1. Introduction
Recently, networked monitoring systems are becoming increasingly popular, where sensor data are transmitted to a monitoring station through wired or wireless networks [
1,
2]. In a monitoring station, estimation algorithms (such as a Kalman filter) are used to estimate the system states. A network between sensor nodes and a monitoring station can induce many problems such as time delays, packet dropouts, and limited bandwidth, where they depend on network types and scheduling methods. We note that the network issue (for example, what kinds of scheduling methods should be used?) itself is a big research area [
3]. Also time delays and packet dropouts [
4–
7] are one of most important problems in networked estimation problems.
In this paper we focus on the case where there are many sensors and the network bandwidth is limited. For example, suppose there are three sensors (A,B,C) and 90 bytes/s can be transmitted over a network. How does one assign 90 bytes/s to each sensor? One method is to assign 30 bytes/s to each sensor. If sensor A monitors fast changing value and sensor B monitors slowly changing value, it might not be the best strategy: more data rate should be assigned to sensor A and the data rate of sensor B should be reduced. These issues are discussed quantitatively in this paper.
Note that the data rate of each sensor depends on the sampling frequency and the quantization bit length. For example, (100 Hz, 8 bit) case and (50 Hz, 16 bit) case have the same data rate (100 bytes/s). Thus given the same data rate, we have many possible combinations of the sampling frequencies and the quantization bit lengths. We first investigate how the sampling frequency and the quantization bit length affect the estimation performance and then propose a method to choose the sampling frequency and the quantization bit length of each sensor.
Using different sampling frequencies for different sensors is discussed in [
10], where the sampling frequencies is chosen by minimizing the Kalman filter error covariance. In [
11], the sampling frequency assignment algorithm is given, where a sampling frequency is chosen from a finite discrete set. In [
12], a similar sampling frequency assignment is considered, where location of sensors and cost of measurement are also considered in the optimization problem. We note there are other attempts, where an event-based transmission method [
8,
9] is used instead of a periodic transmission. In this paper, we assume that periodic sampling of sensor data.
Quantization is an extensively studied area [
13]. Relating the estimation problem, a logarithm quantizer is proposed in [
14]. Although theoretically appealing, the quantizer is applied to the innovation of a filter rather than to an output directly. The effect of quantization can be reduced by treating the quantization error as measurement noises as in [
15]. In [
16] and [
17], quantization bit length assignment algorithms are proposed, where the bit length is computed by minimizing a performance index. The performance index is not directly related to estimation performance (e.g., the filter error covariance).
Simultaneous optimization of the sampling frequency and the quantization bit length has not been reported yet. In this paper, both parameters are selected so that the estimation performance is optimized given the transmission rate constraint.
The paper is organized as follows. In Section 2., estimation performance P is defined, which depends on the sampling periods and quantization bit lengths. In Section 3., a suboptimal algorithm to compute sampling period and quantization bit length combination is proposed. Through numerical examples, the proposed method is verified in Section 4. and conclusion is given in Section 5.
2. Problem Formulation
In this section, estimation performance is defined when the sampling frequency and the quantization bit length of each sensor are given. How to optimize the sampling frequency and the quantization bit length is discussed in Section 3.
Consider a linear time-invariant system given by
where
x ∈
Rn is the state we want to estimate and
y ∈
Rp is the measurement. Process noise
w(
t) and measurement noise
υ(
t), which are uncorrelated, zero mean white Gaussian random processes, satisfy:
where E{·} denotes the mean and
Q and
R are a process noise covariance and a measurement noise covariance, respectively.
Let
Ti be the sampling period of the
i-th output and thus the corresponding sampling frequency is 1/
Ti. We assume that
Ti is an integer multiple of constant
T: that is,
Ti satisfies the following condition:
where
Mi is an integer and
T is the base sampling period.
Let
li be the quantization bit length of the
i-th output. Let
ymax,i be the absolute maximum value of the
i-th output: that is,
where
yk,i is the
i-th element of
yk. The index
k is used to denote the discrete time index. We assume that the uniform quantizer is used. Let
δi be the quantization level of the
i-th output, which is given by
Let
qk be the quantization error in
yk, then the following is satisfied
where
qk,i is the
i-th element of
qk.
Now we are going to model
(1) in the discrete time considering the sampling period
Ti and the quantization length bit
li. Assume
Mi = 1 (1
≤ i ≤ p) temporarily:
where
xk ≜
x(
kT), Φ ≜ exp(
AT) and
yk is the quantized output of
y(
kT). Process noise
wk and
υk are uncorrelated and satisfy
where
We treat the quantization error as an additional measurement noise as in
(6), which is also considered in [
15]. The quantization error
qk is assumed to be uncorrelated with
wk and
υk. If the uniform distribution is assumed, the covariance is given by
Now the temporary assumption (
Mi = 1) is removed. The second equation of
(6) is no longer true and
yk,i is available if
k is an integer multiple of
Mi. Let
ỹk be a collection of all available
yk,i at time
k. To define
ỹk in a more formal way, let {
rk,1,
rk,2, . . .,
rk,pk} be a set of all row numbers of available
yk. Then
ỹk is given by
Similarly
υ̃k and
q̃k can be defined and
C̃k is defined as follows:
where
Ci is the
i-th row of
C. Thus the measurement equation at time
k is given by
where
R̃k ∈
Rpk×pk is a matrix extracted from
R so that
R̃k(
i,
j) =
R(
rk,i,
rk,j). Δ̃
k is defined in the same way.
