Abstract
Entropy has been widely employed as a measure of variability for problems, such as machine learning and signal processing. In this paper, we provide some new insights into the behaviors of entropy as a measure of multivariate variability. The relationships between multivariate entropy (joint or total marginal) and traditional measures of multivariate variability, such as total dispersion and generalized variance, are investigated. It is shown that for the jointly Gaussian case, the joint entropy (or entropy power) is equivalent to the generalized variance, while total marginal entropy is equivalent to the geometric mean of the marginal variances and total marginal entropy power is equivalent to the total dispersion. The smoothed multivariate entropy (joint or total marginal) and the kernel density estimation (KDE)-based entropy estimator (with finite samples) are also studied, which, under certain conditions, will be approximately equivalent to the total dispersion (or a total dispersion estimator), regardless of the data distribution.
Keywords:
entropy; smoothed entropy; multivariate variability; generalized variance; total dispersion MSC:
62B10
1. Introduction
The concept of entropy can be used to quantify uncertainty, complexity, randomness, and regularity [1,2,3,4]. Particularly, entropy is also a measure of variability (or dispersion) of the associated distribution [5]. The most popular entropy functional is the Shannon entropy which is a central concept in information theory [1]. In addition to Shannon entropy, there are many other entropy definitions, such as Renyi and Tsallis entropies [2,3]. Renyi entropy is a generalized entropy which depends on a parameter and includes Shannon entropy as a limiting case (). In this work, to simplify the discussion, we focus mainly on the Shannon and Renyi entropies.
Entropy has found applications in many fields such as statistics, physics, communication, ecology, etc. In the past decades, especially in recent years, entropy and related information theoretic measures (e.g., mutual information) have also been successfully applied in machine learning and signal processing [4,6,7,8,9,10]. Information theoretic quantities can capture higher-order statistics and offer potentially significant performance improvement in machine learning applications. In information theoretic learning (ITL) [4], the measures from information theory (entropy, mutual information, divergences, etc.) are often used as an optimization cost instead of the conventional second-order statistical measures such as variance and covariance. In particular, in many machine learning (supervised or unsupervised) problems, the goal is to optimize (maximize or minimize) the variability of the data, and in these cases one can optimize the entropy of the data so as to capture the underlying structure in the data. For example, in supervised learning, such as regression, the problem can be formulated as that of minimizing the entropy of the error between model output and desired response [11,12,13,14,15,16,17]. This optimization criterion is called in ITL the minimum error entropy (MEE) criterion [4,6].
In most practical applications, the data are multidimensional and multivariate. The total dispersion (i.e., the trace of the covariance matrix) and generalized variance (i.e., the determinant of the covariance matrix) are two widely used measures of multivariate variability, although both have some limitations [18,19,20]. However, these measures of multivariate variability involve only second-order statistics and cannot describe well non-Gaussian distributions. Entropy can be used as a descriptive and comprehensive measure of multivariate variability especially when data are non-Gaussian, since it can capture higher-order statistics and information content of the data rather than simply their energy [4]. There are strong relationships between entropy and traditional measures of multivariate variability (e.g., total dispersion and generalized variance). In the present work, we study this problem in detail and provide some new insights into the behavior of entropy as a measure of multivariate variability. We focus mainly on two types of multivariate entropy (or entropy power) measures, namely joint entropy and total marginal entropy. We show that for the jointly Gaussian case, the joint entropy and joint entropy power are equivalent to the generalized variance, while total marginal entropy is equivalent to the geometric mean of the marginal variances and total marginal entropy power is equivalent to the total dispersion. Further, we study the smoothed multivariate entropy measures and show that the smoothed joint entropy and smoothed total marginal entropy will be equivalent to a weighted version of total dispersion when the smoothing vector has independent entries and the smoothing factor approaches infinity. In particular, if the smoothing vector has independent and identically distributed entries, the two smoothed entropy measures will be equivalent to the total dispersion as the smoothing factor approaches infinity. Finally, we also show that with finite number of samples, the kernel density estimation (KDE) based entropy (joint or total marginal) estimator will be approximately equivalent to a total dispersion estimator if the kernel function is Gaussian with covariance matrix being an identity matrix and the smoothing factor is large enough.
