1. Introduction
Optical tomography is a medical imaging technique in which near infrared light is sent into biological tissue, and the reflected and transmitted outgoing light at the surface of the tissue is measured [
1,
2,
3,
4]. Using information about the incoming and outgoing light, one can determine the properties of the tissue. The use of low-energy light makes optical tomography cheaper and less invasive than traditional methods such as X-ray imaging, although the reconstruction of the properties of the tissue can be more difficult than when high-energy photons are used. Optical imaging can be used to study and monitor many different kinds of tissue, including brain, breast, and joint imaging, as well as monitoring blood oxygenation [
5,
6,
7].
The process of collecting information about the incoming and outgoing light and using it to reconstruct the tissue’s properties is an inverse problem. There are two associated forward models that both map the incoming data (light intensity sent into the tissue) to the outgoing data (light intensity measured coming off the tissue). The first forward model corresponds to the radiative transfer equation (RTE) and is called the albedo operator. Using the albedo operator, the inverse problem may be solved to obtain the scattering coefficient in the RTE. The second forward model corresponds to the diffusion equation (DE) and is called the Dirichlet-to-Neumann (DtN) map. Using the DtN map, one may similarly solve the inverse problem and reconstruct the diffusion coefficient in the DE. Typically, RTE is used for high-energy photons and DE is used for low-energy photons. The energy of photons determines the “mean-free-path” of free transport, and then further determines the strength of scattering. Mathematically, it can be characterized by the Knudsen number, and one can show that in the small Knudsen number regime, the two equations are equivalent, as will be made clearer in
Section 3. It was shown in [
8] that the coefficients of the RTE are uniquely recoverable in 3D when the entire albedo operator is known, and it was shown in [
9] that this reconstruction is Lipschitz stable. On the other hand, using the DtN map to reconstruct the corresponding coefficients of the DE is the famously ill-posed Calderón problem. The uniqueness of the reconstruction has been presented in [
10], and the logarithmically ill-posed nature of the problem has been proved in [
11].
These two forward models are related, as we will describe. The RTE describes light propagating through a material with some optical properties, here taken to be the scattering coefficient of the material. Let
denote the distribution of particles at location
x with direction
v, where
, and
, the unit sphere in
, where
d is the dimension of the problem. In other words, all particles are taken to move with constant unit speed. In the later parts of the paper, we use “velocity” and “direction" interchangeably when no ambiguity is present. For simplicity, we work with a version of the RTE in which the scattering coefficient
depends only on position. Then the RTE is
where
is an integral operator describing photons colliding with the media and scattering off. Its explicit formulation is in
Section 3.
The diffusion equation, on the other hand, is a simplified model from the RTE, accurate for low-energy photons in the high-scattering, low-absorption regime. Since the scattering is very strong, the distribution achieves equilibrium in the velocity domain, and the light intensity, also known as fluence, becomes a function only on physical space. Suppose that
is the light intensity at position
x, and
is the diffusion coefficient (corresponding to
from the RTE, as will be shown in Theorem 2). Then the DE is
where
C is a constant depending on dimension. In this case, the map from the Dirichlet data (light intensity or fluence injected into the tissue) to the Neumann data (light propagating out) is used to reconstruct the diffusion coefficient
. This map is known as the Dirichlet-to-Neumann (DtN) map.
There is a relationship between the two forward models RTE and DE. One would like to understand, physically and mathematically, why the stability of each model is different in the inverse setting. It turns out that if
and
satisfy certain relations, the RTE and DE are asymptotically close in the near infrared case. This is made precise below in Theorem 2. Physically, in the forward setting, high-energy photons experience little scattering before exiting the domain, whereas low-energy photons scatter frequently in the tissue before they exit. As a result, the reconstruction of the tissue using high-energy photons is generally crisp, whereas low-energy photons provide more blurred images. We use the “Knudsen number”
to quantify how much scattering a photon experiences in the material. In the low-energy regime, scattering increases, the Knudsen number shrinks to zero, and the RTE converges to the DE in the forward setting. On the inverse side, the inverse problem for the RTE converges to the inverse problem for the DE, meaning that the information carried in the albedo operator is almost the same as that in the DtN map, and therefore the reconstruction of the tissue properties converges in this limit as well. This has been numerically observed in [
12,
13], and further proved rigorously in [
14,
15].
A Bayesian solution to the inverse problem is seen as the posterior distribution for the quantity of interest (QoI), in our case the scattering coefficient in the RTE and the diffusion coefficient in the DE. Bayesian methods are particularly useful for inverse problems, because noise in the measurement as well as prior information about the QoI is taken into account naturally [
16]. If we observe some noisy data in order to obtain information about the QoI, the solution of the inverse problem is the probability distribution of the QoI given this data, known as the posterior distribution [
17]. Bayes’ theorem allows us to determine this distribution given a guess for the probability distribution of the QoI (the prior distribution) and the probability distribution for the data given the QoI (the likelihood function, obtainable from the forward model). As such, there is a sharp distinction between this probabilistic view and other deterministic tools, and the Bayesian formulation gives one the ability to “regularize” an inverse problem with some prior knowledge.
