This section presents the experiments that we have carried out to check the location accuracy of the algorithm proposed in
Section 4. During the tests we have used an experimental database of RSSI values taken in an indoor area. The objectives of these experiments are twofold. On the one hand, the first objective is to evaluate the error introduced in the database values when the number of reference points is reduced during the training phase. The points not measured are estimated using the interpolations functions seen in
Section 4. On the other hand, it is also important to evaluate the precision achieved in the location algorithm when the database includes interpolated RSSI values.
5.1. Case Study and Configuration
This subsection describes the indoor scenario used in our experiments.
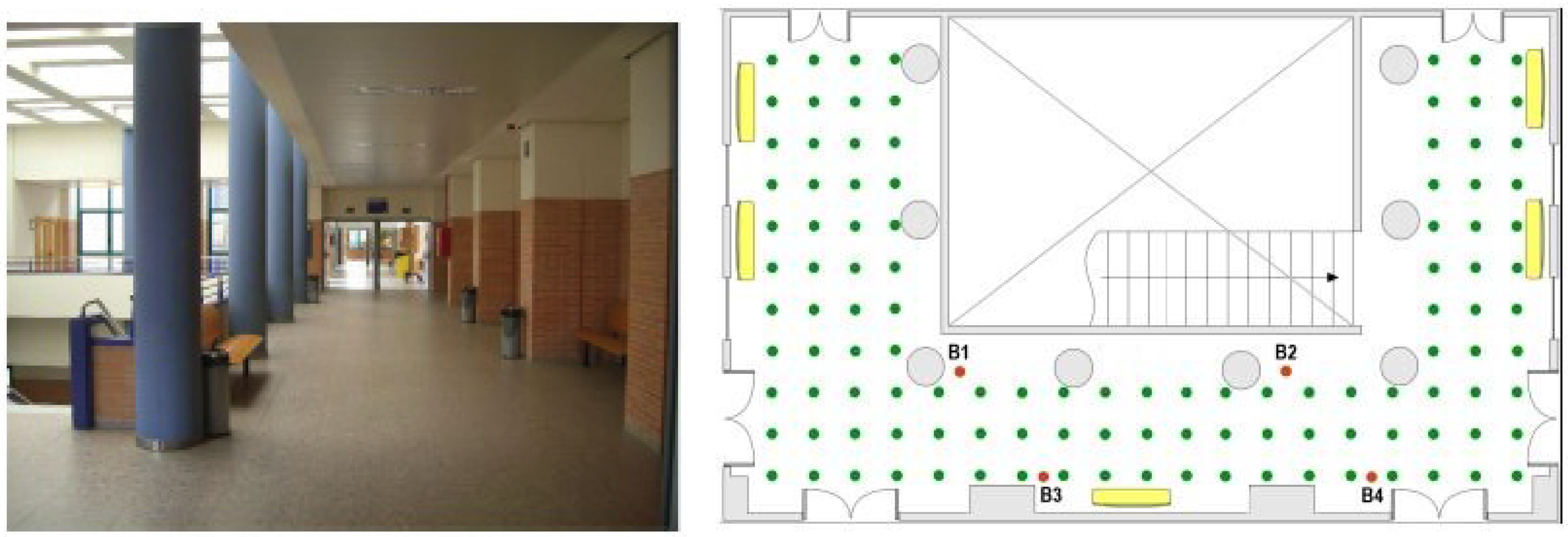
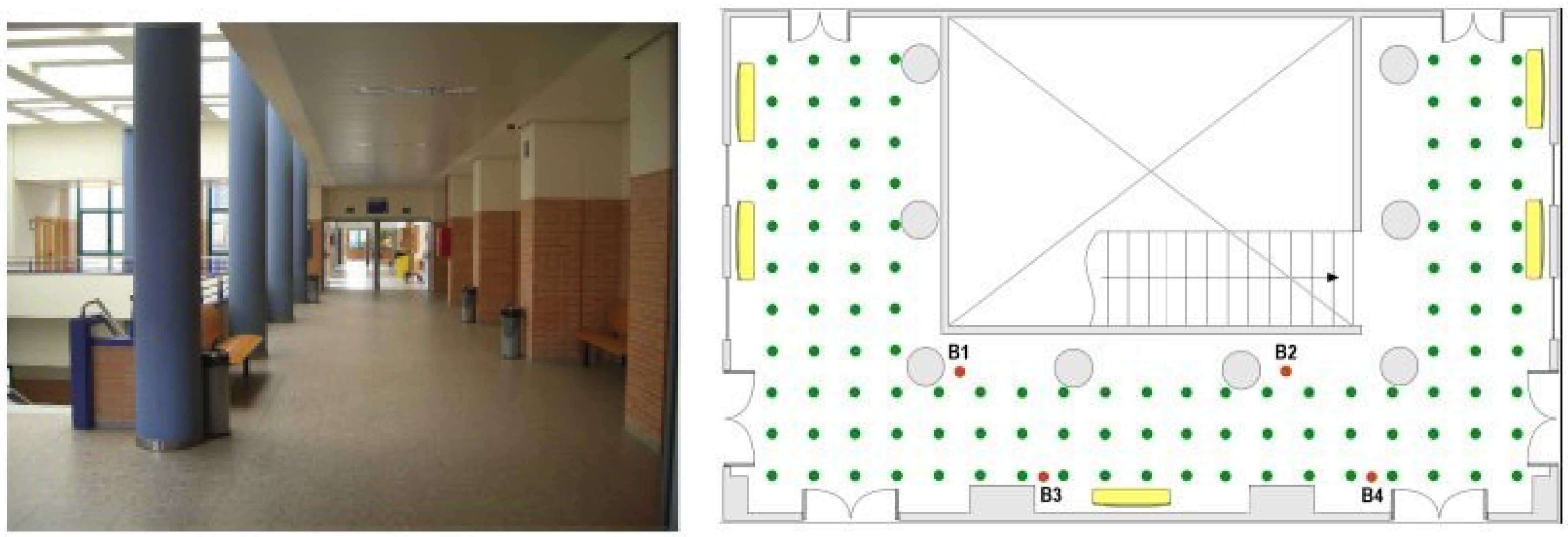
Figure 1 shows the map of the room where the network was deployed. The scenario covers an area of 11 × 19 m and it includes some building elements such as: reinforced concrete columns, stair well with steel rails, metal doors, irregular walls and latticework in the ceiling, elements that substantially disrupt the propagation of signals and complicate the location estimation. There were four beacons placed at positions marked as: B1, B2, B3, and B4 and the mobile sensor was placed at each reference point of the grid marked with a green dot (see
Figure 1). The grid comprised 113 reference points, located one meter apart from each other. During the training phase, the mobile node was placed at every reference point of the grid to exchange data packets with each beacon using six different channels: CH11, CH13, CH16, CH19, CH22, CH26 (with carrier frequencies (MHz): 2405, 2415, 2430, 2445, 2460, and 2480, respectively), and four power levels: P3, P19, P95, P255 (gains (dBm): −25.2, −5.7, −0.4, and 0.6, respectively). Since ten data packets were exchanged with each beacon (5 in each direction) for every different combination of channel and power level, a total amount of 960 RSSI values were measured and saved in the database at each reference point.
Figure 1.
Photo and map of the room where the system was deployed.
Figure 1.
Photo and map of the room where the system was deployed.
5.2. Analysis of the Database Interpolation
The fingerprinting training step represents the main drawback of these localization methods. To lighten this initial effort, the number of reference points can be decreased, but at the expense of decreasing the density of information available during the localization phase. One way to reduce the number of experimental measures required during the training, without decreasing the number of reference points in the database, is to estimate a part of the RSSI values using interpolation functions. In this subsection, the feasibility of this method for different distributions and densities of reference points is evaluated.
