1. Introduction
Chronic diseases are the main problems in public health worldwide. The pattern of disease has been transformed and oral diseases are considered one of the main public health problems due to its high incidence and prevalence in all regions of the world, and, as in all diseases, the greatest burden is on populations disadvantaged and socially marginalized; treatment of the conditions is extremely expensive and is not feasible in most low and middle income countries. This characteristic represents an important problem, since, according to the World Health Organization (WHO), oral diseases are the fourth most expensive cause to treat in the most industrialized countries [
1].
Oral health is an essential component for quality of life of people due to its influence as a determinant factor in general health of individuals and communities becoming a relevant point in health care. Therefore, the serious repercussions in terms of pain and suffering, impairment of function and effect on quality of life should also be considered. An important aspect to consider is that oral diseases increase the risk of chronic diseases, such as: cardiovascular and cerebrovascular, diabetes mellitus and respiratory. On the other hand, epidemiological surveillance of oral diseases becomes important insofar as it provides useful elements for the planning, programming, organization, integration, control and direction of the oral health program, at the same time that it guides the attention to the population [
2].
Caries is the most frequent condition and according to the WHO; it affects between 60% and 90% of children of school age between 5 to 17 years old. The determinants and conditions of oral health status are multicausal, multisectoral and interdisciplinary categories that encompass a series of situations related to the historical and political process that each country experiences. In addition, the report of the Organización Panamericana de la Salud (OPS) describes how the development of this condition depends on the frequency of carbohydrate consumption, the characteristics of the food, the time exposure, plaque removal and susceptibility of the guest, adding the few preventive measures in oral health and the difficulty of making use of specialized dental medical services. These factors interact simultaneously, and their variables correspond to different orders from biological processes, to complex historical-cultural structures and social relationships, socioeconomic level, educational level, among others, making health phenomena complex [
3,
4].
There are too many risk factors and important determinants related to the presence of caries, and it is clear that the greater the degree of risk exposure, the greater the probability of contracting or developing it. Due to the difficulty of representing the control of the incidence of caries due to its high prevalence and the large number of factors that can influence this state, at present, some studies have implemented algorithms and performed analyses based on computer-aided diagnosis (CAD) where prediction models are used when it is necessary to know in the future the behavior of highly related complex data; these have utilities in clinical and research dentistry [
5].
An example of these algorithms are the artificial neural networks (ANNs), a method used for the prediction of diseases, such is the case of oral diseases, as well as being mathematic models based on a principle of learning that is based on the concepts of artificial intelligence and the biological response of the human brain. Likewise, they are involved in systems’ construction processes that allow classifying, modeling and predicting information. ANNs are semiparametric nonlinear models, which allow the integration of variables and easily handle large amounts of data compared to linear analyses. They have processing elements or neurons, which are the units of the system that can be adjusted or trained through a process of learning and generalization. The information of each of these neurons is grouped and processed [
6].
According to the literature, dental caries incidence has been a problem that has been studied by a series of researchers, trying to identify caries risk determinants. Lam et al. [
7] found that dental visits, brushing frequency, lower parental perceived importance of baby teeth, and weaning onto solids are determinants associated with plaque accumulation, validating these results specifically in children. In the work of Fernandes et al. [
8], a cross-sectional study of 274 children and their mothers based on demographic/socio-economic status is presented; through a Poisson regression approach, an analysis was performed, obtaining that dental caries can be mainly found in mothers of children aged 1, demonstrating the relationship between demographic/socio-economic status and caries.
As mentioned in the text, there are different types of risk factors that are associated with genetic and nutritional data. Lips et al. [
9] presented a work where the association between genetic polymorphisms and risk of dental caries is demonstrated for most of the salivary proteins. In addition, diabetic and hypertensive patients have dietary risk factors that can be caused by oral health problems. This affirmation was demonstrated in the work of Asif Ahmed et al. [
10] through a statistical analysis using clinical data, in order to identify that patients with oro-dental problems were hemodynamically stressed.
In the present study, it is intended to analyze the determinants that affect this oral health situation based on dietary and demographic factors. Based on this general description of the oral health problem, specifically caries, the main contribution of this work is to determine that, given the socioeconomic and dietary features, using an ANN can determine if the patient presents an optimal state of health or with the presence of repairs or caries, obtaining a classification system that allows for knowing the differences in the features that affect the population, as well as looking for the future prediction of oral health.
This method is an important tool for human resources and dental services because it reflects information collected in the population groups studied, which could unveil that oral health problems are not simple conditions, but they are obtained from different processes that have their trigger, which can enhance or mitigate them, impacting positively or negatively on the state of oral and general health.
Related Work
The condition of dental caries has been described in the scientific literature under different terms, as a multifactorial disease that is characterized by localized and progressive demineralization of the inorganic portions of the tooth and the subsequent deterioration of its organic part, with a high degree of morbidity and high prevalence [
11,
12,
13].
A related work that suggests CADx to improve oral health prediction is developed by Zhang et al. [
14], where an autoregressive integrated moving average model is performed and a grey predictive model for the estimation of the national prevalence of early childhood caries from 2014 to 2018, finding that the highest annual prevalence would be of 55.8%, being attributed to the socioeconomic developments and the public health service. In the work of Asif et al. [
15], a caries preventive tool based on the influence of genetic pattern using the frequency of occurrence of fingerprint patterns among children, using as a validation measure the
p-value, finding that dermatoglyphics could be an appropriate method to explore the possibility of a noninvasive and early predictor for dental caries. Chapple et al. [
16] performed a systematic appraisal to identify potential risk factors for caries and periodontal diseases using genetic, role of diet and nutrition risk factors, obtained as results that the genetic contribution to these conditions present an attributable risk up to 50%, while controlled diabetes and obesity are common acquired factors. Hayes et al. [
17] had as an objective to determine the risk indicators associated with root caries conducting a prospective longitudinal study using a regression analysis with data related to hygiene habits, diet, smoking habits and education level and as the outcome the root caries experience, suggesting a correlation between root caries and the variables poor plaque control, xerostomia, coronal decay and exposed root surfaces, obtaining a prevention tool for the root caries condition. In the work of Sudhir et al. [
18], evaluating Caries Management by Risk Assessment (CAMBRA) as a tool for caries risk prediction was proposed, using as validation parameter OR value and ROC curve, obtaining that CAMBRA was found to be 47.62% with a specificity of 80% and AUC was found to be 0.638, which means that it is valid and highly predictive in determining the caries risk. Finally, Twetman [
19] proposed to summarise the findings of recent systematic reviews covering caries risk assessment, finding that caries risk assessment should be carried out at the subject’s first dental visit and reassessments should be done during childhood; multivariate models display a better accuracy than the use of single predictors; there is no clearly superior method to predict future caries and no evidence to support the use of one model, program, or technology before the other; and the risk category should be linked to appropriate preventive care with recall intervals based on the individual need.
