1. Introduction
In multi-target tracking (MTT) in clutters, the correspondence between the targets and the measurements is unknown, while the target number is unknown and even time-varying. The objective of MTT is to recursively estimate the target number and target states from a sequence of noisy and cluttered measurement sets [
1,
2].
One common approach for multi-target tracking is the combination of state estimation and data association, along with track initialization and termination [
3]. In fact, data association and state estimation are coupled issues, i.e., the association risk triggers the measurement misuse and the estimation error increases the association risk. In other words, their direct combination above is in principle not suitable to the high uncertainty case; for example, dense targets/dense clutter [
4].
Another approach is to apply random finite sets (RFSs) to represent the collection of individual targets and measurements, and hence recast the MTT problem as the Bayesian estimation problem based on finite set statistics so as to avoid data association risk [
4]. However, the propagation of the multi-target posterior probability density function (PDF) is computationally intensive, which stems from the high-dimension integrations in multi-target state space. Mahler [
5] proposed the first-order moment called the probability hypothesis density (PHD) of the PDF of the random set of state vectors. Vo and Ma [
6] proved that the PHD surface is a Gaussian mixture (GM) in both the linear and Gaussian cases. Clark and Vo [
7] analyzed the convergence property of the Gaussian Mixture Probability Hypothesis Density (GMPHD) filter. Up to now, PHD-related applications have been extended to many fields including visual target tracking [
8], maneuvering target tracking [
9,
10], ground target tracking [
11], extended target tracking [
12,
13], and sensor management [
14].
However, there are still two important but open issues about PHD:
The first is that the computational burden is still too intensive in many actual applications, especially in the case of dense clutters and intensive targets. One possible solution is to discern the measurement originality based on tracking gating [
15,
16]. Nevertheless, such a decision still faces mistake risks.
The second issue is that additional track extraction is needed because the standard PHD only outputs the track points without the corresponding track identities. But the presented track extraction algorithm [
17,
18] is too complex to implement.
In this paper, we present an adaptive collaborative GMPHD (ACo-GMPHD) filter with the capability for automatic track extraction for fast multi-target tracking in dense clutter. In the ACo-GMPHD, the persistent and birth target PHDs are updated respectively based on the corresponding measurement subsets, instead of based on all measurements, so that the computational complexity is expected to be reduced. Meanwhile, the collaboration mechanism among these PHDs regarding measurement utilization is adaptively established to avoid decision risks triggered by measurement partitions. In addition, permanent tracks and temporary tracks can be automatically extracted from the persistent and birth target PHDs. Simulations show that the proposed ACo-GMPHD greatly reduces the computational cost and significantly improves the track extraction, compared with the well-known GMPHD filter.
The remainder of this work is organized as follows.
Section 2 presents the MTT problem and briefly introduces the standard PHD filter. The ACo-GMPHD is proposed in
Section 3, and compared with the GMPHD filter via simulation in
Section 4. Finally,
Section 5 concludes this paper.
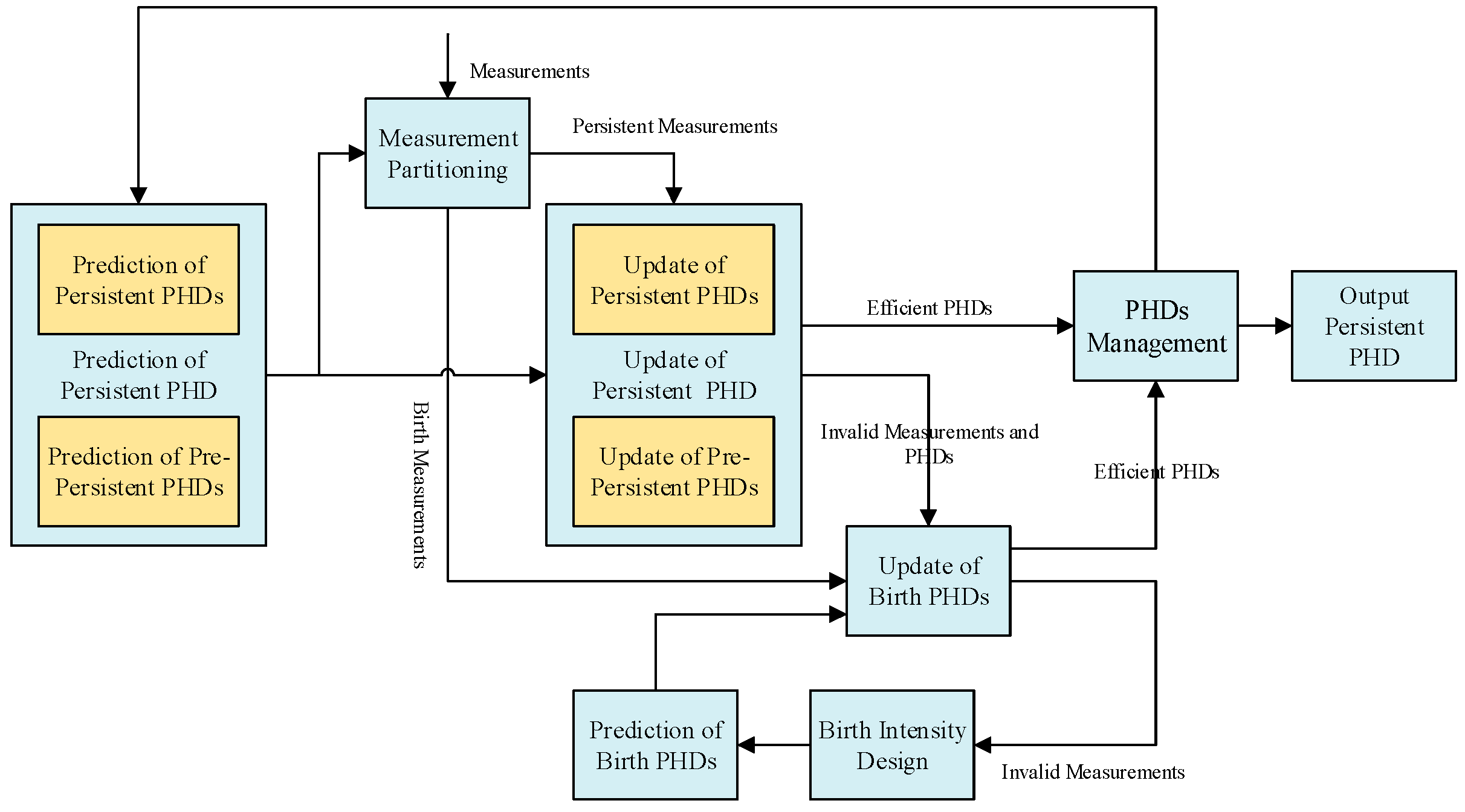
3. Adaptive Collaborative GMPHD (ACo-GMPHD) Filter
Figure 1 is the ACo-GMPHD framework consists of persistent PHDs, birth PHDs, and pre-persistent PHDs. Here, each PHD is specialized for a certain permanent/new-born/temporary target. In order to improve the computational efficiency, after the prediction of persistent PHDs and pre-persistent PHDs, the measurements in the surveillance area are adaptively partitioned into the persistent measurements and the birth measurements. Furthermore, the persistent PHDs and the pre-persistent PHDs are updated only using the persistent measurements, hence avoiding unnecessary data processing.
