Abstract
The quality of online services highly depends on the accuracy of the recommendations they can provide to users. Researchers have proposed various similarity measures based on the assumption that similar people like or dislike similar items or people, in order to improve the accuracy of their services. Additionally, statistical models, such as the stochastic block models, have been used to understand network structures. In this paper, we discuss the relationship between similarity-based methods and statistical models using the Bernoulli mixture models and the expectation-maximization (EM) algorithm. The Bernoulli mixture model naturally leads to a completely positive matrix as the similarity matrix. We prove that most of the commonly used similarity measures yield completely positive matrices as the similarity matrix. Based on this relationship, we propose an algorithm to transform the similarity matrix to the Bernoulli mixture model. Such a correspondence provides a statistical interpretation to similarity-based methods. Using this algorithm, we conduct numerical experiments using synthetic data and real-world data provided from an online dating site, and report the efficiency of the recommendation system based on the Bernoulli mixture models.
1. Introduction
In this paper, we study recommendation problems, in particular, the reciprocal recommendation. The reciprocal recommendation is regarded as an edge prediction problem of random graphs. For example, a job recruiting service provides preferable matches between companies and job seekers. The corresponding graph is a bipartite graph, where nodes are categorized into two groups: job seekers and companies. Directed edges from one group to the other are the expression of the user’s interests. Using this, the job recruiting service recommends unobserved potential matches between users and companies. Another common example is online dating services. Similarly, the corresponding graph is expressed as a bipartite graph with two groups, i.e., males and females. The directed edges are the preference expressions among users. The recommendation system provides potentially preferable partners to each user. The quality of such services depends entirely on the prediction accuracy of the unobserved or newly added edges. The edge prediction has been widely studied as a class of important problems in social networks [1,2,3,4,5].
In recommendation problems, it is often assumed that similar people like or dislike similar items, people, etc. Based on this assumption, researchers have proposed various similarity measures. The similarity is basically defined through the topological structure of the graph that represents the relationship among users or items. Neighbor-based metrics, path-based metrics, and random walk based metrics are commonly used in this type of analysis. Then, a similarity matrix defined from the similarity measure is used for the recommendation. Another approach is employing the statistical models, such as stochastic block models [6], that are used to estimate network structures, such as clusters or edge distributions. The learning methods using statistical models often achieve high prediction accuracy in comparison to similarity-based methods. Details on this topic are reported in [7] and the references therein.
The main purpose of this paper is to investigate the relationship between similarity-based methods and statistical models. We show that a class of widely applied similarity-based methods can be derived from the Bernoulli mixture models. More precisely, the Bernoulli mixture model with the expectation-maximization (EM) algorithm [8] naturally derives a completely positive matrix [9] as the similarity matrix. The class of completely positive matrices is a subset of doubly nonnegative matrices, i.e., positive semidefinite and element-wise nonnegative matrices [10]. Additionally, we provide an interpretation of completely positive matrices as a statistical model satisfying exchangeability [11,12,13,14]. Based on the above argument, we connect the similarity measures using completely positive matrices to the statistical models. First, we prove that most of the commonly used similarity measures yield completely positive matrices as the similarity matrix. Then, we propose an algorithm that transforms the similarity matrix to the Bernoulli mixture model. As a result, we obtain a statistical interpretation of the similarity-based methods through the Bernoulli mixture models. We conduct numerical experiments using synthetic data and real-world data provided from an online dating site, and report the efficiency of the recommendation method based on the Bernoulli mixture models.
Throughout the paper, the following notation is used. Let be for a positive integer n. For the matrices A and B, denotes the element-wise inequality and denotes that A is entry-wise non-negative. The same notation is used for the comparison of vectors. The Euclidean norm (resp. 1-norm) is denoted as (resp. ). For the symmetric matrix A, means that A is positive semidefinite.
In this paper, we mainly focus on directed bipartite graphs. The directed bipartite graph consists of the disjoint sets of nodes, , and the set of directed edges . The sizes of X and Y are n and m, respectively. Using the matrices and , the adjacency matrix of G is given by
where (respectively ) if and only if (respectively ). For the directed graph, the adjacency matrix is not necessarily symmetric. In many social networks, each node of the graph corresponds to each user with attributes such as the age, gender, preferences, etc. In this paper, an observed attribute associated with the node (resp. ) is expressed by a multi-dimensional vector (resp. ). In real-world networks, the attributes are expected to be closely related to the graph structure.
2. Recommendation with Similarity Measures
We introduce similarity measures commonly used in the recommendation. Let us consider the situation that each element in X sends messages to some elements in Y, and vice versa. The messages are expressed as directed edges between X and Y. The observation is, thus, given as a directed bipartite graph . The directed edge between nodes is called the expression of interest (EOI) in the context of the recommendation problems [15]. The purpose is to predict an unseen pair such that these two nodes will send messages to each other. This problem is called the reciprocal recommendation [15,16,17,18,19,20,21,22,23,24,25]. In general, the graph is sparse, i.e., the number of observed edges is much fewer than the number of all possible edges.
