Model Selection Criteria Using Divergences

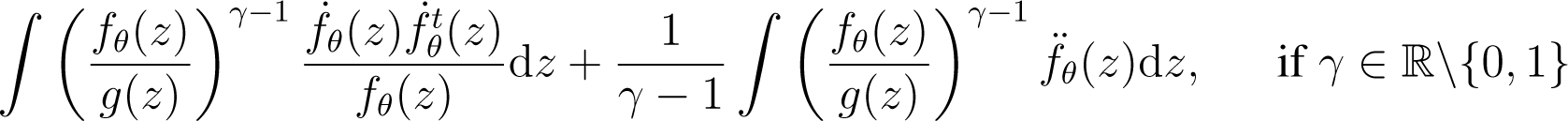{kind=link}
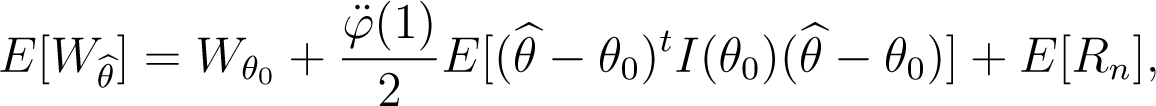{kind=link}
{kind=link}
{kind=link}
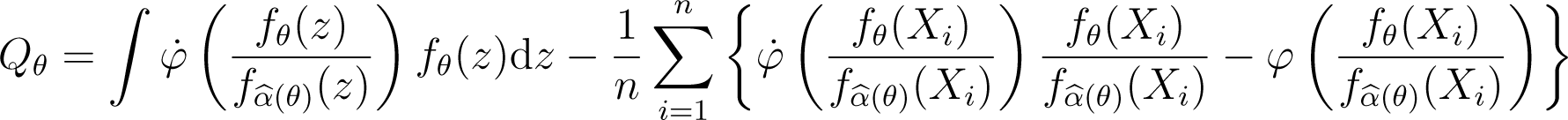{kind=link}
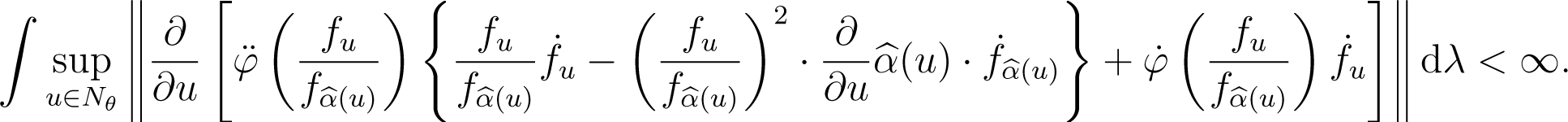{kind=link}
{kind=link}
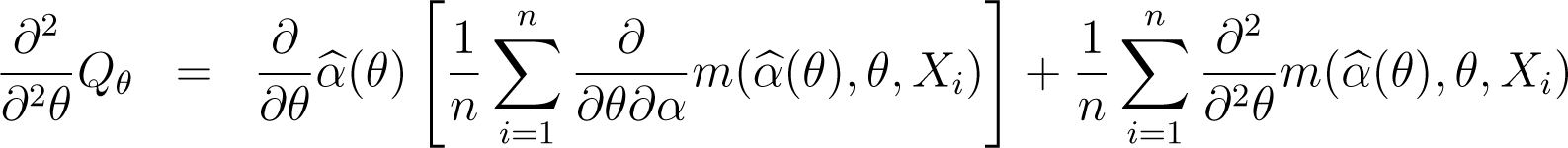{kind=link}
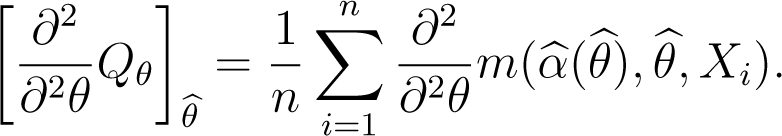{kind=link}
Abstract
: In this note we introduce some divergence-based model selection criteria. These criteria are defined by estimators of the expected overall discrepancy between the true unknown model and the candidate model, using dual representations of divergences and associated minimum divergence estimators. It is shown that the proposed criteria are asymptotically unbiased. The influence functions of these criteria are also derived and some comments on robustness are provided.1. Introduction
The minimum divergence approach is a useful technique in statistical inference. In recent years, the literature dedicated to the divergence-based statistical methods has grown substantially and the monographs of Pardo [1] and Basu et al. [2] are important references that present developments and applications in this field of research. Minimum divergence estimators and related methods have received considerable attention in statistical inference because of their ability to reconcile efficiency and robustness. Among others, Beran [3], Tamura and Boos [4], Simpson [5,6] and Toma [7] proposed families of parametric estimators minimizing the Hellinger distance between a nonparametric estimator of the observations density and the model. They showed that those estimators are both asymptotically efficient and robust. Generalizing earlier work based on the Hellinger distance, Lindsay [8] and Basu and Lindsay [9] have investigated minimum divergence estimators, for both discrete and continuous models. Some families of estimators based on approximate divergence criteria have also been considered; see Basu et al. [10]. Broniatowski and Keziou [11] have introduced a minimum divergence estimation method based on a dual representation of the divergence between probability measures. Their estimators, called minimum dual divergence estimators, are defined in a unified way for both continuous and discrete models. They do not require any prior smoothing and include the classical maximum likelihood estimators as a benchmark. Robustness properties of these estimators have been studied in [12,13].
