Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation


Abstract
:1. Introduction
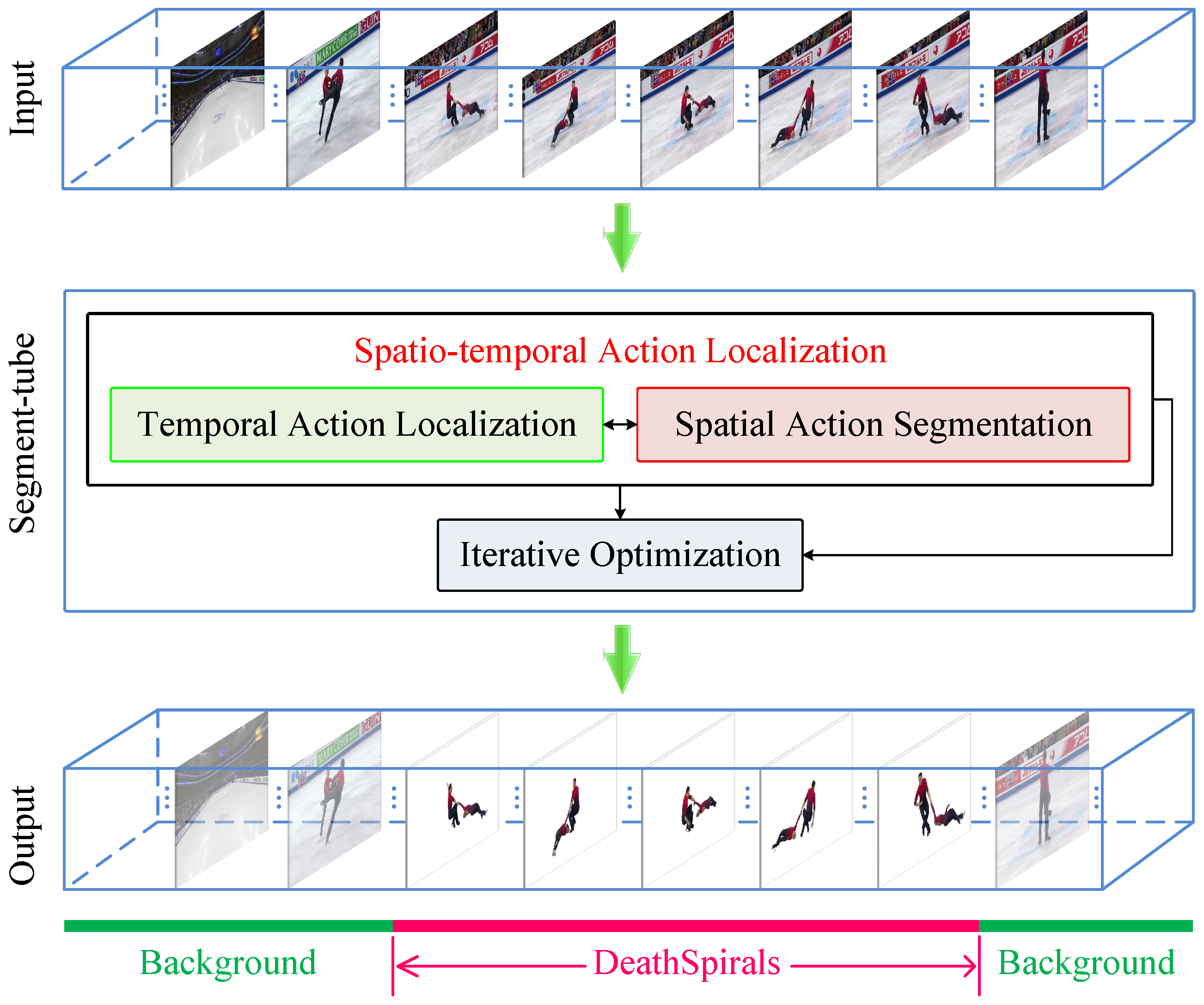
- The spatio-temporal action localization detector Segment-tube is proposed for untrimmed videos, which produces not only the starting/ending frame of an action, but also per-frame segmentation masks instead of sequences of bounding boxes.