This work is organized as follows:
Section 2 briefly describes the materials and methods used for the development of the data analysis, including data preprocessing, data classification and data evaluation.
Section 3 exposes the results obtained. Finally, results are discussed in
Section 4 and concluded in
Section 5.
2. Materials and Methods
In this section, the process that was carried on for the classification between subjects with presence of caries and subjects with absence was presented, based on the information obtained from a series of socioeconomic and nutritional features. The databases that were used in this work were obtained from the National Health and Nutrition Examination Survey (NHANES, 2013–2014). In addition, the description of the subjects and the methods used for their classification are presented.
In
Figure 1, the flowchart of the steps followed for the experimentation of this work is presented. Section (A) presents the data acquisition of the public databases “Demographic” and “Dietary” from NHANES 2013–2014. Section (B) represents the data preprocessing, where a feature reduction is performed due to the high amount of missing data and singular values that are presented, in addition to separating the data in two sets, one for training and one for testing. Section (C) refers to the data classification of subjects according to their oral health status. Finally, in Section (D), the evaluation of the ANN performance is presented, in order to know the accuracy with which the model classifies the subjects.
2.1. Features Description
NHANES is a program of studies designed to evaluate the health and nutritional status of children and adults in United States, and it was founded by Centers of Disease Control and Prevention (CDC) and National Center for Health Statistics (NCHS). The surveys conducted by this program are unique, since it combines interviews and physical exams [
20].
NHANES collects information from different types of data, and, in turn, this information is included in six main contexts; demographic, dietetic, examination, laboratory, questionnaire and limited access. These contexts are contained by the information described as follows:
Demographic: it provides individual, family and household level information in different topics (income of households and families, size of households and families, pregnancy status, among others).
Dietetic: it provides detailed information on dietary intake, in order to estimate the types and amount of food and beverages consumed, in addition to estimating the intake of energy, nutrients, and other food components.
Examination: it provides information of the health status, indicators of disease risk, and access to preventive and treatment services, from different aspects, including oral health.
Laboratory: it provides information of the results obtained from laboratory analysis of different components (components of urine, proteins, triglycerides, plasma, among others).
Questionnaire: it provides information of the data obtained from the interviews conducted through a system of computer-aided personal interview, of different topics (alcohol use, cardiovascular health, dermatology, among others).