Remark 2. One may wonder whether the measurement partition in the ACo-GMPHD filter introduces several decision risks. In fact, the measurements away from the confidence region have little contribution to the persistent targets, and hence the weight of the Gaussian components would not be underestimated in updating the persistent PHD. In other words, the partition of the measurements has nothing to do with updating the persistent targets in setting the large-confidence region. For the birth target, when the confidence region is large, the birth measurements may be possibly partitioned into the persistent measurements, which may lead to missing the birth target. Here the measurement which does not contribute to the update of the persistent PHDs will be introduced into the birth measurement set, which can avoid the birth target missing. In general, adaptive measurement partition is effective as shown in the later simulation.
3.1. Prediction of Persistent PHD
Given the persistent PHD set
and the pre-persistent PHD set
, the target intensity is represented in the Gaussian mixture form of multiple PHDs:
with
where
and
denote the
i-th persistent PHD and the
i-th pre-persistent PHD;
and
are the corresponding labels; and
and
are the corresponding deleting thresholds, respectively.
According to Lemma 1, the predicted persistent PHD is:
where
3.2. Prediction of Birth PHDs
According to reference [
19], we choose the scheme of calculating birth PHD
:
with
where
,
, and
are calculated based on the measurements which were not utilized for track update at time
.
According to Lemma 1, the predicted birth PHD is:
where
3.3. Measurement Partition
As the integral of the PHD equals the expectation of the target number in the surveillance region, the PHD should be updated by using the target-oriented measurements instead of all the measurements. Different kinds of PHDs such as the persistent PHD and the birth PHD should be updated based on the different measurement sets. Thus, we partitioned the measurement space through utilizing the information of the Gaussian terms.
The innovation covariances of the persistent and pre-persistent PHDs are:
The shortest Mahalanobis distance between a real measurement
and the predicted measurement is:
If
, then the measurement
will be assigned to the persistent measurement set
, where the threshold
denotes the
quantile of the upper-tail of a chi-squared distribution with
degrees of freedom [
1], where
is the measurement dimension.
The birth measurement set
is
3.4. Update of Persistent PHD
According to Lemma 2, the persistent PHD is updated based on the persistent measurement set
:
with
where
is the clutter intensity in the survival region;
;
;
; and
.
The corresponding measurement weight of the persistent measurement is:
The measurement set for updating the birth PHDs is defined as:
where
is the threshold for selecting the invalid measurements. Now the birth measurement set contains two parts:
The integrals of the persistent and pre-persistent PHDs are:
Denote the persistent PHD index set by
and the pre-persistent PHD index set by
. The invalid persistent and pre-persistent PHD index sets are:
where
is the upper-bound threshold of the weight of the invalid PHD. The invalid PHDs are treated as the additional birth PHDs in the following processing.
3.5. Update of Birth PHDs
For any birth PHD, its prediction is:
with
where
represents the cardinality of the persistent targets;
represents the cardinality of the invalid persistent targets.
According to Lemma 2, the birth PHDs are updated using the birth measurements
:
where
is the clutter intensity in the birth region.
Then the weight of the birth measurement and the integral of the birth PHD are calculated as:
and the invalid measurement set is constructed:
Denote as the number of birth PHDs at the next time step.
3.6. PHDs Management
3.6.1. Birth PHDs Management
If a birth PHD has a large enough weight, such as , it can be reclassified as a pre-persistent PHD. Then, the pre-persistent PHD set is augmented by in the birth PHD set .
3.6.2. Pre-Persistent PHDs Management
If a pre-persistent PHD has a large enough weight, such as , it can be reclassified as a persistent PHD. Then, the persistent PHD set is augmented by in the pre-persistent PHD set .
3.6.3. Persistent PHDs Management
A persistent PHD with a large enough large weight, for example , is outputted as the stable track. Otherwise, if up to successive time instants, then such a persistent PHD is considered as the terminated track.
3.7. Birth Intensity Design
Here we adopt the strategy previously described in reference [
20] as follows. A one-step initialization method is utilized to select the reliable birth intensity components for the next time step. The measurements near the current multi-target states are deleted to reduce the unnecessary birth intensity components. Without velocity information, the a priori velocity is zero-mean and has the covariance determined based on the maximum expected velocity (For more details, see reference [
21]). The invalid measurement set
is assigned to determine the birth PHD at time
:
with
where the Gaussian term weight
is calculated according to reference [
20];
is an
M-by-
M identity matrix; and
is the cardinality of the measurement set
.
3.8. Output Persistent PHD
At different times, the Gaussian terms with the same label represent the same target. The output track information at time
is the state
and covariance
of the persistent PHDs respectively:
Remark 3. The analysis for the complexity of the ACo-GMPHD is an open issue due to the measurement partition is random. In principle, the ACo-GMPHD and the standard GM-PHD have the similar process flowchart and hence their calculation burden is similar. Differing from the standard GM-PHD, the ACo-GMPHD partitions all measurements into smaller sets and separately processes them. Since the computational complexity of the standard GM-PHD increases exponentially with respect to the number of the related measurements, the ACo-GMPHD is expected to be more cost-efficient, which coincides with the simulation result.
