1. Introduction
Obesity during pregnancy is associated with adverse maternal and neonatal outcomes, and with a higher risk of developing cardiovascular and metabolic diseases in childhood and adult stages. Maternal programming of disease has been widely described [
1,
2,
3,
4,
5,
6,
7,
8,
9]. In particular, obesity programming of the offspring has been postulated to occur periconceptionally and at the end of pregnancy, when an increase in lipid and leptin expression is observed (reviewed by [
4]). Maternal obesity is linked to dysregulation of adipose tissue (AT) metabolism [
8], and an imbalance in the pro-oxidant-antioxidant system with an increase of reactive oxygen species (ROS) that results in oxidative stress [
10,
11,
12,
13]. ROS alter different cellular components such as proteins, lipids and DNA, generating oxidized biomolecules that can be used as biomarkers of oxidative stress. Carbonylated proteins (CP), malondialdehyde (MDA) and the oxidized base 8-oxo-2′-deoxyguanosine (8-oxodG) are indicators of protein oxidation, lipid peroxidation and DNA oxidation, respectively [
13].
Several studies in pregnancy have linked increased oxidative stress with lower birth weight [
14,
15], impaired growth, and higher adiposity in infants [
16]. Moreover, maternal AT secretes adipokines such as leptin, adiponectin and resistin [
17,
18], which have been implicated in metabolic control and fetal programming of adiposity in newborns and infants [
19,
20,
21,
22,
23]. Thus, quantification of maternal adipokines and oxidized biomolecules could be used as potential biomarkers of perinatal and infant health outcomes [
24,
25]. Accordingly, prenatal mathematical modeling to predict these biomarkers during pregnancy without blood sampling becomes critical to implement strategies to improve maternal and neonatal outcomes. Artificial Intelligence, particularly artificial neural network (ANN), is a powerful and rigorous tool for the analysis of non-linear and highly complex relationships that learns from all data including experimental and clinical variables, by allowing a very accurate estimation of parameters [
26,
27]. ANN has been applied in the perinatal field for diagnosis, data mining and clinical decision [
28,
29,
30,
31,
32]. However, currently no mathematical models have been reported that predict maternal blood biomarkers from clinical and anthropometric data.
