To validate the performance of the proposed unknown object detection method, especially for the common robotic manipulation tasks, we use two publicly available RGB-D datasets, object segmentation dataset (OSD) [
7] and RGB-D scene dataset [
20], captured by a Kinect-style sensor to evaluate how successfully the proposed method detects unknown objects. Both datasets incorporate sorts of common indoor scenes where the daily objects are randomly placed on the counter tops, tables, desks, grounds,
etc. In some scenes, the objects are stacked and occluded, making object detection much more challenging. In addition, since our task is focused on object manipulation, the objects we study have a small and graspable size. Therefore, we mainly focus on detecting the unknown daily objects in the evaluations and experiments.
The ground truth of objects is represented as the bounding boxes around the objects of interest. Therefore, we project the point clouds of detected objects in a 3D scene into 2D image and calculate the overlap between the bounding box of projected pixels and the ground truth bounding box. The overlap is computed by the ratio between the intersection and union of the bounding boxes. If the overlap is greater than 0.5, the object is considered detected. The precision, recall and F1-measure scores are calculated to demonstrate the performance of our method. Since the proposed saliency detection method plays an important role in the whole object detection process, we first carry out human fixation prediction experiments to quantitatively and qualitatively evaluate the proposed saliency detection method on several benchmark datasets. Second, we report the object detection accuracy on the two benchmark RGB-D datasets. Finally, the proposed method is applied to detect unknown objects in the real robotic scenes. The detected objects are then manipulated by a mobile manipulator when it is asked to perform actions, such as cleaning up the ground.
4.1. Evaluation of Saliency Detection
We perform human fixation prediction experiments to evaluate the proposed saliency detection method. Three eye movement datasets, MIT [
21], Toronto [
22] and Kootstra [
23], which are publicly available, are used as benchmark datasets. The first dataset, MIT [
21], introduced by Judd
et al., contains 1003 landscape and portrait image. The second dataset Toronto [
22], introduced by Bruce
et al., contains 120 images from indoor and outdoor scenes. The Kootstra [
23] dataset contains 100 images, including animals, flowers, cars and other natural scenes. In order to quantitatively evaluate the consistency between a particular saliency map and a set of eye-tracked fixations of the image, we use three metrics: ROC area under the curve (AUC), normalized scanpath saliency (NSS) and the correlation coefficient (CC). For the AUC metric, we use a type of implementation, AUC-Borji [
24]. These metric codes are available on the website [
25]. We compare the proposed method SS with eight state-of-the-art saliency detection methods, including Itti2 [
26], SigSal [
27], GBVS [
26], SUN [
28], AIM [
22], LP [
21], CAS [
12] and BMS [
14]. For the sake of simplicity, the compared methods are named with no extra meaning here.
The evaluation metrics are quite sensitive to blurring. Parameterized by the Gaussian blur standard deviation (STD) in image width, the factor is explicitly analyzed to provide a better understanding of the comparative performance of each method. We set Gaussian blur STD from 0–0.16 in image width. The optimal AUC-Borji, NSS and CC scores of each method together with the corresponding Gaussian blur STD on the three benchmark datasets are reported in
Table 1,
Table 2 and
Table 3. For each metric, the proposed method SS achieves top performance when comparing the average scores in each method on all three benchmark datasets. The methods GBVS and BMS are also competitive among these compared methods.
Figure 5 shows sample saliency maps generated by SS and the other eight state-of-the-art methods. The sample input images are randomly selected from the three benchmark datasets. From this figure, we can see that many of the compared methods tend to favor the boundaries, rather than the interior region of salient objects. Comparably, our method SS can perform much better in terms of detecting not only the salient boundaries, but also interior regions. Such advantages can facilitate the detection of unknown objects in the later process.
Table 1.
Average AUC-Borji score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
Table 1.
Average AUC-Borji score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
| Dataset | Itti2 [26] | SigSal [27] | GBVS [26] | SUN [28] | AIM [22] | LP [21] | CAS [12] | BMS [14] | SS |
|---|
| MIT [21] | 0.7909 | 0.7678 | 0.8236 | 0.7128 | 0.8095 | 0.7703 | 0.7610 | 0.7868 | 0.8299 |
| Optimal
STD | 0.16 | 0.16 | 0.16 | 0.07 | 0.16 | 0.14 | 0.10 | 0.11 | 0.08 |
| Toronto [22] | 0.8071 | 0.7921 | 0.8248 | 0.7069 | 0.7970 | 0.7854 | 0.7791 | 0.7960 | 0.8270 |
| Optimal STD | 0.14 | 0.12 | 0.10 | 0.05 | 0.16 | 0.12 | 0.08 | 0.08 | 0.07 |
| Kootstra [23] | 0.6467 | 0.6528 | 0.6674 | 0.5699 | 0.6622 | 0.6429 | 0.6445 | 0.6655 | 0.6789 |
| Optimal STD | 0.10 | 0.11 | 0.05 | 0.05 | 0.08 | 0.09 | 0.06 | 0.05 | 0.06 |
| Average | 0.7482 | 0.7376 | 0.7720 | 0.6632 | 0.7563 | 0.7329 | 0.7282 | 0.7495 | 0.7786 |
Table 2.
Average normalized scanpath saliency (NSS) score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
Table 2.
Average normalized scanpath saliency (NSS) score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
| Dataset | Itti2 [26] | SigSal [27] | GBVS [26] | SUN [28] | AIM [22] | LP [21] | CAS [12] | BMS [14] | SS |
|---|
| MIT [21] | 1.1542 | 1.1083 | 1.3821 | 0.8677 | 1.0355 | 1.0478 | 1.1021 | 1.2627 | 1.3817 |
| Optimal STD | 0.11 | 0.06 | 0.01 | 0.05 | 0.16 | 0.05 | 0.05 | 0.05 | 0.05 |
| Toronto [22] | 1.3083 | 1.3787 | 1.5194 | 0.8120 | 1.0015 | 1.1640 | 1.2878 | 1.5191 | 1.4530 |
| Optimal STD | 0.05 | 0.00 | 0.00 | 0.04 | 0.16 | 0.02 | 0.03 | 0.00 | 0.04 |
| Kootstra [23] | 0.5415 | 0.5693 | 0.6318 | 0.2829 | 0.5411 | 0.5363 | 0.5587 | 0.7014 | 0.6968 |
| Optimal STD | 0.08 | 0.07 | 0.02 | 0.04 | 0.10 | 0.06 | 0.04 | 0.04 | 0.04 |
| Average | 1.0013 | 1.0188 | 1.1778 | 0.6542 | 0.8593 | 0.9160 | 0.9828 | 1.1610 | 1.1772 |
Table 3.