4. Simulation Analysis
To verify the systematic performance of the ACo-GMPHD filter, we compared it with the standard GMPHD filter which utilizes a priori birth target intensity and the GMPHD-I filter [
20] via an MTT simulation scenario, similar to reference [
8]. The difference is that six targets are considered here, instead of the three targets in reference [
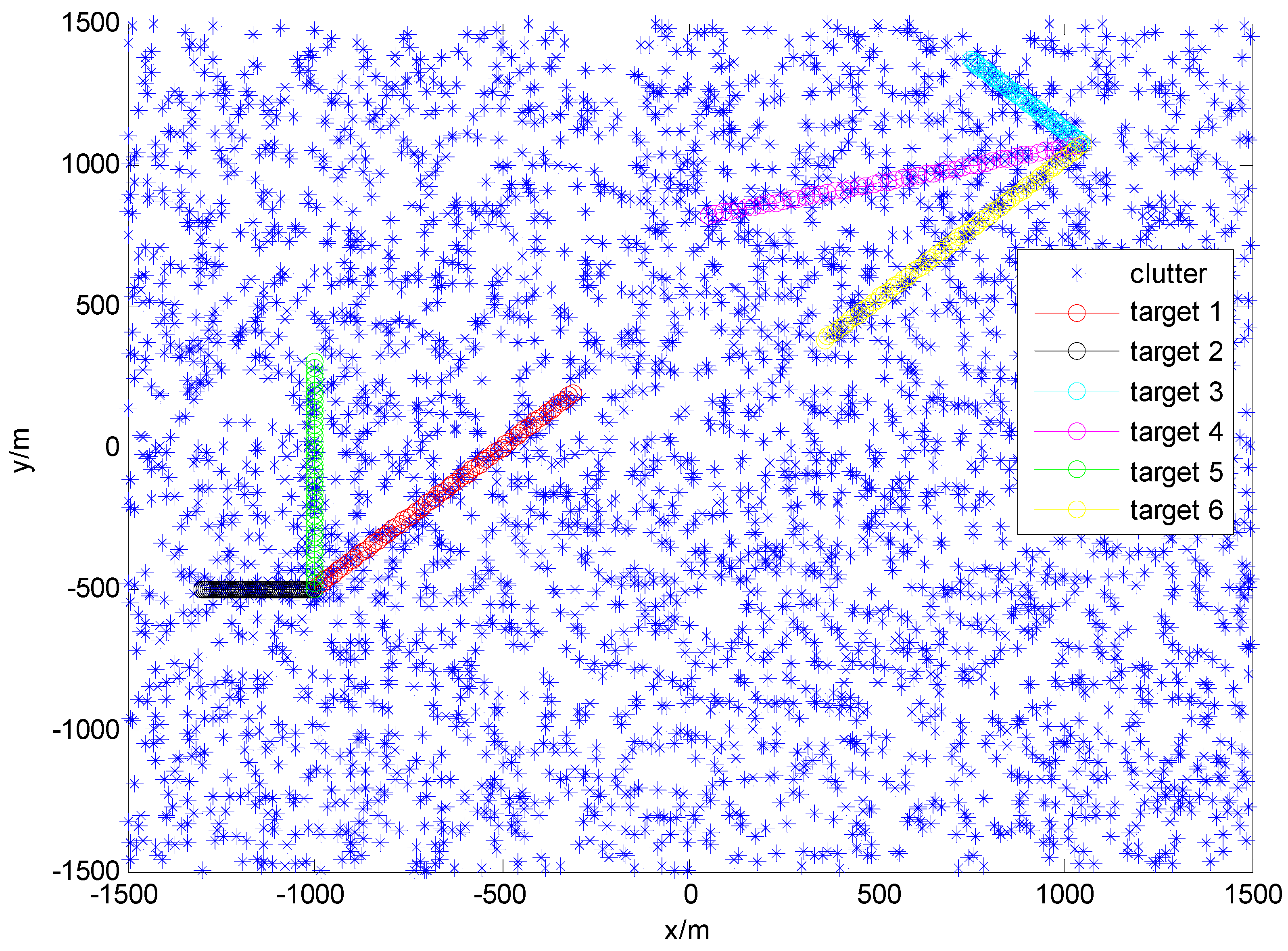
8]. The initial states, appearance, and disappearance of each target are given in
Table 1. True trajectories are shown in
Figure 2.
The detailed scenario parameters are given in
Table 2.
Priori birth target intensity is provided for the standard GMPHD filter with , , and .
We used a performance evaluation metric called the optimal subpattern assignment (OSPA) distance, which is specialized for the MTT filter accuracy test [
22]. We selected OSPA parameters:
and
.
We ran 100 Monte Carlo (MC) trials for each filter to obtain the OSPA distance and the averaged computational cost, and obtained the track-valued estimates in one MC trial. In addition, we validated the performance of each filter in the case of different clutter densities.
