Discourse with Visual Health Data: Design of Human-Data Interaction


Abstract

1. Introduction
2. Background
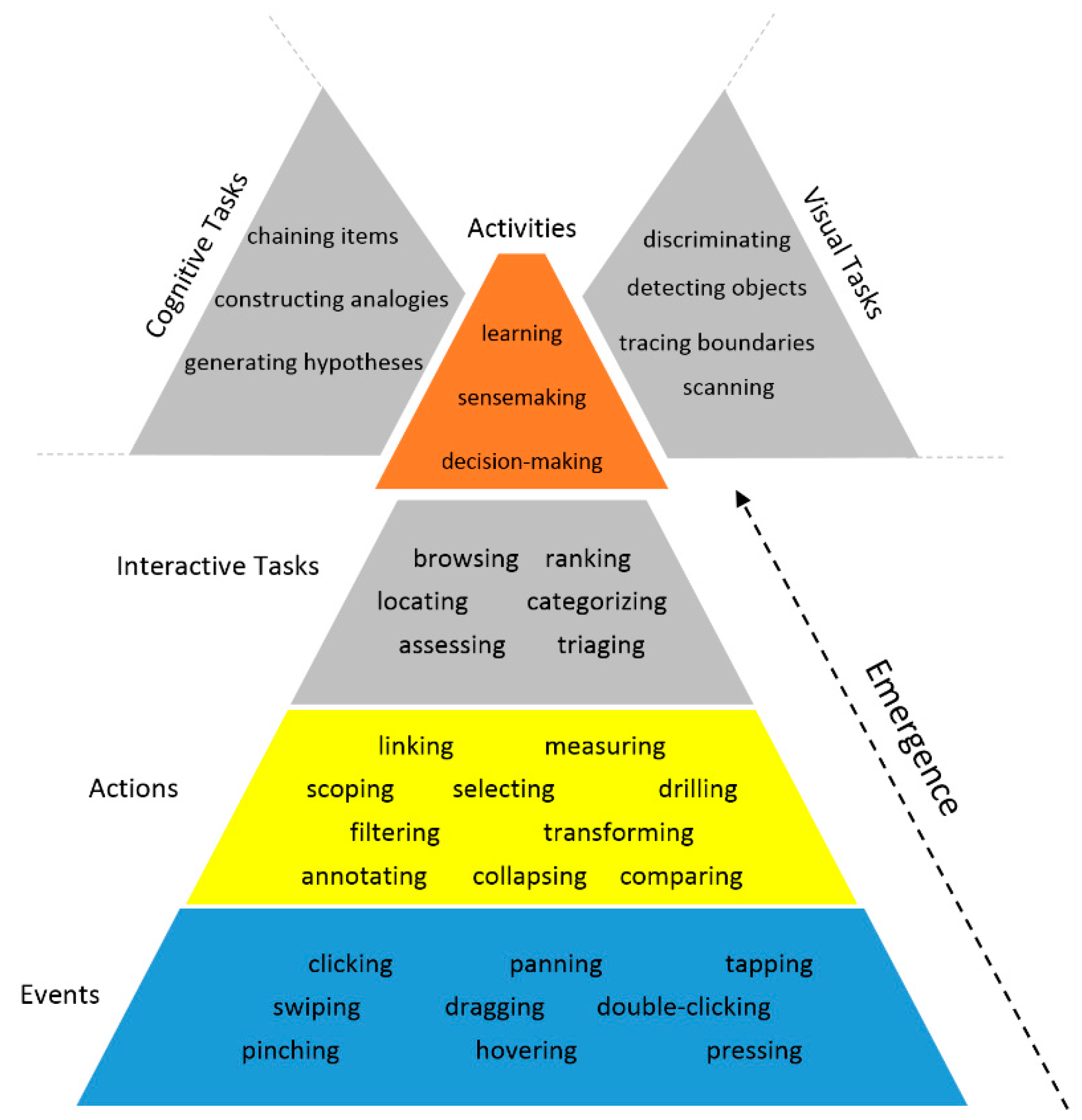
2.1. Data-Driven Tasks
2.2. Visualization Tools
2.3. Interaction
3. Elements of Theoretical Framework
3.1. Conceptualization of the Human-Data Discourse
3.2. Quality of Interaction
- o
