
A Cluster-Based Dual-Adaptive Topology Control Approach in Wireless Sensor Networks

Abstract
:1. Introduction
2. Related Work
3. The Improved Clustering Scheme
3.1. Overview
3.2. Cluster Formation
3.2.1. Neighborhood Discovery
| Algorithm 1. Neighborhood Discovery (ND) | |
| Run at any wireless node (e.g., u) | |
| Input: Nmax | |
| Output: The identifiers and approximate maximum transmission ranges of all neighbors | |
| 1. | Initialize the variables (e.g., Lu,nei = Φ; du,max = 0; N = 0) |
| 2. | Use a CSMA/CA scheme to contend for the channel |
| 3. | if succeed in accessing the channel then |
| 4. | Send [IDu, eu, pu,max, du,max, Lu,nei] at the maximum transmission power pu,max |
| 5. | Set the timer tΔ as Δ |
| 6. | Initialize FLAG1 and FLAG2 as false respectively |
| 7. | while the timer tΔ does not expire do |
| 8. | if receive [IDv, ev, pv,max, dv,max, Lv,nei] from any node v that is not in Lu,nei then |
| 9. | Record the receiving power prv,u and employ the Formula (4) to compute dv,u |
| 10. | Add (IDv, dv,u) to Lu,nei |
| 11. | if du,max < dv,u then du,max = dv,u |
| 12. | FLAG1 = true |
| 13. | else if receive [IDv, ev, pv,max, dv,max, Lv,nei] and node u is not in Lv,nei then |
| 14. | FLAG2 = true |
| 15. | end if |
| 16. | end while |
| 17. | if (FLAG2 == true) then N++ |
| 18. | if (N < Nmax) and (FLAG1 == true or FLAG2 == true) then go to step 2 |
| 19. | else go to step 2 |
| 20. | end if |
3.2.2. Selecting MCHs
| Algorithm 2. MCH Selection (MCHS) | |
| Run at any wireless node (e.g., u) | |
| Input: Nmax | |
| Output: The identifiers and approximate maximum transmission ranges of all neighbors | |
| 1. | Initialize the state variable su as “undecided” |
| 2. | for each entry (IDv, dv,u) in Lu,nei do initialize the state variable sv as “undecided” |
| 3. | Compute node u’s Ru,intra according to the formulas (5) and (6) |
