
Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research


Abstract
:1. Introduction
- Generation of synthetic Arabic handwritings, including Arabic pseudo texts.
- Introduction of a new, segmentation based system of automatic Arabic handwritten word recognition.
- Validation of that system, by using synthesized word databases.
1.1. Arabic Script
- Arabic is written from right to left.
- There are 28 letters (Characters) in the Arabic alphabet, whose shapes are sensitive to their form (isolated, begin, middle and end), see Table 1.
- Only six characters can be in the isolated- or end-form, which splits a word into two or more parts, the PAWs. They consist of the main body (connected component) and related diacritics (dots), supplements like Hamza (أ). In case of handwriting, the ascenders of the letters Kaf (ك), Taa (ط) or Dha(ظ) can also be written as fragments.
- Arabic is semi-cursive: within a PAW, letters are joined to each other, whether handwritten or printed.
- Very often PAWs overlap each other, especially in handwritings.
- Sometimes one letter is written beneath its predecessor, like Lam-Ya (ي) or Lam-Mim (لم), or it almost vanish away when are in middle form, like Lam-Mim-Mim (لمم) (unlike the middle letter of Kaf-Mim-Mim (كمم) ). Hence, in addition to the four basic forms, there are also special forms, which can be seen as exceptions. Additionally, there are a few ligatures, which are two following letters, that build a completely new character like LamAlif(ﻵ).
- Some letters like Tha (ث), Ya (ي) or Jim (ج) have one to three dots above, under or within their “body”.
- Some letters like Ba (ب), Ta (ت), Tha (ث) only differ because of these dots.
1.2. Related Works
Handwriting Recognition
2. Synthesizing Arabic Handwriting Databases
2.1. Data Acquisition using Infrared and Ultrasonic Sensors
