
Perceiving like a Bat: Hierarchical 3D Geometric–Semantic Scene Understanding Inspired by a Biomimetic Mechanism


Abstract
:1. Introduction
- Inspired by bat’s binoculus and vestibular organs, we present a lightweight and drift-free visual–inertia–GNSS tightly coupled multisensor fusion (LDMF) strategy for unmanned aerial vehicle (UAV) pose estimation, which achieves accurate pose estimation by imitating the state estimation system of bats.
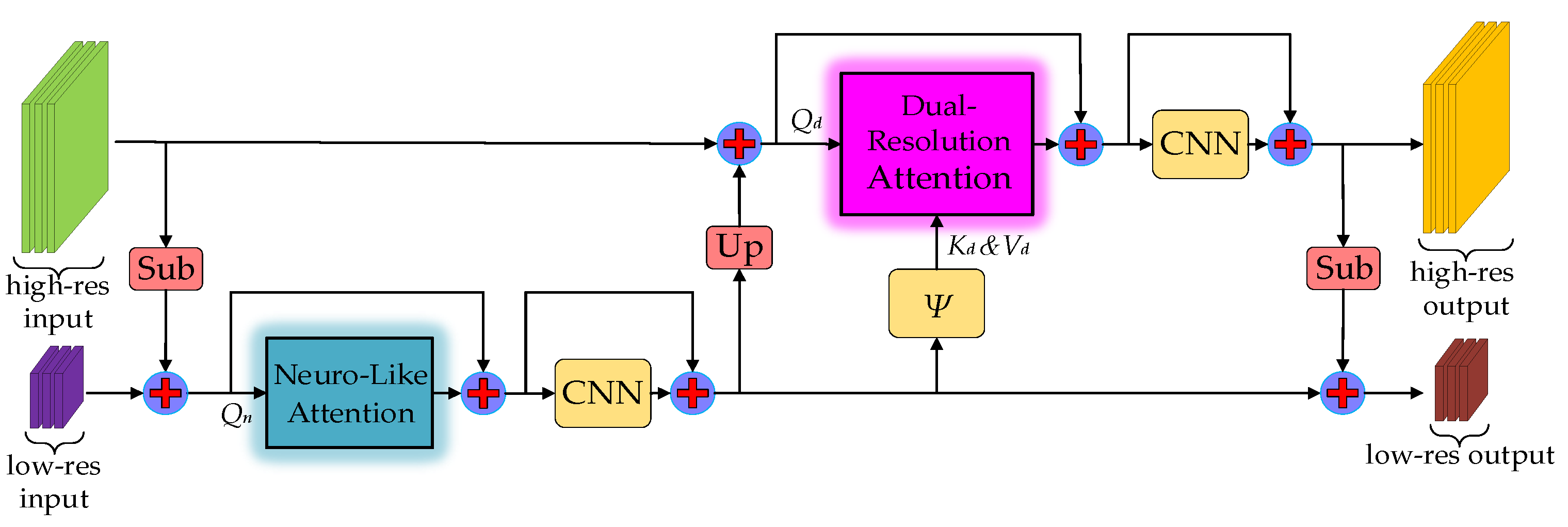
- Inspired by the bat’s optic nervous system, we innovatively designed a neural network sub-module with