Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers


Abstract
:1. Introduction
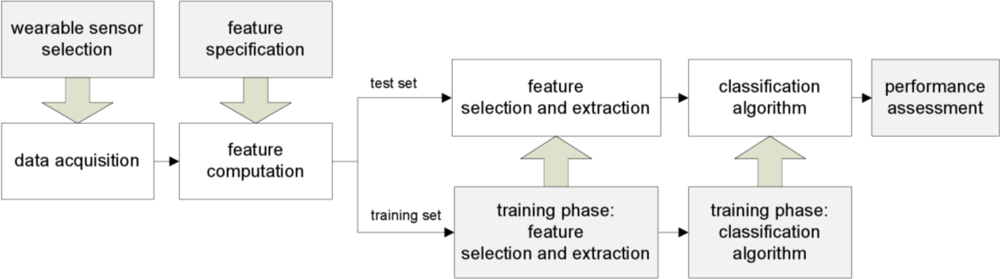
2. Methods for Automatic Classification of Human Physical Activity
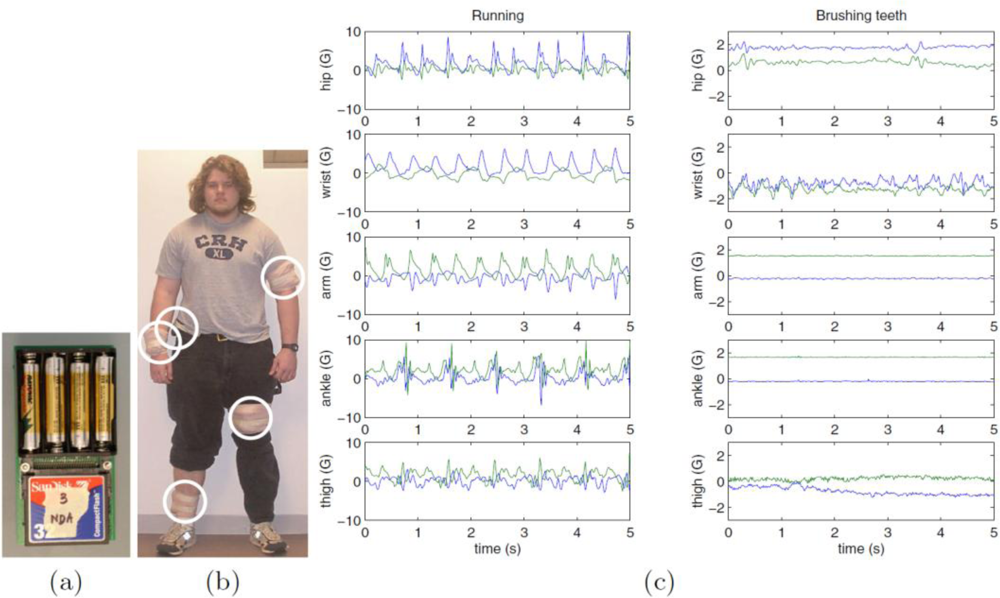
2.1. Wearable sensors and data acquisition
2.2. Feature evaluation
