On the Fisher Metric of Conditional Probability Polytopes


Abstract
: We consider three different approaches to define natural Riemannian metrics on polytopes of stochastic matrices. First, we define a natural class of stochastic maps between these polytopes and give a metric characterization of Chentsov type in terms of invariance with respect to these maps. Second, we consider the Fisher metric defined on arbitrary polytopes through their embeddings as exponential families in the probability simplex. We show that these metrics can also be characterized by an invariance principle with respect to morphisms of exponential families. Third, we consider the Fisher metric resulting from embedding the polytope of stochastic matrices in a simplex of joint distributions by specifying a marginal distribution. All three approaches result in slight variations of products of Fisher metrics. This is consistent with the nature of polytopes of stochastic matrices, which are Cartesian products of probability simplices. The first approach yields a scaled product of Fisher metrics; the second, a product of Fisher metrics; and the third, a product of Fisher metrics scaled by the marginal distribution.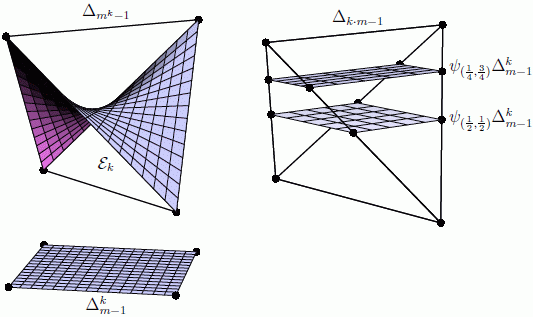
{kind=link}
{kind=link}
{kind=link}
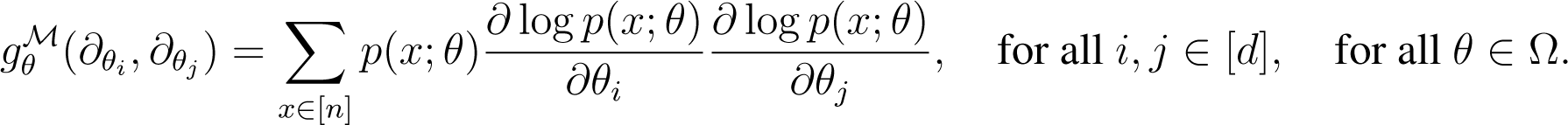{kind=link}
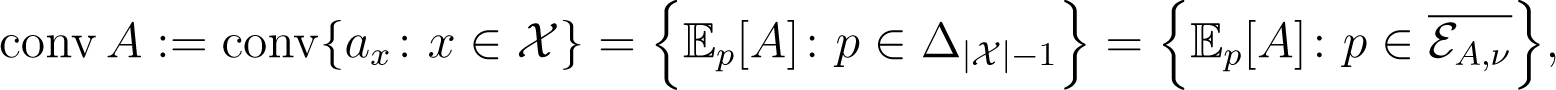{kind=link}
{kind=link}
{kind=link}
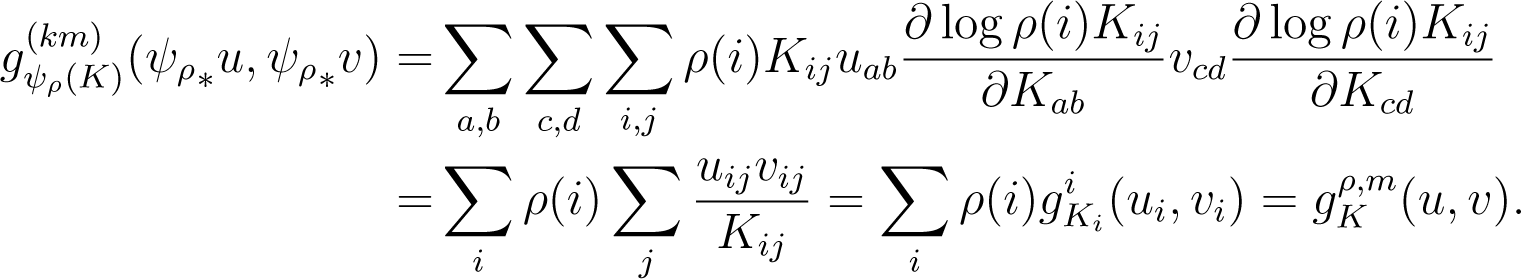{kind=link}
{kind=link}
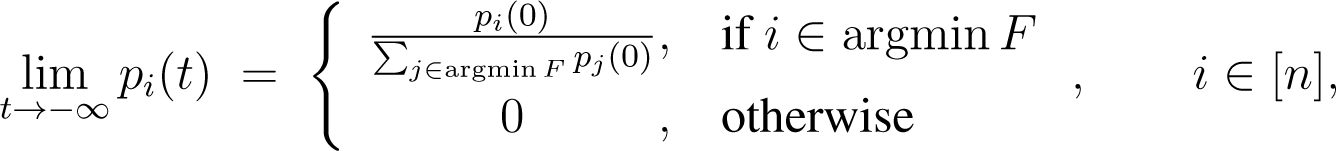{kind=link}
1. Introduction
The Riemannian structure of a function’s domain has a crucial impact on the performance of gradient optimization methods, especially in the presence of plateaus and local maxima. The natural gradient [1] gives the steepest increase direction of functions on a Riemannian space. For example, artificial neural networks can often be trained by following some function’s gradient on a space of probabilities. In this context, it has been observed that following the natural gradient with respect to the Fisher information metric, instead of the Euclidean metric, can significantly alleviate the plateau problem [1,2]. The Fisher information metric, which is also called Shahshahani metric [3] in biological contexts, is broadly recognized as the natural metric of probability spaces. An important argument was given by Chentsov [4], who showed that the Fisher information metric is the only metric on probability spaces for which certain natural statistical embeddings, called Markov morphisms, are isometries. More generally, Chentsov’s theorem characterizes the Fisher metric and α-connections of statistical manifolds uniquely (up to a multiplicative constant) by requiring invariance with respect to Markov morphisms. Campbell [5] gave another proof that characterizes invariant metrics on the set of non-normalized positive measures, which restrict to the Fisher metric in the case of probability measures (up to a multiplicative constant). In this paper, we explore ways of defining distinguished Riemannian metrics on spaces of stochastic matrices.
In learning theory, when modeling the policy of a system, it is often preferred to consider stochastic matrices instead of joint probability distributions. For example, in robotics applications, policies are optimized over a parametric set of stochastic matrices by following the gradient of a reward function [6,7]. The set of stochastic matrices can be parametrized in many ways, e.g., in terms of feedforward neural networks, Boltzmann machines [8] or projections of exponential families [9]. The information geometry of policy models plays an important role in these applications and has been studied by Kakade [2], Peters and co-workers [10–12], and Bagnell and Schneider [13], among others. A stochastic matrix is a tuple of probability distributions, and therefore, the space of stochastic matrices is a Cartesian product of probability simplices. Accordingly, in applications, usually a product metric is considered, with the usual Fisher metric on each factor. On the other hand, Lebanon [14] takes an axiomatic approach, following the ideas of Chentsov and Campbell, and characterizes a class of invariant metrics of positive matrices that restricts to the product of Fisher metrics in the case of stochastic matrices. We will consider three different approaches discussed in the following.
In the first part, we take another look at Lebanon’s approach for characterizing a distinguished metric on polytopes of stochastic matrices. However, since the maps considered by Lebanon do not map stochastic matrices to stochastic matrices, we will use different maps. We show that the product of Fisher metrics can be characterized by an invariance principle with respect to natural maps between stochastic matrices.
In the second part, we consider an approach that allows us to define Riemannian structures on arbitrary polytopes. Any polytope can be identified with an exponential family by using the coordinates of the polytope vertices as observables. The inverse of the moment map then defines an embedding of the polytope in a probability simplex. This embedding can be used to pull back geometric structures from the probability simplex to the polytope, including Riemannian metrics, affine connections, divergences, etc. This approach has been considered in [9] as a way to define low-dimensional families of conditional probability distributions. More general embeddings can be defined by identifying each exponential family with a point configuration, B, together with a weight function, ν. Given B and ν, the corresponding exponential family defines geometric structures on the set (conv B)°, which is the relative interior of the convex support of the exponential family Moreover, we can define natural morphisms between weighted point configurations as surjective maps between the point sets, which are compatible with the weight functions. As it turns out, the Fisher metric on (conv B)° can be characterized by invariance under these maps.
In the third part, we return to stochastic matrices. We study natural embeddings of conditional distributions in probability simplices as joint distributions with a fixed marginal. These embeddings define a Fisher metric equal to a weighted product of Fisher metrics. This result corresponds to the definitions commonly used in robotics applications.
