1. Introduction
The second law of thermodynamics is the governing principle of nature, and entropy is the central concept of the second law. Strangely, however, entropy and the second law are nearly absent from the landscape ecology literature [
1,
2]. The focus of landscape ecology is on understanding pattern-process relationships across scales in space and time [
3]. Cushman [
2] argued that since every interaction between entities leads to irreversible increases of entropy and decreases of free energy, it should follow that landscape patterns, processes of landscape change, and the propagation of pattern-process relationships across space are constrained and directed by the second law, and that entropy should be the operative measure to quantify, compare and predict landscape pattern-process relationships.
The fundamental connections between thermodynamics and entropy were noted in seminal works in the field of landscape ecology (e.g., [
4,
5,
6,
7], and in the subsequent decades a few researchers continued to develop thermodynamic ideas in landscape ecology (e.g., [
8,
9,
10]. However, a recent review of the usage and application of the entropy concept in landscape ecology [
1] unequivocally showed that landscape ecology has largely ignored thermodynamic theory, concepts or methods. This disjunction is the primary motivation for this special issue on the linkage between entropy and landscape ecology, and the purpose of this paper is to advance a recent line of work that formalizes the entropy concept in landscapes [
2], and develops the theory of how to measure it [
11,
12]. The primary objective of this paper is to provide a practical analytical approach to measure and compare the entropies of real landscapes.
I proposed that the Boltzmann relation,
s =
kln
W, provides both a theoretical foundation and a computational solution for calculating the configurational entropy of landscapes [
11]. The Boltzmann relation defines the entropy of a system as proportional to the logarithm of the number of microstates in the macrostate of that system, where the macrostate of the system is some broad-scale, emergent property, and the microstates are unique arrangements of the system that produce that macrostate. I suggest that this concept could be applied to landscapes by defining the macrostate as the amount of edge length between pixels of different cover classes in a landscape mosaic, and the microstate as the unique arrangements that the landscape mosaic could take (e.g., how many unique ways the pixels of that map can be arranged), and the entropy of the landscape is proportional to the logarithm of the number of arrangements of the lattice (microstates) that produce the same amount of total edge length (macrostate). Using this principle I show how to calculate the Boltzmann entropy of several simple landscape mosaics, and demonstrate that this configurational entropy measures the disorder of the landscape, such that both landscapes that are highly aggregated and those that are highly dispersed have low entropy, and random arrangements produce configurations that have an edge length with many microstates corresponding to high configurational entropy.
The utility of the application of Boltzmann entropy to real landscapes appears to be limited (e.g., [
11,
12]) given that it seems to depend on computing all the microstates of a landscape (e.g., all unique configurations), calculating the edge length of each and then calculating the number of arrangements that produce an edge length that matches that of the real, observed landscape. In landscapes of realistic dimensionality there are an intractably large number of possible arrangements, making it impossible to formally calculate
W, the number of microstates in the macrostate [
11]. There are several possible solutions to this difficulty. In [
11] I proposed that the effectively infinite number of unique configurations in landscapes of realistic dimensionality means that one can use neutral models such as QRULE [
13] to generate a large sample of spatially random maps, which can then be used to estimate the l number of microstates in a given macrostate, and the distribution of microstates in all possible macrostates of a landscape mosaic. This paper directly continues this line of thinking to demonstrate a practical solution calculating the relative Boltzmann configurational entropy for landscapes of any dimensionality.
The solution proposed in this paper is based on four key ideas. First, a distribution of microstates for any landscape mosaic can be computed by randomly permuting the lattice to produce random configurations of the same dimensionality. Second, following the central limit theorem, the total edge length in this distribution of randomized landscapes will follow a normal distribution. Third, by fitting a normal probability density function to this distribution of total edge length in the randomized microstates, we can predict the proportion of microstates with any given edge length. Fourth, taking an analogy from Shannon entropy [
14], we can use the proportion of microstates (
p), rather than the number proper (
W), to compute a relative Boltzmann entropy that we can use to compare the relative entropy of landscapes with the same number of pixels and cover types. The goal of this paper is to evaluate each of these four assertions, demonstrate that they hold for a sample of real landscapes of varying dimensionality, patch richness and evenness of cover type proportionality, and finally provide equations that allow researchers to calculate the normal distribution of microstates associated with any landscape directly to enable rapid calculation of landscape entropy without the need to conduct onerous randomization analyses.
2. Methods
The first component of this evaluation uses neutral models to produce 12 different landscape configurations for a landscape of 256 cells in 16 × 16 dimensionality, with two cover types, each with 50% area. I used QRULE [
13] to produce a simple random map (
Figure 1a) and multi-fractal maps with
H parameter (which controls the degree of aggregation), ranging from 0.1 (highly fragmented) to 1 (highly aggregated), at 0.1 an interval of 0.1 H unit (
Figure 1b–k), with a constant random number seed. Finally, to produce a highly dispersed pattern, I generated a perfect checkerboard (
Figure 1l).
I produced a distribution of microstates for these landscapes by randomly permuting them. Simply permuting rows and columns does not fully randomize a landscape mosaic. To create a truly random distribution of configurations for these test landscapes I used a three-step process. First, I vectorized the maps into a single column of 256 rows. Second, I randomly permuted this vector. Third, I reordered the randomized vector into 16 × 16 lattices. For each of the 12 test landscapes I computed 100,000 random permutations (microstates).
I used FRAGSTATS (FRAGSTATS v4: Spatial Pattern Analysis Program for Categorical and Continuous Maps. Computer software program produced by the authors at the University of Massachusetts, Amherst.
http://www.umass.edu/landeco/research/fragstats/fragstats.html) [
15] to calculate the landscape metric total edge length on each of the 12 test landscapes and the 100,000 microstates for each. Total edge length computes the length (in meters) between pixels of different classes in a categorical landscape mosaic, and is the state variable to define the macrostate for landscape entropy [
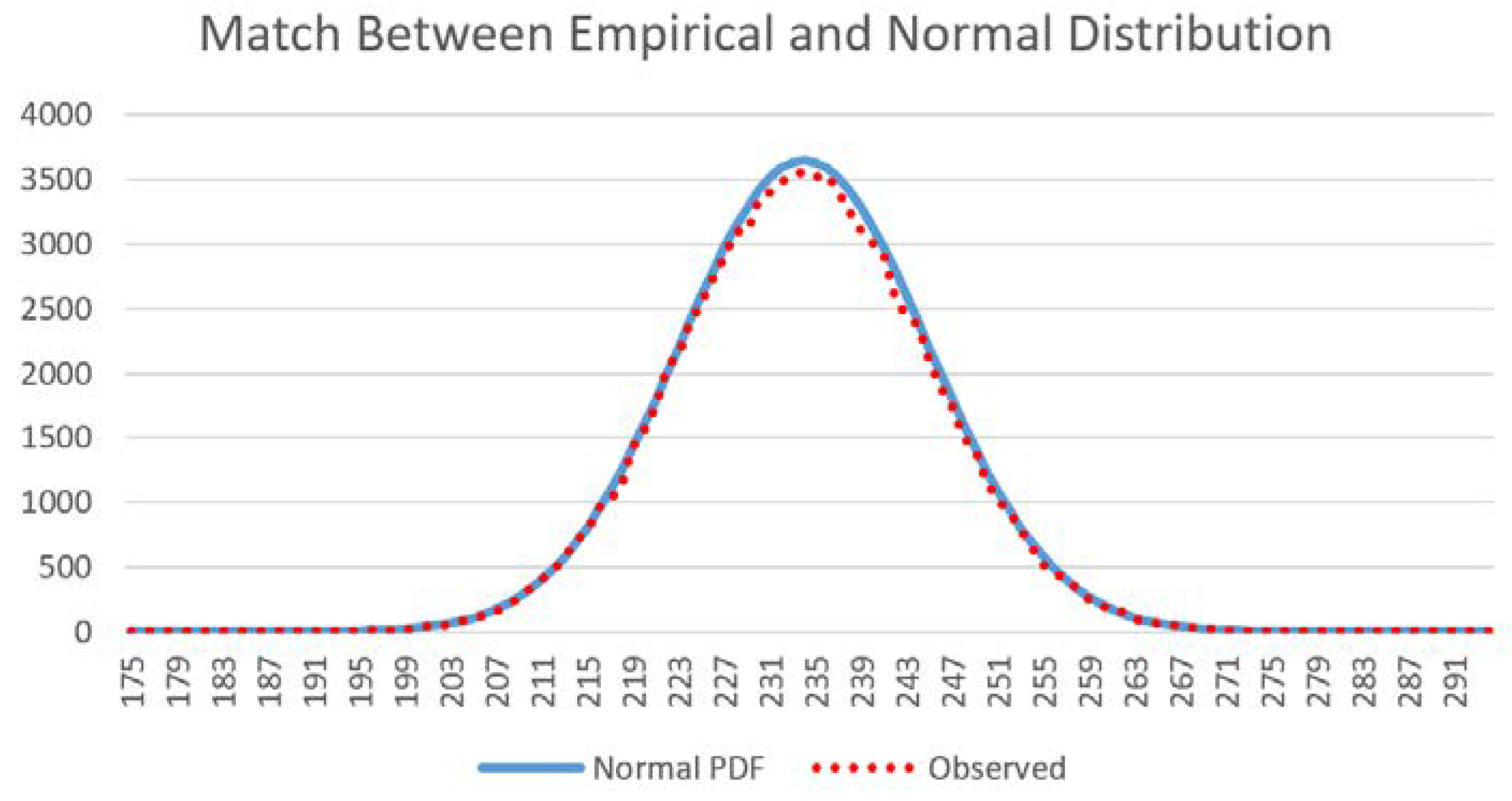
11]. To test the assertion that the distribution of the total edge length in the distribution of permuted landscapes would follow a normal distribution, I computed the histograms of total edge length for the 100,000 permutations of each test landscape, calculated the mean and standard deviation of these, and overlaid the normal distribution with that mean and standard deviation to verify that the permuted distribution followed the parametric probability function perfectly.
