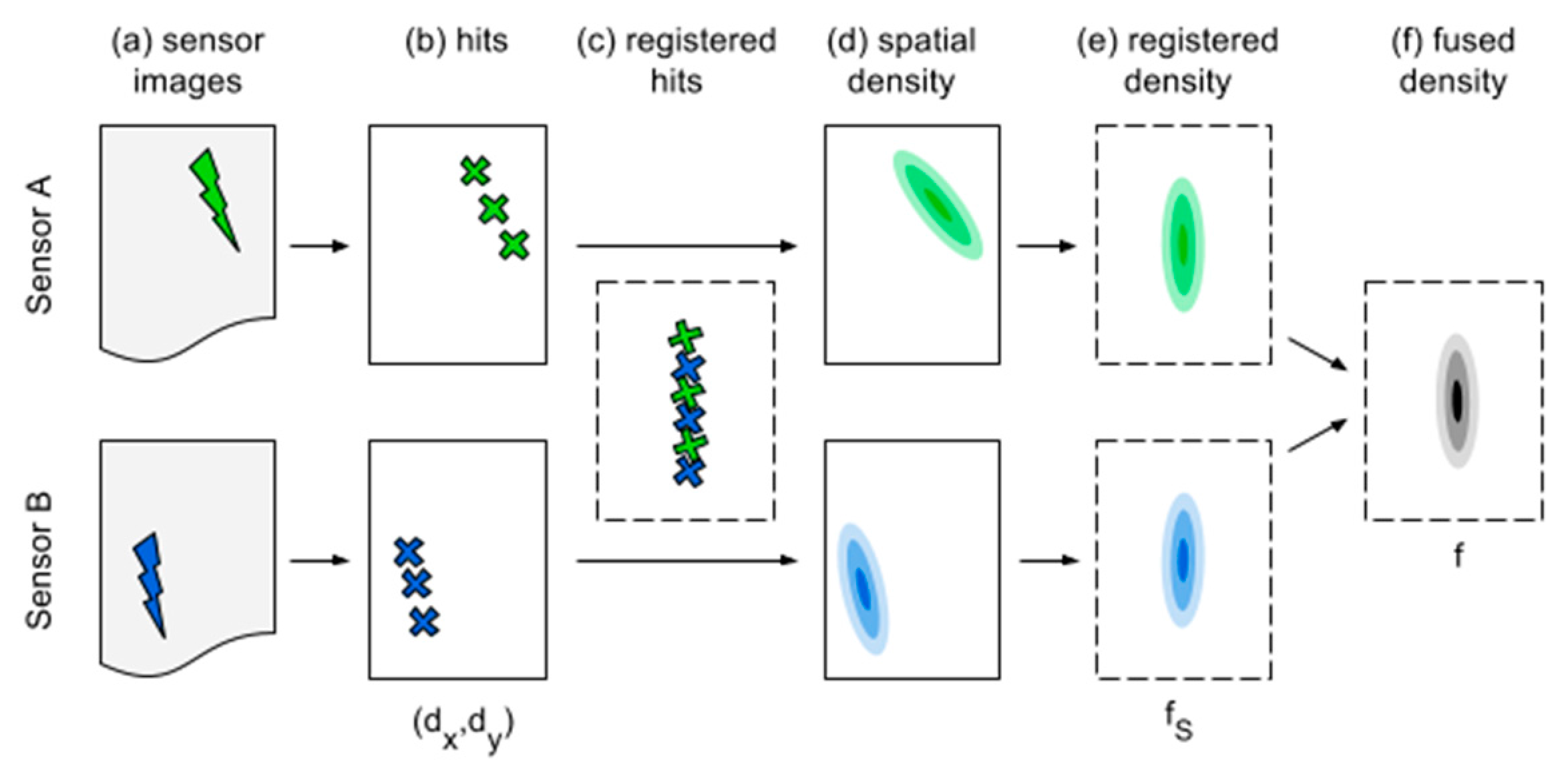
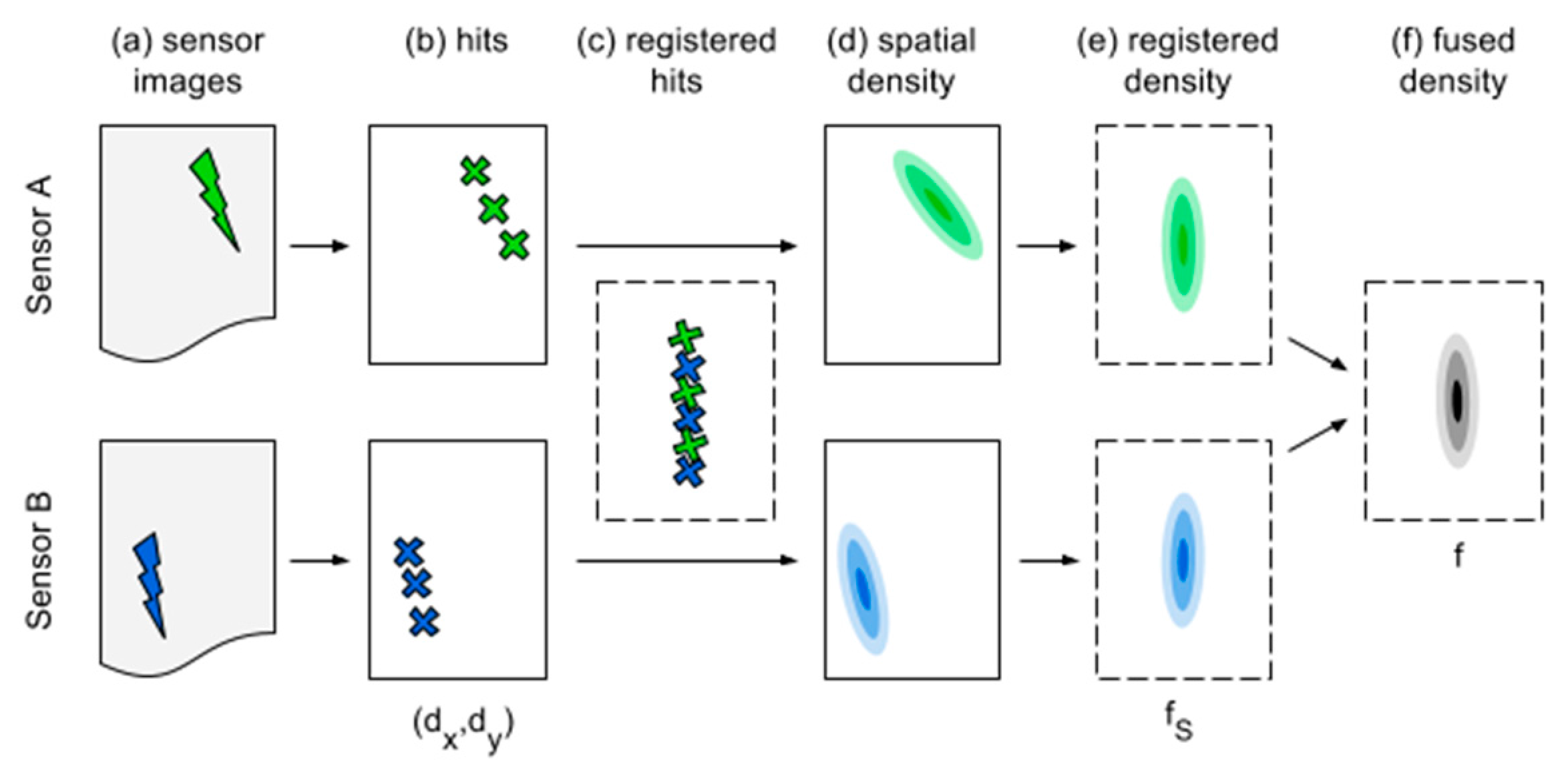
3.2. Individual Measurements and Processing
For crack detection, three different inspection techniques were used that are well-suited for the automated nondestructive evaluation of cracks in ferromagnetic metals. The first method is called eddy current testing (ET). An excitation coil is run over the specimen surface. Using this coil, an alternating current induces circular eddy currents in the specimen’s near-surface region. These currents are blocked by the presence of defects, thus affecting the impedance of the probe coil, which is the measured signal. The second method employed here is the laser-induced active thermography testing (TT). A high-power laser is run across the specimen to locally heat up the surface. In defect-free regions, the heat flow is able to dissipate, whereas defects cause localized heat accumulation. An infrared camera monitors the heat flow decay and generates a digital image sequence for processing. The third method is magnetic flux leakage testing (MFL). The specimen is exposed locally to a static magnetic field, which spreads inside the ferromagnetic material. At near-surface defects, the field is forced to “leak” out of the specimen into the air, although air has lower magnetic permeability than the specimen. This leakage can be detected by magnetic field sensors, such as giant magneto resistance (GMR) sensors. The following three inspections were performed sequentially during the course of about one year.
ET was carried out at an excitation frequency of 500 kHz, which is well-suited to inspect surface defects due to the skin effect [
17]. An automated scanning device rotates the specimen under the fixed probe. Signal processing is based only on the imaginary part of the measured impedance. The obtained one-dimensional signals are preprocessed by high-pass filtering for trend correction, and by low-pass filtering to improve SNR. An image is formed by stacking the line scans in axial direction of the ring.
The MFL data were collected using the same scanner as for ET, and a GMR sensor array developed at BAM [
18]. Using these gradiometers, the normal component of the magnetic stray field was measured while the specimen was locally magnetized. Preprocessing comprised trend correction by high-pass filtering per line scan, and an adaptive 2D wiener filter (We used MATLAB’s function
wiener2. See [
19]) for noise suppression. The image was then Sobel-filtered to highlight the steep flanks that are generated by the gradiometers over the grooves.
Thermography testing was performed by rotating the specimen under a 40 W powered laser while recording with an infrared camera. The movie frames were then composed to form an image of the specimen surface. This image is processed by 2D background subtraction using median filtering, and noise was suppressed by an adaptive 2D wiener filter.
We note that the presented signal acquisition is tailored to the known groove orientation. In a realistic setting, a second scan should be performed for ET and MFL testing to detect any circumferentially oriented defects as well. We further emphasize that for our specific ring specimen, the GMR sensors yield far superior results compared to ET and TT, and would suffice by themselves for surface crack detection. Specifically, the MFL data facilitate zero false alarm rate even for the second shallowest of only 20 µm depth. However, such performance is not guaranteed for other materials or in case of suboptimal surface conditions, so that a multi-method approach is still in demand. To take advantage of as many independent sources of information as possible during fusion, we intentionally lowered the quality of the MFL image before preprocessing and detection. This was done by separating the true defect indications from the background signal variations using the shift-invariant wavelet transform [
20], and by reconstructing the signal with a factor of 0.02 for the noise-free component. Although this does not simulate a lower-quality MFL measurement in a physically realistic way, the approach allows making use of the acquired GMR signals as a third source of information. We justify this alteration in favor of demonstrating the capabilities of our fusion technique in other settings where individual inspection is in fact not reliable enough. Therefore, for the rest of the article, only this modified version of the MFL data is considered.