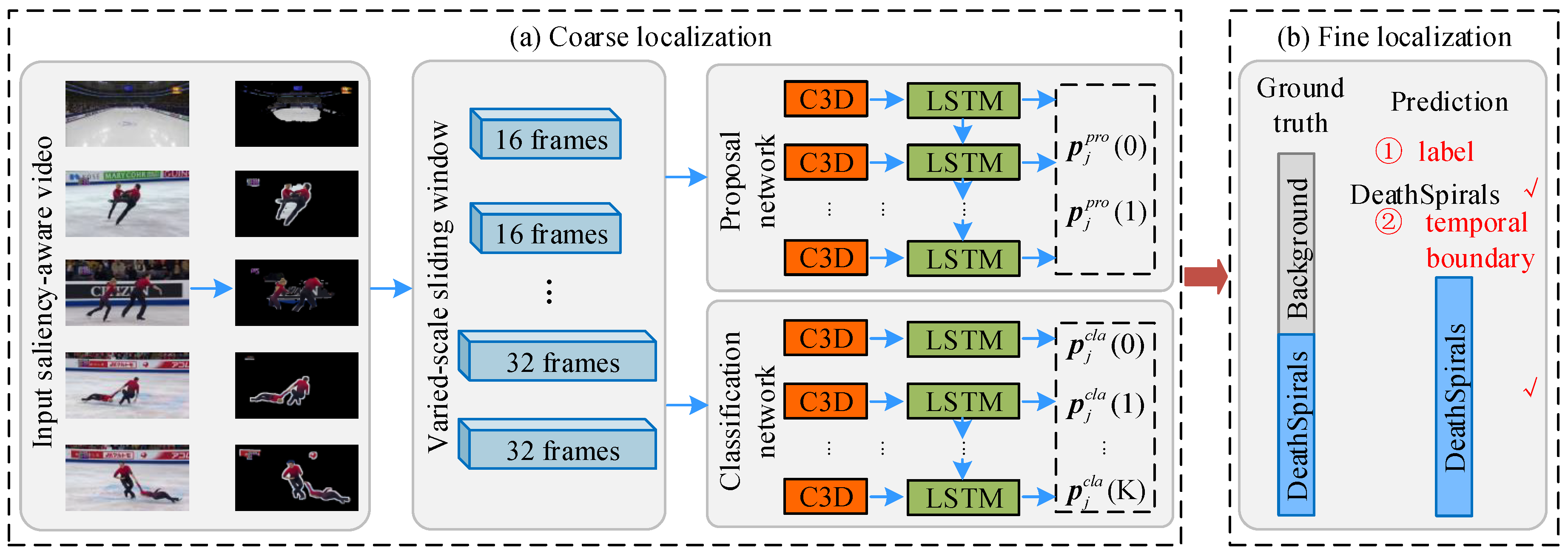
- The proposed Segment-tube detector achieves collaborative optimization of temporal localization and spatial segmentation with a new iterative alternation approach, where the temporal localization is achieved by a coarse-to-fine strategy based on cascaded 3D ConvNets [4] and LSTM.
- To exactly evaluate the proposed Segment-tube and to build a benchmark for future research, a new ActSeg dataset is proposed, which consists 641 videos with temporal annotations and per-frame ground truth segmentation masks.
