
Background Subtraction Based on Three-Dimensional Discrete Wavelet Transform

Abstract
:1. Introduction
2. Related Work
2.1. Methods without a Separate Training Phase
2.2. Methods Based on WT
3. Background Subtraction Based on 3D DWT
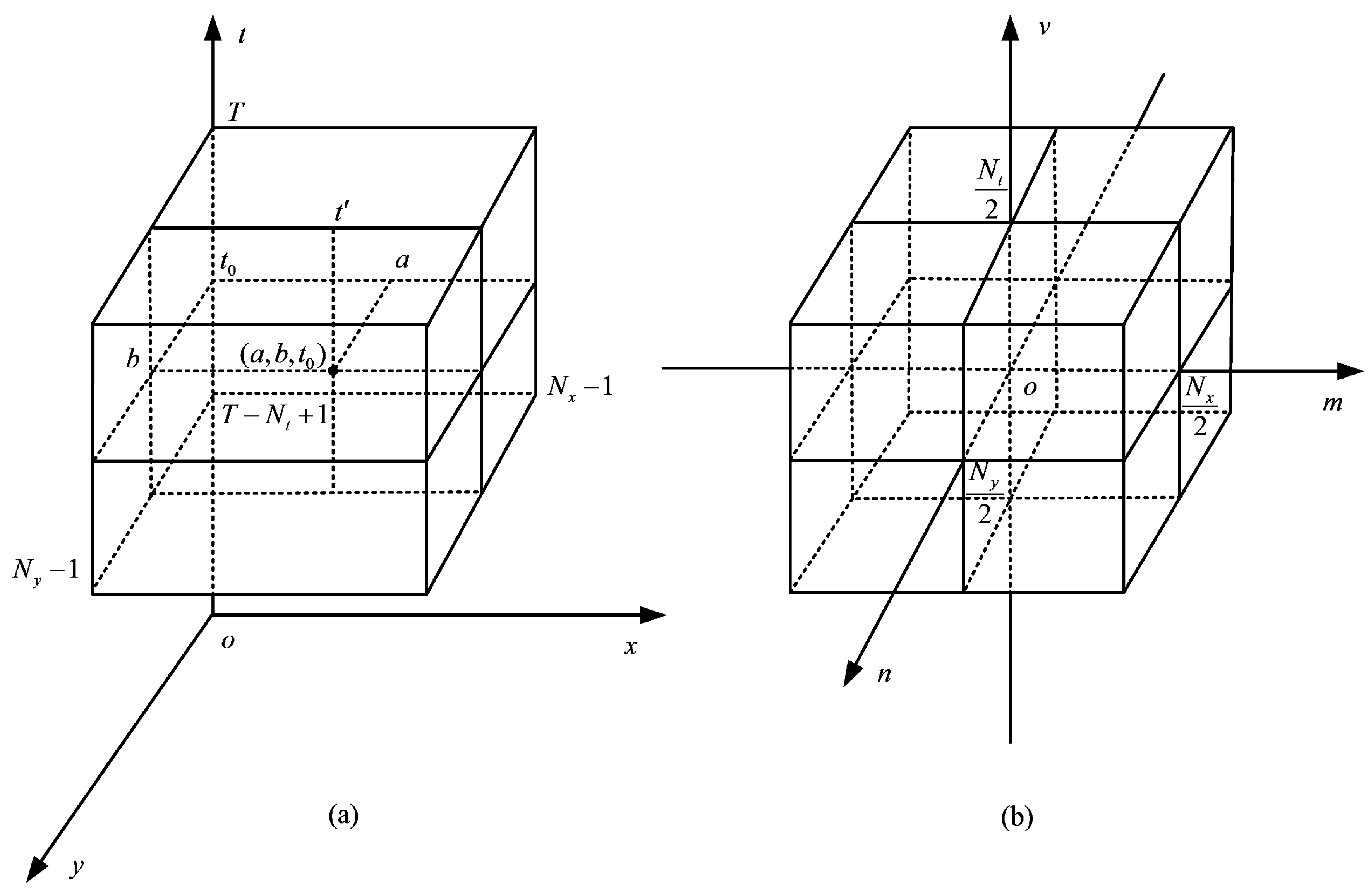
3.1. Analysis of Background Removal in the 3D Wavelet Domain
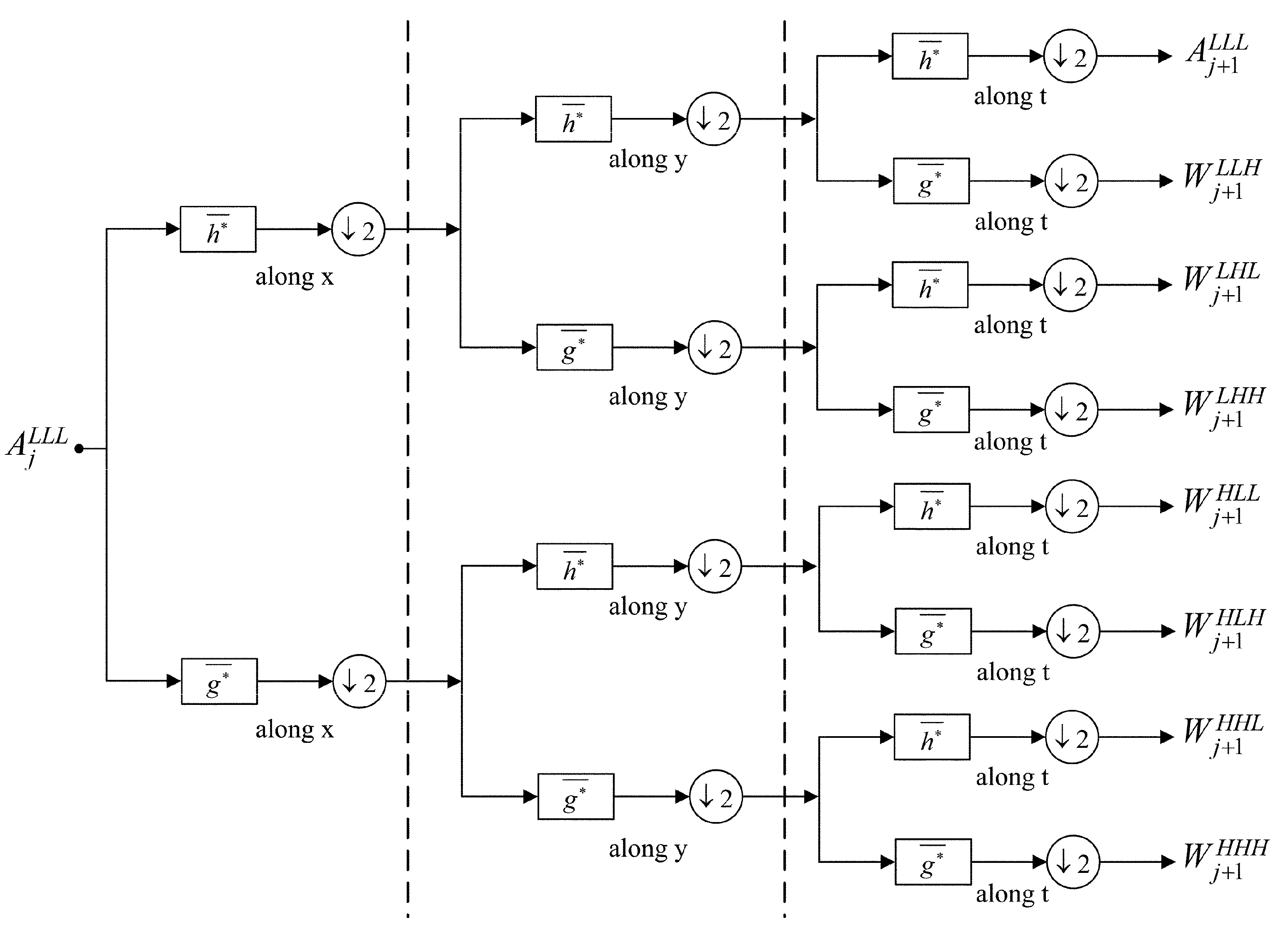
3.2. Procedure of TD-3DDWT
3.2.1. Static Backgrounds Removal
3.2.2. Disturbance Removal
3.2.3. Detection Results Generation
4. Merits of TD-3DDWT
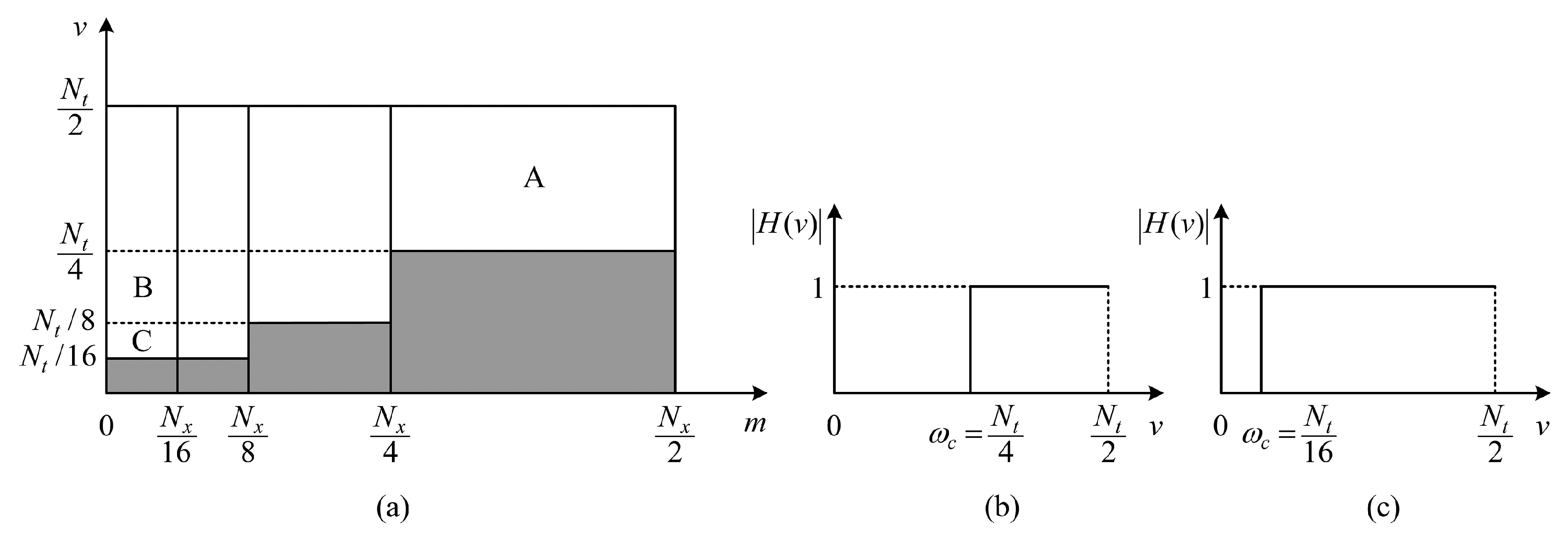
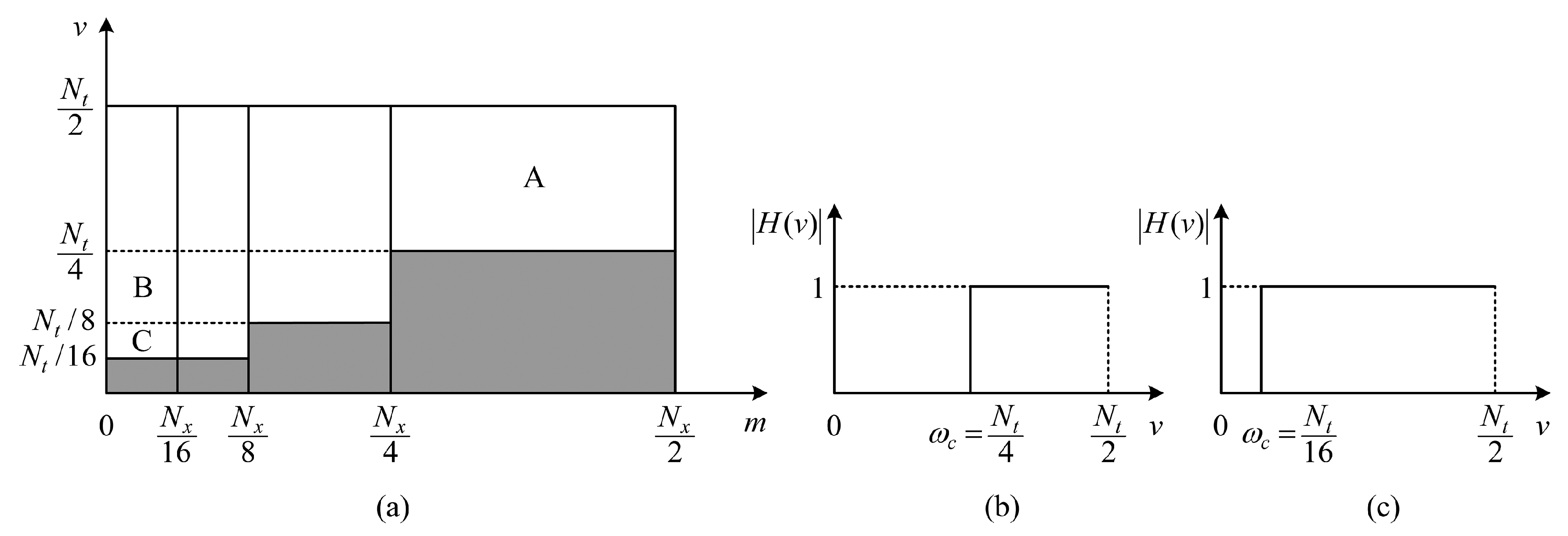
- Our method weakens the ringing on the object boundaries and, thus, locates the object boundaries precisely. As we know, the ringing behavior is a characteristic of IHPFs, and the cutoff frequency affects the range of the ringing. By increasing the cutoff frequency, the ringing will be reduced. In