For testing the accuracy of this method, the measured RSSI values in the database are compared with the estimated values obtained from the interpolation functions. To this end, the initial database, which includes all the testing points shown in the previous section, is reduced removing the RSSI values corresponding to 50% of the total amount of reference points. Using the remaining RSSI values and applying the RBF interpolation functions, the RSSI values for the removed reference points are estimated.
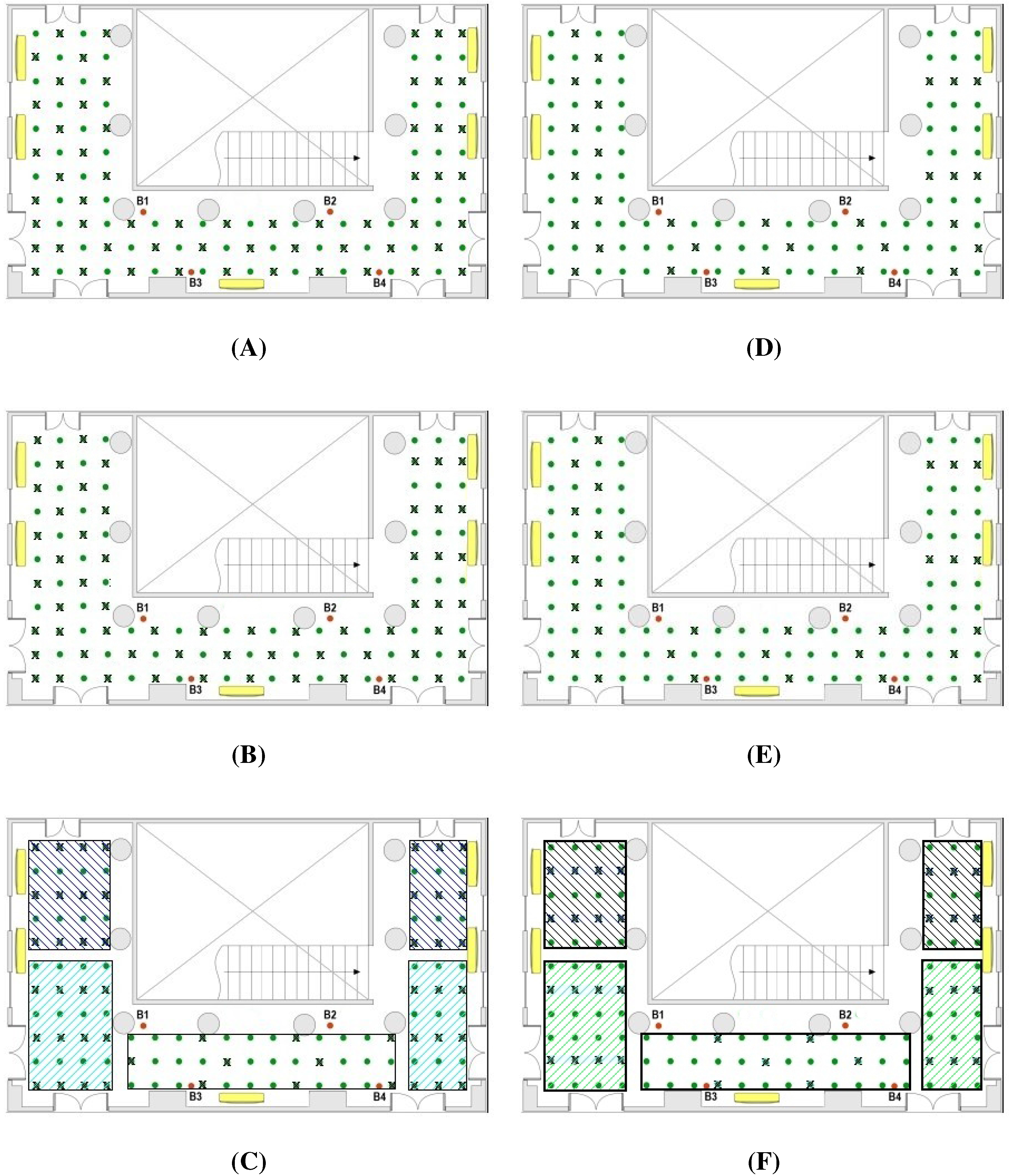
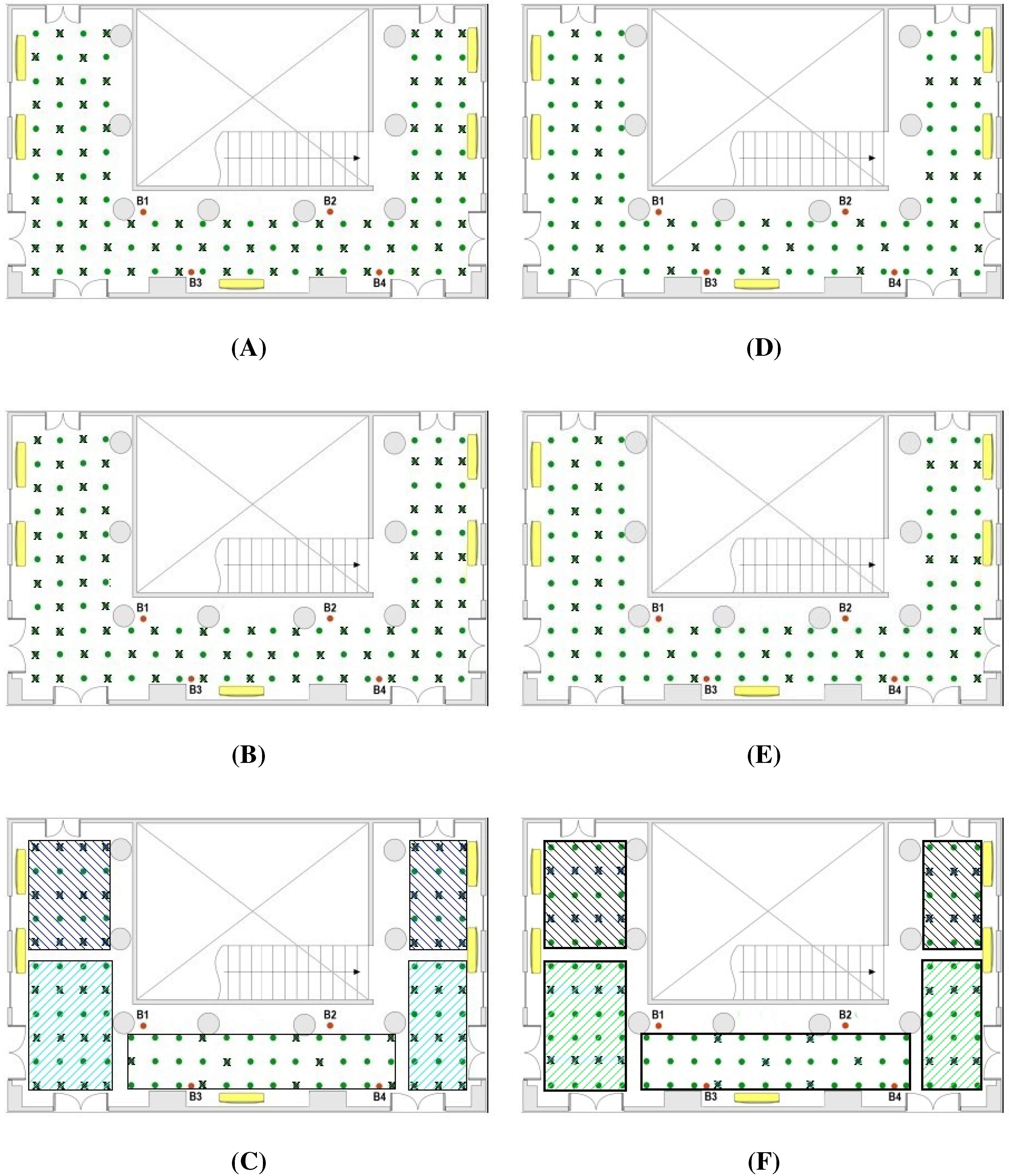
Figure 2 depicts two possible distributions of reference points, where the original reference points are marked by a ×, and the interpolated ones are represented only by a dot.