a neuro-like attention mechanism. Based on this, we constructed a novel Transformer–CNN hybrid neural architecture, dubbed BatNet, for real-time pixel-level semantic segmentation.
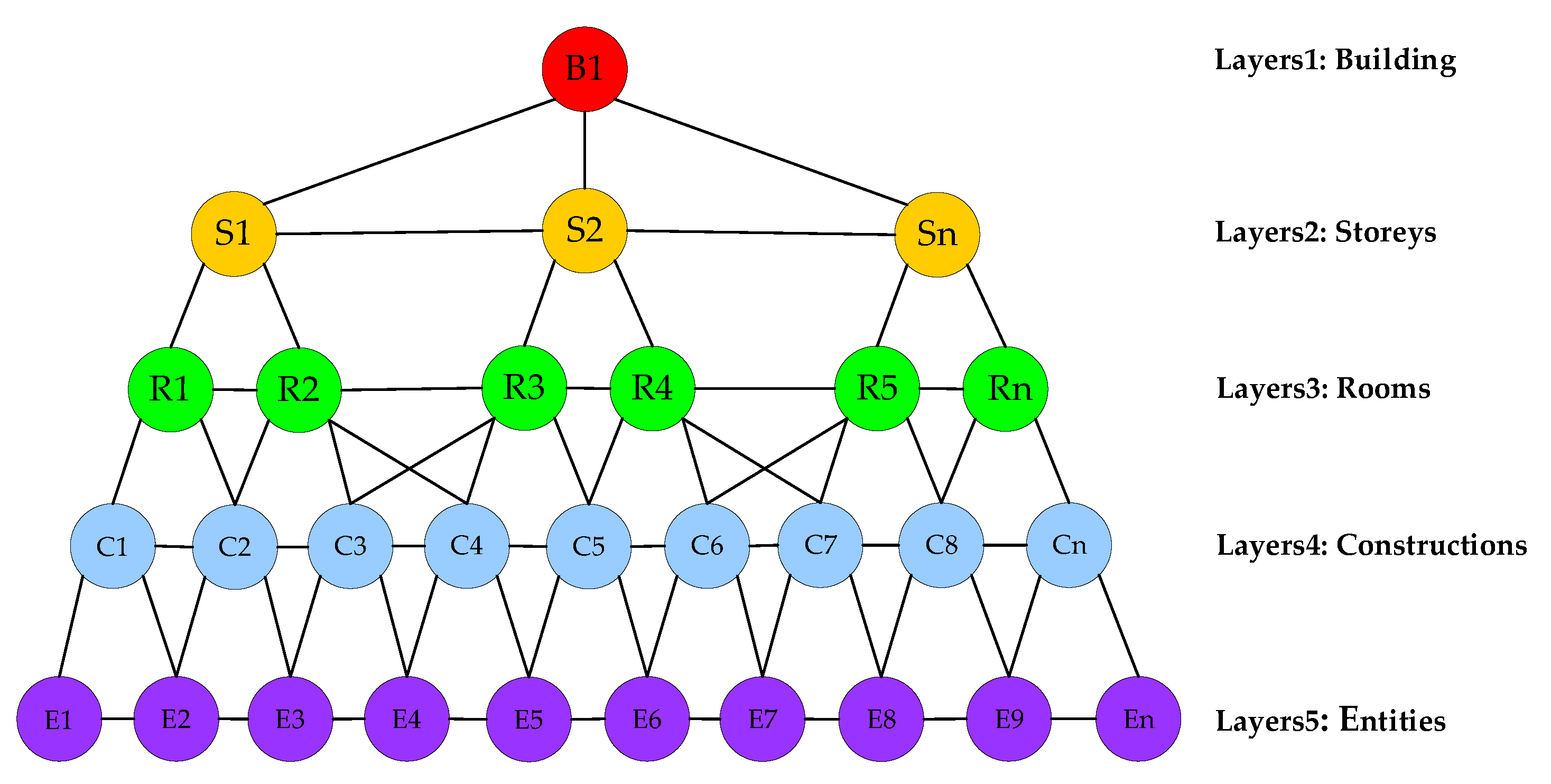
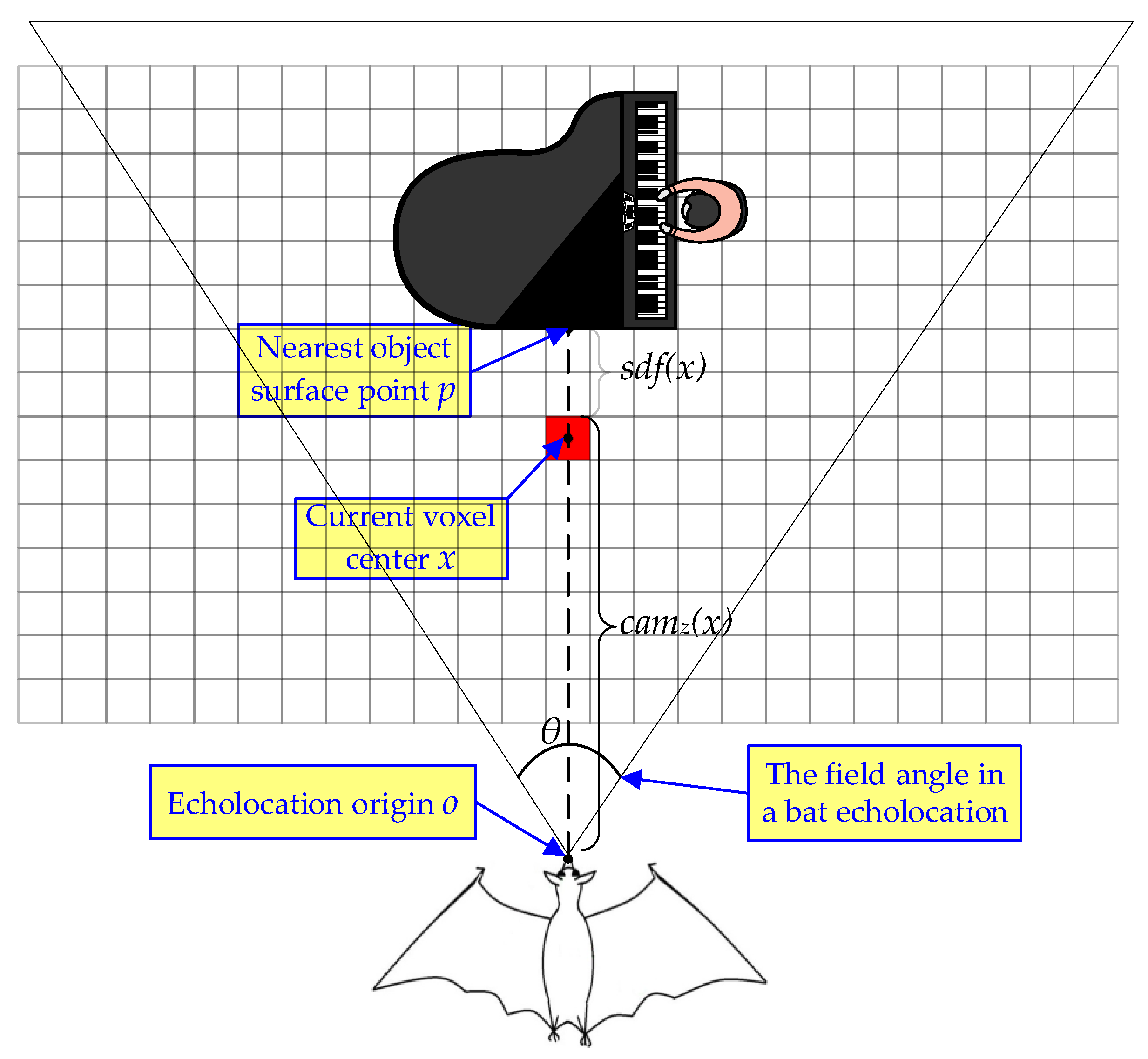
- Inspired by the bat’s spatiotemporal analysis and echolocation system, we propose a layered directed scene graph called a hierarchical scene graph (HSG) to represent the spatiotemporal relationships between substances, and implement a truncated signed distance field (TSDF) to obtain the volumetric scene mesh at each keyframe.
