
A Game Theory Algorithm for Intra-Cluster Data Aggregation in a Vehicular Ad Hoc Network


Abstract
:1. Introduction
2. Related Works
3. Problem Statement
4. MGADA
4.1. Cluster Initialization
4.2. Cluster Stabilization Stage
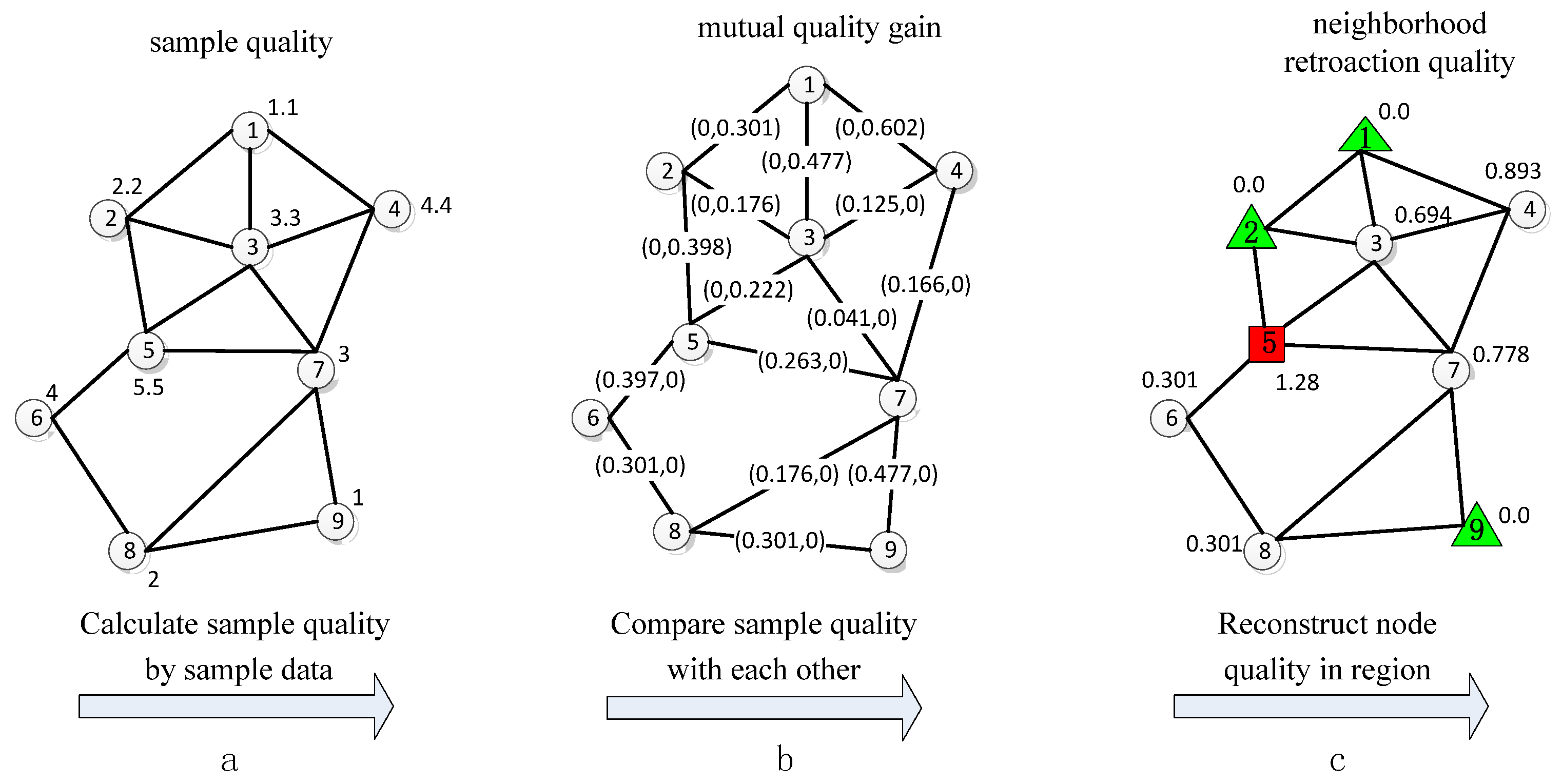
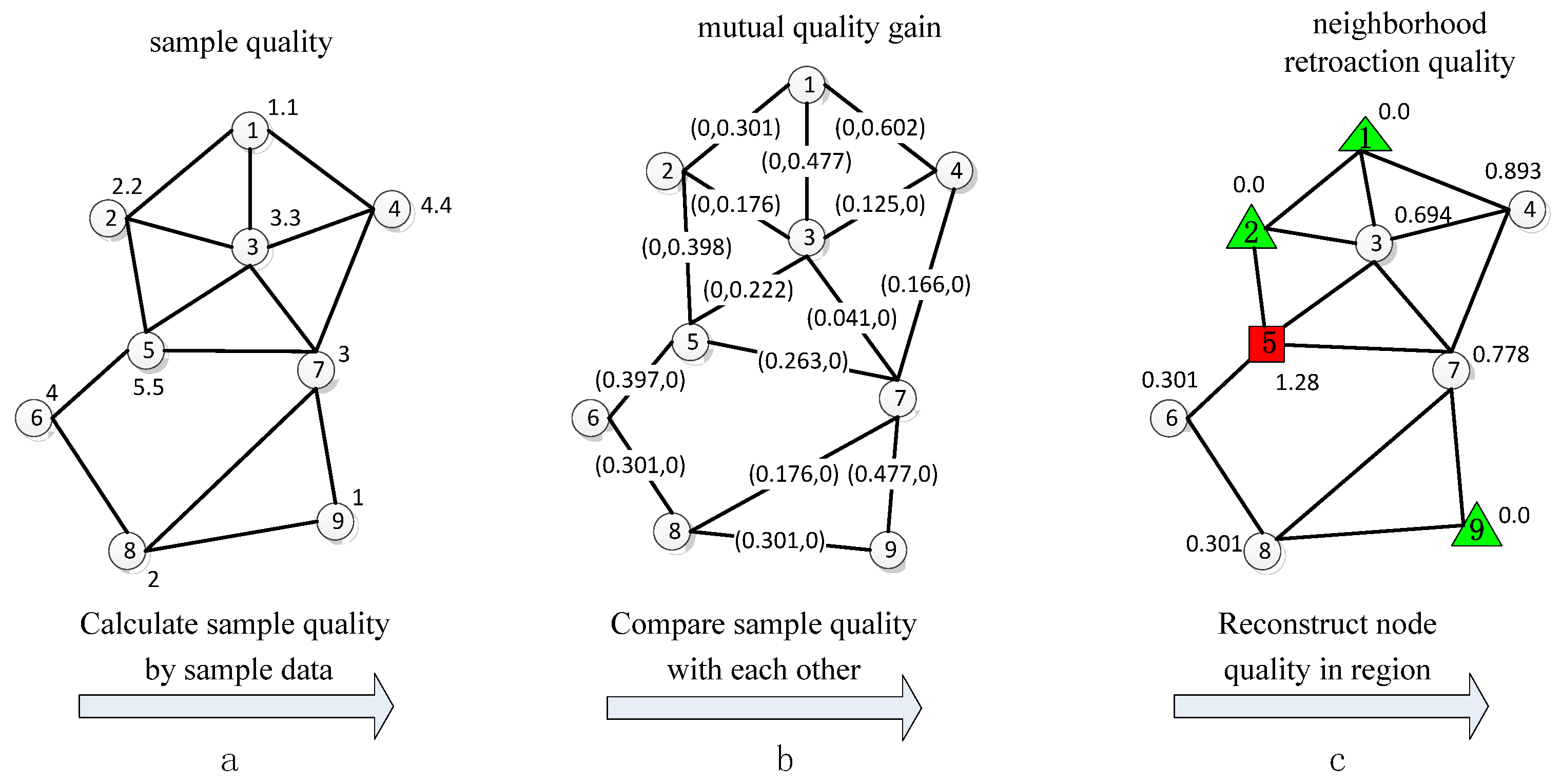
4.2.1. Sample Quality Estimation
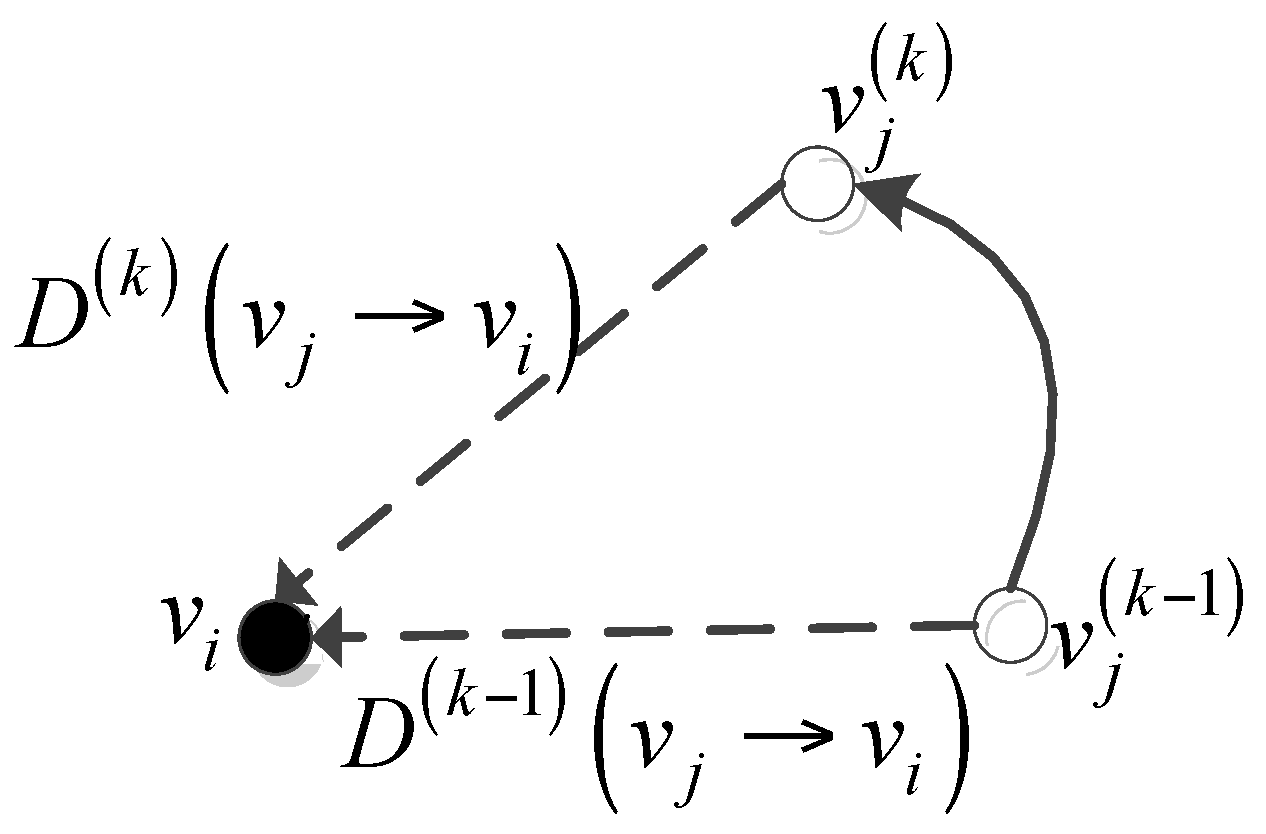
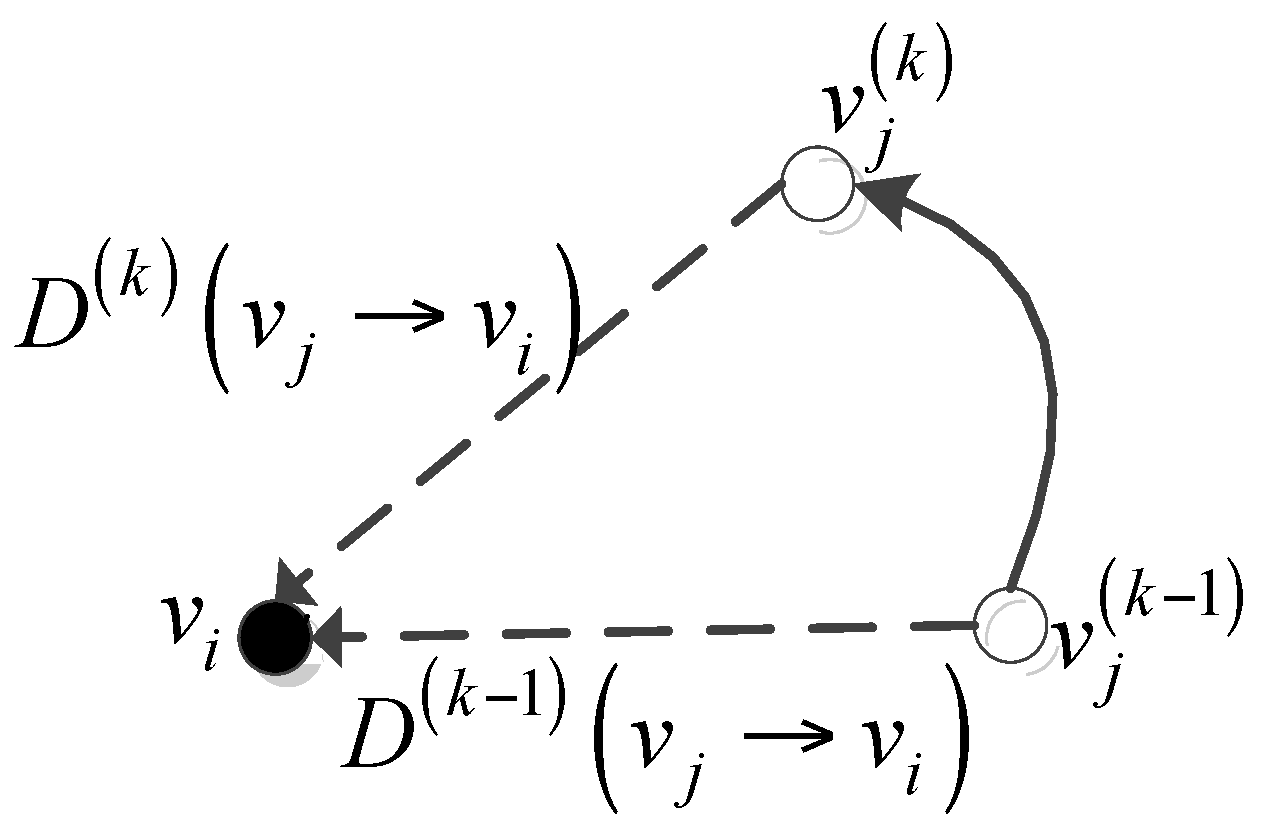
4.2.2. Cluster Stability Estimation
| Algorithm 1. Estimation of Sample Quality and Cluster Stability | |
| 1: | Procedure Estimation |
| 2: | k ← 1 |
| 3: | for k=1 to Number_of_Sampling_Period do |
| 4: | For for each x∈ V |
| 5: | Get sample data in k-th sampling period |
| 6: | Get x’s position in k-th sampling period |
| 7: | Update sliding window |
| 8: | |
| 9: | Broadcast message that contains sample data, position, SQk, node id |
| 10: | |
| 11: | |
| 12: | |
| 13: | Send message (NRQx[k], SVGk, x, k ) to cluster head |
| 14: | end for |
| 15: | k++ |
| 16: | end for |
| 17: | end procedure |
4.2.3. Game Formulation of Data Aggregation
