1. Introduction
Intellectual and technological progress depends on the ability to overcome limitations restricting achievement of human goals. Some of the limitations are real, unavoidable restrictions imposed by the natural laws or logic, other are just results of our habits of thinking “in the box”. Great discoveries or inventions are sometimes serendipitous, but their accidental seed would not have grown into innovation without the fertile soil of the recognition for alternatives to orthodoxy. For this reason, it is important to analyze the status and characteristics of the limitations which we want to transcend.
Complexity is one of the main sources of limitations in human intellectual and technological activity. Ironically, these limitations became commonly recognized mainly because of the advance of computer technology providing tools for solving problems using procedures which require high speed and extensive memory far beyond natural human abilities. The limits which earlier were determined by the border between what we know how to do, and what we do not, now are determined by the border between what we know how to do in a practical, feasible way (typically meaning fast enough) and what we do not, or we know only how to do, but in a way which is impractical (typically too slow).
The importance of these type of problems for the current use of computers and the fame of some more specific theoretical questions (for instance the status of a Millennium Problem for the N = NP question or the controversies related to RSA public-key cryptosystem relying on the impracticality of algorithms performing factorization of integers), together with the common tendency to believe that we know something if we can produce some numbers which “measure” it, focused attention of the studies of complexity on its quite narrow aspect related to temporal efficiency, easily measured by the number of operations in a time unit.
In order to consider alternatives to the current methods of overcoming complexity, we have to clearly identify its sources and characteristics. This will be the first of the objectives of this paper. In particular, the dynamic and structural aspects of complexity will be presented as its necessary complementary characterizations, frequently omitted due to the focus on the quantitative description. In this article, complexity will be described in terms of information, its integration, and its dynamics. The conceptual framework used here was originally developed in the earlier publications of the present author [
1,
2,
3,
4,
5].
The second objective of this paper is to go beyond the identification of the problem and to propose a direction for further study of transcending limitations of our current account of complexity. For this purpose, an outline of processing information process is provided, in which hierarchically structured information systems are used as components in computing devices. The basic idea of multiple-level information systems and their use in computation was presented by the present author in his earlier publications on autonomous computation. Its original motivation came from the context of naturalization of computation for the purpose of creating artificial systems equipped with an authentic intelligence [
5,
6]. The approach recognized the need for a generalization of the concept of computation in such a way that it will have all the characteristics of a natural process (
viz. it should be based on the interaction of components, not intentional actions designed by a human mind, and should be completely autonomous,
i.e., should not require any human involvement, for instance in interpretation of the results).
In the present paper the autonomy or naturalization of computation are not goals, but tools. Instead, we focus on a legitimate question what can be learned from natural, in particular biological, systems regarding methods to overcome complexity. This reverse-engineering approach may not directly bring new designs of mechanisms, but can give us some insight into alternatives to the present methods based primarily on the continuously increasing speed and memory size of the current computing devices.
2. Lessons about Complexity from Nature
First lesson from the nature or its bio-systems can be found in the classical paper of George Miller on limitations of human information processing [
7]. We (and many other animals) can typically make direct distinction and identification of no more than seven objects at a time (Miller’s magical number is 7 ± 2 due to the statistical character of his research). It is not clear what mechanism is behind this limit, but most likely the capacity of some processing unit is limited to three bits (eight equally likely options from zero to seven).
In our everyday activities we are exposed to interactions with a much larger number of objects, and we are surprisingly effective in our dealing with the environment. To overcome the limitation of three bits, our mechanisms of information processing are using “chunking” of the information into a smaller number of higher level objects, each composed of multiple lower units. The number of levels can go beyond two, but is also limited (there are some, mostly speculative estimates that here too the magical number is seven). Attention mechanisms allow an easy transition between different levels of the hierarchy introduced this way into our field of perception.
The fact of the existence of such hierarchy and of its importance was known much earlier, before the famous article of Miller was published, leading to the development of gestalt psychology in works of Kurt Koffka, Max Wertheimer, and Wolfgang Köhler in early 20th Century. The interest in the issues of the mechanisms responsible for the perception of wholes and their parts and of the precedence of one or the other stimulates continuing (but inconclusive) discussions [
8].