| 4. | Compute node u’s MCH eligibility metric MMu according to the Formula (7) |
| 5. | Initialize FLAG1 as true |
| 6. | for each entry (IDv, dv,u) in Lu,nei do |
| 7. | if (sv == “undecided”) and (dv,u ≤ Ru,intra) then |
| 8. | Compute node v’s MCH eligibility metric MMv according to the Formula (7) |
| 9. | if (MMu < MMv) or (MMu == MMv && IDu > IDv) then FLAG1 = false |
| 10. | end if |
| 11. | end for |
| 12. | if (FLAG1 == true) then |
| 13. | Determine itself (i.e., node u) as the MCH and change the value of su as “decided MCH” |
| 14. | Broadcast the updated su to its neighbors to which the distance is not more than Ru,intra from it |
| 15. | else |
| 16. | Set the timer tτ as τ |
| 17. | Initialize FLAG2 as true |
| 18. | while the timer tτ does not expire do |
| 19. | if receive a state variable (e.g., sv) from any node (e.g., v) then |
| 20. | if the received sv is “decided MCH” then |
| 21. | Change the value of su as “decided non-MCH” |
| 22. | Broadcast the updated su to the neighbors to which the distance is not more than Ru,intra from u |
| 23. | FLAG2 = false |
| 24. | else update the initial value of sv kept in u as “decided non-MCH” |
| 25. | end if |
| 26. | end if |
| 27. | end while |
| 28. | if (FLAG2 == true) then go to step 5 |
| 29. | end if |
3.2.3. Selecting SCHs
| Algorithm 3. SCH Selection (SCHS) | |
| Run at any MCH node (e.g., u) | |
| Input: the hello messages of all neighbors | |
| Output: SCH confirmation message | |
| 1. | for each entry (IDv, dv,u) in Lu,nei do initialize the label variable lv as “uninvited” |
| 2. | SMmax = 0; IDsch = maximum number |
| 3. | for each entry (IDv, dv,u) in Lu,nei do |
| 4. | if (dv,u ≤ Ru,intra) and (lv == “uninvited”) then |
| 5. | Compute node v’s SCH eligibility metric SMv,u according to the Formula (8) |
| 6. | if (SMmax < SMv,u) or (SMmax == SMv,u && IDv < IDsch) then {SMmax = SMv,u; IDsch = IDv} |
| 7. | end if |