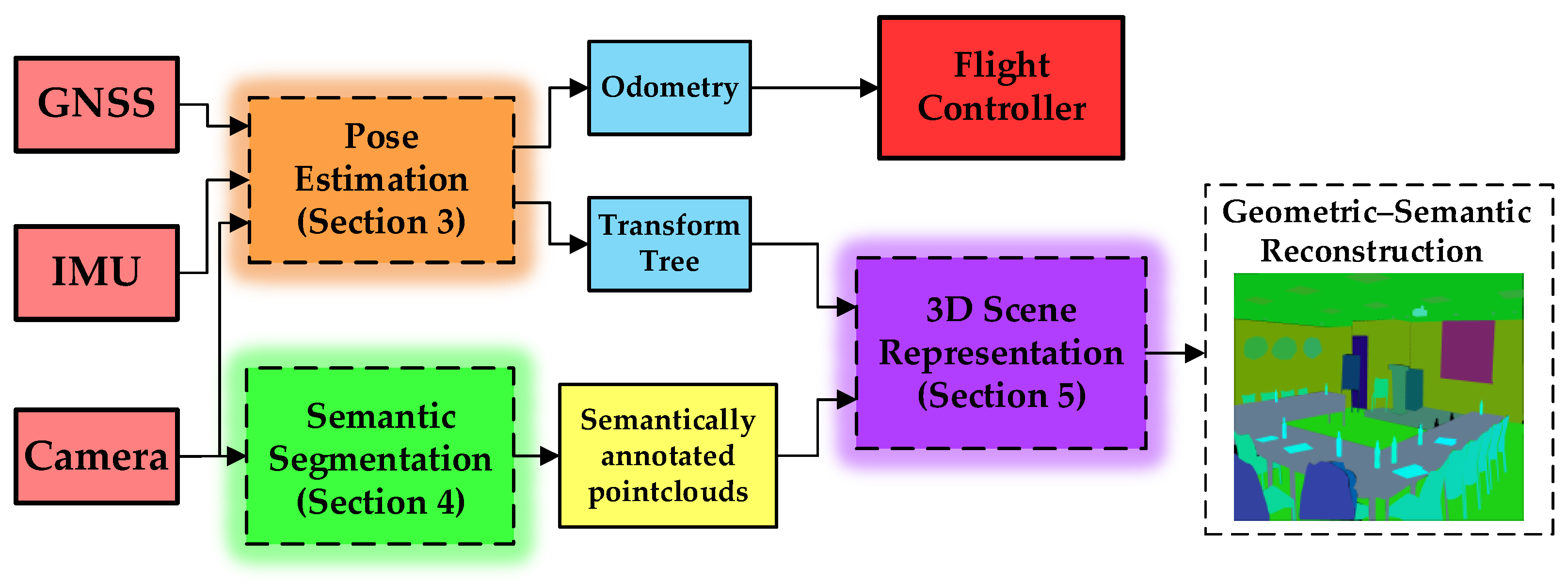
2. System Overview
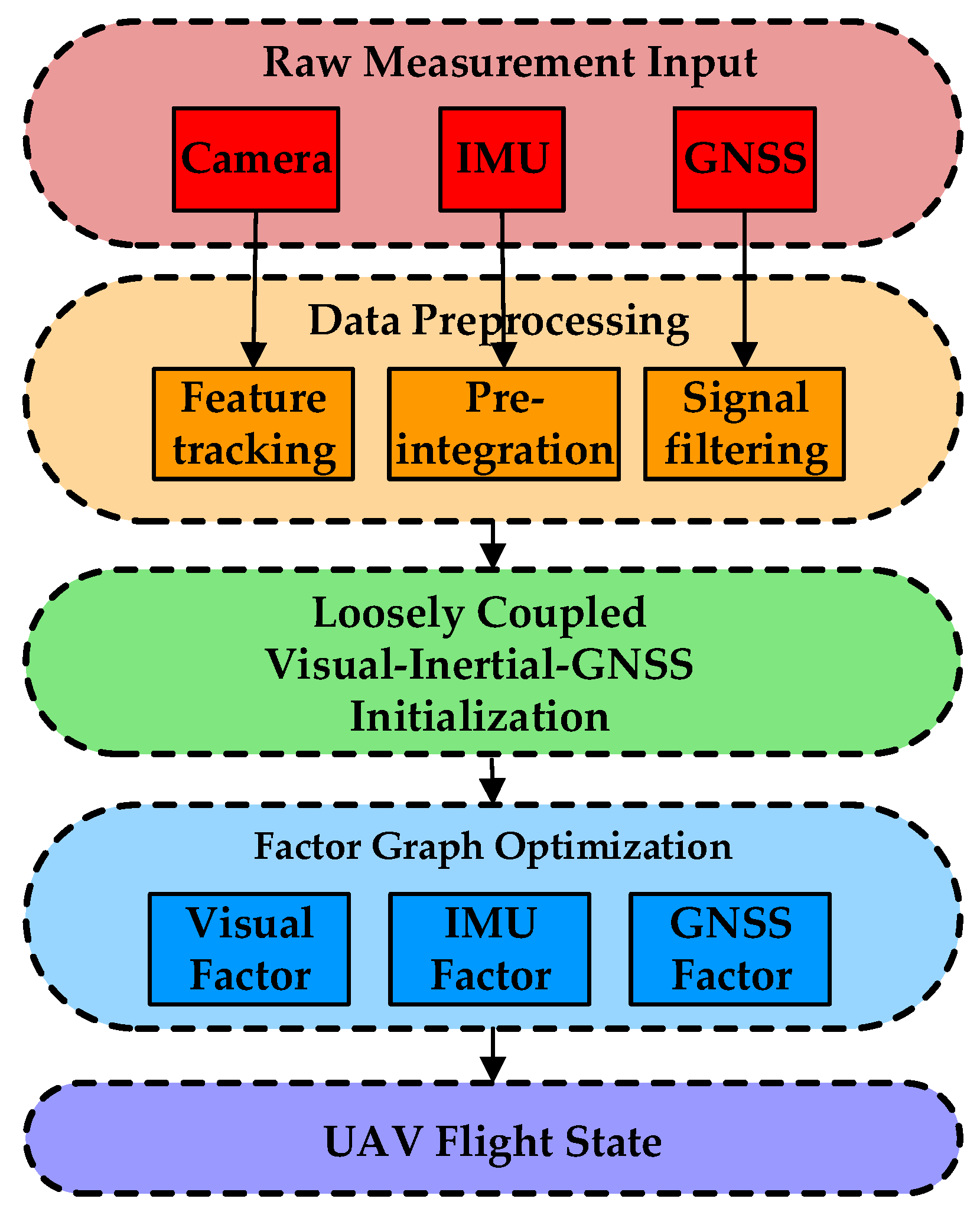
3. Bat-Inspired State Estimation
4. Bat-Inspired Real-Time Semantic Segmentation
4.1. Attention Mechanism
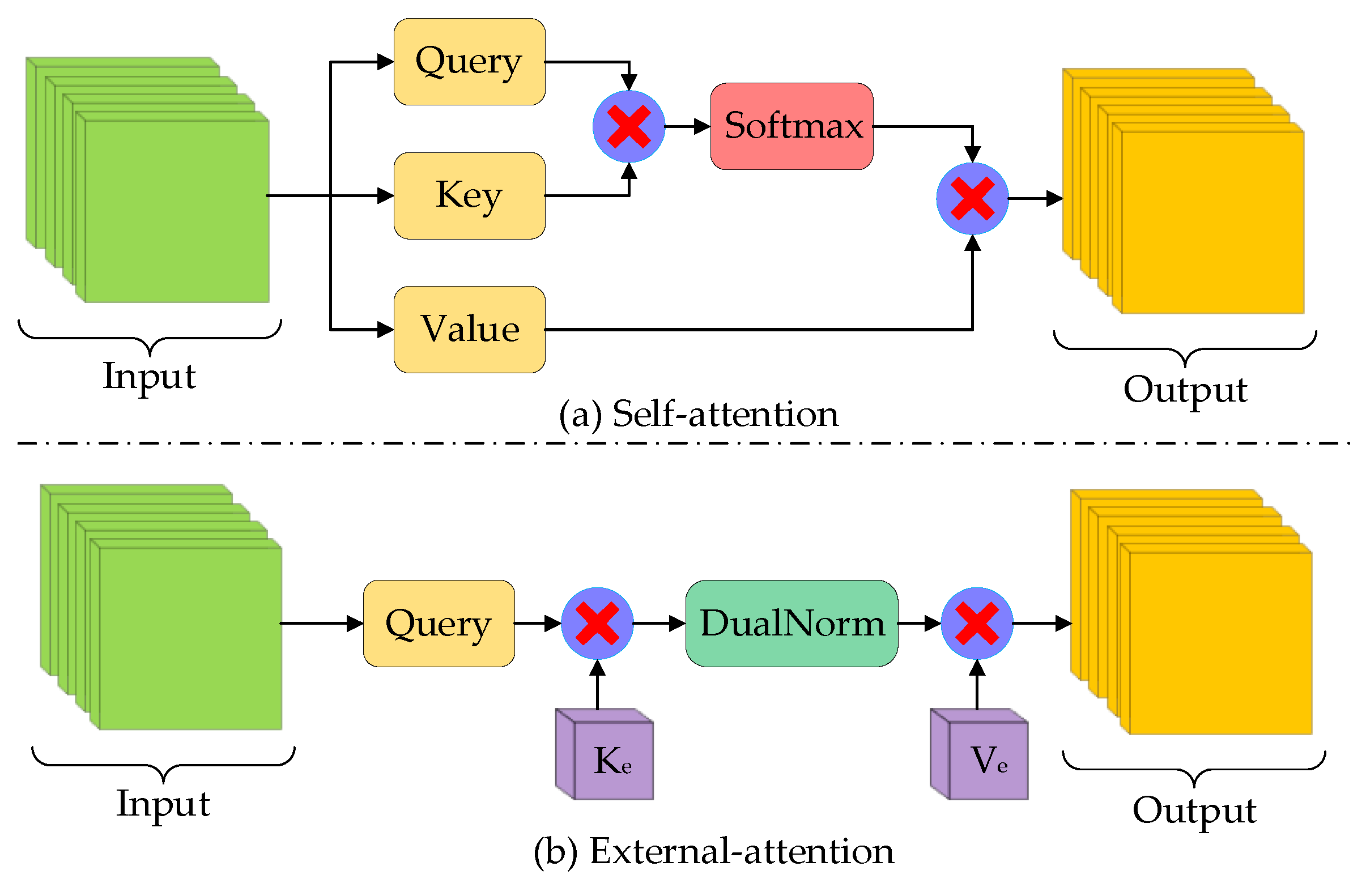
4.1.1. Self-Attention Mechanism
4.1.2. External-Attention Mechanism
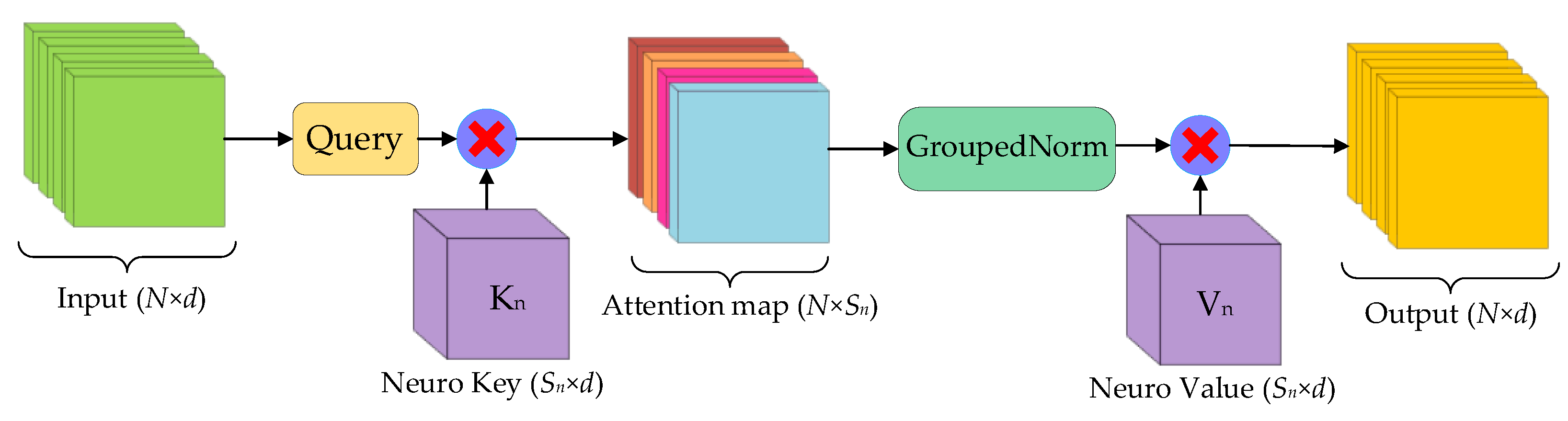
4.1.3. Neuro-like Attention Mechanism
4.1.4. Dual-Resolution Attention Mechanism
4.2. BatNet Architecture
5. Bat-Inspired Hierarchical 3D Scene Representation
5.1. Hierarchical Scene Graph
5.2. Truncated Signed Distance Field
6. Experiments
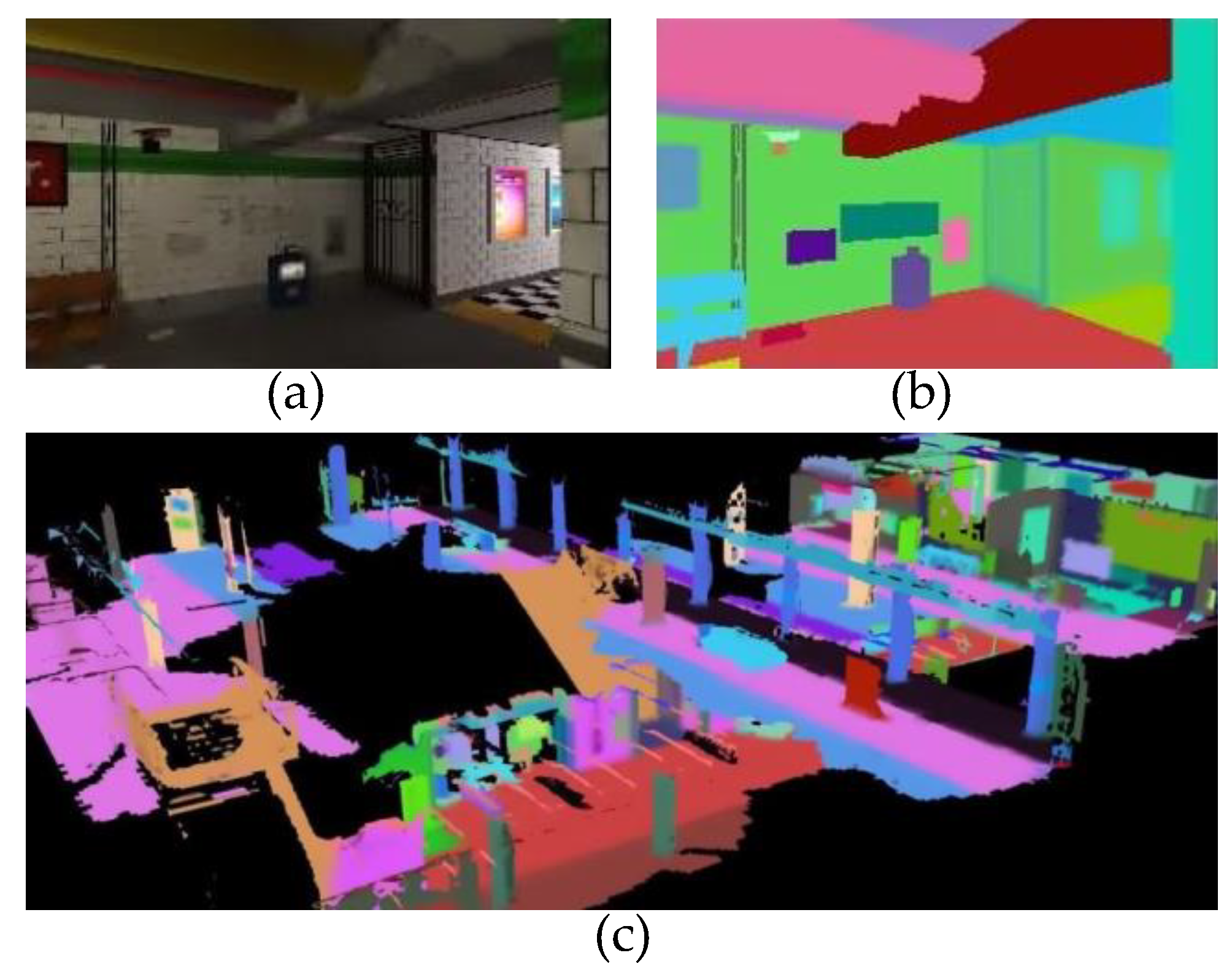
6.1. Image Segmentation
6.1.1. Datasets and Implementation Details
6.1.2. Ablation Study
6.1.3. Comparison with State-of-the-Art Approaches
6.2. Scene Representation
6.2.1. TSDF-Based Volumetric Scene Reconstruction
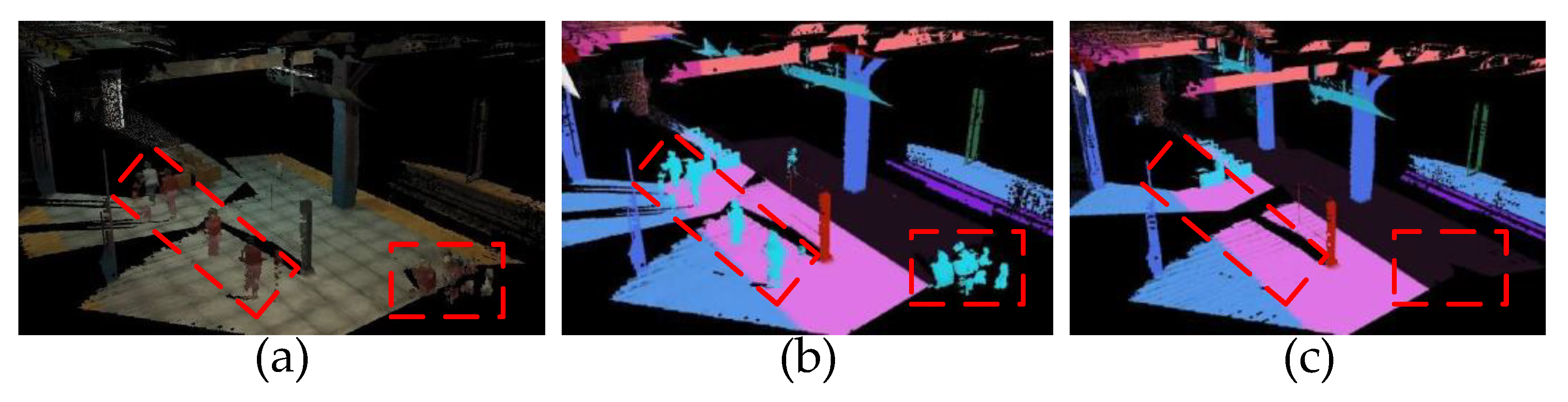
6.2.2. Bat-Inspired Volumetric–Semantic Scene Representation
6.2.3. Visualization of Hierarchical Scene Graph
6.3. Real-World Experiment
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, S.; Yang, K.; Li, C.; Li, Y. Color Constancy Using Double-Opponency. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1973–1985. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Cao, S.; Lu, X.; Shen, S. GVINS: Tightly Coupled GNSS–Visual–Inertial Fusion for Smooth and Consistent State Estimation. IEEE Trans. Robot. 2022, 38, 2004–2021. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, X.; Wang, Z.; Gao, Y.; Li, H.; Wang, Q.; Yang, T.; Lu, H.; Cao, Y.; Xu, C.; et al. Swarm of micro flying robots in the wild. Sci. Robot. 2022, 7, eabm5954. [Google Scholar] [CrossRef]