Limited access: it provides similar information to that found in the questionnaire; however, it isn’t publicly available.
There were 189 features analyzed for this work, of which 188 belonged to demographic data, described in
Appendix A, and dietary data, described in
Appendix B. These features were used as input variables for the classification of subjects, while the remaining feature belonged to examination data, describing the oral health status of the subjects based on the presence/restoration or absence of caries, for which it was used as an output feature.
2.2. Subjects Description
The subjects of these databases were submitted to a series of different questionnaires, related to the different features. These subjects belong to different counties in the USA and they were randomly selected with a computer algorithm by NHANES.
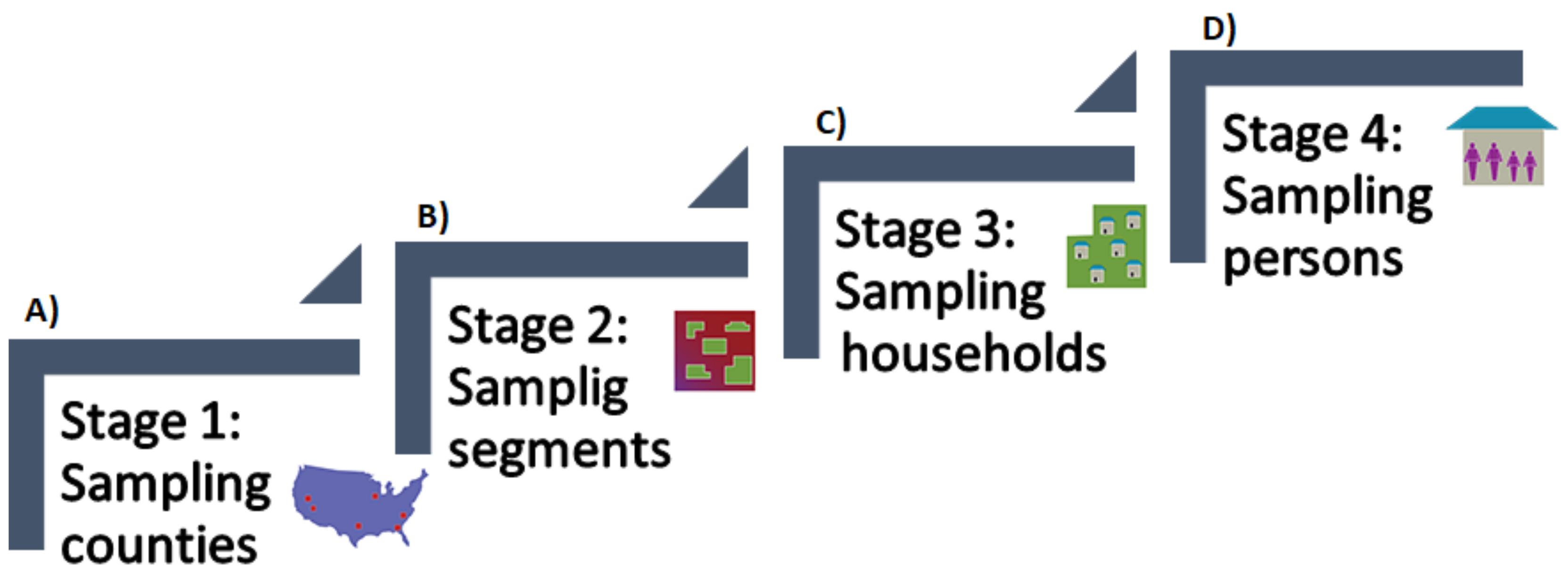
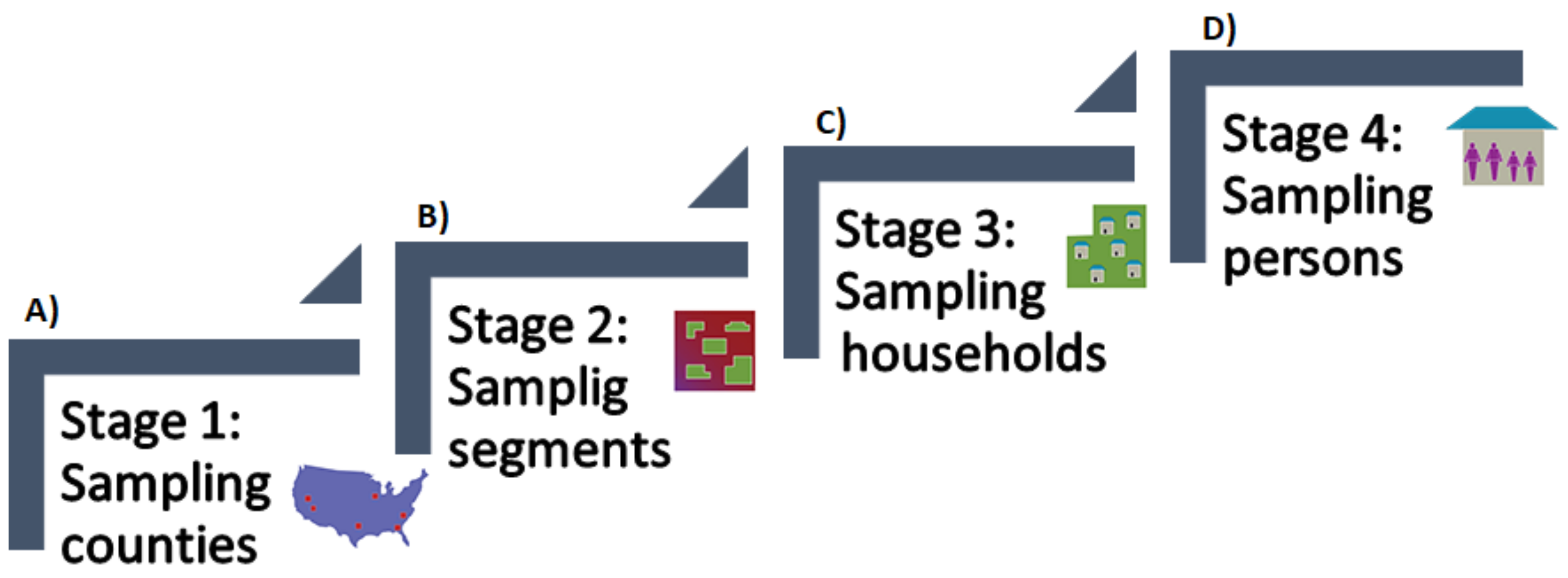
Figure 2 presents a flowchart of the randomly selection process followed by NHANES. (A) presents the first stage that corresponds to the sampling of counties. In this step, all the counties are divided into 15 groups according to their characteristics. Then, from each group, one county is selected, forming the 15 counties in the NHANES surveys for each year. (B) presents the second stage, corresponding to the sampling of segments, where from each county smaller groups are formed (with a large number of households in each group), selecting between 20 and 24 of these groups. (C) presented the third stage, which is referred to the sampling of households, where from all of the houses that correspond to the groups that were selected in the past stage, a sample of about 30 households are selected within each group. Finally, (D) presents the fourth stage, corresponding to the sampling of persons, where the NHANES interviewers go to the selected households and ask for the information of the surveys (age, race, and gender). The members of the households that responded to the surveys were randomly selected through a computer algorithm; they can be selected some, all, or none of the household members.
The main target population for NHANES is the non-institutionalized civilian resident population of the USA. The design of the population selection is based on the sampling of a larger number of specific subgroups that present particular public health characteristics, in order to increase the reliability and precision of health status indicators. NHANES started these design changes in 2011, including in its population the oversampled subgroups survey cycle:
Hispanic persons;
Non-Hispanic black persons;
Non-Hispanic Asian persons;
Non-Hispanic white and other* persons at or below 130% of the poverty level; and
Non-Hispanic white and other* persons aged 80 years and older.
This random selection of subjects avoid presenting any bias problem, favoring the important variety of demography characteristics of the subjects reducing the probability that the methodology followed could be influenced by the data used.
