A Hybrid LSSVR/HMM-Based Prognostic Approach

Abstract
: In a health management system, prognostics, which is an engineering discipline that predicts a system's future health, is an important aspect yet there is currently limited research in this field. In this paper, a hybrid approach for prognostics is proposed. The approach combines the least squares support vector regression (LSSVR) with the hidden Markov model (HMM). Features extracted from sensor signals are used to train HMMs, which represent different health levels. A LSSVR algorithm is used to predict the feature trends. The LSSVR training and prediction algorithms are modified by adding new data and deleting old data and the probabilities of the predicted features for each HMM are calculated based on forward or backward algorithms. Based on these probabilities, one can determine a system's future health state and estimate the remaining useful life (RUL). To evaluate the proposed approach, a test was carried out using bearing vibration signals. Simulation results show that the LSSVR/HMM approach can forecast faults long before they occur and can predict the RUL. Therefore, the LSSVR/HMM approach is very promising in the field of prognostics.1. Introduction
Condition-based maintenance (CBM), which can increase system maintenance efficiency and reduce life cycle cost, is gaining popularity. Developing the capability of prognostics and remaining useful life (RUL) prediction can save great costs and improve the logistics support. Therefore, prognostics and RUL prediction can improve the functions of CBM [1,2].
At present, various health management systems are being gradually proposed and applied, such as health and usage monitoring system (HUMS) [3], integrated vehicle health management (IVHM) [4], and prognostics and health management (PHM) [5,6]. PHM, proposed in Joint Strike Fighter (JSF), represents the highest level of CBM. In these health management systems, prognostics is an important but difficult task. Currently, there is limited research in this field due to the fact that small fault symptoms and disturbances cause difficulties in carrying out studies. Therefore, this paper aims to contribute to the growing body of research in the area of prognostics technology.
Prognostic approaches can be placed into three categories: physical model-based prognostics, evolutionary or trending model-based prognostics, and experience-based prognostics [7]. The physical model-based method has the highest accuracy, but it is often complicated to model precisely and the cost is high. Evolutionary or trending-based prognostics are data-driven and feature-based methods. They are considered effective and available prognostics approaches. The third category, experience-based prognostics, relies on statistical reliability. Some popular prognostic methods of the second category are the auto-regressive moving average (ARMA) model [8], the artificial neural network (ANN) [9], the Bayesian network [10], and the support vector regression (SVR) [11,12]. Among these methods, ANN is a widely-used method. The disadvantages of ANN are that the number of hidden layers is difficult to choose and that the calculation may fall into a local minimum. SVR is a machine-learning algorithm based on Vapnik-Chervonenkis (VC) theory and the structural risk minimization principle; therefore it avoids the disadvantages of ANN [11] and is a potential method in prognostics. There are also other extended SVR methods, such as least squares support vector regression (LSSVR) [13,14]. LSSVR proposed by Suykens [15,16] is often applied to predict non-linear time-series signals. In health management, LSSVR can be used to estimate the future health deterioration and can be extended for remaining useful life (RUL) prediction. There are a series of articles about the use of LSSVR in prognosis and monitoring, such as [17,18]. Although the LSSVR algorithm can predict the signal trends, it is difficult to assess the health status of a system for each stage. To solve this problem and make health assessments more clear, in this paper a hidden Markov model (HMM) method is introduced to describe health states during component degradation. The HMM technique, initially introduced by Baum [19], is a stochastic approach based on Markov chains. HMM has strong fault classification and status classification ability, therefore, the HMM method can be used in fault detection and diagnosis [20–22], but it cannot predict the future health status.
In this paper, a hybrid fault prognosis method based on LSSVR and HMM is proposed. In this method, LSSVR is used to predict the fault features, while HMMs are used to describe health states. Fault processes can be divided into several stages and HMMs are built and trained for each stage. Suppose given an observation sequence, the probabilities of the observation for HMMs are used to determine which health state of the given observations the sequence belongs to. Combining these HMMs with the future features predicted by LSSVR can provide an estimate of the remaining useful life (RUL) of a system.
The remainder of the paper is organized as follows: Section 2 outlines the framework of the LSSVR/HMM prognostics approach. Section 3 presents the training and estimation algorithms of HMM. Section 4 introduces the prediction algorithm based on LSSVR. Section 5 provides an application and simulation results. Section 6 presents our conclusions.
2. LSSVR/HMM Based Prognostics
2.1. The Hidden Markov Model
This aim of this section is to introduce how to use the HMM-based method to describe a fault process. The fault process of a machine has a certain time-span. To analyze the fault process, it can be divided into several health states. However, fault states are unobservable but hidden in some observable signals, such as vibration signals. The HMM-based method provides a way to detect the unobservable fault states, as HMM is a stochastic technique for classifying signals and modeling [23,24]. An HMM describes a double stochastic process. One is the Markov chain, which describes state transitions. Another is the stochastic process, which describes the relations between states and observations. Suppose the number of health states is N, which are h1, h2,…, hN. The last state hN represents that the system fails. This state sequence is a Markov chain. The structure of an N-state left-to-right HMM is commonly used in fault analysis as shown in Figure 1.
As shown in Figure 1, an HMM consists of a finite number of states where aij (i,j = 1,2,…,N) is the transition probability from state hi to state hj. Observation sequences from different conditions can be used to train different HMMs. For instance, observations from normal condition can train an HMM for normal state. An HMM can be described as:
As the observation sequence from a health state can train an HMM, N HMMs can be trained, which are written as λ1, λ2,…, λN. λi represents the HMM trained based on the given observation sequence from the ith health state. Given an observation sequence O={o1, o2,…, oT} where T is the length of the sequence, P(O|λi) is the likelihood probability of observation sequence O occurring at the condition of model λj, which can be used to determine whether O belongs to the health state hi.
As mentioned above, using HMMs can describe machine fault processes. According to the likelihood probabilities of present observations, HMMs can detect and diagnose faults. However, the HMM method cannot predict future health states and the RUL, because the future observation sequence cannot be obtained. To solve this problem, a hybrid prognostics method based on LSSVR and HMM is proposed in this paper, where LSSVR provides a way to predict the future fault features.
2.2. Framework of LSSVR/HMM Prognostics
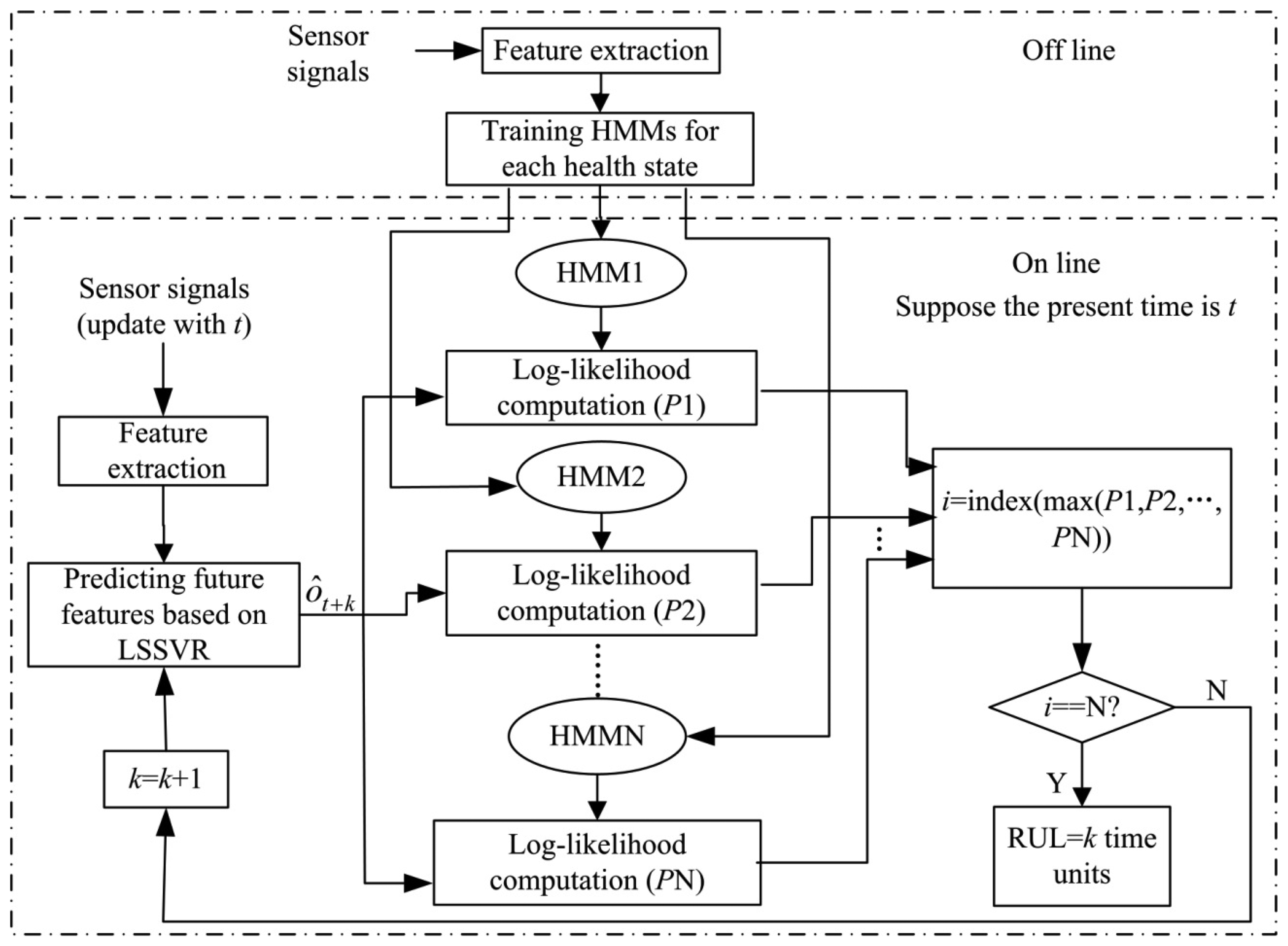
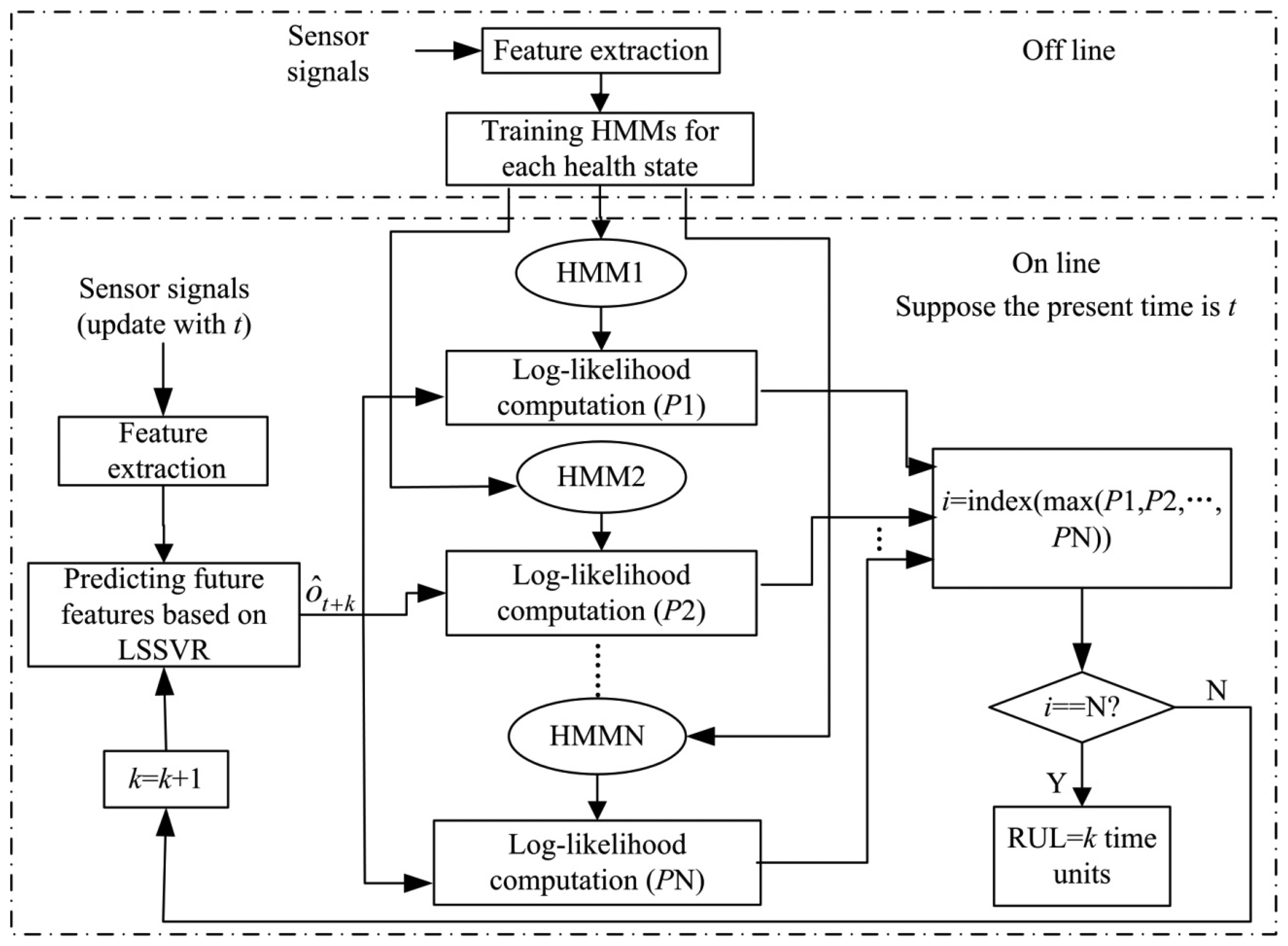
The framework of the hybrid fault prognosis scheme is described in Figure 2. In this scheme, the LSSVR algorithm is used to predict the future fault features and the HMMs are used to describe different health states.