- Appearance: aesthetic features (e.g., color and texture) by which data items are encoded in a visualization
- o
- Complexity: degree to which encoded data items exhibit elaborateness and intricacy in terms of their quantity and interrelationships in a visualization
- o
- Configuration: manner of arrangement, organization, and ordering of data items that are encoded in a visualization
- o
- Density: degree to which data items are encoded compactly in a visualization
- o
- Interiority: degree to which data items are latent and remain hidden below the surface of a visualization but are potentially accessible and encodable
- o
- Type: form of a visualization in which data items are encoded
4. Systematic Design of Interactions
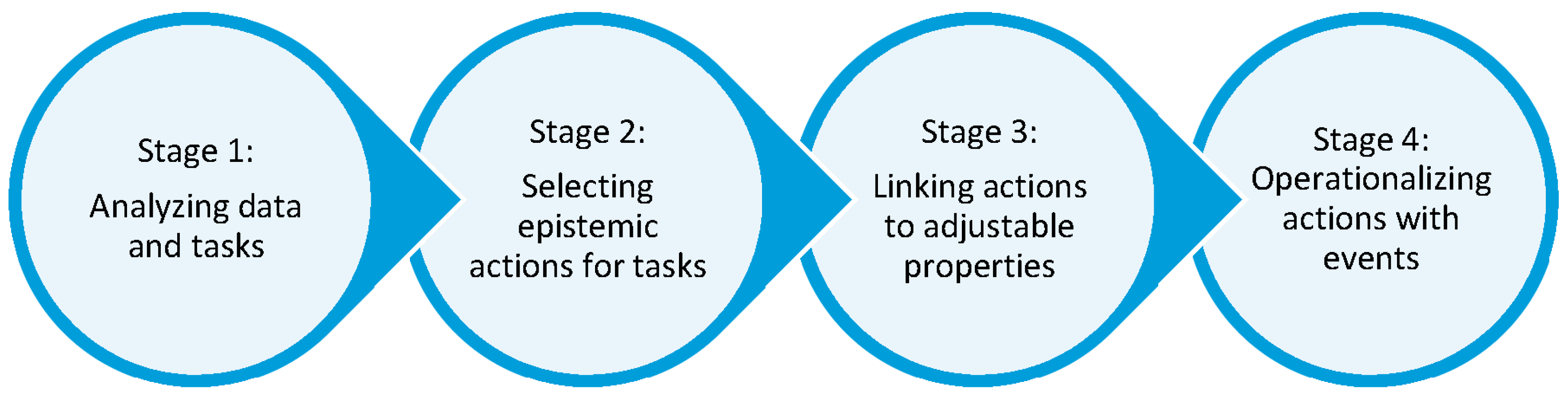
4.1. Process for Designing Interaction for Visualizations
4.2. An Illustrative Example of the Design Process
5. Scenarios
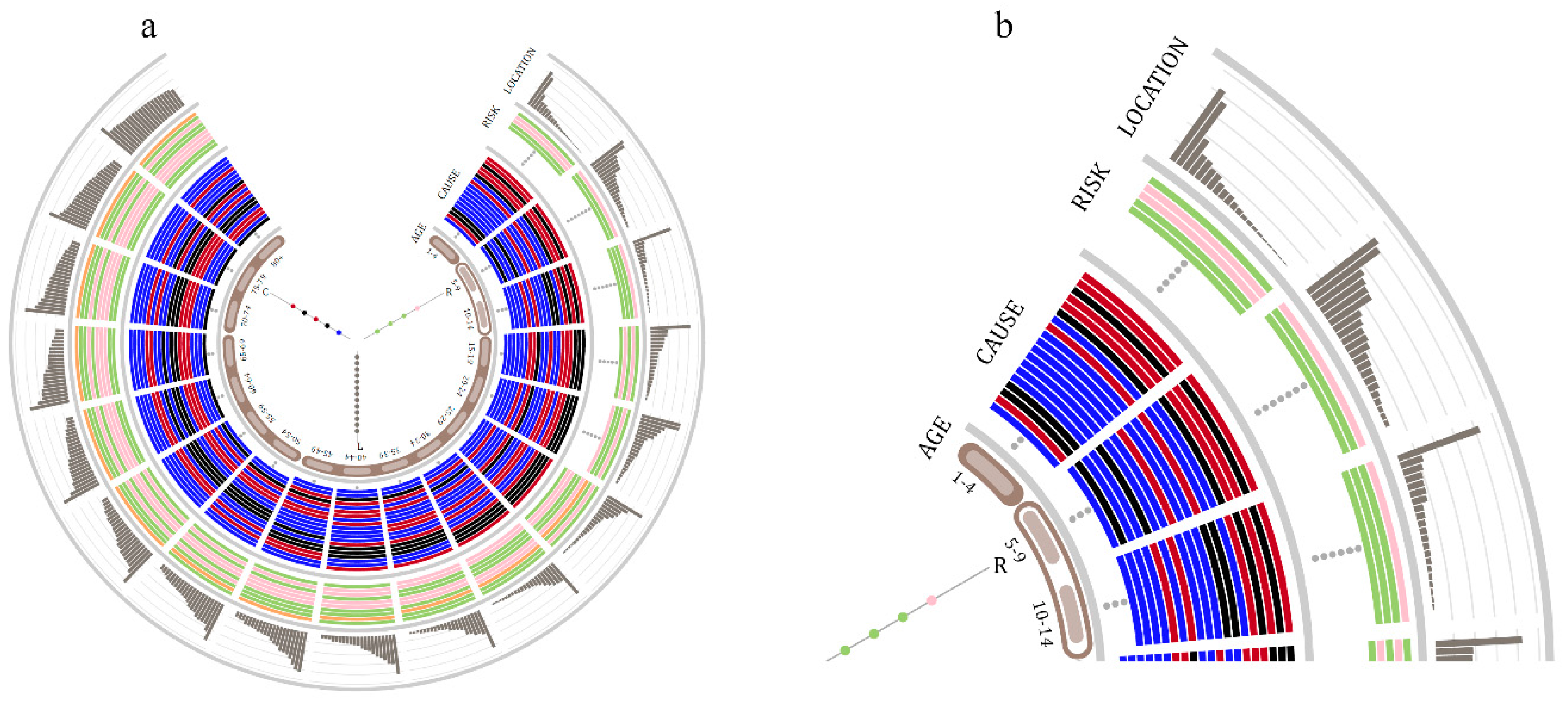
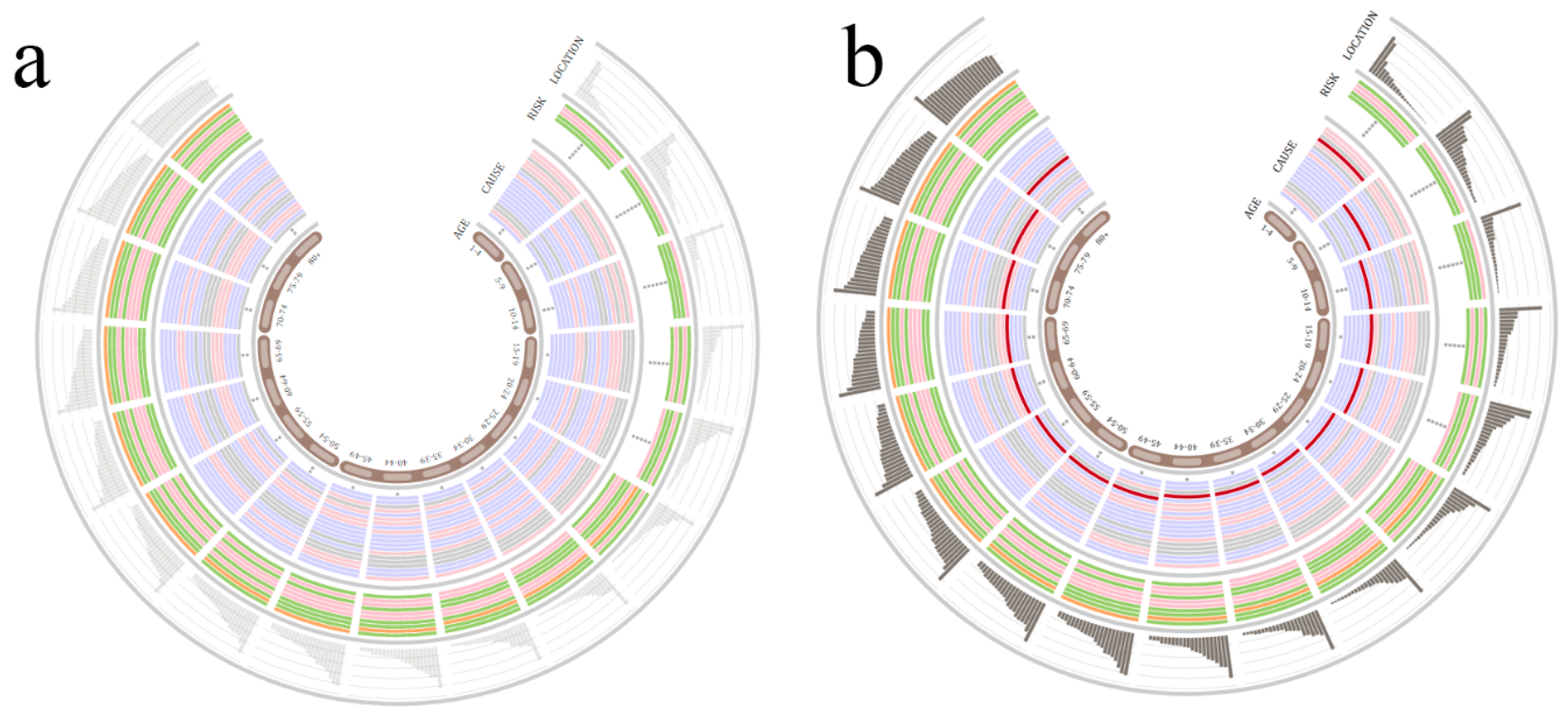
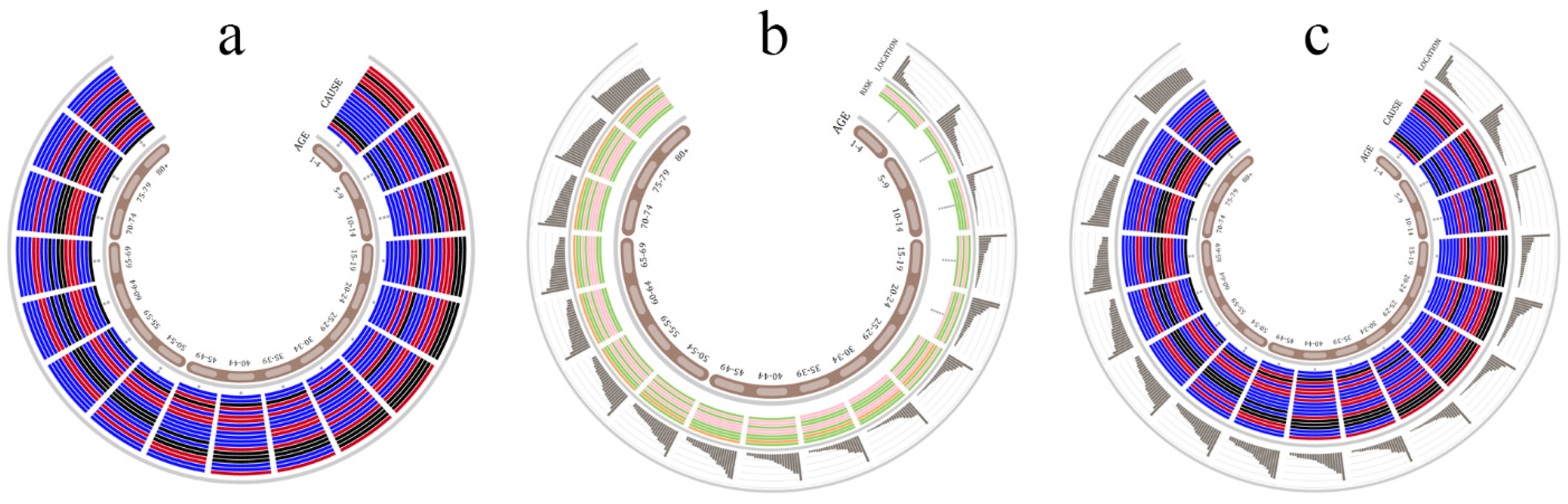
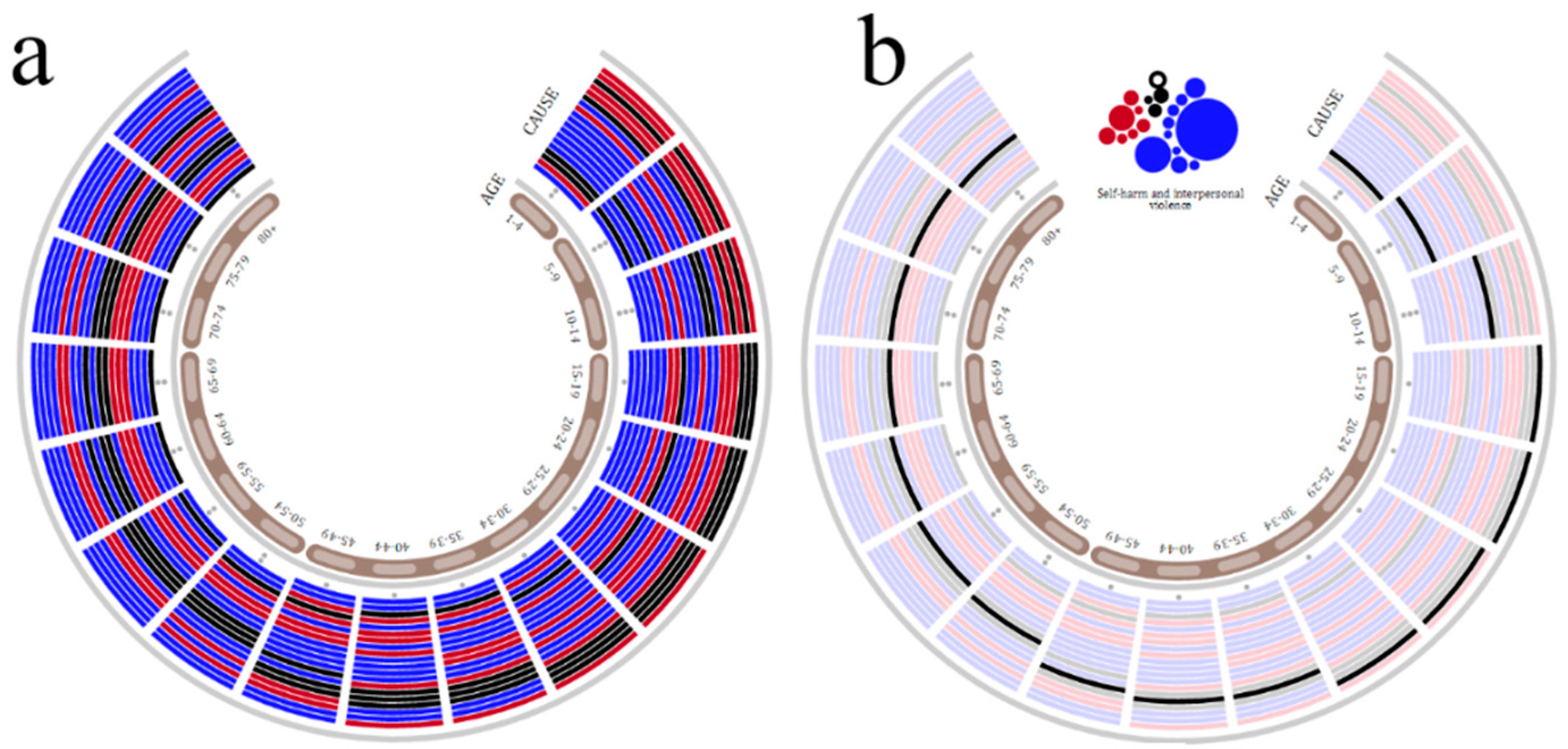