The rest of the paper is organized as follows. In Section 2, we present some entropy measures of multivariate variability and discuss the relationships between entropy and traditional measures of multivariate variability. In Section 3, we study the smoothed multivariate entropy measures and gain insights into the links between the smoothed entropy and total dispersion. In Section 4, we investigate the KDE based entropy estimator (with finite samples), and prove that under certain conditions the entropy estimator is approximately equivalent to a total dispersion estimator. Finally in Section 5, we give the conclusion.
2. Entropy Measuresfor Multivariate Variability
2.1. Shannon’s Entropy
Entropy has long been employed as a measure of variability (spread, dispersion, or scatter) of a distribution [5]. A common measure of multivariate variability is the joint entropy (JE). Given a d-dimensional random vector , with probability density function (PDF) , where , Shannon’s joint entropy of is defined by [1]:
Another natural measure of multivariate variability is the Total Marginal Entropy (TME), defined as:
where denotes the marginal density, and the corresponding marginal entropy. We have , with equality if and only if all elements of are independent. Further, the following theorem holds.
Theorem 1.
If is jointly Gaussian, with PDF:
where denotes the mean vector, stands for the covariance matrix, and denotes the determinant of , then:
where denotes the i-th diagonal element of , i.e., the variance of .
Proof.
Using Equation (3), we derive:
where denotes the trace operator. In a similar way, we get:
□
Remark 1.
Since the logarithm is a monotonic function, for the jointly Gaussian case, the joint entropy is equivalent to the generalized variance (GV), namely the determinant of [18,19,20], and the total marginal entropy is equivalent to the geometric mean of the marginal variances (). The concept of the generalized variance, which can be traced back to Wilks [21], was suggested by Sokal [22] to measure the overall variability in multivariate biometrical studies, and was applied by Goodman [23] to get easily interpretable results on corn and cotton populations, and recently was also applied by Barrett, Barnett, and Seth [24,25] to multivariate Granger Causality analysis. The generalized variance plays an important role in Maximum Likelihood Estimation (MLE) and model selection. Some limitations of the generalized variance, however, were discussed in [18,19,20].
The covariance matrix can be expressed as:
where is the correlation matrix, and is a diagonal matrix with the marginal standard deviations, , along the diagonal. Thus, the generalized variance and the geometric mean of the marginal variances have the following relationship:
where is the determinant of . From Equation (7), one can see that the generalized variance depends on both and the geometric mean of the marginal variances. If the correlation matrix is near-singular, however, the generalized variance will collapse to a very small value regardless of the values of the marginal variances. This is a significant disadvantage of the generalized variance [18].
Remark 2.
Although for the jointly Gaussian case, there is a simple relationship between the entropy based measures of variability and the traditional variance based measures, the two kinds of measures are quite different. The entropy may be related to higher-order moments of a distribution and can provide a much more comprehensive characterization of the distribution. Only when the distribution (e.g., Gaussian) can be well characterized by the first two moments, or when a quadratic approximation is satisfactory, the variance based measures are justifiable [4,6].
2.2. Renyi's Entropy
There are many extensions to Shannon’s measure of entropy. Renyi’s entropy of order- is a well-known generalization of Shannon entropy [2,4]. Based on Renyi’s definition of entropy, the order- joint entropy and total marginal entropy of are:
where , , and denotes the order- Information Potential (IP) [4] of :
Remark 3.
In recent years, Renyi’s entropy of order- is widely accepted as an optimality criterion in Information Theoretic Learning (ITL) [4]. The nonparametric kernel (Parzen window) estimator of Renyi entropy (especially when ) has been shown to be more computationally efficient than that of Shannon entropy [11,12].
Remark 4.
The information potential is actually the Information Generating Function defined in [26]. It is called information potential since each term in its kernel estimator can be interpreted as a potential between two particles [4]. As the logarithm is a monotonic function, minimizing Renyi entropy is equivalent to minimizing (when ) or maximizing (when ) the information potential. Thus, the information potential can be used as an alternative to Renyi entropy as a measure of variability.
