A Novel Radar Sensor for the Non-Contact Detection of Speech Signals

Abstract
:
1. Introduction
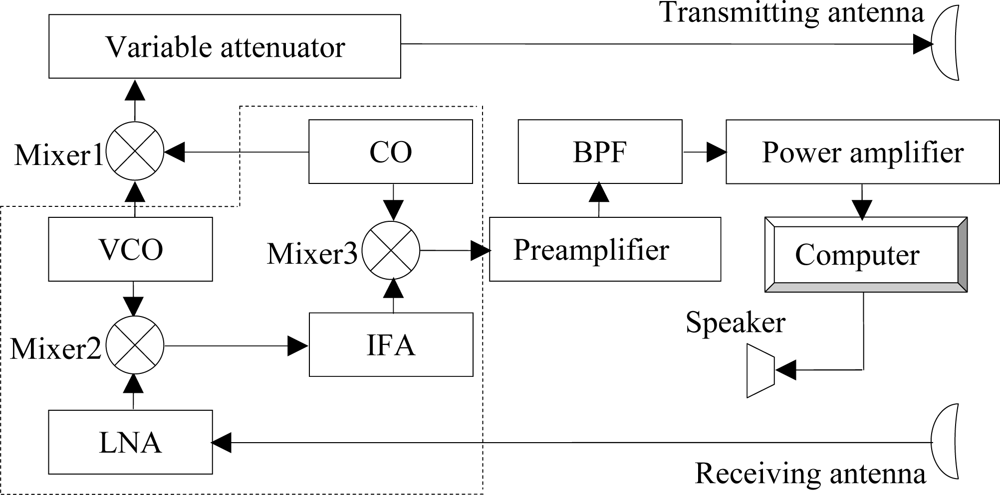
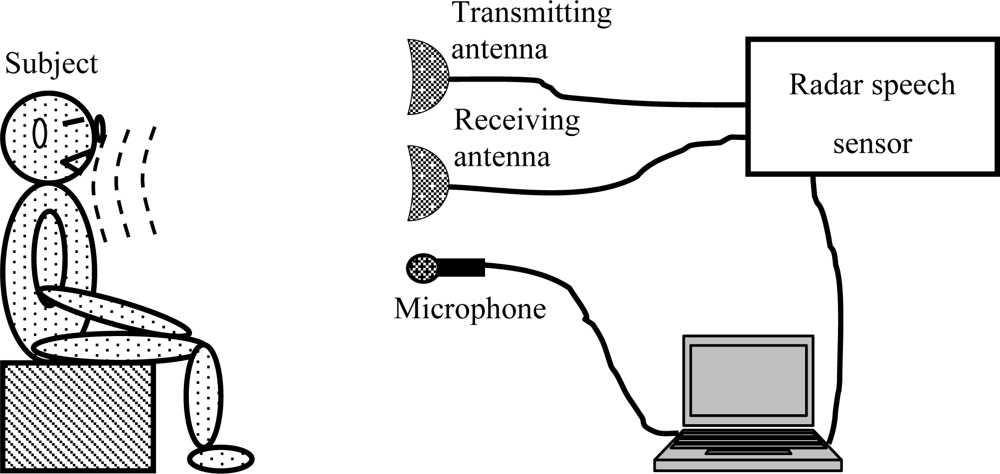
2. Description of the MMW Radar Speech Sensor
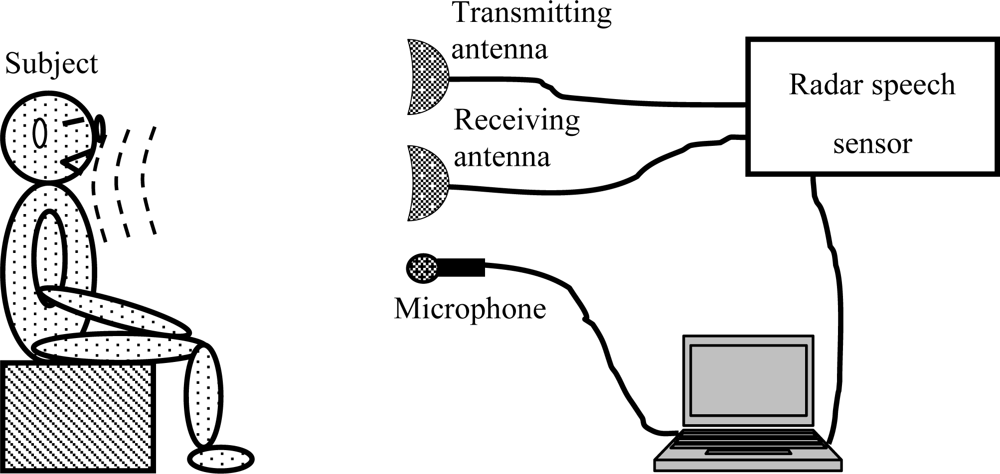
3. Signal Recording and Processing
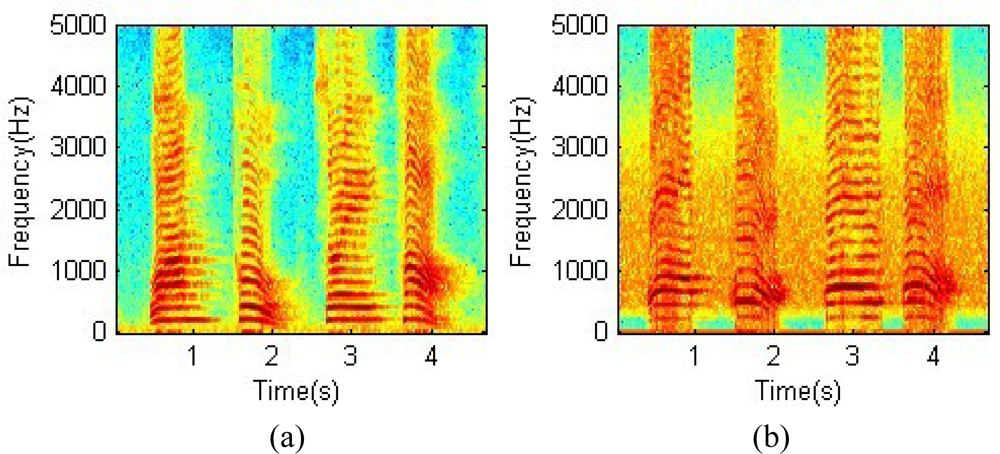
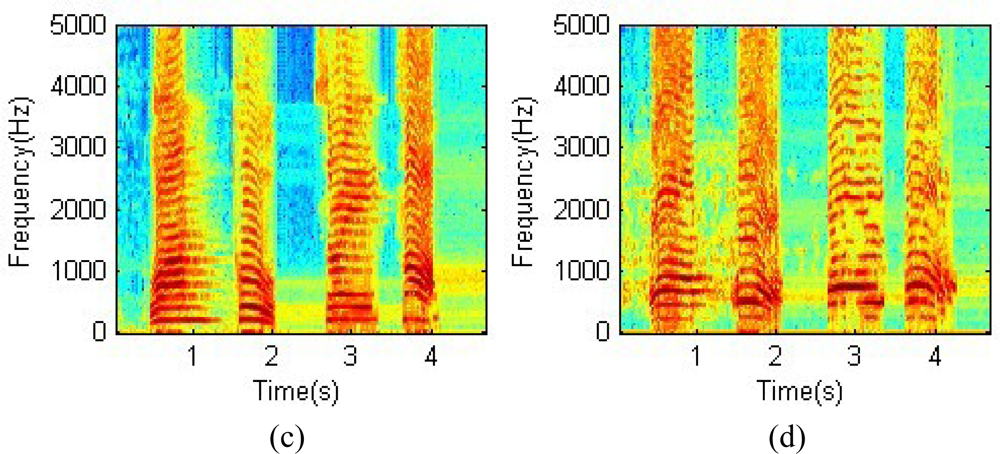
3.1. Denoise of the speech signal recording
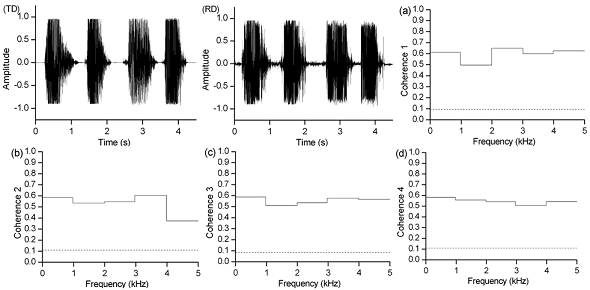
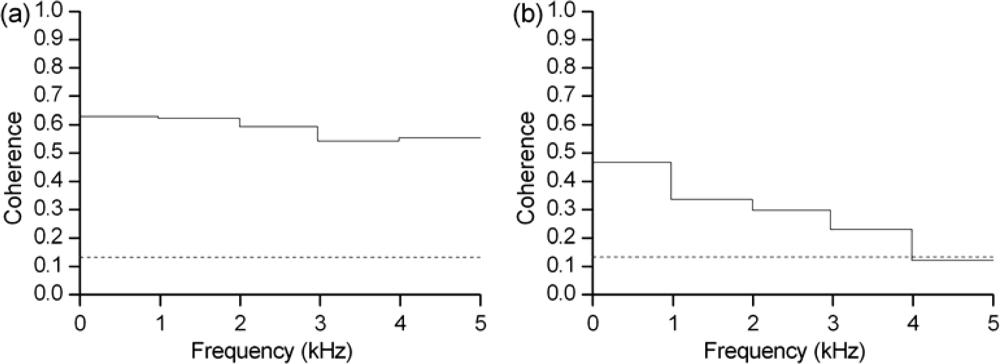
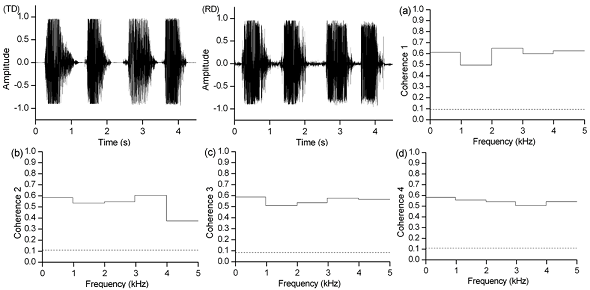
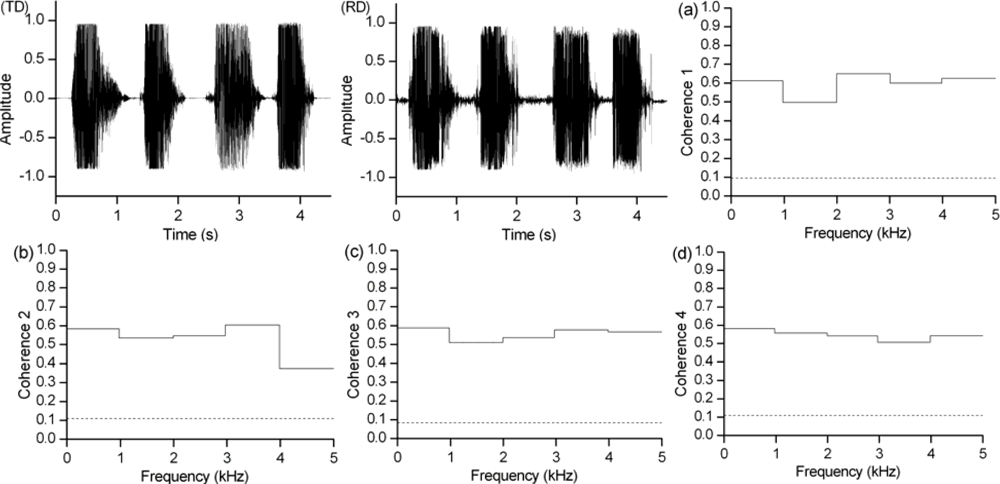
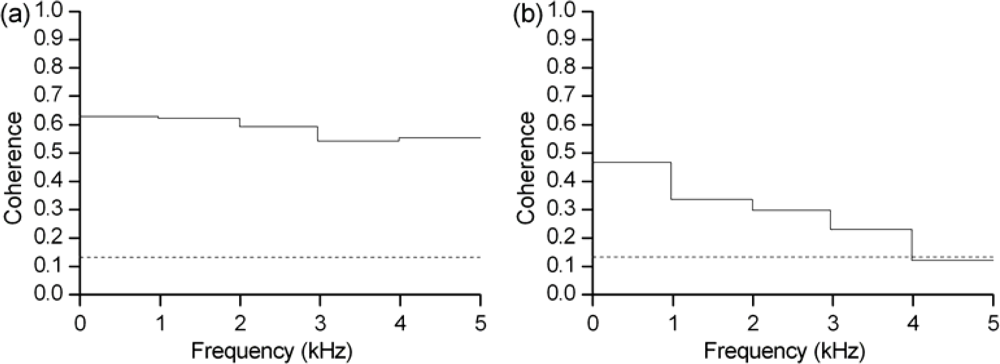
3.2. Coherence analysis of speech signals
3.3. MOS test of speech signal
4. Experimental Results