Consequently, the aim of this study was to develop and validate ANN models to predict blood concentrations of adipokines and oxidative stress biomarkers at the end of pregnancy based on pre-gestational weight status and clinical data. Secondly, we calculated the relative importance of these factors in estimating the biochemical values. The third trimester of pregnancy was chosen for the estimation of maternal biomarkers, since it is considered a critical window for developmental programming by maternal obesity, distinct from early pregnancy [
4].
2. Results
We studied pregnant women during the last trimester of pregnancy (normal weight
n = 25, overweight
n = 21, obesity
n = 22). Mean GA when biochemical measurements were done was 35.2 ± 3.3 weeks.
Table 1 shows maternal anthropometric and biochemical data by BMI classification. Normal weight women were younger compared to obese women and had significantly higher concentrations of adiponectin and resistin together with lower MDA and CP levels (
p < 0.05).
In this study, mathematical models with neural networks were developed to: (1) predict the concentration of either leptin, adiponectin, resistin, 8-oxodG, MDA and CP in maternal blood at the third trimester of pregnancy (output variable) through a simple equation based on four input variables: pre-gestational maternal age, p-BMI, weight status classification and gestational age at which the sample was taken; and (2) to obtain the most critical pre-gestational parameters influencing the predicted biomarkers.
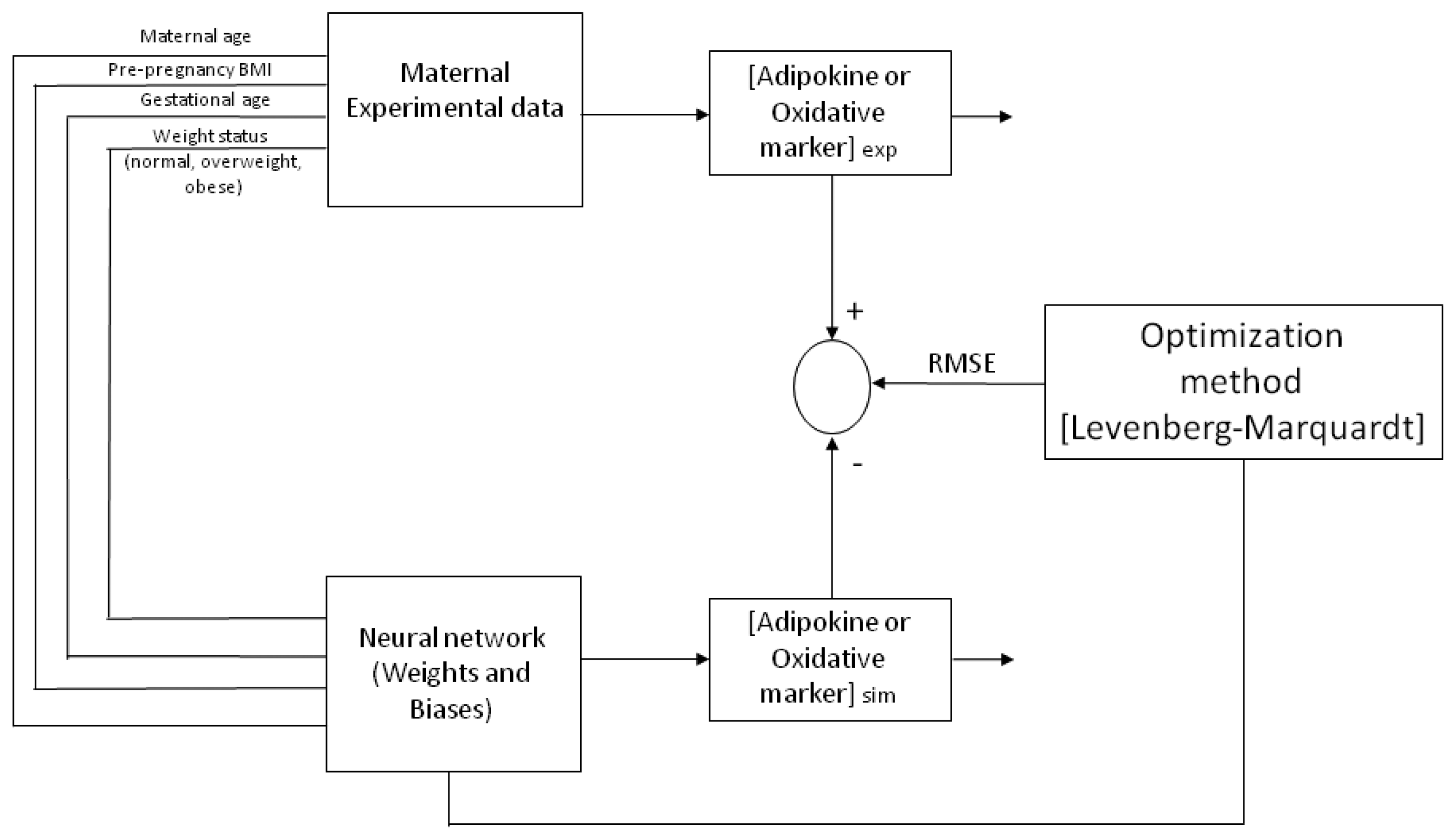
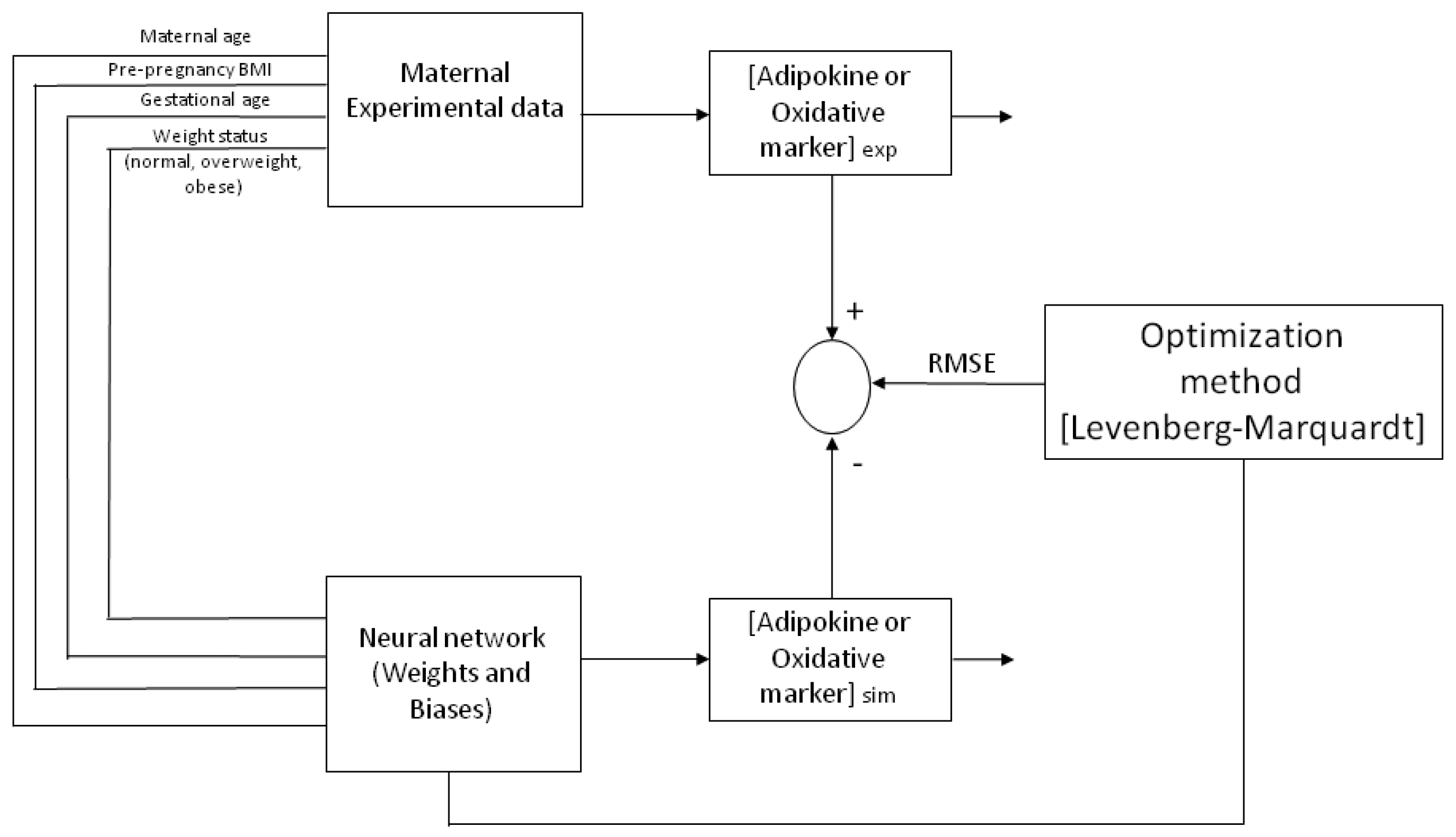
ANN neurons are organized into multiple connected layers to predict a response. The chosen architecture of the model was an input layer, a hidden layer and an output layer, trained and tested by a back-propagation algorithm (BPNN), as previously described [
29]. The percentage of the experimental database (input and output variables) for training and validation was defined. For each model, from one to several neurons were applied in the hidden layer until the minimum root mean square error (RMSE) was obtained between experimental data and predicted values from the neural network (
Figure 1). The Levenberg–Marquardt algorithm was chosen for training the model by changing the weights and biases to get the lowest value for the RMSE and being careful to avoid over fitting. The ANN was developed by software toolbox Matlab
®.