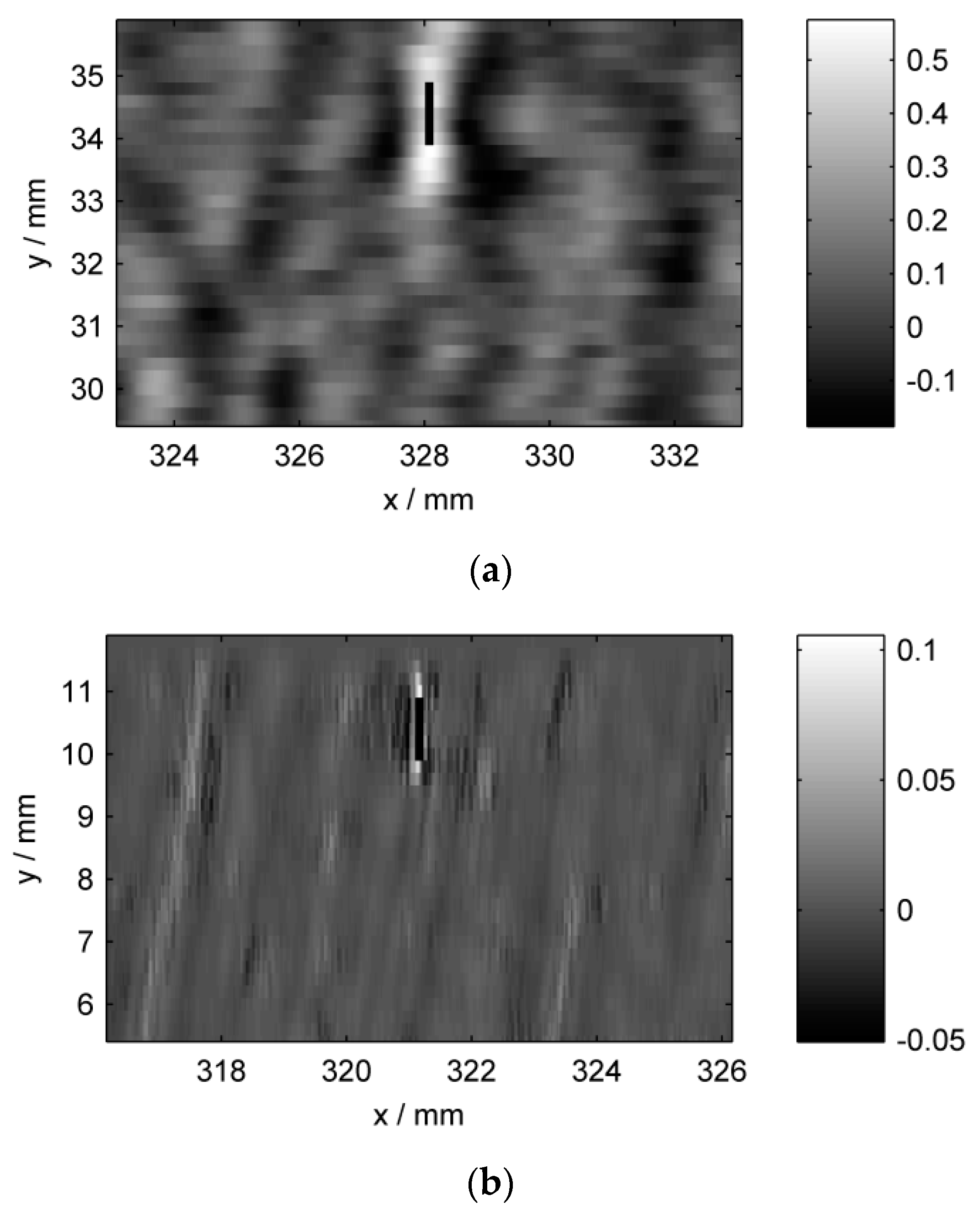
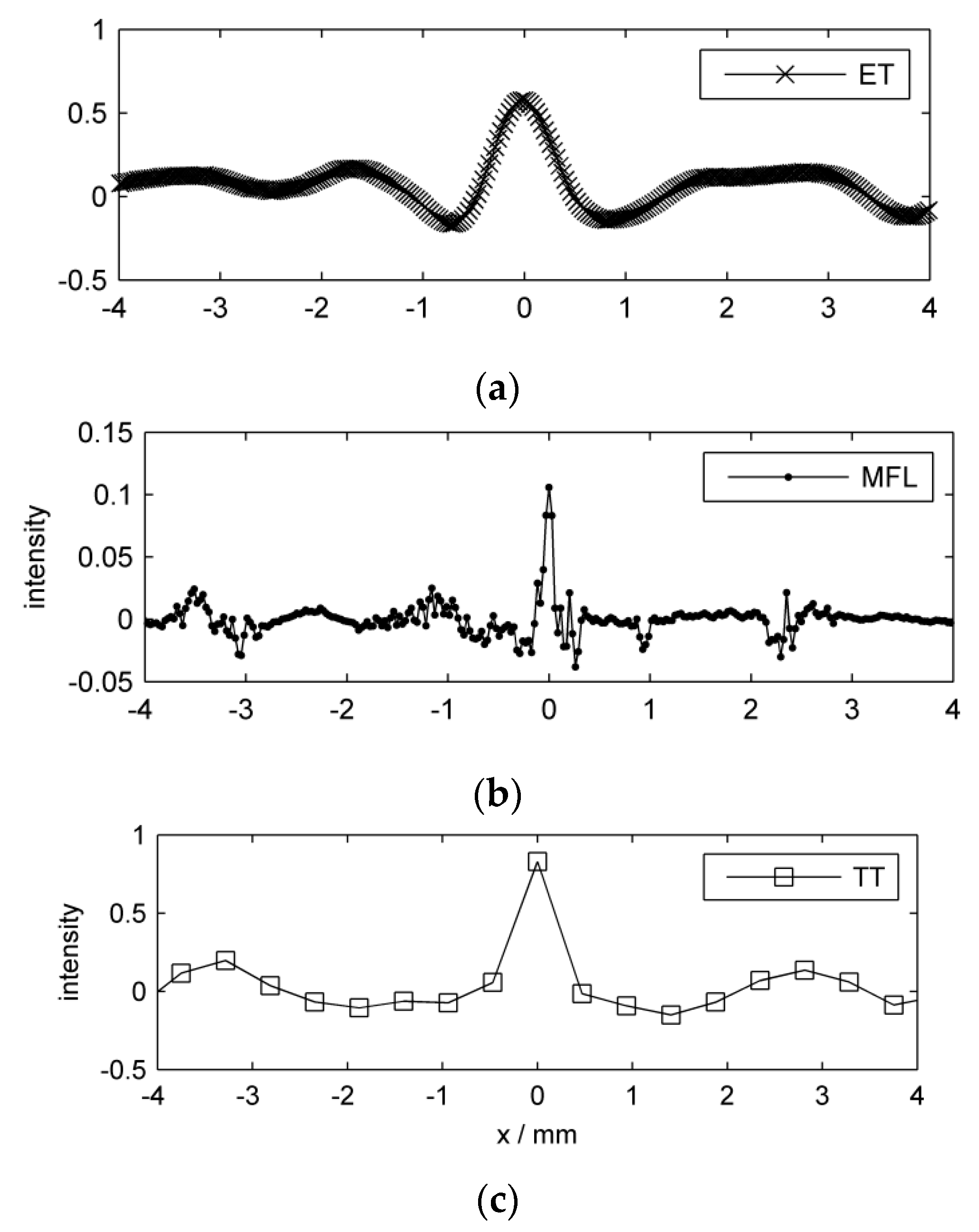
To convey an impression of the signals, we show an exemplary portion of each preprocessed inspection image in
Figure 5. The displayed part of the specimen surface is a 10 mm by 6.5 mm region around groove nr. 13 which is quite shallow, and thus generates relatively weak indications. The figure demonstrates the different signal patterns among sensors, concerning both the groove and the background variations. Also, the different pixel sizes are evident. A related plot is shown in
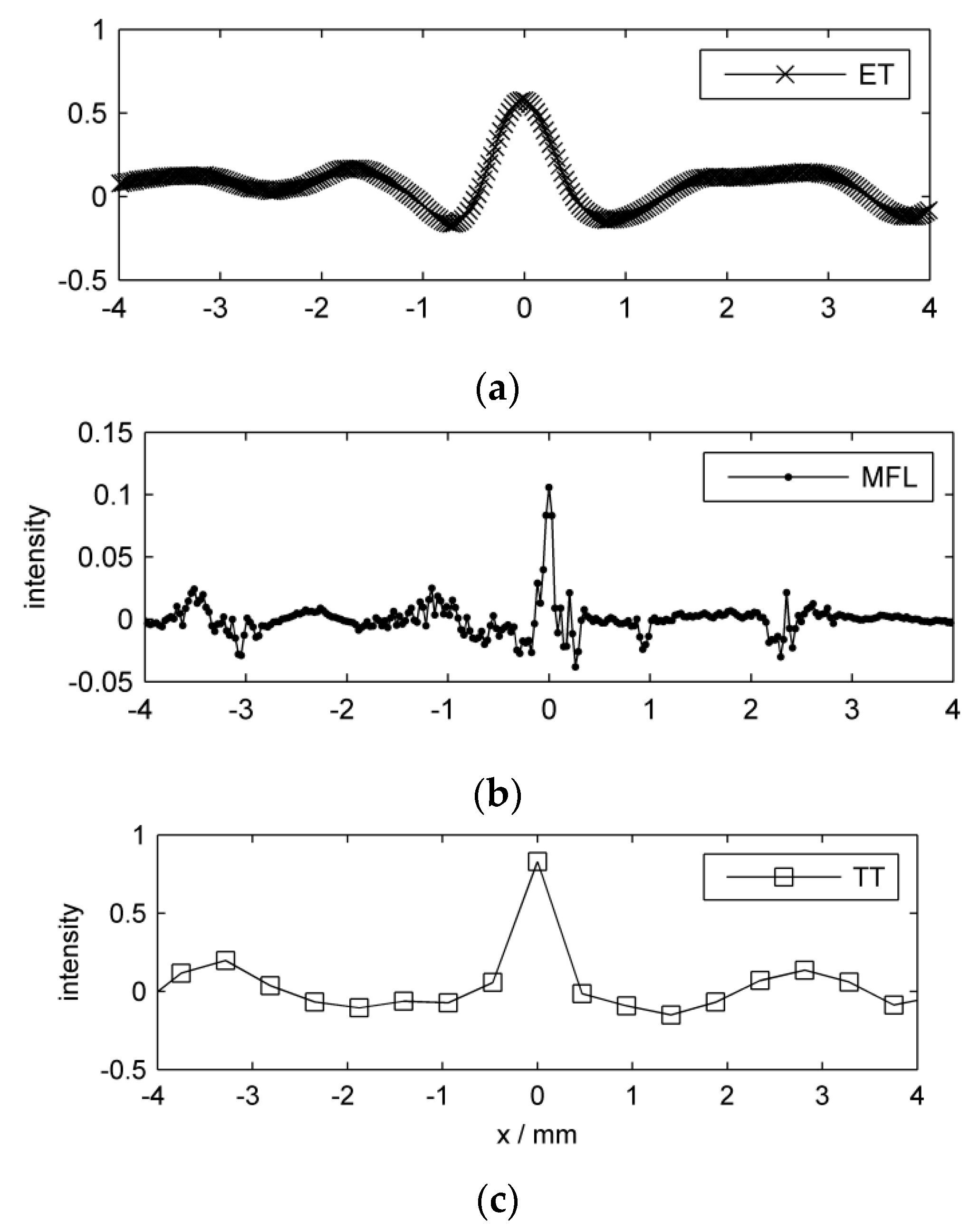
Figure 6, where one-dimensional line scans crossing the groove reveal more clearly the individual sensor responses. The different spatial sampling positions are demonstrated by the line markers.