While we theoretically have the posterior distribution in hand, accessing concrete information about it such as its mean and variance can be challenging. One way to obtain this information is by creating a list of samples from the distribution by some means, such as the Markov chain Monte Carlo (MCMC) method. Even this, however, is not always straightforward. One sample from the RTE represents an entirely new configuration of the media, meaning that one must re-compute the forward albedo map for each MCMC sample. This is especially expensive because the RTE is over phase space: if the domain is three-dimensional, then f is supported on , a five-dimensional space. The same process applies for the DE as well, but since the DE is only over physical space, these computations are much faster. Knowing that the RTE converges to the DE in the high scattering regime, one wishes to combine the two and speed up the computation.
There is a balance to be struck here, and the goal of this paper is to find a way to sample from the posterior distribution for
in a way that combines the DE and RTE. To that end, we employ the two-level MCMC method [
18], also known as the two-stage method. The two-level method uses two models, which we will call the low-resolution model and the high-resolution model. The high-resolution model gives rise to the desired target distribution—for us, the posterior distribution for the RTE. The low-resolution model gives rise to a distribution that approximates the target distribution, and is ideally fast to compute. It is used to filter out poor draws so we need not waste time evaluating the target distribution on them. We know the DE is fast to compute, and that when scattering is sufficiently strong, the posterior based on the DE is a good approximation to the posterior based on the RTE, so we use the posterior based on the DE as the low-resolution model. Then, we can use the DE to reduce the number of times we must solve the RTE by rejecting bad draws. This method combines the inverse problem for the DE and the inverse problem for the RTE to create a faster method for sampling from the inverse problem for the RTE in the diffusion limit.
There are similar methods to approach related problems, such as the multilevel Monte Carlo method for path simulation [
19] or the multilevel Monte Carlo method for parametric integration [
20]. These methods also combine low-resolution models with a high-resolution model. The algorithm our method relies on, introduced in [
18], is similar to the methods proposed in [
21,
22]. In this view, our algorithm is a two-stage method that increases the number of MCMC iterations for a given computational cost. It uses a two-stage delayed acceptance, in which the candidate sample
y has to be accepted with a low-resolution model before it is passed on to be either accepted or rejected by the high-resolution model. However, typically for these methods, a coarse-grid approximation is used for the low-resolution model [
23]. No matter how coarse the grids are for the RTE, however, they are still on phase space and the dimensionality issue is still left open. In our method, however, a completely different model is used: the inverse diffusion equation is used as a low-resolution model for the inverse radiative transfer equation.
This paper is organized as follows. In
Section 2, we provide some necessary background, including a discussion of Bayesian methods for inverse problems, as well as an introduction to Markov chain Monte Carlo methods. In
Section 3, we discuss the diffusion limit of the radiative transfer equation in the forward setting, and go on to discuss the inverse setting convergence of the posterior distributions. In
Section 4, we discuss the DE-assisted two-level MCMC method, and prove its convergence. We also discuss the dependence of the second-level acceptance rate on
, the Knudsen number. In
Section 5, we present our numerical evidence. In particular, we show the convergence of the two forward models, the convergence of the posterior distribution functions quantified using the Hellinger distance, and the improvement of the DE-assisted two-level MCMC over the standard MCMC.
2. Background
In this section, we present preliminaries for studying the inverse problem for the RTE in the diffusion limit. In particular, we will first review basic concepts of the Bayesian formulation, and then review the previous algorithms on which our algorithm is based.
These results will be used to study the convergence of the posterior distribution with the RTE or the DE as the forward model, which will be used to develop our numerical method that combines the two posterior distributions.
2.1. Bayesian Formulation for Inverse Problems
Bayesian inference is a technique for estimating the distribution of some quantity of interest when some measurements are available. It is based on Bayes’ theorem. A given physical problem may be denoted as
where
is the forward map that takes a parameter
to the measurement
b, with an added noise
. The forward problem is to find
for a given
, while most problems in practice are naturally inverse problems, meaning that one conducts experiments and obtains data
b, and tries to use it to reconstruct the quantity of interest
.
The Bayesian formulation is a method for retrieving information about using b. It requires knowledge of the following two probability distribution functions and ahead of time,
- -
without knowledge of the measurement
b, a priori
obeys a certain law,
- -
and the noise is distributed as:
In many cases, both distribution functions can be assumed to be normal, i.e., to have a Gaussian-type density function. Suppose that
is a Gaussian distribution concentrated at
with covariance
and the noise is concentrated at zero with covariance
. If
is finite dimensional then we may express the prior
and likelihood
as follows:
Analogous formulae are also available in the infinite dimensional setting; see [
16,
17] and the references therein.
With this, the posterior distribution of
, under the condition that
b is obtained in experiment, is given by Bayes’ theorem,
where
is the normalization factor.
In optical tomography, there are two fundamental models for describing light propagation: the radiative transfer equation (RTE), and the diffusion equation (DE). They rely on the albedo operator and the DtN map for the reconstruction. In the optically thick case (i.e., when photons scatter frequently), the two models are asymptotically close in some sense,
Correspondingly, the posterior distributions given by the two models are close to each other [
24], meaning:
To be more precise, there are multiple ways to quantify the distance between two distribution functions. Typically, this distance is quantified by the Kullback–Leibler (KL) divergence or the Hellinger distance [
25]. For any two distributions
and
supported on the same space, they are defined by the following,
where
is any pre-chosen distribution function. The Hellinger distance is invariant to the choice of
. Again, these formulae have interpretations in the infinite dimensional setting; see the Appendix of [
17]. In Theorem 3, we quantify the similarity between
and
and find that the two distributions are
apart in the diffusion limit. Therefore, since
is close to
in the optically thick case, the main task in this paper is to use
to sample from
.