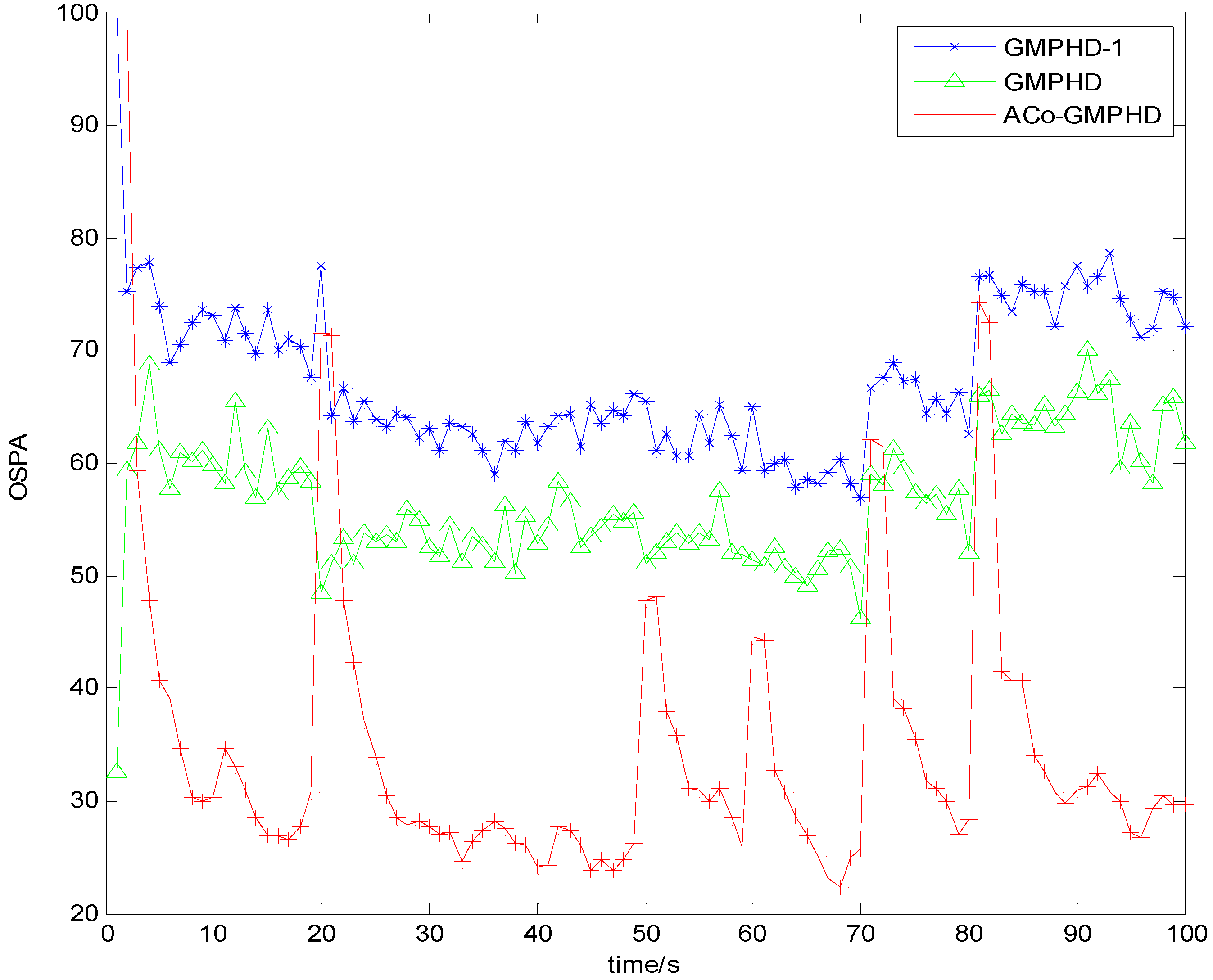
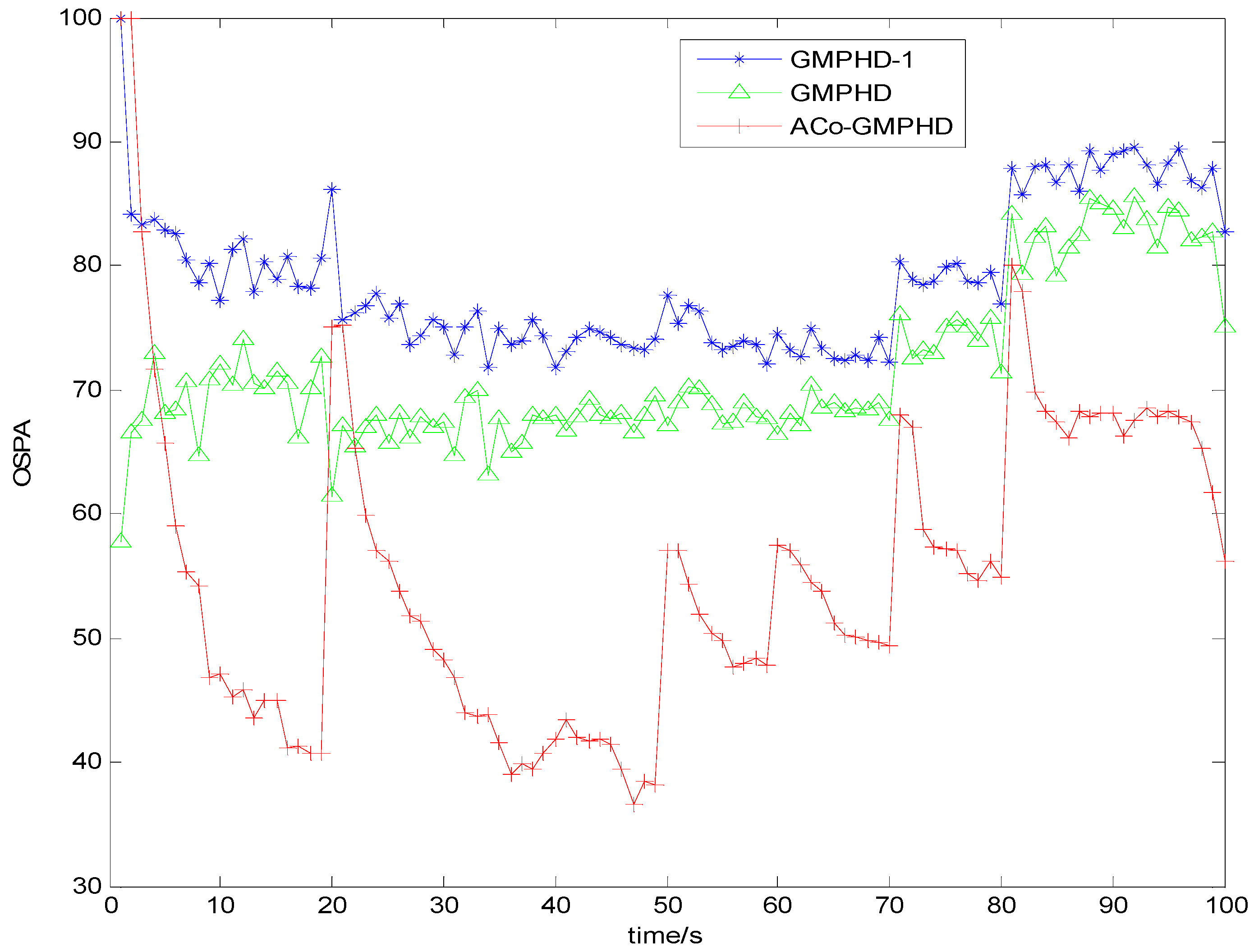
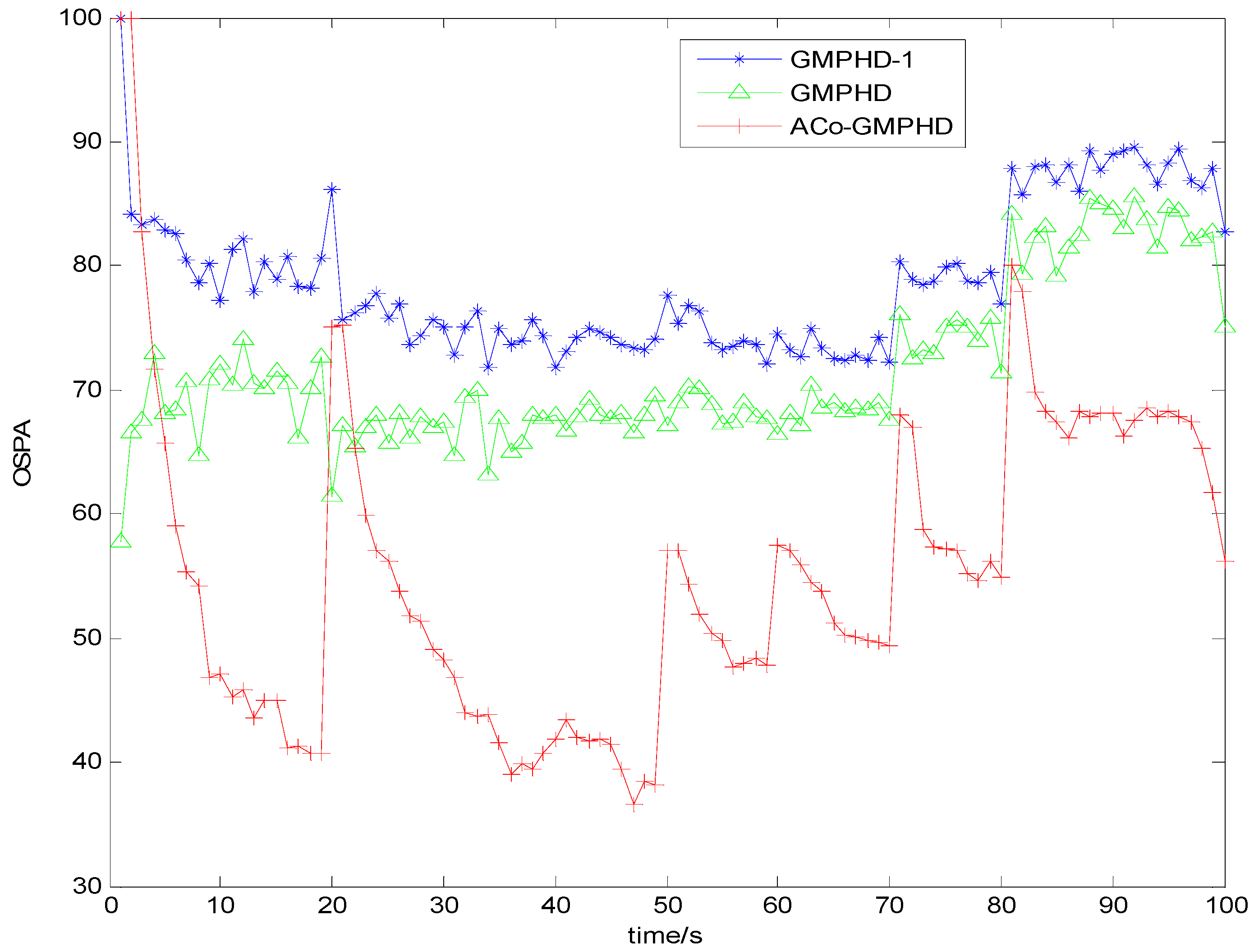
Figure 3 and
Figure 4 show the Monte Carlo average of the OSPA distance with detection probabilities of 0.9 and 0.7, respectively. Compared with the other two filters, the ACo-GMPHD almost always had the lowest OSPA distance, reflecting the effectiveness of the proposed adaptive multi-PHD collaboration and measurement partition.
As shown in
Figure 3 and
Figure 4, there are five OSPA peaks in the ACo-GMPHD at times 20, 50, 60, 70, and 80 s, corresponding to the target appearances and disappearances, respectively. Some peaks are even higher than that of the standard GMPHD, and are always smaller than that of the GMPHD-I. The explanation for this is that:
the ACo-GMPHD does not utilize a priori information of the birth target. At the moment that a target appears, the clutter and birth target measurements are hardly distinguishable without the support of the subsequent measurements. Thus, the birth target measurements may be treated as the clutter, and hence possibly leads to a delay in the cardinality estimation, as shown in
Figure 5 when a target is newly born, which causes the peak of the OSPA distance. This is the cost of the measurement partition.
the GMPHD-I also does not utilize a priori information of the birth target. However, due to the absence of adaptation and collaboration compared with the ACo-GMPHD, the GMPHD-I is the worst regarding the OSPA measure.