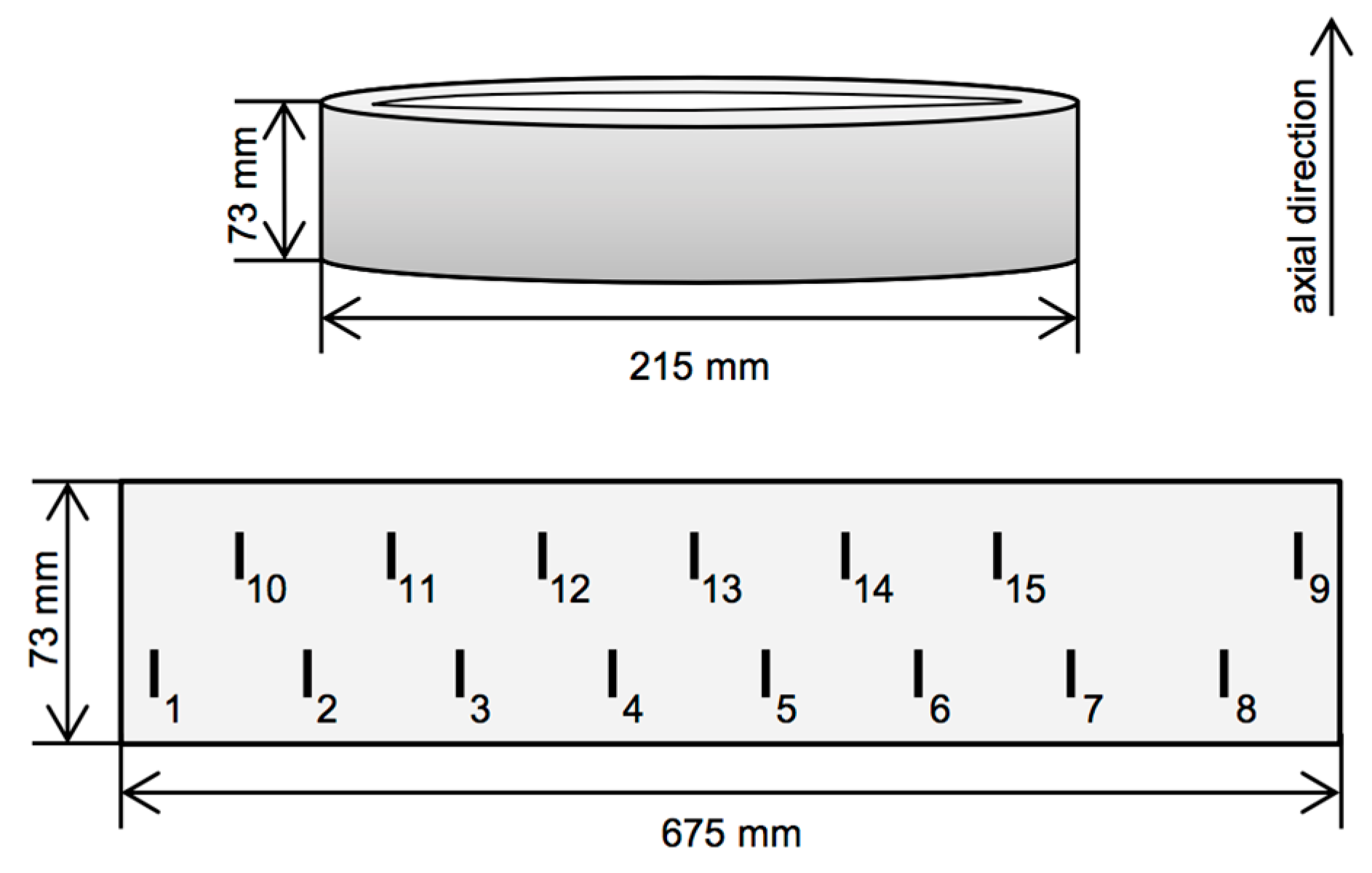
Table 2 (respectively,
Table S2) offers a quantitative comparison of the individual data sets.
Figure 5.
Preprocessed sensor intensity images, zoomed to a region around the groove nr. 13. Higher intensities correspond to indications. (a) ET; (b) MFL; (c) TT. The vertical black line marks the location of the groove. Each image is shown in the respective sensor’s coordinate system, thus explaining the different spatial axis labels.
Figure 5.
Preprocessed sensor intensity images, zoomed to a region around the groove nr. 13. Higher intensities correspond to indications. (a) ET; (b) MFL; (c) TT. The vertical black line marks the location of the groove. Each image is shown in the respective sensor’s coordinate system, thus explaining the different spatial axis labels.
Figure 6.
Preprocessed line scan per inspection method around groove nr. 13. (a) ET; (b) MFL; (c) TT. The signals are shifted so that each peak value is located at . Note the different intensity scales.
Figure 6.
Preprocessed line scan per inspection method around groove nr. 13. (a) ET; (b) MFL; (c) TT. The signals are shifted so that each peak value is located at . Note the different intensity scales.
Table 2.
Quantitative properties of the individual data sets.
Table 2.
Quantitative properties of the individual data sets.
| | ET | MFL | TT |
|---|
| in mm | 0.029 | 0.029 | 0.469 |
| in mm | 0.200 | 0.200 | 0.126 |
| Width of a typical indication, in mm | 2 ≈ 69 | 0.6 ≈ 20 | 0.5 ≈ |
| Avg. nr. of hits per pixel | 0.0023 | 0.0031 | 0.0068 |
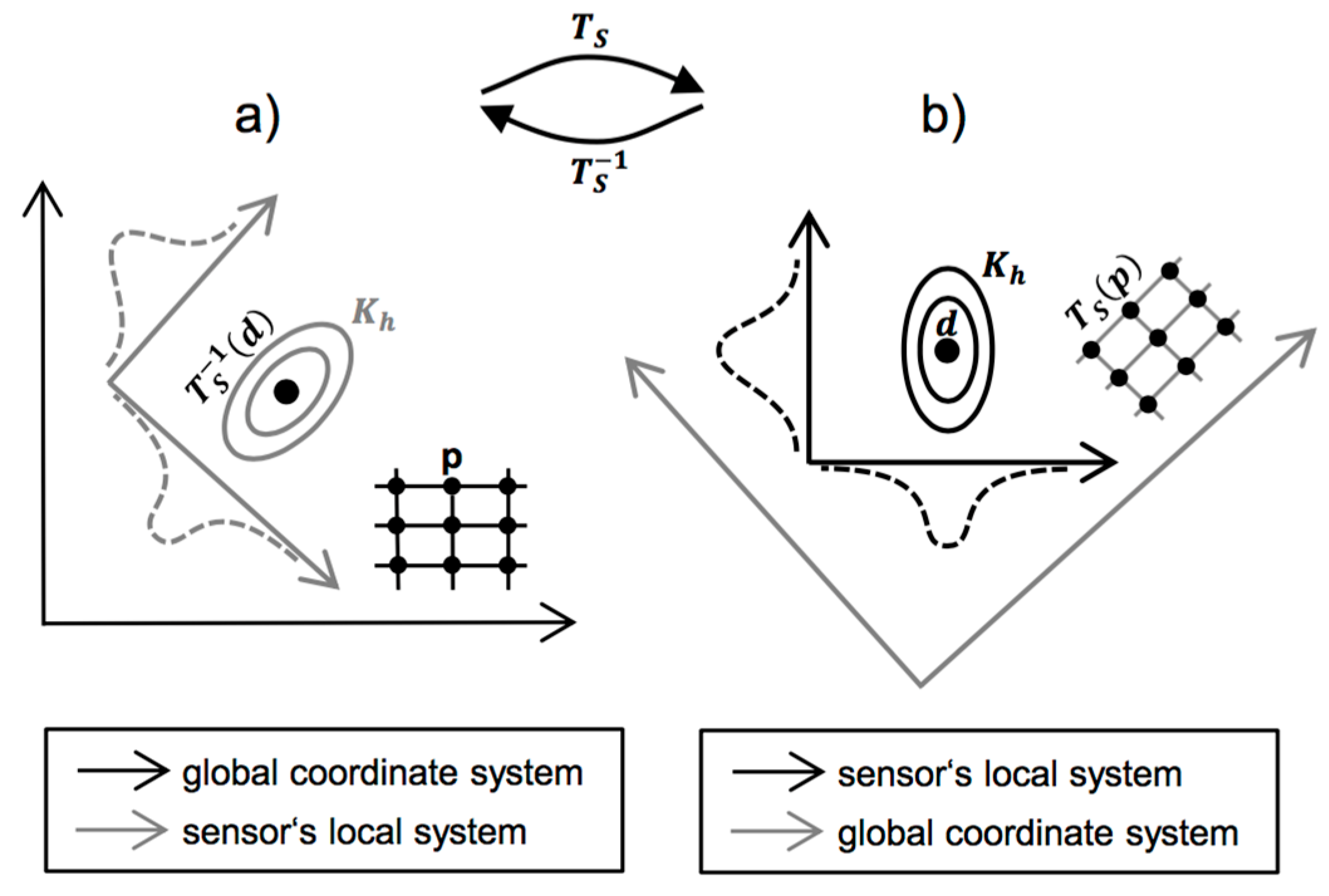
After individual preprocessing, the same detection routine was used for all three images to extract hit locations and confidences, which will later be fused at the decision level. To this end, we convert the signal intensities to confidence values and apply a threshold to extract only significant indications, as follows. Confidence values are computed by estimating the distribution function of background signal intensities from a defect-free area. This estimate serves as the null distribution in the significance test. For each image pixel’s intensity , the probability is computed as the confidence. Pixels are considered significant here, if their confidence exceeds 99%. Additionally, only those hits that are local maxima with regard to their neighboring pixels along the horizontal axis (thus crossing the grooves) are retained. This constraint further filters many false alarms while making the detection results invariant to different peak widths. After detection, each hit is associated with its local signal to noise ratio, which will be used as the weight during density estimation according to Equation (2). To this end, we set . That is, the image intensities are standardized with regard to the null distribution of background signal intensities for each sensor.
After registration to a common coordinate system based on manually defined location correspondences in the data, the final set of hits from all sensors is plotted in
Figure 7. Obviously, the false alarms considerably outnumber the actual groove hits. This is due to our sensitive detection rules, intending that no actual defect is missed during individual processing.