2.2. Active Shape Models
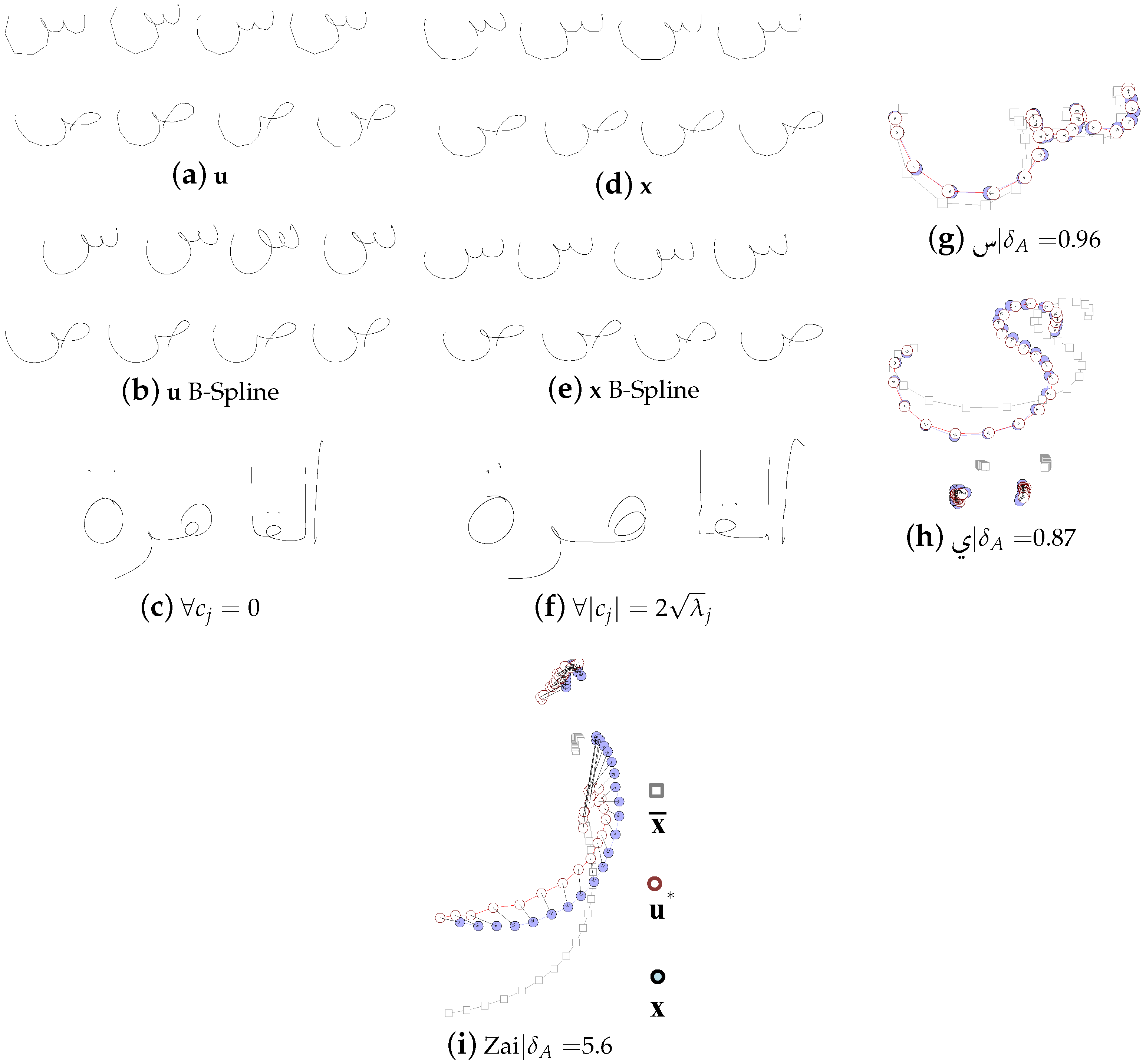
2.3. Word Sample Synthesis
2.4. Generation of Pseudo Texts
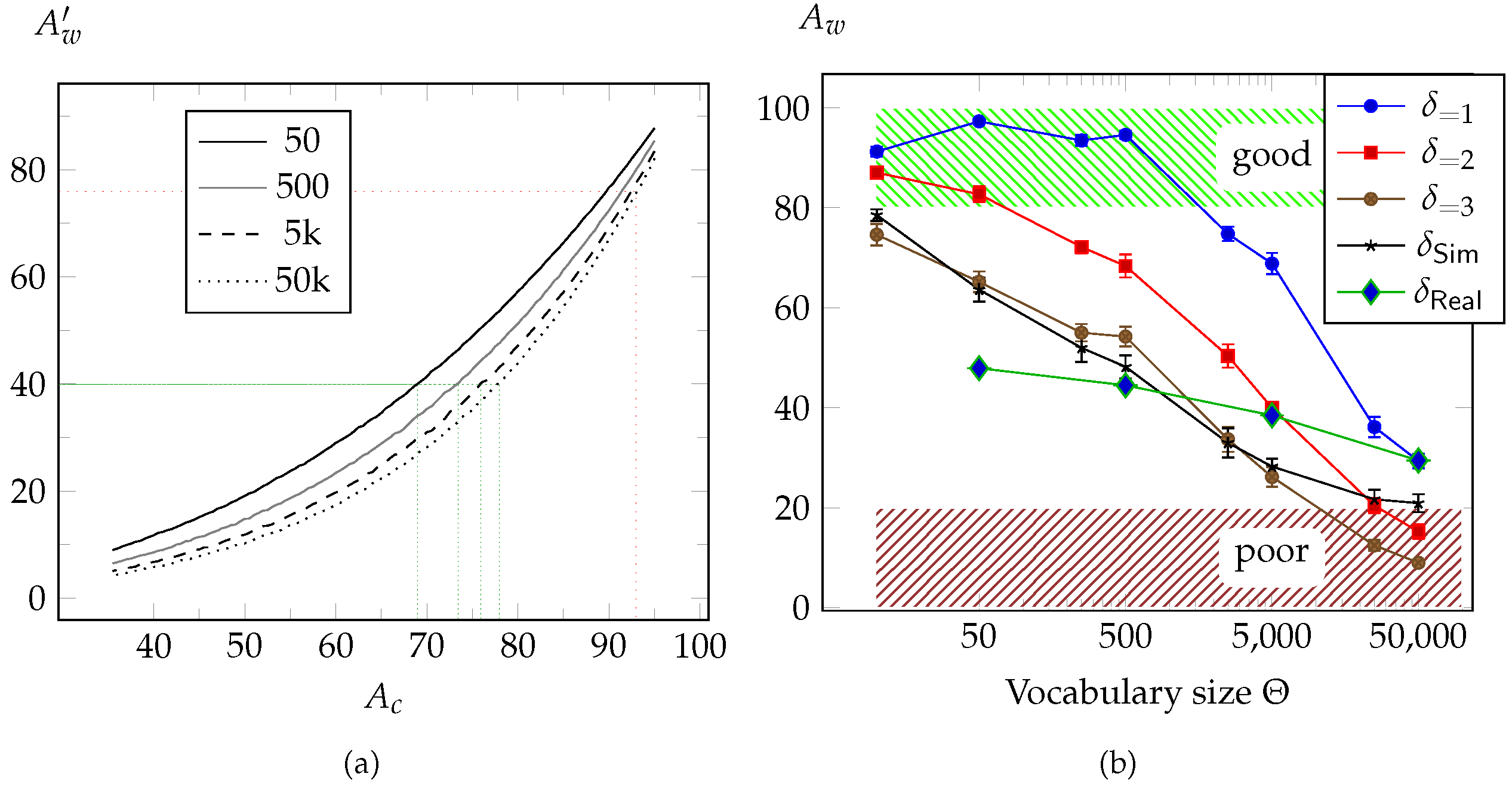
2.5. Extension of the IESK-arDB by Synthesised Samples
3. Segmentation based Recognition of Handwritten Arabic Words
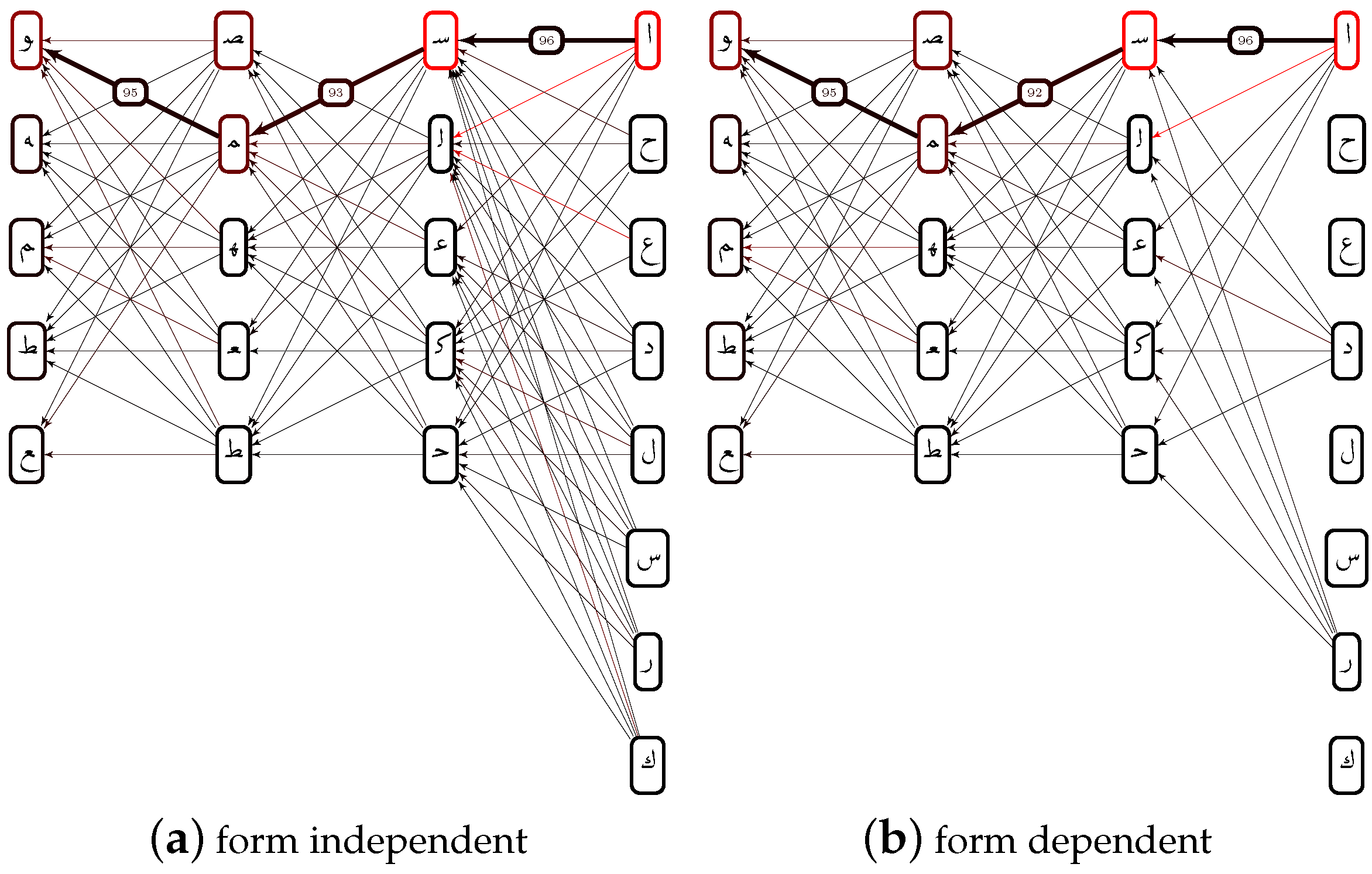
3.1. Segmentation
3.2. Character Recognition
3.2.1. Decision Trees
3.2.2. Support Vector Machines
3.2.3. Active Shape Models
Implementation
Optimization
3.3. Word Recognition
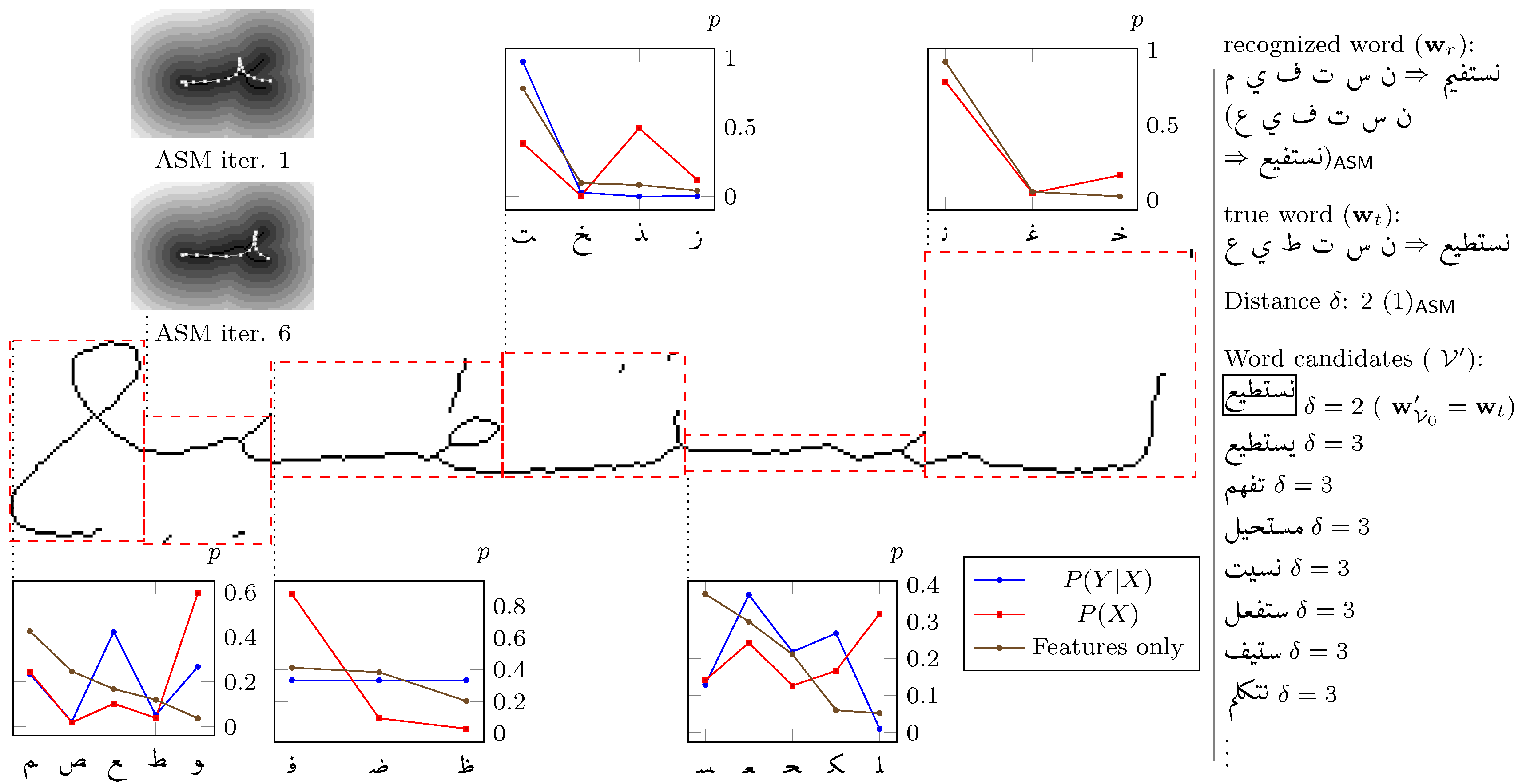
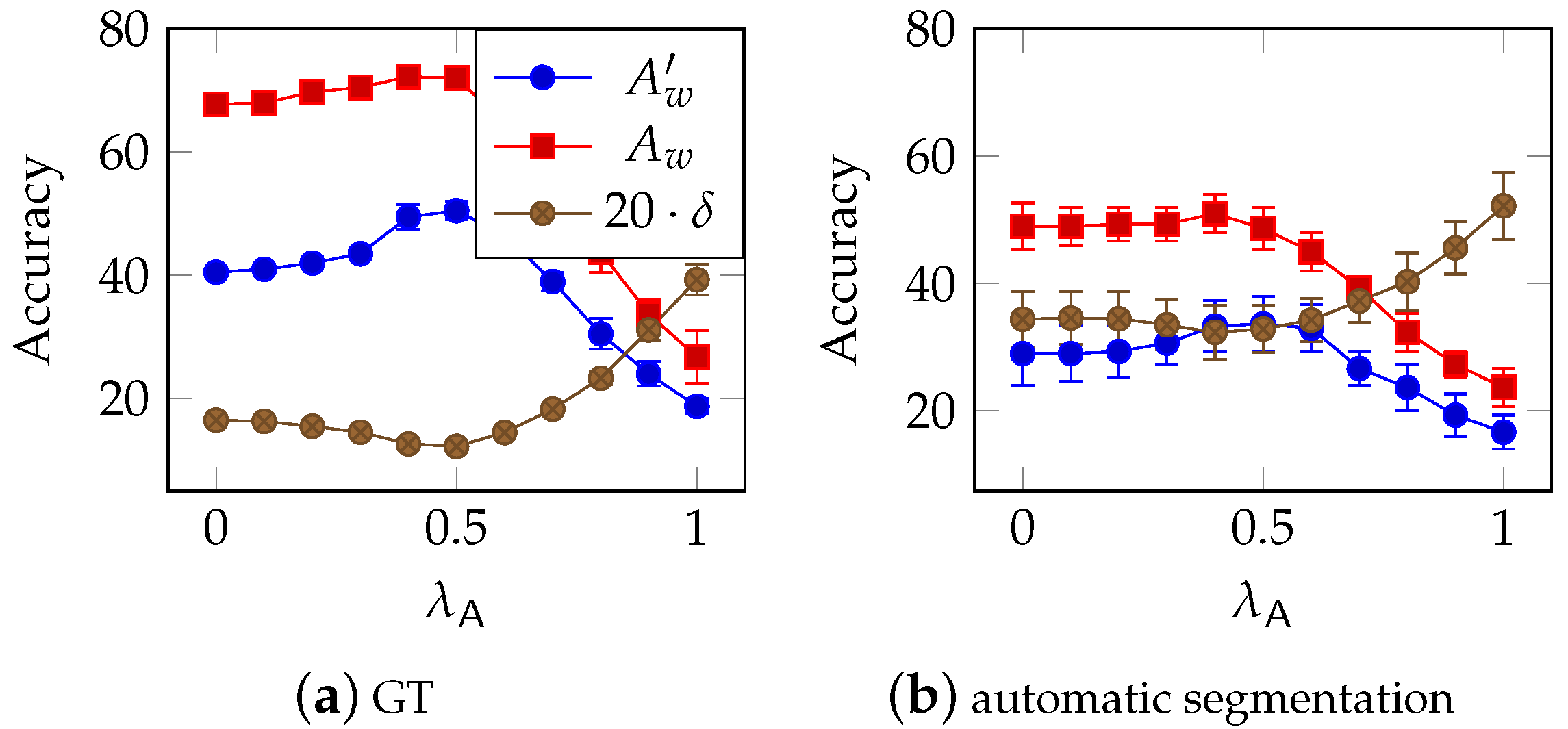
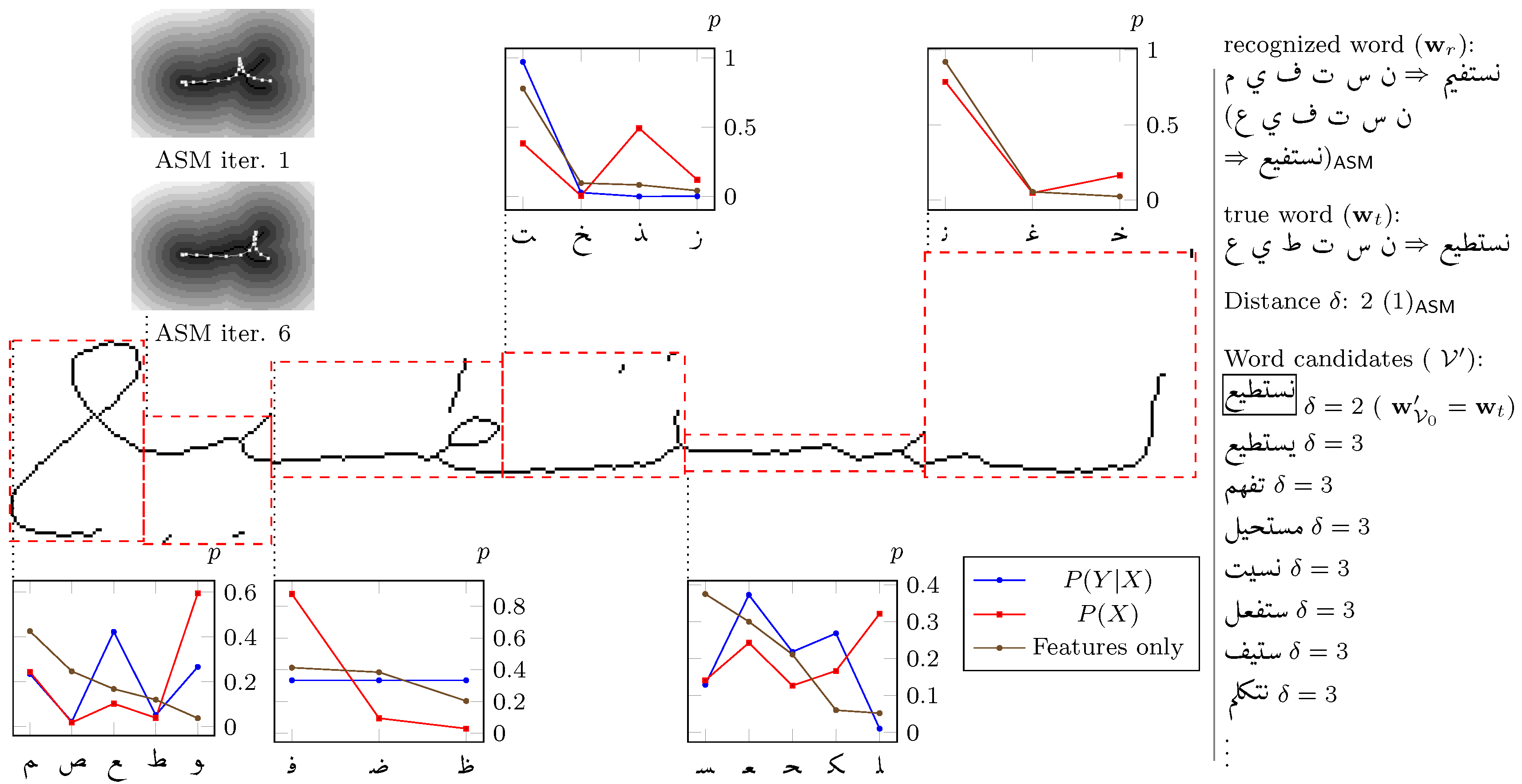