- Liu, L.; Liang, J.; Guo, K.; Ke, C.; He, D.; Chen, J. Dynamic Path Planning of Mobile Robot Based on Improved Sparrow Search Algorithm. Biomimetics 2023, 8, 182. [Google Scholar] [CrossRef] [PubMed]
- Tabib, W.; Goel, K.; Yao, J.; Boirum, C.; Michael, N. Autonomous Cave Surveying with an Aerial Robot. IEEE Trans. Robot. 2021, 9, 1016–1032. [Google Scholar] [CrossRef]
- Zhou, B.; Pan, J.; Gao, F.; Shen, S. RAPTOR: Robust and Perception-Aware Trajectory Replanning for Quadrotor Fast Flight. IEEE Trans. Robot. 2021, 37, 1992–2009. [Google Scholar] [CrossRef]
- Guo, M.; Liu, Z.; Mu, T.; Hu, S. Beyond Self-Attention: External Attention Using Two Linear Layers for Visual Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5436–5447. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Liu, H.; Sun, T.; Lou, H.; Duan, X.; Bi, L.; Liu, L. MC-YOLOv5: A Multi-Class Small Object Detection Algorithm. Biomimetics 2023, 8, 342. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient Object Detection in the Deep Learning Era: An In-depth Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1, 1–20. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Rosinol, A.; Abate, M.; Chang, Y.; Carlone, L. Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1689–1696. [Google Scholar]
- Rosinol, A.; Violette, A.; Abate, M.; Hughes, N.; Chang, Y.; Shi, J.; Gupta, A.; Carlone, L. Kimera: From SLAM to spatial perception with 3D dynamic scene graphs. Int. J. Robot. Res. 2021, 40, 1510–1546. [Google Scholar] [CrossRef]
- Tian, Y.; Chang, Y.; Herrera Arias, F.; Nieto-Granda, C.; How, J.; Carlone, L. Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems. IEEE Trans. Robot. 2022, 38, 2022–2038. [Google Scholar] [CrossRef]
- Mouritsen, H. Long-distance navigation and magnetoreception in migratory animals. Nature 2018, 558, 50–59. [Google Scholar] [CrossRef] [PubMed]