Figure 3a, when , since the 1D IHPFs along the v axis have larger cutoff frequencies (i.e., shown in Figure 3b), the ringing around the edges of moving objects (corresponding to the Support Region A) is slight and imperceptible.
- The detection results of our method include not only the object boundaries, but also the inner parts of moving objects. In Figure 3a, the Support Regions B and C correspond to smooth areas inside the moving objects, and they can be reserved in our method, so that the detection results of our method can include the inner parts of moving objects. Although the 1D IHPFs along the v axis are with smaller cutoff frequencies (i.e., in Figure 3c) when , the ringing mainly emerges inside the moving objects and, hence, does not affect the detection of object boundaries.
5. Experimental Results
5.1. Experimental Setup
5.1.1. Test Sequences
5.1.2. Analysis and Determination of Our Parameters
- Wavelet filter: In most applications, the wavelet filters with the support width ranging from five to nine are appropriate. The wavelet filter with a larger support width will result in a border problem, and the wavelet filter with a smaller support width is disadvantageous for concentrating the signal energy. In our experiments, we find that the choice of the wfilter does not affect our results very much. Consequently, we empirically set the wfilter = db5 throughout our test.
- Decomposition scale: To ensure effective decomposition, the decomposition scale J should satisfy the condition that . As mentioned before, in order to detect smooth areas inside the moving objects, we need to reserve the low-frequency components in support regions, such as B and C in Figure 3a. Hence, in the permitted range, J should be as large as possible. To testify to our analysis, we fix other parameters as and wfilter = db5, while performing our method on the shopping center sequence, and obtain detection results illustrated in Figure 4 for J ranging from two to four. According to Figure 4, it is evident that the result is better for a larger J, and we also find that, to gain satisfactory results, J should be no smaller than 4, i.e., .
- Number of frames in each batch: Given a decomposition scale J, the number of frames in each batch should satisfy the condition that . Moreover, to get rid of the border problem, we should further set . Here, we suppose J = 4 and set wfilter = db5. To determine an optimal value for , we visually compare the results shown in Figure 5 with different . As can be seen, no significant improvements are achieved as the increases. However, the memory cost is indeed increasing when we set a larger . Therefore, we should set the as small as possible in its permitted range.