The normal probability function provides predictions for the frequency at which each value in the distribution will occur. I used this concept to compute the expected frequency of the observed total edge length in the 12 test landscapes among the full distribution of microstates for that test landscape.
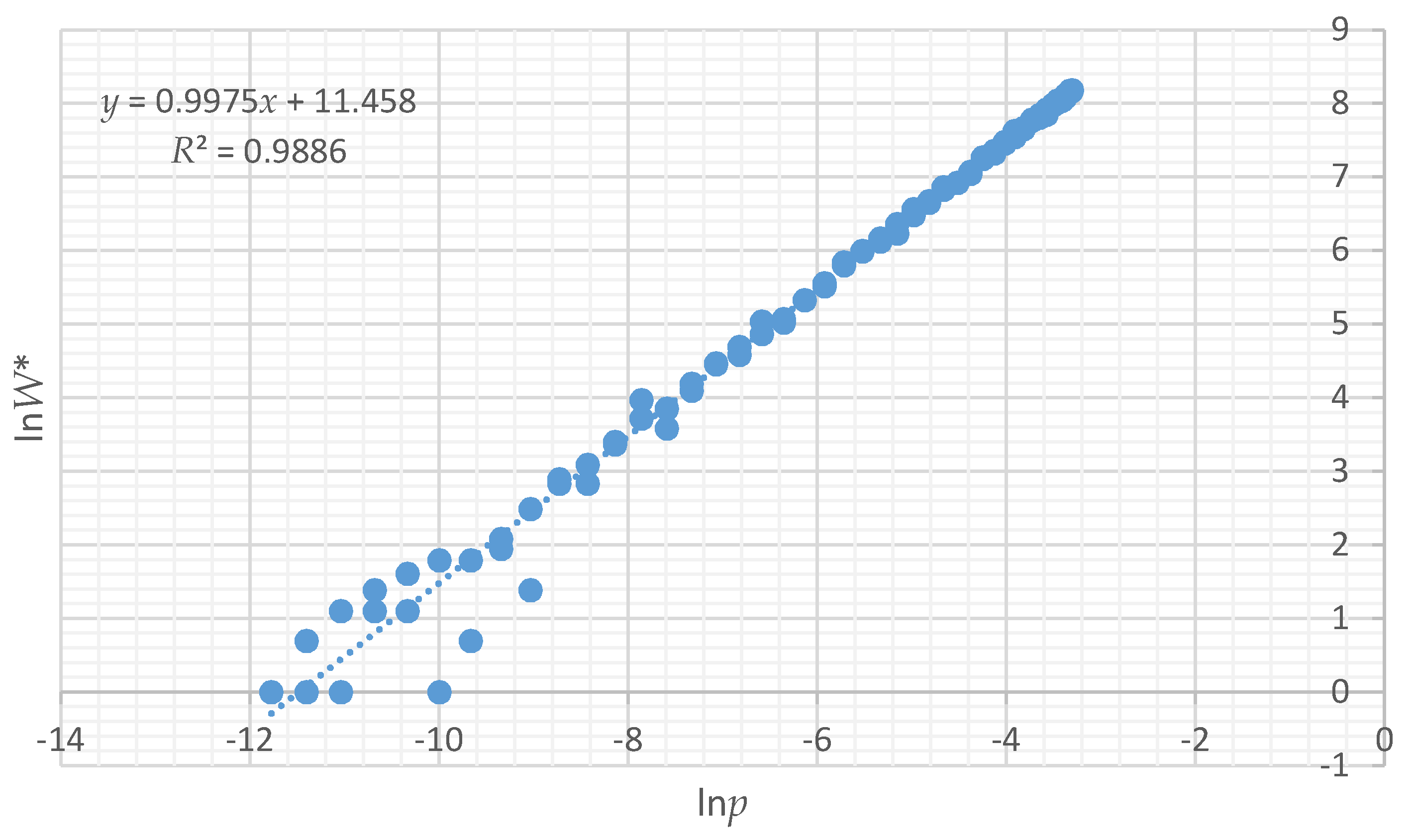
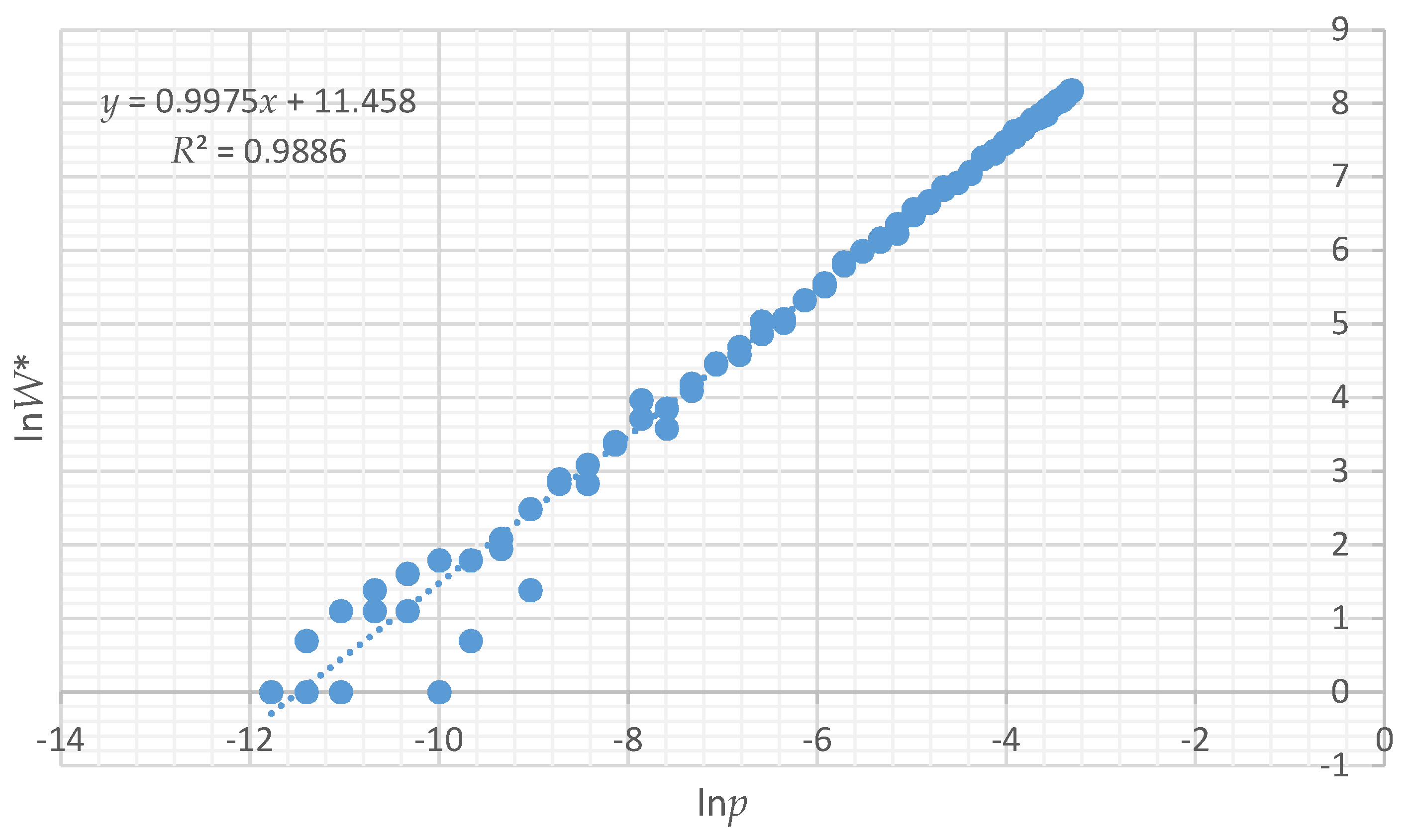
To demonstrate the utility of the proportion of microstates rather than actual number in a macrostate to compute configurational entropy, I produced scatter plots of the relationship between Boltzmann entropy based on computing all actual microstates (lnW) and the logarithm of the probability of a given total edge length in the distribution of microstates for each test landscape (lnp). I used regression to quantify how closely lnp is related to the true Boltzmann entropy (lnW). Finally, using the relationship between lnp and lnW, I calculated the relative configurational entropy of each of the 12 test landscapes and compared them to each other to quantify the degree of disorder in each configuration.