As shown in Figure 2, the process of the hybrid LSSVR/HMM prognostic approach can be summarized in the following steps:
- (1)
Feature extraction
As most observation signals have much random noise and uncertain interferences, features should be extracted from the signals before fault diagnosis and prognosis. In this paper, the linear predictive (LP) method, as mentioned in article [25], is used to extract the features from vibration signals. In the LP method, the signal Sn can be predicted as a linear combination of the ρ previous signal, which can be written as:
where l1, l2, …, lρ are linear prediction coefficients which can be used as feature vector of the signals.The residual errors are written as:
The value of the linear prediction coefficients l1, l2, …, lρ can be calculated by minimizing the mean-square value of the residual errors over a signal window. The mean square value is written as:
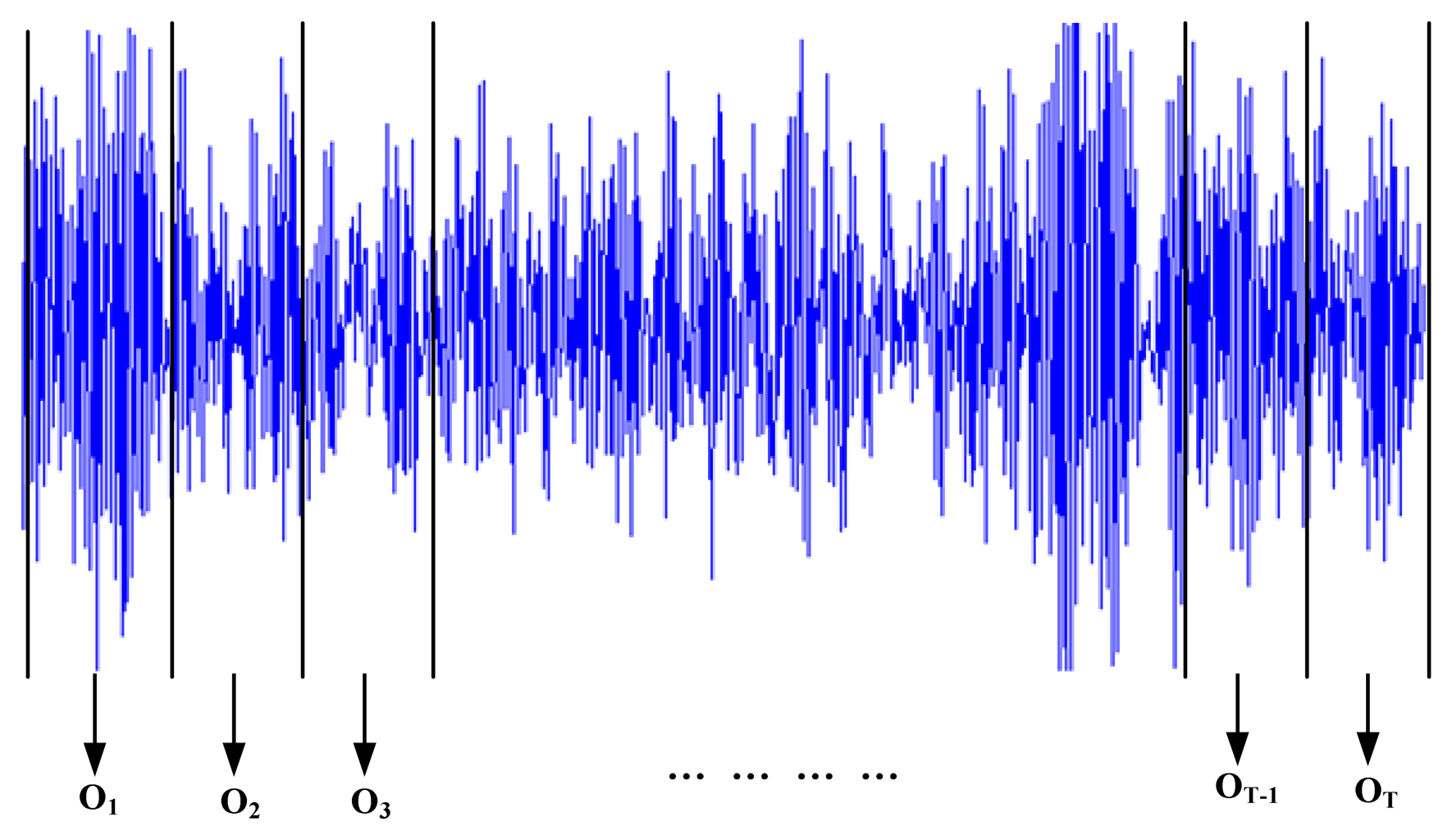
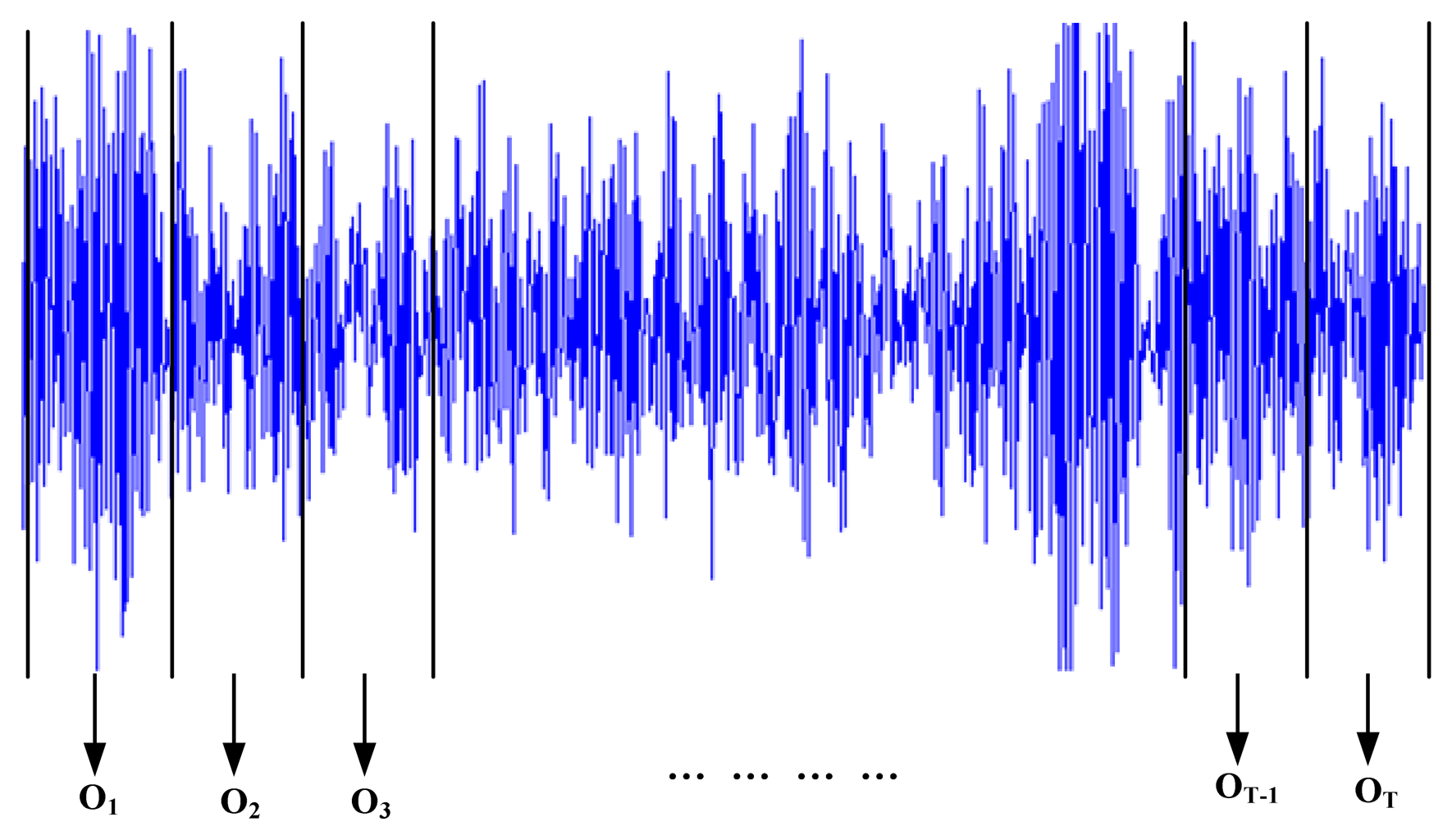
where en(m) = e (n + m), Sn(m) = S(n + m), n is the starting point of the signal window, n + m is the terminal point of the signal window.Vibration signals are always non-stationary. If signals are segmented into several short-time signals, they can be considered stationary. Therefore, we can obtain short-time signals by segmenting vibration signals into small windows; and each window as a frame. To segment the vibration signals into small windows, the length of a small window should be determined. Each window has equal length. Based on the given length, the vibration signals can be divided into several small windows. And then the linear prediction coefficients can be extracted from these windows. The feature extraction is described in Figure 3.