For example, if
M1 = 1 and
M2 = 2, then
ỹk and
C̃k are given in
Table 1. We can see that
C̃k is periodic with the period 2, which is the least common multiple of
M1 = 1 and
M2 = 2.
Generally C̃k is periodic with the period M, where M is the least common multiple of {M1, M2, . . ., Mp}.
Using the first equation of
(6) repeatedly
b times, we have
It is known that a periodic system can be transformed into a time-invariant system [
18,
19]. From
(12) with
a =
kM and
b =
M, we have
Also from
(12) with
a =
kM − j and
b =
j, we have
Multiplying Φ
−j, we obtain a backward equation:
Let
x̄k,
w̄k ȳk,
ῡk and
q̄k be defined by
Combining
(13),
(15) and
(10), we have the following time invariant system:
where
We will apply a Kalman filter to
(16). Note that
where
where
It is standard to apply a Kalman filter to
(16) using
(17),
(18) and
(19): the measurement update and the time update equations are given as follows [
20]:
We will use
P as an estimation performance, where
P is the steady-state value of
:
In the steady state, we have
. Inserting this into the Kalman filter equation, we have the following Riccati equation:
If the sampling period
Ti and the quantization bit length
li are given, the corresponding estimation performance can be computed from
(20).
3. Ti and li Optimization
In this section, a method to select the sampling period Ti and the quantization bit li are proposed. The main trade-off is between the transmission rate and the estimation performance.
The optimization problem can be formulated as follows:
where λ ∈
Rn is a weighting vector. Note that the transmission rate
S is given by
and
Smax is the transmission rate constraint. The transmission rate
S is defined as the sum of each sensor data rate without considering packet overhead. When we apply the algorithm to a specific network, the transmission rate
S should be modified to take the packet overhead into account.
Note that
Ti =
MiT and
P depends on
M, which is the least common multiple of
M1, . . .,
Mp. To make
M constant,
Mi is assumed to satisfy
With this assumption, the least common multiple
M of all possible combinations of
Mi = 2
mi is given by
We assume
li satisfies
If the number of combinations is small, P can be computed for all possible combinations. For a case that the number is too large, we propose a suboptimal algorithm. The proposed algorithm is based on the following lemma.
Lemma 1 Let P (
m1,
l1, . . .,
mi,
li, . . .,
mp,
lp)
be the solution to (20). With the assumption (23), the following is satisfied. Proof: We will prove with a simple case with
m1 = 0
m2 = 0,
T = 1,
M = 2, and
p = 2: note that
T1 = 2
m1T =
T and
T2 = 2
m2T =
T. C̄ for
m1 = 0 and
m2 = 0 is given by
The subscript (
m1 = 0,
m2 = 0) is used to emphasize that
m1 = 0 and
m2 = 0. Also let
R̄m1=0,m2=0 be
R̄ defined in
(18) and
P(0,
l1, 0,
l2) be a solution to
(20) when
m1 = 0 and
m2 = 0.
Now consider a case with
m1 = 0 and
m2 = 1 Instead of computing
P(0,
l1, 1,
l2) using
(20) with
C̄m1=0,m2=1, we can compute
P(0,
l1, 1,
l2) using
(20) with
m1 = 0 and
m2 = 0 except that
R̄m1=0,m2=0 is replaced by
R̄modified, which is defined by
Note that adding ∞ to the (2, 2) element of
R̄m1=0,m2=0 is equivalent to ignoring the second output of
yk when
k is an integer multiple of 2. Thus
P(0,
l1, 1,
l2) computed in this way is the estimation error covariance when
m1 = 0 and
m2 = 1. Since
R̄modified ≥
R̄, we have from the monotonicity of the Riccati equation (see Corollary 5.2 in [
21])
The general case for
(25) can be proved similarly.