5.1.3. Methods Considered for the Comparison and Their Parameter Settings
- ViBe is a background subtraction algorithm using a quick initialization technique realized by random sampling in the first frame. We set the parameters exactly the same as Barnich and Van Droogenbroeck [26], namely the number of background samples N = 20, the distance threshold R = 20, the minimal cardinality and the time subsampling factor .
- PCP (principal component pursuit) is the state-of-the-art algorithm for RPCA. There are two main parameters in PCP: number of frames in each batch and regularization parameter . For the permission of memory cost and also for fair comparison with our method, we set in our experiments. For , we choose exactly the same as Candès et al. [31], namely , where and are the row and column dimensions of the input frames, respectively.
- TD-2DDFT is a transform domain method using the 2D DFT. The parameters are also set as Tsai and Chiu [35], namely number of frames in each batch and notch width of filter .
5.1.4. Other Settings
5.2. Visual Comparisons
5.3. Quantitative Comparisons
5.3.1. Quantitative Comparisons for Situations without Sufficient Training Time
5.3.2. Quantitative Comparisons for Situations without Clean Training Data
5.3.3. Quantitative Comparisons for Normal Videos
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Varona, J.; Gonzalez, J.; Rius, I.; Villanueva, J.J. Importance of detection for video surveillance applications. Opt. Eng. 2008, 47, 087201. [Google Scholar]
- Chiranjeevi, P.; Sengupta, S. Moving object detection in the presence of dynamic backgrounds using intensity and textural features. J. Electron. Imaging 2011, 20, 043009. [Google Scholar] [CrossRef]
- Cuevas, C.; García, N. Improved background modeling for real-time spatio-temporal non-parametric moving object detection strategies. Image Vis. Comput. 2013, 31, 616–630. [Google Scholar] [CrossRef]
- Oreifej, O.; Li, X.; Shah, M. Simultaneous video stabilization and moving object detection in turbulence. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 450–462. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.-M.; Hsia, C.-H.; Liu, Y.-F.; Shih, M.-H.; Chang, C.-H.; Wu, J.-Y. Fast background subtraction based on a multilayer codebook model for moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1809–1821. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. The 3dSOBS+ algorithm for moving object detection. Comput. Vis. Image Underst. 2014, 122, 65–73. [Google Scholar] [CrossRef]
- Tong, L.; Dai, F.; Zhang, D.; Wang, D.; Zhang, Y. Encoder combined video moving object detection. Neurocomputing 2014, 139, 150–162. [Google Scholar] [CrossRef]
- Kim, D.-S.; Kwon, J. Moving object detection on a vehicle mounted back-up camera. Sensors 2016, 16, 23. [Google Scholar] [CrossRef] [PubMed]
- Poppe, C.; Martens, G.; de Bruyne, S.; Lambert, P.; van de Walle, R. Robust spatio-temporal multimodal background subtraction for video surveillance. Opt. Eng. 2008, 47, 107203. [Google Scholar] [CrossRef]
- Benezeth, Y.; Jodoin, P.-M.; Emile, B.; Laurent, H.; Rosenberger, C. Comparative study of background subtraction algorithms. J. Electron. Imaging 2010, 19, 033003. [Google Scholar]
- Varcheie, P.D.Z.; Sills-Lavoie, M.; Bilodeau, G.-A. A multiscale region-based motion detection and background subtraction algorithm. Sensors 2010, 10, 1041–1061. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Hernández, H. Background subtraction approach based on independent component analysis. Sensors 2010, 10, 6092–6114. [Google Scholar] [CrossRef] [PubMed]
- Kim, W.; Kim, C. Background subtraction for dynamic texture scenes using fuzzy color histograms. IEEE Signal Process. Lett. 2012, 19, 127–130. [Google Scholar] [CrossRef]
- Lee, J.; Park, M. An adaptive background subtraction method based on kernel density estimation. Sensors 2012, 12, 12279–12300. [Google Scholar] [CrossRef]
- Xue, G.; Sun, J.; Song, L. Background subtraction based on phase feature and distance transform. Pattern Recognit. Lett. 2012, 33, 1601–1613. [Google Scholar] [CrossRef]