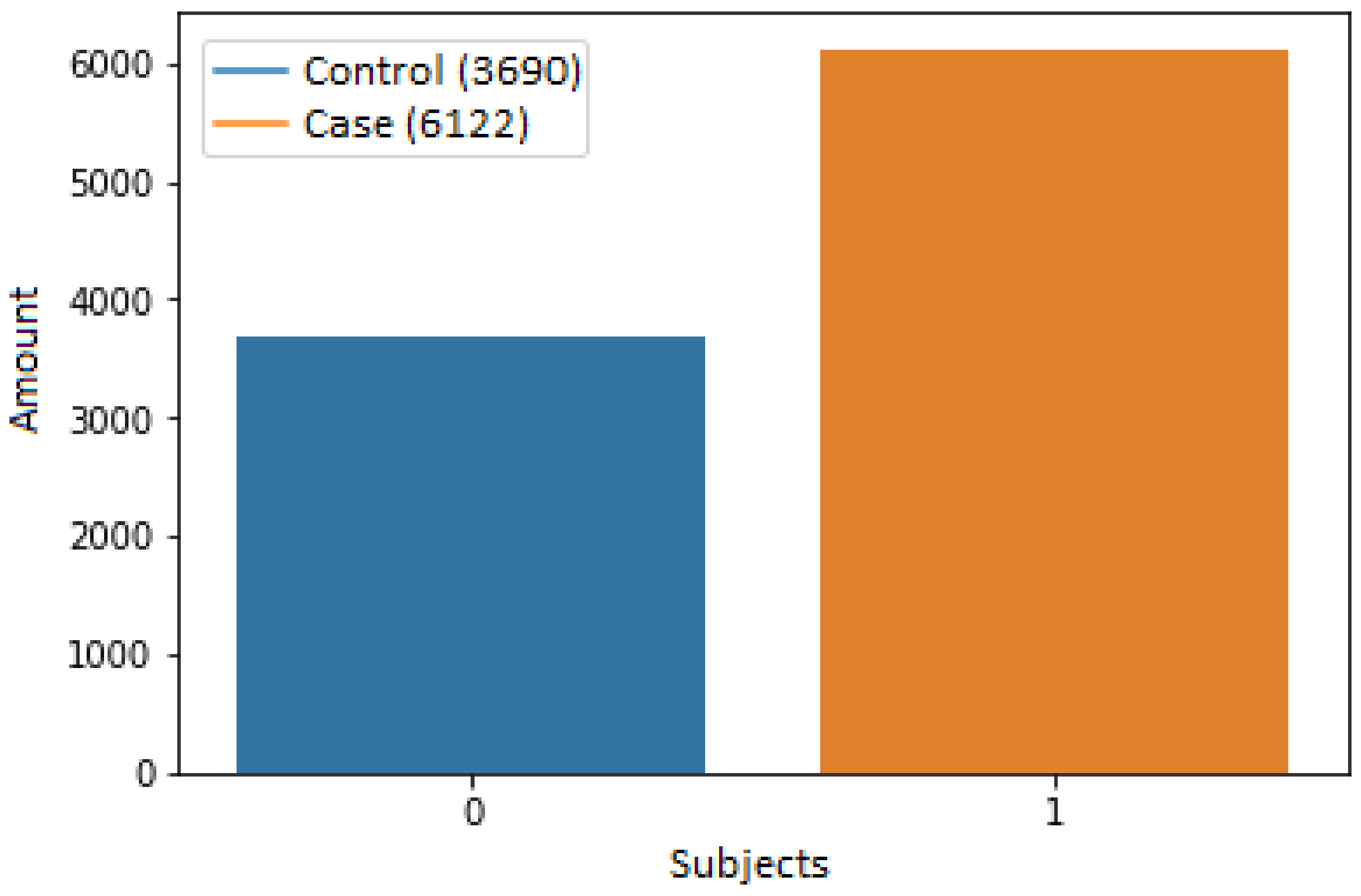
Figure 3 presents the total of subjects contained in the database used. From 9812 subjects, 3690 were control subjects and 6122 were case subjects. The subjects were in an age range of 0 to 80 years old; 4830 belonged to the masculine gender and 4982 to the feminine gender.
It is important to mention that this specific database was chosen in order to show the consistency of the data and the results obtained in the relationship to its background work. In this work [
21] three different models obtained through a fast backward selection (FBS) of features are presented, each model corresponding to a different age group, then a posterior evaluation using a net reclassification improvement (NRI) technique is performed, besides the AUC parameter, obtaining a maximum true positive-true negative rate of 0.787. On the other hand, this work [
22] presents a multivariate model obtained through a FBS method based on the
p-value, in order to classify between three different classes, ”caries”, ”restorations” and ”control”; this model was evaluated using a statistical analysis, obtaining a maximum AUC value of 0.664. Finally, this work [
23] presents a univariate analysis using a linear regression approach in order to classify between subjects with the presence of caries and with absence; then, from the most significant univariate models, a multivariate model contained by three features was developed, which obtained an AUC value of 0.572.
2.3. Data Analysis
The data analysis of this work was performed through a multivariate approach, subjecting the demographic and dietary features to a deep ANN for the classification of subjects according to their health and then a statistical validation was carried out in order to evaluate the results obtained from the ANN developed for these specific data.
2.3.1. Data Preprocessing
The data preprocessing consisted initially in the manual elimination of the features that presented a high percentage of missing values (>30%), represented as “Not a Number” (NaN). Then, of the remaining features, those that presented a low percentage of missing data (≤30%) were imputed with the ”rfimput” function, of the ”randomForest” package (version 4.6-12, 6 October 2015) [
24], for R, which consists of replacing all NaN with the average of the values that present the column where the missing data is located.
The columns containing singular values were also removed because they didn’t provide significant information. Two values are singular if they have multiple values between them or if they present the same value in the whole column.
Finally, the database was separated into two sets, randomly and balanced selecting a set for the training stage, contained with 70% of the data and a set for the testing stage, contained with the remaining 30% of data.
2.3.2. Data Classification
The classification of subjects was performed according to the presence or absence of caries through a dense ANN that was designed based on the data of the subjects, using the package ”Keras”. ”Keras” is a high-level ANN application programming interface written in Python. It was developed with the approach of allowing fast experimentation, facilitating the creation of prototypes in a simple way [
25].
ANNs seek a solution to a specific task, based on the correlation between features, through learning or training that resembles the behavior of biological neural networks. Using different layers composed of nodes or neurons, the ANNs look for a model of the relationship between the input features and the output feature. The number of nodes that exist for each layer is configurable, as is the number of layers and, depending on the data, there is usually a greater capacity of the network, the greater the number of layers and neurons; however, if there isn’t the right amount of these elements, problems of overfitting can be caused .
ANNs present three main elements: (1) a set of synapses or connections, characterized by a ”weight”, where the input signal is connected to a neuron through its product with the weight of that connection; (2) an adder, which adds the contributions of a signal weighted by all the weights; and (3) an activation function, which is equivalent to a transfer function, affecting the neurons, allowing for limiting the amplitude of the network output, providing a permissible range for the output signal in terms of finite values. Among the most common activation functions are the lineal, quadratic, geometric, logistic, and rectified linear unit function, among others.
On the other hand, an ANN is dense when each node of a layer is connected with every node of the next layer; while the recurrence term refers to the network presenting at least one feedback loop, which will provide a deeper impact on the learning capacity of the network, as well as on its performance, since it allows for optimizing its behavior through a parameter that gives knowledge of the behavior of the data and allows for guiding the adjustment of the configuration of the network to improve its accuracy.