2.3. Feature selection and extraction
2.4. Taxonomy of classifiers
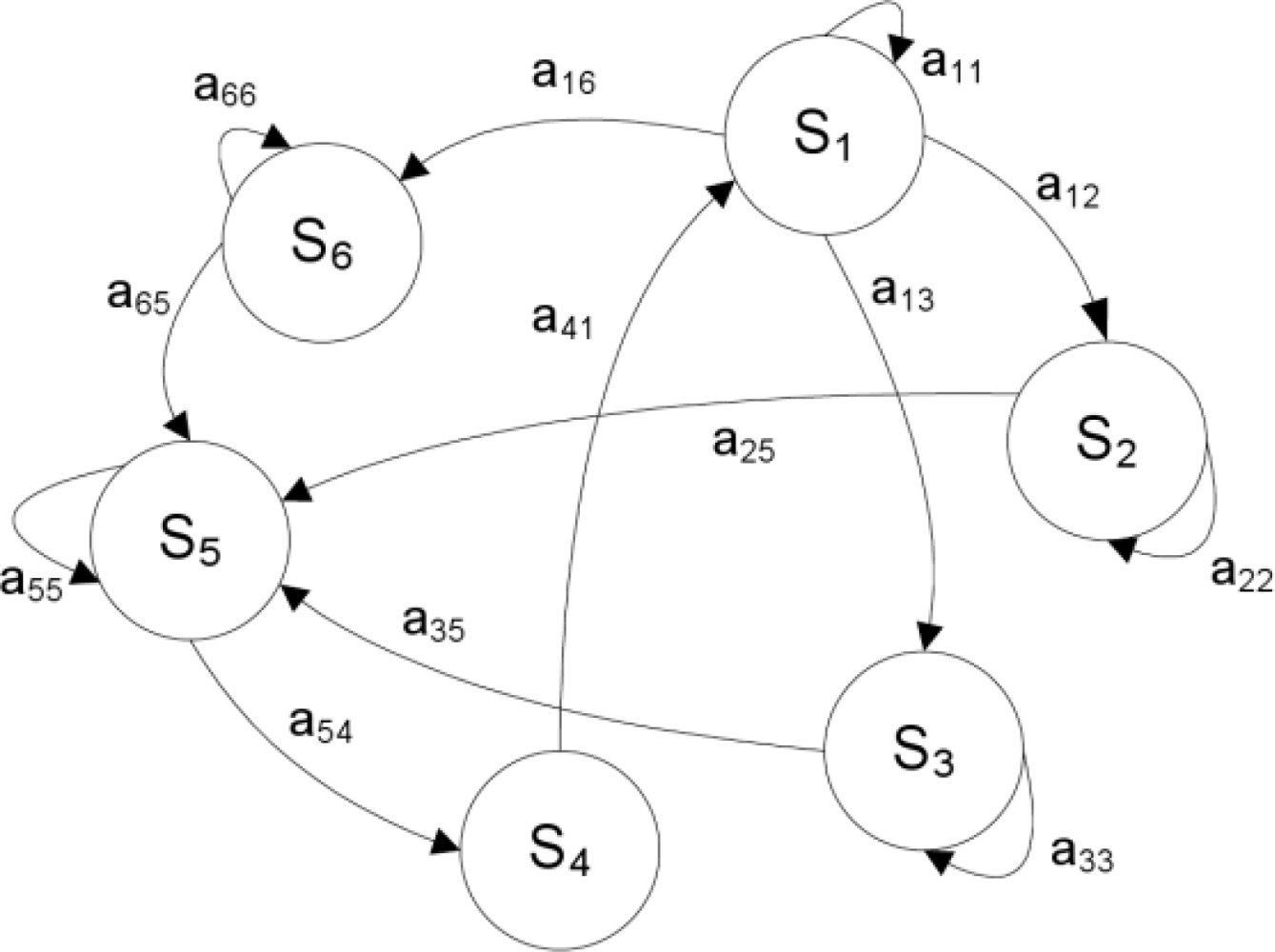
2.5. Background on Markov models and Hidden Markov Models
- prior probability vector π, with size (1 × Q); it is composed of the probabilities πi of each state Si of being the state X at the initial time t0:
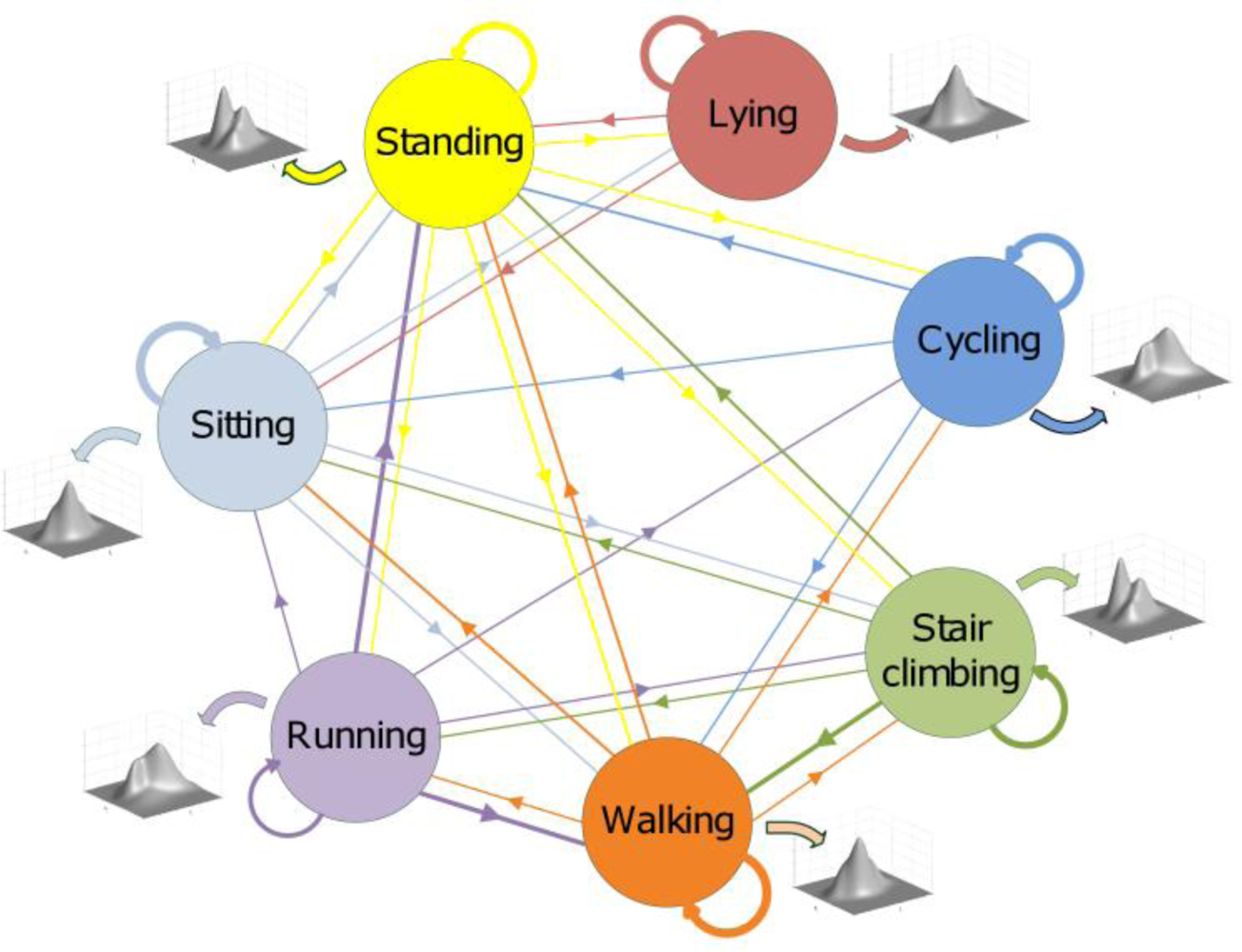
- transition probability matrix (TPM) A, with size (Q × Q), whose elements aij are the probabilities of transitions from the state Si at time tn to the state Sj occupied at time tn+1, as schematically depicted in Figure 2 for a six-state Markov chain:
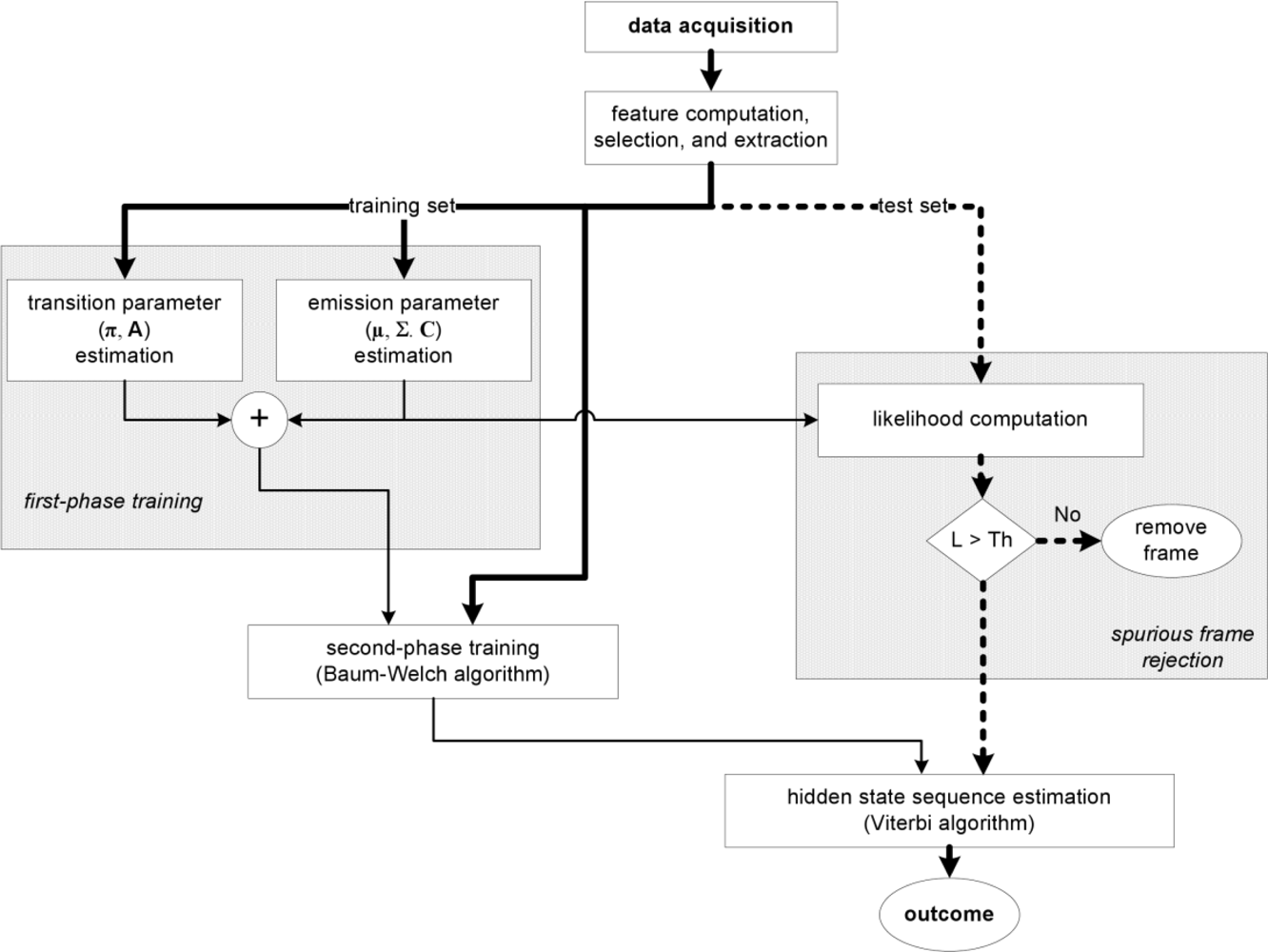
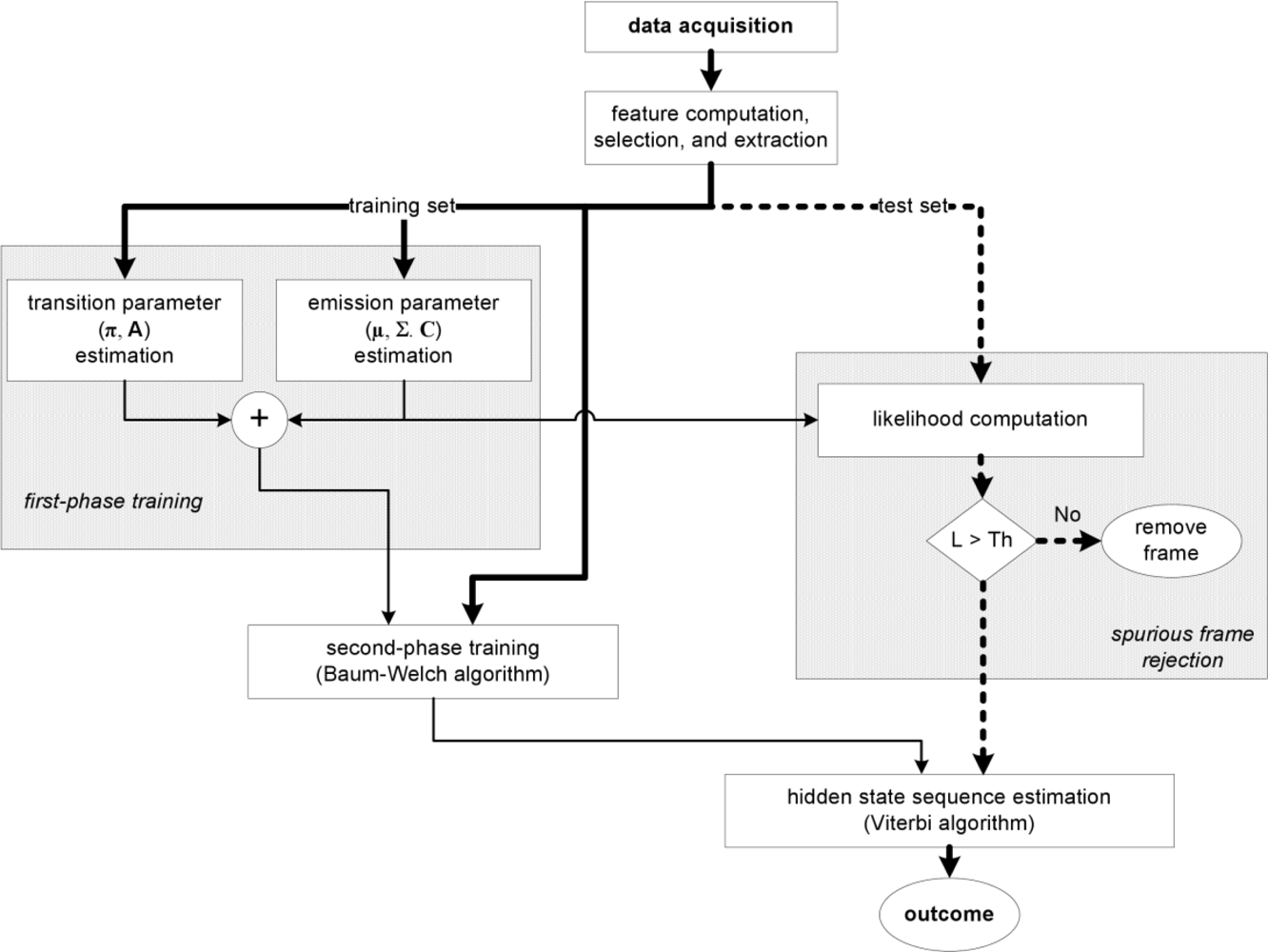
2.6. HMM-based sequential classifiers
- π, prior probability vector, 1 × Q;
- A, transition probability matrix Q × Q;
- μ, set of mean value matrices, Q × M × d;
- Σ, set of covariance matrices, Q × M × d × d;
- C, set of mixing parameters, Q × M.