In social networks, similar people tend to like and dislike similar people, and are liked and disliked by similar people as studied in [15,26]. Such observations motivated us to define similarity measures. Let be a similarity measure between the nodes . In a slight abuse of notation, we write to indicate a similarity measure between the nodes . Based on the observed EOIs, the score of ’s interest to for is defined as
If is similar to and the edge exists, the user gets a high score even if . In the reciprocal recommendation, defined by
is also important. The reciprocal score between and , , is defined as the harmonic mean of and [15]. This is employed to measure the affinity between and .
Table 1 shows popular similarity measures including graph-based measures and a content-based measure [1]. For the node in the graph , let (resp. ) be the index set of outer-edges, (resp. in-edges, ) and be the cardinality of the finite set s. In the following, the similarity measures based on outer-edges are introduced on directed bipartite graphs. The set of outer-edges can be replaced with to define the similarity measure based on in-edges.

Table 1.
Definition of similarity measures between the nodes and . The right column shows whether the similarity measure is a completely positive similarity kernel (CPSK); see Section 4.
In graph-based measures, the similarity between the nodes and is defined based on and . Some similarity measures depend only on and , and others may depend on the whole topological structure of the graph. In Table 1, the first group includes the Common Neighbors, Parameter-Dependent, Jaccard Coefficient, Sørensen Index, Hub Depressed, and Hub Promoted. The similarity measures in this group are locally defined, i.e., depends only on and . The second group includes SimRank, Adamic-Adar coefficient, and Resource Allocation. They are also defined from the graph structure. However, the similarity between the nodes and depends on the topological structure more than and . The third group consists of the content-based similarity, which is defined by the attributes associated with each node.
Below, we supplement the definition of the SimRank and the content-based similarity.
SimRank:
SimRank [33] and its reduced variant [35] are determined from the random walk on the graph. Hence, the similarity between the two nodes depends on the whole structure of the graph. For , the similarity matrix on is given as the solution of
for , while the diagonal element is fixed to 1. Let be the column-normalized adjacency matrix defined from the adjacency matrix of . Then, satisfies , where D is a diagonal matrix satisfying . In the reduced SimRank, D is defined as . For the bipartite graph, the similarity matrix based on the SimRank is given as a block diagonal matrix.
Content-Based Similarity:
In RECON [17,21], the content-based similarity measure is employed. Suppose that is the attributes of the node , where are finite sets and . The continuous variables in the features are appropriately discredited. The similarity measure is defined using the number of shared attributes, i.e.,
In RECON, the score is defined from the normalized similarity, i.e.,
The similarity-based recommendation is simple but the theoretical properties have not been sufficiently studied. In the next section, we introduce statistical models and consider the relationship to similarity-based methods.
3. Bernoulli Mixture Models and Similarity-Based Prediction
In this section, we show that the similarity-based methods are derived from Bernoulli mixture models (BMMs). BMMs have been employed in some studies [36,37,38] for block clustering problems, Here, we show that the BMMs are also useful for recommendation problems.
Suppose that each node belongs to a class . Let (respectively ) be the probability that each node in X (respectively Y) belongs to the class . We assume that the class at each node is independently drawn from these probability distributions. Though the number of classes, C, can be different in each group, here we suppose that they are the same for simplicity. When the node in the graph belongs to the class c, the occurrence probability of the directed edge from to is defined by the Bernoulli distribution with the parameter . As previously mentioned, the adjacency matrix of the graph consists of and . We assume that all elements of A and B are independently distributed. For each , the probability of is given by the BMM,
and the probability of the adjacency submatrix is given by
In the same way, the probability of the adjacency submatrix B is given by
where is the parameter of the Bernoulli distribution. Hence, the probability of the whole adjacency matrix is given by
where is the set of all parameters in the BMM, i.e., and for and . One can introduce the prior distribution on the parameter and . The beta distribution is commonly used as the conjugate prior to the Bernoulli distribution.
The parameter is estimated by maximizing the likelihood for the observed adjacency matrix . The probability is decomposed into two probabilities, and , which do not share the parameters. In fact, depends only on and and depends only on and . In the following, we consider the parameter estimation of . The same procedure works for the estimation of the parameters in .
The expectation-maximization (EM) algorithm [8] can be used to calculate the maximum likelihood estimator. The auxiliary variables used in the EM algorithm have an important role in connecting the BMM with the similarity-based recommendation methods. Using the Jensen’s inequality, we find that the log-likelihood is bounded below as
where the parameter is positive auxiliary variables satisfying . In the above inequality, the equality holds when is proportional to . The auxiliary variable is regarded as the class probability of when the adjacency matrix is observed.