(1) Multi-Player Game Model
(2) Nash Equilibrium
(3) Interruption Process
| Algorithm 2. GameProcess | |
| 1: | Procedure GameProcess |
| 2: | t ← 1 |
| 3: | P* ← Get Nash equilibrium solution by Equation (14) |
| 4: | R* ← 0 |
| 5: | ←Get Nash equilibrium solution by Equation (14) |
| 6: | if P has no decimal solution then |
| 7: | return |
| 8: | end if |
| 9: | Initialize cluster strategy P’ |
| 10: | for each x∈ V do |
| 11: | if (px != 0 && px!= 1) then |
| 12: | Px(t) ← randomly choose 0 or 1 |
| 13: | end if |
| 14: | end for |
| 15: | while the network composed by P is not stable |
| 16: | for each x∈ V do |
| 17: | Rx=generate a random number |
| 18: | if Rx < then |
| 19: | Px’ ← change node strategy |
| 20: | if f(P’) > f(P(t)) then |
| 21: | P(t+1) = P’ |
| 22: | else |
| 23: | P(t+1) = P(t) |
| 24: | end if |
| 25: | end if |
| 26: | end for |
| 27: | end while |
| 28: | end procedure |
(4) Protocol Description
- (1)
- Each node collects a series of sampling data and stores them in the sliding window. Each node broadcasts its own reliability in the “Reliability” message to its neighbors. The “Reliability” message contains the following information: the number of clock period, node ID, node reliability, and node position.
- (2)
- Each node calculates its NRQ and SVG when it receives the “Reliability” message from its neighbors. It then sends its own NRG and SVG in the “Attribute” message to the cluster head. The “Attribute” message contains the number of clock period, node ID, NRQ, and SVG.
- (3)
- The cluster head calculates the CRD and CVD after receiving all the “Attribute” messages from its cluster members and then performs the game process to obtain the transmission strategy.
- (4)
- After the game process, the cluster head broadcasts a “Confirm” message, which contains the node ID of the cluster members selected as the sending nodes to its cluster members. Then the sending nodes send a “Data” message, which contains the number of clock period, node ID, and the sampling value, to the cluster head.
- (5)
- The cluster head aggregates the sampling data from the sending nodes and transmits the aggregated data to the sink node.