Average CC score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
Table 3.
Average CC score with optimal blurring. The highest score on each dataset is shown in bold. The second and third highest are underlined.
| Dataset | Itti2 [26] | SigSal [27] | GBVS [26] | SUN [28] | AIM [22] | LP [21] | CAS [12] | BMS [14] | SS |
|---|
| MIT [21] | 0.1855 | 0.1766 | 0.2211 | 0.1388 | 0.1691 | 0.1670 | 0.1750 | 0.2004 | 0.2229 |
| Optimal STD | 0.11 | 0.06 | 0.01 | 0.05 | 0.16 | 0.05 | 0.05 | 0.05 | 0.06 |
| Toronto [22] | 0.3941 | 0.4050 | 0.4551 | 0.2398 | 0.3133 | 0.3469 | 0.3770 | 0.4401 | 0.4401 |
| Optimal STD | 0.07 | 0.00 | 0.00 | 0.04 | 0.16 | 0.04 | 0.03 | 0.03 | 0.05 |
| Kootstra [23] | 0.2652 | 0.2741 | 0.3088 | 0.1310 | 0.2716 | 0.2568 | 0.2633 | 0.3234 | 0.3365 |
| Optimal STD | 0.08 | 0.08 | 0.03 | 0.04 | 0.10 | 0.07 | 0.05 | 0.05 | 0.04 |
| Average | 0.2816 | 0.2852 | 0.3283 | 0.1699 | 0.2513 | 0.2569 | 0.2718 | 0.3213 | 0.3332 |
Figure 5.
Comparison of saliency maps from nine methods on three benchmark eye movement datasets. The first two columns are the sample images and their fixation heat maps from the MIT, Toronto and Kootstra datasets (each dataset shows herein three sample images). The fixation heat maps are computed by applying Gaussian blur on the raw eye fixation maps. The rest of the columns show the saliency maps from the state-of-the-art methods and our method, SS.
Figure 5.
Comparison of saliency maps from nine methods on three benchmark eye movement datasets. The first two columns are the sample images and their fixation heat maps from the MIT, Toronto and Kootstra datasets (each dataset shows herein three sample images). The fixation heat maps are computed by applying Gaussian blur on the raw eye fixation maps. The rest of the columns show the saliency maps from the state-of-the-art methods and our method, SS.
4.2. Evaluation of Unknown Object Detection
In the OSD dataset [
7], there are 111 RGB-D images of objects on a table. This dataset is very challenging because different types of daily objects are randomly located, stacked and occluded. We detect unknown objects for each pair of RGB and depth images and report the precision, recall and F1-measure scores of object detection over the whole dataset. The detection results are shown in
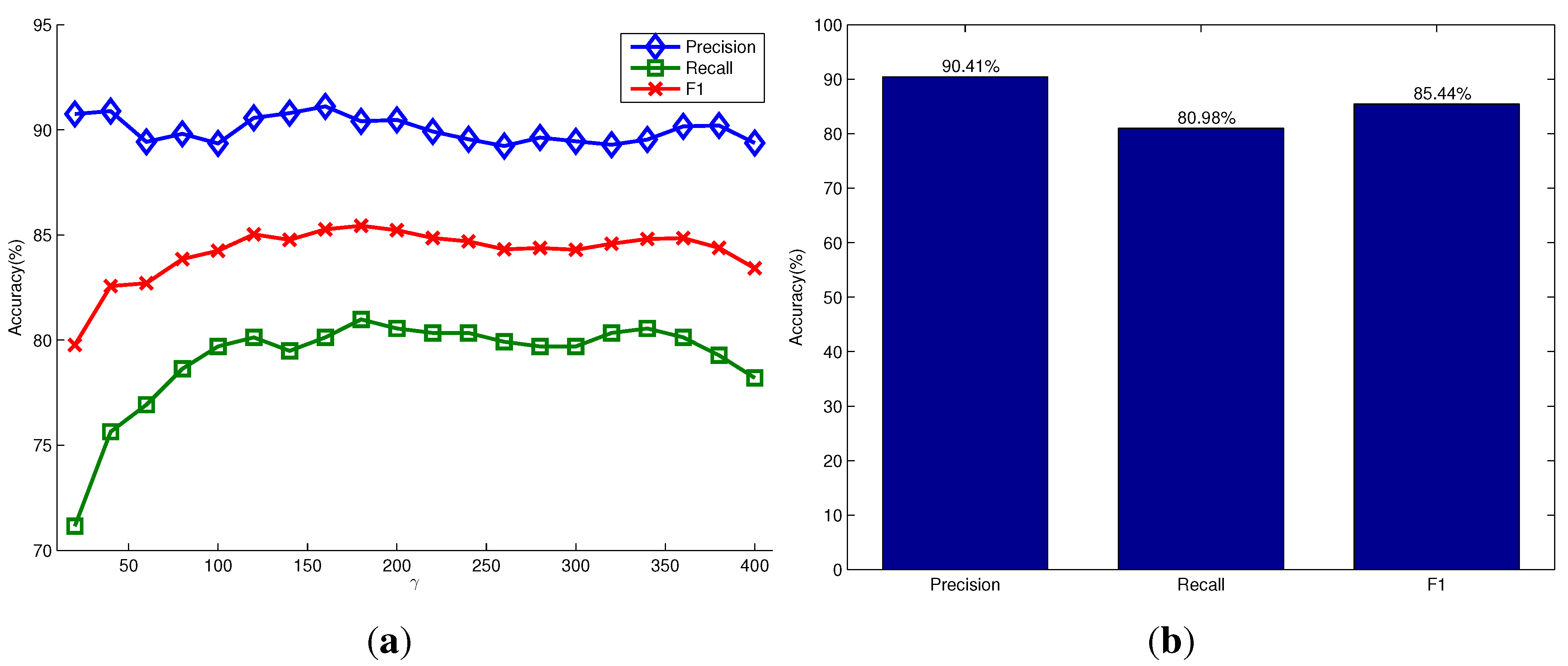
Figure 6.