In the EM algorithm, the lower bound of the log-likelihood, i.e., the function in (6) is maximized. For this purpose, the alternating optimization method is used. Firstly the parameter is optimized for the fixed r, and secondly, the parameter r is optimized for the fixed . This process is repeatedly conducted until the function value converges. Importantly, in each iteration the optimal solution is explicitly obtained. The following is the learning algorithm of the parameters:
Using the auxiliary variables , one can naturally define the “occurrence probability” of the edge from to . Here, the occurrence probability is denoted by . Note that the auxiliary variable is regarded as the conditional probability that belongs to the class c. If belongs to the class c, the occurrence probability of the edge is . Hence, the occurrence probability of the edge is naturally given by
where the updated parameter in (7) is substituted. The similarity measure on X in the above is defined by
where and
The equality holds for r satisfying the update rule (7). The above joint probability clearly satisfies the symmetry, . This property is the special case of the finite exchangeability [11,13]. The exchangeability is related to the de Finetti’s theorem [39], and the statistical models with the exchangeability have been used in several problems such as Bayes modeling and classification [12,40,41]. Here, we use the finite exchangeable model for the recommendation systems.
Equation (9) gives an interpretation of the heuristic recommendation methods (1) using similarity measures. Suppose that a similarity measure is used for the recommendation. Let us assume that the corresponding similarity matrix is approximately decomposed into the form of the mixture model r in (10), i.e.,
Then, defined from S is approximately the same as that computed from the Bernoulli mixture model with the parameter that maximizes for the fixed associated with S. On the other hand, the score for the recommendation computed from the Bernoulli mixture uses the maximum likelihood estimator that attains the maximum value of under the optimal auxiliary parameter . Hence, we expect that the learning method using the Bernoulli mixture model will achieve higher prediction accuracy as compared to the similarity-based methods, if the Bernoulli mixture model approximates the underling probability distribution of the observed data.
For , the probability function satisfying (11) leads to the positive semidefinite matrix with nonnegative elements. As a result, the ratio is also positive semidefinite with nonnegative elements. Let us consider whether the similarity measures in Table 1 yield the similarity matrix with expression (10). Next, we demonstrate that the commonly used similarity measures meet the assumption (12) under a minor modification.
4. Completely Positive Similarity Kernels
For the set of all n by n symmetric matrices , let us introduce two subsets of ; one is the completely positive matrices and the other is doubly nonnegative matrices. The set of completely positive matrices is defined as , and the set of doubly nonnegative matrices is defined as . Though the number of columns of the matrix N in the completely positive matrix is not specified, it can be bounded above by . This is because is expressed as the convex hull of the set of rank one matrices as show in [11]. The Carathéodory’s theorem can be applied to prove the assertion. More detailed analysis of the matrix rank for the completely positive matrices is provided by [42]. Clearly, the completely positive matrix is doubly nonnegative matrix. However, [10] proved that there is a gap between the doubly nonnegative matrix and completely positive matrix when .
The similarity measure that yields the doubly nonnegative matrix satisfies the definition of the kernel function [43]. The kernel function is widely applied in machine learning and statistics [43]. Here, we define the completely positive similarity kernel (CPSK) as the similarity measure that leads to the completely positive matrix as the Gram matrix or similarity matrix. We consider whether the similarity measures in Table 1 yield the completely positive matrix. For such similarity measures, the relationship to the BMMs is established via (10).
Lemma 1.
(i) Let and be completely positive matrices. Then, their Hadamard product is completely positive. (ii) Let be a sequence of completely positive matrices and define . Then, B is the completely positive matrix.
Proof of Lemma 1.
(i) Suppose that and such that and . Then, . Hence, the matrix such that satisfies . (ii) It is clear that is a closed set. ☐
Clearly, the linear sum of the completely positive matrices with non-negative coefficients yields completely positive matrices. Using this fact with the above lemma, we show that all measures in Table 1 except the HP measure are the CPSK. In the following, let for be non-zero binary column vectors, and let A be the matrix . The index set is defined as .
Common Neighbors
The elements of the similarity matrix are given by
Hence, holds. The common neighbors similarity measure yields the CPSK.
Parameter-Dependent:
The elements of the similarity matrix are given by
Hence, we have , where D is the diagonal matrix whose diagonal elements are . The Parameter-Dependent similarity measure yields the CPSK.
Jaccard Similarity:
We have and , where . Hence, the Jaccard similarity matrix is given by
Let us define the matrices and respectively by and . The matrix S is then expressed as . Lemma 1 (i) guarantees that is the CPSK since is the CPSK. Hence, the Jaccard similarity measure is the CPSK.
Sørensen Index:
The similarity matrix based on the Sørensen Index is given as
The integral part is expressed as the limit of the sum of the rank one matrix, , where and is the n-dimensional vector defined by . Hence, the Sørensen index is the CPSK.
Hub Promoted:
The hub promoted similarity measure does not yield the positive semidefinite kernel. Indeed, for the adjacency matrix
the similarity matrix based on the Hub Promoted similarity measure is given as
The eigenvalues of S are 1 and . Hence, S is not positive semidefinite.
Hub Depressed:
The similarity matrix is defined as
Since the min operation is expressed as the integral for , we have
In the same way as the Sørensen Index, we can prove that the Hub Depressed similarity measure is the CPSK.
SimRank:
The SimRank matrix S satisfies for , where is properly defined from and D is a diagonal matrix such that the diagonal element satisfies . The recursive calculation yields the equality , meaning that S is the CPSK.