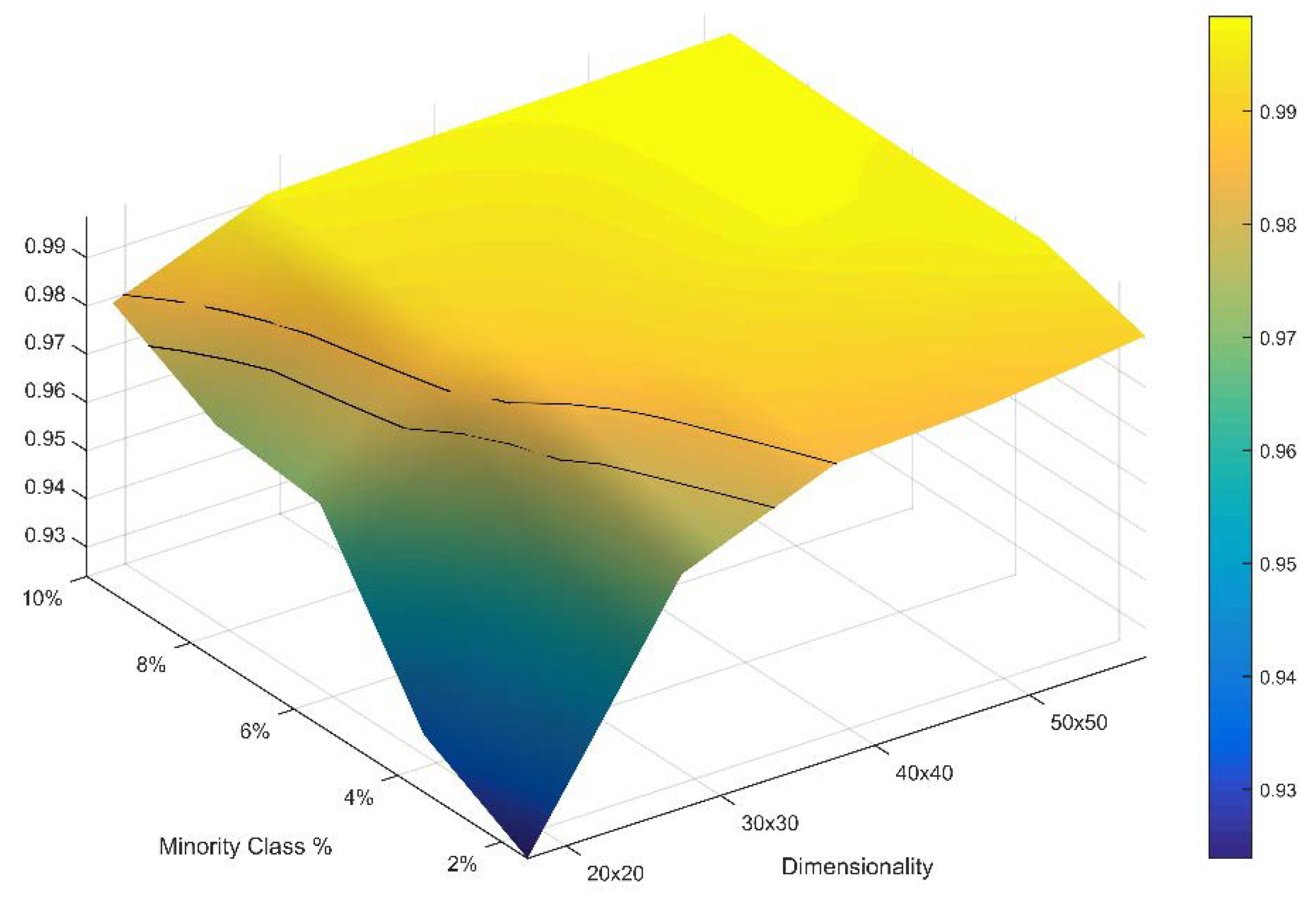
In the second part of this evaluation I explored the boundary limits of the normal approximation for the distribution of total edge length of permuted landscape mosaics. The normal approximation is likely to break down in cases where landscapes are very small, defined by the number of rows and columns, and is very highly dominated by a majority class. This is because when there are relatively few pixels in a landscape and almost all of the pixels are a single class there are few different states possible for total edge length, and the permuted distribution of the total edge length will be truncated at the upper end due to the fact that the total edge length reaches a theoretical maximum when all minority pixels are singletons in isolation surrounded by majority pixels. I explored the boundary limits of the normal approximation by evaluating the normality of the distribution of the permuted total edge lengths for a 5 × 5 factorial (
Table 1) consisting of five levels of landscape extent (20 × 20, 30 × 30, 40 × 40, 50 × 50 and 60 × 60) and five levels of minority proportionality in a two-class landscape (2%, 4%, 6%, 8%, 10%). Landscapes with larger size, a higher proportion of minority class or a larger number of classes will achieve normality more readily than the factors explored here. Therefore, this evaluation provides a strict and conservative evaluation of the boundary limits for the normal approximation.
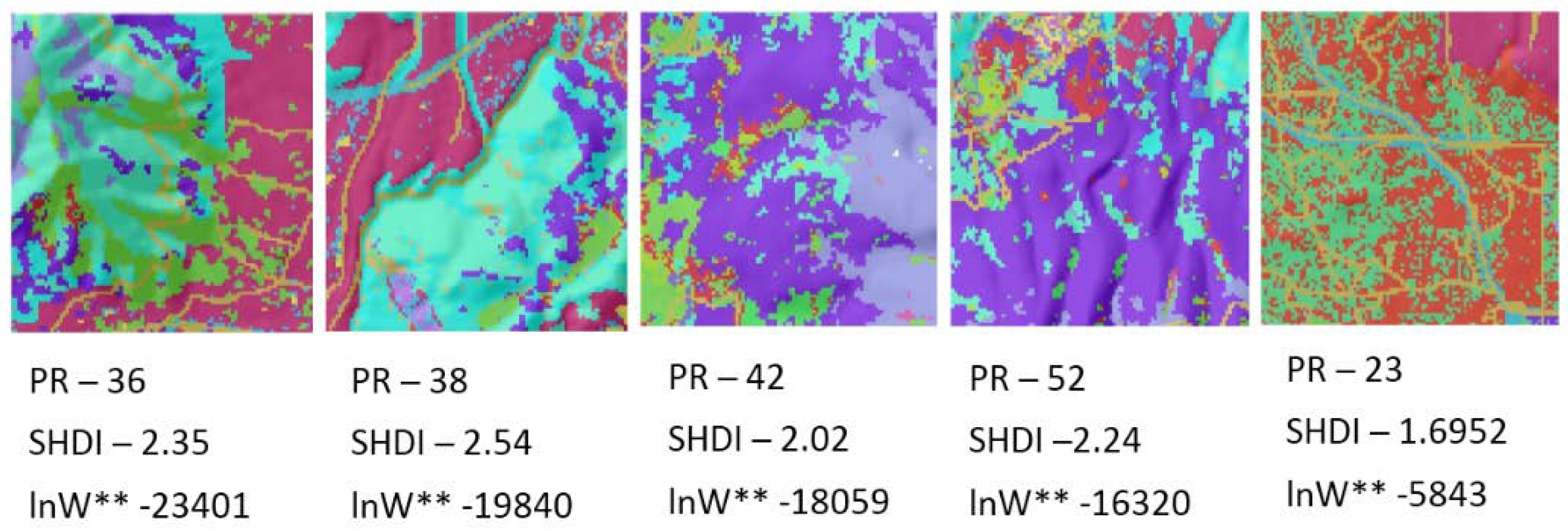
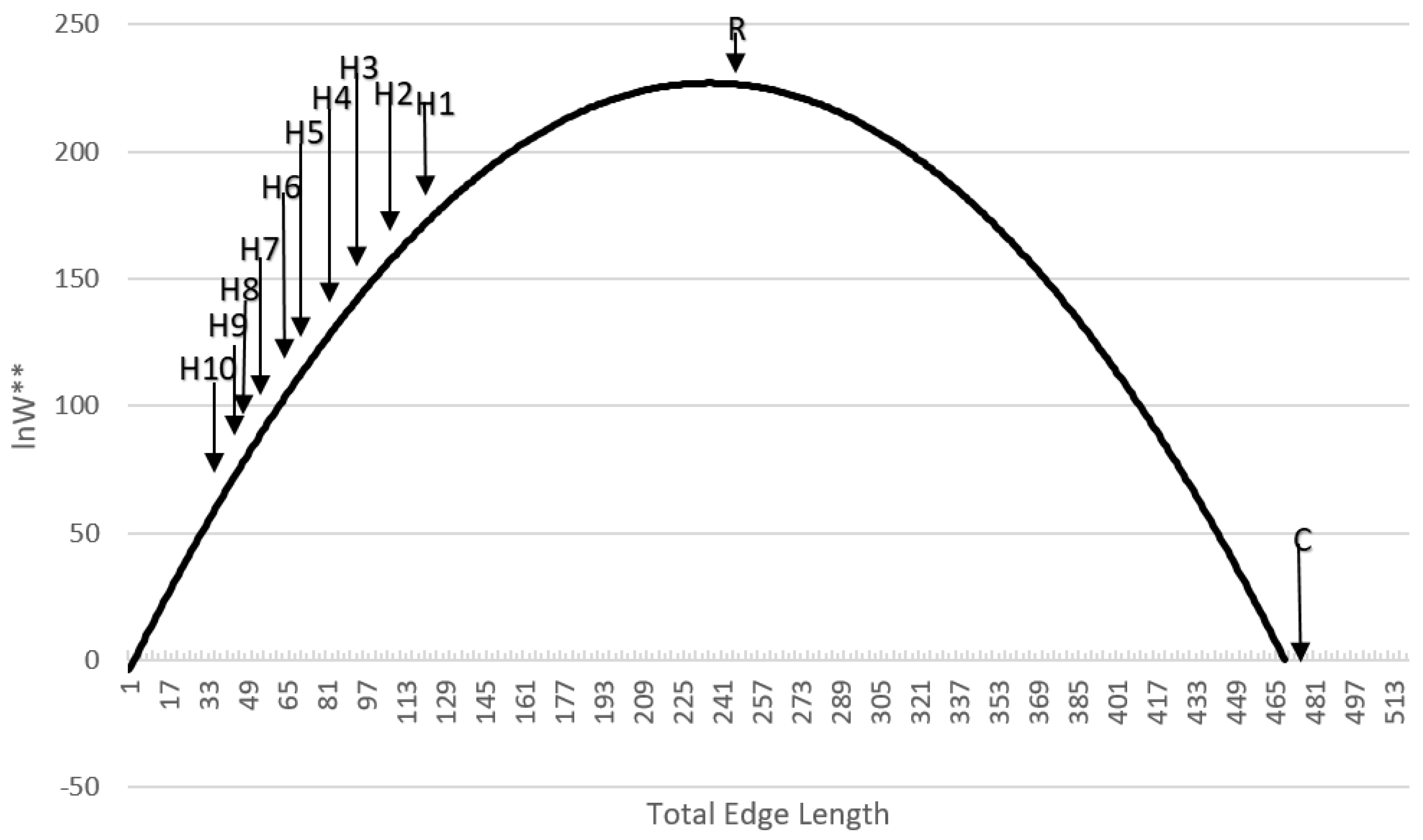
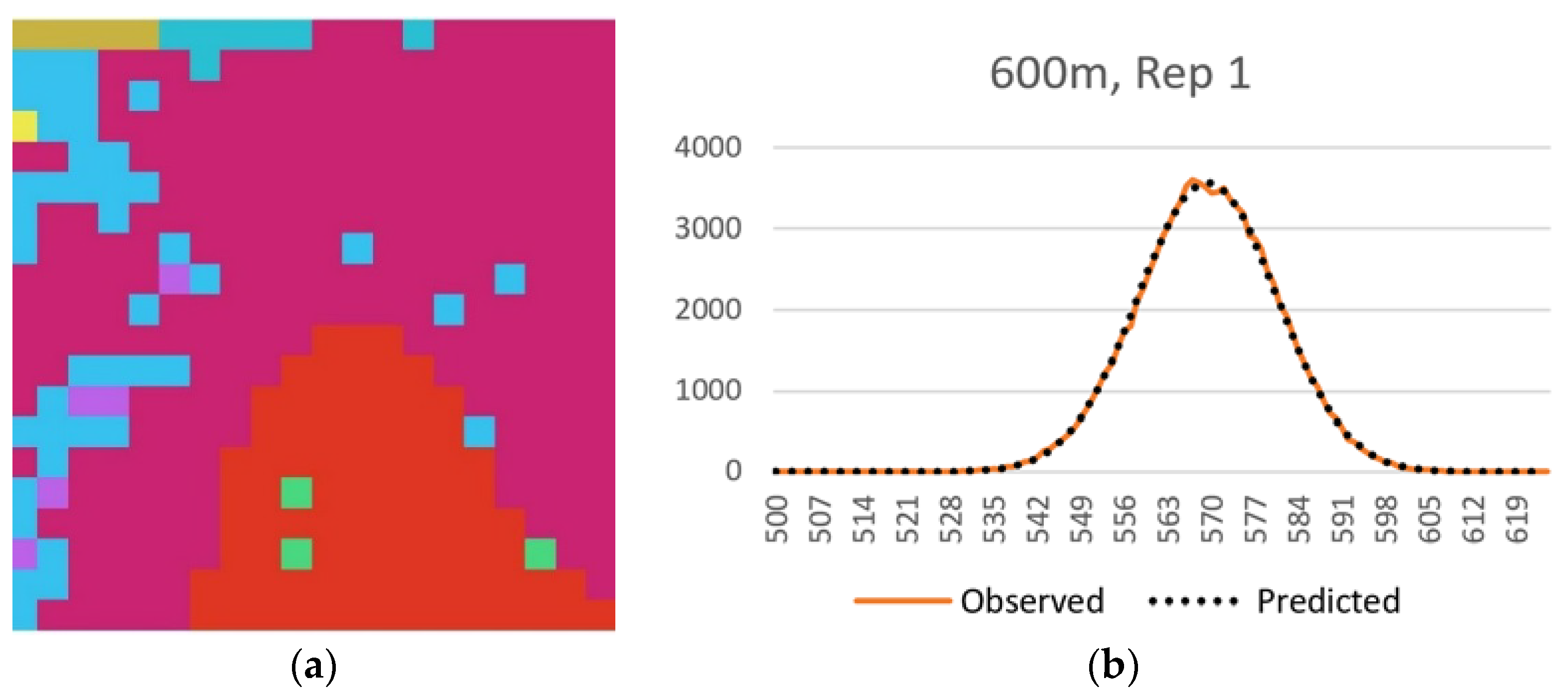
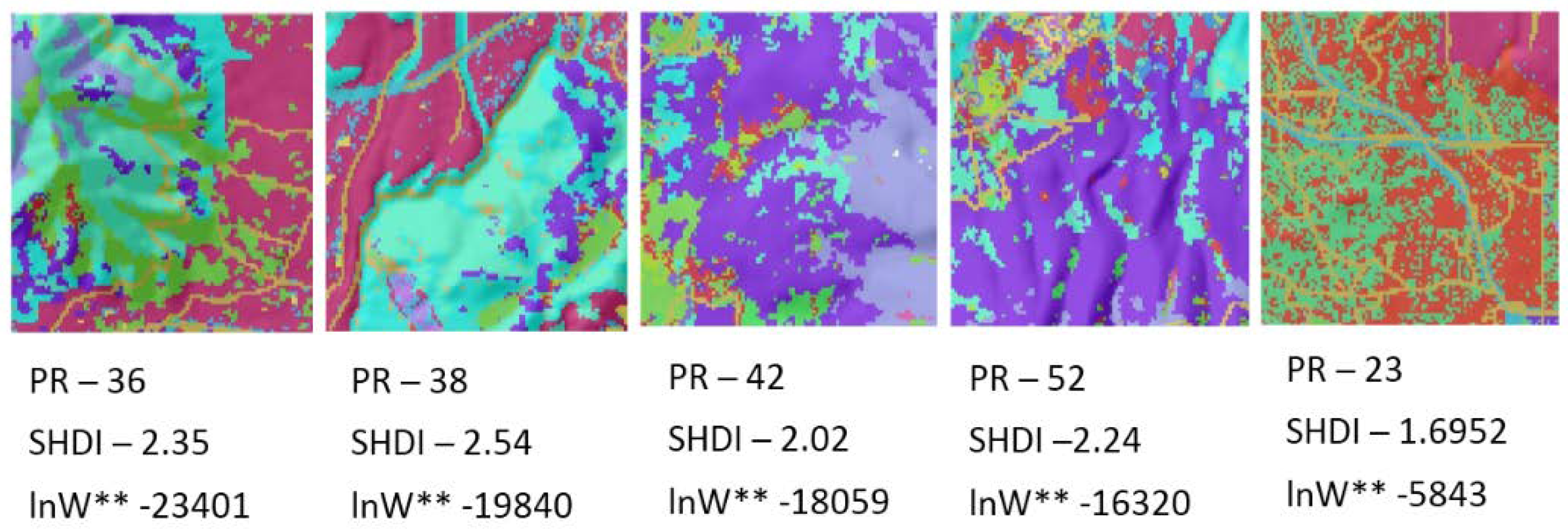
In the third component of this evaluation I evaluated this method using a sample of 25 real landscapes of varying dimensionality (number of columns and rows), patch richness (number of different cover types) and evenness of the proportional amount of each cover type. Specifically, I evaluated a selection of sub-landscapes within a 20 × 20 km landscape centered on the San Francisco Peaks region of Northern Arizona, USA (
Figure 2). I selected a landcover layer that represents vegetation cover type across seral stages, produced by the LANDFIRE program [
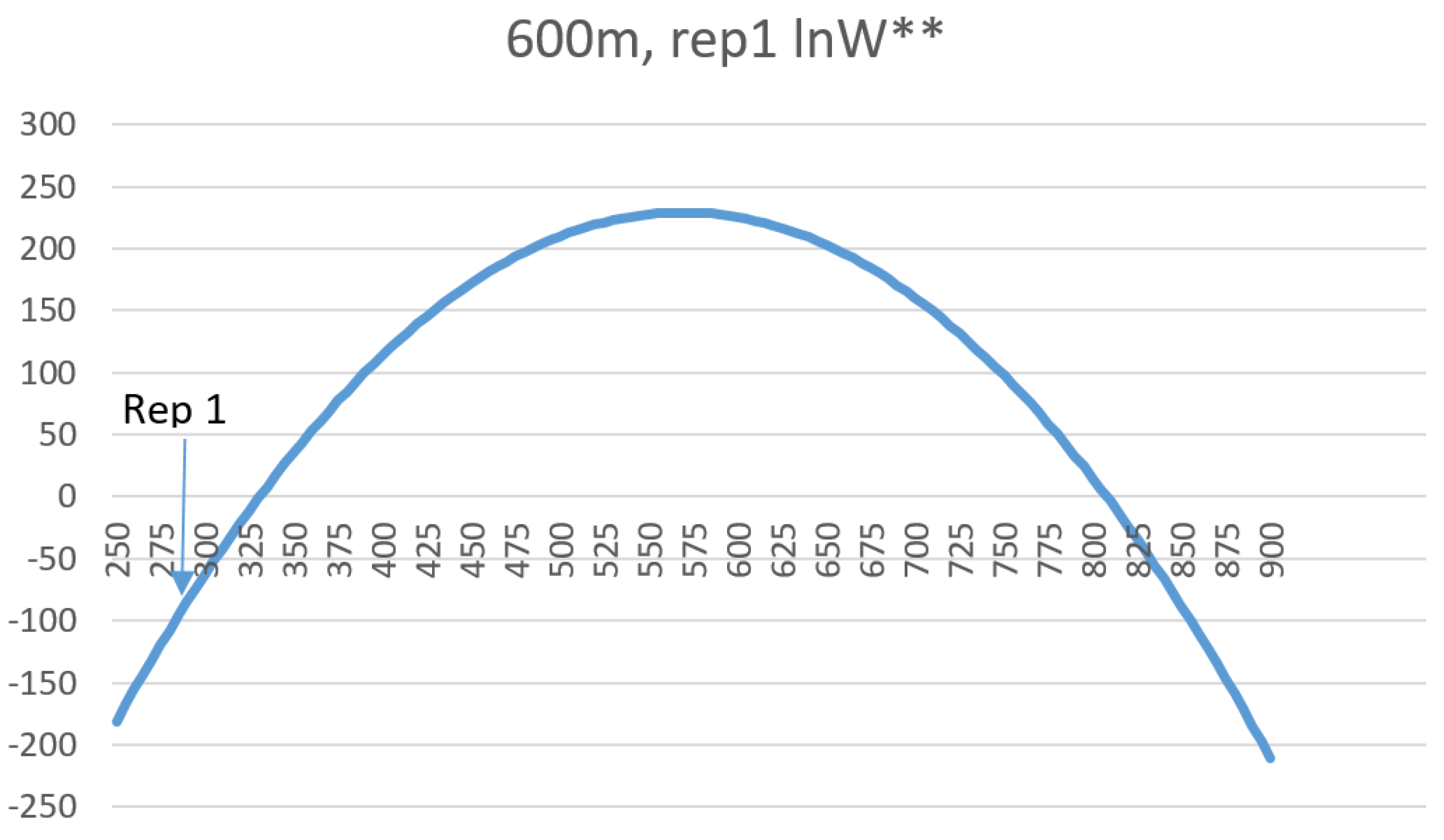