Each window is coded into a feature vector which is written as:
where ot is the feature vector of the ith signal window, lt1, lt2, …, ltρ are the linear prediction coefficients of the tth signal window, T is the number of the windows. Then the observation sequence O={o1, o2, …, oT} is composed of these feature vectors, which will be used for HMM training or LSSVR prediction.- (2)
HMMs training
HMMs training can now be carried out based on the fault features history. In this paper, the historic fault features are experimental data. The training data used for a specific state come from the corresponding experimental conditions. The essence of this step is to estimate the HMM parameters for each state. Based on observation sequences from N different conditions, optimal HMMs λ1, λ2, …, λN are trained for corresponding health state. This step is an off-line process.
- (3)
Prediction of features based on LSSVR
Suppose the present time is t, and the feature vector after k time units is denoted ôt+k which can be predicted based on the data before time t using the LSSVR algorithm. Based on the feature vector ôt+k, one can predict the system health state at the future time t + k.
- (4)
Log-likelihood calculation
Calculating likelihood probabilities P(ôt+k |λi) according to forward or backward algorithms [26,27] and comparing all of these probabilities, one can find the maximum probability:
where P1, P2, …, PN are the likelihood probabilities for the corresponding HMMs.The corresponding state hi is considered the health state of the future time t + k. Therefore, this method can be used to predict future health states. If k = 0, the health state is the present state.
- (5)
RUL prediction
As shown in Figure 2, the fault prognosis should run until the probability for the last state model is higher than for all other state models. Then the probability P(ôt+k|λN) for the last state indicates that the system will fail at the future time t + k. Therefore, the RUL is k time units.
3. HMM Training
HMM training is to obtain the optimal model and the training process needs to estimate the model parameters. An HMM is described in Equation (2). When the observations are discrete, they can be represented by distributed probabilities. However, the observations are always continuous in an actual system. In this situation, a mixture of several Gaussian distributions is used to describe observation probabilities which are written as [26]:
Then an HMM is re-written as:
3.1. Forward-Backward Algorithm
Given an observation sequence O={o1, o2,… , oT} and a model λ, how to calculate the probability P(O|λ) is a basic and important problem. Both forward and backward algorithms can solve this problem.
In a forward algorithm, define the forward variables as ηi(t) = P(o1, o2, …, ot, qt = hi |λ),1 ≤ t ≤ T, which is the probability of generating o1, o2, …, ot and ending in state hi. qt represents the state attime t.
The recursive estimation of the forward is as follows [26,27]:
- (a)
Initialization:
- (b)
Forward recursion (For t=1,2,…,T−1, 1 ≤ j ≤ N):
- (c)
End:
In a backward algorithm, we define the backward variables as βi(t) = P(ot+1, ot+2,…, oT|qt = hi, λ), 1 ≤ t ≤ T, which is the probability of generating ot+1, ot+2,…, oT and ending in state hi.
The recursive estimation of the backward is as follows [26,27]:
- (a)
Initialization (1 ≤ i ≤ N):
- (b)
Backward recursion (For t = T-1,T-2, …, 1, 1 ≤ i ≤ N):
- (c)
End:
3.2. Re-Estimation of the HMM Parameters
The goal of HMM training is to find the model . That means the parameters of each HMM should be re-estimated until the convergence error achieves requirements. The Baum-Welch algorithm [26] provides a solution to this problem.
Given an observation sequence O, define γt(i) = P(qt = hi |O, λ), which is the probability of that the state at time t is hi. γt(i) can be calculated as:
Define γt(i, l) as the probability of the lth mixture Gaussian component when the state at time t is hi. γt(i, l) can be calculated as:
ξt(i, j) = P(qt = hi, qt+1 = hj |O, λ) is defined as the probability of that the state at time t is hi and the state at time t + 1 is hj. ξt(i, j) can be calculated as:
According to Equations (20)–(24), the parameters of the HMMs are re-estimated. Finally, optimal models of the health states can be obtained as shown in Figure 2. Given an observation, the likelihood probabilities for each state can be calculated according to Equations (13) or (16). In the forward-backward algorithm, ηi(t) and βt(i) will tend to be zero as time grows. To avoid this problem, logarithmic values of probabilities are usually used in the actual calculations.
4. Feature Trend Prediction Based on LSSVR
4.1. LSSVR Algorithm
The idea of SVR is to map non-linear problems to linear problems in a high dimension space. LSSVR is an improved algorithm based on SVR, and it uses a least square loss function instead of the ε-insensitive loss function [16,28]. Compared with SVR, the calculation procedure of LSSVR has higher efficiency.