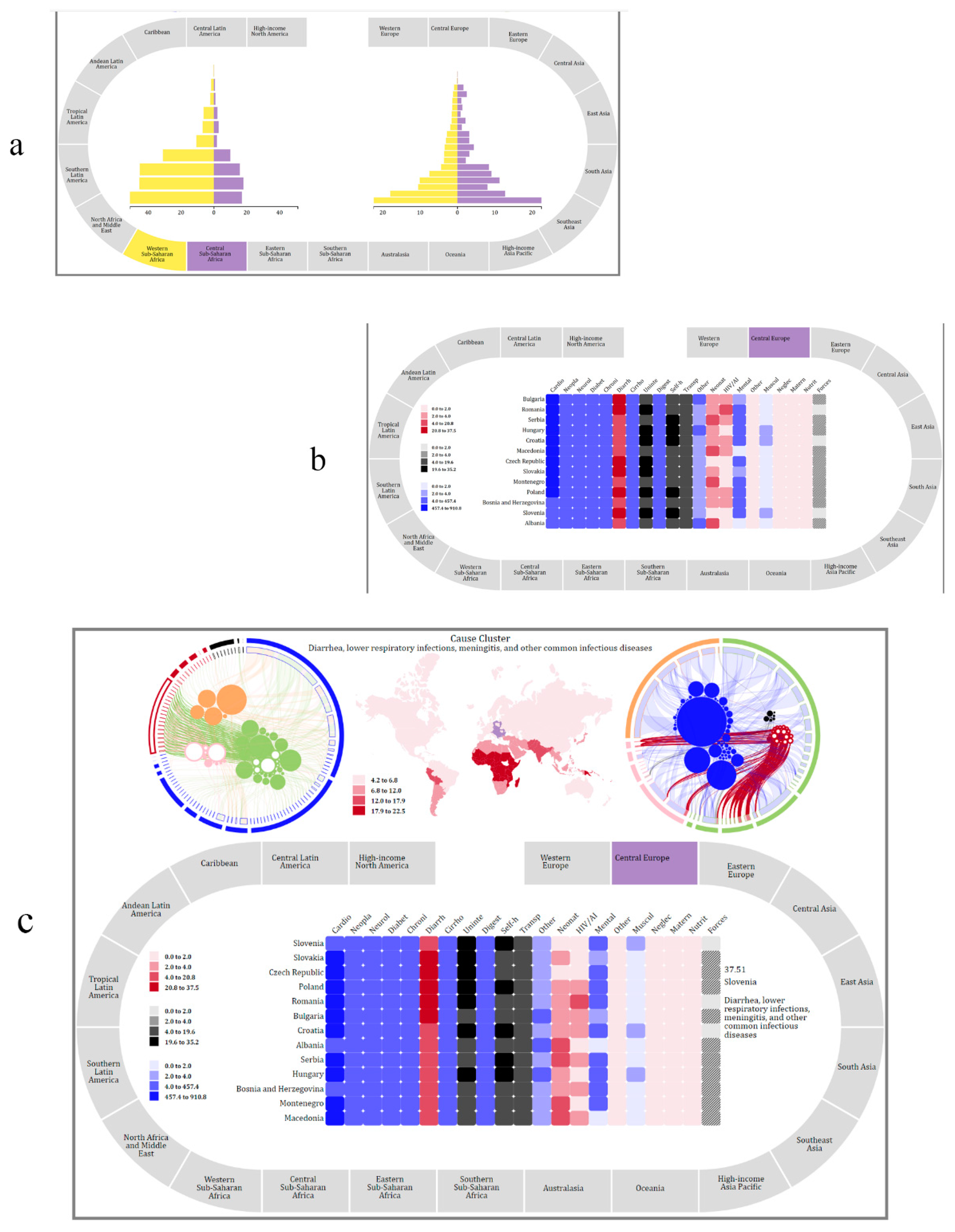
5.1. Demography Visualization
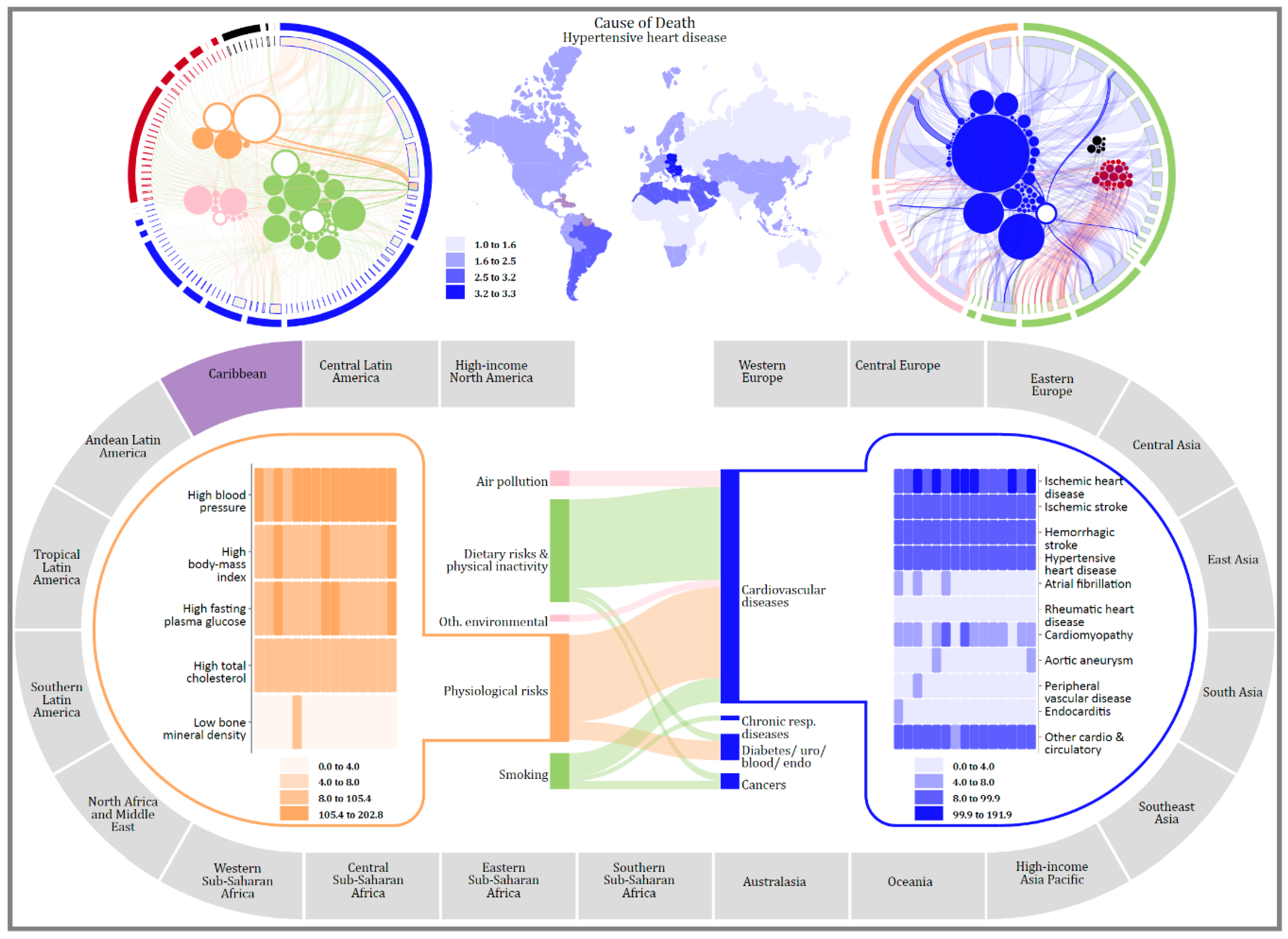
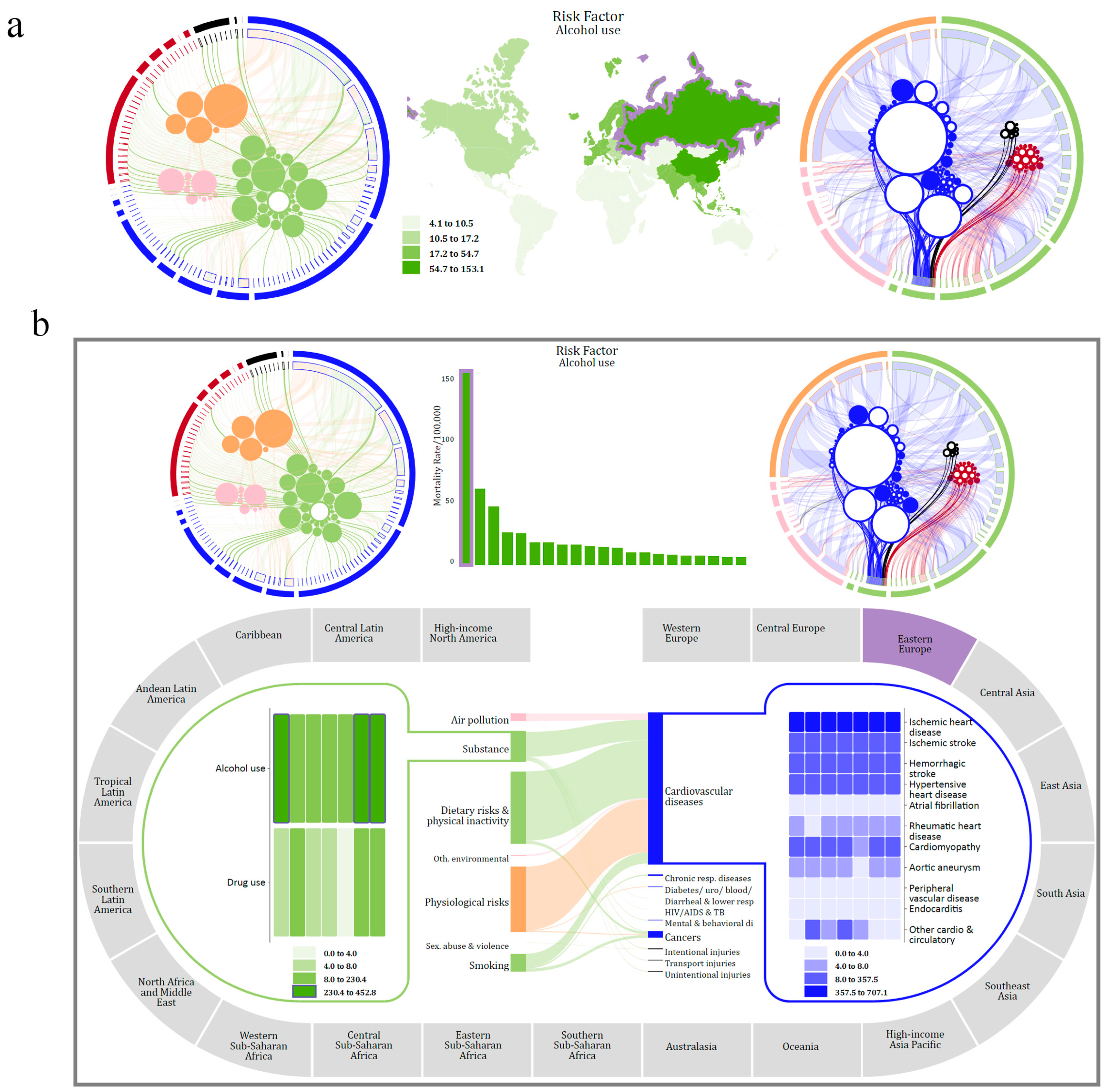
5.2. Geography Visualization
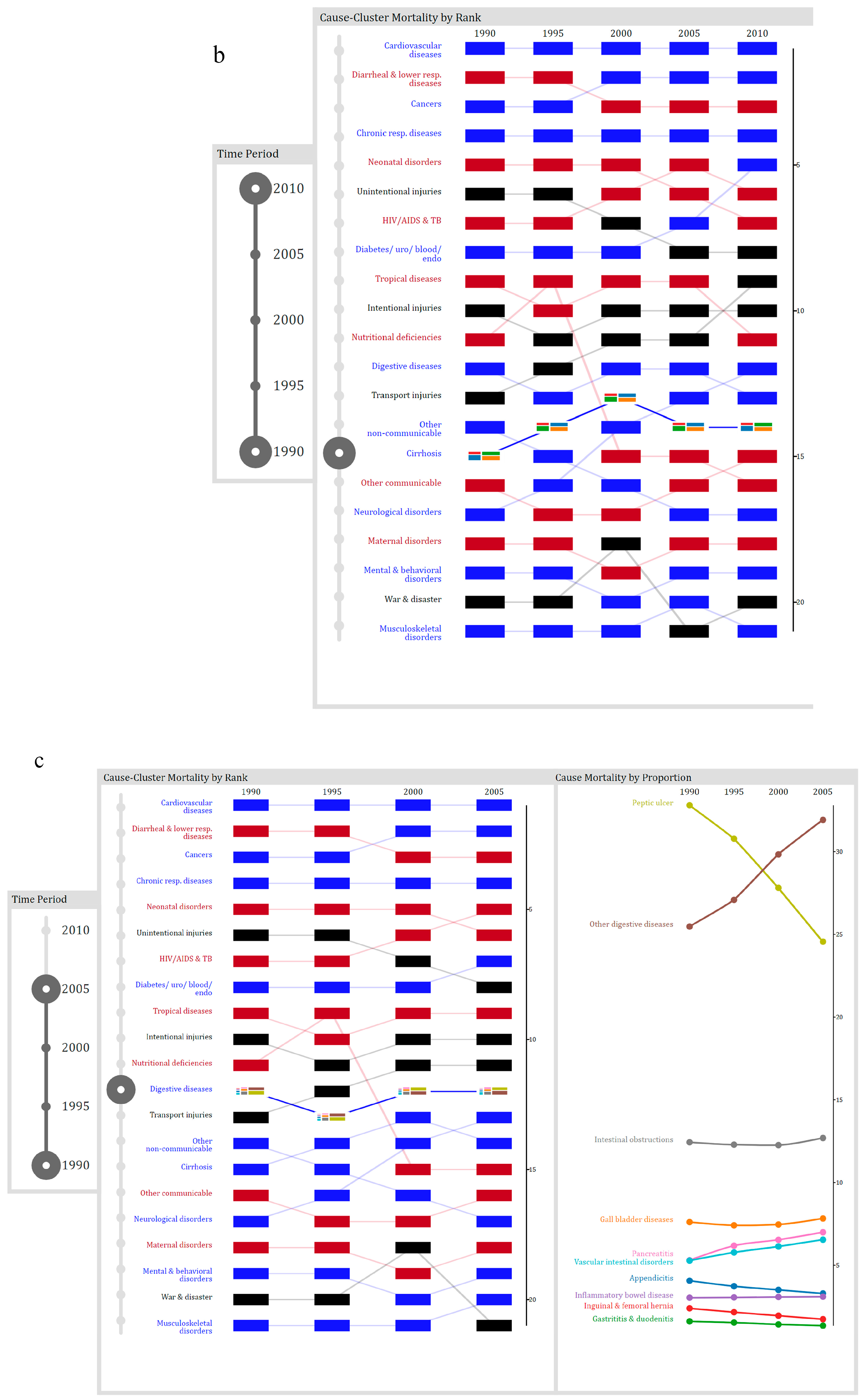
5.3. Chronology Visualization
- Between 1990 and 2010, which cause-cluster increased in rank the most?
