The Development of Data Science: Implications for Education, Employment, Research, and the Data Revolution for Sustainable Development



{kind=link}
{kind=link}
{kind=link}
Abstract
1. Data Science as the Convergence and Bridging of Disciplines
2. Historical Development of Data Science and Some Contemporary Examples of Cross-Disciplinarity
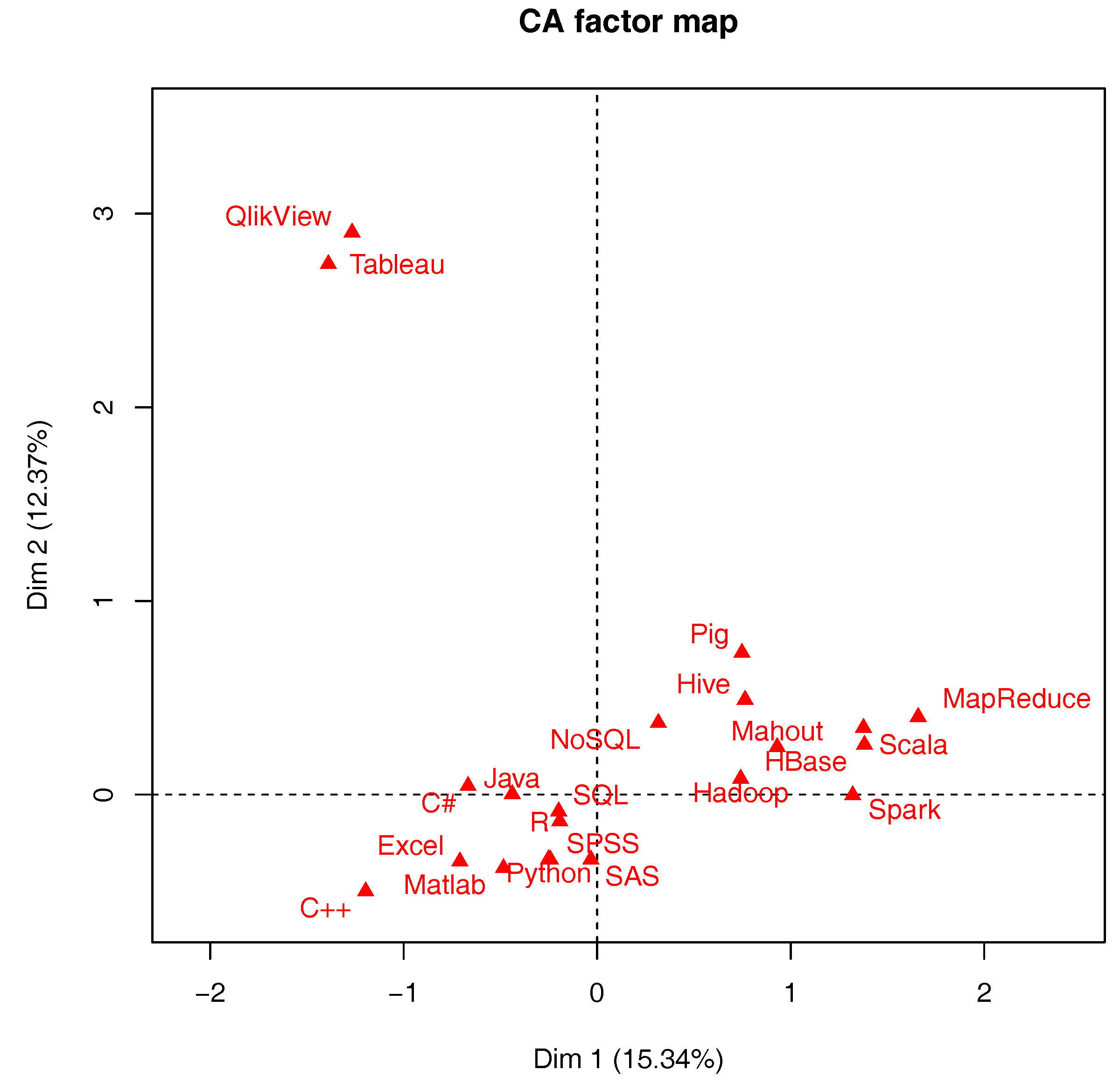
2.1. Historical Prominence of Data Science in Recent Times
- in the design of an overarching semantic layer addressing data and analysis tools,
- in identifying suitable data sources and data patterns that correspond to the appearance of structured and unstructured data, and
- in the management of the information discovery lifecycle and discovery teams.