- Fernandez-Sanchez, E.J.; Diaz, J.; Ros, E. Background subtraction based on color and depth using active sensors. Sensors 2013, 13, 8895–8915. [Google Scholar] [CrossRef] [PubMed]
- Sobral, A.; Vacavant, A. A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. Comput. Vis. Image Underst. 2014, 122, 4–21. [Google Scholar] [CrossRef]
- Bouwmans, T. Traditional and recent approaches in background modeling for foreground detection: An overview. Comput. Sci. Rev. 2014, 11, 31–66. [Google Scholar] [CrossRef]
- Tu, G.J.; Karstoft, H.; Pedersen, L.J.; Jørgensen, E. Illumination and reflectance estimation with its application in foreground detection. Sensors 2015, 15, 21407–21426. [Google Scholar] [PubMed]
- Stauffer, C.; Grimson, W.E.L. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef]
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. IEEE Proc. 2002, 90, 1151–1163. [Google Scholar] [CrossRef]
- Kim, K.; Chalidabhongse, T.H.; Harwood, D.; Davis, L. Real-time foreground-background segmentation using codebook model. Real Time Imaging 2005, 11, 172–185. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. A self-organizing approach to background subtraction for visual surveillance applications. IEEE Trans. Image Process. 2008, 17, 1168–1177. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Yang, C.; Yu, W. Moving object detection by detecting contiguous outliers in the low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 597–610. [Google Scholar] [CrossRef] [PubMed]
- Weeks, M.; Bayoumi, M.A. Three-dimensional discrete wavelet transform architectures. IEEE Trans. Signal Process. 2002, 50, 2050–2063. [Google Scholar] [CrossRef]
- Barnich, O.; van Droogenbroeck, M. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Van Droogenbroeck, M.; Paquot, O. Background subtraction: Experiments and improvements for ViBe. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2012), Providence, RI, USA, 16–21 June 2012; pp. 32–37.
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background segmentation with feedback: The pixel-based adaptive segmenter. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2012), Providence, RI, USA, 16–21 June 2012; pp. 38–43.
- Han, G.; Wang, J.; Cai, X. Improved visual background extractor using an adaptive distance threshold. J. Electron. Imaging 2014, 23, 063005. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Wright, J.; Candès, E.; Ma, Y. Stable principal component pursuit. In Proceedings of the 2010 IEEE International Symposium on Information Theory (ISIT 2010), Austin, TX, USA, 13–18 June 2010; pp. 1518–1522.
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Ding, X.; He, L.; Carin, L. Bayesian robust principal component analysis. IEEE Trans. Image Process. 2011, 20, 3419–3430. [Google Scholar] [CrossRef] [PubMed]
- Babacan, S.D.; Luessi, M.; Molina, R.; Katsaggelos, A.K. Sparse bayesian methods for low-rank matrix estimation. IEEE Trans. Signal Process. 2012, 60, 3964–3977. [Google Scholar] [CrossRef]
- Xu, H.; Caramanis, C.; Sanghavi, S. Robust PCA via outlier pursuit. IEEE Trans. Inf. Theory 2012, 58, 3047–3064. [Google Scholar] [CrossRef]
- Tsai, D.; Chiu, W. Motion detection using Fourier image reconstruction. Pattern Recognit. Lett. 2008, 29, 2145–2155. [Google Scholar] [CrossRef]
- Crnojević, V.; Antić, B.; Ćulibrk, D. Optimal wavelet differencing method for robust motion detection. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP 2009), Cairo, Egypt, 7–12 November 2009; pp. 645–648.
- Antić, B.; Crnojević, V.; Ćulibrk, D. Efficient wavelet based detection of moving objects. In Proceedings of the 16th International Conference on Digital Signal Processing (DSP 2009), Santorini, Greece, 5–7 July 2009.
- Hsia, C.-H.; Guo, J.-M. Efficient modified directional lifting-based discrete wavelet transform for moving object detection. Signal Process. 2014, 96, 138–152. [Google Scholar] [CrossRef]
- Kushwaha, A.K.S.; Srivastava, R. Complex wavelet based moving object segmentation using approximate median filter based method for video surveillance. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC 2014), Gurgaon, India, 21–22 February 2014; pp. 973–978.
