DivCalc: A Utility for Diversity Analysis and Compound Sampling

SciNova Informatics, 161 Madhumanjiri Apartments, Lane 4, Dahanukar Colony, Kothrud, Pune, Maharashtra, India
Molecules 2002, 7(8), 657-661; https://doi.org/10.3390/70800657
Submission received: 1 July 2002
/
Revised: 29 July 2002
/
Accepted: 7 August 2002
/
Published: 31 August 2002
{kind=link}
{kind=link}
{kind=link}
Abstract
:Diversity, in the form of genetic diversity, chemical diversity etc, is a very important concept in several areas of scientific research, and calculation of diversity is one of the most important considerations in pre-clinical drug discovery research and, in particular, in design of diverse chemical libraries for combinatorial chemistry and compound selection for High Throughput Screening (HTS). DivCalc is a WindowsTM based software that implements a previously published method of diversity calculation [1]. This facilitates sampling of a given data matrix to obtain the most diverse compounds that span the entire descriptor space.
Introduction
Pharmaceutical companies routinely screen a very high number of compounds to identify ones showing biological activity (“hits”) and thus, prospective drug candidates [2,3,4,5]. One way to increase the number of compounds in corporate libraries is to use combinatorial chemistry to synthesize a large number of molecules. Diverse corporate compound libraries are thus formed by the combination of basic building blocks like carboxylic acids, amides, amines etc. The diversity in a chemical library can thus be achieved by using diverse reagents for synthesis [2,3]. Another approach followed by many companies is the purchase of chemicals that increase the diversity of their corporate compound collections. A HTS library can easily contain a very high number of compounds ranging between 105 and 109 [5]. The challenge is to obtain a representative but diverse sample of this collection.
Clearly, diverse compound selection is an important step in the application of combinatorial chemistry and HTS in drug discovery. The idea behind diversity based sampling is to get a diverse and representative subset of compounds. [1,5]
There are several proprietary and commercial software products and approaches for diversity analysis e.g. products like DiverseSolutions and Selector from Tripos and Diversity Explorer from Accelrys can select a maximally diverse set of compounds for synthesis and aid in deciding if a purchased library complements an existing corporate collection. However there is a dearth of desktop utilities with similar functionality that quickly enable assessment or sampling of diversity. DivCalc is an attempt to bridge this gap. It implements an algorithm (DISSIM) published earlier by Flower [1] that searches for maximally dissimilar compounds, given an input data matrix of descriptors for all the chemical compounds [1].
Features And Implementation
DivCalc does not attempt to calculate descriptors and this paper does not address the issues behind descriptor calculation and selection. There are many commercial and free software packages available to calculate a number of molecular descriptors. Chemical Diversity Analysis literature is replete with papers that deal with issues of calculation and selection of one-, two- and three-dimensional descriptors. One excellent reference is the Handbook of Molecular Descriptors [6]. In general one- and two-dimensional descriptors are used for diversity analysis and three-dimensional descriptors are used for protein target specific QSAR. One such software that calculates molecular descriptors is Dragon v.2.1, available for download at http://www.disat.unimib.it/chm/.