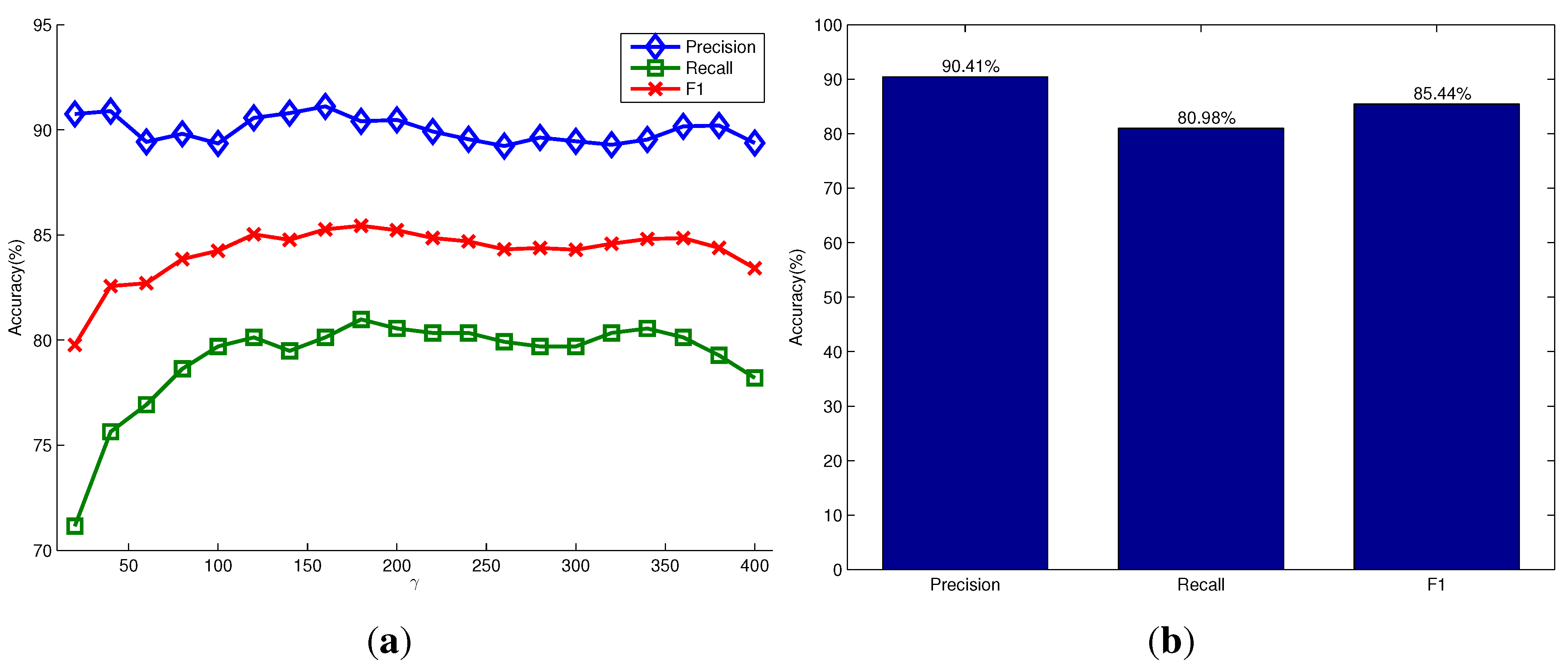
Figure 6a shows the variations of the three types of detection accuracy under different settings of the parameter γ in the model of the object hypotheses. It shows that the parameter γ has little influence on the detection accuracy in this dataset. Our method can achieve a high detection precision of more than
due to the advantage that the proposed saliency detection and seeding methods could generate more seed points of salient objects in the foreground than the non-salient objects in the background. The recall accuracy of detection is relatively low, but still achieves about
. This is because most images in this dataset contain objects that are stacked and occluded. Different parts of the occluded objects are always segmented as different objects, while the stacked objects with a similar appearance are segmented as one object.
Figure 6b shows the corresponding scores when using the relatively optimal parameter