2.2. Practical Association of Disciplines and Sub-Disciplines
3. Open Data, Reproducibility and the Data Curation Challenge
4. Integration of Data and Analytics: Context of Applications
5. Short Review of Contemporary Data Science in Education and in Employment
5.1. Teaching and Learning for Data Science
5.2. Employment Requirements in Data Science
6. Data Science Methodology to Address: Selection Bias, Scale and Aggregation Effects, and Qualitative Evaluation of Decision-Making Impact
7. Benefits of Very High Profiling of Data Science
8. Important New Research Challenges from Data
9. Information Space Theory for Big Data Analytics in Internet of Things and Smart Environments
Context, Situation Theory, Completion Diagrams
10. Conclusions
Author Contributions
Conflicts of Interest
References
- McKinsey Global Institute. The Age of Analytics: Competing in a Data-Driven World. Research Report. (under “Our Research”, “Technology and Innovation”). 2016, p. 136. Available online: www.mckinsey.com/mgi (accessed on 18 June 2018).
- Mahabal, A.A.; Crichton, D.; Djorgovski, S.G.; Law, E.; Hughes, J.S. From sky to earth: Data Science methodology transfer. In Proceedings of the International Astronomical Union, Sydney, Australia, 17 July 2017; Brescia, M., Djorgovski, S.G., Feigelson, E., Long, G., Cavuoti, S., Eds.; Cambridge University Press: Cambridge, UK, 2017; pp. 17–26. Available online: https://arxiv.org/pdf/1701.01775.pdf (accessed on 18 June 2018).
- Murtagh, F. Data Science Foundations: Geometry and Topology of Complex Hierarchic Systems and Big Data Analytics; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Hayashi, C. What is Data Science? Fundamental concepts and a heuristic example. In Data Science, Classification, and Related Methods; Hayashi, C., Yajima, K., Bock, H.H., Ohsumi, N., Tanaka, Y., Baba, Y., Eds.; Springer: Heidelberg, Germany, 1998; pp. 40–51. [Google Scholar]
- Ohsumi, N. From data analysis to data science. In Data Analysis, Classification, and Related Methods; Kiers, H.A.L., Rasson, J.-P., Groenen, P.J.F., Schader, M., Eds.; Springer: Heidelberg, Germany, 2000; pp. 329–334. [Google Scholar]
- Escoufier, Y.; Fichet, B.; Lebart, L.; Hayashi, C.; Ohsumi, N.; Baba, Y. (Eds.) Data Science and Its Applications; Academic Press: Tokyo, Japan, 1995. [Google Scholar]
- Cao, L. Data science: A comprehensive overview. ACM Comput. Surv. 2017, 50, 43:1–43:42. [Google Scholar] [CrossRef]
- Ueno, M. As the oldest journal of Data Science. Behaviormetrika 2017, 44, 1–2. [Google Scholar] [CrossRef]
- Englmeier, K.; Murtagh, F. Data Scientist—Manager of the discovery lifecycle. In Proceedings of the 6th International Conference on Data Science, Technology and Applications—Volume 1: DATA, Madrid, Spain, 26–28 July 2017; pp. 133–140. [Google Scholar]
- Coombs, C.H. A Theory of Data; Wiley: Hoboken, NJ, USA, 1964. [Google Scholar]
- Japec, L.; Kreuter, F.; Berg, M.; Biemer, P.; Decker, P.; Lampe, C.; Lane, J.; O’Neil, C.; Usher, A. AAPOR Report on Big Data; Technical Report; American Association for Public Opinion Research (AAPOR): Oakbrook Terrace, IL, USA, 2015; 50p, Available online: http://www.aapor.org/Education-Resources/Reports/Big-Data.aspx (accessed on 18 June 2018).