Proving the second inequality is more straightforward from the monotonicity of the Riccati equation [
21] and from the fact
The third inequality
(27) is just a combination of
(25) and
(26):
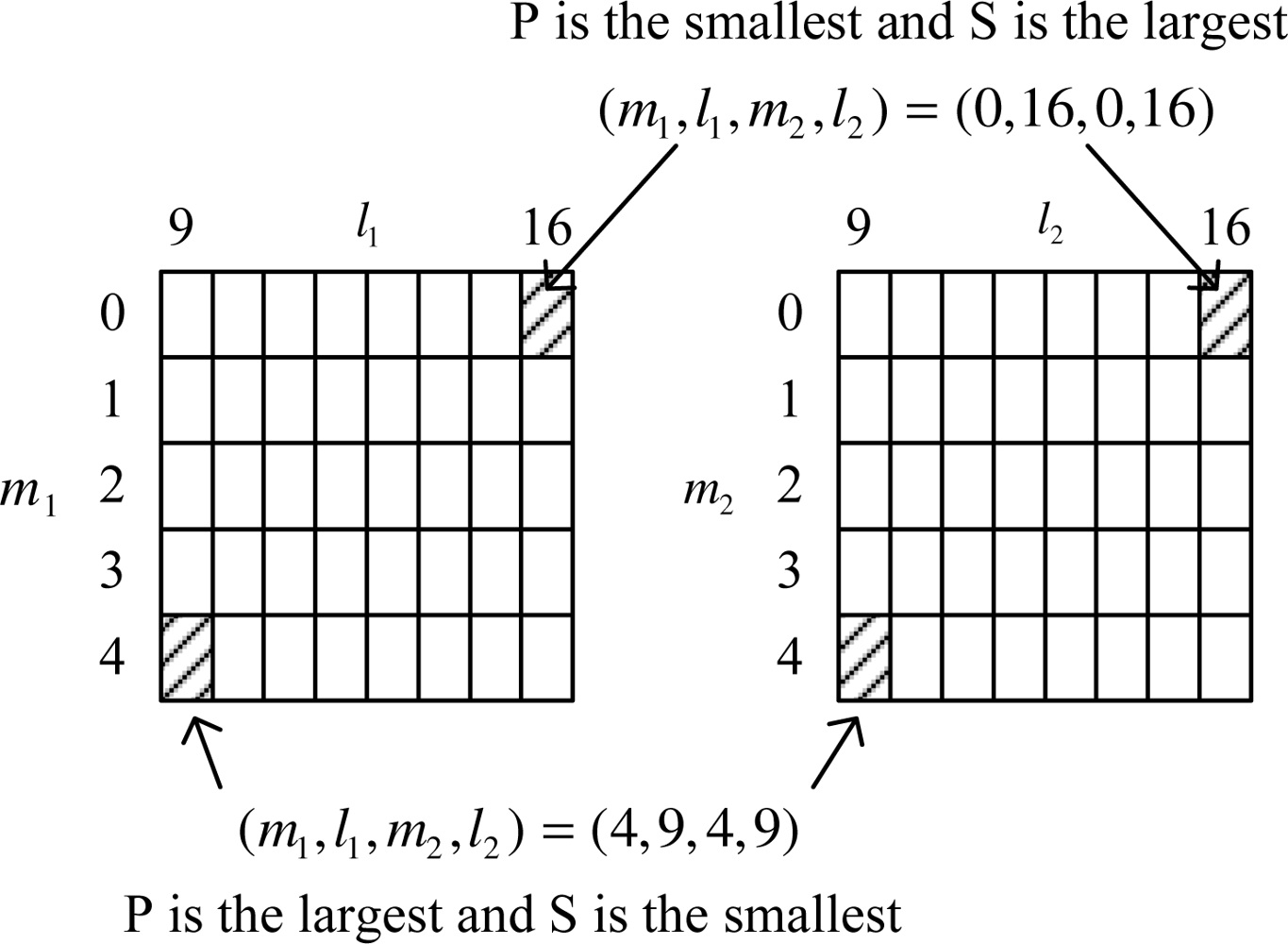
To explain Lemma 1, we consider a simple example with the following parameters:
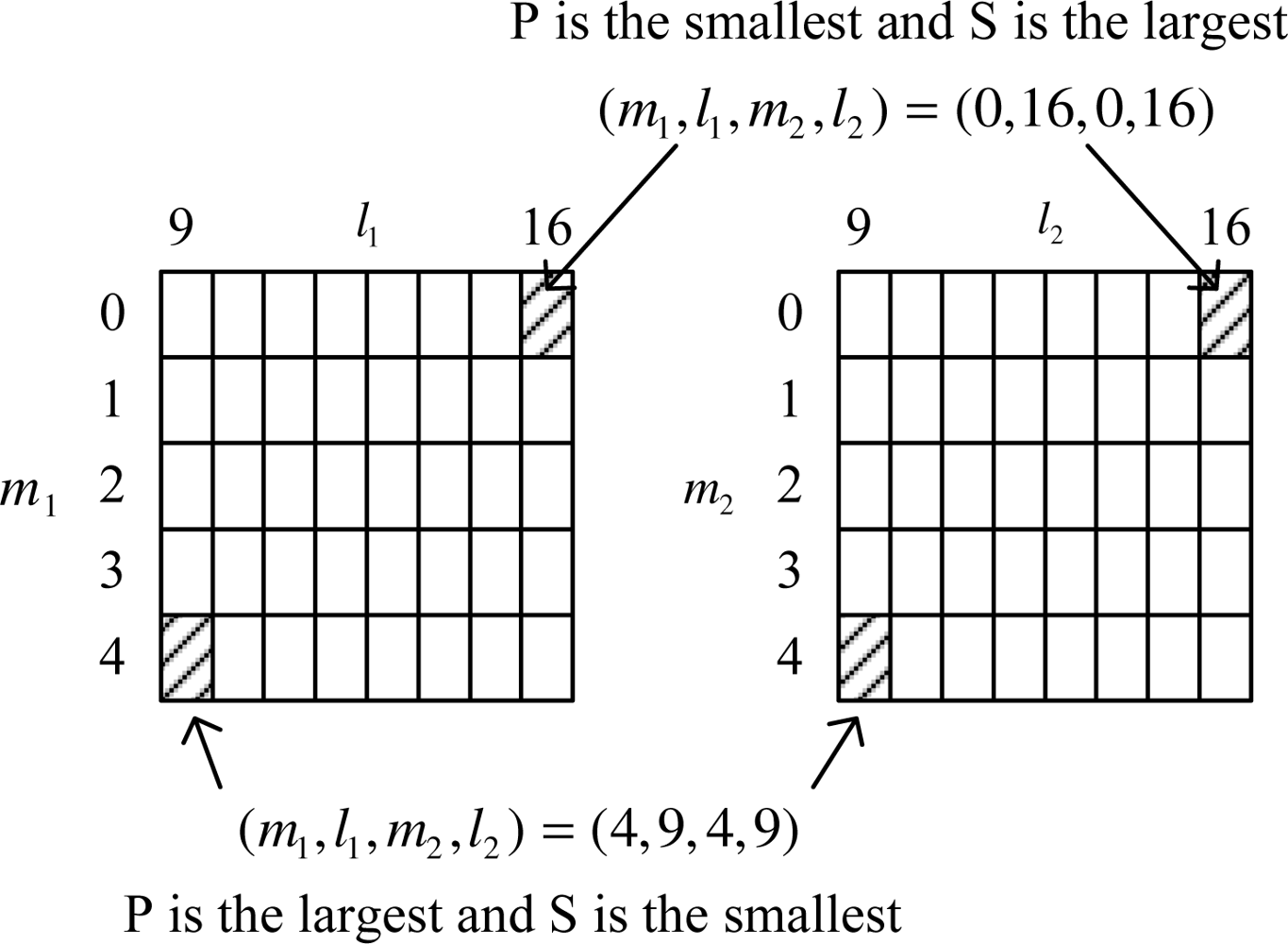
There are 5 × 8 × 5 × 8 = 1, 600 possible combinations (see
Figure 1). Using the result in Lemma 1, we know that
P is the smallest when (
m1,
l1,
m2,
l2) = (0, 16, 0, 16) and the largest when (
m1,
l1,
m2,
l2) = (4, 9, 4, 9). On the other hand, the transmission rate
S is the largest when (
m1,
l1,
m2,
l2) = (0, 16, 0, 16) and the smallest when (
m1,
l1,
m2,
l2) = (4, 9, 4, 9). Note that
mi − 1 and
li + 1 in Lemma 1 corresponds to the upper and right combination of (
mi,
li), respectively. Thus as we move the combination from the left-bottom corner toward the right-top corner, λ′
P becomes smaller while the transmission rate increases.
In the proposed algorithm, we start from the left-bottom corner combination and move the combination toward the right-top corner combination while the transmission constrained is satisfied. The proposed algorithm is stated in pseudo-codes.
(mi, li) = (mi,max, li,min), i = 1, . . ., p
compute λ′P and S
(
P denotes
P(
m1,
l1, . . .,
mp,
lp) and
S is from
(22))
while (S < Smax)
L = { }
for i = 1:p
if (mi > mi,min)
L = L ∪ {(m1, l1, . . ., mi − 1, li, . . ., mp, lp)}
if (li < li,max)
L = L ∪ {(m1, l1, . . ., mi, li + 1, . . ., mp, lp)}
end
for every element of
L, compute
G̃j where
P̃j =
P for the
j-th element of
L and S̃j = S for the j-th element of L
(mi,old, li,old) = (mi, li), i = 1, . . ., p
Find the maximum of Gj and choose the
corresponding combination as (mi, li)
compute λ′P and S
end
Choose the combination (mi,old, li,old)
Note that G̃j represents the estimation performance improvement per transmission rate increase. For each given (mi, li), we choose (mi − 1, li) and (mi, li + 1) for the next combination candidates. There are at most 2p combinations. Among the combinations, we find a combination of which G̃j is the largest. This process is continued until the current transmission rate exceeds Smax.