, and it achieves the highest F1-measure score.
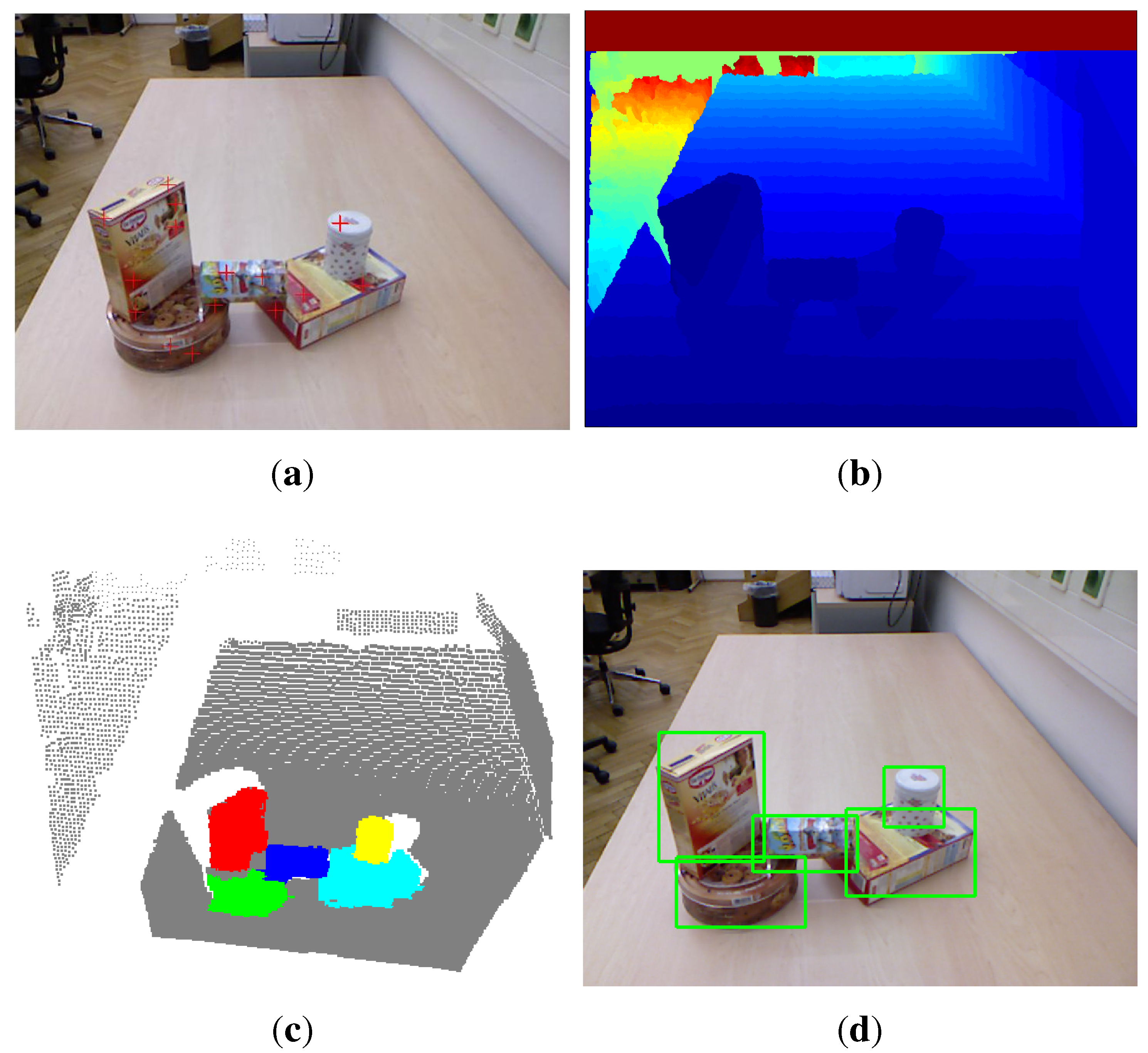
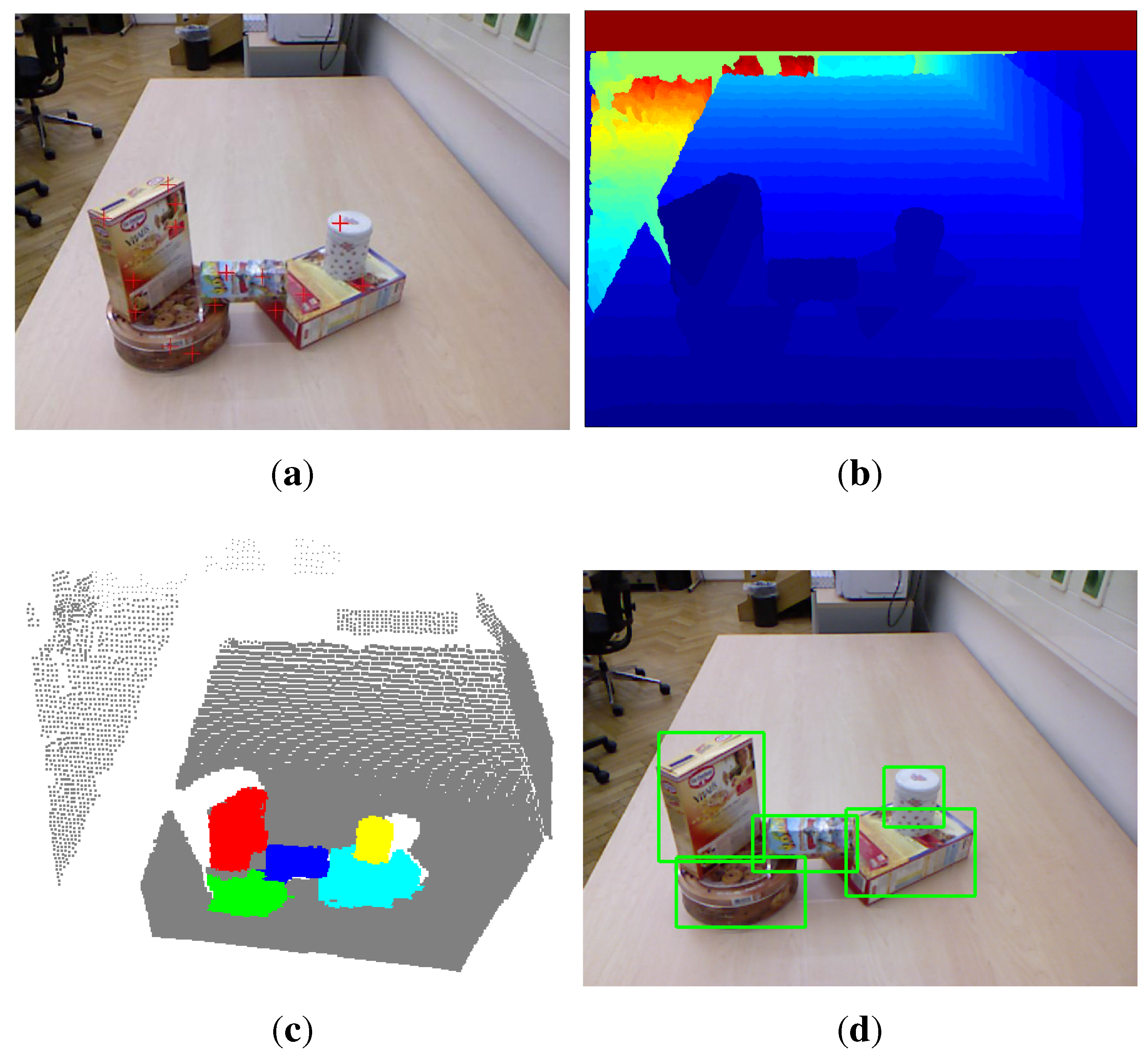
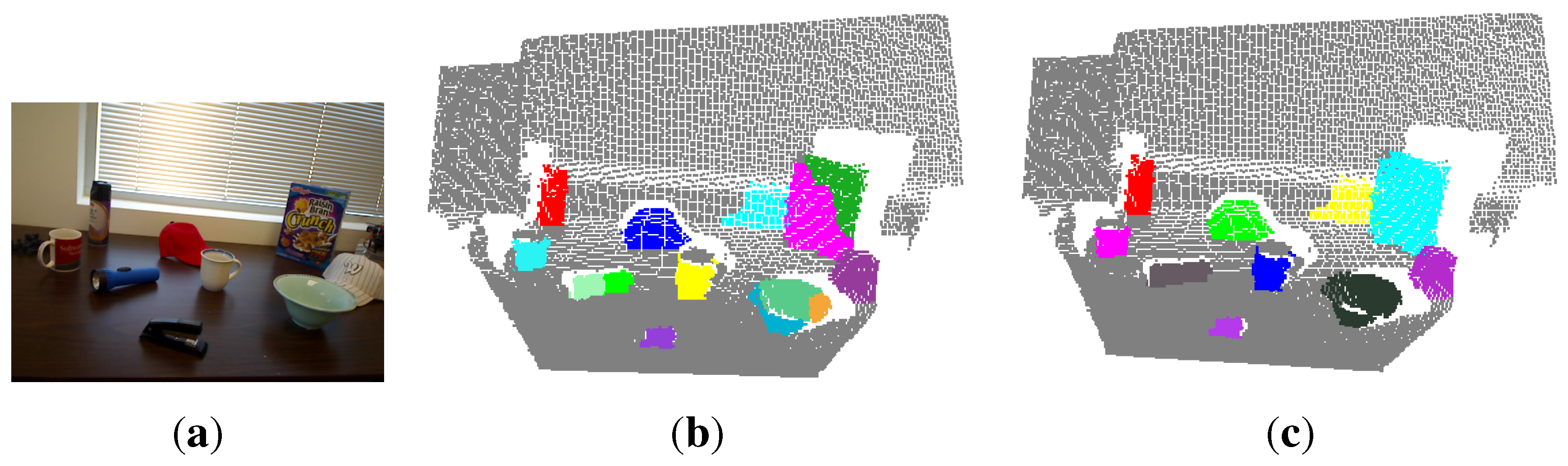
Figure 7 shows some qualitative results of our method, as well as the method proposed by Richtsfeld
et al. [
7]. It shows that the proposed saliency-guided detection method can remove many irrelevant backgrounds and produce a smaller number of object proposals than the method in [
7], which segments objects in the whole image. Although the method in [
7] aims at clustering object surface patches in the whole image using machine learning, there exists an over-segmentation problem. For example, there are only four objects of interest in the first scene of
Figure 7, but the method in [
7] outputs almost 26 objects. The characteristics of these methods will be compared next.
Figure 6.
Quantitative evaluation on the OSD dataset. (a) The precision, recall and F1-measure scores versus the parameter γ in the model of the object hypothesis, respectively; (b) the corresponding scores when using .