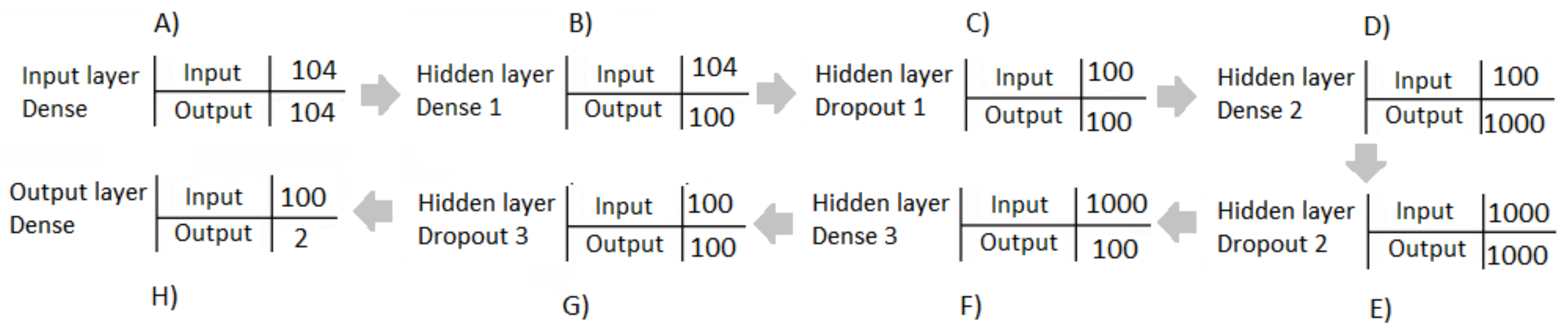
The ANN designed was composed by a series of dense and dropout hidden layers, as shown in the diagram of
Figure 4. The input layer (A) was assigned 104 neurons, making reference to the 104 features of the dataset. The first dense hidden layer (B) was composed of 100 neurons, as was the first dropout hidden layer (C), which had a loss percentage of 50%. The second dense hidden layer (D) was assigned 1000 neurons, as was the second dropout hidden layer (E), which had a loss percentage of 25%. The third dense hidden layer (F) was composed of 100 neurons, as was the third dropout hidden layer (G), which had a loss of 50%. Finally, the fourth dense hidden layer was the output layer (H), which was characterized by two neurons, making reference to the two outputs or possible classifications.
The input layer and the dense hidden layers used as activation function, the Rectified Linear Unit (ReLU) function, which consists of assigning 0 to the values of the neurons that are <0, and to respect the value of the neurons when their values are ≥0, as shown in Equation (
1) [
26]:
The output layer used the Normalized Exponential function as an activation function, also known as ”Softmax”, which represents a general form of the logistic function and it is used to compress a vector of arbitrary values into a vector of real values in a range of [0, 1]. This function is shown in Equation (
2), where
represents the
K-dimensional vector,
z, of binary values [
27]:
Finally, the dropout hidden layers were included in order to avoid overfitting problems, as mentioned before, and its performance is based on assigning the value of 0 to a percentage of the data and thus they are not taken into account for the classification of subjects in that layer. The data subset selected by these layers is changing with each iteration, causing that in each epoch the classification will be done omitting a different percentage of data. On the other hand, due to the recurrence of the ANN, it was possible to optimize its performance. The optimization algorithm, “Adam”, was selected, which bases its operation on stochastic gradient descent algorithms, making use of the average of the first and second moments of the gradients to adapt the rate of the learning parameter. Specifically, “Adam” calculates the exponential moving average of the gradient and the square gradient, and controls the decay rates of that moving average [
28]. Some of the benefits that present “Adam” are that it is a method that is straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and one of the most important points is that is suitable for problems that are large in terms of data or features. In addition, the parameters have intuitive interpretations and typically require little tuning [
28].
It is important to mention that the number of iterations or epochs that the ANN will have for the optimization of its behavior, based on the recurrence, is also configurable and will depend on the type of data. To know what is the appropriate number of epochs, there are some parameters that allow for evaluating the behavior through each iteration, such as the loss function and the accuracy [
29]. The number of the epochs that were selected through a series of tests with different numbers were 100 epochs, since they demonstrated having the best performance in terms of the accuracy of the ANN.
Based on the above, “keras” has the advantage that it allows for designing the architecture of the ANN according to the type of data, configuring the type of ANN, number of nodes, validation, loss function, among others [
30,
31].
2.3.3. Evaluation
Finally, in order to validate the results of classification obtained by the ANN, three parameters were evaluated; loss function, accuracy and ROC curve. The loss function and accuracy were calculated on each epoch, allowing to know if the performance of the ANN was improving, while the ROC curve was calculated based on the average of the general performance of the ANN.
ANNs are mostly trained using gradient methods through an iterative process of decreasing the loss function. A loss is designed to have the main property that the lower its value, the better the model that fits its data and, in addition, it will be differentiable, which will optimize the network directly, giving information of the capacity of the system. Therefore, the loss function is based on the search of the global minimum, which corresponds to the minimum error, based on a learning factor. Some of the most common techniques to calculate the loss function are the mean square error, mean absolute error, binary cross-entropy, and Poisson, among others [
31].
The loss function that was used is preset in “keras” as “binary-crossentropy” and calculates the cross-entropy value for binary classification problems. This method uses the Kullback–Leibler distance, which is a measure between two density functions
g and
h, known as the cross-entropy between
g and
h, as shown in Equation (
3). Its operation is based on iterations, generating a random set of values estimating the value that wants to be obtained and then actualizing the parameters in the next iteration to generate “better” values or more approximate, in terms of the Kullback–Leibler distance [
32]:
On the other side, the accuracy allows for measuring the performance of the ANN through a non-differentiable function. This metric doesn’t allow to optimize the network, but it allows to select the model that shows the most suitable performance in the training of the network, and it is based on the calculation of the average of the differences that exist between the classification calculated by the ANN model and the true classification of the data, as shown in Equation (
4), where the accuracy is reported as 1-
.
refers to the classification value that was calculated by the ANN, while
refers to true classification value [
33]:
In this work, the accuracy was calculated with the “binary-accuracy” function from “keras”, which calculates the average accuracy rate across all predictions for binary classification problems.