All three approaches give very similar results. In all cases, the identified metric is a product metric. This is a sensible result, since the set of k × m stochastic matrices is a Cartesian product of probability simplices , which suggests using the product metric of the Fisher metrics defined on the factor simplices, ∆m−1. Indeed, this is the result obtained from our second approach. The first approach yields that same result with an additional scaling factor of 1/k. Only when stochastic matrices of different sizes are compared, the two approaches differ. The third approach yields a product of Fisher metrics scaled by the marginal distribution that defines the embedding.
Which metric to use depends on the concrete problem and whether a natural marginal distribution is defined and known. In Section 7, we do a case study using a reward function that is given as an expectation value over a joint distribution. In this simple example, the weighted product metric gives the best asymptotic rate of convergence, under the assumption that the weights are optimally chosen. In Section 8, we sum up our findings.
The contents of the paper is organized as follows. Section 2 contains basic definitions around the Fisher metric and concepts of differential geometry. In Section 3, we discuss the theorems of Chentsov, Campbell and Lebanon, which characterize natural geometric structures on the probability simplex, on the set of positive measures and on the cone of positive matrices, respectively. In Section 4, we study metrics on polytopes of stochastic matrices, which are invariant under natural embeddings. In Section 5, we define a Riemannian structure for polytopes, which generalizes the Fisher information metric of probability simplices and conditional models in a natural way. In Section 6, we study a class of weighted product metrics. In Section 7, we study the gradient flow with respect to an expectation value. Section 8 contains concluding remarks. In Appendix A, we investigate restrictions on the parameters of the metrics characterized in Sections 3 and 4 that make them positive definite. Appendix B contains the proofs of the results from Section 4.
2. Preliminaries
We will consider the simplex of probability distributions on [m] := {1,…, m}, m ≥ 2, which is given by . The relative interior of ∆m−1 consists of all strictly positive probability distributions on [m], and will be denoted . This is a subset of , the cone of strictly positive vectors. The set of k × m row-stochastic matrices is given by for all i ∈ [k and is equal to the Cartesian product ×i∈[k] ∆m−1. The relative interior is a subset of , the cone of strictly positive matrices.
Given two random variables X and Y taking values in the finite sets [k] and [m], respectively, the conditional probability distribution of Y given X is the stochastic matrix K = (P(y|x))x∈[k],y∈[m] with rows (P(y|x))y∈[m] ∈ ∆m−1 for all x ∈ [k]. Therefore, the polytope of stochastic matrices is called a conditional polytope.
The tangent space of at a point , denoted by , is the real vector space spanned by the vectors ∂1,…, ∂n of partial derivatives with respect to the n components. The tangent space of at a point is the subspace consisting of the vectors:
The Fisher metric on the positive probability simplex is the Riemannian metric given by:
The same formula (2) also defines a Riemannian metric on , which we will denote by the same symbol. This, however, is not the only way in which the Fisher metric can be extended from to . We will discuss other extensions in the next section (see Campbell’s theorem, Theorem 3).
Consider a smoothly parametrized family of probability distributions , where is open. Then, g(n) induces a Riemannian metric on . Denote by the tangent vector corresponding to the partial derivative with respect to θi, for all i ∈ [d]. Then, the Fisher matrix has coordinates:
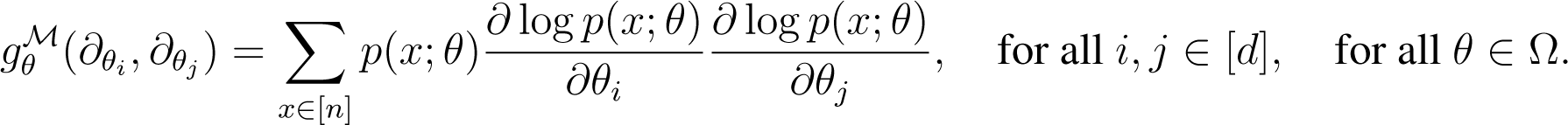
Here, it is not necessary to assume that the parameters θi are independent. In particular, the dimension of may be smaller than d, in which case the matrix is not positive definite. If the map is an embedding (i.e., a smooth injective map that is a diffeomorphism onto its image), then defines a Riemannian metric on Ω, which corresponds to the pull-back of g(n).
Consider an embedding f: ε → ε′. The pull-back of a metric g′ on ε′ through f is defined as:
where f* denotes the push-forward of Tpε through f, which in coordinates is given by:
where spans Tqε and spans Tf(p)ε′.
An embedding f: ε → ε′ of two Riemannian manifolds (ε, g) and (ε′, g′) is an isometry iff:
In this case, we say that the metric g is invariant with respect to f (and g′).
3. The Results of Campbell and Lebanon
One of the theoretical motivations for using the Fisher metric is provided by Chentsov’s characterization [4], which states that the Fisher metric is uniquely specified, up to a multiplicative constant, by an invariance principle under a class of stochastic maps, called Markov morphisms. Later, Campbell [5] considered the characterization problem on the space instead of . This simplifies the computations, since has a more symmetric parametrization.
Definition 1. Let 2 ≤ m ≤ n. A (row) stochastic partition matrix (or just row-partition matrix) is a matrix of non-negative entries, which satisfies for an m block partition {A1,…, Am} of [n]. The linear map defined by:
is called a congruent embedding by a Markov mapping of to or just a Markov map, for short.
An example of a 3 × 5 row-partition matrix is:
Markov maps preserve the 1-norm and restrict to embeddings .
Theorem 2 (Chentsov’s theorem.).
Let g(m) be a Riemannian metric on for m ∈ {2, 3,…}. Let this sequence of metrics have the property that every congruent embedding by a Markov mapping is an isometry. Then, there is a constant C > 0 that satisfies:
Conversely, for any C > 0, the metrics given by Equation (9) define a sequence of Riemannian metrics under which every congruent embedding by a Markov mapping is an isometry.
The main result in Campbell’s work [5] is the following variant of Chentsov’s theorem.
Theorem 3 (Campbell’s theorem.).
Let g(m) be a Riemannian metric on for m ∈ {2,3,…}. Let this sequence of metrics have the property that every embedding by a Markov mapping is an isometry. Then:
where , δij is the Kronecker delta, and A and C are C∞ functions on satisfying C(α) > 0 and A(α) + C(α) > 0 for all α > 0.
Conversely, if A and C are C∞ functions on satisfying C(α) > 0, A(α) + C(α) > 0 for all α > 0, then Equation (10) defines a sequence of Riemannian metrics under which every embedding by a Markov mapping is an isometry.
The metrics from Campbell’s theorem also define metrics on the probability simplices for m = 2,3,…. Since the tangent vectors satisfy , for any two vectors , also for any A. In this case, the choice of A is immaterial, and the metric becomes Chentsov’s metric.
Remark 4. Observe that Chentsov’s theorem is not a direct implication of Campbell’s theorem. However, it can be deduced from it by the following arguments. Suppose that we have a family of Riemannian simplices for m ∈ {2, 3,…}, and suppose that they are isometric with respect to Markov maps. If we can extend every g(m) to a Riemannian metric on in such a way that the resulting spaces still isometric with respect to Markov maps, then Campbell’s theorem implies that g(m) is a multiple of the Fisher metric. Such metric extensions can be defined as follows. Consider the diffeomorphism:
Any tangent vector can be written uniquely as u = up + ur∂r, where up is tangent to . Since each Markov map f preserves the one-norm | · |, its push-forward f* maps the tangent vector to the corresponding tangent vector ; that is, f*u = f*up + ur∂r. Therefore,
is a metric on that is invariant under f.
In what follows, we will focus on positive matrices. In order to define a natural Riemannian metric, we can use the identification and apply Campbell’s theorem. This leads to metrics of the form:
where and . However, a disadvantage of this approach is that the action of general Markov maps on has no natural interpretation in terms of the matrix structure. Therefore, Lebanon [14] considered a special class of Markov maps defined as follows.
Definition 5. Consider a k × l row-partition matrix R and a collection of m × n row-partition matrices Q = {Q(1),…, Q(k)}. The map:
is called a congruent embedding by a Markov morphism of to in [15]. We will refer to such an embedding as a Lebanon map. Here, the row product M ⊗ Q is defined by:
that is, the a-th row of M is multiplied by the matrix Q(a).
In a Lebanon map, each row of the input matrix M is mapped by an individual Markov mapping Q(i), and each resulting row is copied and scaled by an entry of R. This kind of map preserves the sum of all matrix entries. Therefore, with the identification , each Lebanon map restricts to a map . The set can be identified with the set of joint distributions of two random variables. Lebanon maps can be regarded as special Markov maps that incorporate the product structure present in the set of joint probability distributions of a pair of random variables. In Section 4, we will give an interpretation of these maps.