3.3.1. Error Correction
Character Level
Word Level
4. Experimental Results
4.1. Segmentation
- Oversegmentation, that splits a character into two
- Undersegmentation, that fuses two characters into one
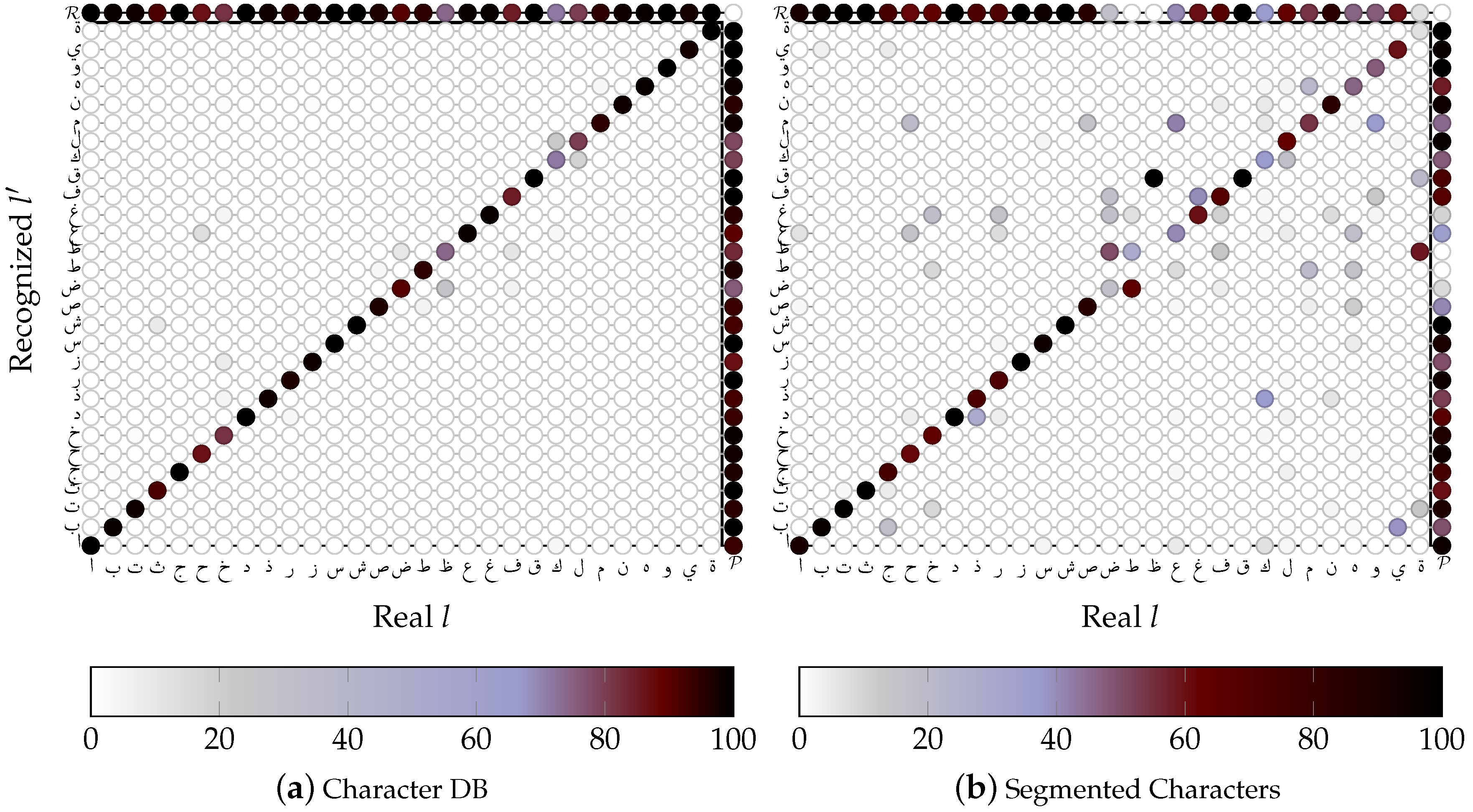
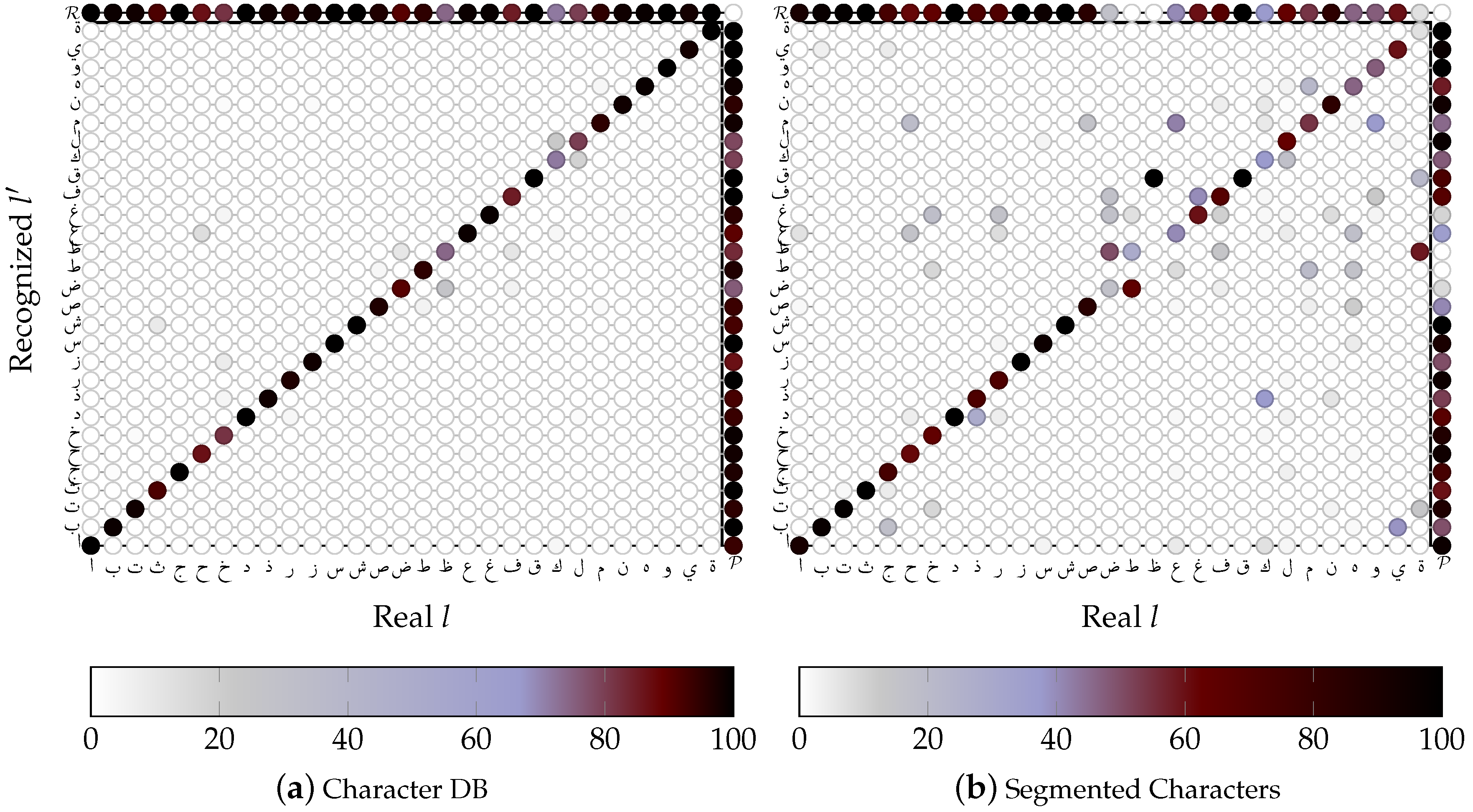
4.2. Character Recognition
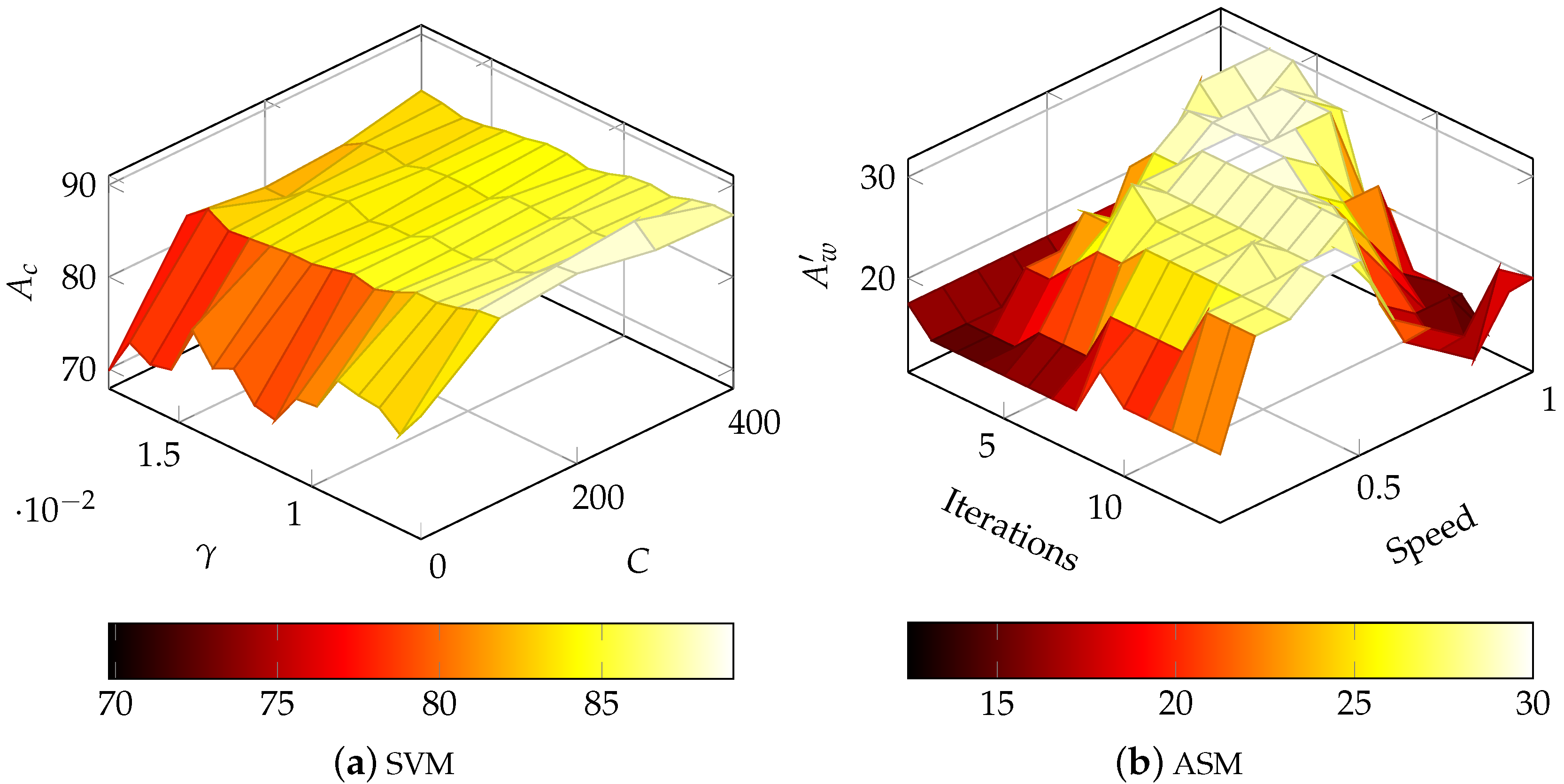
4.2.1. SVM based OCR
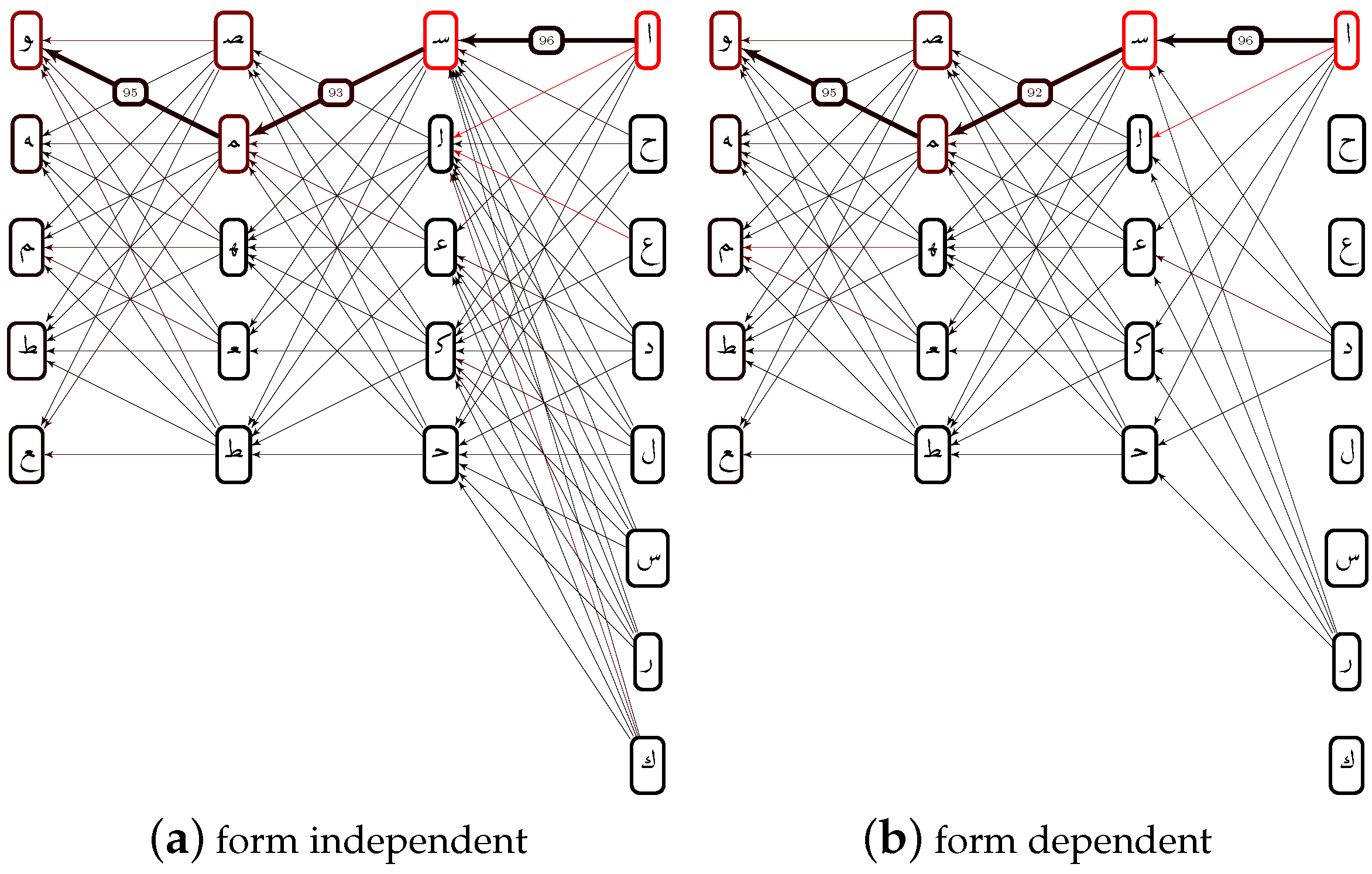
Influence of the Character Form
4.2.2. ASM-Based OCR
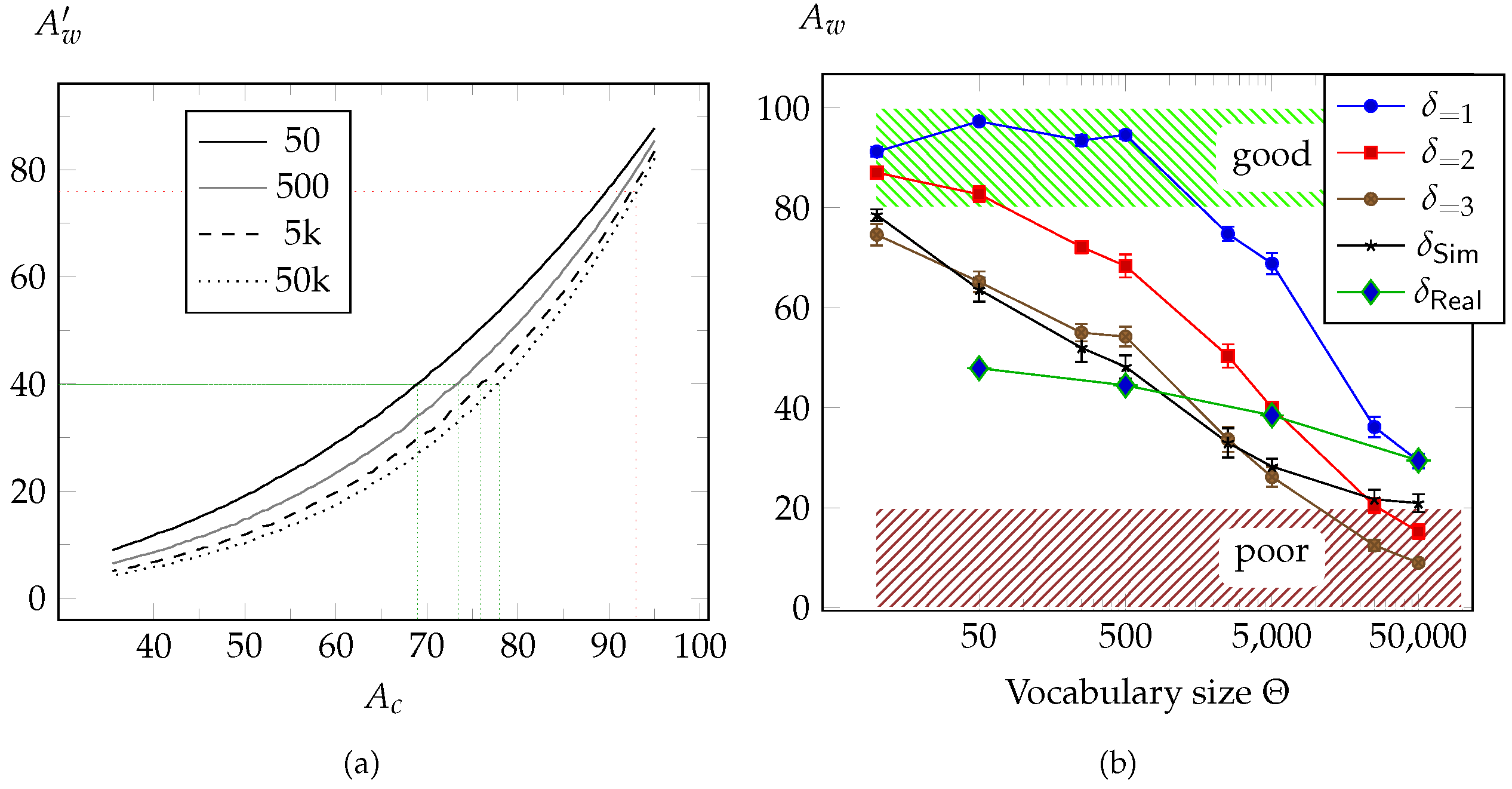
4.3. Word Recognition
ASM vs. SVM
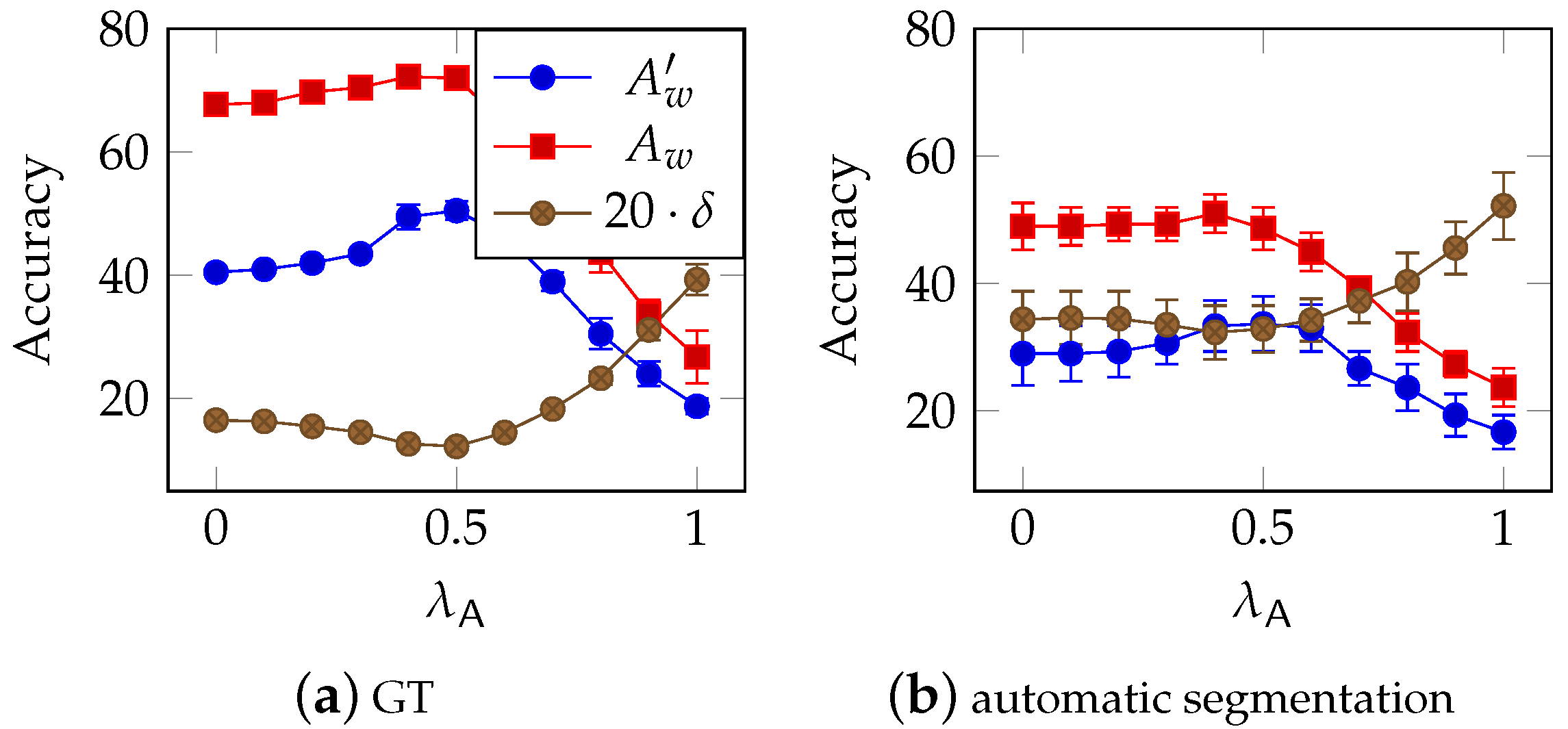
4.4. Error Correction
4.4.1. Character Level Word Correction
4.4.2. Word Level Error Correction
4.4.3. Computational Effort
5. Conclusions and Future Work
Acknowledgments
- This project was funded by the National Plan for Science, Technology and Innovation (MAARIFAH)—King Abdulaziz City for Science and Technology(KACST)—KSA award number Project code: 13-INF604-10.
- Part of this work (e.g., classification and optimization) is part of the project done within the Transregional Collaborative Research Centre SFB/TRR 62 Compnaion-Technology for Cognitive Technical Systems funded by the German Research Foundations (DFG).