Since we do not know the mechanism responsible for Miller’s surprisingly restrictive bottleneck in processing information by humans, it is difficult to assess whether the solution by introducing a hierarchic structure into the field of perception is optimal, but we can observe that it works quite well. We know much more about the general mechanisms of life whose hierarchic architecture is its most striking characteristic. The hierarchic form of life or biological organisms, and its importance were noticed and analyzed already by Aristotle [
9]. Recently, there is an increase of interest in its role in the analysis of life [
10], in computational aspects of life [
11], and in emergence of life as an informational process [
12].
There is a legitimate question as to why we should expect that hierarchic organization of life or of living organisms, which are definitely examples of very high levels of complexity, are relevant to our search of mechanisms overcoming complexity. For instance, organizing the field of perception into a hierarchical structure is definitely a process of overcoming complexity. However, in what sense should the evolutionary increase of complexity of organisms be considered here in the context of their effectiveness in overcoming complexity? To answer this question we should observe that life is not only a complex system itself, but also provides the best example of a system which can adapt to a highly complex environment. An increase of the complexity of organisms is a response to the complexity of environment. Higher level of the complexity of organisms makes them better adapted to the conditions of the environment. Moreover, the direction of biological evolution is determined by the success in this adaptation.
The evolutionary process of development from much simpler unicellular organisms all the way to homo sapiens, whose brain is the most complex system known in the universe, involves a choice of the way to increased complexity. Why did the human organism preserve in the form of cells at the lower level of its hierarchy basically the same type of elementary units as the original organisms? Why does the evolutionary process consist of the enrichment of genetic information in cellular nuclei correlate with the increasing number of higher level, more diversified units (tissues, organs, etc.) built of the cells? We can imagine very different evolutionary processes in which unicellular organisms increase their size, developing their organella into increasingly complex, diversified, and specialized systems, but avoiding hierarchic organization due to a “horizontal” increase of complexity. We have examples of such “emergent”, horizontal forms of complexity at the level of organismal populations, for instance in social insects (bees, ants, etc.), but not in the evolution of organisms.
Of course, at this moment we can only speculate on the advantages of the hierarchic organization of life over the “horizontal” one (hierarchic organization is consistent with different degrees of information integration, while emergent complexity is a product of processes in which there can be no information integration at all), but the effectiveness of life in overcoming complexity of the environment is unquestionable. This is the main reason why, in this article, the focus is on the possibility to use a naturalized form of computation based on hierarchic information systems as a method to overcome complexity.
Finally, there is another, admittedly speculative, very different argument for the consideration of hierarchic organization of systems used in solving complex problems. The experience gained from the study of biological evolution tells us that complex problems require complex tools. Otherwise, why did simple organisms evolve into humans? Thus far, computational methods for dealing with complexity are based on the idea of massively parallel distributive computing. However, the division of the process into concurrent, but independent, parallel tracks reduces the time of computation in a linear way. In order to reduce the time of computing, the distribution has to be based on an irreducible structure with interdependent tracks if all the concepts of a track are to be retained.
This brings the question why hierarchical organization should be considered. There are so many different ways irreducible structures can be involved. To answer this, we can reflect on the way we get problems that require impractically long times of computation. Typically (always?) it happens when the process involves two or more levels of the cardinality of sets. For instance, when in some problem we have to consider configurations of the basic units into all subsets of a given set, we are forced to involve exponential growth of the number of objects. Exponential growth of the time of computing has to be counterbalanced by the exponential growth of the computing power. In this, we can invoke the hierarchic structure of the computing system with sufficiently integrated functions.
3. Complexity as a Characteristic of Information Systems
Contemporary discussions of complexity are focused mainly on its quantitative aspects. Sometimes it is directly identified with the concept of algorithmic complexity which is used as a measure of the amount of temporal or spatial resources, such as the actual time of executing an algorithm, related to the time of elementary operations constituting the algorithm, or the amount of memory used in execution understood as a necessary space for storing information in the process.