Figure 6.
Quantitative evaluation on the OSD dataset. (a) The precision, recall and F1-measure scores versus the parameter γ in the model of the object hypothesis, respectively; (b) the corresponding scores when using .
In the RGB-D scene dataset [
20], there are six categories of objects (e.g., bow, cap, cereal box, coffee mug, flashlight and soda can), which appear in different scene settings, such as in a kitchen, in a meeting room, on a desk and on a table. These settings result in a total of eight scenarios in the dataset. Each scenario contains a sequence of RGB-D images taken from different views. The success rate of object detection only for these six categories of objects are reported, since the ground truth of other categories of objects are not available. The detection results are shown in
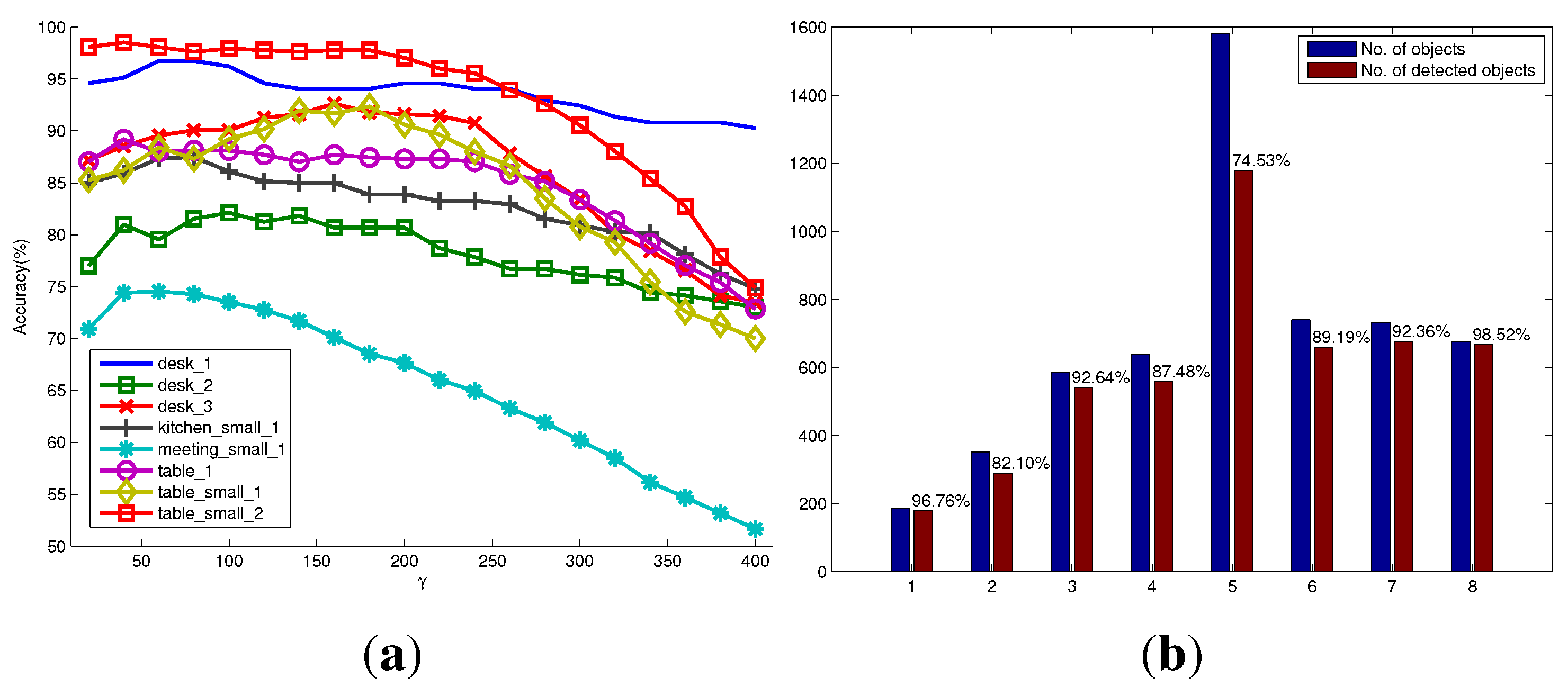
Figure 8.