- Gao, T.; Liu, Z.-G.; Gao, W.-C.; Zhang, J. A robust technique for background subtraction in traffic video. In Proceedings of the 15th International Conference on Neuro-Information Processing (ICONIP 2008), Auckland, New Zealand, 25–28 November 2008; pp. 736–744.
- Guan, Y.-P. Wavelet multi-scale transform based foreground segmentation and shadow elimination. Open Signal Process. J. 2008, 1, 1–6. [Google Scholar] [CrossRef]
- Gao, D.; Ye, M.; Jiang, Z. A new approach of dynamic background modeling for surveillance information. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering (CSSE 2008), Wuhan, China, 12–14 December 2008; pp. 850–855.
- Jalal, A.S.; Singh, V. A robust background subtraction approach based on daubechies complex wavelet transform. In Proceedings of the 1st International Conference on Advances in Computing and Communications (ACC 2011), Kochi, India, 22–24 July 2011; pp. 516–524.
- Mendizabal, A.; Salgado, L. A region based approach to background modeling in a wavelet multi-resolution framework. In Proceedings of the 36th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2011), Prague, Czech Republic, 22–27 May 2011; pp. 929–932.
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2008; pp. 499–508. [Google Scholar]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K.C. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Li, L.; Huang, W.; Gu, I.Y.-H.; Tian, Q. Statistical modeling of complex backgrounds for foreground object detection. IEEE Trans. Image Process. 2004, 13, 1459–1472. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An expanded change detection benchmark dataset. In Proceedings of the 2014 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2014), Columbus, OH, USA, 23–28 June 2014; pp. 393–400.
- I2R Dataset. Available online: http://perception.i2r.a-star.edu.sg/bk_model/bk_index.html (accessed on 30 December 2015).
- Changedetection.net Benchmark Dataset. Available online: http://changedetection.net/ (accessed on 8 February 2016).
- Shensa, M.J. The discrete wavelet transform: Wedding the à trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5932 | 0.4992 | 0.5422 | 0.3719 |
| PCP | 0.6090 | 0.7541 | 0.6738 | 0.5081 |
| TD-2DUWT | 0.7262 | 0.5718 | 0.6398 | 0.4704 |
| TD-3DDWT | 0.5970 | 0.8758 | 0.7103 | 0.5508 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5377 | 0.4796 | 0.5070 | 0.3396 |
| PCP | 0.4678 | 0.8887 | 0.6130 | 0.4419 |
| TD-2DUWT | 0.6759 | 0.6594 | 0.6676 | 0.5010 |
| TD-3DDWT | 0.5893 | 0.9248 | 0.7199 | 0.5623 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5610 | 0.3139 | 0.4026 | 0.2520 |
| PCP | 0.5800 | 0.7864 | 0.6676 | 0.5011 |
| TD-2DUWT | 0.5786 | 0.6474 | 0.6111 | 0.4400 |
| TD-3DDWT | 0.6278 | 0.8281 | 0.7142 | 0.5554 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5210 | 0.3799 | 0.4394 | 0.2816 |
| PCP | 0.4654 | 0.5205 | 0.4914 | 0.3257 |
| TD-2DUWT | 0.2266 | 0.6287 | 0.3332 | 0.1999 |
| TD-3DDWT | 0.6120 | 0.6528 | 0.6336 | 0.4637 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6095 | 0.0982 | 0.1692 | 0.0924 |
| PCP | 0.5939 | 0.8300 | 0.6924 | 0.5295 |