| 8. | end for |
| 9. | Send the “SCH invitation message” to the neighbor IDsch |
| 10. | if eavesdrop the “SCH acceptance message” from the invited node (i.e., IDsch) that does not accept its (i.e., u’s) invitation then |
| 11. | Change the value of the invited node’s label variable as “invited” |
| 12. | Go to step 2 |
| 13. | end if |
| 14. | if receive the “SCH acceptance message” from the invited node (i.e., IDsch) that accepts its (i.e., u’s) invitation then |
| 15. | Broadcast the “SCH confirmation message” at its maximum transmission power |
| 16. | end if |
| Run at any non-MCH node (e.g., v) Input: the hello messages of all neighbors Output: SCH acceptance message | |
| 17. | if receive the first “SCH invitation message” from any MCH (e.g., w) then |
| 18. | dmin = dv,w; IDmch = IDw |
| 19. | Set the timer tζ as ζ |
| 20. | while the timer tζ does not expire do |
| 21. | if receive the “SCH invitation message” from any MCH (e.g., u) then |
| 22. | if (dv,u < dmin) then {dmin = dv,u; IDmch = IDu} |
| 23. | end if |
| 24. | end while |
| 25. | Send the “SCH acceptance message” to the neighbor IDmch |
| 26. | Set the timer tθ as θ |
| 27. | Initialize FLAG as true |
| 28. | while the timer tθ does not expire do |
| 29. | if receive the “SCH confirmation message” from a MCH that selects itself (e.g., v) as SCH then FLAG = false |
| 30. | end while |
| 31. | if (FLAG == true) then move to the next step (determining cluster members and selecting FCHs) |
| 32. | end if |
3.2.4. Determining Cluster Members and Selecting FCHs
| Algorithm 4. Cluster Member Association and FCH Selection (CMA-FCHS) | |
| Run at any non-CH node (e.g., w) Input: the hello messages of all neighbors Output: the membership request message | |
| 1. | for each entry (IDu, du,w) in Lw,nei do |
| 2. | if the state variable su is “decided MCH” then initialize the flag variable fu as “unrequested” |