Adamic-Adar Coefficient:
Given the adjacency matrix , the similarity matrix is expressed as
where is set to zero if . Hence, we have , where D is the diagonal matrix with the elements for and otherwise. Since with holds, the similarity measure based on the Adamic-adar coefficient is the CPSK.
Resource Allocation:
In the same way as the Adamic-adar coefficient, the similarity matrix is given as
where the term is set to zero if . We have , where D is the diagonal matrix with the elements for and otherwise. Since with holds, the similarity measure based on resource allocation is the CPSK.
Content-Based Similarity:
The similarity matrix is determined from the feature vector of each node as follows,
Clearly, S is expressed as the sum of rank-one matrix , where . Hence, Content-based similarity is the CPSK.
5. Transformation from Similarity Matrix to Bernoulli Mixture Model
Let us consider whether the similarity matrix allows the decomposition in (10) for sufficiently large C. Then, we construct an algorithm providing the probability decomposition (10) that approximates the similarity matrix.
5.1. Decomposition of Similarity Matrix
We show that a modified similarity matrix defined from the CPSK is decomposed into the form of (10). Suppose the n by n similarity matrix S is expressed as (10). Then, we have
where . Taking the sum over , we find that the equality
should hold. If the equality (13) is not required, the completely positive matrix S will be always decomposed into the form of (10) up to a constant factor. The equality (13) does not necessarily hold even when the CPSK is used. Let us define the diagonal matrix D as
and let be
Then, holds. Since S is the completely positive matrix, also is the completely positive matrix. Suppose that is decomposed into with the non-negative matrix . Then,
Let us define and . Since , we have . Moreover, the equality guarantees
meaning that for . Hence, we have
The modification (14) corresponds to the change of the balance between the self-similarity and the similarities with others.
5.2. Decomposition Algorithm
Let us propose a computation algorithm to obtain the approximate decomposition of the similarity matrix S. Once the decomposition of S is obtained, the recommendation using the similarity measure is connected to the BMMs. Such a correspondence provides a statistical interpretation of the similarity-based methods. For example, the conditional probability is available to categorize nodes into some classes according to the tendency of their preferences once a similarity matrix is obtained. The statistical interpretation provides a supplementary tool for similarity-based methods.
The problem is to find and such that the equation approximates the similarity matrix , where for . Here, we focus on the similarity matrix on X. The same argument is clearly valid for the similarity matrix on Y.
This problem is similar to the non-negative matrix factorization (NMF) [44]. However, the standard algorithm for the NMF does not work since we have the additional constraint, . Here, we use the extended Kullback–Leibler (ext-KL) divergence to measure the discrepancy [45]. The ext-KL divergence between the two matrices and with nonnegative elements is defined as
The minimization of the ext-KL divergence between and the model is formalized by
This is equivalent with
There are many optimization algorithms that can be used to solve nonlinear optimization problems with equality constants. A simple method is the alternating update of and such as the coordinate descent method [46]. Once is fixed, however, the parameter will be uniquely determined from the first equality constraint in (16) under a mild assumption. This means that the parameter cannot be updated while keeping the equality constants. Hence, the direct application of the coordinate descent method does not work. On the other hand, the gradient descent method with projection onto the constraint surface is a promising method [47,48]. In order to guarantee the convergence property, however, the step-length should be carefully controlled. Moreover, the projection in every iteration is computationally demanding. In the following, we propose a simple method to obtain an approximate solution of (16) with an easy implementation.
The constraint is replaced with the condition that the KL-divergence between the uniform distribution and vanishes, i.e.,
We incorporated this constraint into the objective function to obtain tractable algorithm. Eventually, the optimization problem we considered is
where the minimization problem is replaced with the maximization problem and is the regularization parameter. For a large , the optimal solution approximately satisfies the equality constraint .
For the above problem we use the majorization-minimization (MM) algorithm [49]. Let and be the auxiliary positive variables satisfying and . Then, the objective function is bounded below by
For fixed and , the optimal and are explicitly obtained. The optimal solutions of and for a given and are also explicitly obtained. As a result, we obtain the following algorithm to compute the parameters in the Bernoulli mixture model from the similarity matrix S. Algorithm 1 is referred to as the SM-to-BM algorithm.
The convergence of the SM-to-BM algorithm is guaranteed from the general argument of the MM algorithm [49].
Note that the SM-to-BM algorithm yields an approximate BMM model, even if the similarity matrix S is not completely positive such as the Hub Promoted. However, the approximation accuracy is thought to be not necessarily high, since not-CPSK such as the Hub Promoted does not directly correspond to the exchangeable mixture model (10).
| Algorithm 1: SM-to-BM algorithm. |
| Input: Similarity matrix and the number of classes C. Step 1. Initial values of auxiliary variables and are defined. Step 2. Repeat (i) and (ii) until the solution converges to a point:
Step 3. Terminate the algorithm with the output: “The similarity matrix S is approximately obtained from the Bernoulli mixture model with and the auxiliary variable .” |
6. Numerical Experiments of Reciprocal Recommendation
We conducted numerical experiments to ensure the effectiveness of the BMMs for the reciprocal recommendation. We also investigated how well the SM-to-BM algorithm works for the recommendation. In numerical experiments, we compare the prediction accuracy for the recommendation problems.