The interest in quantitative aspects of complexity, in particular in the temporal quantification seems natural when we consider the fact that our modern methods of overcoming limitations of complexity are usually based on the high speed of computers and on the exponential growth of their memory brought by the technological progress. However, the association of complexity with big numbers was common even before computers became everyday tools.
In the classical article on complexity Warren Weaver distinguished its three levels [
13]. Simple systems devoid of complexity involve small numbers of variables easily separable in analysis. Systems of disorganized complexity involve a numerically-intimidating number of variables, but because of limited interaction of the components, they may be successfully analyzed using statistical methods. Finally, systems of organized complexity reflect “the essential feature of organization” of the big number of components, and escape statistical analysis. In systems of this type components are interacting in an organized way making statistical analysis ineffective.
Today, Weaver’s statements about the lack of effectiveness of statistical methods in the study of organized complexity carried out in his time can be explained by the erroneous insistence on the use of normal distributions for the description of phenomena actually governed by the power laws, but the better knowledge of appropriate distributions does not help much in overcoming limitations of complexity. We know now that what was ignored as highly improbable according to normal distribution, which assumes mutual independence of components in a system, can have very different statuses if an interaction, possibly very limited, is considered and different distribution is appropriate [
14]. The fact that we can only explain
post factum existence of the “black swans” (otherwise rare, but predictable events are not black swans anymore) puts them outside of our control. The need for the description by power laws and following its rise of influence of rare events simply confirm Weaver’s concerns regarding the lack of control or insight into phenomena involving systems with multiple mutually-interacting or self-organizing components.
The present author questioned the tendency to put exclusive emphasis on the number of components in the study of complex systems and presented the view that complexity is, itself, too complex to be described in terms of numerical characteristics [
4]. Quantitative characteristics of complexity have to be complemented by the structural ones. The search for methods to overcome limitations of complexity is basically the same as the search for holistic methods of inquiry. Both have objectives which can be achieved using the concept of information integration and its mathematical formalization [
15].
Going beyond the arguments of the author presented in earlier publications, we can reflect on the historical perspective on complexity which from the very beginning of human intellectual inquiry and human practical exploration of reality was the primary challenge. Overcoming limitations created by complexity was traditionally associated with intelligence and it is surprising that, so rarely, this association is invoked in contemporary discussions. Intelligence in solving complex problems was never associated with systematic, time consuming, repetitive trial-and-error procedures characterizing computer algorithms. Computers are tools not enhancing our intelligence, but allowing us to act in a non-intelligent way, but sufficiently fast to simulate intelligence.
The archetypical instances of complexity in Western civilization can be found in the Gordian knot and Cretan labyrinth. They both involve big numbers only indirectly. The Gordian knot was tying only two ropes attaching the ox-cart of Gordias to a pole. The Cretan labyrinth actually had only one linear corridor, but even if it was an actual maze, it did not have to branch into an intimidating number of side corridors to be confusing and to lead someone into a never ending circular path. In both cases what mattered was the structural complexity, not numerical one.
Alexander the Great would have been considered dumb if he untied the cart by consistent, but multiple, trials, not by the cutting the knot or removing the pin attaching ropes to the cart (whichever solution we believe in) and Theseus would have been caught inside the labyrinth if he explored, systematically, each branch of its corridors (if it had multiple ones). Finally, in the collective memory the task viciously given to Cinderella by her stepmother to separate lintels from ash in order to prevent the girl’s attendance at the ball was not considered complex, but time consuming. Doves, that are not considered very bright birds managed to do it very fast. Thus, the necessity to deal with the big number of small objects is traditionally associated with the flow of time, not with complexity.
Complexity does not have to require involvement of many components, but it is a combination of the plurality of any number of components, big or small, with their involvement in a sufficiently tightly knit structure of some whole. If the structure is intricate, number of components can be small. However, the lower complication of the structure with the big number of components can constitute an equally difficult challenge.
Someone could object that even if the complex system has a small number of components, to be complex it has to have a large number of degrees of freedom or a large number of possible states. Here, we encounter the problem of weak philosophical foundations for the discussions in the domains where scientific, formal progress outpaced philosophical reflection. Many specific, technical concepts with the well-defined roles within originally narrow formalisms of science enter discussions which have objectives far beyond the original context. However, not much effort is usually made to define them or to relate them to some philosophical framework.