In this paper we apply estimators of divergences in dual form and corresponding minimum dual divergence estimators, as presented by Broniatowski and Keziou [11], in the context of model selection.
Model selection is a method for selecting the best model among candidate models. A model selection criterion can be considered as an approximately unbiased estimator of the expected overall discrepancy, a nonnegative quantity that measures the distance between the true unknown model and a fitted approximating model. If the value of the criterion is small, then the approximated candidate model can be chosen.
Many model selection criteria have been proposed so far. Classical model selection criteria using least square error and log-likelihood include the Cp-criterion, cross-validation (CV), the Akaike information criterion (AIC) based on the well-known Kullback–Leibler divergence, Bayesian information criterion (BIC), a general class of criteria that also estimates the Kullback–Leibler divergence (GIC). These criteria have been proposed by Mallows [14], Stone [15], Akaike [16], Schwarz [17] and Konishi and Kitagawa [18], respectively. Robust versions of classical model selection criteria, which are not strongly affected by outliers, have been firstly proposed by Ronchetti [19], Ronchetti and Staudte [20]. Other references on this topic can be found in Maronna et al. [21]. Among the recent proposals for model selection we recall the criteria presented by Karagrigoriou et al. [22], the divergence information criteria (DIC) introduced by Mattheou et al. [23]. The DIC criteria use the density power divergences introduced by Basu et al. [10].
In the present paper, we apply the same methodology used for AIC, and also for DIC, to a general class of divergences including the Cressie–Read divergences [24] in order to obtain model selection criteria. These criteria also use dual forms of the divergences and minimum dual divergence estimators. We show that the criteria are asymptotically unbiased and compute the corresponding influence functions.
The paper is organized as follows. In Section 2 we recall the duality formula for divergences, as well as the definitions of associated dual divergence estimators and minimum dual divergence estimators, together with their asymptotic properties, all these being necessary in the next section where we define new criteria for model selection. In Section 3, we apply the same methodology used for AIC to the divergences in dual form in order to develop criteria for model selection. We define criteria based on estimators of the expected overall discrepancy and prove their asymptotic unbiasedness. The influence functions of the proposed criteria are also derived. In Section 4 we present some conclusions.
2. Minimum Dual Divergence Estimators
2.1. Examples of Divergences
Let φ be a non-negative convex function defined from (0, ∞) onto [0, ∞] and satisfying φ(1) = 0. Also extend φ at 0 defining . Let (X, B) be a measurable space and P be a probability measure (p.m.) defined on (X, B). Following Rüschendorf [25], for any p.m. Q absolutely continuous (a.c.) w.r.t. P, the divergence between Q and P is defined by
When Q is not a.c. w.r.t. P, we set D(Q, P) = ∞. We refer to Liese and Vajda [26] for an overview on the origin of the concept of divergence in statistics.
A commonly used family of divergences is the so-called “power divergences” or Cressie–Read divergences. This family is defined by the class of functions
for γ ∈ ℝ \ {0,1} and φ0(x) := − log x + x − 1, φ1(x) := x log x − x + 1 with , , for any γ ∈ ℝ. The Kullback–Leibler divergence (KL) is associated with φ1, the modified Kullback–Leibler (KLm) to φ0, the χ2 divergence to φ2, the modified χ2 divergence to φ−1 and the Hellinger distance to φ1/2. We refer to [11] for the modified versions of χ2 and KL divergences.
Some applied models using divergence and entropy measures can be found in Toma and Leoni-Aubin [27], Kallberg et al. [28], Preda et al. [29] and Basu et al. [2], among others.
2.2. Dual Form of a Divergence and Minimum Divergence Estimators
Let {Fθ, θ ∈ Θ} be an identifiable parametric model, where Θ is a subset of ℝp. We assume that for any θ ∈ Θ, Fθ has density fθ with respect to some dominating σ-finite measure λ. Consider the problem of estimating the unknown true value of the parameter θ0 on the basis of an i.i.d. sample X1,…, Xn with the law .