- Sulser, R.B.; Patterson, B.D.; Urban, D.J.; Neander, A.I.; Luo, Z.X. Evolution of inner ear neuroanatomy of bats and implications for echolocation. Nature 2022, 602, 449–454. [Google Scholar] [CrossRef] [PubMed]
- Essner, R.L., Jr.; Pereira, R.E.; Blackburn, D.C.; Singh, A.L.; Stanley, E.L.; Moura, M.O.; Confetti, A.E.; Pie, M.R. Semicircular canal size constrains vestibular function in miniaturized frogs. Sci. Adv. 2022, 8, eabn1104. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Chang, S.; Kim, M.; Yeo, J.E.; Kim, M.S.; Lee, G.J.; Kim, D.H.; Song, Y.M. Cuttlefish eye-inspired artificial vision for high-quality imaging under uneven illumination conditions. Sci. Robot. 2023, 8, eade4698. [Google Scholar] [CrossRef]
- Prescott, T.J.; Wilson, S.P. Understanding brain functional architecture through robotics. Sci. Robot. 2023, 8, eadg6014. [Google Scholar] [CrossRef] [PubMed]
- Michael, M.; Nachum, U. Representation of Three-Dimensional Space in the Hippocampus of Flying Bats. Science 2013, 340, 367–372. [Google Scholar] [CrossRef]
- Finkelstein, A.; Derdikman, D.; Rubin, A.; Foerster, J.N.; Las, L.; Ulanovsky, N. Three-dimensional head-direction coding in the bat brain. Nature 2015, 517, 159–164. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Wu, Y.; Ma, S.; Xu, M.; Li, H.; Qu, H.; Song, C.; Wang, T.; Zhao, R.; Shi, L. Brain-inspired multimodal hybrid neural network for robot place recognition. Sci. Robot. 2023, 8, eabm6996. [Google Scholar] [CrossRef] [PubMed]
- Li, H.H.; Pan, J.; Carrasco, M. Different computations underlie overt presaccadic and covert spatial attention. Nat. Hum. Behav. 2021, 5, 1418–1431. [Google Scholar] [CrossRef]