2. Related Works
2.1. Action Classification
2.2. Temporal Action Localization
2.3. Spatio-Temporal Action Localization
2.4. Video Object Segmentation
3. Problem Formulation
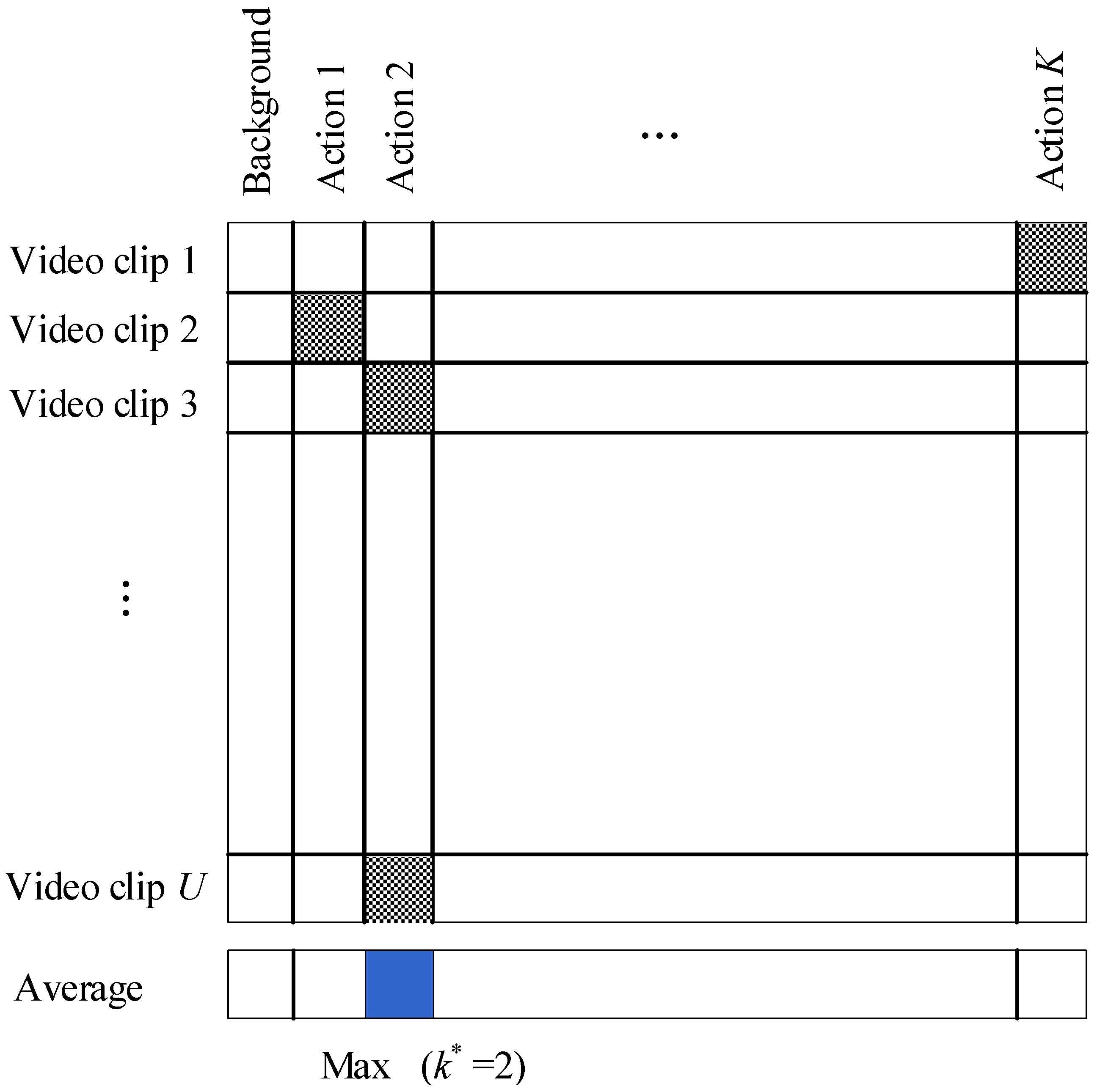
3.1. Temporal Action Localization
3.2. Spatial Action Segmentation
3.3. Iterative and Alternating Optimization
4. Experiments and Discussion
4.1. Datasets and Evaluation Protocol
4.2. Implementation Details
4.3. Temporal Action Localization on the THUMOS 2014 Dataset
4.4. Spatial Action Segmentation on the SegTrack Dataset
4.5. Spatio-Temporal Action Localization on the ActSeg Dataset
4.6. Efficiency Analysis
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| ConvNets | Convolutional Neural Networks |
| I3D | Inflated 3D ConvNet |
| ResNet | Deep Residual Convolutional Neural Networks |
| LSTM | Long-Short Temporal Memory |
| RNNs | Recurrent Neural Networks |
| HOG | Histograms of Image Gradients |
| HOF | Histogram of Flow |
| iDT | improved Dense Trajectory |
| FV | Fisher Vector |
| VLAD | Vector of Linearly Aggregated Descriptors |
| FCNs | Fully Convolutional Networks |
| GMMs | Gaussian Mixture Models |
| HOOF | Histogram of Oriented Optical Flow |
| AP | Average Precision |
| mAP | mean Average Precision |
| IoU | Intersection-over-Union |
| RGB | Red Green Blue |
References
- Wang, L.; Qiao, Y.; Tang, X. Action recognition and detection by combining motion and appearance features. THUMOS14 Action Recognit. Chall. 2014, 1, 2. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4489–4497. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Learning to track for spatio-temporal action localization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3164–3172. [Google Scholar]
- Ma, S.; Sigal, L.; Sclaroff, S. Learning activity progression in lstms for activity detection and early detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1942–1950. [Google Scholar]
- Montes, A.; Salvador, A.; Pascual, S.; Giro-i Nieto, X. Temporal activity detection in untrimmed videos with recurrent neural networks. In Proceedings of the 1st NIPS Workshop on Large Scale Computer Vision Systems, Barcelona, Spain, 10 December 2016. [Google Scholar]
- Caba Heilbron, F.; Carlos Niebles, J.; Ghanem, B. Fast temporal activity proposals for efficient detection of human actions in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1914–1923. [Google Scholar]
- Richard, A.; Gall, J. Temporal action detection using a statistical language model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3131–3140. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1049–1058. [Google Scholar]
