


Forecasting 2026, 8(3), 43; https://doi.org/10.3390/forecast8030043 - 25 May 2026
Abstract
►
Show Figures
This study examines whether decomposition-based deep learning forecasts of daily changes in natural rubber prices can appear directionally accurate while failing to preserve the dispersion of the target series—a failure mode that conventional accuracy metrics cannot detect. Using daily RSS3 FOB price changes
[...] Read more.
This study examines whether decomposition-based deep learning forecasts of daily changes in natural rubber prices can appear directionally accurate while failing to preserve the dispersion of the target series—a failure mode that conventional accuracy metrics cannot detect. Using daily RSS3 FOB price changes in the period 2018–2026, a VMD-Augmented BiLSTM forecasting design is employed as the empirical vehicle for testing this question. Forecasts are evaluated jointly through Pearson correlation, directional accuracy, class-conditional recall, and the Standard Deviation Ratio (StdR), with StdR serving as a diagnostic for variance collapse on differenced series. The deployed model appends all Variational Mode Decomposition (VMD) components directly to the economic feature matrix and feeds the augmented sequence into a bidirectional LSTM encoder with temporal attention; VMD is fitted using an expanding-window procedure to prevent information leakage. The design is compared to a conventional per-IMF decomposition–forecast pipeline, a Vanilla LSTM, ARIMA(2,0,2), and a dual-pathway BiLSTM–Transformer control. On a 175-observation deduplicated test set, the deployed model attains Pearson correlation of

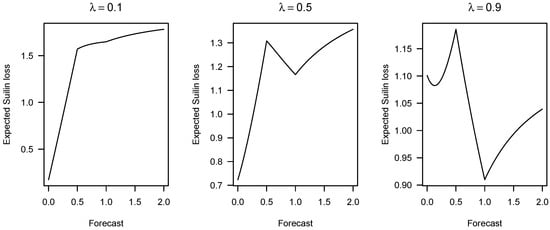
Figure 1























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}