Suppose that there exist two groups, and . Expressions of interest between these two groups are observed and they are expressed as directed edges. Hence, the observation is summarized as the bipartite graph with directed edges between X and Y. If there exists two directed edges and between and , the pair is a preferable match in the graph. The task is to recommend a subset of Y to each element in X and vice versa based on the observation. The purpose is to provide potentially preferable matches as much as possible.
There are several criteria used to measure the prediction accuracy. Here, we use the mean average precision (MAP), because the MAP is a typical metric for evaluating the performance of recommender systems; see [5,50,51,52,53,54,55,56] and references therein for more details.
Let us explain the MAP according to [50]. The recommendation to the element x is provided as the ordered set of Y, i.e., , meaning that the preferable match between x and is regarded to be most likely to occur compared to . Suppose that for each , the preferable matches with elements in the subset are observed in the test dataset. Let us define as if is included in and otherwise . The precision at the position k is defined as . The average precision is then given as the average of with the weight , i.e.,
Note that is well defined unless is zero. For example, we have for with , and for with . In the latter case, for , and for . The MAP is defined as the mean value of over . The high MAP value implies that the ordered set over Y generated by the recommender system is accurate on average. We use the normalized MAP that is the ratio of the above MAP and the expected MAP for the random recommendation. The normalized MAP is greater than one when the prediction accuracy of the recommendation is higher than that of the random recommendation.
The normalized discounted cumulative gain (NDCG) [5,50,57] is another popular measure in the literature of information retrieval. However, the computation of the NDCG requires the true ranking over the node. Hence, the NDCG is not available for the real-world data in our problem setup.
6.1. Gaussian Mixture Models
The graph is randomly generated based on the attributes defined on each node. The size of X and Y is 1000. Suppose that has the profile vector and the preference vector . Thus, the attribute vector of is given by . Likewise, the attribute vector of consists of the profile vector and the preference vector . For each , 100 elements in Y, for example, are randomly sampled. Then, the Euclidean distance between the preference vector of and the profile vector of , i.e., is calculated for each . Then, the 10 closest from in terms of the above distance are chosen and directed edges from to the 10 chosen nodes in Y are added. In the same way, the edges from Y to X are generated and added to the graph. The training data is obtained as a random bipartite graph. Repeating the same procedure again with a different random seed, we obtain another random graph as a test data.
The above setup imitates practical recommendation problems. Usually, a profile vector is observed for each user. However, the preference vector is not directly observed, while the preference of each user can be inferred via the observed edges.
In our experiments, the profile vectors and preference vectors are identically and independently distributed from the Gaussian mixture distribution with two components, i.e.,
meaning that each profile or preference vector is generated from or with probability . Hence, each node in X is roughly categorized into one of two classes, i.e., or , that is the mean vector of the preference, . When the class of is (resp. ), the edge from is highly likely to be connected to having the profile vector generated from (resp. ). Therefore, the distribution of edges from X to Y will be well approximated by the Bernoulli mixture model with . Figure 1 depicts the relationship between the distribution of attributes and edges from X to Y. The same argument holds for the distribution of edges from Y to X.
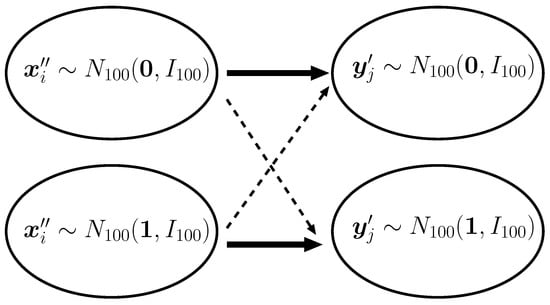
Figure 1.
Edges from X to Y. The bold edges mean that there are many edges between the connected groups. The broken edges mean that there are few edges between the connected groups.
In this simulation, we have focused on the recommendation using similarity measures based on the graph structure. The recommendation to each node of the graph was determined by (1), where the similarity measures in Table 1 or the one determined from the Bernoulli mixture model (10) were employed. Table 2 shows the averaged MAP scores with the median absolute deviation (MAD) over 10 repetitions with different random seeds. In our experiments, the recommendation based on the BMMs with the appropriate number of components outperformed the other methods. However, the BMMs with a high number of components showed low prediction accuracy.
Table 2.
Mean average precision (MAP) values of similarity-based methods under synthetic data. The bold face indicates the top two MAP scores.
Below, we show the edge prediction based on the SM-to-BM algorithm in Section 5. The results are shown in Table 3. The number of components in the Bernoulli mixture model was set to or . Given the similarity matrix S, the SM-to-BM algorithm yielded the parameter and . Next, edges were predicted through the formula (10) using and . The averaged MAP scores of this procedure are reported in the column of “itr:0”. We also examined the edge prediction by the BMMs with the parameter updated from the one obtained by the SM-to-BM algorithm, where the update formula is given by (7) and (8). The “itr:10” (resp. “itr:100”) column shows the MAP scores of the edge prediction using 10 times (resp. 100 times) updated parameter. In addition, the “BerMix” shows the MAP score of the BMMs with the updated parameter from the randomly initialized parameter.