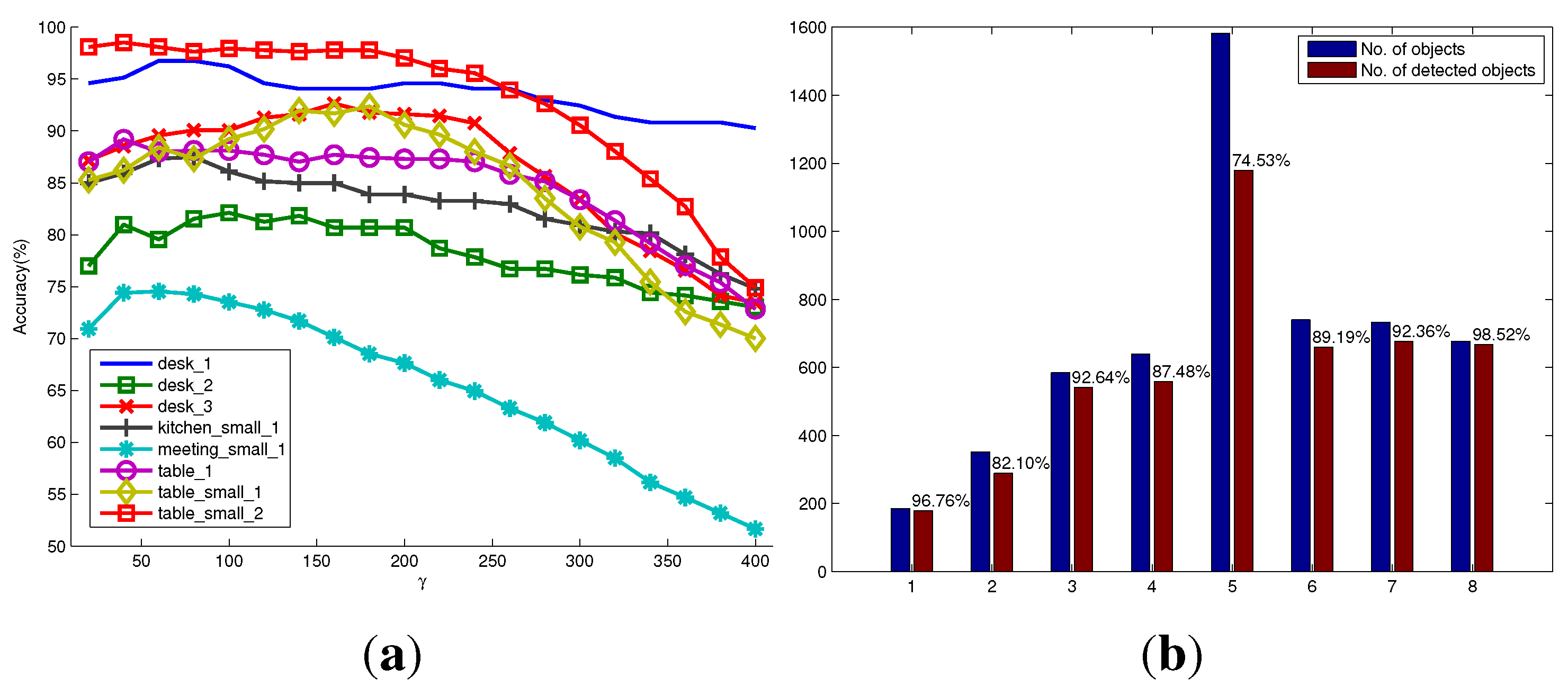
Figure 8a shows the variation of detection accuracy (recall accuracy) on each scenario under different settings of the parameter γ. For most scenarios in the RGB-D scene dataset, the optimal or suboptimal γ for achieving a high recall accuracy of object detection is around 80. This means that we could generate object hypotheses with a little bit larger size, so as to reduce the possibility of over-segmenting. However, it will inevitably sacrifice the detection precision. Empirically, to deal with unpredictable scenes when considering precision and recall accuracy, the good performance of unknown object detection could be achieved by assigning γ with 180. In addition, we found that the parameter γ is related to the method of how to generate seed points of object hypotheses. Other methods of generating seed points may have different optimal γ from what is reported in this paper.
Figure 8b shows the number of successfully detected objects compared to the total number of objects in each scenario when using the optimal parameters. It can be seen that in the eight scenario
, a high detection accuracy up to
is achieved. This is mainly because this scenario contains only four foreground objects that have almost different appearances, and the background is simple. However, the fifth scenario
is more challenging. The number of objects in each image is always more than 10. They are often occluded by other objects or the image borders. Especially, many salient objects are not labeled as foreground objects in the ground truth. Thus, the detection success rate is relatively low. In general, the detection rates over the whole dataset are satisfactory and validate the good performance of the proposed method. As shown in
Table 4, our results are competitive with the detection rates reported in [
5], even though a larger number of images for each scenario in the dataset is used for detection in our evaluation. Some qualitative results are also shown in
Figure 9.
Table 4.
Comparison of the detection rate on the RGB-D scene dataset.
Table 4.
Comparison of the detection rate on the RGB-D scene dataset.
| Scenario | Mishra et al. [5] | Ours |
|---|
| No. of Objects | % of Objects Detected | No. of Objects | % of Objects Detected |
|---|
| desk_1 | 162 | 94.4% | 185 | 96.8% |
| desk_2 | 301 | 94.0% | 352 | 82.1% |
| desk_3 | 472 | 96.0% | 584 | 92.6% |
| kitchen_small_1 | 502 | 82.3% | 639 | 87.5% |
| meeting_small_1 | 1047 | 83.0% | 1582 | 74.5% |
| table_1 | 554 | 92.8% | 740 | 89.2% |
| table_small_1 | 666 | 90.7% | 733 | 92.4% |
| table_small_2 | 584 | 97.6% | 677 | 98.5% |
Table 5 reports the running time of our current single-threaded C++ implementation of the proposed method for a typical
indoor scene RGB-D image. It runs on a 2.4-GHz dual-core 64-bit Linux laptop with 16 GB of memory. In the first stage of active segmentation, it takes about 0.23 s to detect fixation points using color and depth cues. The overwhelming majority of computation is spent on the stage of segmentation, where the calculation of 3D point normals and MRF optimization are time-consuming. Object hypothesis generation, refinement of labeled objects and rendering of detected objects take negligible time. Overall, it requires around 3 s to process an RGB-D frame using our current computing hardware.