- Madore, K.P.; Khazenzon, A.M.; Backes, C.W.; Jiang, J.; Uncapher, M.R.; Norcia, A.M.; Wagner, A.D. Memory failure predicted by attention lapsing and media multitasking. Nature 2020, 587, 87–91. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Nobre, A.C.; van Ede, F. Functional but not obligatory link between microsaccades and neural modulation by covert spatial attention. Nat. Commun. 2022, 13, 3503. [Google Scholar] [CrossRef]
- Nieuwenhuis, S.; Yeung, N. Neural mechanisms of attention and control: Losing our inhibitions? Nat. Neurosci. 2005, 8, 1631–1633. [Google Scholar] [CrossRef]
- Debes, S.R.; Dragoi, V. Suppressing feedback signals to visual cortex abolishes attentional modulation. Science 2023, 379, 468–473. [Google Scholar] [CrossRef]
- Chen, G.Z.; Gong, P. A spatiotemporal mechanism of visual attention: Superdiffusive motion and theta oscillations of neural population activity patterns. Sci. Adv. 2022, 8, eabl4995. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Yang, Z.; Fang, Q.; Xu, C.; Xu, H.; Xu, X.; Zhang, J. FRL-SLAM: A Fast, Robust and Lightweight SLAM System for Quadruped Robot Navigation. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 1165–1170. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; Xu, H.; Liao, L.; Zhu, T.; Li, G.; Yang, X.; Zhang, Q. RRVPE: A Robust and Real-Time Visual-Inertial-GNSS Pose Estimator for Aerial Robot Navigation. Wuhan Univ. J. Nat. Sci. 2023, 28, 20–28. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; Liao, L.; You, Y.; Sui, Y.; Zhu, T. RPEOD: A Real-Time Pose Estimation and Object Detection System for Aerial Robot Target Tracking. Machines 2022, 10, 181. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; Zhuo, H.; Liao, L.; Yang, X.; Zhu, T.; Li, G. A Lightweight and Drift-Free Fusion Strategy for Drone Autonomous and Safe Navigation. Drones 2023, 7, 34. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wang, J.; Gou, C.; Wu, Q.; Feng, H.; Han, J.; Ding, E.; Wang, J. RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer. Adv.Neural Inf. Process. Syst. 2022, 35, 7423–7436. [Google Scholar]