Table 3.
MAP values of updated Bernoulli mixture models with the SM-to-BM algorithm under synthetic data. The results of Bernoulli mixture models with and are reported. The bold face indicates the top two MAP scores in each column.
In our experiments, we found that the SM-to-BM algorithm applied to commonly used similarity measures improved the accuracy of the recommendation. The MAP score for the “itr:0” method achieved a higher accuracy than the original similarity-based methods. The updated parameter from “itr:0”, however, did not improve the MAP score significantly. The results of “itr:10” and “itr:100” for similarity measures were almost the same when the model was the Bernoulli mixture model with . This is because the EM algorithm with 10 iterations achieved the stationary point of this model in our experiments. We confirmed that there was yet a gap between the likelihood of the parameter computed by the SM-to-BM algorithm and the maximum likelihood. However, the numerical results indicate that the SM-to-BM algorithm provides a good parameter for the recommendation in the sense of the MAP score.
6.2. Real-World Data
We show the results for real-world data. The data was provided from an online dating site. The set X (resp. Y) consists of males and females. The data were gathered from 3 January 2016 to 5 June 2017. We used 130,8126 messages from 3 January 2016 to 31 October 2016 as the training data. Test data consists of 177,450 messages from 1 November 2016 to 5 June 2017 [55]. The proportion of edges in the test set to all data set is approximately 0.12.
In the numerical experiments, half of the users were randomly sampled from each group, and the corresponding subgraph with the training edges were defined as the training graph. On the other hand, the graph with the same nodes in the training graph and the edges in the test edges were used as the test graph. Based on the training graph, the recommendation was provided and was evaluated on the test graph. The same procedure was repeated over 20 times and the averaged MAP scores for each similarity measure were reported in Table 4. In the table, the MAP score of the recommendation for X and Y were separately reported. So far, we have defined the similarity measure based on out-edges from each node of the directed bipartite graph, referred to as “Interest”. On the other hand, the similarity measure defined by in-edges is referred to as “Attract”. For the BMMs, “Attract” means that the model of each component is computed under the assumption that each in-edge is independently generated, i.e., the probability of is given by when the class of is c. In the real-world datasets, the SM-to-BM algorithm was not used, because the dataset was too large to compute the corresponding BMMs from similarity matrices.
Table 4.
MAP scores for real-world data. The bold face indicates the top two MAP scores in each column.
As shown in the numerical results, the recommendation based on the BMMs outperformed the other methods. Some similarity measures such as the Common Neighbors or Adamic-Adar coefficient showed relatively good results. On the other hand, the Hub Promoted measure, that is not the CPSK, showed the lowest prediction accuracy. As well as the result for synthetic data, the BMMs with two to five components produced high prediction accuracy. Even for medium to large datasets, we found that the Bernoulli mixture model with about five components worked well. We expect that the validation technique is available to determine the appropriate size of components. Also, the similarity with “Interest” or “Attract” can be determined from the validation dataset.
7. Discussions and Concluding Remarks
In this paper, we considered the relationship between the similarity-based recommendation methods and statistical models. We showed that the BMMs are closely related to the recommendation using completely positive similarity measures. More concretely, both the BMM-based method and completely positive similarity measures share exchangeable mixture models as the statistical model of the edge distribution. Once this was established, we proposed the recommendation methods using the EM algorithm to BMMs to improve similarity-based methods.
Moreover, we proposed the SM-to-BM algorithm that transforms a similarity matrix to parameters of the Bernoulli mixture model. The main purpose of the SM-to-BM algorithm is to find a statistical model corresponding to a given similarity matrix. This transformation provides a statistical interpretation for similarity-based methods. For example, the conditional probability is obtained from the SM-to-BM algorithm. This probability is useful to categorize nodes, i.e., users, into some classes according to the tendency of their preferences once a similarity matrix is obtained. The SM-to-BM algorithm is available as a supplementary tool for similarity-based methods.
We conducted numerical experiments using synthetic and real-world data. We numerically verified the efficiency of the BMM-based method in comparison to similarity-based methods. For the synthetic data, the BMM-based method was compared with the recommendation using the statistical model obtained by the SM-to-BM algorithm. We found that the BMM-based method and the SM-to-BM method provide a comparable accuracy for the reciprocal recommendation. Since the synthetic data is well approximated by the BMM with , the SM-to-BM algorithm was thought to reduce the noise in the similarity matrices. In the real-world data, the SM-to-BM algorithm was not examined, since our algorithm using the MM method was computationally demanding for a large dataset. On the other hand, we observed that the BMM-based EM algorithm was scalable for a large dataset. A future work includes the development of computationally efficient SM-to-BM algorithms.
It is straightforward to show that the stochastic block models (SBMs) [6] are also closely related to the recommendation with completely positive similarity measures. In our preliminary experiments, however, we found that the recommendation system based on the SBMs did not show a high prediction accuracy in comparison to other methods. We expect that detailed theoretical analysis of the relation between the similarity measure and statistical models is an interesting research topic that can be used to better understand the meaning of the commonly used similarity measures.