The ROC curve is a standard method that allows for evaluating the precision with which the model classifies, based on the relationship between sensitivity and specificity. Sensitivity is defined as the proportion of subjects with a condition that were classified as positive, which means the positive predictive values (
); this value is calculated with Equation (
5), where
represents the number of true positives and
represents the number of false positives [
34,
35]:
Specificity is defined as the proportion of subjects without a condition that was classified as negative; this means the negative predictive values (
); this value is calculated with Equation (
6), where
represents the number of true negatives and
represents the number of false negatives [
34,
35]:
The ROC curves were calculated to obtain the true positive and true negative rate for each class, for the macro-average precision and for the micro-average precision.
The macro-average precision is obtained through the sum of the true positives, false positives and false negatives of the system, for different sets, as shown in Equation (
7), where
refers to the true positives of the set one,
refers to the true positives of the set two,
refers to the false positives of the set one and
refers to the false positives of the set two [
36,
37]:
On the other hand, the macro-average precision is a direct method; it takes the average of the accuracy of the system in different sets. It is calculated with Equation (
8), where
refers to the average of the set one and
refers to the average of the set two [
36,
37]:
The analysis of this work was performed in Python (version 3.6), using the packages, “Keras” (version 2.1.5) [
25], “Scipy” (version 1.0.0) [
38], “Pandas” (version 0.22.0) [
39] and “Sklearn” (version 0.19.1) [
36].
3. Results
The two databases that were used in this work were contained by a total of 188 demographic and dietary features, besides a feature being used that was contained by the oral health status as an output feature for the classification of subjects.
After the data preprocessing, only 105 features were conserved, of which 25 belonged to demographic features and 79 to dietary features, the remaining feature refers to the output feature.
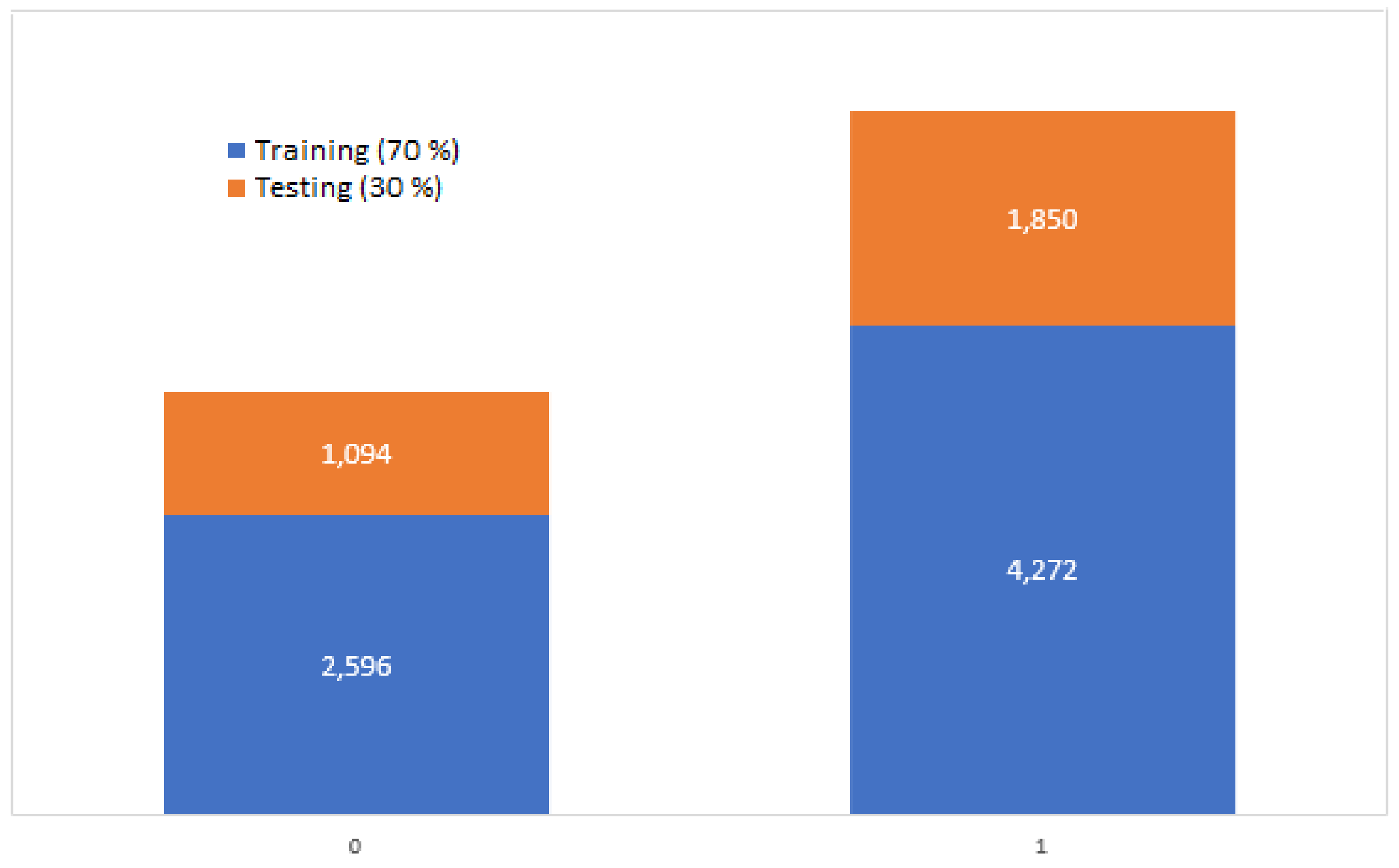
Of the total set of 9812 subjects, 3690 belonged to controls and 6122 belonged to cases. This dataset was divided into two subsets, one for training which was contained by 70% of the data (2596 controls/4272 cases), and one for testing which was contained with the remaining 30% of the data (1094 controls/1850 cases). These data are graphically shown in
Figure 5.
The dataset that was designed for the training stage was evaluated at each of the 100 epochs through the accuracy and loss function values. This number of epochs was selected through a comparison between the values obtained using different number of epochs;
Table 1 presents the values obtained for ten different epochs.
On the other hand, in
Table 2, a comparison of results using different number of layers and neurons is shown. The number of epochs selected was 100, establishing this number according to the result obtained from the previous table. It is possible to observe that the most statically significant values of accuracy and loss function were obtained using an ANN designed with seven layers, four dense layers and three dropout layers. The dense layers were contained by 104, 1000, 100 and two neurons, in descendant order, while the dropout layers represented 0.50, 0.25 and 0.50 percentages, in descendant order too.