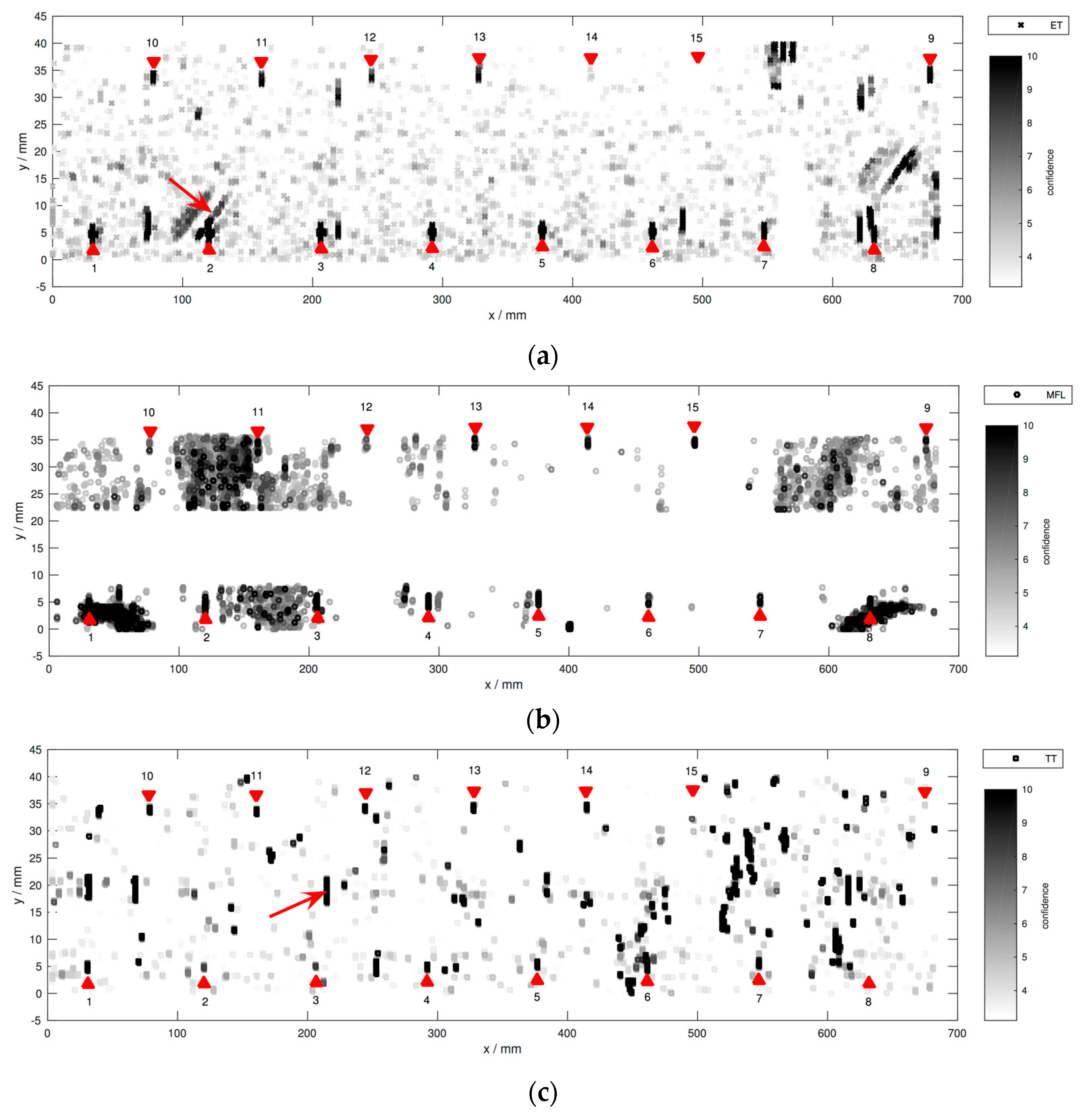
Figure 7.
Hit locations per sensor in a common coordinate system similar to that in
Figure 4. (
a) ET; (
b) MFL; (
c) TT. Darker colors correspond to higher SNR. Note that the color scale is clipped to a maximum of 10 to prevent non-groove hits from dominating. Axes
x and
y are not to scale. The tips of the triangular markers indicate the groove positions. The two arrows point to prominent crack-like indications (false positives) in the ET and TT images.
Figure 7.
Hit locations per sensor in a common coordinate system similar to that in
Figure 4. (
a) ET; (
b) MFL; (
c) TT. Darker colors correspond to higher SNR. Note that the color scale is clipped to a maximum of 10 to prevent non-groove hits from dominating. Axes
x and
y are not to scale. The tips of the triangular markers indicate the groove positions. The two arrows point to prominent crack-like indications (false positives) in the ET and TT images.
Of course, in a single-sensor inspection task, a much more stringent detection criterion is appropriate to limit the number of false alarms. However, this possibly leads to worse sensitivity to small flaws. In contrast, our data fusion approach is supposed to discard most false hits while maintaining high sensitivity to small defects.
We will now briefly compare the individual sensor results. In contrast to ET and TT, the MFL hits cluster spatially. This is because the background variations in this data set are not homogeneous, possibly due to inhomogeneities in the internal magnetic field. MFL data are missing in the strip between the two groove rows. The shallowest groove nr. 15 features low SNR in the ET and TT data due to its shallowness. MFL in contrast is more sensitive. Moreover, grooves nr. 8 and 9 stand out in the TT data, because their confidences are even weaker than the shallower grooves nr. 10–14. Interestingly, in
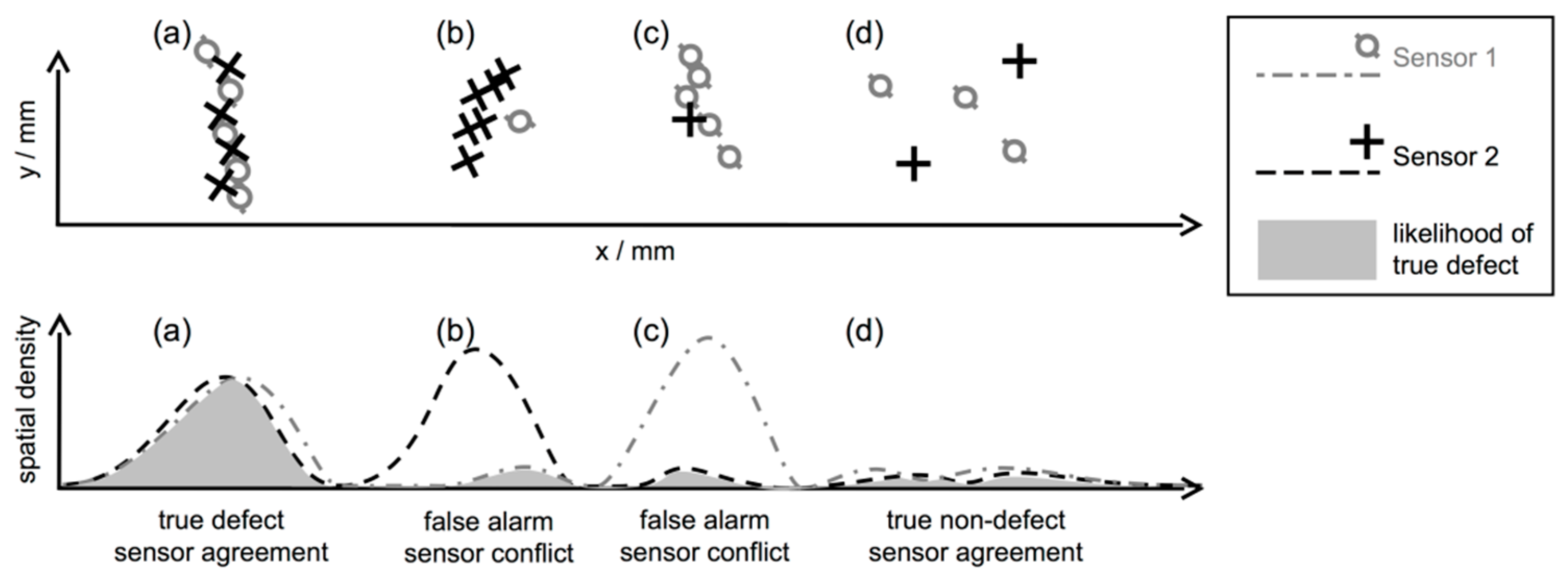
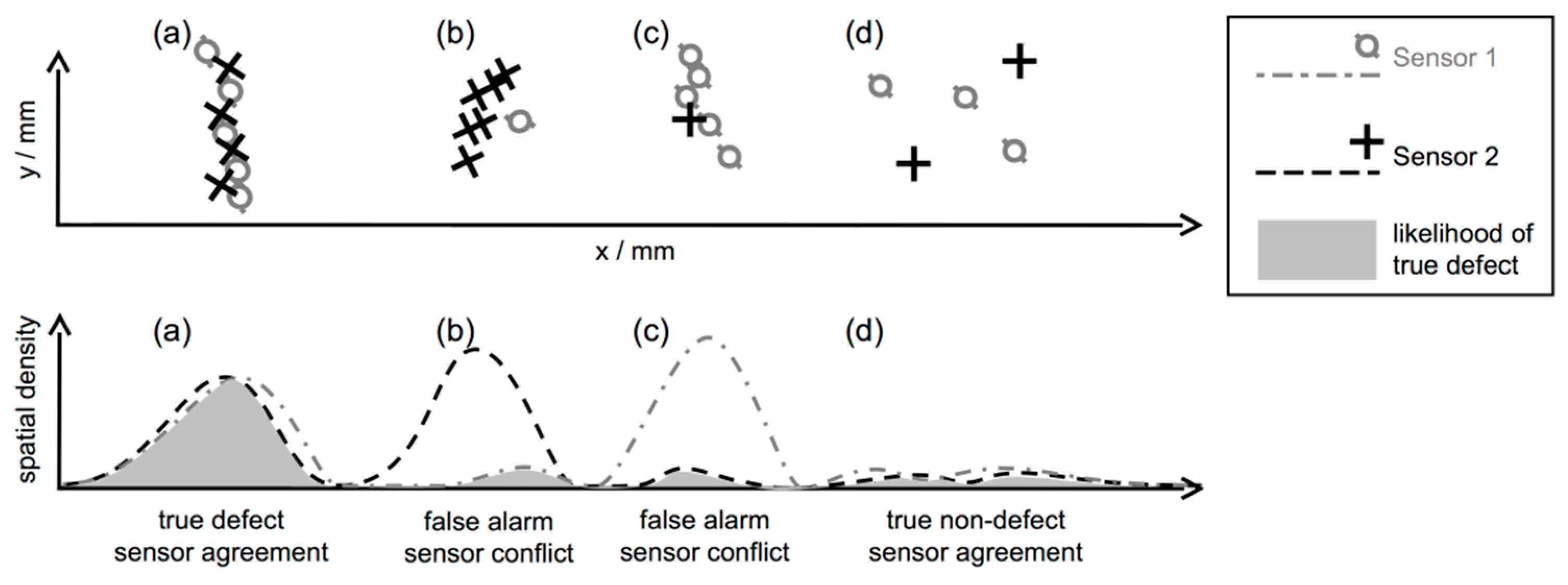
Figure 7, spatial defect-like patterns are formed, although the specimen is not expected to contain any flaws other than the known grooves. For example, see the vertical lines from TT, or the diagonally oriented lines from ET, as highlighted by the arrows. As previously discussed, using individual inspection, it is not easy to classify these obvious indications as structural indications or flaws. In spite of their regular structure, we label these patterns as non-defect indications during the following evaluation, if our multi-sensor data set is not able to give a reliable confirmation. On the other hand, there are a few off-groove locations where different sensors behave consistently. These regions could in fact represent unknown but real defects, and will therefore be excluded from the following evaluation. Note that hits within disregarded areas are not shown in this figure. Moreover, the confidence associated with each hit is not shown, because all hits exceed the chosen threshold of 99% as explained before.