Author Contributions
Conceptualization, T.K. and N.O.; Methodology, T.K.; Software, T.K.; Validation, T.K., N.O.; Formal Analysis, T.K.; Investigation, T.K.; Resources, T.K.; Data Curation, T.K.; Writing—Original Draft Preparation, T.K.; Writing—Review & Editing, T.K.; Visualization, T.K.; Supervision, T.K.; Project Administration, T.K.; Funding Acquisition, N.O.
Funding
T.K. was partially supported by JSPS KAKENHI Grant Number 15H01678, 15H03636, 16K00044, and 19H04071.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef]
- Liben-nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Hasan, M.A.; Zaki, M.J. A Survey of Link Prediction in Social Networks. In Social Network Data Analytics; Springer Science+Business Media: Berlin/Heidelberg, Germany, 2011; pp. 243–275. [Google Scholar]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Agarwal, D.K.; Chen, B.C. Statistical Methods for Recommender Systems; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Stanley, N.; Bonacci, T.; Kwitt, R.; Niethammer, M.; Mucha, P.J. Stochastic Block Models with Multiple Continuous Attributes. arXiv 2018, arXiv:1803.02726. [Google Scholar]
- Mengdi, W. Vanishing Price of Decentralization in Large Coordinative Nonconvex Optimization. SIAM J. Optim. 2017, 27, 1977–2009. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Berman, A.; Shaked-Monderer, N. Completely Positive Matrices; World Scientific Publishing Company Pte Limited: Singapore, 2003. [Google Scholar]
- Burer, S.; Anstreicher, K.M.; Dür, M. The difference between 5 × 5 doubly nonnegative and completely positive matrices. Linear Algebra Its Appl. 2009, 431, 1539–1552. [Google Scholar] [CrossRef]
- Diaconis, P. Finite forms of de Finetti’s theorem on exchangeability. Synth. Int. J. Epistemol. Methodol. Philos. Sci. 1977, 36, 271–281. [Google Scholar] [CrossRef]
- Wood, G.R. Binomial Mixtures and Finite Exchangeability. Ann. Probab. 1992, 20, 1167–1173. [Google Scholar] [CrossRef]
- Diaconis, P.; Freedman, D. Finite Exchangeable Sequences. Ann. Probab. 1980, 8, 745–764. [Google Scholar] [CrossRef]
- De Finetti, B. Theory of Probability; Wiley: Hoboken, NJ, USA, 1970. [Google Scholar]
- Xia, P.; Liu, B.; Sun, Y.; Chen, C. Reciprocal Recommendation System for Online Dating. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, Paris, France, 25–28 August 2015; pp. 234–241. [Google Scholar]
- Li, L.; Li, T. MEET: A Generalized Framework for Reciprocal Recommender Systems. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; ACM: New York, NY, USA, 2012; pp. 35–44. [Google Scholar]
- Pizzato, L.; Rej, T.; Chung, T.; Koprinska, I.; Kay, J. RECON: A Reciprocal Recommender for Online Dating. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; ACM: New York, NY, USA, 2010; pp. 207–214. [Google Scholar]
- Pizzato, L.; Rej, T.; Akehurst, J.; Koprinska, I.; Yacef, K.; Kay, J. Recommending People to People: The Nature of Reciprocal Recommenders with a Case Study in Online Dating. User Model. User-Adapt. Interact. 2013, 23, 447–488. [Google Scholar] [CrossRef]
- Xia, P.; Jiang, H.; Wang, X.; Chen, C.; Liu, B. Predicting User Replying Behavior on a Large Online Dating Site. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Yu, M.; Zhao, K.; Yen, J.; Kreager, D. Recommendation in Reciprocal and Bipartite Social Networks—A Case Study of Online Dating. In Proceedings of the Social Computing, Behavioral-Cultural Modeling and Prediction—6th International Conference (SBP 2013), Washington, DC, USA, 2–5 April 2013; pp. 231–239. [Google Scholar]
- Tu, K.; Ribeiro, B.; Jensen, D.; Towsley, D.; Liu, B.; Jiang, H.; Wang, X. Online Dating Recommendations: Matching Markets and Learning Preferences. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014; pp. 787–792. [Google Scholar]
- Hopcroft, J.; Lou, T.; Tang, J. Who Will Follow You Back?: Reciprocal Relationship Prediction. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; ACM: New York, NY, USA, 2011; pp. 1137–1146. [Google Scholar]
- Hong, W.; Zheng, S.; Wang, H.; Shi, J. A Job Recommender System Based on User Clustering. J. Comput. 2013, 8, 1960–1967. [Google Scholar] [CrossRef]
- Brun, A.; Castagnos, S.; Boyer, A. Social recommendations: Mentor and leader detection to alleviate the cold-start problem in collaborative filtering. In Social Network Mining, Analysis and Research Trends: Techniques and Applications; Ting, I., Hong, T.-P., Wang, L.S., Eds.; IGI Global: Hershey, PA, USA, 2011; pp. 270–290. [Google Scholar]
- Gentile, C.; Parotsidis, N.; Vitale, F. Online Reciprocal Recommendation with Theoretical Performance Guarantees. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 8257–8267. [Google Scholar]