The number of combinations tested in the proposed algorithm is small compared with the brute force search. For example, the proposed algorithm starts with the top-right-most combination (m1, l1, m2, l2) = (0, 16, 0, 16) and moves toward bottom-left-most combination (m1, l1, m2, l2) = (4, 9, 4, 9) at each step until S ≤ Smax is no longer satisfied. Unfortunately, there is no guarantee that the solution found by the proposed method is near the optimal solution. In Section 4., it is shown, however, through a numerical example that the gap between the suboptimal and optimal solution is not large.
We note that the optimization algorithm is applied once when the networked system is designed. Once the sampling period Ti and quantization length li are determined, they are programmed in each sensor node. Thus no additional computation is needed in the sensor node.
4. Numerical Example
In this section, the proposed method is verified for the one dimensional attitude estimation problem. The state is defined by
where
θ is the attitude we want to estimate. An accelerometer-based inclinometer and a gyroscope are used as sensors. The system model is given by
The values given in
(28),
ymax,1 = 3.1416,
ymax,2 = 2.6180 and
T = 1 are used.
The optimization problem
(21) with
Smax = 500 and λ = [1 0 0]′ is considered. λ is a natural choice since we want to estimate
θ.
First the optimization problem is solved by a brute force search: all possible combinations are examined. The optimal solution is given by
and
S and λ
P at the combination are
Secondly the proposed suboptimal algorithm is used, where the solution is given by
and
S and λ
P at the combination are
The proposed method was able to find a nearly optimal solution with less computation time. In the brute force search, 479 combinations are tested while 21 combinations are tested in the proposed algorithm.
