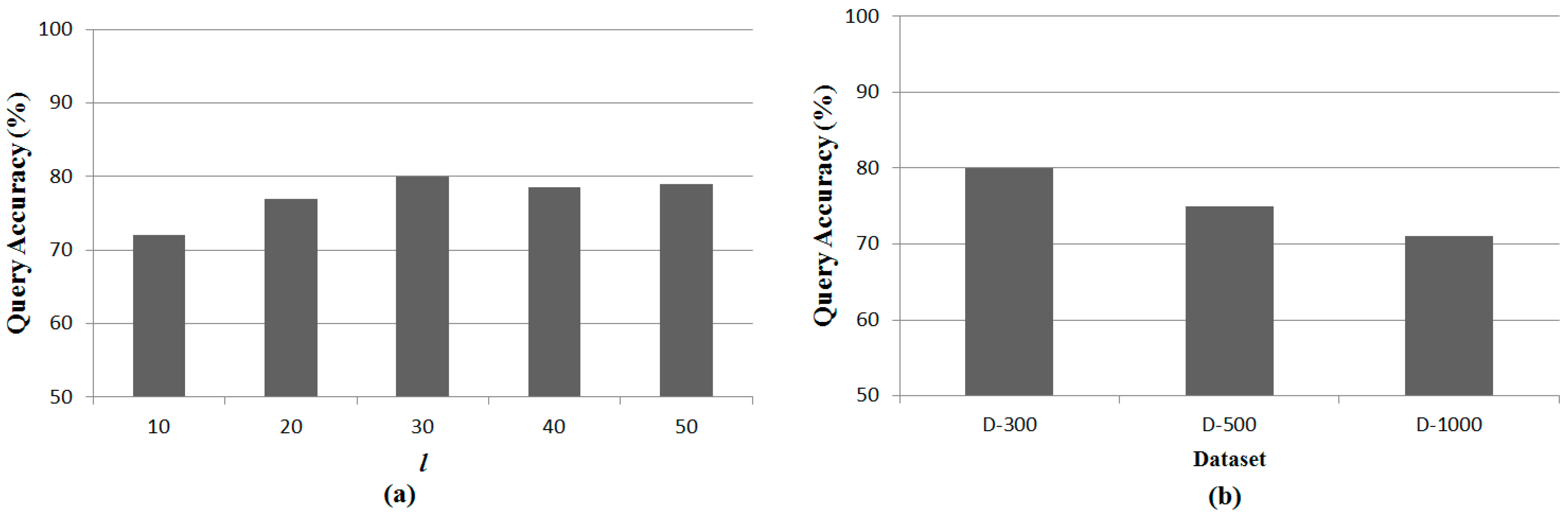
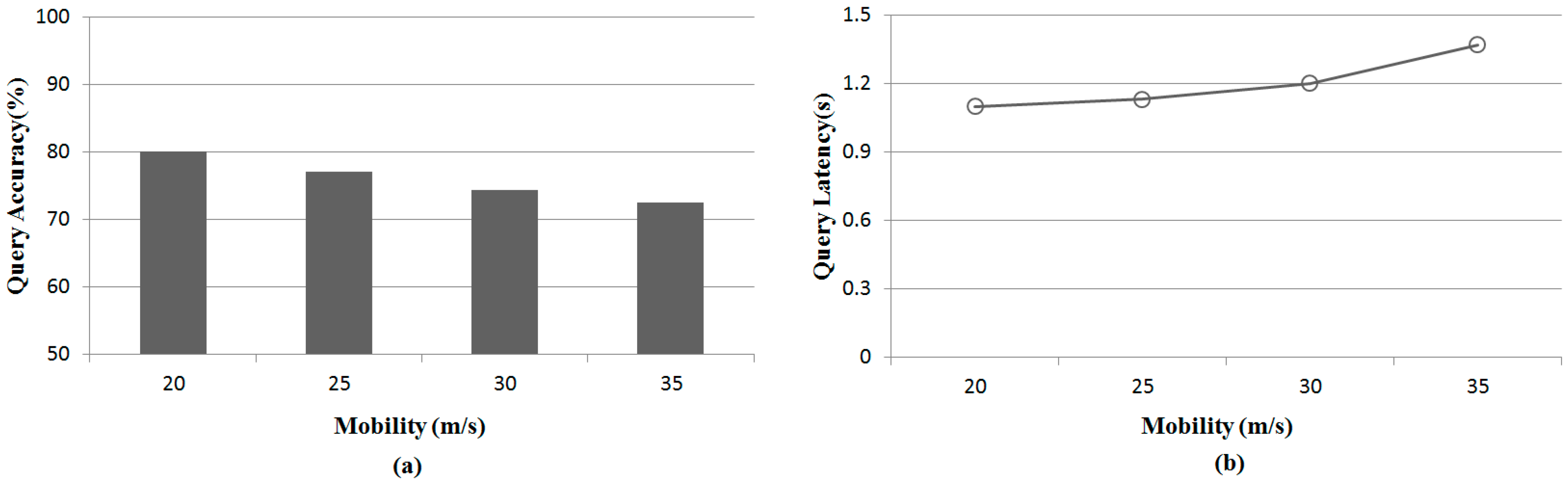
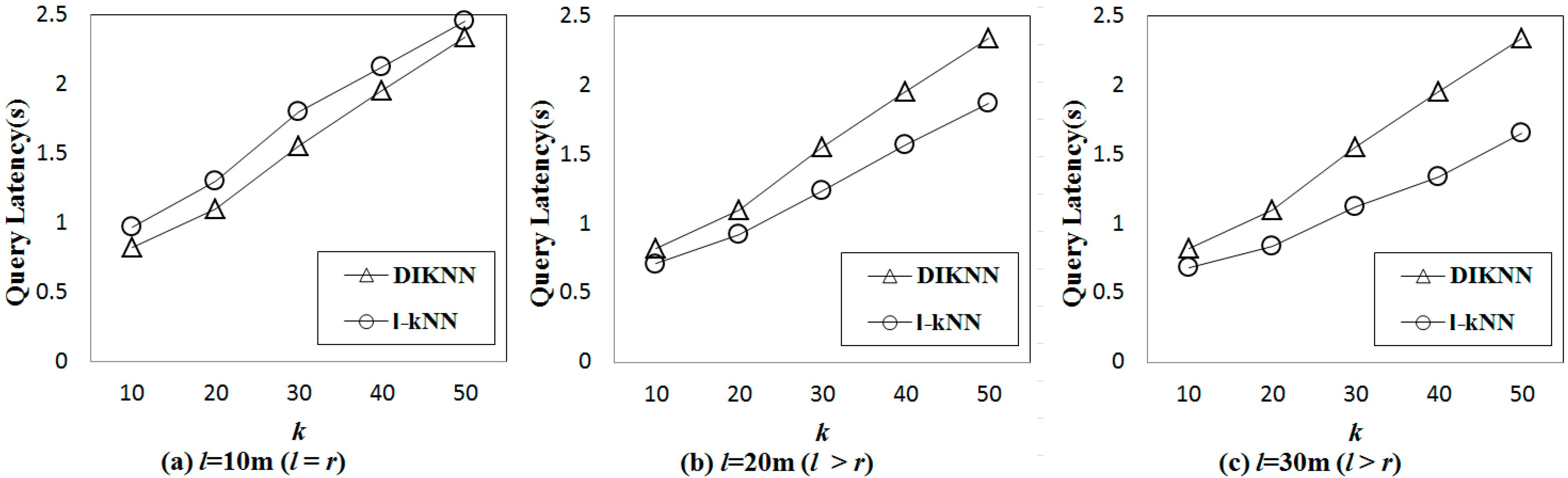
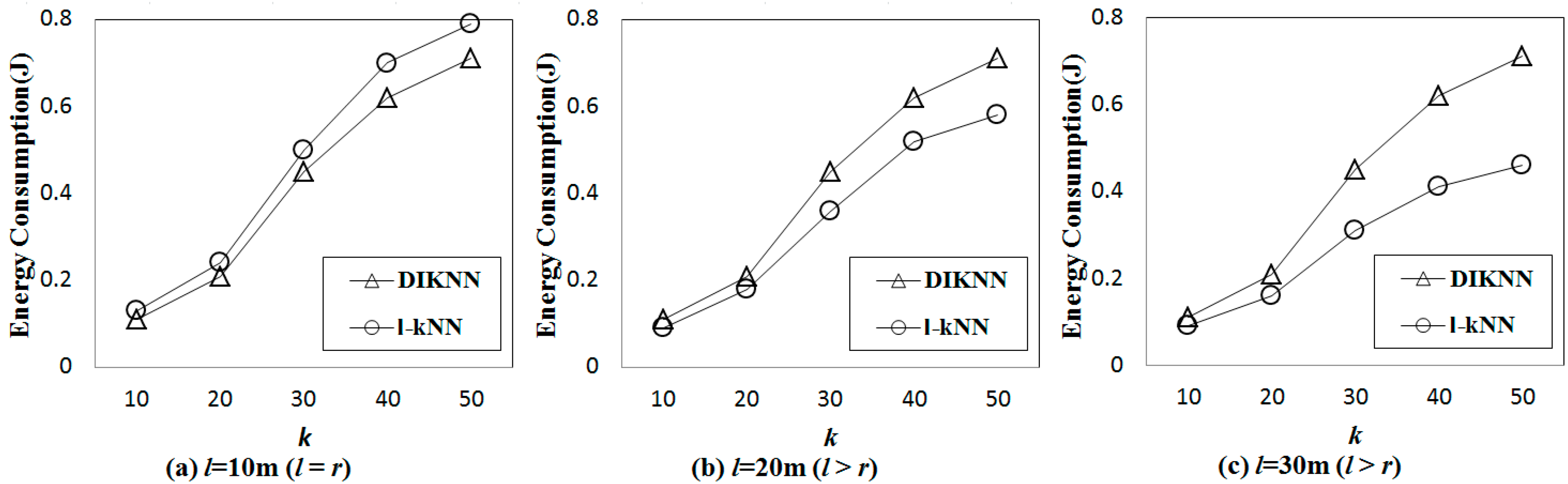
3.3. -NN Boundary Estimation
The H-node disseminates a query message to the other sensor nodes. The query message is progressively propagated to sensor nodes farther from the H-node. Because we do not have information about the sensor node distribution, we must estimate a maximum boundary for the -NN query (-NNB) by considering the worst case. A large -NNB guarantees correct query results but incurs large energy consumption and slow query responses. However, a small -NNB decreases query accuracy because some query results are located outside of the -NNB.
Let
be the radius of the
-
NNB. According to the definition of an
-
NN query, we need to find the
sensor nodes nearest to the H-node that are at least distance
apart. Therefore,
is calculated as in Equation (2). All query results are then guaranteed to be located within the radius
:
A sensor node can send messages to other nodes within the sensor’s radio range. If it sends messages to other nodes located outside its range, the query message traverses several hops between the source and destination. Therefore, we need to estimate
-
NNB differently according to the ratio of
to the sensor radio range
. We refine Equation (2) as Equation (3) with consideration of the ratio:
If , -NNB is estimated as . A single is enough to maintain the distance between two Q-nodes because is shorter than . If , -NNB is estimated as . Although is equal to , we need to ensure the distance is maintained between two Q-nodes. This is because of the possibility that no sensor node exists on the circumference of . If , -NNB is estimated as . To maintain , we need one more than for the case of because is larger than .
