1. Summary
People trust human opinion more so than traditional advertising. For example, consumers are used to seeking advice and recommendation from others before making decisions regarding important purchases. Word of mouth (WOM) has always been salient for consumers when making a decision. Such referrals have a strong impact on both customer decision-making and new customer acquisition for the purchasing of a company’s product or service [
1]. On the other hand, organizations are eager to mine all the activities and interactions of people to understand what their weaknesses and strengths are. This understanding would help them to develop their organizational strategy in this competitive world.
Sentiment analysis (or opinion mining) is a process to determine the viewpoint of a person on a certain topic. It classifies the polarity of a document (i.e., review, tweet, blog, or news), that is, whether the communicated opinion is positive, negative, or neutral. There are three levels at which sentiment is analyzed [
2]: the document level, sentence level, and aspect level. The document level considers that a document has an opinion on an entity, and the task is to classify whether an entire document expresses a positive or negative sentiment. The task at the sentence level regards sentences and determining whether each sentence expresses a positive, negative, or neutral opinion. Neither the document level nor the sentence level analysis discover exactly what people liked and did not like. The aspect level (or aspect-based sentiment analysis—ABSA) performs a finer-grained analysis that identifies the aspects of a given document or sentence and the sentiment expressed towards each aspect. This level of analysis is the most detailed version that is capable of discovering complex opinions from reviews.
There are two major tasks when performing ABSA. The first is to extract the specific areas or aspects mentioned in the opinioned review. The second is to identify the polarity (either positive, negative, or neutral) for every aspect. For example, the following review of a restaurant reveals two aspects: service and food. Both aspects have a positive polarity.
“The service was excellent and the food was delicious.”
As one can see, the name of the aspect categories are explicitly mentioned in this review. A review might also contain implicit categories; for example, “The staff makes you feel at home and the chicken is great.” Here, the same aspects, “service” and “food”, are contained without being directly mentioned.
Semantic Evaluation (SemEval), a reputed workshop in the NLP domain, introduced a complete dataset [
3] in English for the ABSA task. Later this was expanded to the ABSA task by adding multi-lingual datasets in which eight languages over seven domains were incorporated. To perform ABSA, datasets of several languages, such as Arabic [
4], Czech [
5], and French [
6], were created. There is no dataset for Bangla in the field of ABSA. Consequently, no work is being done to extract aspects and to identify corresponding polarities for Bangla reviews. We are currently working on a project to extract the aspects from a Bangla review or comments for a particular product of a company, as online shopping is very popular nowadays in Bangladesh and is growing rapidly. People like to buy products online after reading the comments of others.
In this paper, we have created two new datasets that serve as a benchmark for the ABSA domain in Bangla texts. We present two datasets named “Cricket” and “Restaurant”. The first dataset contains 2900 comments on cricket over 5 aspect categories, and the second dataset contains 2600 restaurant reviews.
Because there is no work in Bangla for the ABSA task, we have introduced ABSA by extracting aspect categories from Bangla texts in order to evaluate our datasets. We performed the task with different training approaches and found a satisfactory outcome compared to evaluations of other languages.
There are some related works from which we founded the idea of this topic. The restaurant review dataset, provided by Ganu et al. [
7], was used to improve rating predictions. Their annotations included six aspect categories and overall sentence polarities. They had not prepared a complete ABSA dataset, as the aspect category was present but the corresponding polarity of that aspect was absent. The SemEval 2014 evaluation campaign [
3] extended their dataset by adding three more fields with the aspect category. They published their dataset with four fields being contained for each review, that is, with the aspect term occurring in the sentences, the aspect term’s polarity, the aspect category, and the aspect category’s polarity. They also provided a laptop-review dataset and manually annotated with similar entities as for the restaurant dataset. These are the benchmark datasets that [
8,
9,
10,
11] researches have used for performing the ABSA task.
The task was repeated in SemEval 2015 [
12], for which aspect categories were the combination of the entity type and an attribute type. Multilingual datasets were released in the SemEval 2016 workshop [
13] on the seven domains (restaurant, laptop, mobile phone, digital camera, hotel, and museum) and in eight languages (English, Arabic, French, Chinese, Turkish, Spanish, Dutch, and Russian).
A book-review dataset in the Arabic language was provided by [
4]. They annotated book reviews into 14 categories and 4 types of polarities, including “Conflict”. In [
5], the author created an IT product-review dataset for the ABSA task, in which a total 2200 reviews were contained.
The contribution of this paper is as follows:
We have collected and presented two Bangla datasets for ABSA and have made them publicly available.