- Abbany, Z. A Public Transport Model Built on Open Data, News Article. Available online: http://www.dw.com/en/a-public-transport-model-built-on-open-data/a-41546053 (accessed on 27 November 2017).
- Darabi, A. The UK’s Next Census Will Be Its Last—Here’s Why, News Report. Available online: https://apolitical.co/solution_article/uks-next-census-will-last-heres (accessed on 5 December 2017).
- Murtagh, F.; Orlov, M.; Mirkin, B. Qualitative judgement of research impact: Domain taxonomy as a fundamental framework for judgement of the quality of research. J. Classif. 2018, 35, 5–28. [Google Scholar] [CrossRef]
- Hand, D. Statistical challenges of administrative and transaction data. J. R. Stat. Soc. Ser. A 2018, 181, 1–24. [Google Scholar] [CrossRef]
- Anderson, C. The End of Theory: The Data Deluge Makes The Scientific Method Obsolete, Wired Magazine. Available online: http://www.wired.com/science/discoveries/magazine/16-07/pb-theory (accessed on 16 July 2008).
- Murtagh, F. Origins of modern data analysis linked to the beginnings and early development of computer science and information engineering. Electron. J. Hist. Probab. Stat. 2008, 4, 26. [Google Scholar]
- Englmeier, K.; Murtagh, F. What can we expect from data scientists? J. Theor. Appl. Electron. Commer. Res. 2017, 12, i–iv. [Google Scholar]
- Murtagh, F.; Farid, M. Contextualizing Geometric Data Analysis and Related Data Analytics: A Virtual Microscope for Big Data Analytics. J. Interdiscip. Methodol. Issues Sci. Spec. Issue Digit. Contex. 2017, 3, 1–19. [Google Scholar]
- Allin, P.; Hand, D.J. New statistics for old?—Measuring the wellbeing of the UK. J. R. Stat. Soc. Ser. A 2017, 180, 3–43. [Google Scholar] [CrossRef]
- Wessel, M. You Don’t Need Big Data—You Need the Right Data. Harvard Business Review. 3 November 2016. Available online: https://hbr.org/2016/11/you-dont-need-big-data-you-need-the-right-data (accessed on 18 June 2018).
- Jobs Rated Report 2017: Ranking 200 Jobs. Available online: https://www.careercast.com/jobs-rated/2017-jobs-rated-report (accessed on 18 June 2018).
- Kei Daniel, B. Reimaging research methodology as Data Science. Big Data Cogn. Comput. 2018, 2. [Google Scholar] [CrossRef]
- Press, G. Graduate Programs in Big Data Analytics and Data Science. (Last updated: October 26, 2017). Available online: https://whatsthebigdata.com/2012/08/09/graduate-programs-in-big-data-and-data-science (accessed on 18 June 2018).
- NewVantage Partners (NVP). Big Data Business Impact: Achieving Business Results through Innovation and Disruption. Big Data Executive Survey 2017, Executive Summary of Findings. 2017, p. 16. Available online: http://newvantage.com/wp-content/uploads/2017/01/Big-Data-Executive-Survey-2017-Executive-Summary.pdf (accessed on 18 June 2018).
- Hayes, B. Empirically-Based Approach to Understanding the Structure of Data Science. Business over Broadway; Seattle, WA, USA, 18 January 2016. Available online: http://businessoverbroadway.com/empirically-based-approach-to-understanding-the-structure-of-data-science (accessed on 18 June 2018).