Weaver, in his classification of complexity, was invoking terms like “variables” or “components” as if their meaning was obvious and easily identified in all philosophical views of reality [
13]. There are several other concepts frequently used in the context of complexity with equally unclear meaning and with unexplained relationships to philosophical matters. The most “infamous” are concepts of information and computation, but concepts such as that of a system, organization, degrees of freedom, or state, are also frequently used in a careless manner, possibly to avoid the necessity to assume a more definite philosophical position.
Sometimes, this lack of attention is noticed with a surprise. For instance, Uri Abraham wondered in the context of computer science “Considering its central place, it is surprising that the general notion state has received so little attention” [
16]. However, typically it is expected naively that the denotations of the terms such as state, organization, or system exist somewhere, and the responsibility for discovering and identifying them belongs to someone else. The recognition that all concepts used in a text should form some structural whole and that this structure has to be constructed by the author of the text is quite rare.
For this reason, the usual reference to complexity as a result of big number of variables or degrees of freedom made in a general context and without any explanation of these seemingly obvious terms is meaningless. Of course, complexity of a problem to be solved requires that there is more than one possible course of action. This is why finding the way in the historical Cretan labyrinth was not a complex problem, since it was enough to follow its one winding corridor. However, we can have complex problems which have only few courses of action, but those which are incorrect may require impractically long trials. Additionally, we can have complex problems when we simply do not see any possible action, but there can be many.
As it was stated above, the main obstacle in many earlier attempts to analyze the concept of complexity was the lack of a sufficiently general, consistent conceptual framework. A conceptual framework involving relevant concepts for the present study of complexity is coming from the earlier publications of the author [
4]. It is derived from the concept of information defined with the use of the categorical opposition of one and many. Of course, the choice of this opposition is a declaration of philosophical conviction of its extraordinary role, but the level of generality achieved this way prevents conflicts with alternative conceptualizations.
Information is identification (“making one”) of a variety (“many”). This identification is understood in terms of the two possible ways in which the many can be made one: by the selection of one out of many or by a structure binding the many into a whole [
1]. The existence of information requires a carrier, multiplicity from which unity is selected or constructed. The carrier, together with the mode of identification, will be called an information system.
These two ways are always associated with each other in the coexisting dual manifestations of the same concept of information, but in two different, although related, carriers. Selective manifestation can be characterized in a quantitative manner through the distribution function describing the choice, and consequently by functional magnitude; for instance, of the type of entropy, quantifying (“measuring”) this distribution in some respects. Structural manifestation can be characterized by the level of information integration understood as a degree in which the binding structure can be decomposed into components (in the mathematical formalism developed by the author it is factorization into the direct product of component structures [
2,
3]).
Here we can pause and ask whether the choice of information as a fundamental concept for the study of complexity is sufficiently broad. Is there any instance of a complex system whose relationship to information is questionable? Since complexity is always associated either with the choice out of multiple alternatives, or with intricate structure, it seems quite safe to give the answer that as long as we understand information as defined above, complexity is a qualification for information systems.
In the context of the dualism of information manifestations, it is possible to consider the dualism of two aspects of complexity which could be called, respectively, structural and dynamic (synchronic and diachronic). In the framework proposed by the present author, the first can be interpreted as a qualification of the information system with the structural manifestation of information at the high level of information integration (i.e., irreducibility into components). This high level of integration requires that the system has to be considered a whole and does not allow the distinction (separation) of any independent parts. The dynamic aspect refers to the question of a dynamic process of the construction or de-construction of the system involving the concepts of time (not necessarily in a physical sense) and interaction of substrate components.
Similar, but different, is the dualism of selective and dynamic complexity. Here, the selection can be deconstructed into component decisions (choices). The dynamic aspect is in the design of a process in which these component choices produce an ultimate selection. We can find a simple example of this type in the question of how to find a false coin (lighter or heavier) among n coins using the smallest number of trials with the scale which can show only on which side is the heavier load. We can easily predict that the number of trials cannot be smaller than the number of bits in the selection of one out of n equally likely false coins. However, the knowledge of the number of trials does not tell us directly how to perform the optimal sequence of trials.