| 3. | end for |
| 4. | dmin = maximum number; IDmch = maximum number |
| 5. | for each entry (IDu, du,w) in Lw,nei do |
| 6. | if (fu == “unrequested”) and ((du,w < dmin) or (du,w == dmin && IDu < IDmch)) then {dmin = du,w; IDmch = IDu} |
| 7. | end for |
| 8. | Send the “membership request message” to the neighboring MCH with IDmch |
| 9. | if receive the “membership list message” from the neighboring MCH with IDmch (e.g., y) then |
| 10. | if find that its ID (i.e., w’s ID) is not in the “membership list message” then |
| 11. | if not more than the given maximum number of resending attempts then |
| 12. | fy = “requested” |
| 13. | Go to step 4 |
| 14. | end if |
| 15. | end if |
| 16. | end if |
| Run at a MCH node (e.g., u) which has a SCH node (e.g., v) Input: the hello messages of all neighbors Output: the membership list message | |
| 17. | if receive the first “membership request message” from any non-CH node (e.g., w) then |
| 18. | Compute node w’s FCH eligibility metric FMw,v,u according to the Formula (9) |
| 19. | FMmax = FMw,v,u; IDfch = IDw |
| 20. | Add IDw to the membership list message |
| 21. | Set the timer tφ as φ |
| 22. | while the timer tφ does not expire do |
| 23. | if receive the “membership request message” from any non-CH node (e.g., x) then |
| 24. | if the number of cluster members is less than the threshold then |
| 25. | Add IDx to the membership list message |
| 26. | Compute node x’s FCH eligibility metric FMx,v,u according to the Formula (9) |
| 27. | if (FMmax < FMx,v,u) or (FMmax == FMx,v,u && IDx < IDfch) then {FMmax = FMx,v,u; IDfch = IDx} |
| 28. | end if |
| 29. | end if |
| 30. | end while |
| 31. | Declare the node with IDfch as the FCH through adding it to the membership list message |
| 32. | Design a TDMA schedule and add it to the membership list message |
| 33. | Broadcast the “membership list message” to its neighbors within the cluster radius |