- Kalogeiton, V.; Weinzaepfel, P.; Ferrari, V.; Schmid, C. Action tubelet detector for spatio-temporal action localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4405–4413. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Yu, P.S. Spatiotemporal pyramid network for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. ActionVLAD: Learning spatio-temporal aggregation for action classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 971–980. [Google Scholar]
- Yuan, Z.; Stroud, J.C.; Lu, T.; Deng, J. Temporal action localization by structured maximal sums. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3215–3223. [Google Scholar]
- Dai, X.; Singh, B.; Zhang, G.; Davis, L.S.; Chen, Y.Q. Temporal context network for activity localization in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5727–5736. [Google Scholar]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.F. CDC: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1417–1426. [Google Scholar]
- Gao, Z.; Hua, G.; Zhang, D.; Jojic, N.; Wang, L.; Xue, J.; Zheng, N. ER3: A unified framework for event retrieval, recognition and recounting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2253–2262. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Learning spatio-temporal features with 3D residual networks for action recognition. In Proceedings of the ICCV Workshop on Action, Gesture, and Emotion Recognition, Venice, Italy, October 2017; Volume 2, p. 4. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Jain, M.; Van Gemert, J.; Jégou, H.; Bouthemy, P.; Snoek, C. Action localization with tubelets from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Jolly, M. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 105–112. [Google Scholar]
- Jiang, Y.; Liu, J.; Zamir, A.R.; Toderici, G.; Laptev, I.; Shah, M.; Sukthankar, R. THUMOS Challenge: Action Recognition with A Large Number of Classes. In Proceedings of the European Conference on Computer Vision Workshop, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Tsai, D.; Flagg, M.; Nakazawa, A.; Rehg, J.M. Motion coherent tracking using multi-label MRF optimization. Int. J. Comput. Vis. 2012, 100, 190–202. [Google Scholar] [CrossRef]
- Li, F.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J.M. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2192–2199. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Kataoka, H.; Satoh, Y.; Aoki, Y.; Oikawa, S.; Matsui, Y. Temporal and fine-grained pedestrian action recognition on driving recorder database. Sensors 2018, 18, 627. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conferemce on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar]
- Oneata, D.; Verbeek, J.; Schmid, C. Action and event recognition with fisher vectors on a compact feature set. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1817–1824. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Mexaction2. Available online: http://mexculture.cnam.fr/xwiki/bin/view/Datasets/Mex+action+dataset (accessed on 15 July 2015).