4.3. Cluster Reconstruction Stage
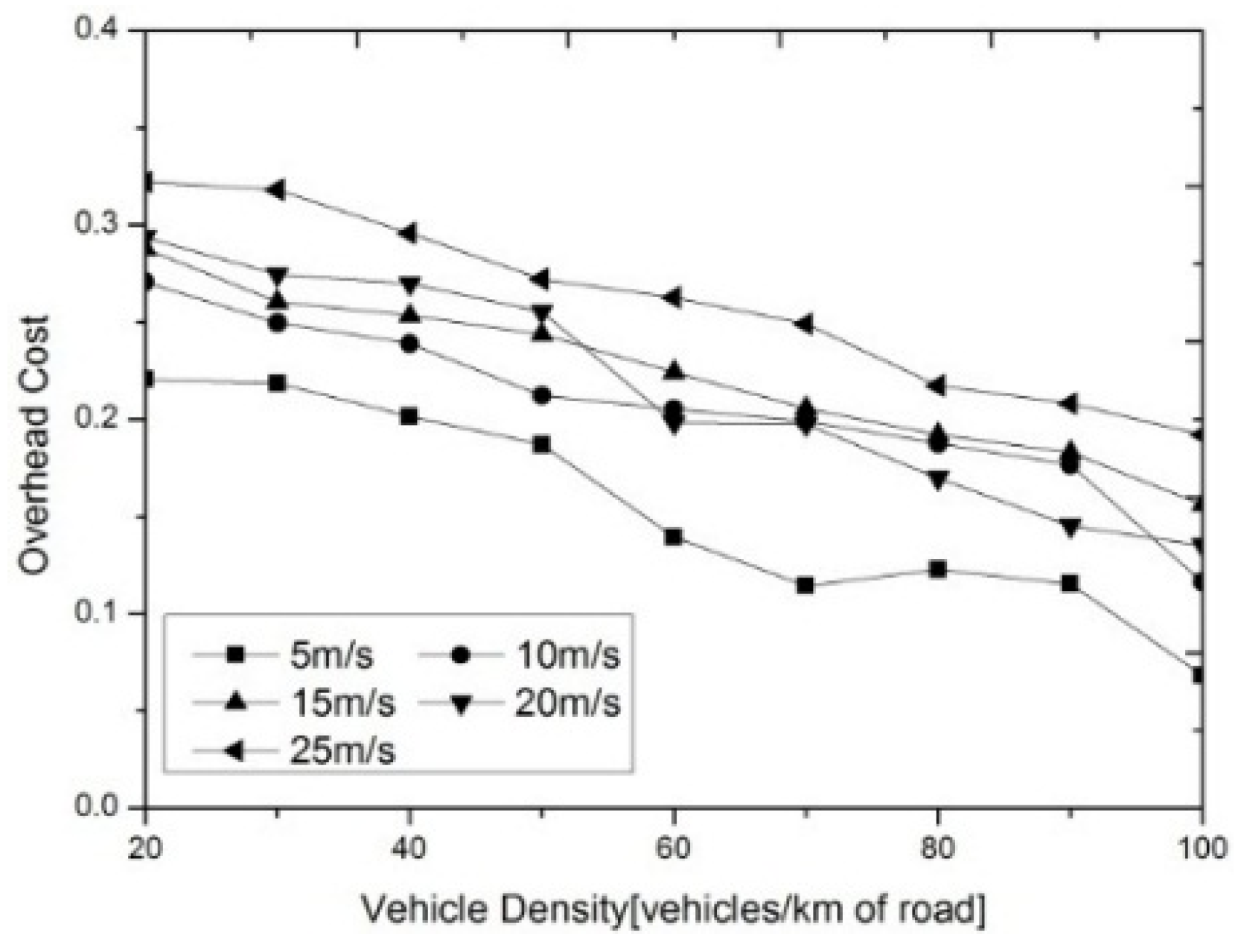
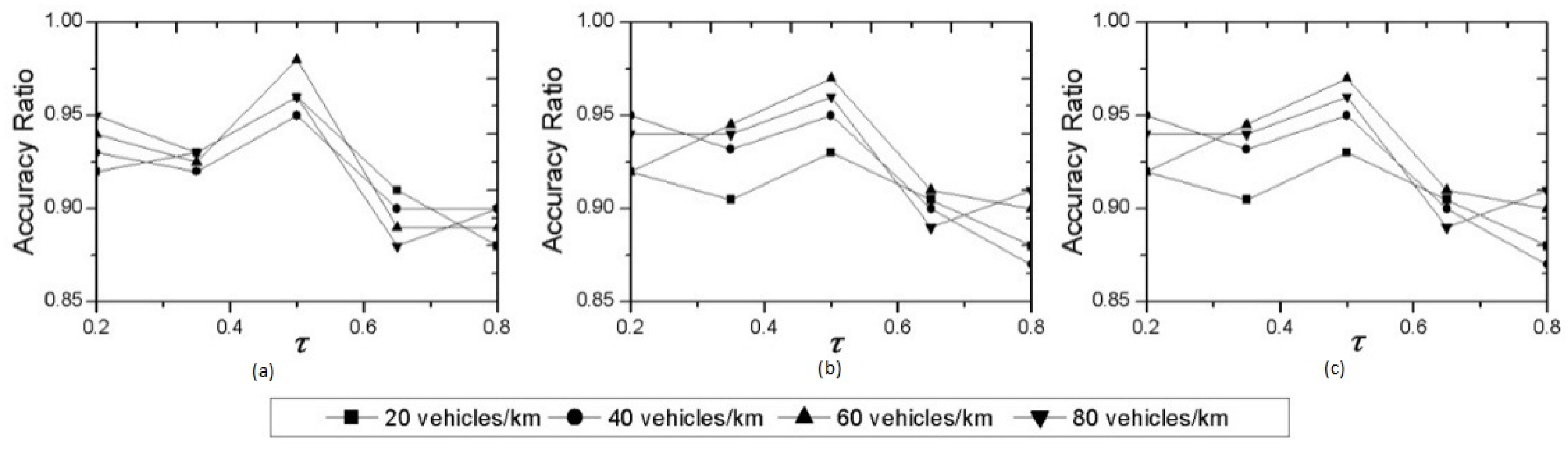
5. Experiments
5.1. Simulation Settings
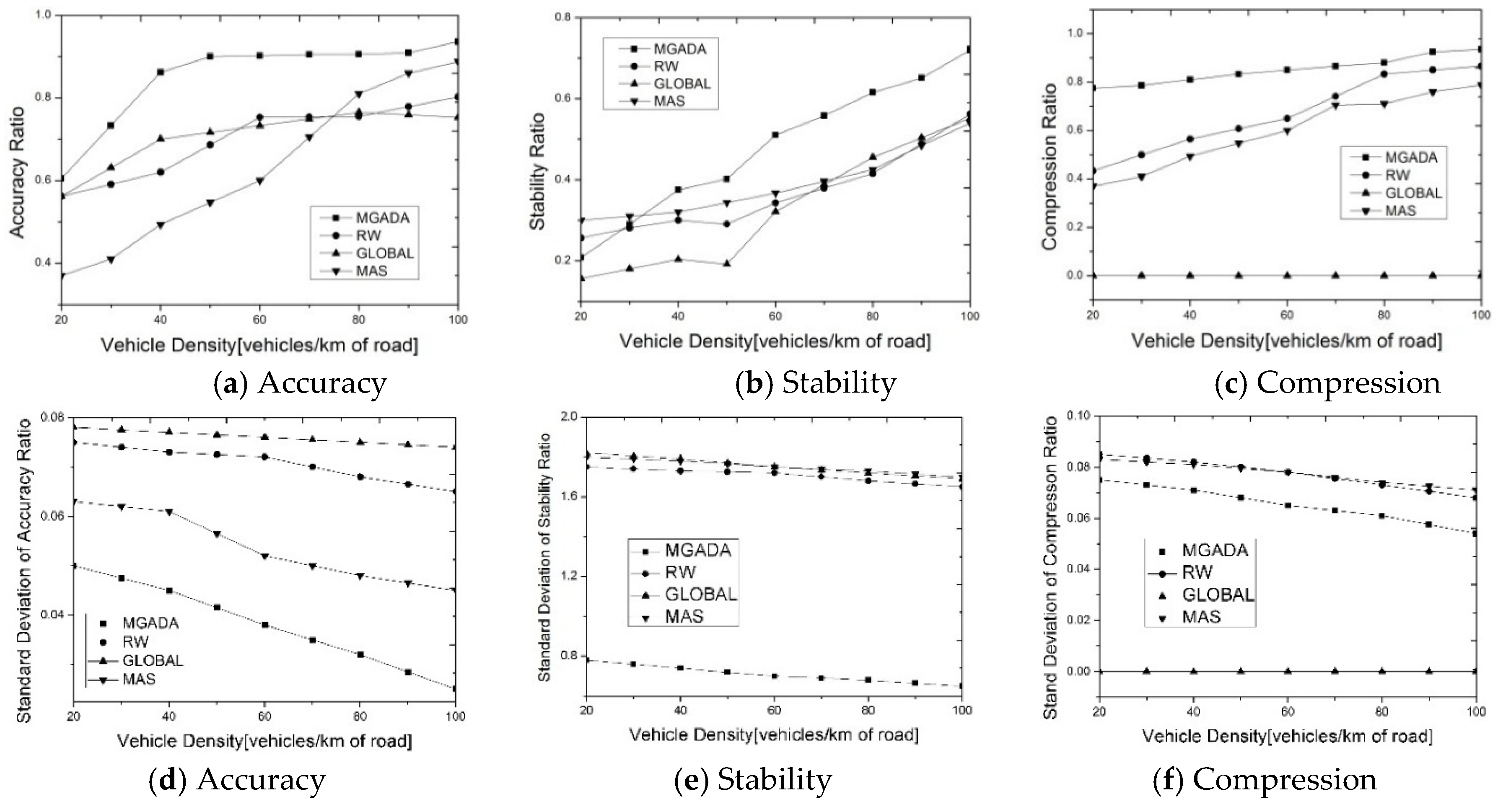
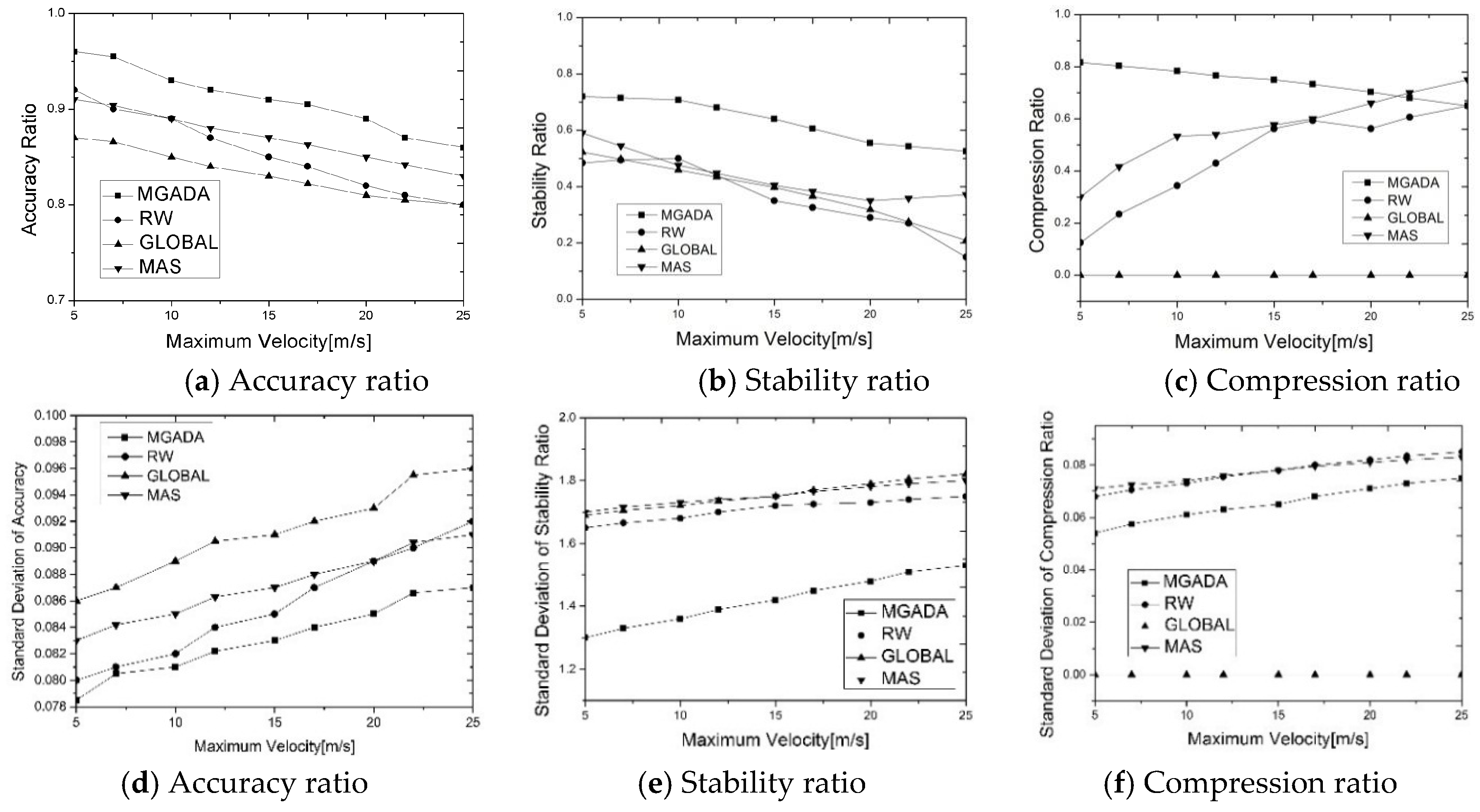