Author Contributions
Conflicts of Interest
References
- Maegner, V.; Abed, H.E. Databases and competitions: strategies to improve Arabic recognition systems. In SACH’06: Proceedings of the 2006 Conference on Arabic And Chinese Handwriting Recognition; Springer-Verlag: Collage Park, MD, USA, 2008; pp. 82–103. [Google Scholar]
- Sajedi, H. Handwriting recognition of digits, signs, and numerical strings in Persian. Comput. Electr. Eng. 2016, 49, 52–65. [Google Scholar] [CrossRef]
- Abdelaziz, I.; Abdou, S. AltecOnDB: A Large-Vocabulary Arabic Online Handwriting Recognition Database. Available online: http://arxiv.org/abs/1412.7626 (accessed on 7 March 2016).
- Elarian, Y.; Al-Muhsateb, H.A.; Ghouti, L.M. Arabic Handwriting Synthesis. In Proceesings of the First International Workshop on Frontiers in Arabic Handwriting Recognition, Istanbul, Turkey, 22 August 2010.
- Elarian, Y.; Ahmad, I.; Awaida, S.; Al-Khatib, W.G.; Zidouri, A. An Arabic handwriting synthesis system. Pattern Recognit. 2015, 48, 849–861. [Google Scholar] [CrossRef]
- Elzobi, M.; Al-Hamadi, A.; Al Aghbari, Z.; Dinges, L. IESK-ArDB: A database for handwritten Arabic and optimized topological segmentation approach. Int. J. Doc. Anal. Recognit. 2013, 16, 295–308. [Google Scholar] [CrossRef]
- Lorigo, L.M.; Govindaraju, V. Offline Arabic Handwriting Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 712–724. [Google Scholar] [CrossRef] [PubMed]
- Hollerbach, J.M. An oscillation theory of handwriting. Biol. Cybernet. 1981, 39, 139–156. [Google Scholar] [CrossRef]
- Gangadhar, G.; Joseph, D.; Chakravarthy, V.S. An oscillatory neuromotor model of handwriting generation. IJDAR 2007, 10, 69–84. [Google Scholar] [CrossRef]
- Plamondon, R.; Guerfali, W. The Generation of Handwriting with Delta-lognormal Synergies; Rapport Technique; Laboratoire Scribens, Département de génie Électrique et de Génie Informatique, École Polytechnique de Montréal: Montréal, QC, Canada, 1996. [Google Scholar]
- Guyon, I. Handwriting Synthesis From Handwritten Glyphs. Available online: http://citeseerx.ist.psu. edu/viewdoc/summary?doi=10.1.1.33.1962 (accessed on 7 March 2016).
- Khader, A.; Saudagar, J.; Mohammed, H.V. Concatenation Technique for Extracted Arabic Characters for Efficient Content-based Indexing and Searching. In Proceedings of the Second International Conference on Computer and Communication Technologies, Advances in Intelligent Systems and Computing, Hyderabad, India, 24–26 July 2015.
- Varga, T.; Bunke, H. Perturbation models for generating synthetic training data in handwriting recognition. In Machine Learning in Document Analysis and Recognition; Marinai, S., Fujisawa, H., Eds.; Springer: Berlin, Germany, 2008; pp. 333–360. [Google Scholar]
- Zheng, Y.; Doermann, D.S. Handwriting Matching and Its Application to Handwriting Synthesis. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR 2005), Seoul, Korea, 29 August–1 September 2005; pp. 861–865.
- Viswanath, P.; Murty, M.N.; Bhatnagar, S. Overlap pattern synthesis with an efficient nearest neighbor classifier. Pattern Recognit. 2005, 38, 1187–1195. [Google Scholar] [CrossRef]
- Choi, H.I.; Cho, S.J.; Kim, J.H. Generation of Handwritten Characters with Bayesian network based On-line Handwriting Recognizers. ICDAR 2003. [Google Scholar] [CrossRef]
- Dolinsky, J.; Takagi, H. Synthesizing handwritten characters using naturalness learning. In Proceedings of the IEEE International Conferenceon Computational Cybernetics (ICCC), Gammarth, Tunisia, 19–21 October 2007; pp. 101–106.
- Al-Zubi, S. Active Shape Structural Model. Ph.D. Thesis, Otto-von-Guericke-University Magdeburg, Magdeburg, Germany, 2004. [Google Scholar]
- Shi, D.; Gunn, S.R.; Damper, R.I. Handwritten Chinese Radical Recognition Using Nonlinear Active Shape Models. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 277–280. [Google Scholar] [CrossRef]
- Helmers, M.; Bunke, H. Generation and use of synthetic training data in cursive handwriting recognition. In Pattern Recognition and Image Analysis; Perales, F.J., Campilho, A.J.C., de la Blanca, N.P., Sanfeliu, A., Eds.; Springer: Berlin, Germany, 2003; Volume 2652, pp. 336–345. [Google Scholar]
- Jawahar, C.V.; Balasubramanian, A.; Meshesha, M.; Namboodiri, A.M. Retrieval of Online Handwriting by Synthesis and Matching. Pattern Recognit. 2009, 42, 1445–1457. [Google Scholar] [CrossRef]
- Rao, P. Shape Vectors: An Efficient Parametric Representation for the Synthesis and Recognition of Hand Script Characters; Saddhana: Bangalore, India, 1993; Volume 18. [Google Scholar]
- Lin, Z.; Wan, L. Style-preserving English Handwriting Synthesis. Pattern Recognit. 2007, 40, 2097–2109. [Google Scholar] [CrossRef]
- Wang, J.; Wu, C.; Xu, Y.-Q.; Shum, H.-Y. Combining Shape and Physical Models for On-Line Cursive Handwriting Synthesis. Int. J. Doc. Anal. Recognit. 2003, 7, 219–227. [Google Scholar] [CrossRef]
- Thomas, A.O.; Rusu, A.; Govindaraju, V. Synthetic handwritten CAPTCHAs. Pattern Recognit. 2009, 42, 3365–3373. [Google Scholar] [CrossRef]
- Gaur, S.; Sonkar, S.; Roy, P.P. Generation of synthetic training data for handwritten Indic script recognition. In Proceedings of the 13th International Conference on Document Analysis and Recognition, Tunis, Tunisia, 23–26 August 2015; pp. 491–495.
- Xu, Y.; Shum, H.; Wang, J.; Wu, C. Learning-Based System and Process for Synthesizing Cursive Handwriting. U.S. Patent 7,227,993, 5 June 2007. [Google Scholar]
- Saabni, R.M.; El-Sana, J.A. Comprehensive Synthetic Arabic Database for On/off-Line Script Recognition Research; Springer-Verlag: Berlin, Germany, 2012. [Google Scholar]
- Dinges, L.; Al-Hamadi, A.; Elzobi, M.; El etriby, S.; Ghoneim, A. ASM based Synthesis of Handwritten Arabic Text Pages. Sci. World J. 2015, 2015, 323575. [Google Scholar] [CrossRef] [PubMed]
- Aghbari, Z.A.; Brook, S. HAH manuscripts: A holistic paradigm for classifying and retrieving historical Arabic handwritten documents. Expert Syst. Appl. 2009, 36, 10942–10951. [Google Scholar] [CrossRef]
- Steinherz, T.; Rivlin, E.; Intrator, N. Off-Line Cursive Script Word Recognition—A Survey. Int. J. Doc. Anal. Recogn. 1999, 2, 90–110. [Google Scholar]
- Al-Jawfi, R. Handwriting Arabic character recognition LeNet using neural network. Int. Arab. J. Inf. Technol. 2009, 6, 304–309. [Google Scholar]
- Ding, X.; Liu, H. Segmentation-driven offline handwritten Chinese and Arabic script recognition. In Proceedings of the 2006 Conference on Arabic and Chinese Handwriting Recognition, College Park, MD, USA, 27–28 September 2006; Springer-Verlag: Berlin, Germany, 2008; pp. 196–217. [Google Scholar]
- Rehman, A.; Mohamed, D.; Sulong, G. Implicit Vs Explicit based Script Segmentation and Recognition: A Performance Comparison on Benchmark Database. Int. J. Open Problems Compt. Math. 2009, 2, 352–364. [Google Scholar]
- Shaik, N.; Ahmed, Z.; Ali, G. Segmentation of Arabic Text into Characters for Recognition. IMTIC 2008, 20, 11–18. [Google Scholar]
- Lorigo, L.; Govindaraju, V. Segmentation and Pre-Recognition of Arabic Handwriting. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 29 Aigust–1 September 2005; pp. 605–609.