3.3. Fusion and Final Detection
To compute the kernel density per sensor, we used Alexander Ihler’s KDE Toolbox for MATLAB [
21]. The fused density, according to Equation (3), is a continuous function that must be evaluated at discrete locations. In fact, to circumvent the discrete sampling, a multivariate mode-seeking algorithm could be used for detection. However, for simplicity, we set up a discrete evaluation grid that is designed fine enough to not miss any mode of the density. Modes are then traced similarly to per-sensor detection by finding local density maxima along parallel lines on the specimen surface.
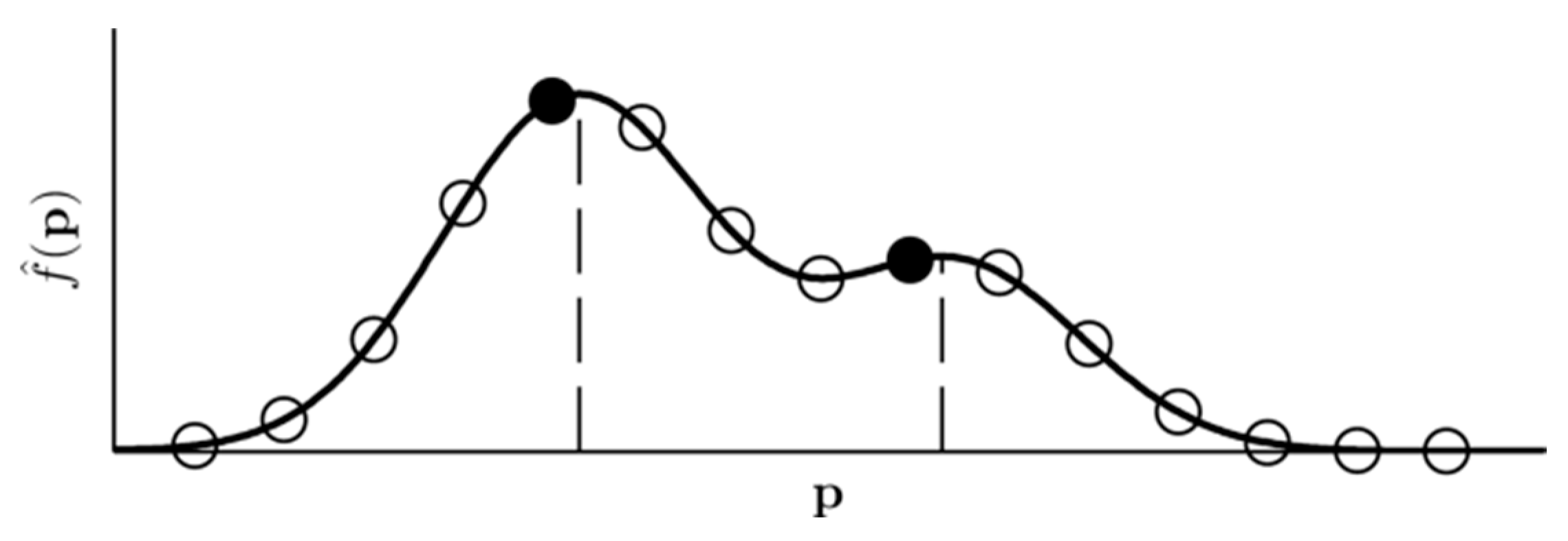
Figure 8 displays the principle of the detection. Finding local maxima along one-dimensional lines is straightforward due to the density’s smoothness, and also makes the detection results more stable across different kernel sizes.
Figure 8.
Final detection by evaluating the fused continuous density function at gridded points (circles) and finding local maxima (filled circles) among them. These hits approximate the true density modes (dashed lines).
Figure 8.
Final detection by evaluating the fused continuous density function at gridded points (circles) and finding local maxima (filled circles) among them. These hits approximate the true density modes (dashed lines).
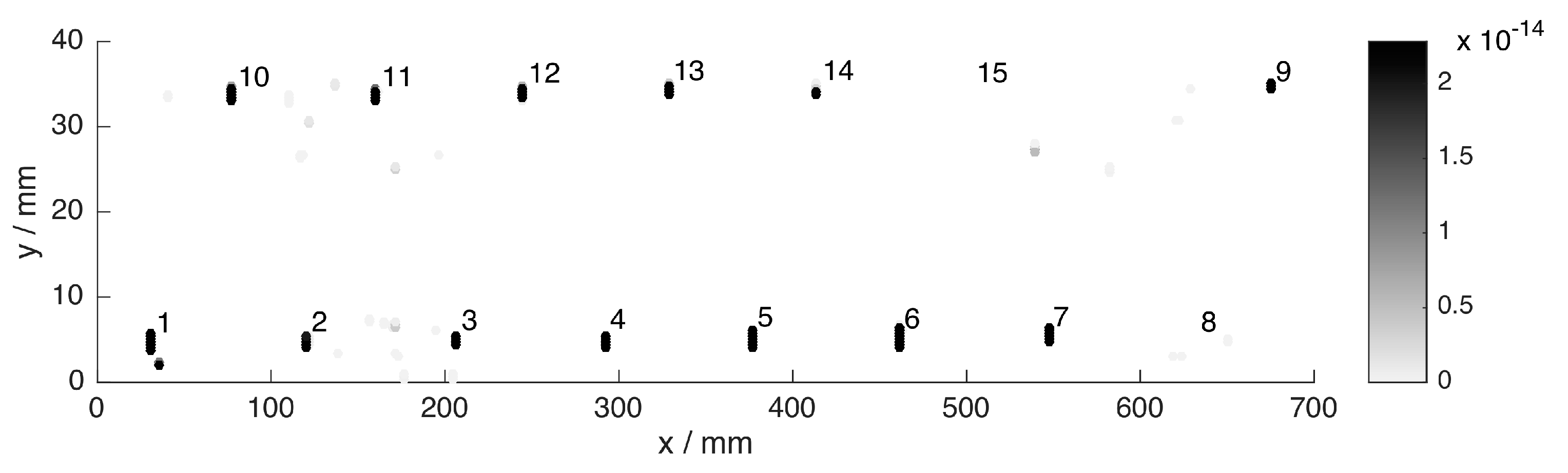
The final hits after fusion are presented in
Figure 9, where fusion is performed according to Equation (3) and the
product fusion rule. Most of the single-sensor false alarms from
Figure 7 were discarded by our fusion method by recognizing the sensor conflicts. Yet, there are a considerable number of remaining false hits. These spurious hits originate from single-sensor hits that overlap purely by chance. Nevertheless, all grooves but the shallowest, nr. 15, clearly stand out against the false alarms considering the fused density measure, which is represented by the marker colors in
Figure 9. Because higher values of the fused measure correspond to increased defect likelihood, a threshold can be applied to produce a binary decision. In the following, the detection performance will be quantitatively assessed under various conditions.
Figure 9.
Result of decision level fusion. Darker markers correspond to increased detection confidence. The colors are scaled so that white represents zero fused intensity, and black corresponds to intensities at least as large as at the shallow defect nr. 14. Axes x and y are not to scale.
Figure 9.
Result of decision level fusion. Darker markers correspond to increased detection confidence. The colors are scaled so that white represents zero fused intensity, and black corresponds to intensities at least as large as at the shallow defect nr. 14. Axes x and y are not to scale.
3.4. Evaluation
In the following sub-sections, our fusion method is quantitatively evaluated with regard to the presented specimen. This evaluation focuses on detectability, meaning the ability to distinguish between grooves and background in the fusion result. Consequently, the ability to accurately localize a defect after fusion is not a part of this evaluation. For each detection result in the next sections, indications are assigned fuzzy membership values to the two sets “defect” and “non-defect”, based on their distances to the known groove locations. Using this ground truth information, evaluation is carried out automatically by means of precision-recall-curves. Similarly to conventional Receiver Operating Characteristic (ROC) analysis [
22], which is based on recall = true positive rate =
#true hits/
#max possible true hits and false alarm rate =
#false hits/
#max possible false hits for each possible detection threshold, we replace false alarm rate with precision =
#true hits/
#all hits. This choice is necessitated by the scattered nature of the hits, which allow an infinite number of possible false alarms, that is off-groove locations. Precision circumvents this restriction by relating hits to hits, rather than hits to non-hits.
The two evaluation measures precision and recall are fuzzyfied in our evaluation to include the fuzzy membership per hit in the analysis ([
23], p. 46). That is, each hit is allowed to be counted partially as a true positive and as a false alarm: Indications near known groove locations are evaluated nearly 100% as true positives, whereas hits that lie further away have an increasing share as a false alarm. The correspondence between distance to the nearest groove location and fuzzy membership is realized by a Gaussian membership function, whose spread parameter
is set equal to the estimated mean registration error for our data set to account for the localization uncertainty.
Once an evaluation curve in fuzzy ROC space per detection method and per groove is established, the area under each precision-recall-curve quantifies detection performance over the full range of detection thresholds. However, we do not compute the area under the whole curve, but only for the curve region where recall >0.5. We denote this measure by AUC-PR-0.5. This focuses our evaluation on thresholds that are low enough to ensure that at least half of a groove is detected. Furthermore, a single false alarm hit with higher intensity than the groove suffices to force the curve down to zero precision for small true positive rates, i.e., high thresholds, and therefore dominates the whole AUC measure. This is another reason for ignoring the lower half of the diagram in the computation of AUC-PR-0.5.