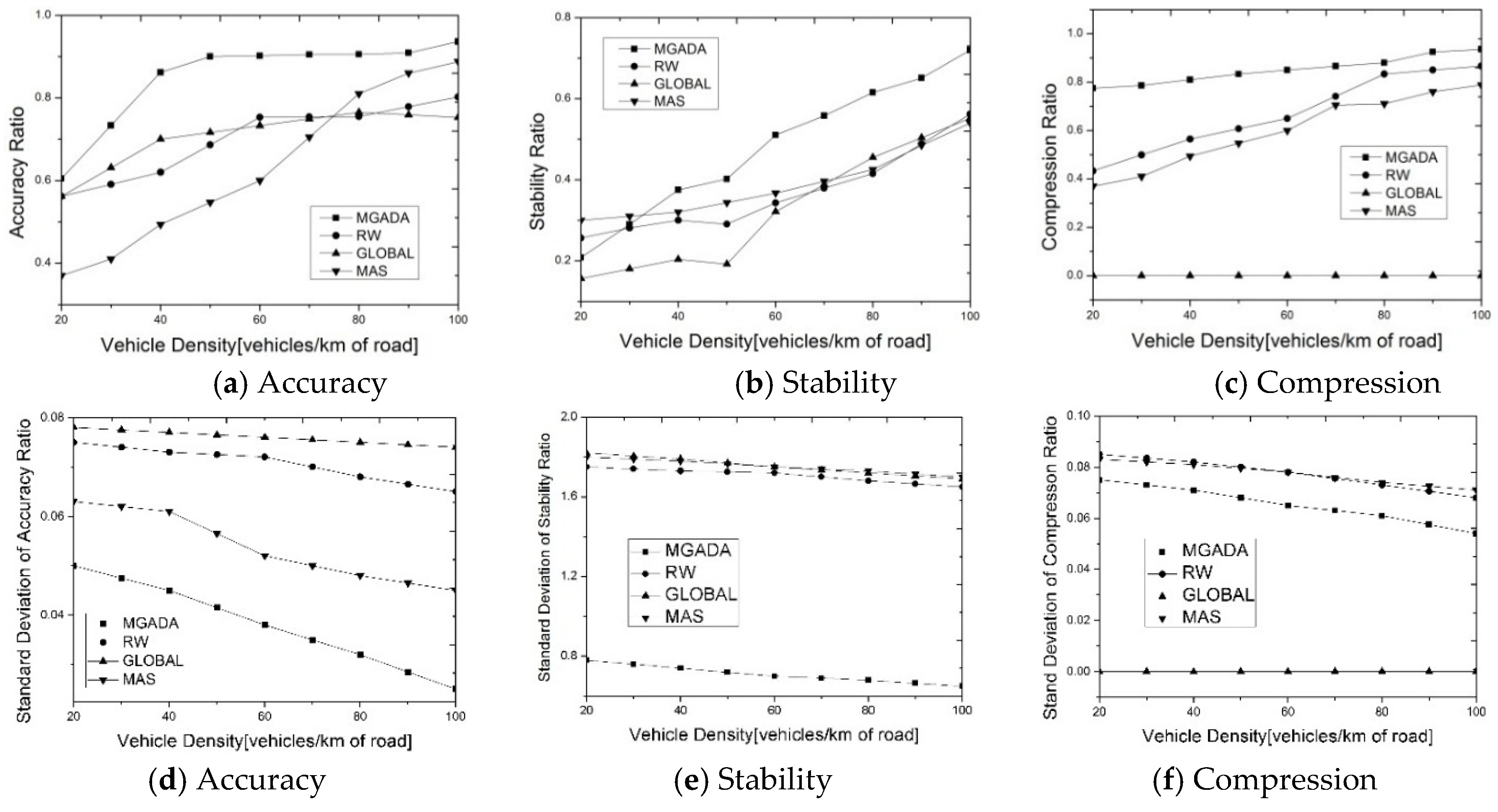
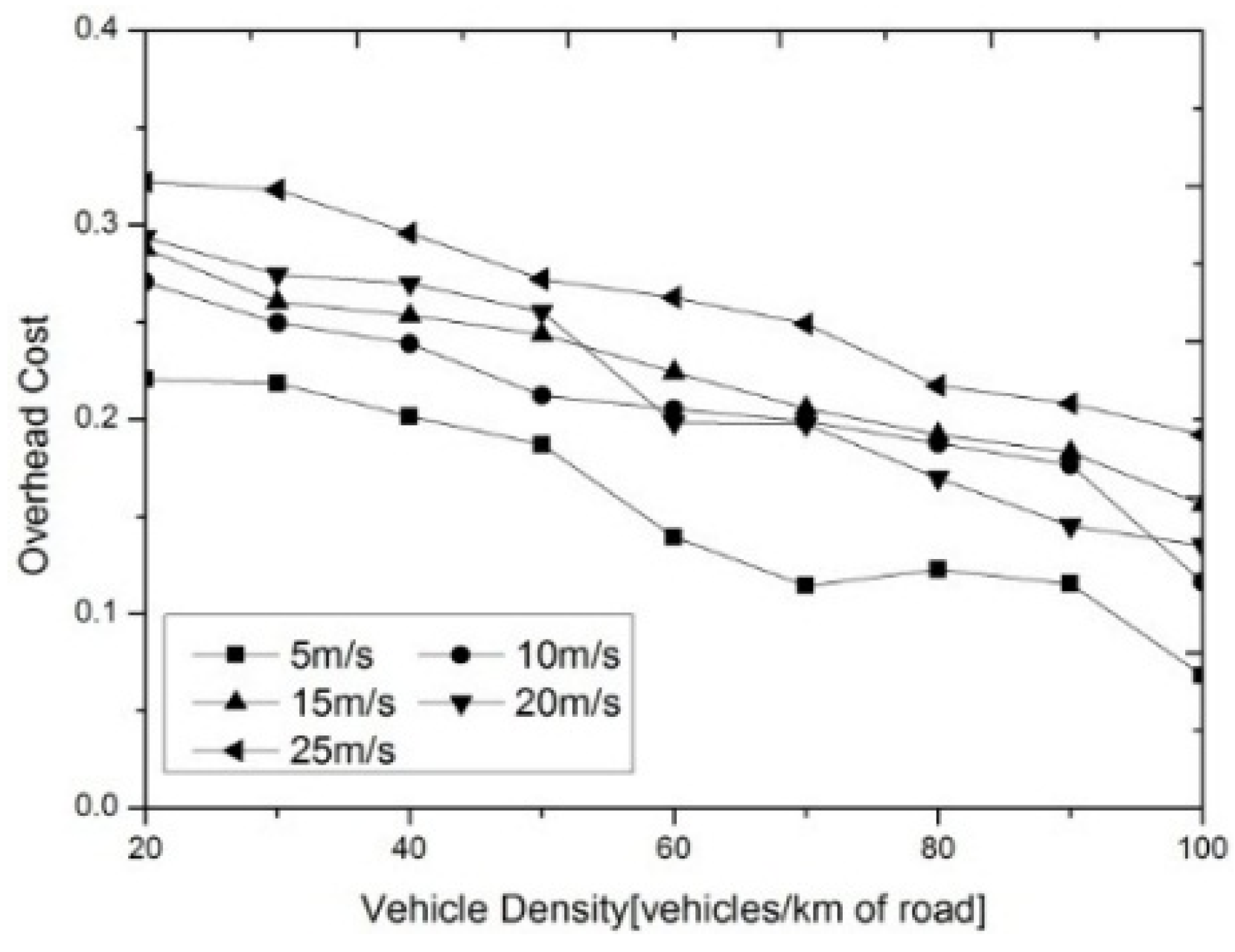
5.2. Analysis of Experimental Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proof of the Existence of a Unique Nash equilibriumin MGADA
Appendix B. Solution to Nash equilibrium
References
- Bedi, P.; Jindal, V. Use of big data technology in vehicular ad-hoc networks. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics, New Delhi, India, 24–27 September 2014; pp. 1677–1683.
