
Sparse Estimation Based on a New Random Regularized Matching Pursuit Generalized Approximate Message Passing Algorithm


Abstract
:1. Introduction
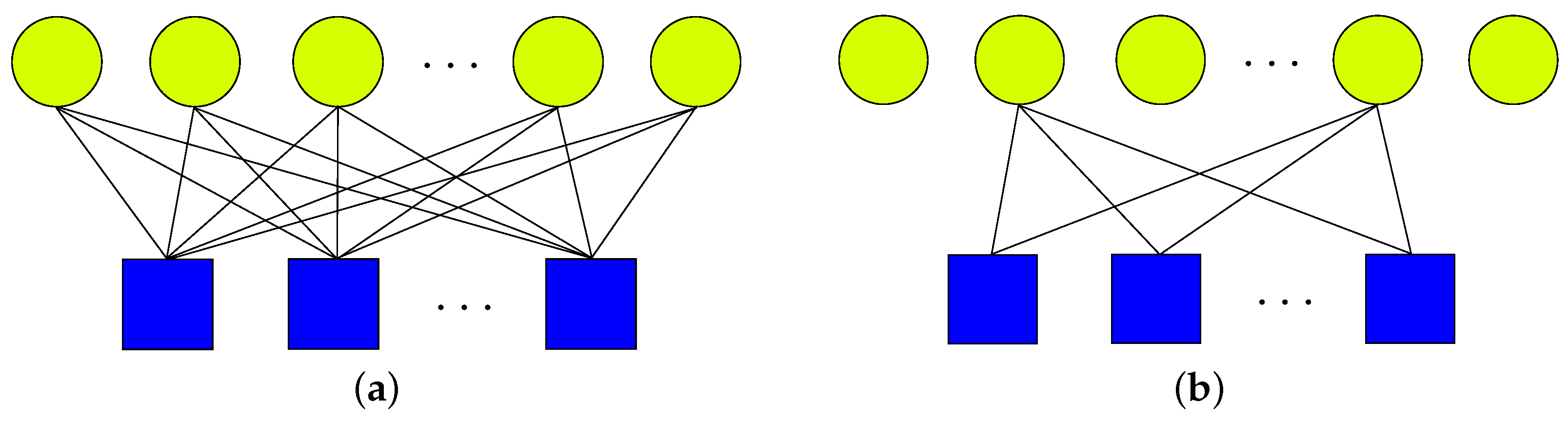
2. Random Regularized Matching Pursuit Generalized Approximate Message Passing
2.1. Random Regularized Matching Pursuit Algorithm
| Algorithm 1 Random Regularized Matching Pursuit. | |
| Input: | |
| Output: | |
| 1: | |
| 2: | |
| 3: | , |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
- If , this means that the absolute amplitudes of the current candidate indexes are much smaller than the absolute amplitudes of the previous pursued indexes, so the algorithm chooses only one current candidate index. This situation corresponds to a sharp ladder step.
- If , this means the absolute amplitudes of the current candidate indexes are just a little smaller than the absolute amplitudes of the previous pursued indexes, so the algorithm chooses those indexes whose absolute amplitudes are greater than . This situation corresponds to a flattened ladder step.
- If , this means the absolute amplitudes of the current candidate indexes are greater than the absolute amplitudes of the previous pursued indexes, but the minimum absolute amplitude of the previous pursued indexes is not a very small value, so the algorithm chooses those indexes whose absolute amplitudes are greater than . This situation also corresponds to a flattened ladder step.
- If , that means the minimum absolute amplitude of the previous pursued indexes is very small, so the algorithm drops a part of the previous pursued indexes and adds a part of the current candidate indexes. This situation corresponds to a sharp ladder step.