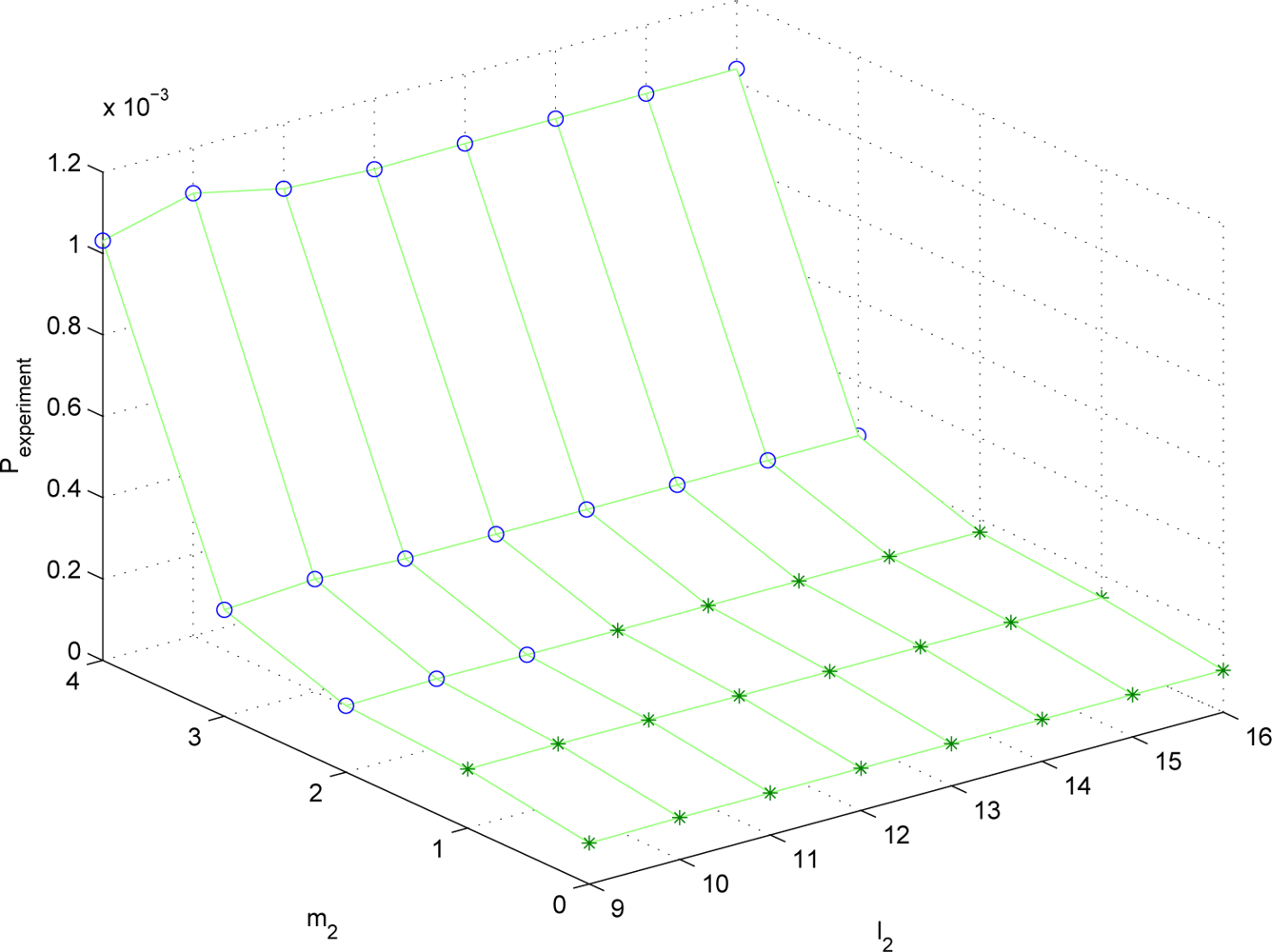
To test whether the proposed λ
P is a good indicator of the estimation performance, the data is generated with Matlab and tested with a Kalman filter. The estimation performance is evaluated with the following:
where
N is the number of data and
θerror,k =
θ − θ̂. Note that
θ̂ is computed by [1 0 0]
◯k. We computed