- Gupta, H.; Navda, V.; Das, S.; Chowdhary, V. Efficient gathering of correlated data in sensor networks. In Proceedings of the 6th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Urbana-Champaign, IL, USA, 25–28 May 2005; pp. 402–413.
- Wen, Y.F.; Anderson, T.A.F.; Powers, D.M.W. On energy-efficient aggregation routing and scheduling in IEEE 802.15. 4-based wireless sensor networks. Wirel. Commun. Mob. Comput. 2014, 14, 232–253. [Google Scholar] [CrossRef]
- Wei, Z.; Tang, H.; Yu, F.R.; Wang, M. Trust establishment with data aggregation for secure routing in MANETs. IEEE Int. Conf. Commun. 2014. [Google Scholar] [CrossRef]
- Liao, X.C.; Qiu, M.; Mai, H.R. The Study on data aggregation algorithms of multi-sensor based on parameter-estimation. Chin. J. Sens. Actuators 2007, 20, 193–197. [Google Scholar]
- Dong, G.J.; Zhang, Y.S.; Dai, C.G.; Fan, Y.H. The processing of information aggregation based on rough set theory. Chin. J. Sci. Instrum. 2005, 26, 570–571. [Google Scholar]
- Zhang, W.; Das, S.K.; Liu, Y. A trust based framework for secure data aggregation in wireless sensor networks. In Proceedings of the 3rd Annual IEEE Communications Society on Sensor and Ad Hoc Communications and Networks, Reston, VA, USA, 28 September 2006; pp. 60–69.
- Kannan, R.; Iyengar, S. Game-theoretic models for reliable path-length and energy-constrained routing with data aggregation in wireless sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 1141–1150. [Google Scholar] [CrossRef]
- Niyato, D.; Hossain, E.; Rashid, M.M.; Bhargava, V.K. Wireless sensor networks with energy harvesting technologies: A game-theoretic approach to optimal energy management. Wirel. Commun. 2007, 14, 90–96. [Google Scholar] [CrossRef]
- Hussain, S.; Matin, A.W.; Islam, O. Genetic algorithm for hierarchical wireless sensor networks. J. Netw. 2007, 2, 87–97. [Google Scholar] [CrossRef]
- Latiff, N.M.A.; Tsimenidis, C.C.; Sharif, B.S. Energy-aware clustering for wireless sensor networks using particle swarm optimization. In Proceedings of the 18th International Symposium on Personal, Indoor and Mobile Radio Communications, Athens, Greece, 3–7 September 2007; pp. 1–5.
- Chaudhury, B.P.; Nayak, A.K. Energy saving performance analysis of hierarchical data aggregation protocols used in wireless sensor network. In Intelligent Computing, Communication and Devices; Springer: Odisha, India, 2015. [Google Scholar]
- Lin, J.; Xiong, N.X.; Vasilakos, A.V.; Chen, G.L.; Guo, W.Z. Evolutionary game-based data aggregation model for wireless sensor networks. IET Commun. 2011, 5, 1691–1697. [Google Scholar] [CrossRef]
- Dehnie, S.; Guan, K.; Gharai, L.; Ghanadan, R.; Kumar, S. Reliable data fusion in wireless sensor networks: A dynamic Bayesian game approach. In Proceedings of the Military Communications Conference, Boston, MA, USA, 18–21 October 2009; pp. 1–7.
- Fan, K.W.; Liu, S.; Sinha, P. On the potential of structure-free data aggregation in sensor networks. IEEE Int. Conf. Comput. Commun. 2006, 6, 1–12. [Google Scholar]
- Mitra, G.; Chowdhury, C.; Neogy, S. Application of mobile agent in VANET for measuring environmental data. Proc. Appl. Innov. Mob. Comput. 2014, 2014, 48–53. [Google Scholar]
- Zhao, M.; Yang, Y. Bounded relay hop mobile data gathering in wireless sensor networks. IEEE Trans. Comput. 2012, 61, 265–277. [Google Scholar] [CrossRef]
- Wang, J.; Yin, Y.; Kim, J.U.; Lee, S.; Lai, C.F. A mobile-sink based energy-efficient clustering algorithm for wireless sensor networks. In Proceedings of the 12th International Conference on Computer and Information Technology, Chengdu, China, 27–29 October 2012; pp. 678–683.
- Lochert, C.; Scheuermann, B.; Caliskan, M.; Mauve, M. The feasibility of information dissemination in vehicular ad-hoc networks. In Proceedings of the 4th Annual Conference on Wireless on Demand Network Systems and Services, Oberguyrgl, Austria, 24–26 January 2007; pp. 92–99.