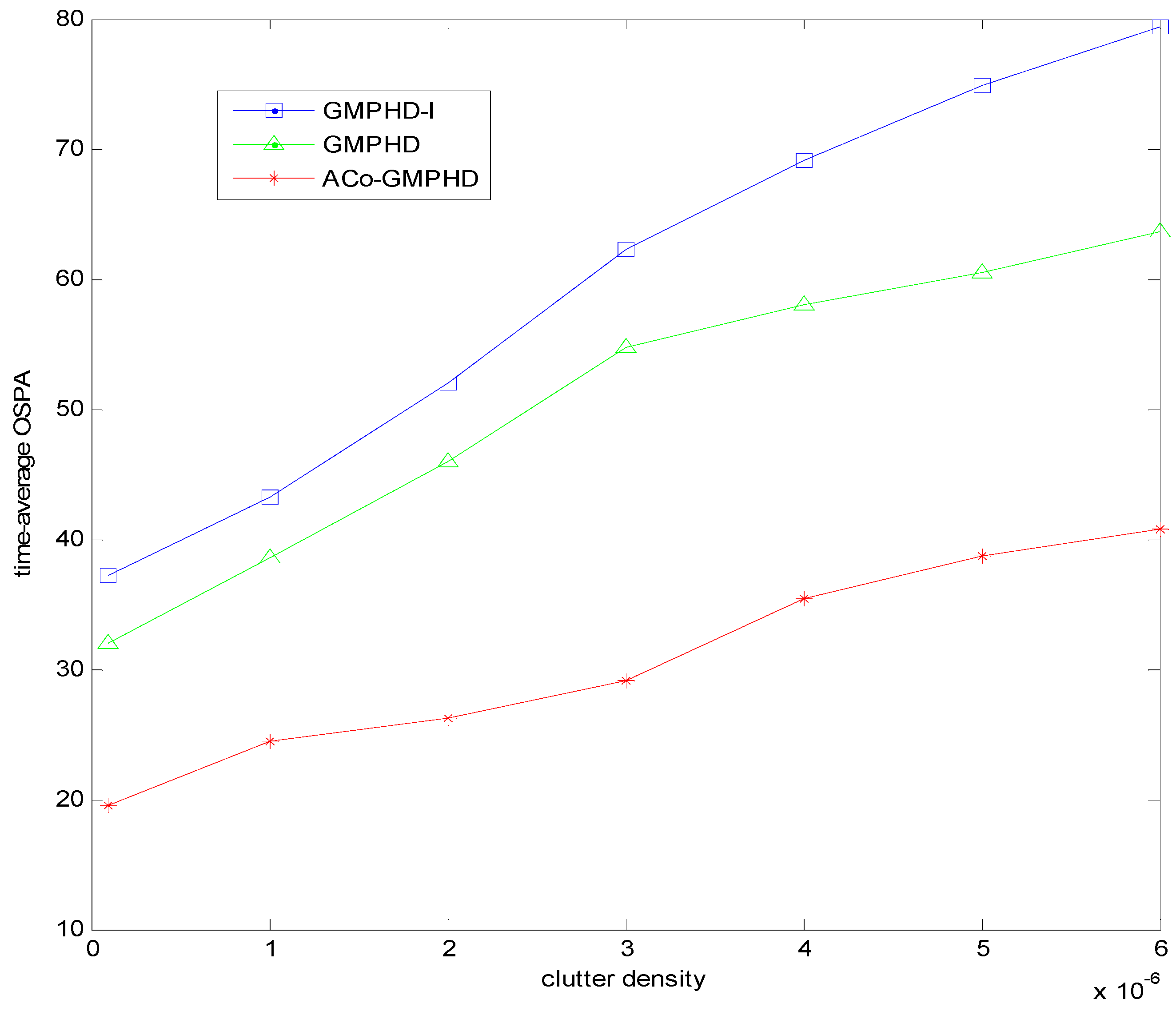
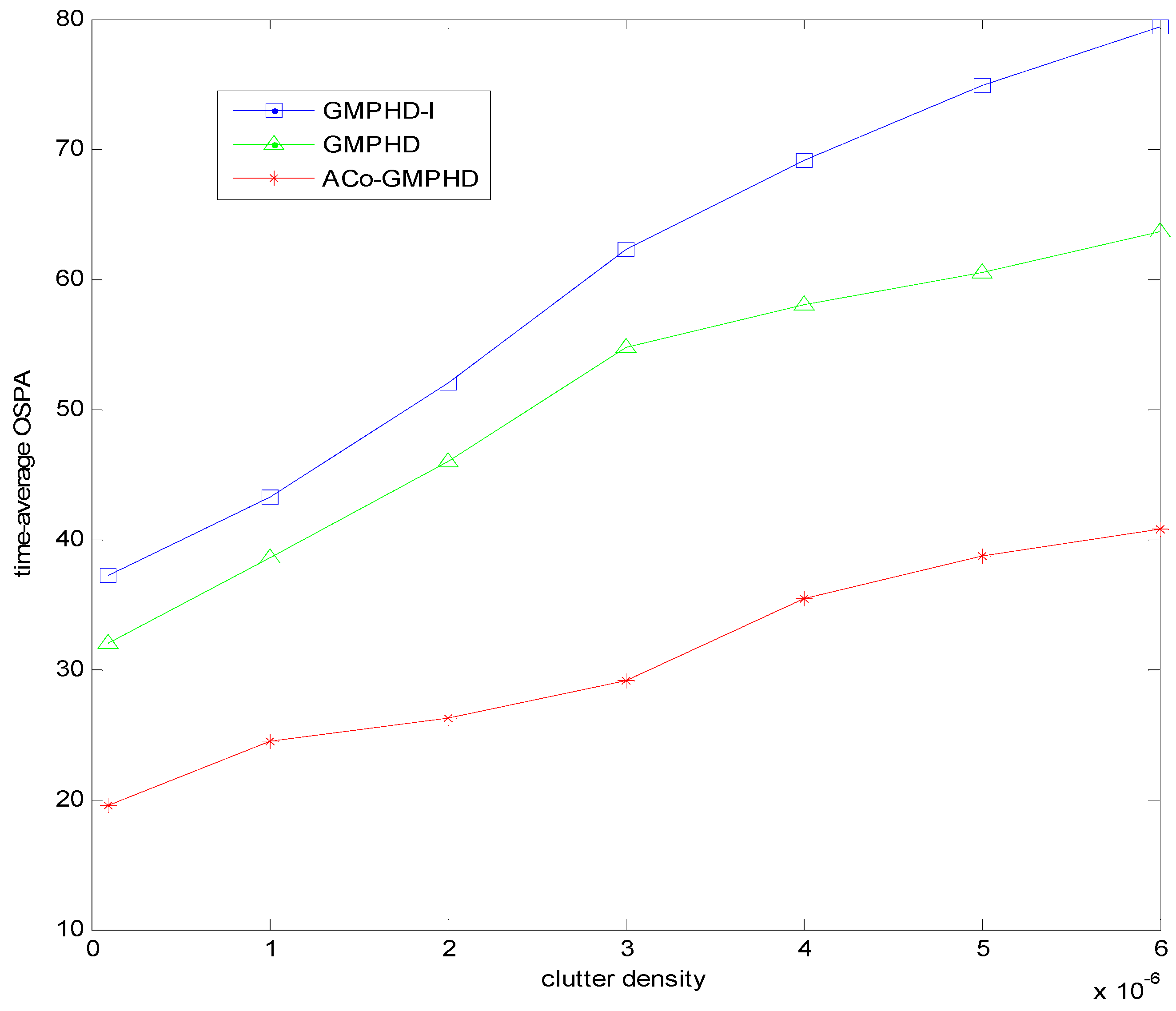
Furthermore, we present the time-averaged OSPA versus the clutter density in
Figure 6. With the increase of clutter density, the OSPA distance of the ACo-GMPHD filter gradually increases, but it is still lower than that of other two comparison algorithms.