Pexperiment for all possible combinations and the minimizing combination is given by
and
S and
Pexperiment at the combination is
It can be seen that the optimal solution predicted by λ
P nearly coincides with the real optimal solution. To see how similar λ
P and
Pexperiment are, λ
P and
Pexperiment are plotted for different (
m1,
l1,
m2,
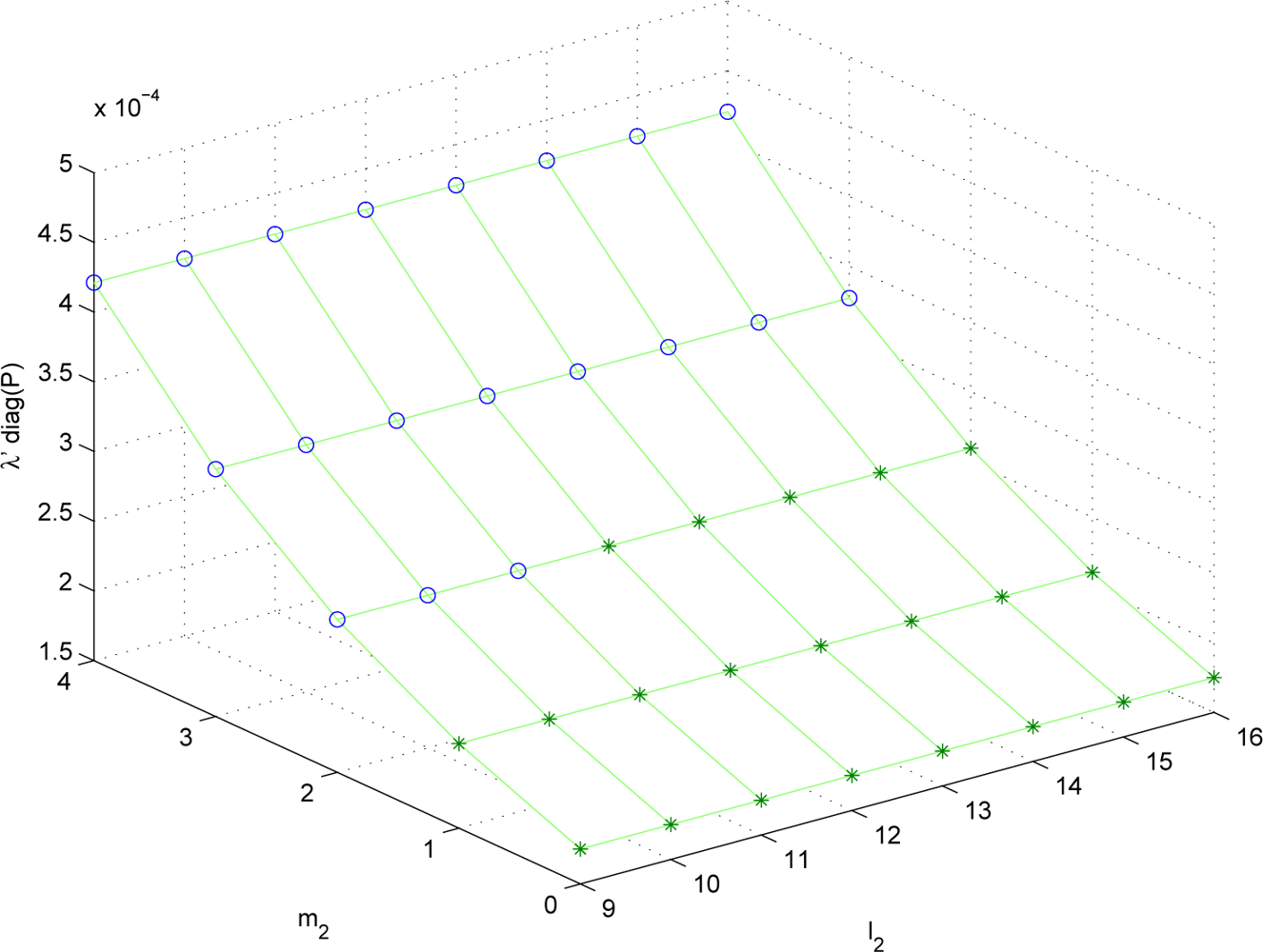