| TD-2DUWT | 0.5940 | 0.5574 | 0.5751 | 0.4036 |
| TD-3DDWT | 0.7502 | 0.8759 | 0.8082 | 0.6781 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6490 | 0.2487 | 0.3596 | 0.2192 |
| PCP | 0.3875 | 0.9564 | 0.5515 | 0.3807 |
| TD-2DUWT | 0.7496 | 0.4212 | 0.5394 | 0.3693 |
| TD-3DDWT | 0.7234 | 0.9059 | 0.8044 | 0.6728 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5047 | 0.0384 | 0.0714 | 0.0370 |
| PCP | 0.4227 | 0.6818 | 0.5129 | 0.3405 |
| TD-2DUWT | 0.3278 | 0.7127 | 0.4491 | 0.2896 |
| TD-3DDWT | 0.6801 | 0.7363 | 0.7071 | 0.5142 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6226 | 0.1052 | 0.1800 | 0.0989 |
| PCP | 0.6727 | 0.4325 | 0.5265 | 0.3573 |
| TD-2DUWT | 0.9461 | 0.0592 | 0.1114 | 0.0590 |
| TD-3DDWT | 0.8258 | 0.7797 | 0.8021 | 0.6634 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5981 | 0.7984 | 0.6839 | 0.5196 |
| PCP | 0.5509 | 0.8158 | 0.6576 | 0.4899 |
| TD-2DUWT | 0.6423 | 0.5871 | 0.6135 | 0.4425 |
| TD-3DDWT | 0.5956 | 0.8726 | 0.7080 | 0.5394 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6233 | 0.8059 | 0.7029 | 0.5419 |
| PCP | 0.5383 | 0.7862 | 0.6390 | 0.4836 |
| TD-2DUWT | 0.5376 | 0.5363 | 0.5369 | 0.3670 |
| TD-3DDWT | 0.5885 | 0.9075 | 0.7140 | 0.5552 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.5431 | 0.7458 | 0.6285 | 0.4583 |
| PCP | 0.5213 | 0.7708 | 0.6220 | 0.4514 |
| TD-2DUWT | 0.5539 | 0.5410 | 0.5474 | 0.3768 |
| TD-3DDWT | 0.5612 | 0.8655 | 0.6809 | 0.5162 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.7975 | 0.7530 | 0.7746 | 0.6321 |
| PCP | 0.4169 | 0.4459 | 0.4309 | 0.2746 |
| TD-2DUWT | 0.1864 | 0.2795 | 0.2237 | 0.1259 |
| TD-3DDWT | 0.7559 | 0.9372 | 0.8368 | 0.7195 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.7195 | 0.3850 | 0.5016 | 0.3347 |
| PCP | 0.6193 | 0.6128 | 0.6160 | 0.4451 |
| TD-2DUWT | 0.6749 | 0.4906 | 0.5682 | 0.3968 |
| TD-3DDWT | 0.7481 | 0.8446 | 0.7935 | 0.6576 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6667 | 0.8303 | 0.7396 | 0.5868 |
| PCP | 0.3786 | 0.9584 | 0.5429 | 0.3726 |
| TD-2DUWT | 0.8002 | 0.4066 | 0.5392 | 0.3691 |
| TD-3DDWT | 0.7440 | 0.9188 | 0.8222 | 0.6981 |
| Method | Recall | Precision | F1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.7888 | 0.9046 | 0.8416 | 0.7297 |
| PCP | 0.5203 | 0.6913 | 0.5569 | 0.4199 |
| TD-2DUWT | 0.5438 | 0.5112 | 0.4681 | 0.3274 |
| TD-3DDWT | 0.7372 | 0.9521 | 0.8279 | 0.7142 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, G.; Wang, J.; Cai, X. Background Subtraction Based on Three-Dimensional Discrete Wavelet Transform. Sensors 2016, 16, 456. https://doi.org/10.3390/s16040456
Han G, Wang J, Cai X. Background Subtraction Based on Three-Dimensional Discrete Wavelet Transform. Sensors. 2016; 16(4):456. https://doi.org/10.3390/s16040456
Chicago/Turabian StyleHan, Guang, Jinkuan Wang, and Xi Cai. 2016. "Background Subtraction Based on Three-Dimensional Discrete Wavelet Transform" Sensors 16, no. 4: 456. https://doi.org/10.3390/s16040456
APA StyleHan, G., Wang, J., & Cai, X. (2016). Background Subtraction Based on Three-Dimensional Discrete Wavelet Transform. Sensors, 16(4), 456. https://doi.org/10.3390/s16040456