2.2. Fixed Support GAMP Algorithm
| Algorithm 2 Fix Support GAMP. | |
| Input: | |
| Output: | |
| 1: | |
| 2: | |
| 3: | while false do |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: | |
| 12: | |
| 13: | {damping steps} |
| 14: | if then |
| 15: | |
| 16: | TRUE |
| 17: | end if |
| 18: | end while |
2.3. Computational Complexity Discussion
3. Convergence Discussion
3.1. The Replica Method Analysis of FsGAMP
3.2. The Prior Matching Conditions and Nishimori Conditions
4. Experiments
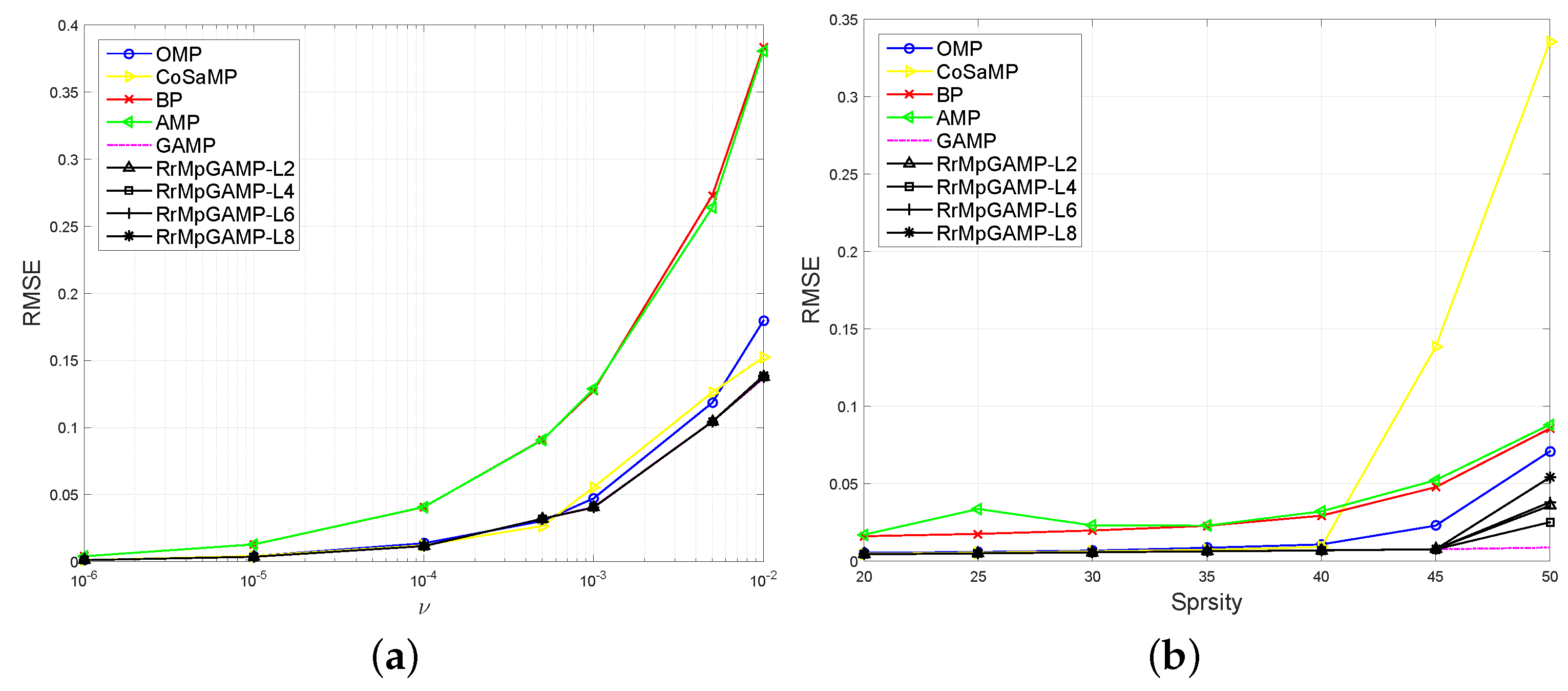
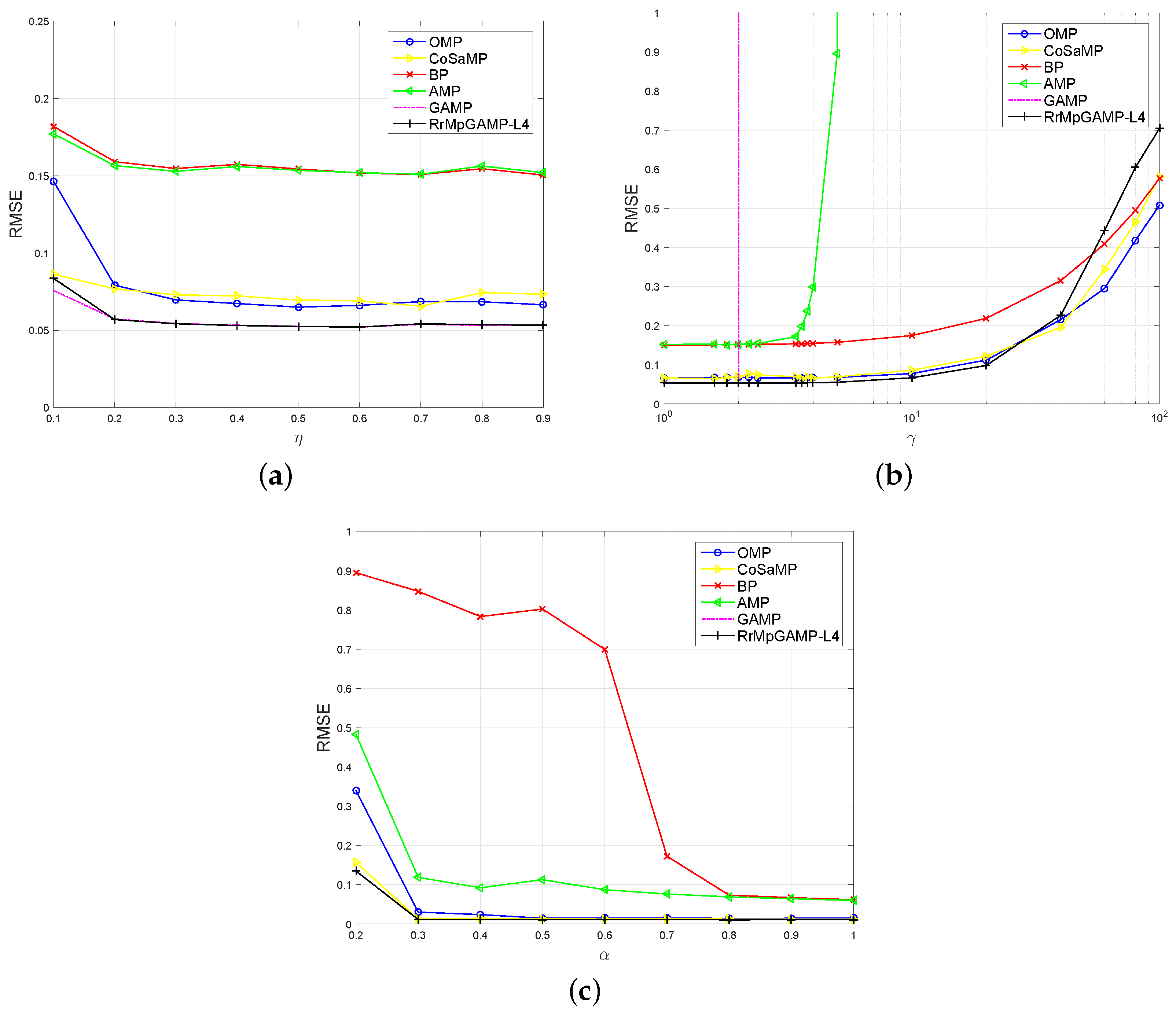
4.1. Zero-Mean Gaussian Projection Matrix Cases
4.2. More General Projection Matrix Cases
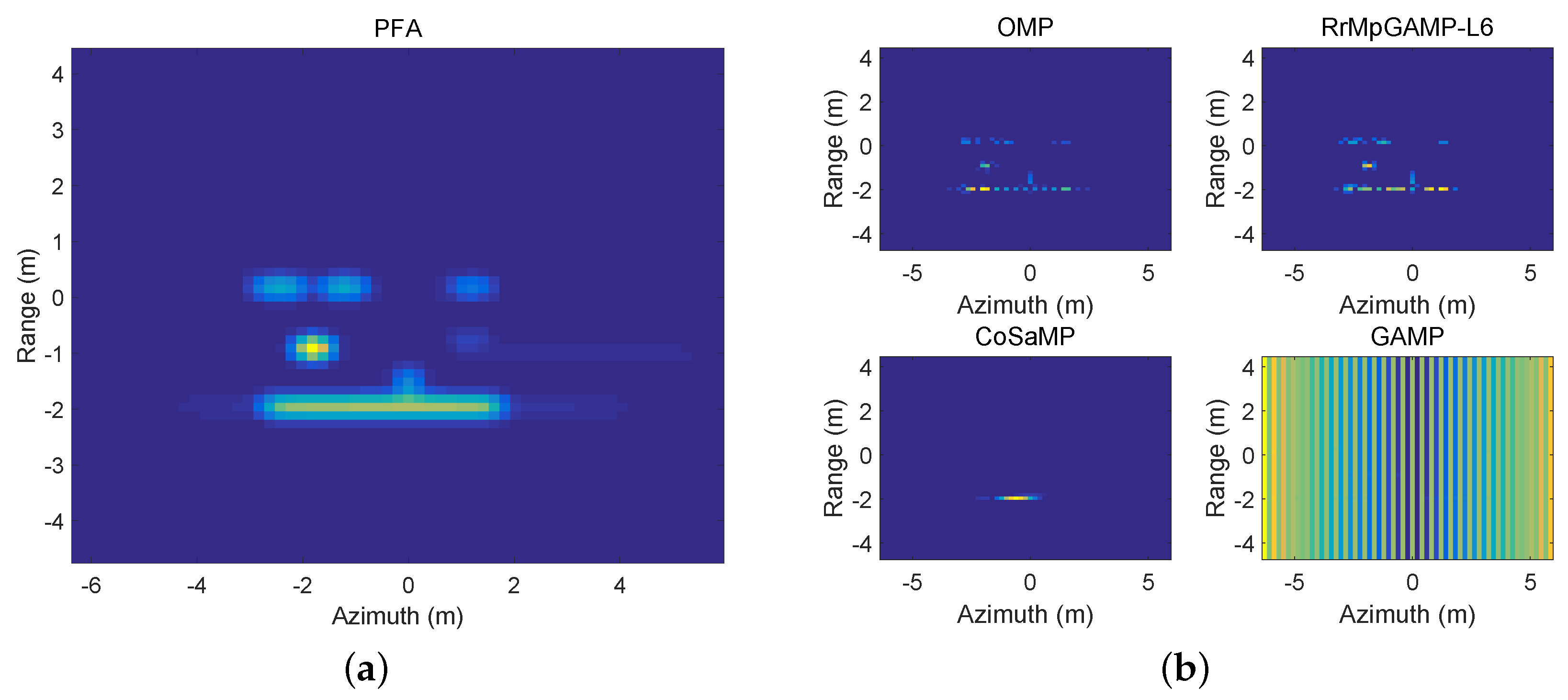
4.3. TomoSAR Imaging Application
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
Appendix A1. Message from the Factor Node to the Variable Node

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Order | Variable | Order | Variable | Order |
|---|---|---|---|---|---|
Appendix A2. Message from the Variable Node to the Factor Node
References