- Gaidon, A.; Harchaoui, Z.; Schmid, C. Temporal localization of actions with actoms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2782–2795. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Pei, Y.; Ni, B.; Moulin, P.; Kassim, A. Adsc submission at thumos challenge 2015. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition THUMOS Workshop, Las Vegas, NV, USA, 11–12 June 2015; Volume 1, p. 2. [Google Scholar]
- Singh, G.; Cuzzolin, F. Untrimmed video classification for activity detection: Submission to activitynet challenge. arXiv, 2016; arXiv:1607.01979. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Jin, N.; Andriluka, M.; Mori, G.; Fei-Fei, L. Every moment counts: Dense detailed labeling of actions in complex videos. Int. J. Comput. Vis. 2018, 126, 375–389. [Google Scholar] [CrossRef]
- Yu, G.; Yuan, J. Fast action proposals for human action detection and search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1302–1311. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Niebles, J.C. Sst: Single-stream temporal action proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6373–6382. [Google Scholar]
- Gong, J.; Fan, G.; Yu, L.; Havlicek, J.P.; Chen, D.; Fan, N. Joint target tracking, recognition and segmentation for infrared imagery using a shape manifold-based level set. Sensors 2014, 14, 10124–10145. [Google Scholar] [CrossRef] [PubMed]
- Soomro, K.; Idrees, H.; Shah, M. Action localization in videos through context walk. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3280–3288. [Google Scholar]
- Gkioxari, G.; Malik, J. Finding action tubes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 759–768. [Google Scholar]
- Singh, G.; Saha, S.; Sapienza, M.; Torr, P.; Cuzzolin, F. Online real-time multiple spatiotemporal action localisation and prediction. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3637–3646. [Google Scholar]
- Palou, G.; Salembier, P. Hierarchical video representation with trajectory binary partition tree. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2099–2106. [Google Scholar]
- Papazoglou, A.; Ferrari, V. Fast object segmentation in unconstrained video. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1777–1784. [Google Scholar]
- Lee, Y.J.; Kim, J.; Grauman, K. Key-segments for video object segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1995–2002. [Google Scholar]
- Khoreva, A.; Galasso, F.; Hein, M.; Schiele, B. Classifier based graph construction for video segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 951–960. [Google Scholar]
- Wang, W.; Shen, J.; Porikli, F. Saliency-aware geodesic video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3395–3402. [Google Scholar]
- Jain, S.D.; Xiong, B.; Grauman, K. Fusionseg: Learning to combine motion and appearance for fully automatic segmention of generic objects in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Märki, N.; Perazzi, F.; Wang, O.; Sorkine-Hornung, A. Bilateral space video segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 743–751. [Google Scholar]
- Tsai, Y.H.; Yang, M.H.; Black, M.J. Video segmentation via object flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3899–3908. [Google Scholar]