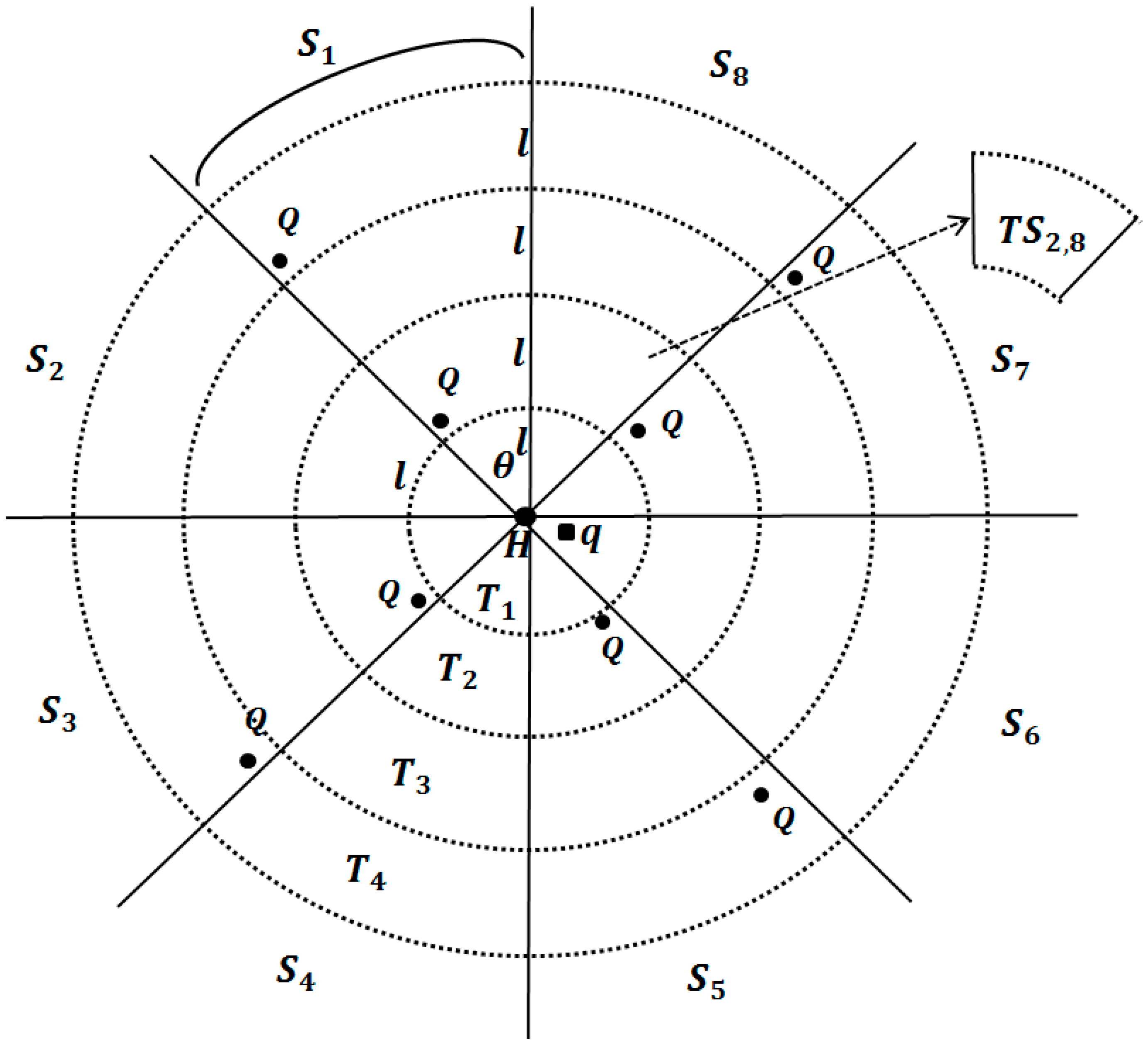
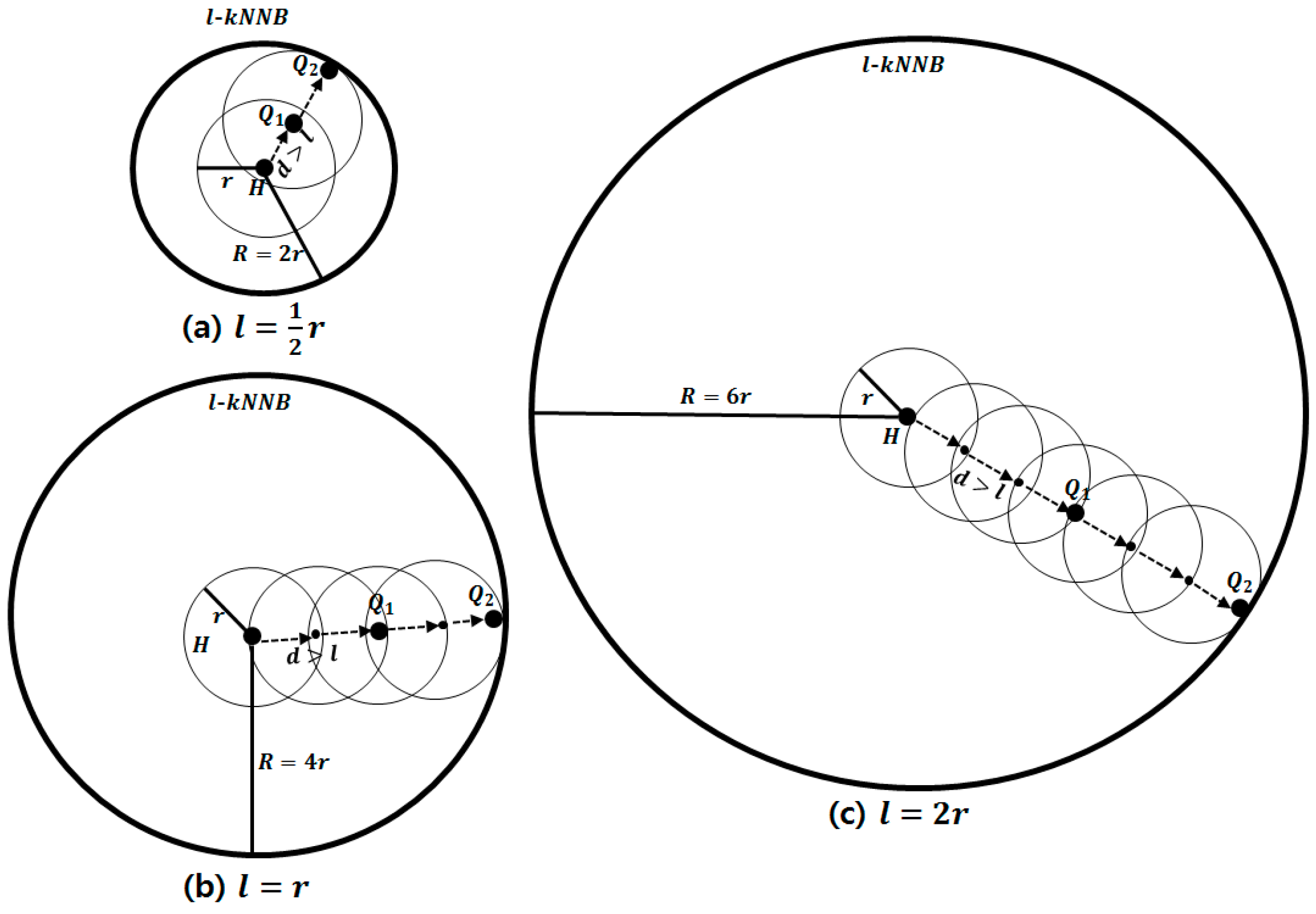
Figure 3 shows examples of
-
NNBs with various ratios of
to
when
is 2.