It is easy to verify that Renyi’s entropy will approach Shannon’s entropy as . In addition, Theorem 1 can be extended to the Renyi entropy case.
Theorem 2.
If is jointly Gaussian, with PDF given by Equation (3), then:
where .
Proof.
One can derive:
Similarly, we have:
Substituting Equations (13) and (14) into Equations (8) and (9), respectively, yields Equations (11) and (12). □
Remark 5.
From Theorem 2 we find that, for the jointly Gaussian case, Renyi’s joint entropy is also equivalent to the generalized variance , and the order- total marginal entropy is equivalent to the geometric mean of the marginal variances.
2.3. Entropy Powers
In [5], the variability (or the extent) of a distribution was measured by the exponential entropy, or equivalently, the entropy power. Shannon and Renyi’s joint entropy powers (JEP) are defined by [27]:
Similarly, the total marginal entropy powers (TMEP) are:
Clearly, we have , . The following theorem holds.
Theorem 3.
If is jointly Gaussian, with PDF given by Equation (3), then:
Proof.
Since , , , and , we have:
□
Remark 6.
For the jointly Gaussian case, the joint entropy powers and are equivalent to the generalized variance , and the total marginal entropy powers and are equivalent to the well-known total dispersion (TD) or total variation (TV), given by [19]. The total dispersion is widely accepted as a measure of variation in regression, clustering, and principal components analysis (PCA). Let , , ..., be the eigenvalues of the covariance matrix . Then the generalized variance and total dispersion can be expressed as:
Table 1 lists Renyi’s entropy (which includes Shannon’s entropy as a special case) based measures of variability and their equivalent variance based measures (for the jointly Gaussian case).

Table 1.
Renyi’s entropy based measures of variability and their equivalent variance based measures.
3. Smoothed Multivariate Entropy Measures
In most practical situations, the analytical evaluation of the entropy is not possible, and one has to estimate its value from the samples. So far there are many entropy estimators, among which the k-nearest neighbors based estimators are important ones in a wide range of practical applications [28]. In ITL, however, the kernel density estimation (KDE) based estimators are perhaps the most popular ones due to their smoothness [4]. By KDE approach [29], with a fixed kernel function, the estimated entropy will converge asymptotically to the entropy of the underlying random variable plus an independent random variable whose PDF corresponds to the kernel function [4]. This asymptotic value of entropy is called the smoothed entropy [16]. In this section, we will investigate some interesting properties of the smoothed multivariate entropy (joint or total marginal) as a measure of variability. Unless mentioned otherwise, the smoothed entropy studied in the following is based on the Shannon entropy, but the obtained results can be extended to many other entropies.
Given a -dimensional random vector , with PDF , and a smoothing vector that is independent of and has PDF , the smoothed joint entropy of , with smoothing factor (), is defined by [16]:
where denotes the PDF of , which is:
where “” denotes the convolution operator, and is the PDF of .
Let be independent, identically distributed (i.i.d.) samples drawn from . By KDE approach, with a fixed kernel function , the estimated PDF of will be [29]:
where is the smoothing factor (or kernel width). As sample number , the estimated PDF will uniformly converge (with probability 1) to the true PDF convolved with the kernel function. So we have:
Plugging the above estimated PDF into the entropy definition, one may obtain an estimated entropy of , which converges, almost surely (a.s.), to the smoothed entropy .
Remark 7.
Theoretically, using a suitable annealing rate for the smoothing factor , the KDE based entropy estimator can be asymptotically unbiased and consistent [29]. In many machine learning applications, however, the smoothing factor is often kept fixed. The main reasons for this are basically two: (1) in practical situations, the training data are always finite; (2) in general the learning seeks extrema (either minimum or maximum) of the cost function, independently to its actual value, and the dependence on the estimation bias is decreased. Therefore, the study of the smoothing entropy will help us to gain insights into the asymptotic behaviors of the entropy based learning.
Similarly, one can define the Smoothed Total Marginal Entropy of :
where denotes the smoothed marginal density, .