5. Discussion
Acknowledgments
References and Notes
- van der Donk, A.G.H.; Scheeper, P.R.; Olthuis, W.; Bergveld, P. Modelling of silicon condenser microphones. Sens. Actuat. A: Phys 1994, 40, 203–216. [Google Scholar]
- Kwon, H.S.; Lee, K.C. Double-chip condenser microphone for rigid backplate using DRIE and wafer bonding technology. Sens. Actuat. A: Phys 2007, 138, 81–86. [Google Scholar]
- Wu, C.Y.; Chen, J.M.; Kuo, C.F. Low polarization voltage and high sensitivity CMOS condenser microphone using stress relaxation design. Procedia Chem 2009, 1, 859–862. [Google Scholar]
- Li, Z.W. Millimeter wave radar for detecting the speech signal applications. Int. J. Infrared Mill. Wave 1996, 17, 2175–2183. [Google Scholar]
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2009, (in press).. [Google Scholar]
- Hemmerling, T.M.; Michaud, G.; Deschamps, S.; Trager, G. An external monitoring site at the neck cannot be used to measure neuromuscular blockade of the larynx. Anesth. Analg 2005, 100, 1718–1722. [Google Scholar]
- Holzrichter, J.F.; Burnett, G.C.; Ng, L.C.; Lea, W.A. Speech articulator measurements using low power EM-wave sensors. J. Acoust. Soc. Am 1998, 103, 622–625. [Google Scholar]
- Hu, R.Q.; Raj, B. A robust voice activity detector using an acoustic doppler radar. Proceedings of IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), San Juan, Puerto Rico, November 27–December 2, 2005; pp. 171–176.