Figure 3a–c represent estimates of
-
NNBs for the cases of
,
and
, repectively. According to Equation (3),
is estimated as
, 2
and
when
is
,
and
, respectively. The distance
between the Q-nodes is longer than
in all cases.
Figure 3.
-NNBs with various ratios of to . (a) -NNB when is larger than ; (b) -NNB when is equal to ; (c) -NNB when is smaller than .
Figure 3.
-NNBs with various ratios of to . (a) -NNB when is larger than ; (b) -NNB when is equal to ; (c) -NNB when is smaller than .
3.4. -NN Query Dissemination
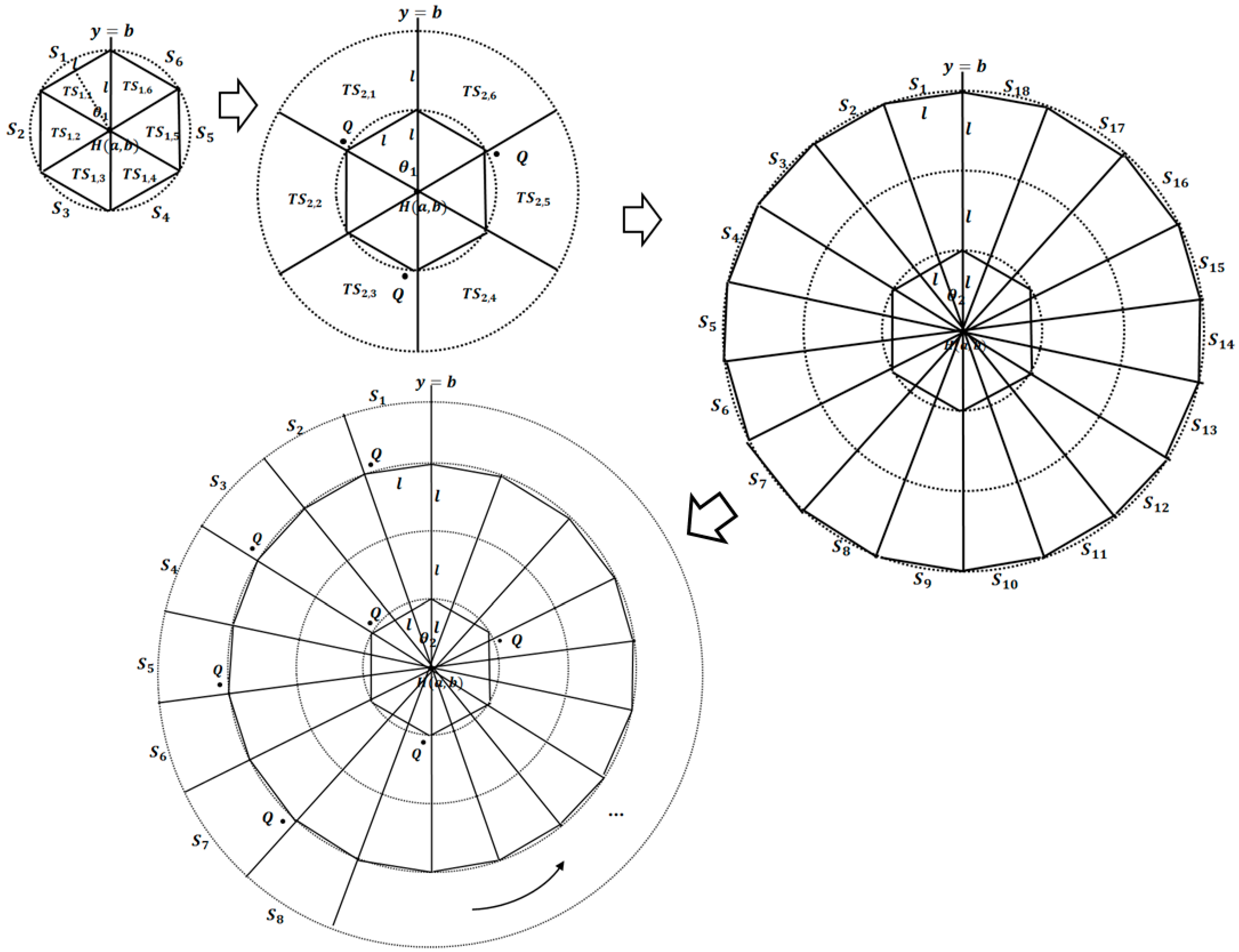
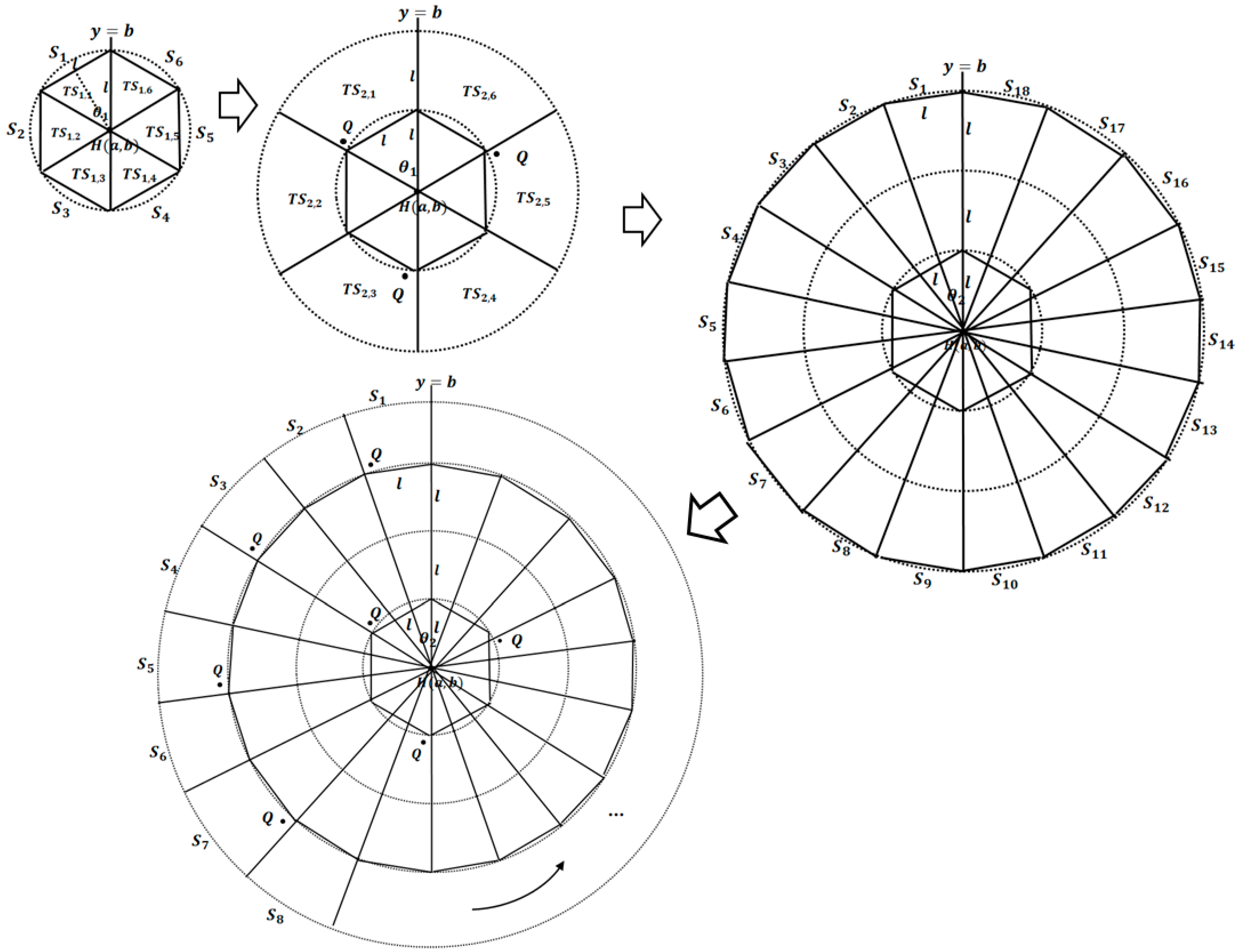
After -NNB is determined, the query message is progressively disseminated from the H-node to the circumference of -NNB. Tracks are extended from the H-node to -NNB, and each track is divided into sectors. The query is propagated to the query tracks and query sectors. This process is repeated until the query message reaches -NNB.
We observe that odd track numbers are margin tracks and even track numbers are query tracks. This is because we select the Q-nodes in the other tracks. In each margin track, the central angle and the number of sectors are calculated for dividing the track into sectors. Notice that the central angle and the number of sectors are recalculated in each margin track. This is because this procedure keeps tight distances between query sectors. If we divide all tracks into sectors with the same central angle as in the first track, farther track-sectors have longer chards than , leading to low quality query results because the size of margin sectors is determined too loosely.
Consider an H-node with coordinates
and any margin track
centered at
with radius
.
is sequentially divided into several sectors from the baseline
=
in the counterclockwise direction. The central angle
and the number of sectors
are determined depending on the distance constraint
. We have a well-known equation involving a central sector, a radius, and a chord as in Equation (4):
Because we want all sides of each track sector to have length , is calculated as . We can also calculate as . When a track is divided into sectors in the counterclockwise direction, the last sector has a central angle smaller than . In this case, the last sector is merged with the previous sector. In this way, we can guarantee that all chords of sectors have lengths of at least .
In each query track, Q-nodes are selected in every other track-sector. In a track-sector, a length of an upper chord is longer than because that of a lower chord is . Therefore, the Q-node is selected around the inner corner intersecting the lower arc and the margin sector in order to keep the distance constraint tight. In a track-sector of a margin track, an upper chord is , and a lower chord is shorter than . This is why we select the Q-nodes in query tracks rather than in margin tracks.
For a tight distance between query tracks and query sectors, it is also possible to set the radius of query tracks and the chords of query sectors to rather than , when is shorter than . If we set the radii of query and margin tracks to the same distance , the average distance between Q-nodes is . By using for the radii of query tracks and chords of query sectors, the distance is reduced by to .