2.2. The Markov Chain Monte Carlo Method
We first present the standard Metropolis–Hastings (MH) algorithm. Given a probability density called the target distribution and defined on X, the MH algorithm constructs a Markov chain on X that is stationary with respect to . The elements of the Markov chain are then regarded as samples from the distribution . More specifically, the MH algorithm starts with an initial guess , and draws new samples according to a proposal distribution q. By adjusting the acceptance rate using the target distribution , the MH algorithm accepts or rejects the draws so that the accepted samples form an empirical distribution that resembles the target distribution . We now present the MH algorithm, shown in Algorithm 1.
| Algorithm 1 Metropolis Hastings |
Given , draw . With probability , accept y and set . Otherwise, set .
|
The transition kernel
P of this algorithm is
In order to demonstrate the convergence of MCMC in Theorem 1, it is necessary to examine the transition kernel, which is the probability that the next draw
is in the set
A given the previous elements of the chain
. It may be written
where the off-diagonal density of the kernel is
and the probability that the process remains at
x is
The goal is to show that the target distribution
is an invariant distribution of the Markov chain
in the sense that all measurable sets
A satisfy
This means that elements of the Markov chain generated by Algorithm 1 give a good representation of the distribution . To show that is the invariant distribution, one first needs to satisfy the detailed balance lemma.
Lemma 1. The off-diagonal density satisfies the following equation known as “detailed balance", This lemma allows us to show the following theorem.
Theorem 1. The target distribution μ is an invariant distribution of the Markov chain with transition kernel P, i.e., For our problem, each new proposal
y is a new configuration of the media
. Thus, to compute
, one must evaluate
and thus re-compute the forward map, which requires solving the RTE many times. As this is computationally prohibitive, we instead use the two-level MCMC method, described in the next section. The cost comparison is discussed further in
Section 5.
2.3. Two-Level MCMC Method
The two-level MCMC method is a method to increase the efficiency of sampling from the target distribution . It requires two distributions: a target distribution , and a second distribution . Here, the target distribution calls for the evaluation of a “high-resolution” model, but if it can be approximated in some sense by which only calls for the evaluation of some “low-resolution” model, then can serve as a good filter to reject poor draws in the MCMC sampling. More specifically, the algorithm goes through two levels of evaluating a proposed sample. First, the sample is evaluated using the low-resolution model and is either accepted or rejected. If it is accepted, the algorithm goes on to evaluate the sample using the high-resolution model. This “pre-acceptance” stage filters out poor draws, allowing one to make more courageous proposals and not waste time evaluating the forward model on them. We present the two-level scheme below in Algorithm 2.
| Algorithm 2 Two-level Metropolis Hastings |
Given , draw With probability , pre-accept y and continue to 4. Otherwise, set and start over. The second-level proposal is now y, effectively drawn from
With probability , accept and set . Otherwise, set .
|
Similarly to the MCMC method (Algorithm 1), in the two-level MCMC method, the draw of
merely depends on the evaluation of
, and the previous draws
are irrelevant. The transition kernel that brings
to
is denoted by
, which we will discuss in more detail in
Section 4.1.
In this paper, the desired high-resolution model will be the posterior distribution for the RTE. The low-resolution model will be the posterior distribution for the DE. Evaluating only involves computing the DE, which is much faster since the DE is supported on the physical domain. Once the DE accepts the proposal y, it passes to the inverse problem for the RTE’s posterior distribution . Thus, we compute the RTE forward model fewer times overall, which saves time.
In
Section 4, we discuss the convergence of this method and the dependence of the second-level acceptance rate
on the Knudsen number
, our limit parameter.
3. Diffusion Limit
In this section, we examine the diffusion limit of our problem in the forward and inverse case. We first study the convergence of the radiative transfer equation to the diffusion equation. Then, we explain how the inverse problems are solved using the forward map. Next, we discuss the convergence of the forward map for the radiative transfer equation to that of the diffusion equation. Finally, we discuss the convergence of the posterior distribution for the radiative transfer equation to the posterior for the diffusion equation.
3.1. Diffusion Limit of the Radiative Transfer Equation
The optical “thickness” of the material physically corresponds to the number of times a photon scatters between entering a medium and escaping. The physical quantity is termed the Knudsen number, which stands for the ratio of mean free path to the domain length. The mean free path is the average distance a photon travels before being scattered. When the Knudsen number is small, photons, on average, scatter many times before they are emitted, and the material is thus regarded as optically “thick”. In this regime, the two mathematical models for light propagation carry the same information, namely, the radiative transfer equation and the diffusion equation are asymptotically converging.