- Over the 20-year period, what was the highest rank for liver cirrhosis?
- Between 1990 and 2005, which digestive diseases significantly decreased in proportion?
- Which region of the world had the lowest mortality rate from cardiovascular and circulatory diseases between 1995 and 2005?
6. User Study
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Kruse, C.S.; Goswamy, R.; Raval, Y.; Marawi, S. Challenges and Opportunities of Big Data in Health Care: A Systematic Review. JMIR Med. Inform. 2016, 4, e38. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Wu, M.; Gopukumar, D.; Zhao, Y. Big Data Application in Biomedical Research and Health Care: A Literature Review. Biomed. Inform. Insights 2016, 8, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Gotz, D.; Borland, D. Data-Driven Healthcare: Challenges and Opportunities for Interactive Visualization. IEEE Comput. Graph. Appl. 2016, 36, 90–96. [Google Scholar] [CrossRef] [PubMed]
- White, S. A Review of Big Data in Health Care: Challenges and Opportunities. Open Access Bioinform. 2014, 6, 13. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big Data Analytics in Healthcare: Promise and Potential. Heal. Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Viceconti, M.; Hunter, P.; Hose, R. Big Data, Big Knowledge: Big Data for Personalized Healthcare. IEEE J. Biomed. Heal. Inform. 2015, 19, 1209–1215. [Google Scholar] [CrossRef] [PubMed]
- Ola, O.; Sedig, K. The Challenge of Big Data in Public Health: An Opportunity for Visual Analytics. Online J. Public Health Inform. 2014, 5, 223. [Google Scholar] [PubMed]
- Pretorius, A.J.; Khan, I.A.; Errington, R.J. A Survey of Visualization for Live Cell Imaging. Comput. Graph. Forum 2016, 36, 46–63. [Google Scholar] [CrossRef]
- Fisher, D.; DeLine, R.; Czerwinski, M.; Drucker, S. Interactions with Big Data Analytics. Interactions 2012, 19, 50. [Google Scholar] [CrossRef]
- Pike, W.A.; Stasko, J.; Chang, R.; O′Connell, T.A. The Science of Interaction. Inf. Vis. 2009, 8, 263–274. [Google Scholar] [CrossRef]
- Bikakis, N.; Athens, N.T.U. Exploration and Visualization in the Web of Big Linked Data: A Survey of the State of the Art—Semantic Scholar. arXiv, 2016; arXiv:1601.08059. [Google Scholar]
- Katsis, Y.; Koulouris, N.; Papakonstantinou, Y.; Patrick, K. Assisting Discovery in Public Health. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, HILDA’17, Chicago, IL, USA, 14–19 May 2017; ACM Press: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Kaufman, D.R.; Kannampallil, T.G.; Patel, V.L. Cognition and Human Computer Interaction in Health and Biomedicine; Springer International Publishing: Cham, Switzerland, 2015; pp. 9–34. [Google Scholar]
- Huang, W.; Eades, P.; Hong, S.-H. Measuring Effectiveness of Graph Visualizations: A Cognitive Load Perspective. Inf. Vis. 2009, 8, 139–152. [Google Scholar] [CrossRef]
- Torres, S.O.S.O.; Eicher-Miller, H.; Boushey, C.; Ebert, D.; Maciejewski, R. Applied Visual Analytics for Exploring the National Health and Nutrition Examination Survey. In Proceedings of the IEEE 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 1855–1863. [Google Scholar]
- Ko, S.; Cho, I.; Afzal, S.; Yau, C.; Chae, J.; Malik, A.; Beck, K.; Jang, Y.; Ribarsky, W.; Ebert, D.S. A Survey on Visual Analysis Approaches for Financial Data. Comput. Graph. Forum 2016, 35, 599–617. [Google Scholar] [CrossRef]
- Parsons, P.; Sedig, K. Adjustable Properties of Visual Representations: Improving the Quality of Human-Information Interaction. J. Assoc. Inf. Sci. Technol. 2014, 65, 455–482. [Google Scholar] [CrossRef]
- Heer, J. Interactive Visualization of Big Data. Available online: http://radar.oreilly.com/2013/12/interactive-visualization-of-big-data.html (accessed on 22 February 2017).
- Che, D.; Safran, M.; Peng, Z. From Big Data to Big Data Mining: Challenges, Issues, and Opportunities. In Proceedings of the International Conference on Database Systems for Advanced Applications, Wuhan, China, 22–25 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–15. [Google Scholar]
- Endert, A.; Ribarsky, W.; Turkay, C.; Wong, B.L.W.; Nabney, I. The State of the Art in Integrating Machine Learning into Visual. Comput. Graph. Forum 2017, 36, 458–486. [Google Scholar] [CrossRef]
- Tominski, C. Interaction for Visualization; Morgan & Claypool Publishers: San Rafael, CA, USA, 2015; Volume 3. [Google Scholar]
- Sedig, K.; Parsons, P.; Dittmer, M.; Ola, O. Beyond Information Access: Support for Complex Cognitive Activities in Public Health Informatics Tools. Online J. Public Health Inform. 2012, 4. [Google Scholar] [CrossRef] [PubMed]
- Sedig, K.; Sumner, M. Characterizing Interaction with Visual Mathematical Representations. Int. J. Comput. Math. Learn. 2006, 11, 1–55. [Google Scholar] [CrossRef]
- Murray, C.J.L.; Vos, T.; Lozano, R.; Naghavi, M.; Flaxman, A.D.; Michaud, C.; Ezzati, M.; Shibuya, K.; Salomon, J.A.; Abdalla, S.; et al. Disability-Adjusted Life Years (DALYs) for 291 Diseases and Injuries in 21 Regions, 1990–2010: A Systematic Analysis for the Global Burden of Disease Study 2010. Lancet 2012, 380, 2197–2223. [Google Scholar] [CrossRef]
- Aigner, W. Understanding the Role and Value of Interaction: First Steps. In Proceedings of the International Workshop on Visual Analytics; Miksch, S., Santucci, G., Eds.; The Eurographics Association: Geneve, Switzerland, 2011. [Google Scholar]
- Dou, W.; Ziemkiewicz, C.; Harrison, L.; Jeong, D.H.; Ribarsky, W.; Wang, X.; Chang, R. Toward a Deeper Understanding of the Relationship between Interaction Constraints and Visual Isomorphs. Inf. Vis. 2012, 11, 222–236. [Google Scholar] [CrossRef]
- Endert, A.; Chang, R.; North, C.; Zhou, M. Semantic Interaction: Coupling Cognition and Computation through Usable Interactive Analytics. IEEE Comput. Graph. Appl. 2015, 35, 94–99. [Google Scholar] [CrossRef]
- Sedig, K.; Parsons, P. Interaction Design for Cognitive Activity Support Tools: A Pattern-Based Taxonomy. AIS Trans. Hum.-Comput. Interact. 2013, 5, 84–133. [Google Scholar] [CrossRef]