- Shanbehzadeh, J.; Pezashki, H.; Sarrafzadeh, A. Features Extraction from Farsi Hand Written Letters. Available online: http://digital.liby.waikato.ac.nz/conferences/ivcnz07/papers/ivcnz07-paper7.pdf (accessed on 7 March 2016).
- Camastra, F. A SVM-based cursive character recognizer. Pattern Recognit. 2007, 40, 3721–3727. [Google Scholar] [CrossRef]
- Oneto, L.; Ridella, S.; Anguita, D. Tikhonov, Ivanov and Morozov Regularization for Support Vector Machine Learning. Mach. Learn. 2015. [Google Scholar] [CrossRef]
- Parkins, A.D.; Nandi, A.K. Simplifying Hand Written Digit Recognition Using a Genetic Algorithm. In Proceedings of the 11th European Signal Processing Conference, Toulouse, France, 3–6 September 2002; pp. 1–4.
- Chergui, L.; Maamar, K. SIFT descriptors for Arabic handwriting recognition. Int. J. Comput. Vis. Robot. 2015, 5, 441–461. [Google Scholar] [CrossRef]
- Han, Y.; Park, K.; Hong, J.; Ulamin, N.; Lee, Y.K. Distance-Constraint k-Nearest Neighbor Searching in Mobile Sensor Networks. Sensors 2015, 15, 18209–18228. [Google Scholar] [CrossRef] [PubMed]
- Aghbari, Z.A.; Al-Hamadi, A. Efficient KNN search by linear projection of image clusters. Int. J. Intell. Syst. 2011, 26, 844–865. [Google Scholar] [CrossRef]
- Del Val, L.; Izquierdo-Fuente, A.; Villacorta, J.J.; Raboso, M. Acoustic Biometric System Based on Preprocessing Techniques and Linear Support Vector Machines. Sensors 2015, 15, 14241–14260. [Google Scholar] [CrossRef] [PubMed]
- Cireşan, D.; Meier, U.; Schmidhuber, J. Multi-column Deep Neural Networks for Image Classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3642–3649.
- Kukich, K. Techniques for Automatically Correcting Words in Text. ACM Comput. Surv. 1992, 24, 377–439. [Google Scholar] [CrossRef]
- Wordfreq. Available online: https://github.com/zacharydenton/zaum/blob/master/ public/data/ wordfreq/ar/ar_50K.txt (accessed on 7 March 2016).
- Dinges, L.; Al-Hamadi, A.; Elzobi, M. An Active Shape Model based approach for Arabic Handwritten Character Recognition. In Proceedings of the 11th International Conference on Signal Processing, Beijing, China, 21–25 October 2012; pp. 1194–1198.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| i | e | m | b | i | e | m | b | ||
|---|---|---|---|---|---|---|---|---|---|
| Alif | ﺍ | ﺎ | Dhad | ﺽ | ﺾ | ﻀ | ﺿ | ||
| Ba | ب | ﺐ | ﺒ | ﺑ | Taa | ط | ﻂ | ﻄ | ﻃ |
| Ta | ت | ﺖ | ﺘ | ﺗ | Dha | ظ | ﻆ | ﻈ | ﻇ |
| Tha | ث | ﺚ | ﺜ | ﺛ | Ayn | ع | ﻊ | ﻌ | ﻋ |
| Jim | ج | ﺞ | ﺠ | ﺟ | Ghayn | غ | ﻎ | ﻐ | ﻏ |
| Ha | ح | ﺢ | ﺤ | ﺣ | Fa | ف | ﻒ | ﻔ | ﻓ |
| Kha | خ | ﺦ | ﺨ | ﺧ | Qaf | ق | ﻖ | ﻘ | ﻗ |
| Dal | د | ﺪ | Kaf | ك | ﻚ | ﻜ | ﻛ | ||
| Thal | ذ | ﺬ | Lam | ل | ﻞ | ﻠ | ﻟ | ||
| Ra | ر | ﺮ | Mim | م | ﻢ | ﻤ | ﻣ | ||
| Zai | ز | ﺰ | Nun | ن | ﻦ | ﻨ | ﻧ | ||
| Sin | س | ﺲ | ﺴ | ﺳ | He | ه | ﻪ | ﻬ | ﻫ |
| Shin | ش | ﺶ | ﺸ | ﺷ | Waw | و | ﻮ | ||
| Sad | ص | ﺺ | ﺼ | ﺻ | Ya | ي | ﻲ | ﻴ | ﻳ |
| Database | IESK-arDB | IESK-arDB-Syn | |
|---|---|---|---|
| Number of Word Samples | 2540 | 9000 | 8000 |
| Error per word | 1.67 ± 0.13 | 0.96 ± 0.019 | |
| Error per letter | 0.35 ± 0.03 | 0.34 ± 5 × 10 | 0.27 ± 6.16 × 10 |
| Over segmentation (per word) | 0.80 ± 0.1 | 0.86 ± 6 × 10 | 0.41 ± 7.41 × 10 |
| Under segmentation (per word) | 0.90 ± 0.07 | 0.88 ± 0.019 | 0.55 ± 0.013 |
| Perfect segmentation (per word) | 0.17 ± 2.5 × 10 | 0.13 ± 7 × 10 | 0.35 ± 8.1 × 10 |
| Character Form | i | e | m | b |
|---|---|---|---|---|
| average Precision | 90(96) | 77.6(87.2) | 89.3(82.3) | 92.5(89.7) |
| average Recall | 89.2(95.9) | 75.8(89.6) | 87.(79.6) | 91.1(85.7) |
| F-score | 88.9(95.6) | 75.5(87.1) | 87.6(80.6) | 91.4(87.2) |
| Rank | ASM | ASM | SVM | SVM |
|---|---|---|---|---|
| 1 | 49 | 74 ± 1.7 | 34 ± 1.7 | 67 ± 0.0 |
| 2 | 53 ± 0.67 | 78 ± 0.33 | 39 ± 0.0 | 75 ± 2.0 |
| 10 | 63 ± 1.3 | 86 ± 0.67 | 50 ± 3.0 | 83 ± 1.0 |
| Fails | 37 ± 1.3 | 14 ± 0.67 | 50 ± 3.0 | 17 ± 1.0 |
| 1.6 ± 0.077 | 0.69 ± 0.043 | 2.0 ± 0.16 | 0.98 ± 0.12 | |
| 49 ± 0.67 | 74 ± 1.7 | 34 ± 1.7 | 67 ± 0.0 | |
| 27 ± 0.33 | 54 ± 0.1 | 13 ± 0.67 | 38 ± 4.7 |
| Original | |||||
|---|---|---|---|---|---|
| نستطيع | نسدطيع | نلستطي | كستتطيع | فزهطيع | نستﺽيو |
| ﺍن | ﺍ | سلي | ﺍن | ﺍن | |
| كﺍن | كﺍزن | ﺍطن | صكن | صذن | كﺍن |
| ﺍلجسم | حﺍلجسم | ﺍلجسمسم | طلةسم | ﺍسسم | ﺍلبسم |
| رغم | رزغم | ررغم | ت | فجت | غغم |
| من | ون | ص | كن | من | من |
| Segmentation | Classification | /word | |
|---|---|---|---|
| (&Preprocessing) | SVM | ASM | |
| x | 0.06 ± 8.8 × 10−3 | ||
| x | |||
| x | x | ||
| x | x | ||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinges, L.; Al-Hamadi, A.; Elzobi, M.; El-etriby, S. Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research. Sensors 2016, 16, 346. https://doi.org/10.3390/s16030346
Dinges L, Al-Hamadi A, Elzobi M, El-etriby S. Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research. Sensors. 2016; 16(3):346. https://doi.org/10.3390/s16030346
Chicago/Turabian StyleDinges, Laslo, Ayoub Al-Hamadi, Moftah Elzobi, and Sherif El-etriby. 2016. "Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research" Sensors 16, no. 3: 346. https://doi.org/10.3390/s16030346
APA StyleDinges, L., Al-Hamadi, A., Elzobi, M., & El-etriby, S. (2016). Synthesis of Common Arabic Handwritings to Aid Optical Character Recognition Research. Sensors, 16(3), 346. https://doi.org/10.3390/s16030346