The smoothing factor is a very important parameter in the smoothed entropy measures (joint or total marginal). As , the smoothed entropy measures will reduce to the original entropy measures, , . In the following, we study the case in which is very large. Before presenting Theorem 4, we introduce an important lemma.
Lemma 1.
(De Bruijn's Identity [30]): For any two independent random d-dimensional vectors, and , with PDFs and , such that exists and has finite covariance, where denotes the Fisher Information Matrix (FIM):
in which is the zero-mean Score of , then:
where denotes the covariance matrix of .
Theorem 4.
As is large enough, we have:
where , and denotes the variance of .
Proof.
The smoothed joint entropy can be rewritten as:
Let , we have:
Then, by De Bruijn’s Identity:
where denotes the higher-order infinitesimal term of the Taylor expansion. Similarly, one can easily derive:
Thus, as is large enough, will be very small, such that Equations (31) and (32) hold. □
Remark 8.
In Equation (31), the term is not related to . So, when the smoothing factor is large enough, the smoothed joint entropy will be, approximately, equivalent to , denoted by:
Similarly, we have:
In the following, we consider three special cases of the smoothing vector .
Case 1.
If is a jointly Gaussian random vector, then , and , where denotes the variance of . In this case, we have:
Case 2.
If has independent entries, then is a diagonal matrix, with along the diagonal. It follows easily that:
Case 3.
If has independent and identically distributed (i.i.d.) entries, then , where is a identity matrix. Thus:
Remark 9.
It is interesting to observe that, if the smoothing vector has independent entries, then the smoothed joint entropy and smoothed total marginal entropy will be equivalent to each other as . In this case, they are both equivalent to a weighted version of total dispersion, with weights . In particular, when has i.i.d. entries, the two entropy measures will be equivalent (as ) to the ordinary total dispersion. Note that the above results hold even if is non-Gaussian distributed. The equivalent measures of the smoothed joint and total marginal entropies as are summarized in Table 2.
Table 2.
Equivalent measures of the smoothed joint and total marginal entropies as .
Example 1.