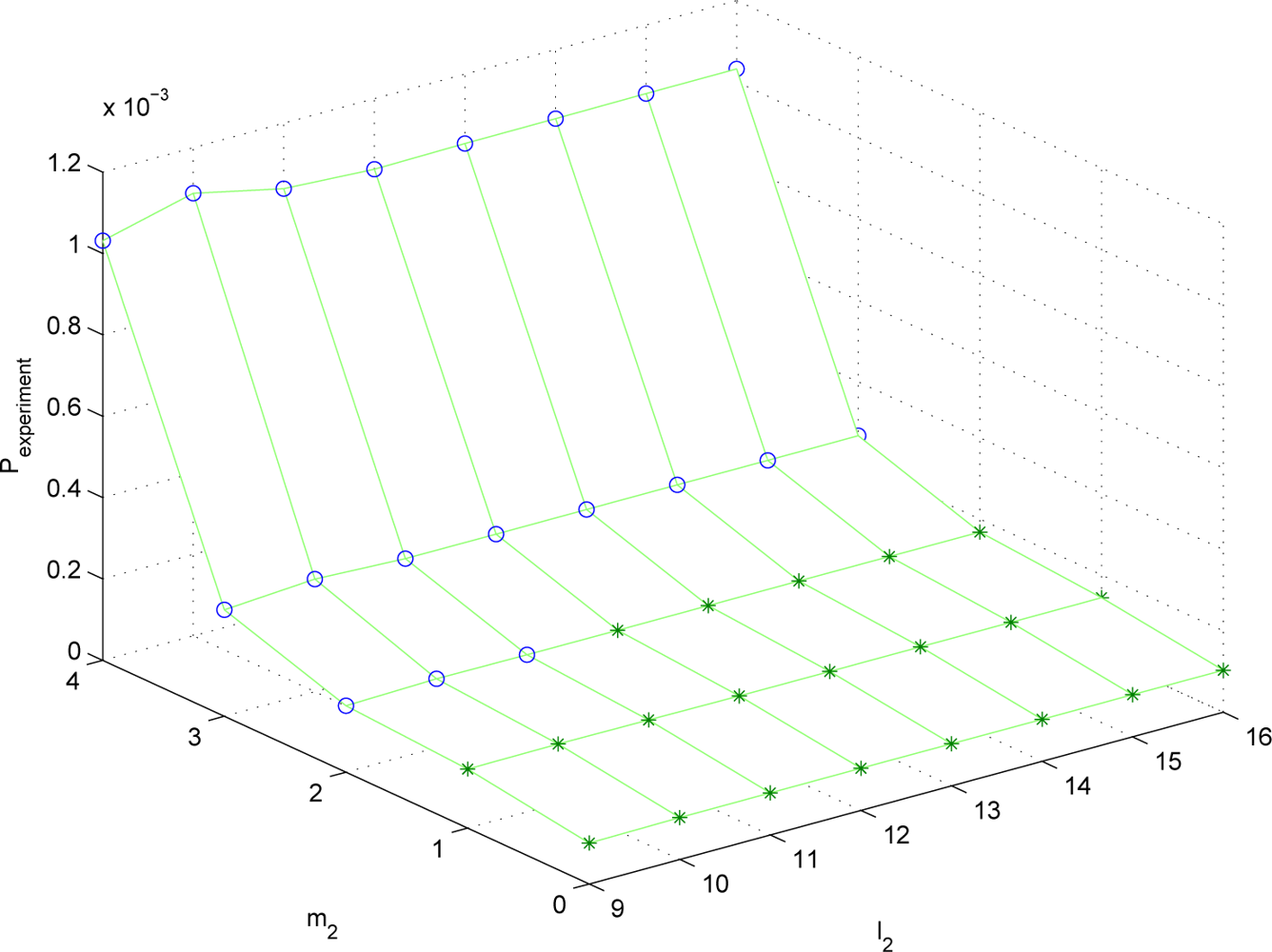
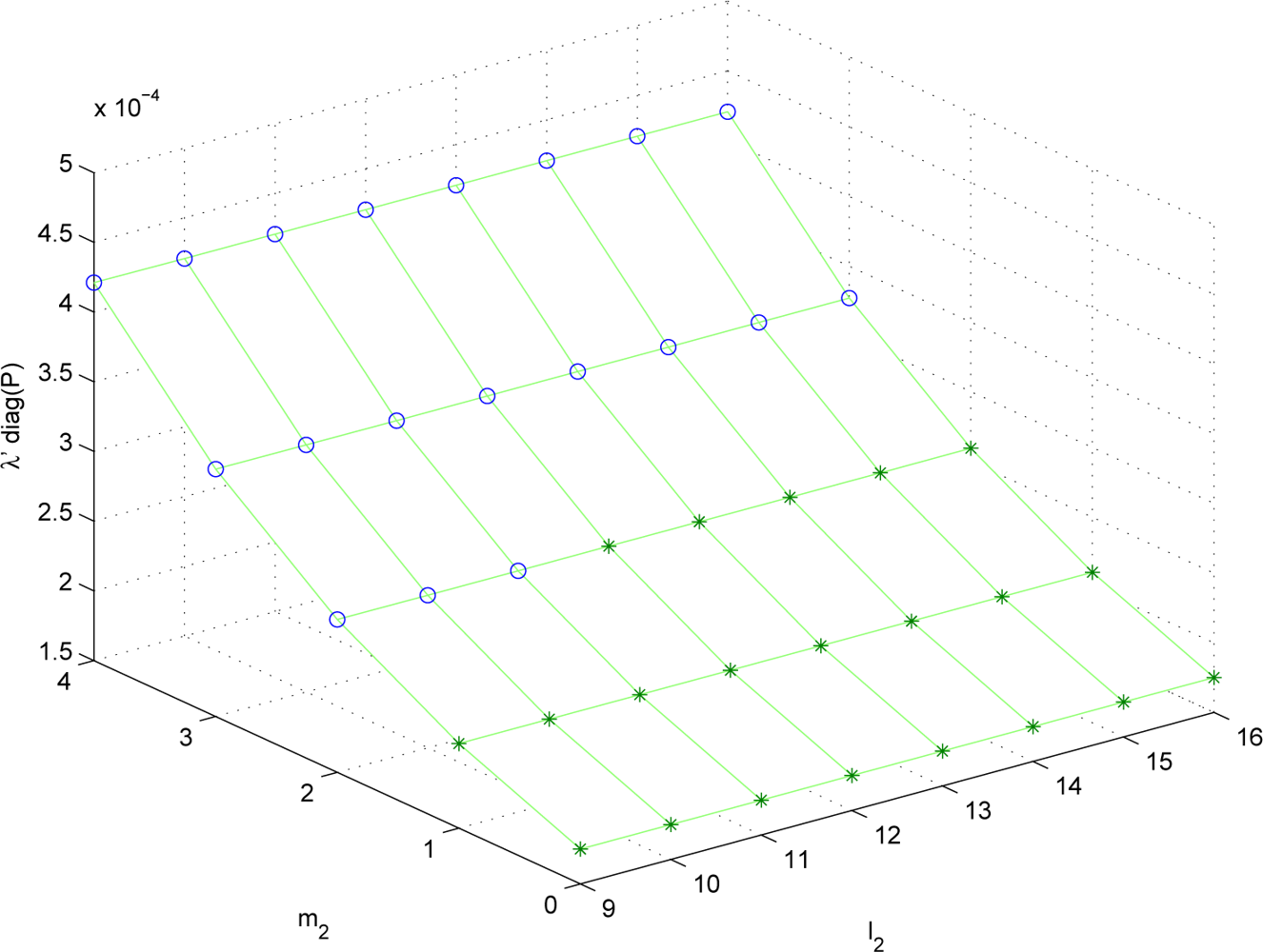
l2) combinations. Since the parameter space is four dimensional, it is not easy to visualize the result. Thus we fix (
m1,
l1) = (2, 9) and plot λ
P and
Pexperiment for (
m2,
l2) combinations in
Figures 2 and
3. The data marked with “o” satisfies
S ≤
Smax and the data marked with “*” does not satisfy
S ≤
Smax.