Table 5.
Running time of the proposed method.
Table 5.
Running time of the proposed method.
| Detection of Fixation Points | Segmentation | Overall |
|---|
| 0.23 s | 2.7 s | 2.93 s |
Table 6 compares the methods in terms of some characteristics. Different from the other two methods that are both biologically inspired, the method in [
7] does not follow the scheme of active segmentation and aims at clustering object surface patches in the whole image using machine learning. Therefore, the segmentation performance would depend on the training set, and it would produce a larger number of object proposals. The method in [
5] relies highly on the edge detector in [
29], which is shown to be very time consuming. It also needs training to learn some parameters for determining the depth boundary in the method. Generally, the proposed method is shown to be more generic and efficient.
Figure 7.
Visual examples of unknown object detection on the OSD dataset. The first column shows the input scene images overlapped with the detected seed points (red plus) of object hypotheses. The second and third columns show the bounding boxes and colored point clouds of detected objects, respectively. The last column shows the detection results using the method proposed in [
7].
Figure 7.
Visual examples of unknown object detection on the OSD dataset. The first column shows the input scene images overlapped with the detected seed points (red plus) of object hypotheses. The second and third columns show the bounding boxes and colored point clouds of detected objects, respectively. The last column shows the detection results using the method proposed in [
7].
Figure 8.
Quantitative evaluation on the RGB-D scene dataset with eight scenarios. (a) The successful detection percentages versus the parameter γ in the model of object hypothesis for eight scenarios, respectively; (b) the number of objects, as well as the number of detected objects in each scenario using the optimal parameters.
Figure 8.
Quantitative evaluation on the RGB-D scene dataset with eight scenarios. (a) The successful detection percentages versus the parameter γ in the model of object hypothesis for eight scenarios, respectively; (b) the number of objects, as well as the number of detected objects in each scenario using the optimal parameters.
Figure 9.
Visual examples of unknown object detection on the RGB-D scene dataset.
Figure 9.
Visual examples of unknown object detection on the RGB-D scene dataset.
Table 6.
Comparison of the method characteristics.
Table 6.
Comparison of the method characteristics.
| Method | Method Characteristics |
|---|
| Biologically Inspired | Need Training | Rely on Edge Detection | Computational Efficiency |
|---|
| Richtsfeld et al. [7] | No | Yes | No | Medium (2–5 s) |
| Mishra et al. [5] | Yes | Partially | Yes | Low (>5 s) |
| Ours | Yes | No | No | Medium (2–5 s) |
4.3. Unknown Object Detection and Manipulation
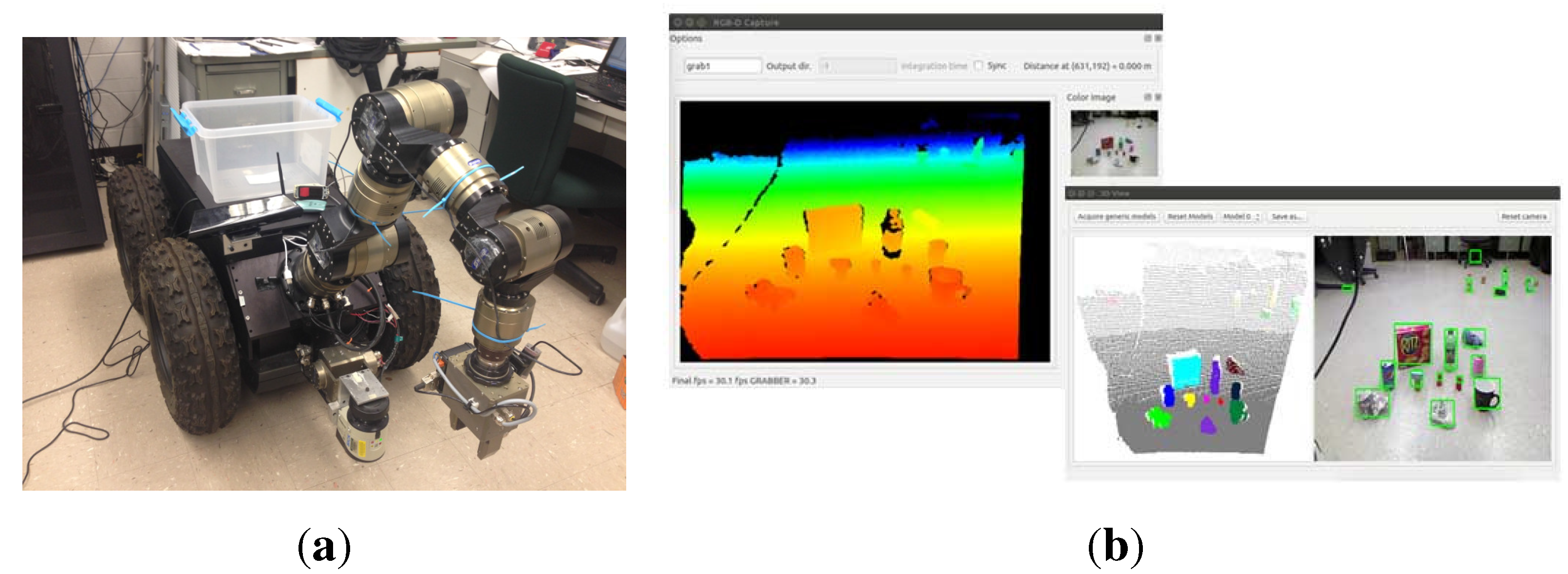
We also test our object detection method for manipulation tasks using a mobile manipulator system equipped with a Kinect camera, as shown in
Figure 10a. This mobile manipulator consists of a seven DOF manipulator and a nonholonomic mobile base. We implemented our object detection algorithm in the perception module of the robot platform based on the core library Nestk developed in [
30]. The developed GUI for observing the object detection process is shown in
Figure 10b. Currently, it takes our version of implementation about three seconds to process a typical indoor scene. In the experiment, the mobile manipulator detects unknown objects using the perception module and calculates the attributes (
i.e., object size, grasping position,
etc.) of the detected objects. When the robot is commanded to perform a task like “cleaning up the ground” via the dialogue-based interface, the robot starts to process the human utterance through the natural language processing module, the grounding module and the action module, which have been developed in our previous works [
31]. The task is then converted to a sequence of robot actions (
i.e., move to, open gripper, close gripper,
etc.) and trajectories for the mobile manipulator to execute.