Figure 2A,B show a uniform distribution in all the location area. Nevertheless,
Figure 2C exhibits an non-uniform distribution by zones, where the global density of reference points is of 50%, but the density in each zone varies from 25% to 60%. The idea is that RF signals have better quality for locations near to the beacons, and poor quality for locations far from the beacons. Hence, for zones near to the centroid of the beacons a low density of reference points (25%) is used, while for zones away from the centroid of the beacons the density of reference points is increased (until 60%).
Figure 2.
Map of the testing scenario with: ( left) 50% of reference points for three different distributions: (A) Uniform; (B) Uniform with the complementary points of case A; (C) Non-uniform by zones; and (right) 25% of reference points for other three distributions: (D) Uniform; (E) Uniform with alternative points of case D; (F) Non-uniform by zones. The “×” denotes the reference points, whereas the green dots are the interpolated ones.
Figure 2.
Map of the testing scenario with: ( left) 50% of reference points for three different distributions: (A) Uniform; (B) Uniform with the complementary points of case A; (C) Non-uniform by zones; and (right) 25% of reference points for other three distributions: (D) Uniform; (E) Uniform with alternative points of case D; (F) Non-uniform by zones. The “×” denotes the reference points, whereas the green dots are the interpolated ones.
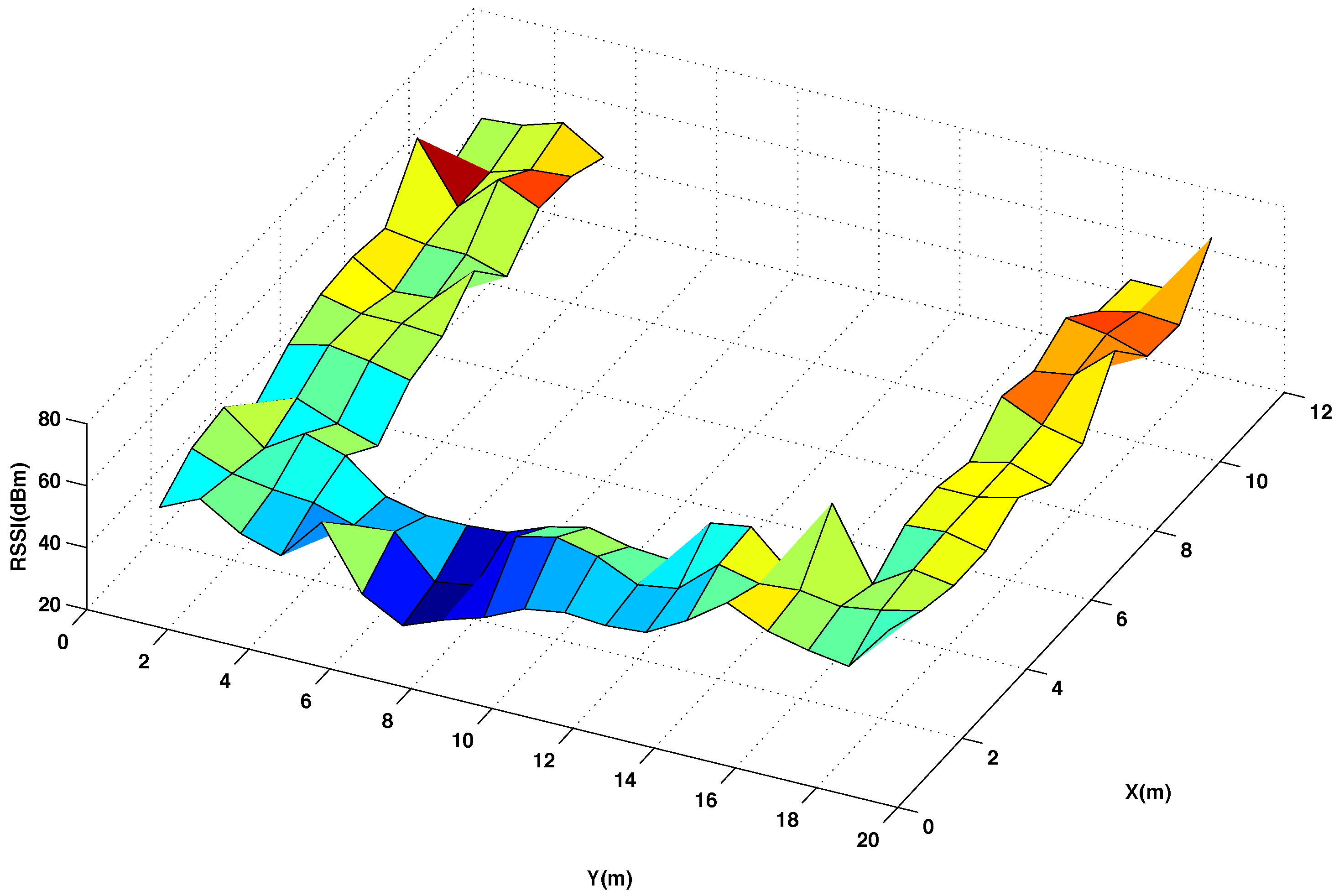
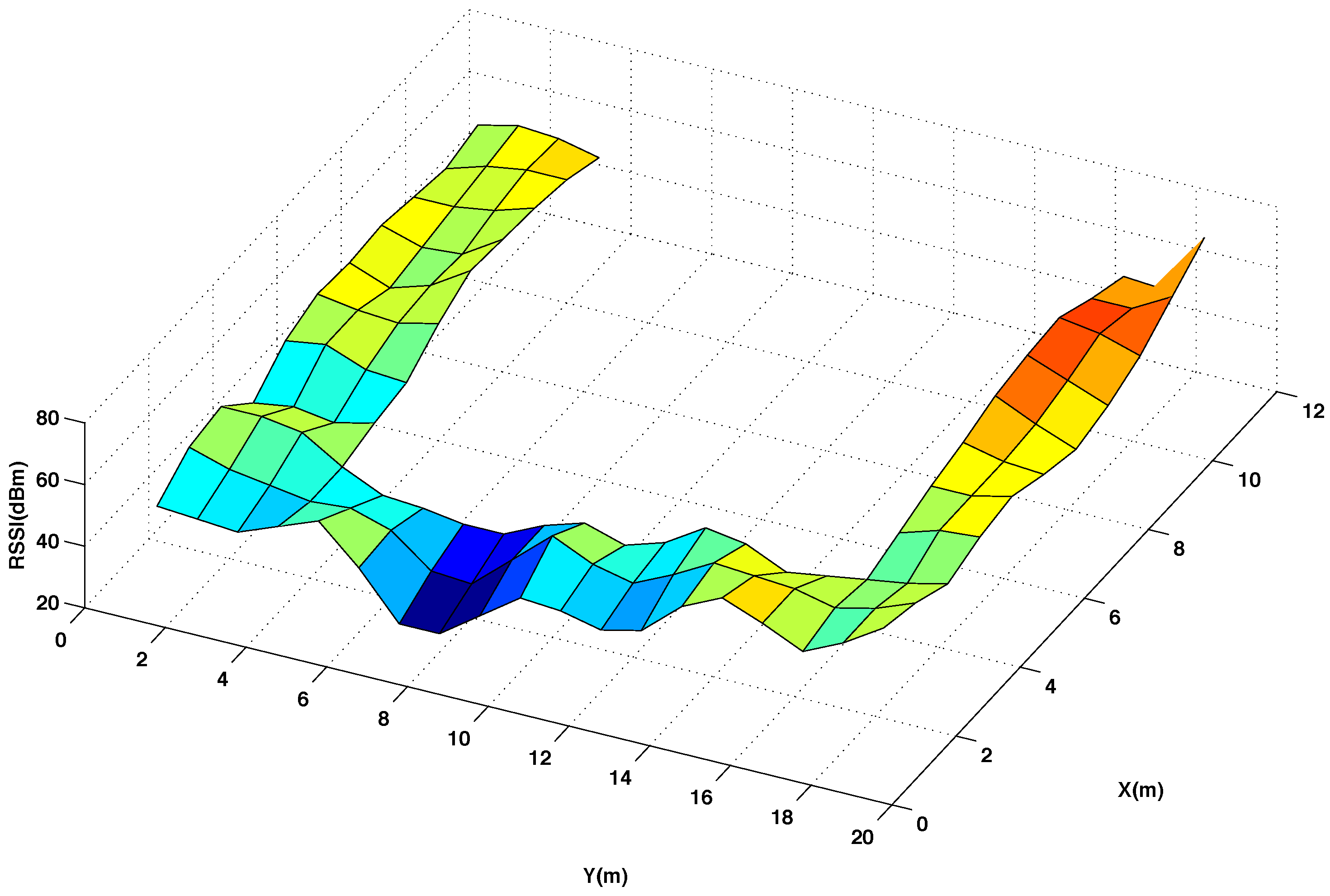
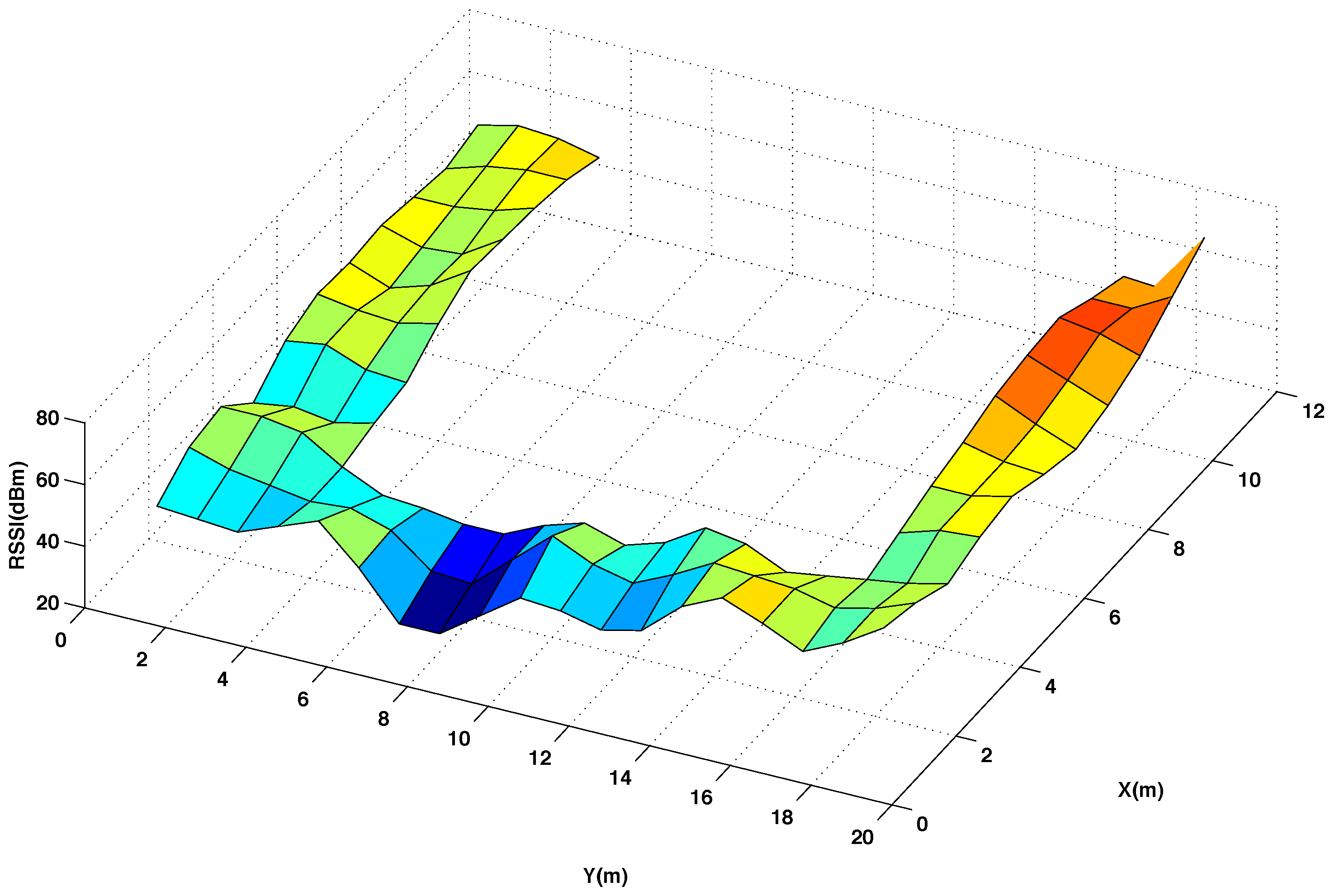
Figure 3 and
Figure 4 show graphically the radio map of RSSI values measured at every reference point of the testing area, with and without interpolated points, respectively. In
Figure 3 and
Figure 4 the RSSI values are the average of 5 five measures taken at the mobile sensor when the beacon 4 transmits 5 packets using channel CH11 and power level P3. Comparing the two radio maps, it can be noticed that the interpolated version smooths out the original surface and produces accurate results for most of the interpolated points, providing that the changes in the RSSI values between neighbouring points are not abrupt.
Figure 3.
Radio map of RSSI for the original reference points in the testing area. Using channel CH11 and power level P3.
Figure 3.
Radio map of RSSI for the original reference points in the testing area. Using channel CH11 and power level P3.
Figure 4.
Radio map of RSSI for 50% original and 50% interpolated (using the thin spline function) reference points in the testing area. Using channel CH11 and power level P3.
Figure 4.
Radio map of RSSI for 50% original and 50% interpolated (using the thin spline function) reference points in the testing area. Using channel CH11 and power level P3.