In the following, denotes the divergence between fθ and , namely
Using a Fenchel duality technique, Broniatowski and Keziou [11] have proved a dual representation of divergences. The main interest on this duality formula is that it leads to a wide variety of estimators, by a plug-in method of the empirical measure evaluated to the data set, without making use of any grouping, nor smoothing.
We consider divergences, defined through differentiable functions φ, that we assume to satisfy (C.0) There exists 0 < δ < 1 such that for all c ∈ [1 − δ, 1 + δ], there exist numbers c1, c2, c3 such that
Condition (C.0) holds for all power divergences, including KL and KLm divergences.
Assuming that is finite and that the function φ satisfies the condition (C.0), the dual representation holds
with
where is the notation for the derivative of φ, the supremum in Equation (5) being uniquely attained in α = θ0, independently on θ.
We mention that the dual representation Equation (5) of divergences has been obtained independently by Liese and Vajda [30].
Naturally, for fixed θ, an estimator of the divergence is obtained by replacing Equation (5) by its sample analogue. This estimator is exactly
the supremum being attained for
Formula (8) defines a class of estimators of the parameter θ0 called dual divergence estimators. Further, since
and since the infimum in the above display is unique, a natural definition of estimators of the parameter θ0, called minimum dual divergence estimators, is provided by
For more details on the dual representation of divergences and associated minimum dual divergence estimators, we refer to Broniatowski and Keziou [11].
2.3. Asymptotic Properties
Broniatowski and Keziou [11] have proved both the weak and the strong consistency, as well as the asymptotic normality for the classes of estimators , and . Here, we shortly recall those asymptotic results that will be used in the next sections. The following conditions are considered.
(C.1) The estimates and exist.
(C.2) tends to 0 in probability.
(a) for any positive ε, there exists some positive η such that for any α ∈ Θ with ||α − θ0 || > ε and for all θ ∈ Θ it holds that .
(b) there exists some neighborhood of θ0 such that for any positive ε, there exists some positive η such that for all and all θ ∈ Θ satisfying ||θ − θ0|| > ε, it holds that .
(C.3) There exists some neighborhood of θ0 and a positive function H with finite, such that for all , ||m(α, θ0, x) || ≤ H (X) in probability.
(C.4) There exists a neighborhood of θ0 such that the first and the second order partial derivatives with respect to α and θ of are dominated on by some λ-integrable functions. The third order partial derivatives with respect to α and θ of m (α, θ, x) are dominated on by some -integrable functions (where is the probability measure corresponding to the law ).
(C.5) The integrals , , , , are finite and the Fisher information matrix is nonsingular, t denoting the transpose.
Proposition 1
Assume that conditions (C.1)–(C3) hold. Then
(a) tends to 0 in probability.
(b) converges to θ0 in probability. If (C.1)–(C.5) are fulfilled, then
(c) and converge in distribution to a centered p-variate normal random variable with covariance matrix I (θ0)−1.
For discussions and examples about the fulfillment of conditions (C.1)–(C5), we refer to Broniatowski and Keziou [11].
3. Model Selection Criteria
In this section, we apply the same methodology used for AIC to the divergences in dual form in order to develop model selection criteria. Consider a random sample X1, …, Xn from the distribution with density g (the true model) and a candidate model fθ from a parametric family of models (fθ) indexed by an unknown parameter θ ∈ Θ, where Θ is a subset of ℝp. We use divergences satisfying (C.0) and denote for simplicity the divergence D (fθ, g) between fθ and the true density g by Wθ.
3.1. The Expected Overall Discrepancy
The target theoretical quantity that will be approximated by an asymptotically unbiased estimator is given by
where is a minimum dual divergence estimator defined by Equation (10). The same divergence is used for both Wθ and . The quantity can be viewed as the average distance between g and (fθ) and it is called the expected overall discrepancy between g and (fθ).
The next Lemma gives the gradient vector and the Hessian matrix of Wθ and is useful for evaluating the expected overall discrepancy through Taylor expansion. We denote by and the first and the second order derivative of fθ with respect to θ, respectively. We assume the following conditions allowing derivation under the integral sign.
(C.6) There exists a neighborhood Nθ of θ such that
(C.7) There exists a neighborhood Nθ of θ such that
Lemma 1
Assume that conditions (C.6) and (C.7) hold. Then, the gradient vector of Wθ is given by
and the Hessian matrix is given by
The proof of this Lemma is straightforward, therefore it is omitted.