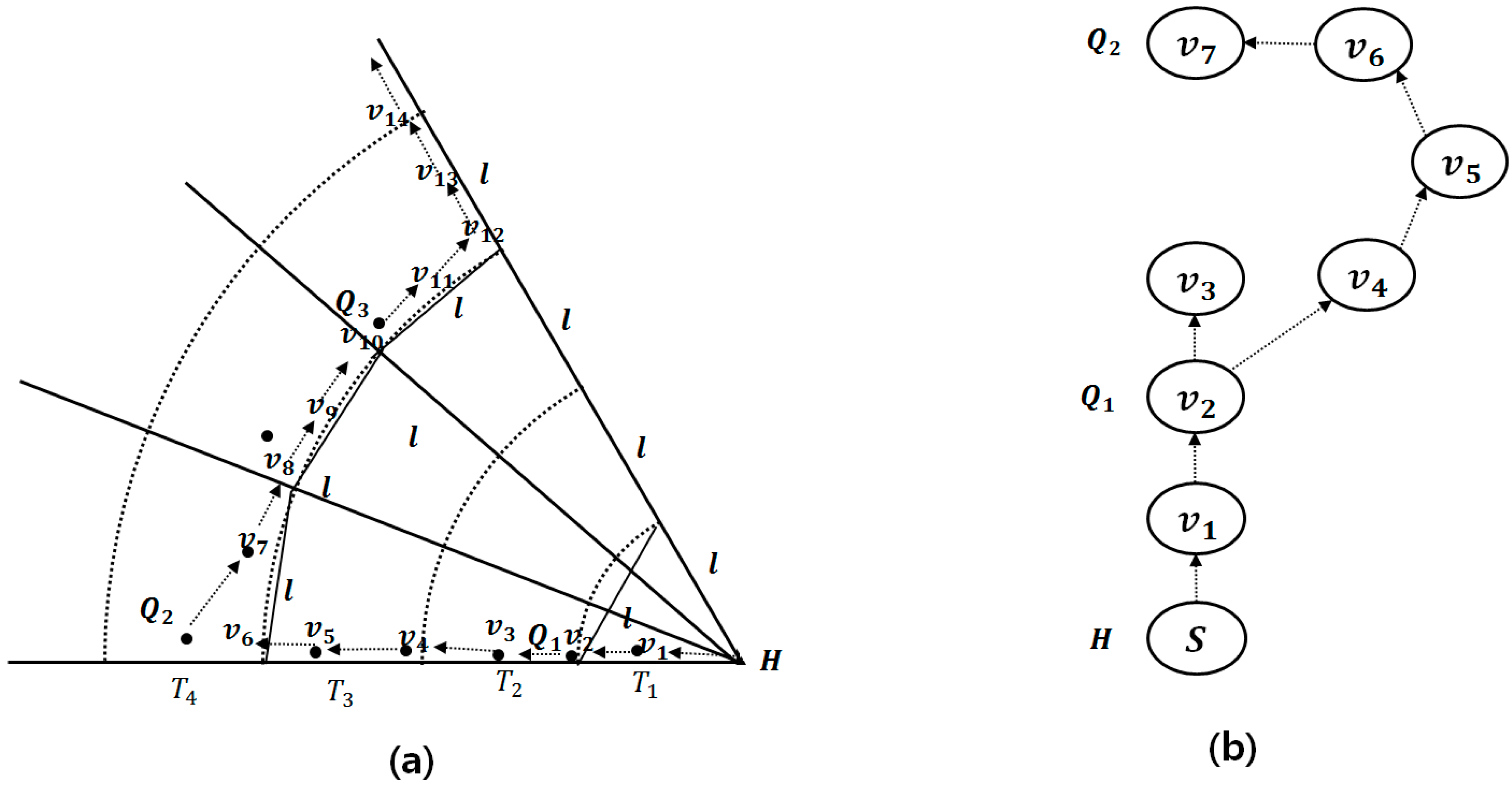
Figure 4 shows an example for calculating the number of sectors.
is calculated as
, and
, in the first track. In the third track,
is calculated again as
, where
. The second and fourth tracks are query tracks. Q-nodes are then selected in
,
,
,
,
,
,
, and so on.
Figure 4.
Dividing the search space into tracks and sectors.
Figure 4.
Dividing the search space into tracks and sectors.
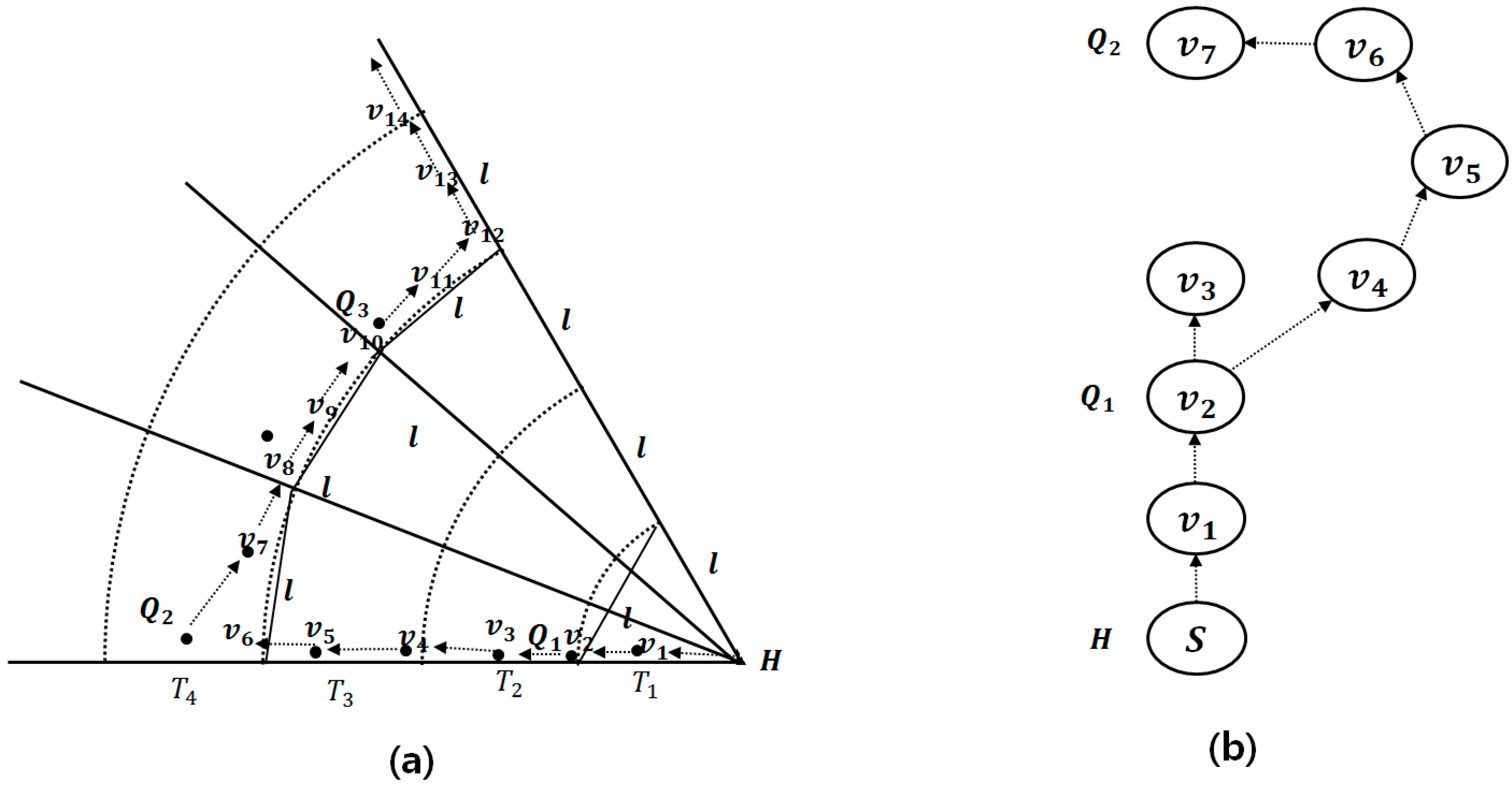
In the following, we explain how the query message is disseminated. In a NN problem, the query message should be disseminated to all sensor nodes in each track-sector because there can be more than one Q-node in a track-sector. However, in our -NN problem, we do not need to traverse all sensor nodes. One track-sector can contain at most one Q-node, and we can calculate roughly where the Q-nodes are. Therefore, once the query message reaches a Q-node in a track-sector, the query message escapes this track-sector and heads quickly to the next track-sector containing a Q-node.
The query message traverses between only those track-sectors containing Q-nodes. As explained above, the Q-node is selected around the inner corner intersecting the lower arc and the margin sector in a query track. We regard the corners as virtual vertices because we cannot know whether any sensor nodes exist in the corners. The query message is propagated to the virtual vertex along borders of tracks and sectors by itinerary traversal [
7]. The Q-node is selected near the virtual vertex. The itinerary traversal selects the next sensor nodes in the range of
rather than
in order to balance query accuracy and energy efficiency [
20]. If there is no sensor node near the virtual vertex, we seek the Q-node by routing around the virtual vertex based on the right-hand rule of GPSR.
Figure 5a shows an example of query dissemination in a sector, where
is a virtual vertex and
is a Q-node. The virtual vertices
,
and
are the corners intersecting the lower arc and the margin sector in query tracks. Q-nodes
,
and
are the nearest vertices to the virtual vertices, respectively. The query message is propagated from
to
and from
to
along the borders of the sector and tracks by itinerary traversal.
Figure 5b shows an example of the right-hand rule of GPSR. If there is no sensor node near the virtual vertex
, we try to route around
to seek the path from H-node to the next Q-node,
.
Figure 5.
Query dissemination among track-sectors. (a) Query dissemination; (b) Right-hand rule of GPSR.
Figure 5.
Query dissemination among track-sectors. (a) Query dissemination; (b) Right-hand rule of GPSR.
For fast query processing, we adopt parallel computing for query dissemination in each sector. The query dissemination in each sector is an independent subtask. Therefore, this parallelization reduces query latency without accuracy degradation. The number of subtasks has a great effect on the performance. When the number of subtasks is large, network throughput degrades because contentions and collisions occur frequently at the data link and physical layers. Conversely, a small number of subtasks increases latency. Considering this analysis, we determine the number of subtasks as the number of sectors in the first track. Since the query message traverses only the track-sectors containing Q-nodes that are surrounded by margin tracks and sectors, contentions and collisions are minimized in the parallel query dissemination.