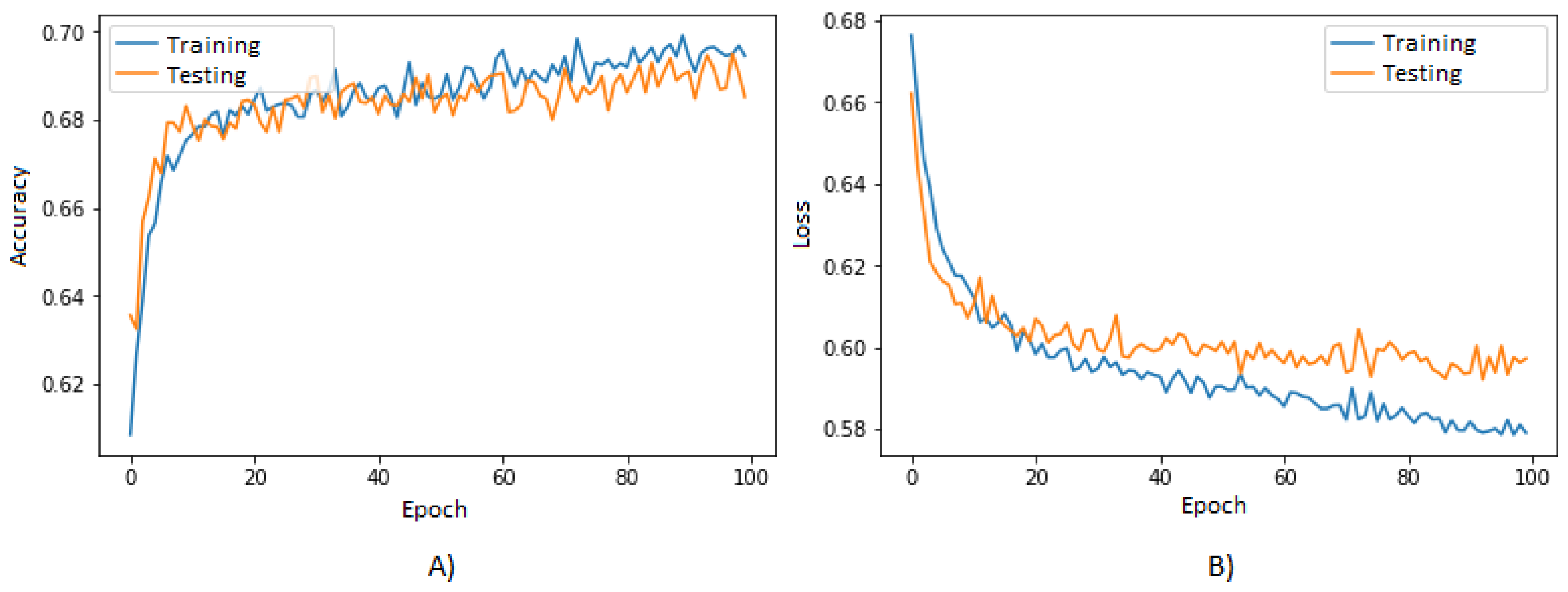
The graph of the performance of the accuracy is shown in
Figure 6A, where the blue line represents the behavior of the training data, obtaining a final accuracy of 0.69, while the orange line represents the behavior of the testing data, obtaining a final accuracy of 0.68.
The graph of the performance of the loss function is shown in
Figure 6B, where the blue line represents the behavior of the training data, obtaining a final value of 0.58, while the orange line represents the behavior of the testing data, obtaining a final value of 0.60.
Both accuracy and loss function values were obtained in order to know the performance of the classification of subjects on each iteration; nevertheless, the accuracy is a parameter that may show an optimistic response if the data presents any bias. Therefore, there were also measured the specificity and sensitivity parameters in order to ensure that the classification of subjects was statistically significant.
The graph of the
Figure 7 shows the ROC curves of the mean performance of the ANN, where the pink line refers to the proportion of sensitivity and specificity for the class “0”, which are the subjects that presented absence of caries, obtaining an AUC value of 0.69. The light blue line refers to the proportion of sensitivity and specificity for the class “1”, which are the subjects that presented presence/restoration of caries, obtaining an AUC value of 0.69. The dotted orange line refers to the curve calculated with the micro-average of the proportion of sensitivity and specificity for the classification of subjects, obtaining an AUC value of 0.75; the dotted dark blue line refers to the curve calculated with the macro-average, obtaining an AUC value of 0.69.
4. Discussion
Of the two datasets that were obtained through the preprocessing step, it is possible to observe that the set of cases contains more data than the set of controls as it is observed in
Figure 5; this was due to the fact that the cases included the subjects with presence of caries and with restorations. Nevertheless, the number of subjects that were contained on each dataset was enough to train the ANN, obtaining statistically significant results.
The data were separated in two sets based on an aleatory and balanced selection; one of the sets was contained with 70% of the data and the other dataset was contained with 30%, as shown in
Figure 5. The dataset that was contained with the largest amount of data had the purpose of training the ANN. The dense ANN was trained during 100 epochs and was optimized through the optimization algorithm, “Adam”, which had the purpose of improving the performance of the ANN with feedback.
Finally, for the validation of the ANN modeling, the accuracy and the loss function in each of the epochs with the dataset that was contained with the least amount of data were obtained. The loss function was calculated using cross-entropy in order to know how the performance of the ANN was modified. The validation was carried out in both datasets, training and testing, in order to ensure that there was no adjustment in the classification of the subjects; that is, if the performance of these parameters is similar for both datasets, it means that the ANN is classifying based on a generalized model, since it manages to classify with an accuracy and a loss function similar in the training dataset and in the testing dataset.
In the graph of
Figure 6A, it is observed that the performance of the accuracy is similar for both datasets, being slightly higher for the training data, which is normal since they are the data on which the ANN modeling is being based. As the performance is similar for both datasets, it is possible to know that the ANN model became generalized through the learning by being able to classify unknown data with a similar accuracy to that obtained with the training data. The final value obtained for the accuracy was 0.69, which is statistically significant since it means that at least 69% of the data was correctly classified.