In the special, but limited context of information systems described in the form of a tape for a Turing machine, the dual character of these two aspects, structural and dynamic, was used independently by Gregory Chaitin and Andrey Kolmogorov to assess the structural complexity of the system in terms of the minimal input for the universal Turing machine which can produce, through computation, the original structure. Complexity of the structure of the string of symbols (for instance of zeros and ones) is assessed by the size of the shortest string, which can produce it by computation (i.e., dynamic process) performed by a universal Turing machine. This quantitative assessment is frequently considered an alternative to Claude Shannon’s information theory based on the concept of entropy, although neither of them actually tells us much about information, or even defines it. However, it is worth noticing the shift of the interest from the length of the computation, the traditional subject of algorithmic complexity, to the length of the input.
Whether we should call the study of the quantitative characteristics of processes, such as communication or computation with Turing machines, a theory of information, or not [
3], for our purpose it is important only to recognize the distinction between structural and dynamic aspects of complexity and to reflect on the potential use of their mutual relationship.
Finally, we can summarize what we mean by a complex information system. It is a system in which a combination of two complementary characteristics, the value of the magnitude characterizing selective information (in which the size of the variety and the type of distribution function play important roles) and the level of information integration (i.e., irreducibility of the binding structure into components) justifies such qualification.
4. Dynamics of Compound Information Systems
The main objective of the present paper is to explore the possibility to overcome limitations brought by complexity through the use of multi-level hierarchic information systems for processing information. In the preceding section, the dynamic and structural aspects of complexity were distinguished in the context of information. Now, it is the turn for the use of the dynamics of information in the description of computation. Our goal is to prepare a conceptual framework for computation performed in the multi-level systems. However, the need for considering at least two levels appears already in the description of the traditional (Turing type) computation in terms of information dynamics.
Dynamics of information in which the interaction of two information systems, each having two levels, was already described elsewhere [
5,
6]. The distinction of the two levels is necessary as the interaction involves duality of the structural and selective manifestations which coexist on different varieties related in such a way that elements of one are subsets of the other. Thus, although formally we have two varieties,
i.e., two information systems, the relation between the varieties justifies their status as levels of one compound information system.
This description of the dynamics of information systems can be applied to systems as different as Watt’s governor and biological evolution of species [
5]. It can also be applied to computation performed by a Turing machine. In order to prepare for a generalization of computation to machines operating in the multilevel architecture, the concept of a Turing machine (a-machine in Turing’s terminology) was slightly generalized to an s-machine, where “s-machine” stands for symmetric Turing machine in which not only cells of the tape can be modified, but also instructions in the head can be altered [
6]. The orthodox a-machine is a special case of s-machine when, instead of interaction (mutual change), there is only one-way action of the head on the tape. In the original article, the author explained that the latter form of dynamics is possible only for open compound systems, and cannot be applied in the general context.