Considering the sample data as {(x1,y1), …, (xi,yi), …, (xD,yD)}, where xi is the input vector, and yi is the objective value. The optimization equation of the LSSVR is described as [13,14]:
The Lagrangian is written as:
According to Karush-Kuhn-Tucker (KKT) optimization conditions, the optimality conditions are given as [13,14]:
By solving Equation (27), the parameters αi and κ can be obtained. Then the LSSVR model for estimation is written as:
Frequently used kernel functions are the polynomial, sigmoid and radial basis kernel (RBF) functions. This paper applies RBF because it can classify multi-dimensional data. The RBF kernel function is given as:
In fault prognosis, time series are the extracted feature data. Suppose the front r data have been obtained, then the object is to predict the future data using the front r data. The input vector and the output value can be constructed as:
As mentioned above, LSSVR can predict future fault features. However, it is difficult to describe and assess health states. Combining LSSVR with HMM, it can realize health state prediction and RUL prediction. The feature vectors predicted based on the LSSVR are used as observations in each HMM to calculate the log-likelihood probabilities as shown in Equation (13) or Equation (16). The model with the highest likelihood probability represents the system health state at the corresponding future time.
4.2. Algorithm Improvement
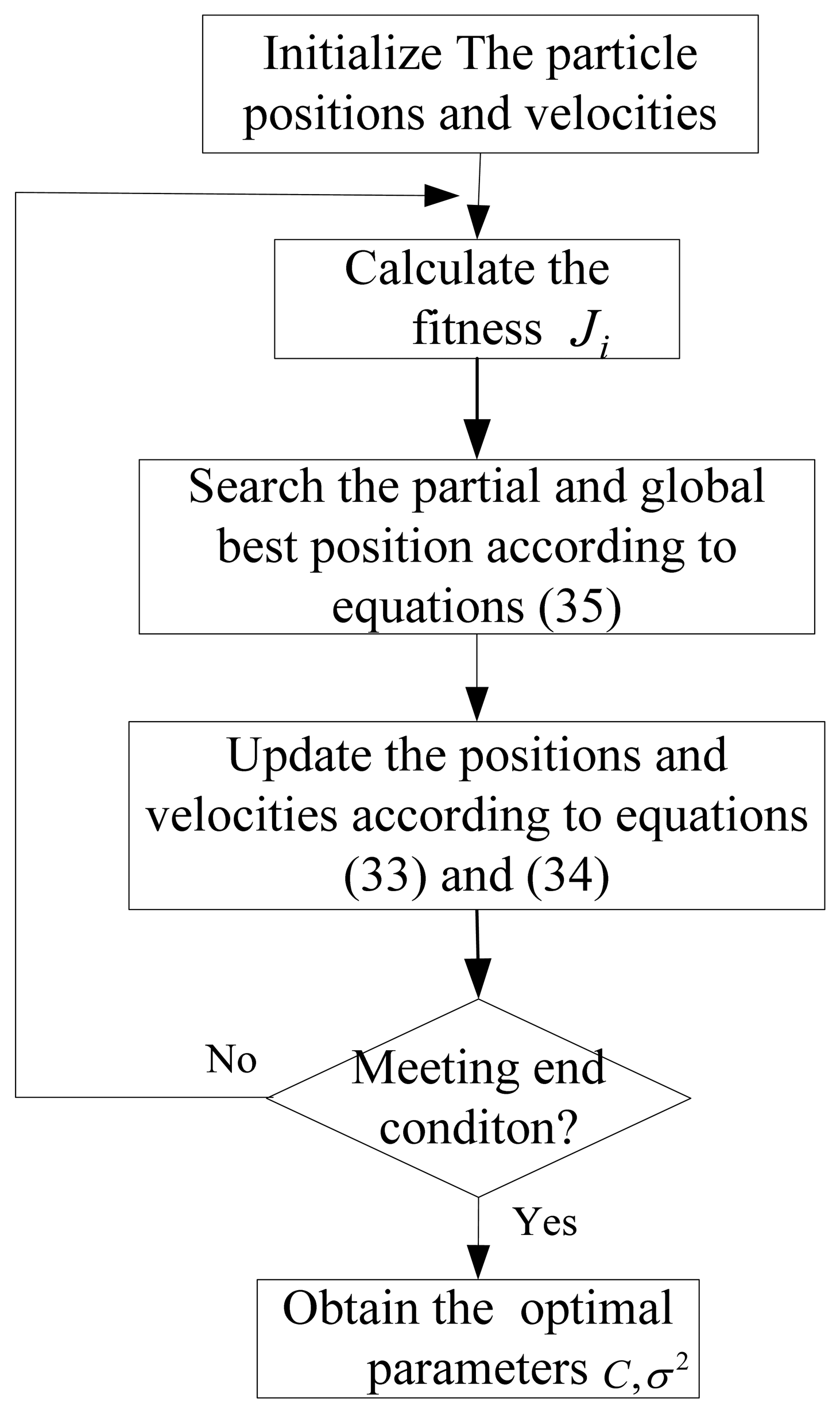
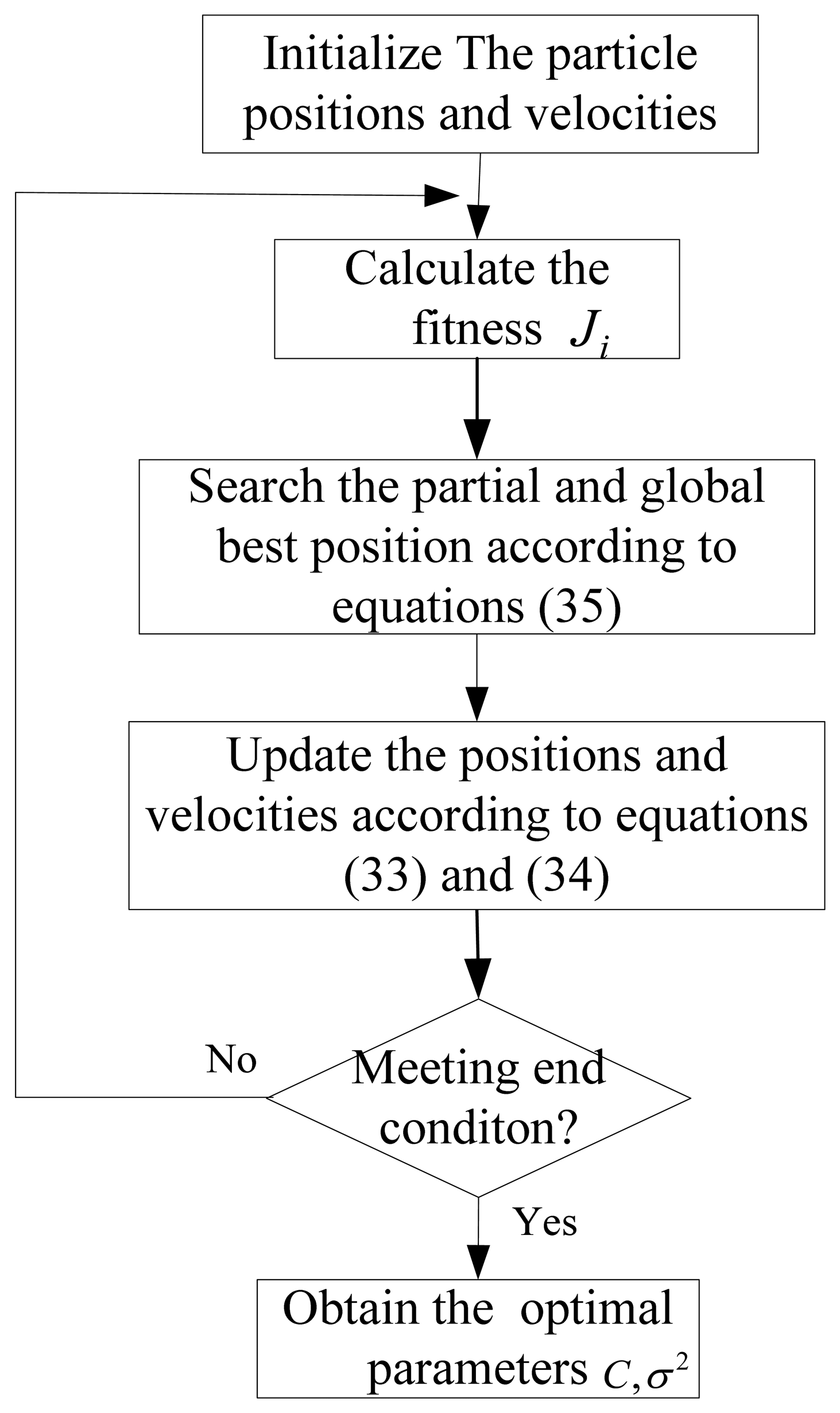
As analyzed above, two parameters C and σin the LSSVR algorithm need to be optimized. Selecting superior parameters can improve the training speed and the performance of LSSVR. Genetic algorithms (GA) [13] and particle swarm algorithms [14] are two optimization methods used to determine the LSSVR parameters. In this paper, particle swarm optimization (PSO) is used. PSO realizes optimization by searching the partial and global optimal solution in a particle swarm. Define the fitness function of the ith particle as:
The particle positions and velocities are written as Xi=(xi1, xi2,…, xiD)T and Vi=(vi1, vi2,…, viD)T (i=1,2, …, m). m is the number of the particles. The partial best position is written as Pi and the global best position is written as Pg. Then the velocity and position updating can be written as:
In Figure 4, the partial and global best position searching process is as follows:
The end condition is meeting the accuracy requirements or arriving at the maximum iterations. When meeting the end condition, the best position is considered as the optimal parameters used in LSSVR.
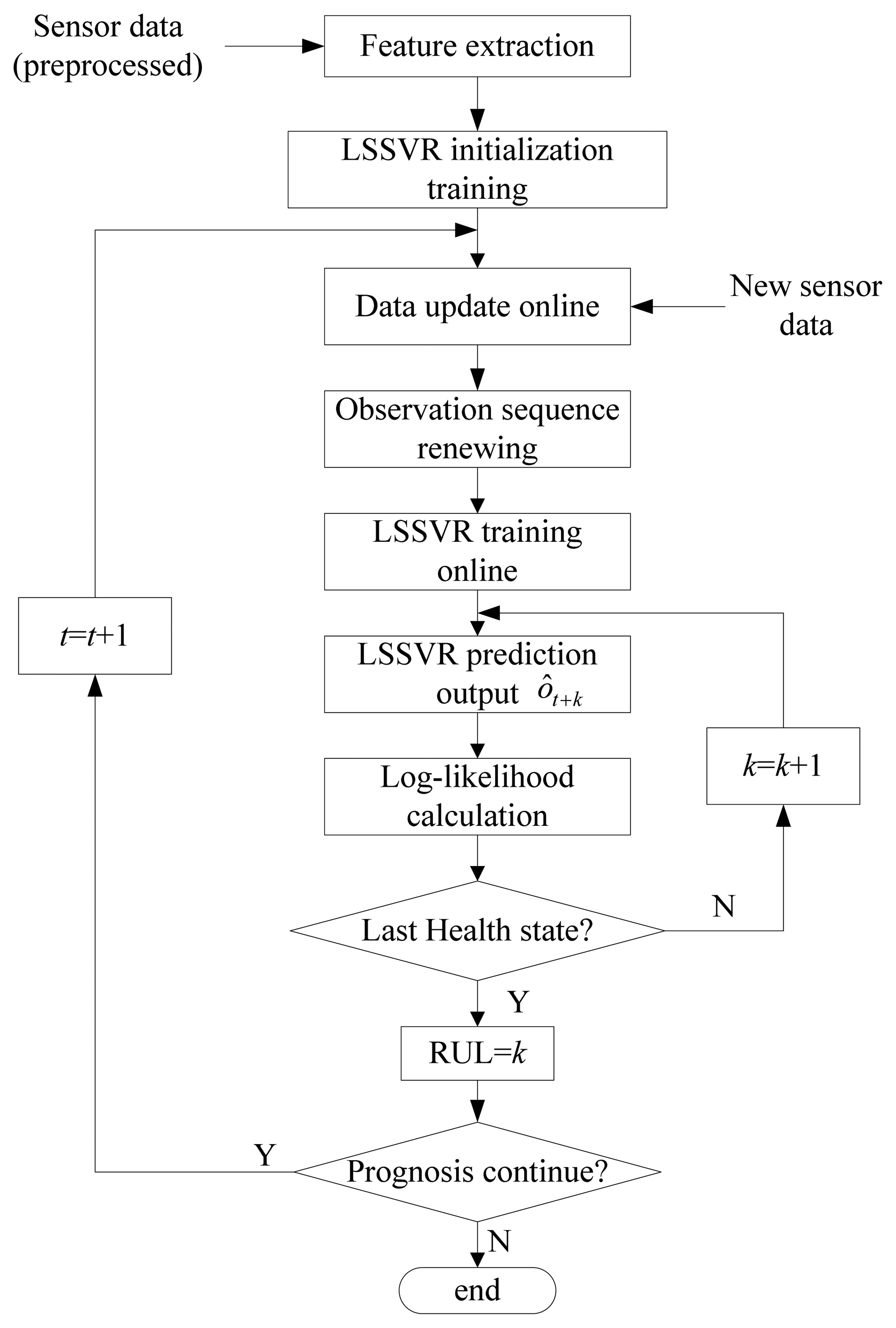
As time goes by, new observations are added which may include fault information and can improve prediction accuracy. However, the training data will become large with time growth. If the number of sample data is too large, it will affect training efficiency. To solve this problem, some unimportant old data, such as non-support vector samples or far history samples, are selected for deletion in this paper. These data will not affect the training accuracy seriously. By adding new data and deleting some old data, the training samples sequence will be renewed online with time growth. The new training sample can be written as:
The RUL prediction process based on the improved LSSVR algorithm is summarized in Figure 5.
As shown in Figure 5, at each time t, RUL equals to the future prediction time whose corresponding state is the last health state. The prediction accuracy of RUL increases as time increases because new observations are added and some unimportant old data are deleted, which makes the feature trend predictions more accurate.
5. Simulations and Results
To evaluate the performance of the LSSVR/HMM prognostic approach, it was tested using experimental bearing vibration data from the Case Western Reserve University Bearing Data Center [29]. The bearing test stand consists of a 2 hp motor, a torque transducer/encoder, a dynamometer, and control electronics. The test bearings support the motor shaft. The details of the test stand are shown in the website [29]. The actual test conditions of the motor as well as the bearing fault status have been carefully documented for each experiment. Different levels of faults in diameter were collected separately for the inner raceway, rolling element (i.e., ball) and outer raceway. Faulted bearings were reinstalled into the test motor and vibration data was recorded.
In our simulation, the inner race vibrations signals are used. Its fault diameter includes the following levels: 0.007 inches, 0.014 inches, and 0.021 inches. The data was sampled at 12 kHz. Added to the normal states, fault process can be divided into four health states. The bearing data center provides vibration data from different health states. Data from different conditions are discrete, which can be used to train HMMs for the corresponding health status.