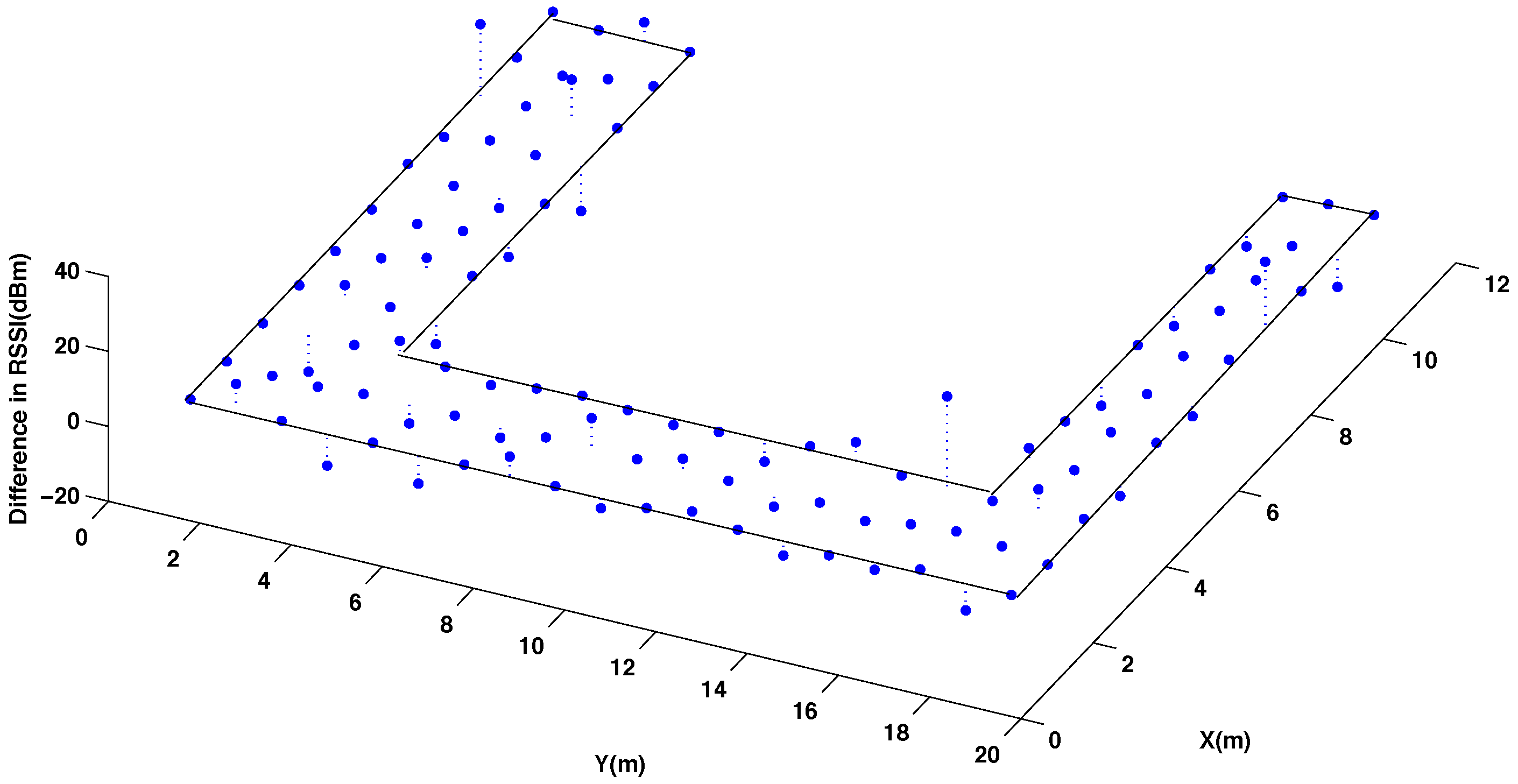
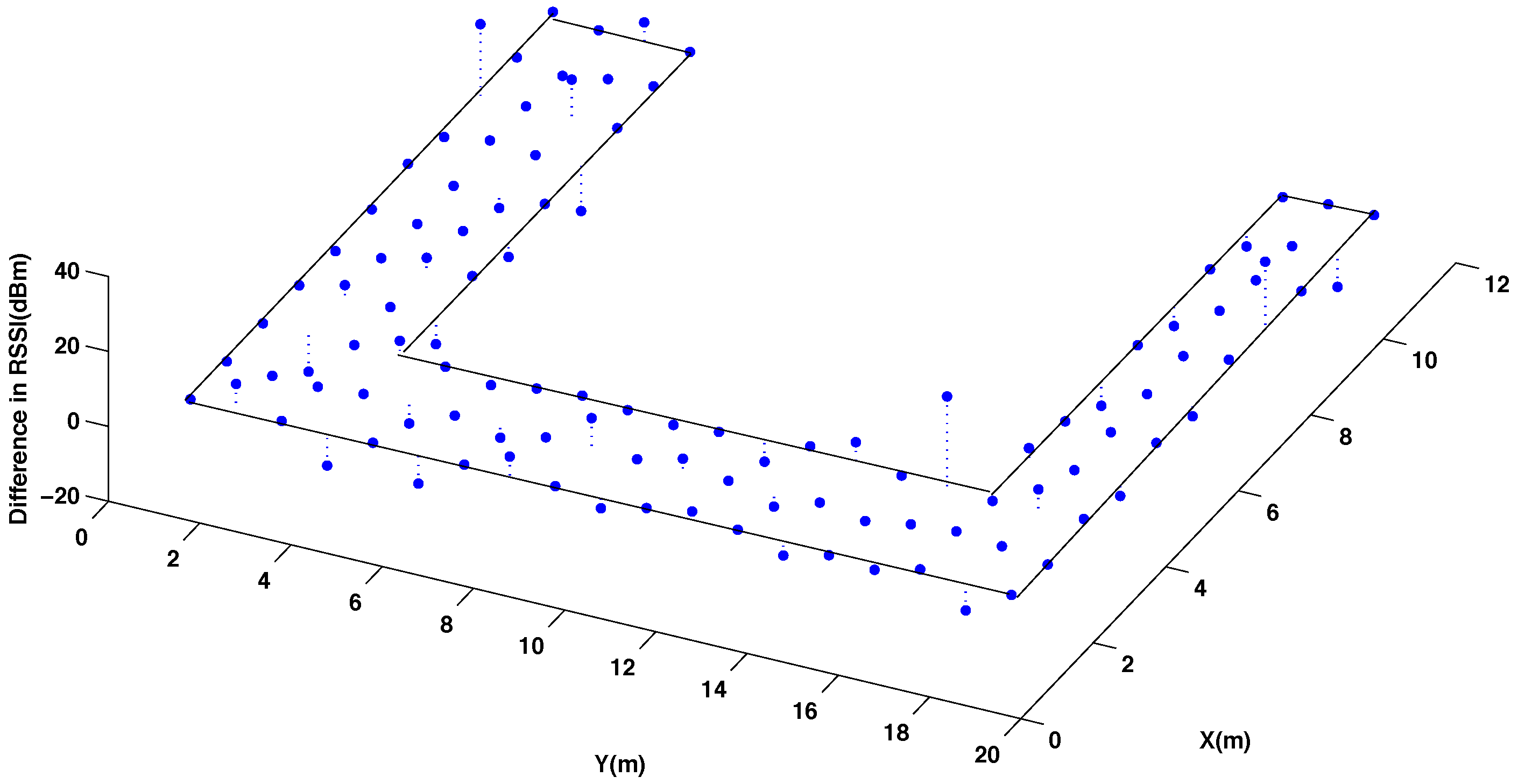
Figure 5 presents the difference of the RSSI values between these two radio maps. As it can be seen, higher errors are mostly concentrated in few points where the original map presents abrupt changes. To quantify the total error committed using the interpolation, it has been calculated the average percentage of error between the measured and the interpolated RSSI values considering all the reference points of the testing room, as it is represented in
Figure 2A.
Figure 5.
Difference in the radio map of RSSI for 50% original and 50% interpolated (using the thin spline function) reference points in the testing area. Using channel CH11 and power level P3.
Figure 5.
Difference in the radio map of RSSI for 50% original and 50% interpolated (using the thin spline function) reference points in the testing area. Using channel CH11 and power level P3.
Table 1 summarizes the results obtained with the four different interpolation functions. As a conclusion, we can see that the best result is achieved for the thin spline function since the obtained radio map has the lower difference with respect to the original one. This is due to fact that the thin function approximates better the real shape of the RSSI behavior measured in dBm.
Table 1.
Average error between the measured and estimated RSSI (in percentage), when 50% of the reference points are interpolated.
Table 1.