Contrary to what is stated in [15], a Lebanon map does not map to , unless k = l. Therefore, later, we will provide a characterization for the metrics on in terms of invariance under other maps (which are not Markov nor Lebanon maps).
The main result in Lebanon’s work [15, Theorems 1 and 2] is the following.
Theorem 6 (Lebanon’s theorem.).
For each k ≥ 1, m ≥ 2, let g(k,m) be a Riemannian metric on in such a way that every Lebanon map is an isometry. Then:
for some differentiable functions.
Conversely, let be a sequence of Riemannian manifolds, with metrics g(k,m) of the form (16) for some. Then, every Lebanon map is an isometry.
Lebanon does not study the question under which assumptions on the formula (16) does indeed define a Riemannian metric. This question has the following simple answer, which we will prove in Appendix A:
Proposition 7. The matrix (16) is positive definite if and only if C(|M|) > 0, B(|M|) + C(|M|) > 0 and A(|M|) + B(|M|) + C(|M|) > 0.
The class of metrics (16) is larger than the class of metrics (13) derived in Campbell’s theorem. The reason is that Campbell’s metrics are invariant with respect to a larger class of embeddings.
The special case with A(|M|) = 0, B(|M|) = 0 and C(|M|) = 1 is called product Fisher metric,
Furthermore, if we restrict to , the functions A and B do not play any role. In this case |M| = k, and we obtain the scaled product Fisher metric:
where is a positive function. As mentioned before, Lebanon’s theorem does not give a characterization of invariant metrics of stochastic matrices, since Lebanon maps do not preserve the stochasticity of the matrices. However, Lebanon maps are natural maps on the set of positive joint distributions. In the same way as Chentsov’s theorem can be derived from Campbell’s theorem (see Remark 4), we obtain the following corollary:
Corollary 8.
Let be a double sequence of Riemannian manifolds with the property that every Lebanon map is an isometry. Then:
for some constants with C > 0 and B + C > 0, where.
Conversely, let be a sequence of Riemannian manifolds with metrics g(k,m) of the form of Equation (19) for some Then, every Lebanon map is an isometry.
Observe that these metrics agree with (a multiple of) the Fisher metric only if B = 0. The case B = 0 can also be characterized; note that Lebanon maps do not treat the two random variables symmetrically Switching the two random variables corresponds to transposing the joint distribution matrix P. When exchanging the role of the two random variables, the Lebanon map becomes P ⟼ (P⊤ ⊗ Q)⊤ R. We call such a map a dual Lebanon map. If we require invariance under both Lebanon maps and their duals in Theorem 6 or Corollary 8, the statements remain true with the additional restriction that B = 0 (as a function or constant, respectively).
4. Invariance Metric Characterizations for Conditional Polytopes
According to Chentsov’s theorem (Theorem 2), a natural metric on the probability simplex can be characterized by requiring the isometry of natural embeddings. Lebanon follows this axiomatic approach to characterize metrics on products of positive measures (Theorem 6). However, the maps considered by Lebanon dissolve the row-normalization of conditional distributions. In general, they do not map conditional polytopes to conditional polytopes. Therefore, we will consider a slight modification of Lebanon maps, in order to obtain maps between conditional polytopes.
4.1. Stochastic Embeddings of Conditional Polytopes
A matrix of conditional distributions P(Y|X) in can be regarded as the equivalence class of all joint probability distributions P(X, Y) ∈ ∆km−1 with conditional distribution P(Y|X). Which Markov maps of probability simplices are compatible with this equivalence relation? The most obvious examples are permutations (relabelings) of the state spaces of X and Y.
In information theory, stochastic matrices are also viewed as channels. For any distribution of X, the stochastic matrix gives us a joint distribution of the pair (X, Y) and, hence, a marginal distribution of Y. If we input a distribution of X into the channel, the stochastic matrix determines what the distribution of the output Y will be.
Channels can be combined, provided the cardinalities of the state spaces fit together. If we take the output Y of the first channel P(Y|X) and feed it into another channel P(Y′|Y) then we obtain a combined channel P(Y′|X). The composition of channels corresponds to ordinary matrix multiplication. If the first channel is described by the stochastic matrix K and the second channel by Q, then the combined channel is described by K · Q. Observe that in this case, the joint distribution P (considered as a normalized matrix P ∈ ∆km−1) is transformed similarly; that is, the joint distribution of the pair (X, Y′) is given by P · Q.
More general maps result from compositions where the choice of the second channel depends on the input of the first channel. In other words, we have a first channel that takes as input X and gives as output Y, and we have another channel that takes as input (X,Y) and gives as output Y′; we are interested in the resulting channel from X to Y′. The second channel can be described by a collection of stochastic matrices Q = {Q(i)}i. If K describes the first channel, then the combined channel is described by the row product K ⊗ Q (see Definition 5). Again, the joint distribution of (X, Y′) arises in a similar way as P ⊗ Q.
We can also consider transformations of the first random variable X. Suppose that we use X as the input to a channel described by a stochastic matrix R. In this case, the joint distribution of the output X′ of the channel and Y is described by R⊤ X. However, in general, there is not much that we can say about the conditional distribution of Y given X′. The result depends in an essential way on the original distribution of X. However, this is not true in the special case that the channel is “not mixing”, that is, in the case that R is a stochastic partition matrix. In this case, the conditional distribution P(Y|X′) is described by , where is the corresponding partition indicator matrix, where all non-zero entries of R are replaced by one. In other words, each state of X corresponds to several states of X′, and the corresponding row of K is copied a corresponding number of times.
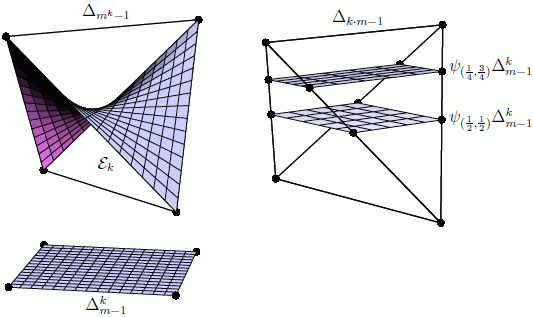
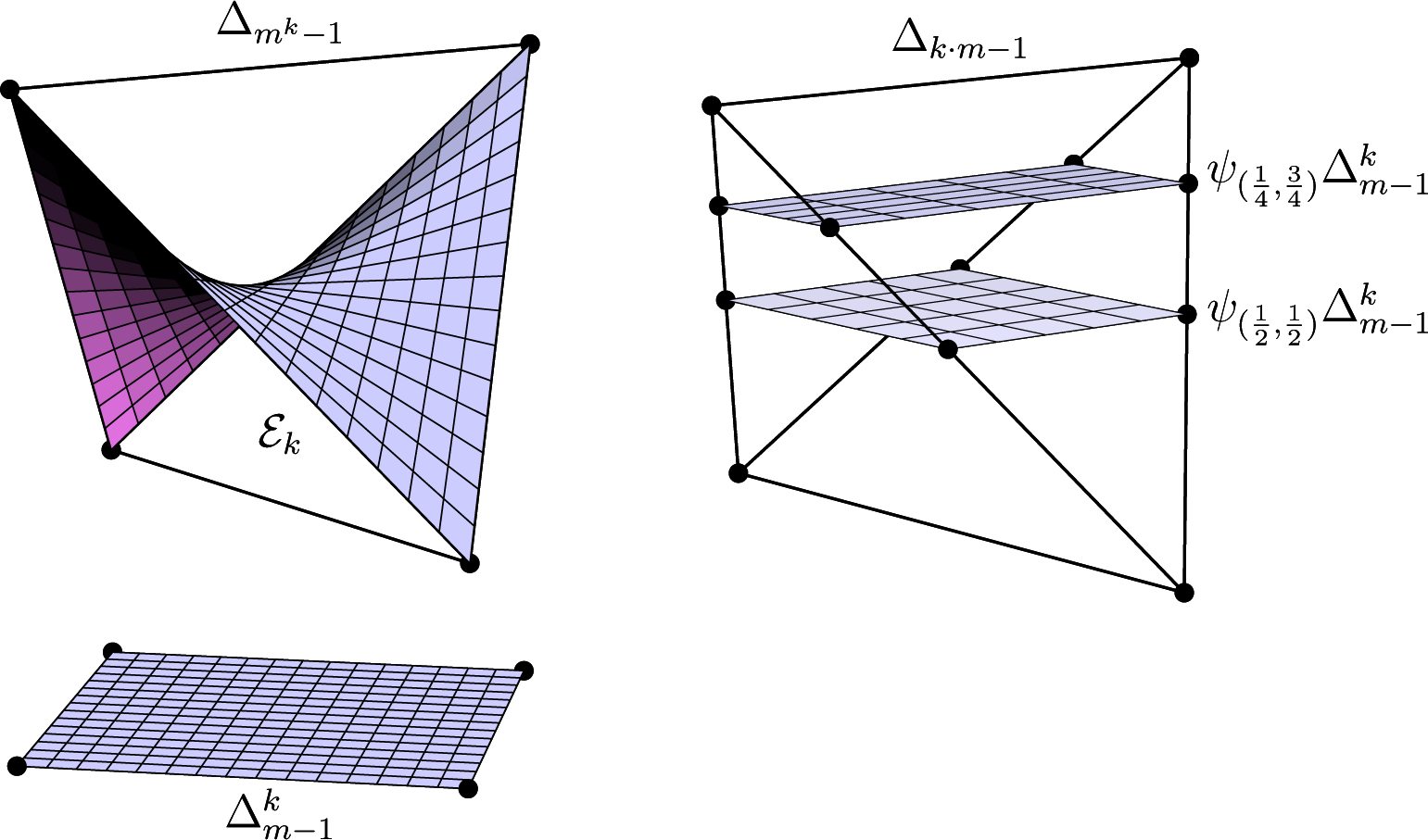
To sum up, if we combine the transformations due to Q and R, then the joint probability distribution transforms as P ⟼ R⊤ (P ⊗ Q) and the conditional transforms as . In particular, for the joint distribution, we obtain the definition of a Lebanon map. Figure 1 illustrates the situation.