The radiative transfer equation takes a statistical mechanics viewpoint, and describes the distribution of photons on the phase domain. Let
denote the number of photons at position
, a bounded domain, moving in direction
, the unit sphere in
(i.e., the speed is normalized to be 1). This distribution satisfies the RTE,
where the collision operator is
In the equation, the term
on the left shows that the photons move with direction
v, and the term on the right shows that the photons colliding with the media and being scattered. We have used the notation
to denote normalized integration over
v, and
is the normalized unit measure, meaning
The equation has a unique solution when it is equipped with the incoming boundary condition, which is the analogue of a Dirichlet boundary condition for equations lacking velocity space. Let
denote the collection of coordinates on the boundary
, so that the velocity
v points in/out of the domain:
. Here,
is the normal vector at
x pointing out of
. The incoming boundary condition is imposed on
, whereas
represents the particles going out of
. For a unique solution to (
7), boundary conditions must be imposed on
,
Remark 1. In fact, a more general model of the radiative transfer equation is It concerns the case when the scattering coefficient, now seen as , may depend on the changing velocity of the particles during a collision, and also includes an absorption coefficient representing the photons being absorbed into the material and lost. A standard k which takes into account other kinds of scattering is given by the Henyey–Greenstein model. The absorption coefficient can be taken to be zero if scattering is sufficiently high, and this is the case we focus on.
The equation is asymptotically equivalent to the diffusion equation in the optically thick regime when the Knudsen number is small. We denote the Knudsen number by
and rescale the problem by setting
. Then, as the Knudsen number becomes small, the scattering effect dominates. Equation (
7) may then be written as
In the small
regime, it was conjectured in [
26] and then proved in [
27,
28] that the equation is asymptotically equivalent to the diffusion equation. One can make the convergence explicit under the following assumptions.
Assumption 1. Both the media and the boundary conditions are bounded.
the admissible media is bounded, meaning that there is a constant so that: and the boundary conditions are bounded, meaning:
We also term the set of admissible media: With the assumption, we have the following theorem.
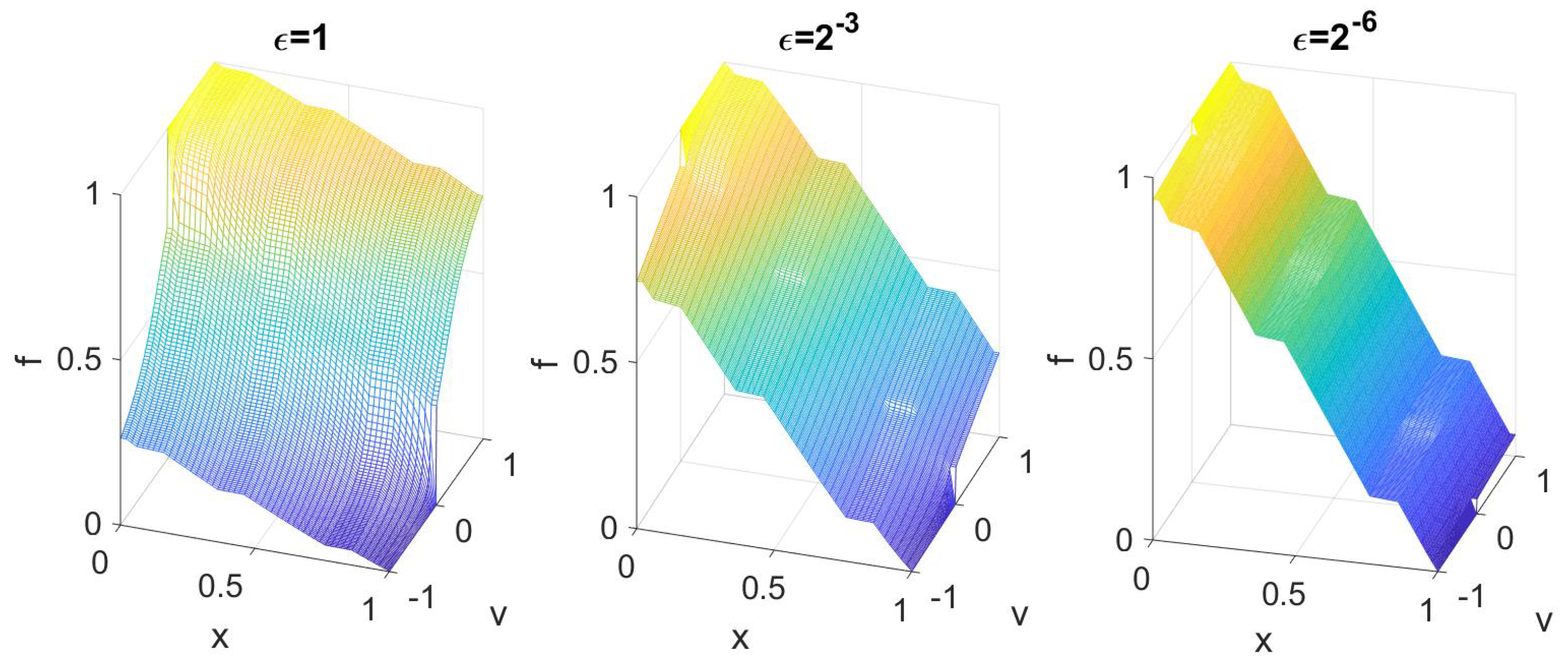
Theorem 2. Suppose that satisfies Equation (9), then as , , which satisfieswhere is defined by . is a constant depending on the dimension d and could be dropped out of Equation (11). In particular, with compatible boundary conditions at different orders, one approximates f through different forms: if : if :
Here, the constant depends on , the upper bound in Assumption 1 for the admissible set.
The proof, which we omit here, relies on asymptotic expansion away from the boundary.