16]. The layer has a 30 m spatial grain (pixel size), and consists of 50 total classes. I randomly selected five replicate landscapes, each of five extents, consisting of 20 × 20 (600 m), 40 × 40 (1200 m), 60 × 60 (1800 m), 80 × 80 (2400 m) and 100 × 100 (3000 m) extents. The lower left corners of these sub-landscapes were spatially randomly located, with the constraint that test landscapes were not allowed to overlap. For each test landscape I followed the same procedure used above in evaluating the QRULE landscapes. Specifically, I vectorized the landscapes and randomized them 100,000 times, calculated the total edge length on each randomized permutation with FRAGSTATS, calculated the mean and standard deviation of this randomized distribution, produced a frequency distribution of the observed frequencies of total edge length for the randomized distribution, and overlaid the associated normal distribution with the same observed mean and standard deviation to confirm the fit between the parametric normal distribution and the observed frequency distribution. Then I calculated the relative Boltzmann entropy for each replicate landscape using the parametric normal probability density function to estimate the number of microstates out of 10
100 random permutations with the same total edge length, and plotted this on the theoretical distribution of macrostates for a landscape with that dimensionality, number of patch types and proportion of each patch type. Finally, I fit linear models to predict the mean and standard deviation of the distributions of macrostates (total edge length) of a landscape as a function of the dimensionality of the landscape, and the Fragstats metrics patch richness (number of cover types) and SHDI (the Shannon diversity of the landscape; [
14]).
4. Discussion
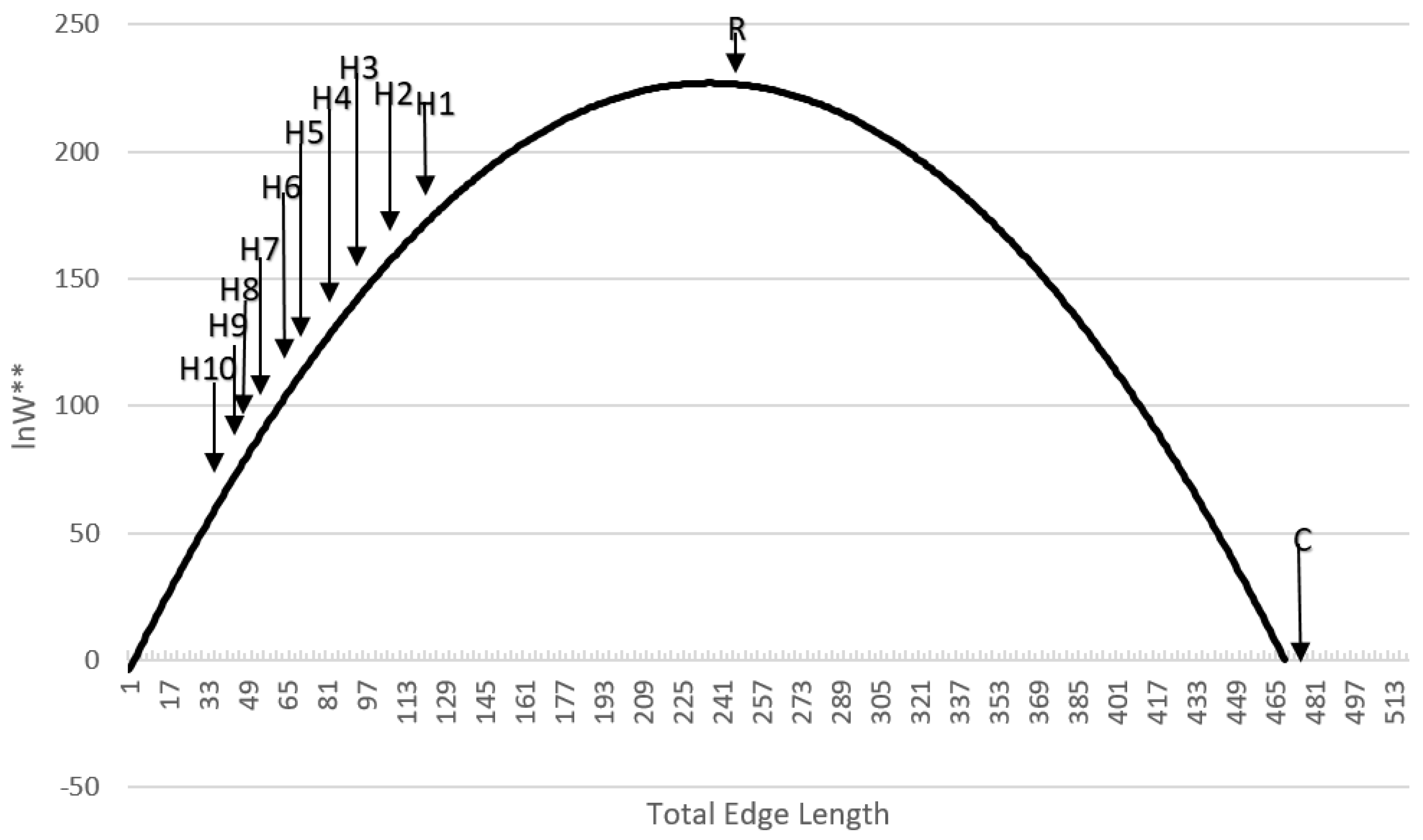
All of the assertions that I proposed are supported by the results of this paper. First, I asserted that a distribution of microstates for any landscape mosaic can be computed by randomly permuting the lattice to produce random configurations of the same dimensionality. The results show that the vector-randomization of a matrix produces a fully randomized lattice, and repeating this a large number of times produces a distribution of randomized configurations that can be used to define the frequencies of microstates of landscape configurations. Second, I asserted that due to the central limit theorem the total edge length in the distribution of randomized landscapes would follow a normal distribution. My results show that this is the case, and that each of the 12 test landscapes produced an identical normal distribution of microstates, which indicates that the frequency of microstates in the landscape configuration is not dependent on the pattern in the focal landscape, but only on the dimensionality, number