We performed statistical linguistic analysis on the datasets.
We implemented state-of-the-art machine learning approaches for the collected datasets and found satisfactory accuracies.
3. Baseline Evaluation
Our objective is to provide benchmark datasets for Bangla ABSA. Our datasets are designed for two major tasks of ABSA. These are aspect category extraction and the identification of polarity for each aspect category. In this paper, we experimented with the first subtask, that is, the extraction of the aspect category. We applied three major steps to extract the aspect category. Firstly, preprocessing was performed on the dataset. After this, we extracted features from the data and finally performed classification using some popular classification models.
3.1. Preprocessing and Feature Extraction
In the preprocessing phase, each Bangla document was represented as a “bag of words”. We applied traditional preprocessing steps for the evaluation. Firstly, punctuations and stop words were removed from each of the comments. After this, we removed the digits from our dataset, because we found that digits were not necessary for the aspect category. Finally, we tokenized each Bangla word from our dataset.
Thus, a vocabulary of Bangla words was prepared after preprocessing. We created a feature matrix for which each review was represented by a vector of that vocabulary. Term frequency–inverse document frequency (TF–IDF) was used for calculating the features.
3.2. Results
In the training phase, extracted feature sets were trained by the popular supervised machine learning algorithms. Because this was a multi-label classification problem, we trained our models by setting up multi-label output. We used linear SVC in the support vector machine (SVM) implementation. The following machine learning algorithms were used:
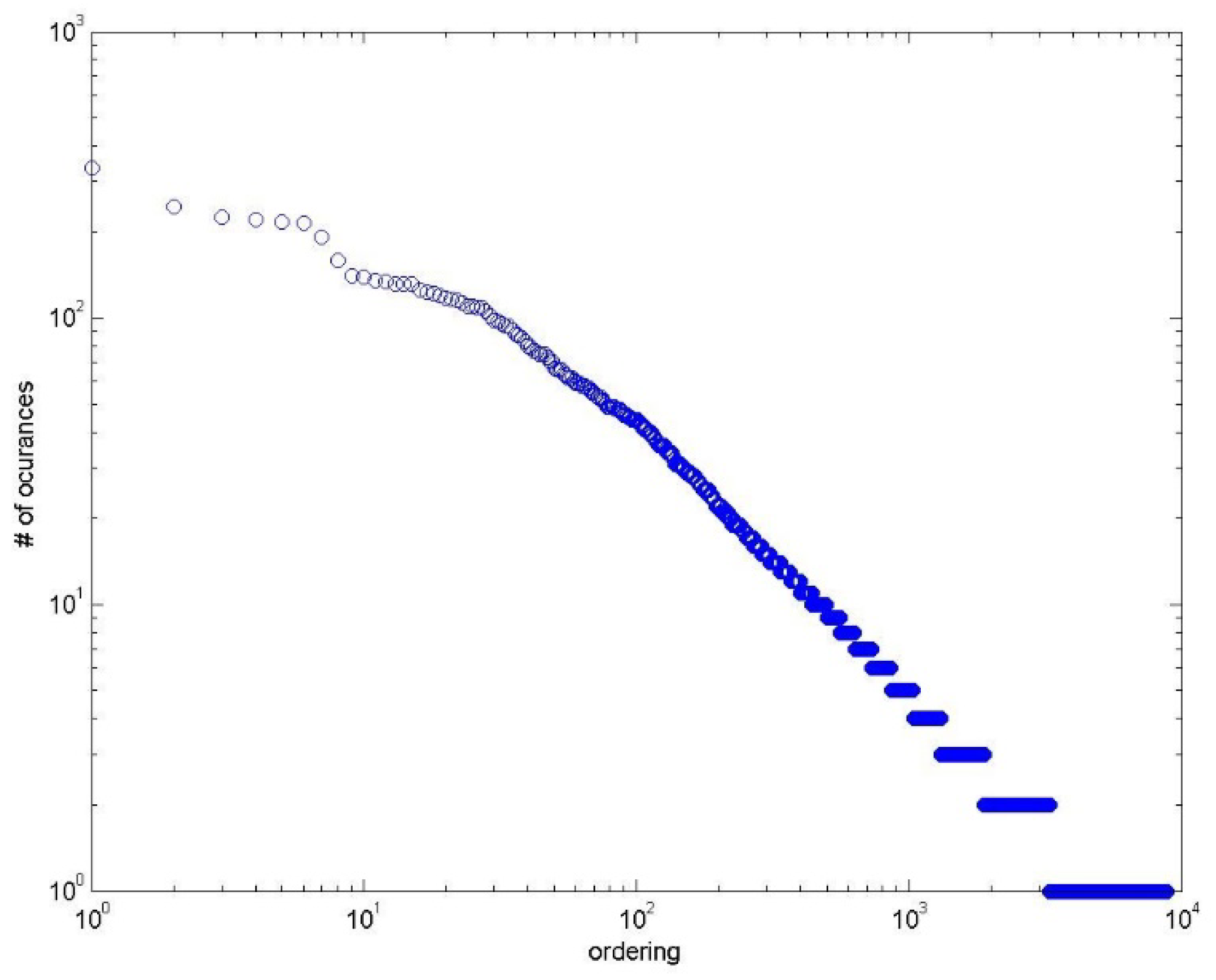
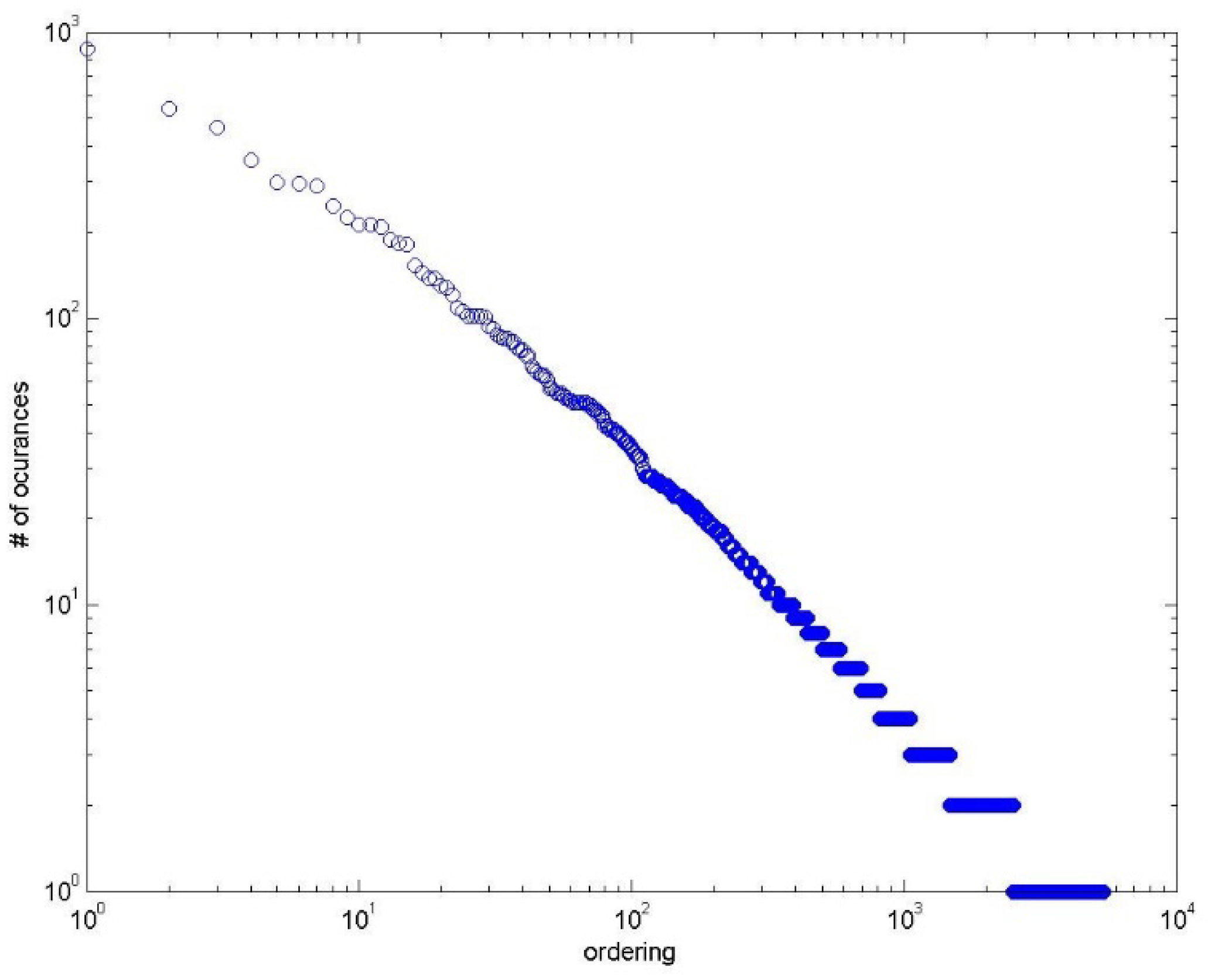
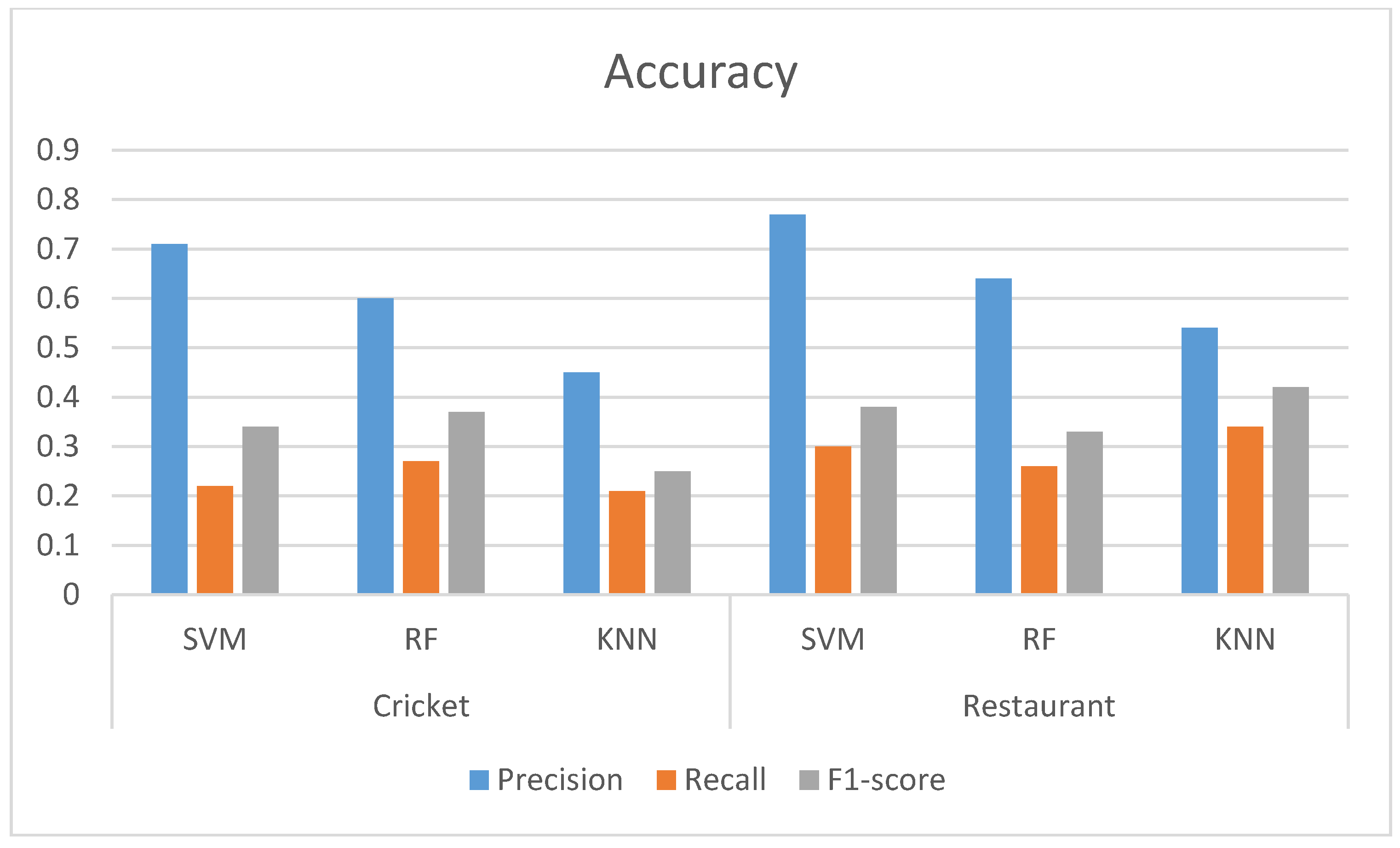
After the training was completed, our proposed Bangla test dataset was executed on the trained model. The result is shown in the following table and figure.
