1. Introduction
Nowadays, as a key component of smart cities, smart transportation systems have attracted widespread attention from researchers around the world. Intelligent transportation systems (ITSs) [
1,
2,
3] can optimize the organization and management of urban road network traffic, improve the efficiency of urban road network traffic, and are also the most effective measures to alleviate urban road traffic congestion without changing existing road facilities. Moreover, the development of intelligent transportation systems not only facilitates people’s travel, but also effectively solves environmental pollution and reduces the occurrence of accidents [
4,
5]. With the development of intelligent transportation systems, the autonomous driving of cars has become a key development direction for the future, and it is inseparable from the accurate automatic prediction of car speed. The accurate modelling and prediction of vehicle speeds in urban traffic are crucial to urban intelligent transportation systems and have been widely used, such as driving safety warning [
6,
7,
8], automatic driving [
9,
10], vehicle navigation [
11,
12,
13], traffic management [
14,
15,
16], etc.
Vehicle speed prediction [
17] refers to the estimation and inference of vehicle speed sequences in the future period based on historical data and environmental modelling to help realize vehicle safety-assisted driving [
18] and intelligent vehicle behavior decision analysis [
19]. Therefore, it is necessary to collect and analyze historical vehicle driving data to develop a corresponding strategy. The earlier and more accurate the data are acquired, the better the decision will be. Through speed prediction methods, a future period of driving data can be transmitted to the vehicle decision-making system for analysis, so as to develop the best behavior strategy which is an indispensable part of the intelligent transportation system coordination and arrangement process [
20]. In addition, predicting vehicle speeds in advance can reduce the fuel consumption of the vehicle and traffic accidents during vehicle driving and improve the stability and safety of the automatic driving system. Traffic management departments can use vehicle speed prediction methods to predict vehicle speeds, thereby optimizing the timing of traffic lights and reducing congestion and traffic accidents. In the field of logistics delivery, vehicle speed prediction can be used to predict the travel time and arrival time of delivery vehicles, thereby assisting enterprises in optimizing logistics and distribution plans, improving efficiency, and reducing costs. In short, vehicle speed prediction plays an important role in real life, helping us better manage traffic, improve road safety, optimize logistics delivery, and ensure driving safety.
Vehicle speed prediction in urban traffic [
21] is different from traditional time series analysis and is influenced by time, space, and many other external factors, such as road conditions, traffic flow status, weather conditions, etc. The speed signals received by sensors have complex dynamic spatial and temporal correlations, which make accurate and real-time prediction of vehicle speeds in urban traffic challenging. Currently, the following four main categories of approaches are classified to solve the vehicle speed prediction task: global positioning system (GPS)-based methods, visual perception methods, vehicle dynamics methods, and machine learning methods. The GPS-based methods [
22,
23,
24] use sensors such as GPS and inertial measurement units (IMUs) to measure the speed and position of a vehicle in real time to complete speed prediction. This type of method requires the usage of high-precision GPS instruments, which can achieve high accuracy while incurring expensive costs. However, the positioning accuracy of GPS data may not necessarily meet complex location conditions. Visual perception methods utilize [
25,
26,
27,
28] devices like cameras to obtain information about the vehicle’s surroundings and combine them with machine learning methods to perform speed prediction. This kind of method can predict the speed and direction of the vehicle but can be more influenced by factors such as weather and lighting intensity. Vehicle-dynamics-based methods [
29,
30,
31,
32] use vehicle dynamics to build a prediction model to predict the future speeds of vehicles, in which a large number of factors such as vehicle dynamics parameters and road conditions are required to be considered. Machine learning methods [
33,
34,
35] are one of the most commonly used techniques for vehicle speed prediction. Through developing models such as deep neural networks (DNNs) [
36], support vector machines (SVMs) [
37], and random forests (RFs) [
38], features are extracted from sensor data to build a speed prediction system. When current data are fed into the model, it can accurately predict the future vehicle speeds. Machine learning methods are the most mature and widely used vehicle speed prediction techniques, but they still face problems such as insufficient generalization ability across scenarios, limited inference efficiency, and long-term data dependence. The focus of the four categories of methods is different and there are also connections between them. The first two focus on the sources and modalities of data used for predicting vehicle speeds, while the latter focus on modelling methods.