of classes, and proportion of each class in that landscape. Third, I evaluated the boundary limits of the normal approximation for small landscapes with low proportional coverage by a minority class, and found that the normal approximation is highly robust, especially for landscapes of realistic size and proportionality. Fourth, as I asserted, we can predict the proportion of microstates with any given edge length by fitting a normal probability density function to this distribution of total edge length in randomized microstates. This provides a critical parametric solution to the challenge of computing the vast number of unique configurations that can be generated from randomizing landscape lattices. Specifically, the normal probability function enables easy calculation of the expected proportion of any observed amount of total edge length in the fully permuted distribution of total edge lengths. Fifth, as I asserted, we can use the proportion of microstates (
p), rather than the number proper (
W), to compute the relative Boltzmann entropy, and we can use this relative entropy to compare the entropies of landscapes with the same number of pixels and cover types. Specifically, the relationship between ln
p and ln
W is linear with a slope of 1, allowing exact calculation of the relative differences in entropy between landscape mosaics with the same dimensionality. In addition, the relationship between configurational entropy and total edge length in a landscape of a given dimensionality, number of classes and proportion of cells in each class is parabolic, with a peak in entropy corresponding to a spatially random arrangements of cells, with entropy declining on both sides, as landscapes become more aggregated (lower total edge length) or more dispersed (higher total edge length) in pattern. This confirms my original findings for a small and simple test landscape [
11].
Furthermore, by evaluating the frequency distributions of total edge length across the permutations of the configurations of 25 sample landscapes of varying size, number of cover types and evenness of proportion in each cover type I demonstrated that the parametric approximation to the normal probability density function is robust in real landscapes. This enables us to have confidence in applying the normal probability density function approach to real landscapes, and obviates the need to compute all possible configurations of a given landscape lattice in order to estimate the number of microstates in its observed macrostate of total edge length. In addition, the results show that real landscapes exhibit relative entropies that are very low, and that they depart from randomness in the direction of aggregation, as has been previously noted (e.g., [