Average error between the measured and estimated RSSI (in percentage), when 50% of the reference points are interpolated.
| | Thin | Euclidean | Multiquadratic | Polyharmonic (n = 4) |
|---|
| Difference in RSSI values (in %) | 6.30 % | 7.80% | 7.80% | 9.80% |
5.3. Analysis of Location Accuracy
This subsection presents a study about the location accuracy obtained for different grades of the experimental database size. This evaluation allows to establish a trade off between the number of experimental reference points taken during the training step and the location accuracy that can be achieved. In the analysis, the same testing network and localization area presented in
Figure 2 has been used. As a first approach, the analysis focuses on the case where 50% of the RSSI values are interpolated, as it is represented in
Figure 2. In this figure, the points marked with the × are the original reference points and the point marked with a dot are interpolated. Once the new database is completed with the interpolated RSSI values, the location algorithm presented in
Section 4.1 is applied. The location algorithm is executed using a second data set of experimental RRSI values taken by the mobile node at the same positions of the testing grid in a second round of experimental measures. The analysis includes the application of the location algorithm presented in reference [
16] with three different densities of reference points:
Table 2 presents the mean location error and the standard deviation for densities with 50% and 25% of reference points.
Table 2.
Average localization accuracy with different interpolation functions (thin spline, euclidean, multiquadratic and polyharmonic with n = 4) and percentage of reference points: 50% and 25%. In both cases, three different selections of the interpolated points are considered.
Table 2.
Average localization accuracy with different interpolation functions (thin spline, euclidean, multiquadratic and polyharmonic with n = 4) and percentage of reference points: 50% and 25%. In both cases, three different selections of the interpolated points are considered.
| | | Thin | Eucl | Multiqua | Polyhar n = 4 |
|---|
| case A (50%) | mean error (m) | 2.02 | 2.09 | 2.12 | 2.22 |
| | standard deviation (m) | 1.90 | 2.51 | 2.27 | 2.42 |
| case B (50%) | mean error (m) | 2.50 | 2.38 | 2.52 | 3.10 |
| | standard deviation (m) | 2.60 | 2.53 | 2.66 | 3.25 |
| case C (50%) | mean error (m) | 2.16 | 2.28 | 2.42 | 2.53 |
| | standard deviation (m) | 2.06 | 2.18 | 2.40 | 2.55 |
| case D (25%) | mean error (m) | 3.04 | 3.12 | 3.26 | 3.34 |
| | standard deviation (m) | 3.18 | 3.25 | 3.45 | 3.59 |
| case E (25%) | mean error (m) | 2.98 | 3.06 | 3.22 | 3.52 |
| | standard deviation (m) | 2.63 | 3.16 | 3.21 | 3.56 |
| case F (25%) | mean error (m) | 3.18 | 3.33 | 3.42 | 3.56 |
| | standard deviation (m) | 3.26 | 3.42 | 3.53 | 3.66 |
A first look at the
Table 2 reveals that the algorithm accuracy does not decrease significantly when the database includes 50% of interpolated points. So, the influence of the interpolation in the algorithm performance is practically negligible for this percentage of reference points.