- Lochert, C.; Scheuermann, B.; Mauve, M. Probabilistic aggregation for data dissemination in VANETs. In Proceedings of the 4th ACM International Workshop on Vehicular Ad Hoc Networks, Montréal, Quebec, Canada, 10–14 September 2007; pp. 1–8.
- Rosen, J.B. Existence and uniqueness of equilibrium points for concave n-person games. Econometrica 1965, 33, 520–534. [Google Scholar] [CrossRef]
- Dietzel, S.; Peter, A.; Kargl, F. Secure cluster-based in-network information aggregation for vehicular networks. In Proceedings of the 81st IEEE International Conference on Vehicular Technology Conference, Glasgow, UK, 11–14 May 2015; pp. 1–5.
- Schoch, E.; Dietzel, S.; Bako, B.Z.; Kargl, F. A structure-free aggregation framework for vehicular ad hoc networks. Ad Hoc Netw. 2009, 11, 89–103. [Google Scholar]
- Dietzel, S.; Bako, B.; Schoch, E.; Kargl, F. A fuzzy logic based approach for structure-free aggregation in vehicular ad-hoc networks. In Proceedings of the 6th ACM International Workshop on Vehicular Inter-Networking, Beijing, China, 20–25 September 2009; pp. 79–88.
- Caliskan, M.; Graupner, D.; Mauve, M. Decentralized discovery of free parking places. In Proceedings of the 3rd International Workshop on Vehicular Ad Hoc Networks, Los Angeles, Ca, USA, 23–29 September 2006; pp. 30–39.
- Lochert, C.; Scheuermann, B.; Wewetzer, C.; Luebke, A.; Mauve, M. Data aggregation and roadside unit placement for a VANET traffic information system. In Proceedings of the 5th ACM International Workshop on Vehicular Inter-Networking, San Francisco, CA, USA, 14–19 September 2008; pp. 58–65.
- Dietzel, S.; Petit, J.; Kargl, F.; Scheuermann, B. In-network aggregation for vehicular ad hoc networks. Commun. Surv. Tutor. 2014, 16, 1909–1932. [Google Scholar] [CrossRef]
- Saraydar, C.; Mandayam, N.; Goodman, D. Efficient power control via pricing in wireless data networks. IEEE Trans. Commun. 2002, 50, 291–303. [Google Scholar] [CrossRef]
- Sengupta, S.; Chatterjee, M. Distributed power control in sensor networks: A game theoretic approach. In Proceedings of the 6th International Workshop on Distributed Computing, Kolkata, India, 27–30 December 2004; pp. 508–519.
- Teerapabkajorndet, W.; Krishnamurthy, P. A game theoretic model for power control in multi-rate mobile data networks. IEEE Int. Conf. Commun. 2003, 1, 56–60. [Google Scholar]
- Nurmi, P. Modelling routing in wireless ad hoc networks with dynamic Bayesian games. In Proceedings of the 1st Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, Santa Clara, CA, USA, 4–7 October 2004; pp. 63–70.
- Wischhof, L.; Ebner, A.; Rohling, H. Information dissemination in self-organizing intervehicle networks. IEEE Trans. Intell. Transp. Syst. 2005, 6, 90–101. [Google Scholar] [CrossRef]
- Fang, Z.; Bensaou, B. Fair bandwidth sharing algorithms based on game theory frameworks for wireless ad-hoc networks. In Proceedings of the 23rd Annual Joint Conference of the IEEE Computer and Communications Societies, Hong Kong, China, 7–11 March 2004; pp. 1284–1295.
- Alpcan, T.; Basar, T. A game-theoretic framework for congestion control in general topology networks. In Proceedings of the 41st IEEE Conference on Decision and Control, Las Vegas, NV, USA, 10–13 December 2002; pp. 1218–1224.
- Ren, H.; Meng, Q.H. Game-theoretic modeling of joint topology control and power scheduling for wireless heterogeneous sensor networks. IEEE Trans. Autom. Sci. Eng. 2009, 6, 610–625. [Google Scholar]
- Fan, P. Improving broadcasting performance by clustering with stability for inter-vehicle communication. In Proceedings of the 65th IEEE International Conference on Vehicular Technology, Dublin, Germany, 22–25 April 2007; pp. 2491–2495.
- Xia, H.; Jia, Z.P.; Zhang, Z.Y.; Edwin, H.S. A Link stability prediction-based multicast routing protocol in mobile ad hoc networks. Chin. J. Comput. 2013, 36, 926–936. [Google Scholar] [CrossRef]
- U.S. Census Bureau. TIGER, TIGER/Line and TIGER-Related Products. Available online: http://www.census.gov/geo/www/tiger/ (accessed on 17 February 2016).
- Gowrishankar, S.; Basavaraju, T.G.; Sarkar, S.K. Effect of random mobility models pattern in mobile ad hoc networks. Int. J. Comput. Sci. Netw. Secur. 2007, 7, 160–164. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Remark, Default Value |
|---|---|
| Simulation time | 1800 s |
| Area range | 10,000 m × 10,000 m |
| Maximum speed | 5, 10, 15, 20, 25 (m/s) |
| Vehicle Density | 20, 40, 60, 80, 100 (vehicles/km) |
| Sampling period | 30 s |
| w | Sliding window size, 10 |
| α | Adjustment factor in Equation (2), 0.5 |
| τ | Adjustment factor in Equation (14), 0.5 |
| Rtrans | Maximum transmission range, 300 m |
| Rnei | Neighborhood radius of cluster members, 100 m |
| Radio Propagation Model | Tow-ray ground |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Weng, S.; Guo, W.; Xiong, N. A Game Theory Algorithm for Intra-Cluster Data Aggregation in a Vehicular Ad Hoc Network. Sensors 2016, 16, 245. https://doi.org/10.3390/s16020245
Chen Y, Weng S, Guo W, Xiong N. A Game Theory Algorithm for Intra-Cluster Data Aggregation in a Vehicular Ad Hoc Network. Sensors. 2016; 16(2):245. https://doi.org/10.3390/s16020245
Chicago/Turabian StyleChen, Yuzhong, Shining Weng, Wenzhong Guo, and Naixue Xiong. 2016. "A Game Theory Algorithm for Intra-Cluster Data Aggregation in a Vehicular Ad Hoc Network" Sensors 16, no. 2: 245. https://doi.org/10.3390/s16020245