Particularly, when using Cressie–Read divergences, the gradient vector of Wθ is given by
and the Hessian matrix is given by
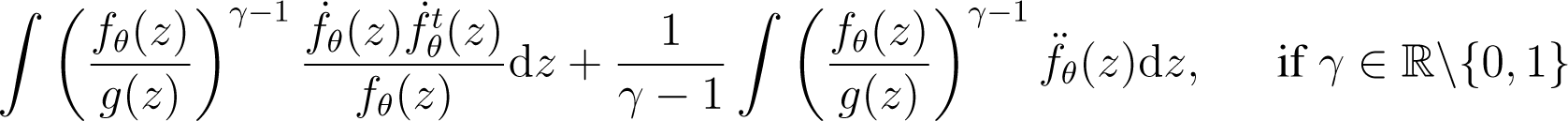
When the true model g belongs to the parametric model (fθ), hence , the gradient vector and the Hessian matrix of Wθ evaluated in θ = θ0 simplify to
The hypothesis that the true model g belongs to the parametric family (fθ) is the assumption made by Akaike [16]. Although this assumption is questionable in practice, it is useful because it provides the basis for the evaluation of the expected overall discrepancy (see also [23]).
Proposition 2
When the true model g belongs to the parametric model (fθ), assuming that conditions (C.6) and (C.7) are fulfilled for and θ = θ0, the expected overall discrepancy is given by
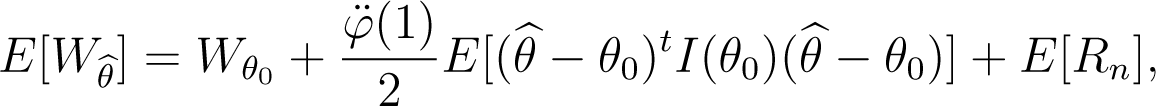
where and θ0 is the true value of the parameter.
Proof
By applying a Taylor expansion to Wθ around the true parameter θ0 and taking , on the basis of Equations (22) and (23), we obtain
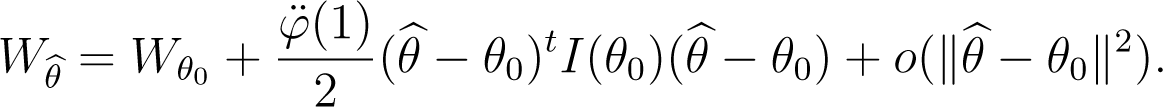
Then Equation (24) is proved.
3.2. Estimation of the Expected Overall Discrepancy
In this section we construct an asymptotically unbiased estimator of the expected overall discrepancy, under the hypothesis that the true model g belongs to the parametric family (fθ).
For a given θ ∈ Θ, a natural estimator of Wθ is
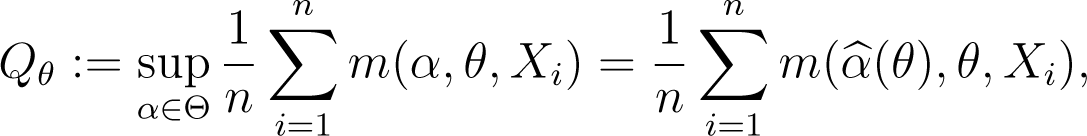
where m (α, θ, x) is given by formula (6), which can also be expressed as
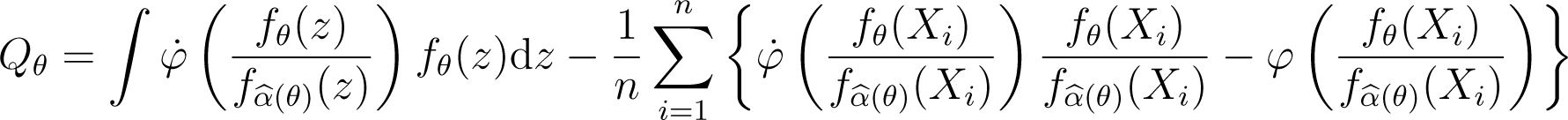
using the sample analogue of the dual representation of the divergence.
The following conditions allow derivation under the integral sign for the integral term of Qθ.