5.1. Feature Extraction
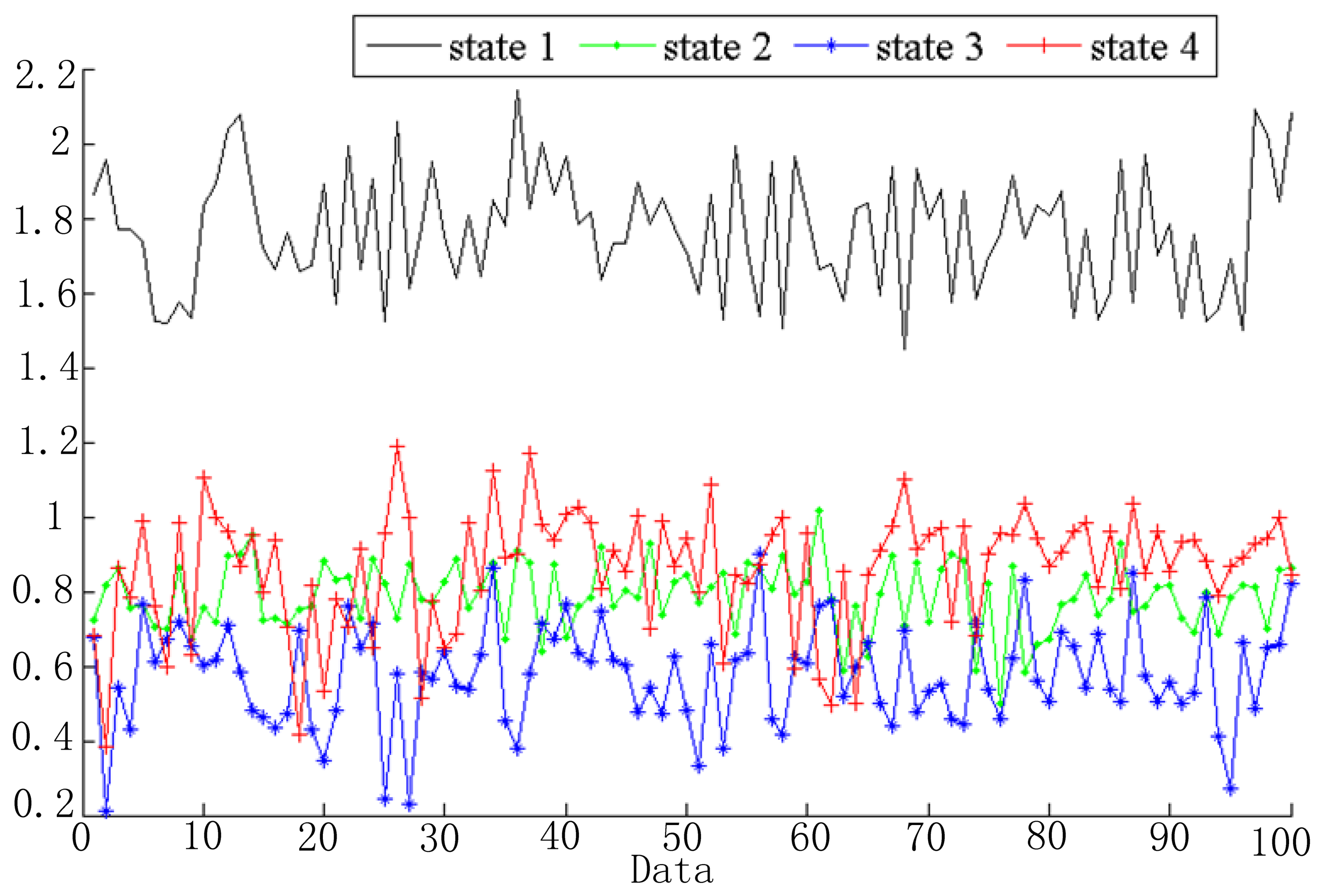
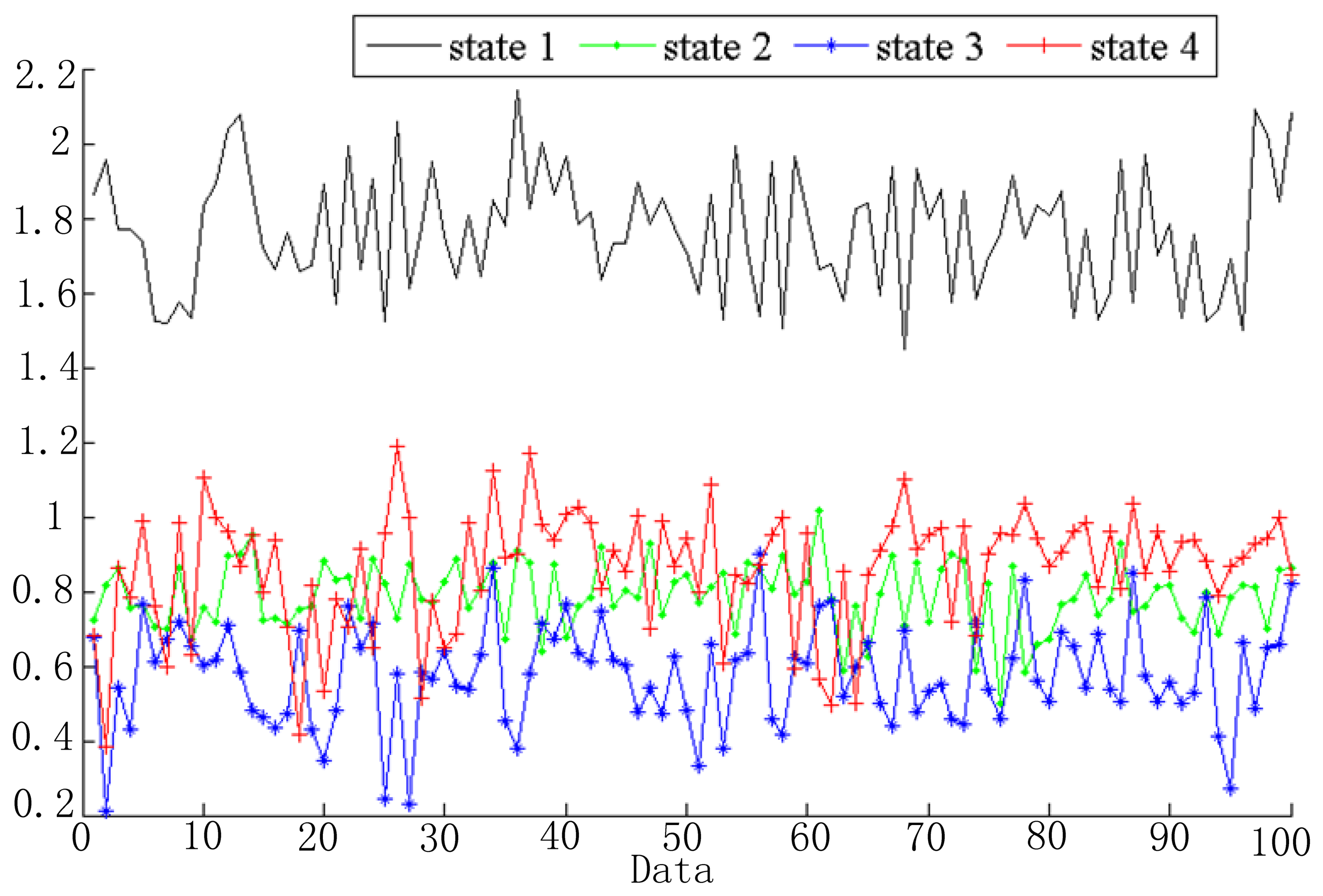
Vibration data are segmented into several windows and extracted feature vectors as mentioned in Section 2.2 and Figure 3. In the simulation, 256 sample data were chosen as a frame. Based on the linear predictive method, signals in each window can be predicted as a linear combination of its ρ previous signal, which is shown in Equation (3). In the simulation, we take ρ as 8. Then the feature vector of each signal window is ot = [lt1, lt2, …, lt8]T and the number of the feature dimensions is 8. Take the first dimension as an example; the features of the four health states are shown in Figure 6. As shown in Figure 6, the extracted feature for each health state is different. This demonstrates that these features can be used to distinguish different fault states.
5.2. HMMs Training and Fault Diagnosis
Suppose three Gaussian distributions are used to describe observation probabilities for each state. Give the initial HMM parameters as follows:
Generally speaking, the influence of the initial values of π and A is not large. But the initial values of μjl, Ujl, and cjl may affect the training result. They can be calculated using K-means method based on the given samples, which are not discussed here in detail. The convergence error is given as 0.00001.
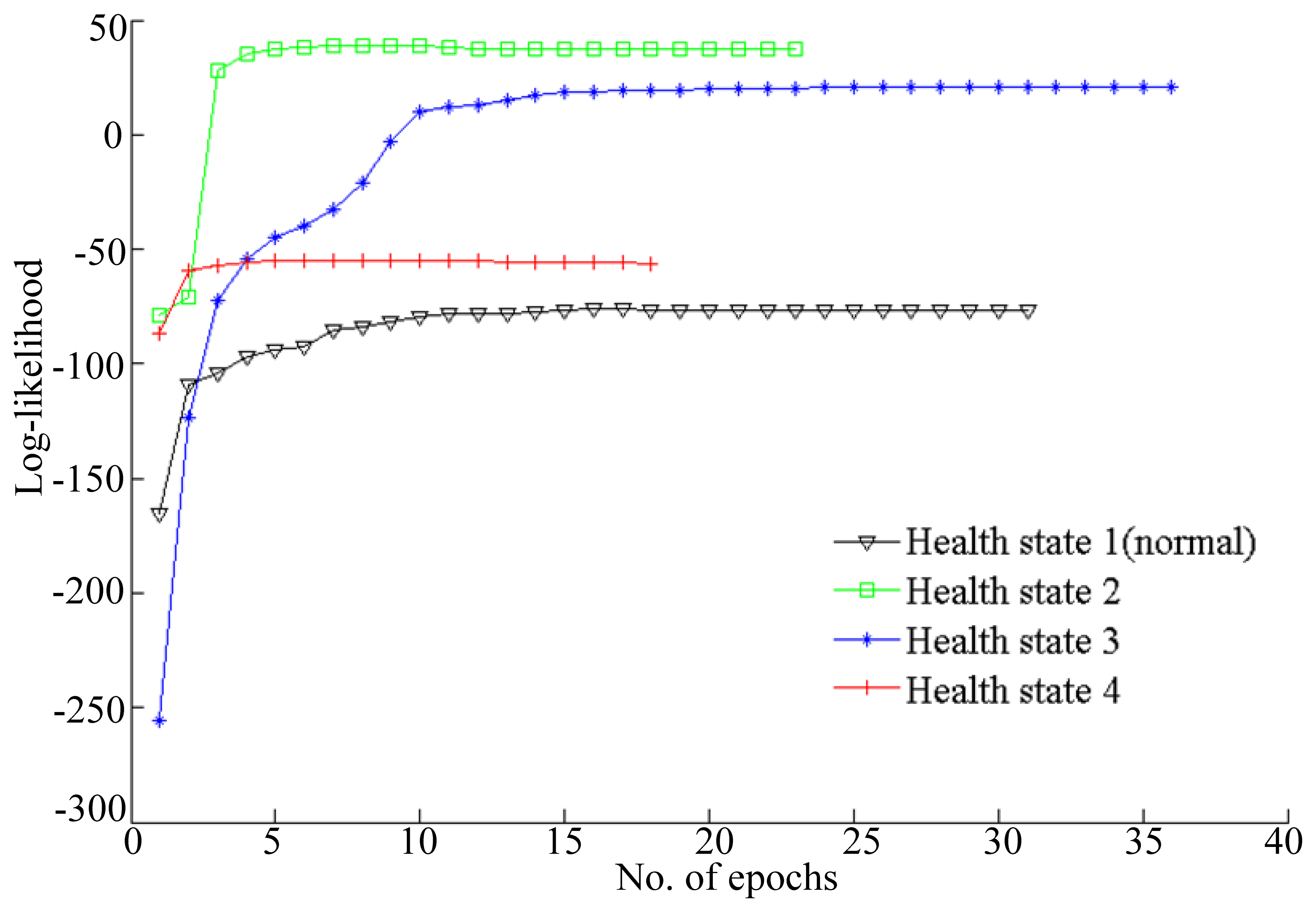
To improve the training accuracy, several observation sequences are used to train HMM for a health state. The log-likelihood probabilities of HMMs training are shown in Figure 7.