For each time step, the averaged computation time (ACT) is shown in
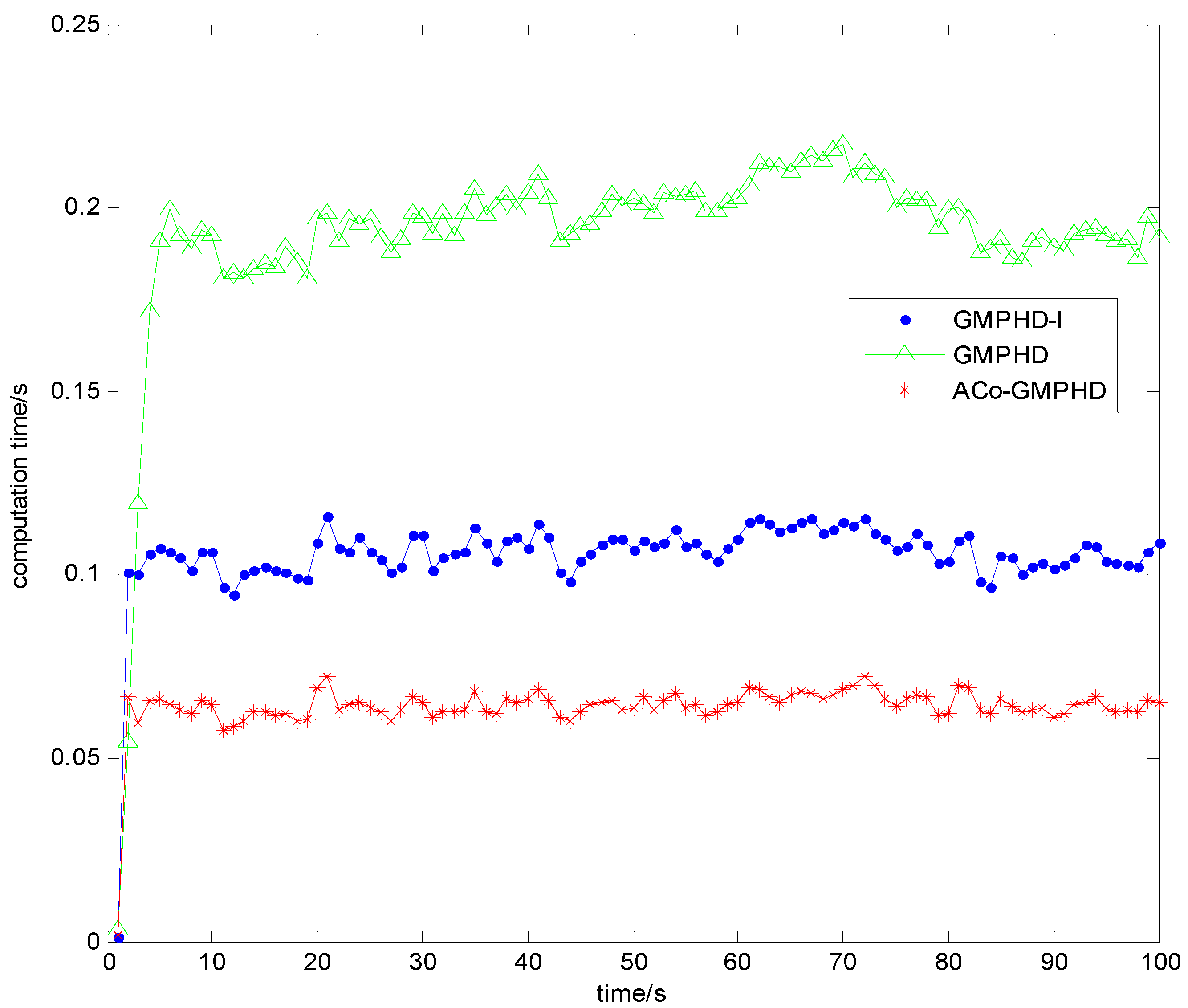
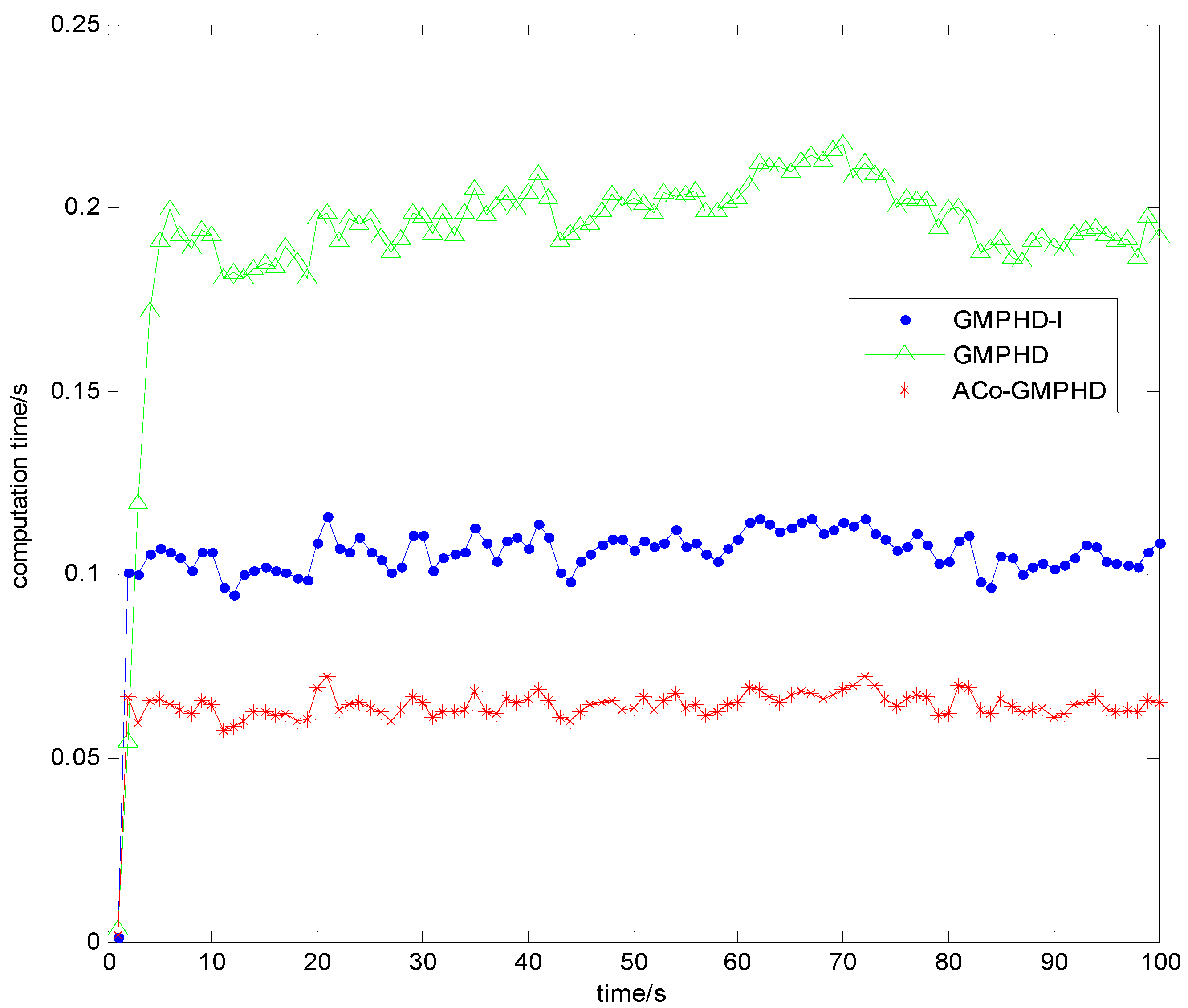
Figure 7. Obviously, the ACo-GMPHD filter significantly decreased the computational burden, compared with the standard PHD or GMPHD-I filters. The ACT of the ACo-GMPHD filter is about 0.65 s, much smaller than the measurement sampling period of 1 s.