(C.8) There exists a neighborhood Nθ of θ such that
(C.9) There exists a neighborhood Nθ of θ such that
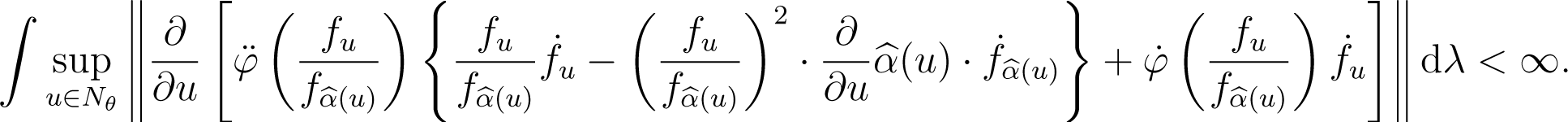
Lemma 2
Under (C.8) and (C.9), the gradient vector and the Hessian matrix of Qθ are
Proof
Since
derivation yields

Note that, by its very definition, is a solution of the equation
taken with respect to α, therefore
On the other hand,
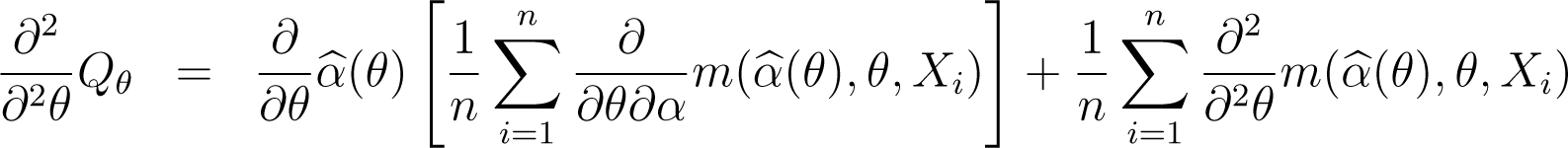
Proposition 3
Under conditions (C.1)–(C.3) and (C.8)–(C.9) and assuming that the integrals , and are finite, the gradient vector and the Hessian matrix of Qθ evaluated in satisfy
Proof
By the very definition of , the equality (38) is verified. For the second relation, we take in Equation (31) and obtain
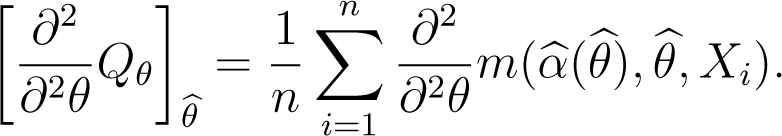
A Taylor expansion of as function of (α, θ) around to (θ0, θ0) yields
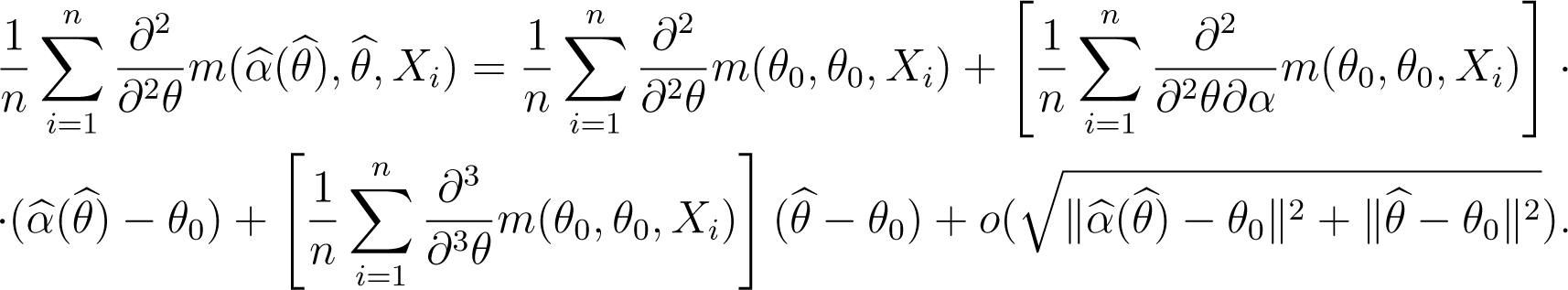
Using the fact that is finite, the weak law of large numbers leads to
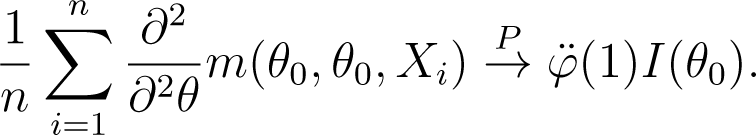
Then, since and , and taking into account that and are finite, we deduce that
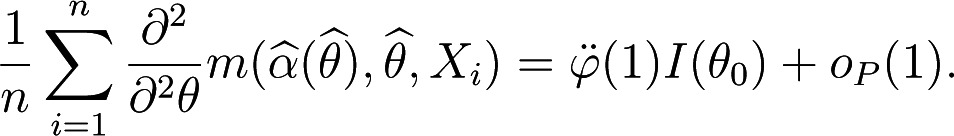
Thus we obtain Equation (39).