After running distinct conditions, the hyperbolic tangential (TANSIG) transfer function presented the best performance in the hidden layer for all models. In the output layer, the Log-sigmoid (LOGSIG) transfer function was applied for adiponectin, resistin, leptin, and 8-oxodG, while the linear (PURELIN) transfer function was used for MDA and CP.
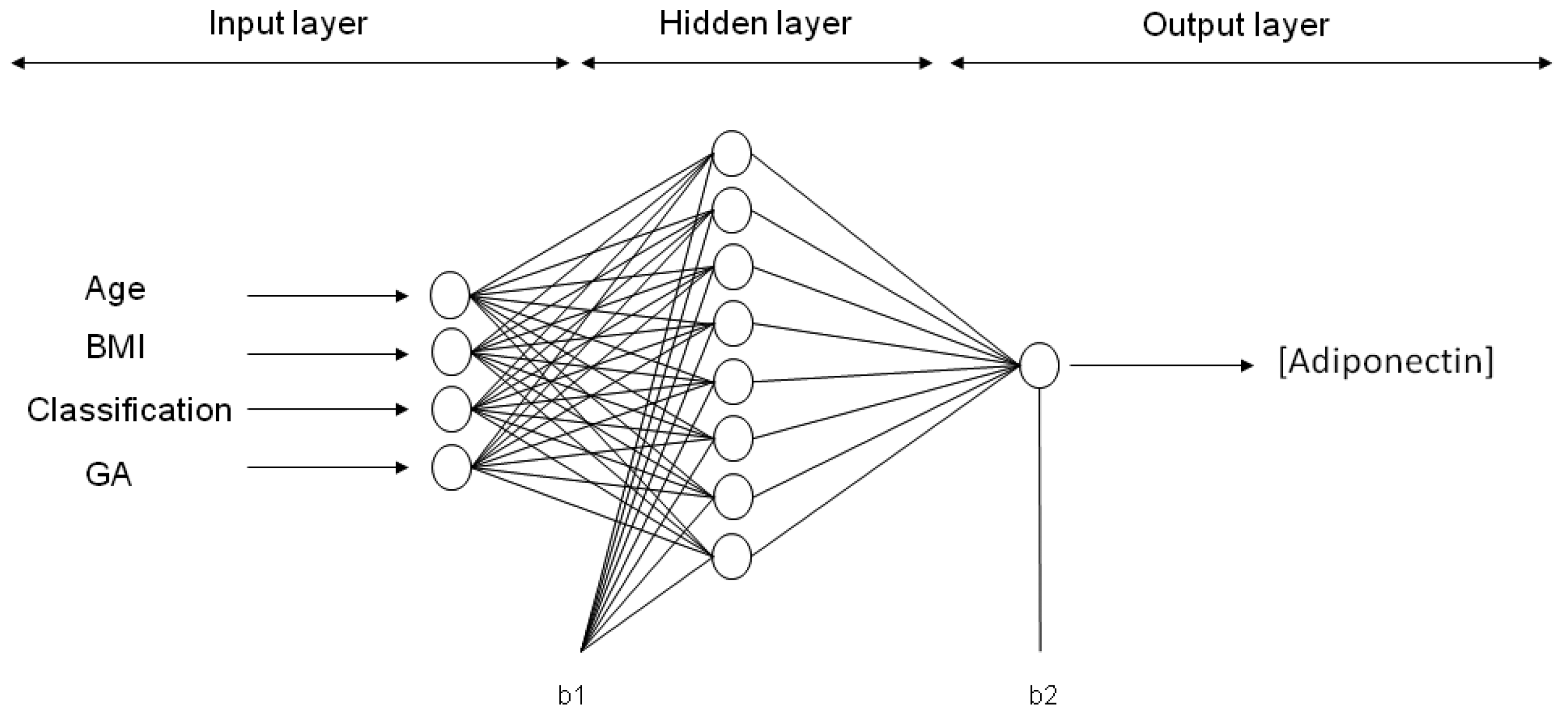
Six ANN models were trained with maternal input variables (age, p-BMI, weight status and GA) to predict the output variable: Either adiponectin, leptin, resistin, CP, MDA or 8-oxodG concentration in maternal blood at the third trimester of pregnancy. After applying 30,000 runs (with 1000 epochs in each model) in the hidden layer (1–9 neurons), the best network architecture performances were found for each adipokine or oxidative stress marker estimation. For ANN models predicting the values of adiponectin, leptin and CP, the final architecture was 4-8-1 (four input variables, eight neurons in the hidden layer, and one neuron in the output layer (biomarker concentration)). The final topology for the MDA model was 4-6-1, while, for resistin and 8-oxodG models, the best performance was 4-9-1. The representative neural architecture for the prediction of adiponectin concentration is shown in
Figure 2, whereas the weights, biases and equations for the prediction of all adipokines and oxidative stress marker concentrations are reported in Materials and Methods and
Appendix A (
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6).