- Wu, Z.; Peng, S. Proportionate Minimum Error Entropy Algorithm for Sparse System Identification. Entropy 2015, 17, 5995–6006. [Google Scholar] [CrossRef]
- Ma, W.; Qu, H. Maximum correntropy criterion based sparse adaptive filtering algorithms for robust channel estimation under non-Gaussian environments. J. Frankl. Inst. 2015, 352, 2708–2727. [Google Scholar] [CrossRef]
- Ma, W.; Chen, B. Sparse least logarithmic absolute difference algorithm with correntropy induced metric penality. Circuit Syst. Signal Process. 2015, 35, 1077–1089. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, S. Online efficient learning with quantized KLMS and L1 regularization. In Proceedings of the International Joint Conference on Neural Networks, (IJCNN 2012), Brisbane, Australia, 10–15 June 2012; pp. 1–6.
- Wang, W.X.; Yang, R.; Lai, Y.C.; Kovanis, V.; Grebogi, C. Predicting Catastrophes in Nonlinear Dynamical Systems by Compressive Sensing. Phys. Rev. Lett. 2011, 106. [Google Scholar] [CrossRef] [PubMed]
- Brunton, S.L.; Tu, J.H.; Bright, I.; Kutz, J.N. Compressive Sensing and Low-Rank Libraries for Classification of Bifurcation Regimes in Nonlinear Dynamical Systems. SIAM J. Appl. Dyn. Syst. 2014, 13, 1716–1732. [Google Scholar] [CrossRef]
- Donoho, D.; Maleki, A.; Motanari, A. Message Passing algorithms for compressed sensing. Proc. Natl. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef] [PubMed]
- Donoho, D.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing: I. motivation and construction. In Proceedings of the 2010 IEEE Information Theory Workshop (ITW), Cairo, Egypt, 6–8 January 2010; pp. 1–5.
- Rangan, S. Generalized approximate message passing for estimation with random linear mixing. In Proceedings of the 2011 IEEE International Symposium on Information Theory Proceedings (ISIT), St. Petersburg, Russia, 31 July–5 August 2011; pp. 2168–2172.
- Pati, Y.; Rezaiifar, R.; Krishnaprasad, P. Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. In Proceedings of the 1993 Conference Record of the Twenty-Seventh Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; Volume 1, pp. 40–44.