In the following, we suppose that conditions of Proposition 1, Proposition 2 and Proposition 3 are all satisfied. These conditions allow obtaining an asymptotically unbiased estimator of the expected overall discrepancy.
Proposition 4
When the true model g belongs to the parametric model (fθ), the expected overall discrepancy evaluated at is given by
where .
Proof
A Taylor expansion of Qθ around to yields
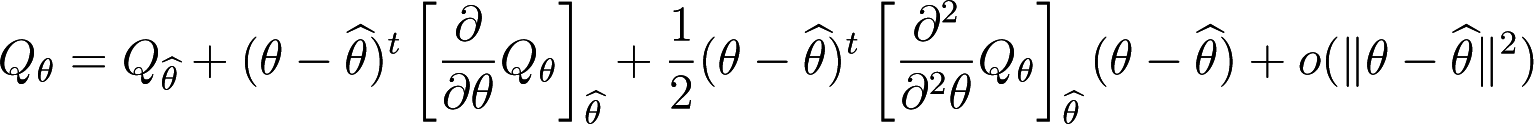
and using Proposition 3, we have
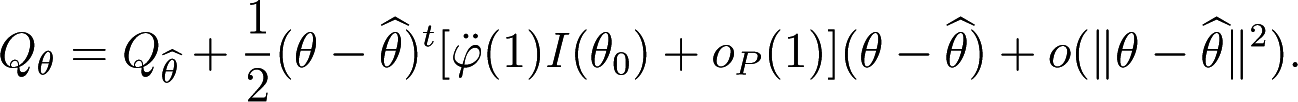
Taking θ = θ0, for large n, it holds
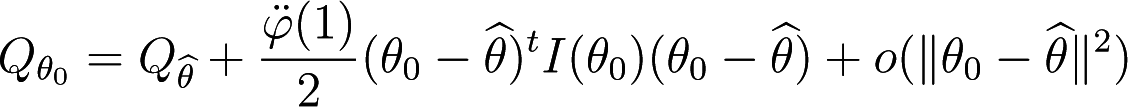
and consequently
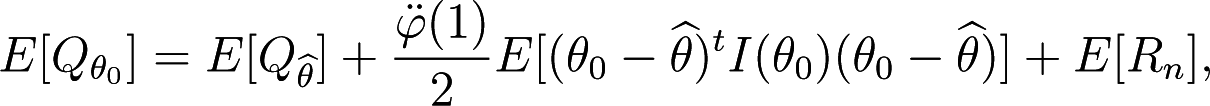
Where .
According to Proposition 2 it holds
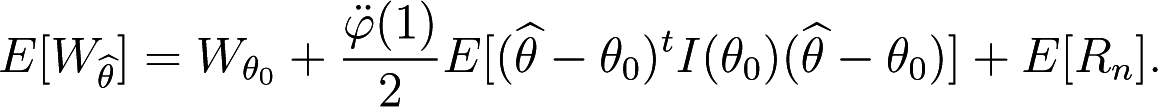
Note that
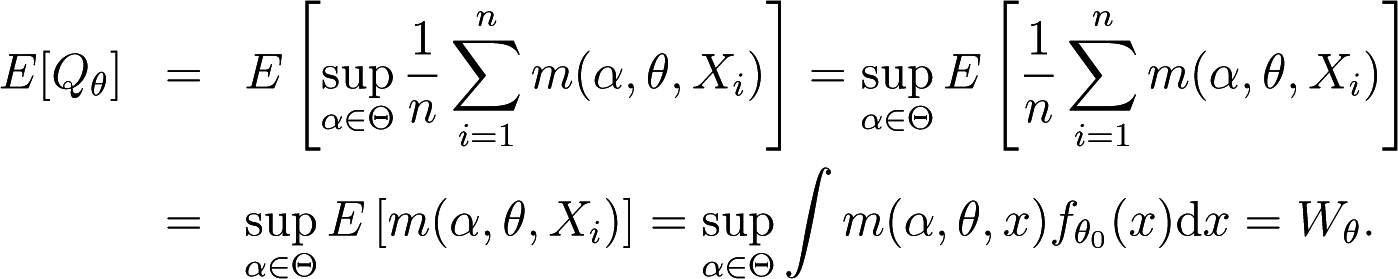
Then, combining Equation (48) with Equations (49) and (47), we get
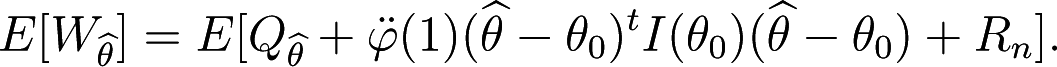
Proposition 4 shows that an asymptotically unbiased estimator of the expected overall discrepancy is given by
According to Proposition 1, is asymptotically distributed as Np (0, I (θ0)−1). Consequently, has approximately a distribution. Then, taking into account that , an asymptotically unbiased estimator of n-times the expected overall discrepancy evaluated at is provided by
3.3. Influence Functions
In the following, we compute the influence function of the statistics . As it is known, the influence function is a useful tool for describing the robustness of an estimator. Recall that a map T defined on a set of distribution functions and parameter space valued is a statistical functional corresponding to an estimator of the parameter θ, if , where Fn is the empirical distribution function associated to the sample. The influence function of T at fθ is defined by
where being the Dirac measure putting all mass at x. Whenever the influence function is bounded with respect to x, the corresponding estimator is called robust (see [31]).