3.2. Convergence in the Inverse Setting
We examine the convergence in the inverse setting in this section. To describe light propagation in a given tissue in , there are two models, the radiative transfer equation that gives a statistical description, and the diffusion equation that characterizes the macroscopic behavior. The two models are asymptotically equivalent, as discussed in the previous section.
In optical tomography, light with a known intensity is injected into the material, and detectors are placed on the tissue boundary to collect the light current emitted from the material. For the RTE, the mapping from the incoming data to the outgoing data is termed the albedo operator, defined by
,
where
f satisfies (
9). It may also be written:
In practice, finitely many incoming data
are injected and finitely many measurements are taken at the boundary location
per experiment. We define the map, determined by the to-be-reconstructed
, from the known incoming data to the measured outgoing data as:
or in a compact form:
where
is a vector of
length that contains the noise in the measurements. Clearly, the
length vector
is the result of a forward map
acting on the quantity of interest
, with a small perturbation due to the noise. We assume that the noise is distributed as a Gaussian,
meaning:
According to Bayes’ theorem, one then has:
For the DE model, we consider the forward map to be the map that takes the Dirichlet data to the Neumann outflow. It is termed the DtN map:
where
satisfies (
11). Another way to write it is:
Again, in practice, finitely many incoming data
are injected and finitely many measurements are taken at the boundary
per experiment. We define the map, determined by the to-be-reconstructed media
, from
to the measured data as:
or:
where
is the same pollution in the measurement. Again, the vector
is the result of the forward map for the diffusion equation acting on the to-be-reconstructed
, with the perturbation from the noise. Then, similarly, we have
It is proved in [
24] that the two forward maps converge, namely:
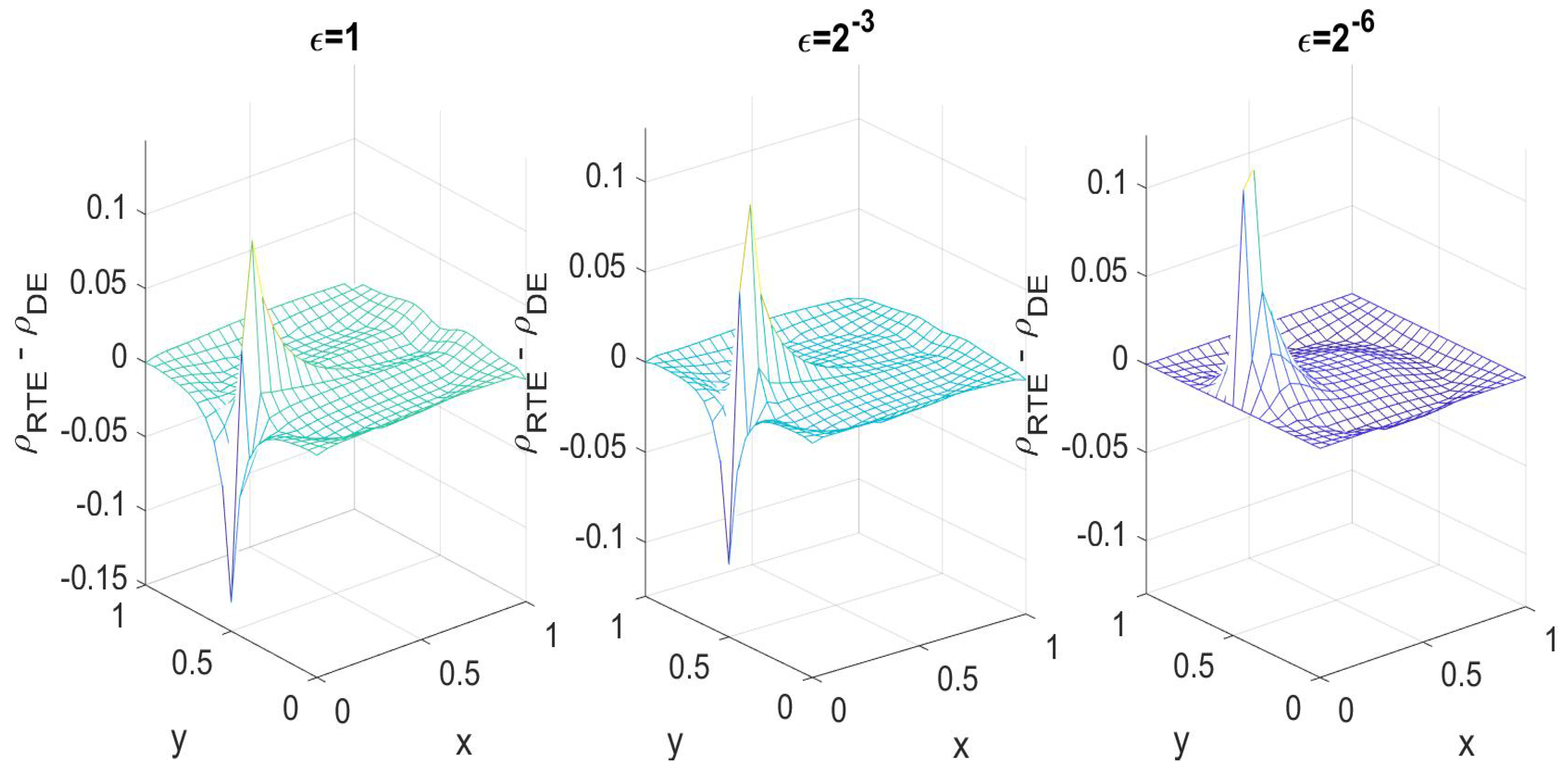
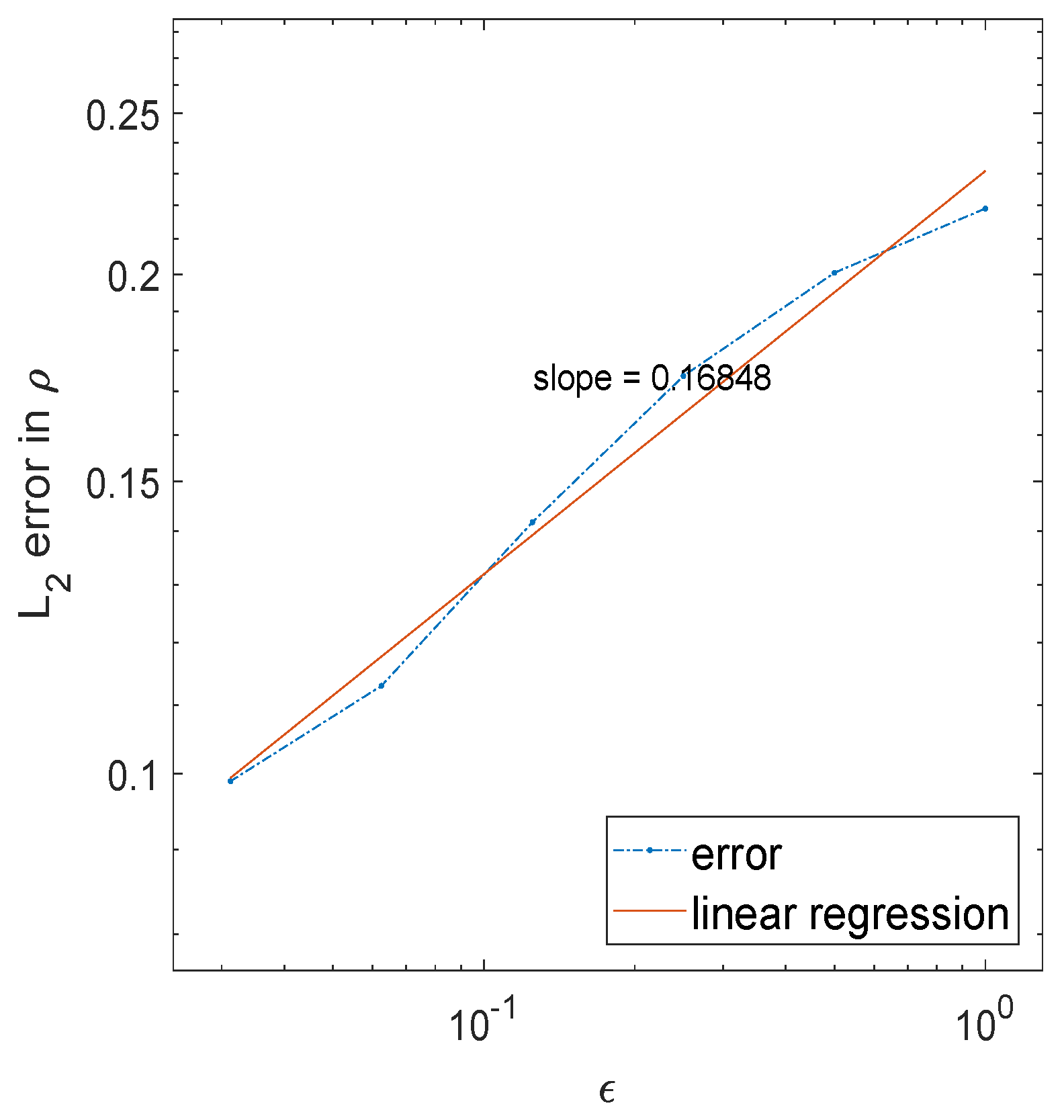
Proposition 1. Under Assumption 1, the forward maps and satisfyfor all . Using this convergence, it was also proved that the posterior distributions are close in the diffusion limit, as in the following theorem.
Theorem 3. Under Assumption 1, the Hellinger distance between the two posterior distribution is bounded by ϵ in the optically thick regime when , namely, Similarly, the Kullback–Leibler divergence between the posterior distribution for the RTE and the posterior distribution for the DE is also , The proof largely depends on the Lipschitz continuity of the Gaussian form in the likelihood function, and the convergence result in Proposition 1. We omit the details and refer interested readers to [
24].