- Caelles, S.; Maninis, K.K.; Pont-Tuset, J.; Leal-Taixé, L.; Cremers, D.; Van Gool, L. One-shot video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 221–230. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Hua, G.; Sukthankar, R.; Xue, J.; Niu, Z.; Zheng, N. Video object discovery and co-segmentation with extremely weak supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2074–2088. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Javed, O.; Shah, M. Video object co-segmentation by regulated maximum weight cliques. In Proceedings of the European Conferemce on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 551–566. [Google Scholar]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1932–1939. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Dauphin, Y.; De Vries, H.; Chung, J.; Bengio, Y. RMSProp and equilibrated adaptive learning rates for non-convex optimization. arXiv, 2015; arXiv:1502.04390. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in the Wild. Comput. Sci. 2012, arXiv:1212.0402. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IoU Threshold | 0.3 | 0.4 | 0.5 |
|---|---|---|---|
| AMA [1] | 14.6 | 12.1 | 8.5 |
| FTAP [9] | - | - | 13.5 |
| ASLM [10] | 20.0 | 23.2 | 15.2 |
| SCNN [11] | 36.3 | 28.7 | 19.0 |
| ASMS [15] | 36.5 | 27.8 | 17.8 |
| Segment-tube | 39.8 | 27.2 | 20.7 |
| Algorithm | VOS [48] | FOS [47] | BVS [52] | Segment-Tube |
|---|---|---|---|---|
| bird_of_paradise | 92.4 | 81.8 | 91.7 | 93.1 |
| birdfall2 | 49.4 | 17.5 | 63.5 | 66.7 |
| frog | 75.7 | 54.1 | 76.4 | 70.2 |
| girl | 64.2 | 54.9 | 79.1 | 81.3 |
| monkey | 82.6 | 65.0 | 85.9 | 86.9 |
| parachute | 94.6 | 76.3 | 93.8 | 90.4 |
| soldier | 60.8 | 39.8 | 56.4 | 64.5 |
| worm | 62.2 | 72.8 | 65.5 | 75.2 |
| Average | 72.7 | 57.8 | 76.5 | 78.8 |
| Number | Total Videos | Untrimmed Videos | Trimmed Videos |
|---|---|---|---|
| ArabequeSpin | 68 | 58 | 10 |
| CleanAndJerk | 73 | 61 | 12 |
| UnevenBars | 67 | 57 | 10 |
| SoccerPenalty | 82 | 67 | 15 |
| PoleVault | 72 | 59 | 13 |
| TripleJump | 62 | 50 | 12 |
| NoHandWindmill | 68 | 57 | 11 |
| DeathSpirals | 78 | 66 | 12 |
| Throw | 71 | 56 | 15 |
| Sum | 641 | 531 | 110 |
| IoU Threshold | 0.3 | 0.4 | 0.5 |
|---|---|---|---|
| ARCN [8] | 39.1 | 33.8 | 17.2 |
| SCNN [11] | 41.0 | 35.9 | 18.4 |
| Segment-tube | 42.6 | 37.5 | 21.2 |
| Video | VOS [48] | FOS [47] | BVS [52] | Segment-Tube |
|---|---|---|---|---|
| ArabequeSpin | 53.9 | 82.5 | 64.0 | 83.4 |
| CleanAndJerk | 20.1 | 50.0 | 85.9 | 87.8 |
| UnevenBars | 12.0 | 40.3 | 59.0 | 56.5 |
| SoccerPenalty | 54.4 | 38.5 | 59.8 | 54.7 |
| PoleVault | 38.9 | 41.2 | 42.6 | 49.8 |
| TripleJump | 30.6 | 36.1 | 33.5 | 58.4 |
| NoHandWindmill | 77.1 | 73.3 | 81.8 | 87.9 |
| DeathSpirals | 1 | 66.7 | 77.9 | 66.5 |
| Throw | 33.8 | 2 | 58.7 | 56.2 |
| Average | 35.8 | 47.8 | 62.6 | 66.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Duan, X.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation. Sensors 2018, 18, 1657. https://doi.org/10.3390/s18051657
Wang L, Duan X, Zhang Q, Niu Z, Hua G, Zheng N. Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation. Sensors. 2018; 18(5):1657. https://doi.org/10.3390/s18051657
Chicago/Turabian StyleWang, Le, Xuhuan Duan, Qilin Zhang, Zhenxing Niu, Gang Hua, and Nanning Zheng. 2018. "Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation" Sensors 18, no. 5: 1657. https://doi.org/10.3390/s18051657
APA StyleWang, L., Duan, X., Zhang, Q., Niu, Z., Hua, G., & Zheng, N. (2018). Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation. Sensors, 18(5), 1657. https://doi.org/10.3390/s18051657