On the other hand, in the graph of
Figure 6B, it is observed that the performance of the loss function is also similar for both datasets. It is notable that, for the training dataset, this parameter is smaller compared to that obtained with the testing dataset; however, as in the case of the accuracy parameter, this performance is normal because the testing dataset was unknown for the model. In addition, having a similar performance allows for knowing that the model doesn’t have overfitting problems and that it manages to classify unknown data in a similar way as it classifies known data. The final value obtained for the accuracy had an average of 0.59. This value isn’t close to the ideal, which is zero; however, it is possible to observe that the data remains tending toward zero for both datasets, showing that the testing dataset decreases slower than the training dataset. This problem can be solved increasing the amount of data, removing features that are not significant or that are redundant for the model and increasing the size if the ANN or the number of epochs.
Although the graph of the loss function doesn’t present very favorable results, it allows for knowing that the modeling of the ANN is robust among the two datasets, in addition to continuing to decrease the loss function and reducing the error through the epochs, which is one of the main purposes of the training stage.
Finally,
Figure 7 shows that all curves presented statistically significant values, obtaining AUC values ≥0.69. These curves are generated based on the proportion of true positives and true negatives, where for class “0”, class “1” and the macro-average, an AUC value of 0.69 was obtained, which implies that 69% of the subjects were classified appropriately for each of the classes and for their general average, while. for the curve generated for the micro-average, an AUC value of 0.75 was obtained, which implies that 75% of the subjects were classified appropriately when the measure was based in subsets of data. The ROC curves of class “0” and class “1” presented a very similar performance, besides obtaining the same AUC value, which means that the classification performance is equitable and the generalization of the model allows for classifying subjects of both classes.
On the other hand, the AUC value is greater for the micro-average than for the macro-average; this may be because the calculation of the macro-average is based in obtaining the true positives/true negatives proportion through the whole amount of data, while, for the micro-average, the calculation of the ROC curve is based in subsets of data, where some subsets can present better AUC values than obtained with the whole set, thus achieving a better average of classification.
Is it important to remark that this generalized model presents an impartial performance, since it was trained with data that cover a reasonable spectrum of the possible outcomes; in addition, the moment of time and geographical location are parameters that were taken into account in the initial data acquisition; regardless of whether the data was acquired in the USA, most of the subjects were from other regions, of which a percentage belongs to Mexican subjects, providing robustness in the results and avoiding any bias problem related to the structure, the moment of time and the geographical location of the data.
Finally, the results obtained allow for supporting the main motivation of this work, which was to develop a tool for human resources and dental services, since this model is able to give a statistically significant response of the possible development of caries based on information that doesn’t require any extra equipment for its acquisition, only the willingness of people to answer the demographic and diet surveys, providing support to the dental specialists in the work of reducing the high incidence of dental caries
Based on these discussions, it can be proposed as future work to add a stage in the methodology that consists of a step for the feature selection using a genetic algorithm approach. This stage will help to remove redundant information and correlated features, keeping only those features that provide the most significant information for the classification of subjects, besides reducing the computational cost. Additionally, for the validation of the feature selection, a forward selection and backward elimination may be used in order to test the accuracy of the set of features obtained through the selection process, ensuring the certainty of the model behavior.
5. Conclusions
According to the results obtained, it is possible to conclude that the amount of data that was used to model the classification of the subjects was adequate for the preliminary generalized learning of the ANN, basing this on the performance that the classification of cases had, being similar to the classification of controls. This performance was observed in the accuracy and loss function graphs, which allows for recognizing that the number of epochs that were assigned to the ANN was sufficient to maintain stable performance of the parameters in both datasets.
The accuracy achieved with this modeling was around 0.70, a value that is statistically significant since it implies that 70% of the time will be correctly classified to the subjects with presence or absence/restoration of caries.
The loss function decreased by approximately 10% since the beginning of the training, showing minor changes throughout the epochs, implying an approximation to the global minimum sought.
As a final evaluation, all the ROC curves obtained an AUC value statistically significant, implying that, around 70% of the time, subjects were correctly classified, according to the true positives and true negatives proportion, a value that corroborates the accuracy obtained. Nevertheless, a methodology was proposed based in convolutional neural networks in order to identify features in a spectral or spatial domain to obtain time-independent abstract features, looking for the improvement in the modeling for the classification of subjects.
Based on this, it is possible to classify subjects with the absence of caries from subjects with presence/restorations, through demographic and dietary data, with a statistically significant accuracy, demonstrating that the socioeconomic and nutritional status are important determinants in the development of caries.
Then, according to the results obtained, it was demonstrated that the demographic situation can significantly affect the prevalence of dental caries. Based on this, the analysis of oral health data from exclusively Mexican subjects is proposed, comparing those results with the ones obtained in this work, with the purpose of proving how demography can influence the oral health status.
On the other hand, even though the results do not show an ideal behavior, they give preliminary knowledge of the benefit that its implementation would have in a real environment, since the requirements for its use are minimal, no in-depth knowledge of the techniques used is required, results are presented quickly and the computational cost is very low, besides the accuracy obtained being statistically significant. In addition, an important point to take into account is that the performed experimental tests were based in a real production environment, since all the subjects that were part for the development of this work were real control and cases, and the demographic and dietary databases were obtained from real information.
The hardware tool that is required for the implementation of this work is a computer, while the free software tool that is required is Python, which is a programming language that allows for working quickly and integrating systems more effectively. As extra information, it is mentioned that the computer that was used for the development of this work was a laptop Acer Aspire F5-573-70LX 15.6” (Acer America Corporation, 333 West San Carlos Street, Suite 1500, San Jose, CA 95110), Intel Core i7-7500U 2.70 GHz (Plot 6, Bayan Lepas Technoplex Medan Bayan Lepas 11900 Bayan Lepas Penang, Malaysia, Georgetown, Pulau Pinang, Malasia), 16 GB, 1 TB + 128 GB Solid State Drive, Windows 10 Home (15010 NE 36th Street, Microsoft Campus, Building 92, Redmond, WA 98052), 64-bit; and the version of Python that was used is 3.6 [
40].
Finally, based on the last point, it is evident that the implementation of the model proposed in this work could provide an easy, free and fast tool that helps the specialists in the preventive diagnosis of dental caries, besides offering an option that collaborates in the decrement of the incidence of this public health problem.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}