- Oleynikova, H.; Taylor, Z.; Fehr, M.; Siegwart, R.; Nieto, J. Voxblox: Incremental 3D Euclidean Signed Distance Fields for on-board MAV planning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1366–1373. [Google Scholar] [CrossRef]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery. IEEE Robot. Autom. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef]
- Schmid, L.; Delmerico, J.; Schönberger, J.L.; Nieto, J.; Pollefeys, M.; Siegwart, R.; Cadena, C. Panoptic Multi-TSDFs: A Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 8018–8024. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Channel Number | Parameters |
|---|---|---|
| BatNet | [64, 128, 128/256, 128/512, 128/512] | 17.1 M |
| BatNet-tiny | [32, 64, 64/128, 64/256, 64/256] | 4.9 M |
| Convolutional FFN | SA | EA | NLA | DRA | mIoU (%) | FPS |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✗ | ✗ | ✗ | 32.6 | 71.3 |
| ✓ | ✗ | ✓ | ✗ | ✗ | 31.4 | 131.5 |
| ✓ | ✗ | ✗ | ✓ | ✗ | 32.5 | 142.7 |
| ✗ | ✗ | ✗ | ✓ | ✓ | 32.3 | 130.4 |
| ✓ | ✗ | ✗ | ✓ | ✓ | 32.8 | 138.1 |
| Model | Backbone | mIoU (%) | Parameters | FPS |
|---|---|---|---|---|
| BiSeNet | Xception | 62.4 | 5.8 M | 75.3 |
| BiSeNetV2 | Booster | 69.3 | - | 68.1 |
| SFNet | ResNet18 | 70.9 | 12.9 M | 46.3 |
| STDCSeg | STDC1 | 68.8 | 14.2 M | 85.3 |
| STDCSeg | STDC2 | 70.7 | 22.2 M | 63.6 |
| BatNet-tiny | HybridBlock | 77.9 | 4.9 M | 114.4 |
| BatNet | HybridBlock | 80.2 | 17.1 M | 68.3 |
| Model | Backbone | mIoU (%) | Parameters | FPS |
|---|---|---|---|---|