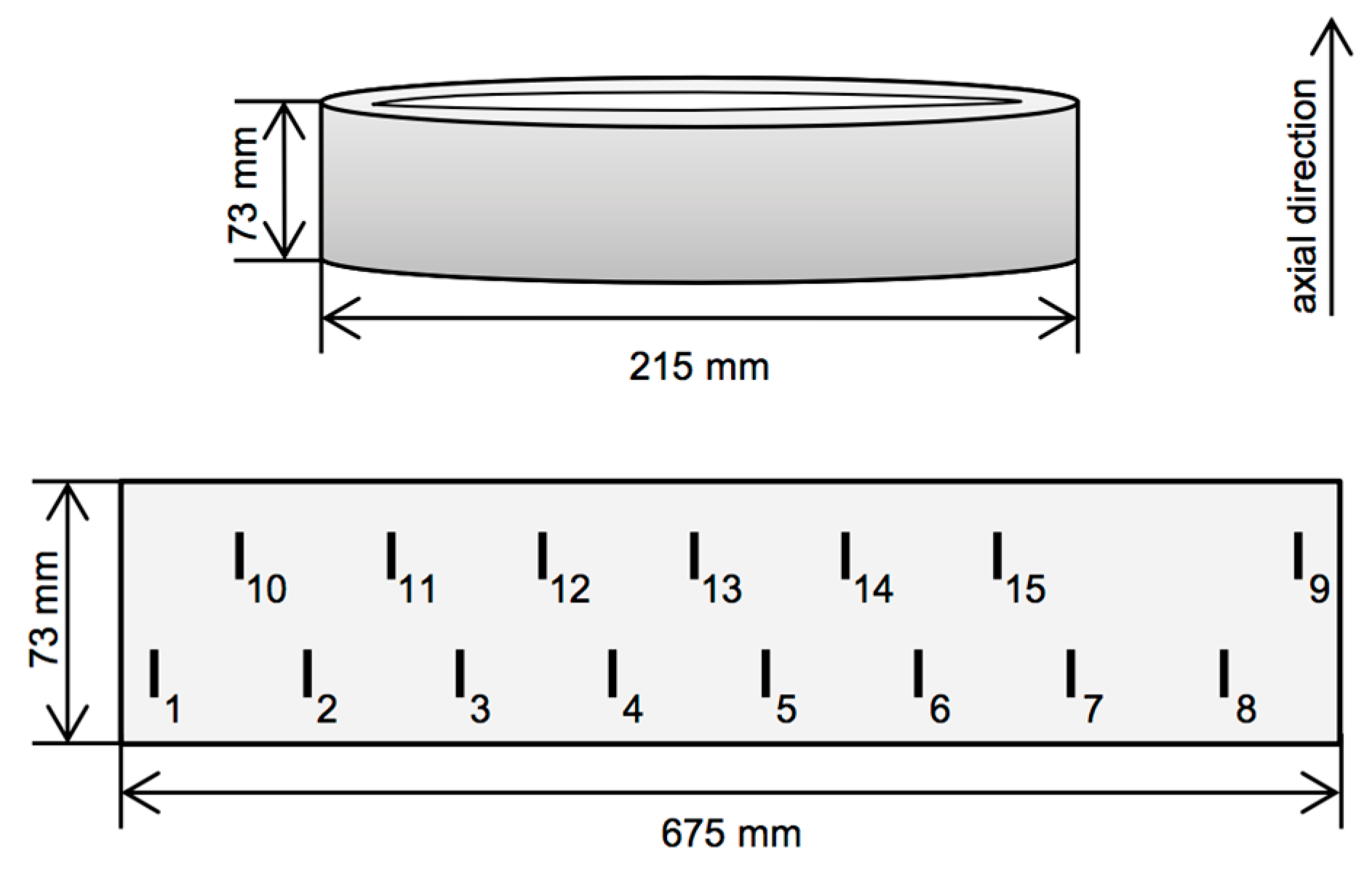
Several regions on the specimen surface are marked to be excluded from the evaluation. These are areas near the border of the specimen, indications that result from experimental modification of the specimen surface and off-groove areas where real unplanned defects exist (which would otherwise be counted as false alarms). Not only are all of these disregarded regions removed from evaluation after fusion, but already the hits in these regions are excluded from the density estimation, so that they don’t affect the density in the surrounding regions. Furthermore, to evaluate detection performance per flaw depth, after fusion each groove is assessed individually while ignoring all others.
All fusion results are evaluated at the same locations on the specimen surface defined by a dense grid with sampling distances
. This choice of grid resolution is given by the finest spatial sampling among all individual sensors in each spatial dimension. Indications are found by local maximum detection as described in
Section 3.3.
If not stated otherwise, fusion is carried out with a fixed kernel size per sensor according to Equation (4), using
. For example, the ET sensor is assigned a kernel size of
. While this automatic formula ensures that the kernel size exceeds the localization uncertainty in both spatial dimensions and retains the ratio of sampling distances, it might lead to situations in which the kernel is extremely large in the coarsely sampled direction, as is seen here: The kernel size in the y direction is even larger than the 1 mm long grooves themselves, which results from the disproportionate sampling distances in our measurements (see
Table 2). To avoid introducing unrealistically large kernels, we restrict the kernel size ratio to at most 3. Consequently, for ET and MFL data, the kernel sizes
are applied. Using this evaluation framework, we investigate the performance of our fusion approach in the following.
3.4.1. Evaluation of Fusion Rules
As described in
Section 2.2.3, the three normalized per-sensor densities are fused at each location of interest on the specimen surface using some fusion rule. In this study, we compare the following eight functions:
minimum,
geometric mean,
harmonic mean,
product,
median,
sum,
sumIgnoreMax according to Equation (7), and the
maximum. These are contrasted with single-sensor performance, both before and after individual kernel density estimation. All single-sensor hits are assessed here, in contrast to the fusion methods where hits below the per-sensor thresholds were discarded. For each groove, a separate ROC analysis was carried out to assess the influence of defect size.
At this point, we emphasize that the results presented in this article are not representative for the general performance of each individual inspection method. It is possible that better individual results than shown here may be obtained by optimizing e.g., the specimen preparation, the sensors or the processing routines. This is especially true for the MFL data, which were artificially degraded as described in
Section 3.2. Rather, in the following our focus is to demonstrate that our technique is able to perform well in the face of imperfect sources of information.
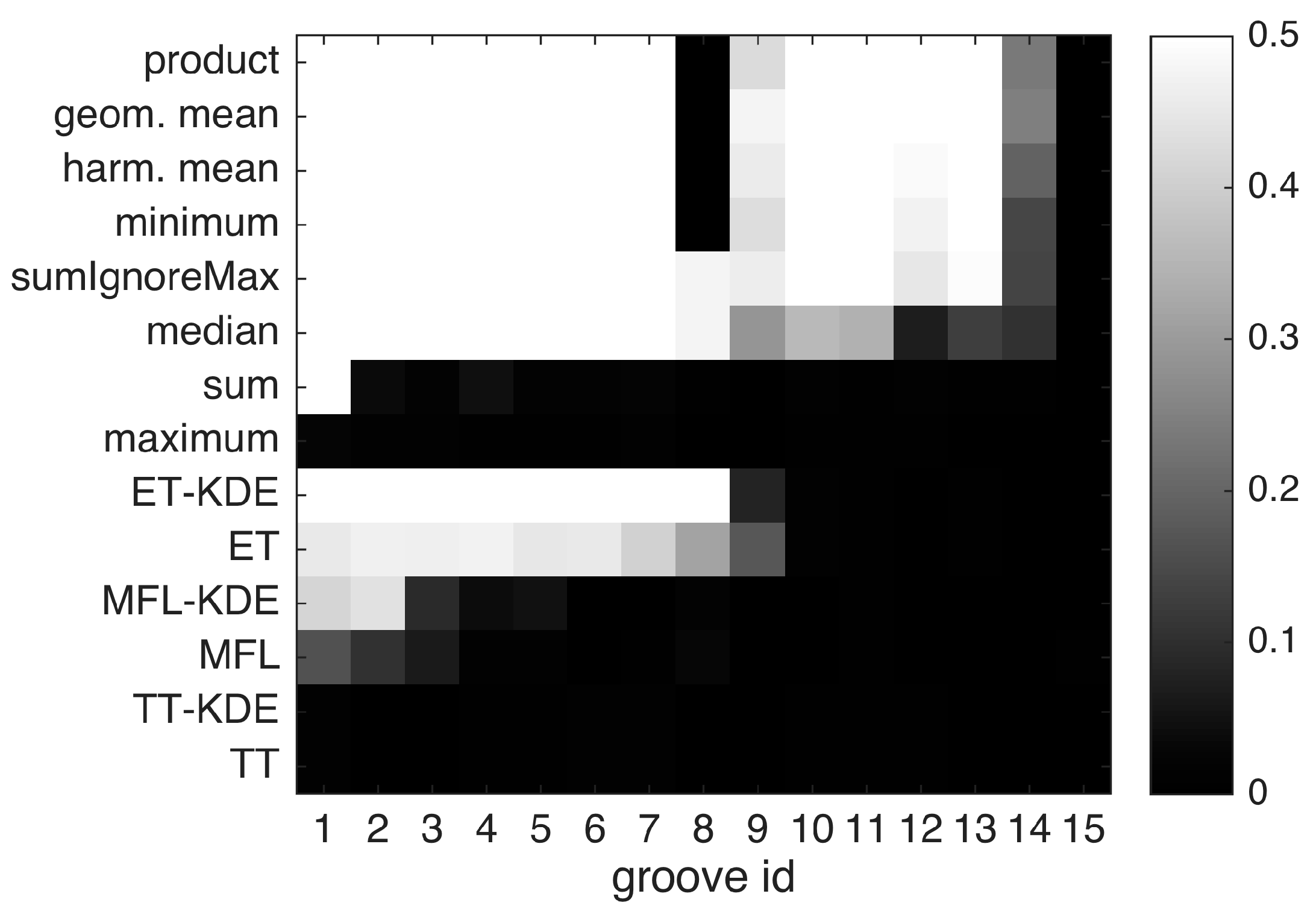
The results are presented in
Figure 10. In agreement with the visual impression from
Figure 7, single-sensor performance (ET, MFL and TT) is unsatisfactory. Although the individual KDEs better pronounce the grooves against more randomly scattered background hits, false alarms still prevent reliable detection even for deep grooves (see TT-KDE and MFL-KDE). After purposely degrading the MFL data (see
Section 3.2), the eddy current technique provides the best single-sensor detection results by reliably indicating groove depths no less than 55 µm (groove nr. 8). In contrast, through multi-sensor fusion, most of the defects can be detected reliably. Two exceptions are the
sum and the
maximum rule, which perform poorly over most if not all grooves. These results are explained by the fact that
sum and
max do not quantify agreement among sensors, but instead retain all indications from any individual sensor in the fusion result. This is prone to false alarms, which is reflected by low evaluation scores. In contrast, the
minimum,
geometric and
harmonic mean and the
product rule yield high scores for most defects. Apparently, grooves nr. 8 and 9 are hard to identify across many fusion methods despite the grooves’ midsize depths. This suggests poor single-sensor SNR at these locations, thus leading to inter-sensor conflict, so that this groove is wrongly classified as a false alarm by the strict fusion methods
product,
geometric and
harmonic mean and
minimum. On the other hand, the milder fusion rules
median and
sumIgnoreMax tolerate unknown single-sensor dropout at the expense of comparably poor detection performance at the shallowest grooves. Specifically, whereas the
median rule might deteriorate in the face of overall low SNR by permitting too many false alarms,
sumIgnoreMax offers a good compromise between strictness and tolerance in our evaluation. However, for the detection of very shallow defects like groove nr. 14 in our specimen, stricter rules appear to offer better performance. The best fusion rule in this evaluation is the
geometric mean, closely followed by the
harmonic mean and the
product. As
product is conceptually extremely simple yet effective, it is considered the winner. Overall, the shallowest detectable groove depth in our study is given by 29 µm at groove nr. 13. The 20 µm groove nr. 14 could not be found reliably, although fusion offers improved detectability compared to single-sensor detection. The shallowest groove nr. 15 (11 µm) is not distinguishable from background noise due to lack of single-sensor sensitivity.