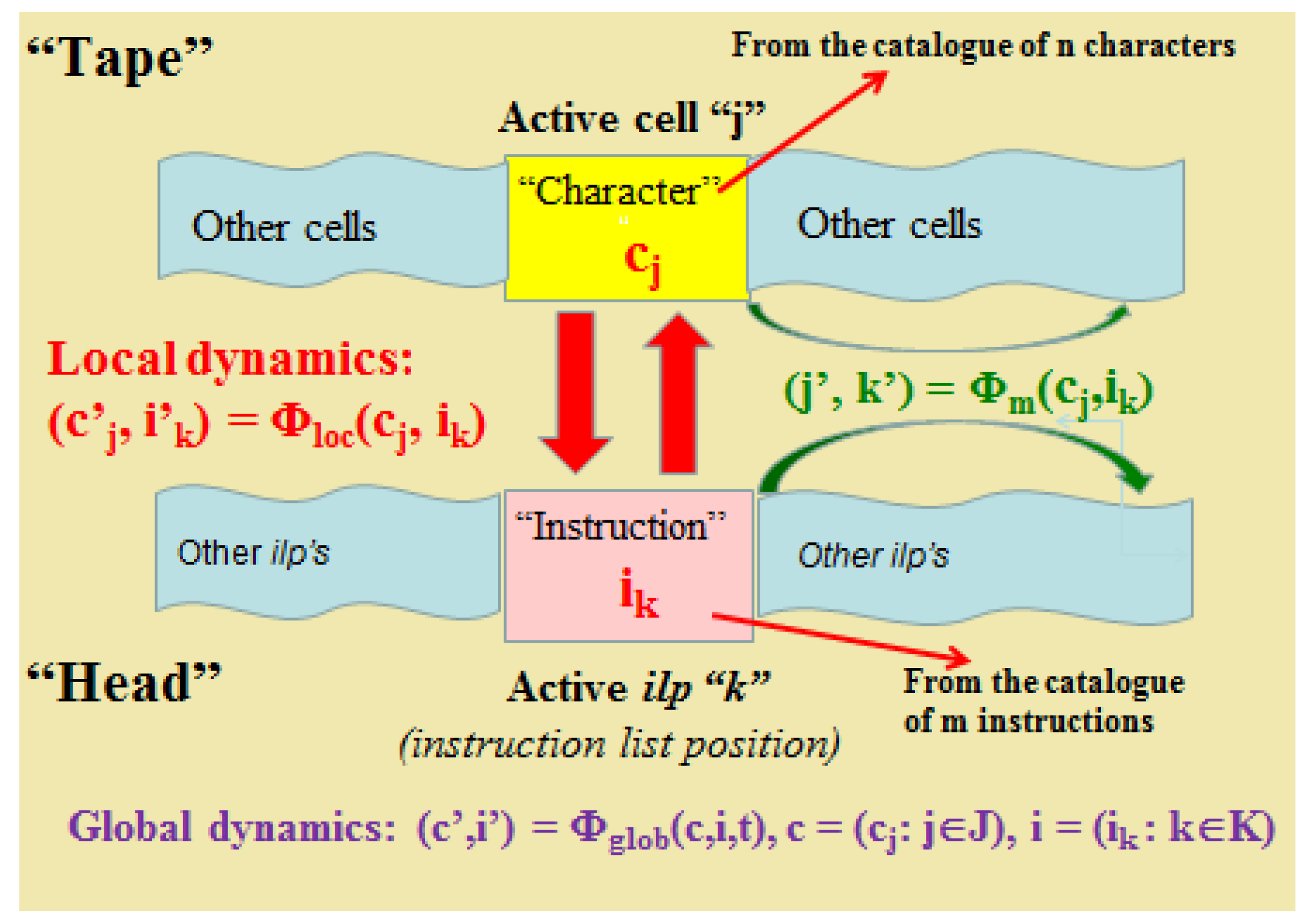
The machine was described as follows [
6] (see
Figure 1). Instead of the two, very different, functional systems of the Turing machine, an active reading/writing head and a passive tape, we have in the s-machine two information systems with basically the same structural and functional characteristics (this is why the machine is called symmetric). For the purpose of easy comparison with the a-machine, traditional names of the head and tape will be retained here, although they lose their literal meaning. Both are compound systems characterized in terms of their components, which are in their respective local states, and of configurations of the component states constituting their global states.
To maintain, as close as possible, similarity with the description of a-machines, it is assumed that the components of both systems can be numbered by natural numbers, which means that both sets of components have linear, discrete ordering.
Figure 1.
Diagram of s-machine [
6].
Figure 1.
Diagram of s-machine [
6].
The components of the tape are called cells; those of the head are called instruction list positions (ilp). Each of the cells can be in one of the n states called characters, each of the instruction list positions in one of the m states called instructions. The characters and instructions do not have any fundamentally different features. The distinction is only relative to the internal structures of the systems. What, in the a-machines, made the tape and head functionally different is here generalized into symmetric interaction in the computing dynamics of fundamentally similar systems.