| 34. | else if a new non-CH wants to join a given MCH and the number of cluster members is less than the threshold then |
| 35. | Update the TDMA schedule to include this node’s ID and add it to the “membership list message” |
| 36. | Broadcast the updated “membership list message” to its neighbors within the cluster radius |
| 37. | end if |
3.3. Power Adjustment for Intra-Cluster Communications
| Algorithm 5. Power Adjustment for FCH (PA-FCH) | |
| Run at a MCH node (e.g., u) Input: Nmax Output: NULL | |
| 1. | Initialize N as zero |
| 2. | Send a PAREQ packet at its maximum transmission power to the FCH (e.g., w) |
| 3. | Set the timer tσ as σ |
| 4. | while the timer tσ does not expire do |
| 5. | if receive the PAREP packet from the FCH (e.g., w) then return |
| 6. | end while |
| 7. | if N < Nmax then {N++; go to step 2} else return end if |
| Run at a SCH node (e.g., v) Input: Nmax Output: NULL | |
| 8. | if hear the PAREQ packet from the MCH (e.g., u) then |
| 9. | Initialize N as zero |
| 10. | Send a PAREQ packet at its maximum transmission power to the FCH (e.g., w) |
| 11. | Set the timer tρ as ρ |
| 12. | while the timer tρ does not expire do |
| 13. | if receive the PAREP packet from the FCH (e.g., w) then return |
| 14. | end while |
| 15. | if N < Nmax then {N++; go to step 10} else return end if |
| 16. | else |
| 17. | Go to step 8 |
| 18. | end if |
| Run at a FCH node (e.g., w) Input: the hello messages of all neighbors and the very small real number ε Output: the adjusted transmission power from FCH to MCH/SCH | |
| 19. | if receive the PAREQ packet from the MCH (e.g., u) then |
| 20. | Adjust the transmission power ptw,u according to the Formula (11) and initialize FLAG as true |
| 21. | Set the timer tψ as ψ |
| 22. | while the timer tψ does not expire do |
| 23. | if receive the PAREQ packet from the SCH (e.g., v) then |