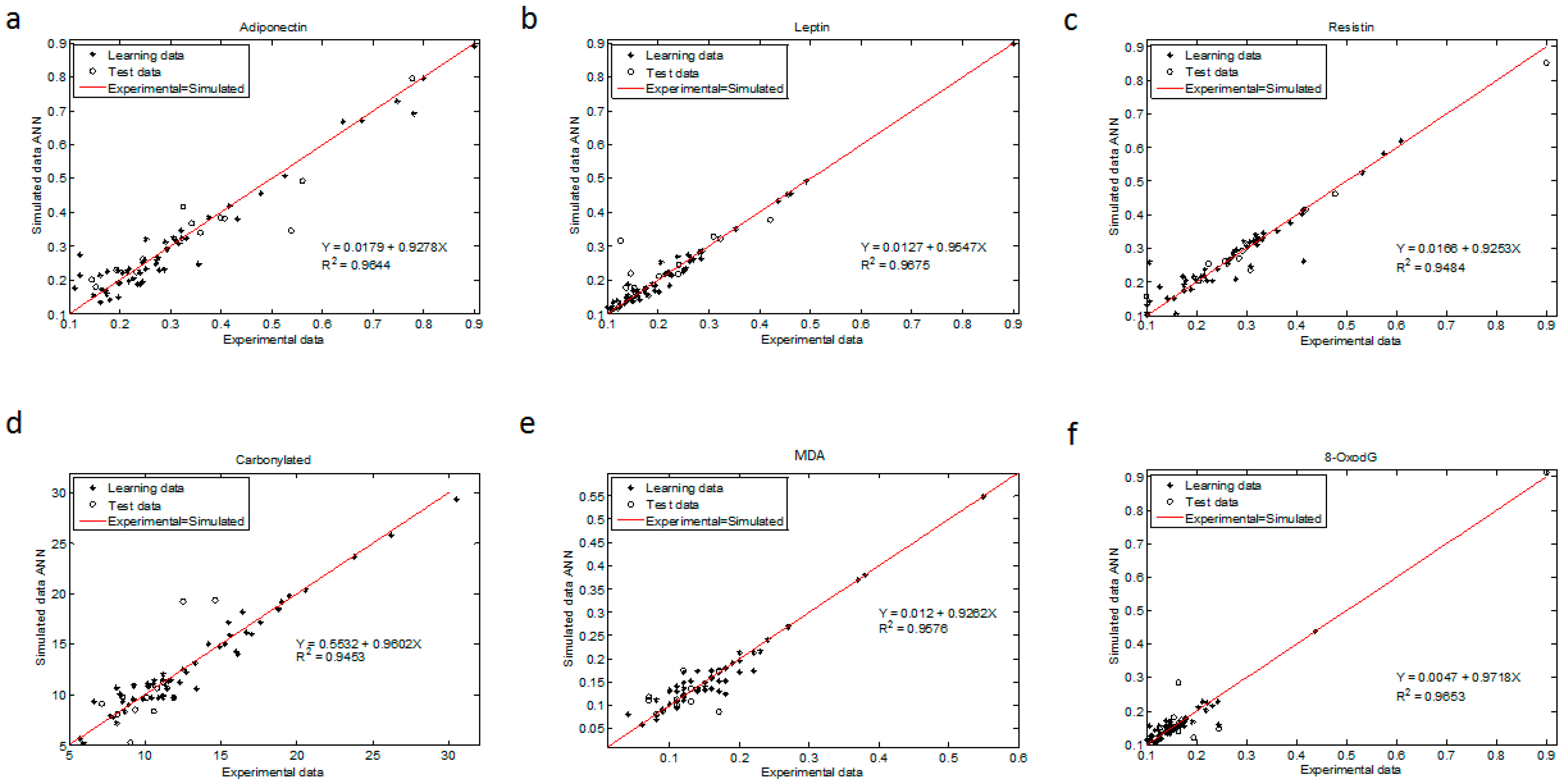
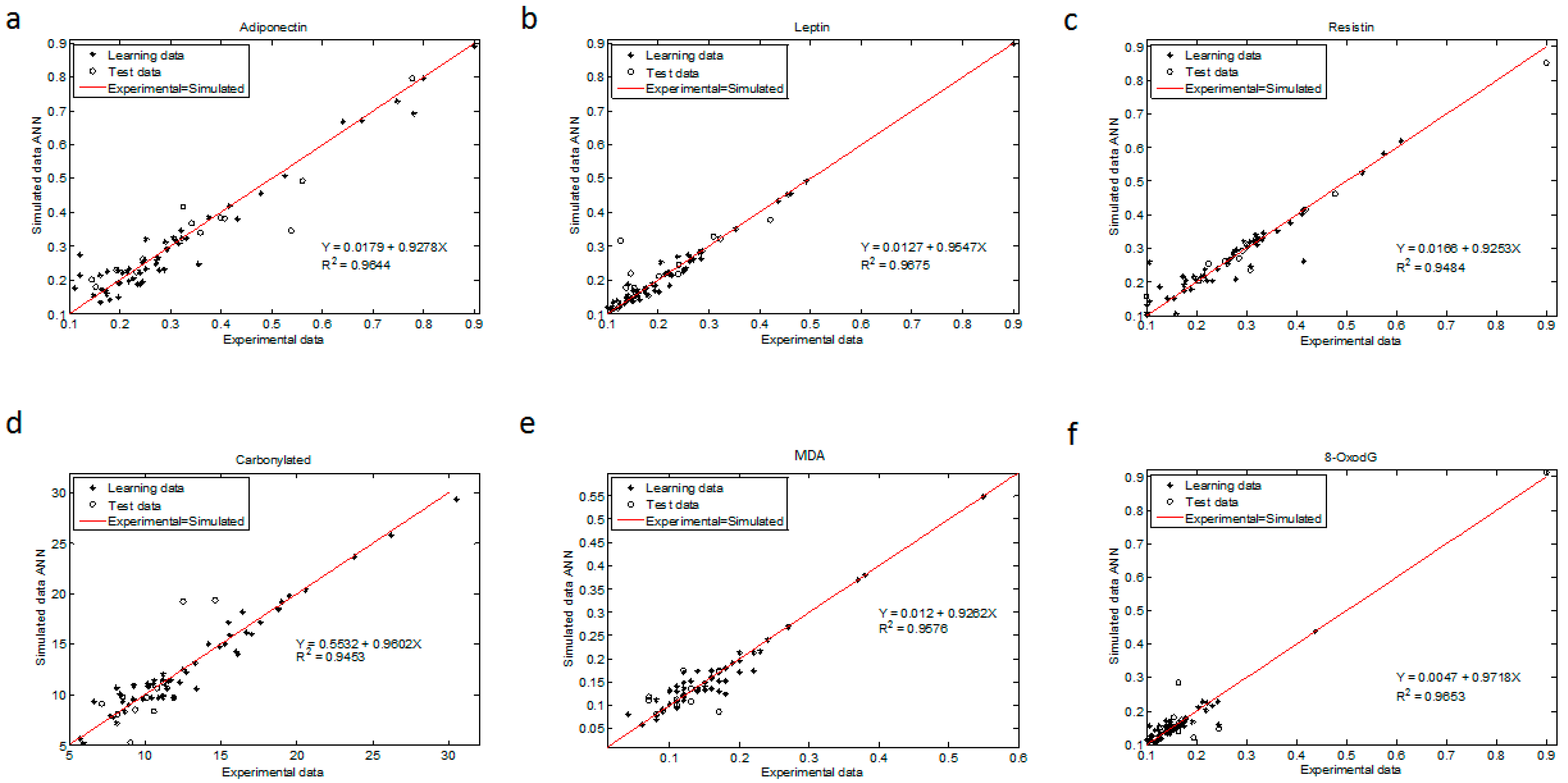
The regression coefficient for all ANN models were above 0.945 (R
2 > 0.9644 for adiponectin, R
2 > 0.9675 for leptin, R
2 > 0.9484 for resistin, R
2 > 0.9453 for CP, R
2 > 0.9576 for MDA and R
2 > 0.9653 for 8-oxodG (
Figure 3)). The statistical test from these plots showed that the upper and lower values of the slope and intercept included 1 and contained 0, respectively, with a 99.9% confidence level for all determinations (Materials and Methods and
Table A7 and
Table A8 in
Appendix A).