Figure 10.
Evaluation of different fusion functions
according to Equation (2), and of single-sensor detection. For each groove and detection method, the AUC-PR-0.5 is shown in shades of gray. Optimal performance is 0.5. Groove numbers correspond to
Table 1, that is groove nr. 1 is the deepest and nr. 15 is the shallowest.
Figure 10.
Evaluation of different fusion functions
according to Equation (2), and of single-sensor detection. For each groove and detection method, the AUC-PR-0.5 is shown in shades of gray. Optimal performance is 0.5. Groove numbers correspond to
Table 1, that is groove nr. 1 is the deepest and nr. 15 is the shallowest.
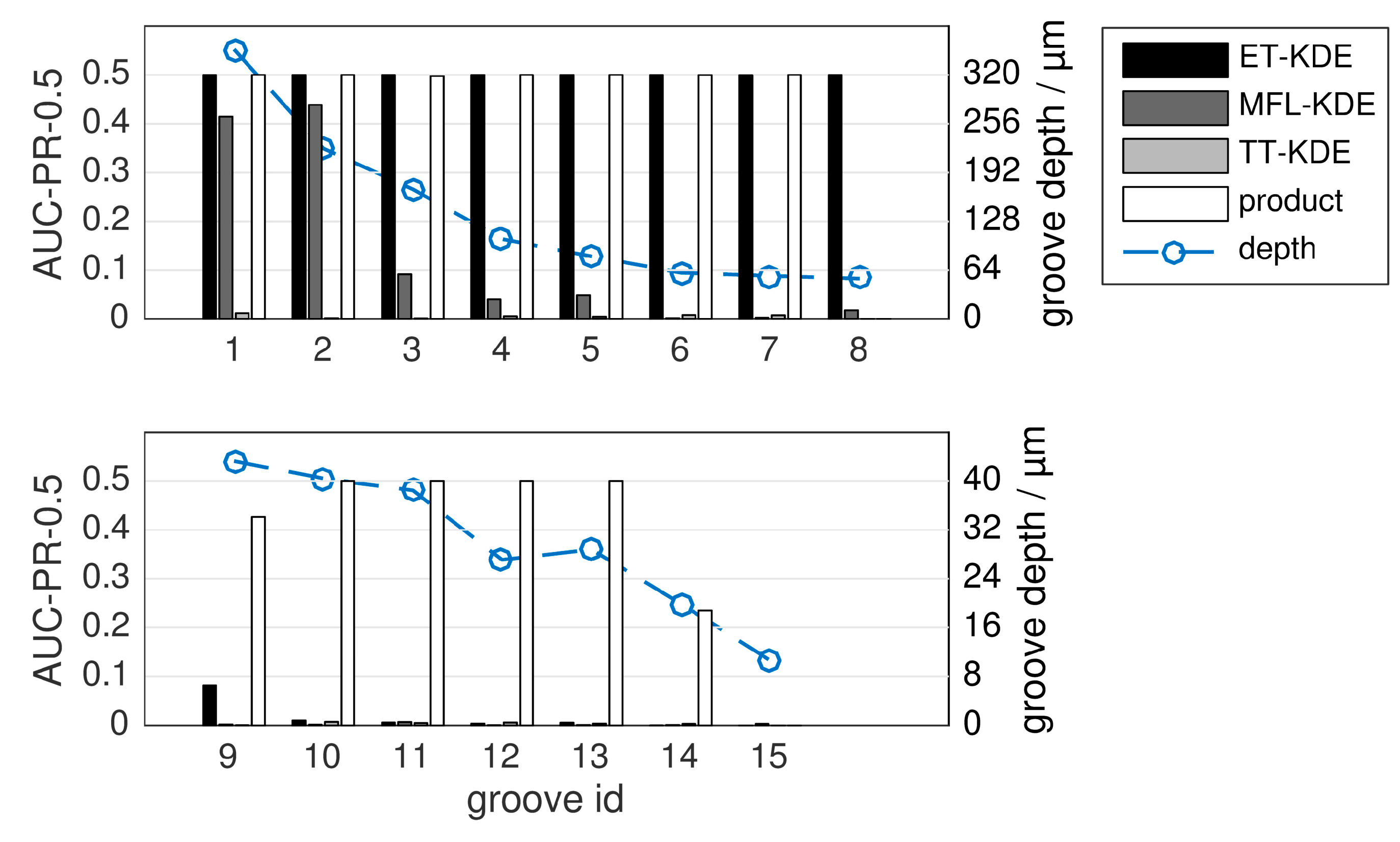
Additionally, the results are more clearly presented in
Figure 11, where only the
product fusion is compared against the single-sensor KDEs. This experiment was also re-produced using a second test specimen, which we report in
Figure S1 in the Supplementary Material to this article.
Figure 11.
Evaluation of single-sensor detection (ET-KDE, MFL-KDE, TT-KDE) versus fusion, for the product fusion rule and a fixed kernel size. The maximum possible score is 0.5 (left vertical axis). The set of grooves is divided into two sub-figures for clarity. Groove depth is indicated by the blue line corresponding to the right vertical axis. Note the different axis scales for groove depth in the two subplots.
Figure 11.
Evaluation of single-sensor detection (ET-KDE, MFL-KDE, TT-KDE) versus fusion, for the product fusion rule and a fixed kernel size. The maximum possible score is 0.5 (left vertical axis). The set of grooves is divided into two sub-figures for clarity. Groove depth is indicated by the blue line corresponding to the right vertical axis. Note the different axis scales for groove depth in the two subplots.
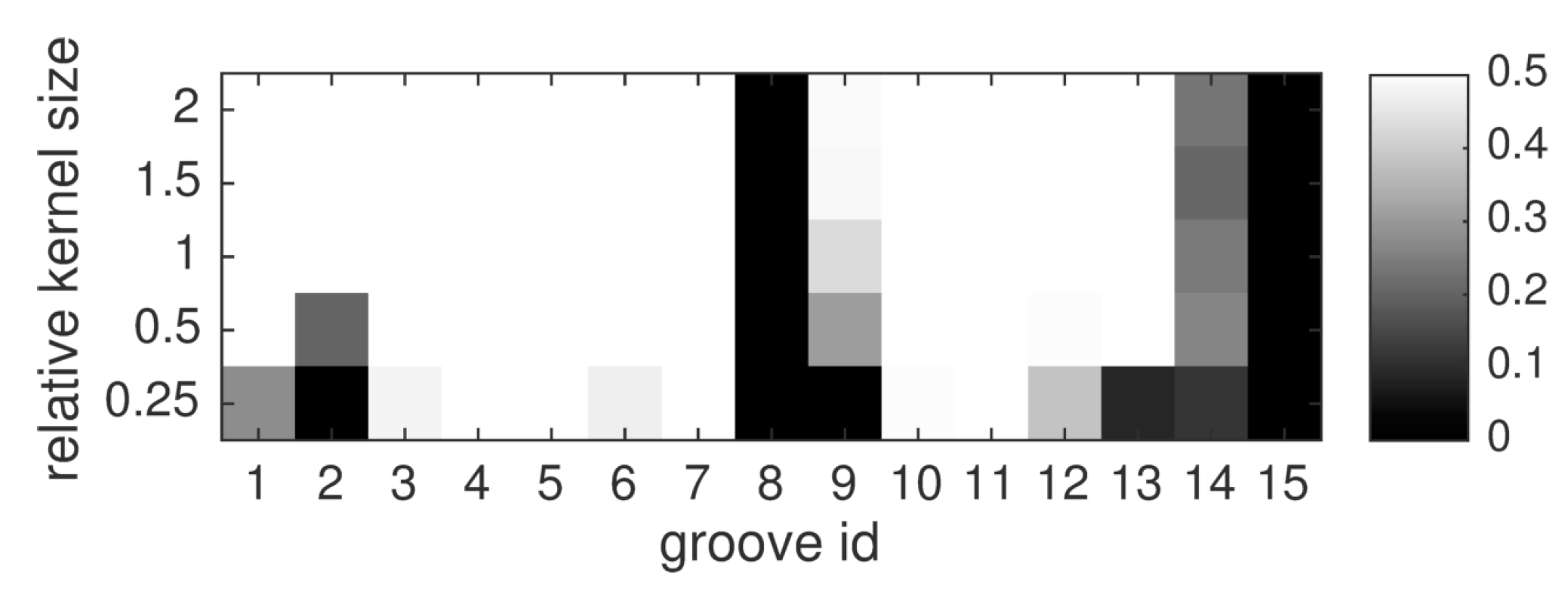
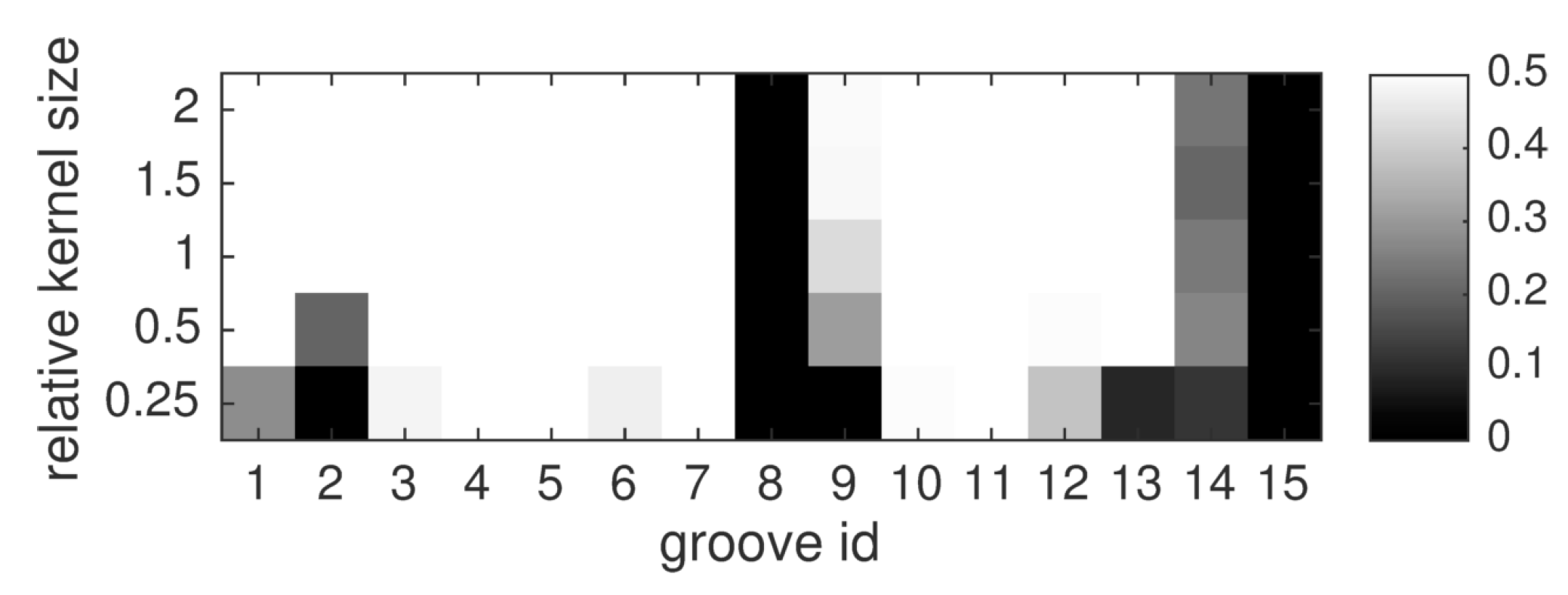
3.4.2. Influence of Kernel Size
Just like in conventional kernel density estimation, the kernel size is an important factor regarding the detection performance. The sizes assessed in this study are arranged in
Table 3. The
product fusion rule is selected here due to its strong performance in the previous experiment. Evaluation results are shown in
Figure 12. The results suggest that given a well-performing fusion method and an accurate estimation of the localization uncertainty
, a range of kernel sizes around the proposed default setting in Equation (4) is adequate. Performance only deteriorates for very small kernel sizes like 25%–50% of the proposed size. The product rule shows no obvious dependence between kernel size and performance at the shallowest two grooves. However, groove nr. 9 is better identified when larger kernels are used. This could be explained by unusually large registration error at this region, but in this case the reason is that thermography only indicates the top part of groove nr. 9 with large enough SNR to pass the individual detection stage. The results presented here might tempt to favor large kernels. However, large kernels increase the chance of falsely associating spatially nearby false alarms, and thus quantify sensor agreement where there is actually conflict. Therefore, the kernel size proposed in Equation (4) was found to be effective in this experiment.