- Akehurst, J.; Koprinska, I.; Yacef, K.; Pizzato, L.A.S.; Kay, J.; Rej, T. CCR—A Content-Collaborative Reciprocal Recommender for Online Dating. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, 16–22 July 2011; pp. 2199–2204. [Google Scholar]
- Newman, M.E.J. Clustering and preferential attachment in growing networks. Phys. Rev. Lett. 2001, 64, 025102. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.X.; Lü, L.; Zhang, Q.M.; Zhou, T. Uncovering missing links with cold ends. Phys. Stat. Mech. Its Appl. 2012, 391, 5769–5778. [Google Scholar] [CrossRef]
- Urbani, C.B. A Statistical Table for the Degree of Coexistence between Two Species. Oecologia 1980, 44, 287–289. [Google Scholar] [CrossRef] [PubMed]
- Sørensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. Kongelige Danske Videnskabernes Selskab 1948, 5, 1–34. [Google Scholar]
- ZhouEmail, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. 2009, 71, 623–630. [Google Scholar]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical Organization of Modularity in Metabolic Networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef] [PubMed]
- Jeh, G.; Widom, J. SimRank: A Measure of Structural-Context Similarity. In Proceedings of the Eighth ACM SIGKDD International Conference, Edmonton, AB, Canada, 23–25 July 2002; pp. 538–543. [Google Scholar]
- Adamic, L.A.; Adar, E. Friends and neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhu, R.; Zou, Z.; Li, J. SimRank on Uncertain Graphs. IEEE Trans. Knowl. Data Eng. 2017, 29, 2522–2536. [Google Scholar] [CrossRef]
- Govaert, G.; Nadif, M. Block clustering with Bernoulli mixture models: Comparison of different approaches. Comput. Stat. Data Anal. 2008, 52, 3233–3245. [Google Scholar] [CrossRef]
- Govaert, G.; Nadif, M. Fuzzy Clustering to Estimate the Parameters of Block Mixture Models. Soft-Comput. Fusion Found. Methodol. Appl. 2006, 10, 415–422. [Google Scholar] [CrossRef]
- Amir, N.; Abolfazl, M.; Hamid, R.R. Reliable Clustering of Bernoulli Mixture Models. arXiv 2019, arXiv:1710.02101. [Google Scholar]
- Finetti, B.D. Probability, Induction and Statistics: The Art of Guessing; Wiley Series in Probability and Mathematical Statistics; Wiley: Hoboken, NJ, USA, 1972. [Google Scholar]
- Niepert, M.; Van den Broeck, G. Tractability through exchangeability: A new perspective on efficient probabilistic inference. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Niepert, M.; Domingos, P. Exchangeable Variable Models. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 271–279. [Google Scholar]
- Barioli, F.; Berman, A. The maximal cp-rank of rank k completely positive matrices. Linear Algebra Its Appl. 2003, 363, 17–33. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Lee, D.D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Proceedings of the 13th International Conference on Neural Information Processing Systems, Denver, CO, USA, 28 November 2000; pp. 535–541. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications and Signal Processing; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Wright, S.J. Coordinate Descent Algorithms. Math. Program. 2015, 151, 3–34. [Google Scholar] [CrossRef]
- Bertsekas, D. Nonlinear Programming; Athena Scientific: Belmont, MA, USA, 1996. [Google Scholar]
- Luenberger, D.; Ye, Y. Linear and Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Lange, K. MM Optimization Algorithms; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Liu, T.Y. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Kishida, K. Property of Average Precision as Performance Measure for Retrieval Experiment; Technical Report; NII-2005-014E; National Institute of Informatics: Tokyo, Japan, 2005. [Google Scholar]
- Cormack, G.V.; Lynam, T.R. Statistical Precision of Information Retrieval Evaluation. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–10 August 2006; pp. 533–540. [Google Scholar]
- McFee, B.; Lanckriet, G. Metric Learning to Rank. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 775–782. [Google Scholar]
- Fukui, K.; Okuno, A.; Shimodaira, H. Image and tag retrieval by leveraging image-group links with multi-domain graph embedding. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 221–225. [Google Scholar]
- Sudo, K.; Osugi, N.; Kanamori, T. Numerical study of reciprocal recommendation with domain matching. Jpn. J. Stat. Data Sci. 2019, 2, 221–240. [Google Scholar] [CrossRef]
- Beitzel, S.M.; Jensen, E.C.; Frieder, O.; Chowdhury, A.; Pass, G. Surrogate Scoring for Improved Metasearch Precision. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; pp. 583–584. [Google Scholar]
- Wang, Y.; Wang, L.; Li, Y.; He, D.; Chen, W.; Liu, T.Y. A theoretical analysis of NDCG type ranking measures. In Proceedings of the 26th Annual Conference on Learning Theory (COLT 2013), Princeton, NJ, USA, 12–14 June 2013; pp. 583–584. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).