3. Validation Study
3.1. Dataset for physical activity classification
3.2. Feature vectors
3.3. Single-frame classification algorithms
3.4. cHMM-based sequential classification algorithm
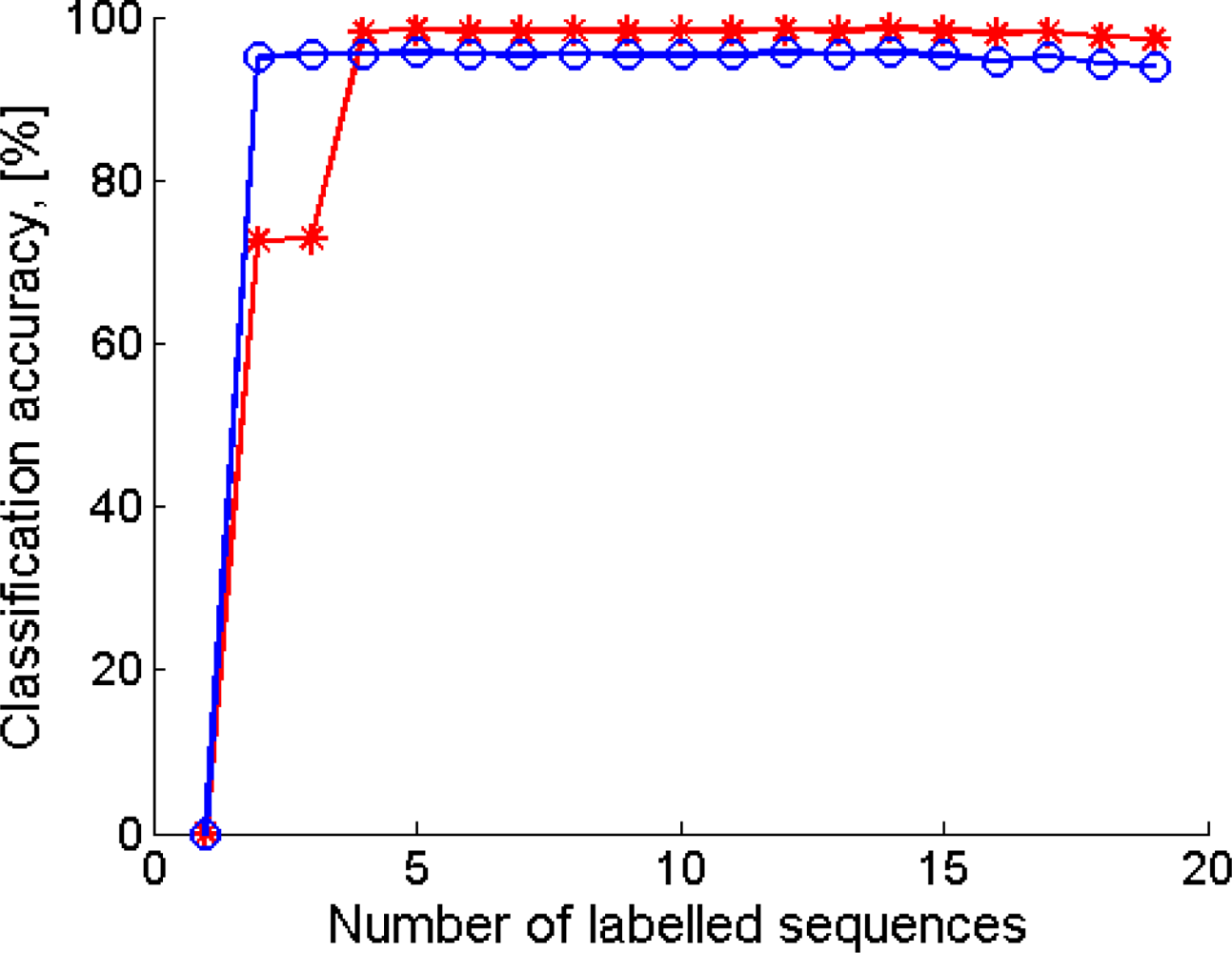
4. Results
5. Discussion and Conclusions
Acknowledgments
References
- Meijer, G.A.L.; Westerterp, K.R.; Verhoeven, F.M.H.; Koper, H.B.M.; ten Hoor, F. Methods to assess physical activity with special reference to motion sensors and accelerometers. IEEE Trans. Biomed. Eng 1991, 38, 221–229. [Google Scholar]
- Bouten, C.V.C.; Koekkoek, K.T.M.; Verduin, M.; Kodde, R.; Janssen, J.D. A triaxial accelerometer and portable data processing unit for the assessment of daily physical activity. IEEE Trans. Biomed. Eng 1997, 44, 136–147. [Google Scholar]
- Brézillon, P. Context in problem solving: a survey. Knowl. Eng. Rev 1999, 14, 47–80. [Google Scholar]
- Wasson, G.; Sheth, P.; Alwan, M.; Granata, K.; Ledoux, A.; Cunjun, H. User intent in a shared control framework for pedestrian mobility aids. Proceedings of the International Conferences on Intelligent Robots and Systems (IROS '03), Las Vegas, NV, USA, October 27–31, 2003.
- Yu, H.; Spenko, M.; Dubowsky, S. An adaptive shared control system for an intelligent mobility aid for the elderly. Auton. Rob 2003, 15, 53–66. [Google Scholar]
- Hirata, Y.; Hara, A.; Kosuge, K. Motion control of passive intelligent walker using servo brakes. IEEE Trans. Rob 2007, 23, 981–990. [Google Scholar]
- Chuy, O.Y.; Hirata, Y.; Zhidong, W.; Kosuge, K. A control approach based on passive behavior to enhance user interaction. IEEE Trans. Rob 2007, 23, 899–908. [Google Scholar]
- Alwan, M.; Ledoux, A.; Wasson, G.; Sheth, P.; Huang, C. Basic walker-assisted gait characteristics derived from forces and moments exerted on the walker's handles: results on normal subjects. Med. Eng. Phys 2007, 29, 380–389. [Google Scholar]
- Glover, J.; Thrun, S.; Matthews, J.T. Learning user models of mobility-related activities through instrumented walking aids. Proceedings of IEEE International Conference on Robotics and Automation (ICRA '04), New Orleans, LA, USA, April 26–May 1, 2004; pp. 3306–3312.
- Sabatini, A.M.; Genovese, V.; Pacchierotti, E. A mobility aid for the support to walking and object transportation of people with motor impairments. Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS '02), Lausanne, Switzerland, September 30–October 2, 2002; pp. 1349–1354.