Finally, we will also consider the special case where the partition of R (and ) is homogeneous, i.e., such that all blocks have the same size. For example, this describes the case where there is a third random variable Z that is independent of Y given X. In this case, the conditional distribution satisfies P(Y|X) = P(Y|X, Z), and R describes the conditional distribution of (X, Z) given X.
Definition 9. A (row) partition indicator matrix is a matrix that satisfies:
for a k block partition {A1,…, Ak} of [l].
For example, the 3 × 5 partition indicator matrix corresponding to Equation (8) is:
Definition 10. Consider a k × l partition indicator matrix and a collection of m × n stochastic partition matrices . We call the map:
a conditional embedding of in . We denote the set of all such maps by . If is the partition indicator matrix of a homogeneous partition (with partition blocks of equal cardinality), then we call f a homogeneous conditional embedding. We denote the set of all such homogeneous conditional embeddings by and assume that l is a multiple of k.
Conditional embeddings preserve the 1-norm of the matrix rows; that is, the elements of map to . On the other hand, they do not preserve the 1-norm of the entire matrix. Conditional embeddings are Markov maps only when k = l, in which case they are also Lebanon maps.
4.2. Invariance Characterization
Considering the conditional embeddings discussed in the previous section, we obtain the following metric characterization.
Theorem 11.
Let g(k,m) denote a metric on for each k ≥ 1 and m ≥ 2. If every homogeneous conditional embedding is an isometry with respect to these metrics, then:
for some constants, where and.
Conversely, given the metrics defined by Equation (23) for any non-degenerate choice of constants, each homogeneous conditional embedding is an isometry.
Moreover, the tensors g(k,m) from Equation (23) are positive-definite for all k ≥ 1 and m ≥ 2 if and only if C > 0, B + C > 0 and A + B + C > 0.
The proof of Theorem 11 is similar to the proof of the theorems of Chentsov, Campbell and Lebanon. Due to its technical nature, we defer it to Appendix B.
Now, for the restriction of the metric g(k,m) to , we have the following. In this case, |M| = k. Since tangent vectors satisfy for all a, the constants A and B become immaterial, and the metric can be written as:
This metric is a specialization of the metric (18) derived by Lebanon (Theorem 6).
The statement of Theorem 11 becomes false if we consider general conditional embeddings instead of homogeneous ones:
Theorem 12. There is no family of metrics g(k,m) on (or on) for each k ≥ 1 and m ≥ 2, for which every conditional embedding is an isometry.
This negative result will become clearer from the perspective of Section 6: as we will show in Theorem 17, although there are no metrics that are invariant under all conditional embeddings, there are families of metrics (depending on a parameter, ρ) that transform covariantly (that is, in a well-defined manner) with respect to the conditional embeddings. We defer the proof of Theorem 12 to Appendix B.
5. The Fisher Metric on Polytopes and Point Configurations
In the previous section, we obtained distinguished Riemannian metrics on and by postulating invariance under natural maps. In this section, we take another viewpoint based on general considerations about Riemannian metrics on arbitrary polytopes. This is achieved by embedding each polytope in a probability simplex as an exponential family. We first recall the necessary background. In Section 5.2, we then present our general results, and in Section 5.3, we discuss the special case of conditional polytopes.
5.1. Exponential Families and Polytopes
Let be a finite set and a matrix with columns ax indexed by . It will be convenient to consider the rows Ai, i ∈ [d] of A as functions Finally, let . The exponential family εA,ν is the set of probability distributions on given by:
with the normalization function . The functions Ai are called the observables and ν the reference measure of the exponential family. When the reference measure ν is constant, ν(x) = 1 for all , we omit the subscript and write εA.
A direct calculation shows that the Fisher information matrix of εA,ν at a point has coordinates:
Here, covθ denotes the covariance computed with respect to the probability distribution p(·; θ).
The convex support of εA,ν is defined as:
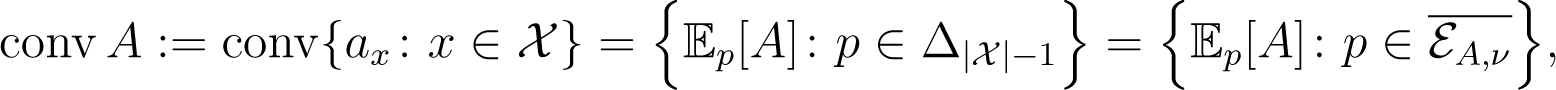
where conv S is the set of all convex combinations of points in S. The moment map restricts to a homeomorphism conv A; see [16]. Here, denotes the Euclidean closure of εA,ν. The inverse of μ will be denoted by . This gives a natural embedding of the polytope conv A in the probability simplex . Note that the convex support is independent of the reference measure ν. See [17] for more details.
5.2. Invariance Fisher Metric Characterizations for Polytopes
Let be a polytope with n vertices a1,…, an. Let A = (a1,…, an) be the matrix with columns for all i ∈ [n]. Then, is an exponential family with convex support P. We will also denote this exponential family by εP. We can use the inverse of the moment map, μ−1, to pull back geometric structures on to the relative interior P° of P.
Definition 13. The Fisher metric on P° is the pull-back of the Fisher metric on by μ−1.
Some obvious questions are: Why is this a natural construction? Which maps between polytopes are isometries between their Fisher metrics? Can we find a characterization of Chentsov type for this metric?
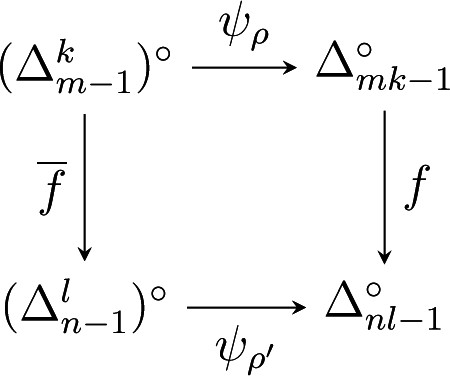
Affine maps are natural maps between polytopes. However, in order to obtain isometries, we need to put some additional constraints. Consider two polytopes , and an affine map that satisfies ϕ(P) ⊆ P′. A natural condition in the context of exponential families is that ϕ restricts to a bijection between the set vert(P) of vertices of P and the set vert(P′) of vertices of P′. In this case, . Moreover, the moment map μ′ of P′ factorizes through the moment map μ of P: μ′ = ϕ ○ μ. Let ϕ−1 = μ ○ μ′−1. Then, the following diagram commutes:
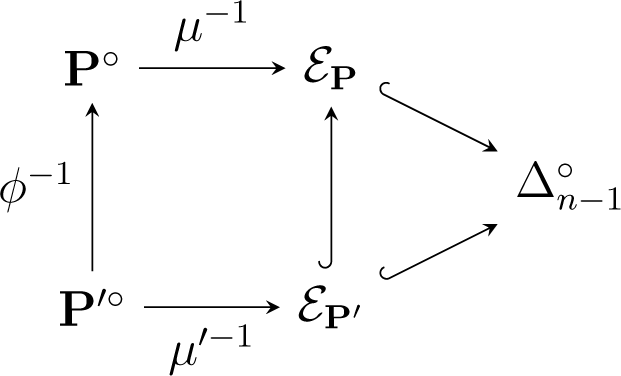
It follows that ϕ−1 is an isometry from P′° to its image in P°. Observe that the inverse moment map itself arises in this way: In the diagram (28), if P is equal to ∆n−1, then the upper moment map μ−1 is the identity map, and ϕ−1 equals the inverse moment map μ'−1 of P′.