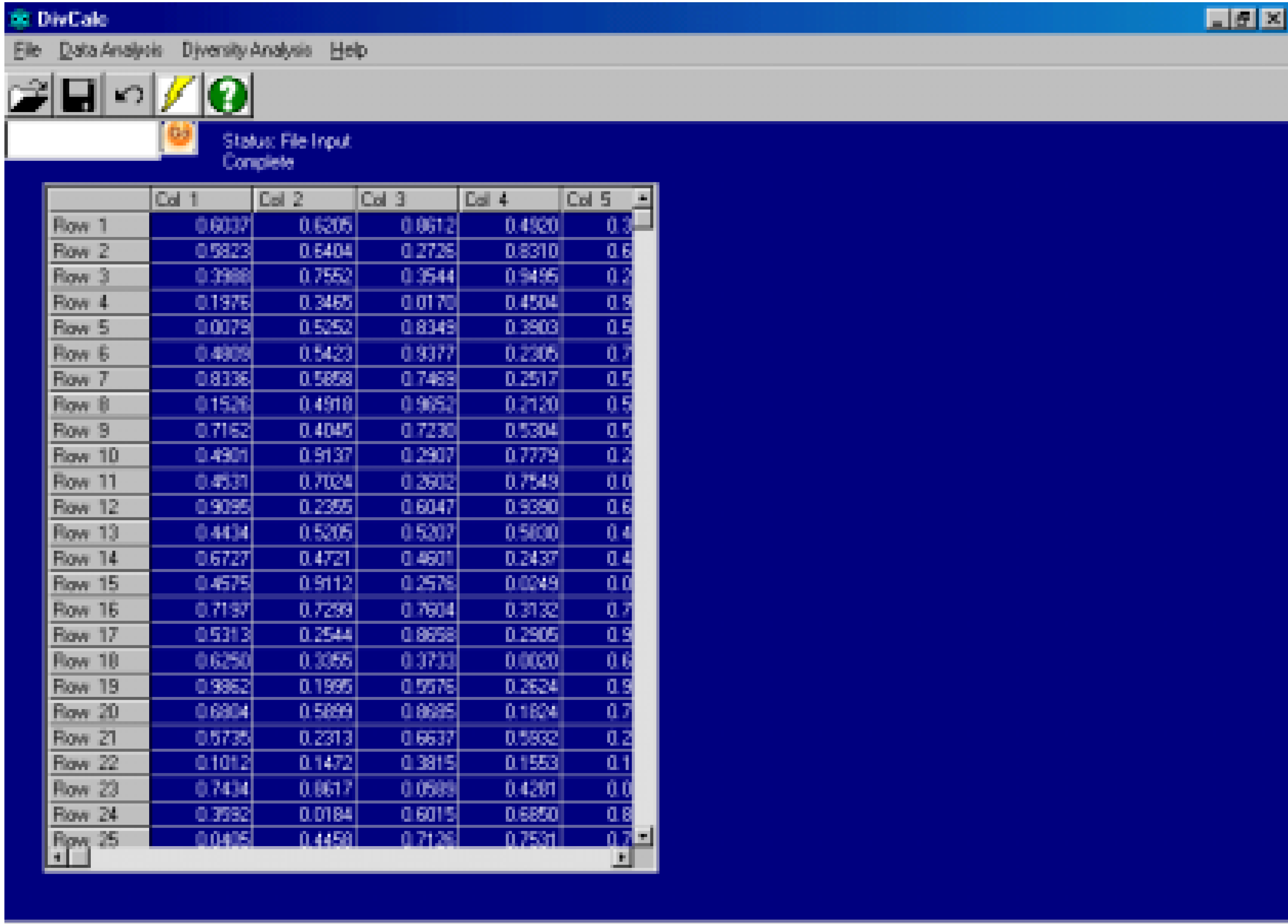
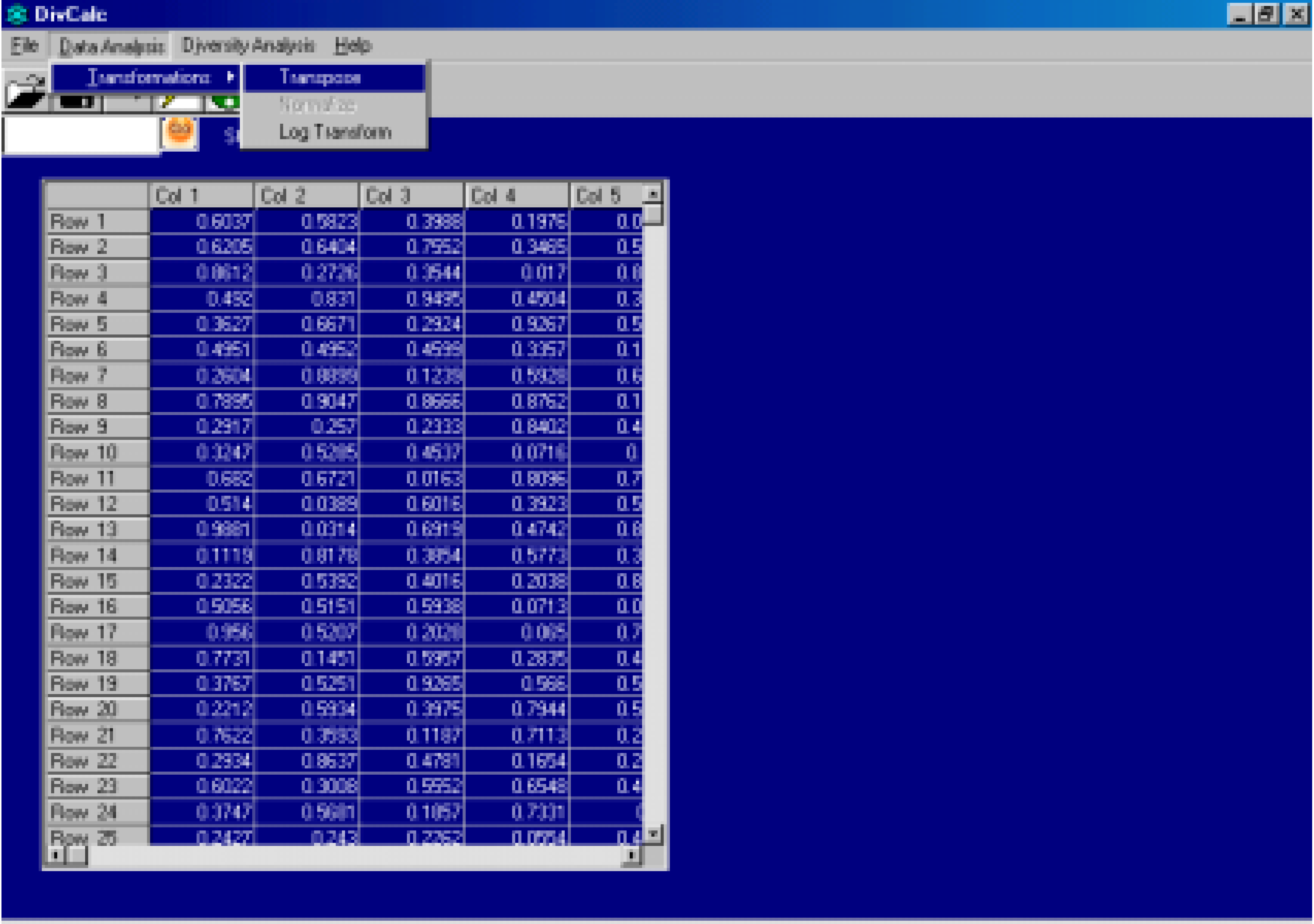
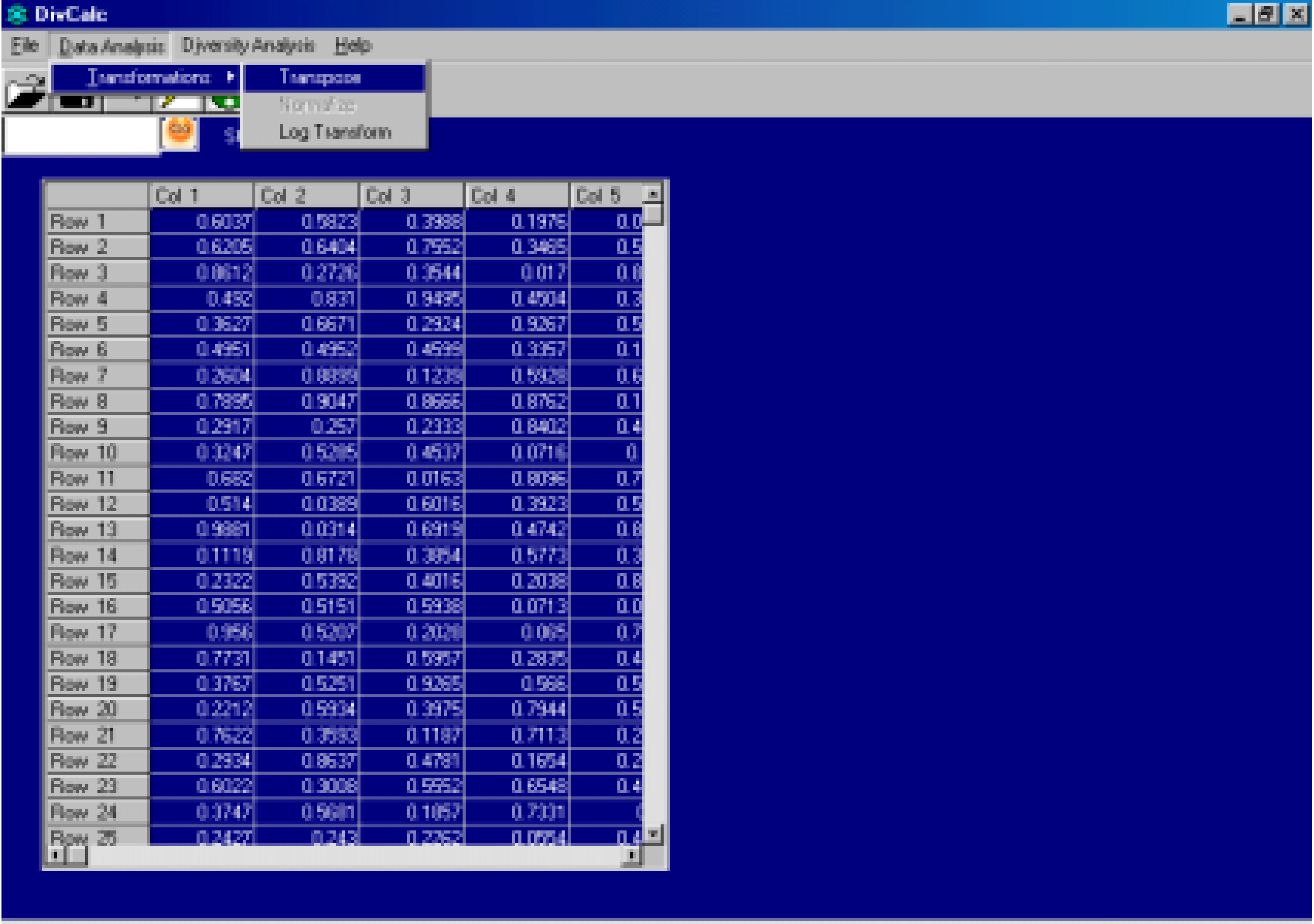
The original implementation of the DivCalc algorithm was for SGI workstations with the source code written in FORTRAN77. The ubiquity of desktops in the scientific world now warrants a re‑implementation for desktop users. The current implementation called DivCalc runs on 32 bit WindowsTM operating systems. Due to memory constraints however the current version is limited to fewer than 25,000 data points. Thus the current version is useful for diversity analysis for reagent selection. The datapoint limitation is an issue with the language used for implementation and efforts are underway to use memory efficient techniques to allow for much greater number of compounds and descriptors. The input to the program is a space delimited data file with no row and column headers. The input data is shown in an Excel™ like grid (Figure 1). Transforms like Log, Transpose and Data Normalization have been provided (Figure 2). Data Normalization is a method for scaling data by using the mean and standard deviation. Sometimes the descriptors calculated have very different ranges in which they can occur. Some descriptor values can lie between 0 and 1 and others can be large real numbers. Thus the Euclidean distance can be unnecessarily biased by large values. To avoid this, Data normalization is selected by default in DivCalc and can be deselected if not needed.