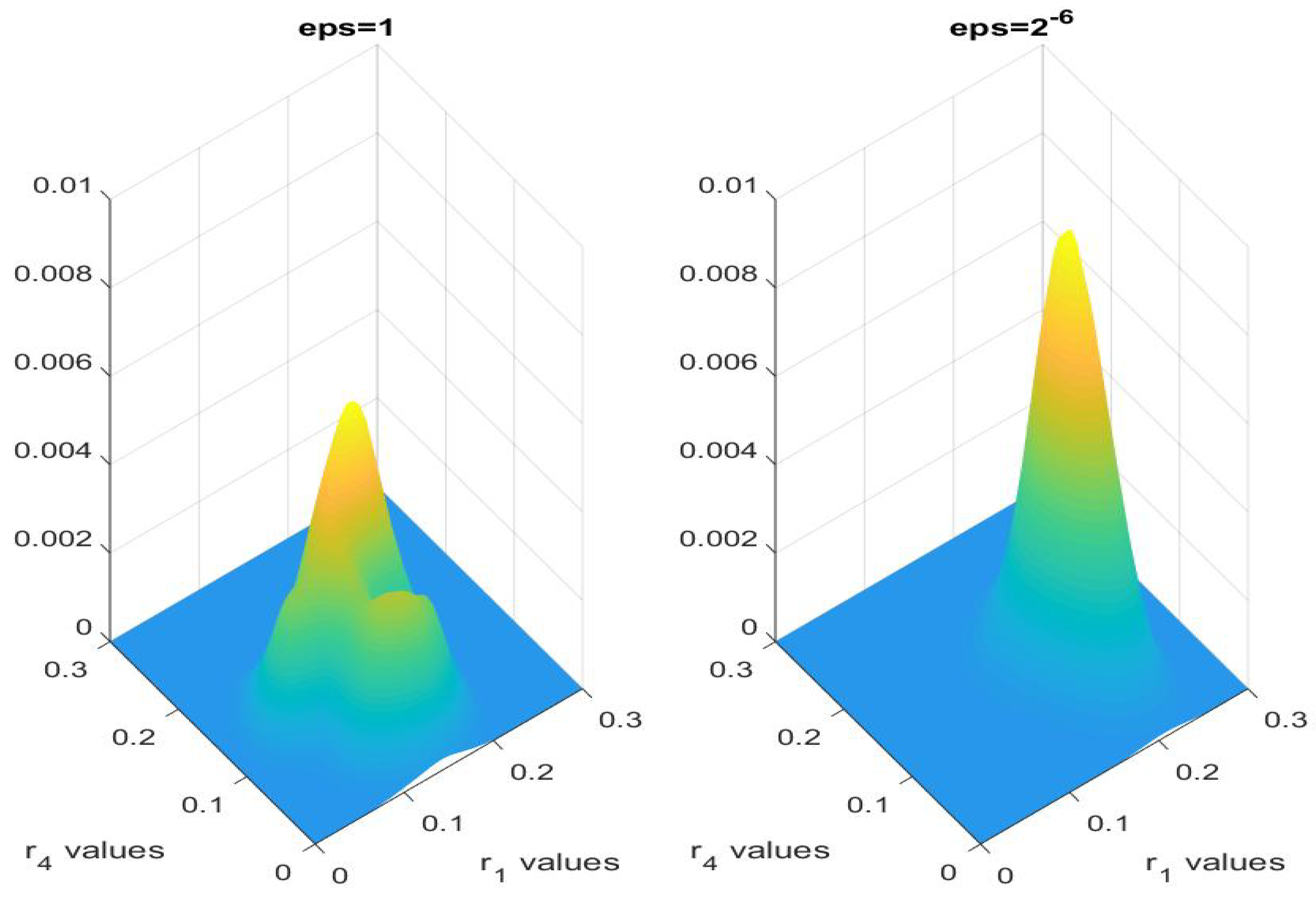
Using Theorem 3, when is sufficiently small, one may use the diffusion equation posterior to approximate the radiative transfer equation posterior. This approximation allows us to speed up the MCMC computation by setting as the low-resolution model in the first level. This filters out bad draws, passing better draws to on the second level.
4. Algorithm
In this section, we discuss the DE-assisted two-level MCMC method and its convergence for our case, the inverse problem for the RTE in the diffusion limit. We present a result about the second-level acceptance rate of two-level MCMC and its dependence on and a result about the computational cost of our algorithm compared to the one-level MCMC method.
4.1. DE-Assisted Two-Level MCMC Method
In this section, we discuss our algorithm, the DE-assisted two-level MCMC method. It is shown below in Algorithm 3.
| Algorithm 3 DE-assisted two-level Metropolis Hastings |
Given , draw With probability , pre-accept y and continue to 4. Otherwise, set and start over. The second-level proposal is now y, effectively drawn from
With probability , accept and set . Otherwise, set .
|
The transition kernel
may be written
where
is called the second-level off-diagonal density, and
. As before, to demonstrate the convergence of MCMC, we will examine the transition kernel, which is the probability that the next draw
is in the set
A given the previous elements of the chain
.
For the two-level MCMC method, one desires that the high-resolution target distribution
is an invariant distribution of the Markov chain
. By definition, this is true if for all measurable sets
A,
This means that elements of the Markov chain generated by Algorithm 3 give a good representation of the distribution . To show that is the invariant distribution, we first need the following two lemmas.
Lemma 2. The second-level acceptance rate may be writtenwhere is defined as in Algorithm 2. Proof. From Lemma 3, for
, we have
Plugging this in to our definition of
, we find
□
The importance of this lemma is that it equates
, which depends on
, to a form that is computable. Note that
has a complicated integral form and thus is numerically challenging to compute. This form of the second-stage acceptance rate
has been calculated in [
18]. Later, we will discuss the dependence of
on
through the inverse problem for the RTE’s posterior distribution and show that when the RTE and DE are close,
is close to one.
We next discuss a property of that we will need to show the convergence of the two-level MCMC method.