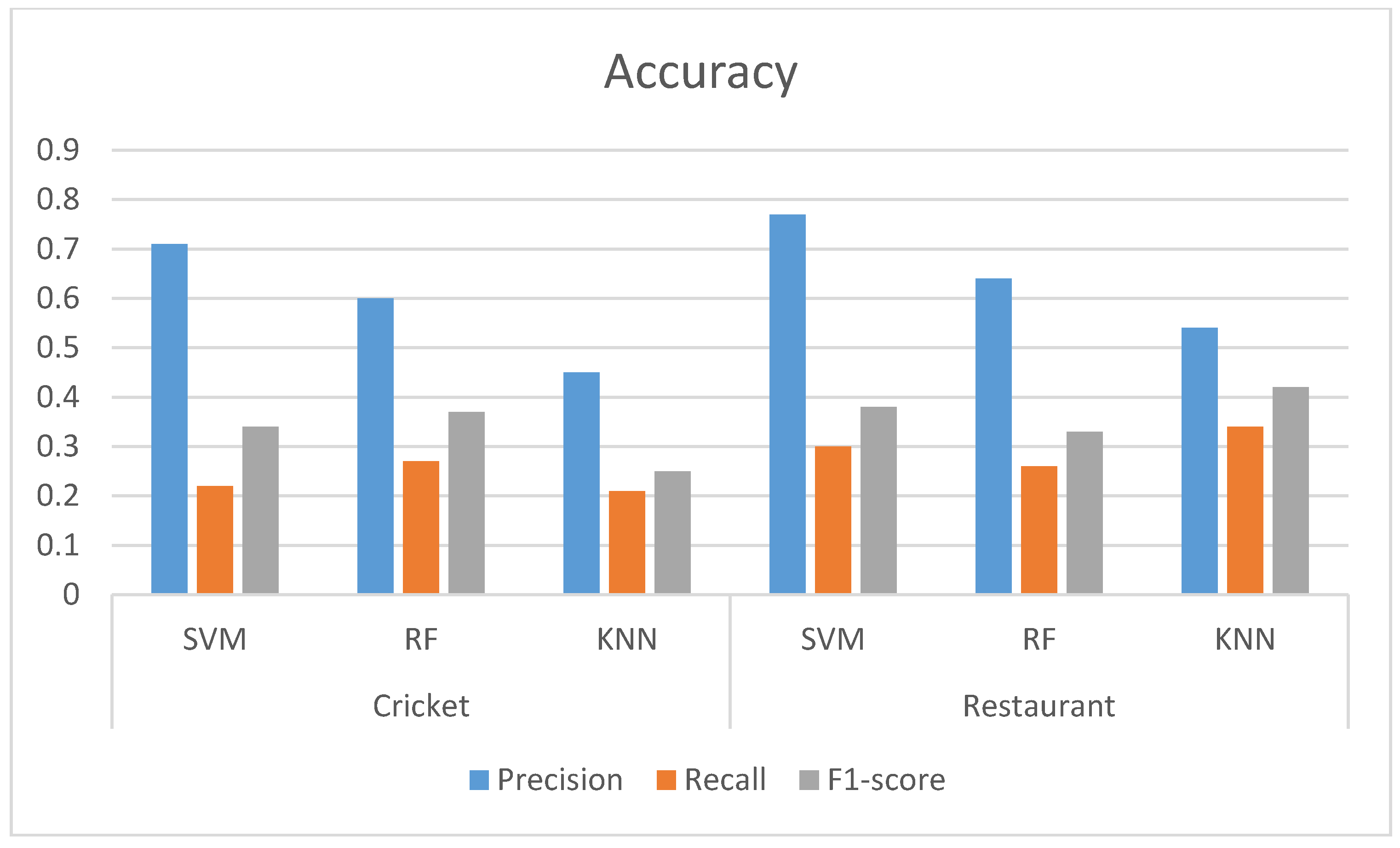
Table 10 shows the results for the task of aspect category extraction of the datasets we have presented in this paper. We can see that using the SVM, we obtained the highest precision rate for both of the datasets. Both datasets showed a low recall and F1-score.
Figure 3 shows the overall accuracy of the models using our datasets. The inherent nature of the datasets is the reason behind the lower performance of the models for both datasets. People share their opinion with their individual judgment. Therefore, the variety of opinions in the datasets is much larger. On the other hand, aspect extraction is a multi-label classification problem. One’s opinion might have multiple aspect categories. Conventional classifiers miss some of these aspect categories.
These results can be improved if we process and train the datasets in a more sophisticated way. In this work, we have taken all of the vocabulary as features for the evaluation after removing punctuation, stop words, and digits. Some state-of-the-art techniques for information gain can be applied to the dataset before classification and after the preprocessing steps to attain better results.


{kind=link}
{kind=link}
{kind=link}