At the end of dissemination, query responses are aggregated at the H-node. The H-node can take more than number of Q-nodes because -NNB is the estimated boundary considering the worst case. To select the nearest number of Q-nodes, the Q-nodes are sorted in ascending order according to their distances from the H-node. Finally, the H-node selects the top- number of Q-nodes and transmits back to the query source by GPSR.
3.5. Algorithm for Query Dissemination
Algorithm 1 is the pseudo code for processing the
-
NN query. The algorithm searches an H-node
nearest to the given query point
(line 1). The H-node
is included in a query result set (line 3). Flag
is used to check whether any Q-node is selected in a query sector (line 4). The query message is propagated forward from the H-node
to other sensor nodes within the
-
NNB (line 5).
search_next_vnode( ) is called to determine the next forward sensor node (line 6). We explain
search_next_vnode( ) in Algorithm 2, as follows. If the
next_vnode is the starting point of a new track-sector, the flag
is set to “false” in order to select a Q-node in this track-sector (lines 7–8). The algorithm selects the next forward sensor node nearest to the
next_vnode by using GPSR (line 9). Lines 6–9 are repeated until reaching
-
NNB. The Q-nodes in the resulting set
are sorted in ascending order according to their distances from the H-node (line 10). The top-
sensor nodes in
are returned as the query result (lines 11–12).
| Algorithm 1 --NN Query Processing |
| QueryDissemination (, , , , ) |
- ⦁Input:
number of sectors , query point , distance constraint , number of nearest neighbors , and --NNB - ⦁Output:
a result set including Q-nodes ;
|
- 1:
Search a home node nearest to the query point ; - 2:
cur_node ; - 3:
Initialize a result set ; - 4:
flag false; // the status that the Q-node is not selected yet in a query sector - 5:
while (cur_radius < b) - 6:
next_vnode search_next_vnode(, , , , , cur_node); // find the next virtual node - 7:
if ( next_vnode is the vnode intersecting track and sector) // the starting search point of TS - 8:
false; - 9:
cur_node GPSR (cur_node, next_vnode); // find the sensor node nearest to the next_vnode - 10:
Sort Q-nodes in in ascending order according to the distance from the H-node; - 11:
select top- Q-nodes; - 12:
return ;
|
Algorithm 2 is the pseudo code for determining the next search direction. To determine the direction, each sensor node should know its own sector number and track number, and the four borderlines of the track-sector. Algorithm 2 includes the calculation of all of this information about the current sensor node. Each sensor node can calculate the discriminants determining the borderlines of its own track-sector by using its own coordinates and those of the H-node.