The constraint of mapping vertices to vertices bijectively is very restrictive. In order to consider a larger class of affine maps, we need to generalize our construction from polytopes to weighted point configurations.
Definition 14. A weighted point configuration is a pair (A, ν) consisting of a matrix with columns a1,…, an and a positive weight function assigning a weight to each column ai. The pair (A, ν) defines the exponential family εA,ν.
The (A, ν)-Fisher metric on (conv A)° is the pull-back of the Fisher metric on through the inverse of the moment map.
We recover Definition 13 as follows. For a polytope P, let A be the point configuration consisting of the vertices of P. Moreover, let ν be a constant function. Then, εP = εA,ν, and the two definitions of the Fisher metric on P° coincide.
The following are natural maps between weighted point configurations:
Definition 15. Let (A, ν), (A′, ν′) be two weighted point configurations with and . A morphism (A,ν) → (A′,ν′) is a pair (ϕ, σ) consisting of an affine map and a surjective map σ: {1,…, n} → {1,…, n′} with and , where α > 0 is a constant that does not depend on j.
Consider a morphism (ϕ, σ): (A, ν) → (A′, ν′). For each j ∈ [n′], let . Then, is a partition of [n]. Define a matrix by:
Then, Q is a Markov mapping, and the following diagram commutes:
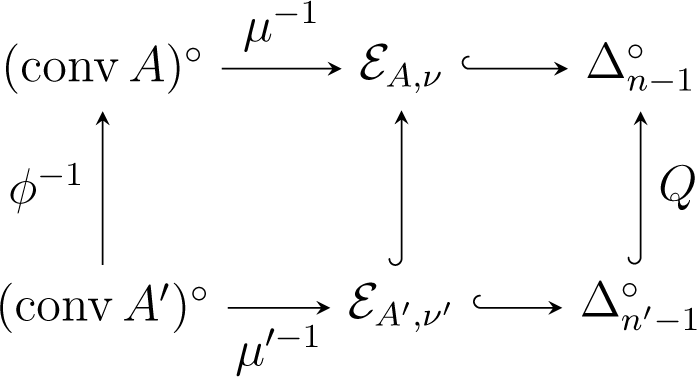
By Chentsov’s theorem (Theorem 2), Q is an isometric embedding. It follows that ϕ−1 also induces an isometric embedding. This shows the first part of the following theorem:
Theorem 16.
Let (ϕ, σ): (A, ν) → (A′, ν′) be a morphism of weighted point configurations. Then, ϕ−1: (conv A′)° → (conv A)° is an isometric embedding with respect to the Fisher metrics on (conv A)° and (conv A')°.
Let gA,ν be a Riemannian metric on (conv A)° for each weighted point configuration (A, ν). If every morphism (ϕ, σ): (A, ν) → (A′, ν′) of weighted point configurations induces an isometric embedding ϕ−1: (convA′)° → (conv A)°, then there exists a constant such that gA,ν is equal to α times the (A, ν)-Fisher metric.
Proof. The first statement follows from the discussion before the theorem. For the second statement, we show that under the given assumptions, all Markov maps are isometric embeddings. By Chentsov’s theorem (Theorem 2), this implies that the metrics gP agree with the Fisher metric whenever P is a simplex. The statement then follows from the two facts that the metric on P° or (conv A)° is the pull-back of the Fisher metric through the inverse of the moment map and that μ−1 is itself a morphism.
Observe that ∆n−1 = conv In = conv{e1,…, en} is a polytope, and is the corresponding exponential family. Consider a Markov embedding , p ⟼ p·· Q. Let be the value of the unique non-zero entry of Q in the i-th column. This defines a morphism and an embedding as follows:
Let A be the matrix that arises from Q by replacing each non-zero entry by one. We define ϕ as the linear map represented by the matrix A, and define σ: [n] → [n'] by σ(j) = i if and only if aj = ei, that is, σ(j) indicates the row i in which the j-th column of A is non-zero. Then, (ϕ, σ) is a morphism , and by assumption, the inverse ϕ−1 is an isometric embedding . However, ϕ−1 is equal to the Markov map Q. This shows that all Markov maps are isometric embeddings, and so, by Chentsov’s theorem, the statement holds true on the simplices. □
Theorem 16 defines a natural metric on that we want to discuss in more detail next.
5.3. Independence Models and Conditional Polytopes
Consider k random variables with finite state spaces [n1],…, [nk]. The independence model consists of all joint distributions of these variables that factorize as:
where for all i ∈ [k]. Assuming fixed n1,…, nk, we denote the independence model by . It is the Euclidean closure of an exponential family (with observables of the form ). The convex support of εk is equal to the product of simplices . The parametrization (31) corresponds to the inverse of the moment map.
We can write any tangent vector of this open product of simplices as a linear combination , where for all i ∈ [k]. Given two such tangent vectors, the Fisher metric is given by:
Just as the convex support of the independence model is the Cartesian product of probability simplices, the Fisher metric on the independence model is the product metric of the Fisher metrics on the probability simplices of the individual variables. If n1 = … = nk =: n, then can be identified with the set of k × n stochastic matrices.
The Fisher metric on the product of simplices is equal to the product of the Fisher metrics on the factors. More generally, if P = Q1 × Q2 is a Cartesian product, then the Fisher metric on P° is equal to the product of the Fisher metrics on and . In fact, in this case, the inverse of the moment map of P can be expressed in terms of the two moment map inverses and and the moment map of the independence model , by:
Therefore, the pull-back by μ−1 factorizes through the pull-back by , and since the independence model carries a product metric, the product of polytopes also carries a product metric.
Let us compare the metric from Equation (24), with the Fisher metric from Equation (32) on the product of simplices . In both cases, the metric is a product metric; that is, it has the form:
where gi is a metric on the i-th factor . For , gi is equal to the Fisher metric on . However, for , gi is equal to 1/k times the Fisher metric on . Since this factor only depends on k, it only plays a role if stochastic matrices of different sizes are compared. The additional factor of 1/k can be interpreted as the uniform distribution on k elements. This is related to another more general class of Riemannian metrics that are used in applications; namely, given a function , it is common to use product metrics with gi equal to ρK(i) times the Fisher metric on . When K has the interpretation of a channel or when K describes the policy by which a system reacts to some sensor values, a natural possibility is to let ρK be the stationary distribution of the channel input or of the sensor values, respectively. We will discuss this approach in Section 6.
6. Weighted Product Metrics for Conditional Models
In this section, we consider metrics on spaces of stochastic matrices defined as weighted sums of the Fisher metrics on the spaces of the matrix rows, similar to Equation (34). This kind of metric was used initially by Amari [1] in order to define a natural gradient in the supervised learning context. Later, in the context of reinforcement learning, Kakade [2] defined a natural policy gradient based on this kind of metric, which has been further developed by Peters et al. [10]. Related applications within unsupervised learning have been pursued by Zahedi et al. [18].
Consider the following weighted product Fisher metric:
where denotes the Fisher metric of at the a-th row of K and is a probability distribution over a associated with each . For example, the distribution ρK could be the stationary distribution of sensor values observed by an agent when operating under a policy described by K.
In the following, we will try to illuminate the properties of polytope embeddings that yield the metric (35) as the pull-back of the Fisher information metric on a probability simplex. We will focus on the case that ρK = ρ is independent of K.
There are two direct ways of embedding in a probability simplex. In Section 5, we used the inverse of the moment map of an exponential family, possibly with some reference measure. This embedding is illustrated in the left panel of Figure 2. If we have given a fixed probability distribution , there is a second natural embedding defined as follows:
If ρ is the distribution of a random variable X and is the stochastic matrix describing the conditional distribution of another variable Y given X, then ψρ(K) is the joint distribution of X and Y. Note that ψρ is an affine embedding. See the right panel of Figure 2 for an illustration.