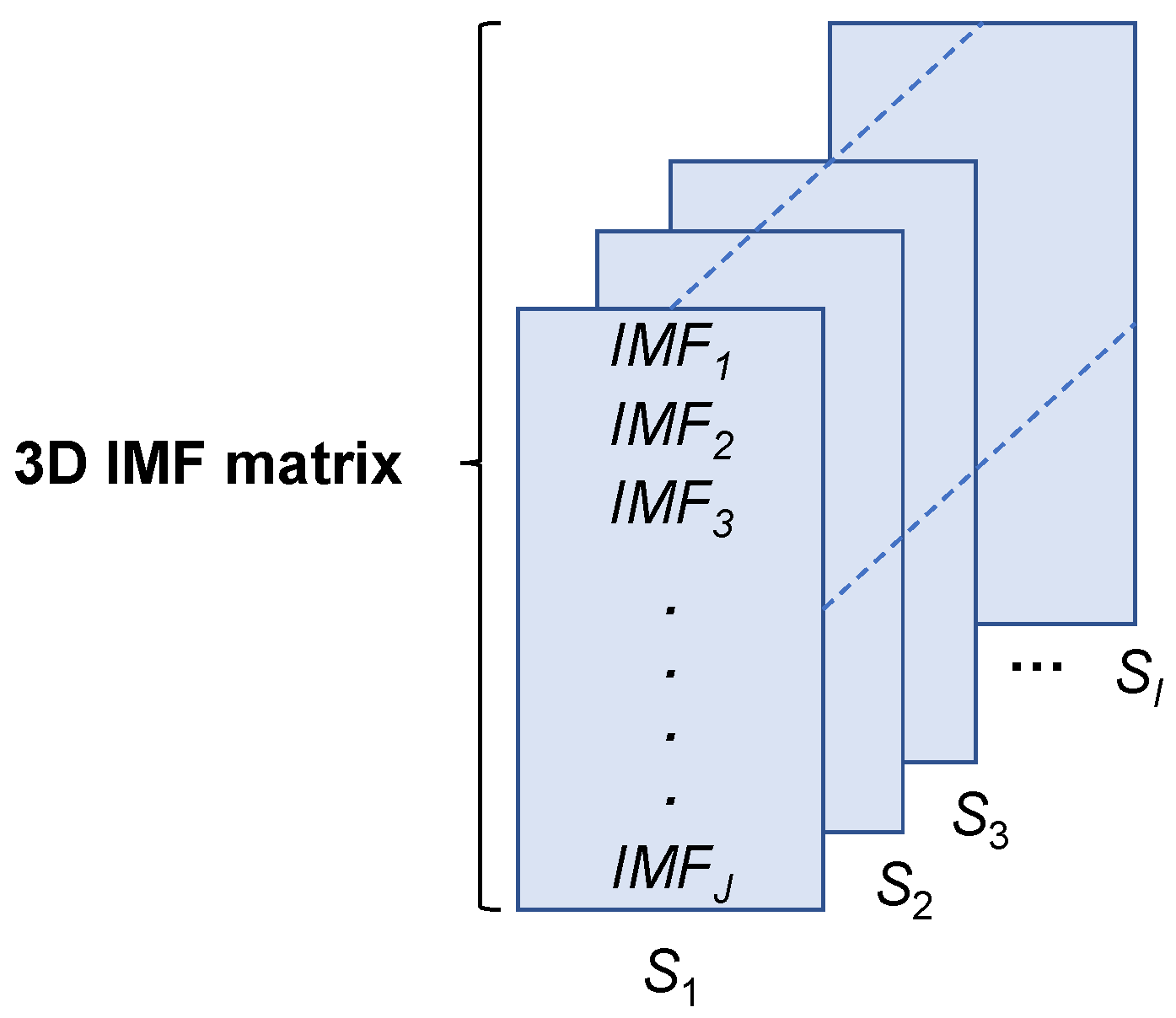
In this paper, we propose a real-time vehicle speed prediction method based on a lightweight deep learning model driven by big temporal data. Firstly, the temporal data collected by automotive sensors is decomposed into a feature matrix through empirical mode decomposition (EMD). Then, an informer model based on the attention mechanism is designed to extract key information for learning and prediction. During the iterative training process of the informer, redundant parameters are removed through importance measurement criteria to achieve real-time inference. Finally, experimental results demonstrate that the proposed method achieves superior speed prediction performance through comparing it with state-of-the-art statistical modelling methods and deep learning models. As a regression task, both accuracy and inference time pose challenges to the model. The design of a lightweight model structure helps to achieve vehicle speed prediction while being deployed in practical scenarios. To the best of our knowledge, this is the first attempt to develop and deploy a lightweight deep learning model specifically for temporal feature learning and real-time prediction of vehicle speeds and has been tested on the edge computing device EAIDK-310.
The remainder of the paper is organized as follows. In
Section 2, we describe the related work of vehicle speed automatic prediction from two perspectives: traditional modelling methods and modern deep learning models. In
Section 3, we introduce the lightweight informer model. The experimental results and analysis are reported in
Section 4. Finally, we conclude with achievements, shortcomings, and future research directions in
Section 5.
5. Conclusions
Nowadays, automatic vehicle speed prediction based on artificial intelligence plays a positive role in promoting traffic safety, improving energy efficiency, promoting intelligent transportation, and achieving precise road condition monitoring. It is of great significance for accelerating transportation modernization, improving social and economic benefits, and promoting sustainable development. In this paper, we propose a real-time vehicle speed prediction method based on the lightweight deep learning model informer driven by big temporal data. To the best of our knowledge, this is the first attempt to develop and deploy a lightweight deep learning model specifically for temporal feature learning and real-time prediction of vehicle speeds and has been tested on the edge computing device EAIDK-310. For the regression task of predicting vehicle speed, we have taken into account both the prediction accuracy and inference speed of the deep learning model and verified its effectiveness through the actual collection of time series data in multiple scenarios. Compared with a series of deep learning models, the experimental results illustrate its superiority. Moreover, ablation studies have demonstrated its robustness in practical applications.
In fact, different road conditions, such as highways and rural roads, may lead to completely different driving patterns, which pose even greater challenges to predicting vehicle speed. The introduction of more types of sensor data helps to model driving behaviors under different road conditions. In the future, we plan to test the effectiveness of the proposed method on more complex road conditions (e.g., complex terrain like curves and rugged mountain roads, and varying degrees of traffic congestion) and improve the prediction accuracy of vehicle speeds through introducing more modal sensor data, such as vision and GPS. Detailed information about the test section, such as the speed limits of the area and the speed range recorded for each coordinate, will also be considered during the experimental process.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}