It can be seen that the trend of λP is almost similar to that of Pexperiment. Thus λP can be used to predict the estimation performance given the sampling periods and the quantization bit lengths.
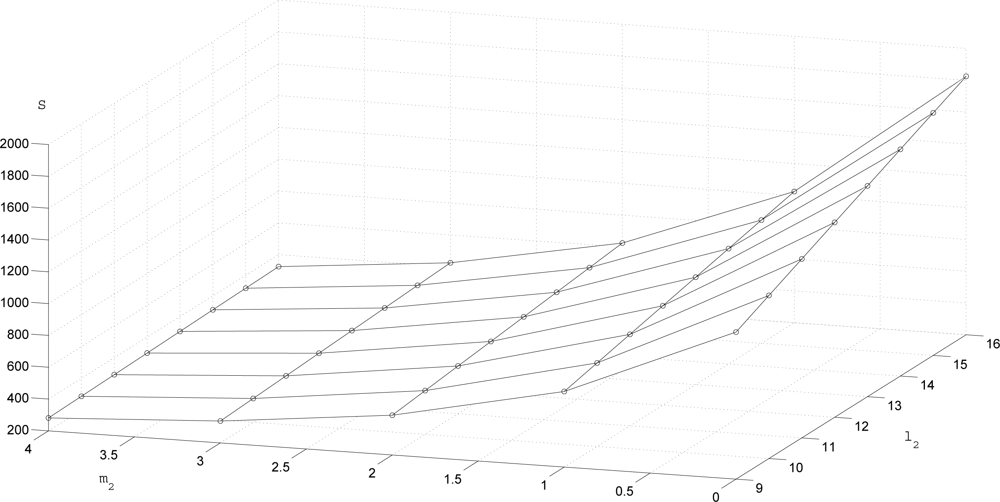
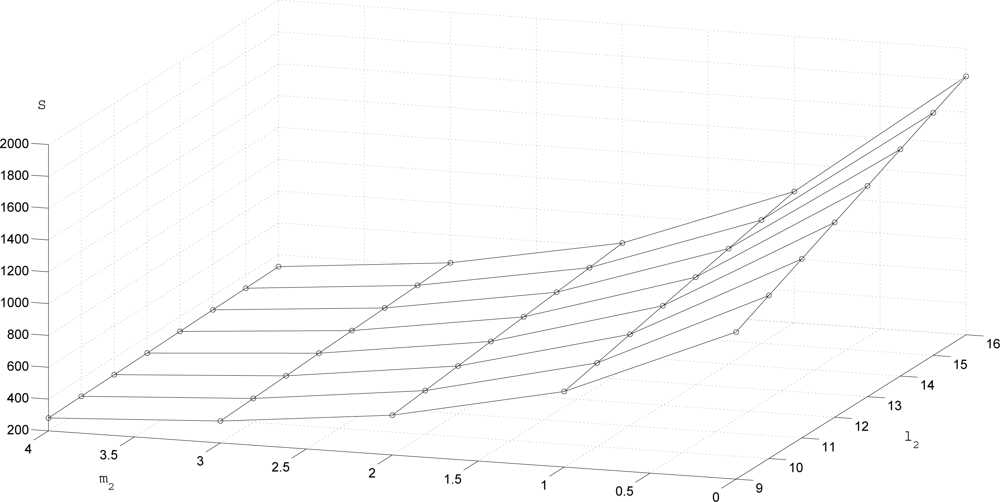
The transmission rate
S is given in
Figure 4. To see the trade-off between
S and the estimation performance,
S and λ
P are given for three (
m1,
l1,
m2,
l2) combinations in
Table 2. We can see that when
S decreases (that is, if we transmit less data), λ
P tends to increase (that is, the estimation performance degrades).
Finally, to test the efficiency of the proposed algorithm, we applied the proposed algorithm to 100 random models, where
A is randomly generated and the same
C as in the previous simulation is used. In the brute force method, 479 combinations are tested as in the previous simulation since the same setting is used. In the proposed algorithm, the number of combinations tested is between 13 and 21. That is, the number of combinations tested in the worst case is 21. Thus we can see the convergence rate is relatively fast. To see the accuracy of the proposed algorithm, the following value is computed:
where
Poptimal is computed using the brute force method. In the 100 trials, the worst case accuracy was 7.26% while the average value is 1.73%. Thus we believe the proposed method can find near optimal value while avoiding the large computation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}