The pull-back of the Fisher metric on through ψρ is given by:
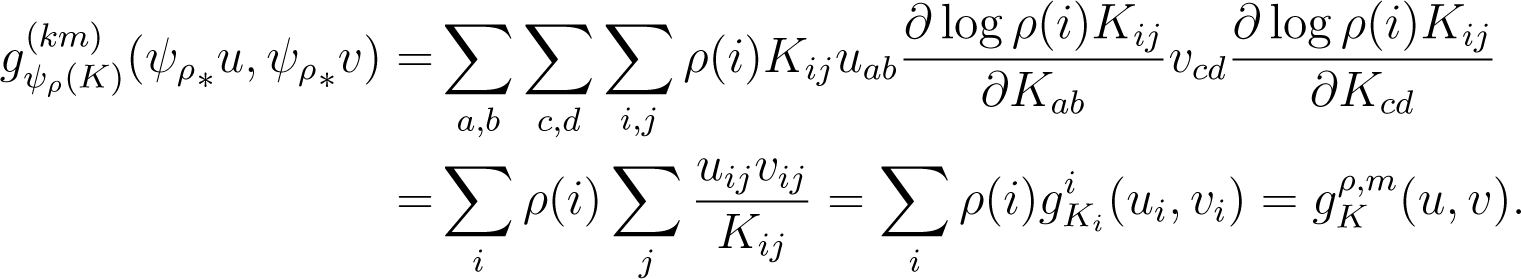
This recovers the weighted sum of Fisher metrics from Equation (35).
Are there natural maps that leave the metrics gρ,m invariant? Let us reconsider the stochastic embeddings from Definition 10. Let be a k × l indicator partition matrix and R a stochastic partition matrix with the same block structure as . Observe that to each indicator partition matrix there are many compatible stochastic partition matrices R, but the indicator partition matrix for any stochastic partition matrix R is unique. Furthermore, let Q = {Q(a)}a∈[k] be a collection of stochastic partition matrices. The corresponding conditional embedding maps to .
Let . Suppose that K describes the conditional distribution of Y given X and that ψρ(K) describes the joint distribution of Y and X. As explained in Section 4.1, the matrix f(P) := R⊤(P⊗Q) describes the joint distribution of a pair of random variables (X′, Y′), and the conditional distribution of Y′ given X′ is given by . In this situation, the marginal distribution of X′ is given by ρ′ = ρR. Therefore, the following diagram commutes:
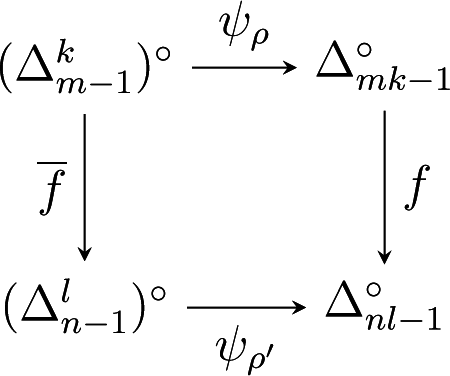
The preceding discussion implies the first statement of the following result:
Theorem 17.
For any k ≥ 1 and m ≥ 2 and any , the Riemannian metric gρ,m on satisfies:
for any conditional embedding.
Conversely, suppose that for any k ≥ 1 and m ≥ 2 and any, there is a Riemannian metric g(ρ,m) on, such that Equation (39) holds for all conditional embeddings, and suppose that g(ρ,m) depends continuously on ρ. Then, there is a constant A > 0 that satisfies g(ρ,m) = Agρ,m.
Proof. The first statement follows from the commutative diagram (38). For the second statement, denote by ρk the uniform distribution on a set of k elements. If is a homogeneous conditional embedding of in , then is a stochastic partition matrix corresponding to the partition indicator matrix . Observe that ρl = ρkR. Therefore, the family of Riemannian metrics on satisfies the assumptions of Theorem 11. Therefore, there is a constant A > 0 for which equals A/k times the product Fisher metric. This proves the statement for uniform distributions ρ.
A general distribution can be approximated by a distribution with rational probabilities. Since g(ρ,m) is assumed to be continuous, it suffices to prove the statement for rational ρ. In this case, there exists a stochastic partition matrix R for which ρ′ := ρR is a uniform distribution, and so, is of the desired form. Equation (39) shows that g(ρ,m) is also of the desired form. □
7. Gradient Fields and Replicator Equations
In this section, we use gradient fields in order to compare Riemannian metrics on the space .
7.1. Replicator Equations
We start with gradient fields on the simplex . A Riemannian metric g on allows us to consider gradient fields of differentiable functions . To be more precise, consider the differential of F in p. It is a linear form on , which maps each tangent vector u to . Using the map u ⟼ gp(u, ·), this linear form can be identified with a tangent vector in , which we denote by gradpF. If we choose the Fisher metric g(n) as the Riemannian metric, we obtain the gradient in the following way. First consider a differentiable extension of F to the positive cone , which we will denote by the same symbol F. With the partial derivatives ∂iF of F, the Fisher gradient of F on the simplex is given as:
Note that the expression on the right-hand side of Equation (40) does not depend on the particular differentiable extension of F to . The corresponding differential equation is well known in theoretical biology as the replicator equation; see [19,20].
We now apply this gradient formula to functions that have the structure of an expectation value. Given real numbers Fi, i ∈ [n], referred to as fitness values, we consider the mean fitness:
Replacing the pi by any positive real numbers leads to a differentiable extension of F, also denoted by F. Obviously, we have ∂iF = Fi, which leads to the following replicator equation:
This equation has the solution:
Clearly, the mean fitness will increase along this solution of the gradient field. The rate of increase can be easily calculated:
As limit points of this solution, we obtain:
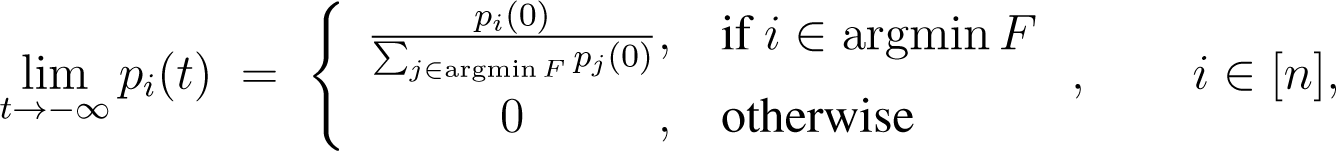
and:
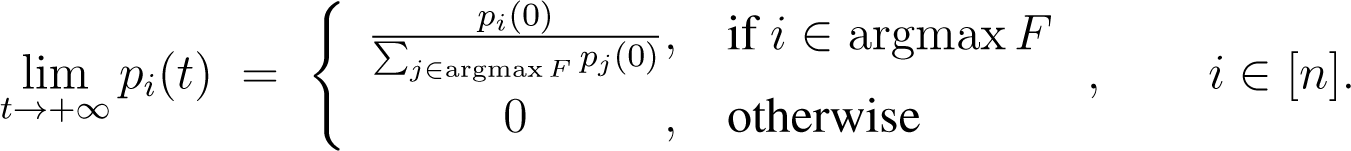
7.2. Extension of the Replicator Equations to Stochastic Matrices
Now, we come to the corresponding considerations of gradient fields in the context of stochastic matrices . We consider a function:
One way to deal with this is to consider for each i ∈ [k] the corresponding replicator equation:
Obviously, this is the gradient field that one obtains by using the product Fisher metric on (Equation (17)):
If we replace the metric by the weighted product Fisher metric considered by Kakade (Equation (35)),
then we obtain
7.3. The Example of Mean Fitness
Next, we want to study how the gradient flows with respect to different metrics compare. We restrict to the class of metrics gρ,m (Equation (35)), where is a probability distribution. In principle, one could drop the normalization condition and allow arbitrary coefficients ρi. However, it is clear that the rate of convergence can always be increased by scaling all values ρi with a common positive factor. Therefore, some normalization condition is needed for ρ.
With a probability distribution and fitness values Fij, let us consider again the example of an expectation value function:
With , this leads to:
The corresponding solutions are given by:
Since and are independent of ρi > 0, the limit points are given independently of the chosen ρ as:
and:

This is consistent with the fact that the critical points of gradient fields are independent of the chosen Riemannian metric. However, the speed of convergence does depend on the metric:
For each i, let Gi = maxj Fij and be the largest and second-largest values in the i-th row of Fij, respectively. Then, as: t → ∞,
Therefore,
Thus, in the long run, the rate of convergence is given by , which depends on the parameter ρ of the metric. As a result, in this case study, the optimal choice of ρi, i.e., with the largest convergence rate, can be computed if the numbers Gi and gi are known.
Consider, for example, the case that the differences Gi – gi are of comparable sizes for all i. Then, we need to find the choice of ρ that maximizes . Clearly, (since there is always an index i with pi ≤ ρi). Equality is attained for the choice ρi = pi. Thus, we recover the choice of Kakade.
8. Conclusions
So, which Riemannian metric should one use in practice on the set of stochastic matrices, ? The results provided in this manuscript give different answers, depending on the approach. In all cases, the characterized Riemannian metrics are products of Fisher metrics with suitable factor weights. Theorem 11 suggests to use a factor weight proportional to 1/k, and Theorem 16 suggests to use a constant weight independent of k. In many cases, it is possible to work within a single conditional polytope and a fixed k, and then, these two results are basically equivalent. On the other hand, Theorem 17 gives an answer that allows arbitrary factor weights ρ.