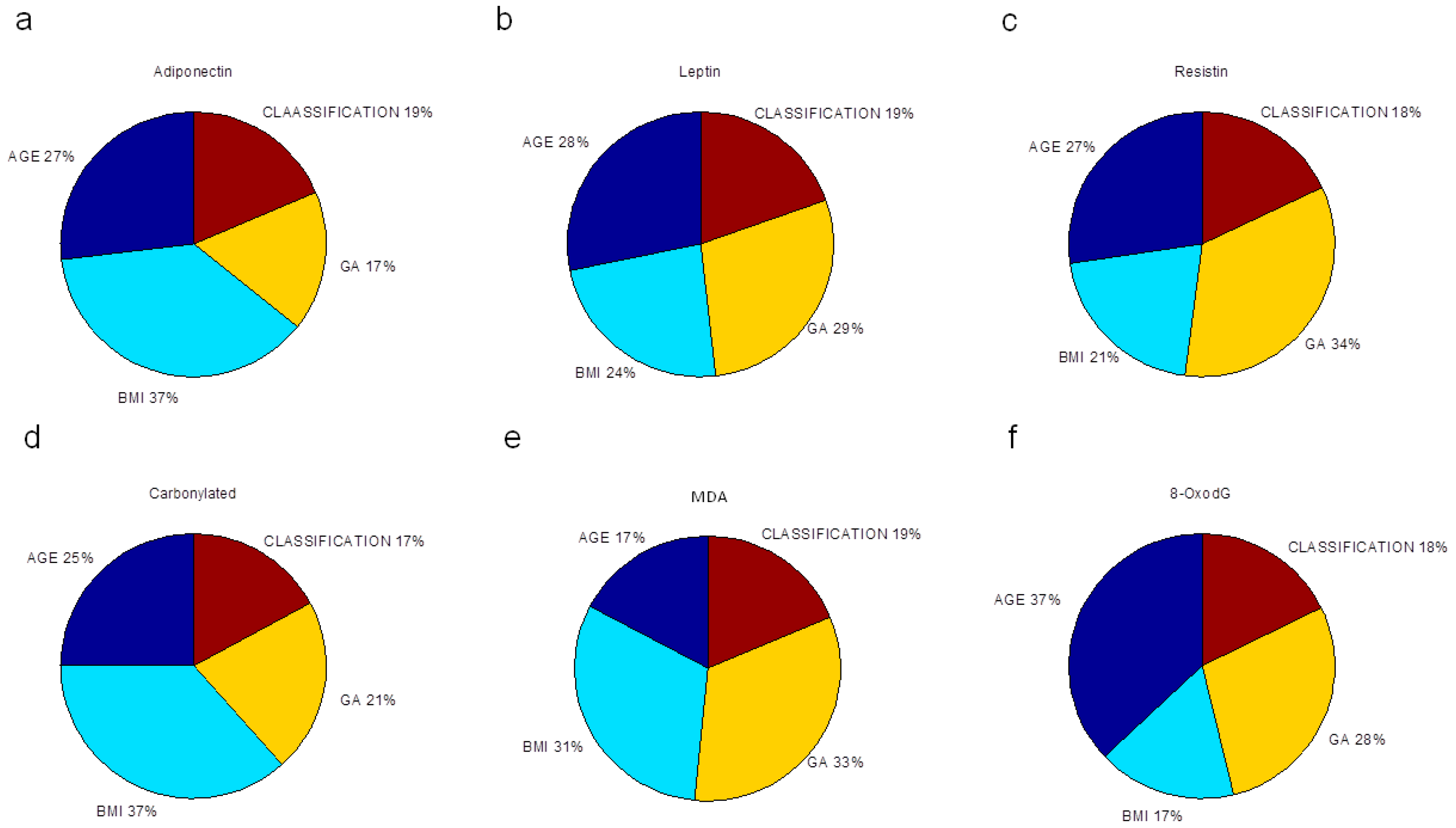
Finally, we evaluated the relative importance of pre-gestational variables in the neural network modeling of adipokine and oxidative stress marker concentrations, depicted as the percentage of quantitative significance (
Figure 3). The sensitivity analysis is based on the ANN weight matrix and the Garson equation [
33] (Materials and Methods). All maternal factors were essential in estimating the studied biochemical markers. P-BMI was the most important predictor of adiponectin followed by age. For leptin prediction, age, GA and p-BMI value had the same importance. The most relevant factor in forecasting resistin was GA; other predictor factors were age and p-BMI value. For oxidative markers, GA and p-BMI estimated MDA, while CP were predominantly predicted by p-BMI, followed by age and GA. Finally, for 8-oxodG, the meaningful variable was age, then GA and p-BMI. Weight status was the weakest predictor in all models.
3. Discussion
Nutrition and metabolic changes occur during pregnancy to promote optimal fetal growth and development. The presence of obesity in pregnancy is associated with nutrient and hormonal imbalances, and with inflammation [
34]. Altered leptin, adiponectin, and oxidative stress markers have been documented in pregnant women with obesity [
25,
35], and have been associated with adverse perinatal outcomes [
36,
37,
38]. The early prediction of alterations in these markers at the end of pregnancy is very relevant, considering the high prevalence of overweight/obesity in women of reproductive age in many countries [
39].
ANN is a tool that allowed the estimation of these biochemical markers with anthropometric and clinical variables that are generally used in clinical practice. We present six ANN models that accurately predict third trimester maternal concentrations of adipokines (adiponectin, leptin, and resistin) and DNA, lipid and protein oxidative damage markers (8-oxodG, MDA and CP, respectively). Regression coefficients between the experimental and predicted values for all determinations were superior to R2 = 0.945.
For adipokines, the model correctly estimated higher leptin concentrations together with lower adiponectin and resistin values in obese mothers in comparison with normal and overweight pregnant women, a finding that has been reported before [
25,
40]. In particular, the ANN-predicted adiponectin values (that learned from the experimental data) were similar to those found in the literature [
41].