15,
17] I observed that the relative entropy of the sample landscapes decreased dramatically as their dimensionality increased. This follows from the fact that (1) real landscapes are aggregated; (2) as dimensionality increases the number of possible permutations of a given landscape lattice increases greatly; and therefore (3) larger landscapes will have many more permutations that have a greater total edge length than the observed landscape. This observation also suggests that care must be taken in comparing the relative entropies of landscapes of different dimensionality, as larger landscapes will generally have lower entropy because of the effect of their size alone. Thus in order to objectively compare the relative entropies of landscapes across dimensionality it may be useful to compare the relative entropy of a given landscape to the maximum possible entropy of that landscape lattice. This can be done by dividing the observed relative entropy by the maximum value of the entropy curve for that landscape. Doing this provides a measure of the entropy of a landscape as a proportion of the maximum entropy possible for a lattice of that dimensionality, number of classes, and evenness of proportionality of amount of each cover class.
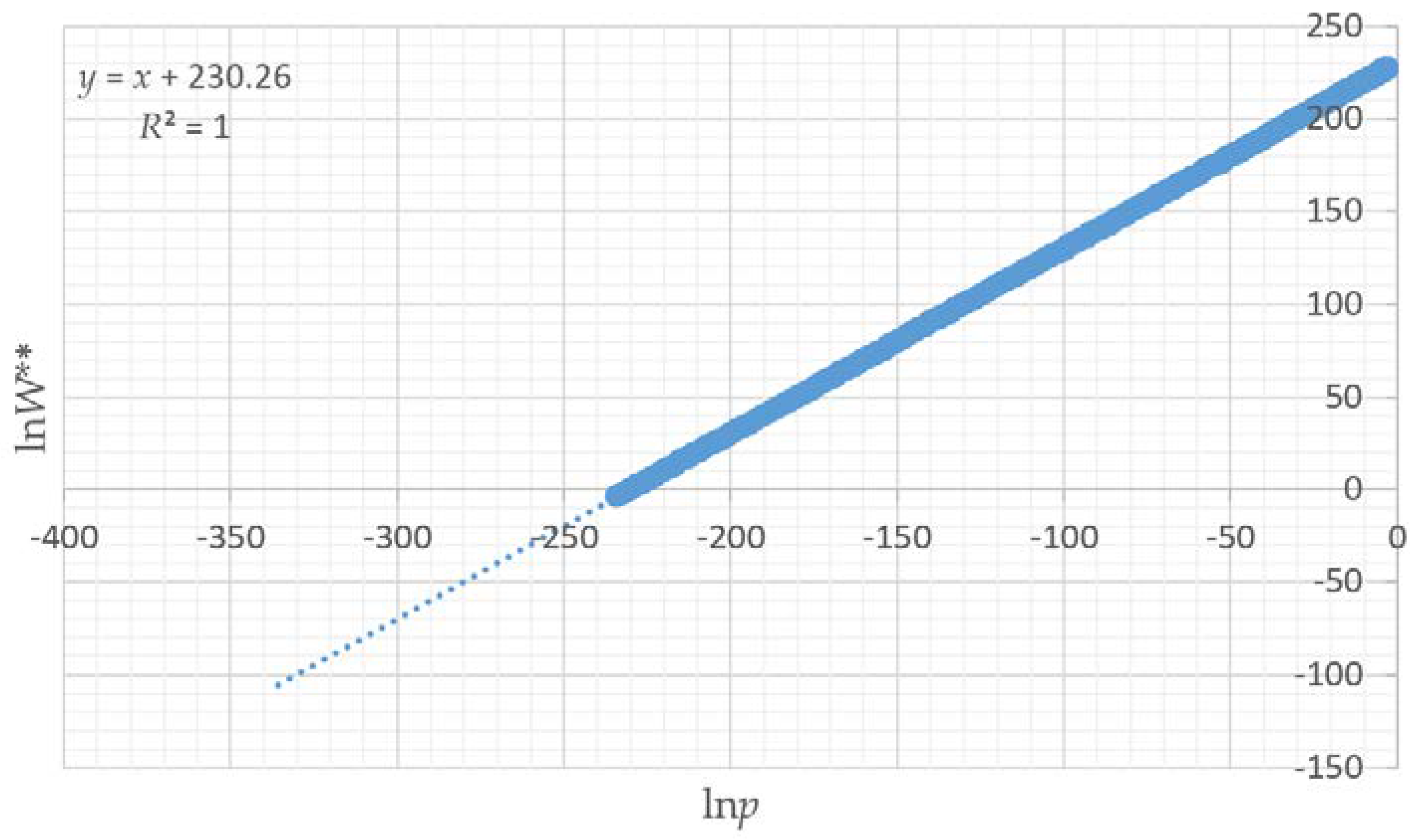
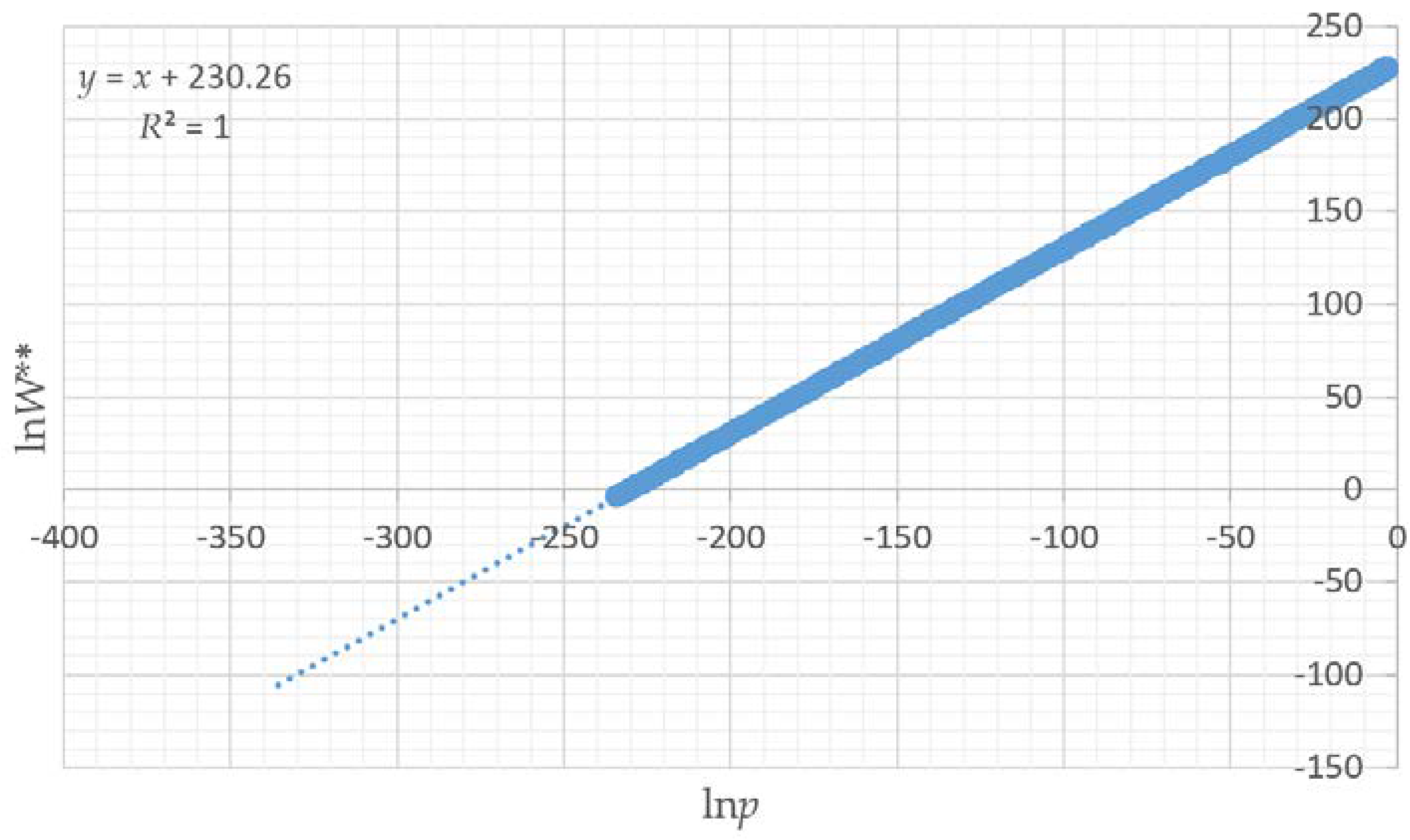
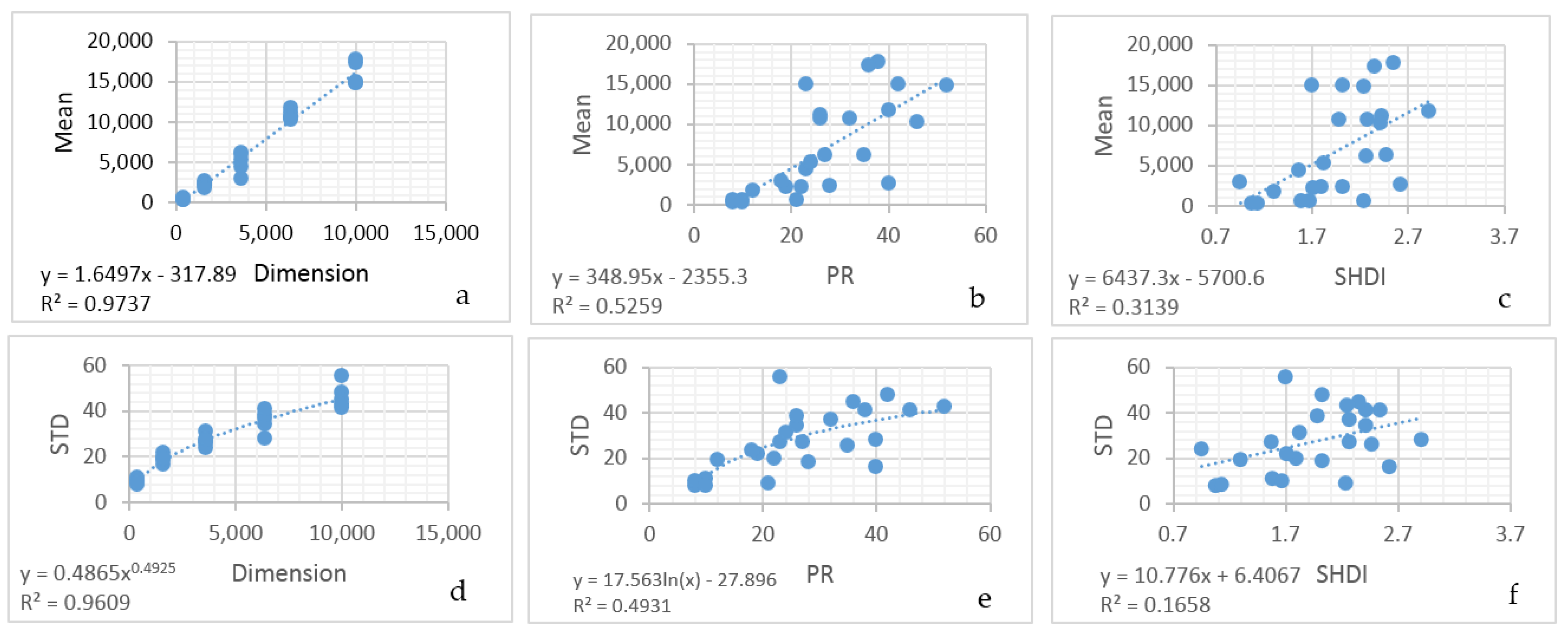
Also, by fitting linear models to predict the mean and standard deviation of the normal probability density function of the total edge length as a function of landscape dimensionality, patch richness and Shannon diversity, I demonstrated that there is a functional relationship between the entropy curve and landscape size and composition. These functions explained nearly all the variance in the parameters of the normal probability density function, which provides a critical shortcut to scientists seeking to use this method when analyzing real landscapes. Specifically, the linear equations enable a researcher to estimate the key parameters of the normal probability density function (mean and standard deviation) directly without having to permute the configuration and calculate the total edge length. Thus, with these equations researchers can directly parameterize a normal probability density function for the total edge length of any landscape, which in turn enables