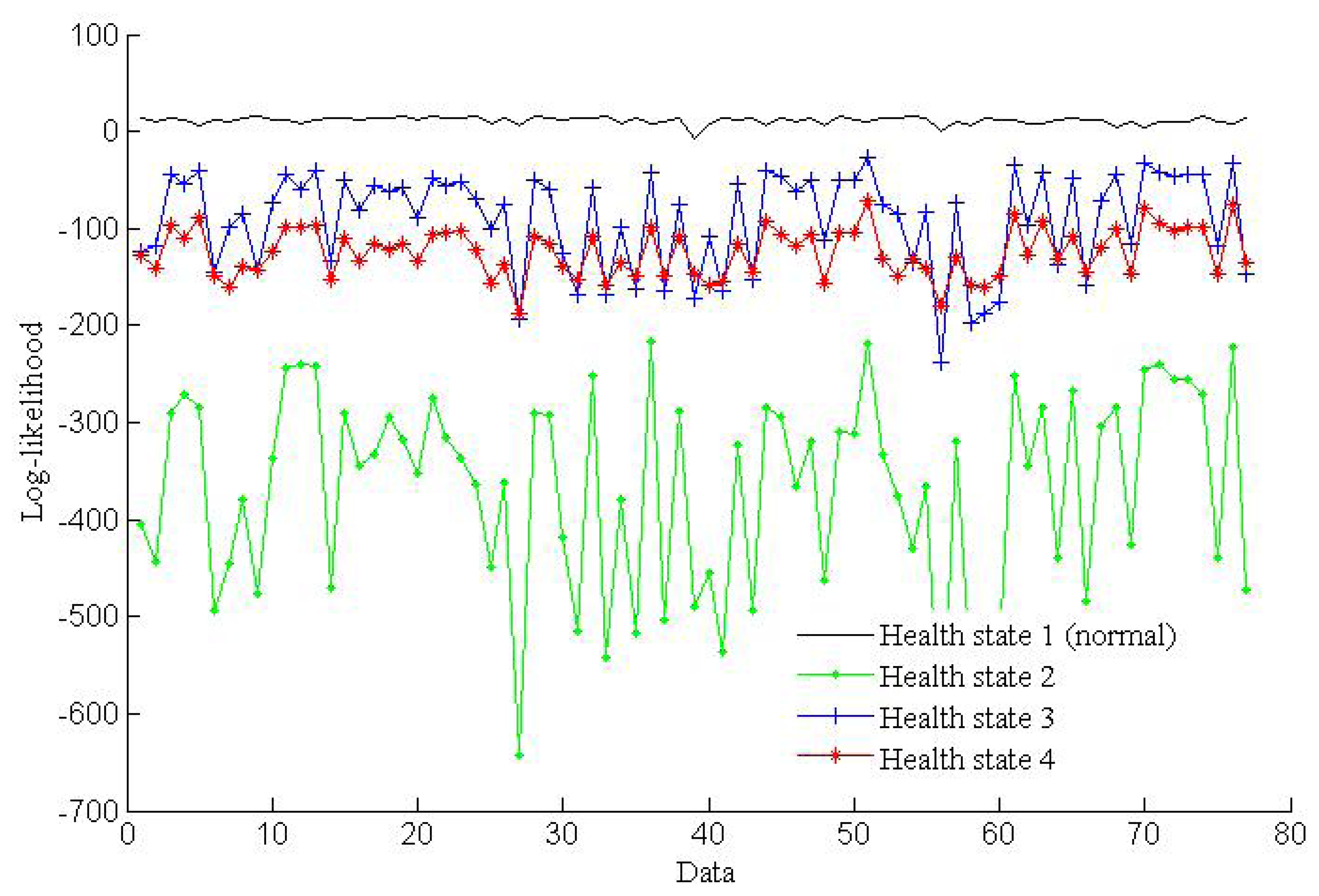
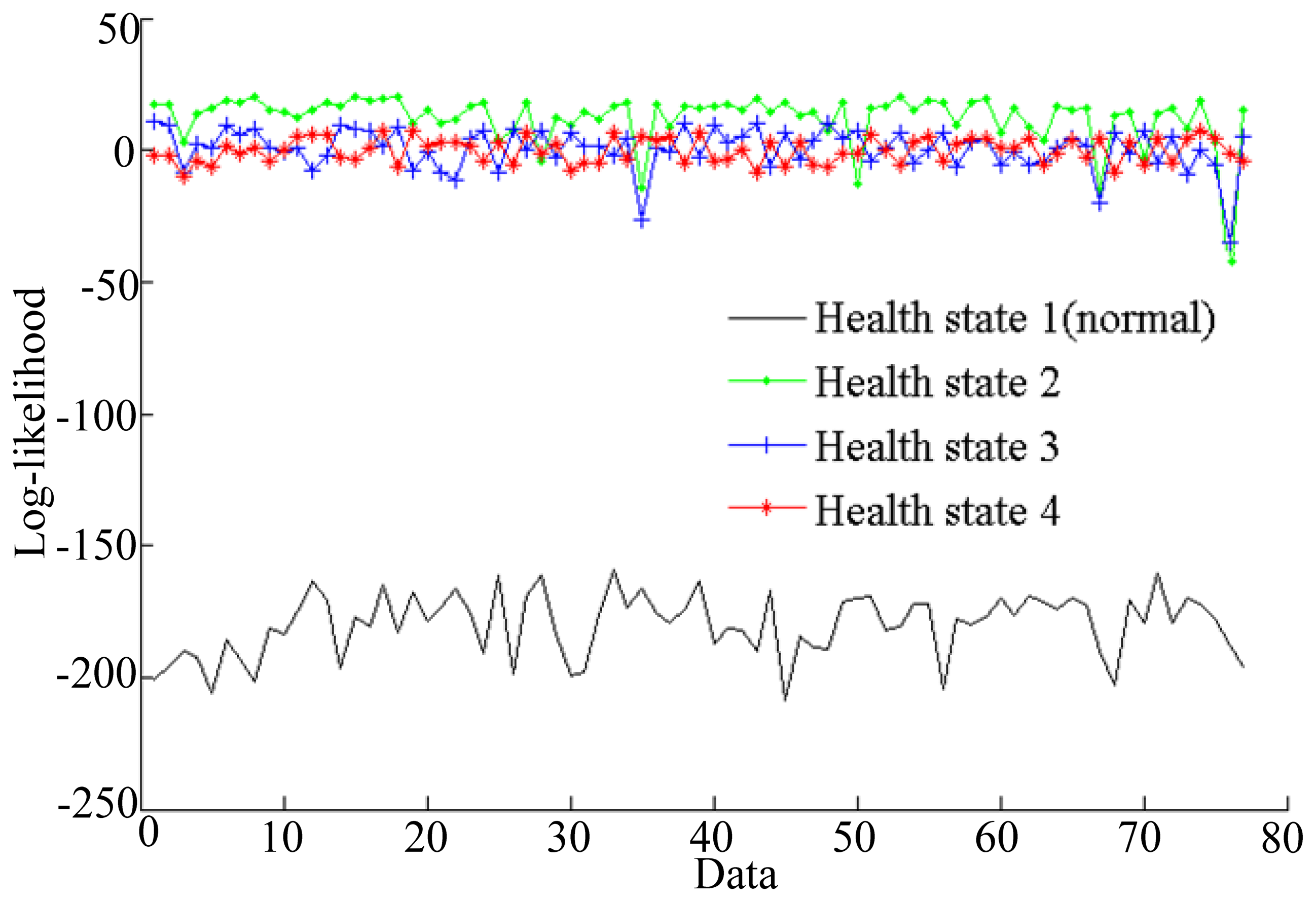
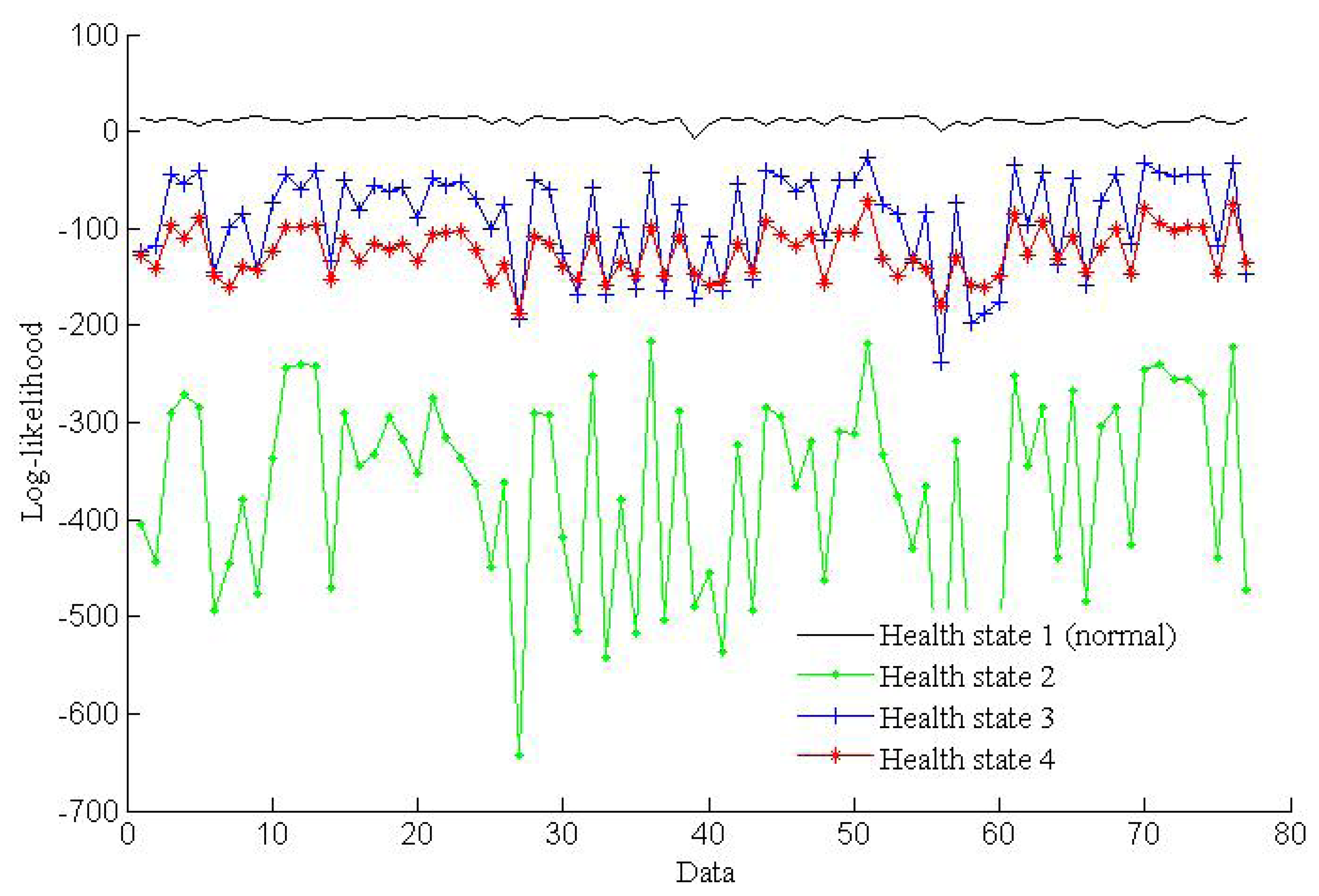
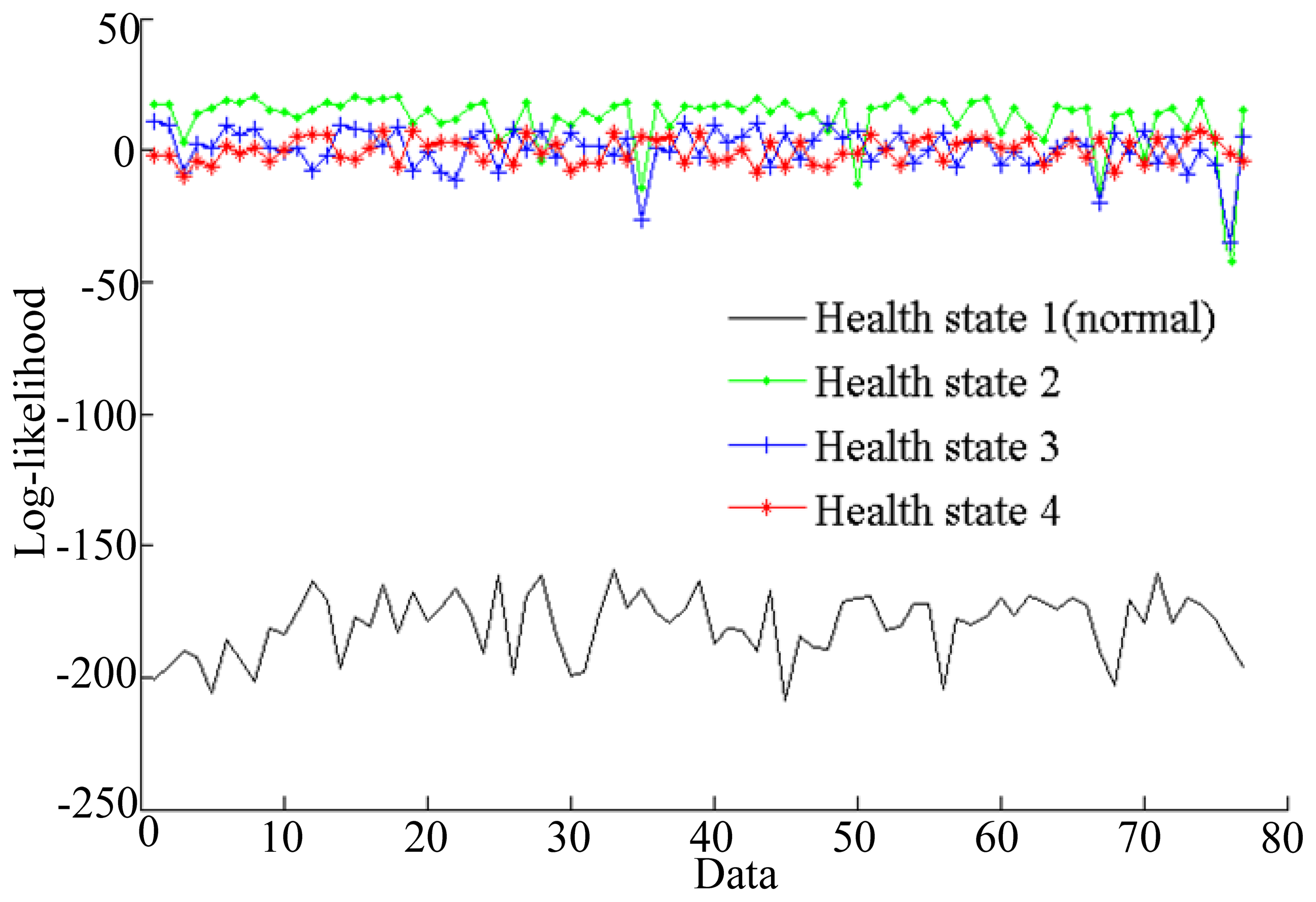
The simulation results shown in Figure 7 illustrate that the log-likelihoods tend to stabilize with the growth of the number of epochs. All of the training epochs are less than 40. These trained HMMs can be used to diagnose faults. In this paper, two vibration data sequences are specimens for fault diagnosis testing, where one is fault-free data and another is data with a fault diameter of 0.007 inches. The log-likelihood probabilities of the test vibration data with fault-free are shown in Figure 8, while the log-likelihood probabilities of the data with fault diameter of 0.007 inches are shown in Figure 9.
As shown in Figure 8, the HMM with the highest probability is health state 1, which represents fault-free state. That is to say the test data are fault-free. The result is consistent with the given data. Figure 9 shows that the HMM with the highest probability is health state 2, which represents the fault diameter of 0.007 inches. Therefore, the diagnosis result is consistent with the given data. According to the above two tests, fault diagnosis based on HMMs is efficient.
5.3. Features and RUL Prediction