- Xiao, Y.M.; Lin, J.; Boric-Lubecke, O.; Lubecke, V.M. A ka-band low power doppler radar system for remote detection of cardiopulmonary motion. Proceedings of the 27th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Shanghai, China, September 1–4, 2005; pp. 7151–7154.
- Erzin, E. Improving throat microphone speech recognition by joint analysis of throat and acoustic microphone recordings. IEEE Trans. Audio, Speech Lan. P 2009, 17, 1316–1324. [Google Scholar]
- Quatieri, T.F. Exploiting nonacoustic sensors for speech encoding. IEEE Trans. Audio, Speech Lan. P 2006, 14, 533–544. [Google Scholar]
- Akargün, Ü.ç.; Erzin, E. Estimation of acoustic microphone vocal tract parameters from throat microphone recordings. In In-Vehicle Corpus and Signal Processing for Driver Behavior; Springer: Boston, MA, USA, 2009; pp. 1–9. [Google Scholar]
- Plant, G.; Gnosspelius, J.; Levitt, H. The use of tactile supplements in Lipreading Swedish and English: A single-subject study. J. Speech Lan. Hear. Res 2000, 43, 172–183. [Google Scholar]
- Weik, M. Superheterodyne receiver. In Computer Science and Communications Dictionary; Springer: Boston, MA, USA, 2001. [Google Scholar]
- Maughan, S.M.; Kee, H.H.; Newson, T.P. Novel distributed fibre sensor using microwave heterodyne detection of spontaneous Brillouin backscatter. Proceedings of the 14th International Conference on Optical Fibre Sensors (OFS 2000), Venice, Italy, October 11–13, 2000.
- Droitcour, A.D.; Boric-Lubecke, O.; Lubecke, V.M.; Lin, J.; Kovacs, G.T.A. Range correlation and I/Q performance benefits in single-chip silicon doppler radars for noncontact cardiopulmonary monitoring. IEEE Trans. Microwave Theory Tech 2004, 52, 838–848. [Google Scholar]
- Gu, Q. Radio architectures and design considerations. In RF System Design of Transceivers for Wireless Communications; Springer: New York, NY, USA, 2005; pp. 113–227. [Google Scholar]
- Wang, J.Q.; Zheng, C.X.; Lu, G.H.; Jing, X.J. A new method for identifying the life parameters via radar. EURASIP J. Appl. Signal Process 2007, 2007, 16–24. [Google Scholar]
- Lu, G.; Yang, F.; Tian, Y.; Jing, X.; Wang, J. Contact-free Measurement of Heart Rate Variability via a Microwave Sensor. Sensors 2009, 9, 9572–9581. [Google Scholar]
- Goldstein, M. Classification of methods used for assessment of text-to-speech systems according to the demands placed on the listener. Speech Commun 1995, 16, 225–244. [Google Scholar]
- Viswanathan, M.; Viswanathan, M. Measuring speech quality for text-to-speech systems: development and assessment of a modified mean opinion score (MOS) scale. Comput. Speech Lan 2005, 19, 55–83. [Google Scholar]
- Kempka, T.; Kaiser, T.; Solbach, K. Microwaves in fire detection. Fire Safety J 2006, 41, 327–333. [Google Scholar]
- Berouti, M.; Schwartz, R.; Makhoul, J. Enhancement of speech corrupted by acoustic noise. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’79), Washington, DC, USA, April 2–4, 1979; pp. 208–211.