- Thomas, J.; Cook, K. Illuminating the Path: The Research and Development Agenda for Visual Analytics; Thomas, J., Cook, K.A., Eds.; IEEE Computer Society: Los Alamitos, CA, USA, 2005. [Google Scholar]
- Purchase, H.C.; Andrienko, N.; Jankun-Kelly, T.; Ward, M. Theoretical Foundations of Information Visualization. In Information Visualization: Human-Centered Issues and Perspectives (Lecture Notes in Computer Science); Springer: Berlin, Germany, 2008; Volume 4950, pp. 46–64. [Google Scholar]
- Sedig, K.; Parsons, P.C.; Dittmer, M.; Haworth, R. Human-Centered Interactivity of Visualization Tools: Micro- and Macro-Level Considerations. In Handbook of Human Centric Visualization; Huang, T., Ed.; Springer: New York, NY, USA, 2013; pp. 717–743. [Google Scholar]
- Turner, A.M.; Stavri, Z.; Revere, D.; Altamore, R. From the Ground up: Information Needs of Nurses in a Rural Public Health Department in Oregon. J. Med. Libr. Assoc. 2008, 96, 335–342. [Google Scholar] [CrossRef] [PubMed]
- Carroll, L.N.; Au, A.P.; Detwiler, L.T.; Fu, T.-C.; Painter, I.S.; Abernethy, N.F. Visualization and Analytics Tools for Infectious Disease Epidemiology: A Systematic Review. J. Biomed. Inform. 2014, 51C, 287–298. [Google Scholar] [CrossRef] [PubMed]
- Folorunso, O.; Ogunseye, O.S. Challenges in the Adoption of Visualization System: A Survey. Kybernetes 2008, 37, 1530–1541. [Google Scholar] [CrossRef]
- Ola, O.; Sedig, K. Beyond Simple Charts: Design of Visualizations for Big Health Data. Online J. Public Health Inform. 2016, 8, 195. [Google Scholar] [CrossRef] [PubMed]
- Wurman, R.S. Information Anxiety, 1st ed.; Doubleday: New York, NY, USA, 1989. [Google Scholar]
- Sedig, K.; Parsons, P. Design of Visualizations for Human-Information Interaction: A Pattern-Based Framework. Synth. Lect. Vis. 2016, 4, 1–185. [Google Scholar] [CrossRef]
- Parsons, P.; Sedig, K. Distribution of Information Processing While Performing Complex Cognitive Activities with Visualization Tools. In Handbook of Human Centric Visualization; Huang, T., Ed.; Springer: New York, NY, USA, 2013; pp. 639–715. [Google Scholar]
- Knauff, M.; Wolf, A.G. Complex Cognition: The Science of Human Reasoning, Problem-Solving, and Decision-Making. Cogn. Process. 2010, 11, 99–102. [Google Scholar] [CrossRef] [PubMed]
- Shneiderman, B.; Plaisant, C.; Hesse, B.W. Improving Healthcare with Interactive Visualization. Computer 2013, 46, 58–66. [Google Scholar] [CrossRef]
- Sedig, K.; Parsons, P.C.; Babanski, A. Towards a Characterization of Interactivity in Visual Analytics. J. Multimed. Process. 2012, 3, 12–28. [Google Scholar]
- Parsons, P.; Sedig, K.; Didandeh, A.; Khosravi, A. Interactivity in Visual Analytics: Use of Conceptual Frameworks to Support Human-Centered Design of a Decision-Support Tool. In Proceedings of the IEEE 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 1138–1147. [Google Scholar]
- Zhang, J. External Representations in Complex Information Processing Tasks. Encycl. Libr. Inf. Sci. 2001, 68, 164–180. [Google Scholar]
- Dou, W.; Ziemkiewicz, C.; Harrison, L.; Jeong, D.H.; Ryan, R.; Ribarsky, W.; Wang, X.; Chang, R. Comparing Different Levels of Interaction Constraints for Deriving Visual Problem Isomorphs. In Proceedings of the 2010 IEEE Symposium on Visual Analytics Science and Technology (VAST), Salt Lake City, UT, USA, 25–26 October 2010; pp. 195–202. [Google Scholar]
- Liu, Z.; Stasko, J. Mental Models, Visual Reasoning and Interaction in Information Visualization: A Top-down Perspective. IEEE Trans. Vis. Comput. Graph. 2010, 16, 999–1008. [Google Scholar] [PubMed]
- Kirsh, D. Interaction, External Representation and Sense Making. In Proceedings of the 31st Annual Conference of the Cognitive Science Society, Amsterdam, The Netherlands, 29 July–1 August 2009; pp. 1103–1108. [Google Scholar]
- Ziemkiewicz, C.; Kosara, R. The Shaping of Information by Visual Metaphors. IEEE Trans. Vis. Comput. Graph. 2007, 14, 1269–1276. [Google Scholar] [CrossRef] [PubMed]
- Endert, A.; North, C.; Chang, R.; Zhou, M. Toward Usable Interactive Analytics: Coupling Cognition and Computation. In Proceedings of the KDD 2014 Workshop on Interactive Data Exploration and Analytics (IDEA), New York, NY, USA, 24 August 2014. [Google Scholar]
- Cao, N.; Lin, Y.-R.; Gotz, D.; Du, F. Z-Glyph: Visualizing Outliers in Multivariate Data. Inf. Vis. 2017, 17, 22–40. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Jankowski, P.; Keim, D.A.; Kraak, M.-J.; MacEachren, A.; Wrobel, S. Geovisual Analytics for Spatial Decision Support: Setting the Research Agenda. Int. J. Geogr. Inf. Sci. 2007, 21, 839–857. [Google Scholar] [CrossRef]
- Kamel Boulos, M.N.; Viangteeravat, T.; Anyanwu, M.N.; Ra Nagisetty, V.; Kuscu, E. Web GIS in Practice IX: A Demonstration of Geospatial Visual Analytics Using Microsoft Live Labs Pivot Technology and WHO Mortality Data. Int. J. Health Geogr. 2011, 10, 19. [Google Scholar] [CrossRef] [PubMed]
- Greitzer, F.L.; Noonan, C.F.; Franklin, L.R. Cognitive Foundations for Visual Analytics; Pacific Northwest National Laboratory (PNNL): Richland, WA, USA, 2011. [Google Scholar]
- Elmqvist, N.; Moere, A.V.; Jetter, H.-C.; Cernea, D.; Reiterer, H.; Jankun-Kelly, T. Fluid Interaction for Information Visualization. Inf. Vis. 2011, 10, 327–340. [Google Scholar] [CrossRef]
- Wagner, M.; Fischer, F.; Luh, R.; Haberson, A.; Rind, A.; Keim, D.A.; Aigner, W. A Survey of Visualization Systems for Malware Analysis. In Proceedings of the EG Conference on Visualization (EuroVis)-STARs, Cagliari, Italy, 25–29 May 2015. [Google Scholar]
- Thomas, J.; Cook, K. Visualization Viewpoints a Visual Analytics Agenda. IEEE Comput. Graph. Appl. 2006, 26, 10–13. [Google Scholar] [CrossRef] [PubMed]
- Shneiderman, B. The Eyes Have It: A Task by Data Type Taxonomy for Information Visualizations. In Proceedings of the IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- Amar, R.; Eagan, J.; Stasko, J. Low-Level Components of Analytic Activity in Information Visualization. In Proceedings of the 2005 IEEE Symposium on Information Visualization, Washington, DC, USA, 23–25 October 2005; pp. 111–117. [Google Scholar]