- Hirata, Y.; Komatsuda, S.; Kosuge, K. Fall prevention control of passive intelligent walker based on human model. Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS'08), Nice, France, September 22–26, 2008; pp. 1222–1228.
- Krause, A.; Siewiorek, D.P.; Smailagic, A.; Farringdon, J. Unsupervised, dynamic identification of physiological and activity context in wearable computing. Proceedings of the 7th IEEE International Symposium on Wearable Computers, White Plains, NY, USA, October 21–23, 2003; pp. 88–97.
- Su, M.C.; Chen, Y.Y.; Wang, K.H.; Tew, C.Y.; Huang, H. 3D arm movement recognition using syntactic pattern recognition. Artif. Intell. Eng 2000, 14, 113–118. [Google Scholar]
- Begg, R.; Kamruzzaman, J. A machine learning approach for automated recognition of movement patterns using basic, kinetic and kinematic gait data. J. Biomech 2005, 38, 401–408. [Google Scholar]
- Poppe, R. Vision-based human motion analysis: an overview. Comput. Vis. Image Underst 2007, 108, 4–18. [Google Scholar]
- Welch, G.; Foxlin, E. Motion tracking: no silver bullet, but a respectable arsenal. IEEE Comput. Graph. Appl 2002, 22, 24–38. [Google Scholar]
- Yazdi, N.; Ayazi, F.; Najafi, K. Micromachined inertial sensors. Proc. IEEE 1998, 86, 1640–1659. [Google Scholar]
- Sabatini, A.M. Inertial sensing in biomechanics: a survey of computational techniques bridging motion analysis and personal navigation. In Computational Intelligence for Movement Sciences: Neural Networks and Other Emerging Techniques; Begg, R., Palaniswami, M., Eds.; Idea Group Pubilishing: Hershey, PA, USA, 2006; pp. 70–100. [Google Scholar]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: a validation study in ambulatory monitoring. Comput. Hum. Behav 1999, 15, 571–583. [Google Scholar]
- Morris, J.R.W. Accelerometry—a technique for the measurement of human body movements. J. Biomech 1973, 6, 729–736. [Google Scholar]
- Padgaonkar, A.J.; Krieger, K.W.; King, A.I. Measurement of angular acceleration of a rigid body using linear accelerometers. ASME J. Appl. Mech 1975, 42, 552–556. [Google Scholar]
- Cappa, P.; Masia, L.; Patane, F. Numerical validation of linear accelerometer systems for the measurement of head kinematics. J. Biomech. Eng 2005, 127, 919–928. [Google Scholar]
- Aminian, K.; Robert, P.; Buchser, E.; Rutschmann, B.; Hayoz, D.; Depairon, M. Physical activity monitoring based on accelerometry: validation and comparison with video observation. Med. Biol. Eng. Comput 1999, 37, 304–308. [Google Scholar]
- Aminian, K.; Najafi, B.; Büla, C.; Leyvraz, P.F.; Robert, P. Spatio-temporal parameters of gait measured by an ambulatory system using miniature gyroscopes. J. Biomech 2002, 35, 689–699. [Google Scholar]
- Sabatini, A.M.; Martelloni, C.; Scapellato, S.; Cavallo, F. Assessment of walking features from foot inertial sensing. IEEE Trans. Biomed. Eng 2005, 52, 486–494. [Google Scholar]
- Foxlin, E. Pedestrian tracking with shoe-mounted inertial sensors. IEEE Comput. Graph. Appl 2005, 25, 38–46. [Google Scholar]
- Elble, R.J. Accelerometry. In Handbook of Clinical Neurophysiology; Mark, H., Ed.; Elsevier: Maryland Heights, MO, USA, 2003; pp. 181–190. [Google Scholar]
- Mathie, M.J.; Celler, B.G.; Lovell, N.H.F.; Coster, A.C. Classification of basic daily movements using a triaxial accelerometer. Med. Biol. Eng. Comput 2004, 42, 679–687. [Google Scholar]
- Rothney, M.P.; Neumann, M.; Beziat, A.; Chen, K.Y. An artificial neural network model of energy expenditure using nonintegrated acceleration signals. J. Appl. Physiol 2007, 103, 1419–1427. [Google Scholar]
- Veltink, P.H.; Bussmann, H.J.; de Vries, W.; Martens, W.J.; Van Lummel, R.C. Detection of static and dynamic activities using uniaxial accelerometers. IEEE Trans. Rehab. Eng 1996, 4, 375–385. [Google Scholar]
- Kiani, K.; Snijders, C.J.; Gelsema, E.S. Computerized analysis of daily life motor activity for ambulatory monitoring. Technol. Health Care 1997, 5, 307–318. [Google Scholar]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Pervasive Computing; Springer Berlin/Heidelberg: Berlin, Germany, 2004; pp. 1–17. [Google Scholar]
- Van Laerhoven, K.; Cakmakci, O. What shall we teach our pants? Proceedings of the 4th IEEE International Symposium on Wearable Computers (ISWC'00), Atlanta, GA, USA, October 16–17, 2000; pp. 77–83.
- Mantyjarvi, J.; Himberg, J.; Seppanen, T. Recognizing human motion with multiple acceleration sensors. Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Tucson, AZ, USA, October 7–10, 2001; pp. 747–752.