- Murtagh, F. Security and ethics in Big Data: Analytical foundations for surveys. Arch. Data Sci. 2018. submitted. [Google Scholar]
- Hand, D. The Dangers of Not Seeing What Isn’t There: Selection Bias in Statistical Modelling. In Proceedings of the ISA Gosset Lecture, Dublin, Ireland, 6 April 2017; Royal Irish Academy: Dublin, Ireland, 2017. [Google Scholar]
- Keiding, N.; Louis, T.A. Perils and Potentials of Self-Selected Entry to Epidemiological Studies and Surveys. J. R. Stat. Soc. Ser. A 2016, 179, 319–376. [Google Scholar] [CrossRef]
- O’Neill, C. Weapons of Math Destruction; Crown/Archetype: Danvers, MA, USA, 2016. [Google Scholar]
- Le Roux, B.; Lebaron, F. Idées-clefs de l’analyse géométrique des données. In La Méthodologie de Pierre Bourdieu en Action: Espace Culturel, Espace Social et Analyse des Données; Lebaron, F., Le Roux, B., Eds.; Dunod: Paris, France, 2015; pp. 3–20. [Google Scholar]
- Murtagh, F.; Pianosi, M.; Bull, R. Tracking and mapping Habermas’s communicative action: A case study using Twitter social media. Qual. Quant. 2016, 50, 1675–1694. [Google Scholar] [CrossRef]
- United Nations. “Open Universe” Proposal, an Initiative Under the Auspices of the Committee on the Peaceful Uses of Outer Space For Expanding Availability of and Accessibility to Open Source Space Science Data. In Proceedings of the Committee on the Peaceful Uses of Outer Space, 59th Sesssion, Vienna, Austria, 8–17 June 2016; Available online: http://www.unoosa.org/res/oosadoc/data/documents/2016/aac_1052016crp/aac_1052016crp_6_0_html/AC105_2016_CRP06E.pdf (accessed on 18 June 2018).
- Wilkinson, M.D.; Dumontier, M.; jan Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Devlin, K. Logic and Information; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Devlin, K. A Uniform Framework for Describing and Analyzing the Modern Battlefield, US Army Feasibility Study Report. 2011. Available online: http://web.stanford.edu/~kdevlin/Papers/Army_report_0711.pdf (accessed on 18 June 2018).
- Devlin, K.; Rosenberg, D. Language at Work: Analyzing Communication Breakdown in the Workplace to Inform Systems Design; CSLI Publications: Stanford, CA, USA, 1996. [Google Scholar]
- Devlin, K.; Rosenberg, D. Information in the study of human interaction. In Handbook of the Philosophy of Information; Adriaana, P., van Benthem, J., Gabbay, D., Thagard, P., Woods, J., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; pp. 685–710. Available online: http://web.stanford.edu/~kdevlin/Papers/HPI_SocialSciences.pdf (accessed on 18 June 2018).
- Barwise, J.; Perry, J. Situations and Attitudes; CSLI Publications: Stanford, CA, USA, 1999. [Google Scholar]
- Sustainable Accommodation in the New Economy (SANE). European Union Framework 5 Project. Result in Brief. 2005. Available online: https://cordis.europa.eu/project/rcn/58059_en.html (accessed on 18 June 2018).
- Rosenberg, D.; Foley, S.; Lievonen, M.; Kammas, S.; Crisp, M.J. Interaction spaces in computer-mediated communication. AI Soc. 2005, 19, 22–33. [Google Scholar] [CrossRef]
- Walkowski, S.; Doerner, R.; Lievonen, M.; Rosenberg, D. Using Game controller for Relaying Deictic Gestures in Computer Mediated Communication. Int. J. Hum.-Comput. Stud. 2011, 69, 362–374. [Google Scholar] [CrossRef]



© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murtagh, F.; Devlin, K. The Development of Data Science: Implications for Education, Employment, Research, and the Data Revolution for Sustainable Development. Big Data Cogn. Comput. 2018, 2, 14. https://doi.org/10.3390/bdcc2020014
Murtagh F, Devlin K. The Development of Data Science: Implications for Education, Employment, Research, and the Data Revolution for Sustainable Development. Big Data and Cognitive Computing. 2018; 2(2):14. https://doi.org/10.3390/bdcc2020014
Chicago/Turabian StyleMurtagh, Fionn, and Keith Devlin. 2018. "The Development of Data Science: Implications for Education, Employment, Research, and the Data Revolution for Sustainable Development" Big Data and Cognitive Computing 2, no. 2: 14. https://doi.org/10.3390/bdcc2020014
APA StyleMurtagh, F., & Devlin, K. (2018). The Development of Data Science: Implications for Education, Employment, Research, and the Data Revolution for Sustainable Development. Big Data and Cognitive Computing, 2(2), 14. https://doi.org/10.3390/bdcc2020014