate on streams of photon-counts. These solutions should also sidestep image reconstruction and focus directly on the task at hand.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}