According to Theorem 4, if has independent entries, the smoothed joint entropy and the smoothed total marginal entropy will approach a same value with increasing. Below we present a simple example to confirm this fact.
Consider a two-dimensional case in which is mixed-Gaussian with PDF:
where , , and is uniformly distributed over . Figure 1 illustrates the smoothed entropies (joint and total marginal) with different values. As one can see clearly, when is small (close to zero), the smoothed total marginal entropy is larger than the smoothed joint entropy, and the difference is significant; while when gets larger (say, larger than 2.0), the discrepancy between the two entropy measures will disappear.
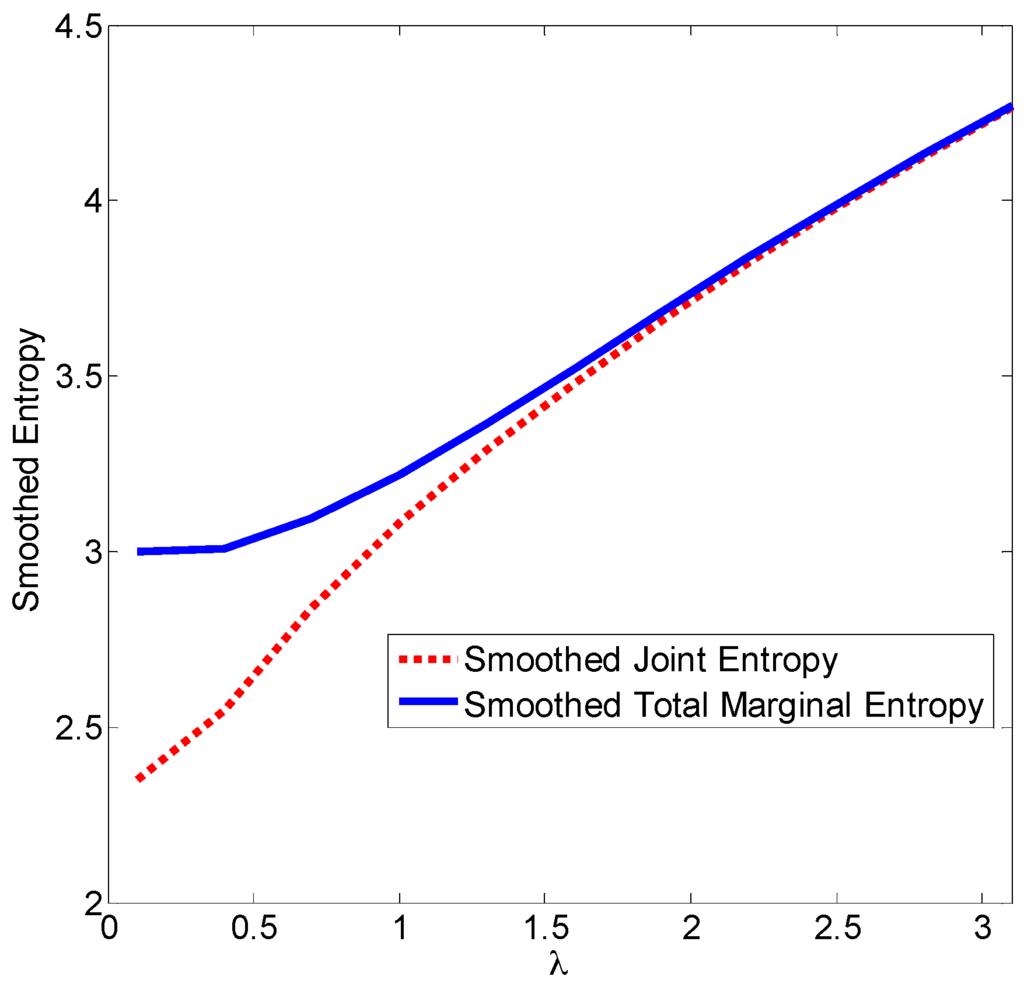
Figure 1.
Smoothed entropies with different smoothing factors.
4. Multivariate Entropy Estimators with Finite Samples
The smoothed entropy is of only theoretical interest since in practical applications, the number of samples is always limited, and the asymptotic value of the entropy estimator can never be reached. In the following, we show, however, that similar results hold for finite samples case. Consider again the kernel density estimator Equation (26). For simplicity we assume that the kernel function is Gaussian with covariance matrix , where is a identity matrix. In this case, the estimated PDF of becomes:
where denotes the i-th element of vector . With the above estimated PDF, a sample-mean estimator of the joint entropy is [4]:
Similarly, an estimator for the total marginal entropy can be obtained as follows:
The following theorem holds.
Theorem 5.
As is large enough, we have:
where is the estimated variance of .
Proof.
When , we have . It follows that:
where (a) comes from as , (b) comes from as , and (c) comes from:
In a similar way, we prove:
Combining Equations (47) and (49) we obtain Equation (46). □
Remark 10.
When the kernel function is Gaussian with covariance matrix being an identity matrix, the KDE based entropy estimators (joint or total marginal) will be, approximately, equivalent to the total dispersion estimator () as the smoothing factor is very large. This result coincides with Theorem 4. For the case in which the Gaussian covariance matrix is diagonal, one can also prove that the KDE based entropy (joint or total marginal) estimators will be approximately equivalent to a weighted total dispersion estimator as . Similar results hold for other entropies such as Renyi entropy.
Example 2.