Which metric performs best obviously depends on the concrete application. The first observation is that in order to use the metric gρ,m of Theorem 17, it is necessary to know ρ. If the problem at hand suggests a natural marginal distribution ρ, then it is natural to make use of it and choose the metric gρ,m. Even if ρ is not known at the beginning, a learning system might try to learn it to improve its performance.
On the other hand, there may be situations where there is no natural choice of the weights ρ. Observe that ρ breaks the symmetry of permuting the rows of a stochastic matrix. This is also expressed by the structural difference between Theorems 11 and 16 on the one side and Theorem 17 on the other. While the first two theorems provide an invariance metric characterization, Theorem 17 provides a “covariance” classification; that is, the metrics gρ,m are not invariant under conditional embeddings, but they transform in a controlled manner. This again illustrates that the choice of a metric should depend on which mappings are natural to consider, e.g., which mappings describe the symmetries of a given problem.
For example, consider a utility function of the form . Row permutations do not leave gρ,m invariant (for a general ρ), but they are not symmetries of the utility function F, either, and hence, they are not very natural mappings to consider. However, row permutations transform the metric gρ,m and the utility function in a controlled manner; in such a way that the two transformations match. Therefore, in this case, it is natural to use gρ,m. On the other hand, when studying problems that are symmetric under all row permutations, it is more natural to use the invariant metric g(k,m).
Acknowledgments
The authors are grateful to Keyan Zahedi for discussions related to policy gradient methods in robotics applications. Guido Montúfar thanks the Santa Fe Institute for hosting him during the initial work on this article. Johannes Rauh acknowledges support by the VW Foundation. This work was supported in part by the DFG Priority Program, Autonomous Learning (DFG-SPP 1527).
Author Contributions
All authors contributed to the design of the research. The research was carried out by all authors, with main contributions by Guido Montúfar and Johannes Rauh. The manuscript was written by Guido Montúfar, Johannes Rauh and Nihat Ay. All authors read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interests.
Appendix
A. Conditions for Positive Definiteness
Equation (16) in Lebanon’s Theorem 6 defines a Riemannian metrics whenever it defines a positive-definite quadratic form. The next proposition gives sufficient and necessary conditions for which this is the case.
Proposition 18. For each pair k ≥ 1 and m ≥ 2, consider the tensor ondefined by:
for some differentiable functions. The tensor g(k,m) defines a Riemannian metric for all k and m if and only if C(α) > 0, B(α) + C(α) > 0 and A(α) + B(α) + C(α) > 0 for all.
Proof. The tensors are Riemannian metrics when:
is strictly positive for all non-zero , for all .
We can derive necessary conditions on the functions A, B, C from some basic observations. Choosing V = ∂ab in Equation (A2) shows that has to be positive for all a ∈ [k], b ∈ [m], for all . Since Mab can be arbitrarily small for fixed |M| and |Ma|, we see that C has to be non-negative. Since we can choose |Ma| ≈ Mab ≪ |M| for a fixed |M|, we find that B + C has to be non-negative. Further, since we can choose Mab ≈ |Ma| ≈ |M| for a given |M|, we find that A + B + C has to be non-negative. This shows that the quadratic form is positive definite only if C ≥ 0, B + C ≥ 0, A + B + C ≥ 0. Since the cone of positive definite matrices is open, these inequalities have to be strictly satisfied. In the following, we study sufficient conditions.
For any given , we can write Equation (A2) as a product V⊤GV, for all , where is the sum of a matrix GA with all entries equal to A(|M|), a block diagonal matrix GB whose a-th block has all entries equal to , and a diagonal matrix GC with diagonal entries equal to . The matrix G is obviously symmetric, and by Sylvester’s criterion, it is positive definite iff all its leading principal minors are positive. We can evaluate the minors using Sylvester’s determinant theorem. That theorem states that for any invertible m × m matrix X, an m × n matrix Y and an n × m matrix Z, one has the equality det(X + YZ) = det(X) det(In + ZX−1Y).
Let us consider a leading square block G′, consisting of all entries Gab,cd of G with row-index pairs (a, b) satisfying b ∈ [m] for all a < a′ and b ≤ b′ for a = a′ for some a′ ≤ k and b′ ≤ m; and the same restriction for the column index pairs. The corresponding block can be written as the rank-a′ matrix YZ, with Y consisting of columns 1a for all a ≤ a′ and Z consisting of rows for all a ≤ a′. Hence, the determinant of G′ is equal to:
Since G′C is diagonal, the first term is just:
The matrix in the second term of Equation (A3) is given by:
By Sylvester’s determinant theorem, we have:
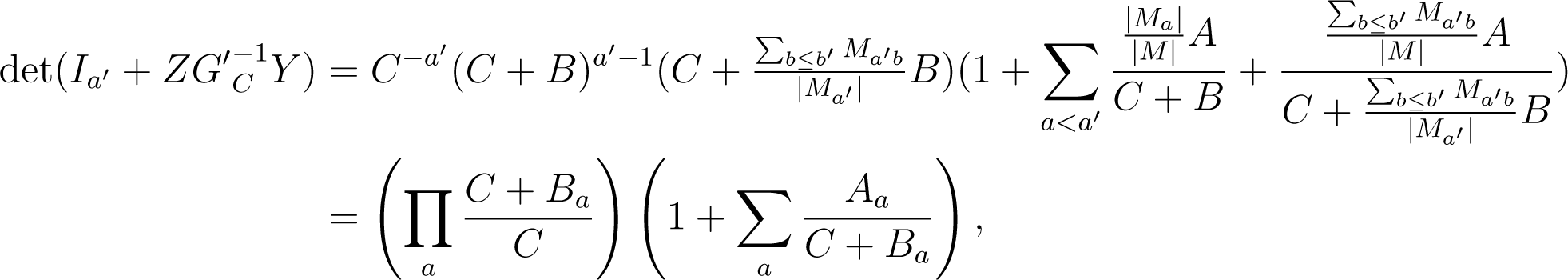
where for a < a′ and , and Ba = B for a < a′ and .
This shows that the matrix G is positive definite for all M if and only if C > 0, C + B > 0 and for all a′ and b′. The latter inequality is satisfied whenever A + B + C > 0. This completes the proof. □
B. Proofs of the Invariance Characterization
The following lemma follows directly from the definition and contains all the technical details we need for the proofs.
Lemma 19. The push-forward of a map is given by:
and the pull-back of a metric g(l,n) on through f is given by:
Proof of Theorem 11. We follow the strategy of [5,14]. The idea is to consider subclasses of maps from the class and to evaluate their push-forward and pull-back maps together with the isometry requirement. This yields restrictions on the possible metrics, eventually fully characterizing them.
First. Consider the maps , resulting from permutation matrices for all a ∈ [k], and . Requiring isometry yields:
Second. Consider the maps defined by and being uniform. In this case, for some permutations π and σ,
Third. For a rational matrix with and row-sum for all a ∈ [k], consider the map that maps M to a constant matrix. In this case, and Q(a) has the b-th row with entries with value , at positions , and:
Step 1: a ≠ c. Consider a constant matrix M = U. Then:
This implies that when a ≠ c.
Using the second type of map, we get:
which implies , when a ≠ c. Considering a rational matrix M and the map vM yields:
Step 2: b ≠ d. By similar arguments as in Part 1, . Evaluating the map rzw yields:
and therefore,
which implies that is independent of m and scales with the inverse of k, such that it can be written as . Rearranging the terms yields , for b ≠ d.