Lemma 3. The second-level off-diagonal density satisfies the detailed balance equation Proof. Considering the form of
in Equation (
24), when
,
Similarly, when
,
so dividing them gives
using Lemma 1. Simplifying gives
□
This lemma gives rise to the following theorem.
Theorem 4. The second-level distribution is the invariant distribution of the Markov chain with second-level transition kernel , i.e.,where the transition kernel is defined as Proof. Consider
using Lemma 3 and using the delta function to perform the integration over
x in the second term. Then, from the definition of
,
□
This theorem demonstrates that the high-resolution target distribution, for us , is the invariant distribution of . Thus, the two-level MCMC method gives a list of elements that can be regarded as samples from .
To generate samples from the posterior based on the RTE, using the one-level MCMC method, for each new proposal, the forward map must be computed. To do this, one injects K boundary data and computes J outgoing data , meaning that the RTE is solved K times and each time the solution is evaluated at J locations. As this is computationally expensive, one looks for a cheaper way to sample from the distribution. From Theorem 3, we have that in the diffusion limit, the posterior based on the RTE is close to the posterior based on the DE. The diffusion equation is significantly faster to solve because it is only over physical space. Therefore, in the strong scattering regime, we can save time on the computation by using the DE-assisted two-level MCMC method, in which the DE is used as a surrogate model to filter out bad draws. This saves computational effort spent on evaluating bad samples using the high-resolution model. The diffusion equation posterior can be used to reject bad samples, so that we have to evaluate the RTE posterior fewer times overall.
4.2. Properties of DE-Assisted Two-Level MCMC
In this section, we first present our result concerning the acceptance rate of the DE-assisted MCMC method and its dependence on , and then present the computational cost of our method compared to the one-level MCMC method.
4.2.1. Acceptance Rate of DE-Assisted Two-Level MCMC
There are many ways to improve MCMC. Different sampling methods such as the Gibbs sampler or independence samplers can make the algorithm more efficient. There are also delayed acceptance/rejection methods, and adaptive methods in which the low-resolution model is improved at each stage using results from the high-resolution model [
23]. However, this is not the focus of the current paper. Our method is a delayed acceptance method. It relies on the two-level MCMC algorithm and the diffusion limit to improve the efficiency of sampling from the posterior distribution for the RTE.
We emphasize that the DE-assisted two-level MCMC algorithm in Algorithm 3 has two acceptance rates, and . The first-level acceptance rate depends only on the posterior based on the DE, so it can have no dependence. The second-level acceptance rate , depends on through the posterior based on the RTE. As , the posterior based on the RTE becomes closer to the posterior based on the DE, so we expect that the samples that pass the selection criterion have a high chance of being accepted in the second step as well. We quantify this in the following proposition.
Proposition 2. In the diffusion limit, the acceptance rate β is high:as long as the proposal is reasonably close to the measured data,where γ is the variance of the noise and α is any constant between 0 and 1. Proof. Suppose
. Then, the likelihood function for the inverse diffusion equation is
Since the likelihood function is greater than
and the prior has no
dependence, the posterior distribution will also be greater than
,
Considering the form of
in Equation (
24), we have
using Theorem 3. Considering
where the Taylor expansion is possible due to Equation (
27). Therefore, for small
,
□
This proposition demonstrates that as and the posterior based on the RTE becomes closer to the posterior based on the DE, more and more samples are accepted at the second level.
4.2.2. Computational Cost Comparison
In this section, we discuss the computational cost of our method compared to the one-level MCMC method.
Proposition 3. Let Cost denote the cost of obtaining k accepted samples using the one-level MCMC method, and Cost denote the cost of obtaining k accepted samples using the DE-assisted two-level MCMC method. Let denote the acceptance rate of the one-level MCMC method. Let α denote the first-level acceptance rate of the DE-assisted two-level MCMC method, and β denote the second-level acceptance rate of the method.
Proof. First, we examine the cost of evaluating the posterior distribution based on the diffusion equation compared to the posterior based on the radiative transfer equation. The cost of evaluating each posterior distribution is directly proportional to the cost of computing each solution to the equation, so we examine instead the cost of computing a solution to the diffusion equation and the radiative transfer equation. Considering , and , we see that the diffusion equation is significantly cheaper to compute than the radiative transfer equation, depending on the number of grid points in the velocity domain.
Next, we compute the number of MCMC iterations required to obtain
k accepted samples for each method. For the one-level MCMC method, we simply have
where
is the acceptance rate and
is the total number of iterations considered. For the two-level method,
where
is the total number of iterations, and
is the overall acceptance rate. To be more specific, a single sample must go through both levels of evaluation in order to be accepted. Supposing that the acceptance rate at the first level is
, and the acceptance rate at the second level is
, then, the overall acceptance rate is
, which gives us
Using the above results, we can compute the cost of obtaining
k accepted samples using the one-level MCMC method,
Similarly, the cost of obtaining
k accepted samples using the two-level method is
Considering
, the term containing
may be dropped out of Equation (
29). Then we have
Then for , the cost of obtaining k samples using the DE-assisted two-level MCMC is much less than the cost of obtaining k samples using the one-level MCMC. □
In practice, and depend on the sampling strategy used, the initial values of the MCMC parameters, and the step size, so we give only a theoretical asymptotic estimate of the cost comparison.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}