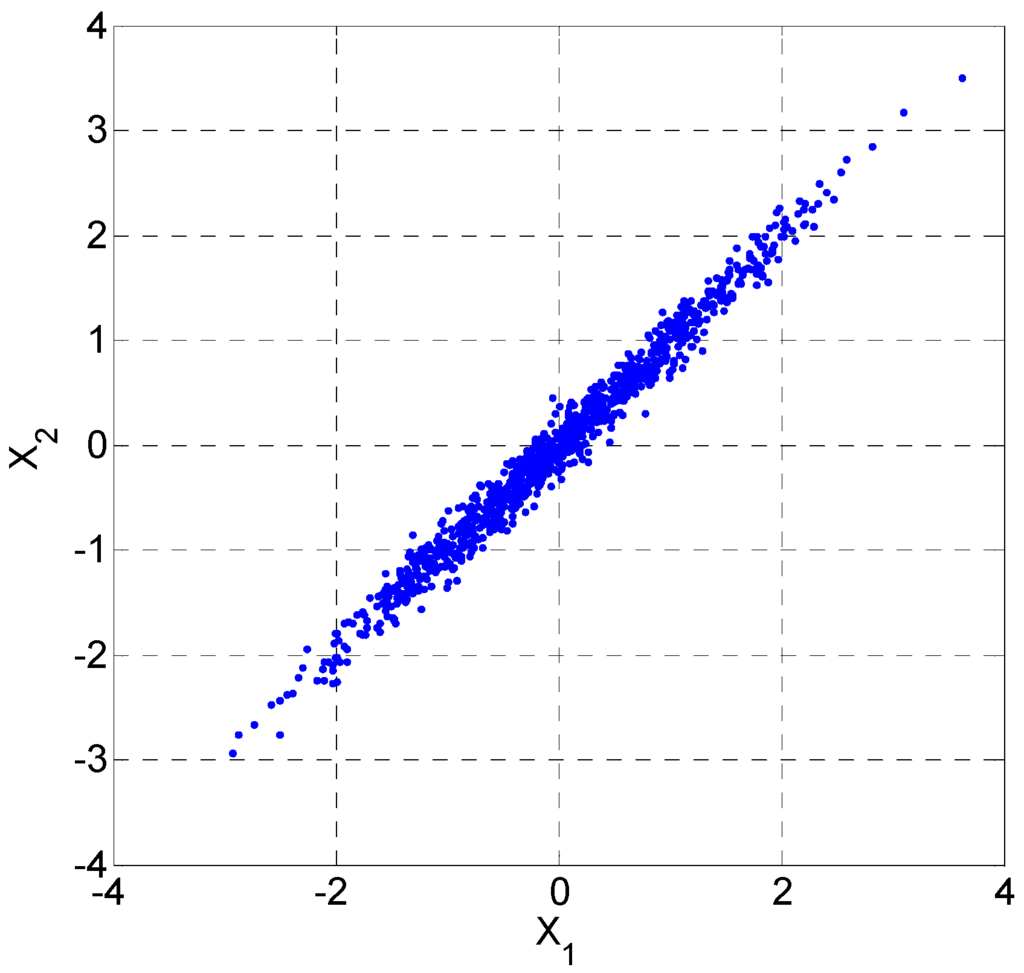
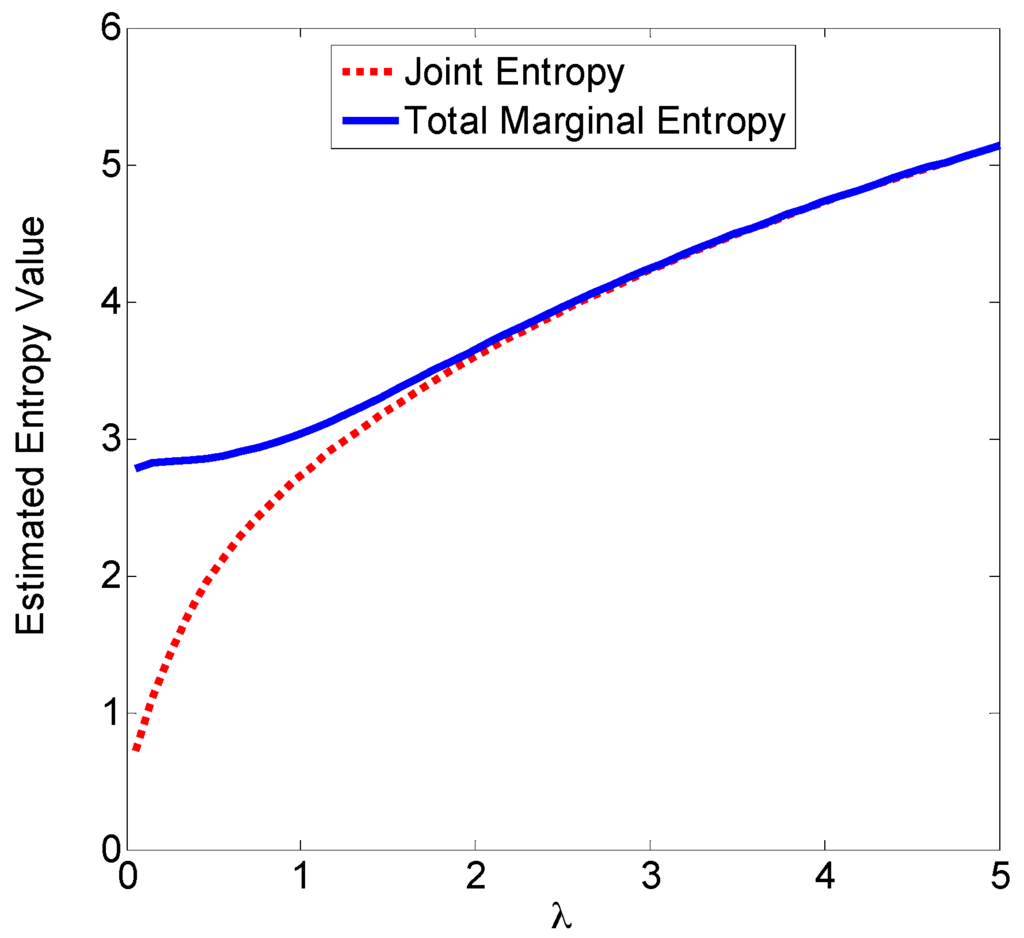
Consider 1000 samples drawn from a two-dimensional Gaussian distribution with zero-mean and covariance matrix . Figure 2 shows the scatter plot of the samples. Based on these samples, we evaluate the joint entropy and total marginal entropy using Equations (44) and (45), respectively. The estimated entropy values with different are illustrated in Figure 3, from which we observe that when becomes larger, the difference between the two estimated entropies will disappear. The results support the Theorem 5.
Figure 2.
Scatter plot of the two-dimensional Gaussian samples.
Figure 3.
Estimated entropy values with different smoothing factors.
5. Conclusions
Measures of the variability of data play significant roles in many machine learning and signal processing applications. Recent studies suggest that machine learning (supervised or unsupervised) can benefit greatly from the use of entropy as a measure of variability, especially when data possess non-Gaussian distributions. In this paper, we have studied the behaviors of entropy as a measure of multivariate variability. The relationships between multivariate entropy (joint or total marginal) and traditional second-order statistics based multivariate variability measures, such as total dispersion and generalized variance, have been investigated. For the jointly Gaussian case, the joint entropy (or entropy power) is shown to be equivalent to the generalized variance, while total marginal entropy is equivalent to the geometric mean of the marginal variances, and total marginal entropy power is equivalent to the total dispersion. We have also gained insights into the relationships between the smoothed multivariate entropy (joint or total marginal) and the total dispersion. Under certain conditions, the smoothed multivariate entropy will be, approximately, equivalent to the total dispersion. Similar results hold for the multivariate entropy estimators (with finite number of samples) based on the kernel density estimation (KDE). The results of this work can help us to understand the behaviors of multidimensional information theoretic learning.
Acknowledgments
This work was supported by 973 Program (No. 2015CB351703) and National NSF of China (No. 61372152).
Author Contributions
Badong Chen proved the main results and wrote the draft; Jianji Wang and Haiquan Zhao provided the illustrative examples and polished the language; Jose C. Principe was in charge of technical checking. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Renyi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1961; pp. 547–561.