The set for reference points selected has an influence in the average error obtained. Thus, for the case A the average location accuracy is practically equal to the case with 100% of the reference points, whereas for the case B, using the complementary reference points, the average location accuracy is clearly worse. This behavior is the same for all the interpolation functions, therefore there is a direct influence on the quality of the selected reference points. The difference between the results of case A and B can be due to the number of points blocked by obstacles taken in the database as reference or interpolated points. Thus, the A distribution includes most of the blocked points as reference points, whereas in the B distribution they are interpolated. Another issue that can be considered is the distance between the reference points and the beacons. This matter is evaluated using the case C, which represents a non-uniform distribution divided in zones with different densities of reference points. In case C, the global distribution of reference points is 50%, but depending of the distance of the zone to the beacons, the density of reference points goes from 25% (near to beacons) to 60% (far from beacons).
Table 2 shows that this distribution could be a good option because of the average location accuracy has an intermediate value between the case A and B.
This is an important result because it means that with half the number of experimental points we can achieve the same location precision. However, when the number of reference points that are interpolated grows too much, i.e. the case D with 25% of reference points, the precision of the location algorithm falls, achieving a mean error around 3 m. The same behavior can be observed in the two other distributions E and F.
In the case of 50%, it can be noticed that the best location precision is obtained with the thin spline interpolation function. This fact is in accordance with the results of the previous subsection, because this is the function that produces a lower difference between the interpolated RSSI values and the experimental measures. So, it is reasonable that this interpolation function provides the highest location accuracy.
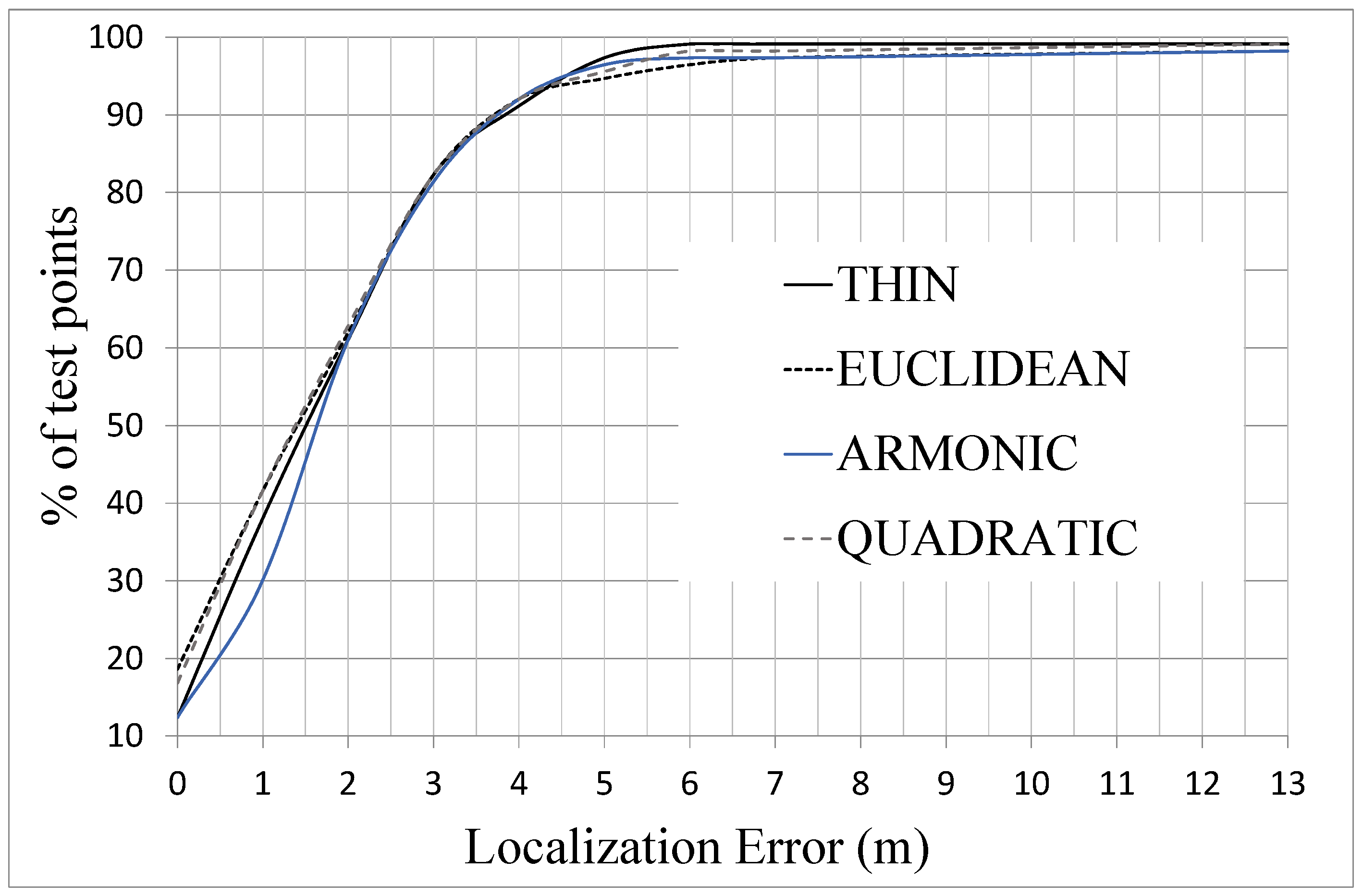
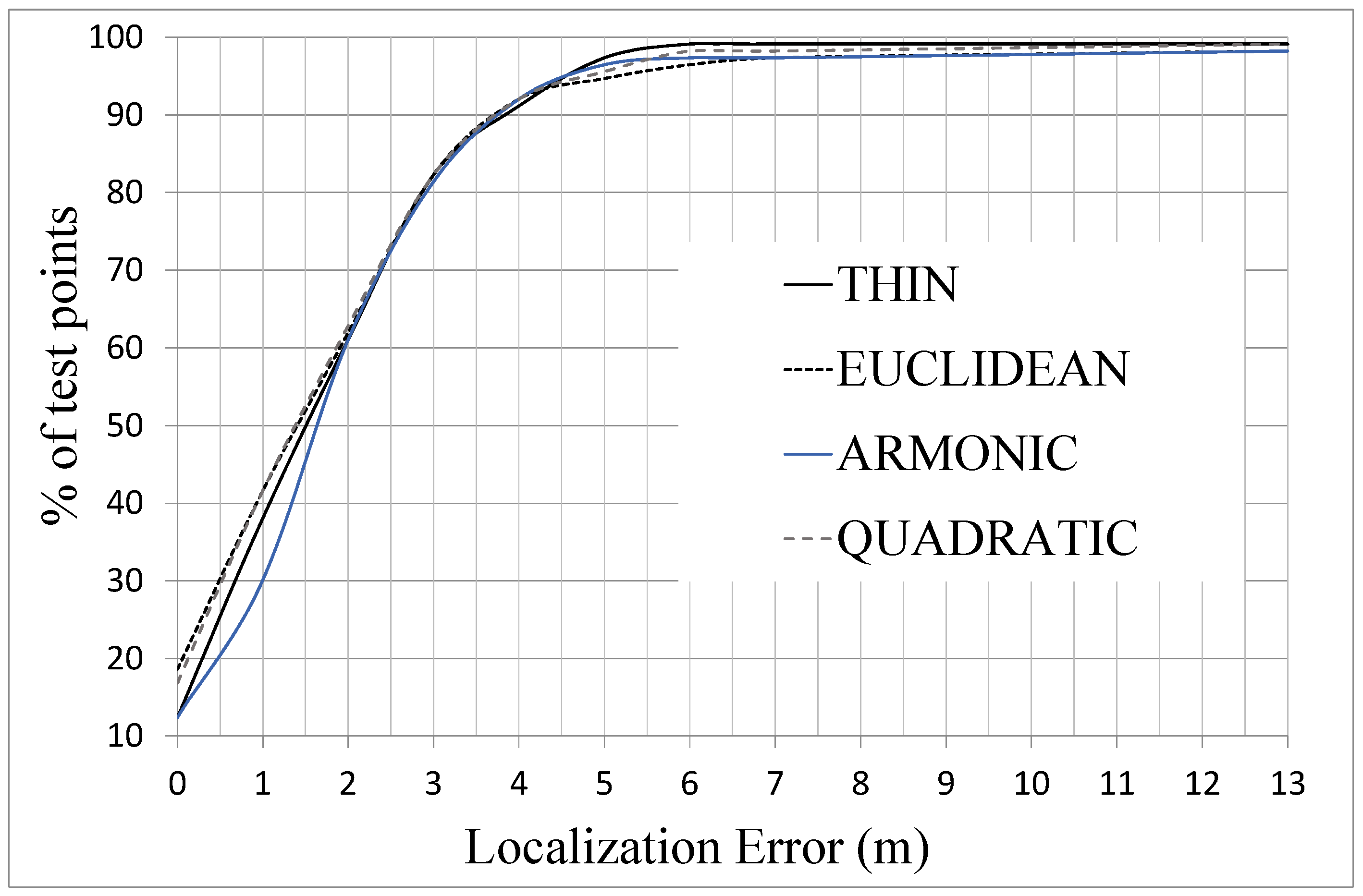
Additionally, in
Figure 6 it is shown the percentage of test points that produce a localization error that is lower than a certain value. The main result drawn from this graph is that 80% of test points produce an error lower than 3 m and only a 10% of test points are located with an error higher than 4 m. The differences between the interpolation functions are not very important, although it can be seen that the thin function is closer to 100% of test points when the localization error exceeds 4 m.
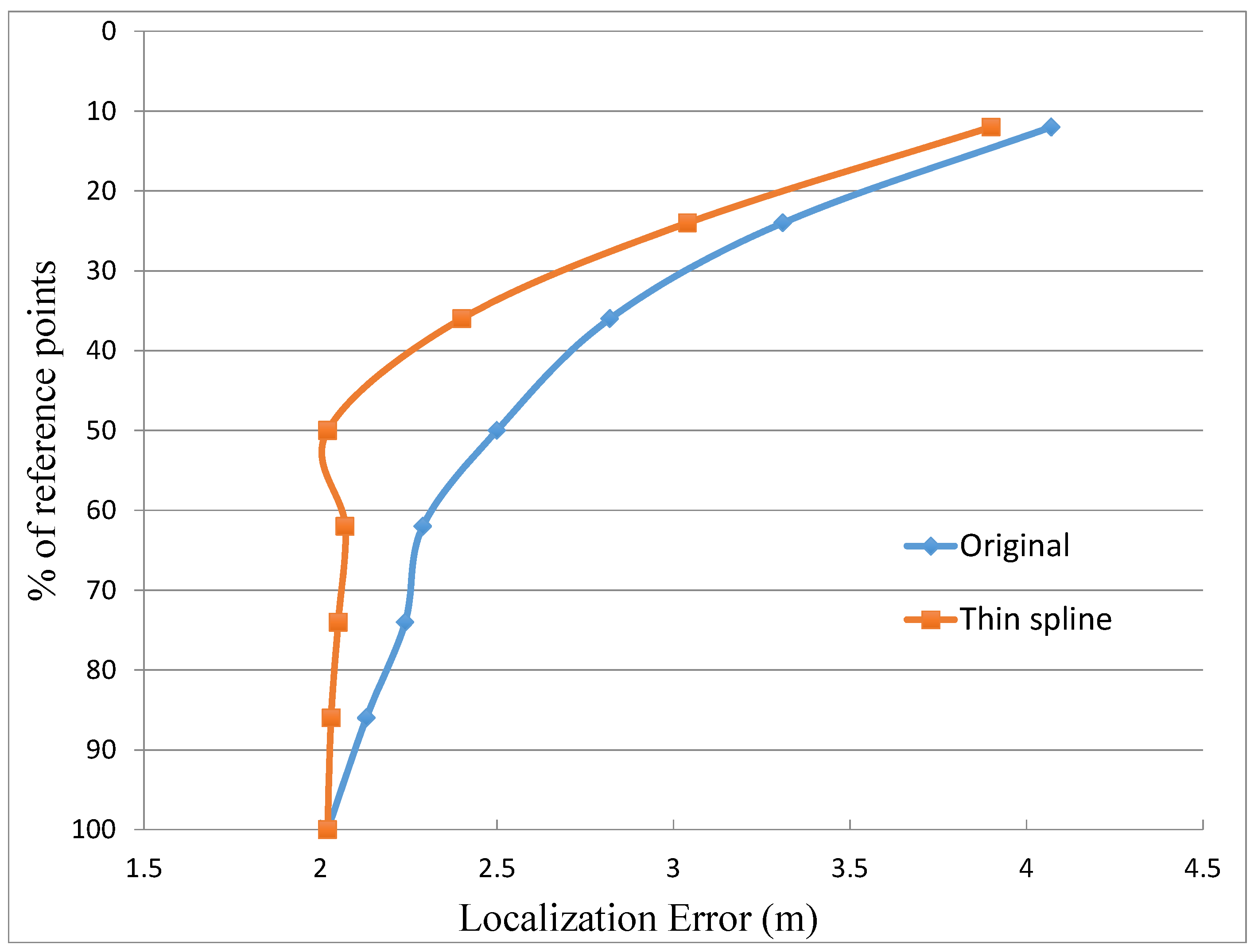
Another important issue that must be considered is the dependence of the location accuracy on the total amount of reference points. This matter has been evaluated taking eight different percentages of reference points, spaced in the interval from 100% to 10% of the total amount of reference points. For every percentage, the original case without interpolation and the one applying the “Thin spline” interpolation have been applied.