The s-machine is a two-part system equipped with a dynamical structure which in each state of the machine allows for an interaction of one particular cell with one particular instruction list position (active cell and active list position). The choice of the pair of active components is a state of the entire s-machine, different from the global states of compound systems which form the two interacting parts of the machine (head and tape), and of course different from the local states. The outcome of the interaction is a possible local change of the state of both active components (active cell and active ilp) and possible change of the state of the machine, i.e., the choice of the pair of an active cell and active instruction list position. The changes are described as possible, as in some cases the states may remain the same.
The three components of computational dynamics require separate considerations. At the local level, each step of computation at the state of the machine (j,k), meaning that j-th cell and k-th ilp are active, is described by a function (c’j,i’k) = Φloc(cj,ik), where cj and c’j belong to the catalogue of the n cell states (characters), and ik with i’k belonging to the catalogue of the m states of the ilp (instructions). The function Φloc does not depend explicitly on j and k, but exclusively on the values of cj, ik.
The change of the state of entire machine (describing which local elements are active, i.e., which cell, and which ilp are entering into interaction) is another function (j’,k’) = Φm(cj,ik) which, in this case, is, in principle, a compound function of j and k, but its dependence on j and k may be eliminated (by defining each j’ as j+s where s is an integer function of the values of cj and ik), and then it depends exclusively on the values of cj, ik.
Finally, we have a function (c’,i’) = Φglob(c,i,t) describing the change of the global states of the two interacting systems which form the machine after t iterations starting from the global states c = (cj: j∈J) and i = (ik : k∈K).
Although we have three functions describing computation ((c’j,i’k) = Φloc(cj,ik), (j’,k’) = Φm(cj,ik), (c’,i’) = Φglob(c,i,t)), there are only two levels of the process which are called local and global. The second function is between these two levels with arguments at the local level (content of a cell, i.e., character and content of the ilp, i.e., instruction) and values at the global level (location of the active cell and active ilp within the string).
It is obvious that the s-machine, in which the state of each instruction list position (ilp) remains always the same, allowing identification of ilp’s with their respective instructions, is a usual a-machine. For this reason, in the orthodox Turing machine there was no need for the distinction between the ilp and the instruction placed in it. If we additionally assume that the local states of the tape remain unchanged, we get an automaton. The possibility of the change of instructions, i.e., local states of at least some instruction list positions makes the s-machine slightly more general than the a-machine. However, disassociation of the change of the local state of the tape from the head and describing it as an interaction between active local components of the compound systems is just a reinterpretation.
Computation by s-machine is a dynamical process of the interaction of two, two-level information systems, where the levels are determined by the duality of structural and selective manifestations of information. It is not the most general form of interaction. We assume here that interaction at the lower (local) level is between two specific local elements (active cell and active ilp) and that this local interaction is producing as a result interaction at the upper (global) level in the form of the change of the localization of interaction (expressed in the upper level). We will not pursue the path of generalization to remove this restriction in this paper, but other forms of localization (for instance, in multiple locations) should be considered as one of the possible future directions of inquiry.
Symmetry of the operation of s-machines make them suitable for being parts of multi-level machines in which the lower level of a given pair of consecutive levels can function as the upper one for the pair of levels below, and the upper level as the lower level for the pair above. This concurrent mode of operation at all levels at the same time is what we can find in living organisms and what makes the present model essentially different from all current systems of distributed computing. In the latter, the distinction between different paths of computation is an expression of disintegration of information.
5. Construction of the Hierarchic Structure
The idea of the construction of multi-level information systems was presented above based on the vague statement that every instance of information produces two coexistent, dual manifestations of information in different, but related, information systems (with the carrier of one consisting of a class of subsets of the other). In the description of an s-machine the tape could be considered an example of the structural manifestation of information, when we take into account the structure of the sequence of zeros and ones. However, at the lower level, tape consists of cells, and each cell is an information system in which selective manifestation is the specific choice of zero or one. The varieties (i.e., information carriers) are different, but related. Tape (upper level information system) consists of the multiplicity of cells (lower level systems).
This article is concluded with the description of the mathematical construction which allows the transition of the information system structure from any set to its power set (set of all subsets). Using this construction consecutively, we can build a consistent hierarchical system of arbitrary height.