them to readily calculate the relative frequency of the observed total edge length and compute the lnW** value (W** is the number of microstates (configurations of the lattice) with a given macrostate (total edge length) expected in 10 × 10100 permutations of the lattice) of configurational entropy, as well as the index of the proportion of maximum possible entropy described above.
The model averaged GLM predictions of configurational entropy values as a function of landscape dimensionality, composition and configuration also provide important insights into how configurational entropy varies across real landscapes. First, it shows that the dimensionality of the landscape has a dominant effect of the configurational entropy, such that large landscapes tend to have smaller values of configurational entropy. This is true regardless of other factors, such as aggregation, edge density or evenness, and suggests that it is not readily possible to directly compare the configurational entropies of landscapes of different size, making configurational entropy a highly scale-dependent quantity. Scale dependence is a central focus in landscape ecology research, and future work should directly focus on exploring the scale dependence of configurational landscape entropy, by formally evaluating how configurational entropy changes with changes in the extent and grain of the landscape. Second, the model shows that configurational entropy increases with increasing landscape heterogeneity. This is expected given the fact that configurational entropy is a measure of disorder, and the most disordered state is a random configuration. Increasing heterogeneity results in the increasing disorder of the landscape mosaic, for landscapes that lie on the left side of the entropy curve (more aggregated than random), which nearly all landscapes do. Third, the model indicated that entropy decreased with increasing evenness. This at first glance is counterintuitive, given that in [
11] I showed that compositional entropy increases with the increasing number and evenness of the proportional coverage of classes in a categorical map. However, this result makes sense when we understand that the configurational entropy is the logarithm of the number of ways a lattice can be arranged to produce the same total edge length, and as the evenness of the landscape increases there are many more possible permutations of the landscape (and thus higher configurational entropy), and thus fewer microstates in a given macrostate (lower configurational entropy).