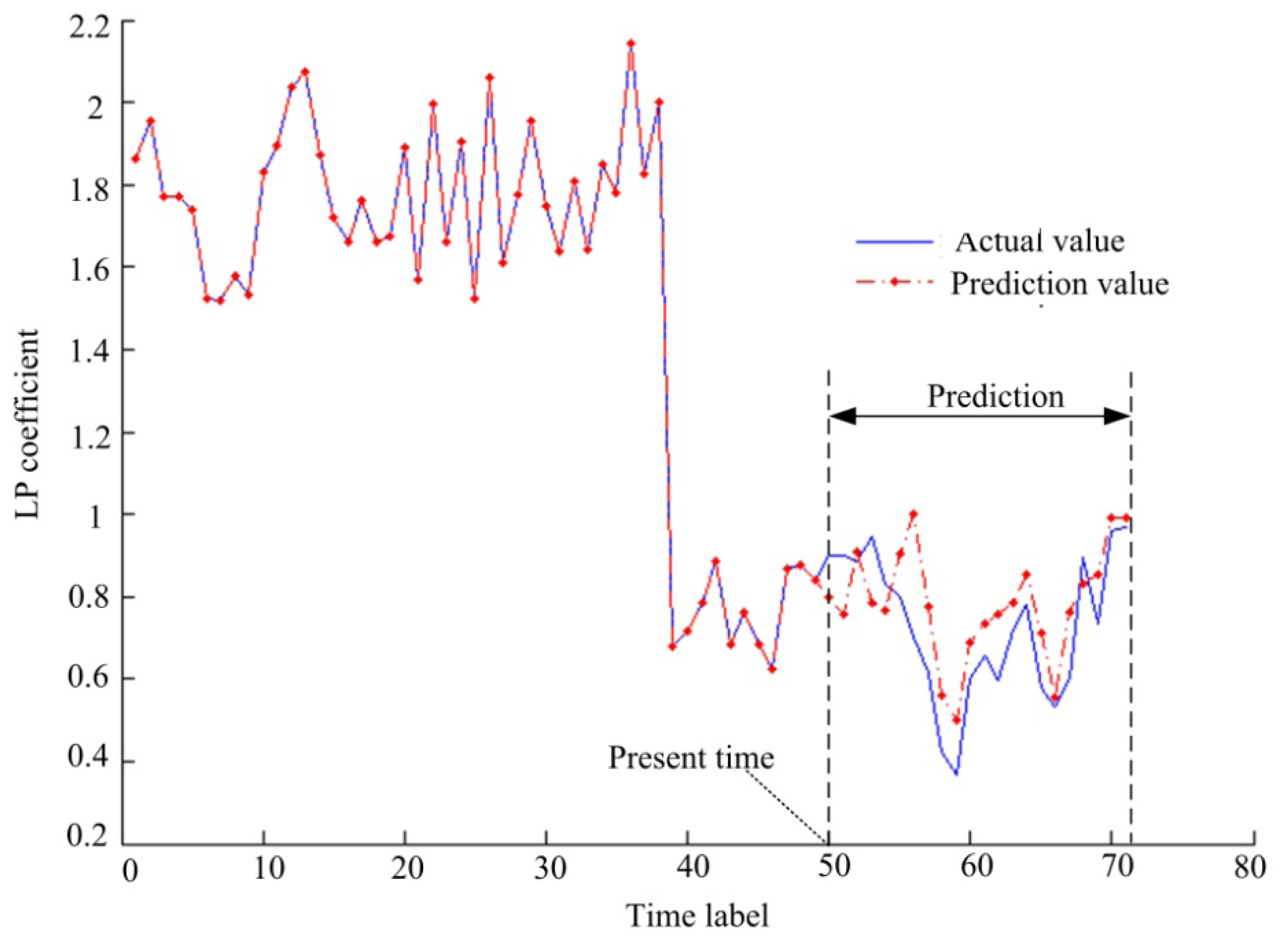
Collecting lifetime data is a difficult work and the bearing data center does not provide this lifetime data. Therefore, we construct a lif time data sequence by taking some vibration data separately from each health states. Then the constructed lifetime data sequence is used to test for features prediction and fault prognostics. After frame segmentation and feature extraction, the length of the feature sequence is 71. We take the front 50 feature vectors as LSSVR training data, and the back 21 as unknown test data. With these parameters, the present time is t = 50 and the future prediction time is k = 21. We take the first dimension of the feature vectors as an example, and the prediction result is shown in Figure 10.
In Figure 10, the data before t = 50 are regression estimation results and the data after t = 50 are prediction results according to Equation (28). The simulation results indicate that the prediction feature trend is essentially consistent with the actual trend. The simulation results can therefore be used to make a fault prognosis.
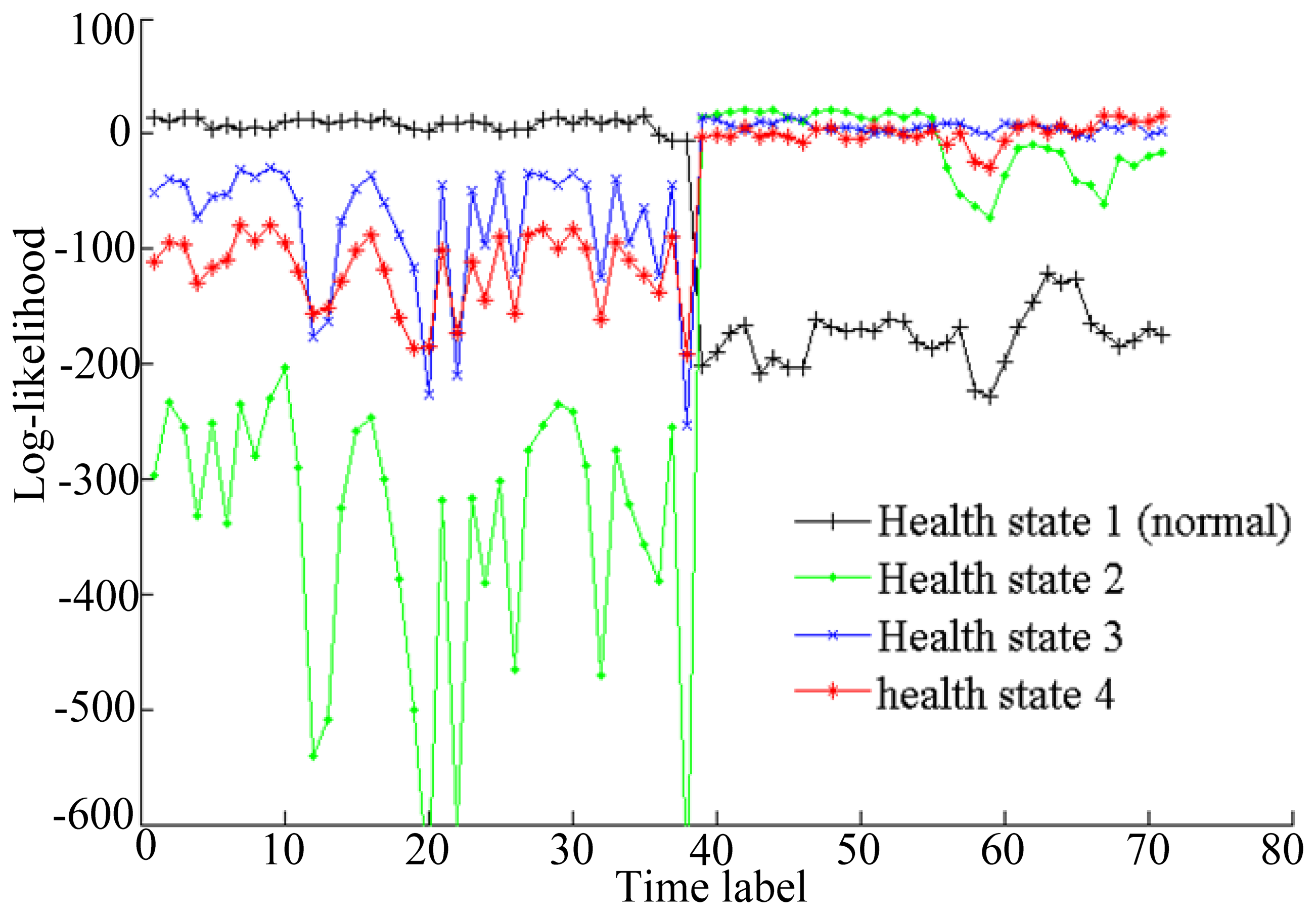
Based on the trained four HMMs, the log-likelihood probabilities of the life time data for each state are shown in Figure 11.