The current sensor node calculates its distance from the H-node. The track index that the sensor node belongs to is calculated by dividing the distance by the track radius (line 2). The algorithm calculates the radius of the current track by multiplying the track index by the track radius , which is the upper arc of the current track (line 3). The lower arc of the current track is- because the radii of the tracks increase by . Therefore, we can derive the discriminants that calculate the upper and lower arcs of the track having radius centered at (lines 4–5).
The algorithm checks whether the current track is a margin track or a query track (line 6). If the current track is a margin track, the query message is passed to the next track (lines 11–12). Otherwise, the algorithm checks whether a Q-node is selected (line 7). If a Q-node is selected, the query message is passed to the next track-sector (lines 7–8). Otherwise, the query message is passed to the next_vnode along the lower arc in the current track-sector (lines 9–10). The chord is calculated as for the central angle . This is the optimal chord to select the next sensor node without interference among the sensor nodes.
After obtaining for dividing the search space into sectors, the algorithm calculates the sector number of the current sensor node by using the coordinates of the current sensor node and the home node (lines 13–14). The algorithm derives the discriminants that calculate the right- and left-side lines of the current track-sector by using and (lines 15–16).
We can obtain the corner points from the four discriminants of the borderlines of the current track sector (line 17). If the current track-sector is a query one and no Q-node is selected, the algorithm selects the sensor node nearest to the corner intersecting the lower arc and the margin sector (lines 18–21).
After selecting the Q-node, the algorithm determines the next direction and the
next_vnode (lines 22–23). Because the algorithm adopts itinerary traversal [
13] to select the next track in a sector, the query message is passed to the next sensor node in the east direction in odd-number tracks. Conversely, the query message is passed in the west direction in even-number tracks. The algorithm finally returns the
next_vnode as the coordinates of the corner of the next track-sector (line 24).
Algorithm 3 determines the next forward direction of the query message from the current sensor node. According to the itinerary traversal algorithm, the forward direction is determined to be east if the current track index is an odd number, and west if even (lines 1–8). If the current track-sector is the last sector or the margin track, the forward direction is determined to be north because the algorithm does not need to select the Q-node (line 9).
| Algorithm 2 Determining the Next Search Direction |
| search_next_vnode (, , , , , ) |
- ⦁Input:
the home node , the distance constraint, the number constraint , a status flag , the query result set , the current sensor node - ⦁Output:
the coordinates of the next virtual node
|
- 1:
Initialize a track-sector discriminants set of current node ; /* find four discriminants determining border lines of a track-sector */ - 2:
⌈
⌉
; // calculate the track index of cur_node by using and - 3:
// calculate the current track radius - 4:
; // a upper arc of the track-sector - 5:
}; // a lower arc of the track-sector - 6:
if ( is an even number ) // if the current track is a query track - 7:
if ( is true) // if a Q-node is selected - 8:
calculate the angle of a tractor-sector by ; // move to the next track-sector - 9:
else // if a Q-node is not selected - 10:
calculate the angle for the next vnode by ; // move to the next vnode - 11:
else // if current track is a margin track - 12:
; // move to the next query track - 13:
calculate the angle between the baseline and the current node by ; - 14:
calculate the sector index of current node by ⌈⌉ ; - 15:
; // a left-side line of the track-sector - 16:
; // a right-side line of the track-sector - 17:
Calculate intersecting points between each pair of the track-sector discriminants, such as the upper arc , the lower arc , the left-side line , and the right-side line ; /* check that whether the Q-node is selected or not in this tracksector */ - 18:
if (IsSelectTrackSector () is ) - 19:
Find the sensor node nearest to the corner intersecting the lower arc and the margin sector; - 20:
; - 21:
; - 22:
dir getNextDirection(); // decide the next direction by using the track and sector indexes - 23:
next_vnode select the next moving point in according to dir; - 24:
return next_vnode;
|
| Algorithm 3 Determining the Next Forward Direction |
| getNextDirection () |
- ⦁Input:
a track index , a sector index - ⦁Output:
the direction of the next virtual node
|
- 1:
calculate the total number of partial sectors in the current sector - 2:
if (%4 == 3) // query track - 3:
if ( N) return southeast; - 4:
else return northeast; - 5:
else if (%4 == 1) // query track - 6:
if () return southwest; - 7:
else return northwest; - 8:
else if (%4 == 2) return northwest; // margin track - 9:
else return northeast; // margin track
|
Algorithm 4 checks whether the current track-sector
is a query sector or a margin sector. If the track-sector has an odd-number sector, it is a query sector (lines 1–9). However, if the total number of sectors is an odd number and the current track-sector is the last sector, it is determined to be a margin sector because two consecutive sectors that are the first and the last sectors cannot be query sectors (lines 3–5).
| Algorithm 4 Determining the Sector Type |
| IsSelectTrackSector () |
⦁Input: a track index , a sector index
⦁Output: a Boolean value representing whether this TS is in a query sector or in a margin sector |
1: calculate the total number of tracks
2: calculate the total number of sectors in the current track
3: if ( is an odd number)
4: if ( is an odd number & )
5: //current track-sector is in a query sector
6: else
7: if ( is an odd number)
8: //current track-sector is in a query sector
9: return false; //current track-sector is in a margin sector |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}