We found that leptin prediction was equally dependent on GA, p-BMI and maternal age. This is in agreement with the literature where leptin concentration increases with gestational age in normal pregnancies, mainly produced by adipose tissue, placenta, skeletal muscle and mammary gland (reviewed by [
42]). Many studies also have shown increased leptin concentrations with higher p-BMI and in overweight/obese women [
35,
43,
44].
Maternal adiponectin has been inversely related with BMI [
45], GA and positively associated with maternal age [
46,
47]. The ANN adiponectin model derived from this study was able to predict these associations too. P-BMI was the most important parameter in estimating adiponectin and carbonylated proteins.
Pregnancy per se is an oxidative stress condition due to a higher oxygen demand [
48]. Protein carbonylation is caused by the direct attack of free radicals, by interaction with transition metals, by glycation or by adduct formation with final lipoperoxidation products (MDA) (reviewed by [
49]). In our models, CP and MDA estimated values were significantly increased in obese pregnancies compared to normal weight mothers, suggesting an increased oxidative damage in the latter and in line with the literature [
24,
50]. In this work, a higher p-BMI was related to decreased adiponectin and increased MDA concentrations, in agreement with a negative correlation between adiponectin and oxidative lipid damage during pregnancy [
51].
Gestational age at sample collection was a relevant factor (34%) for resistin and MDA predictions, suggesting that resistin and MDA levels are greatly influenced by gestational age at the end of pregnancy, despite differences in maternal BMI. These results could be explained by the resistin-dependent insulin resistance that is increased during pregnancy and is modulated in part by a higher glucose transporter 1 (GLUT-1) expression in trophoblast cells induced by resistin [
52].
Concerning oxidative damage markers, there is a physiological increase associated with women’s aging [
53] as well as with advanced gestational age in normal pregnancies [
54]. Interestingly, for 8-oxodG, the meaningful variable was maternal age (37%). The link between oxidative stress and aging has been discussed in recent years. In human clinical cohorts, increased 8-oxodG levels in muscle and leukocyte DNA were observed with increasing age [
55]. No studies have been reported in pregnancy. Investigating changes in this DNA oxidative marker during pregnancy in different age groups is pending.
Study Limitations and Strengths
A limitation of this study is the sample size (
n = 68), however, the model accurately estimated blood concentrations with regression coefficients with values >0.9. Furthermore, other ANN studies have shown validated results with smaller samples [
30]. It is important to mention that these ANN models will predict accurately adipokines and oxidative stress markers within the range in which they learn, for example healthy women with singleton pregnancy, maternal p-BMI range between 18.6 and 48.3 kg/m
2.
4. Materials and Methods
4.1. Study Design and Ethical Approval
This research was approved by the IRB of the Instituto Nacional de Perinatología Isidro Espinosa de los Reyes (register 3300-11402-01-575-17), and was conducted according to the relevant national regulations and the Helsinki Declaration with its later amendments (1985). Participation was voluntary and all women who agreed to participate signed an informed consent.
4.2. Characteristics of the Population
Healthy women with singleton pregnancy, and with blood sample taken during the third trimester of gestation (28–40 weeks of gestation) were enrolled in the study (n = 68). Samples were selected by convenience and stratified by pregestational body mass index (p-BMI). Gestational age (GA) was determined using the last menstrual period date; if GA with this method differed significantly from first trimester ultrasound measurement, then the latter was used. Women with multiple pregnancies, Type 2 Diabetes Mellitus or gestational diabetes mellitus, chronic or gestational hypertension, renal or autoimmune disease, intrauterine fetal growth restriction, fetal structural abnormalities or drug intake that affects metabolism and/or inflammation (metformin, steroids, insulin, and antihypertensives, among others) were excluded.
4.3. Anthropometry
Pre-gestational weight was self-reported. Stature (cm) was measured with a stadiometer (SECA 220, Hamburg, Germany) by trained personnel. P-BMI was calculated using the following formula: Weight/stature2. BMI classification was done according to the World Health Organization criteria, where a p-BMI > 18.5 was classified as normal weight, p-BMI > 25 as overweight, and >30 as obesity.
4.4. Biochemical Markers
Maternal blood samples were collected in the fasting state, in Vacutainer tubes (Becton-Dickinson, Franklin Lakes, NJ, USA) and centrifuged at 4 °C for 15 min at 1000× g. The serum and plasma samples were stored at −80 °C until the assays were performed.
Serum glucose, adiponectin, leptin, resistin, and insulin concentrations were measured by ELISA commercial kits, as previously described [
20]. Adiponectin, leptin and resistin (R & D Systems Inc., Minneapolis, MN, USA) had the following sensitivities: 0.891 ng/mL, 7.8 ng/mL and 0.055 ng/mL, respectively; and assay ranges: 3.9–250 ng/mL; 15.6–1000 pg/mL and 0.2–10 ng/mL, respectively. Insulin (Sigma-Aldrich, St. Louis, MO, USA) and glucose (DiaSys Diagnostic Systems GmbH, Holzheim, Germany) sensitivities were: 2.15 pmol/L, and 1 mg/dL, respectively; and assay ranges were: 15.6–500 pmol/mL and 1–400 mg/dL, respectively.