Figure 10.
Our mobile manipulator (a) and the developed GUI (b) for observing the object detection process.
Figure 10.
Our mobile manipulator (a) and the developed GUI (b) for observing the object detection process.
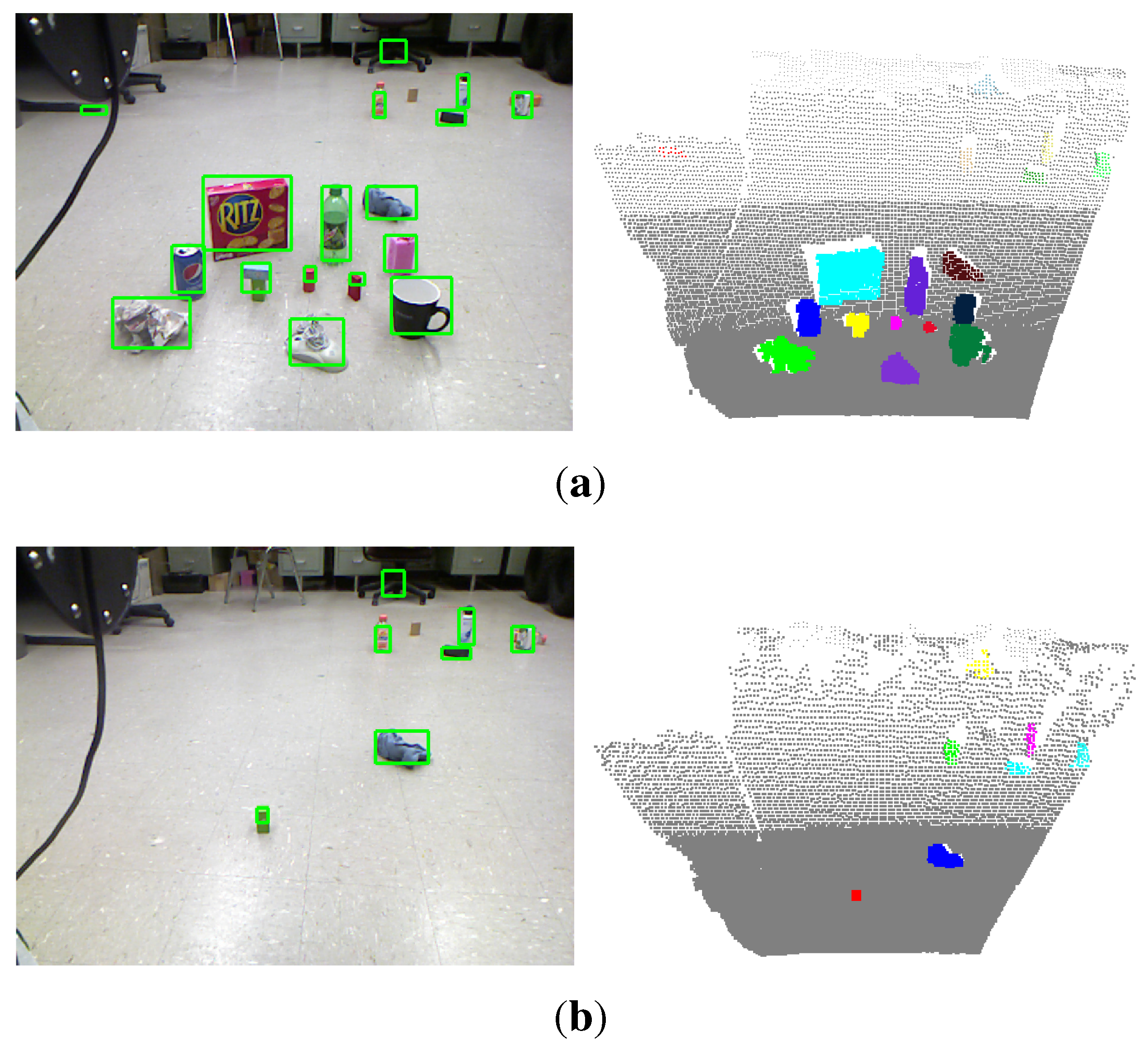
Figure 11.
A typical experimental scene seen from the robot. (a,b) show the detected objects before and after the robot picking up all detected objects within its manipulation range, respectively.
Figure 11.
A typical experimental scene seen from the robot. (a,b) show the detected objects before and after the robot picking up all detected objects within its manipulation range, respectively.
A typical experimental scene is shown in
Figure 11. Several daily used objects are randomly placed on the ground of our laboratory. The robot is commanded to automatically find, pick up these objects and put them into the box on the top of the robot base. At the beginning, the robot detects the objects in its field of view, as shown in
Figure 11a, and starts to pick up the objects within its manipulation range. After a round of manipulations, the scene shows that the green block and the blue cleaning rag have not been recycled yet, as shown in
Figure 11b. This is because the green block is stacked with another block and has not been detected before, and the blue cleaning rag is out reach of the manipulator. Thus, the robot detects the objects in the current scene again to make sure that there is no object left before navigating to the next spot. After detecting and picking up the green block, the robot moves to the cleaning rag and then picks it up. The robot repeats the procedures of detecting objects, approaching the objects, detecting objects again and picking them up.
Figure 12 shows some typical snapshots of scenes when the robot is performing these procedures automatically.
Figure 12.
Snapshots of scenes when our robot is performing the task of cleaning up the ground. After detecting the unknown objects, the robot moves its gripper to the nearest object (a), grasps the object (b) and then puts it into the box. When the objects are out reach of the manipulator, the robot moves its base to facilitate grasping (c). After recycling all objects in the current spot, the robot continues to find objects and moves to the next spot (d).
Figure 12.
Snapshots of scenes when our robot is performing the task of cleaning up the ground. After detecting the unknown objects, the robot moves its gripper to the nearest object (a), grasps the object (b) and then puts it into the box. When the objects are out reach of the manipulator, the robot moves its base to facilitate grasping (c). After recycling all objects in the current spot, the robot continues to find objects and moves to the next spot (d).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}