- Lee, S.H.; Park, H.D.; Hong, S.Y.; Lee, K.J.; Kim, Y.H. A study on the activity classification using a triaxial accelerometer. Proceedings of the 25th Silver Anniversary International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS'03), Cancun, Mexico, September 17–21, 2003; pp. 2941–2943.
- Aminian, K.; Robert, P.; Jequier, E.; Schutz, Y. Estimation of speed and incline of walking using neural network. IEEE Trans. Instrum. Meas 1995, 44, 743–746. [Google Scholar]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: a review. IEEE Trans. Pattern Anal. Mach. Intell 2000, 22, 4–37. [Google Scholar]
- Allen, F.R.; Ambikairajah, E.; Lovell, N.H.; Celler, B.G. Classification of a known sequence of motions and postures from accelerometry data using adapted Gaussian mixture models. Physiol. Meas 2006, 27, 935–951. [Google Scholar]
- Song, K.-T.; Wang, Y.Q. Remote activity monitoring of the elderly using a two-axis accelerometer. Proceedings of the CACS Automatic Control Conference, Tainan, Taiwan, November 18–19, 2005.
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligenc, Pittsburgh, PA, USA, July 9–13, 2005; pp. 1541–1546.
- Randell, C.; Muller, H. Context awareness by analysing accelerometer data. Proceedings of the 4th IEEE Internat. Symp. Wearable Computers (ISWC '00), Atlanta, GA, USA, October 16–17, 2000; pp. 175–176.
- Sekine, M.; Tamura, T.; Akay, M.; Fujimoto, T.; Togawa, T.; Fukui, Y. Discrimination of walking patterns using wavelet-based fractal analysis. IEEE Trans. Neur. Syst. Rehab. Eng 2002, 10, 188–196. [Google Scholar]
- Sekine, M.; Tamura, T.; Togawa, T.; Fukui, Y. Classification of waist-acceleration signals in a continuous walking record. Med. Eng. Phys 2000, 22, 285–291. [Google Scholar]
- Najafi, B.; Aminian, K.; Paraschiv-Ionescu, A.; Loew, F.; Büla, C.; Robert, P. Ambulatory system for human motion analysis using a kinematic sensor: monitoring of daily physical activity in the elderly. IEEE Trans. Biomed. Eng 2003, 50, 711–723. [Google Scholar]
- Lee, S.W.; Mase, K. Activity and location recognition using wearable sensors. IEEE Perv. Comput 2002, 1, 24–32. [Google Scholar]
- Bussmann, J.B.J.; Martens, W.L.J.; Tulen, J.H.M.; Schasfoort, F.C.; Van Den Berg Emons, H.J.G.; Stam, H.J. Measuring daily behavior using ambulatory accelerometry: the Activity Monitor. Behav. Res. Meth. Instrum. Comp 2001, 33, 349–356. [Google Scholar]
- Karantonis, D.M.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Informat. Technol. Biomed 2006, 10, 156–167. [Google Scholar]
- Yang, J.; Xu, Y.; Chen, C.S. Human action learning via Hidden Markov Model. IEEE Trans. Syst. Man Cybern., Part A 1997, 27, 34–44. [Google Scholar]
- Rabiner, L.R. A tutorial on Hidden Markov Models and selected applications in speech recognition. Proc. EEE 1989, 77, 257–286. [Google Scholar]
- Pylvalainen, T. Accelerometer based gesture recognition using continuous HMMs. Pattern Recogn. Image Anal 2005, 1, 639–646. [Google Scholar]
- Liang, R.-H.; Ouhyoung, M. A real-time continuous alphabetic sign language to speech conversion VR system. Comput. Graph. Forum 1995, 14, 67–76. [Google Scholar]
- Hannaford, B.; Lee, P. Hidden Markov Model analysis of force/torque information in telemanipulation. Internat. J. Rob. Res 1991, 10, 528–539. [Google Scholar]
- Sundaresan, A.; Chowdhury, A.R. A Hidden Markov Model based framework for recognition of humans from gait sequences. Proceedings of IEEE International Conferences on Image Processing (ICIP'03), Barcelona, Spain, September 14–17, 2003; pp. 93–96.
- PRTools toolbox. Available online: http://www.prtools.org/ (accessed on 29 January 2010).
- MATLABArsenal. Available online: http://www.informedia.cs.cmu.edu/yanrong/ (accessed on 29 January 2010).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: an update. SIGKDD Explor. Newsl 2009, 11, 10–18. [Google Scholar]
- LIBSVM toolbox. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 30 January 2010).
- HMM toolbox. Available online: http://people.cs.ubc.ca/~murphyk/Software/HMM/ (accessed on 30 January 2010).