| BiSeNet | Xception | 66.1 | 5.8 M | 49.4 |
| BiSeNetV2 | Booster | 70.5 | - | 45.2 |
| SFNet | ResNet18 | 72.9 | 12.9 M | 8.2 |
| STDCSeg | STDC1 | 71.7 | 14.2 M | 38.3 |
| STDCSeg | STDC2 | 73.2 | 22.2 M | 33.5 |
| BatNet-tiny | HybridBlock | 73.3 | 4.9 M | 49.6 |
| BatNet | HybridBlock | 76.1 | 17.1 M | 27.2 |
| Model | Backbone | mIoU (%) | Parameters | FPS |
|---|---|---|---|---|
| FCN | MobileNetV2 | 18.1 | 9.8 M | 47.4 |
| DeepLabV3 | MobileNetV2 | 30.5 | 15.4 M | 32.9 |
| BiSeNetV2 | Booster | 31.4 | - | 95.3 |
| SegFormer | MiT-B0 | 35.7 | 3.8 M | 42.8 |
| BatNet-tiny | HybridBlock | 32.8 | 4.9 M | 138.1 |
| BatNet | HybridBlock | 38.5 | 17.1 M | 69.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Yang, Z.; Xue, B.; Zhuo, H.; Liao, L.; Yang, X.; Zhu, Z. Perceiving like a Bat: Hierarchical 3D Geometric–Semantic Scene Understanding Inspired by a Biomimetic Mechanism. Biomimetics 2023, 8, 436. https://doi.org/10.3390/biomimetics8050436
Zhang C, Yang Z, Xue B, Zhuo H, Liao L, Yang X, Zhu Z. Perceiving like a Bat: Hierarchical 3D Geometric–Semantic Scene Understanding Inspired by a Biomimetic Mechanism. Biomimetics. 2023; 8(5):436. https://doi.org/10.3390/biomimetics8050436
Chicago/Turabian StyleZhang, Chi, Zhong Yang, Bayang Xue, Haoze Zhuo, Luwei Liao, Xin Yang, and Zekun Zhu. 2023. "Perceiving like a Bat: Hierarchical 3D Geometric–Semantic Scene Understanding Inspired by a Biomimetic Mechanism" Biomimetics 8, no. 5: 436. https://doi.org/10.3390/biomimetics8050436
APA StyleZhang, C., Yang, Z., Xue, B., Zhuo, H., Liao, L., Yang, X., & Zhu, Z. (2023). Perceiving like a Bat: Hierarchical 3D Geometric–Semantic Scene Understanding Inspired by a Biomimetic Mechanism. Biomimetics, 8(5), 436. https://doi.org/10.3390/biomimetics8050436