Since
the statistical functional corresponding to , which we denote by U (•), is defined by
where tθ(f) is the statistical functional associated to the estimator and V (F) is the statistical functional associated to the estimator .
Proposition 5
The influence function of is
Proof
For the contaminated model , it holds
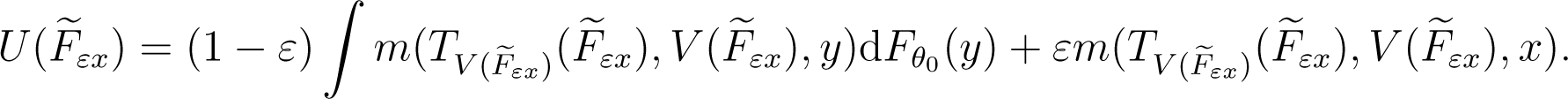
Derivation with respect to ε yields
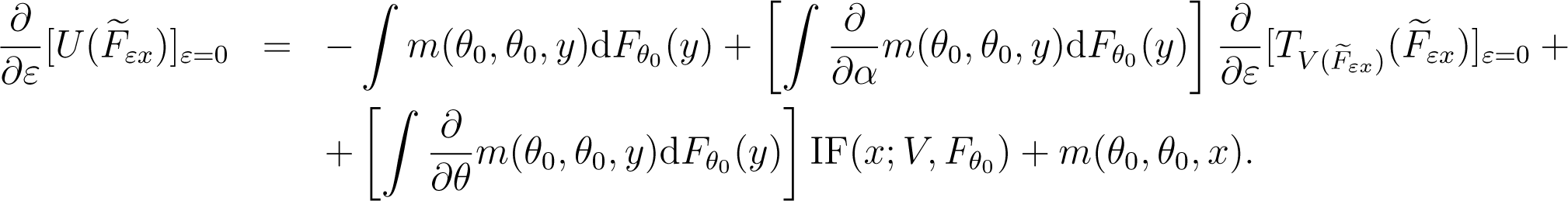
Note that m (θ0, θ0, y) = 0 for any y and . Also, some straightforward calculations give
On the other hand, according to the results presented in [12], the influence function of the minimum dual divergence estimator is
Consequently, we obtain Equation (60).
Note that, for Cressie–Read divergences, it holds
irrespective of the used divergence, since , for any γ.
Generally, is not bounded, therefore the robustness of the statistics , as measured by the influence function, does not hold.
4. Conclusions
The dual representation of divergences and corresponding minimum dual divergence estimators are useful tools in statistical inference. The presented theoretical results show that, in the context of model selection, these tools provide asymptotically unbiased criteria. These criteria are not robust in the sense of the bounded influence function, but this fact does not exclude the stability of the criteria with respect to other robustness measures. The computation of could lead to serious difficulties, for example when considering various regression models to choose from. Such difficulties are implied by the double optimization in the criterion. Therefore, from the computation point of view, some other existing model selection criteria could be preferred. On the other hand, some performant computation techniques, involving such a double optimization, could arrive in the favor of using these new criteria also. These problems represent the topic of future research.
Acknowledgments
The author thanks the referees for a careful reading of the paper and for the suggestions leading to an improved version of the paper. This work was supported by a grant of the Romanian National Authority for Scientific Research, CNCS-UEFISCDI, project number PN-II-RU-TE-2012-3-0007.
Conflicts of Interest
The author declares no conflict of interest.