| 24. | Adjust the transmission power ptw,v according to the Formula (11) |
| 25. | if ptw,u > ptw,v then |
| 26. | Broadcast a PAREP packet at ptw,u and set FLAG as false |
| 27. | else |
| 28. | Broadcast a PAREP packet at ptw,v and set FLAG as false |
| 29. | end if |
| 30. | end if |
| 31. | end while |
| 32. | if (FLAG == true) then Broadcast a PAREP packet at ptw,u |
| 33. | end if |
| 34. | if receive the repeated PAREQ packet from the MCH (e.g., u) or the SCH (e.g., v) then |
| 35. | if (FLAG == true) then {ptw,u = ptw,u + ε; Broadcast a PAREP packet at ptw,u} |
| 36. | else if ptw,u > ptw,v then {ptw,u = ptw,u + ε; Broadcast a PAREP packet at ptw,u} |
| 37. | else {ptw,v = ptw,v + ε; Broadcast a PAREP packet at ptw,v} end if |
| 38. | end if |
| 39. | end if |
| Algorithm 6. Power Adjustment for Cluster Members (PA-CM) | |
| Run at a FCH node (e.g., w) Input: the hello messages of all neighbors Output: NULL | |
| 1. | Broadcast a PAREQ packet at its maximum transmission power to the cluster members |
| 2. | if receive the first PAREP packet from any cluster member (e.g., x) then |
| 3. | Add IDx to the power acknowledge list message |
| 4. | Set the timer tφ as φ |
| 5. | while the timer t does not expire do |
| 6. | if receive the PAREP packet from any cluster member (e.g., y) then add IDy to the power acknowledge list message |
| 7. | end while |
| 8. | end if |
| 9. | Broadcast the power acknowledge list message at its maximum transmission power |
| 10. | if the PAREP packet of any cluster member (e.g., x) arrives after the time φ then go to step 3 |
| Run at any cluster member (e.g., x) Input: the hello messages of all neighbors and the very small real number ε Output: the adjusted transmission power from cluster member to FCH | |
| 11. | if receive the PAREQ packet from the FCH (e.g., w) then |
| 12. | Adjust the transmission power ptx,w according to the Formula (11) |