I presented the basic relationship between total edge length, number of configurations with a given edge length, the Boltzmann equation, and configurational entropy [
11]. However, in that paper I recognized that the formal application of the Boltzmann equation to calculate the entropy of landscape mosaics required the calculation of the total edge length of each unique configuration of the landscape, and this is intractable in landscapes of realistic size, given the vast number of possible unique spatial configurations. In that paper I proposed that one could use neutral models, such as QRULE [
13], to produce large numbers of configurations that could then provide a sample distribution to compute a proportion of microstates and relative configurational entropy. The major contribution of this paper is that there is an even simpler and more powerful way to compute the configurational entropy of landscapes. Specifically, the fact that randomly permuted configurations of a landscape mosaic are normally distributed allows us to utilize the normal probability density function to calculate the expected proportion of permuted landscapes with a given edge length. Furthermore, the observation that the parameters of the normal probability density function are functions of landscape dimensionality, patch richness and diversity enables the estimation of the total edge length curve without permutations. Thus, all that is required to compute the relative Boltzmann configurational entropy of a landscape is to calculate the extent, patch richness and Shannon diversity of a given landscape and then apply the linear models presented in this paper to estimate the normal probability density function of total edge length that describes the frequency of each macrostate (different values of total edge length) possible, given the composition of that landscape. Once this normal probability density function has been defined it provides direct means to estimate the proportions of configurations (microstates) with a given total edge length (macrostate), which is the key to computing the Boltzmann entropy. In addition, the observation that there is a direct, linear relationship between ln
p and ln
W enables us to compute the relative configurational entropy precisely and without bias for any given landscape and quantitatively compare the entropies of different landscapes. This is the key to making the entropy concept useful in a practical way in understanding landscape patterns.
The entropy of landscape patterns is highly informative. Configurational entropy quantitatively measures the disorder of a landscape. A randomly configured landscape is the most disordered possible configuration, and our calculation of configurational entropy shows this and quantifies its degree of disorder relative to more aggregated or dispersed patterns. In addition, configurational entropy allows quantitative comparison of the degree of disorder of landscapes, which is the key foundation for using configurational entropy as a metric for quantitative landscape analysis and efforts to link pattern-process relationships to thermodynamic principles.
Quantifying the disorder of a landscape would seem to be a breakthrough that can link landscape pattern analysis to physical and ecological theory. Much of the history of landscape ecology has been devoted to the development and description of many metrics that quantify landscape patterns (e.g., [
15]). However, very few landscape metrics are connected in a direct way to fundamental theory or underlying processes. The second law of thermodynamics is the fundamental theory underlying all natural change, and increasing entropy in all actions is the fundamental process that controls the emergence and decay of all structure, in landscapes or elsewhere in the universe [
2,
11]. Therefore, the theoretically sound and quantitative means to measure the thermodynamic disorder of landscapes developed in this paper can allow researchers to begin developing and testing theories about how pattern-process relationships operate, and to what degree they create order in landscape patterns.
In the context of research in the field of landscape ecology, how the pattern of real landscapes in natural and human modified systems fall on the distribution of configurational entropy is noteworthy (
Figure 6). Real landscapes are nearly universally highly aggregated, relative to random distributions [
16,
17]. The test landscapes in this study were produced using a neutral model, QRULE [
13], that controls the degree of aggregation,
H. Empirical research has shown that analogs of this aggregation parameter, such as the aggregation index or contagion, in real landscapes tend to vary within a narrow range at the upper end of their theoretical distributions [
16,
17]. This range of high aggregation corresponds to low entropy and high order. Real landscapes are aggregated and ordered. However, the natural tendency of any natural process under the second law of thermodynamics is toward increasing disorder. The observation of a highly ordered structure at any scale requires a process that drives the creation of thermodynamic order, at the expense of the creation of more disorder in the broader system. Therefore, a promising avenue for future research would focus on quantifying the thermodynamic order of real landscapes, and then connecting those patterns to the organizing processes that create and maintain them. This provides a vehicle to transform landscape ecology from a largely descriptive field to one that explicitly links patterns and processes through the lens of the second law of thermodynamics.
Next Steps
This paper has taken an important step forward in applying thermodynamic concepts to landscape ecology by identifying a means to efficiently calculate and compare the entropies of landscape mosaics, and clarifying the relationships between total edge length, the normal distribution, probability, microstate, macrostate, entropy and the disorder of landscape patterns. An important next step would focus on the scale-dependence of configurational entropy. The conceptualization presented here is based on a simplified model of a two-class landscape, with an equal proportion of pixels in each class, and of dimensions of 16 × 16, amounting to 256 pixels. However, a fundamental concept in geographical information systems, remote sensing and landscape ecology is that the apparent pattern of a landscape changes as one changes the resolution of analysis. Resampling a landscape mosaic to a coarser pixel resolution changes the observed pattern, as does reclassifying the number of cover types in a landscape mosaic. How this affects the entropy of a landscape mosaic is an important question, as there is no natural scale at which all landscape patterns or processes should be observed [
18], and pattern-process relationships are fundamentally scale-dependent [
19,
20]. Understanding how the entropy of a landscape changes with variations in grain, extent and thematic resolution will be critical to integrating thermodynamic measurements and concepts into the multiscale paradigm. Gao et al. [
21] have taken a first step in this regard, presenting a framework to evaluate how different levels of coarseness of resampling affects the emergent entropy of landscape patterns. Additional work is needed to clarify how entropy changes with the scale of analysis, and to link these changes to scale-dependence in pattern-process relationships.
Another avenue that promises to produce interesting work is the extent to which the landscape configurational entropy concept can be applied beyond categorical mosaics to quantify the entropy of point patterns and gradient landscapes. It has been argued that the categorical patch mosaic is an abstract simplification of what is usually a truly continuous and multi-scale, multivariate pattern in real landscapes [
21,
22]. To integrate the second law and the entropy concept into this multi-scale gradient paradigm we urgently need methods to robustly measure the entropy of surface patterns. Gao et al. [
21] have taken an important first step in this approach, showing how one can calculate the entropy of landscape gradients using a multiscale approach in which the macrostate is a coarsened resampling of a surface, and the microstates are the individual ways that a finer grain map can be configured to produce that same macrostate. This is an important first step to integrating gradient theory and landscape entropy. A promising additional idea is analogous to the approach used here. Specifically, instead of using spatial randomization to shuffle the configuration of a categorical lattice, one could use randomization to shuffle the pixels of a continuous landscape surface. Instead of calculating the number of microstates that produce a given level of total edge length, one could calculate the number of microstates that produce the same global sum of difference between the values of a pixel and its eight neighbors. This would produce an equivalent model of the configurational entropy of a landscape gradient. Landscapes with low entropy would have low differences from their neighbors compared to the distribution of possible differences in the shuffled distribution, while landscapes with high entropy would have differences with their neighbors that are most frequent among the shuffled distribution. An analogous idea could be used in point-pattern analysis. Specifically, the long-established variance–mean ratio of a number of points within a moving box to quantify dispersion, aggregation, or randomness could be converted to a measure of entropy [
11]. Specifically, point patterns producing highly aggregated or highly dispersed patterns are low in entropy, while those approaching randomness are high in entropy.
5. Conclusions
Why do we care? What difference does it make to be able to calculate an objective and quantitative measure of the entropy of a landscape? The most basic answer is also the most profound. All processes in nature tend to increase entropy, decrease free energy and lead to an increased dissipation of energy and increase in disorder [
2]. Therefore, the observation of structure implies the action of a process that actively is organizing that structure. Ecosystems are networks of dissipative structures where the flow of energy enables the emergence of organization and structure, but at the expense of the creation of more disorder in the broader system. Landscape patterns emerge from a variety of processes acting on multiple scales. Geomorphology, including plate tectonics, orography, weathering and erosion, control major patterns of landforms and these drive many ecological processes and their effects on spatial patterns [
23]. The atmosphere and ocean interact with landform and geography to drive patterns in climate gradients that control temperature and precipitation regimes, which fundamentally drive biomes [
24]), species distributions [
25], and community structure [
26]. Human activities have fundamentally modified landscapes and ecological processes in the Anthropocene [
27], and the interplay of human actions, ecological gradients, climate, and geography fundamentally drive the emergence of patterns in landscapes. I assert that we cannot understand landscapes scientifically until we can quantify their disorder rigorously, and then associate their degree of structure with processes that drive its emergence. We must link pattern and process to have a science of landscape ecology [
3], and the relationships between patterns and process are fundamentally thermodynamic. Entropy and the measurement of disorder, therefore, are central to the growth of landscape ecology into a mature, theory-based, predictive science.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}