- Wang, D.J.L. The unimportance of phase in speech enhancement. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’82), Paris, France, May 3–5, 1982; pp. 679–681.
- Ding, H.; Soon, I.Y.; Koh, S.N.; Yeo, C.K. A spectral filtering method based on hybrid wiener filters for speech enhancement. Speech Commun 2009, 51, 259–267. [Google Scholar]
- Stagray, J.R.; Downs, D.; Sommers, R.K. Contributions of the fundamental, resolved harmonics, and unresolved harmonics in tone-phoneme identification. J. Speech Hear. Res 1992, 35, 1406–1409. [Google Scholar]
- Shen, J.X.; Xia, Y.F.; Xu, Z.M.; Zhao, S.Q.; Guo, J.Z. Speech evaluation of partially implantable piezoelectric middle ear implants in vivo. Ear Hear 2000, 21, 275–279. [Google Scholar]
- Achermann, P.; Borbély, A. Coherence analysis of the human sleep electroencephalogram. Neuroscience 1998, 85, 1195–1208. [Google Scholar]
- Salza, P.L.; Foti, E.; Nebbia, L.; Oreglia, M. MOS and Pair Comparison Combined Methods for Quality Evaluation of Text-to-Speech Systems. Acta Acust. United Acust 1996, 82, 650–656. [Google Scholar]
- Schaefer, C.; Enderes, T.; Ritter, H.; Zitterbart, M. Subjective quality assessment for multiplayer real-time games. Proceedings of the 1st Workshop on Network and System Support for Games, Braunschweig, Germany, April 16–17, 2002; pp. 74–78.
- Zha, W.; Chan, W.Y. Objective speech quality measurement using statistical data mining. EURASIP J. Appl. Signal Process 2005, 2005, 1410–1424. [Google Scholar]
- Ng, L.C.; Burnett, G.C.; Holzrichter, J.F.; Gable, T.J. Denoising of human speech using combined acoustic and EM sensor signal processing. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’00), Istanbul, Turkey, June 5–9, 2000; 1.
- Lawrence, D.E. Acoustic and electromagnetic wave interaction: analyticalformulation for acousto-electromagnetic scattering behavior of adielectric cylinder. IEEE Trans. Anten. Propag 2001, 49, 1382–1392. [Google Scholar]
- Ramm, A.G. Electromagnetic wave scattering by many small particles. Phys. Lett. A 2007, 360, 735–741. [Google Scholar]
- Yu, M.Y.; Shukla, P.K.; Ong, R.S.B. Scattering of electromagnetic waves by electron acoustic waves. Planet. Space Sci 1987, 35, 295–298. [Google Scholar]
- Hanamitsu, M.; Kataoka, H. Effect of artificially lengthened vocal tract on vocal fold oscillation’s fundamental frequency. J. Voice 2004, 18, 169–175. [Google Scholar]
- Brown, C.A.; Bacon, S.P. Fundamental frequency and speech intelligibility in background noise. Hear. Res. 2009, (in press).. [Google Scholar]
- Lin, J.C. A new IEEE standard for safety levels with respect to human exposure to radiofrequency radiation. IEEE Ant. Propag. Mag 2006, 48, 157–159. [Google Scholar]
- Kubel, E. Advancements in microwave heating technology. Indust. Heat 2005, 72, 43–53. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microphone | G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 |
|---|---|---|---|---|---|---|---|---|
| Radar | 4.50 | 4.35 | 4.58 | 4.57 | 4.25 | 4.37 | 4.13 | 4.46 |
| Traditional | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Jiao, M.; Lu, G.; Jing, X.; Li, S.; Li, Y.; Wang, J. A Novel Radar Sensor for the Non-Contact Detection of Speech Signals. Sensors 2010, 10, 4622-4633. https://doi.org/10.3390/s100504622
Jiao M, Lu G, Jing X, Li S, Li Y, Wang J. A Novel Radar Sensor for the Non-Contact Detection of Speech Signals. Sensors. 2010; 10(5):4622-4633. https://doi.org/10.3390/s100504622
Chicago/Turabian StyleJiao, Mingke, Guohua Lu, Xijing Jing, Sheng Li, Yanfeng Li, and Jianqi Wang. 2010. "A Novel Radar Sensor for the Non-Contact Detection of Speech Signals" Sensors 10, no. 5: 4622-4633. https://doi.org/10.3390/s100504622