| 13. | Send a PAREP packet at ptx,w to the FCH |
| 14. | end if |
| 15. | if receive the “power acknowledge list message” from the FCH (e.g., w) then |
| 16. | if the IDx is not in the “power acknowledge list message” then |
| 17. | ptx,w = ptx,w + ε |
| 18. | Send a PAREP packet at ptx,w to the FCH |
| 19. | else return end if |
| 20. | end if |
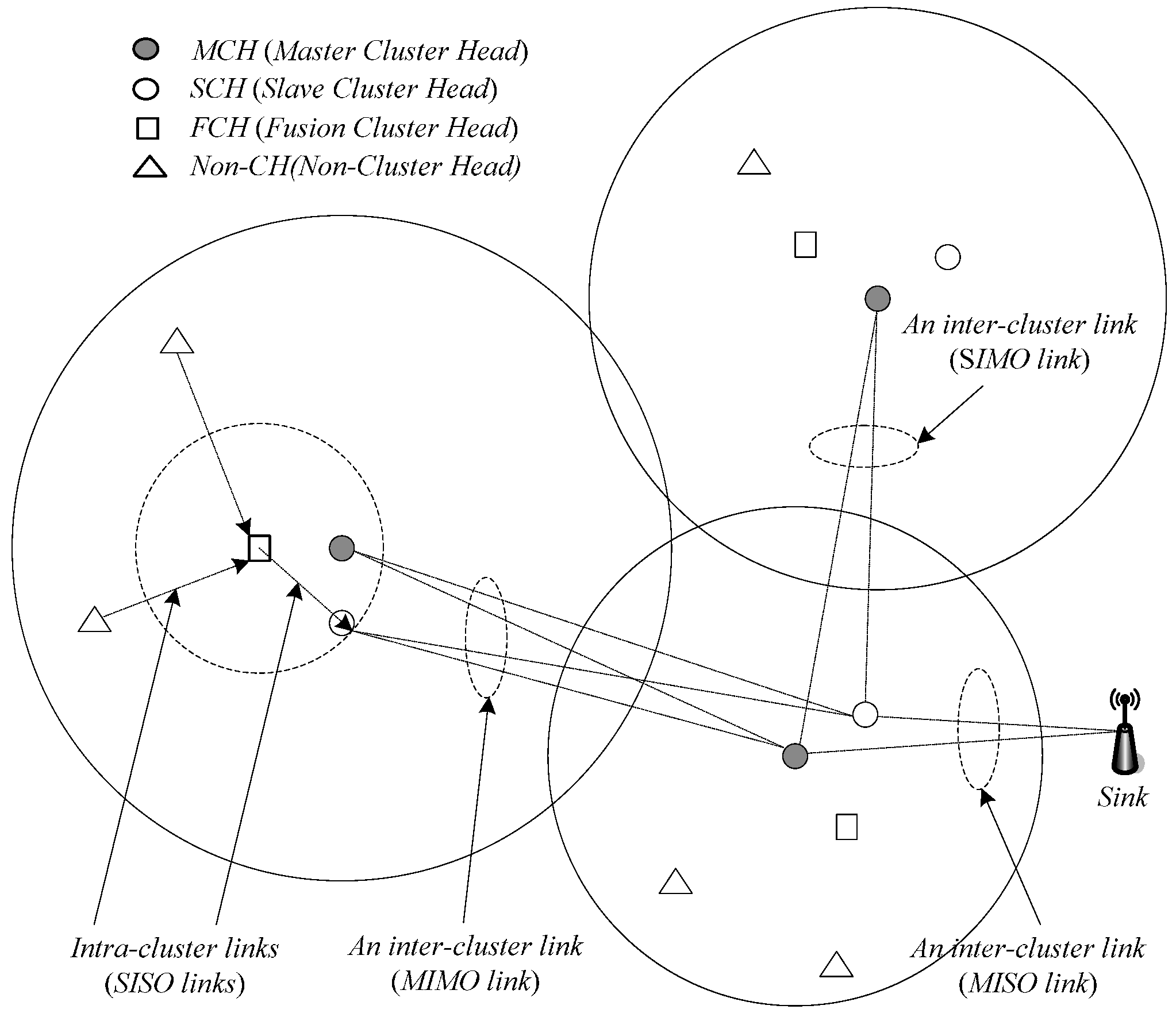
3.4. Determination for Inter-Cluster Transmission Modes
3.5. Design Issues of the ICV-MIMO Scheme
4. Performance Evaluation
4.1. Energy Model
4.2. Simulation Metrics and Deployment Settings
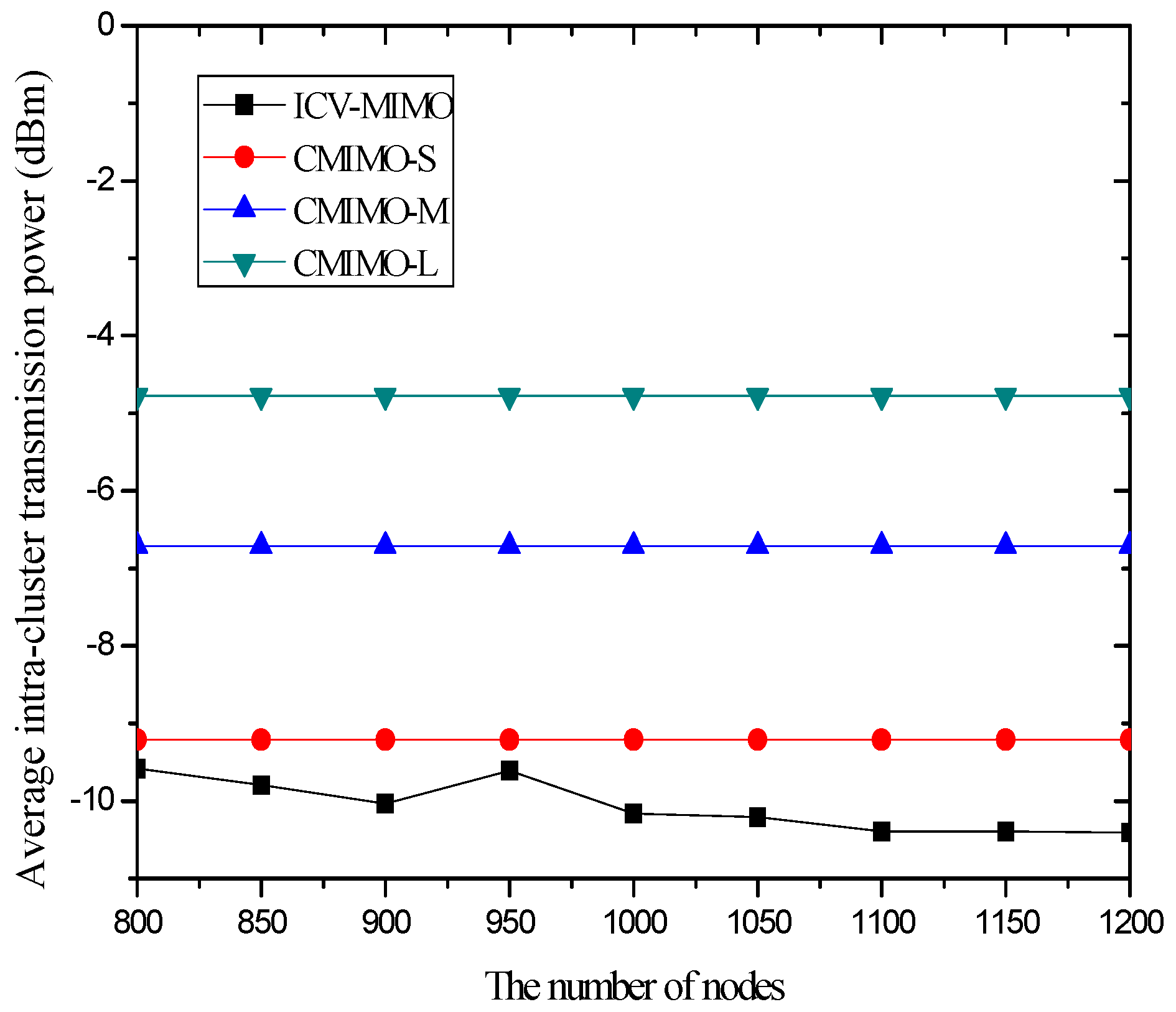
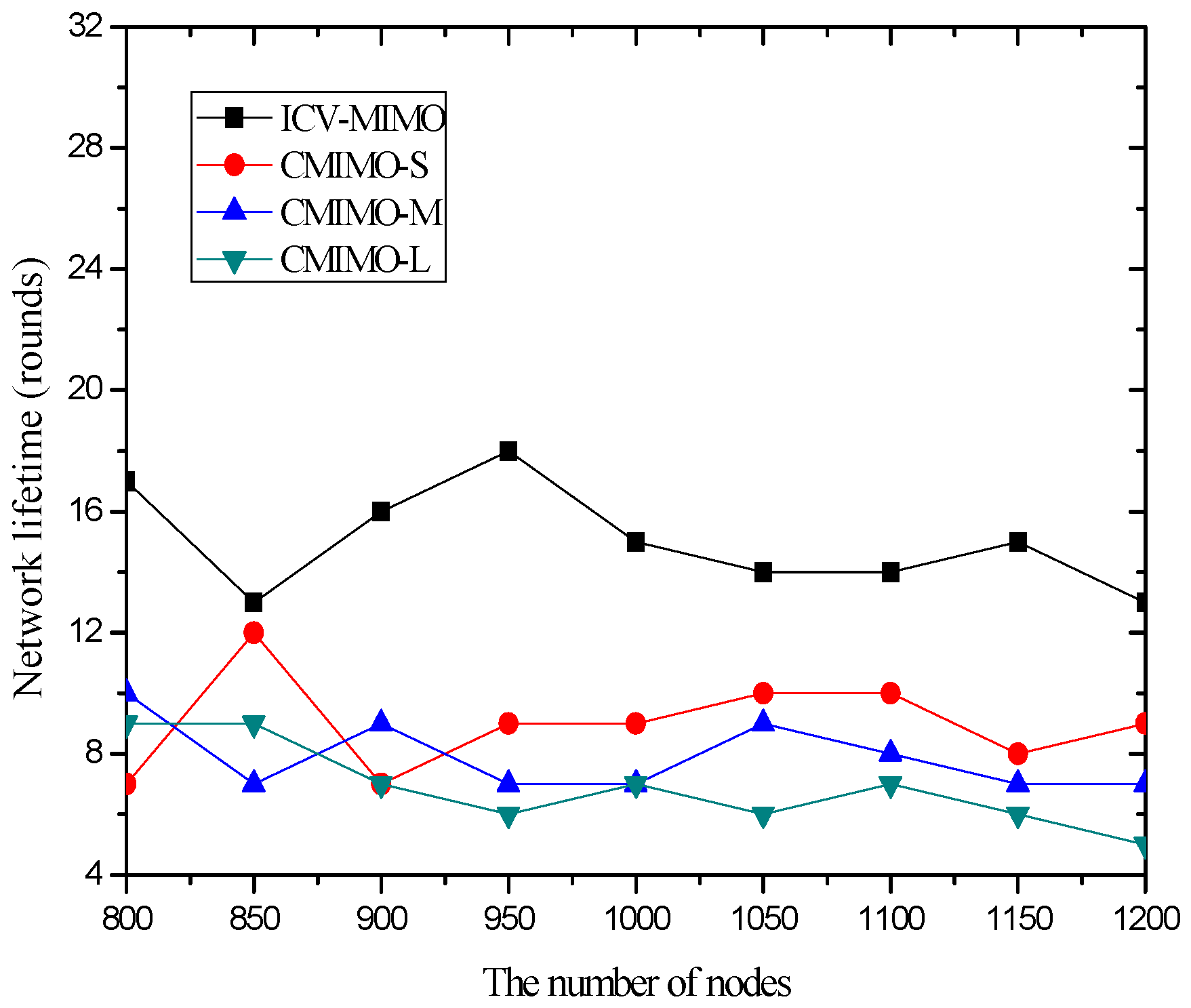
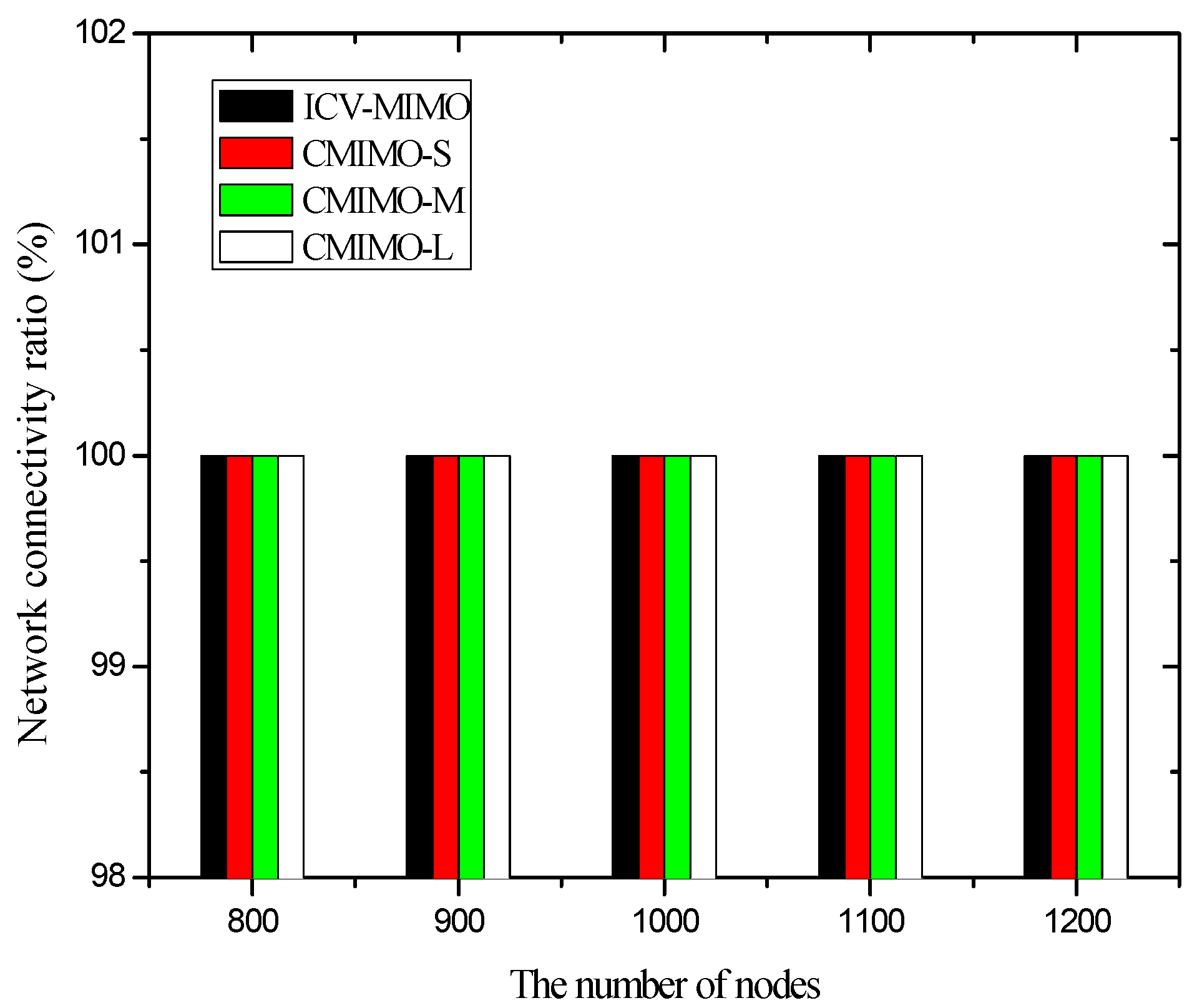
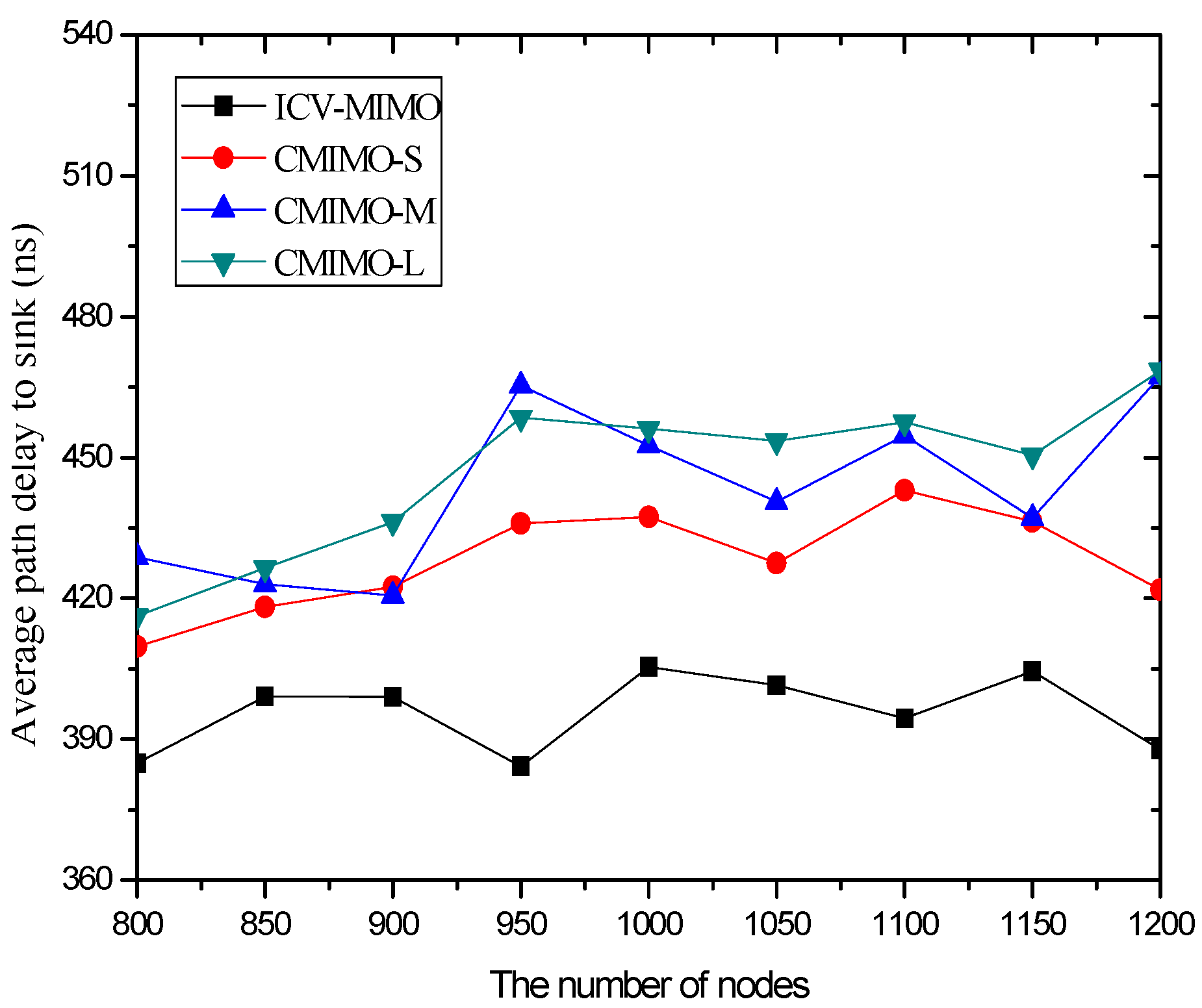
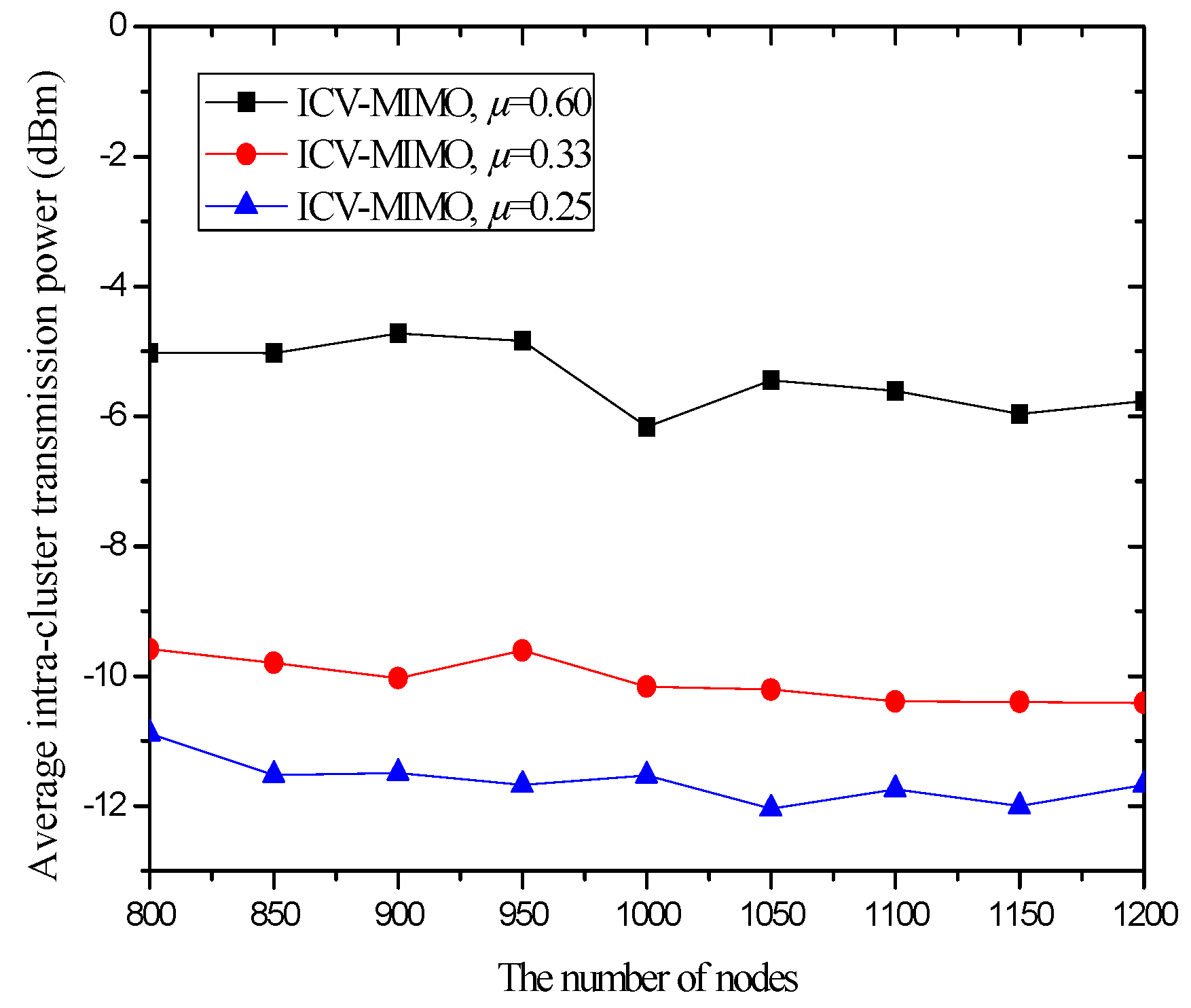
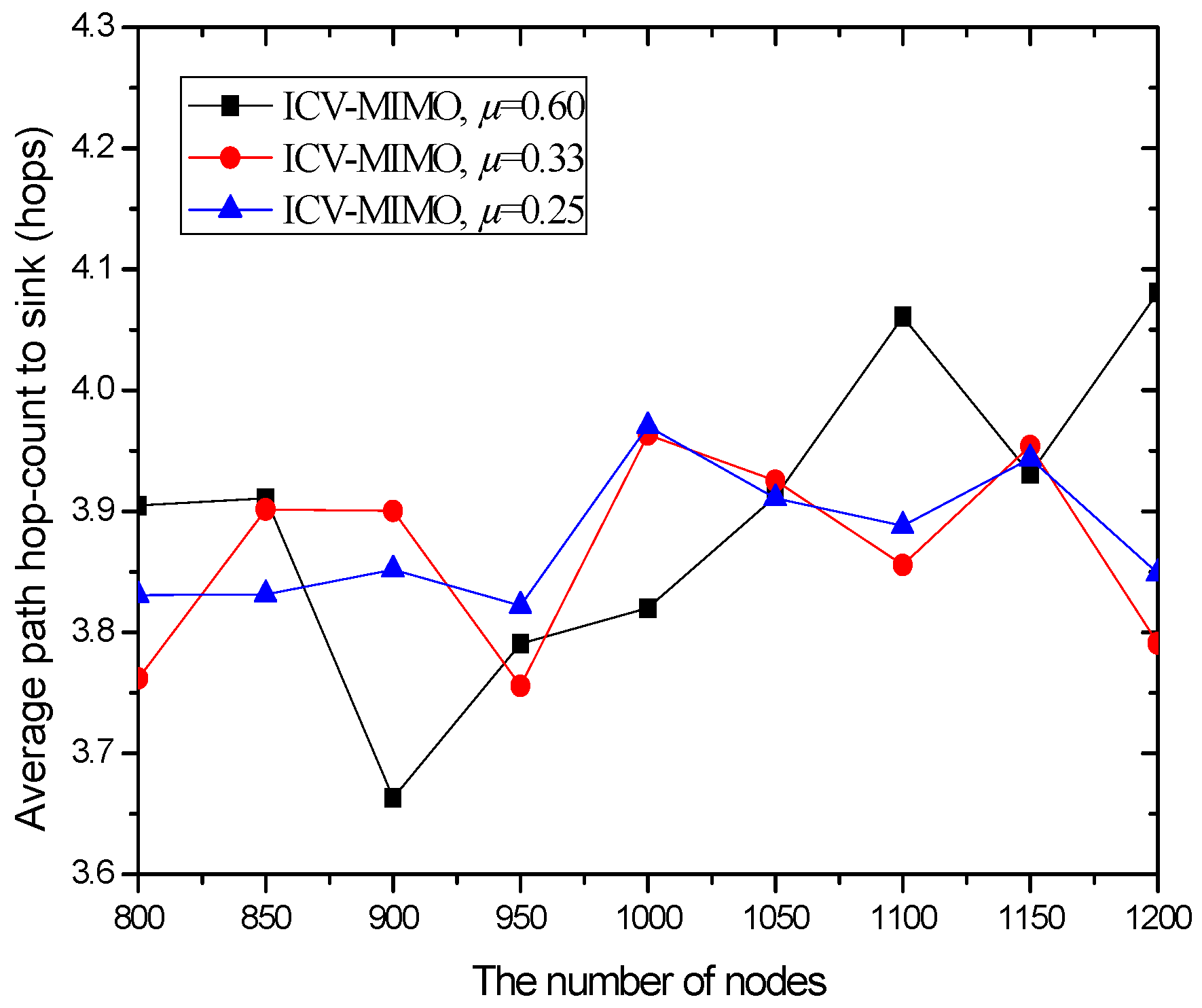
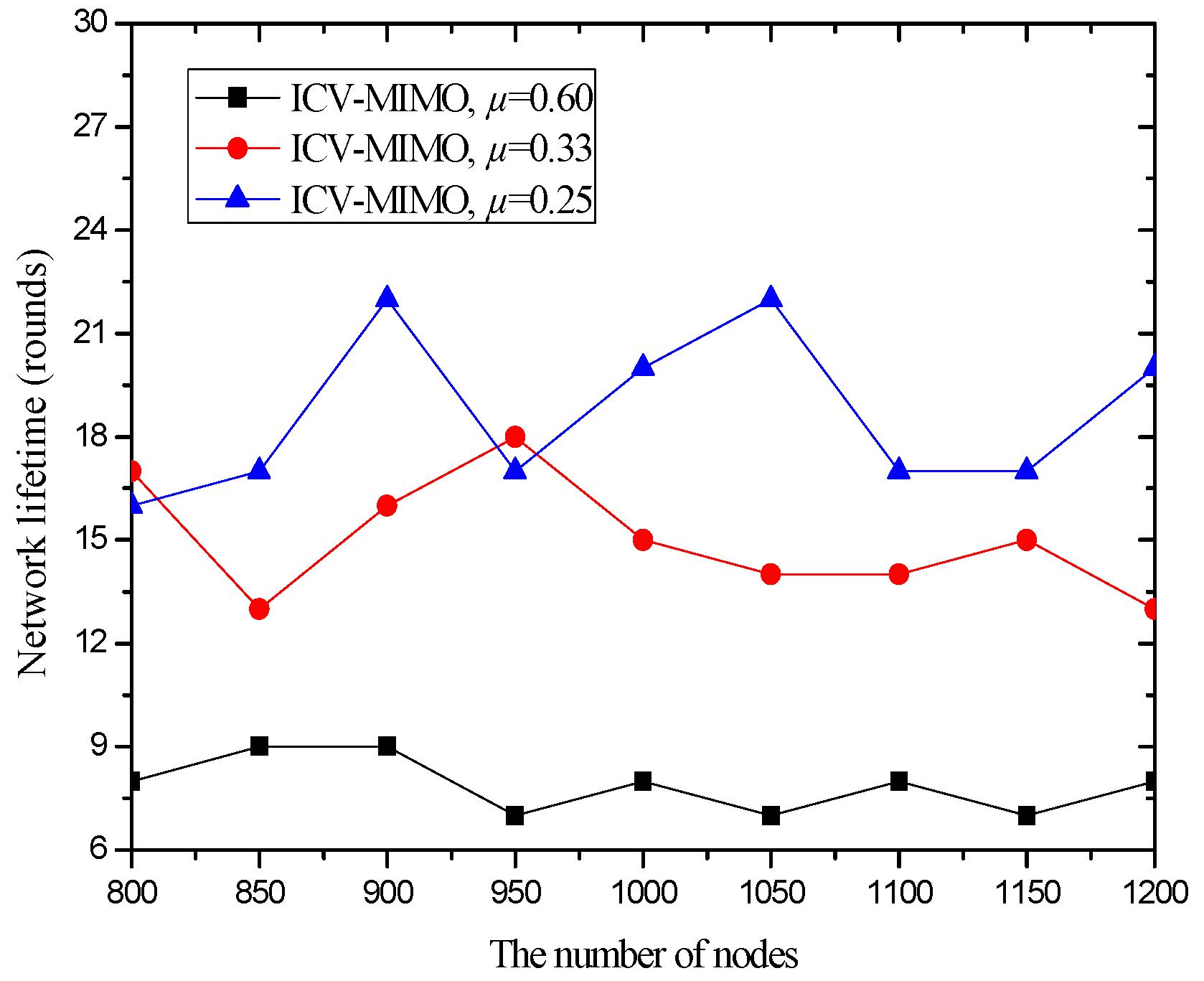
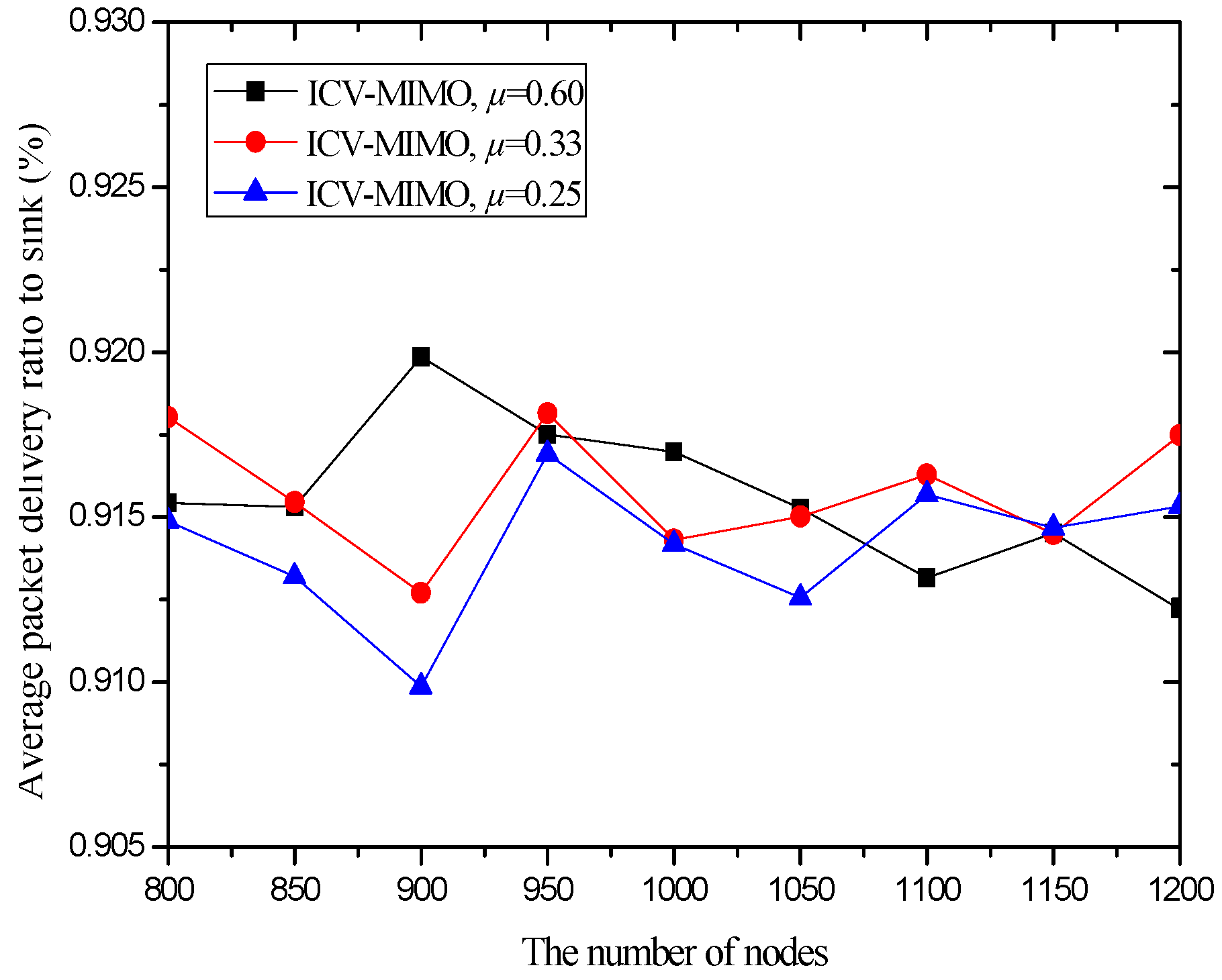
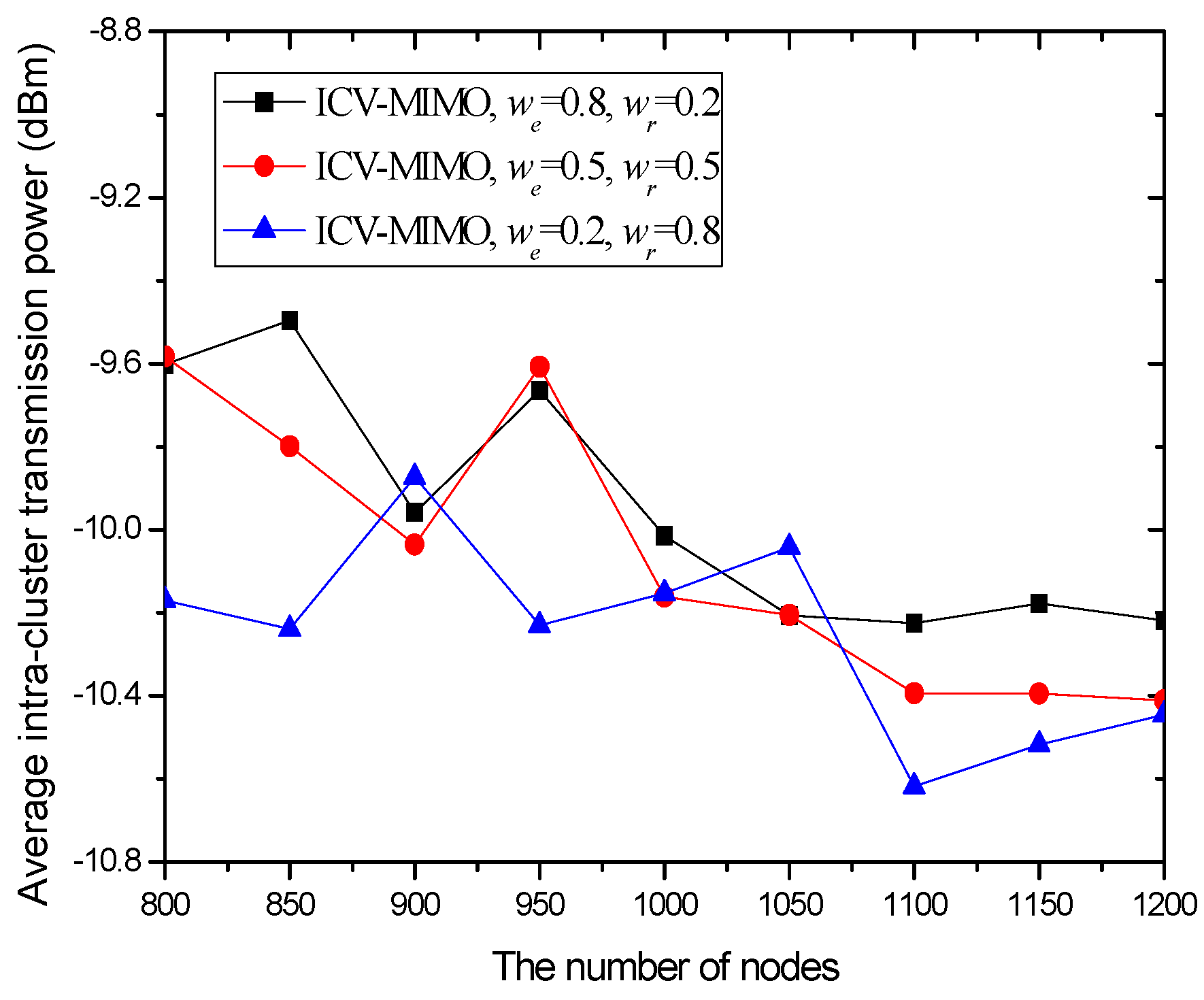
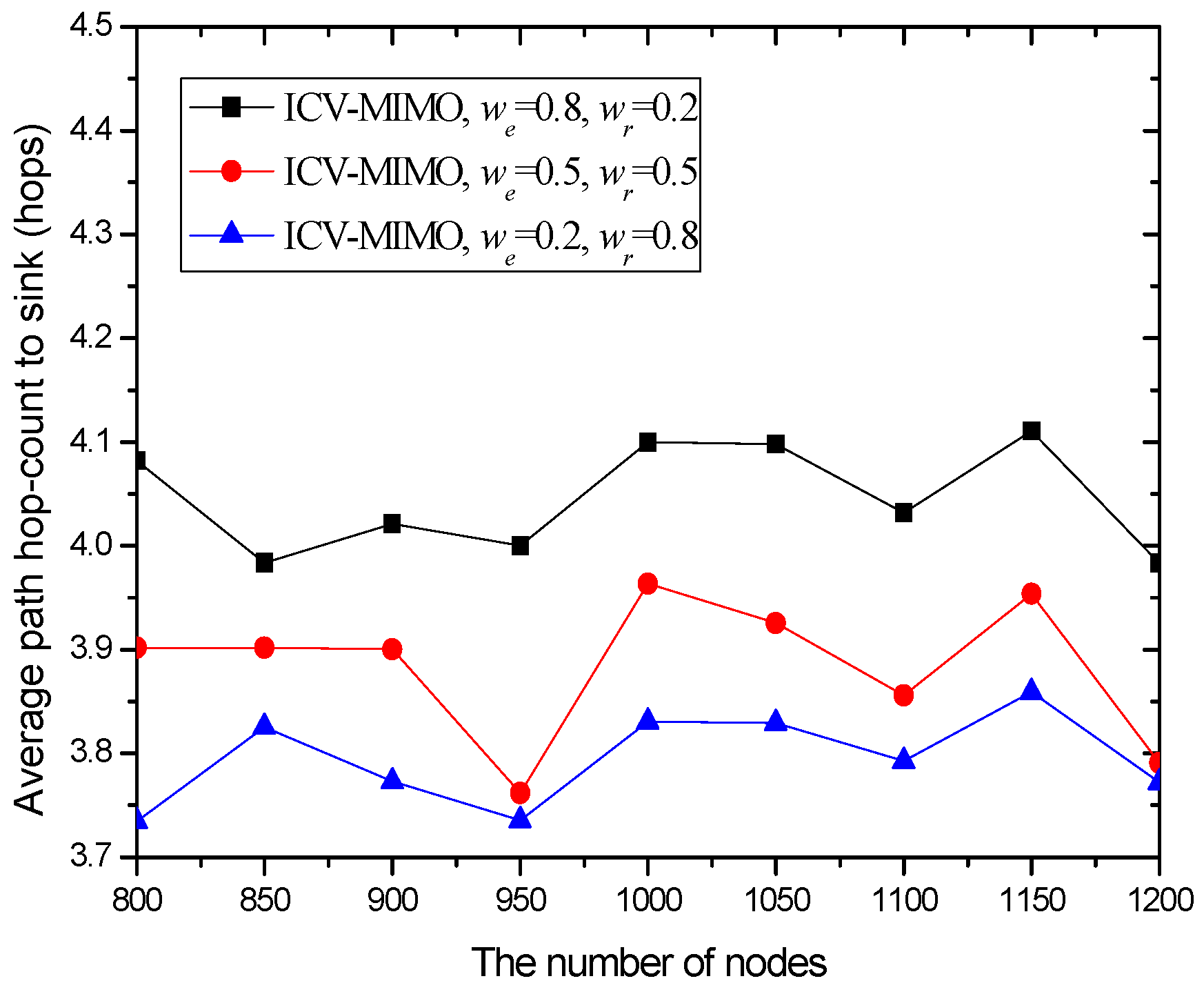
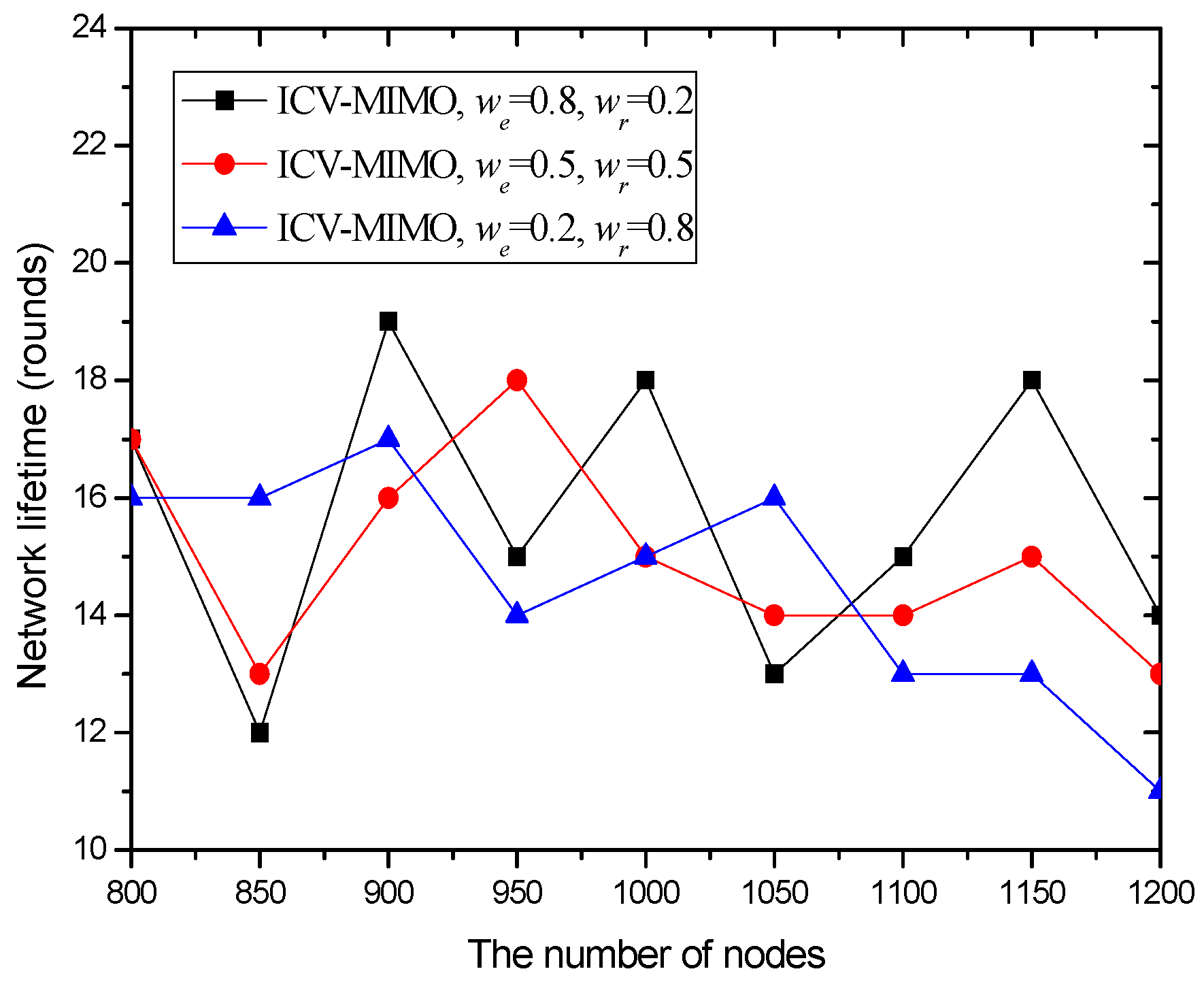
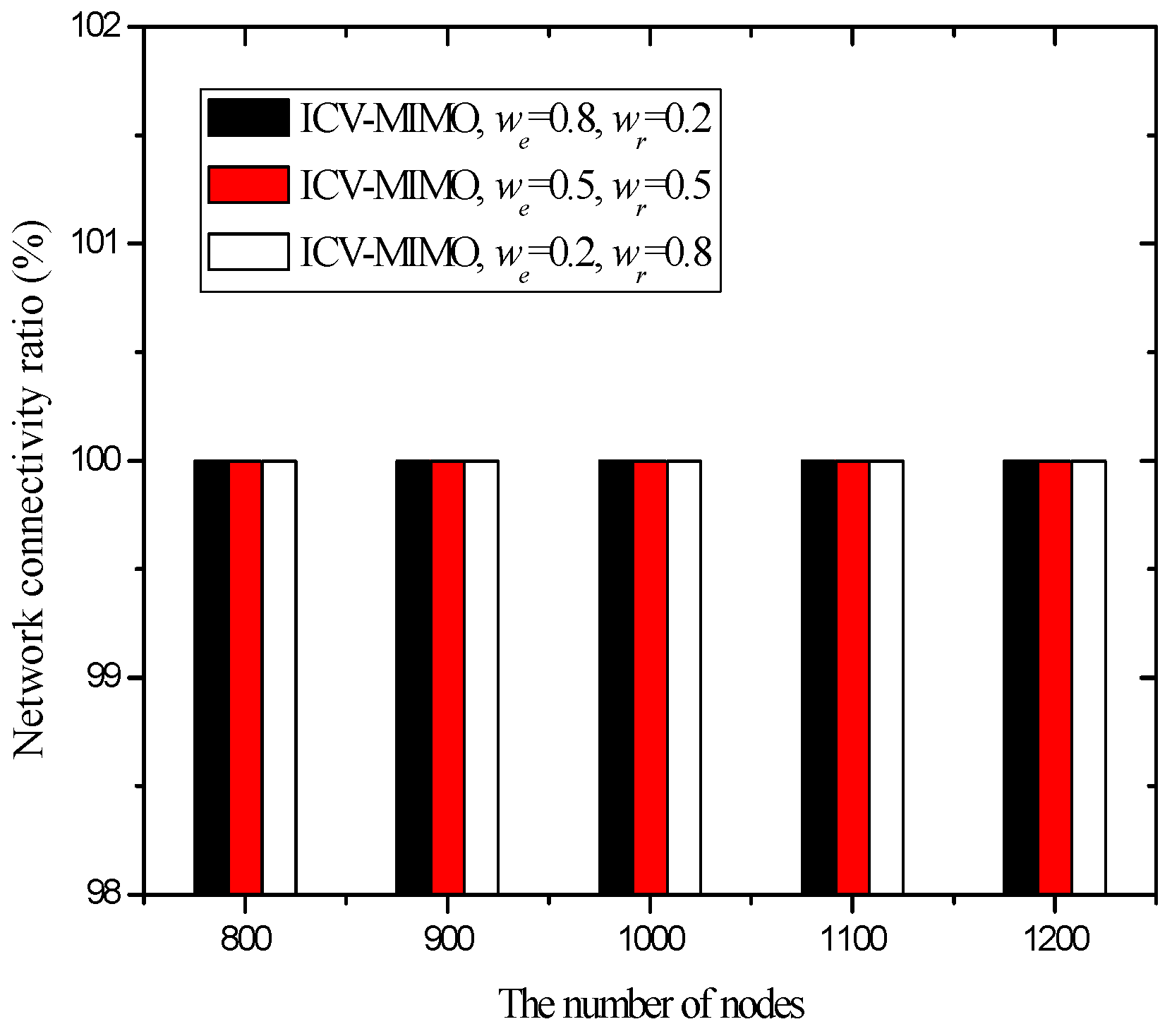
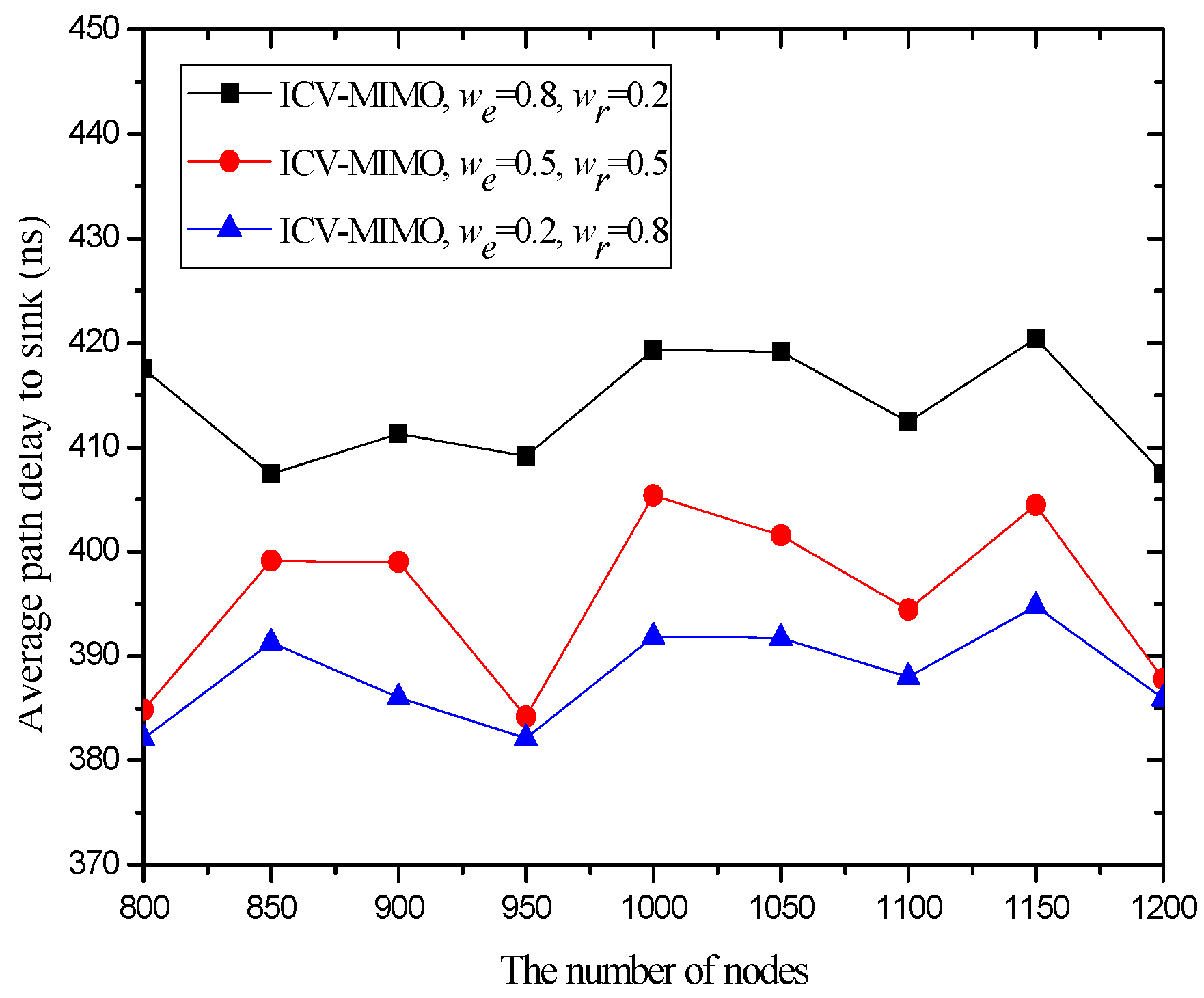
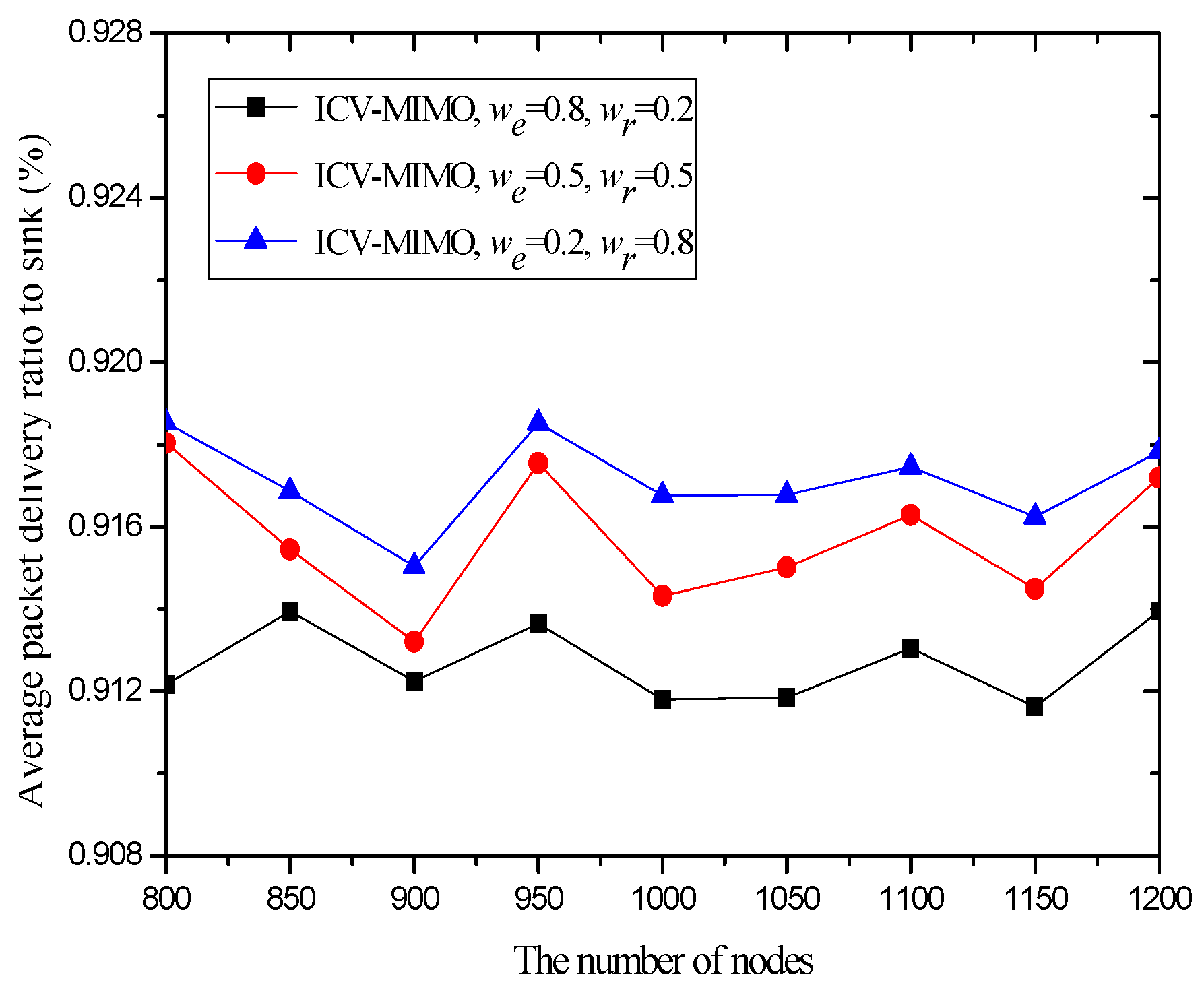
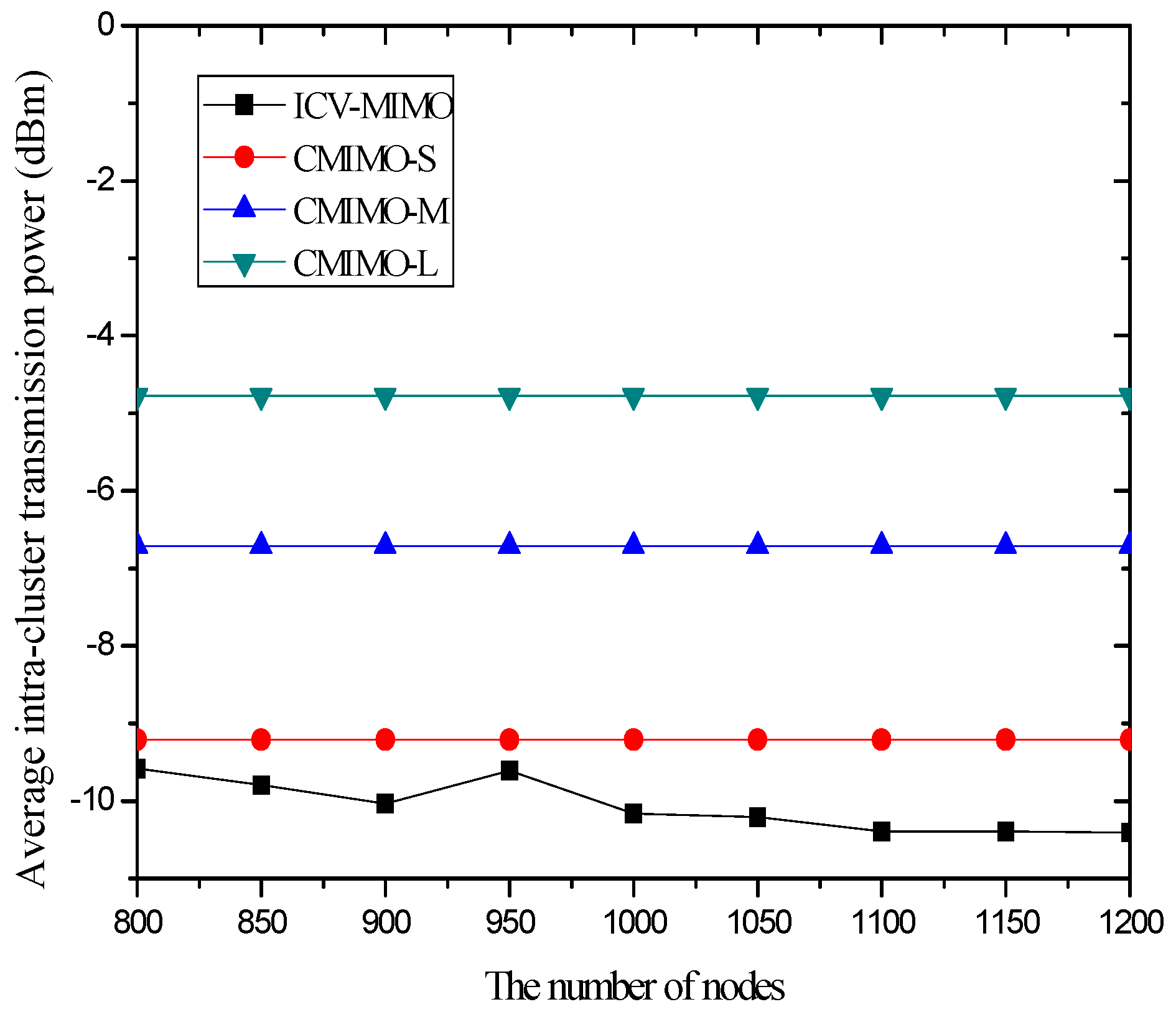
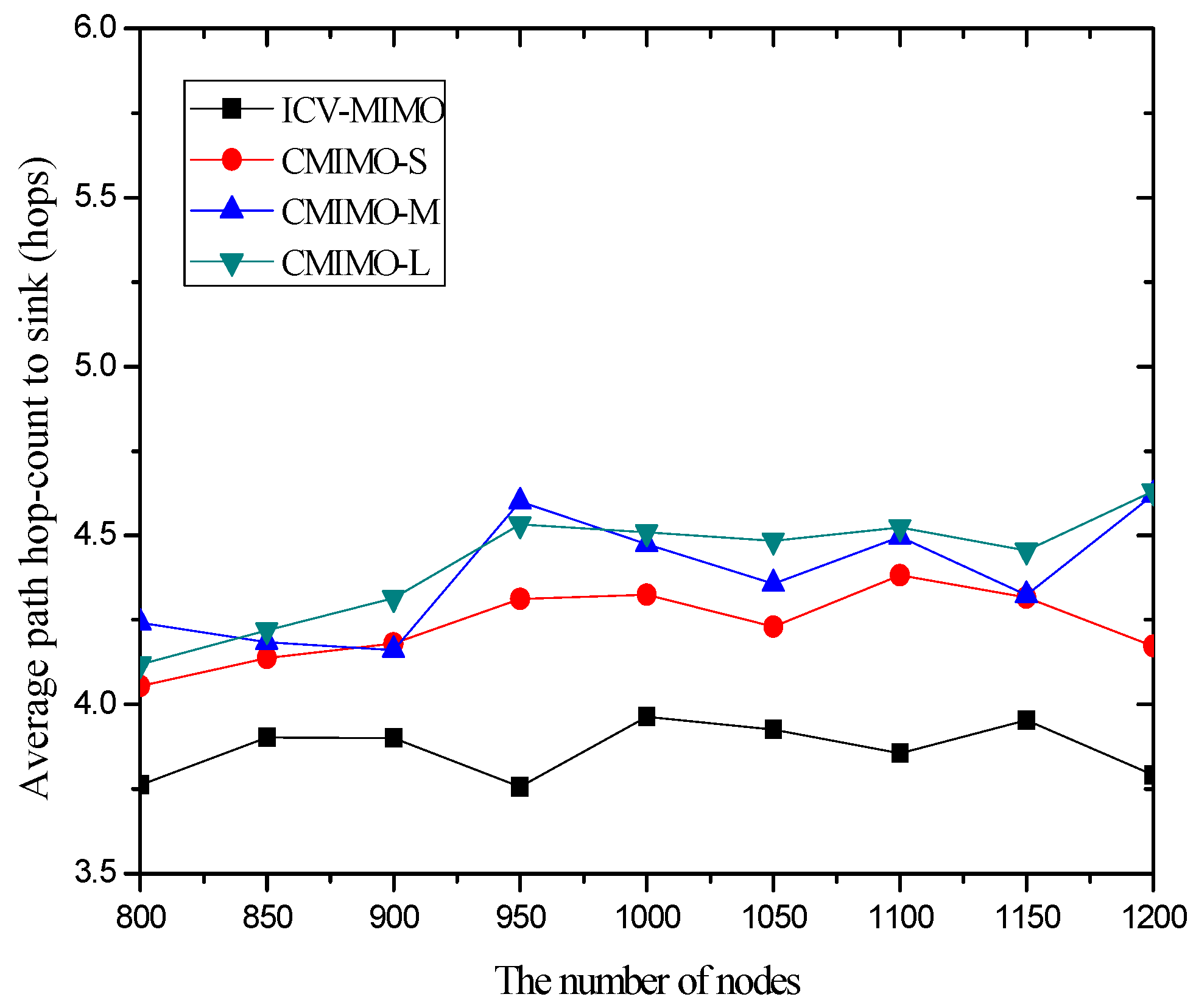
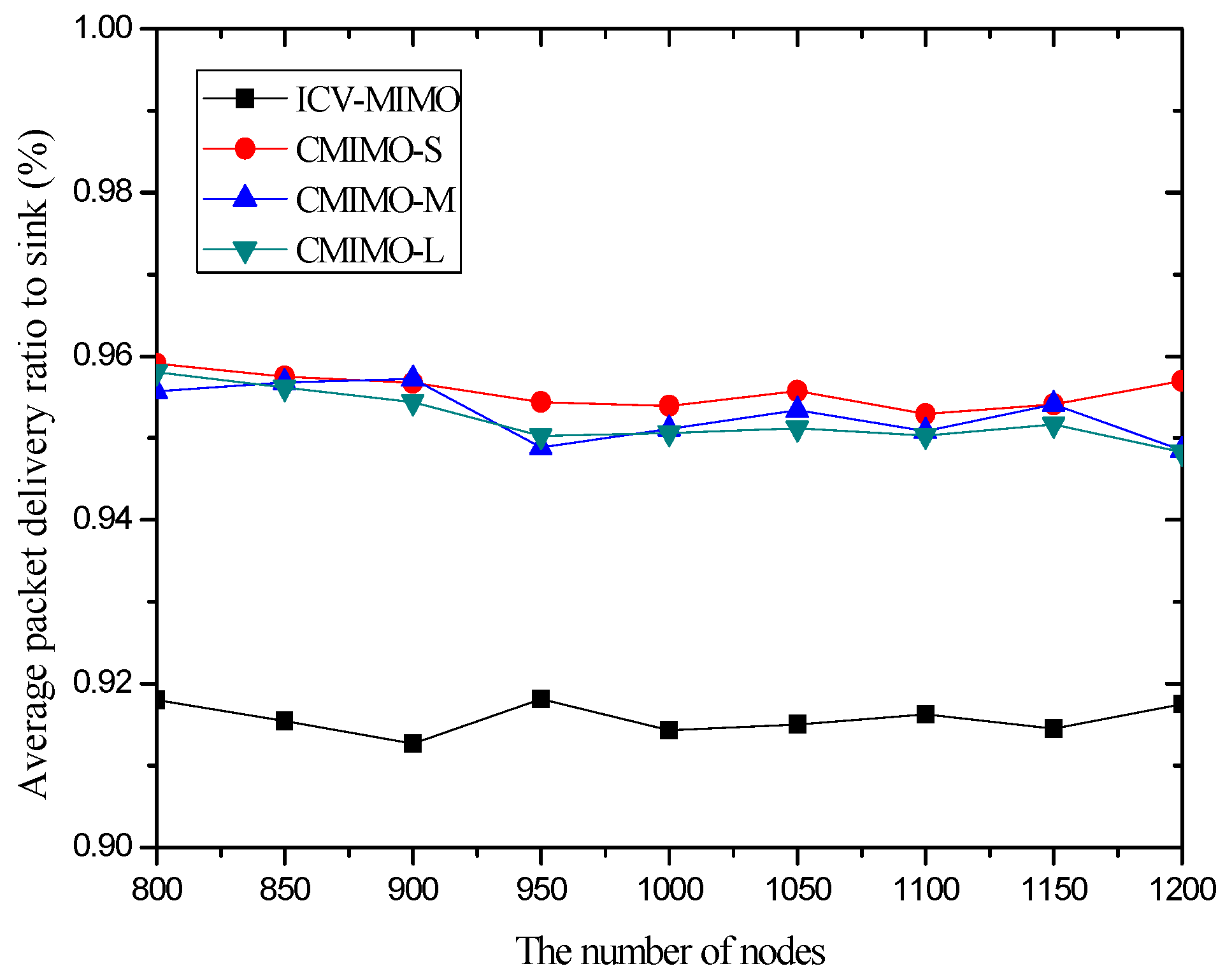
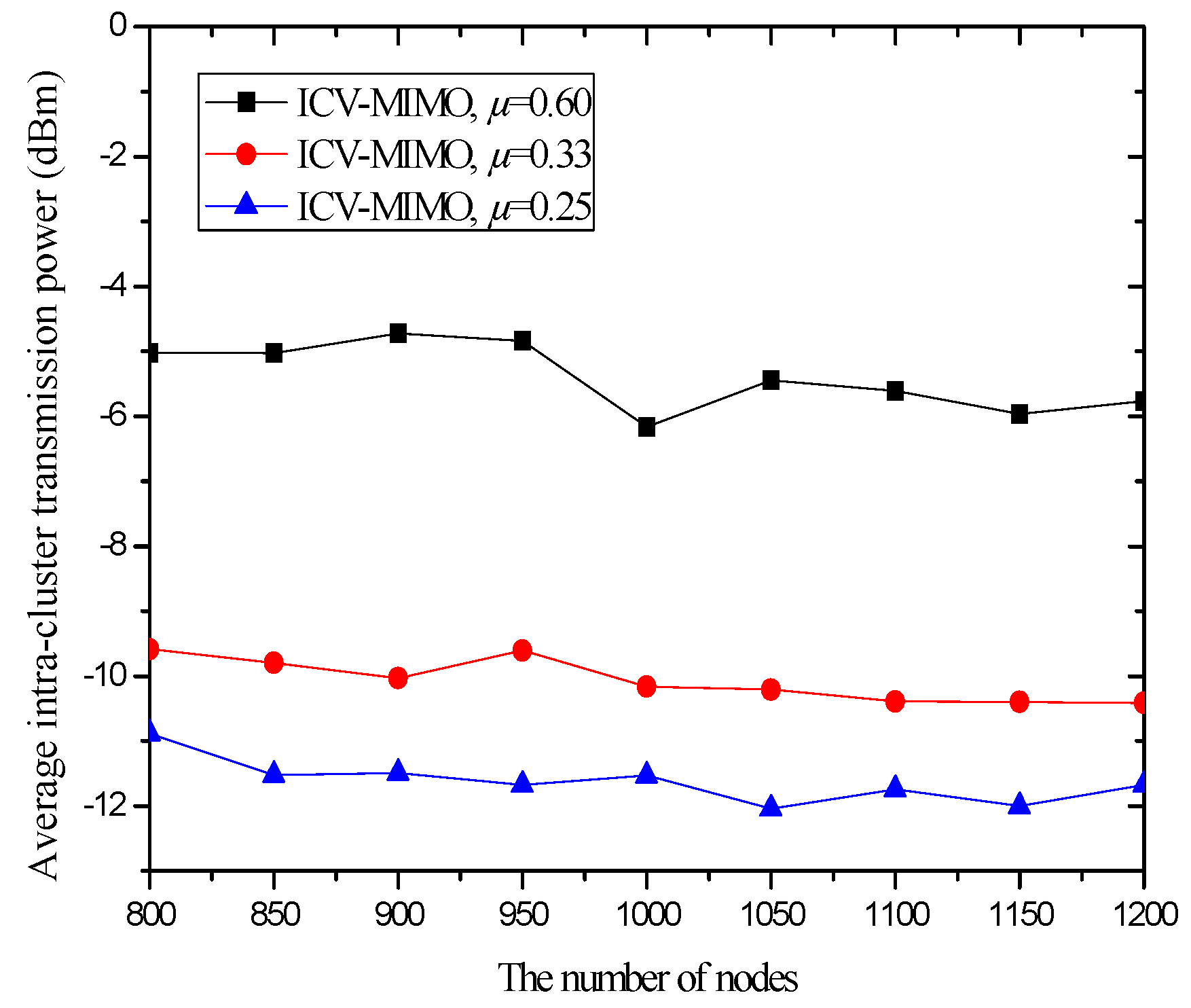
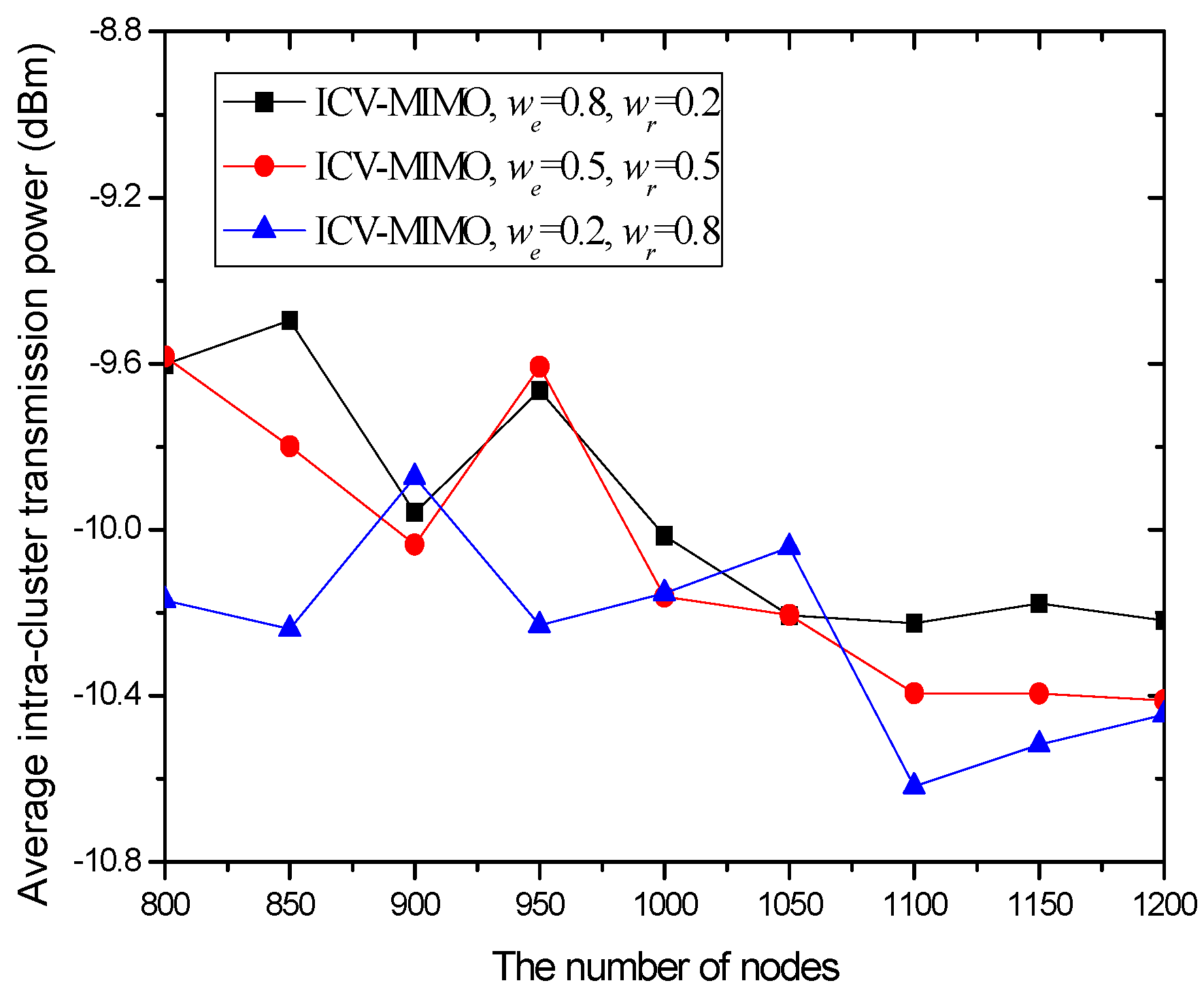
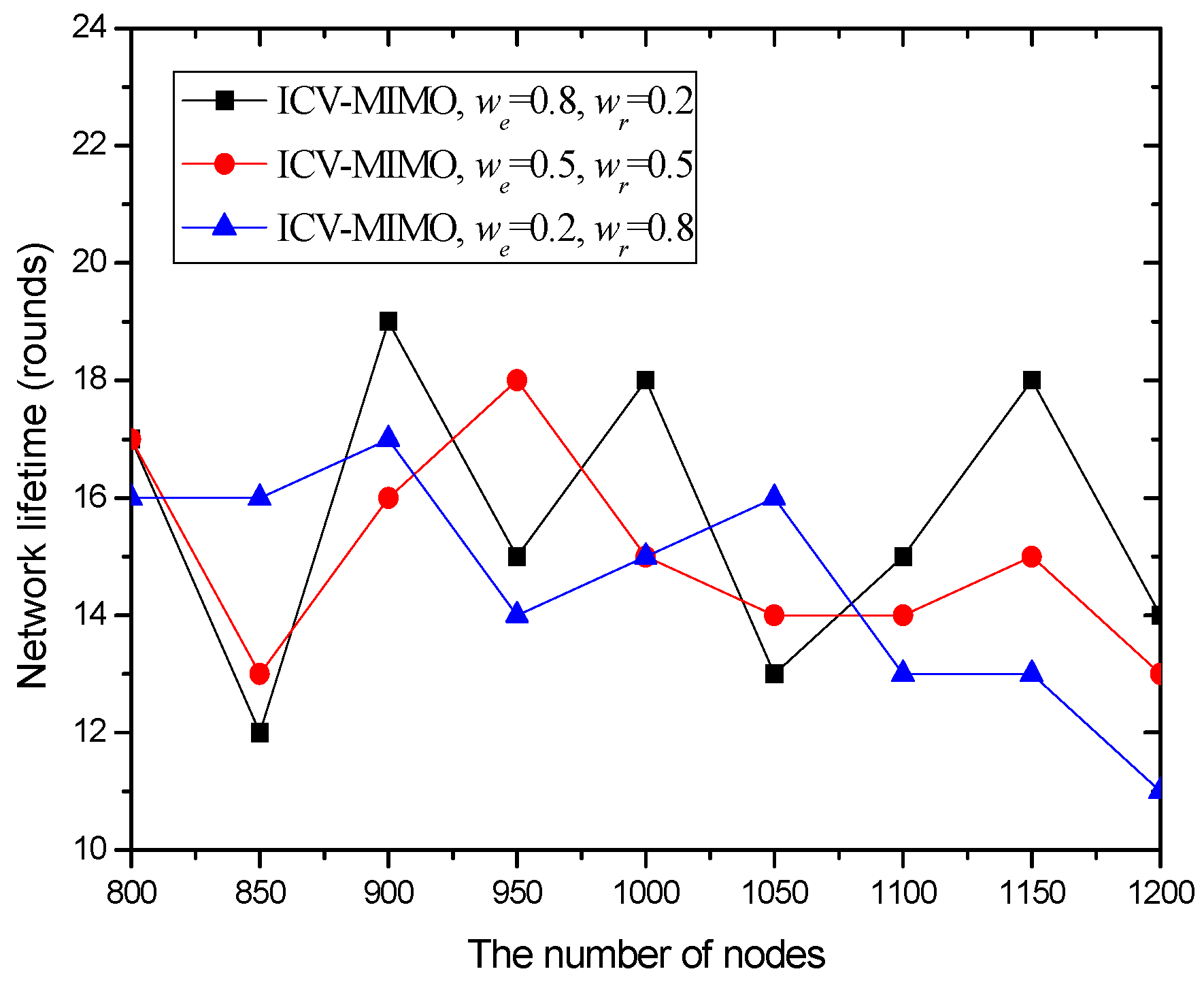
4.3. Simulation Results and Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nguyen, D.N.; Krunz, M. Cooperative MIMO in Wireless Networks: Recent Developments and Challenges. IEEE Netw. 2013, 27, 48–54. [Google Scholar] [CrossRef]
- Nguyen, D.N.; Krunz, M. A Cooperative Clustering Protocol for Energy Constrained Networks. In Proceedings of the 8th IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON), Salt Lake City, UT, USA, 27–30 June 2011; pp. 574–582.