For a rational matrix M, the pull-back through vM shows then:
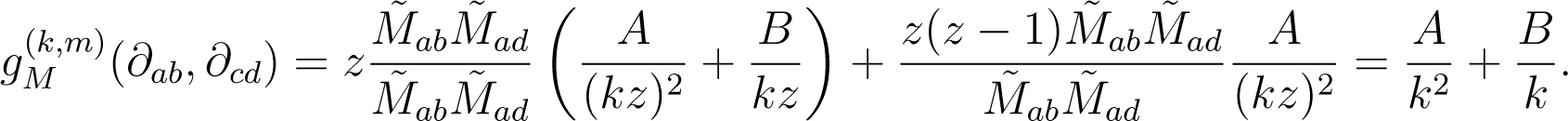
Step 3: a = c and b = d. In this case, and:
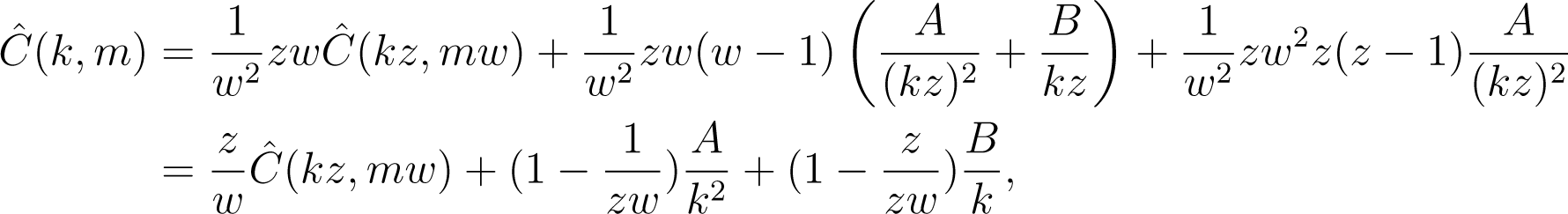
which implies:
such that the left-hand side is a constant C, and . Now, for a rational matrix M, pulling back through vM gives:
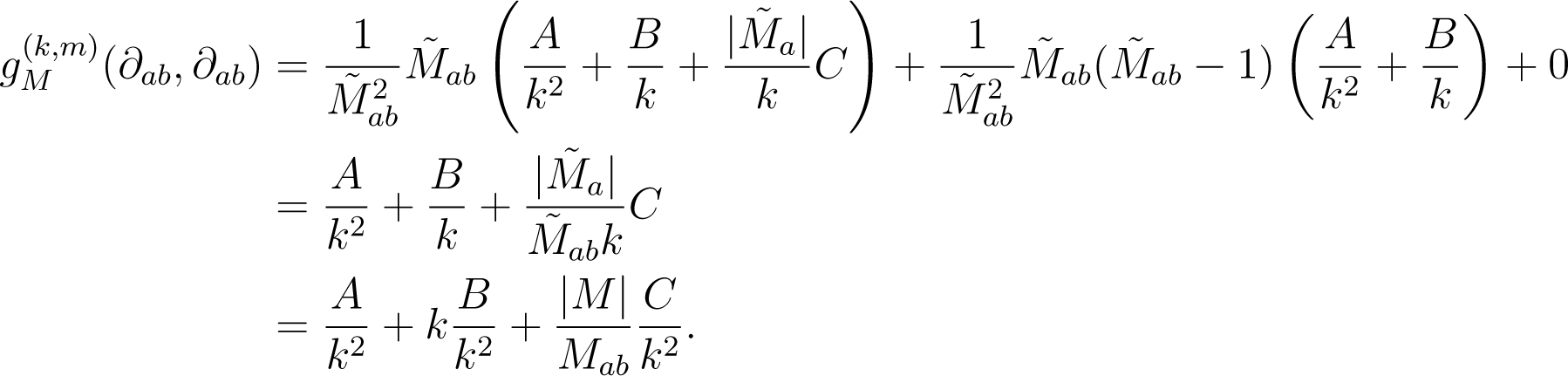
Summarizing, we found:
which proves the first statement. The second statement follows by plugging Equation (23) into Equation (A8). Finally, the statement about the positive-definiteness is a direct consequence of Proposition 7. □
Proof of Theorem 12. Suppose, contrary to the claim, that a family of metrics exists, which is invariant with respect to any conditional embedding. By Theorem 11, these metrics are of the form of Equation (23). To prove the claim, we only need to show that A, B and C vanish. In the following, we study conditional embeddings where Q consists of identity matrices and evaluate the isometry requirement .
Step 1: In the case a ≠ c, we obtain from the invariance requirement and Equation (A8), that:
Observe that:
In fact, is the cardinality of the i-th block of the partition belonging to . Therefore, if we choose to be the partition indicator matrix of a partition that is not homogeneous and in which and , then Equation (A25) implies that A = 0.
Step 2: In the case a = c and b ≠ d, we obtain from invariance and Equation (A8), that:
Again, we may chose in such a way that and find that B = 0.
Step 3: Finally, in the case a = c and b = d, we obtain from invariance and Equation (A8), that:
If we chose , such that , then we see that C = 0. Therefore, g(k,m) is the zero-tensor, which is not a metric. □
References
- Amari, S. Natural gradient works efficiently in learning. Neur. Comput 1998, 10, 251–276. [Google Scholar]
- Kakade, S. A Natural Policy Gradient. In Advances in Neural Information Processing Systems 14; MIT Press: Cambridge, MA, USA, 2001; pp. 1531–1538. [Google Scholar]
- Shahshahani, S. A New Mathematical Framework for the Study of Linkage and Selection; American Mathematical Society: Providence, RI, USA, 1979. [Google Scholar]
- Chentsov, N. Statistical Decision Rules and Optimal Inference; American Mathematical Society: Providence, RI, USA, 1982. [Google Scholar]
- Campbell, L. An extended Čencov characterization of the information metric. Proc. Am. Math. Soc 1986, 98, 135–141. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Advances in Neural Information Processing Systems 12; MIT Press: Cambridge, MA, USA, 2000; pp. 1057–1063. [Google Scholar]
- Marbach, P.; Tsitsiklis, J. Simulation-based optimization of Markov reward processes. IEEE Trans. Autom. Control 2001, 46, 191–209. [Google Scholar]
- Montúfar, G.; Ay, N.; Zahedi, K. Expressive power of conditional restricted boltzmann machines for sensorimotor control 2014, arXiv, 1402.3346.
- Ay, N.; Montúfar, G.; Rauh, J. Selection Criteria for Neuromanifolds of Stochastic Dynamics. In Advances in Cognitive Neurodynamics (III); Yamaguchi, Y., Ed.; Springer-Verlag: Dordrecht, The Netherlands, 2013; pp. 147–154. [Google Scholar]
- Peters, J.; Schaal, S. Natural Actor-Critic. Neurocomputing 2008, 71, 1180–1190. [Google Scholar]
- Peters, J.; Schaal, S. Policy Gradient Methods for Robotics, Proceedings of the IEEE International Conference on Intelligent Robotics Systems (IROS 2006), Beijing, China, 9–15 October 2006.
- Peters, J.; Vijayakumar, S.; Schaal, S. Reinforcement learning for humanoid robotics, Proceedings of the third IEEE-RAS international conference on humanoid robots, Karlsruhe, Germany, 29–30 September 2003; pp. 1–20.
- Bagnell, J.A.; Schneider, J. Covariant policy search, Proceedings of the 18th International Joint Conference on Artificial Intelligence, Acapulco, Mexico, August 9–15 2003; Morgan Kaufmann Publishers Inc: San Francisco, CA, USA, 2003; pp. 1019–1024.
- Lebanon, G. Axiomatic geometry of conditional models. IEEE Trans. Inform. Theor 2005, 51, 1283–1294. [Google Scholar]
- Lebanon, G. An Extended Čencov-Campbell Characterization of Conditional Information Geometry, Proceedings of the 20th Conference in Uncertainty in Artificial Intelligence (UAI 04), Banff, AL, Canada, 7–11 July 2004; Chickering, D.M., Halpern, J.Y., Eds.; AUAI Press: Arlington, VA, USA, 2004; pp. 341–345.
- Barndorff-Nielsen, O. Information and Exponential Families: In statistical Theory; John Wiley & Sons, Inc: Hoboken, NJ, USA, 1978. [Google Scholar]
- Brown, L.D. Fundamentals of Statistical Exponential Families with Applications in Statistical Decision Theory; Institute of Mathematical Statistics: Hayward, CA, USA, 1986. [Google Scholar]
- Zahedi, K.; Ay, N.; Der, R. Higher coordination with less control—A result of informaion maximiation in the sensorimotor loop. Adapt. Behav 2010, 18. [Google Scholar]
- Hofbauer, J.; Sigmund, K. Evolutionary Games and Population Dynamics; Cambridge University Press: Cambridge, United Kingdom, 1998. [Google Scholar]
- Ay, N.; Erb, I. On a notion of linear replicator equations. J. Dyn. Differ. Equ 2005, 17, 427–451. [Google Scholar]


© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Montúfar, G.; Rauh, J.; Ay, N. On the Fisher Metric of Conditional Probability Polytopes. Entropy 2014, 16, 3207-3233. https://doi.org/10.3390/e16063207
Montúfar G, Rauh J, Ay N. On the Fisher Metric of Conditional Probability Polytopes. Entropy. 2014; 16(6):3207-3233. https://doi.org/10.3390/e16063207
Chicago/Turabian StyleMontúfar, Guido, Johannes Rauh, and Nihat Ay. 2014. "On the Fisher Metric of Conditional Probability Polytopes" Entropy 16, no. 6: 3207-3233. https://doi.org/10.3390/e16063207