References
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapmann & Hall: Boca Raton, FL, USA, 2006. [Google Scholar]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; Chapmann & Hall: Boca Raton, FL, USA, 2011. [Google Scholar]
- Beran, R. Minimum Hellinger distance estimates for parametric models. Ann. Stat 1977, 5, 445–463. [Google Scholar]
- Tamura, R.N.; Boos, D.D. Minimum Hellinger distance estimation for multivariate location and covariance. J. Am. Stat. Assoc 1986, 81, 223–229. [Google Scholar]
- Simpson, D.G. Minimum Hellinger distance estimation for the analysis of count data. J. Am. Stat. Assoc 1987, 82, 802–807. [Google Scholar]
- Simpson, D.G. Hellinger deviance tests: Efficiency, breakdown points, and examples. J. Am. Stat. Assoc 1989, 84, 104–113. [Google Scholar]
- Toma, A. Minimum Hellinger distance estimators for multivariate distributions from Johnson system. J. Stat. Plan. Inference 2008, 183, 803–816. [Google Scholar]
- Lindsay, B.G. Efficiency versus robustness: The case of minimum Hellinger distance and related methods. Ann. Stat 1994, 22, 1081–1114. [Google Scholar]
- Basu, A.; Lindsay, B.G. Minimum disparity estimation for continuous models: Efficiency, distributions and robustness. Ann. Inst. Stat. Math 1994, 46, 683–705. [Google Scholar]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimising a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar]
- Broniatowski, M.; Keziou, A. Parametric estimation and tests through divergences and duality technique. J. Multivar. Anal 2009, 100, 16–36. [Google Scholar]
- Toma, A.; Broniatowski, M. Dual divergence estimators and tests: Robustness results. J. Multivar. Anal 2011, 102, 20–36. [Google Scholar]
- Toma, A.; Leoni-Aubin, S. Robust tests based on dual divergence estimators and saddlepoint approximations. J. Multivar. Anal 2010, 101, 1143–1155. [Google Scholar]
- Mallows, C.L. Some comments on Cp. Technometrics 1973, 15, 661–675. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B 1974, 36, 111–147. [Google Scholar]
- Akaike, H. Information theory and an extension of the maximum likelihood principle, Proceedings of the Second International Symposium on Information Theory, Akademiai Kaido, Budapest, 1973; Petrov, B.N., Csaki, I.F., Eds.; pp. 267–281.
- Schwarz, G. Estimating the dimension of a model. Ann. Stat 1978, 6, 461–464. [Google Scholar]
- Konishi, S.; Kitagawa, G. Generalised information criteria in model selection. Biometrika 1996, 83, 875–890. [Google Scholar]
- Ronchetti, E. Robust model selection in regression. Stat. Probab. Lett 1985, 3, 21–23. [Google Scholar]
- Ronchetti, E.; Staudte, R.G. A robust version of Mallows’ CP. J. Am. Stat. Assoc 1994, 89, 550–559. [Google Scholar]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J. Robust Statistics: Theory and Methods; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Karagrigoriou, A.; Mattheou, K.; Vonta, F. On asymptotic properties of AIC variants with applications. Open J. Stat 2011, 1, 105–109. [Google Scholar]
- Mattheou, K.; Lee, S.; Karagrigoriou, A. A model selection criterion based on the BHHJ measure of divergence. J. Stat. Plan. Inference 2009, 139, 228–235. [Google Scholar]
- Cressie, N.; Read, T.R.C. Multinomial goodness of fit tests. J. R. Stat. Soc. Ser. B 1984, 46, 440–464. [Google Scholar]
- Ru¨schendorf, L. On the minimum discrimination information theorem. Stat. Decis 1984, 1, 163–283. [Google Scholar]
- Liese, F.; Vajda, I. Convex Statistical Distances; BSB Teubner: Leipzig, Germany, 1987. [Google Scholar]
- Toma, A.; Leoni-Aubin, S. Portfolio selection using minimum pseudodistance estimators. Econ. Comput. Econ. Cybern. Stud. Res 2013, 46, 117–132. [Google Scholar]
- Kallberg, D.; Leonenko, N.; Seleznjev, O. Statistical inference for Re´nyi entropy functionals. In Conceptual Modelling and Its Theoretical Foundations; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7260, pp. 36–51. [Google Scholar]
- Preda, V.; Dedu, S.; Sheraz, M. New measure selection for Hunt-Devolder semi-Markov regime switching interest rate models. Physica A 2014, 407, 350–359. [Google Scholar]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar]
- Hampel, F.R.; Ronchetti, E.; Rousseeuw, P.J.; Stahel, W. Robust Statistics: The Approach Based on Influence Functions; Wiley: New York, NY, USA, 1986. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Toma, A. Model Selection Criteria Using Divergences. Entropy 2014, 16, 2686-2698. https://doi.org/10.3390/e16052686
Toma A. Model Selection Criteria Using Divergences. Entropy. 2014; 16(5):2686-2698. https://doi.org/10.3390/e16052686
Chicago/Turabian StyleToma, Aida. 2014. "Model Selection Criteria Using Divergences" Entropy 16, no. 5: 2686-2698. https://doi.org/10.3390/e16052686