The state with the highest log-likelihood is the health state of the corresponding time. As shown in Figure 11, the system goes from health state 1 to health state 4 during the lifetime. The system is in a normal state before t = 38. During the time from t = 39 to t = 55, the system is in health state 2 which means the fault diameter is at 0.007 inches. During the time from t = 56 to t = 65, the system is in health state 3, which means the fault diameter is at 0.014 inches. After t = 66, the system is in health state 4. That indicates that the system fails after t = 66. RUL values can be predicted at each time. The RUL prediction results at different times are shown in Table 1.
In Table 1, the actual value of RUL is the time between the present time and the failure time t = 66. The predicted value of RUL is calculated based on the proposed LSSVR/HMM method. As shown in Table 1, the predicted RUL is less than the actual RUL. Therefore, the LSSVR/HMM hybrid prognosis method can forecast faults long before the actual fault occurs. The RUL prediction errors reduce with increasing time and it tends to be 1 time unit in the simulation, but in real situations, the prediction results may be not so good because the test lifetime data used in the simulation is perfect and shorter than an actual lifetime data sequence.
6. Conclusions
Fault prognosis is an essential and difficult technology in health management and CBM. In this paper, a hybrid prognostics approach which integrates the HMM method and LSSVR is presented. In the proposed LSSVR/HMM approach, the fault process is divided into several health states modeled by HMMs. These HMMs are trained based on history sample data. The lot-likelihood probabilities of the HMMs are used to classify data and determine the health state. The state with the highest log-likelihood is the corresponding health state of given data. LSSVR is used to predict the feature trend. Based on the predicted features and trained HMMs, the future health state can be predicted. LSSVR trains and predicts RULs online until the highest probability of the predicted feature vector is at the last health state. Then the RUL is equal to the prediction time.
Testing of the proposed LSSVR/HMM prognostics approach was carried out using bearing vibration data. The simulation results showed that the novel approach is efficient in fault diagnosis and prognostics and can also predict the RUL. Furthermore, the results showed that the RUL prediction accuracy increases with the passing of time. Future work will focus on how to improve the prediction accuracy and expand the applications.
Conflict of Interest
The authors declare no conflict of interest.
References
- Cheng, S.; Azarian, M.; Pecht, M. Sensor system for prognostics and health management. Sensors 2010, 10, 5774–5797. [Google Scholar]
- Pecht, M. Progn and Health Management of Electron; Wiley-Interscience: New York, NY, USA, 2008. [Google Scholar]
- Dickson, B.; Cronkhite, J.; Bielefeld, S.; Killian, L.; Hayden, R. Feasibility Study of a Rotorcraft Health and Usage Monitoring System (HUMS): Usage and Structural Life Monitoring Evaluation; NASA Contractor Report 198447; DOT/FAA/AR-95/9, ARL-CR-290; February; 1996. [Google Scholar]
- Baroth, E.; Powers, W. T.; Fox, J.; Prosser, B.; Pallix, J.; Schweikard, K.; Zakrajsek, J. IVHM (Integrated Vehicle Health Management) Techniques for Future Space Vehicles. Proceedings of the AIAA 37th Joint Propulsion Conference and Exhibit, Salt Lake City, UT, USA, 8–11 July 2001.
- Ferrell, B.L. Air Vehicle Prognostics and Health Management. Proceedings of the IEEE Conference on Aerospace, Big Sky, MT, USA, 18–25 March 2000; pp. 145–146.
- Hess, A.; Calvello, G.; Dabney, T. PHM a key Enabler for the JSF Autonomic Logistics Support Concept. Proceedings of the IEEE Conference on Aerospace, Big Sky, MT, USA, 6–13 March 2004; pp. 3543–3550.
- Roemer, M.; Dzakowic, J.; Orsagh, R.; Byington, C.; Vachtsevanos, G. An Overview of Selected Prognostic Technologies with Reference to an Integrated PHM Architecture. Proceedings of the First International Forum on Integrated System Health Engineering and Management in Aerospace, Big Sky, UT, USA; 2005; pp. 3941–3947. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Anal: Forecast and Control, 3rd ed.; Holden-Day: San Francisco, CA, USA, 1994. [Google Scholar]
- Xue, G.X.; Xiao, L.C.; Bie, M.H.; Lu, S.W. Fault Prediction of Boilers with Fuzzy Mathematics and RBF Neural Network. Proceeding of the International Conference on Communications, Circuits and Systems, Jiangsu, China, 27–30 May 2005; pp. 1012–1016.
- Ferreiro, S.; Arnaiz, A.; Sierra, B.; Irigoien, I. A bayesian network model integrated in a prognostics and health management system for aircraft line maintenance. J. Aerosp. Eng. 2011, 225, 886–901. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar]
- Zhang, J.F.; Hu, S.S. Nonlinear time series fault prediction based on clustering and support vector machines (in Chinese). Control Theory Appl. 2007, 24, 64–68. [Google Scholar]
- Qu, J.; Zuo, M.J. An LSSVR-based algorithm for online system condition prognostics. Expert Syst. Appl. 2012, 39, 6089–6102. [Google Scholar]
- Liu, S.; Jia, S.; Li, B.; Li, G.Y. Investigation of Steering Dynamics Ship Model Identification Based on PSO-LSSVR. Proceedings of the 2nd International Symposium on Systems and Control in Aerospace and Astronautics, Shenzhen, China, 10–12 December 2008; pp. 1–6.
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar]
- Suykens, J.A.K.; Lukas, L.; Vandewalle, J. Spare Least Squares Support Vector Machine Classifiers. Proceeding of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 26–28 April 2000; pp. 37–42.
- Khawaja, T.; Vachtsevanos, G. A Novel Architecture for On-line Failure Pognosis Using Probabilistic Least Squares Support Vector Regression Mmachines. Proceeding of Annual Conference of the Prognostics and Health Management Society, San Diego, CA, USA, 27 September–12 October 009; pp. 1–8.
- Ge, Z.G.; Song, Z.H. Online monitoring of nonlinear multiple mode processes based on adaptive local model approach. Control Eng. Pract. 2008, 16, 1427–1437. [Google Scholar]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state markov chain. Ann. Math. Statist. 1966, 37, 1554–1563. [Google Scholar]
- Atlas, L.; Ostendorf, M.; Bernard, G.D. Hidden Markov Models for Monitoring Machining Tool-Wear. Proceeding of 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP'00, Istanbul, Turkey, 5–9 June 2000; pp. 3887–3890.
- Lee, J.M.; Kim, S.J.; Hwang, Y.; Song, C.S. Diagnosis of mechanical fault signals using continuous hidden markov model. J. Sound Vib. 2004, 27, 1065–1080. [Google Scholar]
- Ocak, H.; Loparo, K.A. A New Bearing Fault Detection and Diagnosis Scheme Based on Hidden Markov Modeling of Vibration Signals. Proceeding of the International Conference on Acoustics, Speech and Signal Processing, Cleveland, OH, USA, 7–11 May 2001; pp. 3141–3144.
- Ertunc, H.M.; Loparo, K.A. A decision fusion algorithm for tool wear condition monitoring in drilling. Int. J. Machine Tools Manuf. 2001, 41, 1347–1362. [Google Scholar]
- Wang, L.; Mehrabi, M.G.; Kannatey-Asibu, E. Hidden markov model-based tool wear monitoring in machining. ASME J. Manuf. Sci. Eng. 2002, 124, 651–658. [Google Scholar]
- Ocak, H.; Loparo, K.A. HMM-based fault detection and diagnosis scheme for rolling element bearings. J. Vib. Acoust. 2005, 127, 299–306. [Google Scholar]
- Blimes, J.A. A Gentle Tutor. of the EM Algorithm and Its Appl. to Parameter Estim. for Gaussian Mixture and Hidden Markov Models; Report; University of Berkeley: Berkeley, CA, USA, 1998. [Google Scholar]
- Baruah, P.; Chinnam, R.B. HMMs for diagnostics and prognostics in machining processes. Int. J. Production Res. 2005, 43, 1275–1293. [Google Scholar]
- Suykens, J.A.K.; Brabanter, J.D.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar]
- The Bearing Data Center, the Case Western Reverse University. Available online: http://www.eecs.case.edu/laboratory/bearing/welcom_overview.htm (accessed on 20 March 2012).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Present time | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 |
| Actual RUL | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 |
| Predicted RUL | 9 | 10 | 10 | 11 | 9 | 10 | 9 | 8 | 7 | 6 | 5 |
| Prediction errors | 7 | 5 | 4 | 2 | 3 | 1 | 1 | 1 | 1 | 1 | 1 |
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/
Share and Cite
Liu, Z.; Li, Q.; Liu, X.; Mu, C. A Hybrid LSSVR/HMM-Based Prognostic Approach. Sensors 2013, 13, 5542-5560. https://doi.org/10.3390/s130505542
Liu Z, Li Q, Liu X, Mu C. A Hybrid LSSVR/HMM-Based Prognostic Approach. Sensors. 2013; 13(5):5542-5560. https://doi.org/10.3390/s130505542
Chicago/Turabian StyleLiu, Zhijuan, Qing Li, Xianhui Liu, and Chundi Mu. 2013. "A Hybrid LSSVR/HMM-Based Prognostic Approach" Sensors 13, no. 5: 5542-5560. https://doi.org/10.3390/s130505542
APA StyleLiu, Z., Li, Q., Liu, X., & Mu, C. (2013). A Hybrid LSSVR/HMM-Based Prognostic Approach. Sensors, 13(5), 5542-5560. https://doi.org/10.3390/s130505542