Lack of space does not allow presentation here of the details of the formalization of information theory based on the one-and-many opposition, but they can be found in earlier publications [
3,
17]. The basic idea of the approach is that within a variety (set
S) an element
x can be selected by a specification of its properties, which can be interpreted in the terms of the set theory as a distinction of the family of subsets whose intersection has
x as its element. On the other hand, the structure built on the variety can be characterized by the family of substructures defined within
S. In both cases, an information system is associated with a closure operator
f on S. The concept of a closure operator and other related terminology are explained in every text on general algebra [
18]. Closed subsets for this closure operator (
i.e., sets satisfying
f(A) = A that can be associated with actual properties of objects) form a complete lattice
Lf which can be considered a generalization of the concept of logic for information). It is reducibility or irreducibility of this lattice that shows the level of integration of information.
The point of departure in the formalization of the duality of information manifestation can be found in the way we are associating information understood in the linguistic way with the relation between sets and their elements formally expressed by “x∈A”. The informational aspect of the set theory can be identified in the separation axiom schema (alternatively called specification axiom schema), which allows interpretation of x∈A, as a statement of some formula φ(x) formulated in the predicate logic which is true whenever x∈A. The subset A of S consists, then, of all elements which possess the property expressed by φ(x).
If we are interested in a more general concept of information, not necessarily based on any language, we can consider a more general relationship than x∈A described by a binary relation R between the set S and its power set 2S: xRA if x∈f(A).
If this closure operator is trivial (for every subset A its closure f(A) = A) we get the usual set-theoretical relation of belonging to a set xRA if x∈A. In more general case, only closed subsets correspond to properties.
Let S, T be sets, and R ⊆ S×T be a binary relation between sets S and T. R* is the converse relation of R, i.e., the relation R* ⊆ T×S such that ∀x∈S∀y∈T: xRy iff yR*x. Then we define:
Ra(A) = {y∈T: ∀x∈A: xRy}, Re(A) = {y∈T: ∃y∈A: xRy}.
If
R is a binary relation between sets
S and
T, the pair of functions
φ: 2S→2T and
ψ: 2T→2S between the power sets of
S and
T defined on subsets
A of
S by
φ: A → Ra(A) and on subsets
B of
T by
ψ: B → R*a(B) forms a Galois connection and, therefore, both of their compositions, defined on subsets
A of
S by
f(A) = φψ(A) = RaR*a(A) and on subsets
B of
T by
g(B) = φψ(B) = R*aRa(B) are transitive closure operators. Additionally, the functions
φ,
ψ are dual
isomorphisms between the lattices
Lf and
Lg of closed subsets for the closure operators
f and
g [
18].
Now, let <S,f> be closure space which represents an information system. Define for x∈S and A∈2S a binary relation Rf ⊆ S × 2S such that xRf A iff x∈f(A). If no confusion is likely, we will write simply R instead of Rf.
One way the Galois connection is defined by this relation and described above will return us back to the original closure f, as for every subset A of S: Rf*aRfa(A) = f(A). For us, more interesting is the other way which generates the closure operator g defined on 2S by: ∀β⊆2S: g(β) = RaR*a(β) = {A⊆S:∩{f(B):B∈β} ⊆ f(A)}.
We know from the properties of Galois connections that the complete lattice Lf of f-closed subsets of S is dually isomorphic to the lattice lattices Lg of g-closed subsets of the power set 2S. Thus, we have that every information system in a set S is associated with an information system in the set of all subsets of S, in such way that their logics are dually isomorphic.
This correspondence is expressing in mathematical language the duality of information manifestations in hierarchically-related information systems, which links the consecutive levels in such a way that the information structure is preserved in a (lattice-theoretic) dual way. Since we can repeat the reasoning for the “upper level” closure operator g, our construction can produce an unlimited number of levels and we have the formal description of multi-level hierarchic information systems.
6. Conclusions
The two preceding sections of this paper show the theoretical construction of a multi-level hierarchic information system and the way in which dynamics (interaction) of such information systems can be used for computation. The next step in research in this direction is to implement an example of the computation.


{kind=link}