- Sabatini, A.M. Adaptive filtering algorithms enhance the accuracy of low-cost inertial/magnetic sensing in pedestrian navigation systems. Int. J. Comput. Intell. Appl 2008, 7, 351–361. [Google Scholar]
- Sabatini, A.M. Dead-reckoning method for personal navigation systems using Kalman filtering techniques to augment inertial/magnetic sensing. In Kalman Filter: Recent Advances and Applications; Moreno, V.M., Pigazo, A., Eds.; I-Tech Education and Publishing KG: Vienna, Austria, 2009; pp. 251–268. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Sensors | Features | Classifiers | Activity | Subjects | Accuracy [%] |
|---|---|---|---|---|---|---|
| [38] | 1 tri-axis accelerometer (3D acc) | Raw data Delta coefficients DC component | GMM | 8 | 6 | 91.3 |
| [39] | 1 bi-axis accelerometer (2D acc) | Wavelet coefficients | k-NN | 5 | 6 | 86.6 |
| [40] | 1 3D acc | Standard deviation Energy distribution DC component Correlation coefficients | Naive Bayesian k-NN SVM Binary decision | 8 | NA | 46.3–99.3 |
| [32] | 5 2D acc | Standard deviation Energy distribution DC component Entropy Correlation coefficients | Naive Bayesian k-NN Binary decision | 20 | 20 | 84 |
| [34] | 2 3D acc | Wavelet coefficients | ANN | 4 | 6 | 83–90 |
| [41] | 1 2D acc | RMS velocity | ANN | 6 | 10 | 95 |
| [33] | 1 2D acc Ambient sensors | Standard deviation FFT coefficients Derivative | ANN Markov chains | 7 | NA | 42–96 |
| [42] | 1 3D acc | Wavelet coefficients Fractal dimension | Threshold-based | 3 | 23 | p < 0.01 |
| [43] | 1 3D acc | Wavelet coefficients | Threshold-based | 3 | 20 | 98.8 |
| [44] | 1 2D acc 1 gyro | Wavelet coefficients | Threshold-based | 5 | 44 | > 90 |
| [35] | 1 3D acc | FFT | Threshold-based | 9 | 12 | 95.1 |
| [45] | 1 2D acc 1 gyro 1 compass | Raw data Standard deviation Derivative | Threshold-based | 5 | 8 | 92.9–95.9 |
| [23] | 2 uni-axis acc (1D acc) | Median Absolute deviation | Threshold-based | 4 | 5 | 89.3 |
| [19] | 4 1D acc Heart and breath rate | FFT | Template matching | 9 | 24 | 95.8 |
| [30] | 3 1D acc | DC component Standard deviation Signal morphology | Threshold-based Template matching | 6 | 10 | 80–97.5 |
| [46] | 5 1D acc 1 2D acc | Angular signal Motility FFT | Binary decision | 23 | NA | 81–93 |
| [47] | 1 3D acc | Magnitude area/vector Tilt angle FFT | Binary decision | 10 | 6 | 90.8 |
| Posture | Motion |
|---|---|
| sitting | walking |
| lying | stair climbing |
| standing | running |
| cycling |
| Probabilistic approach | Geometric approach | Binary decision |
|---|---|---|
| Naive Bayesian (NB) | Support vector machine (SVM) | Binary decision tree (C4.5) |
| Gaussian Mixture Model (GMM) | Nearest mean (NM) | |
| Logistic classifier | k-NN | |
| Parzen classifier | ANN (multilayer perceptron) |
| Activity | lying | cycling | climbing | walking | running | sitting | standing |
|---|---|---|---|---|---|---|---|
| lying | 0.9500 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0100 | 0.0400 |
| cycling | 0.0001 | 0.8999 | 0.0000 | 0.0400 | 0.0000 | 0.0100 | 0.0500 |
| climbing | 0.0001 | 0.0000 | 0.6199 | 0.2500 | 0.0100 | 0.0200 | 0.1000 |
| walking | 0.0001 | 0.0100 | 0.0300 | 0.7999 | 0.0200 | 0.0700 | 0.0700 |
| running | 0.0001 | 0.0100 | 0.0100 | 0.3500 | 0.3999 | 0.0100 | 0.2200 |
| sitting | 0.0200 | 0.0000 | 0.0100 | 0.0400 | 0.0000 | 0.8500 | 0.0900 |
| standing | 0.0100 | 0.0300 | 0.0100 | 0.1800 | 0.0300 | 0.1200 | 0.6200 |
| Classifiers | Classification accuracy, [%] |
|---|---|
| NB | 97.4 |
| GMM | 92.2 |
| Logistic | 94.0 |
| Parzen | 92.7 |
| SVM | 97.8 |
| NM | 98.5 |
| k-NN | 98.3 |
| ANN | 96.1 |
| C4.5 | 93.0 |
| Training | Classification accuracy, [%] |
|---|---|
| First-phase only | 95.6 |
| First and second-phase combined | 98.4 |
| Implementation | Classification accuracy, [%] |
|---|---|
| Without rejection of spurious data | 73.3 |
| With rejection of spurious data | 99.1 |
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Mannini, A.; Sabatini, A.M. Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers. Sensors 2010, 10, 1154-1175. https://doi.org/10.3390/s100201154
Mannini A, Sabatini AM. Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers. Sensors. 2010; 10(2):1154-1175. https://doi.org/10.3390/s100201154
Chicago/Turabian StyleMannini, Andrea, and Angelo Maria Sabatini. 2010. "Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers" Sensors 10, no. 2: 1154-1175. https://doi.org/10.3390/s100201154
APA StyleMannini, A., & Sabatini, A. M. (2010). Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers. Sensors, 10(2), 1154-1175. https://doi.org/10.3390/s100201154