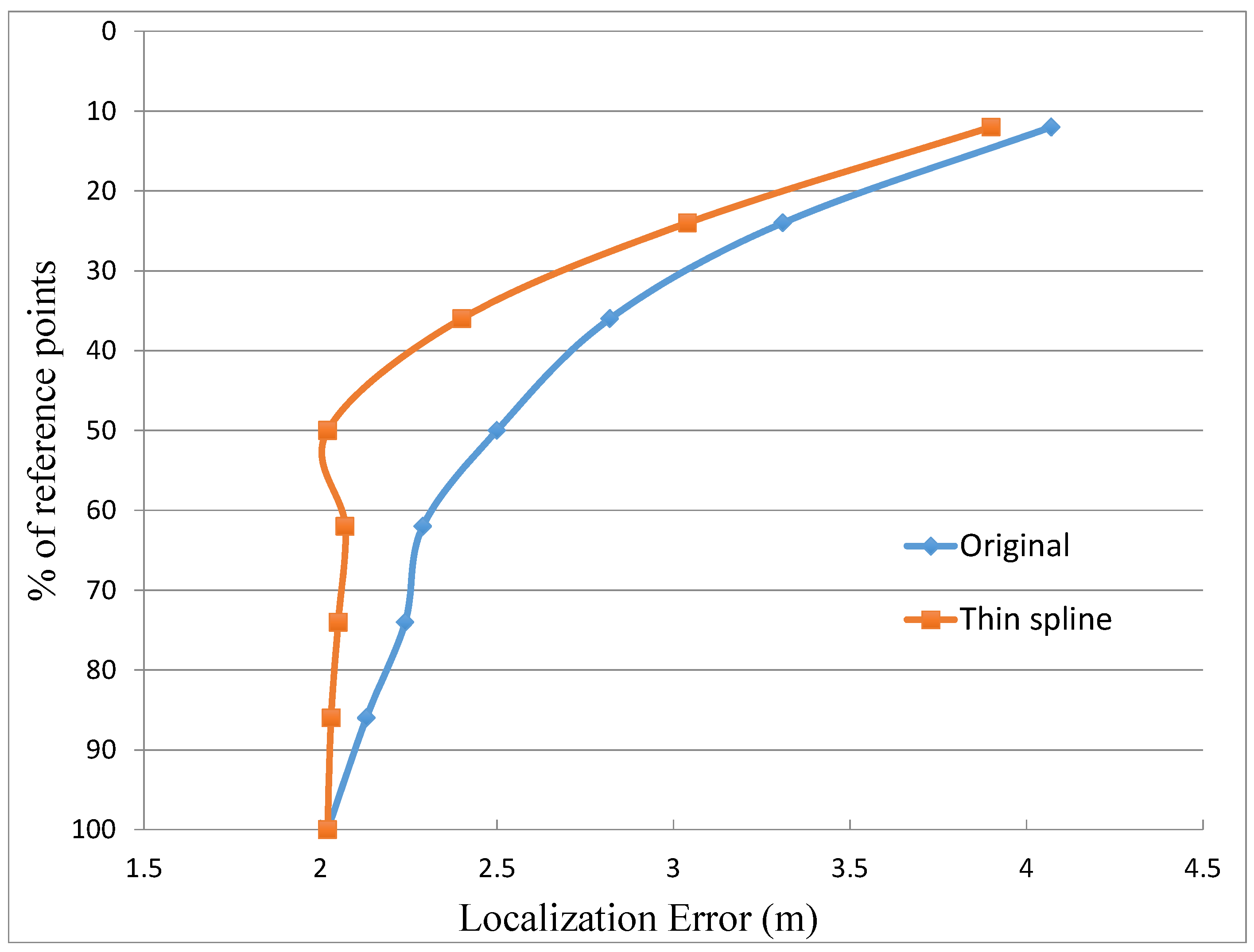
Figure 7 presents the obtained results, which shows clearly how the case without interpolation rapidly worsens when the number of reference points decreases. Thus, the elimination of only around 10% of the total amount of reference points makes this case to lose more than 10% of the location accuracy. In contrast, the case with interpolation keeps a good precision even with percentages of reference points in the order of 50%. In this interval, from 100% to 50%, the case with interpolation produces results with a degradation lower than 10% of the initial precision. Only when the limit of 50% of reference points is reached, the case with interpolation starts to follow the same tendency than the case without interpolation. It can be noticed that when the graph passes from 60% of reference points to 50% the location error decreases from 2.16 m to 2.02 m. This improvement in the location error is due to the selection of the reference points. In some cases there are particular distributions in which the change in the selection of some few interpolated points can improve slightly the location estimation. The rationale behind this fact is that the location algorithm uses a set of candidate points with RSSI values concentrated in a small interval. Thus, in some cases the interpolated points replace some original misleading reference points and within this small degree of change in the database the average error can decrease slightly. In any case, this improvement is very small, lower than 10% of the location error that in the case of 60% of reference points. As a conclusion, this comparison demonstrates clearly the advantages of the interpolation to maintain the location accuracy when the number of reference points in the fingerprinting database is reduced.
Figure 6.
Percentage of test points by localization error for case A of
Table 2 using different interpolation functions.
Figure 6.
Percentage of test points by localization error for case A of
Table 2 using different interpolation functions.
Finally, just for the sake of comparison, two last experiments were carried out. In the first assessment, a comparison with the algorithm proposed in reference [
7] is performed. The objective of this algorithm is to reduce the complexity of the database and the computation time decreasing the number of power levels and frequency channels used in the location, but it does not change the number of reference points. Thus, using the same experimental scenario presented in
Section 5.1 with all the reference points and only the information that comes from one power level (P3) and three frequency channels (CH11, CH13, CH16), the algorithm achieves an average location error of 2.05 m. This result is practically the same that the one obtained in case A (with 50% reference points) using “Thin spline” interpolation, as it is shown in
Table 2. So, it is concluded that with the interpolation the same location accuracy is achieved, but reducing significantly the initial effort to collect the reference points.
Figure 7.
Percentage of reference points included in the database against the localization error for the original case without interpolation and using thin spline interpolation.
Figure 7.
Percentage of reference points included in the database against the localization error for the original case without interpolation and using thin spline interpolation.
The second comparison is made introducing a threshold in the RSSI values saved in the database following the method proposed in the SIB algorithm [
23]. The test was repeated with different thresholds, but with none of them the average localization error dropped below 2.5 m. The poor performance obtained with this variation of the location algorithm and its difference regarding the results presented in [
23] might be due to: (a) the different size of both scenarios because the covered area in our case is smaller (19 × 11 m as opposed to the 52 × 48 m of SIB reference); (b) the number of beacons (4 in our case as opposed to 37); and (c) the power levels (4 in our case and 29 in the SIB reference). All these issues produce an important loss of information in our case that degrades the overall algorithm performance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}