Table 3.
Kernel sizes used in the experiment. All sizes are in mm. Relative kernel size denotes the fraction of that was used to compute the kernel sizes according to Equation (4). That is, a range of smaller and larger kernels compared to the default size (relative kernel size = 1, bold faced column) were assessed. To prevent unrealistically large kernels due to the disproportionate spatial sampling distances in our data, kernel sizes were limited to 0.6 mm for ET and MFL, and to 0.75 mm for TT (gray shaded table cells).
Table 3.
Kernel sizes used in the experiment. All sizes are in mm. Relative kernel size denotes the fraction of that was used to compute the kernel sizes according to Equation (4). That is, a range of smaller and larger kernels compared to the default size (relative kernel size = 1, bold faced column) were assessed. To prevent unrealistically large kernels due to the disproportionate spatial sampling distances in our data, kernel sizes were limited to 0.6 mm for ET and MFL, and to 0.75 mm for TT (gray shaded table cells).
| | Relative Kernel Size |
|---|
| 0.25 | 0.5 | 1.0 | 1.5 | 2 |
|---|
| ET | | 0.05 | 0.1 | 0.2 | 0.3 | 0.4 |
| 0.346 | 0.6 | 0.6 | 0.6 | 0.6 |
| MFL | | 0.05 | 0.1 | 0.2 | 0.3 | 0.4 |
| 0.345 | 0.6 | 0.6 | 0.6 | 0.6 |
| TT | | 0.186 | 0.373 | 0.746 | 0.746 | 0.746 |
| 0.05 | 0.1 | 0.2 | 0.3 | 0.4 |
Figure 12.
Evaluation of different kernel sizes, for the product fusion rule. For each groove and fusion method, the AUC-PR-0.5 is shown in shades of gray.
Figure 12.
Evaluation of different kernel sizes, for the product fusion rule. For each groove and fusion method, the AUC-PR-0.5 is shown in shades of gray.
3.4.3. Influence of Weights
In the previous experiments, the individual sensors’ hits were weighted by factors
in Equation (2) to take into account the local SNR. This experiment assesses the benefit of these weights over an unweighted approach (
) in which the densities
are only influenced by the spatial proximity of neighboring hits. This setting represents inspection results for which no measure of confidence is available. In both experimental cases, the
product fusion rule was chosen and the kernel size was set to the value suggested by Equation (4).
Figure 13 illustrates the respective detection performances. According to the results, the unweighted variant never surpasses the proposed weighted density estimation at any groove. Interestingly, although the unweighted method does not take into account the local SNR and therefore is not influenced by defect depth, it is clearly observed that most of the deeper grooves (e.g., nr. 1–5) are more reliably found than the shallower grooves (e.g., nr. 9–15). This is because during the first stage of individual detection before fusion, only parts of the shallower grooves might be retained whereas deeper grooves are completely preserved. Therefore, the weighted approach should be favored over the unweighted method if possible. Otherwise, much effort should be spent on high-quality registration to make the sole feature of spatial proximity of hits across different sensors a reliable indicator of defect presence. Yet, even without weights,
product-fusion still outperforms any individual method in our evaluation for grooves shallower than 43 µm (groove nr. 9).
Figure 13.
Comparison between the weighted approach (as proposed; top row) and the unweighted variant, for the product fusion rule.
Figure 13.
Comparison between the weighted approach (as proposed; top row) and the unweighted variant, for the product fusion rule.
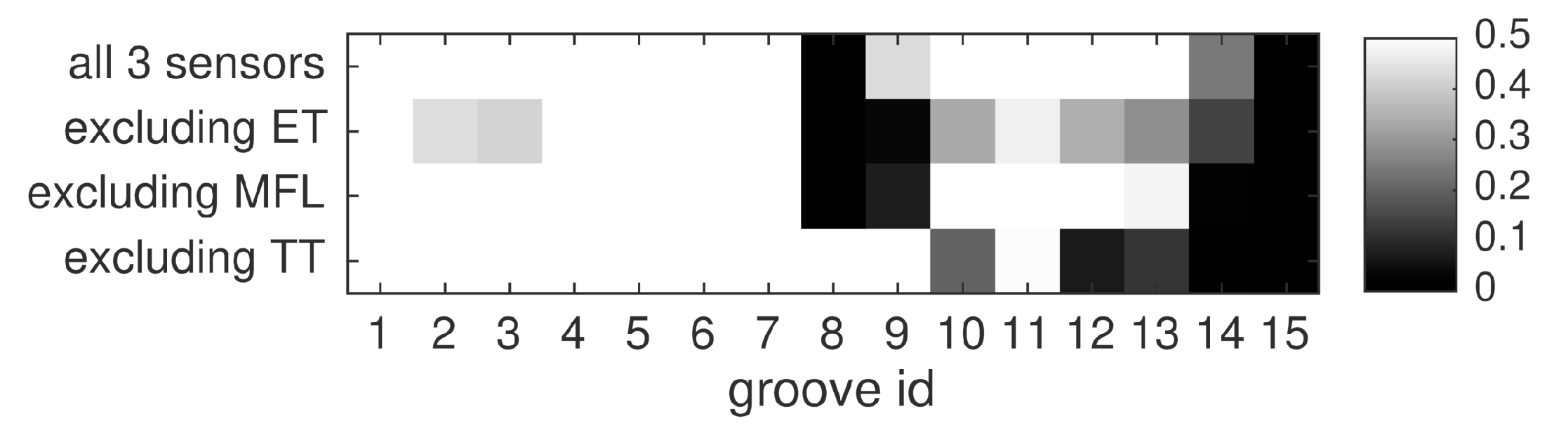
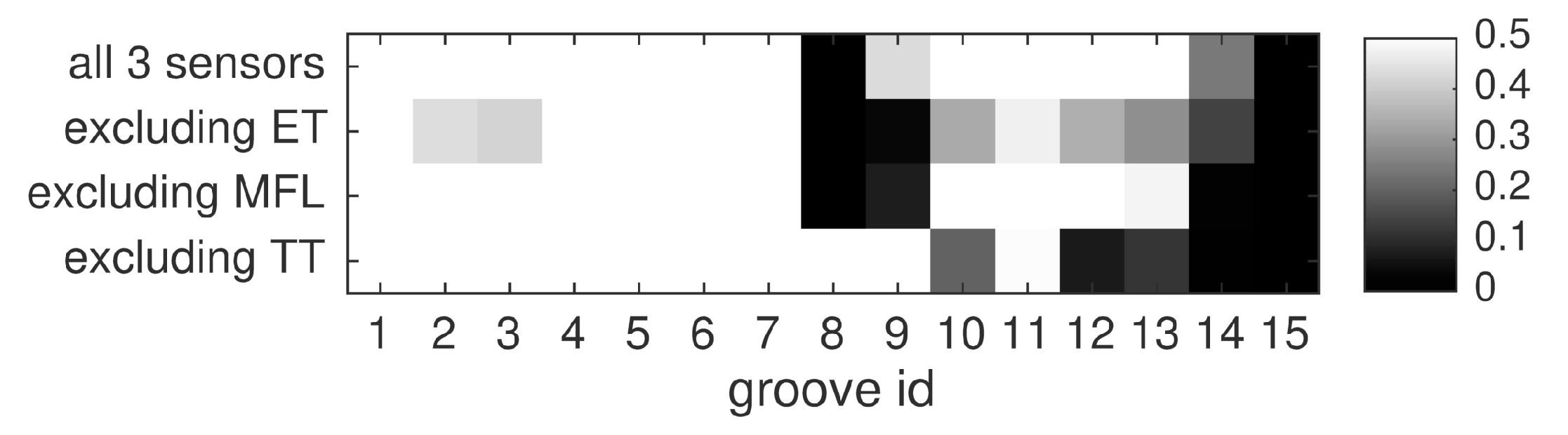
3.4.4. Influence of Individual Sensors
The effect of individual sensors on the fused performance is assessed in this study. To this end, fusion is carried out three times, while leaving out the hits of one of the sensors in each run. The results are compared to fusing the full data set. Again, the
product fusion rule is applied, and hits are weighted. The results are presented in
Figure 14. Each two-sensor subset of inspection methods shows slightly different effects. Apparently, the thermographic data mainly help in detecting the shallow grooves 12–14. However, the same inspection seems to have missed the flaws 8 and 9, because the information from both MFL and ET is crucial for detection here. On the other hand, TT is required to identify most of the shallow grooves in this evaluation. The same observation holds for ET. In contrast, by purposely degrading the MFL data (see
Section 3.2), we reduced the positive effect this inspection method has on multi-sensor detection. Still, although this low-quality data has a large set of false alarms, it impairs multi-sensor detection for none of the grooves. On the contrary, MFL improves the detection quality of grooves 9, 13 and 14. Among the deeper grooves, nrs. 1, 4, 5, 6 and 7 are perfectly found using any two-sensor configuration, thus indicating that they are clearly represented in all three measurements. Overall, the evaluation demonstrates that the full set of sensors is required for optimal performance with our data set. Yet, with the right choice of sensors two-source fusion already has the potential to outperform individual detection.
Figure 14.
Influence of individual sensors on the fusion result, for the median fusion rule and a fixed kernel size.
Figure 14.
Influence of individual sensors on the fusion result, for the median fusion rule and a fixed kernel size.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}