Homeostatic model assessment (HOMA) index was calculated according to [
56]. Oxidative DNA damage level was measured using an 8-oxodG ELISA kit (TREVIGEN, Gaithersburg, MD, USA) with a sensitivity and assay range of 0.57 ng/mL and 0.89–56.7 ng/mL, respectively. Plasma malondialdehyde (MDA) was quantified as described by Gerard et al. [
57] with 1-methyl-2-phenylindole (Sigma-Aldrich, St. Louis, MO, USA) as a standard. Sensitivity for MDA determination was 17 ng/mL and assay range of 0.27–2000 ng/mL. Protein damage was evaluated by plasma carbonyl group content, which was determined with 2,4-dinitrophenylhydrazine (DNPH), and measured according to Amici et al. [
58]. Assay range and sensitivity for CP evaluation were: 1–10 mg/mL and 1.5 nmol/mg, respectively.
4.5. Statistical Analysis
Descriptive analysis (data distribution, frequencies) were done. One-way ANOVA with DMS post hoc test was used to analyze differences by p-BMI categories (normal weight, overweight or obese). Data are expressed as mean ± SEM, and p values ≤ 0.05 were considered statistically significant. Statistical analysis was performed using the IBM SPSS v20.0 software (IBM Corporation, Armonk, NY, USA).
4.6. ANN (Learning, Testing and Validation)
An artificial neural network utilizes nodes (neurons) connected between each other in distinct layers, their relationship being defined by weights (
Wi,
Wo) and biases (
b1,
b2) that are obtained by iterations with the ANN algorithm.
Figure 4 depicts a representative architecture for the neural network model (multi-layer) with an input layer, a hidden layer and an output layer, trained and tested by a Back-propagation algorithm (BPNN). The ANN is “fed” randomly with the database and calculates the error between the experimental and predicted values. Then, it back propagates changing the weights and biases to obtain the smallest error. For all the models, the input variables chosen from the entire database were four maternal parameters: Age, p-BMI, weight status (normal weight, overweight, or obese) and GA at which maternal blood sample was taken. The output maternal variable was one biomarker: leptin, adiponectin, resistin, 8-oxodG, MDA or CP concentrations at the third trimester of pregnancy (input and output variables are depicted in
Table 2).
4.6.1. ANN Model
The experimental database (
n = 68) was randomly divided into learning (79%) and validation (21%) and then, the input variables were normalized in the range of 0.1 to 0.9, as previously described [
29]. The output variable was not normalized.
Each neuron (
n) has weights (
Wi and
Wo) and biases (
b1 and
b2) in the hidden and output layers (1) and (2):
where
In is the input variable. The value of each neuron is the argument of the transfer functions (
f and
g):
where
f is a hyperbolic tangent transfer function (TANSIG) and
g is a linear transfer function (PURELIN) or Log-Sigmoid function (LOGSIG).
We applied different transfer functions to obtain the best performance for the models. As a result of the ANN model, Equation (2) with TANSIG-PURELIN was Equation (3):
For other ANN models, Equation (2) considering TANSIG-LOGSIG was Equation (4), where
noutput is:
4.6.2. ANN Learning
In this work, to change the weights and biases, we applied the Levenberg–Marquardt (LM) algorithm, following our previously reported methods [
29]. This uses the adaptation as follows:
where
J is the Jacobian matrix (first derivative);
e is a vector of network errors;
μ is the combination coefficient with a value of 0.001 and
I is the identity matrix.
The root mean square error (RMSE) was applied as the error function which describes the performance of the network according to the following Equation (6):
where
Q is the number of data points (
n = 68);
is the experimental data and
is the network prediction.
4.6.3. Results for Maternal Adipokines and Oxidative Stress Marker ANN Models
The proposed ANN models for MDA and CP followed Equation (7) with TANSIG-PURELIN:
Equation (8) gives adiponectin, leptin, resistin and 8-oxodG with TANSIG-LOGSIG, where
noutput is:
Equations (7) and (8) give the maternal adipokine or oxidative stress marker concentrations with weights and biases in
Table A1 (Adiponectin ANN model, 4-8-1),
Table A2 (Leptin ANN model, 4-8-1),
Table A3 (Resistin ANN model, 4-9-1),
Table A4 (carbonylated proteins ANN model, 4-8-1),
Table A5 (MDA ANN model, 4-6-1) and
Table A6 (8-oxodG ANN model, 4-9-1) in
Appendix A.
4.6.4. Statistical Tests for ANN Model Validation
ANN model validation was performed using linear regression models of the experimentally measured adipokines and oxidative stress marker concentrations versus the simulated ones (learning and validation database), obtaining the slope and intercept (
Figure 3). Then, we applied a statistical test (slope and intercept, [
59]) in which the upper and lower intervals of the slope and intercept must be near 1.0 and 0 respectively, with a 99.8% confidence level according to the Student
t-test.
The regression coefficient (R
2) was then obtained from linear regression models for each biochemical value:
4.7. Sensitivity Analysis
To obtain the relative biological importance of maternal variables in predicting adipokine and oxidative stress marker concentrations, we performed a sensitivity analysis, as proposed by [
33], based on the partitioning of connection weights:
where
is the relative importance of the input variable on the output variable;
is the number of input neurons;
is the number of hidden neurons;
is the connection weight; and the superscripts
and
refer to input, hidden and output layer.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}