- Krunz, M.; Siam, M.Z.; Nguyen, D.N. Clustering and Power Management for Virtual MIMO Communications in Wireless Sensor Networks. Ad Hoc Netw. 2013, 11, 1571–1587. [Google Scholar] [CrossRef]
- Sajid, H.; Anwarul, A.; Jong, H.P. Energy Efficient Virtual MIMO Communication for Wireless Sensor Networks. Telecommun. Syst. 2009, 42, 139–149. [Google Scholar]
- Xu, H.; Huang, L.; Qiao, C.; Zhang, Y.; Sun, Q. Bandwidth-Power Aware Cooperative Multipath Routing for Wireless Multimedia Sensor Networks. IEEE Trans. Wirel. Commun. 2012, 99, 1–12. [Google Scholar] [CrossRef]
- Dohler, M.; Lefranc, E.; Aghvami, H. Virtual Antenna Arrays for Future Wireless Mobile Communication Systems. In Proceedings of the ICT Conference, Beijing, China, 25–28 June 2002.
- Dohler, M.; Lefranc, E.; Aghvami, H. Space Time Block Codes for Virtual Antenna Arrays. In Proceedings of the PIMRC Conference, Lisbon, Portugal, 15–18 September 2002.
- Cui, S.; Goldsmith, A.J.; Bahai, A. Energy-efficiency of MIMO and Cooperative MIMO Techniques in Sensor Networks. IEEE J. Sel. Areas Commun. 2004, 22, 1089–1098. [Google Scholar] [CrossRef]
- Li, X. Energy Efficient Wireless Sensor Networks with Transmission Diversity. IEE Electron. Lett. 2003, 39, 1753–1755. [Google Scholar] [CrossRef]
- Jayaweera, S.K. Energy Analysis of MIMO Techniques in Wireless Sensor Networks. In Proceedings of the 38th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 17 March 2004.
- Gao, Q.; Zuo, Y.; Zhang, J.; Peng, X.H. Improving Energy Efficiency in a Wireless Sensor Network by Combining Cooperative MIMO with Data Aggregation. IEEE Trans. Veh. Technol. 2010, 59, 3956–3965. [Google Scholar] [CrossRef]
- Jaafar, W.; Ajib, W.; Haccoun, D. On the Performance of Distributed-STBC in Multi-hop Wireless Relay Networks. In Proceedings of the European Wireless Conference, Paris, France, 27–28 September 2010; pp. 223–230.
- Jayaweera, S. Virtual MIMO-based Cooperative Communication for Energy-constrained Wireless Sensor Networks. IEEE Trans. Wirel. Commun. 2006, 5, 984–989. [Google Scholar] [CrossRef]
- Qu, Q.; Milstein, L.B.; Vaman, D.R. Cooperative and Constrained MIMO Communications in Wireless Ad Hoc/Sensor Networks. IEEE Trans. Wirel. Commun. 2010, 9, 3120–3129. [Google Scholar] [CrossRef]
- Salvo Rossi, P.; Ciuonzo, D.; Kansanen, K.; Ekman, T. On Energy Detection for MIMO Decision Fusion in Wireless Sensor Networks over NLOS Fading. IEEE Commun. Lett. 2015, 19, 303–306. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Romano, G.; Salvo Rossi, P. Performance Analysis and Design of Maximum Ratio Combining in Channel-Aware MIMO Decision Fusion. IEEE Trans. Wirel. Commun. 2013, 12, 4716–4728. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Salvo Rossi, P.; Dey, S. Massive MIMO Channel-Aware Decision Fusion. IEEE Trans. Signal Process. 2015, 63, 604–619. [Google Scholar] [CrossRef]
- Shirazinia, A.; Dey, S.; Ciuonzo, D.; Salvo Rossi, P. Massive MIMO for Decentralized Estimation of a Correlated Source. IEEE Trans. Signal Process. 2016, 64, 2499–2512. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, M.; Kwon, T. A Novel Cluster-Based Cooperative MIMO Scheme for Multi-Hop Wireless Sensor Networks. EURASIP J. Wirel. Commun. Netw. 2006, 2006, 38. [Google Scholar] [CrossRef]
- Heinzelman, W.R. Application-Specific Protocol Architectures for Wireless Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Boston, MA, USA, 2000. [Google Scholar]
- Siam, M.Z.; Krunz, M.; Younis, O. Energy-efficient Clustering/Routing for Cooperative MIMO Operation in Sensor Networks. In Proceedings of the IEEE INFOCOM Conference, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 621–629.
- Hua, H.; Qiu, J.; Song, S.; Wang, X.; Dai, G. A Cluster Head Rotation Cooperative MIMO Scheme for Wireless Sensor Networks, Wireless Algorithms, Systems, and Applications; Springer: Cham, Switzerland, 2015; pp. 212–221. [Google Scholar]
- Li, B.; Zheng, G.; Li, N.; Li, J. A Virtual MIMO Communication Strategy Based on Cooperative Groups for Wireless Sensor Networks. Int. J. Future Gen. Commun. Netw. 2015, 8, 223–234. [Google Scholar] [CrossRef]
- Li, N.; Hou, J.C. Localized Topology Control Algorithms for Heterogeneous Wireless Networks. IEEE/ACM Trans. Netw. 2005, 13, 1313–1324. [Google Scholar]
- England, D.; Veeravalli, B.; Weissman, J.B. A Robust Spanning Tree Topology for Data Collection and Dissemination in Distributed Environments. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 608–620. [Google Scholar] [CrossRef]
- Gui, J.S.; Liu, A.F. A New Distributed Topology Control Algorithm Based on Optimization of Delay and Energy in Wireless Networks. J. Parallel Distrib. Comput. 2012, 72, 1032–1044. [Google Scholar] [CrossRef]
- Gui, J.S.; Zeng, Z.W. Joint Network Lifetime and Delay Optimization for Topology Control in Heterogeneous Wireless Multi-hop Networks. Comput. Commun. 2015, 59, 24–36. [Google Scholar] [CrossRef]
- Gui, J.S.; Zhou, K. Flexible Adjustments Between Energy and Capacity for Topology Control in Heterogeneous Wireless Multi-hop Networks. J. Netw. Syst. Manag. 2016, 24, 789–812. [Google Scholar] [CrossRef]
- Heinzelman, W.R.; Chandrakasan, A.; Balakrishnan, H. An Application Specific Protocol Architecture for Wireless Micro-Sensor Networks. IEEE Trans. Wirel. Commun. 2002, 1, 660–670. [Google Scholar] [CrossRef]
- Younis, O.; Fahmy, S. HEED: A Hybrid, Energy-efficient, Distributed Clustering Approach for Ad Hoc Sensor Networks. IEEE Trans. Mob. Comput. 2004, 3, 366–379. [Google Scholar] [CrossRef]
- Liu, Y.; Xiong, N.; Zhao, Y.; Vasilakos, A.V.; Gao, J.; Jia, Y. Multi-layer Clustering Routing Algorithm for Wireless Vehicular Sensor Networks. IET Commun. 2010, 4, 810–816. [Google Scholar] [CrossRef]
- Santi, P. Topology Control in Wireless Ad Hoc and Sensor Networks. ACM Comput. Surv. 2005, 37, 164–194. [Google Scholar] [CrossRef]
- The OMNeT++ Discrete Event Simulation System, Version 4.1. Available online: http://www.omnetpp.org (accessed on 26 August 2016).
- Bacci, G.; Luise, M.; Poor, H.V. Game-Theoretic Power Control in Impulse Radio UWB Wireless Networks. In Proceedings of the 13th European Wireless Conference, Paris, France, 1–4 April 2007.
- Wei, G.; Vasilakos, A.V.; Zheng, Y.; Xiong, N. A Game-Theoretic Method of Fair Resource Allocation for Cloud Computing Services. J. Supercomput. 2010, 54, 252–269. [Google Scholar] [CrossRef]
- Gui, J.S.; Ahmadi, M.; Tong, F. Dynamically Constructing and Maintaining Virtual Access Points in a Macro Cell with Selfish Nodes. J. Syst. Softw. 2015, 108, 1–22. [Google Scholar] [CrossRef]
- Xiong, N.; Vasilakos, A.V.; Yang, L.T.; Song, L.; Pan, Y.; Kannan, R.; Li, Y. Comparative Analysis of Quality of Service and Memory Usage for Adaptive Failure Detectors in Healthcare Systems. IEEE J. Sel. Areas Commun. 2009, 27, 495–509. [Google Scholar] [CrossRef]
- Yin, J.; Lu, X.; Zhao, X.; Chen, H.; Liu, X. BURSE: A Bursty and Self-Similar Workload Generator for Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 668–680. [Google Scholar] [CrossRef]
- Liu, A.; Hu, Y.; Chen, Z. An Energy-Efficient Mobile Target Detection Scheme with Adjustable Duty Cycles in Wireless Sensor Networks. Int. J. Ad Hoc Ubiquitous Comput. 2016, 22, 203–225. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, M.; Ota, K.; Liu, A. ActiveTrust: Secure and Trustable Routing in Wireless Sensor Networks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2013–2027. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Message Overhead | Time Overhead |
|---|---|---|
| ICV-MIMO | O(Nnei) | max{O(Tt), O(Nnei·Tr)} |
| CMIMO | O(Ndeg) | max{O(Tt), O(Ndeg·Tr)} |
| Description | Parameter | Value |
|---|---|---|
| Transmitting antenna gain | Gt | 1 |
| Receiving antenna gain | Gr | 1 |
| Transmitting antenna height | ht | 1 m |
| Receiving antenna height | hr | 1 m |
| Maximum transmitting power | pi,max | For any node i, pi,max is set as randomly distributed between 0 dBm and 20 dBm |
| Receiver sensitivity | phi | For any node i, phi is as −85 dBm |
| Carrier signal wavelength | λ | 0.1224 m |
| System loss factor | L | 1 |
| Crossover distance | dcrossover | 103 m |
| Initial battery capacity | ei,int | For any node i, ei,int is randomly distributed between 0.05 J and 0.2 J |
| Bit rate | Rb | 2 Mbit/s |
| SNR threshold | γ(Mt,Mr) | γ(1,1) = 54.4 dBm; γ(1,2) = 40.6 dBm; γ(2,1) = 44.1 dBm; γ(2,2) = 36.9 dBm |
| Factor depending on amplifier drain efficiency and underlying modulation | δ | 0.5 |
| Single-sided thermal noise PSD | No | −171 dBm/Hz |
| Passband bandwidth | B | 10 kHz |
| Receiver noise figure | Nf | 40 dBm |
| Constant depending on transmitter and receiver antenna gains | Go | 1 |
| Link margin compensating for hardware variations and other sources of interference | Ml | 40 dBm |
| Power consumption for digital-to-analog converter | PDAC | 12 dBm |
| Power consumption for mixer | Pmix | 15 dBm |
| Power consumption for low noise amplifier | PLNA | 13 dBm |
| Power consumption for intermediate frequency amplifier | PIFA | 3 dBm |
| Power consumption for active filter at the transmitter side | Pfilt | 4 dBm |
| Power consumption for active filter at receiver side | Pfilr | 4 dBm |
| Power consumption for analog-to-digital converter | PADC | 12 dBm |
| Power consumption for frequency synthesizer | Psyn | 17 dBm |
| Length of data packet consisting of 4 sub-packages | l | 10,000 bit |
| Reference energy | eref | 0.2 J |
| Reference distance | dref | 420 m |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, J.; Zhou, K.; Xiong, N. A Cluster-Based Dual-Adaptive Topology Control Approach in Wireless Sensor Networks. Sensors 2016, 16, 1576. https://doi.org/10.3390/s16101576
Gui J, Zhou K, Xiong N. A Cluster-Based Dual-Adaptive Topology Control Approach in Wireless Sensor Networks. Sensors. 2016; 16(10):1576. https://doi.org/10.3390/s16101576
Chicago/Turabian StyleGui, Jinsong, Kai Zhou, and Naixue Xiong. 2016. "A Cluster-Based Dual-Adaptive Topology Control Approach in Wireless Sensor Networks" Sensors 16, no. 10: 1576. https://doi.org/10.3390/s16101576