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmonic Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Needell, D.; Vershynin, R. Uniform uncertainty principle and signal recovery via regularized orthogonal matching pursuit. Found. Comput. Math. 2009, 9, 317–334. [Google Scholar] [CrossRef]
- Needell, D.; Vershynin, R. Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit. IEEE J. Sel. Top. Signal Process. 2010, 4, 310–316. [Google Scholar] [CrossRef]
- Wainwright, M.J.; Jordan, M.I. Graphical models, exponential families, and variational inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Rangan, S.; Schniter, P.; Fletcher, A. On the convergence of approximate message passing with arbitrary matrices. In Proceedings of the 2014 IEEE International Symposium on Information Theory (ISIT), Honolulu, HI, USA, 29 June–4 July 2014; pp. 236–240.
- Golub, G.H.; van Loan, C.F. Matrix Computations, 3rd ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 2012. [Google Scholar]
- Ḿezard, M.; Parisi, G.; Virasoro, M.A. Spin-Glass Theory and Beyond. In World Scientific Lecture Notes in Physics; World Scientific: Singapore, Singapore, 1987; Volume 9. [Google Scholar]
- Ḿezard, M.; Montanari, A. Information, Physics, and Computation; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Rangan, S.; Goyal, V.; Fletcher, A.K. Asymptotic analysis of map estimation via the replica method and compressed sensing. IEEE Trans. Inform. Theory 2012, 58, 1902–1923. [Google Scholar] [CrossRef] [Green Version]
- Kabashima, Y.; Wadayama, T.; Tanaka, T. Statistical mechanical analysis of a typical reconstruction limit of compressed sensing. In Proceedings of the 2010 IEEE International Symposium on Information Theory (ISIT), Austin, TX, USA, 13–18 June 2010; pp. 1533–1537.
- Ganguli, S.; Sompolinsky, H. Statistical mechanics of compressed sensing. Phys. Rev. Lett. 2010, 104. [Google Scholar] [CrossRef] [PubMed]
- Solomon, A.T.; Bruhtesfa, E.G. Compressed Sensing Performance Analysis via Replica Method Using Bayesian framework. In Proceedings of the 17th UKSIM-AMSS International Conference on Modelling and Simulationm, Cambridge, UK, 25–27 March 2015; pp. 281–289.
- Krzakala, F.; Mézard, M.; Sausset, F.; Sun, Y.; Zdeborová, L. Probabilistic reconstruction in compressed sensing: Algorithms, phase diagrams, and threshold achieving matrices. J. Stat. Mech. Theory Exp. 2012, 2012. [Google Scholar] [CrossRef]
- Needell, D. Available online: http://www.cmc.edu/pages/faculty/DNeedell (accessed on 23 May 2016).
- ℓ1-MAGIC. Available online: http://users.ece.gatech.edu/ justin/l1magic (accessed on 23 May 2016).
- Kamilov, U.S. Available online: http://www.ukamilov.com (accessed on 23 May 2016).
- GAMP. Available online: http://gampmatlab.wikia.com/wiki/Generalized_Approximate_Message_Passing (accessed on 23 May 2016).
- Zhu, X.X.; Bamler, R. Superresolving SAR Tomography for Multidimensional Imaging of Urban Areas: Compressive Sensing-Based TomoSAR inversion. IEEE Signal Process. Mag. 2014, 31, 51–58. [Google Scholar] [CrossRef]
- Carrara, W.G.; Goodman, R.S.; Majewski, R.M. Spotlight Synthetic Aperture Radar: Signal Processing Algorithms; Artech House: Norwood, MA, USA, 1995. [Google Scholar]
- Cong, X.; Liu, J.; Long, K.; Liu, Y.; Zhu, R.; Wan, Q. Millimeter-wave spotlight circular synthetic aperture radar (SCSAR) imaging for Foreign Object Debris on airport runway. In Proceedings of the 12th International Conference on Signal Processing (ICSP), HangZhou, China, 26–30 October 2014; pp. 1968–1972.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Gui, G.; Cong, X.; Wan, Q. Sparse Estimation Based on a New Random Regularized Matching Pursuit Generalized Approximate Message Passing Algorithm. Entropy 2016, 18, 207. https://doi.org/10.3390/e18060207
Luo Y, Gui G, Cong X, Wan Q. Sparse Estimation Based on a New Random Regularized Matching Pursuit Generalized Approximate Message Passing Algorithm. Entropy. 2016; 18(6):207. https://doi.org/10.3390/e18060207
Chicago/Turabian StyleLuo, Yongjie, Guan Gui, Xunchao Cong, and Qun Wan. 2016. "Sparse Estimation Based on a New Random Regularized Matching Pursuit Generalized Approximate Message Passing Algorithm" Entropy 18, no. 6: 207. https://doi.org/10.3390/e18060207