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Principe, J.C. Information Theoretic Learning: Rényi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Campbell, L.L. Exponential entropy as a measure of extent of a distribution. Probab. Theory Relat. Fields 1966, 53, 217–225. [Google Scholar] [CrossRef]
- Chen, B.; Zhu, Y.; Hu, J.; Principe, J.C. System Parameter Identification: Information Criteria and Algorithms; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Gokcay, E.; Principe, J.C. Information theoretic clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 158–171. [Google Scholar] [CrossRef]
- Erdogmus, D.; Principe, J.C. From linear adaptive filtering to nonlinear information processing. IEEE Signal Process. Mag. 2006, 23, 15–33. [Google Scholar] [CrossRef]
- Brown, G.; Pocock, A.; Zhao, M.; Luján, M. Conditional likelihood maximization: A unifying framework for information theoretic feature selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]
- Chen, B.; Zhu, P.; Principe, J.C. Survival information potential: A new criterion for adaptive system training. IEEE Trans. Signal Process. 2012, 60, 1184–1194. [Google Scholar] [CrossRef]
- Erdogmus, D.; Principe, J.C. An error-entropy minimization algorithm for supervised training of nonlinear adaptive systems. IEEE Trans. Signal Process. 2002, 50, 1780–1786. [Google Scholar] [CrossRef]
- Erdogmus, D.; Principe, J.C. Generalized information potential criterion for adaptive system training. IEEE Trans. Neural Netw. 2002, 13, 1035–1044. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Hu, J.; Pu, L.; Sun, Z. Stochastic gradient algorithm under (h, φ)-entropy criterion. Circuits Syst. Signal Process. 2007, 26, 941–960. [Google Scholar] [CrossRef]
- Chen, B.; Zhu, Y.; Hu, J. Mean-square convergence analysis of ADALINE training with minimum error entropy criterion. IEEE Trans. Neural Netw. 2010, 21, 1168–1179. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Principe, J.C. Some further results on the minimum error entropy estimation. Entropy 2012, 14, 966–977. [Google Scholar] [CrossRef]
- Chen, B.; Principe, J.C. On the Smoothed Minimum Error Entropy Criterion. Entropy 2012, 14, 2311–2323. [Google Scholar] [CrossRef]
- Chen, B.; Yuan, Z.; Zheng, N.; Príncipe, J.C. Kernel minimum error entropy algorithm. Neurocomputing 2013, 121, 160–169. [Google Scholar] [CrossRef]
- Kowal, R.R. Note: Disadvantages of the Generalized Variance as a Measure of Variability. Biometrics 1971, 27, 213–216. [Google Scholar] [CrossRef]
- Mustonen, S. A measure for total variability in multivariate normal distribution. Comput. Stat. Data Anal. 1997, 23, 321–334. [Google Scholar] [CrossRef]
- Peña, D.; Rodríguez, J. Descriptive measures of multivariate scatter and linear dependence. J. Multivar. Anal. 2003, 85, 361–374. [Google Scholar] [CrossRef]
- Wilks, S.S. Certain generalizations in the analysis of variance. Biometrika 1932, 24, 471–494. [Google Scholar] [CrossRef]
- Sokal, R.R. Statistical methods in systematics. Biol. Rev. 1965, 40, 337–389. [Google Scholar] [CrossRef] [PubMed]
- Goodman, M. Note: A Measure of “Overall Variability” in Populations. Biometrics 1968, 24, 189–192. [Google Scholar] [CrossRef] [PubMed]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger causality and transfer entropy are equivalent for Gaussian variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A.B.; Barnett, L.; Seth, A.K. Multivariate Granger causality and generalized variance. Phys. Rev. E 2010, 81, 041907. [Google Scholar] [CrossRef] [PubMed]
- Golomb, S. The information generating function of a probability distribution. IEEE Trans. Inf. Theory 1966, 12, 75–77. [Google Scholar] [CrossRef]
- Bobkov, S.; Chistyakov, G.P. Entropy power inequality for the Renyi entropy. IEEE Trans. Inf. Theory 2015, 61, 708–714. [Google Scholar] [CrossRef]
- Kraskov, A.; Stogbauer, H.; Grassberger, P. Estimating Mutual Information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall: New York, NY, USA, 1986. [Google Scholar]
- Rioul, O. Information theoretic proofs of entropy power inequalities. IEEE Trans. Inf. Theory 2011, 57, 33–55. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).