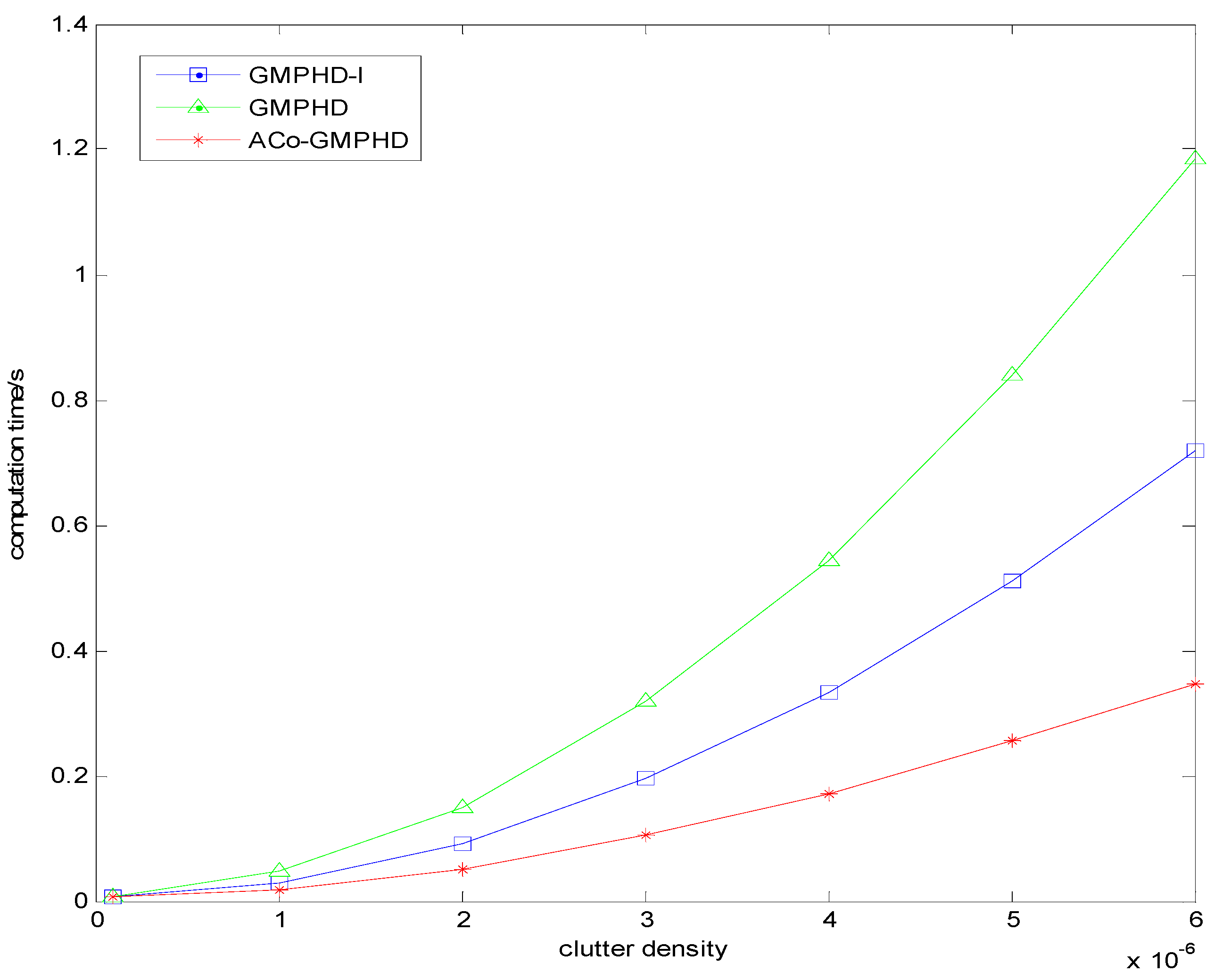
Figure 8 plots the curves of the ACT versus the clutter density. As the clutter density increases, the ACTs of all the filters increase; however, the ACo-GMPHD filter has the lowest rate of increase, implying that it is more suitable for the dense clutter case.
5. Conclusions
In this paper, we proposed the ACo-GMPHD filter with automatic track extraction, which was shown to be satisfactory for multi-target tracking. It costs less computational time and has better OSPA, except for some undesirable peaks at the moment of birth targets appear. Hence, one possible avenue for future research is to introduce priori information about birth targets, which would be helpful in order to better discern the target and the clutter, and hence more effectively reduce the corresponding OSPA peaks. Additionally, the threshold at the step of PHDs management was considered as constant in the proposed filter, and a possible future research study is to adaptively choose the threshold under some optimal performance index.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}