Figure 1.
Main interface screenshot of DivCalc
Figure 2.
Data Analysis Menu screenshot: Transpose
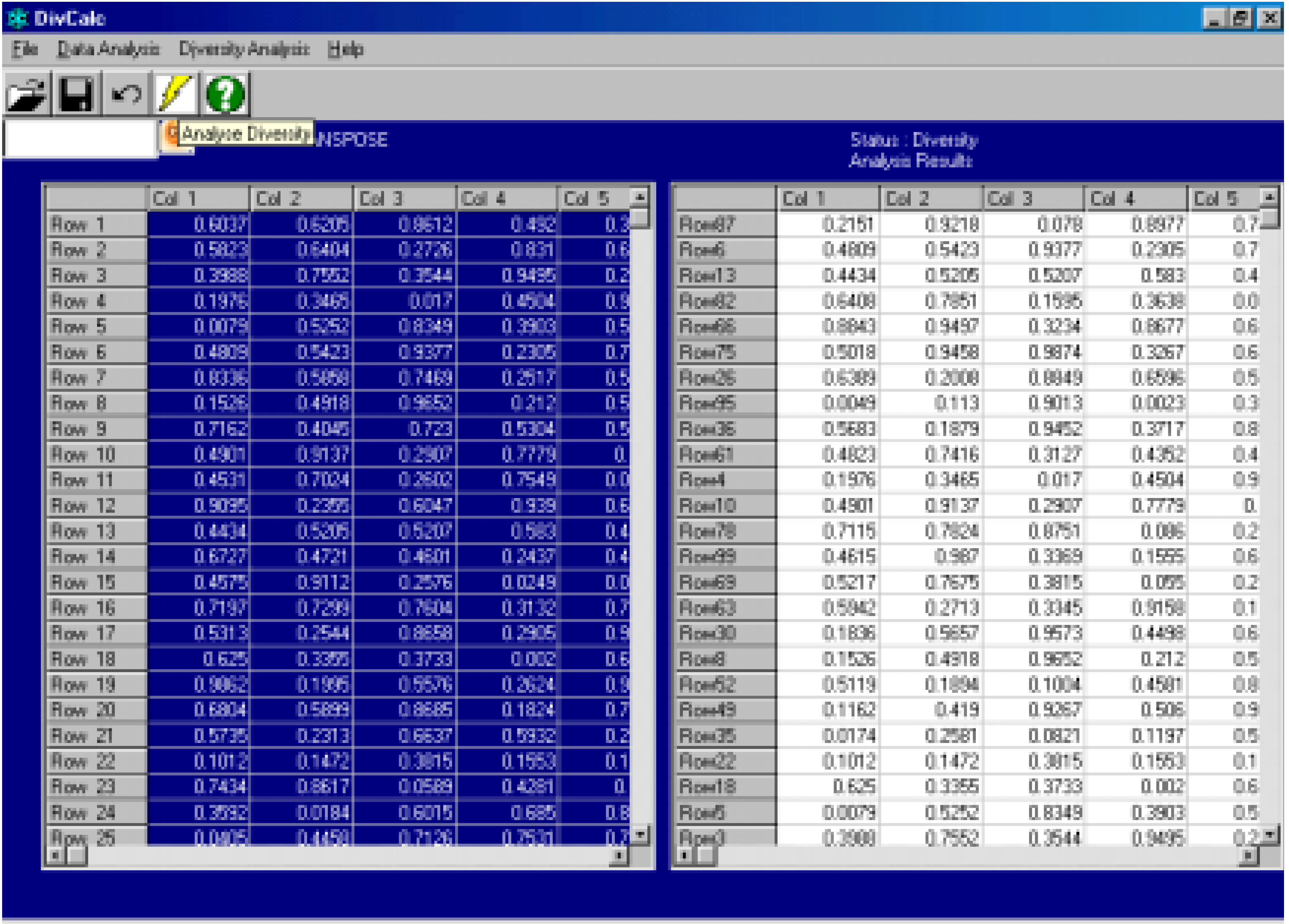
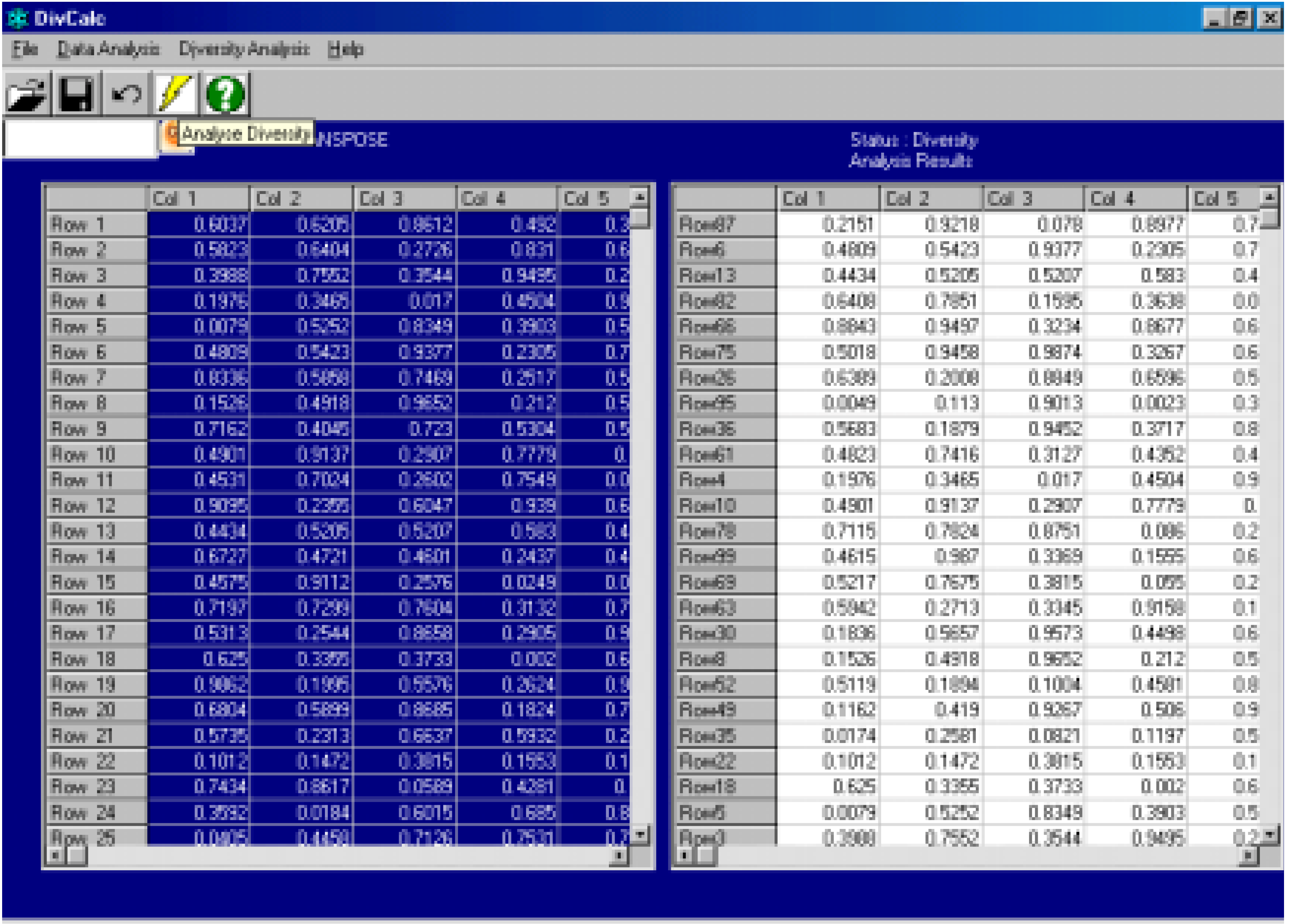
The main functionality in the menu is of course to select the most diverse compounds from the dataset. The user can set a predefined limit on the number or percentage of compounds to be displayed in the output. By default, all rows/compounds in the input are ranked by their diversity and shown in the output (Figure 3).