- Gotz, D.; Zhou, M.X. Characterizing Users Visual Analytic Activity for Insight Provenance. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Columbus, OH, USA, 19–24 October 2008; Ebert, D., Ertl, T., Eds.; IEEE: Piscataway Township, NJ, USA, 2008; pp. 123–130. [Google Scholar]
- Yi, J.S.; Kang, Y.A.; Stasko, J.; Jacko, J. Toward a Deeper Understanding of the Role of Interaction in Information Visualization. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1224–1231. [Google Scholar] [CrossRef] [PubMed]
- Brehmer, M.; Munzner, T. A Multi-Level Typology of Abstract Visualization Tasks. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2376–2385. [Google Scholar] [CrossRef] [PubMed]
- Pohl, M.; Wiltner, S.; Miksch, S.; Aigner, W.; Rind, A. Analysing Interactivity in Information Visualisation. KI Künstliche Intelligenz 2012, 26, 151–159. [Google Scholar] [CrossRef]
- Amy, F.; Johnson, T.R.; Thimbleby, H.; Killoran, P. Cognitive Informatics for Biomedicine; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Kirsh, D.; Maglio, P. On Distinguishing Epistemic from Pragmatic Action. Cogn. Sci. A Multidiscip. J. 1994, 18, 513–549. [Google Scholar] [CrossRef]
- Sedig, K.; Parsons, P.; Liang, H.; Morey, J. Supporting Sensemaking of Complex Objects with Visualizations: Visibility and Complementarity of Interactions. Informatics 2016, 3, 20. [Google Scholar] [CrossRef]
- Wang, T.D.; Wongsuphasawat, K.; Plaisant, C.; Shneiderman, B. Extracting Insights from Electronic Health Records: Case Studies, a Visual Analytics Process Model, and Design Recommendations. J. Med. Syst. 2011, 35, 1135–1152. [Google Scholar] [CrossRef] [PubMed]
- Siirtola, H.; Räihä, K.-J. Interacting with Parallel Coordinates. Interact. Comput. 2006, 18, 1278–1309. [Google Scholar] [CrossRef]
- Groth, D.P.; Streefkerk, K. Provenance and Annotation for Visual Exploration Systems. IEEE Trans. Vis. Comput. Graph. 2006, 12, 1500–1510. [Google Scholar] [CrossRef] [PubMed]
- Turner, A.M.; Liddy, E.D.; Bradley, J.; Wheatley, J.A. Modeling Public Health Interventions for Improved Access to the Gray Literature. J. Med. Libr. Assoc. 2005, 93, 487–494. [Google Scholar] [PubMed]
- Berner, E.S.; Moss, J. Informatics Challenges for the Impending Patient Information Explosion. J. Am. Med. Inform. Assoc. 2005, 12, 614–617. [Google Scholar] [CrossRef] [PubMed]
- Munzner, T. Visualization Analysis and Design; A K Peters/CRC Press: New York, NY, USA, 2014. [Google Scholar]
- Ward, M.; Grinstein, G.G.; Keim, D. Interactive Data Visualization: Foundations, Techniques, and Applications, 2nd ed.; A K Peters/CRC Press: New York, NY, USA, 2015. [Google Scholar]
- van Wijk, J.J. Views on Visualization. IEEE Trans. Vis. Comput. Graph. 2006, 12, 421–432. [Google Scholar] [CrossRef] [PubMed]
- Lam, H. A Framework of Interaction Costs in Information Visualization. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1149–1156. [Google Scholar] [CrossRef] [PubMed]
- Lozano, R.; Naghavi, M.; Foreman, K.; Lim, S.; Shibuya, K.; Aboyans, V.; Abraham, J.; Adair, T.; Aggarwal, R.; Ahn, S.Y.; et al. Global and Regional Mortality from 235 Causes of Death for 20 Age Groups in 1990 and 2010: A Systematic Analysis for the Global Burden of Disease Study 2010. Lancet 2012, 380, 2095–2128. [Google Scholar] [CrossRef]
- Moody, D. What Makes a Good Diagram? Improving the Cognitive Effectiveness of Diagrams in IS Development. In Advances in Information Systems Development; Springer: Boston, MA, USA, 2007; pp. 481–492. [Google Scholar]
- Rosenholtz, R.; Li, Y.; Nakano, L. Measuring Visual Clutter. J. Vis. 2007, 7, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Hornbæk, K.; Hertzum, M. The Notion of Overview in Information Visualization. Int. J. Hum. Comput. Stud. 2011, 69, 509–525. [Google Scholar] [CrossRef]
- Ola, O.; Sedig, K. Health Literacy for the General Public: Making a Case for Non-Trivial Visualizations. Informatics 2017, 4, 33. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Characterization: Acting upon Visualizations to … |
|---|---|
| Annotating | augment them with additional visual marks and coding schemes, as personal meta-information |
| Arranging | change their ordering, either spatially or temporally |
| Blending | fuse them together such that they become one indivisible, single, new visualization |
| Comparing | determine degree of similarity or difference between them |
| Drilling | bring out, make available, and display interior, deep information |
| Filtering | display a subset of their elements according to certain criteria quantify |
| Navigating | move on, through, and/or around them |
| Searching | seek out the existence of or locate position of specific items, relationships, or structures |
| Selecting | focus on or choose them, either as an individual or as a group |
| Translating | convert them into alternative informationally- or conceptually-equivalent forms |
| Collapsing/Expanding | fold in or compact them, or conversely, fold them out or make them diffuse assemble |
| Linking/Unlinking | establish a relationship or association between them or, conversely, dissociate them and disconnect their relationships |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ola, O.; Sedig, K. Discourse with Visual Health Data: Design of Human-Data Interaction. Multimodal Technol. Interact. 2018, 2, 10. https://doi.org/10.3390/mti2010010
Ola O, Sedig K. Discourse with Visual Health Data: Design of Human-Data Interaction. Multimodal Technologies and Interaction. 2018; 2(1):10. https://doi.org/10.3390/mti2010010
Chicago/Turabian StyleOla, Oluwakemi, and Kamran Sedig. 2018. "Discourse with Visual Health Data: Design of Human-Data Interaction" Multimodal Technologies and Interaction 2, no. 1: 10. https://doi.org/10.3390/mti2010010
APA StyleOla, O., & Sedig, K. (2018). Discourse with Visual Health Data: Design of Human-Data Interaction. Multimodal Technologies and Interaction, 2(1), 10. https://doi.org/10.3390/mti2010010