Figure 3.
Diversity Analysis screenshot
Algorithm
The algorithm selects k most diverse compounds from a given set of m compounds where k<=m. All calculations are performed using Euclidean distance as a measure of dissimilarity.
- The centroid of the input data is calculated.
- The compound most distant from the centroid is the first selected compound. Thus the compound with the maximum Euclidean distance from the centroid is the first selected compound.
- The compound most distant from the 1st compound is selected next.
- Hereafter the algorithm increases in complexity. At each iteration the procedure is to find the compound from the list of unselected compounds whose minimum distance to selected compounds is a maximum amongst all unselected compounds.
- Step 4 is repeated till the required number of compounds are selected.
A visual reproduction of the above steps can be seen in the paper describing the original implementation [1].
Discussion
DivCalc is a desktop program to calculate diversity for a set of compounds and to select a subset of maximally diverse compounds. The algorithm has been implemented with the desktop user in mind working in a WindowsTM environment. Work is in progress to enhance the number of data points that can be handled and provision of alternative distance formulae like Manhattan distance, correlation etc.
When DivCalc is used to find a small number of compounds, the algorithm identifies a set that is broadly spread over the whole descriptor space. However as the size of the subset increases, the dissimilarity of newly selected compounds to ones already selected, decreases rapidly[1]. So, another feature being currently worked upon is a default calculation of the ideal sample size of the subset that should be drawn. Copies of DivCalc can be obtained by sending a request to [email protected]
References
- Flower, D. DISSIM: A program for the analysis of chemical diversity. J. Mol. Graphics Mod. 1998, 16, 239–253. [Google Scholar] [CrossRef]
- Van Drie, J. H.; Lajiness, M. S. Approaches to virtual library design. DDT 1998, 3, 274–283. [Google Scholar]
- Linusson, A.; Gottfries, J.; Lindgren, F.; Wold, S. Statistical Molecular Design of Building Blocks for Combinatorial Chemistry. J. Med. Chem. 2000, 43, 1320–1328. [Google Scholar] [CrossRef]
- Leach, A. R.; Hann, M. M. The in silico world of virtual libraries. DDT 2000, 5, 326–336. [Google Scholar] [CrossRef]
- Gorse, D.; Rees, A.; Kaczorek, M; Lahana, R. Molecular Diversity and its analysis. DDT 1999, 4, 257–385. [Google Scholar] [CrossRef]
- Todeschini, R; Consonni, V. Handbook of Molecular Descriptors; Wiley-VCH: Weinheim (Germany), 2000; vol. 11; p. 667. [Google Scholar]
- Sample Availability: Not applicable
© 2002 by MDPI (http://www.mdpi.org). Reproduction is permitted for noncommercial purposes.
Share and Cite
MDPI and ACS Style
Gangal, R. DivCalc: A Utility for Diversity Analysis and Compound Sampling. Molecules 2002, 7, 657-661. https://doi.org/10.3390/70800657
AMA Style
Gangal R. DivCalc: A Utility for Diversity Analysis and Compound Sampling. Molecules. 2002; 7(8):657-661. https://doi.org/10.3390/70800657
Chicago/Turabian StyleGangal, Rajeev. 2002. "DivCalc: A Utility for Diversity Analysis and Compound Sampling" Molecules 7, no. 8: 657-661. https://doi.org/10.3390/70800657